Поддерживаемые версии PostgreSQL с сервером PostgreSQL с поддержкой Azure Arc
Список поддерживаемых версий развивается со временем по мере прогресса по обеспечению паритета с управляемыми службами PostgreSQL в Azure PaaS. Сегодня основная версия, поддерживаемая PostgreSQL 14.
В отношении технологии (как предварительной версии функции), описанной в этой статье, действуют дополнительные условия использования предварительных версий Microsoft Azure.
Последние обновления доступны в заметках о выпуске.
Как выбрать между версиями?
Рекомендуется ознакомиться с версиями приложений, предназначенными для каждой из этих версий. Чтобы узнать больше, ознакомьтесь с каждой версией на официальном сайте PostgreSQL:
Как создать определенную версию на сервере PostgreSQL с поддержкой Azure Arc?
В настоящее время поддерживается только PostgreSQL версии 14.
В кластере Kubernetes существует только один настраиваемый определение ресурсов PostgreSQL (CRD), независимо от того, какие версии мы поддерживаем. Например, выполните следующую команду:
kubectl get crds Он возвращает выходные данные, такие как:
NAME CREATED AT dags.sql.arcdata.microsoft.com 2021-10-12T23:53:40Z datacontrollers.arcdata.microsoft.com 2021-10-13T01:00:27Z exporttasks.tasks.arcdata.microsoft.com 2021-10-12T23:53:39Z healthstates.azmon.container.insights 2021-10-12T19:04:44Z monitors.arcdata.microsoft.com 2021-10-13T01:00:26Z postgresqls.arcdata.microsoft.com 2021-10-12T23:53:37Z sqlmanagedinstancerestoretasks.tasks.sql.arcdata.microsoft.com 2021-10-12T23:53:38Z sqlmanagedinstances.sql.arcdata.microsoft.com 2021-10-12T23:53:37Z В этом примере выходные данные указывают на наличие одного CRD, связанного с PostgreSQL: postgresqls.arcdata.microsoft.com shortname postgresqls . CRD не является сервером PostgreSQL. Наличие CRD не является признаком того, что у вас есть сервер или нет. CRD — это указание типа ресурсов, которые можно создать в кластере Kubernetes.
Как получить уведомление, когда станут доступны другие версии?
Вернитесь и прочтите эту статью. Он обновляется соответствующим образом.
Связанное содержимое:
- Сведения о создании сервера PostgreSQL с поддержкой Azure Arc
- Узнайте о получении списка серверов PostgreSQL с поддержкой Azure Arc, созданных в контроллере данных Arc.
Дистрибутив PostgreSQL для Windows
Компанией Постгрес Профессиональный подготовлены дистрибутивы PostgreSQL для Windows.
Это сборки PosgreSQL на основе кода из основной ветки без каких-либо дополнений и изменений.
Если Вам нужна версия PosgreSQL для Windows с поддержкой 1С, то Вы можете ее найти на сайте https://1c.postgres.ru
Дополнительные возможности и российскую техническую поддержку Вы можете получить вместе с Postgres Pro Standard и Enterprise.
- PostgreSQL 16.1: 64-разрядная,
- PostgreSQL 15.5: 64-разрядная,
- PostgreSQL 14.10: 64-разрядная,
- PostgreSQL 13.13: 64-разрядная,
- PostgreSQL 12.17: 64-разрядная, 32-разрядная,
- PostgreSQL 11.22: 64-разрядная, 32-разрядная,
- PostgreSQL 10.23: 64-разрядная, 32-разрядная .
Данное ПО поставляются «как есть», без какой-либо гарантии, явной или подразумеваемой.
Установка PostgreSQL для Windows
Рекомендуем устанавливать нашу сборку PostgreSQL на версиях Windows, для которых продолжается поддержка компании Microsoft. Технически PosgreSQL может работать и на более ранних версиях. Для установки 32 разрядной версии требуется Windows 7 SP1 и выше, для установки 64 разрядной — Windows 7 SP1 64bit и выше.
В процессе установки выбираются компоненты и задаются основные параметры сервера. Далее происходит инициализация нового сервера и создаются ярлыки для его управления.
Возможен «тихий» режим установки без вывода на экран.
Если обнаружено, что PostgreSQL сервер уже установлен, то предлагается остановить сервер и обновить его. При этом все соединения с сервером будут отключены. Для определения существования сервера используются данные о предыдущих установках из реестра, поэтому, если Вы ранее запускали сервер нестандартно, он может остаться не обнаруженным.
Выбор компонентов для установки
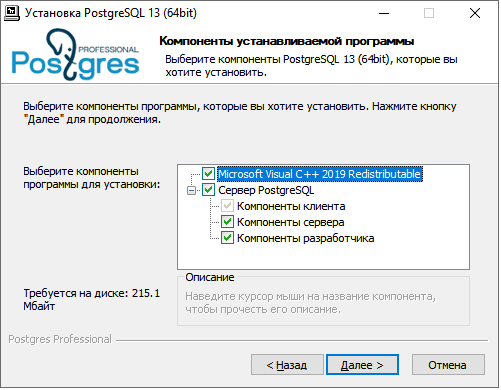
Вы можете установить все основные компоненты PostgreSQL или настроить установку, исключив серверную часть или компоненты для разработчика. Клиентская часть устанавливается всегда.
Клиентская часть содержит документацию и утилиты, которые могут потребоваться без установки сервера, например, psql, pg_dump и другие.
Компоненты для разработчика содержат заголовочные файлы, библиотеки и отладочную информацию.
Требуется также установить распространяемый пакет Visual C++, если он еще не установлен. Это небольшой набор системных библиотек от компании Microsoft.
Выбор путей для установки
Задается каталог для установки файлов сервера и каталог для создания базы данных. По умолчанию для установки предлагается каталог C:\Program Files\PostgreSQL\Номер_версии, а для данных C:\Program Files\PostgreSQL\Номер_версии\data.
Выбранный каталог данных должен быть пустым. В противном случае PostgreSQL не сможет создать начальную базу данных.
Допускается также указать каталог, содержащий данные. Тогда новая база данных не создается, а используется существующая. Важно, чтобы версия сервера совпадала с существующей базой данных.
Задание параметров сервера
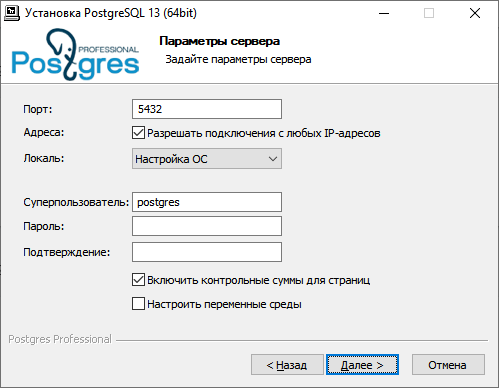
В процессе установки предлагается ввести некоторые параметры сервера.
Номер порта используется при подключению к серверу. Значение по умолчанию — 5432. При установке подбираются свободные номера портов начиная с 5432.
Локаль. По умолчанию для инициализации базы данных используется системна локаль Windows, но, при необходимости, можно выбрать нужную из списка.
Имя супер пользователя и пароль рекомендуем вводить только латинскими буквами. Имя пользователя по умолчанию — postgres. Запомните имя и пароль пользователя, заданные вами при установке, так как они потребуются для подключения к серверу при использовании аутентификации с проверкой пароля.
Если включен параметр «Разрешить подключения с любых IP-адресов», то в файлы сервера с настройками postgresql.conf и pg_hba.conf будут внесены параметры для разрешения внешнего доступа. Также изменяется конфигурация брандмауэра Windows для внешних подключений к серверу.
Параметр «Включить контрольные суммы для страниц» рекомендуем всегда включать, так как это повышает надежность хранения данных без заметного снижения производительности.
При включении параметра «Настроить переменные среды» программа установки создаст переменные среды с параметрами сервера: PGDATA, PGDATABASE, PGUSER, PGPORT, PGLOCALEDIR, а также добавит путь к исполняемым файлам сервера в переменную PATH.
Дополнительные параметры установки
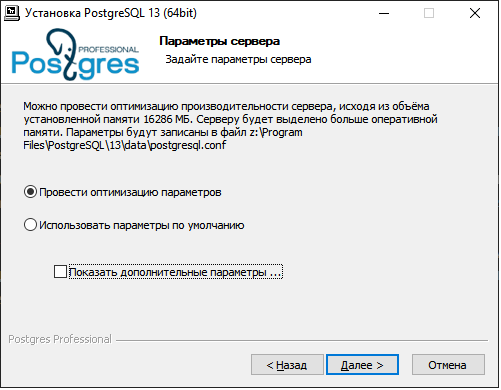
На следующем экране предлагается провести некоторую оптимизацию параметров сервера исходя из установленной оперативной памяти (если ее больше 1Gb). Для этого включите параметр «Провести оптимизацию параметров». Параметры сохраняются в файл postgresql.conf, который находится в папке с данными. Оптимизируются 2 параметра: shared_buffers и work_mem. Потом Вы можете самостоятельно изменять эти и другие параметры в зависимости от условий эксплуатации сервера.
Если включить параметр «Показать дополнительные параметры», то далее появится окно настроек системной службы PostgreSQL:
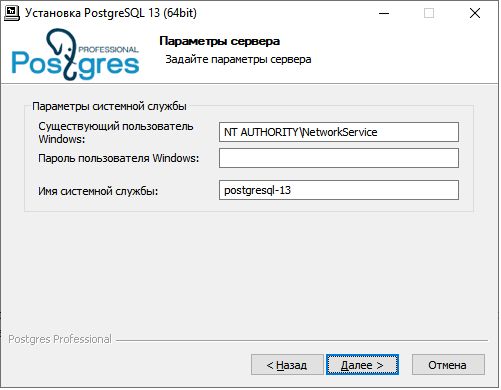
Для запуска сервера используется специальная встроенная учетная запись Windows: «NT AUTHORITY\NetworkService». Запуск службы можно настроить от другого пользователя, для этого введите имя и пароль уже существующего пользователя. Это может быть пользователь домена. Важно, чтобы пользователь уже существовал на момент установки и имел все необходимые права. В противном случае регистрация и запуск службы сервера не произойдет и потребуется удаление и новая установка PostgreSQL.
Возможно также изменить имя системной службы Windows для сервера. По умолчанию используется имя «postgresql-номер_версии», например, postgresql-13.
После успешной установки PostgreSQL сервер запускается и готов к работе
- SQL Shell (psql) — основное, консольное средство управления сервером и выполнения запросов.
- Reload Configuration — перезагрузить конфигурацию сервера из файлов конфигурации. Следует отметить, что для некоторых параметров требуется перезагрузка сервера.
- Restart Server — остановить и запустить сервер заново. Все активные соединения с сервером будут закрыты.
- Stop Server — остановить сервер. Все активные соединения с сервером будут закрыты.
- Start Server — запустить сервер.
В процессе установки создается тестовый файл install.log в каталоге установки. В нем сохраняются запускаемые команды и результат их выполнения во время установки.
Удаление сервера
Для удаления сервера выберите ярлык Uninstall, или запустите Uninstall.exe в каталоге установки, или используйте панель управления Windows. При удалении сервер останавливается, все активные соединения с сервером будут закрыты. Папка с данными не удаляется. Перезагрузка компьютера не требуется.
Ваши замечания и предложения по нашим сборкам PostgreSQL и по программе установки присылайте по e-mail: info@postgrespro.ru
Лицензия
PostgreSQL распространяется по специальной лицензии PostgreSQL License, свободной open source лицензии, близкой к лицензиям BSD и MIT.
PostgreSQL Database Management System (formerly known as Postgres, then as Postgres95)
Portions Copyright © 1996-2022, The PostgreSQL Global Development Group
Portions Copyright © 1994, The Regents of the University of California
Permission to use, copy, modify, and distribute this software and its documentation for any purpose, without fee, and without a written agreement is hereby granted, provided that the above copyright notice and this paragraph and the following two paragraphs appear in all copies.
IN NO EVENT SHALL THE UNIVERSITY OF CALIFORNIA BE LIABLE TO ANY PARTY FOR DIRECT, INDIRECT, SPECIAL, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, INCLUDING LOST PROFITS, ARISING OUT OF THE USE OF THIS SOFTWARE AND ITS DOCUMENTATION, EVEN IF THE UNIVERSITY OF CALIFORNIA HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
THE UNIVERSITY OF CALIFORNIA SPECIFICALLY DISCLAIMS ANY WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE. THE SOFTWARE PROVIDED HEREUNDER IS ON AN «AS IS» BASIS, AND THE UNIVERSITY OF CALIFORNIA HAS NO OBLIGATIONS TO PROVIDE MAINTENANCE, SUPPORT, UPDATES, ENHANCEMENTS, OR MODIFICATIONS.
Новое в 14-й и 15-й версиях Postgres
Иван Панченко, заместитель генерального директора Postgres Professional, на конференции Infostart Event 2022 Saint Petersburg рассказал о новшествах 14-й и 15-й версий PostgreSQL. Часть из них повышает производительность Postgres, часть – необходима для наиболее удобной работы, а некоторые, в дополнение, весьма полезны и для платформы 1С. В докладе приводятся практические примеры и результаты оригинальных тестов.

Я сегодня расскажу не обо всем, что нового появилось в Postgres, но о том, что в последних версиях, по моим представлениям, может быть полезным и интересным для 1С-ников. Приблизительно 14 лет назад фирма «1С» начала поддерживать Postgres, и это – очень хорошо. Можно порадоваться провидческой мудрости руководства фирмы и лично Бориса Нуралиева, который обратился в свое время к моим коллегам, разработчикам Postgres, чтобы сдружить эти две могучие экосистемы. Благодаря этому из 1С сейчас можно прекрасно работать на Postgres. Платформа 1С сейчас развивается навстречу Postgres – все лучше и лучше работает на нем. И Postgres тоже развивается – всем нам от этого хорошо. Лично я с Postgres знаком очень давно, с 1999 г., при этом сам являюсь скорее не разработчиком (написал только несколько патчей), а прикладным пользователем – в течение большого количества лет разрабатывал на PostgreSQL очень много разных систем. И когда в 2015-м году мы создали компанию Postgres Professional, я стал одним из ее соучредителей.
PostgreSQL и Postgres Pro: как правильно называются

Любой доклад по Postgres правильнее всего начать с разъяснения, почему он так называется. Существует заблуждение, что PostgreSQL – это Postgre и SQL. Очень многие люди, которые много используют Postgres, хорошо в нем разбираются, называют его Postgre. Но такого слова нет. У этого продукта есть два общепринятых названия – PostgreSQL или просто Postgres (он так назывался изначально, до 1996 года). Когда придумывали название PostgreSQL, народ уже тогда сомневался, что его будет удобно произносить – и там произошло слияние букв, свойственное для английского языка. А наша компания называется Postgres Pro, а не PostgreSQL Pro, потому что это по-русски было бы вообще не произнести.
PostgreSQL 14
 Теперь к сути. PostgreSQL 14 вышел в конце 2021 года, и все мы им уже активно пользуемся. Он оказался заметно быстрее, чем предыдущие версии, хотя, возможно, вы и не видите этой разницы. PostgreSQL и так уже достаточно быстр, и те оптимизации и ускорения, которые в нем появляются, проявляются не всегда, а в каких-то конкретных случаях – их у вас может не быть. Или, если у вас маленькая база, вы можете не заметить этих проблем. Но дальний конец (Hi End) всегда упирается в определенные проблемы производительности – и их разработчики решают в первую очередь. На слайде приведен грубый список того, что было реализовано для PostgreSQL 14 и, вероятно, относится к 1С. Сейчас я хочу чуть детальнее рассказать про все эти вещи. И потом еще расскажу про 15-й PostgreSQL, потому что там тоже появились интересные штуки, которые 1С-никам могут пригодиться.
Теперь к сути. PostgreSQL 14 вышел в конце 2021 года, и все мы им уже активно пользуемся. Он оказался заметно быстрее, чем предыдущие версии, хотя, возможно, вы и не видите этой разницы. PostgreSQL и так уже достаточно быстр, и те оптимизации и ускорения, которые в нем появляются, проявляются не всегда, а в каких-то конкретных случаях – их у вас может не быть. Или, если у вас маленькая база, вы можете не заметить этих проблем. Но дальний конец (Hi End) всегда упирается в определенные проблемы производительности – и их разработчики решают в первую очередь. На слайде приведен грубый список того, что было реализовано для PostgreSQL 14 и, вероятно, относится к 1С. Сейчас я хочу чуть детальнее рассказать про все эти вещи. И потом еще расскажу про 15-й PostgreSQL, потому что там тоже появились интересные штуки, которые 1С-никам могут пригодиться. 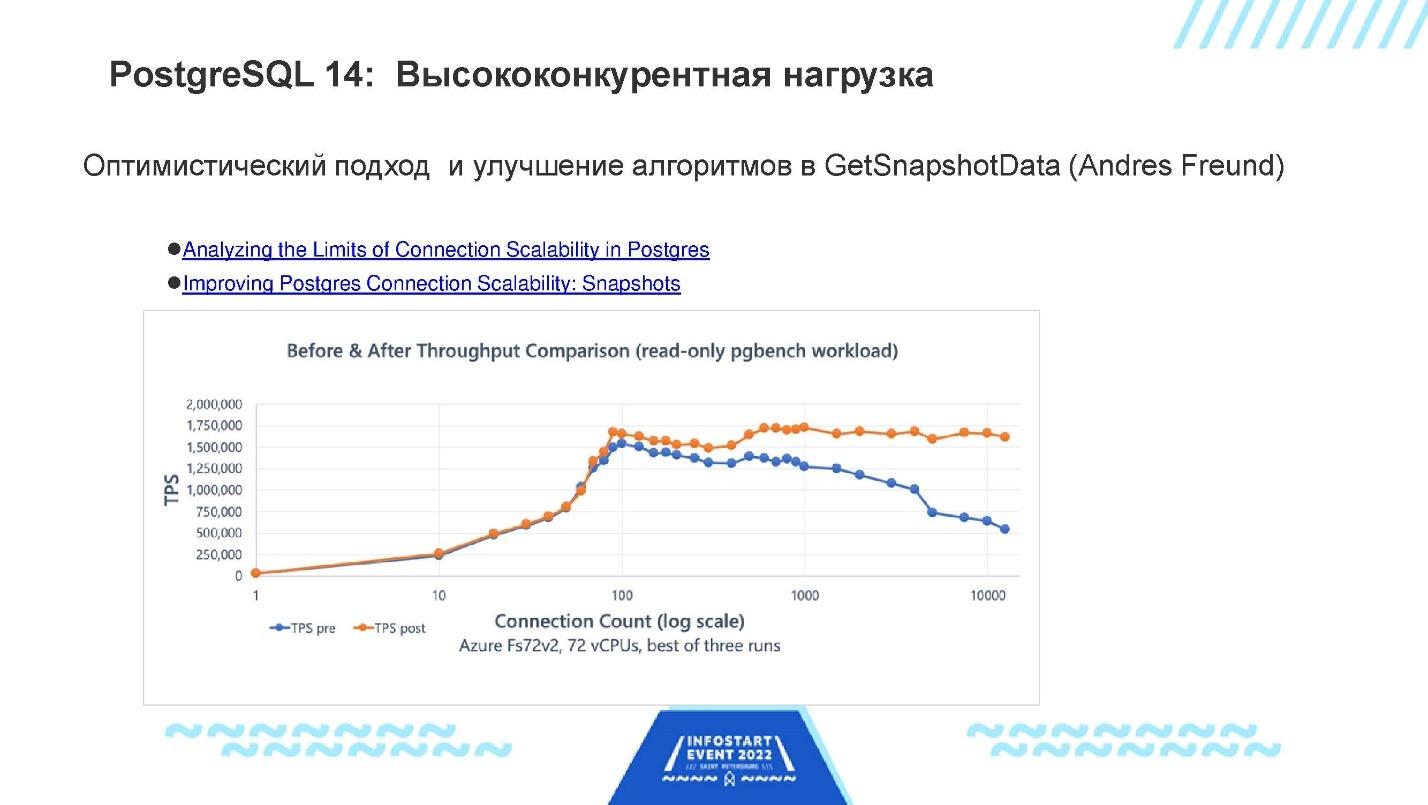 Высококонкурентная нагрузка. Первый и, с моей точки зрения, самый важный патч, который вошел в состав PostgreSQL 14 – это патч Андерса Фройнда для того, чтобы ускорить получение снапшота в базе. Снапшотом в PostgreSQL называют описание текущего состояния базы. Снапшот – это текущее состояние базы с точки зрения взаимной видимости транзакций, т.е.информация о том наборе (м.б. большом) транзакций, которые одновременно исполняются в настоящий момент. Чтобы понять, какие версии записей одна данная транзакция должна видеть, нужно иметь представление о том, какие транзакции вообще в это время существуют, в каком они состоянии – какие уже закоммичены, а какие – нет. Совокупно все это называется снапшот. И вычисление снапшота – это довольно трудная операция, когда действует параллельно много транзакций, много сессий. Разработчики постгреса всё время пытаются оптимизировать эту операцию. И Андерс Фройнд в данном случае очень глубоко проанализировал все эти алгоритмы и описал свои выводы в статьях:
Высококонкурентная нагрузка. Первый и, с моей точки зрения, самый важный патч, который вошел в состав PostgreSQL 14 – это патч Андерса Фройнда для того, чтобы ускорить получение снапшота в базе. Снапшотом в PostgreSQL называют описание текущего состояния базы. Снапшот – это текущее состояние базы с точки зрения взаимной видимости транзакций, т.е.информация о том наборе (м.б. большом) транзакций, которые одновременно исполняются в настоящий момент. Чтобы понять, какие версии записей одна данная транзакция должна видеть, нужно иметь представление о том, какие транзакции вообще в это время существуют, в каком они состоянии – какие уже закоммичены, а какие – нет. Совокупно все это называется снапшот. И вычисление снапшота – это довольно трудная операция, когда действует параллельно много транзакций, много сессий. Разработчики постгреса всё время пытаются оптимизировать эту операцию. И Андерс Фройнд в данном случае очень глубоко проанализировал все эти алгоритмы и описал свои выводы в статьях:
- Analyzing the Limits of Connection Scalability in Postgres
- Improving Postgres Connection Scalability: Snapshots
Там можно почитать, как он к этому шел.
На слайде приведен график результата. По горизонтальной оси – количество соединений, а по вертикальной оси – количество транзакций в секунду в простом read-only-тесте, который фактически ничего не ищет в базе, а только получает снапшот.
Видно, что PostgreSQL 14 стал лучше работать с большим количеством соединений. А с маленьким – ничего не поменялось.
Это очень большое достижение, и оно некоторым нашим заказчикам сильно помогло на 50%-100% поднять скорость работы PostgreSQL при большом количестве соединений.
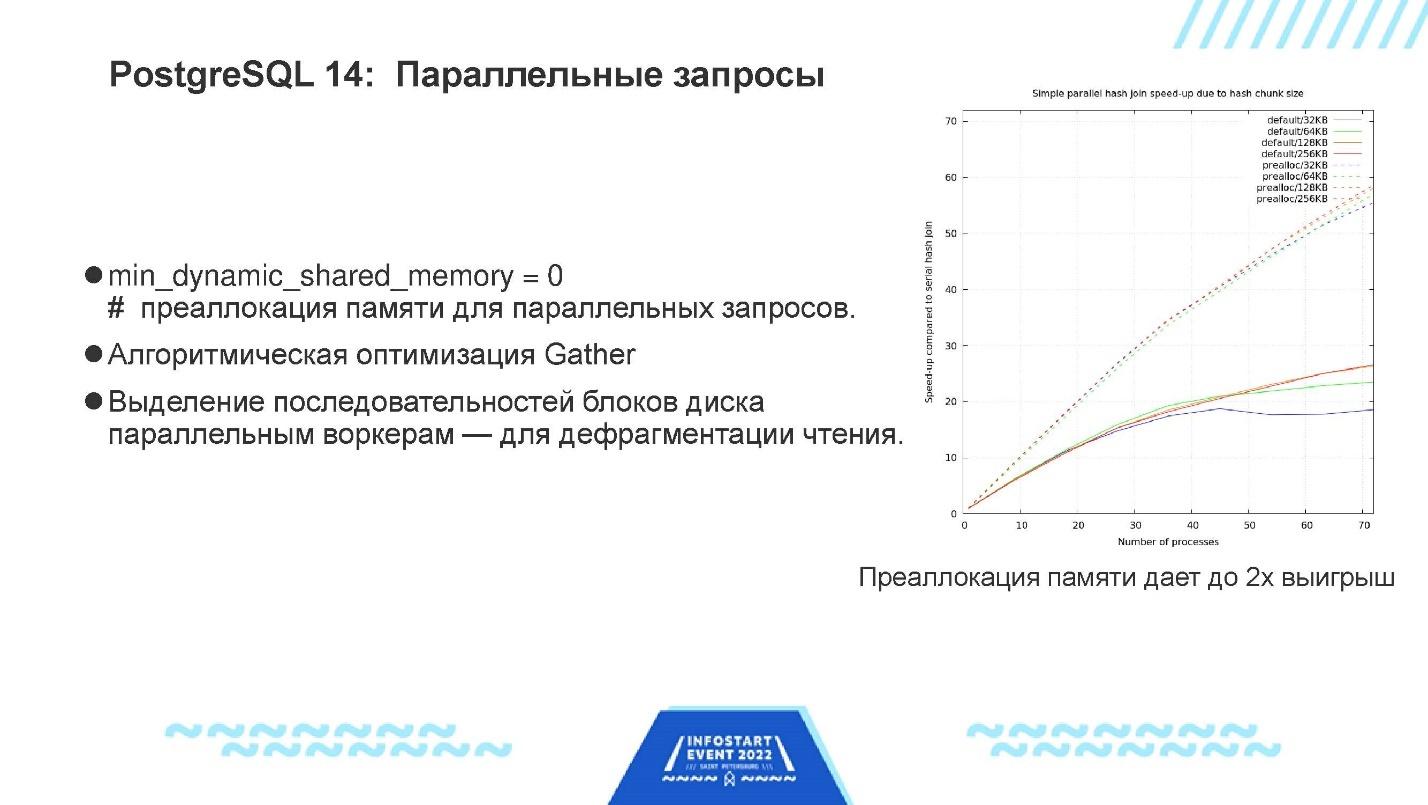
Параллельные запросы.
- Появилась возможность предварительно выделять память для использования в параллельных запросах. Это – память, через которую отдельные воркеры обмениваются между собой данными. Никто не ожидал от этой возможности заметного эффекта, но оказалось, что здесь очень легко получить выигрыш примерно в два раза.
- В 14-м PostgreSQL есть и другие оптимизации, связанные с параллельными запросами. Например, раньше, когда несколько воркеров читали одну и ту же таблицу, им выделялись отдельные несвязанные куски этой таблицы, что заставляло их читать ее хаотическим образом, не подряд. А когда из памяти читаешь не подряд, это всегда медленнее, чем подряд. Поэтому сейчас им выделяются большие куски, каждый из которых читается подряд, чтобы чтение было менее фрагментированным.
Все это в совокупности дает достаточно большой выигрыш для параллельного исполнения запросов.
Напомню, что параллельное исполнение запросов помогает для больших аналитических долго идущих запросов. Для них есть смысл распараллелить вычисления, потому что в этом случае обмен данными между отдельными воркерами не является большим оверхедом, который сильно замедлит запрос.
Т.е. понятно, что маленькие запросы, которые достают из базы одну-две записи, параллелить не стоит. А вот большие запросы от параллелизима хорошо выигрывают.
График на слайде – аналогичный. Здесь по горизонтали – количество процессов, которые исполняют данный конкретный запрос. А по вертикали – производительность. Те кривули, которые идут выше всего – это новая 14-я версия с преаллокацией памяти и всеми остальными фичами.
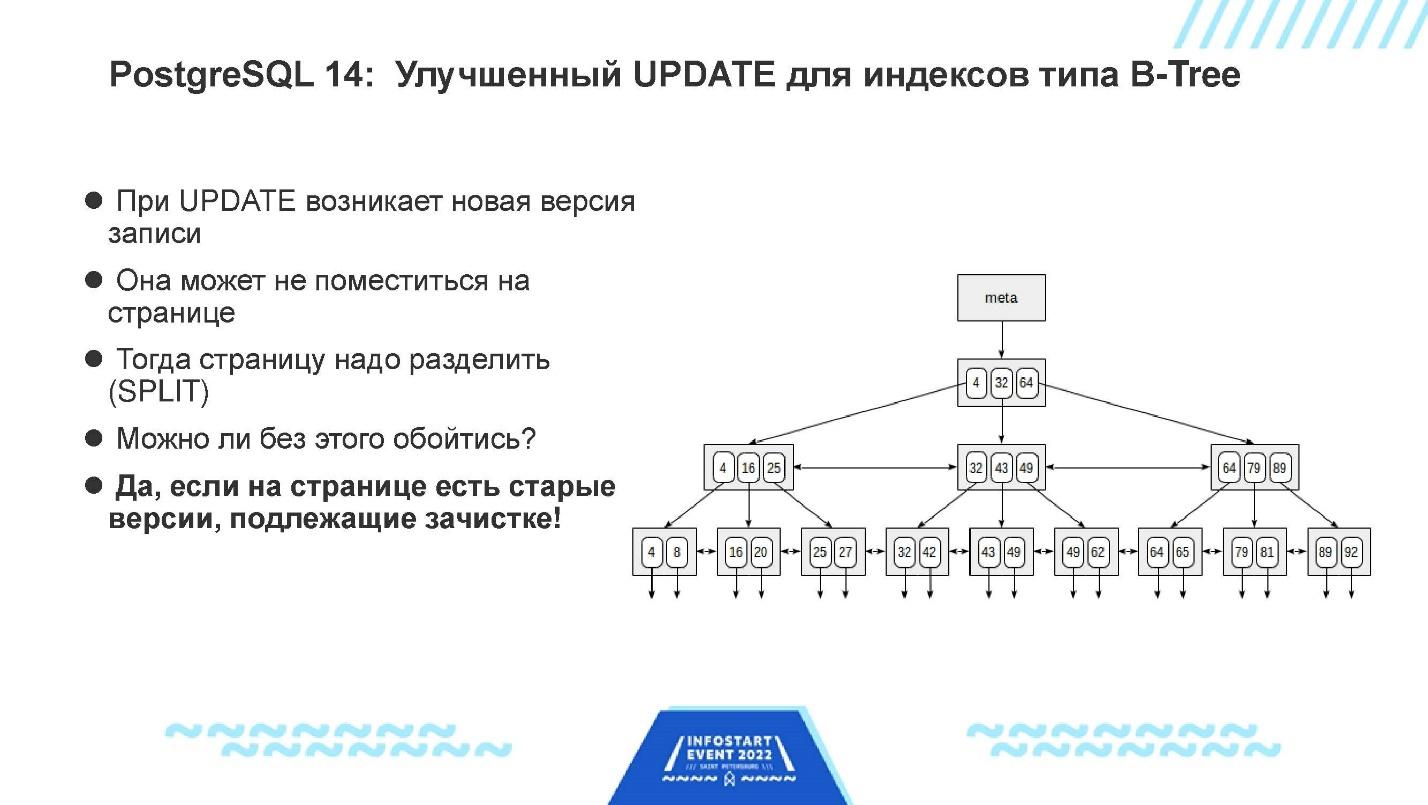
Оптимизация UPDATE – это еще одна важная вещь, которая появилась в 14-м PostgreSQL.
На картинке – схематическое изображение B-дерева (основной тип индекса, который используется в PostgreSQL чаще всего).
Когда мы апдейтим запись, для нее возникает новая версия, которая с большой долей вероятности где-то попадает в индекс.
Для PostgreSQL существует HOT (Heap only tuples) оптимизация, когда при апдейте записи новой вставки в индекс не происходит. Но предположим, что эта оптимизация не сработала – новая версия возникает и вставляется в индекс.
Индекс состоит из отдельных страниц – как и все в PostgreSQL. И если, например, мы не уместились на страницу, происходит операция SPLIT, когда страница индекса раздвигается на две – в ней становится больше узлов.
Понятно, что индекс при этом распухает – в нем добавляется целая страница. Причем, может быть, он распухает зря, потому что старую неактуальную версию записи через некоторое время удалят, но лишняя страница в индексе уже есть. И получается, что размер индекса все время чуть больше, чем нужно. Это не очень хорошо.
Поэтому появилась новая интересная оптимизация, которая прежде, чем раздвинуть индекс, выполняет конкретно для этой страницы операцию вакуума. Она смотрит – есть ли на текущей странице записи, которые уже подлежат удалению. Если они есть, она их удаляет, после чего на странице появляется место, и, если его хватает, SPLIT не происходит.
Благодаря этого индекс не растет, дисковых операций меньше, и индекс меньше. Поэтому и поиск по нему производится быстрее.
Эта штука очень помогает, если у вас большая апдейтовая нагрузка – много раз апдейтятся одни и те же записи.

Кеширование Nested Loop в памяти. Эта возможность – более туманная, потому что она срабатывает только для некоторых типов запросов. В реальной жизни мы крайне редко попадаем в ситуацию, когда это срабатывает.
Но это – еще одна новая операция, которая совершается исполнителем запросов, когда он обрабатывает узлы (ноды) в дереве запроса. Напоминаю — для исполнения SQL-запроса он компилируется в дерево, узлы которого – это отдельные операции.
В 14-й версии появилась новая операция, которую назвали ResultCache, потом поняли, что это название слишком общее, поэтому в 15-й версии ее переименовали в Memoize. Так называется операция, когда при выполнении в запросе Nested Loop (вложенного цикла) мы кешируем результаты промежуточных вычислений.
На слайде приведен пример простого запроса с SELECT из таблиц customer и issue, в котором JOIN делается с помощью Nested Loop (вложенного цикла). Запрос обходит в цикле все записи внешней таблицы customer, и для каждого элемента таблицы customer ищется подходящий ему issue.
Этот запрос может выполняться двумя способами – либо мы сканируем вначале customer, а потом для него ищем issue, либо наоборот – вначале issue, а потом для него находим customer. Планировщик выбирает, что из этого эффективнее.
В данном примере планировщик нам подобрал, что эффективнее вначале идти по issue, для него по ID искать customer и результат запоминать в кэш памяти с помощью операции Memoize.
Важно, что Memoize работает в памяти, в отличие от варианта Hash Join, когда вначале строится хэш таблицы, а потом из нее уже по ключу все выбирается. Здесь кэш строится по ходу исполнения запроса – только в том случае, если известно, что результат поместится в память. Если результат в память не помещается, смысла в этом алгоритме уже никакого нет, это не быстро – то же самое, что и просто достать по индексу.
Иногда помогает. Есть специальный параметр, которым такое кеширование можно отключить. По умолчанию оно включено. Есть встретится в плане запроса слово Memoize – не пугайтесь, это сработала новая фишка. Возможно, она вам поможет.

Возможность бесшовно перенести индекс в другое табличное пространство – еще одна полезная вещь для админов баз.
В PostgreSQL есть ключевое слово CONCURRENTLY, которое означает, что операция совершается без блокировок, легко и незаметно, на фоне всего остального. С 14-го PostgreSQL вы можете в таком режиме произвести реиндексацию так, что новый индекс будет в другом табличном пространстве.
Т.е. если у вас кончается место на диске, вы можете сразу строить индекс на другом диске, который вы принесли и подключили – построить индекс в нем. И это можно делать в режиме CONCURRENTLY – без каких-либо дополнительных блокировок.
Раньше вы могли переносить индекс с помощью команд:
ALTER INDEX SET TABLESPACE
или даже ALTER TABLE SET TABLESPACE (перенести вместе с таблицей)
Но эти варианты плохие, потому что они блокируют вам этот индекс (или эту таблицу, что практически то же самое). И эти блокировки длятся все время, пока у вас происходит операция. Это может быть долго.
Начиная с PostgreSQL 14 вы это можете делать совершенно незаметно, прозрачно и бесшовно, в режиме CONCURRENTLY.
Для предыдущих версий PostgreSQL есть расширение pg_squeeze – кто не боится, может с его помощью те же операции проделывать.

Другие новые бесшовные операции, которые появились в PostgreSQL 14 – это:
Возможность отцеплять партицию от партицированной таблицы. Фактически, таблица отцепляется, когда она уже никому не нужна. Просто она дожидается, пока завершатся все транзакции, которые использовали находящиеся в этой партиции записи или версии записей.
Кроме этого, теперь вы можете запускать одновременно несколько конкурентных операций по разным таблицам. Раньше в режиме CONCURRENTLY можно было делать только одну операцию одновременно – например, только один конкурентный реиндекс.
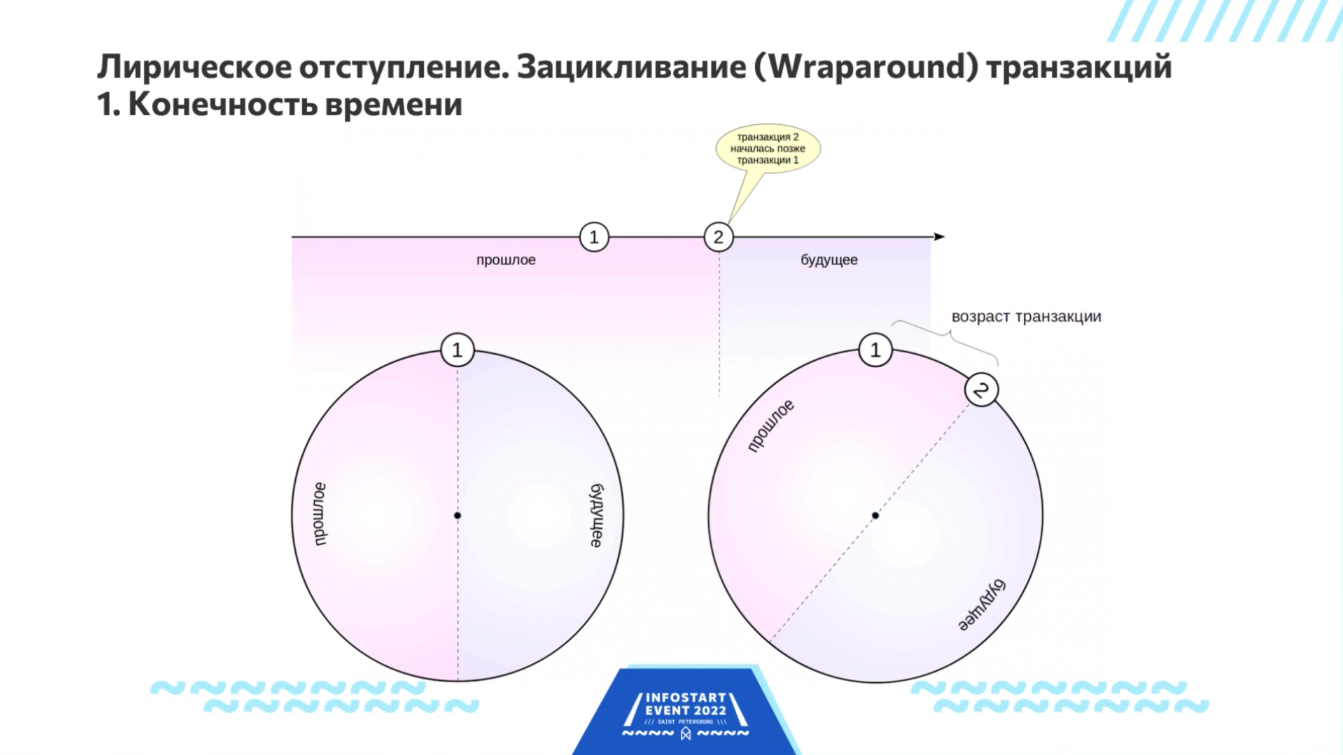
Wraparound: решение проблемы выхода за пределы кольца времени
Теперь я должен напомнить вам о Wraparound – это одна из больших проблем PostgreSQL, которая связана с тем, что у тех, кто реализовывал PostgreSQL, были другие приоритеты. Очень многое из того, что есть в PostgreSQL сейчас, связано с теми или иными решениями, которые были приняты еще 30 лет назад. Может быть, с точки зрения современности они кажутся нам неправильными – знай мы тогда то, что будет сейчас, мы бы сделали по-другому, были бы мудрее Стоунбрейкера и его последователей. Но они жили тогда и знали то, что тогда было известно.
Итак, в PostgreSQL есть проблема зацикливания транзакций. Она связана с тем, что есть прошлое и будущее. Транзакции идут, завершаются, у каждой версии записи есть область видимости, которая прописана во времени.
В реальности, время бесконечное, но в PostgreSQL для обозначения времени и нумерации транзакций используются 32-битные числа, которые, конечно, небесконечны – образуют так называемую циклическую группу, когда вы прибавляете к самому большому числу единицу и получаете самое маленькое число. Так нужно делать, потому что иначе через миллиард транзакций у вас все встанет колом — упрётся в стену недостижимого будущего. Чтобы оно колом не становилось, время пришлось зациклить.
Стрелка этого времени крутится по кругу. И считается, что половина этого круга, где находятся номера транзакций справа от текущего момента – это будущее, а та половина, которая находится слева от текущего момента – это прошлое. И так постепенно это все крутится.
С другой стороны, если какая-то транзакция существует очень давно, она может из прошлого переползти в будущее. И это нехорошо.
Этот эффект называется Wraparound или зацикливание – когда транзакция из прошлого, которая уже завершилась, вдруг оказывается в будущем. В этой ситуации PostgreSQL говорит – я больше не могу работать.
Подобная ситуация возникает, когда у вас транзакция открылась, и ждет, пока два миллиарда транзакций пройдет, чтобы попасть из прошлого в будущее. Такое редко, но бывает, если есть еще какие-то причины, по которым прошлое у нас не может быть забыто. Точнее — заморожено.
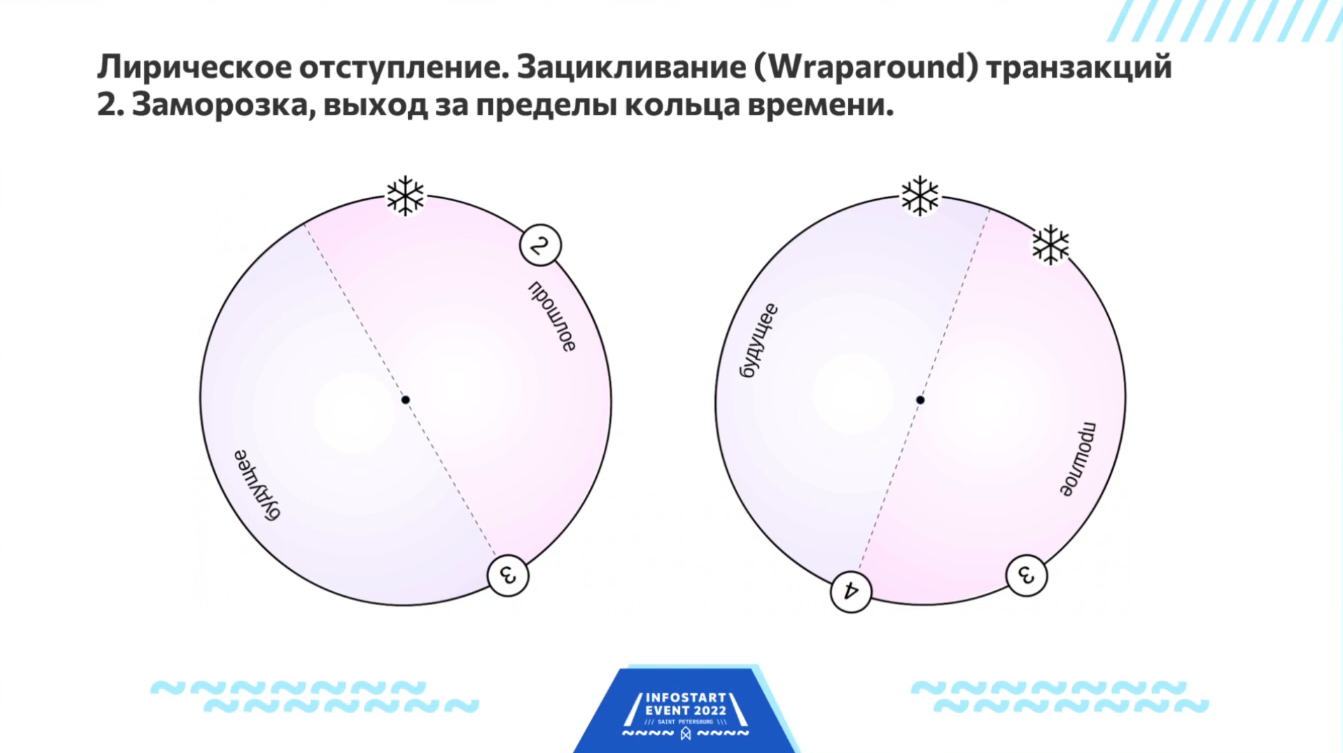
Чтобы при выходе за пределы кольца времени прошлое не исчезало совсем, происходит так называемый FREEZE (заморозка).
Помимо прошлого, которое отображается на нашем циферблате, есть еще абсолютное прошлое. FREEZE – это перенос относительного прошлого, которое умещается на циферблате, в абсолютное прошлое, которое «заморожено».
Какие-то версии записей помечаются как замороженные, это значит, что они всегда в прошлом, какой бы номер транзакций у них ни был. Это – одна из функций Vacuum, процесса непрерывного обслуживания базы – он удаляет старые версии записей, ставшие ненужными после завершения транзакций, работавших с ними,, а нужные версии, остающиеся в прошлом – замораживает, т.е. объявляет, что они в прошлом всегда и для них уже не страшно, что циферблат прокрутится.
Чтобы Wraparound не было, вам нужно, чтобы Vacuum всегда успевал подходить и делать этот FREEZE – замораживать старые записи.

В PostgreSQL 14, чтобы Wraparound не наступал так скоро, с такой неотвратимостью, на помощь приходит некоторые дополнительные настройки, которые подсказывают серверу, что если Wraparound близко, т.е. если этот циферблат подкручивается, т.е. прошлое уже подступает к будущему, нужно проводить autovacuum активнее. Он перестает делать какие-то менее срочные задачи и сосредотачивается на том, чтобы замораживать все больше и больше записей.
Он должен успеть «зафризить» (заморозить) нужные записи, пока вы не достигли «предела будущего» – есть специальные параметры vacuum_failsafe_age и vacuum_multixact_failsafe_age, которые управляют тем, насколько активно он это делает.

Статистика по выражениям на таблицах – не знаю, используются ли в 1С хранимые функции, но для того, чтобы планировщик Постгреса лучше оптимизировал запросы по ним, можно создавать специальную статистику.

Новое в статистических представлениях.
- Если вы используете pg_stat_activity и pg_stat_statements, между ними теперь можно делать JOIN, потому что у этих таблиц появился общий идентификатор queryid. Это бывает очень удобно.
- Кроме того, появилась вьюха (системное представление) pg_backend_memory_contexts, которая позволяет смотреть, какой бекэнд у вас сколько памяти съел и для чего.
- И в таблице pg_locks появилось поле waitstart – оно показывает, когда был получен лок. Т.е. вы теперь можете узнать, сколько времени эта блокировка висит.
PostgreSQL 15

Кое-что полезное появилось и в 15-м PostgreSQL.
- Самая громкая вещь, которая там появилась – это SQL-операция MERGE, но она в 1С не используется.
- Появился вариант компрессии Zstd, наряду со старой lz4-компрессией. Она чуть побыстрее, чуть получше – возможно, даст небольшой эффект.
- Есть некие оптимизации по сортировкам, по статистике. Здесь идет речь о статистике, которая считает, сколько было апдейтов, сколько чтений, записи и т.д.
- Появились новые возможности, связанные с pg_basebackup
- С архивацией WAL-ов.
- И, как всегда, ряд оптимизаций в планировщике.

Как изменилась работа со статистикой в PostgreSQL 15. Раньше:
- каждый бекэнд копил в себе статистику, считал, сколько было апдейтов, сколько инсертов и т.д.;
- время от времени StatsCollector (отдельный процесс) это сбрасывал на диск в директорию PGDATA/pg_stat_tmp/;
- из этой директории вы эту статистику зачитывали, когда делали запрос SELECT from pg_stat_tables и смотрели, сколько раз использовался тот или иной индекс, таблица и т.д.
- Сейчас бекэнды пишут прямо в shared-память.
- На диск это сбрасывается только при остановке сервера.
Если сервер остановили неаккуратно, часть данных по статистике пропадет – но это не столь важно, зато меньше издержек и меньше лишних шевелений с диском.

Оптимизация планировщика.
- Если в базе много вложенных view, планировщик расходует время по количеству view. Сначала мы думали, что количество времени расходуется в экспоненциальной зависимости от количества. Потом Том Лейн аккуратно посчитал – оказалось, что зависимость кубическая. В PostgreSQL 15 удалось сделать эту зависимость квадратичной – т.е. большое количество вложенных вьюшек теперь не так страшно.
- При создании в SQL-запросе функции появилась возможность указать для нее SUPPORT-функцию, которая будет подсказывать планировщику, как эту функцию планировать – как у нее статистические параметры. Такие вспомогательные функции пока можно написать только на C, но в будущем возможности их создания будут расширены.
- Для рекурсивных запросов появился параметр recursive_worktable_factor – можно указать, сколько итераций будет в рекурсивном SQL-запросе. Неправильно, потому что в одном рекурсивном запросе может быть несколько рекурсивных частей, и у них может быть разный фактор рекурсии. Пока что этот параметр общий, поэтому нужно задавать что-то среднее.
- Про оптимизацию планирования group by я расскажу далее.

Архивация WAL. Известно, что логи транзакций WAL сбрасываются на диск, их можно архивировать и куда-то переносить.
- Раньше для этого запускалась команда, которая задавалась в параметре конфигураций archive_command.
- Теперь это может быть не только внешняя утилита, но и какая-то библиотечка, которая в каком-то расширении определяется. Понятно, что функцию из библиотеки быстрее вызывать, чем запускать внешнюю команду. Особенно, под большой нагрузкой, когда это делается часто. У нас есть такие клиенты, у которых WAL-трафик сотни мегабайт в секунду.
В качестве примера такого модуля сейчас есть расширение basic_archive, которое реализует перенос этих WAL-ов.
Также для WAL появилась интересная утилита pg_walinspect, которая позволяет смотреть, что записывается в WAL. Тоже довольно интересно, когда WAL-трафик большой.

Логическая репликация. Я знаю, что некоторые 1С-ники используют логическую репликацию. В ней появилась важнейшая вещь.
Теперь можно публиковать не всю таблицу, а только часть этой таблицы – определенные колонки или определенную выборку WHERE. Это позволяет вам частично реплицировать таблицы. Очень удобно, когда речь идет об аналитике, и вам нужно куда-то копировать часть данных.
Раньше при логической репликации могли происходить ошибки – в процессе репликации вы можете локально что-то поменять в этой базе, из-за этого происходил конфликт. Раньше она долбилась до тех пор, пока этот конфликт кто-нибудь не решит. Сейчас появилась установка disable_on_error, которая отключала подписку при ошибке. О том, что произошла ошибка, вы узнаете из лога. Появились специальные системные вьюшки, вы можете сказать потом, что какую-то транзакцию нужно пропустить, а потом дать команду ALTER SUBSCRIPTION enable, и она пойдет дальше.
У вас есть время, не напрягая сервер, спокойно решить ситуацию.

Оптимизация GROUP BY. Раньше планирование запроса с GROUP BY по двум или нескольким колонкам зависело от порядка полей в группировке, что, в принципе, неправильно.
Но Федор Сигаев нашел эту штуку – как раз при работе с 1С. И исправил. Теперь, в каком бы порядке ни был GROUP BY, оптимизатор будет исследовать все варианты, в каком порядке по этим полям можно группировать.

Несколько оптимизаций для SELECT DISTINCT – для него теперь доступно больше вариантов:
- может использоваться HashAggregate,
- может использоваться сортировка
- или не использоваться сортировка
В разных случаях разные способы оказываются быстрее.

Оптимизация сортировки для выборки – когда вам нужно одну колонку достать и по ней же отсортировать. Тогда будут сортироваться не записи, содержащие эту колонку, а сами значения колонки – понятно, что это – гораздо быстрее.
Также нашли в третьем томе Кнута алгоритм сбалансированного многопоточного слияния и применили его для случая, когда сортировка не умещается в памяти, и промежуточные результаты сбрасываются на диск.

Оптимизация IN в большом списке кажется мне очень важной для 1С. Ее применительно к 1С и реализовали. Запрос IN или NOT IN – если список большой, стал работать намного быстрее. Нужно будет это проверить на реальных 1С-ных случаях и посмотреть, какой будет результат.

Результат pg_basebackup теперь можно направлять в пайп (не только на диск) и делать с ним там, что угодно.

Кроме этого, появился еще ряд оптимизаций по VACUUM (по той же заморозке). И другие вещи.
Что нового в Postgres Pro

А что интересного в последних версиях Postgres Pro, насколько он отличается от обычного PostgreSQL?
Напоминаю, что сборка PostgreSQL от Postgres Pro:
- поддерживает 1С без дополнительных патчей и настроек;
- в нем вообще нет Wraparound, потому что счетчик транзакций 64-битный – как, кстати, изначально и хотел сделать Стоунбрейкер в 1986 году;
- в нем поддерживается блочная компрессия, о которой рассказывал Антон Дорошкевич;
- есть инкрементальный бэкап, который позволяет вам легко бэкапить большие таблицы;
- и, внимание, в 15-й версии Postgres Pro Enterprise блочная компрессия будет совместима с инкрементальным бэкапом – это то, чего давно народ ждал.
Подробности
- В серии статей Павла Лузанова на Habr.com все изменения 14-й и 15-й версии описаны детальнейшим образом:
- PostgreSQL 15 https://habr.com/ru/company/postgrespro/blog/679264/
- PostgreSQL 14 https://habr.com/ru/company/postgrespro/blog/550632/
В заключение хочу сказать, что с 3 по 4 апреля пройдет большая всероссийская конференция PGConf.Russia 2023 – присоединяйтесь!
Вопросы:
Все изменения, о которых говорилось в докладе, касаются «ванильной» версии PostgreSQL?
Да, все эти изменения есть в ванильной версии. В Postgres Pro большого количества сейчас нет, кроме того, что я уже говорил. Все изменения связаны с тем, что все работает еще быстрее, еще надежнее. Для 1С есть специальная новая фича – это совместимость дисковой компрессии с инкрементальным бэкапом. Есть еще ряд фич по безопасности, но они больше касаются банков, чем 1С.
Мы сейчас переводим базы с MS SQL. Берем PostgreSQL с сайта 1С. Нас волнуют планы обслуживания и автоматический бэкап. Там это просто отсутствует. Как там делать бэкапы и как обслуживать базы?
В PostgreSQL так устроено, что бэкап – это внешняя задача, которую не сам PostgreSQL делает, а вы с ним делаете. Способов для бэкапа много, они описаны в документации.
Стандартный полный бэкап базы делается с помощью утилиты pg_basebackup – его можно делать непосредственно по ходу работы без каких-то блокировок по расписанию, которое вы сами определите.
Чтобы можно было восстановиться на любую точку времени, параллельно используйте архивирование WAL-ов. Это – простейший способ.
Если вы хотите чего-то продвинутого, вы можете использовать утилиты, которые не входят в состав PostgreSQL, а присутствуют где-то на GitHub, или, если речь идет о Postgres Pro, то в репозитории Postgres Pro.
В частности, мы разрабатываем утилиту pg_probackup – она распространяется свободно и разрабатывается в опенсорсе. Утилита pg_probackup дает вам дополнительные возможности по управлению бэкапами, по тому, чтобы делать инкрементальный бэкап. Но расписание бэкапа – это все равно вопрос к вам. Вы должны настроить его внешними средствами – кроном или чем-то еще.
Но в планы обслуживания входят не только бэкапы, но еще и другие вещи, связанные со статистикой, вакуум и прочее. Хотелось бы, чтобы было такое средство – прямо встроенное.
Вакуум встроенный. Он работает сам из коробки. Настраивает его не нужно, если вы вдруг не чувствуете, что он плохо справляется с этим. Как определить, что он плохо справляется, написано в статье Егора, про которую я говорил в докладе. Если вы видите, что база распухает, происходит ее рост – это связано с тем, что вакуум не успевает зачистить лишние записи. Нужно сделать его более агрессивным, чтобы он чаще и активнее зачищал старые версии. Тогда вы смотрите в статье Егора или в документации PostgreSQL, что за параметры за это отвечают, и их меняете. Примерно так.
В ближайшее время появится графическое средство для администрирования PostgreSQL, которое разрабатываем мы. Там вам станет легче диагностировать эти ситуации. Но пока мы его еще никому не показывали. Надеюсь, на следующей конференции Инфостарта, я расскажу уже про него.
В большинстве Enterprise-решений в самой базе хранится информация о том, когда для нее делали бэкап. Планируется ли когда-нибудь в PostgreSQL добавить строчку о том, когда был сделан последний бэкап?
Мы обсуждали, что такую штуку нужно сделать. Только запись о том, что есть бэкап, не означает, что есть бэкап. Да и что вам самим мешает добавить табличку, и средством, которым вы делаете бэкап, писать туда, когда был последний бэкап.
Вопрос про расширение pg_stat_statements. Практика разработки на 1С подразумевает очень большое использование временных таблиц. И один и тот же запрос, когда у вас большое количество пользователей, он в статистике pg_stat_statements будет выглядеть очень большим количеством разных запросов. Планируется ли нормализация какая-либо?
Нет, такого пока никто от нас не просил. Вы – первые. У нас в Enterprise-версии есть такая фишка как глобальная временная таблица – она всегда одна, но разные сеансы видят из нее свою часть. В Oracle такое тоже есть.
Если перейти на ее использование, тогда автоматически это будет одна и та же таблица, и вашей проблемы не будет.
Но расширение pg_stat_statements все равно это не поймет – все равно на GitHub нужно будет записать это пожелание.
На одном из прошлых мероприятий Инфостарта было обещано, что в pg_hint_plan скоро появится вылавливание параметров GUC в любом месте запроса, включая текстовые литералы – по-моему, это будет называться hints_anywhere. Потому что по-другому никак не повлиять на план запроса из кода 1С – у нас платформа почти всегда генерит уникальный запрос, и стандартное использование расширения не работает. Есть ли информация, когда это появится?
Патч готов, его можно использовать как расширение. Но в релиз эта возможность пока не вошла. Может быть, мы сможем ее встроить в Postgres Pro в ближайшее время – нужно посмотреть.
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event 2022.
30 мая — 1 июня 2024 года состоится конференция Анализ & Управление в ИТ-проектах, на которой прозвучит 130+ докладов.
Темы конференции:
- Программная инженерия.
- Инструментарий аналитика.
- Решения 1С: архитектура, учет и кейсы автоматизации на 1С.
- Управление проектом.
- Управление продуктом.
- Soft skills, управление командой проекта.
Конференция для аналитиков и руководителей проектов, а также других специалистов из мира 1С, которые занимаются системным и бизнес-анализом, работают с требованиями, управляют проектами и продуктами!
Postgresql какую версию выбрать
На диске 1с предприятие сервер мини есть папка PostgreSQL, в которой есть два файла
postgresql-9.3.4-1.1C.msi
postgresql-9.3.4-1.1C-int.msiПодскажите пожалуйста, чем они отличаются и какой надо запускать?
На сайте 1С есть версия 10.5-6.1C, стоит ли ставить последнюю версию?postgresql-9.3.4-1.1C-int.msi
9.6.7 стоит у меня, полет нормальный, более новые версии не тестил. Но учитываю глючный интерфейс 9.6.7, возможно будет лучше попробывать последнюю версию. Так же тюнинг немного изменился, стоит учитывать. На 9.6.7 перешли чисто из-за того, что в начиная с этой версии запросы с множественным внутренним соединением стали отрабатыватся так же быстро как и MSSQL
(0) А вы точно уверены, что оно вам вообще надо? Может лучше по-старинке — MS SQL?
Если уж ставить сервер, то лучше, наверное ставить более свежие релизы. Быть может не 10.5, но и не древний 9.3.4.(0) postgresql-9.3.4 что-то старовата. не?
(4) точно не ставь эту версию, там проблемы с некторыми запросами
(4) ставь начиная с 9.6.7(3) после версии 9.6.7 доволен как мамонт ))) Нехватает только что инструментов анализ запросов и плана запросов удобного, но это дело привычки
(0) если будешь качать соотв. этому релизу свежую платформу 1С , то ставь вот самый свежий постгрес и платформу.
(0) на юзерсе не последняя версия постгри. это последняя прошедшая аттестацию под нужды платформы 1с.
т.е. можно ее ставить достаточно смело.(8)(9) я б не рубил так с гореча, может падать, бывало, не все релизы одинаково стабильны. Но мы будем рады, ели ты поюзаешь и дашь отзыв сообществу ))))
мы сначало тестим на одной из баз 3 месяца, потом потихоньку переводим все остальное
для каждой новой версии(9) Выражайся точнее.
«это последняя прошедшая аттестацию» — это про какую версию? Про ту, что указана в (0) — 9.3.4? Тогда это не так.
Если про ту, что указана на сайте 1С в разделе для скачивания дистрибутивов https://releases.1c.ru/total то там последняя — 10.5. Но прежде чем её ставить надо знать о какой версии платформы идёт речь. На более старых версиях чем 8.3.12 может не взлететь.msi — это на винду ставить? У старых версий на винде были проблемы с обновлением статистики, выливающиеся в жуткие тормоза. Решено вроде только в последних версиях, после 9.6.
На линуксе можно и старую поставить, только зачем? )(4) вот диск пришел из 1С, держу коробку в руках 🙂
попробую скачать
postgresql-10.5-6.1C-int.msi(15) так там и платформа на диске будет старая. Ты посмотри, для какой программы нужна установка Платформы. Если это для БП 3, к примеру, то обязательно платформу обнови тоже. Соотв. и скл бери свежий.
(15) платформу и субд ставь с юзерса.
если там же найдешь свежий установщик конфы — тоже используй его. иначе сиди и обновляй.
версию платформы бери минимально совместимую к последней версии твоей конфы.(17) хотя бы минимально совместимую. можно выше в пределах ревизии. 8.3.12.ххх или 8.3.13.ххх
Спасибо всем :), буду брать последний 10.5-6.1.
А в чем все таки разница
. msi
. -int.msiПодниму тему.
Сейчас работает связка
windows server 2008 r2 + postgresql 9.3.4 + 1С:Предприятие 8.3 (8.3.13.1690).Подскажите пожалуйста, надо ли менять postgresql 9.3.4 на postgresql 10.5?
Если да, то как это делается, так как никогда postgresql не обновлял еще ни разу?(20) на 10.5 есть проблемы 8.3.13.1644 и PosgreSQL: ошибка «variable not found in subplan target lists»
Получается лбио как советовали 9.6.7 либо 10.3.
Базы выгрузить из конфигуратора, удалить postgres, установить новый, загрузить базы.
Но был случай когда я не удалял постгрес, а просто сразу запустил новый инсталятор и чего то у меня после это не стартовал он, хорошо бэкап всей системы перед этим сделал, восстановил и все норм, поэтому тоже на всякий случай сделать образ всей системы с выключенными службами сервера постгреса и агнета 1с. И да на 10 версии постгреса вход в pgadmin последней версии через бразуер, какуто ошибку выдает, не запускается, разбираться не стал, поставил старый pgadmin 2.1 вроде работает.И еще неплохо бы батник на каждую базу сделать и поставить на автозапуск по утрам. Например:
SET PGPASSWORD=test1
«C:\Program Files\PostgreSQL\9.6.5-4.1C\bin\psql.exe» —dbname unf_tr —host 127.0.0.1 —port 5432 —username postgres —command analyze(22) то есть, обновление заключается в том, что делаем архив в старой версии, устанавливаем новую и в ней разворачиваем архив.
«Базы выгрузить из конфигуратора» — а как то можно сделать выгрузку сразу всех баз с помощью постгри?
(23) Я имел ввиду выгрузку в файл .dt
В конфигураторе: администрирование -> выгрузить информационную базу.
Есть вариант просто поставить новый постгрес и выполнить pg_upgrade, но во первых не стал вникать, во вторых как он там базы обновить не ясно, как бы не было проблем. Надежней через конфигуратор, но если баз много то надо тестировать на виртуалке https://postgrespro.ru/docs/postgresql/9.6/pgupgradeПро бекап сразу всех баз кластера постгреса не слыхал. Возможно есть, надо читать документацию.
(24) «но если баз много » — да, я это и имел ввиду, если их много, то придется каждую выгружать..
но в целом понятно, значит
1 делаем бэкап баз (дт-шки)
2 ставим postgresql 10.5 (например)
3 восстанавливаем базы на новом сервере из дт(25) Да, верно. Вот даже 1С пишет что после перехода на 10.3 и выше:
«Если переход на версию PostgreSQL 10.3 выполняется с помощью утилиты pg_upgrade, то рекомендуется выполнить переиндексацию таблиц базы данных для того, чтобы работа с буквой «ё» стала соответствовать правилам русского языка. Переиндексацию рекомендуется выполнять с помощью механизма тестирования и исправления конфигуратора, указав режим Реиндексация таблиц информационной базы.
В вашем случае тогда проще выполнить pg_upgrade, главное потестить на виртуалке хотя бы на одной базе как это работает.
(26) спасибо
Скачал с сайта 1С версию PostgreSQL, версия 10.3-3.1C.
Установил все по умолчанию.При запуске pgAdmin 4 выдается ошибка
«the application server could not be contacted»Делал, но не помогло
— запустить PgAdmin отмени администратора.
— добавьте путь к bin-папке Postgresql в переменные окружения.
— очистите папку C:\Users\%USERNAME%\AppData\Roaming\pgAdminПодскажите пожалуйста, что можно сделать, что бы запустить pgAdmin?
Или все таки ставить еще один pgAdmin4 и мириться с тем, что их будет два, как сказано в одной из веток форума?
При запуске pgAdmin 4 выдается ошибка
«the application server could not be contacted»Подскажите по поводу ошибки? Как ее исправить?
(29) Написать в 1С, чтобы собрали pgAdmin правильно.
PostgreSQL, версия 10.5-24.1C выложили вчера, посмотри, может там что изменилось.на винду — ни каккую
все работает, но просто хотелось бы лишний софт не ставить :).
(32) хлебнешь ты горюшка с пг на винде еще
(33) Это пук в лужу. Подробности давай.
(30) в 1с написал.. жду ответа..
(34) Знал бы, где упасть, соломки бы подостлалСейчас работает на винде 9.3.4. И уже достаточно давно. База не маленькая. Никаких особых проблем не замечаем.
Вот решили просто идти вперед и пробуем новую версию. Сразу столкнулись вот с ошибкой.
Может кому то интересно, то поддержка 1с ответила
«Попробуйте использовать PgAdmin4 1.6 с сайта.»
То есть так и получается, что надо качать и ставил отдельно pg Admin 4.
(2) УПП на 9.6.7 можно юзать без тормозов по отношению к MSSQL?
(42) а можно качать отсюда? а тогда на сайте 1С что за версии?(43) На сайте 1С версии официально протестированные самой 1С на их стендах.
На сайте PostgresPro версии прошедшие тестирование только самими разработчиками PostgresPro.
Фактически о случаях, чтобы сборки от PostgresPro не работали, я не слышал. Хотя естественно сама 1С официально поддерживает только те, что опубликованы только на её сайте.Единственный нюанс — надо уточнять совместимость версий платформы 1С и версий PostgreSQL (вне зависимости от того чьей сборки).
(44) спасибо
Я бы тоже поставил 10.5-24.1C или с сайта https://postgrespro.ru/products/postgrespro/standard 10 релиз. Они в ней ошибки поправили серьезные с backup. И реализовали лучшую совместимость со сложными выборками 1С.
Продолжу изучать PostgreSQL :).
Сейчас работает
— windows server 2008 r2 standart
— PostgreSQL Database Server 10.3-3.1C(x64)
— 1С: Предприятие 8.3 (8.3.13.1690).Если качать, то лучше 64-bit?
PostgreSQL, версия 10.5-24.1C
Дистрибутив СУБД PostgreSQL для Windows одним архивом
Дистрибутив СУБД PostgreSQL для Windows (64-bit) одним архивом64 конечно. x32 максимум 3 с крохами гигов памяти на процесс.
Кто нибудь ставил 10.5-24.1C? 🙂А как обновлять Постгри? Стоит сейчас старая версия 9, хочется обновить платформу и Постгри — есть смысл или работает- не трож?
Ну у меня две базы, поэтому я планирую
1 сделать архив
2 снести старый постгри
3 поставить новый постгри4 пока не знаю, оставлять 8.3.13.1690 или ставить более свежую..
на 15 платформе интерфейс покрасивше. Хочется применить, но что-то страшновато — с бантиками можно и проблем получить.
(52) а накатить сверху никак — чтоб не сносить — как то это муторно.(53) выше в ветки есть сообщение, как накатить..
(50) Работает, полгода, с платформой 8.3.14, платформу желательно обновлять до последней, в предыдущих были глюки в определенных случаях, такие rphost.exe грузит проц и жрет память
Сейчас все нормально, без жалоб и проблем.
Там уже 10.8-3.1С есть, тестовая.Сегодня обновили до 10.8-10.1C.
(56) хочу спросить
— 10.8-10.1C — на сайте 1С вижу только 10.5-24.1C
— обновили — как это происходит? делать бекап, сносить старую версию, ставить новую?(57) Имелось в виду, что обновили тестовую версию PostgreSQL на сайте 1С, с 10.8-3.1С до 10.8-10.1C.
У себя тестовую в качестве рабочей не ставил, пусть переведут в актуальную, а там посмотрю, может, через месяц-другой и поставлю.(58) круто!
пусть они зарелизят ее, а мы посмотрим тогда после тестов уже готового релиза : стоит ли этот релиз усилий на его установку(59) Его(PostgreSQL) еще регулярно дорабатывают, если в 9.6.7 было 9 патчей, то в последнем — 15, все что-то оптимизируют. Так что, как говорил персонах одного известного фильма — «Торопиться не надо».
Была 9.6, поставили 10.5. Накрылась некоторые старые(ручной лепки) отчеты с вложенными запросами.
Поставил PostgreSQL Database Server 10.5-24.1C(x64) — посмотрю как и что.
Конечно же есть архивы баз :).Хочу спросить тут, что бы создавать отдельную ветку.
На сервере стоит сервер 1С:Предприятия 8.2.
Но пришло время переходить на 1С:Предприятия 8.3.Я представляю как это делать теоретически, но хотелось бы услышать мнение тех, кто уже делал это. Баз достаточно много, что бы каждые архивировать, а потом восстанавливать.
Поэтому подскажите пожалуйста, как правильно и «красиво» перейти на 8.3?
(62) а вы без архивов живёте. ну, удачи
(63) с архивами конечно :), без них нельзя!Можно ли просто установить версию 8.3, с тем же портом 1541 и в консоли прописать все базы? Или как то по другому делать?
Подскажите пожалуйста, как правильно? 🙂
(59) Уже актуальная версия, 10.8-13.1C. Пишут, что исправлены различные выявленные ошибки.В итоге сейчас работаем на
PostgreSQL Database Server 10.5-24.1C(x64)
1С:Предприятие 8.3 (8.3.15.1656)
Количество пользователей 10Сам SQL-сервер и сервер 1С стоят на одной машине
ASUSTeK COMPUTER INC. Z97-K
Intel Core i7 4770K @ 3.50GHz
16 ГБ DDR3 @ 665 МГцИзменить железо, разделить сервера, перейти на MS SQL
и тд не предлагать :). Будем считать, что эти данные
являются константами.Поэтому подскажите пожалуйста, можно ли
оптимизировать скорость работы 1С?То есть я имею ввиду менять значения
— в файле postgresql.conf
— в параметрах локального кластера 1С
— в параметрах центрального сервера 1C(68) >>- в параметрах локального кластера 1С
>>- в параметрах центрального сервера 1C
Без лицензии уровня КОРП уже ничего не поменять.А постгри сейчас как с winserver дружит?
Можно или оставаться на никсах?(51) Судя по форумам, если стоит 9-тая, не стоит переходить на новую, покуда 1С не допишет свою платформу для новой версии 🙂
. Вот так вот.(71) Уже 8.3.13 умеет с PG 10 норм общаться, а 8.3.15 прям аж капец как круто. Ну и типовые тоже оптимизируются.
постгреспро смотри случайно не поставь, дорогой очень
то есть все эти изменения без КОРП не работают?
А еще прочитал статьи и сделал как там написано в postgresql.conf
Настройки PostgreSQL для работы с 1С:Предприятием. Часть 2
https://its.1c.ru/db/metod8dev#content:5866:hdocНо хотелось бы услышать мнение других, кто нибудь так настраивает сервера?
Какие параметры ставите и исходя из чего?(69) у него 10 юзеров. как -бэ нельзя, но до 50 юзеров на ИБ проф вроде работает как корп. а нам тупо разлочили ограничения по ядрам и памяти (т.к. куплено до 02.02.2019) и опа! на овер 1500 сеансов на сервере никаких ограничений на функциональность не появилось!
И потом тупо миграция с виндос на линукс постгри ранее давало прирост скорости примерно на 40-45%, но нужно с пингвином дружитьДесятую ставь
Вот эту PostgreSQL 10.5-24.1C(x64)
Она по скорости сопоставима, местами лучше, местами хуже MSSQL
(78) На виндовсеУх-ты сколько спецов по PG.
Может кто скажет, в какой версии PG решили проблему с бекапами бинарных файлов более 1 Гб?
КА 1.1.107.4 — проблемы с архивацией на СУБД Postgres(80) PG сейчас просто и доступно с коробки — накатил, pgAdmin установил, по инструкции с ИТС прошелся, попугаи Гилева показали что-то около 30-40, всё. Ты «спец» по PG.
(80) Обычно еще вспоминают про дифференциальные бэкапы, вернее их отсутствие в оригинальной свободно распространяемой версии, считая это большим недостатком.
Посмотрел очередной дайджест https://habr.com/ru/company/postgrespro/blog/466065/
Есть и решение для бэкапов с бинарной строкой, так и называется — pg_dumpbinary.
Есть и дифференциальные бэкапы — pgBackRest.
И репликацию можно настроить, в случае необходимости.честно, приятно общаться.. все по делу 🙂
(77) у меня и так 10
PostgreSQL Database Server 10.5-24.1C(x64)
1С:Предприятие 8.3 (8.3.15.1656)(80) я бэкапы пока делаю руками из 1С, скриптами еще не научился, не дошел
(81) pgAdmin ставлю отдельно, не из сборки 1С, там вроде ошибка какая та
— по инструкции с ИТС прошелся — это о чем я писал и ссылки давал?
— попугаи Гилева показали что-то около 30-40 — что это такое?В итоге то что, никто не меняет, все по умолчанию
— в файле postgresql.conf
— в параметрах локального кластера 1С
— в параметрах центрального сервера 1C(84) То что вы делает бекап из 1С, на самом деле не бекап.
— Плохая новость, сэр. То, что я принимала за беременность, оказалось не беременностью.
— Как, леди, y нас не будет наследника?
— К сожалению, нет, сэр.
— Боже мой, опять эти нелепые телодвижения!(73) Разве бесплатного postgrespro нет?
(85) ну архив же делается и можно если что восстановить
(86) https://postgrespro.ru/docs
есть PostgreSQL, а есть Postgres Pro.другие не пробовал
В итоге то что, никто не меняет, все по умолчанию
— в файле postgresql.conf
— в параметрах локального кластера 1С
— в параметрах центрального сервера 1CКто нибудь пользовался
https://pgtune.leopard.in.ua/#/Режим распределения нагрузки — есть два варианта параметра
«Приоритет по производительности» — памяти сервера тратится больше и производительность выше
«Приоритет по памяти» — кластер 1С экономит память сервераКакое значение лучше ставить?
(80) Ээээээ, вы таки в БД храните бинарное мегафайло?
PS «И они еще борются за почетное звание дома высокой культуры»
(93) а у вас лицензия корп?
+ (95) если память не подпирает — первый вариант
(92) рекомендации от 1С с ИТС рульнее. Самому посчитать не сложно(75) А можно и >12 ядер и >500 юзеров одновременно, или что-то одно из двух? Я так толком и не понял.
(94) А по ссылке пройти? Это не мы храним, а PG так хранит конфигурацию 1С.
Для любой конфы 1С, размер конфигурации поставщика которой превышает 512 Мб (А сейчас это УПП, КА, ERP и УТ11 с 11.4.10) включение изменений в конфигурации приводит к тому, что невозможно сделать бекап базы 1С с помощью pg_dump(95) проф
(96) 16 ГБ DDR3
(97) читал итс и не только 🙂вроде как документы открываются нормально 🙂
(100) в итоге поставил вот так…
А лицензии 1С все Корп? Иначе после 10 подключений сюрприз будет от таких настроек кластера.(101) проф..
10 подключений — посмотрю что будет 🙂на рис 3 видно, что rphosts 5 штук
а если посомтреть тут https://yadi.sk/i/Mgr6gwRFzOP1ig
то рабочий процессов триэто нормально? или это не взаимосвязано?
(94) Это к самой фирме 1с претензии. Вместо того, чтобы хранить метаданные как положено, в связанных таблицах, они тупо кладут всю конфигурацию в блоб. Именно поэтому так долго и грузится 1с в первый раз, приходится парсить этот блоб и класть его в развернутом виде в кэш пользователя..
(103) хорошие сборки?
(99) я попробую воспроизвести но это потребует много времени и не на работе уж точно, так что не ранее выходных, может быть даже этих
(99)>>невозможно сделать бекап базы 1С с помощью pg_dump
Можно выгрузить базу, исключив таблицу config, потом ее выгрузить отдельно командой COPY config TO имя_файла WITH FORMAT binary; Восстанавливается аналогично. Да — неудобно, но вполне решаемо. Трагедии никакой нет.
Если(когда-нибудь) pg_dumpbinary (см. (83)) решат включить в основной дистрибутив или напишут что-нибудь аналогичное, проблемы не будет вовсе.
Во всяком случае, разработчики платформы тоже могут внести свой посильный вклад и перестать держать конфигурацию целиком в одной записи.(105) Это сами постгресмены пишут, что сборки для 1с перекочевали на этот сайт.
Скажите пож, делал бэкап базы с помощью pgAdmin 4 v4
получился размер файла 1829887 Кб
а если делать выгрузку из 1С, то dt-файл 619949 Кб, то есть в три раза меньше.Можно ли как то сделать, что бы уменьшить архив выгрузки?
(109) Установить коэффициент сжатия 9(сколько там по умолчанию — не знаю).
Или потом сжать выгрузку, многопоточно, чтобы быстрее было.(101) Корп то причем? Там только если больше 12 ядер и 500 пользователей реально что-то интересное. До 200 не нужно если руки прямые.
Это совсем старье. Используй от postgresql.pro сборки — они даже сертифицированы. До 9.6 там совсем все печально с производительностью.
>>Вместо того, чтобы хранить метаданные как положено, в связанных таблицах, они тупо кладут всю конфигурацию в блоб.
8.3.15 ставь — там поправили. С 8.3.14 уже шло в одной таблице, но не одним блобом.
(109) можно! ДТ — уже архив, пройдись поверх дампа tar|gz.
(111)как обещал в (106) 8.3.14.1630 + 10.9.5-1С проверю в выхи. cf от upp1.3 уже достал.(111) уже поставил:
— PostgreSQL Database Server 10.9-5.1C(x64) — это крайняя версия на сайте 1С
— 1С:Предприятие 8.3 (8.3.15.1656) — предпоследняя+ сделал настройки кластера и сервера сделал..
вроде как «полет» нормальный..
(112) сделал бэкап так, затем создал в консоли пустую базу и через pgAdmin пробовал восстановить — не получилось.. ошибки..
(115) создавай базу через pg admin , восстанавливай в нее и потом уже подключай ее к серверу 1С
CREATE DATABASE test
WITH OWNER = postgres
ENCODING = ‘UTF8’
TABLESPACE = pg_default
LC_COLLATE = ‘ru_RU.UTF-8’
LC_CTYPE = ‘ru_RU.UTF-8’
CONNECTION LIMIT = -1;(0) месяц как заменил Postgres Pro 9.6 на сборку от 1С 10.9-5.1C(x64)
пользователи не разницы не заметили, перепроведение стало чуть чуть шустрее
Здравствуйте.Хочу попробовать перейти на 10.9-5.1C(x64). Чем можно и лучше заменить логшипинг MSSQL?
(116) Не получилось.. Пробовал и в консоли 1С делать базу, и в pgAmin, и через платформу 1С..
Бэкап делается с помощью pgAmin или скрипта, а вот восстановление в чистую базу не получается.
Может кто то поделиться скриптами? 🙂
(118) А зачем? в слоне Wal а не логшиппинг — это версионник, а не блокировщик.
(121) Мне главное аналогичный конечный результат. WAL значит, спасибо(120) а можно выводить сам процесс восстановления в файл?
оишбка
ещ ьфтн сщььфтв .(120) у меня на «черном» экране в консоли вывелось 🙂
warning: errors ignored on restore: 3
а вот что это за ошиьки не совсем понятно..
А еще смущает следующее сообщение при бэкапе
pg_dump: dumping contents of table «public.config»
pg_dump: Dumping the contents of table «config» failed: PQgetResult() failed.
pg_dump: Error message from server: ERROR: out of shared memory
HINT: You might need to increase max_locks_per_transaction.
pg_dump: The command was: COPY public.config (filename, creation, modified, attributes, datasize, binarydata, partno) TO stdout;так запустишь ночью, а потом ничего не восстановится..
Ставь ванильный Постгрес, сдались тебе эти патчи
(125) В ссылке из (80) и в (99) подробно описано, почему выдаются такие сообщения.
В (107) — краткое описание того, как можно обойти проблему.
Здесь — http://catalog.mista.ru/public/956734/ готовое решение в виде команд для скриптов с подробным описанием их работы.(126) патчи — я понимаю, что это все от 1C 🙂
(127) «Ниже привожу примеры bat-файлов (качайте) » — не качается 🙂
В юникс-мире ПО ванильный = оригинальный, типа ствол дерева от которого уже ответствления всякие делаются
(129) Замени catalog.mista на infostart и все скачается.
(132) просит стартмани.. у меня нет..
можете прислать на first_may@mail.ru ??
(126) Строки полетят и поиск. Патчи как раз сравнение исправляют.
(126) «иди проспись» ((С) Cyberhawk)pg_dump —host=localhost4 —username=postgres —no-password —format=c —file=buh.backup buh
pg_restore —host=localhost4 —clean —if-exists —jobs=2 —username=postgres —dbname=buh buh.backupпароль можно в файлик .pgpass записать и кинуть в домашний каталог пользователя от имени которого выполняются скрипты. Формат файла тоже в справке есть
Кстати базу (когда все на одном компе) можно подключать без TCP/IP, а по Unix сокетам,
путь к серверу в свойствах базы надо прописать /tmp
в основном конф файле есть параметр где оно сокеты создаетя восстанавливал так
сначала создаем пустую базу в pg_admin, не подключаем ее к 1С, потом pg_restore, потом подрубаем базу в сервере 1С предприятия 1С.(138) не получается..
думаю тут все правильно сказали — (127)
нужны такие скрипты, так как выгрузка идет через раз..
(125) а параметр max_locks_per_transaction в конфиге сколько стоит?
(140) по моему я его не менял, вот
max_locks_per_transaction = 150 # min 10кстати, получилось сделать бэкап/ресторе без ошибок через pgAdmin как написано тут
http://catalog.mista.ru/public/540298/как советовали тут (139)
(141) так я про это еще в (116) писал
> создавай базу через pg admin , восстанавливай в нее и потом уже подключай ее к серверу 1С
(142) пропустил наверное, спасибо 🙂
(99) забавно.
1.создал пустую базу.
2.из конфигуратора объединил с cf
3.выгрузил pg_dump.exe -c -C -v -f C:\test\upp_.sql
4.грохнул базу
5.загружал так:
SET PGBIN=C:\Program Files (x86)\PostgreSQL\10.9-5.1C\bin\
SET PGDATABASE=upp_test
SET PGHOST=127.0.0.1
SET PGPORT=5432
SET PGUSER=postgres
SET PGPASSWORD=**********
createdb
PAUSE
psql -f C:\DSK\upp_.sqlИтого получаем базу, в консоли кластера она подключается, но в конфигураторе ИБ как буд-то созданная для разработки. сам каталог СУБД с базой 200 с небольшим мег.
Проверяю гипотезу с таблицей config:
select count(*) from configsave
————
0н-да, придётся скрипт бэкапа допиливать.
делал бэкап так:
+ (144) каталоги для загрузки и выгрузки разные — это норм, из одного в другой ручками переносил
Если у меня есть выгрузка кластера db.out, то как сделать его восстановление?
Командой pg_restore -d имя_БД имя_файла?
А надо же указать наверное сервер, порт. Подсмкажите пожалуйста
pg_restore.exe -h=localhost -p=5432 -U=postgres -d=zup2014 -f=c:\1.log c:\db.out —verbose
Делаю вот так
pg_restore.exe —host localhost —port 5432 —username postgres —dbname z2014 —clean —verbose C:\db.outвыдается
pg_restore: [archiver] input file does not appear to be a valid archiveСкажите пож, можно ли узнать по структуре как делался бэкап и как восстановить одну базу, если в файле db.out содержится
—
— PostgreSQL database cluster dump
—SET default_transaction_read_only = off;
SET client_encoding = ‘UTF8’;
SET standard_conforming_strings = on;CREATE ROLE postgres;
ALTER ROLE postgres WITH SUPERUSER INHERIT CREATEROLE CREATEDB LOGIN REPLICATION BYPASSRLS PASSWORD ‘md54ef7cf478a39b5af1a2d160388faf58f’;CREATE DATABASE a2014 WITH TEMPLATE = template0 OWNER = postgres;
CREATE DATABASE a2019 WITH TEMPLATE = template0 OWNER = postgres;
CREATE DATABASE centr WITH TEMPLATE = template0 OWNER = postgres;
CREATE DATABASE retailpharmacy_demo WITH TEMPLATE = template0 OWNER = postgres;
REVOKE CONNECT,TEMPORARY ON DATABASE template1 FROM PUBLIC;
GRANT CONNECT ON DATABASE template1 TO PUBLIC;
CREATE DATABASE testgilev WITH TEMPLATE = template0 OWNER = postgres;
CREATE DATABASE z2014 WITH TEMPLATE = template0 OWNER = postgres;
CREATE DATABASE z2014_old WITH TEMPLATE = template0 OWNER = postgres;
CREATE DATABASE z2014_test WITH TEMPLATE = template0 OWNER = postgres;
CREATE DATABASE z2019 WITH TEMPLATE = template0 OWNER = postgres;(149) то есть
1 надо сделать пустую базу в pgАдмине, например test
2 выполнить psql —set ON_ERROR_STOP=on dbname < dumpfile
где dbname = test, dumpfile = C:\db.outа как подключаться к ккластеру?
(151) это одно и тоже. не совсем понимаю, как выполнить подключение.
psql -h localhost z2014
(151) а тут psql —set ON_ERROR_STOP=on имя_базы < файл_дампа
psql —host localhost —set ON_ERROR_STOP=on z2014 < C:\db.out
1 сделал пустую z2014
2 выполнил
psql —host localhost —port 5432 —username postgres —set ON_ERROR_STOP=on z2014 < C:\db.out3 получил ошибку
role «postgres» already exists
—
— PostgreSQL database cluster dump
—SET default_transaction_read_only = off;
SET client_encoding = ‘UTF8’;
SET standard_conforming_strings = on;CREATE ROLE postgres;
Может это надо запускать при пустом кластере как то?
(155) Да, у тебя полный дамп всего кластера, вообще всех баз и прочего.
Восстановить все:
psql -f all_databases.sql
(отсюда) https://the-bosha.ru/2016/06/01/backup-restore-postgresql-bazy-dannykh-s-pg_dump/(156) у меня файл db.out. сервер виндовый.
в консоле пишу
psql -f db.outтак? а где прописано, что надо подключиться к серверу?
(157)
«Подключение к базе данных
psql это клиент для PostgreSQL. Для подключения к базе данных нужно знать имя базы данных, имя сервера, номер порта сервера и имя пользователя, под которым вы хотите подключиться. Эти свойства можно задать через аргументы командной строки, а именно -d, -h, -p и -U соответственно. Если в командной строке есть аргумент, который не относится к параметрам psql, то он используется в качестве имени базы данных (или имени пользователя, если база данных уже задана). Задавать все эти аргументы необязательно, у них есть разумные значения по умолчанию. Если опустить имя сервера, psql будет подключаться через Unix-сокет к локальному серверу, либо подключаться к localhost по TCP/IP в системах, не поддерживающих UNIX-сокеты. Номер порта по умолчанию определяется во время компиляции. Поскольку сервер базы данных использует то же значение по умолчанию, чаще всего указывать номер порта не нужно. Имя пользователя по умолчанию, как и имя базы данных по умолчанию, совпадает с именем пользователя в операционной системе.»
Весьма хорошая документация на русском — https://postgrespro.ru/docs/postgresql/10/app-psql
Дальше тоже можно почитать, так, для разнообразия.(158) как я показал, в файле db.out написано
CREATE ROLE postgres;
ALTER ROLE postgres WITH SUPERUSER INHERIT CREATEROLE CREATEDB LOGIN REPLICATION BYPASSRLS PASSWORD ‘md54ef7cf478a39b5af1a2d160388faf58f’;CREATE DATABASE a2014 WITH TEMPLATE = template0 OWNER = postgres;
CREATE DATABASEа когда я ставлю сервер и указываю параметры кластера, то он создается и
в нем уже есть база postgre, роль postgres..и если выполню psql -f db.out, то будет же ошибка про то, что роль есть.
Сам кластер надо удалить?
(159) Вы читали ссылку на sql.ru из (156)?
Там, в частности, говорится, что в этом файле руками убирали то, что не нужно, оставляли только нужное и потом скармливали Постгресу. Вот не нужно вам в новом кластере создавать роль Постгрес — так удалите эти строки из файла и все.
(159) делайте дампы не в SQL формате, а в формате Postgres, в pg_dump кажется есть ключик, и не придется мучаться с редактированием огромного SQL скрипта.
PostgreSQL 10.10-1.1C и 11.5-1.1C вышли сегодня, причем, сразу актуальной версией.
(162) забавно, обе что-б не ниже 8.3.14.1565.После перегрузки сервера Служба постгри не запускается.
(164) Смотри в журнале событий, он туда пишет почему не может запуститься. Если сервер на Винде.
+(165) иногда и в логфайле постгри бывает ценная инфа.
И да. на одном сервере под виндой была странная фигня: служба стартовала и через 1-2 мин стопалась, но постгри норм работал.
(165) на винде..
А ещё, при установке был пользователь постгри, работали с базой, а сейчас его нет.
Не нормально же.В журнале написано про postmaster.pid
(167) С копии восстанавливались?
(168) архивы то есть, но зайти в базу не могу, сервер не запускается
Подскажите как запустить это сервер?
Уже готов вернуться в файловый вариантВообщем как результат, были танцы с бубном, но в базу зашли.
В итоге все работаем, служба не запущена, однако в процессах висит postgres.exe.Тогда теоретический вопрос, почему служба PostgreSQL Database Server 10.9-5.1C(x64) падает и не запускается? Что с этим делать?
(167) >>В журнале написано про postmaster.pid
Что именно написано? Если «FATAL: lock file «postmaster.pid» already exists»,
то нужно остановить службу PostgreSQL(может быть даже просто прибить postgres.exe, если он не завершается сам), потом удалить его и снова запустить службу. Смотреть что пишет в каталог pg_log, в последний по времени файл лога.
Если что-нибудь о «recovery», значит, какие-то данные были повреждены, то лучше создать новый кластер и восстановить в него базы из заведомо годного бэкапа.
Как мог пользователь postgres просто пропасть.(172) это журнал виндовс
< 2019-10-29 07:18:40.796 MSK >FATAL: lock file «postmaster.pid» already exists
< 2019-10-29 07:18:40.796 MSK >HINT: Is another postmaster (PID 4700) running in data directory «D:/PostgreData»?а это весь лог постгри
< 2019-10-29 06:45:59.678 MSK >LOG: received fast shutdown request
< 2019-10-29 06:45:59.678 MSK >ERROR: canceling statement due to user request
< 2019-10-29 06:45:59.818 MSK >LOG: aborting any active transactions
< 2019-10-29 06:45:59.834 MSK >LOG: worker process: logical replication launcher (PID 5116) exited with exit code 1
< 2019-10-29 06:45:59.834 MSK >LOG: shutting down
< 2019-10-29 06:46:00.598 MSK >LOG: database system is shut down
< 2019-10-29 06:52:11.993 MSK >LOG: database system was shut down at 2019-10-29 06:46:00 MSK
< 2019-10-29 06:52:12.227 MSK >LOG: database system is ready to accept connections
< 2019-10-29 07:04:13.256 MSK >LOG: could not open file «postmaster.pid»: No such file or directory
< 2019-10-29 07:04:13.256 MSK >LOG: performing immediate shutdown because data directory lock file is invalid
< 2019-10-29 07:04:13.256 MSK >LOG: received immediate shutdown request
< 2019-10-29 07:04:13.256 MSK >LOG: could not open file «postmaster.pid»: No such file or directory
< 2019-10-29 07:04:13.285 MSK >WARNING: terminating connection because of crash of another server process
< 2019-10-29 07:04:13.285 MSK >DETAIL: The postmaster has commanded this server process to roll back the current transaction and exit, because another server process exited abnormally and possibly corrupted shared memory.
< 2019-10-29 07:04:13.285 MSK >HINT: In a moment you should be able to reconnect to the database and repeat your command.
< 2019-10-29 07:04:13.291 MSK >WARNING: terminating connection because of crash of another server process
< 2019-10-29 07:04:13.291 MSK >DETAIL: The postmaster has commanded this server process to roll back the current transaction and exit, because another server process exited abnormally and possibly corrupted shared memory.
< 2019-10-29 07:04:13.291 MSK >HINT: In a moment you should be able to reconnect to the database and repeat your command.
< 2019-10-29 07:04:13.499 MSK >LOG: database system is shut down
< 2019-10-29 07:05:18.589 MSK >LOG: database system was interrupted; last known up at 2019-10-29 06:57:13 MSK
< 2019-10-29 07:16:26.998 MSK >FATAL: the database system is starting up
< 2019-10-29 07:16:55.684 MSK >FATAL: the database system is starting up
< 2019-10-29 07:16:57.557 MSK >FATAL: the database system is starting up
< 2019-10-29 07:16:58.376 MSK >FATAL: the database system is starting up
< 2019-10-29 07:16:59.505 MSK >FATAL: the database system is starting up
< 2019-10-29 07:18:00.348 MSK >FATAL: the database system is starting up
< 2019-10-29 07:18:01.819 MSK >FATAL: the database system is starting up
< 2019-10-29 07:18:03.537 MSK >FATAL: the database system is starting up
< 2019-10-29 07:18:24.544 MSK >FATAL: the database system is starting up
< 2019-10-29 07:19:03.914 MSK >FATAL: the database system is starting up
< 2019-10-29 07:19:08.216 MSK >FATAL: the database system is starting up
< 2019-10-29 07:19:08.967 MSK >FATAL: the database system is starting up
< 2019-10-29 07:19:28.636 MSK >FATAL: the database system is starting up
< 2019-10-29 07:20:05.767 MSK >FATAL: the database system is starting up
< 2019-10-29 07:20:14.494 MSK >FATAL: the database system is starting up
< 2019-10-29 07:20:33.328 MSK >FATAL: the database system is starting up
< 2019-10-29 07:20:34.012 MSK >FATAL: the database system is starting up
< 2019-10-29 07:21:08.300 MSK >FATAL: the database system is starting up
< 2019-10-29 07:21:19.622 MSK >FATAL: the database system is starting up
< 2019-10-29 07:21:38.329 MSK >FATAL: the database system is starting up
< 2019-10-29 07:21:57.307 MSK >FATAL: the database system is starting up
< 2019-10-29 07:22:11.379 MSK >FATAL: the database system is starting up
< 2019-10-29 07:22:25.481 MSK >FATAL: the database system is starting up
< 2019-10-29 07:22:42.835 MSK >FATAL: the database system is starting up
< 2019-10-29 07:23:01.842 MSK >FATAL: the database system is starting up
< 2019-10-29 07:23:15.886 MSK >FATAL: the database system is starting up
< 2019-10-29 07:23:28.905 MSK >FATAL: the database system is starting up
< 2019-10-29 07:23:48.062 MSK >FATAL: the database system is starting up
< 2019-10-29 07:24:07.117 MSK >FATAL: the database system is starting up
< 2019-10-29 07:24:20.917 MSK >LOG: could not open file «postmaster.pid»: No such file or directory
< 2019-10-29 07:24:20.917 MSK >LOG: performing immediate shutdown because data directory lock file is invalid
< 2019-10-29 07:24:20.917 MSK >LOG: received immediate shutdown request
< 2019-10-29 07:24:20.917 MSK >LOG: could not open file «postmaster.pid»: No such file or directory
< 2019-10-29 07:24:20.958 MSK >FATAL: the database system is starting up
< 2019-10-29 07:24:20.977 MSK >LOG: database system is shut down
< 2019-10-29 07:25:49.350 MSK >LOG: database system was interrupted; last known up at 2019-10-29 06:57:13 MSK
< 2019-10-29 07:26:00.999 MSK >FATAL: the database system is starting up
< 2019-10-29 07:26:19.209 MSK >FATAL: the database system is starting up
< 2019-10-29 07:26:33.411 MSK >FATAL: the database system is starting up
< 2019-10-29 07:26:46.618 MSK >FATAL: the database system is starting up
< 2019-10-29 07:27:04.144 MSK >FATAL: the database system is starting up
< 2019-10-29 07:27:24.173 MSK >FATAL: the database system is starting up
< 2019-10-29 07:27:38.396 MSK >FATAL: the database system is starting up
< 2019-10-29 07:27:50.978 MSK >FATAL: the database system is starting up
< 2019-10-29 07:28:09.535 MSK >FATAL: the database system is starting up
< 2019-10-29 07:28:29.045 MSK >FATAL: the database system is starting up
< 2019-10-29 07:28:43.821 MSK >FATAL: the database system is starting up
< 2019-10-29 07:28:56.071 MSK >FATAL: the database system is starting up
< 2019-10-29 07:29:14.536 MSK >FATAL: the database system is starting up
< 2019-10-29 07:29:35.986 MSK >FATAL: the database system is starting up
< 2019-10-29 07:29:48.222 MSK >FATAL: the database system is starting up
< 2019-10-29 07:29:57.438 MSK >FATAL: the database system is starting up
< 2019-10-29 07:30:20.932 MSK >FATAL: the database system is starting up
< 2019-10-29 07:30:40.968 MSK >FATAL: the database system is starting up
< 2019-10-29 07:30:53.000 MSK >FATAL: the database system is starting up
< 2019-10-29 07:30:59.716 MSK >FATAL: the database system is starting up
< 2019-10-29 07:31:22.831 MSK >FATAL: the database system is starting up
< 2019-10-29 07:31:44.137 MSK >FATAL: the database system is starting up
< 2019-10-29 07:31:58.215 MSK >FATAL: the database system is starting up
< 2019-10-29 07:32:04.047 MSK >FATAL: the database system is starting up
< 2019-10-29 07:32:24.447 MSK >FATAL: the database system is starting up
< 2019-10-29 07:32:46.412 MSK >FATAL: the database system is starting up
< 2019-10-29 07:33:04.091 MSK >FATAL: the database system is starting up
< 2019-10-29 07:33:08.905 MSK >FATAL: the database system is starting up
< 2019-10-29 07:33:29.698 MSK >FATAL: the database system is starting up
< 2019-10-29 07:33:52.456 MSK >FATAL: the database system is starting up
< 2019-10-29 07:34:10.119 MSK >FATAL: the database system is starting up
< 2019-10-29 07:34:11.153 MSK >FATAL: the database system is starting up
< 2019-10-29 07:34:30.970 MSK >FATAL: the database system is starting up
< 2019-10-29 07:34:55.335 MSK >FATAL: the database system is starting up
< 2019-10-29 07:35:15.253 MSK >FATAL: the database system is starting up
< 2019-10-29 07:35:16.920 MSK >FATAL: the database system is starting up
< 2019-10-29 07:35:33.900 MSK >FATAL: the database system is starting up
< 2019-10-29 07:35:58.315 MSK >FATAL: the database system is starting up
< 2019-10-29 07:36:18.978 MSK >FATAL: the database system is starting up
< 2019-10-29 07:36:23.003 MSK >FATAL: the database system is starting up
< 2019-10-29 07:36:37.658 MSK >FATAL: the database system is starting up
< 2019-10-29 07:36:59.855 MSK >FATAL: the database system is starting up
< 2019-10-29 07:37:22.787 MSK >FATAL: the database system is starting up
< 2019-10-29 07:37:28.201 MSK >FATAL: the database system is starting up
< 2019-10-29 07:37:43.445 MSK >FATAL: the database system is starting up
< 2019-10-29 07:38:04.437 MSK >FATAL: the database system is starting up
< 2019-10-29 07:38:24.340 MSK >FATAL: the database system is starting up
< 2019-10-29 07:38:33.659 MSK >FATAL: the database system is starting up
< 2019-10-29 07:38:45.789 MSK >FATAL: the database system is starting up
< 2019-10-29 07:39:08.709 MSK >FATAL: the database system is starting up
< 2019-10-29 07:39:27.780 MSK >FATAL: the database system is starting up
< 2019-10-29 07:39:37.747 MSK >FATAL: the database system is starting up
< 2019-10-29 07:39:47.734 MSK >FATAL: the database system is starting up
< 2019-10-29 07:40:09.961 MSK >FATAL: the database system is starting up
< 2019-10-29 07:40:32.308 MSK >FATAL: the database system is starting up
< 2019-10-29 07:40:42.698 MSK >FATAL: the database system is starting up
< 2019-10-29 07:40:52.220 MSK >FATAL: the database system is starting up
< 2019-10-29 07:41:11.019 MSK >FATAL: the database system is starting up
< 2019-10-29 07:41:34.039 MSK >FATAL: the database system is starting up
< 2019-10-29 07:41:46.148 MSK >FATAL: the database system is starting up
< 2019-10-29 07:41:55.168 MSK >FATAL: the database system is starting up
< 2019-10-29 07:42:15.607 MSK >FATAL: the database system is starting up
< 2019-10-29 07:42:36.191 MSK >FATAL: the database system is starting up
< 2019-10-29 07:42:52.279 MSK >FATAL: the database system is starting up
< 2019-10-29 07:42:57.267 MSK >FATAL: the database system is starting up
< 2019-10-29 07:43:03.673 MSK >LOG: database system was not properly shut down; automatic recovery in progress
< 2019-10-29 07:43:04.009 MSK >LOG: redo starts at 1/9D3973E8
< 2019-10-29 07:43:04.009 MSK >LOG: invalid record length at 1/9D3974C8: wanted 24, got 0
< 2019-10-29 07:43:04.009 MSK >LOG: redo done at 1/9D397490
< 2019-10-29 07:43:04.642 MSK >LOG: database system is ready to accept connectionsно при этом сейчас все в базе и работаем
(172) это
» Если «FATAL: lock file «postmaster.pid» already exists»,
то нужно остановить службу PostgreSQL(может быть даже просто прибить postgres.exe, если он не завершается сам), потом удалить его и снова запустить службу. » — поздно заметил.. попробую вечером, когда сделаю архив базы :)..