Реверсивный инжиниринг
Реверс-инжиниринг с компенсацией до 100% по государственной программе
Программа поддержки позволяет промышленным предприятиям получить субсидию до 100% при разработке и производстве импортозамещающей продукции
Реверсивный инжиниринг (реверс инжиниринг, обратное проектирование, reverse-engineering) – процесс создания точной копии объекта по уже существующему образцу, обладающей такими же физическими характеристиками. Реверс-инжиниринг полезен в случаях, когда производитель хочет импортозаместить компонент или восстановить конструкторскую документацию и процесс производства.
Технология реверсивного инжиниринга получила наибольшее распространение в высокотехнологичных отраслях, но может применяется во всех отраслях промышленности.
Инжиниринговый центр цифровых технологий машиностроения обладает всем необходимым оборудованием для проведения комплекса работ при реверсивном инжиниринге изделия:
- определение размеров, геометрии, внутреннего и внешнего строения;
- определение структуры и химического состава материала;
- определение механических свойств;
- определение режимов работы.
Применение комплекса технологий «Цифрового КБ» позволяет определить все функциональные особенности изделия, подобрать материалы и отработать технологический процесс изготовления, учитывая производственные мощности заказчика. Заказать реверсинжиниринг

Этапы реверсивного инжиниринга:
- Подготовка изделия к сканированию: разборка изделия на детали и определение применяемых материалов.
- Трехмерное сканирование и получение 3D-модели.
- Разработка рабочей трехмерной модели: моделирование и редактирование полученной модели, перевод облака точек в полигональную 3D-модель.
- Определение детализированных требований к изделию за счет описания его окружения и разработки архитектуры изделия с применением подходов системной инженерии.
- Проведение инженерных расчетов для подтверждения требуемых характеристик отдельной детали или изделия.
- Разработка конструкторской документации.
- Изготовление прототипа по конструкторской документации.
- Испытание полученной детали для подтверждения расчетных характеристик.
Цифровой двойник, полученный по итогу выполнения всех этапов реверсивного инжиниринга, позволяет приступить к улучшению технических характеристик изделия за счет серии инженерных расчетов возможных режимов работы и изменения внутренних конструктивных решений, не изменяя общих геометрических размеров.
Для разработки технологии производства ИЦЦТМ УрФУ оснащен новейшим оборудованием

- Производство точных отливок способом литья по выплавляемым моделям;
- Литье в песчано-глинистые и песчано-смоляные формы из чугуна и стали различных марок, в частности, из жаропрочных и жароупорных сплавов (высоколегированные чугуны и стали);
- Получение методами литья наплавочных прутков из специальных твердых сплавов;
- Участок электрофизической обработки;
- Участок металлорежущих станков с ЧПУ;
- Участок обработки полимерных и композитных материалов
- Прецизионная лазерная резка;
- Роботизированная лазерная сварка;
- Поверхностное лазерное термоупрочнение;
- Лазерная пробивка отверстий, перфорации;
- Аддитивные машины;
- Оборудование для изготовления прототипов;
- Оборудование для вакуумного литья полиуретанов.
Испытание изделия производится программе и методиками испытаний соблюдая все стандарты соответствующей отрасли.
Благодаря обратному инжинирингу вы можете заменить импортные, сохранить работающие и воссоздать неисправные детали, независимо от того, работает ли первоначальный производитель.
ДОГОВОРИТЬСЯ О ДЕМОНСТРАЦИИ
Свяжитесь с нами и узнайте больше о возможностях реверсивного инжиниринга
- Программное обеспечение
- Гидрогазодинамика и теплообмен
- Междисциплинарный инженерный анализ
- Управление данными о материалах
- Многодисциплинарная параметрическая оптимизация
- Решение задач трещиностойкости
- Системное моделирование, 1D-расчеты
- Составление и расчет гидравлических цепей
- Управление CAE-моделями
- Администрирование лицензий ПО
- Система управления жизненным циклом изделия
- Проектирование изделий
- Управление цифровой инфраструктурой инжиниринга
- Российское ПО
- Программное обеспечение
- Цифровое КБ
- Поставщики
- Академическая программа GO PLM
- Программные решения для стартапов
- Импортозамещение
- Реверс-инжиниринг
- Расчеты
- Разработка ПО
- Аренда ПО
- НИОКР
- Промышленный дизайн
- Курсы обучения
- О компании
- Наш подход
- История успеха
- Карьера
- Вакансии
- О центре
- Производственные возможности
Мы в социальных сетях
Наш сайт сохранит анонимные идентификаторы (cookie-файлы) на ваше устройство. Это способствует персонализации контента, а также используется в статистических целях. Вы можете отключить использование cookie-файлов, изменив настройки Вашего браузера. Пользуясь этим сайтом при настройках браузера по умолчанию, вы соглашаетесь на использование cookie-файлов и сохранение информации на Вашем устройстве.
Реверс-инжиниринг для начинающих: основные концепции программирования
В этой статье мы заглянем под капот программного обеспечения. Новички в реверс-инжиниринге получат общее представление о самом процессе исследования ПО, общих принципах построения программного кода и о том, как читать ассемблерный код.
Примечание Программный код для этой статьи компилируется с помощью Microsoft Visual Studio 2015, так что некоторые функции в новых версиях могут использоваться по-другому. В качестве дизассемблера используется IDA Pro.
- Инициализация переменных
- Стандартная функция вывода
- Математические операции
- Вызов функций
- Циклы
- Условный оператор
- Оператор выбора
- Пользовательский ввод
Инициализация переменных
Переменные — одна из основных составляющих программирования. Они делятся на несколько видов, вот некоторые из них:
- строка;
- целое число;
- логическая переменная;
- символ;
- вещественное число с двойной точностью;
- вещественное число;
- массив символов.
string stringvar = "Hello World"; int intvar = 100; bool boolvar = false; char charvar = 'B'; double doublevar = 3.1415; float floatvar = 3.14159265; char carray[] = < 'a', 'b', 'c', 'd', 'e' >;Примечание в С++ строка — не примитивная переменная, но важно понять, как она будет выглядеть в машинном коде.
Давайте посмотрим на ассемблерный код:
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Здесь можно увидеть как IDA показывает распределение пространства для переменных. Сначала под каждую переменную выделяется пространство, а потом уже она инициализируется.
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Как только пространство выделено, в него помещается значение, которое мы хотим присвоить переменной. Инициализация большинства переменных представлена на картинке выше, но как инициализируется строка, показано ниже.
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Для инициализации строки требуется вызов встроенной функции.
Стандартная функция вывода
Примечание Здесь речь пойдёт о том, что переменные помещаются в стек и затем используются в качестве параметров для функции вывода. Концепт функции с параметрами будет рассмотрен позднее.
Для вывода данных было решено использовать printf() , а не cout .
printf("Hello String Literal"); printf("%s", stringvar); printf("%i", intvar); printf("%c", charvar); printf("%f", doublevar); printf("%f", floatvar); printf("%c", carray[3]);Теперь посмотрим на машинный код. Сначала строковый литерал:
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Как видите, строковый литерал сначала помещается в стек для вызова в качестве параметра функции printf() .
Теперь посмотрим на вывод одной из переменных:
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Как можно заметить, сначала переменная intvar помещается в регистр EAX, который в свою очередь записывается в стек вместе со строковым литералом %i , используемым для обозначения целочисленного вывода. Эти переменные затем берутся из стека и используются в качестве параметров при вызове функции printf() .
Математические операции
Сейчас мы поговорим о следующих математических операциях:
- Сложение.
- Вычитание.
- Умножение.
- Деление.
- Поразрядная конъюнкция (И).
- Поразрядная дизъюнкция (ИЛИ).
- Поразрядное исключающее ИЛИ.
- Поразрядное отрицание.
- Битовый сдвиг вправо.
- Битовый сдвиг влево.
void mathfunctions() < // математические операции int A = 10; int B = 15; int add = A + B; int sub = A - B; int mult = A * B; int div = A / B; int and = A & B; int or = A | B; int xor = A ^ B; int not = ~A; int rshift = A >> B; int lshift = A
Переведём каждую операцию в ассемблерный код:
сначала присвоим переменной A значение 0A в шестнадцатеричной системе счисления или 10 в десятичной. Переменной B — 0F , что равно 15 в десятичной.
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Для сложения мы используем инструкцию add :
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
При вычитании используется инструкция sub :
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
При умножении — imul :
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Для деления используется инструкция idiv . Также мы используем оператор cdq , чтобы удвоить размер EAX и результат деления уместился в регистре.
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
При поразрядной конъюнкции используется инструкция and :
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
При поразрядной дизъюнкции — or :
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
При поразрядном исключающем ИЛИ — xor :
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
При поразрядном отрицании — not :
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
При битовом сдвиге вправо — sar :
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
При битовом сдвиге влево — shl :
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Вызов функций
Мы рассмотрим три вида функций:
- Функция, не возвращающая значение (void).
- Функция, возвращающая целое число.
- Функция с параметрами.
newfunc(); newfuncret(); funcparams(intvar, stringvar, charvar);Сначала посмотрим, как происходит вызов функций newfunc() и newfuncret() , которые вызываются без параметров.
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Функция newfunc() просто выводит сообщение «Hello! I’m a new function!»:
void newfunc() < // новая функция без параметров printf("Hello! I'm a new function"!); >На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Эта функция использует инструкцию retn , но только для возврата к предыдущему местоположению (чтобы программа могла продолжить свою работу после завершения функции). Посмотрим на функцию newfuncret() , которая генерирует случайное целое число с помощью функции С++ rand() и затем его возвращает.
int newfuncret() < // новая функция, которая что-то возвращает int A = rand(); return A; >На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Сначала выделяется место под переменную A . Затем вызывается функция rand() , результат которой помещается в регистр EAX. Затем значение EAX помещается в место, выделенное под переменную A , фактически присваивая переменной A результат функции rand() . Наконец, переменная A помещается в регистр EAX, чтобы функция могла его использовать в качестве возвращаемого параметра. Теперь, когда мы разобрались, как происходит вызов функций без параметров и что происходит при возврате значения из функции, поговорим о вызове функции с параметрами.
Вызов такой функции выглядит следующим образом:
funcparams(intvar, stringvar, charvar);На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Строки в С++ требуют вызова функции basic_string , но концепция вызова функции с параметрами не зависит от типа данных. Сначала переменная помещается в регистр, затем оттуда в стек, а потом происходит вызов функции.
Посмотрим на код функции:
void funcparams (int iparam, string sparam, char cparam) < // функция с параметрами printf("%i \n", iparam); printf("%s \n", sparam); printf("%c \n", cparam); >На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Эта функция берёт строку, целое число и символ и печатает их с помощью функции printf() . Как видите, сначала переменные размещаются в начале функции, затем они помещаются в стек для вызова в качестве параметров функции printf() . Очень просто.
Циклы
Теперь, когда мы изучили вызов функции, вывод, переменные и математику, перейдём к контролю порядка выполнения кода (flow control). Сначала мы изучим цикл for:
void forloop (int max) < // обычный цикл for for (int i = 0; i < max; ++i)< printf("%i \n", i); >>На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Прежде чем разбить ассемблерный код на более мелкие части, посмотрим на общий вариант. Как вы можете видеть, когда цикл for запускается, у него есть 2 варианта:
- он может перейти к блоку справа (зелёная стрелка) и вернуться в основную программу;
- он может перейти к блоку слева (красная стрелка) и вернуться к началу цикла for.
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Сначала сравниваются переменные i и max , чтобы проверить, достигла ли переменная максимального значения. Если переменная i не больше или не равна переменной max , то подпрограмма пойдёт по красной стрелке (вниз влево) и выведет переменную i , затем i увеличится на 1 и произойдёт возврат к началу цикла. Если переменная i больше или равна max , то подпрограмма пойдёт по зелёной стрелке, то есть выйдет из цикла for и вернётся в основную программу.
Теперь давайте взглянем на цикл while :
void whileloop() < // цикл while int A = 0; while (A<10) < A = 0 + (rand()%(int)(20-0+1)) >printf("I'm out!"); >На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
В этом цикле генерируется случайное число от 0 до 20. Если число больше 10, то произойдёт выход из цикла со словами «I’m out!», в противном случае продолжится работа в цикле.
В машинном коде переменная А сначала инициализируется и приравнивается к нулю, а затем инициализируется цикл, A сравнивается с шестнадцатеричным числом 0A , которое равно 10 в десятичной системе счисления. Если А не больше и не равно 10, то генерируется новое случайное число, которое записывается в А , и снова происходит сравнение. Если А больше или равно 10, то происходит выход из цикла и возврат в основную программу.
Условный оператор
Теперь поговорим об условных операторах. Для начала посмотрим код:
void ifstatement() < // условные операторы int A = 0 + (rand()%(int)(20-0+1)); if (A < 15) < if (A < 10) < if (A < 5) < printf("less than 5"); >else < printf("less than 10, greater than 5"); >> else < printf("less than 15, greater than 10"); >> else < printf("greater than 15"); >>Эта функция генерирует случайное число от 0 до 20 и сохраняет получившееся значение в переменной А . Если А больше 15, то программа выведет «greater than 15». Если А меньше 15, но больше 10 — «less than 15, greater than 10». Если меньше 5 — «less than 5».
Посмотрим на ассемблерный граф:
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Граф структурирован аналогично фактическому коду, потому что условный оператор выглядит просто: «Если X, то Y, иначе Z». Если посмотреть на первую сверху пару стрелок, то оператору предшествует сравнение А с 0F , что равно 15 в десятичной системе счисления. Если А больше или равно 15, то подпрограмма выведет «greater than 15» и вернётся в основную программу. В другом случае произойдёт сравнение А с 0A (1010). Так будет продолжаться, пока программа не выведет что-нибудь на экран и не вернётся.
Оператор выбора
Оператор выбора очень похож на оператор условия, только в операторе выбора одна переменная или выражение сравнивается с несколькими «случаями» (возможными эквивалентностями). Посмотрим код:
void switchcase() < // оператор выбора int A = 0 + (rand()%(int)(10-0+1)); switch (A) < case 0: printf("0"); break; case 1: printf("1"); break; case 2: printf("2"); break; case 3: printf("3"); break; case 4: printf("4"); break; case 5: printf("5"); break; case 6: printf("6"); break; case 7: printf("7"); break; case 8: printf("8"); break; case 9: printf("9"); break; case 10: printf("10"); break; >>В этой функции переменная А получает случайное значение от 0 до 10. Затем А сравнивается с несколькими случаями, используя switch . Если значение А равно одному из случаев, то на экране появится соответствующее число, а затем произойдёт выход из оператора выбора и возврат в основную программу.
Оператор выбора не следует правилу «Если X, то Y, иначе Z» в отличии от условного оператора. Вместо этого программа сравнивает входное значение с существующими случаями и выполняет только тот случай, который соответствует входному значению. Рассмотрим два первых блока подробней.
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Сначала генерируется случайное число и записывается в А . Теперь программа инициализирует оператор выбора, приравняв временную переменную var_D0 к А , затем проверяет, что она равна хотя бы одному из случаев. Если var_D0 требуется значение по умолчанию, то программа пойдёт по зелёной стрелке в секцию окончательного возврата из подпрограммы. Иначе программа совершит переход в нужный case .
Если var_D0 (A) равно 5, то код перейдёт в секцию, которая показана выше, выведет «5» и затем перейдёт в секцию возврата.
Пользовательский ввод
В этом разделе мы рассмотрим ввод пользователя с помощью потока сin из C++. Во-первых, посмотрим на код:
void userinput() < // ввод с клавиатуры string sentence; cin >> sentence; printf("%s", sentence); >В этой функции мы просто записываем строку в переменную sentence с помощью функции C++ cin и затем выводим предложение с помощью оператора printf() .
Разберём это в машинном коде. Во-первых, функция cin :
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Сначала происходит инициализация строковой переменной sentence , затем вызов cin и запись введённых данных в sentence .
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Сначала программа устанавливает содержимое переменной sentence в EAX, затем помещает EAX в стек, откуда значение переменной будет использоваться в качестве параметра для потока cin , затем вызывается оператор потока >>. Его вывод помещается в ECX, который затем помещается в стек для оператора printf() :
Мы рассмотрели лишь основные принципы работы программного обеспечения на низком уровне. Без этих основ невозможно понимать работу ПО и, соответственно, заниматься его исследованием.
Что такое реверс-инжиниринг

Реверс инжиниринг — это процесс анализа скомпилированного бинарного файла с целью понять, как программа работает. Программисты, как правило, пишут программы на высокоуровневых языках программирования, таких как C++ или Visual Basic. Т.к. компьютер не может напрямую исполнить код такой программы, код, написанный программистом компилируется в код, непосредственно понятный процессору. Этот код называют машинным кодом. Машинный код тяжел для восприятия и понимания, поэтому реверс-инженеру в процессе его анализа часто требуется прилагать значительные умственные усилия.
В каких случаях реверс-инжиниринг может быть полезен?
Реверс-инжиниринг применятся во многих компьютерных областях, вот только несколько примеров такого применения:
- Сделать возможным взаимодействие с кодом, написанным не вами;
- Взлом платной программы, что бы бесплатно получить полную версию;
- Исследование вирусов и малвари;
- Нахождение и исправление ошибок в программах;
- Добавление функционала в существующее приложение.
В первом случае мы анализируем скомпилированную программу, к исходному коду которой у нас нет доступа, что бы понять, как с ней можно взаимодействовать и как можно использовать ее функции внутри свой программы.
Второй случай – взлом платных программ – является достаточно распространенным явлением. Его суть заключается в отключение ограничений, выполнение регистрации и другие вещи, которые позволяют использовать коммерческий софт бесплатно. Мы обсудим это более подробно.
Третий случай – анализ работы вирусов и малвари. Реверс-инженеринг требуется для таких задач, т.к. немного вирусописателей снабжают свои детища исходным кодом или какой-либо документацией 🙂 Это довольно интересное направление, но оно требует большого количества знаний.
Четвертый случай – исправление ошибок в программах. В любых больших программных продуктах как правило содержатся ошибки и уязвимости и навыки реверс-инжиниринга могут сильно помочь в их поисках и устранении.
Последний случай из рассмотренных нами – добавление функционала в существующие приложения. Лично я думаю, что это довольно весело. Вам не нравится графика в каком-нибудь дизайнерском приложении? Измените ее. Хотите добавить пункт меню с новым функционалом в ваш любимый текстовой редактор? Добавьте. Хотите подшутить над коллегами и добавить всплывающие окна в Windows-калькулятор? Сделайте это. Мы также подробнее затронем этот вопрос позже.
Какие знания нам необходимы?
Как вы вероятно, догадаетесь, что бы быть эффективным реверс-инженером, требуется солидный багаж знаний. Но начать делать какие-то базовые вещи можно и без него. Для новичков требуется знание основ программирования (что такое оператор, что такое условие, цикл и т.д.). Также очень неплохо было бы быть знакомым с ассемблером и иметь базовое представление об архитектуре компьютера. На первых порах потребуется уделить некоторое время осваиванию инструментов, которые используются для реверс-инжиниринга. Эти инструменты оказывают большую помощь, но в свою очередь требуют знаний того, как их грамотно применять. Что бы прокачать навыки в реверс-инжиниринге как и везде требуется делать много практической работы – разбираться со снятием различных пакеров/протекторов/крипторов, изучать программы, написанные на различных языках программирования, обходить анти-отладочные приемы… список можно долго продолжать. В конце этого туториала я привел некоторые ссылки с полезными материалами. Если вы хотите стать хорошим реверс-инженером – требуется заниматься самообразованием.
Какие инструменты использовать?
В процессе реверс-инжиниринга используется множество различных инструментов. Многие их них заточены под какую-то конкретную задачу (снятие определенного упаковщика, например). Некоторые более универсальны. Инструменты можно классифицировать следующим образом:
1. Дизассемблеры
Дизассемблеры берут машинный код, представленный в бинарном формате и отображают его в более удобной для восприятия манере. Они также облегчают процесс идентификации функций, переменных и текстовых строк. Это делает код исполняемого файла более читабельный, нежели мы просто смотрели бы на набор единиц и нулей.
Существует довольно много дизассемблеров, и из них можно выбрать удобный именно для вас и ваших задач. Лично для меня самым лучшим выбором является IDA Pro ( hex-rays.com ). (Примечание переводчика: обратите также внимание на бесплатный, но мощный дизассемблер Ghidra ( https://ghidra-sre.org/ )).
2. Отладчики
Отладчики это важнейший инструмент для реверс-инженера. В чем-то их функционал пересекается с дизассемблерами: они также представляют бинарный код в более удобном для восприятия формате. Но помимо этого они также позволяют пошагово исполнять этот код, инструкция за инструкцией, и наблюдать за результатами. Это дает хорошее понимание того, как работает программа. Наконец, некоторые отладчики позволяют изменять некоторые инструкции в коде и потом мы можем еще раз запустить программу уже с этими изменениями. В качестве примера отладчиков можно назвать Windbg, Ollydbg, x64dbg. Лично я предпочитаю Ollydbg, если только не надо отлаживать код на уровне ядра операционной системы.
3. HEX-редакторы
Хекс-редакторы позволяют видеть бинарный код как таковой, а также изменять его. Они также предоставляют такую функцию как поиск определенного набора байтов в бинарном коде. Существует несколько неплохих хекс-редаторов и они по-большей части взаимозаменяемы. В данных туториалах мы обычно не будем прибегать к их использованию, но в некоторых ситуациях хекс-редакторы могут сослужить хорошую службу.
4. Редакторы ресурсов.
Каждый бинарный файл, который должен запускаться в операционной системе содержит в самом своем начале содержит информацию для операционной системы о том, как запускать и инициализировать программу. Там содержится такая информация как сколько памяти требуется данной программе, функции из каких DLL программа использует и т.д.
Для реверс-инженера такие бинарные структуры являются очень важными, поскольку позволяют многое понять об исполняемом файле. Также если вдруг возникнет необходимость изменить поведение программы, вам может понадобится модифицировать эти структуры. Большинство исполняемых файлов также содержит секцию ресурсов. В ней находятся графические изображения, окна меню, иконки и текстовые строки. С помощью редакторов ресурсов мы можем просматривать и менять эти вещи.
5. Системные мониторы
В процессе реверсинга какой-либо программы (особенно вредоносной) часто бывает необходимо узнать, какие изменения эта программа вносит в операционную систему. Создает ли она записи в реестре? Создает ли она текстовые файлы? Запускает ли она новый процессы? Ответы на эти вопросы помогают понять системные мониторы. Примерами таких программ являются procmon, regshot и process hacker.
6. Дополнительные инструменты
Существуют также полезные инструменты, которые не попали в приведенные выше категории. Например, различные скрипты, распаковщики, определители упаковщиков и т.д. Также полезно иметь доступ к документации по API-функциям вашей целевой операционной системы, поскольку программы как правило часто используют подобные функции и реверс-инженеру необходимо знать их назначение.
Давайте начнем прямо сейчас!
Несмотря на то, что мы начинаем с минимальными знаниями мы попробуем сделать что-нибудь практическое прямо в первом туториале. Скачайте себе редактор ресурсов XN Resource Editor. Он бесплатен. Как вы, скорее всего догадались, это программа позволяет просматривать, а также модифицировать ресурсы в исполняемых файлах. Можно делать довольно много вещей: менять название пунктов меню, иконки, графические изображения и т.д. Давайте попробуем.
Для начала запустите XN, нажмите на иконку для открытия файла и выберите файл калькулятора (Windows/System32/calc.exe). Слева вы должны увидеть список:
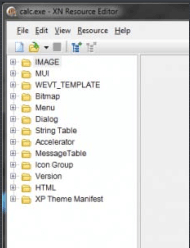
Вы видите, что в этом списке присутствует раздел Bitmap (графические изображение, которые содержит программа), Menu (пункты меню), String Table, Icon Group и т.д. Попробуйте покликать по этим разделам. Вы можете поменять что-нибудь, но лучше сохраните измененный вариант калькулятора в другом месте, что бы не затрагивать оригинал!
Дополнительные материалы
- С чего начать изучение реверс-инжиниринга ;
- Assembly Language for X86 Processors — Хорошая книга для знакомства с ассемблером под x86;
- PE Format — Описание структуры исполняемых файлов под Windows;
- Windows Internals — Книга описывает внутреннее устройство операционной системы Windows;
- Tuts4you.com — Сайт с большим количеством туториалов по реверс-инжинирингу.
Reverse engineering
Вы освоите на практике важнейшие приемы реверс-инжиниринга: статический и динамический анализ. Познакомитесь с низкоуровневым и системным программированием, подробно разберете аспекты внутреннего устройства Windows. Вам предстоит изучить и классифицировать вредоносное ПО на примерах реальных malware, выловленных в сети.
ЧТО ТАКОЕ РЕВЕРС-ИНЖИНИРИНГ?
Реверс-инжиниринг кода (обратная разработка кода) — это процесс анализа машинного кода программы, который ставит своей целью понять принцип работы, восстановить алгоритм, обнаружить недокументированные возможности программы, и т.п. Основные методы реверс-инжиниринга — это статический или динамический анализ кода. При статическом анализе исследователь дизассемблирует код программы, используя специальное ПО, и далее анализирует ассемблерный код. При динамическом анализе исследователь запускает код в изолированной среде (песочнице) или отладчике и анализирует код в динамике.
Для кого этот курс?
- Для системных программистов, разрабатывающих низкоуровневый софт. Вы поймете, как код работает изнутри после компиляции, и сможете повысить качество своих решений.
- Для начинающих вирусных аналитиков и специалистов ИБ. Вы научитесь всем must have практикам реверс-инжиниринга и получите комплексное представление о вредоносном ПО.
- Практика по распаковке файлов
- Практический разбор PE формата (таблица импорта, таблица экспорта, таблица релокаций)
- Практический анализ шифровальщиков, банковских троянов, ботов.
- Проектная работа, в рамках которой вы можете выбрать одну из предложенных преподавателем тем или реализовать свою идею.
Как проходит практика?
Студенты заранее получают стенды и разворачивают их у себя локально до начала занятия.
На курсе вас ждет:

Преподаватели
Артур Пакулов
Ex-вирусный аналитик в Kaspersky Lab.Специалист в области низкоуровневого программирования, обратной разработки и анализа вредоносного программного обеспечения. В период 12.2015 — 05.2017 — специалист по образовательным программам и преподаватель Образовательного департамента «Лаборатории Касперского». Преподаватель и методист-разработчик курсов и программ по направлениям: «Защита информации от вредоносного ПО», «Низкоуровневое программирование», «Профессиональный пентестинг». Программы, разработанные Пакуловым, включены в учебные планы российских и зарубежных университетов, в том числе МГТУ им. Н.Э. Баумана, МГУ им. М.В. Ломоносова. Преподаватель международных магистерских программ по информационной безопасности.
Навыки:
Низкоуровневое программирование,
Системное программирование,
Реверс-инжиниринг,
Анализ вредоносного ПО,
Веб-безопасность,
Программирование: Assembler, C/C++, Delphi, PythonПреподаватели
Артур Пакулов
Ex-вирусный аналитик в Kaspersky Lab.Специалист в области низкоуровневого программирования, обратной разработки и анализа вредоносного программного обеспечения. В период 12.2015 — 05.2017 — специалист по образовательным программам и преподаватель Образовательного департамента «Лаборатории Касперского». Преподаватель и методист-разработчик курсов и программ по направлениям: «Защита информации от вредоносного ПО», «Низкоуровневое программирование», «Профессиональный пентестинг». Программы, разработанные Пакуловым, включены в учебные планы российских и зарубежных университетов, в том числе МГТУ им. Н.Э. Баумана, МГУ им. М.В. Ломоносова. Преподаватель международных магистерских программ по информационной безопасности.
Навыки:
Низкоуровневое программирование,
Системное программирование,
Реверс-инжиниринг,
Анализ вредоносного ПО,
Веб-безопасность,
Программирование: Assembler, C/C++, Delphi, PythonОтзывы
Артем
БогомоловОтличный курс. Описывает самые необходимые основы по реверсу. Достаточно подробно рассказывается о многих важных аспектах обратной разработки. Дается полноценное объяснение функционирования вредоносных программ. Мне очень понравился. А главное — все по теме
Читать целиком
Во-первых, хочется отметить отзывчивость ваших менеджеров. Когда проходил курс в первый раз я был вынужден остановиться на половине. Когда стал свободнее решил продолжить курс. Менеджер закинул меня в след группу без оплаты первой половины курса и я продолжил заниматься
Во-вторых, Артур очень компетентный специалист и классный препод. Пройдя примерно 3/4 курса я нашёл работу реверсера. Очень много из того, что говорил Артур было на собесах.
Буду рекомендовать ваш курс. Спасибо!
Читать целиком
Константин
КозулинКурс больше подходит для вирусных аналитиков, но мне был интересен этот курс с точки зрения разработки операционных систем. Едва ли где-то есть курсы по этой тематике, да и книг немного. Но здесь даются знания об ассемблере (я хочу писать именно на ассемблере). Мне интересен реверс-инжиниринг, поскольку при разработке операционных систем нужно разрабатывать и драйверы. А многие драйверы имеют закрытый код и чтобы их понять, нужны навыки реверс-инжиниринга. Этот курс даёт хорошие знания о строении операционной системы Windows, что мне тоже очень пригодится. Я узнал больше про режимы процессора, устройство памяти, научился работать с дизассемблерами, отладчиками и шестнадцатиричными редакторами. Из недостатков — очень малое внимание к ОС Linux. В курсе не разбираются отладчики и дизассемблеры под эту систему: GDB, Ghidra. Но курс прекрасный! Задания сложные: CrackMe, внедрение кода в прошивку маршрутизатора, работа с загрузочным сектором. Они помогут мне значительно продвинуться в движении к мечте. Спасибо!
Читать целиком
Вадим
ДемьяновЯ инженер-программист АСУТП, часто сталкиваюсь с задачами низкоуровневого программирования, программирования embedded-устройств. Иногда интересуюсь онлайн-обучением в этих областях, даже начинал один курс на Coursera, но забросил. В целом я не видел интересного обучающего курса, который стоило бы начать, ведь вся информация и так есть в сети, можно самостоятельно все изучать.
Случайно узнал про данный курс по реверс-инжинирингу, видимо попалась реклама, до этого даже не слышал, что есть такая специальность как реверс-инженер. Это показалось мне возможностью глубже понять, как все работает внутри компьютера, научиться анализу скомпилированного кода, изучить какую-то совсем новую интересную предметную область. Конечно всю информацию по реверсу также можно найти в сети, но для начала нужно понимать, что искать. Проблема в том, что информации слишком много, и конечно наличие базы в виде такого курса сильно экономит время, дает какое-то структурированное понимание.
Сам курс для меня оказался довольно сложным, часто приходилось пересматривать лекции чтобы понять, что же мы вообще делали. Домашние задания также оказались сложнее, чем я думал и некоторые требовали довольно много времени. В своей практике я никогда не сталкивался с дебаггерами, дизасемблерами и прочими утилитами, которые применяются на курсе, все программы были для меня совершенно новыми, это тоже создавало некоторые трудности. Но в целом курсом я очень доволен, наверно именно потому, что он оказался таким сложным. Однозначно хочется дальше продолжать изучение реверс-инжиниринга.
Отдельная благодарность преподавателю – Артуру Пакулову, за интересный курс и готовность отвечать на все вопросы.
Есть пара моментов, которые я бы хотел добавить. Во-первых, уделить какое-то время изучению используемых программ, даже в рамках существующих лекций и домашних заданий. Во-вторых, выделить больше времени на итоговый проект, т.к. запланированного явно недостаточно.Читать целиком
Александра
КибаОчень качественный курс. Хотя я уже была знакома с изрядной долей материала, все равно понравилось. Больше всего впечатлил разбор того, как хранятся аргументы/локальные переменные с точки зрения ассемблера (т.е. как их найти и понять, что код к ним обращается) и работа с крэкми и идой
Немного поленилась выполнять домашку, не уверена, что это ключевой момент для освоения, но ковыряться в иде — давняя мечта