Ссылка на файл
В вызове после предыдущей части мы размечали рецепт печенья для Кекса. Он оказался настолько хорошим, что мы решили сделать его доступным для всех. Мы сохранили рецепт в формате PDF, чтобы любой желающий мог его скачать и распечатать. Осталось добавить ссылку на этот самый файл.
Когда мы переходим по ссылкам, то попадаем на другие страницы или места на странице. Но при переходе по ссылке на файл браузер предложит его скачать.
Однако, если браузер умеет обрабатывать файлы этого типа, то содержимое файла откроется прямо в браузере. Чаще всего так происходит с изображениями. Но в последнее время браузеры научились открывать PDF-файлы и многие другие.
Для того чтобы предотвратить открытие файлов прямо в браузере, у тега существует атрибут download , который поможет именно скачать файл.
При скачивании или загрузке файлов со сторонних сайтов для безопасности можно использовать атрибут rel=»noopener» . Этот атрибут позволяет игнорировать скрипты сторонней страницы, которые могут влиять на загрузку файла. Особенно актуален этот атрибут в случае, если загрузка происходит в новой вкладке или новом окне.
Перейти к заданию
- index.html Сплит-режим
- style.css Сплит-режим
Блог
День двенадцатый. Все любят печенье
Сегодня Кекс попросил меня сделать рецепт того самого рыбного печенья доступным для всех своих клиентов. Но вот незадача, у меня нет принтера, да и печатать рецепт на всех, тратить бумагу, не хочется. Пришлось сделать ссылку для скачивания файла.
Скачать
Открытие и копирование HTML-кода любого сайта
Вам требуется открыть и скопировать код HTML-документа или web-сайта? Если да, то этот онлайн-сервис поможет вам сделать это быстро и легко. Вам не придётся устанавливать программы на компьютер, ноутбук или приложения на телефон. Копировать код веб-страницы вы сможете с помощью обычного браузера и на любом мобильном. HTML-файлы открываются, как на iPhone, так и на смартфонах с операционной системой Android. Открывать консоль или настройки браузера, устанавливать дополнительные расширения больше не нужно. Сохранить код вы сможете по ссылке на интернет-ресурс.
ГлавнаяИнструменты Открытие и копирование HTML-кода любого сайта
Сервис для копирования HTML-файла сайта
Если вам требуется скопировать HTML-документ сайта из интернета, то данный сервис и онлайн-поиском кода поможет вам в этом. Здесь вы сможете осуществить копирование кода без установки специальных программ и приложений. Сохранить HTML-код можно будет, как на компьютере или на ноутбуке, так и на любом смартфоне.
При этом не важно какое у вас мобильное устройство. Это может быть Айфон от Apple или телефон с операционной системой Андроид. Всё что вам нужно — это открыть браузер, скопировать ссылку на web-страницу и воспользоваться сервисом. Кстати, устанавливать дополнительные расширения в браузер не потребуется.

Больше нет необходимости открывать настройки браузера и консоль интернет-навигатора. Осуществить копирование содержимого HTML-документа, понравившегося вам веб-ресурса, вы сможете по ссылке на страницу. При этом не важно какой интернет-источник, это может быть как обычный сайт, так и защищенный.
Стоит заметить, что операционная система на вашем ПК также не имеет значения. Это могут быть такие ОС, как Windows, Linux или Mac OS для MacBook. Воспользуйтесь онлайн-парсером HTML-файла , чтобы в потом сохранить его содержимое, например, в Ворде, блокноте или в обычном текстовом документе.
Скопируйте HTML-документ по ссылке на сайт
Скачайте HTML-код необходимого вам веб-ресурса быстро, бесплатно и легко. Для того чтобы получить содержимое web-документа выполните следующие действия. Сначала из адресной строки браузера скопируйте веб-ссылку на страницу сайта. Далее вставьте её в поле ниже и запустите процесс копирования.
Сканирование web-страницы.
Не обновляйте и не покидайте страницу! Идет сканирование содержимого web-ресурса.
Возможно ссылка указана не верно, а может что-то пошло не так. Повторите сканирование или обратитесь за помощью к специалисту!
Выделите и скопируйте содержимое
В результате сканирования найден HTML-код, который вы можете выделить и сохранить на компьютере или телефоне. Внимательно ознакомьтесь с найденными данными, пролистав содержимое окна ниже.
Пожалуйста поддержите работу сервиса, если он оказался вам полезен.
Как открыть и скопировать HTML-код страницы

Копируем ссылку на страницу web-сайта
Итак, первое, что вам потребуется сделать перед тем, как вы скопируете HTML-код — это открыть веб-страницу ресурса. Для этой цели вам подойдет любой гаджет с браузером. Этим устройством может быть, как компьютер, так и мобильный телефон, разницы нет. Как только страница будет загружена, обратите внимание на адресную строку вверху интернет-навигатора. Здесь располагается уникальная ссылка, которую вам нужно будет выделить и скопировать.

Сканируем содержимое HTML-документа
Следующим этапом, после того, как вы скопируете web-адрес, будет сканирование интернет-ресурса с помощью web-сканера кода . Для того чтобы получить содержимое HTML-документа, вставьте скопированную ссылку в поле для веб-адреса и запустите процесс копирования, нажав на кнопку «Скопировать». В результате этих действий начнётся выгрузка содержимого HTML-файла. Процедура парсинга страницы не займёт у вас много времени.

Выделяем и сохраняем код веб-ресурса
По завершению процесса извлечение данных вы увидите специальное окно, в котором будет отображаться содержимое web-источника. Вам предстоит выполнить заключительное действие — копировать HTML-код. Для этого выделите необходимые вам строчки кода и скопируйте их. Далее вам останется всего лишь сохранить информацию у себя на устройстве. Для этой цели вам подойдет Word, блокнот или любой другой текстовый редактор.
Самые популярные вопросы
Скопировать HTML-код сайта можно будет бесплатно?
Да, безусловно. Для того чтобы сохранить содержимое HTML-документа любого web-ресурса вам достаточно следовать простой инструкции, указанной выше. Для начала вам потребуется скопировать ссылку на интересующую вас веб-страницу, а затем воспользоваться онлайн-поиском кода . Для этих целей вам подойдет любой современный браузер, например, Google Chrome, Opera, Mozilla Firefox или Safari.
Как копировать содержимое HTML-файла на компьютер?
Если вам требуется осуществить копирование кода интернет-ресурса на ПК или ноутбук, то для начала вам необходимо будет открыть интересующий сайт в браузере. Далее скопируйте ссылку из адресной строки интернет-навигатора и воспользуйтесь данным сервисом. После того, как вы получите желаемый HTML-код, сохраните его в текстовом файле. Для этого отлично подойдет Ворд, блокнот или любой другой текстовый редактор. Кстати, стоит заметить, что не важно какая у вас операционная система, это может быть Windows, Linux или Mac OS от Apple.
Требуется сохранить web-документ на телефон. Как это сделать?
Процесс сохранения HTML-данных на смартфонах и планшетах в точности повторяет процедуру копирования на ПК. Для открытия и копирования кода веб-ресурса вам всего лишь нужен браузер и данный онлайн-сервис. Для начала скопируйте электронный адрес web-страницы, а затем воспользуйтесь HTML-парсером сайта . В результате парсинга данных вам будет доступно содержание HTML-документа, которое вы позже сможете сохранить в блокноте или любом другом текстовом документе.
Как скачать код веб-страницы на Айфоне и Андроиде?
Абсолютно неважно каким мобильным устройством вы пользуетесь для того, чтобы открыть HTML-файл сайта. Это может быть iPhone от Apple или любой гаджед на базе операционной системы Android. Для того чтобы сохранить код web-страницы, достаточно будет на вашем смартфоне или планшете открыть обычный браузер. При этом не потребуется устанавливать дополнительные расширения и плагины для него. Просто запустите интернет-навигатор и воспользуйтесь данным сервисом.
Необходимо ли устанавливать программы и приложения, чтобы выгрузить код?
Нет. Вам не потребуется ставить дополнительные программы и свой компьютер и приложения на мобильный. Всё что вам потребуется для того чтобы получить код web-страницы — это стандартный интернет-навигатор, который есть на каждом мобильном устройстве. Откройте понравившийся сайт и воспользуйтесь HTML-парсингом кода . В результате вы сможете получить, необходимые вам данные, и скопировать их себе на PC или смарфон.
Нужно устанавливать расширения для браузера, чтобы открыть HTML-файл?
Нет. Никакие расширения для web-браузера вам не потребуются. Для того чтобы получить содержимое HTML-документа любого сайта, вам достаточно иметь под рукой обычный интернет-навигатор, без предустановленных плагинов. Следуйте инструкции, указанной выше, и вы сможете открыть код нужного вам web-ресурса и скопировать его строчки себе на жесткий диск или флешку.
Как можно получить код страницы по ссылке на web-сайт?
Для того чтобы открыть HTML-код по ссылке вам достаточно скопировать url-адрес страницы и воспользоваться web-сканером сайта . Следуйте простой инструкции, которая есть на этой странице и вы сможете посмотреть содержимое, интересующего вас веб-ресурса. Вначале вам потребуется запустить парсинг интернет-источника, а затем скопировать полученные данные на компьютер или мобильное устройство.
Как сохранить содержимое HTML-документа в Word?
Если вам требуется выгрузить данные HTML-страницы в Word или любой другой текстовый редактор, то в этой процедуре нет ничего сложного. Достаточно лишь ознакомиться с руководством по копированию кода, которое указано выше, а потом сделать всё как в инструкции. Весь процесс сохранения состоит из трёх простых операций. Вначале вам нужно будет скопировать урл-адрес интересующего вас веб-ресурса. Затем запустить сканирование web-страницы. А после парсинга скопировать данные в буфер обмена, после чего вставить их в текстовом файле. Такую процедуру вы можете произвести, как на ПК, так и на любом мобильном. Сохранить полученный HTML-код можно будет не только в Ворде, но и, к примеру, в блокноте.
Как скачать файлы с сайта через код страницы.
Мне нужно скачать около трехсот png (единый pdf сайт не дает) и при этом не тыкать на каждый пкм -> открыть в новой вкладке и скачать. Они не выделяются.
Голосование за лучший ответ
Есть программы граббер сайта …используй их))
Ссылку на сайт с этими картинками можно?
Андрей КейльЗнаток (487) 2 года назад
Это сайт типографии учебника, злые люди не дают учебник (только купить доступ на год за 150 рублей онлайн, скачать его нельзя)
Lame Wolf Искусственный Интеллект (355758) Андрей Кейль, Мне насрать кто там не дает тебе книги! Тебя просили ссылку на сайт!
На странице с нужными картинками:
ПКМ — Сохранить как html
Затем посмотреть любым текстовым редактором (например Notepad++) на наличие ссылок на картинки.
Если таковые имеются, то попытаться найти все такие (см. скриншот 1)
Ещё немного терпения… Может быть какие-то дополнительные условия… Может быть с помощью макросов… Получим голый список (см. скриншот 2)
Сохранить его в файл и с помощью какой-нибудь утилитки типа WGET (https://eternallybored.org/misc/wget/) и скармливаем ему этот файлик…
Но это при условии, что нужные картинки именно в html присутствуют. Динамические сайты не всегда это дают.
Прячут картинки за своими движками… ;–)


Как утащить простой сайт за 5 минут
Когда начинаешь практиковаться в вёрстке сайтов, может быть очень полезно разобраться, как устроены сайты у других ребят. Вот как это сделать.
�� Всё, что мы делаем в этой статье, мы делаем в учебных целях. Если вы просто скопируете себе чужой сайт и будете выдавать его за свой, это может плохо кончиться.
�� На самом деле всё сказанное в этой статье нужно для тех, кто боится отключения интернета и хочет сохранить у себя на компьютере самую важную информацию. Но эта мысль бредовая сразу на стольких уровнях, что мы стесняемся её произносить вслух. Разве что шёпотом.
В чём идея
Мы будем копировать чужой сайт, чтобы его можно было запустить на своём сервере или на домашнем компьютере. Задача — не просто открыть сайт в браузере и посмотреть его код, а забрать из него все важные файлы — и стили, и скрипты, и изображения. Чтобы было проще, мы будем практиковаться на одностраничном сайте, но всё то же самое будет работать и на многостраничном.
❌ Мы не сможем утащить чужие PHP-скрипты и страницы, связанные с данными пользователя (например, не сможем утащить из интернет-магазина рабочую версию корзины с покупками). Для этого нужен доступ к файлам сервера, а этого у нас нет.
Главный принцип этой работы: когда ваш браузер запрашивает страницу чужого сайта, веб-сервер отправляет ему эту страницу, в буквальном смысле. То же с картинками, стилями и скриптами: каждый раз, когда вы посещаете сайт, вы как будто делаете его копию у себя на компьютере. Браузер получает страницу от сервера и выводит её копию на экран, а в памяти держит исходный код. Разве что он не сохраняет эту страницу на диск, чтобы вы могли её редактировать.
Вот этот последний этап мы и исправим: теперь мы будем сохранять чужие сайты к себе на диск.
Весь процесс покажем на примере сайта ux-posters.ru – простом одностраничном сайте, где есть картинки, стили и скрипты. Автору этого текста пришлось помогать авторам этого сайта с похожей задачей, так что пример свеженький.
Быстрый путь: грабберы
Есть категория программ под названием «веб-грабберы», или «веб-рипперы». Они работают так:
- Ты говоришь программе, на какую страницу сайта зайти.
- Программа собирает все ссылки с этой страницы, переходит по этим ссылкам и строит себе виртуальную карту сайта — то есть пытается понять, сколько на этом сайте страниц и как они связаны.
- Потом граббер начинает ползать по этим страницам подряд, запрашивать их у сервера, получать ответы и сохранять ответы на вашем жёстком диске.
- В какой-то момент граббер останавливается, потому что он скачал все доступные ему страницы с этого сайта.
После работы граббер оставляет у вас на диске гору файлов, которые представляют собой статичный отпечаток чужого сайта. Эту гору можно загрузить на собственный сервер, и издалека это будет похоже на чужой сайт.
✅ Плюсы: граббер может быстро охватить много страниц и скачать из них огромное количество стилей, картинок и всего подряд. Работа очень быстрая и хорошо автоматизирована.
❌ Минусы: часто он качает всё без разбора, оставляя на диске много дублей. Также он бессилен с сайтами, в которых контент выводится динамически или имеет нестандартную систему адресации.
�� В целом грабберы можно использовать, чтобы скачивать сайты библиотек, архивов и других мест, где документов много и всё устроено логично. Например, с помощью граббера можно скачать какую-нибудь классическую книгу из онлайн-библиотеки.
Вот ссылки на грабберы для разных платформ:
- HTTrack — старый интерфейс из нулевых, но свою задачу выполняет полностью. Бесплатный и надёжный, работает везде.
- Getleft — мультиплатформенный граббер, который пытается выкачивать всё, до чего дотянется, включая PHP-скрипты.
- Cyotek WebCopy — для тех, кто любит только Windows, тоже бесплатный.
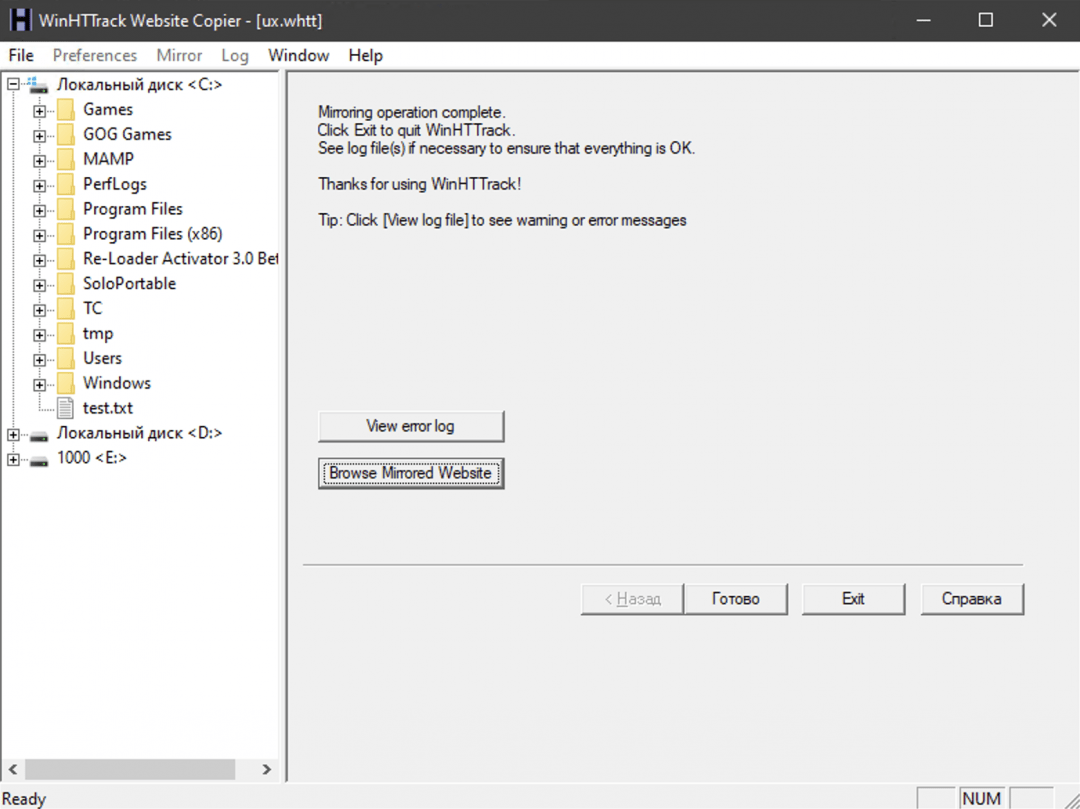
Сложный путь: ручное сохранение
Допустим, мы хотим сохранить какую-то отдельную страницу сайта или конкретные её части (например, картинки). Но эти картинки как-то так хитро встроены, что вы не можете просто нажать «Сохранить картинку как. ». Тогда потребуется ручной метод.
Заходим на страницу и нажимаем в браузере Ctrl + I (в Виндоус) или ⌥ + ⌘ + I (если у вас мак). Появляется окно «Инспектора», где видна внутренняя структура страницы:
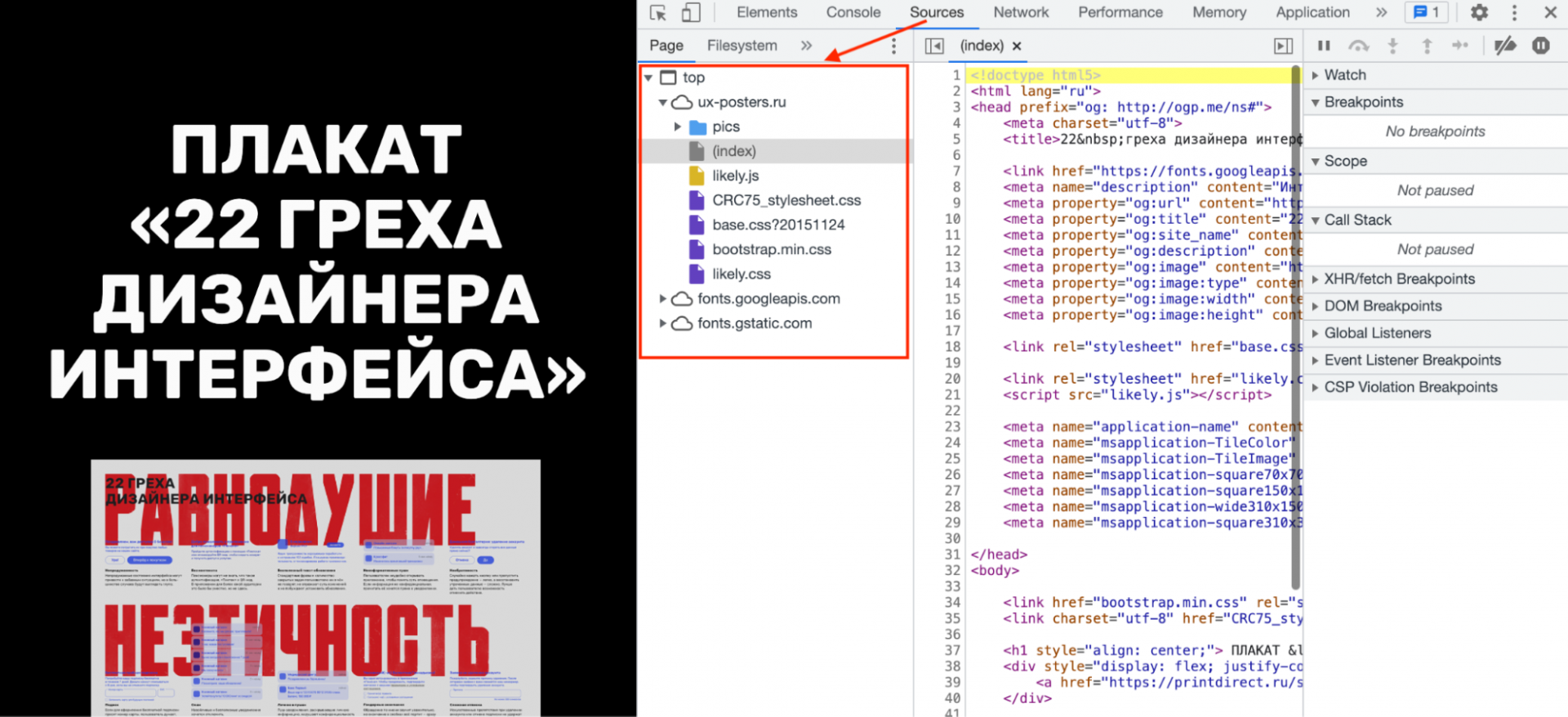
Мы видим, что текущий документ в браузере состоит:
- из страницы index.html;
- скрипта likely.js;
- четырёх таблиц стилей;
- шрифтов, подключённых через сервис Google;
- папки с картинками.
Шрифты нам скачивать необязательно — сайт и так их подключит с сервера гугла, а всё остальное скачать нужно. Чтобы не создавать хаос на компьютере, создадим сначала папку ux-posters — в ней будет храниться наш сайт. Потом в эту папку сохраняем все файлы таким способом:
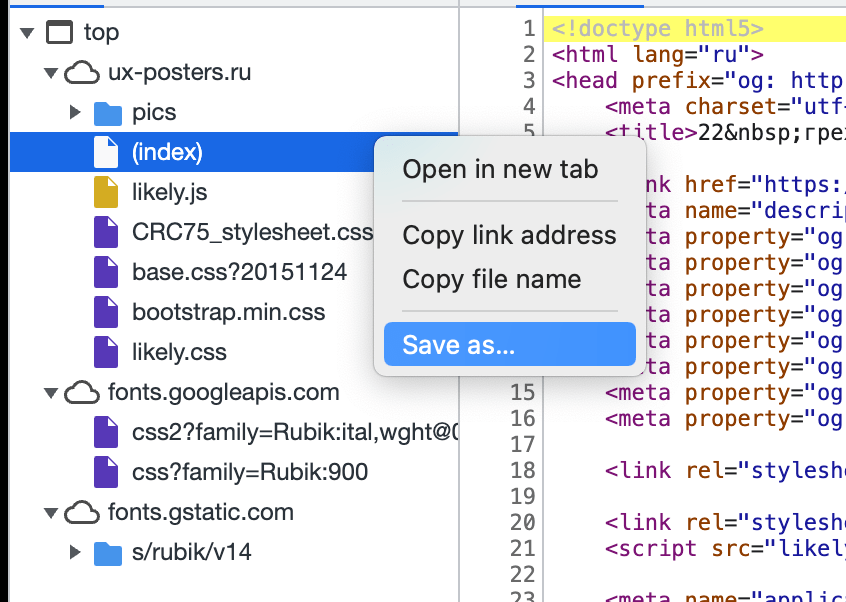
- Нажимаем правой кнопкой мыши на очередной файл.
- Выбираем пункт Save as, или «Сохранить как».
- Пишем имя и расширение файла — точно так, как указано в списке.
- Если лень писать самому — скопируйте перед этим название файла, нажав правую кнопку мыши и выбрав Copy file name, или «Скопировать имя файла».
- Чаще всего название файла подставится само, но если нет — смотрите пункт 4.
Исключения в названии файлов два:
- (index) — это index.html.
- В любом файле знак вопроса и всё, что после него, писать не нужно.
Скачать можно всё, а можно только то, что вам нужно для работы и экспериментов. Например, если вам нужны только стили и код страницы, сохраняйте файлы .css и (index). Если нужны картинки, заходите в папку pics и сохраняйте всё оттуда.
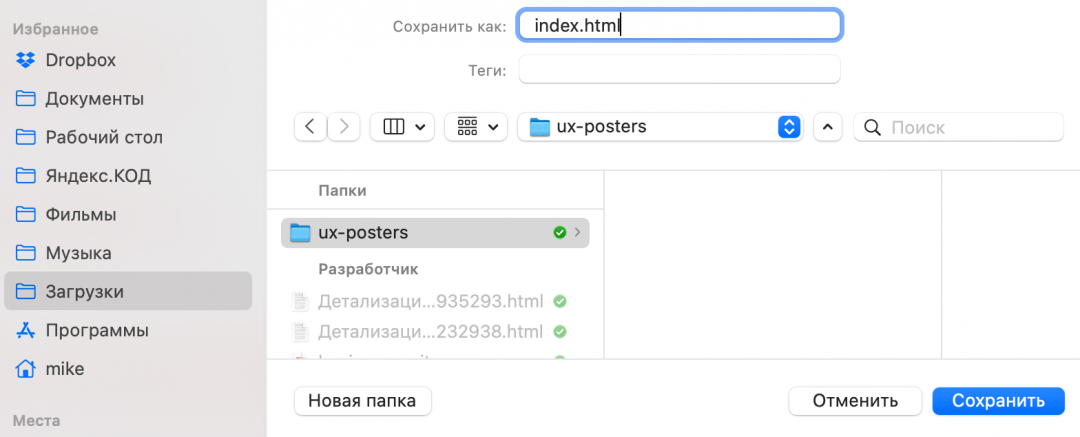
Что в итоге
Если мы пройдёмся по всем папкам и сохраним в них всё нужное нам, у нас получится локальный слепок сайта. Теперь можно:
- Изучить, как он устроен, что-то отредактировать и увидеть результат у себя на компьютере.
- Открыть файл index.html в браузере, и будет ощущение, что вы зашли на сайт, но с локального компьютера. Сайт откроется по протоколу file:// — это так браузер говорит нам, что файл взялся с нашего компьютера, а не из интернета.
- Запустить MAMP и завести на нём локальную копию сайта для экспериментов. Тогда браузер будет думать, что ходит за этим сайтом в интернет. Можно написать какие-нибудь php-скрипты и оживить сайт.
�� Важно понимать, что перед нами именно «слепок» — то, что мы бы увидели, если бы сервер сегодня ответил на наш запрос. Если завтра сервер будет отвечать по-другому, мы этого в своей локальной копии не увидим.
Когда ещё это пригодится
Защитить сайт перед наплывом пользователей. С помощью грабберов можно быстро создать неубиваемую статическую копию сайта и временно подменить ей динамическую версию сайта. Это полумера, но может сработать. А вообще вместо этого есть специальные надстройки, которые делают почти то же самое, но более умно, — поищите слово «кеширование».
Сделать копию своего блога, личного сайта или ещё чего-то важного вам, если вы потеряли к нему доступ, но сайт всё ещё на ходу.
Если вы едете туда, где не будет интернета, а вам нужна информация с сайта (например, путеводитель по чужой стране). Помните, что динамические карты и видеоролики так не сохранятся.
Сделать собственный «веб-архив» — это сервис, который ползает по сайтам и делает их «слепки» для истории. Благодаря этому сервису можно посмотреть, как выглядели ваши любимые сайты много лет назад — например, Яндекс.