Сломать контроль ресурсов в контрольных группах Linux. Часть 1
Контрольные группы или cgroups — основные строительные блоки, обеспечивающие контейнеризацию на уровне операционной системы. Подобно процессам они организованы иерархически, и дочерние группы наследуют атрибуты родительских. В этой статье мы покажем, что наследование контрольных групп не всегда гарантирует последовательный и справедливый учёт ресурсов. Опишем стратегии, позволяющие избежать контроля использования ресурсов, и разберём основные причины, почему контрольные группы не могут отслеживать потребляемые ресурсы. Дополнительно исследуем сценарии, как вредоносные контейнеры могут потреблять больше ресурсов, чем разрешено.

Организация контрольных групп
Контрольные группы позволяют распределять ресурсы (процессорное время, память, доступ к сети) между процессами. Настройки существующих групп можно менять динамически, запрещать и разрешать их доступ к ресурсам. Cgroups осуществляют тонкий контроль распределения, приоритизации и управления системными ресурсами. При этом ресурсы эффективно распределяются между пользователями и заданиями.
К основным сходствам контрольных групп и процессов относят:
- организацию в виде иерархии;
- возможность дочерних групп выборочно наследовать атрибуты родительской группы.
Отличие заключается в том, что в системе одновременно может существовать множество независимых иерархий контрольных групп. Каждая иерархия может соответствовать одной или нескольким подсистемам.

Подсистемы, которые рассмотрим в рамках статьи:
- blkio: ограничивает ввод-вывод блочных устройств;
- cpu: использует планировщик для управления доступом к процессору;
- cpuacct: генерирует отчеты об использовании процессорных ресурсов;
- cpuset: отвечает за выделение процессоров и узлов памяти в многопроцессорных системах;
- memory: накладывает ограничения и генерирует отчёты об использовании памяти;
- pid: используется для установки ограничения на количество задач контейнера.
Подсистема pid прекращает разветвление или клонирование задачи после достижения предела. Cgroups запретит процессу выполнять системные вызовы fork и clone в случае, если после этого параметр pids.current станет больше, чем pids.max
Наследование контрольных групп
Системные процессы в терминологии cgroup называют задачами. Каждый раз при создании дочернего процесса запускается функция разветвления в ядре для копирования инициирующегося процесса. Недавно разветвлённый процесс сначала присоединяется к корневой контрольной группе, после копирования регистров и других частей вызывается функция для копирования родительских контрольных групп. В частности, функция привязывает задачу к своим родительским группам путем рекурсивного обхода всех подсистем. В результате после процедуры копирования дочерняя задача наследует членство в точно таких же группах, что и ее родительская задача.
Например, если cpusets устанавливает привязку CPU родительского процесса ко второму ядру, разветвлённый дочерний процесс также будет закреплён на втором ядре. Однако если подсистема CPU ограничивает квоту до 50 000 с периодом 100 000 для родительской контрольной группы, общее использование CPU контрольной группы (включая как новый разветвленный процесс, так и его родительский процесс) не может превышать 50% на втором ядре.
Стратегии ухода от контроля над ресурсами cgroups
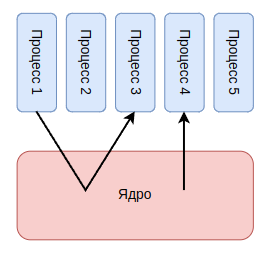
В механизме контрольных групп все потоки ядра присоединяются к корневой контрольной группе, поскольку поток ядра создается ядром. Таким образом, все процессы, созданные с помощью fork или clone потоками ядра, присоединяются к той же контрольной группе, что и их родители. В результате процесс внутри одной группы может использовать потоки ядра в качестве прокси для порождения новых процессов и, таким образом, выйти из-под контроля cgroups.

Первая стратегия: входящие вызовы из ядра. Процесс может сначала вызвать ядро для инициализации одного потока ядра (№1 на рисунке). Этот поток ядра, действующий как прокси, дополнительно создаёт новый процесс. Поскольку поток ядра присоединён к корневой контрольной группе, вновь созданный процесс также присоединяется к корневой контрольной группе. Все рабочие нагрузки, выполняемые во вновь созданном процессе, не будут ограничены подсистемами cgroup и не будут нарушать контроль над ресурсами.
Однако механизм требует, чтобы процесс пользовательского пространства сначала вызывал функции ядра в пространстве ядра, а затем вызывал процесс пользовательского пространства из пространства ядра. Хотя естественно вызывать функции ядра (например, системные вызовы) из пользовательского пространства, обратный алгоритм встречается не часто. Один из возможных путей — через вспомогательный API пользовательского режима. Он сначала вызывает очередь, работающую в потоке ядра, и дополнительно создаёт поток ядра для запуска пользовательского процесса. Обычно вспомогательный API пользовательского режима используется при загрузке модулей, перезагрузке компьютеров, создания ключей безопасности и доставке событий ядра.
Вторая стратегия: делегирование рабочих нагрузок потокам ядра. Другой способ преодолеть ограничения cgroups — делегировать рабочие нагрузки потокам ядра (№2 на рисунке). Опять же, поскольку все потоки ядра подключены к корневой контрольной группе, количество ресурсов, потребляемых рабочими нагрузками, будет учитываться целевым потоком ядра, а не инициирующим процессом пользовательского пространства.
Ядро Linux запускает несколько потоков ядра, обрабатывающих разные функции и выполняющих код в контексте процесса. Например, kthreadd, или «мастер потоков» создаёт процессы для управления аппаратной составляющей; kworker объединяет все процессы, выполняющиеся в ядре; а ksoftirqd запускается, когда требуется уменьшить нагрузку на IRQ. Для этих потоков ядро может запускать только один поток в системе (например, kthreadd), или один поток на ядро (например, ksoftirqd), или несколько потоков на ядро (например, kworker). Если процесс может заставить потоки ядра выполнять делегированные рабочие нагрузки, соответствующие потребляемые ресурсы не будут ограничены cgroups.
Третья стратегия: использование процессов обслуживания. Помимо потоков ядра, поддерживаемых ядром, Linux также запускает несколько системных процессов. Например, как управление процессами, регистрацию системной информации, отладку и др. Они отслеживают другие процессы и генерируют рабочие нагрузки после запуска определённых действий.
Многие процессы пользовательского пространства служат зависимостями для других процессов и выполняются одновременно для поддержки обычных функций других процессов. Если пользовательский процесс может генерировать рабочие нагрузки ядра для этих процессов (№3 на рисунке), потребленные ресурсы не будут взиматься с инициирующего процесса — механизм cgroups можно избежать.
Четвертая стратегия: контекст прерывания. Последняя стратегия заключается в использовании ресурсов, потребляемых в контексте прерывания. Механизм cgroup вычисляет ресурсы, потребляемые в контексте процесса. Как только ядро запускается в других контекстах (например, в контексте прерывания — №4 на рисунке), все потребляемые ресурсы не будут списываться ни с одной из групп.
Прерывание служб ядра Linux состоит из аппаратных прерываний и программных прерываний. Поскольку аппаратное прерывание может быть вызвано в любое время, здесь выполняются только легкие действия. При выполнении программных прерываний ядро не будет взимать плату с какого-либо процесса за системные ресурсы, CPU. Начиная с ядра 3.6, обработка отложенных прерываний привязана к процессам, которые их генерируют. Это значит, что все ресурсы, потребляемые в контексте отложенных прерываний (softirqs), не будут потреблять ресурсы запущенного процесса.
Исследование: обработка исключений в модуле ядра
Мы разобрали потенциальные стратегии ухода от контроля над ресурсами cgroups, но в реальных контейнерных средах эксплуатация сложнее из-за наличия других совместных политик безопасности. Рассмотрим один из сценариев, как преодолеть возможные узкие места.
Вы можете вызвать вспомогательный API пользовательского режима и дополнительно запустить процесс пользовательского пространства с помощью исключений. Многократно генерируя исключения, контейнер потребляет ресурсы процессора примерно в 200 раз больше предельного значения и тем самым снижает производительность других контейнеров на том же хосте на 85-95%.
Ядро Linux обеспечивает обработку исключений для разных исключений, например, ошибки разделения (divide error) или переполнения контента (overflow). Ядро поддерживает таблицу дескрипторов прерываний IDT, содержащую адрес каждого обработчика прерываний или исключений. Если центральный процессор вызывает исключение в пользовательском режиме, соответствующий обработчик вызывается в режиме ядра. Обработчик сначала сохраняет регистры в стеке ядра, обрабатывает исключения и возвращается обратно в пользовательский режим. Вся процедура выполняется в пространстве ядра и в контексте процесса, запускающего исключение.
Исключения ведут к завершению начальных процессов и вызывают сигналы, которые дополнительно вызывают функцию core dump для создания дампа памяти. Код дампа памяти вызывает приложение пользовательского пространства из ядра через вспомогательный API пользовательского режима. В Ubuntu приложением дампа памяти пользовательского пространства по умолчанию является Apport.
Инстанс Apport запускается ядром Linux на всех ядрах CPU для балансировки нагрузки, что приводит к нарушению правил группы cpusets cgroup. Для выполнения Apport требуется больше ресурсов, чем для обработки исключений, и если контейнер продолжает вызывать исключения, процессор оказывается полностью занят процессами Apport. Выход из cpu cgroup приводит к огромному увеличению системных ресурсов, выделяемых контейнеру.
Усиление рабочих нагрузок. Чтобы исследовать влияние, мы запускаем и закрепляем контейнер на одном ядре, а также устанавливаем ограничения ресурсов CPU, регулируя период и квоту. Далее выполняем несколько типов исключений, доступных программам пользовательского пространства. Поскольку результаты одинаковы для разных типов исключений, используем исключение div 0 в качестве примера.
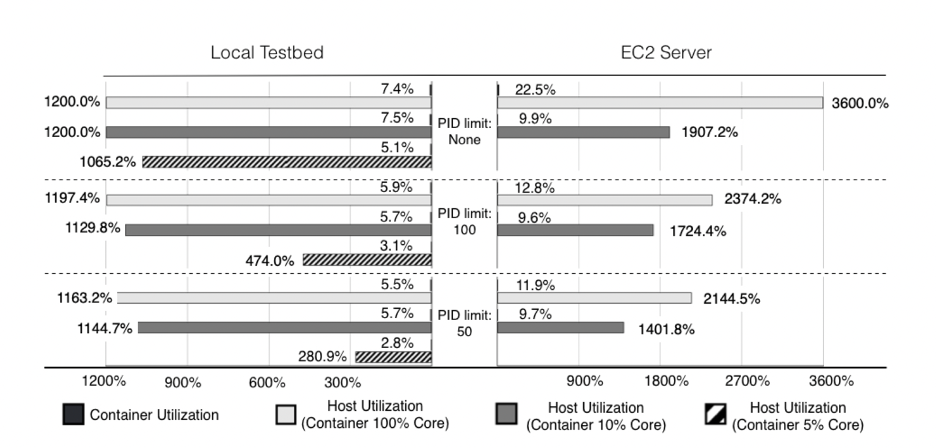
Контейнер — единственная активная программа, которая выполняется на тестовых стендах. Мы измеряем загрузку процессора тестового стенда с помощью команды top и загрузку процессора контейнера с помощью статистического инструмента Docker. Далее суммируем загрузку процессора всеми ядрами и определяем коэффициент усиления как отношение загрузки процессора хоста к загрузке процессора контейнера.
На рисунке показано, что вспомогательный API пользовательского режима может запускать программы пользовательского пространства, чтобы увеличивать использование CPU контейнера. На локальном стенде с загрузкой CPU всего 7,4% на одно ядро все 12 ядер полностью заняты. Эту проблему нельзя решить уменьшением ресурсов CPU до 10 % ядра (период на 200 000 и квоту на 20 000). Дополнительно нужно уменьшить ограничение CPU контейнера до 20% ядра и ограничить общее использование 12 ядер до 1065%, что даст коэффициент усиления 207X.
Подсистема pid. Используем подсистему pid cgroup, чтобы установить ограничение на количество задач контейнера. Как показано на рисунке выше, pid не может уменьшить результат усиления, даже когда количество активных процессов ограничено 50 (небольшое число, которое потенциально может повлиять на удобство использования контейнеров). Коэффициент усиления можно уменьшить до 98X, если мы установим ограничение pid на 50 при вычислительной способности одного ядра 20%. На сервере EC2 коэффициент усиления составляет около 144X за счет ограничения pid до 50 в контейнере с 10% вычислительной способностью процессора одного ядра.
DoS-атаки. Если контейнеры работают на одном ядре, они совместно используют ресурсы CPU и конкурируют за них. Система Linux CFS распределяет циклы CPU на основе доли каждого контейнера. CFS обеспечивает справедливость, разрешая контейнеру полностью использовать все ресурсы в своём слоте. Но если вредоносный контейнер будет создавать новые нагрузки за пределами своей контрольной группы, система CFS выделит циклы CPU для этих процессов, тем самым уменьшив ресурсы для других контейнеров.
В рамках исследования мы измеряем влияние DoS-атак с помощью механизма обработки исключений во вредоносном контейнере. Мы запускаем два контейнера, один из которых вредоносный. Далее сравниваем производительность атак, когда вредоносный контейнер выполняет обычные рабочие нагрузки (т. е. базовые). Контейнер-жертва запускает рабочие нагрузки sysbench для измерения производительности.
Результаты на обоих серверах:

Сначала мы установили оба контейнера на одно и то же ядро с одинаковыми долями CPU и квотами. Обнаружили, что создание исключений может значительно снизить производительность CPU и памяти на 95%, а также примерно на 17% производительность ввода-вывода на тестовом стенде. На сервере EC2 это число составляет около 85% для производительности CPU и памяти, 82% для производительности ввода-вывода. Это разумно, поскольку возбуждение исключений вызывает огромное количество приложений дампа ядра в пользовательском пространстве, которые конкурируют за циклы CPU с контейнером-жертвой.
Далее мы меняем привязку вредоносного контейнера, закрепляя его на другом ядре. Хотя вредоносный контейнер больше не конкурирует за ресурсы CPU на одном ядре с жертвой, он по-прежнему показывает схожие результаты по производительности. Причина в том, что основным конкурентом за ресурсы CPU являются не вредоносные контейнеры, а запущенные приложения дампа памяти.
Это говорит о том, что злоумышленники легко могут использовать контейнер, чтобы уменьшать производительность других контейнеров на том же хосте и снижать качество обслуживания поставщика услуг, что потенциально может привести к огромным финансовым потерям при небольших затратах.
В следующей статье проанализируем ещё четыре сценария, которые могут возникать в контейнерных средах, а также разберём методы, позволяющие избежать проблем или минимизировать их влияние.
kthreadd ?
Что такое kthreadd? У меня он (вроде) вешает систему на секунд 15, если вынять питание ноутбука. По лампочке ноутбука заметно, что он вешает винчестер. Если быть точнее, то это процесс jbd2/sda5-8, но его создает отцовский процесс kthreadd.
Дистр Kubuntu 10.10 x64.
ПС. Еще не работает повер девил, то есть изменение профилей потребления енергии ни к чему не приводит.
Кто-то что-то может подкажет? Я вообще склоняюсь в сторону баговости последнего ядра.
Sysadminium
В статье я покажу вам как осуществляется управление процессами в Linux. Вы узнаете про сигналы, передний и задний фон, и приоритеты процессов.
Оглавление скрыть
Сигналы
Управление процессами в Linux — это довольно обширная темя. Но все сводится к одному, мы различными способами меняем характеристики процессов. При этом мы можем преследовать совершенно разные цели: например мы можем хотеть завершить или приостановить процесс, поменять ему приоритет, заставить работать в фоне и другое.
Управление процессами может происходить по разному. Начнём наше обучение с сигналов, которые мы можем отправлять процессам.
Сигналы нужны для асинхронного оповещения процессов о разнообразных событиях в системе. Это могут быть события оборудования или события других процессов. Работа сигналов очень похожа на прерывания. То есть, если процесс получает сигнал, то он прерывает свою обычную работу, обрабатывает сигнал, а затем продолжает работать.
Сигналы от ядра поступают процессам напрямую. А сигналы от одних процессов другим поступают через ядро, то есть с помощью системных вызовов. Системный вызов, который обрабатывает сигналы называется — kill(). Его так назвали, так как большинство стандартных сигналов завершают (убивают) процесс.
Посмотреть обзор на сигналы можно выполнив man 7 signal . Или вы можете почитать эту же документацию здесь.
Стандартные сигналы
В этой документации вы можете посмотреть список стандартных сигналов:
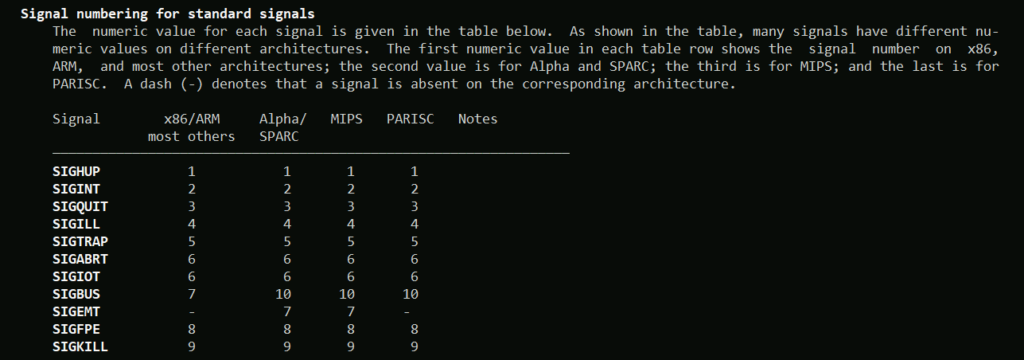
Разберём некоторые из низ:
- SIGHUP (1) — разрыв с управляющим терминалом. Процесс либо что-то предпримет (если программист об этом позаботился), либо завершится. Например, вы работаете с сервером, подключившись к нему по ssh, и вдруг связь пропадает, SSH сессия рвётся. Все ваши процессы неожиданно теряют управляющий терминал и начинают завершаться, так как получают от ядра этот сигнал.
- SIGINT (2) — клавиатурный сигнал, срабатывает когда мы нажимаем Ctrl+c. Это штатное завершение, то есть процесс будет завершён корректно (если процесс вообще умеет завершаться корректно).
- SIGQUIT (3) — клавиатурный сигнал, срабатывает когда мы нажимаем Ctrl+\. Аварийное завершение с выдачей отладочной информации.
- SIGABRT (6) — аналог SIGQUIT (3). Если у процесса нет управляющего терминала, то отправить ему клавиатурный сигнал не получится, поэтому используется этот сигнал.
- SIGKILL (9) — этот сигнал сразу завершает процесс (некорректно). И это поведение нельзя изменить, то есть программист не может сам указать программе что делать в случае получения этого сигнала.
- SIGTERM (15) — это аналог SIGINT (2). Если у процесса нет управляющего терминала, то отправить ему клавиатурный сигнал не получится, поэтому используется этот сигнал.
- SIGTSTP (20) — клавиатурный сигнал, когда мы нажимаем Ctrl+z. Этот сигнал приостанавливает процесс на управляющем терминале и переводит процесс на задний фон. То есть процесс переходит в состояние T (stopped by job control signal — остановленный специальным сигналом).
Утилита kill
Существует специальная команда — kill, она позволяет отправлять сигналы процессам. Тип сигнала указывается в качестве параметра в виде номера (например, -9) или имени (например, -SIGKILL). Следующим параметром нужно указать PID процесса, которому мы отправляем сигнал. Вот примеры:
$ kill -9 9898 $ kill -SIGKILL 2565
Вы можете отправить сигнал своему процессу, а если хотите отправить сигнал чужому, то нужно использовать sudo, или запускать команду kill из под пользователя root.
Передний и задний фон
Когда вы работаете в графической системе, то вы можете одновременно работать в нескольких программах. Для этого используются окна приложений. Пока вы работаете с одной программой, её окошко работает на переднем фоне. А в это время другие окна могут оставаться на заднем фоне.
Управление процессами в Linux можно применять и для того, чтобы в терминале можно было работать также, на заднем и переднем фоне. Представьте, что вы читаете справку (man) и захотели что-то попробовать. Чтобы не закрывать man, вы можете нажать Ctrl+z и приостановить man. При этом работа man не просто приостанавливается, она уходит на задний фон.
alex@deb-11:~$ man 7 signal (тут я нажал Ctrl+z) [1]+ Остановлен man 7 signal
Дальше вы можете поработать в терминале. А затем, когда захотите, вернёте man на передний фон. А чтобы увидеть процессы на заднем фоне используется команда jobs:
alex@deb-11:~$ jobs [1]+ Остановлен man 7 signal
Разберём вывод: [1] — номер задания, + означает что это последнее приостановленное задание, а дальше идёт состояние и название процесса.
И наконец, чтобы вернуть задание на передний фон, нужно выполнить fg % . Или можно выполнить fg без указания номера задания, тогда на передний план вернётся задание, которое было помечено плюсиком в выводе jobs.
alex@deb-11:~$ fg %1
После выполнения последней команды, на передний план вернется работа man.
Группа переднего фона — это терминал и то что на нём сейчас выполняется. Все остальные группы — это группы заднего фона.
Работа процесса на заднем фоне
Выше я показал как остановить процесс и поместить его на задний фон. Но на заднем фоне процесс может быть не только в приостановленном состоянии. Если выполнение процесса не требует от вас каких-то интерактивных действий (никакого ввода или вывода), то можно заставить процесс выполнятся на заднем фоне. Для этого нужно выполнить bg % .
Например, начнём скачивание большого файла с помощью команды wget:
alex@deb-11:~$ wget https://releases.ubuntu.com/22.04.1/ubuntu-22.04.1-desktop-amd64.iso
Затем переведём процесс скачивания на задний фон, то-есть нажмём Ctrl+z. И посмотрим список заданий на заднем фоне:
alex@deb-11:~$ jobs [1]- Остановлен man 7 signal [2]+ Остановлен wget https://releases.ubuntu.com/22.04.1/ubuntu-22.04.1-desktop-amd64.iso
Теперь, с помощью команды bg, запустим процесс на заднем фоне:
alex@deb-11:~$ bg %2 [2]+ wget https://releases.ubuntu.com/22.04.1/ubuntu-22.04.1-desktop-amd64.iso & Вывод перенаправляется в «wget-log».
Wget должен выводить информацию о скачивании файла, но на заднем фоне запрещено выводить информацию на терминал. Именно поэтому весь вывод автоматически перенаправляется в файл — wget-log.
С помощью команды ls можем убедиться что файл скачивается (его размер увеличивается):
alex@deb-11:~$ ls -lh ubuntu-22.04.1-desktop-amd64.iso -rw-r--r-- 1 alex alex 435M сен 26 11:30 ubuntu-22.04.1-desktop-amd64.iso alex@deb-11:~$ ls -lh ubuntu-22.04.1-desktop-amd64.iso -rw-r--r-- 1 alex alex 956M сен 26 11:31 ubuntu-22.04.1-desktop-amd64.iso
Выше я уже писал, что запустить процесс на заднем фоне можно только, если он не интерактивный. Например запустить остановленный man не получится:
alex@deb-11:~$ jobs [1]+ Остановлен man 7 signal [2]- Запущен wget https://releases.ubuntu.com/22.04.1/ubuntu-22.04.1-desktop-amd64.iso & alex@deb-11:~$ bg %1 [1]+ man 7 signal & [1]+ Остановлен man 7 signal alex@deb-11:~$ jobs [1]+ Остановлен man 7 signal [2]- Запущен wget https://releases.ubuntu.com/22.04.1/ubuntu-22.04.1-desktop-amd64.iso &
Как только man попытался вывести на терминал справку, то сразу был опять остановлен. И остановлен он был тоже с помощью сигнала. Вот два сигнала, которые работают для фоновых заданий:
- SIGTTIN (21) — остановлен за попытку чтения из stdin (на заднем фоне).
- SIGTTOU(22) — остановлен за попытку вывода на stdout (на заднем фоне).
Если плохо помните стандартные потоки ввода вывода (stdin, stdout, stderr), то про них я писал здесь.
Изменение приоритета процесса
Приоритеты процессов Linux
В работающей системе Linux выполняется множество процессов. И каждому запущенному процессу назначается приоритет. Как ни странно, но чем больше значение приоритета, тем меньше сам приоритет. То есть, процесс с приоритетом 15 будет более приоритетным, чем процесс с приоритетом 20.
Более приоритетные процессы получают больше процессорного времени. Они более отзывчивы, выполняются более быстро. Но при этом, они сильнее нагружают процессор и замедляют все остальные процессы.
Но никакие пользователи и даже root не могут управлять приоритетами процессов. Они могут управлять другим значением — nice. Диапазон nice имеет 40 приоритетов от -20 до +19. По умолчанию, любой процесс Linux, созданный пользователем, имеет значение nice равное 0, и приоритет равный 20.
Вы можете увидеть значение nice для процессов своего пользователя и своего терминала с помощью следующей команды (утилиту ps я рассматривал здесь):
alex@deb-11:~$ ps -o pid,comm,nice,priority PID COMMAND NI PRI 5564 bash 0 20 5761 ps 0 20
Или можно получить список всех процессов, а не только ваших:
alex@deb-11:~$ ps ax -o pid,comm,nice,priority PID COMMAND NI PRI 1 systemd 0 20 2 kthreadd 0 20 3 rcu_gp -20 0 4 rcu_par_gp -20 0 6 kworker/0:0H-ev -20 0 ****
Разница в том, что priority — это реальный приоритет процесса в данный момент, а nice — подсказка для ядра указывающая нужно ли увеличить или уменьшить приоритет процессу.
Для пользовательских процессов, в большинстве случаев, значение priority можно рассчитать по следующей формуле: priority = 20 + nice. Таким образом, процесс с nice=3 имеет priority=23, а процесс с nice=-7 имеет priority=13.
Кроме ps, для просмотра приоритетов процессов можно использовать top и htop.
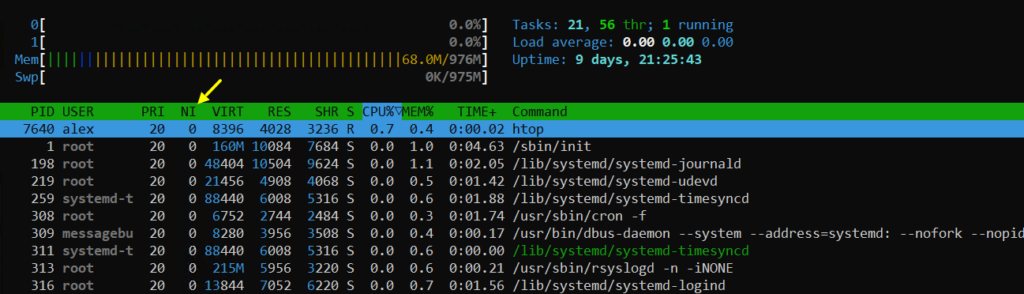
В Linux управление процессами, а точнее их уровнем nice, происходит с помощью команд:
- nice — настраивает приоритет процесса перед его запуском;
- renice — позволяет изменить приоритет уже запущенного процесса.
- обычный пользователь может лишь уменьшить nice своего процесса;
- root может уменьшить или увеличить nice своего или чужого процесса.
Команда nice
Вы можете легко проверить значение nice для своего терминала (или оболочки), выполнив команду nice без каких-либо аргументов:
alex@deb-11:~$ nice 0
То есть любые команды запущенные из этой оболочки будут иметь значение nice=0.
А чтобы запустить команду с изменённым значением nice, её нужно запускать таким образом: nice . Например, запустим две программы с разным приоритетом (что-бы запустить их две в одном терминале, я использую выполнение на заднем фоне):
alex@deb-11:~$ nice -2 md5sum /dev/urandom ^Z [1]+ Остановлен nice -2 md5sum /dev/urandom alex@deb-11:~$ bg [1]+ nice -2 md5sum /dev/urandom & alex@deb-11:~$ nice -8 md5sum /dev/urandom ^Z [2]+ Остановлен nice -8 md5sum /dev/urandom alex@deb-11:~$ bg [2]+ nice -8 md5sum /dev/urandom & alex@deb-11:~$ jobs [1]- Запущен nice -2 md5sum /dev/urandom & [2]+ Запущен nice -8 md5sum /dev/urandom &
Теперь, с помощью htop, посмотрим на приоритеты процессов для нашего пользователя:
alex@deb-11:~$ htop -u alex
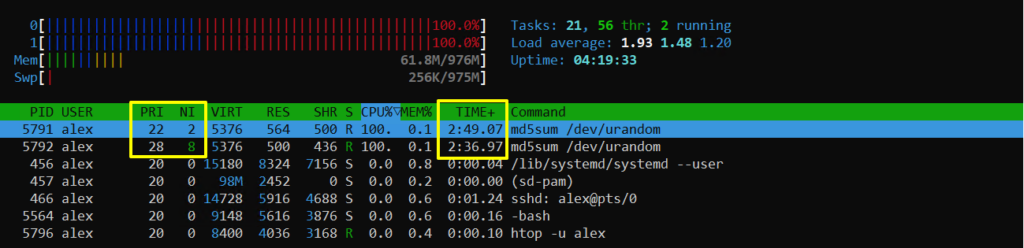
Как видите команды md5sum работают параллельно. Но у одной команды приоритет стал 22, а у другой 28. При этом более приоритетный процесс получает больше процессорного времени, это видно в колонке TIME+.
А если мы хотим указать отрицательное значение для nise. Другими словами, уменьшить nice и уменьшить priority, тем самым увеличив приоритет. То должны использовать двойное тире и sudo (так как обычный пользователь не имеет право запускать процессы с повышенным приоритетом):
alex@deb-11:~$ sudo nice --2 md5sum /dev/urandom [sudo] пароль для alex: ^Z [3]+ Остановлен sudo nice --2 md5sum /dev/urandom alex@deb-11:~$ bg [3]+ sudo nice --2 md5sum /dev/urandom & alex@deb-11:~$ jobs [1] Запущен nice -2 md5sum /dev/urandom & [2]- Запущен nice -8 md5sum /dev/urandom & [3]+ Запущен sudo nice --2 md5sum /dev/urandom &
Кстати, этот экземпляр md5sum, будет работать от пользователя root. Вот так можно посмотреть на все процессы md5sum с помощью ps:
alex@deb-11:~$ ps -C md5sum -o pid,user,comm,nice,priority,time,%cpu PID USER COMMAND NI PRI TIME %CPU 5791 alex md5sum 2 22 00:13:35 90.6 5792 alex md5sum 8 28 00:09:31 64.3 5802 root md5sum -2 18 00:06:34 98.4
Выше видно, что сильнее всего нагружает процессор процесс с уровнем nice равным -2.
Команда renice
Чтобы изменить приоритет уже работающего процесса нужно использовать команду renice -n -p . И этой командой может пользоваться только root.
Вернём всем процессам значение nice=0:
alex@deb-11:~$ sudo renice -n 0 -p 5791 5791 (process ID) old priority 2, new priority 0 alex@deb-11:~$ sudo renice -n 0 -p 5792 5792 (process ID) old priority 8, new priority 0 alex@deb-11:~$ sudo renice -n 0 -p 5802 5802 (process ID) old priority -2, new priority 0 alex@deb-11:~$ ps -C md5sum -o pid,user,comm,nice,priority,time,%cpu PID USER COMMAND NI PRI TIME %CPU 5791 alex md5sum 0 20 00:17:29 87.5 5792 alex md5sum 0 20 00:10:40 53.9 5802 root md5sum 0 20 00:11:28 98.3
А ещё вы можете изменить приоритет всех процессов определённого пользователя таким образом: sudo renice -n -u . Например:
alex@deb-11:~$ sudo renice -n 5 -u alex 1000 (user ID) old priority 0, new priority 5 alex@deb-11:~$ ps -C md5sum -o pid,user,comm,nice,priority,time,%cpu PID USER COMMAND NI PRI TIME %CPU 5791 alex md5sum 5 25 00:18:47 85.7 5792 alex md5sum 5 25 00:11:58 55.1 5802 root md5sum 0 20 00:12:46 93.9
Обратите внимание, процессы alex стали с уровнем nice=5, а процесс root так и остался с уровнем nice=0.
Итог
Статья получилось довольно длинной. Я показал как происходит некоторое управление процессами в Linux.
Рассказал про сигналы и как их отправлять процессам с помощью клавиатуры или с помощью команды kill. Также я показал, как можно использовать передний (fg) и задний (bg) фон терминала, и этим реально можно пользоваться. Также я разобрал приоритеты процессов и как их можно менять с помощью команд nice и renice.
В статье много примеров использования команды ps. Думаю, что умение работать с этой утилитой, это очень полезный навык для системного администратора Linux.
Управление процессами и наблюдение за ними в дистрибутивах Linux (CentOS)
В данном материале мы рассмотрим, как основные команды, предусмотренные в дистрибутивах Linux по умолчанию для просмотра, управления и мониторинга текущих процессов, так и сторонние средства, дающие более расширенный доступ к просмотру и анализу текущих системных процессов.
Аренда выделенного сервера
Используйте готовые решения, чтобы быстро подобрать оптимальный для себя вариант аренды сервера
- Intel® Xeon® E3-1230 v2, 3,3 GHz/4core
3.3 , 4 ядра - 8Gb DDR3
- 2 x SSD: 480Gb, Ent
- 2 x SATA3: 1 TB
Недорогой, выделенный сервер, для задач средней сложности.
- Intel® Xeon® E3-1270 v2, 3,5 GHz/4core
3.5 , 4 ядра - 32Gb DDR3
- 2 x SSD: 480Gb, Ent
- 2 x SATA3: 1 TB
Хорошее решение, для задач средней ложности.
Любой выбранный сервер, всегда можно улучшить в процессе работы, если вы поймете что вам не достаточно производительности.
- 2 x Intel® Xeon® E5-2667, 3,3 GHz/HT32core
3.3 , 16 ядер - 32Gb DDR3
- 2 x SSD: 480Gb, Ent
- 2 x SATA3: 2 TB
Аренда сервера для удаленного доступа и 1С.
Позволит экономить и безопасно работать на арендованном сервере, через удаленный рабочий стол и Веб браузер.
Работа с запущенными процессами
На Linux-серверах, как и любых других серверных машинах, имеется возможность запуска приложений, которые компьютер рассматривает в виде процессов. При обработке системой закадрового, низкоуровневого управления жизненными циклами процессов, пользователь зачастую нуждается в другом способе взаимодействия с ОС, чтобы иметь возможность управлять процессами на высоких уровнях. Для начала рассмотрим простейшие моменты, связанные с управлением процессами средствами инструментов, интегрированных в дистрибутивы Linux.
Команда top
Это наиболее простой способы выяснить, какие процессы запущены на серверной машине в настоящее время:
- top
top — 15:14:40 up 46 min, 1 user, load average: 0.00, 0.01, 0.05
Tasks: 56 total, 1 running, 55 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 1019600k total, 316576k used, 703024k free, 7652k buffers
Swap: 0k total, 0k used, 0k free, 258976k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 24188 2120 1300 S 0.0 0.2 0:00.56 init
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:00.07 ksoftirqd/0
6 root RT 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
7 root RT 0 0 0 0 S 0.0 0.0 0:00.03 watchdog/0
8 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 cpuset
9 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 khelper
10 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kdevtmpfs
В верхней части выводимой информации предоставлена статистика работы системы, а если конкретнее, нагрузка на систему и число выполняемых задач. В нижней части отображается информация по запущенным процессам и статистики их использования.
Команда htop
Посредством этой усовершенствованной версии команды top можно получать более развернутые данные по процессам. Она доступна в хранилищах. Для установки используем:
sudo apt-get install htop
Использование ps для получения процессов в виде списка
Посредством приведенных выше команд можно получить удобный интерфейс, позволяющий мониторить запущенные процессы, который аналогичен более привычному для многих диспетчеру задач. Однако такого инструментария далеко не всегда достаточно в плане гибкости и не позволяют адекватно охватывать требуемые системные сценарии.
Для получения более полной картины процессов можно запустить такую команду:
- ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.2 24188 2120 ? Ss 14:28 0:00 /sbin/init
root 2 0.0 0.0 0 0 ? S 14:28 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? S 14:28 0:00 [ksoftirqd/0]
root 6 0.0 0.0 0 0 ? S 14:28 0:00 [migration/0]
root 7 0.0 0.0 0 0 ? S 14:28 0:00 [watchdog/0]
root 8 0.0 0.0 0 0 ? S< 14:28 0:00 [cpuset]
root 9 0.0 0.0 0 0 ? S < 14:28 0:00 [khelper]. . .
Данные параметры отображают ps процессы, которые принадлежат всем пользователям, вне зависимости от пользовательского терминала.
Использование PID процессорных идентификаторов
В Unixо-подобных системах для каждого процесса существует собственный PID-идентификатор, посредством которого ОС способна отслеживать и идентифицировать любую активность процессов. Чтобы узнать идентификатор того или иного процесса можно воспользоваться следующей командой:
Таким образом, можно запросить идентификатор процесса и вернуть его. В процессе запуска первый запущенный процесс называется init с PID 1. Он отвечает за инициацию/запуск всех остальных системных процессов. Существует такое понятие, как родительский процесс, который ответственен за запуск других процессов. В случае, когда порождающие процессы прекращаются, дочерние процессы также прекращают работу. PID родительских процессов называют PPID. Когда пользователь общается с операционной системой и нуждается в чтении процессов, имеет место перевода идентификаторов в имена процессов и наоборот. Именно для этого различные утилиты отправляют свой PID.
Один из наиболее распространенных способов передачи сигналов посредством PID является команда kill. По умолчанию ее функционал сводится к завершению процесса (kill PID_of_target_process). При выполнении данной команды всем процессам отправляется TERM-сигнал. Таким образом, рабочая программа выполняет требуемые операции по очистке и безопасно завершает работу.
Наблюдаем за процессами посредством утилиты strace
Утилита strace присутствует во многих Linux-дистрибутивах по умолчанию и зачастую используется в целях отладки, обучения и диагностики. Посредством strace можно решать самые разные задачи, включая мониторинг старта/завершения процессов, а также избавить себя от проблем с поиском возникших программных сбоев без доступа к исходным кодам.
Также данную программу можно использовать при необходимости получения/отправки bug-репортов для разработчиков того или иного ПО. Средствами данного инструмента можно воочию увидеть, как именно работает запущенная программа в подробностях.
Особенности запуска
Системный вызов представляет собой обращение программ к системному ядру для выполнения того или иного действия. Такие вызовы необходимы потому, что процесс не способен взаимодействовать с системой непосредственным образом.
Работа представленной утилиты заключается в том, что она отслеживает системные вызовы конкретных процессов и получаемые ими сигналы. В принципе может иметь место ситуация, в которой процессы не посылают никаких системных вызовов. В таких случаях strace, естественно, не способна ничего отследить.
Для запуска утилиты strace используется команда
После ее запуска происходит запуск программы program_name с выведением в поток стандартных выводов сообщений о выполняемых вызовах в системе. Существуют текстовые редакторы, такие как Vim, которые оснащены цветной подсветкой вывода strace, а это существенно упрощает анализ крупных файлов с трассировочными текстами.
Как вариант strace может запускаться для трассировки уже запущенных процессов. Для этого как раз потребуется PID требуемого процесса, о чем мы говорили выше. Этот идентификатор необходимо передать, как параметр в опциях –p для утилиты:
- strace -o trace_output.txt -p 1234
Анализ вывода – наиболее полезная функция данной программы. Структура для строй вывода strace предполагает, что сначала идет имя системного вызова, после чего в круглых скобках будет выведен список параметров, которые переданы вызову. Последний выводящийся информационный блок, который отображается после знака «=», отображает код, по которому завершается системный вызов. В качестве примера приведем несколько строк кода с анализом вывода посредство strace:
- execve(«/bin/ls», [«/bin/ls»], [/* 37 vars */]) = 0
- brk(0) = 0x9841000
- access(«/etc/ld.so.nohwcap», F_OK) = -1 ENOENT (No such file or directory)
- mmap2(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb779e000
- access(«/etc/ld.so.preload», R_OK) = -1 ENOENT (No such file or directory)
- open(«/etc/ld.so.cache», O_RDONLY) = 3
- fstat64(3, ) = 0
- mmap2(NULL, 78866, PROT_READ, MAP_PRIVATE, 3, 0) = 0xb778a000
- close(3) = 0
- Собрать свой сервер
- Готовые решения