Как объединить разделы диска C и D;
В этой статье рассказывается, как объединить диски C и D на Windows 10/8/7/Vista/XP & Server 2019/2016/2012/2008/2003, 2 способа объединить диски C и D без переустановки Windows Операционная система.
Относится к: Windows 10, Windows 8, Windows 7, Windows Виста, Windows XP, Windows Server 2019, Windows Server 2016, Windows Server 2012 (R2), Малый бизнес-сервер 2011, Windows Server 2008 (R2) и Windows Server 2003 (Р2).

Жесткий диск является обязательным компонентом для обоих Windows server и персональный компьютер. Чтобы использовать дисковое пространство более эффективно, вам нужно выполнить множество операций, таких как создание, удаление, форматирование, изменение размера, копирование или преобразование разделов. В последнее время меня многие спрашивают, можно ли объединить диск C и D без переустановки Windows и программы, потому что система C диск не хватает места, Ответ да, после объединение диска D в C, на диске C снова будет больше свободного места. В этой статье я покажу вам, как объединить разделы C и D без потери данных.
Как объединить диск C и D с управлением дисками
В консоли управления дисками Windows 10/8/7/Виста и Server 2019/2016/2012/2008, вы можете косвенно объединить два диска с помощью функции «Расширить том». Но для Windows XP или Server 2003, такой функции нет, поэтому придется использовать сторонние partition editor .
Графический интерфейс в этом управлении дисками абсолютно такой же, поэтому приведенные ниже шаги действительны для Windows 10/8/7/Виста и Server 2019/ 2016 / 2012 / 2008.
Шаги для объединения C и Drive вместе с Windows Управление диском:
- Резервное копирование или передача всех файлов на диске D в другое место.
- Нажмите Windows и R вместе на клавиатуре наберите diskmgmt.msc и нажмите Enter открыть Управление дисками.
- Щелкните правой кнопкой мыши D: диск и выберите Удалить громкости , тогда его дисковое пространство будет изменено на Нераспределенное.
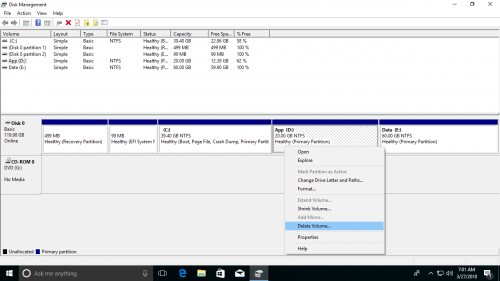
- Щелкните правой кнопкой мыши C: диск и выберите Расширить том .
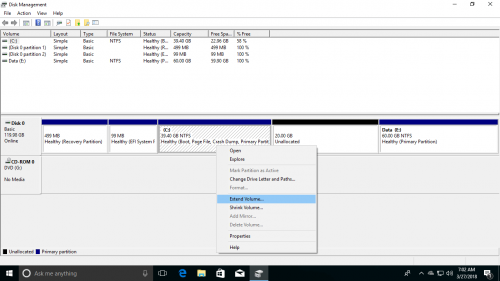
- Нажмите Следующая во всплывающем окне Расширить том мастера окно.
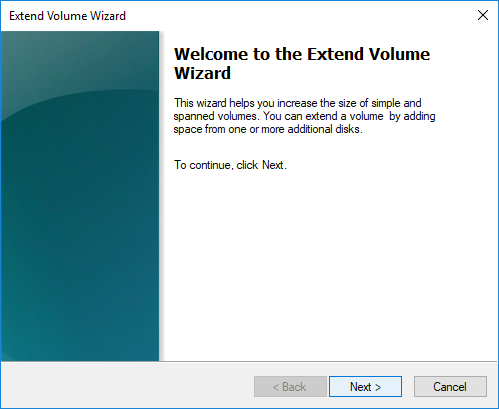
- Доступное дисковое пространство было выбрано по умолчанию, просто нажмите Следующая для продолжения.
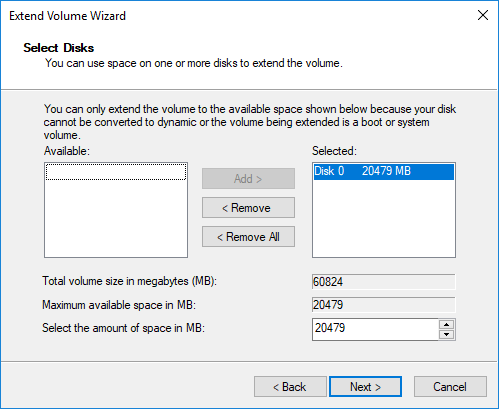
- Подтвердите эту операцию и нажмите Завершить продолжать.
Через некоторое время диск D объединяется с C.
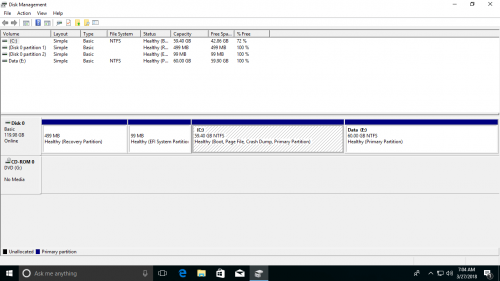
Если диск D является логический раздел, метод выше недействителен. Дисковое пространство логического раздела будет изменено на Бесплатное после удаления его нельзя объединить с основным разделом C с помощью функции «Расширить том» в «Управление дисками».
Как совместить привод C и D с бесплатным partition editor
Это намного проще с сторонним программным обеспечением. к Windows 10/8/7/Vista/XP пользователи домашних компьютеров, есть бесплатная версия. Лучше, чем другие программы, NIUBI Partition Editor Бесплатная версия на 100% чистая без каких-либо пакетов. Кроме того, для защиты системы и данных в NIUBI используются передовые технологии отката в 1 секунду, виртуального режима и отмены скважины. С этим бесплатный менеджер разделоввсе файлы на диске D будут автоматически перемещены в папку в C после объединения.
Шаги для объединения дисков C и D на Windows 10/8/7/Vista/XP и Server 2019/ 2016/2012/2008/2003:
- Скачать и установить NIUBI Partition Editorщелкните правой кнопкой мыши диск C или D и выберите Объединить том.

- Во всплывающем окне выберите оба диска C и D, а затем нажмите OK.

- Нажмите Apply Кнопка в левом верхнем углу, чтобы выполнить. (В противном случае эта операция работает только в виртуальном режиме).

Изменить размер разделов вместо того, чтобы объединять их вместе
При объединении диска D с C на диске C снова будет больше свободного места, но есть проблема, что диск D будет удален. Если вы установили программы на диск D, все эти программы перестанут работать, даже если все файлы будут перемещены в новые места.
Предлагается изменять размеры разделов вместо того, чтобы объединить их вместе. После сжатия диска D часть свободного неиспользуемого пространства изменится на Нераспределенный, и все файлы останутся нетронутыми. Нераспределенное пространство может быть легко объединено с диском C. Таким образом, операционная система, программы и все остальное остается прежним. Следуйте инструкциям, чтобы расширить диск C сжимая D или другой объем:

Помимо слияния, сжатия и расширения перегородок, NIUBI Partition Editor помогает выполнять многие другие операции, такие как копирование, преобразование, скрытие, стирание, дефрагментация, сканирование поврежденных секторов.
Как объединить разделы в Windows Server 2012 R2
Изначально после создания разделов вы не можете изменить размер раздела в Server 2012. Когда раздел становится заполненным или по другим причинам, вам необходимо сделать резервную копию всего, пересоздать разделы и восстановить из резервной копии. На выполнение задачи может уйти целый день. Чтобы решить эту проблему проще и быстрее, вы можете объединить 2 диска или сжать раздел на другой. Чтобы объединить разделы в Windows Server 2012, вы можете использовать Управление дисками или стороннее программное обеспечение. Из-за некоторых недостатков родной инструмент управления дисками — не лучший выбор. В этой статье я расскажу, как объединить 2 раздела в Windows Server 2012 (R2) с помощью обоих инструментов.
- Объединение разделов в Server 2012 Disk Management
- Объедините 2 диска с помощью программного обеспечения для безопасных разделов
- Лучшая идея, чем объединение разделов
1. Объедините разделы с помощью управления дисками
То же самое с предыдущей версией, нет “Merge Volumeв Server 2012 Disk Management, но можно добиться косвенным путем. Обратите внимание, что этот метод не рекомендуется. Он используется только в том случае, если макет вашего раздела соответствует приведенным ниже требованиям.
Требования для объединения разделов Server 2012 с Управлением дисками:
- Эти разделы должны находиться на одном диске.
- Целевой раздел должен быть отформатирован с помощью NTFS файловая система, любые другие типы разделов не поддерживаются.
- Объединяемые перегородки должны быть тоже самое Основной или логический диск.
- Управление дисками может только объединить раздел в левый смежный один, например: объединить диск D с диском C или объединить диск E с диском D. Он не может объединить раздел с правильным или объединить 2 несмежных раздела.
Нажмите Windows + X ключи вместе и нажмите «Управление дисками», проверьте, соответствует ли структура разделов вашего диска всем требованиям. Если да, выполните следующие действия. В противном случае перейдите к следующему разделу.
Как объединить разделы в Server 2012 r2 без каких-либо программ:
Шаг 1: Переместить все файлы из соседнего раздела (здесь E:) в другое место. Щелкните правой кнопкой мыши этот раздел и выберите «Удалить том…».
Шаг 2: Щелкните правой кнопкой мыши левый непрерывный раздел (здесь C:) и выберите «Расширить том…».
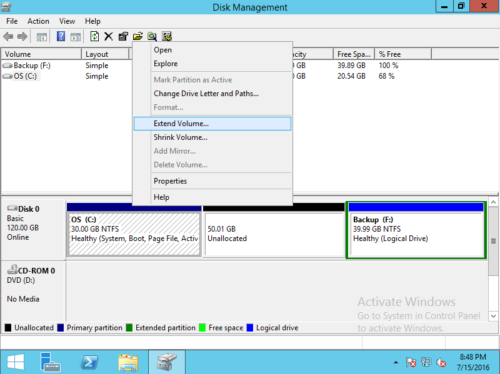
Расширить том мастера будет запущен, нажмите Следующая для продолжения.
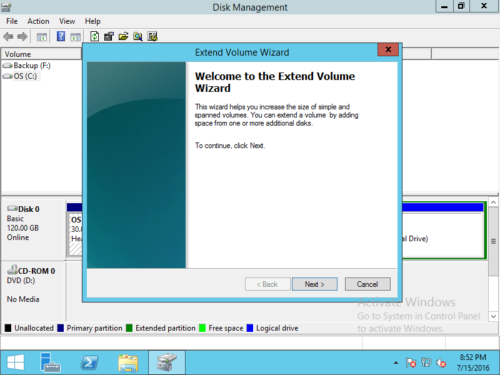
Шаг 3: Если имеется только одно доступное нераспределенное пространство, оно будет выбрано автоматически, в противном случае вам нужно выбрать диск, нажмите Следующая для продолжения.
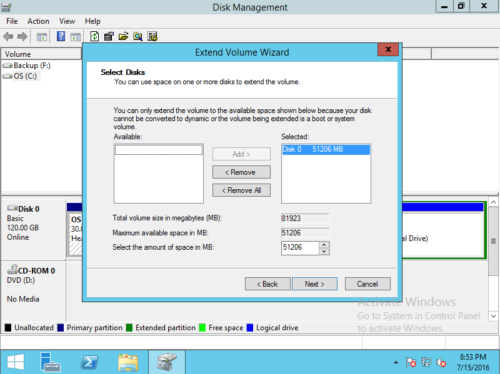
Шаг 4: Подтвердите операцию, нажмите Завершить продолжать.
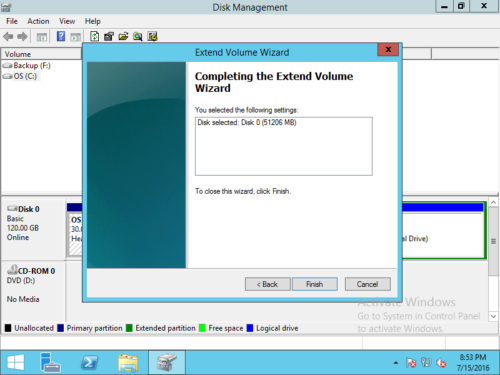
За короткое время исходный диск E объединяется с диском C.
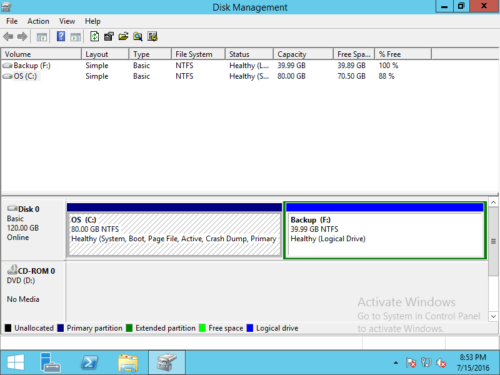
2. Объединяйте разделы с помощью безопасного программного обеспечения для разделов
Чтобы объединить 2 диска в Windows Server 2012 (R2), NIUBI Partition Editor лучший выбор. По сравнению с Управлением дисками, он имеет больше преимуществ, таких как:
- Оба раздела могут быть как NTFS, так и FAT32.
- Оба раздела могут быть основными или логическими.
- Целевой раздел может быть левым или правым.
- Он может автоматически перемещать все файлы в корневую папку другого.
- Он может перемещать нераспределенное пространство и объединять 2 несмежных раздела.
Лучше, чем другие программы, NIUBI Partition Editor имеет уникальные технологии 1-Second Rollback, Virtual Mode и Cancel-at-well для защиты вашей системы и данных. Это намного быстрее из-за продвинутого алгоритма перемещения файлов. Эти возможности очень важны для сервера.
Как объединить разделы в Windows Server 2012 R2 с помощью NIUBI:
- Скачать серверную версию, щелкните правой кнопкой мыши любой диск, который вы хотите объединить, и нажмите «Merge Volume».
- Установите оба флажка для двух разделов и нажмите OK во всплывающем окне.
- Нажмите Применить в левом верхнем углу, чтобы вступить в силу.
Лучшая идея, чем объединение разделов Server 2012
Если ваша цель заключается в продлить диск C или другой том, не рекомендуется объединять разделы. Вы можете уменьшить большой раздел, чтобы освободить место, а затем добавить его на диск C. Таким образом, вы не потеряете ни одного раздела, операционной системы, программ и всего остального, что было раньше. Посмотрите видео как работать.
Помимо сжатия, расширения и объединения разделов в Windows Server 2012/2016/2019/2022/2003/2008, NIUBI Partition Editor поможет вам сделать много других операций управления разделами диска.
Оптимизируем NiFi Flow. Настройка Load Balancing, подходы к Scheduling и выбор метода merge
Если вы используете в своей работе NiFi, то наверняка не раз задумывались об оптимизации, а может быть, и делали ее. В этом посте я поделюсь своими наработками в области настроек NiFi, благодаря которым мы получили позитивные результаты и улучшили работу наших собственных сервисов. А если конкретно, речь пойдет о выборе стратегии балансировки нагрузки между нодами кластера (load balancing), о настройке работы процессоров NiFi в рамках одной ноды (Concurrent tasks, Run Duration), а также о том, что делать с косяками Merge Record. Если интересно, ныряйте под кат и давайте обсудим, что еще хорошего можно сделать с NiFi.

Меня зовут Рустем, и я работаю дата-инженером в Леруа Мерлен. Мы используем в своей работе NiFi, и иногда очень хочется его оптимизировать. Самый очевидный вариант — задействовать все ноды кластера NiFi и производить вычисления параллельно, а значит — задачи нужно балансировать.
Параметр Load Balancing отвечает за распределение данных (flow files) между доступными нодами NiFi кластера. Важно понимать, что в NiFi распределение данных не происходит автоматически и эта настройка остается на совести разработчика.
В системе предусмотрено 4 стратегии Load Balancing.
- Do not balance — ничего не делаем, обрабатываем данные на тех нодах кластера, куда они изначально попали.
- Partition by attribute — распределяем данные по значению выбранного flow file attribute, файлы с одинаковым значением атрибута гарантированно распределяются на одну ноду.
- Round Robin — распределение flow-файлов равномерно по всем нодам.
- Single node — все файлы едут на одну ноду, но на какую именно, неизвестно.
Использовать Load Balancing имеет смысл в том случае, когда накладные расходы на распределение данных оказываются сильно ниже, чем выигрыш от последующей параллельной обработки. Например, если вы селектите что-то из БД на primary node NiFi, а затем хотите как-то трансформировать эти данные параллельно на кластере, использовать балансировку в таком случае будет хорошей идеей.

Поделюсь своим опытом балансировки. Во-первых, сразу скажу, что я использую метод Round Robin, и именно его мы и будем рассматривать. Round Robin применяется чаще всего, чтобы просто равномерно раскидать данные между узлами для более эффективной параллельной обработки, не задумываясь о том, какие у них атрибуты, куда что направлять и так далее. Все примеры мы будем рассматривать на кластере NiFi из 3-х нод.
Давайте посмотрим на этот процесс на наглядном примере.
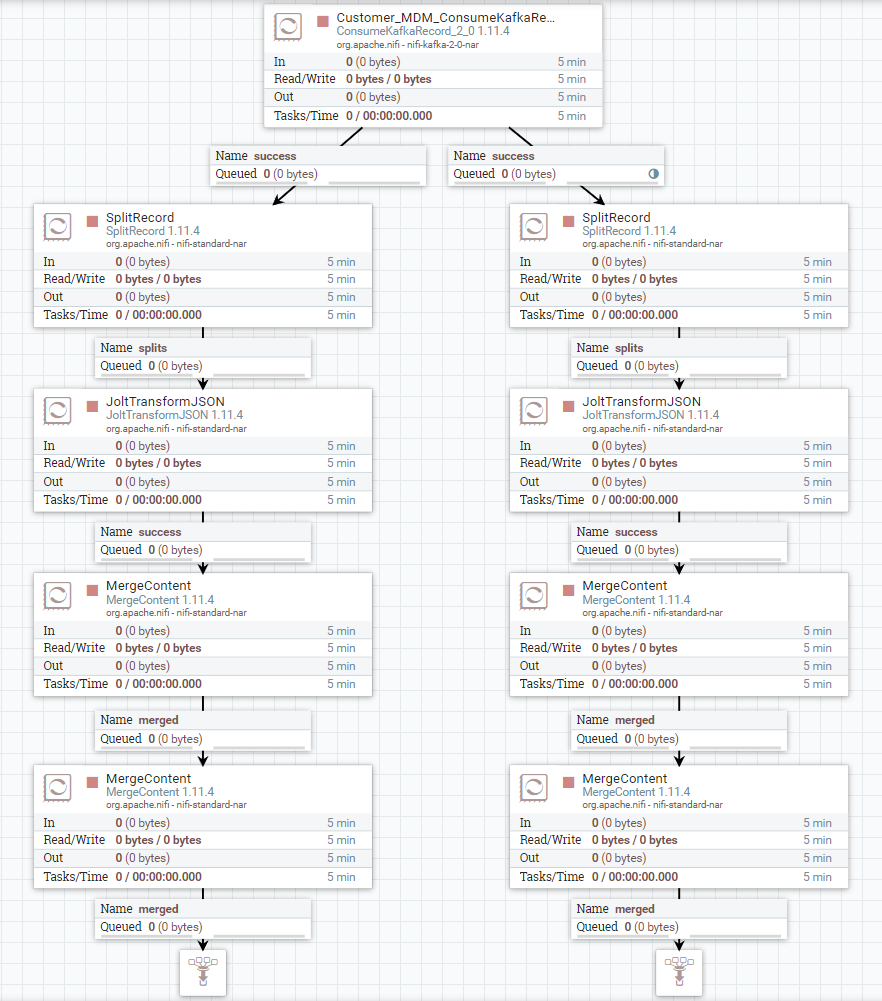
На скриншоте вы видите Flow — раздвоенный поток, каждая ветвь которого делает одинаковые действия с данными из сообщений Kafka. Тут происходит какая-то трансформация и идет merging.
Балансировка выставляется в очереди. Для этого нужно открыть настройки очереди. И в нижней левой части диалогового окна выбрать метод балансировки.
Кружочек в первой очереди правой части Flow означает, что на очереди установлена балансировка. Когда данные попадают в эту очередь, они перераспределяются по всем нодам кластера равномерно (ведь мы выбрали Round Robin).
Давайте подготовим данные для нашего теста и соберем их в первых очередях каждой из ветвей Flow. Обратите внимание, что в момент работы Flow при попадании данных в очередь с балансировкой кружок будет краситься в синий цвет, это является индикатором того, что данные в данный момент распределяются по нодам. На скриншоте ниже видно, как очередь слева переполняется, а справа нет. Причина в том, что на ней установлена балансировка, и NiFi раскидывает данные в 3 разные очереди на каждой из нод.
Итак, запускаем Flow целиком, чтобы проверить, действительно ли данные со сбалансированной стороны обрабатываются быстрее. И… да! Так оно и происходит.
Здесь я сразу поделюсь своим опытом — не надо ставить балансировку на каждую очередь. Это может показаться логичным, но на самом деле будет происходить ненужное перераспределение, ведь flow-файлы уже были распределены на ноды, соответственно, дальше они будут в любом случае обрабатываться на этих нодах. Поэтому со всех последующих очередей нужно убрать балансировку — вначале Round Robin, а дальше Do Not Balance.
Можно ли лучше?
Можно! Ведь мы берем данные из Kafka, а она поддерживает queuing semantics, поэтому при чтении данных NiFi из Kafka существует поддержка загрузки данных с партиций кафки на ноды NiFi без принудительной установки load balancing. В результате данные могут попадать в NiFi уже распределенными на ноды.
Такой же финт можно провернуть с другими очередями (JMS Queues, Amazon SQS, MQTT).
Но чтобы все это работало, количество партиций должно быть равно количеству нод на кластере (или больше, но при этом оставаться целочисленнократным — то есть 3 и 9, например). В нашем случае имеется 3 ноды и 5 партиций. А это значит, что балансировки нормальной не будет, несмотря на дружбу между NiFi и Kafka. Именно поэтому балансировка методом Round Robin дала те результаты, которые вы видели выше.
Нюансы других источников
А что если мы берем данные… например, из Google Cloud Storage или какой-то иной файловой системы? Тут уже нет никаких встроенных совместимостей. Для получения данных берется листинг (процессор List), а далее идет процессор Fetch. Листинг делается только на primary-ноде, иначе будет дублирование… и при таких задачах желание поиграть с балансировкой также закономерно появляется.
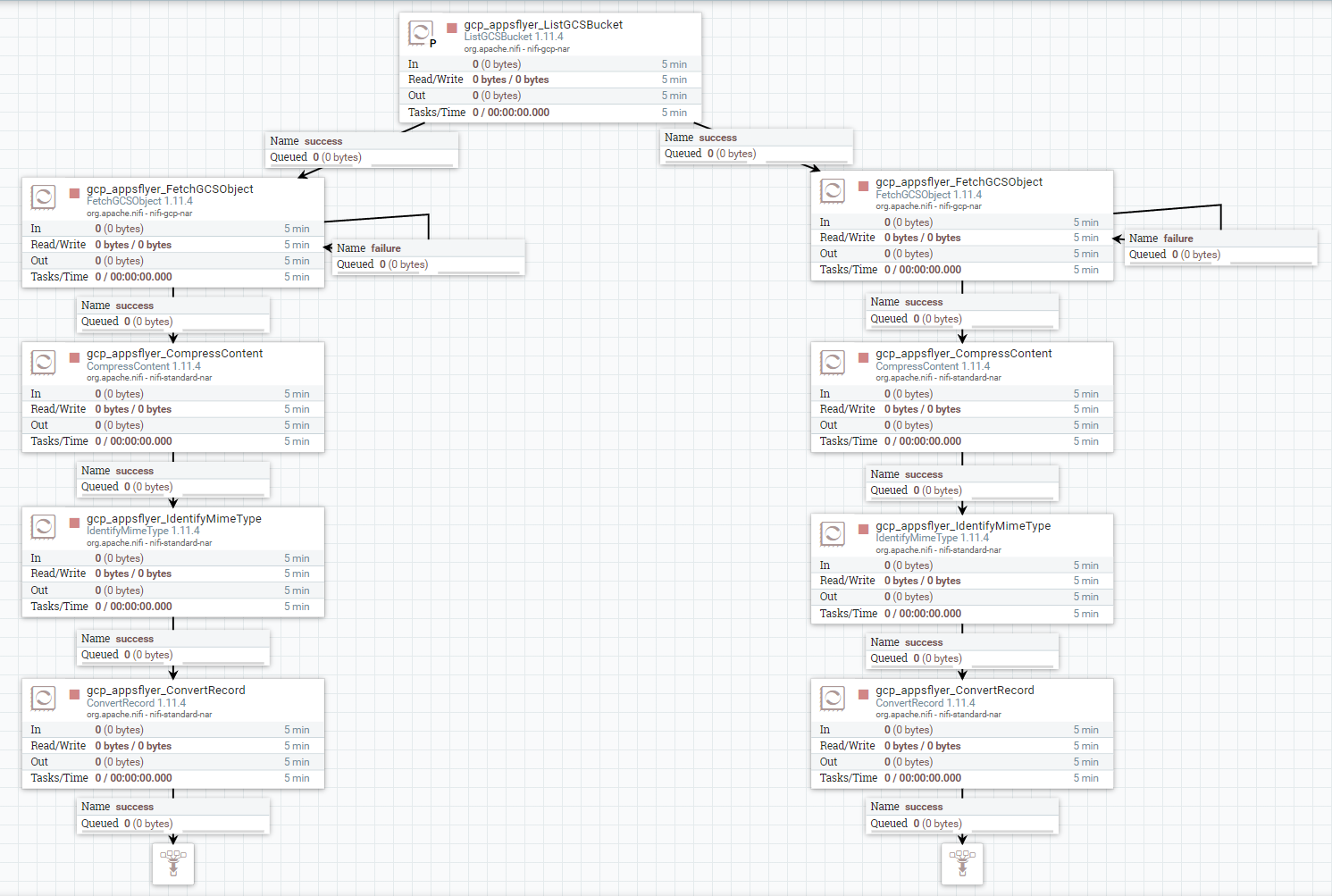
Cначала может показаться, что балансировку можно делать прямо после Fetch. Но это не лучший вариант, потому что на этапе Fetch будет уже много извлеченных из FS данных. В этом случае придется потратить ресурсы на распределение выгруженных данных.
Эталонный вариант использования балансировки при чтении из различных файловых систем — вот здесь.
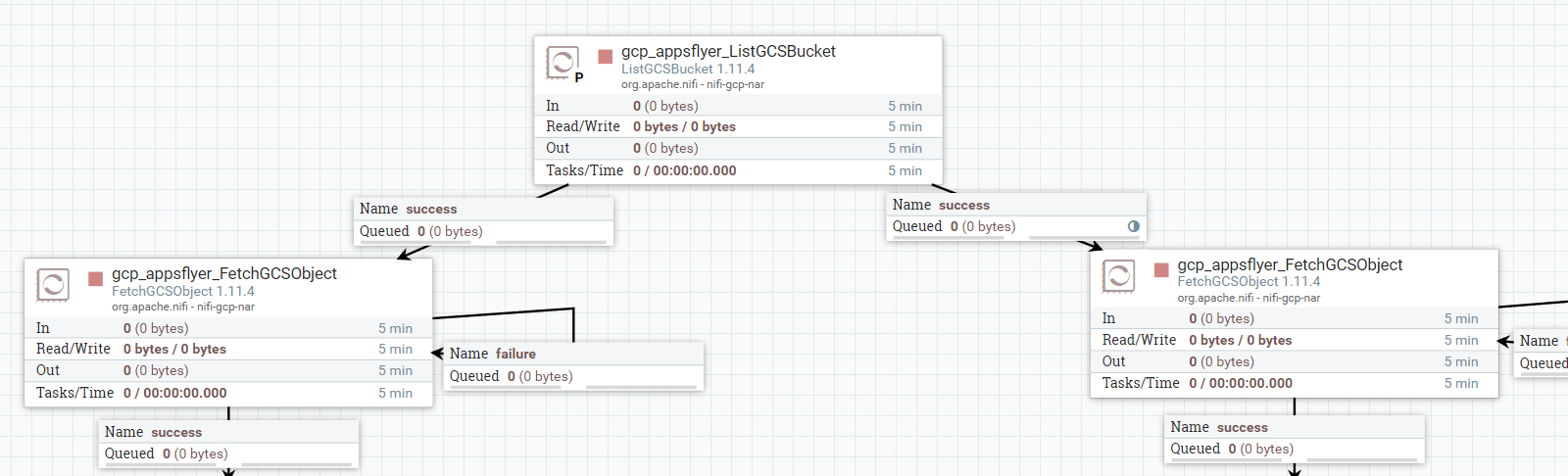
На этапе листинга будет очень мало данных, по сути, нам потребуется всего лишь распределить названия файлов, с праймари ноды по остальным. А процессор Fetch будет работать параллельно, используя свой кусок листинга на каждой из нод, и оптимально использовать ресурсы.
Но не буду голословным. Проверим на практике, есть ли какой-то смысл в этой балансировке.
Если запустить обе ветки, сразу становится видно, что сбалансированная сторона обгоняет несбалансированную. Когда слева не было обработано и половины файлов, справа — уже все.
Делаем два вывода:
- Нужно стараться балансировать меньший объем данных, если это возможно. Например: листинги путей FS, списки дат, иные сиквенсы.
- Чем раньше вы ставите балансировку, тем больше процессоров выполняются параллельно. Но не нужно повторять ее в каждой очереди, иначе эффект будет обратным.
Scheduling и его тонкости
Теперь давайте нырнем немного глубже. Ведь NiFi можно оптимизировать не только на уровне всего кластера, но и на уровне одной ноды. Для этого предусмотрено несколько параметров:
- Timer-Driven Thread Pool — это настройка NiFi, определяющая максимальное количество одновременно работающих процессоров (тредов процессоров) для одной ноды. Рекомендуемое значение — на уровне в 2-4 раза больше реального количества ядер CPU.
- Concurrent Tasks — параметр, определяющий количество используемых потоков для процессора. То есть если у вас n нод, а параметр процессора concurrent task установлен в значение m, максимально возможное число потоков для этого процессора = n*m.
- Execution — параметр процессора, определяющий, на каких нодах кластера он будет запускаться. То есть на всех нодах или только на primary.
- Run Duration — очень интересный параметр процессора, определяющий, как долго он должен работать с момента его запуска планировщиком (0 ms Lower Latency – 2000 ms Higher throughput).
Уровень общего concurrent tasks для кластера определяется через параметр Maximum Timer Driven Thread Count, при конфигурации этого параметра стоит начать с 2хCPU, затем медленно увеличивать при необходимости, следя за утилизацией ресурсов кластера.
Посмотреть значения параметра можно в Controller settings.
Мониторить утилизацию CPU можно через system diagnostics, значения актуальны в течение минуты.
Run Duration очень полезен, если, например, к вам летят микробатчи, чтобы собирался батч покрупнее и обрабатывался целиком.
Приведу пример — запустим генерацию файлов.
На Flow видно, как очередь разбухает. Нам это не нравится, и мы хотим что-то с этим сделать. Казалось бы, логично увеличить количество тредов. Я ставлю 2… и на скрине видно, что это не помогает. Можно, конечно, увеличивать и дальше, нам это рано или поздно поможет, но тут может возникнуть проблема с дефицитом ресурсов. Поэтому решение с раздуванием количества тредов выглядит так себе. Но если мы оставим concurrent tasks=1, и вместо него увеличим Run Duration, чтобы больше файлов успело пролететь за раз, ситуация изменится. Посмотрим, что из этого получается.
Очередь начала рассасываться, значит, метод помогает. Простой вывод из этой ситуации: оптимизация NiFi может быть хитрее, чем наращивание количества ресурсов на одну задачу.
Что делать, если Merge Record вас не радует?
И еще один вопрос, о котором я просто не могу не сказать, когда речь идет о NiFi — это проблемы с Merge Record. Я не могу дать 100% объяснения этого феномена, но когда я сам пользовался Merge Record, он доставил мне массу головной боли. Этот процессор не всегда точно склеивает файлы в батчи нужного размера. И никакая игра с параметрами порой не помогает. Я даже не допускал файлы с разными значениями атрибута merge, но так и не избавился от мелких файлов на выходе. В некоторых случаях такие проблемы приводят к падению скорости дальнейшей обработки файлов из-за их большого количества (в нашем случае — уже за рамками NiFi).
Что с этим можно сделать? Если коротко, то я советую переходить на Merge Content, который надежнее, чем Merge Record, и, судя по моим наблюдениям, всегда ожидаемо склеивает файлы в батчи нужного размера. К тому же Merge Content более производительный, потому что он не нуждается в парсинге Flow-файлов для дальнейшего слияния.
Лучше использовать Merge Content, если можете… хотя бы потому, что он просто производительнее.
Покажу это на реальном примере. В этом Flow происходит разветвление на Merge Record и Merge Content. Очередь Merge Content разгружается намного быстрее.
Но я понимаю, что бывают случаи, когда использование Merge Content невозможно, например если вам нужно соединять файлы на основе их содержания. Поэтому расскажу, как можно делать debug для Merge Record, чтобы посмотреть, почему он не склеивает файлы как надо. Может быть, это поможет вам найти проблему и жить дальше с Merge Record, если это необходимо.
После каждого Merge Record можно зайти в очереди и посмотреть Data Provenance.
Здесь можно увидеть, из каких именно файлов смерджен текущий файл, а в разделе details указывается причина, почему данный Flowfile смерджился. Исходя из этой причины можно понять, какой из параметров MergeRecord процессора нужно подкрутить, чтобы файлы мерджились так, как вы этого хотите.
Заключение
Подводя черту, скажу, что оптимизировать NiFi, конечно, нужно. Но делать это следует с умом. В итоге выделил бы следующие рекомендации.
- Чем раньше в Flow вы установите балансировку, тем больше процессоров будут параллельно выполняться на нодах кластера.
- Возможности queuing semantics некоторых коннекторов позволяют получить «native» балансировку.
- Балансируйте как можно меньшие данных (листинги, даты, сиквенсы).
- Помните, что процесс распределения данных по нодам — не бесплатный! Очень большой поток данных будет сильно нагружать кластер при распределении.
- Осторожно увеличивайте число concurrent tasks и только в узких местах (т. н. bottle neck), большие значения не помогут, т. к. будут упираться в доступные ресурсы и работать наносекунды, что несерьезно.
- Используйте Run Duration для микробатчей, чтобы увеличить пропускную способность процессора.
- Используйте MergeContent вместо MergeRecord, когда это возможно.
- Тестируйте Flow и его оптимизации на релевантных объемах данных, чтобы понять, будет ли польза от ваших действий.
Помните, что в итоге вы можете упираться не только в количество нод или потоков, а банально в физические возможности диска или в специфику работы конкретного процессора NiFi.
Merged partition content что это
тремя советами, в единый комплексный проект реализации Глобальной системы наблюдений за океаном в прибрежной зоне.
unesdoc.unesco.org
In pursuance of 30 C/Resolution 36 whereby the General Conference authorized the Executive Board to merge the General Information Programme (PGI) and the Intergovernmental Informatics Programme (IIP) into a new programme, the Commission recommended that the Board approve the creation of the Information for All Programme in replacement of the General Information Programme (PGI) and the Intergovernmental Informatics Programme (IIP), as well as the relevant Statutes of the Intergovernmental Council for the Information for All Programme.
unesdoc.unesco.org
Во исполнение резолюции 30 С/36, в которой Генеральная конференция уполномочила Исполнительный совет заменить Общую программу по информации (ОПИ) и Межправительственную программу по информатике (МПИ) новой программой, Комиссия рекомендовала Исполнительному совету одобрить создание программы «Информация для всех» взамен Общей программы по информации (ОПИ) иМежправительственной программы по информатике (МПИ), а также разработку соответствующего устава Межправительственного совета программы «Информация для всех».