Python. Урок 3. Типы и модель данных


В данном уроке разберем как Python работает с переменными и определим какие типы данных можно использовать в рамках этого языка. Подробно рассмотрим модель данных Python, а также механизмы создания и изменения значения переменных.
Немного о типизации языков программирования
Если достаточно формально подходить к вопросу о типизации языка Python, то можно сказать, что он относится к языкам с неявной сильной динамической типизацией.
Неявная типизация означает, что при объявлении переменной вам не нужно указывать её тип, при явной – это делать необходимо. В качестве примера языков с явной типизацией можно привести Java, C++. Вот как будет выглядеть объявление целочисленной переменной в Java и Python.
int a = 1;
a = 1
Также языки бывают с динамической и статической типизацией. В первом случае тип переменной определяется непосредственно при выполнении программы, во втором – на этапе компиляции (о компиляции и интерпретации кратко рассказано в уроке 2). Как уже было сказано Python – это динамически типизированный язык, такие языки как С, C#, Java – статически типизированные.
Сильная типизация не позволяет производить операции в выражениях с данными различных типов, слабая – позволяет. В языках с сильной типизацией вы не можете складывать например строки и числа, нужно все приводить к одному типу. К первой группе можно отнести Python, Java, ко второй – С и С++.
За более подробным разъяснением данного вопроса советуем обратиться к статье “Ликбез по типизации в языках программирования” .
Типы данных в Python
В Python типы данных можно разделить на встроенные в интерпретатор (built-in) и не встроенные, которые можно использовать при импортировании соответствующих модулей.
К основным встроенным типам относятся:
- None (неопределенное значение переменной)
- Логические переменные (Boolean Type)
- Числа (Numeric Type)
- int – целое число
- float – число с плавающей точкой
- complex – комплексное число
- list – список
- tuple – кортеж
- range – диапазон
- str
- bytes – байты
- bytearray – массивы байт
- memoryview – специальные объекты для доступа к внутренним данным объекта через protocol buffer
- set – множество
- frozenset – неизменяемое множество
- dict – словарь
Модель данных
Рассмотрим как создаются объекты в памяти, их устройство, процесс объявления новых переменных и работу операции присваивания.
Для того, чтобы объявить и сразу инициализировать переменную необходимо написать её имя, потом поставить знак равенства и значение, с которым эта переменная будет создана. Например строка:
b = 5
объявляет переменную b и присваивает ей значение 5.
Целочисленное значение 5 в рамках языка Python по сути своей является объектом. Объект, в данном случае – это абстракция для представления данных, данные – это числа, списки, строки и т.п. При этом, под данными следует понимать как непосредственно сами объекты, так и отношения между ними (об этом чуть позже). Каждый объект имеет три атрибута – это идентификатор, значение и тип. Идентификатор – это уникальный признак объекта, позволяющий отличать объекты друг от друга, а значение – непосредственно информация, хранящаяся в памяти, которой управляет интерпретатор.
При инициализации переменной, на уровне интерпретатора, происходит следующее:
- создается целочисленный объект 5 (можно представить, что в этот момент создается ячейка и 5 кладется в эту ячейку);
- данный объект имеет некоторый идентификатор, значение: 5, и тип: целое число;
- посредством оператора “=” создается ссылка между переменной b и целочисленным объектом 5 (переменная b ссылается на объект 5).
Имя переменной не должно совпадать с ключевыми словами интерпретатора Python. Список ключевых слов можно найти здесь . Также его можно получить непосредственно в программе, для этого нужно подключить модуль keyword и воспользоваться командой keyword.kwlist.
>>> import keyword >>> print("Python keywords: ", keyword.kwlist)
Проверить является или нет идентификатор ключевым словом можно так:
>>> keyword.iskeyword("try") True >>> keyword.iskeyword("b") False
Для того, чтобы посмотреть на объект с каким идентификатором ссылается данная переменная, можно использовать функцию id().
>>> a = 4 >>> b = 5 >>> id(a) 1829984576 >>> id(b) 1829984592 >>> a = b >>> id(a) 1829984592
Как видно из примера, идентификатор – это некоторое целочисленное значение, посредством которого уникально адресуется объект. Изначально переменная a ссылается на объект 4 с идентификатором 1829984576, переменная b – на объект с id = 1829984592. После выполнения операции присваивания a = b, переменная a стала ссылаться на тот же объект, что и b.

Тип переменной можно определить с помощью функции type(). Пример использования приведен ниже.
>>> a = 10 >>> b = "hello" >>> c = (1, 2) >>> type(a) class 'int'> >>> type(b) class 'str'> >>> type(c) class 'tuple'>
Изменяемые и неизменяемые типы данных
В Python существуют изменяемые и неизменяемые типы.
К неизменяемым (immutable) типам относятся: целые числа (int), числа с плавающей точкой (float), комплексные числа (complex), логические переменные (bool), кортежи (tuple), строки (str) и неизменяемые множества (frozen set).
К изменяемым (mutable) типам относятся: списки (list), множества (set), словари (dict).
Как уже было сказано ранее, при создании переменной, вначале создается объект, который имеет уникальный идентификатор, тип и значение, после этого переменная может ссылаться на созданный объект.
Неизменяемость типа данных означает, что созданный объект больше не изменяется. Например, если мы объявим переменную k = 15, то будет создан объект со значением 15, типа int и идентификатором, который можно узнать с помощью функции id().
>>> k = 15 >>> id(k) 1672501744 >>> type(k) class 'int'>
Объект с id = 1672501744 будет иметь значение 15 и изменить его уже нельзя.
Если тип данных изменяемый, то можно менять значение объекта. Например, создадим список [1, 2], а потом заменим второй элемент на 3.
>>> a = [1, 2] >>> id(a) 47997336 >>> a[1] = 3 >>> a [1, 3] >>> id(a) 47997336
Как видно, объект на который ссылается переменная a, был изменен. Это можно проиллюстрировать следующим рисунком.

В рассмотренном случае, в качестве данных списка, выступают не объекты, а отношения между объектами. Т.е. в переменной a хранятся ссылки на объекты содержащие числа 1 и 3, а не непосредственно сами эти числа.
P.S.
Если вам интересна тема анализа данных, то мы рекомендуем ознакомиться с библиотекой Pandas. На нашем сайте вы можете найти вводные уроки по этой теме. Все уроки по библиотеке Pandas собраны в книге “Pandas. Работа с данными”.
Раздел: Python Уроки по Python Метки: Python, Уроки Python
Python. Урок 3. Типы и модель данных : 12 комментариев
- Артем 25.04.2018 У Вас в коде
>>> print “Python keywords: “, keyword.kwlist
не хватает круглых скобок:
>>> print(“Python keywords: “, keyword.kwlist)
- writer 25.04.2018 Спасибо! Поправил.
Pandas: как проверить dtype для всех столбцов в DataFrame
Вы можете использовать следующие методы для проверки типа данных ( dtype ) для столбцов в кадре данных pandas:
Способ 1: проверить dtype одного столбца
df.column_name.dtypeСпособ 2: проверить dtype всех столбцов
df.dtypesСпособ 3: проверьте, какие столбцы имеют определенный тип dtype
df.dtypes [df.dtypes == 'int64']В следующих примерах показано, как использовать каждый метод со следующими пандами DataFrame:
import pandas as pd #create DataFrame df = pd.DataFrame() #view DataFrame print(df) team points assists all_star 0 A 18 5 True 1 B 22 7 False 2 C 19 7 False 3 D 14 9 True 4 E 14 12 True 5 F 11 9 TrueПример 1: проверка dtype одного столбца
Мы можем использовать следующий синтаксис, чтобы проверить тип данных только столбца точек в DataFrame:
#check dtype of points column df.points.dtype dtype('int64')Из вывода мы видим, что столбец точек имеет целочисленный тип данных.
Пример 2: Проверка dtype всех столбцов
Мы можем использовать следующий синтаксис для проверки типа данных всех столбцов в DataFrame:
#check dtype of all columns df.dtypes team object points int64 assists int64 all_star bool dtype: objectИз вывода мы видим:
- Столбец команды : объект (это то же самое, что и строка)
- столбец очков : целое число
- столбец помогает : целое число
- столбец all_star : логическое значение
Используя эту одну строку кода, мы можем увидеть тип данных каждого столбца в DataFrame.
Пример 3: проверьте, какие столбцы имеют определенный тип dtype
Мы можем использовать следующий синтаксис, чтобы проверить, какие столбцы в DataFrame имеют тип данных int64:
#show all columns that have a class of int64 df.dtypes [df.dtypes == 'int64'] points int64 assists int64 dtype: objectИз вывода мы видим, что столбцы очков и помощи имеют тип данных int64.
Мы можем использовать аналогичный синтаксис, чтобы проверить, какие столбцы имеют другие типы данных.
Например, мы можем использовать следующий синтаксис, чтобы проверить, какие столбцы в DataFrame имеют тип данных объекта:
#show all columns that have a class of object (i.e. string) df.dtypes [df.dtypes == 'O'] team object dtype: objectМы видим, что только столбец team имеет тип данных «O», что означает объект.
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные операции с пандами DataFrames:
Изучаем pandas. Урок 2. Структуры данных Series и DataFrame
Во втором уроке мы познакомимся со структурами данных pandas – это Series и DataFrame. Основное внимание будет уделено вопросам создания и получения доступа к элементам данных структур, а также общим понятиям, которые позволят более интуитивно работать с ними в будущем.
Введение
Библиотека pandas предоставляет две структуры: Series и DataFrame для быстрой и удобной работы с данными (на самом деле их три, есть еще одна структура – Panel , но в данный момент она находится в статусе deprecated и в будущем будет исключена из состава библиотеки pandas ). Series – это маркированная одномерная структура данных, ее можно представить, как таблицу с одной строкой. С Series можно работать как с обычным массивом (обращаться по номеру индекса), и как с ассоциированным массивом, когда можно использовать ключ для доступа к элементам данных. DataFrame – это двумерная маркированная структура. Идейно она очень похожа на обычную таблицу, что выражается в способе ее создания и работе с ее элементами. Panel – про который было сказано, что он вскоре будет исключен из pandas , представляет собой трехмерную структуру данных. О Panel мы больше говорить не будем. В рамках этой части мы остановимся на вопросах создания и получения доступа к элементам данных структур Series и DataFrame .
Структура данных Series
Для того, чтобы начать работать со структурами данных из pandas требуется предварительно импортировать необходимые модули. Убедитесь, что нужные модули установлены на вашем компьютере, о том, как это сделать, можно прочитать в первой части данного курса. Также будем считать, что вы знакомы с языком Python . Если нет, то специально для вас мы подготовили он-лайн курс и книгу.
Помимо самого pandas нам понадобится библиотека numpy . Наши эксперименты будем проводить с использованием пакета Anaconda , в качестве среды разработки советуем взять Spyder , который входит в базовую поставку Anaconda . Для того, чтобы запустить Spyder , перейдите в каталог Scripts , который находится в папке с установленной Anaconda и запустите spyder.exe . Для нас он в первую очередь имеет ценность в том, что в нем есть редактор исходного кода, на случай, если нам понадобится написать довольно большую программу, и интерпретатор для быстрых экспериментов. Если строки кода будут содержать префикс в виде цифры в квадратных скобках, то это означает, что данные команды мы вводим в интерпретаторе, в ином случае, это будет означать, что код написан в редакторе.
Пора переходить к практике!
Импортируем нужные нам библиотеки.
In [1]: import numpy as np In [2]: import pandas as pd
Создать структуру Series можно на базе различных типов данных:
- словари Python ;
- списки Python ;
- массивы из numpy: ndarray ;
- скалярные величины.
Конструктор класса Series выглядит следующим образом:
pandas.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False)data – массив, словарь или скалярное значение, на базе которого будет построен Series;
index – список меток, который будет использоваться для доступа к элементам Series . Длина списка должна быть равна длине data ;
dtype – объект numpy.dtype , определяющий тип данных;
copy – создает копию массива данных, если параметр равен True в ином случае ничего не делает.
В большинстве случаев, при создании Series, используют только первые два параметра. Рассмотрим различные варианты как это можно сделать.
Создание Series из списка Python
Самый простой способ создать Series – это передать в качестве единственного параметра в конструктор класса список Python.
In [3]: s1 = pd.Series([1, 2, 3, 4, 5]) In [4]: print(s1) 0 1 1 2 2 3 3 4 4 5 dtype: int64
В данном примере была создана структура Series на базе списка из языка Python . Для доступа к элементам Series , в данном случае, можно использовать только положительные целые числа – левый столбец чисел, начинающийся с нуля – это как раз и есть индексы элементов структуры, которые представлены в правом столбце.
Можно попробовать использоваться больше возможностей из тех, что предлагает pandas , для этого передадим в качестве второго элемента список строк (в нашем случае – это отдельные символы). Такой шаг позволит нам обращаться к элементам структуры Series не только по численному индексу, но и по метке, что сделает работу с таким объектом, похожей на работу со словарем.
In [5]: s2 = pd.Series([1, 2, 3, 4, 5], ['a', 'b', 'c', 'd', 'e']) In [6]: print(s2) a 1 b 2 c 3 d 4 e 5 dtype: int64
Обратите внимание на левый столбец, в нем содержатся метки, которые мы передали в качестве index параметра при создании структуры. Правый столбец – это по-прежнему элементы нашей структуры.
Создание Series из ndarray массива из numpy
Создадим простой массив из пяти чисел, аналогичный списку из предыдущего раздела. Библиотеки pandas и numpy должны быть предварительно импортированы.
In [3]: ndarr = np.array([1, 2, 3, 4, 5]) In [4]: type(ndarr) Out[4]: numpy.ndarray
Теперь создадим Series с буквенными метками.
In [5]: s3 = pd.Series(ndarr, ['a', 'b', 'c', 'd', 'e']) In [6]: print(s3) a 1 b 2 c 3 d 4 e 5 dtype: int32
Создание Series из словаря (dict)
Еще один способ создать структуру Series – это использовать словарь для одновременного задания меток и значений.
In [7]: d = 'a':1, 'b':2, 'c':3> In [8]: s4 = pd.Series(d) In [9]: print(s4) a 1 b 2 c 3 dtype: int64
Ключи ( keys ) из словаря d станут метками структуры s4 , а значения ( values ) словаря – значениями в структуре.
Создание Series с использованием константы
Рассмотрим еще один способ создания структуры. На этот раз значения в ячейках структуры будут одинаковыми.
In [10]: a = 7 In [11]: s5 = pd.Series(a, ['a', 'b', 'c']) In [12]: print(s5) a 7 b 7 c 7 dtype: int64
В созданной структуре Series имеется три элемента с одинаковым содержанием.
Работа с элементами Series
В будущем будет написан отдельный урок, посвященный индексации и работе с элементами Series и DataFrame , сейчас рассмотрим основные подходы.
К элементам Series можно обращаться по численному индексу, при таком подходе работа со структурой не отличается от работы со списками в Python .
In [13]: s6 = pd.Series([1, 2, 3, 4, 5], ['a', 'b', 'c', 'd', 'e']) In [14]: s6[2] Out[14]: 3
Можно использовать метку, тогда работа с Series будет похожа на работу со словарем (dict) в Python.
In [15]: s6['d'] Out[15]: 4
Доступно получение slice’ов.
In [16]: s6[:2] Out[16]: a 1 b 2 dtype: int64
В поле для индекса можно поместить условное выражение.
In [17]: s6[s6 3] Out[17]: a 1 b 2 c 3 dtype: int64Со структурами Series можно работать как с векторами: складывать, умножать вектор на число и т.п.
In [18]: s7 = pd.Series([10, 20, 30, 40, 50], ['a', 'b', 'c', 'd', 'e']) In [19]: s6 + s7 Out[19]: a 11 b 22 c 33 d 44 e 55 dtype: int64 In [20]: s6 * 3 Out[20]: a 3 b 6 c 9 d 12 e 15 dtype: int64
Структура данных DataFrame
Если Series представляет собой одномерную структуру, которую для себя можно представить как таблицу с одной строкой, то DataFrame – это уже двумерная структура – полноценная таблица с множеством строк и столбцов.
Перед работой с DataFrame не забудьте импортировать библиотеку pandas .
Конструктор класса DataFrame выглядит так:
class pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)data – массив ndarray , словарь ( dict ) или другой DataFrame ;
index – список меток для записей (имена строк таблицы);
columns – список меток для полей (имена столбцов таблицы);
dtype – объект numpy.dtype , определяющий тип данных;
copy – создает копию массива данных, если параметр равен True в ином случае ничего не делает.
Структуру DataFrame можно создать на базе:
- словаря ( dict ) в качестве элементов которого должны выступать: одномерные ndarray , списки, другие словари, структуры Series ;
- двумерные ndarray ;
- структуры Series ;
- структурированные ndarray ;
- другие DataFrame .
Рассмотрим на практике различные подходы к созданию DataFrame’ов .
Создание DataFrame из словаря
В данном случае будет использоваться одномерный словарь, элементами которого будут списки, структуры Series и т.д.
Начнем с Series.
In [3]: d = "price":pd.Series([1, 2, 3], index=['v1', 'v2', 'v3']), . : "count": pd.Series([10, 12, 7], index=['v1', 'v2', 'v3'])> In [4]: df1 = pd.DataFrame(d) In [5]: print(df1) count price v1 10 1 v2 12 2 v3 7 3 In [6]: print(df1.index) Index(['v1', 'v2', 'v3'], dtype='object') In [7]: print(df1.columns) Index(['count', 'price'], dtype='object')
Теперь построим аналогичный словарь, но на элементах ndarray .
In [8]: d2 = "price":np.array([1, 2, 3]), . : "count": np.array([10, 12, 7])> In [9]: df2 = pd.DataFrame(d2, index=['v1', 'v2', 'v3']) In [10]: print(df2) count price v1 10 1 v2 12 2 v3 7 3 In [11]: print(df2.index) Index(['v1', 'v2', 'v3'], dtype='object') In [12]: print(df2.columns) Index(['count', 'price'], dtype='object')
Как видно – результат аналогичен предыдущему. Вместо ndarray можно использовать обычный список из Python .
Создание DataFrame из списка словарей
До это мы создавали DataFrame из словаря, элементами которого были структуры Series , списки и массивы, сейчас мы создадим DataFrame из списка, элементами которого являются словари.
In [13]: d3 = ["price": 3, "count":8>, "price": 4, "count": 11>] In [14]: df3 = pd.DataFrame(d3) In [15]: print(df3) count price 0 8 3 1 11 4 In [16]: print(df3.info()) class 'pandas.core.frame.DataFrame'> RangeIndex: 2 entries, 0 to 1 Data columns (total 2 columns): count 2 non-null int64 price 2 non-null int64 dtypes: int64(2) memory usage: 112.0 bytes None
Создание DataFrame из двумерного массива
Создать DataFrame можно также и из двумерного массива, в нашем примере это будет ndarray из библиотеки numpy .
In [17]: nda1 = np.array([[1, 2, 3], [10, 20, 30]]) In [18]: df4 = pd.DataFrame(nda1) In [19]: print(df4) 0 1 2 0 1 2 3 1 10 20 30
Работа с элементами DataFrame
Работа с элементами DataFrame – доступ к элементам данной структуры – тема достаточно обширная и она будет освещена в одном из ближайших уроков. Сейчас мы рассмотрим наиболее часто используемые способы работы с элементами DataFrame .
Основные подходы представлены в таблице ниже.
Операция Синтаксис Возвращаемый результат Выбор столбца df[col] Series Выбор строки по метке df.loc[label] Series Выбор строки по индексу df.iloc[loc] Series Слайс по строкам df[0:4] DataFrame Выбор строк, отвечающих условию df[bool_vec] DataFrame Теперь посмотрим, как использовать данные операций на практике.
Для начала создадим DataFrame .
In [3]: d = "price":np.array([1, 2, 3]), . : "count": np.array([10, 20, 30])> In [4]: df = pd.DataFrame(d, index=['a', 'b', 'c']) In [5]: print(df) count price a 10 1 b 20 2 c 30 3
Операция: выбор столбца.
In [6]: df['count'] Out[6]: a 10 b 20 c 30 Name: count, dtype: int32
Операция: выбор строки по метке.
In [7]: df.loc['a'] Out[7]: count 10 price 1 Name: a, dtype: int32
Операция: выбор строки по индексу.
In [8]: df.iloc[1] Out[8]: count 20 price 2 Name: b, dtype: int32
Операция: slice по строкам.
In [9]: df[0:2] Out[9]: count price a 10 1 b 20 2
Операция: выбор строк, отвечающих условию.
In [10]: df[df['count'] >= 20] Out[10]: count price b 20 2 c 30 3
P.S.
Раздел: Pandas Python Машинное обучение и анализ данных Метки: ML, Pandas, Python, Машинное обучение
Изучаем pandas. Урок 2. Структуры данных Series и DataFrame : 6 комментариев
- Lumen 15.03.2019 Опечатка: случае[т]
В большинстве случает, при создании Series P.S. Спасибо за статью!
- writer 16.03.2019 Спасибо! Поправили))
- writer 21.10.2019 Спасибо! Добавим!
- writer 21.10.2019 Как мне кажется, ‘slice’ стало уже сленговым словом, и его вполне можно употреблять. Но слово ‘срез’ звучит тоже не плохо))) В данном случае выбор был сделан в пользу первого.
Моя шпаргалка по pandas
Один преподаватель как-то сказал мне, что если поискать аналог программиста в мире книг, то окажется, что программисты похожи не на учебники, а на оглавления учебников: они не помнят всего, но знают, как быстро найти то, что им нужно.
Возможность быстро находить описания функций позволяет программистам продуктивно работать, не теряя состояния потока. Поэтому я и создал представленную здесь шпаргалку по pandas и включил в неё то, чем пользуюсь каждый день, создавая веб-приложения и модели машинного обучения.

Нельзя сказать, что это — исчерпывающий список возможностей pandas , но сюда входят функции, которыми я пользуюсь чаще всего, примеры и мои пояснения по поводу ситуаций, в которых эти функции особенно полезны.
1. Подготовка к работе
Если вы хотите самостоятельно опробовать то, о чём тут пойдёт речь, загрузите набор данных Anime Recommendations Database с Kaggle. Распакуйте его и поместите в ту же папку, где находится ваш Jupyter Notebook (далее — блокнот).
Теперь выполните следующие команды.
import pandas as pd import numpy as np anime = pd.read_csv('anime-recommendations-database/anime.csv') rating = pd.read_csv('anime-recommendations-database/rating.csv') anime_modified = anime.set_index('name')После этого у вас должна появиться возможность воспроизвести то, что я покажу в следующих разделах этого материала.
2. Импорт данных
▍Загрузка CSV-данных
Здесь я хочу рассказать о преобразовании CSV-данных непосредственно в датафреймы (в объекты Dataframe). Иногда при загрузке данных формата CSV нужно указывать их кодировку (например, это может выглядеть как encoding=’ISO-8859–1′ ). Это — первое, что стоит попробовать сделать в том случае, если оказывается, что после загрузки данных датафрейм содержит нечитаемые символы.
anime = pd.read_csv('anime-recommendations-database/anime.csv')
Загруженные CSV-данные
Существует похожая функция для загрузки данных из Excel-файлов — pd.read_excel .
▍Создание датафрейма из данных, введённых вручную
Это может пригодиться тогда, когда нужно вручную ввести в программу простые данные. Например — если нужно оценить изменения, претерпеваемые данными, проходящими через конвейер обработки данных.
df = pd.DataFrame([[1,'Bob', 'Builder'], [2,'Sally', 'Baker'], [3,'Scott', 'Candle Stick Maker']], columns=['id','name', 'occupation'])
Данные, введённые вручную
▍Копирование датафрейма
Копирование датафреймов может пригодиться в ситуациях, когда требуется внести в данные изменения, но при этом надо и сохранить оригинал. Если датафреймы нужно копировать, то рекомендуется делать это сразу после их загрузки.
anime_copy = anime.copy(deep=True)
Копия датафрейма
3. Экспорт данных
▍Экспорт в формат CSV
При экспорте данных они сохраняются в той же папке, где находится блокнот. Ниже показан пример сохранения первых 10 строк датафрейма, но то, что именно сохранять, зависит от конкретной задачи.
rating[:10].to_csv('saved_ratings.csv', index=False)Экспортировать данные в виде Excel-файлов можно с помощью функции df.to_excel .
4. Просмотр и исследование данных
▍Получение n записей из начала или конца датафрейма
Сначала поговорим о выводе первых n элементов датафрейма. Я часто вывожу некоторое количество элементов из начала датафрейма где-нибудь в блокноте. Это позволяет мне удобно обращаться к этим данным в том случае, если я забуду о том, что именно находится в датафрейме. Похожую роль играет и вывод нескольких последних элементов.
anime.head(3) rating.tail(1)
Данные из начала датафрейма

Данные из конца датафрейма
▍Подсчёт количества строк в датафрейме
Функция len(), которую я тут покажу, не входит в состав pandas . Но она хорошо подходит для подсчёта количества строк датафреймов. Результаты её работы можно сохранить в переменной и воспользоваться ими там, где они нужны.
len(df) #=> 3▍Подсчёт количества уникальных значений в столбце
Для подсчёта количества уникальных значений в столбце можно воспользоваться такой конструкцией:
len(ratings['user_id'].unique())▍Получение сведений о датафрейме
В сведения о датафрейме входит общая информация о нём вроде заголовка, количества значений, типов данных столбцов.
anime.info()
Сведения о датафрейме
Есть ещё одна функция, похожая на df.info — df.dtypes . Она лишь выводит сведения о типах данных столбцов.
▍Вывод статистических сведений о датафрейме
Знание статистических сведений о датафрейме весьма полезно в ситуациях, когда он содержит множество числовых значений. Например, знание среднего, минимального и максимального значений столбца rating даёт нам некоторое понимание того, как, в целом, выглядит датафрейм. Вот соответствующая команда:
anime.describe()
Статистические сведения о датафрейме
▍Подсчёт количества значений
Для того чтобы подсчитать количество значений в конкретном столбце, можно воспользоваться следующей конструкцией:
anime.type.value_counts()
Подсчёт количества элементов в столбце
5. Извлечение информации из датафреймов
▍Создание списка или объекта Series на основе значений столбца
Это может пригодиться в тех случаях, когда требуется извлекать значения столбцов в переменные x и y для обучения модели. Здесь применимы следующие команды:
anime['genre'].tolist() anime['genre']
Результаты работы команды anime[‘genre’].tolist()

Результаты работы команды anime[‘genre’]
▍Получение списка значений из индекса
Поговорим о получении списков значений из индекса. Обратите внимание на то, что я здесь использовал датафрейм anime_modified , так как его индексные значения выглядят интереснее.
anime_modified.index.tolist()
Результаты выполнения команды
▍Получение списка значений столбцов
Вот команда, которая позволяет получить список значений столбцов:
anime.columns.tolist()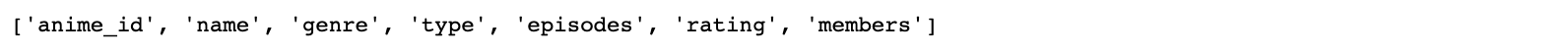
Результаты выполнения команды
6. Добавление данных в датафрейм и удаление их из него
▍Присоединение к датафрейму нового столбца с заданным значением
Иногда мне приходится добавлять в датафреймы новые столбцы. Например — в случаях, когда у меня есть тестовый и обучающий наборы в двух разных датафреймах, и мне, прежде чем их скомбинировать, нужно пометить их так, чтобы потом их можно было бы различить. Для этого используется такая конструкция:
anime['train set'] = True▍Создание нового датафрейма из подмножества столбцов
Это может пригодиться в том случае, если требуется сохранить в новом датафрейме несколько столбцов огромного датафрейма, но при этом не хочется выписывать имена столбцов, которые нужно удалить.
anime[['name','episodes']]
Результат выполнения команды
▍Удаление заданных столбцов
Этот приём может оказаться полезным в том случае, если из датафрейма нужно удалить лишь несколько столбцов. Если удалять нужно много столбцов, то эта задача может оказаться довольно-таки утомительной, поэтому тут я предпочитаю пользоваться возможностью, описанной в предыдущем разделе.
anime.drop(['anime_id', 'genre', 'members'], axis=1).head()
Результаты выполнения команды
▍Добавление в датафрейм строки с суммой значений из других строк
Для демонстрации этого примера самостоятельно создадим небольшой датафрейм, с которым удобно работать. Самое интересное здесь — это конструкция df.sum(axis=0) , которая позволяет получать суммы значений из различных строк.
df = pd.DataFrame([[1,'Bob', 8000], [2,'Sally', 9000], [3,'Scott', 20]], columns=['id','name', 'power level']) df.append(df.sum(axis=0), ignore_index=True)
Результат выполнения команды
Команда вида df.sum(axis=1) позволяет суммировать значения в столбцах.
Похожий механизм применим и для расчёта средних значений. Например — df.mean(axis=0) .
7. Комбинирование датафреймов
▍Конкатенация двух датафреймов
Эта методика применима в ситуациях, когда имеются два датафрейма с одинаковыми столбцами, которые нужно скомбинировать.
В данном примере мы сначала разделяем датафрейм на две части, а потом снова объединяем эти части:
df1 = anime[0:2] df2 = anime[2:4] pd.concat([df1, df2], ignore_index=True)
Датафрейм df1

Датафрейм df2

Датафрейм, объединяющий df1 и df2
▍Слияние датафреймов
Функция df.merge , которую мы тут рассмотрим, похожа на левое соединение SQL. Она применяется тогда, когда два датафрейма нужно объединить по некоему столбцу.
rating.merge(anime, left_on=’anime_id’, right_on=’anime_id’, suffixes=(‘_left’, ‘_right’))
Результаты выполнения команды
8. Фильтрация
▍Получение строк с нужными индексными значениями
Индексными значениями датафрейма anime_modified являются названия аниме. Обратите внимание на то, как мы используем эти названия для выбора конкретных столбцов.
anime_modified.loc[['Haikyuu!! Second Season','Gintama']]
Результаты выполнения команды
▍Получение строк по числовым индексам
Эта методика отличается от той, которая описана в предыдущем разделе. При использовании функции df.iloc первой строке назначается индекс 0 , второй — индекс 1 , и так далее. Такие индексы назначаются строкам даже в том случае, если датафрейм был модифицирован и в его индексном столбце используются строковые значения.
Следующая конструкция позволяет выбрать три первых строки датафрейма:
anime_modified.iloc[0:3]
Результаты выполнения команды
▍Получение строк по заданным значениям столбцов
Для получения строк датафрейма в ситуации, когда имеется список значений столбцов, можно воспользоваться следующей командой:
anime[anime['type'].isin(['TV', 'Movie'])]
Результаты выполнения команды
Если нас интересует единственное значение — можно воспользоваться такой конструкцией:
anime[anime[‘type’] == 'TV']▍Получение среза датафрейма
Эта техника напоминает получение среза списка. А именно, речь идёт о получении фрагмента датафрейма, содержащего строки, соответствующие заданной конфигурации индексов.
anime[1:3]
Результаты выполнения команды
▍Фильтрация по значению
Из датафреймов можно выбирать строки, соответствующие заданному условию. Обратите внимание на то, что при использовании этого метода сохраняются существующие индексные значения.
anime[anime['rating'] > 8]
Результаты выполнения команды
9. Сортировка
Для сортировки датафреймов по значениям столбцов можно воспользоваться функцией df.sort_values :
anime.sort_values('rating', ascending=False)
Результаты выполнения команды
10. Агрегирование
▍Функция df.groupby и подсчёт количества записей
Вот как подсчитать количество записей с различными значениями в столбцах:
anime.groupby('type').count()
Результаты выполнения команды
▍Функция df.groupby и агрегирование столбцов различными способами
Обратите внимание на то, что здесь используется reset_index() . В противном случае столбец type становится индексным столбцом. В большинстве случаев я рекомендую делать то же самое.
anime.groupby(["type"]).agg(< "rating": "sum", "episodes": "count", "name": "last" >).reset_index()▍Создание сводной таблицы
Для того чтобы извлечь из датафрейма некие данные, нет ничего лучше, чем сводная таблица. Обратите внимание на то, что здесь я серьёзно отфильтровал датафрейм, что ускорило создание сводной таблицы.
tmp_df = rating.copy() tmp_df.sort_values('user_id', ascending=True, inplace=True) tmp_df = tmp_df[tmp_df.user_id < 10] tmp_df = tmp_df[tmp_df.anime_id < 30] tmp_df = tmp_df[tmp_df.rating != -1] pd.pivot_table(tmp_df, values='rating', index=['user_id'], columns=['anime_id'], aggfunc=np.sum, fill_value=0)
Результаты выполнения команды
11. Очистка данных
▍Запись в ячейки, содержащие значение NaN, какого-то другого значения
Здесь мы поговорим о записи значения 0 в ячейки, содержащие значение NaN . В этом примере мы создаём такую же сводную таблицу, как и ранее, но без использования fill_value=0 . А затем используем функцию fillna(0) для замены значений NaN на 0 .
pivot = pd.pivot_table(tmp_df, values='rating', index=['user_id'], columns=['anime_id'], aggfunc=np.sum) pivot.fillna(0)
Таблица, содержащая значения NaN

Результаты замены значений NaN на 0
12. Другие полезные возможности
▍Отбор случайных образцов из набора данных
Я использую функцию df.sample каждый раз, когда мне нужно получить небольшой случайный набор строк из большого датафрейма. Если используется параметр frac=1 , то функция позволяет получить аналог исходного датафрейма, строки которого будут перемешаны.
anime.sample(frac=0.25)
Результаты выполнения команды
▍Перебор строк датафрейма
Следующая конструкция позволяет перебирать строки датафрейма:
for idx,row in anime[:2].iterrows(): print(idx, row)
Результаты выполнения команды
▍Борьба с ошибкой IOPub data rate exceeded
Если вы сталкиваетесь с ошибкой IOPub data rate exceeded — попробуйте, при запуске Jupyter Notebook, воспользоваться следующей командой:
jupyter notebook — NotebookApp.iopub_data_rate_limit=1.0e10Итоги
Здесь я рассказал о некоторых полезных приёмах использования pandas в среде Jupyter Notebook. Надеюсь, моя шпаргалка вам пригодится.
Уважаемые читатели! Есть ли какие-нибудь возможности pandas , без которых вы не представляете своей повседневной работы?

- Блог компании RUVDS.com
- Веб-разработка
- Python