ПЕРЕВОД ЧИСЕЛ ИЗ ДВОИЧНОЙ СИСТЕМЫ В ДЕСЯТИЧНУЮ
Задача перевода чисел из двоичной системы счисления в десятичную чаще всего возникает уже при обратном преобразовании вычисленных либо обработанных компьютером значений в более понятные пользователю десятичные цифры. Алгоритм перевода двоичных чисел в десятичные достаточно прост (его иногда называют алгоритмом замещения):
Для перевода двоичного числа в десятичное необходимо это число представить в виде суммы произведений степеней основания двоичной системы счисления на соответствующие цифры в разрядах двоичного числа.
Например, требуется перевести двоичное число 10110110 в десятичное. В этом числе 8 цифр и 8 разрядов ( разряды считаются, начиная с нулевого, которому соответствует младший бит). В соответствии с уже известным нам правилом представим его в виде суммы степеней с основанием 2:
101101102 = (1·2 7 )+(0·2 6 )+(1·2 5 )+(1·2 4 )+(0·2 3 )+(1·2 2 )+(1·2 1 )+(0·2 0 ) = 128+32+16+4+2 = 18210
Из этого примера видно, в частности, что десятичная система счисления более компактно отображает числа — 3 цифры (т.е. бита) вместо 8 цифр в двоичной системе счисления. Для вычислений «вручную» и решения примеров и контрольных заданий вам могут пригодиться таблицы степеней оснований изучаемых систем счисления (2, 8, 10, 16), приведенные в Приложении.
Двоичная система счисления
Чисто технически было бы очень сложно сделать компьютер, который бы «понимал» десятичные числа. А вот сделать компьютер, который понимает двоичные числа достаточно легко. Двоичное число оперирует только двумя цифрами – 0 и 1. Несложно сопоставить с этими цифрами два состояния – вЫключено и включено (или нет напряжения – есть напряжение). Процессор – это микросхема с множеством выводов. Если принять, что отсутствие напряжения на выводе – это 0 (ноль), а наличие напряжения на выводе – это 1 (единица), то каждый вывод может работать с одной двоичной цифрой. Сейчас мы говорим о процессоре очень упрощённо, потому что мы изучаем не процессоры, а системы исчисления. Об устройстве процессора вы можете почитать здесь: Структура процессора.
Конечно, это касается не только процессоров, но и других составляющих компьютера, например, шины данных или шины адреса. И когда мы говорим, например, о разрядности шины данных, мы имеем ввиду количество выводов на шине данных, по которым передаются данные, то есть о количестве двоичных цифр в числе, которое может быть передано по шине данных за один раз. Но о разрядности чуть позже.
Итак, процессор (и компьютер в целом) использует двоичную систему, которая оперирует всего двумя цифрами: 0 и 1. И поэтому основание двоичной системы равно 2. Аналогично, основание десятичной системы равно 10, так как там используются 10 цифр.
Каждая цифра в двоичном числе называется бит (или разряд). Четыре бита – это полубайт (или тетрада), 8 бит – байт, 16 бит – слово, 32 бита – двойное слово. Запомните эти термины, потому что в программировании они используются очень часто. Возможно, вам уже приходилось слышать фразы типа слово данных или байт данных. Теперь, я надеюсь, вы понимаете, что это такое.
Отсчёт битов в числе начинается с нуля и справа. То есть в двоичном числе самый младший бит (нулевой бит) является крайним справа. Слева находится старший бит. Например, в слове старший бит – это 15-й бит, а в байте – 7-й. В конец двоичного числа принято добавлять букву b. Таким образом вы (и ассемблер) будете знать, что это двоичное число. Например,
101 – это десятичное число 101b – это двоичное число, которое эквивалентно десятичному числу 5.
А теперь попробуем понять, как формируется двоичное число.
Ноль, он и в Африке ноль. Здесь вопросов нет. Но что дальше. А дальше разряды двоичного числа заполняются по мере увеличения этого числа. Для примера рассмотрим тетраду. Тетрада (или полубайт) имеет 4 бита.
| Двоичное | Десятичное | Пояснения |
| 0000 | 0 | — |
| 0001 | 1 | В младший бит устанавливается 1. |
| 0010 | 2 | В следующий бит (бит 1) устанавливается 1, предыдущий бит (бит 0) очищается. |
| 0011 | 3 | В младший бит устанавливается 1. |
| 0100 | 4 | В следующий бит (бит 2) устанавливается 1, младшие биты (бит 0 и 1) очищаются. |
| 0101 | 5 | В младший бит устанавливается 1. |
| 0110 | 6 | Продолжаем в том же духе. |
| 0111 | 7 | . |
| 1000 | 8 | . |
| 1001 | 9 | . |
| 1010 | 10 | . |
| 1011 | 11 | . |
| 1100 | 12 | . |
| 1101 | 13 | . |
| 1110 | 14 | . |
| 1111 | 15 | . |
Итак, мы видим, что при формировании двоичных чисел разряды числа заполняются нулями и единицами в определённой последовательности:
Если младший равен нулю, то мы записываем туда единицу. Если в младшем бите единица, то мы переносим её в старший бит, а младший бит очищаем. Тот же принцип действует и в десятичной системе:
0…9 10 – очищаем младший разряд, а в старший добавляем 1
Всего для тетрады у нас получилось 16 комбинаций. То есть в тетраду можно записать 16 чисел от 0 до 15. Байт – это уже 256 комбинаций и числа от 0 до 255. Ну и так далее. На рис. 2.2 показано наглядно представление двоичного числа (двойное слово).
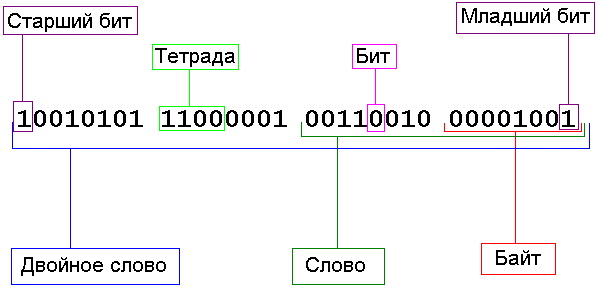
Рис. 2.2. Двоичное число.
Дневники чайника. Чтива 0, виток0
Системы счисления и устройство памяти.
Второй день
Поскольку компьютер в основе своей имеет только 0 и 1, на первых этапах освоения ассемблера (может быть, год) нам будут нужны только целые числа, мало того, очень долго можно работать всего лишь с положительными целыми числами, о которых здесь и пойдёт речь.
Только целые и только положительные.
Возможно, вы проходили эту тему в школе, и кто-то из вас даже что-то помнит, но начинать нужно именно отсюда.
Нас будут интересовать 3 системы счисления — dec, bin, hex.
Десятичная — Decimal (Dec или буква «d»)
Aрабская система — она называется десятичной, потому что в ней используются 10 символов.
0,1,2,3,4,5,6,7,8,9
Все значения представляются этими символами. Вы и сами знаете, как пользоваться десятичной системой, так как мы все выросли на ней и каждую минуту чего-нибудь считаем.
Запомни, юнга! В космосе нет верха, нет низа — это всё условности. И то, что у тебя десять пальцев на руках, это всего лишь исключение. У наших бинарных братьев всего два пальца, они смеются над тобой — урод десятипалый :). У них есть на это право, их больше и они старше. С Бинарниками надо дружить, иначе корабль собьют на подходе к первой же станции.
Двоичная система счисления — Binary (Bin или буква «b»)
Нетрудно догадаться, что двоичная система имеет всего два символа 0 и 1.
Компьютер — это очень простой прибор, в нём есть только выключатели — биты (вкл. =1, выкл. =0).
Понятие Bit, скорее всего, произошло от английских слов Binary — двоичная и Digit — цифра. Но поскольку битов о-о-очень много, биты строятся в байты.
11111111 - это байт 01010101 - и это байт 00000000 - и это тоже байт
Бит может иметь значение 0 или 1.
Байт — это 8 бит, и он может иметь значения от 0000 0000 — ноль, до 1111 1111 — 255 в десятичной системе (пробелы для читаемости). Получается, что у байта 256 значений (всегда считается вместе с нулевым).
биты dec-цифры | биты dec-цифры 00000001 = 1 | 00001011 = 11 00000010 = 2 ! | 00001100 = 12 00000011 = 3 | 00001101 = 13 00000100 = 4 ! | 00001110 = 14 00000101 = 5 | 00001111 = 15 00000110 = 6 | 00010000 = 16 ! 00000111 = 7 | 00010001 = 17 00001000 = 8 ! | 00010010 = 18 00001001 = 9 | 00010011 = 19 00001010 = 10 | 00010100 = 20 И так до 11111111 = 255.
Переводить из десятичных цифр в биты (то есть в двоичные цифры) и обратно можно на виндовом калькуляторе (в инженерном режиме). Потренируйтесь пока так. Учить наизусть всю таблицу не нужно, познакомились — уже хорошо. 🙂
Как вы думаете, почему я выделил 2,4,8,16?
Правильно, это «круглые» цифры. В десятичной системе они, конечно, не круглые, но в двоичной получается 10,100,1000,10000. Поэтому десятичная система для компьютерных вычислений не очень подходит. Вместо неё используется.
Шестнадцатиричная система счисления — Hexadecimal (Hex или буква «h»)
Имеет целых 16 символов. Чтоб не придумывать новые символы, в hex используются буквы латинского алфавита.
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F - это цифры
Я приравняю все hex-символы к десятичным значениям.
h d h d h d h d 0=0 4=4 8=8 C=12 1=1 5=5 9=9 D=13 2=2 6=6 A=10 E=14 3=3 7=7 B=11 F=15
В этой системе счисления ноль справа прибавляется при умножении на 16 (десятичных).
Лишние нули слева от числа значения не имеют, так же, как и в математике.
Однако если число начинается с буквы (A-F), ноль слева нужен при наборе программ. Иначе как компилятор будет определять, что началось число? А чтобы не путать числа в разных системах и писать при этом коротко, пишут:
d — десятичные значения
01,02,03,04,05,06,07,08,09,10d,11d,12d,13d,14d,15d,16d,17d,18d,19d,20d.
h — шестнадцатиричные значения
01,02,03,04,05,06,07,08,09,0Ah,0Bh,0Ch,0Dh,0Eh,0Fh,10h,11h,12h,13h,14h.
b — двоичные значения
0,1,10b,11b,100b.
01 * 16d = 10h (получается 16d) 10h * 16d = 100h (получается 256d) 100h * 16d = 1000h (получается 4096d) 1 * 10h = 10h 10h + 10h = 20h 10h * 10h = 100h 100h + 100h = 200h 10b * 10b = 100b
Удобно, правда? А вот так?
10d + 10h = 1Ah или 26d
Неудобно. Поэтому всегда ВСЕ ВЫЧИСЛЕНИЯ ДЕЛАЙТЕ В ОДНОЙ СИСТЕМЕ!
Сам я никогда не перевожу из hex в dec и в bin в уме или на листочке, для этого есть калькулятор. И мне знакома эта растерянность перед новыми цифрами. Но я и не рассчитываю, что стало понятно хоть что-то. Просто вы должны знать, что системы счисления hex & bin существуют. Через месяц практики вы привыкнете к шестнадцатиричной системе как к родной. А вот двоичная будет использоваться только в пределах четырёх байт. На экране монитора мне лишь изредка приходится видеть биты как «01011010», хотя часто их очень не хватает.
Теперь ещё раз про байт.
bin-числа hex-числа 00001000 = 08 00010000 = 10h 00100000 = 20h 01000000 = 40h 10000000 = 80h . 11111111b = FFh
В байт умещаются ровно два разряда hex-системы счисления! Именно так мы и будем видеть байты. Вспомните наш нулевой эксперимент:
байты в hex символы в кодировке DOS (Р - русская буква) 90 41 90 41 90 90 41 41 42 43 44 | РAРAРРAABCD
Теперь вы понимаете, что я имел в виду, сказав: «90 здесь 144». Правильнее было бы сказать 90h = 144d.
Байт это 8 бит, и что самое главное, байт — минимально адресуемая ячейка памяти.
Если нужно прочитать информацию, например, из бита 900, то нам нужно обратиться к 112-му байту и посмотреть в нём бит номер 4.
| Адрес в байтах | Информация в БИТАХ | | 76543210 - номера бит (разряд) ------|-------------------|----------------------------------------------- 111d | 0000006F | 00000000 112d | 00000070 | 000?0000 113d | 00000071 | 00000000 114d | 00000072 | 00000000
Конечно же, в компьютере физически биты не разделяются пробелами. Вся оперативная память, например, — сплошной поток выключателей :).
Но при отображении биты обычно разделяют на:
байты — 8 бит, две hex-цифры, или
тетрады — 4 бита, одна hex-цифра.
Обратите внимание на запись. Мы нумеруем биты справа налево и обязательно от нуля — это стандарт для учебников и документации. Кроме того, нумерация от нуля имеет математический смысл (разряды нужно осознать!).
Хотя так информацию мы видеть практически не будем. Вместо битов везде будут hex-байты, вот так:
Адрес в байтах | Информация в БАЙТАХ -------------------|--------------------------------------- 0000006F | 00 00000070 | 00 00000071 | 00 00000072 | 00
Адрес в байтах | Информация в БАЙТАХ -------------------|--------------------------------------- 0000006F | 00 00 00 00
Здесь вынужден заметить: адреса в файле и адреса в оперативной памяти — это совершенно разные вещи.
Далее по тексту я буду грубо писать: «адрес в памяти», под этими словами мы будем подразумевать часть логического адреса, которую принято называть смещением (offset). В рамках наших уроков смещение — вполне достаточный адрес в памяти. Однако смещение — это не полный логический адрес и называть смещение адресом без оговорок — довольно грубо! В следующем витке мы обязательно разберём адресацию памяти в разных режимах процессора, и там я расскажу, что такое сегмент и смещение.
А сейчас запомните. Когда я пишу: адрес в файле, я подразумеваю номер байта в файле от нуля. И это норма. А вот когда я пишу: адрес в памяти, это значит, что речь идёт о части логического адреса, называемой смещением (тоже от нуля).
Да простят меня профи за такую вольность.
Юнга, после обеда я научу тебя писать дельные программы для вспомогательного бортового оборудования. Ты, конечно, пуст, как первая ступень, и ни черта не понял за сегодня, но у меня нет времени рассусоливать, нас давно ждут.
Первая полезная программа
Что там у нас дальше по учебнику? Этого вам пока не надо. Этого я и сам ещё не знаю. Тут слишком много умностей. Нет, пожалуй, продолжу, как предложил Олег Калашников. Пожалуй, лучший подход для любителей практики.
Эксперимент 01 (prax01.com)
Я по-прежнему подразумеваю, что вы используете WinXP и пример должен работать.
Создайте файл с расширением «com» (напомню в FAR’e — Shift+F4). Назвав файл, напечатайте в нём любую букву или цифру, ну, допустим, «1». Сохраните файл (в FAR’e — Esc).
Нет, это ещё не программа, этот файл выполнять не нужно. Откройте в Hiew’e.
Сейчас вы видите 1, если нажать «F4» (Mode), то, как и в тот раз, вы увидите байт в hex-виде. F4 еще раз покажет дизассемблерный код. Если в файле единица, то выглядеть код будет так:
Адреса Байты Имена Операнды 00000000: 31 xor [bx][si],ax
В отличие от команды nop, которую вы уже видели, большинство команд используют предметы для действия.
Предмет, с (или над) которым производится действие, называется операнд.
Операнды в ассемблере для Интел-совместимых процессоров принято разделять запятыми. То есть в некоторых системах или в других языках программирования пишут:
AX xor 44
или вполне может быть такая форма записи:
44,55 xоr AX
Но в x86 ассемблере принято писать так:
xor AX,44 где AX - операнд 1 (он же приёмник), а 44 - операнд 2 (он же источник).
Из всего этого главное сейчас усвоить, что операндов не больше трёх (чащё всего 2), они разделяются запятыми и идут после имени команды. Давайте писать настоящую программу на ассемблере.
В Hiew’e (когда вы видите дизассемблерный код нашего файла) нажмите F3 и затем Enter. Теперь можно набирать программу на ассемблере (символ «1» в файле должен стереться). Каждая инструкция вводится Enter’ом и превращается в строку, если нет явной ошибки. Пробелы нужны только для удобства, поэтому неважно, сколько их. Пишите как хотите, строчными или прописными буквами, но только по-англицки. 🙂
Вот код программы, его нужно набрать:
mov ah,9 mov dx,10Dh int 21h mov ah,10h int 16h int 20h
Когда всё напишете, нажмите один раз Esc, чтобы прекратить ассемблирование, и F9, чтобы сохранить файл.
Это был весь код программы, которая должна выводить строку на экран! Круто, правда? Только не хватает самой строки.
Для того, чтоб вписать строку, нужно открыть файл в текстовом редакторе (в FAR’e — F4).
Допишите после всех закорючек (только не сотрите ничего) любую текстовую строку и в конце поставьте знак $.
Это может выглядеть примерно так:
_?_? _?_?_?_?_Good Day!$
Закорючки будут другие, но вид такой. Сохраните программу. Откройте снова в Hiew’e.
Адреса Маш.команды Команды Асма комментарии Байты Имена Операнды 00000000: B409 mov ah,009 ; Поместить значение 9 в регистр AH (параметр1) 00000002: BA0D01 mov dx,0010D ; Поместить адрес текстовой строки в DX (параметр2) 00000005: CD21 int 021 ; Вызвать подпрограмму, в которой ; отработает функция вывода текста на экран (AH=09) 00000007: B410 mov ah,010 ; Поместить значение 10h в регистр AH (параметр1) 00000009: CD16 int 016 ; Вызвать подпрограмму ожидания нажатия клавиши 0000000B: CD20 int 020 ; Подпрограмма завершения 0000000D: 47 inc di 0000000E: 6F outsw 0000000F: 6F outsw 00000010: 64204461 and fs:[si][61],al 00000014: 7921 jns 000000037 ---X 00000016: 24 and al,000
Принято так, что после точки с запятой идёт комментарий, просто пояснение для людей. В этом примере я откомментировал все строки кода программы. Только вам от этого пока не легче.
Видите, начиная с адреса в файле 0000000Dh, появились команды, которые вы не писали, это всего лишь строка текста. Её процессор выполнять не будет только потому, что перед строкой текста стоит код завершения (int 20).
Запустите программу (можно из проводника). Если компьютер с вами поздоровался — я вас тоже поздравляю! Значит, у вас есть шанс научить его делать и более сложные вещи.
Если же этого не произошло — не расстраивайтесь. Перепроверьте всё несколько раз, может быть, вы опечатались. Прочитайте «Аннотацию» в последней главе или комментарии. Я пока ничего подобного не написал, но, возможно, когда-нибудь придётся. Ведь у нас нет гарантии, что новые твАрения MS или других «рук» не изменят ситуацию в худшую сторону. Хотя, будем надеяться, что программа заработает и на новых OS’ях и процессорах.
«$» не выводится. Хм, интересно :/ Это условный символ конца строки?
Да, но в windows мы будем использовать нулевой байт (00h) для этой же цели.
Вот, уже получилась полнофункциональная программа для DOS, которая будет работать и в Windows.
Прямо так и вижу следующие «почему»:
Почему mov?
Почему ah?
Почему 9?
И вообще, что это за подпрограммы-прерывания int 16, int 21, int 20.
Последний вопрос меня тоже очень огорчил, когда впервые столкнулся с этим примером. Я ожидал получить программу на чистом Ассемблере, а был вынужден использовать какие-то непонятные функции, которых не писал.
На самом деле вывод строки на экран без специальной DOS-функции ничуть не сложнее. Мы используем именно такой способ из-за того, что он наиболее схож с программированием под Win. Здесь было бы аккуратнее и быстрее выводить на экран без специальной подпрограммы DOS-функций.
Но ДОС в прошлом, а нас ждёт Win32.
Cамое главное не переживать, если вы вдруг не понимаете что здесь к чему, поверьте, через пару уроков вы полностью поймёте эту программу.
Мы завтра весь день будем искать ответ на вопрос «Почему ah», так как этот «почему» — самый важный во всём ассемблере. Серьёзно!
Двоичная система счисления. Бит и байт. Сегментация памяти.
Вообще, как компьютер может хранить, например, слово «диск»? Главный принцип — намагничивание и размагничивание одной дорожки (назовем ее так). Одна микросхема памяти — это, грубо говоря, огромное количество дорожек. Сейчас попробуем разобраться. Например:
нуль будет обозначаться как 0000 (четыре нуля),
один 0001, два 0010,
(т.е. правую единицу заменяем на 0 и вторую устанавливаем в 1).
три 0011 четыре 0100 пять 0101 шесть 0110 семь 0111 восемь 1000 девять 1001
Уловили принцип? «0» и «1» — это т.н. биты. Один бит, как вы уже заметили, может быть нулем или единицей, т.е. размагничена или намагничена та или иная дорожка («0» и «1» это условное обозначение). Если еще присмотреться, то можно заметить, что каждый следующий установленный бит (начиная справа) увеличивает число в два раза: 0001 в нашем примере = 1; 0010 два; 0100 четыре; 1000 восемь и т.д. Это и есть т.н. двоичная форма представления данных.
Т.о. чтобы обозначить числа от 0 до 9 нам нужно четыре бита (хоть они и не до конца использованы. Можно было бы продолжить: десять 1010, одиннадцать 1011 , пятнадцать 1111).
Компьютер хранит данные в памяти именно так. Для обозначения какого-нибудь символа (цифры, буквы, запятой, точки. ) в компьютере используется определенное количество бит. Компьютер «распознает» 256 (от 0 до 255) различных символов по их коду. Этого достаточно, чтобы вместить все цифры (0 — 9), буквы латинского алфавита (a — z, A — Z), русского (а — я, А — Я), а также другие символы. Для представления символа с максимально возможным кодом (255) нужно 8 бит. Эти 8 бит называются байтом. Т.о. один любой символ — это всегда 1 байт (см. рис. 1).
| 0 | 1 | 0 | 1 | 1 | 0 | 1 | 0 |
| р | н | р | н | н | р | н | р |
Рис. 1. Один байт с кодом буквы Z
(буквы н и р обозначают: намагничено или размагничено соответственно)
Можно элементарно проверить. Создайте в текстовом редакторе файл с любым именем и запишите в нем один символ, например, «М» (но не нажимайте Enter!). Если вы посмотрите его размер, то файл будет равен 1 байту. Если ваш редактор позволяет смотреть файлы в шестнадцатеричном формате, то вы сможете узнать и код сохраненного вами символа. В данном случае буква «М» имеет код 4Dh в шестнадцатеричной системе, которую мы уже знаем или 1001101 в двоичной.
Т.о. слово «диск» будет занимать 4 байта или 4*8 = 32 бита. Как вы уже поняли, компьютер хранит в памяти не сами буквы этого слова, а последовательность «единичек» и «ноликов». «Почему же тогда на экране мы видим текст, а не «единички-нолики»? — спросите вы. Чтобы удовлетворить ваше любопытство, я забегу немного вперед и скажу, что всю работу по выводу самого символа на экран (а не битов) выполняет видеокарта (видеоадаптер), которая находится в вашем компьютере. И если бы ее не было, то мы, естественно, ничего бы не видели, что у нас творится на экране.
В Ассемблере после двоичного числа всегда должна стоять буква «b». Это нужно для того, чтобы при ассемблировании нашей программы Ассемблер смог отличать десятичные, шестнадцатеричные и двоичные числа. Например: 10 — это «десять», 10h — это «шестнадцать» а 10b — это «два» в десятичной системе.
Т.о. в регистры можно загружать двоичные, десятичные и шестнадцатеричные числа.
mov ax,20 mov bh,10100b mov cl,14h
В результате в регистрах AX, BH и CL будет находится одно и тоже число, только загружаем мы его в разных системах. Компьютер же будет хранить его в двоичном формате (как в регистре BH).
Итак, подведем итог. В компьютере вся информация хранится в двоичном формате (двоичной системе) примерно в таком виде: 10101110 10010010 01111010 11100101 (естественно, без пробелов. Для удобства я разделили биты по группам). Восемь бит — это один байт. Один символ занимает один байт, т.е. восемь бит. По-моему, ничего сложного. Очень важно уяснить данную тему, так как мы будем постоянно пользоваться двоичной системой, и вам необходимо знать ее на «отлично».
Как перевести двоичное число в десятичное:
Надо сложить двойки в степенях, соответствующих позициям, где в двоичном стоят единицы. Например:
Возьмем число 20. В двоичной системе оно имеет следующий вид: 10100b
Итак (начнем слева направо, считая от 4 до 0; число в нулевой степени всегда равно единице (вспоминаем школьную программу по математике)):
10100b = 1*24 + 0*23 + 1*22 + 0*21 + 0*20 = 20 --------------------------------------------- 16+0+4+0+0 = 20
Как перевести десятичное число в двоичное:
Можно делить его на два, записывая остаток справа налево:
20/2 = 10, остаток 0 10/2=5, остаток 0 5/2=2, остаток 1 2/2=1, остаток 0 1/2=0, остаток 1
В результате получаем: 10100b = 20
Как перевести шестнадцатеричное число в десятичное:
В шестнадцатеричной системе номер позиции цифры в числе соответствует степени, в которую надо возвести число 16:
8Ah = 8*16 + 10 (0Ah) = 138
В настоящий момент есть множество калькуляторов, которые могут считать и переводить числа в разных системах счисления. Например, калькулятор Windows, который должен быть в инженерном виде. Очень удобен калькулятор и в DOS Navigator’е. Если у вас есть он, то отпадает необходимость в ручном переводе одной системы в другую, что, естественно, упростит вам работу. Однако, знать этот принцип крайне важно!
Сегментация памяти в DOS.
Возьмем следующее предложение: «Изучаем сегменты памяти». Теперь давайте посчитаем, на каком месте стоит буква «ы» в слове «сегменты» от начала предложения включая пробелы. На шестнадцатом. Подчеркну, что мы считали слово от начала предложения.
Теперь немного усложним задачу и разобьем предложение следующим образом (символом «_» обозначен пробел):
Пример N 1: 0000: Изучаем_ 0010: сегменты_ 0020: памяти 0030:
В слове «Изучаем» символ «И» стоит на нулевом месте; символ «з» на первом, «у» на втором и т.д. В данном случае мы считаем буквы начиная с нулевой позиции, используя два числа. Назовем их сегмент и смещение. Тогда, символ «ч» будет иметь следующий адрес: 0000:0003, т.е. сегмент 0000, смещение 0003. Проверьте.
В слове «сегменты» будем считать буквы начиная с десятой позиции, но с нулевого смещения. Тогда символ «н» будет иметь следующий адрес: 0010:0005, т.е. пятый символ начиная с десятой позиции. 0010 — сегмент, 0005 смещение. Тоже проверьте.
В слове «память» считаем буквы начиная с 0020 сегмента и также с нулевой позиции. Т.о. символ «а» будет иметь аодрес 0020:0001, т.е. сегмент 0020, смещение 0001. Опять проверим.
Итак, мы выяснили, что для того, чтобы найти адрес нужного символа необходимо два числа: сегмент и смещение внутри этого сегмента. В Ассемблере сегменты хранятся в сегментных регистрах: CS, DS, ES, SS (см. предыдущий выпуск ), а смещения могут храниться в других (но не во всех).
Регистр CS служит для хранения сегмента кода программы (Code Segment — сегмент кода);
Регистр DS для хранения сегмента данных (Data Segment — сегмент данных);
Регистр SS для хранения сегмента стека (Stack Segment — сегмент стека);
Регистр ES дополнительный сегментный регистр, который может хранить любой другой сегмент (например, сегмент видеобуфера).
Пример N 2:
Давайте попробуем загрузить в пару регистров ES:DI сегмент и смещение буквы «м» в слове «памяти» из примера N 1 (см. выше). Вот как это запишется на Ассемблере:
(1) mov ax,0020 (2) mov es,ax (3) mov di,2
Теперь в регистре ES находится сегмент с номером 20, а регистре DI смещение к букве «м» в слове «памяти». Проверьте, пожалуйста.
Здесь стоит отметить, что загрузка числа (т.е. какого-нибудь сегмента) напрямую в сегментый регистр запрещена. Поэтому мы в строке (1) загрузили сегмент в AX, а в строке (2) загрузили в регистр ES число 20, которое находилось в регистре AX:
mov ds,15---> ошибка!mov ss,34h---> ошибка!
Когда мы загружаем программу в память, она автоматически располагается в первом свободном сегменте. В файлах типа *.com все сегментные регистры автоматически инициализируются для этого сегмента (устанавливаются значения равные тому сегменту, в который загружена программа). Это можно проверить при помощи отладчика. Если, например, мы загружаем программу типа *.com в память, и компьютер находит первый свободный сегмент с номером 5674h, то сегментные регистры будут иметь следующие значения:
CS = 5674h DS = 5674h SS = 5674h ES = 5674h
Код программы типа *.com должны начинаться со смещения 100h. Для этого мы, собственно, и ставили в наших прошлых примерах программ оператор org 100h, указывая Ассемблеру при ассемблировании использовать смещение 100h от начала сегмента, в который загружена наша программа (позже мы рассмотрим для чего это нужно). Сегментные же регистры, как я уже говорил, автоматически принимают значение того сегмента, в который загрузилась наша программа.
Пара регистров CS:IP задает текущий адрес кода. Теперь рассмотрим, как все это происходит на конкретном примере:
Пример N 3.
(1) CSEG segment (2) org 100h (3) _start: (4) mov ah,9 (5) mov dx,offset My_name (6) int 21h (7) int 20h (8) My_name db 'Oleg$' (9) CSEG ends (10) end _start
Итак, строки (1) и (8) описывают сегмент: CSEG (даем имя сегменту) segment (оператор Ассемблера, указывающий, что имя CSEG — это название сегмента); CSEG ends (end segment — конец сегмента) указывает Ассемблеру на конец сегмента.
Строка (2) сообщает, что код программы (как и смещения внутри сегмента CSEG) необходимо отсчитывать с 100h. По этому адресу в память всегда загружаются программы типа *.com.
Запускаем программу из Примера N 3 в отладчике. Допустим, она загрузилась в свободный сегмент 1234h. Первая команда в строке (4) будет располагаться по такому адресу:
1234h:0100h (т.е. CS = 1234h, а IP = 0100h) (посмотрите в отладчике на регистры CS и IP).
Перейдем к следующей команде (в отладчике CodeView нажмите клавишу F8, в другом посмотрите какая клавиша нужна; будет написано что-то вроде «F8-Step»). Теперь вы видите, что изменились следующие регистры:
AX = 0900h (точнее, AH = 09h, а AL = 0, т.к. мы загрузили командой mov ah,9 число 9 в регистр AH, при этом не трогая AL. Если бы AL был равен, скажем, 15h, то после выполнения данной команды AX бы равнялся 0915h)
IP = 102h (т.е. указывает на адрес следующей команды. Из этого можно сделать вывод, что команда mov ah,9 занимает 2 байта: 102h — 100h = 2).
Следующая команда (нажимаем клавишу F8) изменяет регистры DX и IP. Теперь DX указывает на смещение нашей строки («Oleg$») относительно начала сегмента, т.е. 109h, а IP равняется 105h, т.е. адрес следующей команды. Нетрудно посчитать, что команда mov dx,offset My_name занимает 3 байта (105h — 102h = 3).
Обратите внимание, что в Ассемблере мы пишем:
mov dx,offset My_name
а в отладчике видим следующее:
mov dx,109 (109 — шестнадцатеричное число, но CodeView символ ‘h’ не ставит. Это надо иметь в виду).
Почему так происходит? Дело в том, что при ассемблировании программы, Ассемблер подставляет вместо offset My_name реальный адрес строки с именем My_name в памяти. Можно, конечно, записать сразу
mov dx,109h
Программа будет работать нормально. Но для этого нам нужно высчитать самим этот адрес. Попробуйте вставить следующие команды, начиная со строки (7) в примере N 3:
(7) int 20h (8) int 20h (9) My_name db 'Oleg$' (10) CSEG ends (11) end _start
Просто продублируем команду int 20h (хотя, как вы уже знаете, до строки (8) программа не дойдет).
Теперь ассемблируйте программу заново. Запускайте ее под отладчиком. Вы увидите, что в DX загружается не 109h, а другое число. Подумайте, почему так происходит. Это просто!
В окне «Memory» («Память») вы должны увидеть примерно такое:
1234:0000 CD 20 00 A0 00 9A F0 FE = .a. |N1_|_N2_| |_________N3__________| |N4_|
Позиция N1 (1234) — сегмент, в который загрузилась наша программа (может быть любым).
Позиция N2 (0000) — смещение в данном сегменте (сегмент и смещение отделяются двоеточием (:)).
Позиция N3 (CD 20 00 . F0 FE) — код в шестнадцатеричной системе, который располагается с адреса 1234:0000.
Позиция N4 (= .a.) — код в ASCII (ниже рассмотрим), соответствующий шестнадцатеричным числам с правой стороны.
В Позиции N2 (смещение) введите значение, которое находится в регистре DX после выполнения строки (5). После этого в Позиции N4 вы увидите строку «Oleg$», а в Позиции N3 — код символов «Oleg$» в шестнадцатеричной системе. Вот что загружается в DX! Это не что иное, как АДРЕС (смещенеие) нашей строки в сегменте!
Но вернемся. Итак, мы загрузили в DX адрес строки в сегменте, который мы назвали CSEG (строки (1) и (9) в Прмере N 3). Теперь переходим к следующей команде: int 21h. Вызываем прерывание DOS с функцией 9 (mov ah,9) и адресом строки в DX (mov dx,offset My_name).
Как я уже говорил раньше, для использования прерываний в программах, в AH заносится номер функции. Номера функций нужно запоминать.
Наше первое прерывание.
Функция 09h прерывания 21h выводит строку на экран, адрес которой указан в регистре DX.
Вообще, любая строка, состоящая из ASCII символов, называется ASCII-строка. ASCII символы — это символы от 0 до 255 в DOS, куда входят буквы русского и латинского алфавитов, цифры, знаки препинания и пр.
Изобразим это в таблице (так всегда теперь будем делать):
Функция 09h прерывания 21h — вывод строки символов на экран в текущую позицию курсора:
Вход: AH = 09h, DX = адрес ASCII-строки символов, заканчивающийся ‘$’
Выход: ничего
В поле «Вход» мы указываем, в какие регистры что загружать, а в поле «Выход» — что возвращает функция. Сравните эту таблицу с Примером N 3.
Вот мы и рассмотрели сегментацию памяти. Если я что-то упустил, то это рассмотрим в последующих выпусках. Очень надеюсь на то, что вы разобрались в данной теме.
Теперь интересная программка для практики, которая выводит в верхний левый угол экрана веселую рожицу на синем фоне:
(1) CSEG segment (2) org 100h (3) _beg: (4) mov ax,0B800h (5) mov es,ax (6) mov di,0 (7) (8) mov ah,31 (9) mov al,1 (10) mov es:[di],ax (11) (12) mov ah,10h (13) int 16h (14) (15) int 20h (16) (17) CSEG ends (18) end _beg
Многие операторы вы уже знаете. Поэтому я буду объяснять только новые.
В данном примере мы используем вывод символа прямым отображением в видеобуфер.
В строках (4) и (5) загружаем в сегментный регистр ES число 0B800h, которое соответствует сегменту дисплея в текстовом режиме (запомните его!). В строке (6) загружаем в регистр DI нуль. Это будет смещение относительно сегмента 0B800h. В строках (8) и (9) в регистр AH заносится атрибут символа (31 — ярко-белый символ на синем фоне) и в AL — ASCII-код символа (01 — это рожица) соответственно.
В строке (10) заносим по адресу 0B800:0000h (т.е. первый символ в первой строке дисплея — верхний левый угол) атрибут и ASCII-код символа (31 и 01 соответственно) (сможете разобраться?).
Обратите внимание на запись регистров в строке (10). Скобки ( [ ] ) указывают на то, что надо загрузить число не в регистр, а по адресу, который содержится в регистре (в данном случае, как уже отмечалось, — это 0B800:0000h).
Можете поэксперементировать с данным примером. Только не меняйте строки (4) и (5). Сегментный регистр должен быть ES (можно, конечно, и DS, но тогда надо быть осторожным). Более подробно данный метод рассмотрим позже. Сейчас нам из него нужно понять принцип сегментации на практике.
Следует отметить, что вывод символа прямым отображением в видеобуфер является самым быстрым. Выполнение команды в строке (10) занимает 3 — 5 тактов. Т.о. на Pentium-100Mhz можно за секунду вывести 20 миллионов(!) символов или чуть меньше точек на экран! Если бы все программисты (а особенно Microsoft) выводили бы символы или точки на экран методом прямого отображения в видеобуфер на Ассемблере, то программы бы работали чрезвычайно быстро. Я думаю, вы представляете.