Dapper: опыт применения

Привет, дорогой читатель, в этой статье я хотел бы поделиться опытом работы с базой данных посредством ORM Dapper на .NET Core, а также рассказать полезные лайфхаки, которые нам помогают удобно использовать его при разработке приложений и рассмотрим как мог бы выглядеть сервис по созданию ведьмаков с использованием Dapper. В данной статье будет много примеров кода и комментариев к нему, а также граблей, по которым мы прошли. Статья рассчитана на тех, кто хочет начать использовать dapper в своих проектах либо тех, кто его уже использует. Итак начнем.
Введение
Dapper — это что-то вроде mini ORM не такая монструозная и более быстрая по сравнению с популярной на .NET Entity Framework. Dapper позволяет писать SQL-запросы к БД и маппить их на C# классы, в общем позволяет связать .Net код и SQL. Из очевидных минусов даппер не автогенерирует код и многие шаблонные запросы, такие как SELECT, INSERT, DELETE, приходится писать вручную, но зато он позволяет писать сложные запросы практически не жертвуя скоростью работы программы и без всякой черной магии и тонны кода.
Как настоящие ведьмаки сразу ринемся в бой с монстрами и посмотрим практические примеры. Будем считать, что БД у нас уже есть и в ней находятся все необходимые таблицы, так что сосредоточимся только на C# составляющей.
Select запрос
Ну и начнем мы, пожалуй, с самых популярных SELECT запросов. В первую очередь нам необходим класс, который мы хотим наполнять данными.
public class Witcher < public string WitcherNickname < get; set; >public string SwordName < get; set; >public string WitchersSchool < get; set; >>Затем напишем SQL запрос к базе данных, чтобы загрузить все данные по ведьмакам.
private static readonly string _selectQuery = $@"select witcher_nickname as WitcherNickname, silver_sword_name as SilverSwordName, witchers_school as WitcherSchool from witchers";Далее выполним данный запрос к БД.
private static readonly IDbConnection _dbConnection; public static void Main() < var witchers = _dbConnection.Query(_selectQuery); >Dapper позволяет связать запрос с классом благодаря алиасам “as” внутри запроса, но требует, чтобы алиас соответствовал названию свойства класса. В нашем примере “witcher_nickname as WitcherNickname” внутри запроса позволяет связать поле “witcher_nickname” из БД со свойством “WitcherNickname” в нашем классе. И все бы хорошо, но что, если мы захотим переименовать свойство класса? Нам придется править все SQL запросы, где используется этот класс, а таких мест может быть много. Чтобы избежать этой проблемы поправим немного наш запрос.
private static readonly string _selectQuery = $@"select witcher_nickname as , sword_name as , witchers_school as from witchers";Заменим алиасы на конструкцию nameof(), которая позволит нам связать запрос со свойствами класса, но при этом, в случае рефакторинга класса Witcher в любимой IDE, у нас автоматически подменяется названия свойств в запросах или, в случае удаления свойства, приложение просто не сбилдится, с ошибкой, что в запросе используется имя, которое удалено. В общем, использование данной конструкции значительно уменьшает количество ошибок, головной боли и повышает качество кода.
Запросы с параметрами
Скорее всего, рано или поздно придет аналитик с продактом и скажут, что делать выборку по всем ведьмакам уже неактуально, и надо строить рейтинги по ведьмакам из каждой школы. Мы, конечно, знаем, что Геральт и школа волка даст всем прикурить, но запрос все равно напишем.
private static readonly string _selectQuery = $@"select witcher_nickname as , sword_name as , witchers_school as from witchers where witchers_school = @Name"; private static readonly IDbConnection _dbConnection; public static void Main() < var wolfWitchers = _dbConnection.Query( _selectQuery, new ); >В Dapper любой параметр, который необходимо передать в запрос помечается @, где Name должен совпадать с названием параметра в коде. Затем в функцию Query передаются значения этих параметров. В данном примере мы использовали анонимный класс для передачи параметров.
Но, как не трудно догадаться, тут можно использовать и обычный класс, давайте создадим класс ведьмачьих школ и передадим его в запрос.
public class WitcherSchool < public string Name < get; set; >public string Location < get; set; >> private static readonly string _selectQuery = $@"select witcher_nickname as , sword_name as , witchers_school as from witchers where witchers_school = @Name"; private static readonly IDbConnection _dbConnection; public static void Main() < var wolfSchool = new WitcherSchool < Name = "Школа волка", Location = "Каер Морхен" >; var wolfWitchers = _dbConnection.Query(_selectQuery, wolfSchool); >Теперь наш запрос принимает на вход wolfSchool и в SQL подставляется значение свойства Name. В данном примере мы создали экземпляр класса WitcherSchool вручную, но, как можно догадаться, он мог бы быть загружен из базы или еще откуда. Использовать класс вместо анонимного типа полезно, когда у нас есть связанные классы и таблицы, и для написания запроса можно не создавать анонимный класс, а использовать уже готовый.
Ну и соответственно, раз мы теперь передаем в качества параметра не анонимный класс, то мы можем использовать оператор nameof().
private static readonly string _selectQuery = $@"select witcher_nickname as , sword_name as , witchers_school as from witchers where witchers_school = @";Теперь при рефакторинге и изменении класса WolfSchool мы получаем стабильно работающий код и можем не боятся за наши запросы в БД.
Insert запрос
Без лишних отступлений создадим несколько ведьмаков и сохраним их в БД.
private static readonly string _insertQuery = $@"insert into witchers (witcher_nickname, sword_name, witchers_school) values @, @, @"; private static readonly IDbConnection _dbConnection; public static void Main() < var geralt = new Witcher < WitcherNickname = "Гервант из Рыблии", SwordName = "Махакамский рунный сигиль", WitchersSchool = "Школа волка" >; var lambert = new Witcher < WitcherNickname = "Ламберт", SwordName = "Новиградский меч", WitchersSchool = "Школа волка" >; var witchers = new List < geralt, lambert >; _dbConnection.Execute(_insertQuery, witchers); >Тут мы написали Insert запрос, замапили его на класс ведьмаков, затем создали двух ведьмаков: Геральта и Ламберта и собрали список ведьмаков, которых необходимо добавить в БД. Для выполнения запросов, которые не возвращают результата, используем метод Execute и передаем ему коллекцию ведьмаков для вставки.
Скорее всего, в таблице ведьмаков имеется автоинкрементарное поле id, и было бы неплохо при вставке получить его значения. Перепишем запрос, чтобы получить id добавленных записей.
private static readonly string _insertQuery = $@"insert into witchers (witcher_nickname, sword_name, witchers_school) values @, @, @ returning id";Ну и соответственно изменим вызов к БД.
var ids = _dbConnection.Query(_insertQuery, witchers);Теперь при вставке ведьмаков в БД будут возвращаться id вставленных записей в соответствующем порядке, их можно использовать, например, чтобы потом проставить ссылки на ведьмаков в другие таблицы.
Delete запрос
Предположим, что на школу грифона напала дикая охота и уничтожила всех ведьмаков.
private static readonly string _deleteQuery = $@"delete from witchers where witchers_school = @SchoolName"; private static readonly IDbConnection _dbConnection; public static void Main() < _dbConnection.Execute(_deleteQuery, new < SchoolName = "Школа грифона" >); >Да, удалять данные в приложениях равно самоубийству, потому что потом придет менеджер и скажет, что хочет сделать корзину или дать возможность пользователю восстанавливать удаленные данные, но иногда есть ситуации, когда и такие запросы пригодятся.
Copy запрос
Часто встречающаяся задача — это копирование данных в таблицах, мы обычно реализуем следующим образом.
private static readonly string _copyQuery = $@"insert into witchers (witcher_nickname, sword_name, witchers_school) select @NewName, sword_name, witchers_school from witchers where witcher_nickname = @Name"; private static readonly IDbConnection _dbConnection; public static void Main() < _dbConnection.Execute( _copyQuery, new < Name = "Геральт", NewName = "Магический клон Геральта" >); >В запрос передаем имя ведьмака, чей клон при помощи астральной магии мы хотим создать, и новое название для клона. В БД получаем новую запись с таким же мечом и школой, как у Геральта, но новым именем.
Транзакции
Часто приходится выполнять несколько запросов друг за другом, но в рамках одной транзакции. Например, мы хотим удалить все данные по школе волка и сразу занести в нее двух новых ведьмаков. Вот как это выглядит с использованием Dapper.
public static void Main() < var geralt = new Witcher < WitcherNickname = "Гервант из Рыблии", SwordName = "Махакамский рунный сигиль", WitchersSchool = "Школа волка" >; var lambert = new Witcher < WitcherNickname = "Ламберт", SwordName = "Новиградский меч", WitchersSchool = "Школа волка" >; var witchers = new List < geralt, lambert >; using var transaction = _dbConnection.BeginTransaction(); _dbConnection.Execute(_deleteQuery, new < SchoolName = "Школа волка" >, transaction); var ids = _dbConnection.Query(_insertQuery, witchers, transaction); transaction.Commit(); >Создаем транзакцию методом BeginTransaction(). И во все запросы передаем ее в качестве аргумента функции. В конце не забываем закоммитить транзакцию. Таким образом мы можем выполнить 2 и более запроса за 1 транзакцию. В случае если во время выполнения запроса происходит ошибка, то транзакция автоматически откатывается и вываливается ексепшн.
В заключение
В данной статье отражены основные операции, с которыми сталкиваются наши команды разработки при работе с БД и то, как их можно реализовать при помощи библиотеки Dapper. Сложные SQL запросы пишутся по аналогии. Для получения результатов мапим возвращаемые значения на классы или просто получаем dynamic в ответ, для передачи параметров используем @.
Мы стараемся всегда использовать классы и маппинг на основе конструкции nameof(), чтобы случайный рефакторинг или удаление классов или их свойств не уронили приложение, и все ошибки выявились на этапе билда приложения. Когда лень создавать класс под запрос, то позволяем себе пользоваться анонимными классами, но всегда строго прописываем имя передаваемого параметра, чтобы избежать проблем с рефакторингом.
Для тех, кто заинтересовался в использовании Dapper, ссылка на официальный туториал.
Использование Dapper C# в программировании
Отинчиев, А. К. Использование Dapper C# в программировании / А. К. Отинчиев, Л. Г. Касенова. — Текст : непосредственный // Актуальные вопросы технических наук : материалы V Междунар. науч. конф. (г. Санкт-Петербург, февраль 2019 г.). — Санкт-Петербург : Свое издательство, 2019. — С. 5-8. — URL: https://moluch.ru/conf/tech/archive/324/14815/ (дата обращения: 08.01.2024).
В данной статье рассматривается проблема обработки больших данных в современных системах. Возможность использования инновационной программы для качественной, быстрой и легкодоступной системы.
Ключевые слова: sql, C#, кросс-платформенность, open source, CRUD методы.
This article presents the problems of big data processing in modern systems. The ability to use innovative programs for high-quality, fast and easily accessible system.
Keywords: sql, C#, cross-platform, open source, CRUD methods
Dapper ASP.NET CORE — инструмент созданный компание Stack Exchange, который преобразует результаты sql запросов с классами C#. У Dapper есть схожести с Entity Framework. Благодаря своему малому весу Dapper предоставляет высокую производительность и позволяет выполнять запросы быстрее, чем EF Core, а так же быстрее Entity Framework в 10 раз(Рис 1). Dapper применяется в работе сайта stackoverflow.com, на котором разработчики со всего мира могут задавать ответы по программированию и получать качественные ответы.
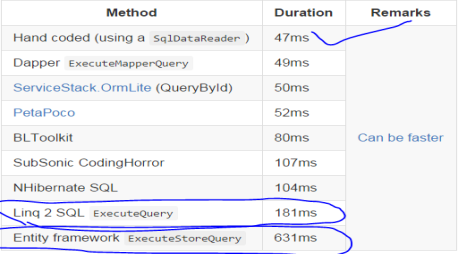
Рис. 1. Сравнение скоростей
Платформа ASP.NET Core технология от компании Microsoft, предназначенную для создания веб-приложений: от простых веб-сайтов до огромных веб-порталов и веб-сервисов.
ASP.NET Core представляет собой следующим этапом развития платформы ASP.NET. Но с другой стороны, это не просто очередной релиз. Появление ASP.NET Core в действительности означает революцию всей платформы, ее качественное изменение. Создание платформы началась еще в 2014 году. Первое название платформы условно называлась ASP.NET vNext. В июне 2016 года вышел первый релиз платформы. А в мае 2018 года вышла версия ASP.NET Core 2.1. ASP.NET Core теперь полностью является opensource-фреймворком.
В качестве инструментария разработки мы можем использовать последние выпуски Visual Studio, начиная с версии Visual Studio 2015. Кроме того, мы можем создавать приложения в среде Visual Studio Code, которая является кросс-платформенной и может работать как на Windows, так и на Mac OS X и Linux. Для обработки запросов теперь используется новый конвейер HTTP, который основан на компонентах Katana и спецификации OWIN. А его модульность позволяет легко добавить свои собственные компоненты. Если суммировать, то можно выделить следующие ключевые отличия ASP.NET Core от предыдущих версий ASP.NET:
Переработанный легковесный и модульный конвейер HTTP-запросов
Возможность развертывать приложение как на IIS, так и в рамках своего собственного процесса
Использование пакетов платформы через NuGet
Единый стек веб-разработки, сочетающий Web UI и Web API Конфигурация для упрощенного использования в облаке
Встроенная поддержка для внедрения зависимостей
Кроссплатформенность: возможность разработки и развертывания приложений ASP.NET на Mac, Windows и Linux
Развитие как open source, открытость к изменениям
Для работы нужно подключить в Nuget Dapper (Рис 2)
Рис. 2. Nuget Dapper
Проект можно разделить по папкам для оптимальной работы (Рис 3), Content используется для хранения фотографий и файлов HTML & CSS, Controller центральный компонент в архитектуре проекта, отвечающий за вводом пользователя, обработкой данными и возврату результата, Helpers методы которые часто вызываются, для того чтобы не писать огромный код каждый раз, его можно создать как хелпер и вызывать его, данная механика убирает лишние строки кода, requests это DTO (DTO это Data Transfer Object — шаблон проектирования, использующийся для передачи информации между подсистемами приложения) которые принимают данные с FrontEnd, Domain Models модели принимаемых данных, Repositories классы которые содержат запросы к базе MsSql.
В Dapper можно использовать CRUD методы (Create, Read, Update, Delete).
Существуют специальные запросы, которые могут ускорить процесс сбора данных и комфортного чтения кода.
Рассмотрим на модели User:
public class ProjectsUsers
public string FirstName
public string LastName
public string Grade
1) public IEnumerable List()
var sql = “SELECT * FROM Project.Department_User ”
return Connection.Query (sql);
2) public IEnumerable List()
В данном случае мы можем увидеть, что в первом примере создается переменная sql в которую мы записываем запрос в базу данных, названия таблиц может быть довольно длинными и нечитабельными
Во втором примере наглядно видно, что вызывается метод GetAll(), этот запрос записан в библиотеке Dapper, данная форма вызова оптимальна, читабельна для разработчика и требует меньше строк кода, что может сыграть на скорости выполнения задач.
1) public void Update(ProjectsUsers users)
SET firstName = @firstname,
2) public void Update(ProjectsUsers users)
Connection.Update(users);
При обновлении таблицы Project.Department_User заметно как отличаются запросы к базе данных, в первом примере мы вводим каждую строку из модели ProjectsUsers и таких моделей может быть множество, что может сказаться на быстродействии, во втором примере все просто написано в одну строку.
Dapper на данный момент один из самых удобных инструментов для работы с большими данными, прост в освоении, универсальный для API, высокопроизводительный, скоростной и легковесный ORM.
- Kevin Davis, Notoriously Dapper: How to Be a Modern Gentleman with Manners, Style and Body Confidence Paperback.
- Ben Albahari, C# 6.0 in a Nutshell: The Definitive Reference.
- Maheshwari, Data Analytics Made Accessible.
- Simon, Too Big to Ignore: The Business Case for Big Data
Основные термины (генерируются автоматически): CRUD, API, CORE, FROM, HTTP, IIS, ORM, OWIN, SELECT, SET.
Ключевые слова
SQL, C#, кросс-платформенность, open source, CRUD методы
Похожие статьи
Оптимизация взаимодействия web-приложения с базой данных.
В данной работе проведено исследование производительности ORM-библиотек, на основании которого выбрана библиотека для работы с. Оптимизация взаимодействия web-приложения с базой данных в информационно-исследовательской системе «Шлаковые расплавы».
Слушатель события обновления сцены. Кадронезависимое.
Приводится решение кадронезависимого движения в приложениях под Android на примере классов фреймворка PeeKaBoo. Описывается создание слушателя обновления сцены, зависящего от времени, выбранного разработчиком игры.
Модификация архитектуры web-приложения, основанной на.
В работе рассматривается способ организации архитектуры web-приложения на основе паттерна CQRS. В основе архитектуры лежит разделение на write- и read- модели, которые используют SQL и NoSql базы данных. Результатом применения архитектуры стало возможность.
Исследование производительности ASP.NET-приложений
− Использование HTTP-сжатия. Это самое простое правило, так как для его соблюдения чаще всего не требуется дополнительных затрат
Причем в ASP.NET реализованы так называемые профили кэширования. Они позволяют заранее создать в файле web.config настройки.
Системы сбора информации в аспекте кибербезопасности
Легкость настройки системы. Минимальная нагрузка системы на узлы. Универсальная система, не зависящая от ОС, используемой на узлах.
– Система должна иметь возможность извлекать данные анализа для визуализации через API или иметь средство визуализации данных анализа.
Эволюция веб-фреймворков Microsoft. ASP.NET vNext (ASP.NET 5)
Данная статья рассказывает о платформе Microsoft.NET Framework и технологии создания веб-приложений и веб-сервисов от вышеупомянутой компании — ASP.NET. Описывается история развития данной технологии и последние новшества, такие как ASP.NET vNext.
Интеграция Telegram-ботов в информационных системах
В статье раскрывается понятие о создания Telegram ботов для автоматизации получения информации с информационных систем. Даются определения информационной системы и интеграции с базой данных. Делается вывод, что с помощью ботов можно получить.
Организация сбора технологических данных с буровой и передачи.
Автоматизация технологического процесса составляет важную часть научно-технического прогресса в проведении геологоразведочных работ. Теоретические исследования в области совершенствования управления процессом бурения и его оптимизации получили новые.
Использование Dapper в ASP.NET WEB API 2 приложении

Dapper.NET — это «mini-ORM» на которой работает движок StackExchange и сайт StackOverflow в частности. Dapper это технология маппинга результатов sql-запросов с классами c#. Dapper чем то похож на Entity Framework, но за счет легковесности Dapper обеспечивает большую производительность и работает быстрее, нежели Entity Framework. Далее рассмотрим как можно построить REST’ful api controller с запросами к базе через dapper.
1. Создаем class library для Dapper’a

2. Подключаем Dapper с nuget’a

3. Создаем WebApi проект в visual studio
Теперь когда у нас есть каркас, мы можем приступить к созданию базы данных.
4. Создание базы
- Переходим в SQL Management Studio
- Нажимаем правой кнопкой на базы данных и выбираем создать новую

- Вводим название новой базы (например Dapper) и нажимаем ОК.

5. Создаем таблицу «Книги»
для этого выполним следующий sql скрипт:
CREATE TABLE Books ( Id int NOT NULL IDENTITY, Author nvarchar(100) NOT NULL, Name nvarchar(250) NOT NULL, PageCount int, PRIMARY KEY (Id) );Теперь когда наша база готова, можем приступать к программированию.
5. Создаем класс Book
namespace Dapper.Entities < public class Book < public int Id < get; set; >public string Name < get; set; >public string Author < get; set; >public int PageCount < get; set; >> >6. Создаем репозиторий для Book
Для класса книга, теперь можно создать репозиторий который будет выполнять CRUD операции.
Создаем интерфейс IBookRepository
using System.Collections.Generic; using Dapper.Entities; namespace Dapper.Repositories < public interface IBookRepository < void Create(Book book); void Delete(int id); Book Get(int id); IEnumerableGetAllBooks(); void Update(Book book); > >И его реализацию BookRepository
using System.Collections.Generic; using System.Data; using Dapper.Entities; using System.Data.SqlClient; using System.Linq; using System.Configuration; namespace Dapper.Repositories < public class BookRepository : IBookRepository < private readonly string _connectionString = ConfigurationManager.ConnectionStrings["DapperConnection"].ConnectionString; public IEnumerableGetAllBooks() < using (IDbConnection db = new SqlConnection(_connectionString)) < return db.Query("SELECT * FROM Books"); > > public Book Get(int id) < using (IDbConnection db = new SqlConnection(_connectionString)) < return db.Query("SELECT * FROM Books WHERE new < id >).FirstOrDefault(); > > public void Create(Book book) < using (IDbConnection db = new SqlConnection(_connectionString)) < var sqlQuery = "INSERT INTO Books (Name, Author, PageCount) VALUES(@Name, @Author, @PageCount); SELECT CAST(SCOPE_IDENTITY() as int)"; int userId = db.Query(sqlQuery, book).First(); book.Id = userId; > > public void Update(Book book) < using (IDbConnection db = new SqlConnection(_connectionString)) < var sqlQuery = "UPDATE Books SET Name = @Name, Author = @Author, PageCount = @PageCount WHERE db.Execute(sqlQuery, book); >> public void Delete(int id) < using (IDbConnection db = new SqlConnection(_connectionString)) < var sqlQuery = "DELETE FROM Books WHERE db.Execute(sqlQuery, new < id >); > > > >Следует заметить, что мы используем DapperConnection connectionstring.
Добавим ее в webapi проект в web.config.
7. Переходим к созданию API BooksController’y
using Dapper.Repositories; using System.Collections.Generic; using System.Threading.Tasks; using System.Web.Http; using Dapper.Entities; namespace WebApiTest.Controllers < public class BooksController : ApiController < private readonly IBookRepository _bookRepository = new BookRepository(); // GET: api/Books public async Task> Get() < return _bookRepository.GetAllBooks(); >// GET: api/Books/5 public Book Get(int id) < return _bookRepository.Get(id); >// POST: api/Books public IHttpActionResult Post([FromBody]Book book) < _bookRepository.Create(book); return Created(Request.RequestUri + book.Id.ToString(), book); >// PUT: api/Books/5 public IHttpActionResult Put(int id, [FromBody]Book book) < book.Id = id; _bookRepository.Update(book); return Ok(); >// DELETE: api/Books/5 public IHttpActionResult Delete(int id) < _bookRepository.Delete(id); return Ok(); >> >Следует отметить, что строчка private readonly IBookRepository _bookRepository = new BookRepository(); к использованию не желательна, тут она продемонстрирована ислючительно в качестве примера, я рекомендую использовать какой-то IoC контейнер и инджектить IBookRepository в конструктор.
Наш RESTful API готов к использованию, давайте протестируем его через постмен и посмотрим что получилось.
Доступ к данным — Гибридные приложения Dapper и Entity Framework
.png)
Вероятно, вы заметили, что я много пишу об Entity Framework — Microsoft Object Relational Mapper (ORM), который является основным API доступа к данным в .NET с 2008 года. Существуют другие .NET ORM, но конкретной их категории, микро-ORM, уделяют большое внимание из-за высокой производительности. Среди них чаще всего упоминают Dapper. Мой интерес возбудили сообщения от разных разработчиков о том, что они создали гибридные решения с помощью EF и Dapper, позволяя каждому ORM в рамках одного приложения делать то, в чем он наиболее силен.
После прочтения множества статей и публикаций в блогах, общения с разработчиками и некоторых экспериментов с Dapper я захотела поделиться своими открытиями с вами, особенно с теми, кто, как и я, возможно, слышал о Dapper, но на деле не знает, что это такое, как он работает и почему он так нравится многим людям. Помните, что я ни в коей мере не являюсь экспертом в Dapper. Скажем так: я знаю достаточно, чтобы удовлетворить свое любопытство на данный момент, и надеюсь вызвать у вас интерес к Dapper, чтобы вы потом самостоятельно углубились в изучение этого микро-ORM.
Почему Dapper?
Dapper имеет интересную историю, появившись на свет на одном ресурсе, который, по-видимому, очень хорошо известен вам: Марк Грэвелл (Marc Gravell) и Сэм Саффрон (Sam Saffron) в период своей работы в Stack Overflow создали Dapper, решая проблемы с производительностью на этой платформе. Stack Overflow — это сайт с очень интенсивным трафиком, который неизбежно вызывает озабоченности по поводу производительности. Согласно странице About на Stack Exchange, в 2015 году на Stack Overflow было отмечено 5,7 миллиардов просмотров страниц. В 2011 году Саффрон написал статью в блоге о проделанной им и Грэвеллом работе — «How I Learned to Stop Worrying and Write My Own ORM» (aka.ms/Vqpql6), в которой разъяснялись проблемы с производительностью, имевшиеся у Stack в то время; они были связаны с использованием LINQ to SQL. Затем он подробно обосновал то, почему написание собственного ORM, Dapper, было решением для оптимизации доступа к данным на Stack Overflow. Прошло пять лет, и вот Dapper широко используется как проект с открытым исходным кодом. Грэвелл и член команды Ник Крейвер по-прежнему активно руководят проектом на github.com/StackExchange/dapper-dot-net.
Dapper в общих чертах
Dapper позволяет задействовать ваши навыки в SQL для конструирования запросов и команд в том виде, в каком они должны быть по вашему мнению. Он ближе к «железу», чем стандартный ORM, облегчая усилия в интерпретации таких запросов, как LINQ to EF, в SQL. В Dapper действительно есть некоторые впечатляющие средства преобразования, например возможность разбивать список, передаваемый блоку WHERE IN. Но по большей части SQL, передаваемый вами в Dapper, готов к работе, и запросы попадают в базу данных гораздо быстрее. Если вы хорошо знаете SQL, то, безусловно, напишете настолько производительные команды, насколько это возможно. Для выполнения запросов вы должны создать какой-то тип IDbConnection, например SqlConnection с известной строкой подключения. Затем Dapper с помощью своего API может выполнять запросы за вас и (при условии, что схему результатов запроса можно соотнести со свойствами целевого типа) автоматически создавать и заполнять объекты результатами запроса. Здесь вы получаете еще один существенный выигрыш в производительности: Dapper эффективно кеширует сопоставление, которое стало ему известно, что обеспечивает очень быструю десериализацию последующих запросов. Класс, который я буду заполнять, DapperDesigner (рис. 1), определен для управления дизайнерами, которые шьют очень элегантную одежду.
Рис. 1. Класс DapperDesigner
public class DapperDesigner < public DapperDesigner() < Products = new List(); Clients = new List(); > public int Id < get; set; >public string LabelName < get; set; >public string Founder < get; set; >public Dapperness Dapperness < get; set; >public List Clients < get; set; >public List Products < get; set; >public ContactInfo ContactInfo < get; set; >> Проект, где я выполняю запросы, имеет ссылку на Dapper, который я получила через NuGet (командой install-package dapper). Вот пример вызова из Dapper для выполнения запроса на получение всех строк из таблицы DapperDesigners:
var designers = sqlConn.Query( "select * from DapperDesigners"); Заметьте, что в листингах кода в этой статье я использую select * вместо явного проецирования полей для запросов, когда мне нужны все столбцы из таблицы. Переменная sqlConn — это существующий объект SqlConnection, экземпляр которого я уже создала наряду с его строкой подключения, но пока не открыла.
Query — метод расширения, предоставляемый Dapper. Когда выполняется эта строка, Dapper открывает соединение, создает DbCommand, выполняет запрос именно так, как я написала его, создает экземпляр объекта DapperDesigner для каждой строки в результатах и помещает значения из результатов запроса в свойства этих объектов. Dapper может соотносить значения результатов со свойствами посредством нескольких шаблонов, даже если имена свойств не совпадают с именами полей и даже если свойства не находятся в том же порядке, что и совпадающие поля. Но читать мысли он не умеет, поэтому не ждите от него понимания задействованных сопоставлений, например многочисленных строковых значений, где порядок или имена полей и свойств не согласованы. Я пыталась проделать несколько замысловатых экспериментов, чтобы понять, как он будет реагировать на такие вещи; кроме того, имеются глобальные параметры, управляющие тем, как Dapper может логически распознавать сопоставления.
Dapper и реляционные запросы
Мои тип DapperDesigner имеет ряд отношений: «один ко многим» (с Products), «один к одному» (ContactInfo) и «многие ко многим» (Clients). Я экспериментировала с выполнением запросов через эти отношения, и Dapper оказался способен обрабатывать их. Это определенно не столь легко, как выражать запрос LINQ to EF с помощью метода Include или даже проекции. Однако мои навыки в TSQL были исчерпаны до предела, потому что за прошедшие годы EF позволила мне так облениться.
Вот пример выдачи запроса через отношение «один ко многим» на SQL, который я использовала бы прямо в базе данных:
var sql = @"select * from DapperDesigners D JOIN Products P ON P.DapperDesignerId = D.Id"; var designers = conn.Query (sql,(designer, product) => < designer.Products.Add(product); return designer; >); Заметьте, что метод Query требует указать оба типа, которые должны быть сконструированы, а также задать возвращаемый тип, выражаемый заключительным параметром-типом (DapperDesigner). Я использую многострочную лямбду, чтобы сначала сконструировать графы, добавить релевантные товары (products) в их родительские объекты дизайнеров, а затем вернуть каждый дизайнер в IEnumerable, возвращаемый методом Query.
Недостаток такого варианта, потребовавшего от меня максимальных усилий в SQL, заключается в том, что результаты становятся плоскими, как при использовании EF-метода Include. Я получу одну строку на каждый продукт с продублированными дизайнерами. В Dapper есть метод MultiQuery, способный возвращать несколько наборов результатов. В сочетании с GridReader из Dapper производительность этих запросов безусловно превосходит таковую у EF-методов Include.
Труднее в кодировании, быстрее в выполнении
Выражение SQL-кода и заполнение релевантных объектов — задачи, которые я позволила EF обрабатывать в фоне, так что это определенно требует больше усилий в кодировании. Но если вы работаете с большими объемами данных и вам важна производительность исполняющей среды, это, разумеется, стоит таких усилий. В моем примере базы данных около 30 000 дизайнеров. Лишь у нескольких из них есть товары. Я проделала некоторые простые эталонные тесты (benchmark tests), где убедилась, что сравниваю одинаковые вещи. Прежде чем рассматривать результаты тестов, обсудим несколько важных моментов, относящихся к тому, как я выполняла эти замеры.
Помните, что по умолчанию EF отслеживает объекты, являющиеся результатами запросов. Это означает, что она создает дополнительные отслеживающие объекты (tracking objects), вызывающих некоторые издержки, и что ей также требуется взаимодействовать с этими отслеживающими объектами. Dapper, напротив, просто помещает результаты в память. Поэтому важно вывести из игры отслеживание изменений EF при любых сравнениях производительности. Для этого я определяю все свои EF-запросы с методом AsNoTracking. Кроме того, сравнивая производительность, вы должны применять ряд стандартных шаблонов эталонных тестов, такие как подготовка («разогрев») базы данных, многократное повторение запроса и отбрасывание самых низких и самых высоких результатов. Все детали того, как я создавала свои эталонные тесты, вы увидите в пакете исходного кода, сопутствующем этой статье. Тем не менее, я считаю эти эталонные тесты «облегченными», так как они дают лишь некоторое представление о различиях. Для серьезных эталонных тестов вам понадобилось бы гораздо больше итераций, чем мои 25 (от 500 и выше), и учет производительности системы, в которой вы работаете. Я выполняла эти тесты на лэптопе, используя экземпляр SQL Server LocalDB, поэтому мои результаты пригодны лишь для сравнения.
Показатели, которые я отслеживала в своих тестах, — это время выполнения запроса и время формирования результатов. Создание соединений или объектов DbContext не учитывалось. DbContext используется повторно, чтобы не принимать во внимание время, затрачиваемое EF на создание модели в памяти, так как это происходило бы лишь раз для каждого экземпляра приложения, а не для каждого запроса.
На рис. 2 показаны тесты «select *» для запросов Dapper и EF LINQ, так что вы можете понять базовую конструкцию моих шаблонов тестирования. Заметьте, что, помимо сбора самих показателей, я записываю время каждой итерации в список (с именем times) для последующего анализа.
Рис. 2. Тесты для сравнения EF и Dapper при запросе всех DapperDesigner
[TestMethod,TestCategory("EF"),TestCategory("EF,NoTrack")] public void GetAllDesignersAsNoTracking() < Listtimes = new List(); for (int i = 0; i < 25; i++) < using (var context = new DapperDesignerContext()) < _sw.Reset(); _sw.Start(); var designers = context.Designers.AsNoTracking().ToList(); _sw.Stop(); times.Add(_sw.ElapsedMilliseconds); _trackedObjects = context.ChangeTracker.Entries().Count(); >> var analyzer = new TimeAnalyzer(times); Assert.IsTrue(true); > [TestMethod,TestCategory("Dapper") public void GetAllDesigners() < Listtimes = new List(); for (int i = 0; i < 25; i++) < using (var conn = Utils.CreateOpenConnection()) < _sw.Reset(); _sw.Start(); var designers = conn.Query( "select * from DapperDesigners"); _sw.Stop(); times.Add(_sw.ElapsedMilliseconds); _retrievedObjects = designers.Count(); > > var analyzer = new TimeAnalyzer(times); Assert.IsTrue(true); > Стоит отметить еще один момент, касающийся сравнения одинаковых вещей. Dapper принимает чистый SQL. По умолчанию EF-запросы выражаются с помощью LINQ to EF и должны подвергаться некоторой обработке для создания SQL-кода за вас. Как только этот SQL создан, даже если он полагается на параметры, он кешируется в памяти приложения, из-за чего при повторении издержки уменьшаются. Кроме того, EF способна выполнять запросы, использующие чистый SQL, поэтому я приняла во внимание оба подхода. В табл. 1 перечислены сравнительные результаты четырех наборов тестов. В сопутствующем этой статье пакете исходного кода содержится еще больше тестов.
Табл. 1. Среднее время (в мс) выполнения запроса и заполнения объекта на основе 25 итераций с исключением самого быстрого и самого медленного результата
| * Запросы с AsNoTracking | Отношение | LINQ to EF* | Чистый SQL, EF* | Чистый SQL, Dapper |
| Все дизайнеры (30 000 строк) | – | 96 | 98 | 77 |
| Все дизайнеры с товарами (30 000 строк) | 1 : * | 251 | 107 | 91 |
| Все дизайнеры с клиентами (30 000 строк) | * : * | 255 | 106 | 63 |
| Все дизайнеры с Contact (30 000 строк) | 1 : 1 | 322 | 122 | 116 |
В сценариях, показанных в табл. 1, легко убедиться в преимуществе использования Dapper по сравнению с LINQ to Entities. Но небольшие различия между чистыми SQL-запросами могут не всегда оправдывать переход на Dapper для конкретных задач в системе, где вы в остальных случаях используете EF. Естественно, ваши требования будут другими и могут повлиять на меру различий между EF-запросами и Dapper. Однако в системе с интенсивным трафиком вроде Stack Overflow даже пара миллисекунд экономии на каждом запросе может оказаться крайне существенной.
Dapper и EF для других требований
До сих пор я замеряла простые запросы, где просто извлекаются все столбцы из таблицы, которые точно соответствуют свойствам возвращаемых типов. А как быть, если вы проецируете запросы на типы? Пока схема результатов совпадает с типом, Dapper не видит никакой разницы при создании объектов. Но EF приходится поработать больше, если результаты проекции не совпадают с типом, который является частью модели.
DapperDesignerContext имеет DbSet для типа DapperDesigner. В моей системе есть другой тип, MiniDesigner, который имеет подмножество свойств DapperDesigner:
public class MiniDesigner < public int Id < get; set; >public string Name < get; set; >public string FoundedBy < get; set; >> MiniDesigner не является частью моей EF-модели данных, поэтому DapperDesignerContext ничего не знает об этом типе. Я обнаружила, что запрос всех 30 000 строк и их проецирование на 30 000 объектов MiniDesigner на 25% быстрее в случае Dapper, чем в случае EF, использующей чистый SQL. И вновь для принятия решений конкретно в вашей системе я рекомендую выполнить собственное профилирование производительности.
Dapper также можно использовать для передачи данных в базу данных с помощью методов, позволяющих вам идентифицировать, какие свойства следует применять для параметров, указанных командой, будь то чистая SQL-команда INSERT/UPDATE или вызов функции/хранимой процедуры в базе данных. Для этих задач я не делала никаких сравнений по производительности.
Гибрид «Dapper плюс EF» в реальном мире
Существует очень много систем, которые на 100% используют Dapper для сохранения данных. Но вспомните, что у меня интерес возник из-за того, что разработчики говорили о гибридных решениях. В некоторых случаях это системы с EF, где нужно оптимизировать конкретные проблемные области. В других случаях группы предпочитают использовать Dapper для всех запросов, а EF для всех операций сохранения.
В ответ на мои вопросы по этому поводу в Twitter я получила самые разнообразные отклики.
@garypochron сказал мне, что его группа «собирается задействовать Dapper в областях, где наблюдается высокая интенсивность вызовов и очень частое использование файлов ресурсов». Я изумилась, узнав, что Саймон Хьюз (Simon Hughes) (@s1monhughes), автор популярного проекта EF Reverse POCO Generator, движется в противоположном направлении: по умолчанию везде применяет Dapper и использует EF только для решения изощренных задач. Он сказал мне, что «использует Dapper везде, где только можно. Если же я имею дело со сложной операцией обновления, то перехожу на EF».
Я также видела множество дискуссий о том, где применение гибридного подхода стимулируется разделением обязанностей, а не повышением производительности. Чаще всего в решениях используется надежность ASP.NET Identity в EF, а Dapper применяется для всех остальных операций с базами данных.
Более прямая работа с базой данных имеет и другие преимущества помимо производительности. Роб Салливан (Rob Sullivan) (@datachomp) и Майк Кэмпбелл (Mike Campbell) (@angrypets), эксперты в области SQL Server, любят Dapper. Роб указывает, что вы получаете возможность задействовать такую функциональность баз данных, к которой EF не дает доступа, например полнотекстовый поиск. В конечном счете эта функциональность на самом деле связана с производительностью.
С другой стороны, есть вещи, которые позволяет делать EF, а Dapper — нет, и это не только отслеживание изменений. Хороший пример — возможность выполнять миграции базы данных по мере изменения модели с помощью EF Code First Migrations (чем я и воспользовалась при создании решения для этой статьи).
Однако Dapper не подходит всем и каждому. @damiangray сказал мне, что Dapper не годится для его решения, поскольку ему нужно возвращать IQueryable-объекты из одной части системы в другую, а не сами данные. Эта тематика, отложенное выполнение запросов (deferred query execution), поднималась в репозитарии GitHub для Dapper по ссылке bit.ly/22CJzJl, если вас интересуют подробности. При проектировании гибридной системы хорошей идеей является использование какой-либо разновидности архитектуры Command Query Separation (CQS), где вы создаете раздельные модели для конкретных типов транзакций (как раз то, к чему я всегда стремлюсь). Тем самым вы не пытаетесь создавать код для доступа к данным, достаточно универсальный для работы как с EF, так и с Dapper, в котором зачастую приходится жертвовать преимуществами каждого из этих ORM. Когда я работала над этой статьей, Курт Доусвелл (Kurt Dowswell) опубликовал статью «Dapper, EF and CQS» (bit.ly/1LEjYvA). Очень удачно и для меня, и для вас.
Для тех, кто ожидает CoreCLR и ASP.NET Core, полезно знать, что в Dapper включена и их поддержка. Более подробную информацию вы найдете в репозитарии GitHub для Dapper по ссылке bit.ly/1T5m5Ko.
Итак, я посмотрела Dapper. Что я думаю?
Каковы мои мысли насчет Dapper? Я сожалею, что не нашла время посмотреть Dapper раньше, и счастлива, что наконец-то сделала это. Я всегда рекомендовала применение AsNoTracking или использование представлений либо процедур в базе данных для смягчения остроты проблем с производительностью. Это никогда не подводило ни меня, ни моих клиентов. Но теперь у меня появился другой туз в рукаве, который я намерена рекомендовать разработчикам, заинтересованным выжать еще капельку производительности из своих систем, использующих EF. Это не панацея на все случаи жизни. Моя рекомендация будет заключаться в том, чтобы исследовать Dapper, замерить разницу в производительности (при больших масштабах) и найти баланс между производительностью и тяжестью кодирования. Примите во внимание очевидный шаблон использования Stack Overflow: запросы вопросов, комментариев и ответов, затем возврат графов одного вопроса с комментариями и ответами наряду с некоторыми метаданными (правками) и информацией о пользователе. Они выполняют одни и те же типы запросов и сопоставляют одну и ту же форму результатов снова и снова. Dapper блистает при таком типе повторяющихся запросов, с каждым разом становясь все интеллектуальнее и быстрее. Даже если у вас нет системы с невероятным количеством транзакций, на которое рассчитан Dapper, вы скорее всего обнаружите, что гибридное решение дает вам как раз то, что нужно.
Джули Лерман (Julie Lerman) — Microsoft MVP, преподаватель и консультант по .NET, живет в Вермонте. Часто выступает на конференциях по всему миру и в группах пользователей по тематике, связанной с доступом к данным и другими технологиями Microsoft .NET. Ведет блог thedatafarm.com/blog и является автором серии книг «Programming Entity Framework» (O’Reilly Media, 2010), в том числе «Code First Edition» (2011) и «DbContext Edition» (2012), также выпущенных издательством O’Reilly Media. Вы можете читать ее заметки в twitter.com/julielerman и смотреть ее видеокурсы для Pluralsight на juliel.me/PS-Videos.
Выражаю благодарность за рецензирование статьи экспертам Stack Overflow Нику Крейверу (Nick Craver) и Марку Грэвеллу (Marc Gravell).