Big Data Mapping: что такое маппирование больших данных
В этой статье рассмотрено, что такое маппирование больших данных, как это связано с Data Science, когда и как часто выполняется этот процесс, а также, какие программные инструменты позволяют автоматизировать Big Data mapping.
Что такое маппирование данных и где это используется
Представим, что в одной из корпоративных систем сведения о семейном положении сотрудника хранятся так, что «1» в поле «дети» означает их наличие. В другой системе эти же данные записаны с помощью значения «True», а в третьей – словом «да». Таким образом, разные системы для обозначения одних и тех же данных используют разные отображения. Чтобы привести информацию к единообразию, следует сопоставить обозначения одной системы обозначениям в других источниках, т.е. выполнить процедуру мэппинга данных (от английского map – сопоставление). В широком смысле маппирование – это определение соответствия данных между разными семантиками или представлениями одного объекта в разных источниках. На практике этот термин чаще всего используется для перевода или перекодировки значений [1].
Дисциплина управления данными, Data Management, трактует маппинг как процесс создания отображений элементов данных между двумя различными моделями, который выполняется в начале следующих интеграционных задач [2]:
- преобразование или передача данных между источником и приемником;
- идентификация отношений данных как часть анализа происхождения данных (data lineage);
- обнаружение скрытых конфиденциальных данных, при их маскировании или де-идентификации, например, когда один идентификатор содержится в другом;
- консолидация нескольких баз данных в одну и определение избыточных столбцов для их исключения.
Таким образом, маппирование данных представляет собой процесс генерации инструкций по объединению информации из нескольких наборов данных в единую схему, например, конфигурацию таблицы. Поскольку схемы данных в разных источниках обычно отличаются друг от друга, информацию из них следует сопоставить, выявив пересечение, дублирование и противоречия [3].
С прикладной точки зрения можно следующие приложения маппинга данных [4]:
- одноразовая миграция, когда данные перемещаются из одной системы в другую. После удачного завершения этого процесса новое место назначения становится местом хранения перенесенных данных, а исходный источник удаляется. В этом случае мапирование нужно для сопоставления исходных полей с полями назначения.
- Регулярная интеграция данных, когда выполняется периодический обмен данными между несколькими разными системами. Как и при вышеописанном переносе данных, маппинг нужен для сопоставления исходных полей с полями назначения.
- Преобразование данных из одного формата в другой, включая очистку (удаление пропущенных значений и дублей), изменение типов, агрегирование, обогащение и прочие преобразования.
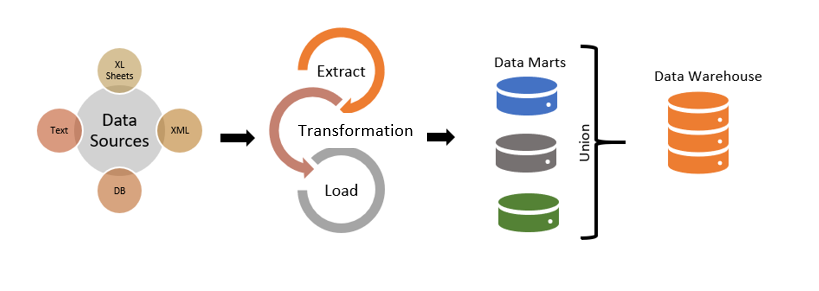
В Big Data мэппинг выполняется при загрузке информации в озеро данных (Data Lake) и корпоративное хранилище (DWH, Data Warehouse). Чем Data Lake отличается от DWH, рассмотрено здесь. В этом случае маппинг реализуется в рамках ETL-процесса (Extract, Transform, Load) на этапе преобразования. При этом настраивается соответствие исходных данных с целевой моделью (рис. 1). В случае реляционных СУБД для идентификации одной сущности в разных представлениях нужно с ключами таблиц и настройкой отношений (1:1, *:1, 1:* или *:*) [5].

В Data Science маппирование данных входит в этап их подготовки к ML-моделированию, когда выполняется формирование датасета в виде матрицы значений для обработки соответствующими алгоритмами. В частности, когда Data Scientist обогащает исходный датасет данными из сторонних источников, он занимается маппингом данных. Проводить процедуру дата мэппинга можно вручную или автоматически с помощью соответствующих подходов и инструментов, которые рассмотрены далее.
Особенности процесса дата мэппинга
На практике трудоемкость мэппинга зависит от следующих факторов [3]:
- размеры сопоставляемых датасетов;
- количество объединяемых источников информации;
- форматы схемы данных, в т.ч. первичные и внешние ключи в реляционных таблицах;
- различия между исходными и целевой структурами данных;
- иерархия данных.
Облегчить процесс маппирования можно за счет метаданных – сведениях о признаках и свойствах объектов, которые позволяют автоматически искать и управлять ими в больших информационных потоках. В частности, если каждое приложение будет выполнять публикацию метаданных, что позволит создать их стандартизированный реестр, то маппинг будет полностью автоматизированным [2]. Однако в большинстве случаев процесс мапирования данных не полностью автоматизирован и состоит из следующих этапов [4]:
- определение данных, которые нужно переместить, включая таблицы, поля в каждой таблице и формат поля после его перемещения. При регулярной интеграции также определяется частота передачи данных.
- сопоставление исходных полей с полями назначения;
- преобразование значений, включая кодирование формулы или правила преобразования;
- тестирование полученных результатов переноса (обогащения) путем сравнения их с образцами данных из первичных источников.
- развертывание production-решений по регулярной консолидации данных в соответствии с планом переноса или интеграции.
При работе с большими объемами данных выделяют 3 основных подхода к маппированию [2]:

- ручное кодирование, когда приходится писать код для консолидации данных из разных таблиц или форматов. Сюда же можно отнести сопоставление данных в графическом режиме, когда GUI специализированных программ позволяет пользователю рисовать линии от полей в одном наборе данных до соединения с другим источником. При этом «под капотом» автоматически генерируется программный код преобразования на SQL, XSLT, Java, C++ и прочих языках программирования. Такие графические средства часто встречаются в ETL-инструментах в качестве основного средства задания мэппингов для перемещения данных. Например, SAP BODS, Informatica PowerCenter и Talend Data Fabric (рис. 2).
- data-driven мэппинг, который сочетает оценку фактических значений данных в разных источниках данных с использованием эвристики и статистики для автоматического обнаружения сложных взаимосвязей между ними. Этот интеллектуальный подход используется для поиска преобразований между разными датасетами, выявления подстрок, конкатенаций, математический зависимостей, условных операторов и прочих логический преобразований. Также он позволяет найти исключения, которые не соответствуют обнаруженной логике преобразования. Обычно именно этот подход используется в специализированных системах подготовки данных к ML-моделированию, например, SAS, IBM SPSS и т.д.
- семантический маппинг похож на вышеописанный data-driven метод, но здесь к интеллектуальному сопоставлению также подключается реестр метаданных. Например, если в исходной системе указано FirstName, а в системе-приемнике есть поле PersonGivenName, сопоставление будет успешно выполнено, если эти элементы данных перечислены как синонимы в реестре метаданных. Семантическое сопоставление способно выявить только точные совпадения между столбцами данных, но не обнаружит никакой логики преобразования или исключений между столбцами. На практике этот подход применяется при интеграции реляционных СУБД и построении DWH.
Также стоит упомянуть полуавтоматическое маппирование в виде конвертирования схем данных, когда специализированная программа сравнивает источники данных и целевую схему для консолидации. Затем разработчик проверяет схему маппирования и вносит исправления, где это необходимо. Далее программа конвертирования схем данных автоматически генерирует код на C++, C # или Java для загрузки данных в систему приемник (рис. 3) [3].

Далее рассмотрим, какие инструментальные средства реализуют вышеперечисленные подходы.
Инструменты маппирования больших данных
Как и большинство прикладных решений, все средства для маппинга данных можно разделить на 3 категории [6]:
- проприетарные (on-premise), например, Centerprise Data Integrator, CloverDX, IBM InfoSphere, Informatica PowerCenter, Talend Data Integration. Как правило, эти продукты широко используются в корпоративном секторе.
- открытые (open-source), которые дешевле предыдущих аналогов и являются более легковесными с точки зрения функциональных возможностей. Однако их вполне достаточно для индивидуальных исследований Data Science. Наиболее популярными в этой категории считаются Pentaho, Pimcore, Talend Open Studio.
- облачныесервисы, такие как, Informatica Cloud Data Integration, Oracle Integration Cloud Service, Talend Cloud Integration, Dell Boomi AtomSphere, DX Mapper, Alooma, Jitterbit. Современные Cloud-решения считаются безопасными, быстрыми, масштабируемыми, относительно недорогими и удобными для использования. Поэтому их можно применять как в корпоративных, так и в личных целях.
Большинство перечисленных продуктов поддерживают все 3 подхода к маппированию: ручной (GUI и кодирование), data-driven и семантический. Однако, семантический мэппинг требует наличия реестров метаданных, что имеется далеко не в каждом предприятии. А публичные реестры метаданных, такие как национальные, отраслевые или городские репозитории [7] не всегда напрямую коррелируют, например, с задачами построения локального DWH. Но, наряду с открытыми государственными данными и другими публичными датасетами, их можно использовать в исследовательских DS-задачах.
При выборе конкретного инструмента для маппинга больших данных стоит учитывать следующие факторы:
- cложность данных – объемы, разнообразие форматов и схем. Этот критерий непосредственно связан со спецификой задачи. Например, если требуется обогатить не слишком большой датасет для ML-моделирования, сопоставив данные из нескольких источников, Data Scientist может воспользоваться простым облачным сервисом или написать собственный скрипт. Однако, в случае регулярной загрузки информации из множества СУБД в корпоративное хранилище или озеро данных, необходимо выбирать надежное ETL-средство enterprise-уровня.
- расширяемость– наглядный GUI повышает удобство пользования, однако, на практике часто возникает задача кастомизации автоматически сгенерированных соответствий. Поэтому инструмент маппирования должен включать возможность править созданные мэппинги, настраивать правила и писать собственные преобразования в виде программных скриптов.
- стоимость, включая все затраты на приобретение, использование, техническую поддержку и прочие расходы.
Резюме
Итак, маппирование данных – это важная часть процесса работы с данными, в том числе и для Data Scientist’а. Эта процедура выполняется в рамках подготовки к ML-моделированию, в частности, при обогащении датасетов. В случае одноразового формирования датасета из нескольких разных источников сопоставление данных можно выполнить вручную или с помощью самописного Python-скрипта. Однако, такой подход не применим в промышленной интеграции нескольких информационных систем или построении корпоративных хранилищ и озер данных. Поэтому знание инструментов дата мэппинга пригодится как Data Scientist’у, так и Data Engineer’у. Наконец, сопоставление данных с целью избавления от дублирующихся и противоречивых значений входит в задачи обеспечения качества данных (Data Quality) [4]. В свою очередь, Data Quality относится к области ответственности стратега по данным и инженера по качеству данных. Таким образом, понимание процесса маппирования необходимо каждому Data-специалисту.
- https://ru.wikipedia.org/wiki/Мапирование
- https://en.wikipedia.org/wiki/Data_mapping
- https://www.xplenty.com/blog/data-mapping-an-overview-of-data-mapping-and-its-technology/
- https://www.talend.com/resources/data-mapping/
- https://habr.com/ru/post/248231/
- https://dzone.com/articles/what-is-data-mapping
- https://en.wikipedia.org/wiki/Metadata_registry
Что такое хранилище данных Data Warehouse и зачем оно бизнесу
Рассказываем, что такое Data Warehouse, какие у этой технологии особенности и зачем ее используют компании.
В статье рассказываем, что такое Data Warehouse, какие у этой технологии особенности и зачем ее используют компании.
Что такое Data Warehouse
Обычно данные в организациях хранятся «разрозненно». В бухгалтерии одна система хранения, в логистике и прочих отделах — другая. Желательно, чтобы эти системы хранения не пересекались — и в этом есть логика. Так, например, информация о финансовых поступлениях и налоговых отчислениях не будет доступна никому, кроме сотрудников отдела бухгалтерии.
Но эта «разрозненность» вызывает много вопросов. Например, как подготовить аналитику состояния компании за год? Как объединить данные из разных источников и информационных систем в одном месте? Ведь база данных (БД) склада хранит только информацию о складских запасах, а база отдела кадров — данные о сотрудниках. Как их очистить, структурировать и анализировать? На помощь приходит Data Warehouse.
Data Warehouse (DWH) — это хранилище, в которое из разных систем хранения собираются исторические данные компании. Это некая библиотека, в которой упорядочена и каталогизирован весь объем информации. Она может быть в основе, например, платформы обработки данных.
Признаки и особенности DWH:
- Аналитику не нужно запрашивать доступы к базам данных разных отделов. Все хранится в одном месте, при этом в DWH могут храниться агрегированные данные за десятки лет.
- Данные в хранилище добавляются, удаляются, очищаются, выгружаются. К этому хранилищу выполняются запросы, также с ним производятся другие манипуляции.
- При использовании систем бизнес-аналитики (BI) совместно с DWH у пользователей появляется возможность искать закономерности и взаимосвязи в данных, аналитически обрабатывать и визуализировать информацию. Аналитик изучает данные из хранилища, формирует отчет, подкрепляя статистической информацией, визуализирует.
Корпоративное хранилище данных, КХД
DWH называют хранилищем данных или корпоративным хранилищем данных (КХД). Это хранилище структурированных данных, с одной широкой или большим количеством отдельных таблиц.
DWH не только хранят данные, но и выполняют вычисления, так как аналитические — например, OLAP — запросы зачастую требуют много ресурсов. Например, представим гигантский ангар, заставленный полками вдоль и поперек, а полки — вещами в коробках, пакетах, пленке. Здание поделено на секции для канцтоваров, ГСМ, средств гигиены и прочего.
Если просто использовать ангар как склад — это будет простое хранилище. Но если добавить на все коробки штрих-коды, а на входе и выходе — лазерные сканеры для их считывания, то условный завхоз сможет отслеживать насколько заполнены стеллажи. Это полезно, если ему нужно прогнозировать, например, расход материалов — чтобы они не простаивали и не перегружали стеллажи. Такой прокачанный ангар — это хранилище данных, DWH.
Трехуровневая архитектура хранилища данных
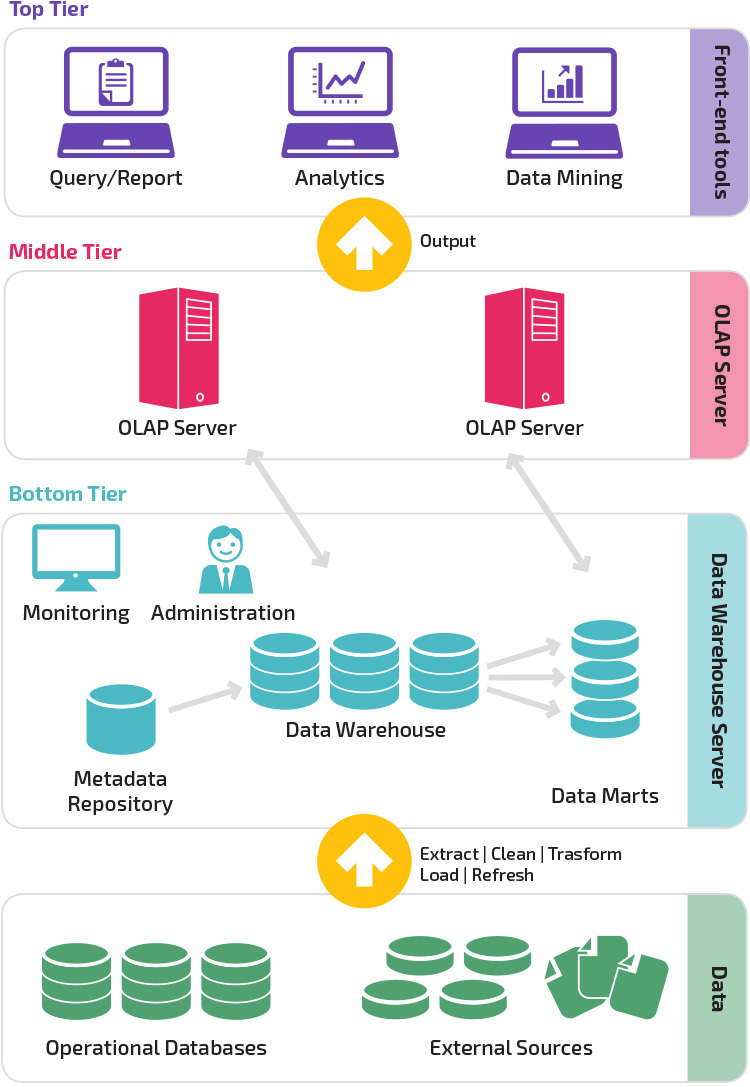
В традиционном виде часто архитектура хранилища данных состоит из трех уровней.
- Нижний уровень — база данных (или даже несколько), которые объединяют в себе данные из различных источников информации — например, из транзакционных СУБД или SaaS-сервисов.
- Средний уровень — сервисы и приложения, которые преобразуют данные в специальную структуру для анализа и сложных запросов (уровень моделирования, либо семантической слой). Это может быть сервер OLAP, например, который работает в качестве расширенной системы управления реляционными базами данных. И отображает операции над многомерными данными в стандартных реляционных операциях.
- Верхний уровень — инструменты для создания отчетов, визуализации и последующего анализа данных. Его также называют уровнем клиента.
Концептуально все понятно — рассмотрим DWH подробней, через призму LSA.
Облачное объектное хранилище Selectel
Храните данные для работы сервисов, аналитики и обучения ML-моделей. Обеспечим моментальное масштабирование и репликацию.
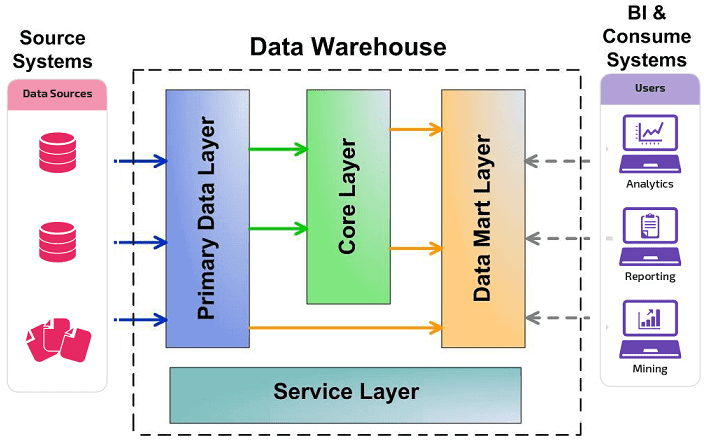
Полная архитектура хранилища данных
Одна из моделей проектирования Data Warehouse — «слоеный пирог», построенный по архитектуре LSA, Layered Scalable Architecture. Она реализует логическое деление структур с данными на несколько функциональных уровней:
- Стейджинг (Primary Data Layer) — уровень, на котором подгружаются данные из внешних источников. Например, из таблиц, ERP-системы или биллинговой системы.
- Ядро хранилища (Core Data Layer) — центральный уровень, который подгоняет данные к единым структурам и ключам. На этом слое обеспечивается целостность и качество данных.
- Аналитические витрины (Data Mart Layer) — слой, который преобразует данные к структурам, удобным для анализа и использования в BI-дашбордах и других аналитических системах.
- Сервисный слой (Service Layer) — уровень, на котором обеспечивается управление предыдущими слоями, мониторинг и диагностика ошибок.
Визуально LSA-архитектуру Data Warehouse можно представить так:
Проектирование хранилища данных: модели Кимбалла и Инмона
Существует две модели, описывающие то, как должны быть устроены хранилища данных. Их идейные вдохновители — Билл Инмон, «отец хранилищ данных», и Ральф Кимбалл, идейный лидер в области хранилищ многомерных данных.
Хранение данных по модели Инмона
По модели Инмона (Inmon) данные из источников должны поступать в хранилище после процесса ETL (Extract, Transformation, Load).
Хранение данных по модели Кимбалла
По модели Кимбалла (Kimball) после процесса ETL данные загружаются в витрины данных, а объединение витрин создает концептуальное (а не фактическое) хранилище данных.
От выбора двух подходов будет зависеть исходный результат. Представим хранилище в виде картотеки — библиотечного шкафа с карточками, в котором хранятся данные.
- По Инмону мы сначала берем 10 карточек, выписываем из них самое важное на листочек и кладем в шкаф. Подобный подход используют в страховании. Сначала формируют общую картинку о всех застрахованных, собирают данные о доходе, возрасте, хронических болезнях, распространении определенных болезней в регионе, демографии, авариях на дорогах и пр. Все аспекты взаимосвязаны, поэтому сначала собираются все возможные данные, а после фильтруются и ложатся в основу модели.
- По Кимбаллу мы начинаем с нескольких ящиков (витрин данных), а потом решаем, что сложить в общий шкаф. Такой подход используют, например, в маркетинге: чтобы анализировать рекламные кампании не нужно знать абсолютно все, к метрикам нужно подходить выборочно.
При создании DWH также следует учитывать и специфику данных, взаимосвязи внутри групп данных, связи между ними, типы преобразования данных, частоту обновления, взаимосвязь между объектами хранилища, процессы передачи, резервного копирования, восстановления.
Архитектуры облачных хранилищ данных Amazon Redshift, Google BigQuery, Panoply
Последние несколько лет хранилища данных перемещаются в гипероблака вроде Amazon, Google, Microsoft Azure или облачные сервисы вроде Snowflake, Panoply и их аналоги. Агрегаторы постепенно прекращают придерживаться традиционной архитектуры DWH и создают собственные. Например, Amazon Redshift и Google BigQuery. В их основе — различные механизмы вроде MPP и Dremel. Подробнее о новых архитектурах облачных хранилищ можно почитать по ссылке.
Чем DWH отличается от базы данных, Data Lake и Data Mart
Базы данных и хранилища данных — это разные вещи
Многие базы данных — OLTP, рассчитаны на операционную нагрузку, поэтому они выполняют много небольших операций записи, изменения и удаления. В остальном, можно выделить следующие признаки для баз данных:
- информация в первую очередь хранится,
- информация от разных информационных систем компании хранится в разных БД (например, у службы поддержки и отдела логистики БД разные — никто не будет их объединять),
- обновления выполняют конечные пользователи с помощью специальных команд (SQL),
- существуют сложности с агрегированием данных.
С Data Warehouse ситуация другая, хранилище:
- объединяет массивы данных из различных источников — начиная от отдела продаж, заканчивая данными о транзакциях,
- обновляет операционные данные не в real-time, а с некоторой периодичностью — например, раз в час,
- консолидирует данные вместе,
- позволяет получать ответы на большие аналитические запросы (OLAP).
DWH — единый источник информации, основанный на структурированных и неструктурированных данных бизнеса. Инструмент, который используется для аналитики и обнаружения закономерностей и взаимосвязей в данных, которые появляются со временем.
Витрины данных и хранилища данных — разные вещи
Витрины нужны для того, чтобы предоставлять обработанные данные в BI- или отчетную систему, наряду с этим:
- витрины ограничены — подразделением или направлением бизнеса,
- они строятся из данных, которые запрашивают чаще других, поэтому витрины создавать легче и быстрее, чем хранилища,
- комплекс из нескольких витрин обычно ведет к потере целостности данных, потому что сложно обеспечить управление данными и контроль между витринами,
- доступ к историческим данным ограничен.
Озера данных и хранилища данных — не одно и то же
Они отличаются архитектурно и функционально.
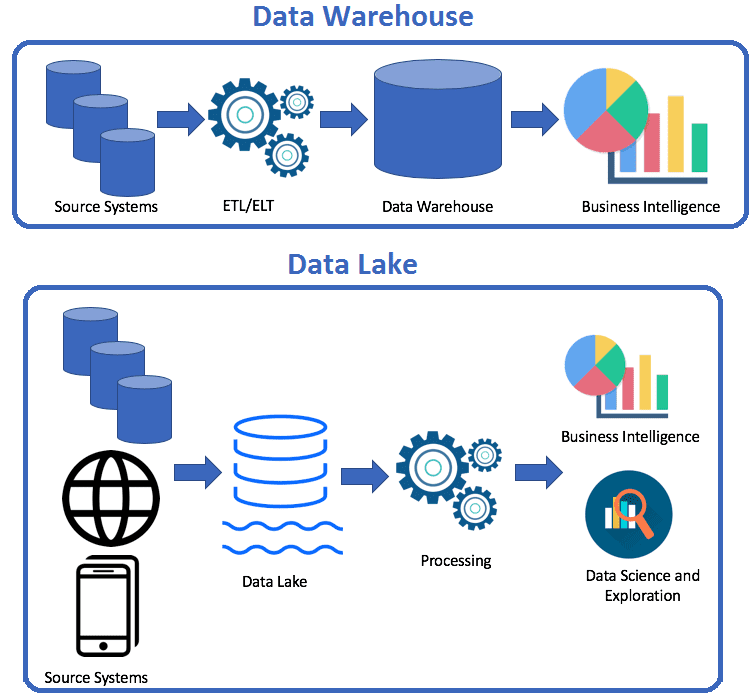
DWH как инструмент для анализа данных
«Озера данных», или Data Lake, используют для хранения неформатированных, неструктурированных данных из большого количества внешних источников. Они могут строиться, например, на базе облачного хранилища (S3) и быть дешевле в работе. DWH же предназначены не только для хранения, но и для анализа данных.
Подробнее о разнице между Data Lake и Data Warehouse читайте по ссылке →
Для чего крупному бизнесу хранилище данных
Мы уже определили, что хранилище данных — это информационная система, предназначенная для подготовки отчетов и бизнес-анализа. Наряду с этим DWH помогает:
- безопасно хранить данные в одном месте из множества источников,
- создавать специальные отчеты и работать со сложными запросами,
- преобразовывать данные в стандартный формат даже из устаревших систем,
- очищать и удалять некачественную информации, обнаруживать повторяющиеся, поврежденные или неточные наборы данных,
- сократить общее время обработки для анализа и отчетности,
- хранить большое количество исторических данных.
Что такое Data Warehouse (DWH)?

Использование Data Warehouse — это один из способов хранения данных. Это отличный вариант для бизнеса, которому необходимо просматривать огромное количество информации из множества источников.
В этой публикации мы рассмотрим, что представляет собой DWH и как оно может помочь вам анализировать вашу информацию.
Data Warehouse: что это?
Хранилище данных или DWH — это Data Management System, включающая в себя огромное количество информации из множества источников. Бизнесы используют Data Warehouse для создания отчетов и аналитической обработки. Используя хранилище, руководители компаний могут обосновывать важные решения, подкрепляя свои идеи качественными и количественными данными.
С помощью DWH вы можете выполнять запросы и просматривать историческую информацию с течением времени, чтобы улучшить процесс принятия решений.
Data Warehouse будет получать информацию из множества источников, включая Relational Databases, транзакционные системы. Для подключения к информации аналитики могут пользоваться Business Intelligence Tools, которые помогают собирать, анализировать, визуализировать, а также составлять отчеты по данным. Поскольку информация постоянно продолжает развиваться, компаниям необходимо использовать ее, чтобы оставаться конкурентоспособными.
Зачем использовать Data Warehouse?
Конечным результатом создания DWH является:
- получение информации;
- мониторинг производительности;
- улучшение процесса принятия решений.
Используя отчеты, информационные панели и визуализации, аналитики получают все инструменты, необходимые для принятия правильных решений.
Отличие Data Warehouse и других терминов
Когда вы впервые слышите термин «хранилище данных», вы можете подумать о некоторых других терминах, таких как «озеро данных», «база данных» или «витрина данных». Однако это разные вещи, потому что они имеют более ограниченную область применения. Хотя они могут выполнять схожую функцию, структура отличается.
Давайте рассмотрим отличия подробнее:
- Data Warehouse и Database
Базы данных часто путают с хранилищами, потому что они служат схожей цели. Но следует знать, что Data Warehouse и Database — это разные понятия, поскольку функциональные возможности каждой из них существенно разнятся.
Отличие в том, что Database не предназначены для анализа большого количества информации. Базы данных используются для записи и извлечения информации, а DWH предназначены для анализа больших ее объемов. Можно посмотреть на это так: хранилища содержат информацию из нескольких баз данных.
- Хранилище данных и Data Lake
Кроме того, DWH отличается от Data Lake. В “озере данных” хранятся Raw Data из нескольких источников, которые используются для определенной цели. Это означает, что вы просматриваете необработанную информацию из чего-то вроде социальных сетей или приложения. Наборы данных создаются во время анализа. Это недорогое хранилище для неотформатированной, неструктурированной информации.
С другой стороны, DWH используются для анализа и обработки информации. В хранилище она уже собрана, согласована с контекстом и готова к анализу. В конечном счете, DWH — это более совершенный инструмент хранения информации, который может использовать большие объемы исторических данных.
- Data Warehouse и Витрина данных
Витрины данных или Data Mart представляет собой часть DWH. Обычно они предназначены для простой доставки определенной информации конкретному пользователю для конкретного приложения. Витрины данных по своей природе являются одним предметом, а хранилища охватывают несколько предметов.
Data Mart — это часть хранилища данных. Обычно они предназначены для простой доставки определенной информации конкретному пользователю в конкретном приложении. Еще разница в том, что витрина данных является одним предметом, а DWH охватывают несколько предметов.
3 типа Data Warehouses
- Enterprise Data Warehouse
Корпоративное хранилище — это центральные Databases. Информация в них систематизируется, классифицируется и служит для поиска решений. Такие базы данных будут маркировать, а также разделять информацию по категориям для облегчения доступа.
- Operational Data Store или Хранилище оперативных данных
В то время как Enterprise Data Warehouse лучше подходит для долгосрочных решений в компаниях, Operational Data Store предпочтительнее использовать для повседневной рутинной деятельности. Operational Data Store постоянно предоставляет обновленную информацию и хранит ту, которая относится к выбранной деятельности.
- Data Mart или Витрина данных
Витрина данных — это часть DWH. Она разработана для поддержки определенного отдела, команды или функции. Любая передаваемая информация автоматически сохраняется и упорядочивается для последующего использования.
Архитектура хранилища данных
Data Warehouse Architecture — это метод, который вы используете для организации, передачи и представления информации.
Вы можете использовать:
- Basic Data Warehouse или базовую архитектуру;
- Data Warehouse With Staging Area или хранилище с промежуточной областью;
- Data Warehouse With Data Marts или хранилище с промежуточной областью и витриной данных.
Это означает, что вы можете получить данные из DWH, а затем позволить пользователям просматривать отчеты и анализ. Или вы можете разбить их на Data Marts, прежде чем пользователи увидят анализ и отчеты.
Промежуточная область или Staging Area, которую вы видите на некоторых изображениях ниже, используется для очистки и обработки данных перед их помещением на DWH. Это упрощает их подготовку. Рассмотрим детальнее каждую архитектуру хранилища.
- Basic Data Warehouse
Базовое хранилище данных направлено на минимизацию общего объема информации в файлах, которые хранятся в системе. Он делает это, удаляя любую избыточность в информации, делая ее ясной и легкой для просмотра.
Как вы можете видеть в приведенном ниже примере, эта концепция централизует информацию из различных источников. Затем сотрудники получают доступ к данным прямо со DWH. Эта система полезна для малого и среднего бизнеса, которым нужен простой подход к хранению данных.

- Data Warehouse With Staging Area
Некоторые хранилища очищают и обрабатывают данные перед перемещением файлов в DWH. В этих системах есть «промежуточные области», где информация просматривается, оценивается, затем удаляется или передается на склад. Это гарантирует, что в программном обеспечении будут храниться только актуальные и полезные данные.
Если вы посмотрите на пример ниже, вы увидите, что промежуточная область или Staging Area расположена между источниками данных и хранилищем. Для предприятий, обрабатывающих большие объемы информации о клиентах, этот процесс будет отфильтровывать нерелевантную информацию, невыгодную вашей команде.

I am text block. Click edit button to change this text. Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.
- Data Warehouse With Staging Area and Data Marts
Data Marts или витрины данных добавляют еще один уровень настройки вашего DWH. После того как информация обработана и оценена, Data Marts упорядочивают ее для групп и сотрудников, которые в ней больше всего нуждаются. Это делает ваши отделы значительно более продуктивными, поскольку информация о клиентах доставляется непосредственно им.
В приведенном ниже примере мы можем увидеть, как витрины данных используются для отправки информации в группы продаж и инвентаризации. Это помогает бизнес-лидерам быстрее принимать решения и извлекать выгоду из своевременных маркетинговых возможностей.

Преимущества использования хранилища данных
Основными преимуществами использования DWH являются:
- Доступ к историческим данным
Большим преимуществом хранения файлов в DWH есть возможность просматривать большой объем исторической информации с течением времени. С помощью хранилища вы можете консолидировать большой объем информации из многих источников, чтобы лучше информировать свои бизнес-решения. Просмотр исторических данных позволит вам анализировать тенденции с течением времени и эффективно вырабатывать стратегию.
- Комбинирование данных из нескольких источников
С DWH вы будете получать данные из нескольких источников, поэтому у вас будет более полная информационная картина, когда придет время проводить анализ. Например, с витриной вы получаете информацию только от одного субъекта, в отличие от DWH, поскольку они обрабатывают и организуют данные из множества источников.
DWH представляет собой стабильный источник, который используется для просмотра информации на высоком или детальном уровне. В результате этого вы можете внимательно просматривать информацию, а также с высокой скоростью обрабатывать запросы. Data Warehouse содержит высококачественные данные, так как они идут с множества источников, являются согласованными и более точными.
Что такое Data Warehouse (DWH) и зачем крупному бизнесу корпоративное хранилище данных
Данные — новая нефть. Чем больше их у компании, тем эффективнее она сможет привлекать новых клиентов, разрабатывать стратегии развития и укреплять свою позицию на рынке.
Для хранения данных используются специальные типы хранилищ — Data Warehouse. Разберемся, чем DWH отличается от других способов хранения данных, как используются такие решения и для каких компаний они актуальны.
DWH: чем отличается корпоративное хранилище от обычных БД
Бизнес стал активно интересоваться корпоративными хранилищами еще в конце прошлого века. Их внедряли для увеличения скорости реагирования на изменения, мониторинга показателей эффективности и автоматизации процессов. Разные приложения отвечали за разные процессы: одни использовались для финансовых операций, другие — для координации цепочек поставок, третьи помогали анализировать показатели продаж.
Однако такой подход привел к тому, что ключевые данные бизнеса хранились разрозненно. Компаниям требовалось решение, которое бы позволило анализировать информационную картину целиком, а не данные из разных систем по отдельности.
Для решения этой проблемы был создан особый инструмент — корпоративное хранилище данных, или Data Warehouse. Фактически DWH — это предметно-ориентированная база данных, которая консолидирует важную бизнес-информацию и позволяет в автоматическом режиме подготавливать консолидированные отчеты.
Data Warehouse — это единое корпоративное хранилище архивных данных из разных источников (систем, департаментов и прочее). Цель Data Warehouse — обеспечить пользователя (компанию и ее ключевых лиц) возможностью принимать верные решения в ключе управления бизнесом на основе целостной информационной картины.
DWH — это не просто база данных
Корпоративное хранилище данных отличается от обычных БД, используемых в бизнесе, по нескольким параметрам:
- Тип и источник данных
Обычные БД хранят данные от конкретных информационных систем компании. Например, в базе данных HR-отдела мы увидим информацию о сотрудниках, а вот данных о поставках там не будет. DWH строится по другому принципу: такое корпоративное хранилище консолидирует в себе информацию от всех департаментов компании — от статистики продаж до сведений о сотрудниках. - Объем данных
Обычные базы используются для хранения только актуальной информации — в ней не имеет смысла хранить данные за несколько лет работы предприятия. В Data Warehouse, наоборот, стекаются исторические данные и архивные сведения. Например, заглянув в DWH, можно получить информацию о всех сделках за последние несколько лет. - Роль в бизнес-процессах
Изначально данные хранятся в обычных БД и уже оттуда поступают в DWH. Иными словами, Data Warehouse всегда содержит последние версии данных.
Как бизнес использует DWH
DWH — не только склад важных данных компании, но еще и основа бизнес-аналитики (BI). Именно из корпоративного хранилища компания получает сведения, необходимые для принятия управленческих и стратегических решений.
Давайте на простом примере посмотрим, как это работает.
- У крупного интернет-ретейлера зафиксировано снижение продаж. Для решения проблемы привлекается бизнес-аналитик.
- Специалист, получив доступ к DWH, начинает изучать ключевые показатели: размер выручки, количество клиентов, издержки и прочее.
- После этапа изучения аналитик формирует отчет, в котором, на основе полученных из Data Warehouse данных, указаны причины возникновения проблемы. Результат отчета подкрепляется статистической информацией.
- Принимающие решения лица на основе сведений из аналитического отчета, принимают эффективные меры по увеличению уровня продаж, например, корректируют стратегии и политики продвижения продуктов компании.
Корпоративное хранилище позволяет не искать решение вслепую, а выявить источники проблемы. Обычные базы данных просто не позволяют этого сделать, потому что:
- не хранят исторических сведений;
- данные из разных БД хранятся разрозненно, не давая единой информационной картины;
- на поиск и сопоставление информации из обычных БД уйдет внушительное количество времени и других ресурсов.
Почему DWH — эффективный инструмент аналитики
Корпоративное хранилище играет роль большого склада данных. Давайте посмотрим, в погоне за какими возможностями компании организовывают DWH.
- Оперативный доступ к нужной информации
Чем крупнее компания — тем больше в ней отделов, каждый из которых генерирует свои потоки данных. И тем сложнее аналитику получить быстрый доступ к нужным сведениям. Только представьте: для анализа одной проблемы необходимо запрашивать доступы и разрешения к разным БД разных департаментов. Пока аналитик получит все необходимые ему сведения, пройдет очень много времени. DWH решает эту проблему, обеспечивая быстрое получение всей необходимой информации. - Продолжительная сохранность данных
Как правило, обычные БД не используются для хранения информации за десять последних лет работы компании. А вот для DWH такой срок — абсолютная норма. При этом все данные хранятся в оптимальном формате, включая агрегированные значения. - Исключение влияния бизнес-аналитики на другие процессы и системы
Если аналитическому отделу вдруг понадобятся большие массивы данных и специалисты пойдут выгружать их из DWH, нагрузка на хранилище не повлияет на работу других информационных систем и бизнес-приложений.
Структура DWH
Data Warehouse состоит из нескольких уровней:
- Область сбора первичных данных. Сюда стекается информация из разных отделов компании и БД.
- Ядро. Вся поступившая в DWH разрозненная информация приводится к нужным структурам и ключам. Именно этот ключевой компонент хранилища обеспечивает целостность и полноту данных.
- Витрины аналитики. Данные преобразовываются в массивы, которые удобно использовать для решения конкретных задач. Такие витрины могут быть первичными (помогают решать относительно простые задачи) и вторичными (для сложных аналитических отчетов и нетиповых задач).
- Сервисный слой. Отвечает за управление тремя предыдущими уровнями. Обеспечивает мониторинг данных и оперативное устранение ошибок.
DWH и Business Intelligence
Актуальные инструменты бизнес-аналитики (BI) вкупе с возможностями DWH позволяют принимать управленческие решения с гарантированным результатом. Благодаря эффективному анализу больших массивов данных менеджмент компании также может выдвигать гипотезы, построенные на реальных бизнес-показателях, и тестировать их.
Data Warehouse не только помогает решать конкретные прикладные задачи (например, увеличение прибыли, снижение издержек), но и выстраивать стратегию развития компании на основе data-driven подхода.