Какие узлы являются потомками узла а
По книге Laszlo
«Вычислительная геометрия и компьютерная графика на С++»
Двоичные деревья представляют эффективный способ поиска. Двоичное дерево представляет собой структурированную коллекцию узлов. Коллекция может быть пустой и в этом случае мы имеем пустое двоичное дерево. Если коллекция непуста, то она подразделяется на три раздельных семейства узлов: корневой узел n (или просто корень), двоичное дерево, называемое левым поддеревом для n, и двоичное дерево, называемое правым поддеревом для n. На рис. 1а узел, обозначенный буквой А, является корневым, узел В называется левым потомком А и является корнем левого поддерева А, узел С называется правым потомком А и является корнем правого поддерева А.
Рис. 1: Двоичное дерево с показанными внешними узллами (а) и без них (б)
Двоичное дерево на рис. 1а состоит из четырех внутренних узлов (обозначенных на рис. кружками) и пяти внешних (конечных) узлов (обозначены квадратами). Размер двоичного дерева определяется числом содержащихся в нем внутренних узлов. Внешние узлы соответствуют пустым двоичным деревьям. Например, левый потомок узла В — непустой (содержит узел D), тогда как правый потомок узла В — пустое дерево. В некоторых случаях внешние узлы обозначаются каким-либо образом, в других — на них совсем не ссылаются и они считаются пустыми двоичными деревьями (на рис. 16 внешние узлы не показаны).
Основанная на генеалогии метафора дает удобный способ обозначения узлов внутри двоичного дерева. Узел р является родителем (или предком) узла n, если n — потомок узла р. Два узла являются братьями, если они принадлежат одному и тому же родителю. Для двух заданных узлов n1 и nk таких, что узел nk принадлежит поддереву с корнем в узле n1, говорят, что узел nk является потомком узла n1, а узел n1 — предком узла nk. Существует уникальный путь от узла n1 вниз к каждому из потомков nk, a именно: последовательность узлов n1 и n2. nk такая, что узел ni является родителем узла ni+1 для i = 1, 2. k-1. Длина пути равна числу ребер (k-1), содержащихся в нем. Например, на рис. 1а уникальный путь от узла А к узлу D состоит из последовательности А, В, D и имеет длину 2.
Глубина узла n определяется рекурсивно:
| < 0 | если n — корневой узел |
| глубина (n) = | |
| < 1 + глубина (родителя (n)) | в противном случае |
Глубина узла равна длине уникального пути от корня к узлу. На рис. 1а узел А имеет глубину 0, а узел D имеет глубину, равную 2.
Высота узла n также определяется рекурсивно:
| < 0 | если n — внешний узел |
| высота (n) = | |
| < 1 + max( высота(лев(n)), высота(прав(n)) ) | в противном случае |
где через лев(n) обозначен левый потомок узла n и через прав(n) — правый потомок узла n. Высота узла n равна длине самого длинного пути от узла n вниз до внешнего узла поддерева n. Высота двоичного дерева определяется как высота его корневого узла. Например, двоичное дерево на рис. 1а имеет высоту 3, а узел D имеет высоту 1.
При реализации двоичных деревьев, основанной на точечном представлении, узлы являются объектами класса TreeNode.
template class TreeNode < protected: TreeNode *_lchild; TreeNode *_rchild; Т val; public: TreeNode(T); virtual ~TreeNode(void); friend class SearchTree; // возможные пополнения friend class BraidedSearchTree; // структуры >;
Элементы данных _lchild и _rchild обозначают связи текущего узла с левым и правым потомками соответственно, а элемент данных val содержит сам элемент.
Конструктор класса формирует двоичное дерево единичного размера — единственный внутренний узел имеет два пустых потомка, каждое из которых представлено нулем NULL:
template TreeNode::TreeNode(T v) : val(v), _lchild(NULL), _rchild (NULL)
Деструктор ~TreeNode рекурсивно удаляет оба потомка текущего узла (если они существуют) перед уничтожением самого текущего узла:
template TreeNode::~TreeNode(void)
Основное назначение двоичных деревьев заключается в повышении эффективности поиска. При поиске выполняются такие операции, как нахождение заданного элемента из набора различных элементов, определение наибольшего или наименьшего элемента в наборе, фиксация факта, что набор содержит заданный элемент. Для эффективного поиска внутри двоичного дерева его элементы должны быть организованы соответствующим образом. Например, двоичное дерево будет называться двоичным деревом поиска, если его элементы расположены так, что для каждого элемента n все элементы в левом поддереве n будут меньше, чем n, а все элементы в правом поддереве — будут больше, чем n. На рис. 2 изображены три двоичных дерева поиска, каждое из которых содержит один и тот же набор целочисленных элементов.
Рис. 2: Три двоичных дерева поиска с одним и тем же набором элементов
В общем случае существует огромное число двоичных деревьев поиска (различной формы) для любого заданного набора элементов.
Предполагается, что элементы располагаются в линейном порядке и, следовательно, любые два элемента можно сравнить между собой. Примерами линейного порядка могут служить ряды целых или вещественных чисел в порядке возрастания, а также слов или строк символов, расположенных в лексикографическом (алфавитном, или словарном) порядке. Поиск осуществляется путем обращения к функции сравнения для сопоставления любых двух элементов относительно их линейного порядка. В нашей версии деревьев поиска действие функции сравнения ограничено только явно определенными объектами деревьев поиска.
Также очень полезны функции для обращения к элементам дерева поиска и воздействия на них. Такие функции обращения могут быть полезны для вывода на печать, редактирования и доступа к элементу или воздействия на него каким-либо иным образом. Функции обращения не принадлежат деревьям поиска, к элементам одного и того же дерева поиска могут быть применены различные функции обращения.
Определим шаблон нового класса SearchTree для представления двоичного дерева поиска. Класс содержит элемент данных root, который указывает на корень двоичного дерева поиска (объект класса TreeNode) и элемент данных cmp, который указывает на функцию сравнения.
template class SearchTree < private: TreeNode *root; int (*) (T,T) cmp; TreeNode*_findMin(TreeNode *); void _remove(T, TreeNode * &); void _inorder(TreeNode *, void (*) (T) ); public: SearchTree (int(*) (Т, Т) ); ~SearchTree (void); int isEmpty (void); Т find(T); Т findMin(void); void inorder (void(*) (T) ); void insert(T); void remove(T); T removeMin (void); >;
Для упрощения реализации предположим, что элементами в дереве поиска являются указатели на объект заданного типа, когда шаблон класса SearchTree используется для создания действительного класса. Параметр Т передается в виде типа указателя.
Конструкторы и деструкторы
Конструктор SearchTree инициализирует элементы данных cmp для функции сравнения и root для пустого дерева поиска:
template SearchTree::SearchTree (int (*с) (Т, Т) ) : cmp(с), root (NULL)
Дерево поиска пусто только, если в элементе данных root содержится нуль (NULL) вместо разрешенного указателя:
template int SearchTree::isEmpty (void)
Деструктор удаляет все дерево путем обращения к деструктору корня:
template SearchTree::~SearchTree (void)
Поиск
Чтобы найти заданный элемент val, мы начинаем с корня и затем следуем вдоль ломаной линии уникального пути вниз до узла, содержащего val. В каждом узле n вдоль этого пути используем функцию сравнения для данного дерева на предмет сравнения val с элементом n->val, записанном в n. Если val меньше, чем n->val, то поиск продолжается, начиная с левого потомка узла n, если val больше, чем n->val, то поиск продолжается, начиная с правого потомка n, в противном случае возвращается значение n->val (и задача решена). Путь от корневого узла вниз до val называется путем поиска для val.
Этот алгоритм поиска реализуется в компонентной функции find, которая возвращает обнаруженный ею указатель на элемент или NULL, если такой элемент не существует в дереве поиска.
template T SearchTree::find (T val) < TreeNode *n = root; while (n) < int result = (*cmp) (val, n->val); if (result < 0) n = n->_lchild; else if (result > 0) n = n->_rchild; else return n->val; > return NULL; >
Этот алгоритм поиска можно сравнить с турниром, в котором участвуют некоторые кандидаты. В начале, когда мы начинаем с корня, в состав кандидатов входят все элементы в дереве поиска. В общем случае для каждого узла n в состав кандидатов входят все потомки n. На каждом этапе производится сравнение val с n->val. Если val меньше, чем n->val, то состав кандидатов сужается до элементов, находящихся в левом поддереве, а элементы в правом поддереве n, как и сам элемент n->val, исключаются из соревнования. Аналогичным образом, если val больше, чем n->val, то состав кандидатов сужается до правого поддерева n. Процесс продолжается до тех пор, пока не будет обнаружен элемент val или не останется ни одного кандидата, что означает, что элемент val не существует в дереве поиска.
Для нахождения наименьшего элемента мы начинаем с корня и прослеживаем связи с левым потомком до тех пор, пока не достигнем узла n, левый потомок которого пуст — это означает, что в узле n содержится наименьший элемент. Этот процесс также можно уподобить турниру. Для каждого узла n состав кандидатов определяется потомками узла n. На каждом шаге из состава кандидатов удаляются те элементы, которые больше или равны n->val и левый потомок n будет теперь выступать в качестве нового n. Процесс продолжается до тех пор, пока не будет достигнут некоторый узел n с пустым левым потомком и, полагая, что не осталось кандидатов меньше, чем n->val, и будет возвращено значение n->val.
Компонентная функция findMin возвращает наименьший элемент в данном дереве поиска, в ней происходит обращение к компонентной функции _findMin, которая реализует описанный ранее алгоритм поиска, начиная с узла n :
template T SearchTree::findMin (void) < TreeNode*n = _findMin (root); return (n ? n->val : NULL); > template TreeNode *SearchTree::_findMin (TreeNode *n) < if (n == NULL) return NULL; while (n->_lchild) n = n->_lchild; return n; >
Наибольший элемент в дереве поиска может быть найден аналогично, только отслеживаются связи с правым потомком вместо левого.
Симметричный обход
Обход двоичного дерева — это процесс, при котором каждый узел посещается точно только один раз. Компонентная функция inorder выполняет специальную форму обхода, известную как симметричный обход. Стратегия заключается сначала в симметричном обходе левого поддерева, затем посещения корня и потом в симметричном обходе правого поддерева. Узел посещается путем применения функции обращения к элементу, записанному в узле.
Компонентная функция inorder служит в качестве ведущей функции. Она обращается к собственной компонентной функции _inorder, которая выполняет симметричный обход от узла n и применяет функцию visit к каждому достигнутому узлу.
template void SearchTree::inorder (void (*visit) (Т) ) < _inorder (root, visit); >template void SearchTree::inorder (TreeNode *n, void(*visit) (T) < if (n) < _inorder (n->_lchild, visit); (*visit) (n->val); _inorder (n->_rchild, visit); > >
При симметричном обходе каждого из двоичных деревьев поиска, показанных на рис. 2, узлы посещаются в возрастающем порядке: 2, 3, 5, 7, 8. Конечно, при симметричном обходе любого двоичного дерева поиска все его элементы посещаются в возрастающем порядке. Чтобы выяснить, почему это так, заметим, что при выполнении симметричного обхода в некотором узле n элементы меньше, чем n->val посещаются до n, поскольку они принадлежат к левому поддереву n, а элементы больше, чем n->val посещаются после n, поскольку они принадлежат правому поддереву n. Следовательно, узел n посещается в правильной последовательности. Поскольку n — произвольный узел, то это же правило соблюдается для каждого узла.
Компонентная функция inorder обеспечивает способ перечисления элементов двоичного дерева поиска в отсортированном порядке. Например, если а является деревом поиска SearchTree для строк, то эти строки можем напечатать в лексикографическом порядке одной командой а.inorder(printstring). Для этого функция обращения printstring может быть определена как:
void printstring(char *s)
При симметричном обходе двоичного дерева узел, посещаемый после некоторого узла n, называется последователем узла n, а узел, посещаемый непосредственно перед n, называется предшественником узла n. Не существует никакого предшественника для первого посещаемого узла и никакого последователя для последнего посещаемого узла (в двоичном дереве поиска эти узлы содержат наименьший и наибольший элемент соответственно).
Включение элементов
Для включения нового элемента в двоичное дерево поиска вначале нужно определить его точное положение — а именно внешний узел, который должен быть заменен путем отслеживания пути поиска элемента, начиная с корня. Кроме сохранения указателя n на текущий узел мы будем хранить указатель р на предка узла n. Таким образом, когда n достигнет некоторого внешнего узла, р будет указывать на узел, который должен стать предком нового узла. Для осуществления включения узла мы создадим новый узел, содержащий новый элемент, и затем свяжем предок р с этим новым узлом (рис. 3).
Компонентная функция insert включает элемент val в это двоичное дерево поиска:
Рис. 3: Включение элемента в двоичное дерево поиска
template void SearchTree::insert(T val) < if (root == NULL) < root = new TreeNode(val); return; > else < int result; TreeNode*p, *n = root; while (n) < p = n; result = (*cmp) (val, p->val); if (result < 0) n = p->_lchild; else if (result > 0) n = p->_rchild; else return; > if (result < 0) p->_lchild = new TreeNode(val); else p-> rchild = new TreeNode(val); > >
Удаление элементов
Удаление элемента из двоичного дерева поиска гораздо сложнее, чем включение, поскольку может быть значительно изменена форма дерева. Удаение узла, у которого есть не более чем один непустой потомок, является равнительно простой задачей — устанавливается ссылка от предка узла на потомок. Однако ситуация становится гораздо сложнее, если у подлежащего удалению узла есть два непустых потомка: предок узла может быть связан с одним из потомков, а что делать с другим? Решение может заключаться не в удалении узла из дерева, а скорее в замене элемента, содержащегося в нем, на последователя этого элемента, а затем в удалении узла, содержащего этот последователь.
Рис. 4: Три ситуации, возникающие при удалении элемента из двоичного дерева поиска
Чтобы удалить элемент из дерева поиска, вначале мы отслеживаем путь поиска элемента, начиная с корня и вниз до узла n, содержащего элемент. В этот момент могут возникнуть три ситуации, показанные на рис. 4:
- Узел n имеет пустой левый потомок. В этом случае ссылка на n (записанная в предке n, если он есть) заменяется на ссылку на правого потомка n.
- У узла n есть непустой левый потомок, но правый потомок пустой. В этом случае ссылка вниз на n заменяется ссылкой на левый потомок узла n.
- Узел n имеет два непустых потомка. Найдем последователя для n (назовем его m), скопируем данные, хранящиеся в m, в узел n и затем рекурсивно удалим узел m из дерева поиска.
Очень важно проследить, как будет выглядеть результирующее двоичное дерево поиска в каждом случае. Рассмотрим случай 1. Если подлежащий удалению узел n, является левым потомком, то элементы, относящиеся к правому поддереву n будут меньше, чем у узла р, предка узла n. При удалении узла n его правое поддерево связывается с узлом р и элементы, хранящиеся в новом левом поддереве узла р конечно остаются меньше элемента в узле р. Поскольку никакие другие ссылки не изменяются, то дерево остается двоичным деревом поиска. Аргументы остаются подобными, если узел n является правым потомком, и они тривиальны, если n — корневой узел. Случай 2 объясняется аналогично. В случае 3 элемент v, записанный в узле n, перекрывается следующим большим элементом, хранящимся в узле m (назовем его w), после чего элемент w удаляется из дерева. В получающемся после этого двоичном дереве значения в левом поддереве узла n будут меньше w, поскольку они меньше v. Более того, элементы в правом поддереве узла n больше, чем w, поскольку (1) они больше, чем v, (2) нет ни одного элемента двоичного дерева поиска, лежащего между v и w и (3) из них элемент w был удален.
Заметим, что в случае 3 узел m должен обязательно существовать, поскольку правое поддерево узла n непустое. Более того, рекурсивный вызов для удаления m не может привести к срыву рекурсивного вызова, поскольку если узел m не имел бы левого потомка, то был бы применен случай 1, когда его нужно было бы удалить.
На рис. 5 показана последовательность операций удаления, при которой возникают все три ситуации. Напомним, что симметричный обход каждого дерева в этой последовательности проходит все узлы в возрастающем порядке, проверяя, что в каждом случае это двоичные деревья поиска.
Компонентная функция remove является общедоступной компонентной функцией для удаления узла, содержащего заданный элемент. Она обращается к собственной компонентной функции _remove, которая выполняет фактическую работу:
Рис. 5: Последовательность операций удаления элемента: (а) и (б) — Случай 1: удаление из двоичного дерева элемента 8; (б) и (в) — Случай 2: удаление элемента 5; (в) и (г) — Случай 3: удаление элемента 3
template void SearchTree::remove(Т val) < _remove(val, root); >template void SearchTree::_remove(Т val, TreeNode * &n) < if (n == NULL) return; int result = (*cmp) (val, n->val); if (result < 0) _remove(val, n->_lchild); else if (result > 0) _remove (val, n->_rchild); else < // случай 1 if (n->_lchild == NULL) < TreeNode*old = n; n = old->_rchild; delete old; > else if (n->_rchild == NULL < // случай 2 TreeNode *old = n; n = old->_lchild; delete old; > else < // случай 3 TreeNode *m = _findMin(n->_rchild); n->val = m->val; remove(m->val, n->_rchild); > > >
Параметр n (типа ссылки) служит в качестве псевдонима для поля ссылки, которое содержит ссылку вниз на текущий узел. При достижении узла, подлежащего удалению (old), n обозначает поле ссылки (в предке узла old), содержащее ссылку вниз на old. Следовательно команда n=old->_rchild заменяет ссылку на old ссылкой на правого потомка узла old.
Компонентная функция removeMin удаляет из дерева поиска наименьший элемент и возвращает его:
template Т SearchTree::removeMin (void)
Древовидная сортировка — способ сортировки массива элементов — реализуется в виде простой программы, использующей деревья поиска. Идея заключается в занесении всех элементов в дерево поиска и затем в интерактивном удалении наименьшего элемента до тех пор, пока не будут удалены все элементы. Программа heapSort(пирамидальная сортировка) сортирует массив s из n элементов, используя функцию сравнения cmp:
template void heapSort (T s[], int n, int(*cmp) (T,T) ) < SearchTreet(cmp); for (int i = 0; i
Также доступна реализация двоичного дерева на Си с базовыми функциями. Операторы typedef T и compGT следует изменить так, чтобы они соответствовали данным, хранимым в дереве. Каждый узел Node содержит указатели left, right на левого и правого потомков, а также указатель parent на предка. Собственно данные хранятся в поле data. Адрес узла, являющегося корнем дерева хранится в укзателе root, значение которого в самом начале, естественно, NULL. Функция insertNode запрашивает память под новый узел и вставляет узел в дерево, т.е. устанавливает нужные значения нужных указателей. Функция deleteNode, напротив, удаляет узел из дерева (т.е. устанавливает нужные значения нужных указателей), а затем освобождает память, которую занимал узел. Функция findNode ищет в дереве узел, содержащий заданное значение.
Деревья
Прежде, чем мы приступим к рассмотрению типов узлов и отношений между ними, необходимо определиться с самой структурой дерева. Древовидная структура задает для своих элементов отношение ветвления, очень похожее на строение обычного дерева — есть корневой узел (ствол), от которого происходят другие узлы (ветки).
Формально [Кнут 2000] дерево определяется, как конечное множество T, состоящее из одного или нескольких элементов (узлов), обладающих следующими свойствами:
? во множестве T выделяется единственный узел, называемый корневым узлом или корнем;
? все остальные узлы разделены на m?0 непересекающихся множеств T1, …, Tm, каждое из которых в свою очередь также является деревом.
Деревья T1, …, Tm называются поддеревьями корня дерева T.
Это определение является рекурсивным, то есть в нем дерево определяется само через себя. Конечно, существуют нерекурсивные определения, но, пожалуй, следует согласиться с тем, что рекурсивное определение лучше всего отражает суть древовидной структуры: ветки дерева также являются деревьями.
В XSLT и XPath деревья являются упорядоченными, то есть для множеств T1, …, Tm задается порядок следования, который называется порядком просмотра документа. В XSLT деревья упорядочиваются в порядке появления текстового представления их узлов в документах.
Существует множество способов графического изображения деревьев. Мы будем рисовать их так, что корень дерева будет находиться наверху, а поддеревья будут упорядочены слева направо. Такой способ является довольно стандартным для XML, хотя и здесь существует множество вариантов. Примером изображения дерева может быть следующий рисунок (рис. 3.2):
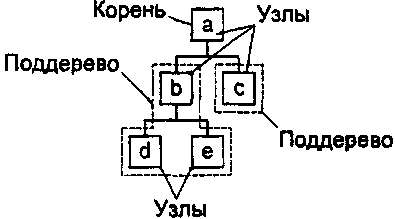
Рис. 3.2. Изображение дерева
Мы часто будем говорить о дочерних узлах, родительских узлах, братских узлах, узлах-предках и узлах-потомках. Дадим определения этим понятиям.
? Дочерним узлом текущего узла называется любой из корней его поддеревьев. Например, в дереве на рис. 3.2 дочерними узлами узла а являются узлы b и с, а дочерними узлами узла b — узлы d и e. Узел с не имеет дочерних узлов — такие узлы иначе называются листьями.
? Каждый узел называется родительским узлом корней своих поддеревьев. На рис. 3.2 узел а является родителем узлов b и с, а узел b — родителем узлов d и e.
? Корни поддеревьев называются братскими узлами или узлами-братьями. На рис. 3.2 братьями являются узлы b и с, а также узлы d и e.
? Предками текущего узла являются его родитель, а также родители его родителей и так далее. На рис. 3.2 предками узла d являются узлы b и а.
? Потомками текущего узла являются его дочерние узлы, а также дочерние узлы его дочерних узлов и так далее. На рис. 3.2 потомками узла а являются узлы b, c, d и e.
Читайте также
14.4.1. Введение в двоичные деревья
14.4.1. Введение в двоичные деревья Массивы являются почти простейшим видом структурированных данных. Их просто понимать и использовать. Хотя у них есть недостаток, заключающийся в том, что их размер фиксируется во время компиляции. Таким образом, если у вас больше данных,
Списки и деревья областей памяти
Списки и деревья областей памяти Как уже рассказывалось, к областям памяти осуществляется доступ с помощью двух структур данных дескриптора памяти: полей mmap и mm_rb. Эти две структуры данных независимо друг от друга указывают на все области памяти, связанные с данным
Деревья и узлы
Деревья и узлы При работе с XSLT следует перестать мыслить в терминах документов и начать — в терминах деревьев. Дерево представляет данные в документе в виде множества узлов — элементы, атрибуты, комментарии и т.д. трактуются как узлы — в иерархии, и в XSLT структура дерева
Деревья с двоичным основанием
Деревья с двоичным основанием Описанный выше метод двоичного поиска можно представить в виде древовидной структуры. Дерево будет содержать два типа узлов: тестовые и окончательные. Каждый тестовый узел дерева проверяет один разряд числа. По тому, равен разряд 1 или 0, в
3.1. Структуры и деревья
3.1. Структуры и деревья Чтобы легче было понять сложную структуру, ее обычно представляют в виде дерева, в котором каждому функтору соответствует вершина, а компонентам соответствуют ветви дерева. Каждая ветвь может указывать на другую структуру, так что мы можем иметь
Глава 9 Деревья и кустарники
Глава 9 Деревья и кустарники В данной главе описываются примеры проектирования всевозможных растительных форм, а также возможности использования библиотек растительных элементов в некоторых программах. Здесь рассмотрены приложения 3D Home Architect Design Suite Deluxe и
9.3. Деревья
9.3. Деревья Я не увижу никогда, наверное, Поэму столь прекрасную как дерево. Джойс Килмер, «Деревья»[11] В информатике идея дерева считается интуитивно очевидной (правда, изображаются они обычно с корнем наверху, а листьями снизу). И немудрено, ведь в повседневной жизни мы
Глава 8. Бинарные деревья.
Глава 8. Бинарные деревья. Подобно массивам и связным спискам, деревья того или иного вида — это структуры данных, которые используются программистами практически повсеместно. В главе 3 были рассмотрены односвязные списки, в которых существовала единственная связь,
Скошенные деревья
Скошенные деревья Как бы то ни было, ознакомившись с этими операциями простых и спаренных двухсторонних и односторонних поворотов, мы может их использовать в структуре данных, называемой скошенным деревом. Скошенное дерево (splay tree) — это дерево бинарного поиска,
Красно-черные деревья
Красно-черные деревья Рассмотрев простые и спаренные двусторонние и односторонние повороты и ознакомившись с реорганизацией деревьев бинарного поиска за счет использования скошенных деревьев, пора приступить к исследованию соответствующего алгоритма
Деревья
Деревья Прежде, чем мы приступим к рассмотрению типов узлов и отношений между ними, необходимо определиться с самой структурой дерева. Древовидная структура задает для своих элементов отношение ветвления, очень похожее на строение обычного дерева — есть корневой узел
Окна — это деревья и прямоугольники
Окна — это деревья и прямоугольники Рассмотрим оконную систему с произвольной глубиной вложения окон: Рис. 15.5. Окна и подокнаВ соответствующем классе WINDOW мы найдем компоненты двух основных видов:[x]. те, что рассматривают окно как иерархическую структуру (список подокон,
Деревья — это списки и их элементы
Деревья — это списки и их элементы Класс дерева TREE — еще один яркий пример множественного наследования.Деревом называется иерархическая структура, составленная из узлов с данными. Обычно ее определяют так: «Дерево либо пусто, либо содержит объект, именуемый его корнем, с
У15.1 Окна как деревья
У15.1 Окна как деревья Класс WINDOW порожден от TREE [WINDOW]. Поясните суть родового параметра. Покажите, какое новое утверждение появится в связи с этим в инварианте
Деревья аннулирования сертификатов
Деревья аннулирования сертификатов Деревья аннулирования сертификатов, ДАС (Certificate Revocation Trees — CRTs) — это технология аннулирования, разработанная американской компанией Valicert. Деревья ДАС базируются на хэш-деревьях Merkle, каждое дерево позволяет отобразить всю известную
Какие узлы являются потомками узла а



Скачай курс
в приложении
Перейти в приложение
Открыть мобильную версию сайта
© 2013 — 2023. Stepik
Наши условия использования и конфиденциальности
![]()
Public user contributions licensed under cc-wiki license with attribution required
Какие узлы являются потомками узла а
Дерево — это нелинейная динамическая структура данных, представленных в виде иерархии элементов, называемых узлами . Схематично дерево можно изобразить так, как показано на рисунке ниже:
На самом верхнем уровне такой иерархии всегда имеется только один узел, называемый корнем дерева . У нас это узел A . Каждый узел, кроме корневого, связан только с одним узлом более высокого уровня, называемым узлом-предком . Например, для узла D предком является узел A , предок для узла G — это D и т.д. При этом каждый элемент дерева может быть связан с помощью ветвей ( ребер ) с одним или несколькими узлами более низкого уровня. Они для данного узла являются дочерними узлами ( узлами-потомками ). Так, для узла A потомками будут B , C и D , для узла B — E и F и т.д. Элементы, расположенные в конце ветвей и не имеющие дочерних узлов, называют листьями . На рисунке выше листьями являются узлы E , F , C , G , J и I .
От корня до любого узла всегда существует только один путь. Максимальная длина пути от корня до листьев называется высотой дерева . У нас максимально длинный путь образует цепочка узлов A , D , H и J , т.е. высота дерева равна 3 .
Любой узел дерева с его потомками также образует дерево, называемое поддеревом (относительно исходного дерева). Например, можно рассматривать поддерево, начинающееся с узла D (это узлы D , G , H , I , J ).
Число поддеревьев для данного узла образует степень узла . Для узлов A и D степень равна 3 , степень узла B равна 2 , узел H имеет степень 1 , а у листьев (узлы E , F , C , G , J и I ) степень равна 0 . Максимальное значение среди степеней всех узлов определяет степень дерева . Если максимальная степень узлов в каком-то дереве равна n , то его называют n -арным деревом . Наше дерево имеет степень 3 (из-за узлов A и D ), и его можно называть триарным .
Дерево степени 2 называется бинарным . Бинарные деревья наиболее просты с точки зрения сложности реализации алгоритмов работы с деревьями, поэтому именно бинарные деревья применяются там, где требуется динамическая структура типа дерево. Если формально требуется дерево степени большей, чем 2 , например, 5 -й степени, то, сформировав такое дерево, его можно преобразовать в бинарное, а далее работать как с бинарным деревом.
Как правило, в дереве всегда задают какой-либо принцип упорядоченности, например, по возрастанию какого-то параметра (ключа). То есть, для каждого узла ключи наследников располагаются слева направо по возрастанию. В бинарном дереве для каждого узла значение ключа левого наследника будет меньше значения ключа узла, в свою очередь значение ключа в узле меньше значения ключа в правом наследнике.
Типовые операции с двоичными деревьями
Для работы с двоичными деревьями используем две структуры:
1) Структура, содержащая собственно сами данные . Она может иметь любое количество полей. Одно из полей (или совокупность из нескольких полей) будет ключевым . Именно по нему будет вестись упорядочивание данных. Для рассматриваемой ниже задачи нам достаточно одного поля, которое будет ключом:
2) Структура, определяющая узел дерева :