Что такое CLI? (интерфейс командной строки)?

Интерфейс командной строки (CLI) – это программный механизм, используемый для взаимодействия с операционной системой с помощью клавиатуры. Другой механизм – графический пользовательский интерфейс (GUI), распространенный сегодня во всех приложениях и программных системах. Его можно использовать для визуальной навигации и выполнения действий посредством нажатия значков и изображений. Однако графический интерфейс неэффективен для задач системного администрирования, особенно в виртуальной или удаленной среде. В интерфейсе командной строки можно вводить текстовые команды для настройки, навигации или запуска программ на любом сервере или компьютерной системе. Все операционные системы, включая Linux, macOS и Windows, имеют CLI для ускорения системного взаимодействия.
В чем заключаются основные преимущества CLI?
Интерфейс командной строки (CLI) предлагает несколько преимуществ.
Эффективность
Чтобы не тратить время на поиск отдельных файлов и переходы между ними, можно использовать интерфейс командной строки для выполнения действий с несколькими файлами с помощью одной текстовой команды. Если вы освоили эти команды, то сможете быстро ориентироваться в системе и взаимодействовать с ней. Для автоматизации монотонных или повторяющихся задач можно также создавать сценарии, выполняющие несколько команд в CLI.
Удаленный доступ
Приложения CLI часто потребляют меньше сетевых ресурсов по сравнению с графическими приложениями, что позволяет использовать их в системах с ограниченными аппаратными возможностями или в удаленных серверных средах.
Вы можете управлять серверами удаленно, передавая команды через защищенную оболочку, даже при использовании подключений с низкой пропускной способностью. Это предпочтительный метод управления серверами и облачными инстансами, особенно в средах без заголовков, в которых нет графического интерфейса.
Поиск и устранение неполадок
Для разработчиков и системных администраторов работа с интерфейсами командной строки является ценным навыком, способствующим более глубокому пониманию базовой системы. С его помощью можно лучше ориентироваться в различных инструментах и утилитах, а также улучшить работу с ошибками.
Например, можно использовать интерфейс командной строки для просмотра системных журналов и быстрого поиска исчерпывающих сообщений об ошибках и данных об отладке. Текстовые команды также можно легко задокументировать, чтобы обеспечить возможность воспроизведения задач и упростить устранение неполадок в будущем.
Для чего используют CLI?
Интерфейс командной строки (CLI) можно использовать во многих случаях благодаря его универсальности. К примеру, если вы являетесь системным администратором, инженером-программистом, специалистом по обработке данных или техническим пользователем, который хочет получить больше контроля. Далее представлены несколько примеров.
Системное администрирование
Системные администраторы используют интерфейсы командной строки для устранения проблем, связанных с системой, проверки конфигураций операционной системы и изменения или обновления конфигураций на удаленных компьютерах. Они могут выполнять команды и управлять системами в любом масштабе.
Разработка программного обеспечения
Разработчики программного обеспечения регулярно используют инструменты CLI для экономии времени и оптимизации рабочих процессов. Например, во время работы они часто обращаются к сторонним библиотекам. Если добавлять ссылки на эти библиотеки с помощью CLI, то достаточно будет вводить одну команду, а не отправлять инструкции по поиску библиотеки с помощью графического интерфейса. Такой подход экономит как время разработчика, так и время будущих пользователей, взаимодействующих с системой.
Облачные вычисления
В облачных средах интерфейс командной строки необходим для управления виртуальными машинами, контейнерами, облачными сервисами и конфигурациями серверов. Разработчики и администраторы используют интерфейсы командной строки для взаимодействия с API поставщиков облачных услуг, автоматизации предоставления ресурсов и развертывания приложений.
Управление сетями
Сетевые администраторы используют интерфейсы командной строки для настройки маршрутизаторов, коммутаторов, брандмауэров и других сетевых устройств. Инструменты CLI помогают отслеживать сетевой трафик, устранять проблемы с подключением и внедрять политики безопасности. Специалисты по тестированию на проникновение также используют инструменты командной строки для поиска уязвимостей, исследования сети и анализа инцидентов.
В чем состоит принцип работы CLI?
Интерфейс командной строки (CLI) – это текстовый интерфейс, в котором можно вводить команды, взаимодействующие с операционной системой компьютера. Интерфейс командной строки работает с помощью стандартной оболочки, которая находится между операционной системой и пользователем.
Оболочка интерфейса командной строки
Оболочка – это программа, которая является посредником между пользователем и операционной системой. В качестве примеров можно упомянуть Bash, cmd.exe, PowerShell и другие оболочки для реализации конкретных функций.
Оболочка отвечает за выполнение различных задач, таких как синтаксический анализ команд, управление средой и выполнение процессов. Оболочки также предоставляют указанные возможности:
- история команд, в которой можно получить доступ к ранее запущенным командам с помощью клавиш со стрелками или других сочетаний клавиш;
- перенаправление входных и выходных сигналов;
- система водопровода – подключение выхода одной команды к входу другой и управление переменными среды.
Кроме того, вы можете настроить среду оболочки. Для этого необходимо установить переменные среды, определить псевдонимы (ярлыки для более длинных команд), а также создать сценарии оболочки для автоматизации или повторения задач.
Как работают команды
Когда вы вводите команду в CLI, выполняются такие действия:
- Оболочка-интерпретатор командной строки выполняет синтаксический анализ введенной команды, чтобы понять ее структуру и разделить имя команды, параметры и аргументы.
- Оболочка ищет имя команды в списке доступных команд. Имя команды представляет собой действие, которое пользователь намерен выполнить с помощью операционной системы.
- В системной переменной PATH (список каталогов, в которых находятся системные файлы) выполняется поиск соответствующего файла, связанного с командой.
- Оболочка CLI вызывает соответствующий файл, передавая любые указанные параметры и аргументы в качестве входных данных.
- Операционная система выполняет необходимые действия.
- В результате выполнения команды можно получить выходные данные, такие как информационные сообщения, сообщения об ошибках, запрашиваемая информация или результат выполнения операции.
- Оболочка CLI отображает выходные данные, поэтому вы можете увидеть результат выполнения команды.
Оболочка CLI работает циклично, ожидая ввода очередной команды. При взаимодействии с оболочкой CLI повторяется процесс ввода, синтаксического анализа, выполнения и вывода команд. Таким образом, обеспечивается непрерывный интерфейс для взаимодействия на основе команд.
Как открыть интерфейс командной строки в вашей системе?
В каждой основной операционной системе доступ к интерфейсу командной строки (CLI) осуществляется по-разному.
Windows
Ниже описано, как открыть CLI в Windows на платформе Windows 8 и более новых версиях.
- Нажмите клавишу Windows и S.
- Введите cmd в поле поиска.
- Нажмите правой кнопкой мыши на командную строку и выберите «Запуск от имени администратора».
- Теперь можно войти в командную строку.
Mac
Ниже описано, как открыть CLI на Mac.
- Найдите приложение Finder, которое обычно расположено на панели инструментов.
- Перейдите в /Приложения/Утилиты.
- Выберите «Терминал».
- Теперь можно войти в командную строку.
Linux
В Linux есть простой способ доступа к интерфейсу командной строки: используйте сочетание клавиш CTRL+ALT+T.
Кроме того, вы можете использовать сочетание клавиш ALT+F2, а затем ввести gnome-terminal.
Какие есть общие команды интерфейса командной строки?
Интерфейс командной строки (CLI) содержит множество различных команд для разных типов задач. В разных операционных системах команды незначительно различаются. Далее мы рассмотрим несколько примеров команд.
Команды файловой системы
Команда CLI
Windows
Linux
Сетевые команды
Команда CLI
Windows
Linux
Информационные команды
Команда CLI
Windows
Linux
Информация о системе
Какие существуют лучшие способы работы с CLI?
Хотя интерфейс командной строки (CLI) является удобным и может предоставить удаленный доступ, для его использования требуется точность и знание правильных команд. Понимая смысл вводимых команд, можно добиться желаемого результата. Если вы не знаете какую-либо команду, то прежде чем вводить ее в CLI, следует изучить ее назначение. Также убедитесь, что команда введена без изменений или орфографических ошибок.
Еще одна важная рекомендация – ограничение доступа к CLI для всех непривилегированных пользователей. При этом права администратора предоставляются только надежным сотрудникам. В результате можно ограничить ненужное взаимодействие с системой и предотвратить несанкционированный доступ к критически важным ресурсам.
Дополнительной мерой безопасности, которую следует учитывать, является постоянное обновление системы. В обновлениях доступны исправления ошибок, средства повышения производительности и, что немаловажно, исправления безопасности. Следите за постоянным обновлением CLI, чтобы обеспечить максимальную безопасность системы. Наконец, рекомендуется регистрировать все действия CLI, чтобы обнаружить изменения, выявить подозрительное поведение и устранить неполадки, если что-то пойдет не так.
Что такое Интерфейс командной строки AWS?
Интерфейс командной строки AWS (AWS CLI) – это инструмент с открытым исходным кодом от Amazon Web Services (AWS). Его можно использовать для взаимодействия с сервисами AWS с помощью команд в командной строке.
После минимальной настройки вы можете использовать AWS CLI для команд, которые обеспечивают функциональность, эквивалентную той, которую предоставляет браузерная Консоль управления AWS. Ниже приведены действия, которые можно выполнить из командной строки программы терминала:
- Использование распространенных программ-оболочек Linus, таких как Bash, zsh и tcsh, для выполнения команд в Linux или macOS.
- Выполнение команд в Windows в командной строке Windows или в PowerShell.
- Удаленный запуск команд на инстансах Эластичного вычислительного облака Amazon (Amazon EC2) через программу удаленного терминала, например PuTTY, SSH, или с помощью Менеджера систем AWS.
Браузерная оболочка AWS CloudShell позволяет быстро запускать скрипты с помощью AWS CLI, экспериментировать в нем с API сервисов, а также использовать другие инструменты для повышения производительности. Значок CloudShell отображается в тех регионах AWS, где доступна данная функция.
Создайте аккаунт уже сегодня и начните работу с AWS CLI.
Как пользоваться CLI для автоматизации рутинных процессов

Пятьдесят лет назад у программ не было удобных пользовательских интерфейсов: единственным средством ввода была клавиатура, приложения вызывались путем написания их имен, а вывод был текстовым.
Разработчикам приходилось проявлять изобретательность, чтобы сделать программы более гибкими. Так появился интерфейс командной строки (или пользовательский интерфейс командной строки — CLI). Его определение звучит как «параметрическая компьютерная программа, которая получает входные данные (параметры и опции) через консольный интерфейс или скрипт».
Следующим шагом было появление графического пользовательского интерфейса (GUI), который вытеснил CLI в узкую область системного администрирования, разработки и поклонников Unix.
Хотя CLI далек от былой популярности, среди разработчиков он переживает период возрождения. Многие приложения (например, VS Code и Spotify) интегрировали CLI в свои пользовательские интерфейсы, а языки программирования (например, Node.js и Golang) используют его для упрощения процесса разработки.
Интерфейс командной строки полезен, когда нужно передавать сценарии или команды с одинаковым набором параметров, а также для автоматизации определенных последовательностей действий.
Преимущества CLI
Инструменты интерфейса командной строки можно рассматривать как набор сценариев автоматизации, объединенных удобным API. Речь идет обо всех преимуществах автоматизации рутинных действий (повышение производительности, снижение количества ошибок и других) в купе с гибкостью.
Вероятно, вы подумали, что графический интерфейс лучше подходит для этих целей и выглядит удобнее. Однако он потребляет больше ресурсов при запуске и его сложно масштабировать. Кроме того, разработка графического интерфейса занимает больше времени и стоит дороже, чем CLI.
Преимущества CLI для бизнеса можно описать так:
- Использование интерфейса командной строки ускоряет время вывода продукта на рынок
- Снижает затраты по сравнению с использованием пользовательского интерфейса
- Снижает затраты на онбординг новых сотрудников.
Подробно эти пункты раскрыты в исследовании IBM и Forbes, а также в отчете McKinsey.
Как создать собственный CLI
Можно создать собственный интерфейс командной строки с нуля, но гораздо удобнее использовать фреймворки: они существуют для Python, Javascript, Golang и многих других языков программирования.
Для этой статьи я использовал JS-фреймворк с открытым исходным кодом commander.js, который работает на Node.js.
Прежде чем перейти к коду, рассмотрим некоторые особенности commander.js:
- Команды в этом фреймворке похожи на исполняемые файлы. Это программы, которым задаются параметры и аргументы
- Аргумент — то, что передается команде для обработки
- Параметры — то, что изменяет поведение команды. Они могут быть заданы в короткой (например, -h ) или длинной ( —help ) формах.
Перейдем к коду. Начнем с простого примера, который можно использовать в каждом проекте: вывода «Hello, World!». Создадим файл с именем my.js и добавим в него следующий код:
#!/usr/bin/env node // file: my.js import program > from 'commander'; const command = () => console.log('Hello, World!'); >; program .version('0.0.1') .action(command) .parse(process.argv); Эта программа вызывается так:
$ node ./my.js Hello, World! Теперь сделаем так, чтобы программа могла учитывать некоторые параметры (аргументы). Например, приветствовать людей по именам:
#!/usr/bin/env node // file: my.js import program > from 'commander'; const command = (names) => for (const name of names) console.log(`Hello, $name>!`); > >; program .version('0.0.1') .arguments(' ') .action(command) .parse(process.argv); Из примера выше видно, что программа принимает количество имен, отличное от нуля, в качестве аргументов. Для этого используется метод arguments(args) , а в методе action(Function) имена можно обрабатывать так, как мы хотим. Аргументы передаются вместе с командой вызова и указываются через пробелы:
$ node ./my.js Alpha Bravo Charlie Hello, Alpha! Hello, Bravo! Hello, Charlie! В таком виде программа уже выглядит интереснее. Теперь реализуем одно из главных преимуществ CLI — возможность работать с несколькими командами одновременно:
#!/usr/bin/env node // file: my.js import program > from 'commander'; program .version('0.0.1') .command('hello ', 'says hello to people') .parse(process.argv); Теперь создадим другой файл, следуя правилу имен: файл точки входа и имя команды через дефис. В этом примере файл точки входа my.js, значит чтобы вызвать команду hello , мне понадобится файл my-hello.js.
#!/usr/bin/env node // file: my-hello.js import program > from 'commander'; const command = (names) => for (const name of names) console.log(`Hello, $name>!`); > >; program.parse(process.argv); const args > = program; command(args); Попробуем вызвать команду hello передав её вместе с именами:
$ node ./my.js hello Alpha Bravo Charlie Hello, Alpha! Hello, Bravo! Hello, Charlie! Теперь проверим, как CLI может менять функциональность, передавая параметры. Чтобы сделать это, просто вызовем метод option(opts, description) :
#!/usr/bin/env node // file: my.js import program > from 'commander'; const hello = (name) => return `Hello, $name>!`; >; const command = (names, lower, upper) => for (const name of names) const msg = hello(name); if (lower) console.log(msg.toLowerCase()); > else if (upper) console.log(msg.toUpperCase()); > else console.log(msg); > > >; program .option('-l, --lower', 'only use lowercase letters') .option('-u, --upper', 'only use uppercase letters') .parse(process.argv); const args > = program; const options = program.opts(); const lower, upper > = options; command(args, lower, upper); В результате получаем следующее:
$ node ./my.js --lower Alpha Bravo Charlie hello, alpha! hello, bravo! hello, charlie! $ node ./my.js -u Alpha Bravo Charlie HELLO, ALPHA! HELLO, BRAVO! HELLO, CHARLIE! Заключение
Мы только что создали очень упрощенный, но рабочий инструмент, используя возможности интерфейса командной строки. Посмотреть результат можно здесь. Чтобы развернуть его, можно отправить код в npm, локально связать с npm-пакетами или создать имя для команды оболочки.
Хотя именно этот инструмент бесполезен в практических целях, в документации commander.js есть описание инструментов, которые принесут реальную пользу.
Никогда не останавливайтесь: В программировании говорят, что нужно постоянно учиться даже для того, чтобы просто находиться на месте. Развивайтесь с нами — на Хекслете есть сотни курсов по разработке на разных языках и технологиях
Построение приложений командной строки (CLI)
Данная статья написана под влиянием книги Дэвида Коупленда «Build Awesome Command-Line Application in Ruby» (купить, скачать и изучить дополнительные материалы). Большая её часть будет посвящена проектированию дизайна CLI-приложений вне зависимости от используемого языка. По ходу будут обсуждаться и вещи специфичные для ruby, но не страшно, если вы его не знаете, кода будет не слишком много. Можно считать эту статью довольно подробным обзором вышеупомянутой книги с вкраплениями собственного опыта. Книжку рекомендую!
Для начала я задам вопрос. Если посмотреть на сообщества IT-шников, можно заметить, что несмотря на обилие программ с красивым графическим интерфейсом, приложения командной строки остаются весьма популярны. Почему?
Ответов несколько. Во-первых, это красиво удобно — если вы можете описать задачу командой в командной строке, то её гораздо проще автоматизировать, чем если вам приходится анализировать передвижения мыши и клики на разные пункты меню. Во-вторых, это даёт возможность комбинировать программы невероятным числом способов, чего сложно добиться с помощью графических интерфейсов.
В значительной степени философия Unix базируется на том принципе, что множество маленьких утилит, каждая из которых умеет делать свою конкретную задачу — это лучше, чем одна многофункциональная программа-универсал. И это одна из причин успеха Unix-систем в мире IT-шников.
Наверное, каждый понимает, что обычного пользователя вряд ли удастся сманить от GUI к CLI, давайте сосредоточимся на нас, «компьютерщиках» и конкретизируем наши пожелания к CLI-приложениям.
Общие требования
- Easy to use — Оно должно быть простым в использовании и иметь четкую цель. Желательно одну. Тулы, которые как швейцарский нож умеют все, как правило сложны в использовании и никто не знает всех их возможностей. Впрочем, про то, как проектировать многофункциональные приложения, чтобы сделать их проще в использовании и в поддержке, мы тоже поговорим.
Минимум, который вы можете сделать для упрощения работы с вашей программой — это следование соглашениям о формате опций. Не заставляйте ваших пользователей переучиваться! О том, как принято указывать опции, и как их именовать, я напишу подробно. - Helpful — Это означает, что пользователь должен иметь простой доступ к хелпу о том, как что делает приложение, как его запускать, и как его настроить. Желательно, чтобы приложение добавляло свою страничку в man. Кроме того, не помешает интеграция с шеллом на уровне автодополнения команды.
- Plays well with others — Приложение должно быть способным взаимодействовать с другими приложениями. Это означает модульность приложений, как принято в Unix. Не следует пренебрегать кодами возврата, продуманной работой с потоками ввода-вывода и не только.
- Has sensible defaults but is configurable — Стандартные сценарии использования должны быть доступны без указания тысячи опций. Нестандартные сценарии не обязаны быть простыми в использовании, но должны быть все-таки доступными. Кроме того, набор опций-по-умолчанию должен быть настраиваемым.
- Installs painlessly — Легко устанавливается вместе со всеми зависимостями, устанавливает путь к приложению в переменные окружения для более простого запуска. Обновления должны происходить так же легко.
- Fails gracefully — В случае ошибки в вызове приложения, оно должно сообщить, в чем была ошибка и как её исправить. Кроме того, приложение должно быть non-destructive, т.е. не должно перезаписывать или стирать файлы, если в аргументах допущена ошибка (а идеально, если оно вообще не будет выполнять опасные операции без подтверждения)
- Gets new features and bug fixes easily — Приложение должно быть поддерживаемым. Дробите приложение на модули и раскидывайте их по разным файлам. Пишите тесты. Пользуйтесь семантическим версионированием. Используйте систему контроля версий.
- Delights users — Вывод приложения должен быть приятным глазу. К вашему распоряжению цвета, форматирование (например, табличное или html). Также сюда входит интерактивное взаимодействие с пользователем.
Easy to use
Утилитки и программные пакеты. Что удобнее?
Итак, все приложения можно условно поделить на два типа: утилитки и программные пакеты (в оригинале, Command Suite).
Первый тип — это приложения, которые имеют одну цель, один режим работы. Примеров этому типу программ бесчисленно, почти всех Unix-команды такие: ls, grep, diff,… (рубисты могут вспомнить, например, команду rspec) Удобство этих программ в том, что их возможности проще запомнить и труднее в них запутаться. Кроме того, их проще склеивать в цепочки для последовательной обработки. Тут будет уместной следующая аналогия. Представьте, что вы строите дом, притом дом не типового образца. Гораздо удобнее строить его из кирпичей, а не из монолитных блоков, ведь кое-где вам эти блоки пришлось бы подпиливать, а где-то пришлось бы заделывать стыки камнями. Да и блоки можно только подъемным краном тягать, тогда как кирпичи можно класть руками.
Второй тип программ можно сравнить с швейцарским ножом или кухонным комбайном. Иногда они крайне удобны. Посмотрите на git (в мире руби сразу вспоминаются gem, rails, bundle) — одна программа, а сколько всего умеет. И коммитить/чекаутиться может, и ищет в истории сама, и изменения между файлами считает. Так что grep, diff и прочее в неё встроено, ничего комбинировать с гитом и не надо, сам всё умеет. Если вернуться к аналогии с домом, то у гита есть типовой проект на каждый случай жизни (и попробуй ещё запомни их все).
И всё же, не всем программам стоит быть многофункциональными: всё равно все варианты использования вы не переберете. В подтверждение этого тезиса предлагаю вам представить себе «мультитул», который умеет делать cd, ls, pwd, diff, df и ещё кучу полезных операций одной командой, только опции надо будет слегка менять (например, filesystem change, filesystem show, filesystem where итд). Будете такой пользоваться? Думаю, что выкинете за излишнюю громоздкость. Хотя программные пакеты и бывают чрезвычайно удобными, имеет смысл хорошенько подумать, прежде чем писать своего кентавра с восемью щупальцами.
Кстати, если вы написали десяток утилит, а потом поняли, что хотите, чтобы это был программный пакет, то это не так уж и сложно поправить. Достаточно написать обертку, которая будет маршрутизировать команды. Вы, возможно не знаете, но git состоит из десятков утилиток типа git-commit, git-show, git-hash-object, git-cat-file, git-update-index итд, которым передает управление команда git, основываясь на типе команды и опциях (разумеется, за одной командой может стоять целая цепочка из вызовов утилит). Так что даже крупные проекты начинать лучше с набора небольших программ, которые вы в дальнейшем будете комбинировать. Их проще писать, отлаживать, поддерживать и использовать.
Синтаксис аргументов командной строки или «в этом доме есть свои традиции».
Начну с терминологии. Когда вы запускаете приложение командной строки, вы указываете какой-то набор параметров. Они делятся на следующие типы: опции и аргументы. Дэвид Коупленд дополнительно делит опции на два подтипа: флаги и свитчи.
Схематично можно изобразить это следующим образом executable [options] . Думаю, что все и так в курсе, но на всякий случай поясню, что параметры в квадратных скобках опциональны, а в угловых — обязательны.
Аргументы (или позиционные аргументы) — это параметры, которые необходимо указать для работы программы. Их порядок сторого определен.
Опции — это не обязательные параметры. Они могут быть указаны в любом порядке.
Опции типа свитч — это булевы опции, программа проверяет их наличие или отсутствие. Пример: —ignore-case (или, иногда, —no-ignore-case ).
Опции типа флаг — это опции с параметром. Этот параметр может иметь значение по-умолчанию. Например, grep -C . и grep -C 2 . в моей версии утилиты grep эквивалентны.
И аргументы, и опции могут иметь значения по-умолчанию, но могут и не иметь.
В качестве примера, в команде grep —ignore-case -r -С 4 «some string» /tmp аргументами являются «some string» /tmp , а опциями —ignore-case -r -С 4 . При этом —ignore-case и -r — это свитчи, а -C 4 — это флаг.
Соглашения по использованию опций
- Длинная опция ( —long-option ) начинается с двух дефисов. В названии опции не может быть пробелов, зато одиночные дефисы вполне допустимы.
- Короткая опция ( -l ) состоит из одной буквы (как правило, регистр имеет значение) и предшествующего ей дефиса — одного. Удобно, когда короткая опция — это первая буква длинного аналога, так проще запомнить её значение.
- Несколько коротких опций можно объединить вместе следующим образом: ls -a -l эквивалентно ls -al . После одиночного дефиса может идти сколько угодно опций без аргументов
- Если у короткой опции есть параметр, обычно он может идти как сразу после опции, так и отделяться от неё пробелом. -C4 или -C 4 . Я не случайно сказал «обычно». Так, например, стандартная руби-библиотека optparse обрабатывает эти два случая одинаково. Утилита ls обрабатывает сходные опции также одинаково. А вот утилита grep, например, считает, что -C отдельно, а 4 — отдельно. Может быть, это баг. Я не мог не упомянуть, что исключения бывают, но пользователи вряд ли будут вам благодарны, если ваша программа станет ещё одним исключением.
Я не знаю, как обычно поступают в случае, когда короткая опция имеет нечисловой параметр со значением по-умолчанию ( -c [param] ), ведь -cxyz можно трактовать и как -с xyz , и как -c -x -y -z . Пользователю лучше всегда писать пробел в случае наличия у опции необязательного параметра. Программисту лучше заранее подумать о том, как минимизировать проблемы связанные со слитным написанием опций. - В случае длинной опции обычно допускается использование пробела перед параметром, но желательно использовать знак равенства. ls —width=10 или ls —width 10
Без разделительного символа после длинной опции параметр не указывают (сами посудите, какая путаница получится, особенно если параметр не числовой). - Каждая опция может иметь как короткую форму, так и длинную. А может быть и так, что есть только короткая или только длинная. Впрочем, наличие длинной формы для каждой из опций крайне желательно.
- Для булевых опций можно указать опциональный префикс no- , например: —[no-]pager . Опция —pager задает разделение на страницы, —no-pager указывает, что разделения на страницы быть не должен, а отсутствие опции сохраняет значение по-умолчанию. Это особенно важно в случае, когда опции по-умолчанию конфигурируемы. Без префикса, например, невозможно было бы отменить значение опции заданной по-умолчанию.
Почему желательно всегда иметь длинный вариант опции
Длинная форма опций, как правило, используется в написании скриптов, использующих ваше приложение. Длинные опции следует делать самодокументирующимися. Представьте, что сисадмин заглядывает в cron и видит там запуск задачи бэкапа БД с непонятными опциями -zsf -m 100 . Если он не автор скрипта, то ему придется залезать в хелп, чтобы понять, что имеется в виду. Согласитесь, набор опций —scheme —max-size 100 —gzip —force скажет ему гораздо больше и не заставит его тратить лишнее время.
Кроме того, не рекомендуется делать короткие опции для редко используемых опций. Во-первых, букв в алфавите не так уж много, чтобы тратить их на все подряд опции. Во-вторых, и это даже важнее, отсутствие короткой опции подсказывает пользователю, что эта опция второстепенна или даже нежелательна при нормальной работе, и что не надо использовать её бездумно, просто потому что можно.
Итак, часто используемые опции имеют и короткую форму, и длинную, а редко используемые — только длинную.
Различия в параметрах командной строки для однофункциональных и многофункциональных приложений
Эти два типа приложений имеют немного разный порядок аргументов при вызове.
Для первого типа приложений вызов обычно выглядит так: executable [options]
Для программных пакетов формат несколько сложнее: executable [global options] [command options]
Приведу пример из книги: git —no-pager push -v origin_master Здесь —no-pager — это опция, которая может быть применена к любой команде git’а, а -v — это опция специфичная для команды push. Следует отметить, что глобальные опции и опции специфичные для команды могут иметь одинаковые имена. Но в таком случае для их обработки подойдут не все средства, так например стандартная руби-библиотека OptionParser не справится с этой задачей, так как не различает в каком месте месте встретилась опция. Если вы делаете программный пакет, воспользуйтесь лучше библиотекой GLI.
На всякий случай напомню читателю, что технически программы на вход получают не строку параметров, а уже разделенный на элементы массив параметров. В ruby этот массив называется ARGV . Именно с ним мы и работаем, напрямую или при помощи специальных библиотек. Надо отметить, что разбит он на элементы не по пробелам (иначе не могло бы быть, например, имен файлов с пробелами), у shell’а чуть более сложные правила. Там участвует и экранировка символов, и использование кавычек для группировки. Если вам потребуется экранировать, склеивать или разрезать строки параметров в массивы и обратно — посмотрите на стандартную библиотеку shellwords. Она как раз состоит из трех методов для этих целей: String#shellsplit , String#shellescape и Array#shelljoin .
В сообществе ruby большая часть приложений командной строки использует либо OptionParser, либо библиотеки на его основе. В разделе про конфигурацию — когда мы узнаем чуть больше — я приведу пример кода, сделанного написанного с помощью OptionParser.
Helpful
Представьте, что вы впервые видите программу awesome_program, которую вы собираетесь использовать. Будучи опытным пользователем, вы наверняка наберете awesome_program —help в надежде увидеть порядок аргументов, набор опций и примеры использования. Когда вы выпускаете свою программу, помните, что пользователь, который впервые её увидел, наверняка первым делом сделает то же самое, поэтому пусть у вас будут ключи -h , —help наготове. Если вы используете библиотеку типа OptionParser, в строку подсказки у вас автоматически будет внесено перечисление всех опций, которые программа распознает с теми описаниями, которые вы дадите.
Помимо строки подсказки имеет смысл написать расширенную справку в man. Впрочем, насколько я знаю, rubygems автоматически не устанавливает странички в man. Однако существует гем gem-man, который позволяет показывать странички man-документации для установленных в системе гемов.
Для того, чтобы создать man-документацию необходимо создать файл в непростом формате nroff. Для упрощения задачи воспользуйтесь библиотекой-конвертером ronn, которая позволяет писать странички документации в более простом формате. Когда всё будет готово, вы можете воспользоваться командой gem man awesome_gem — и увидеть строку помощи. Кроме того, вы можете прописать alias gem=’gem man -s’ . При этом команда man заменяется командой gem man, что позволяет искать man-ом помощь по гемам. По тем запросам, которые gem-man обработать не смог, происходит автоматическое перенаправление на соответствующую страничку обычного man-а.
Если соберетесь делать свои man-подсказки, загляните в книгу, там этому уделяется значительно больше внимания.
Чтобы ещё больше облегчить пользователю запуск команды, можно сделать автодополнение команды на уровне шелла (работает не во всех шеллах). Это позволит по нажатию на кнопку tab автоматически дополнять названия команд, имена файлов итд. У пользователя будет меньше шансов сделать орфографическую ошибку, и он потратит намного меньше времени на написание команды.
Для того, чтобы сделать tab-completion и хранить историю команд внутри программы (в интерактивном режиме в программах типа irb) достаточно воспользоваться встроенной в руби библиотекой readline. Она позволяет автоматически сохранять историю всех введенных команд — за счет использования команды Readline.readline вместо gets .
Tab-completion делается следующим образом: методу Readline.completion_proc=(block) передается блок, возвращающий массив возможных дополнений по строке уже введенного текста, вот и вся задача. Например:
Readline.completion_proc = proc < |input| allowed_commands.grep /^#/ > Если вам нужен tab-completion не на уровне уже запущенной программы, а на уровне шелла, то это несколько сложнее. Вам придется повозиться с файлом .bashrc .
Во-первых, добавьте к нему строчку complete -F get_my_app_completions my_app
Теперь каждый раз, когда вы набираете my_app(пробел)[какой-то текст] , а затем клавишу tab — будет вызываться функция get_my_app_completions . Эта функция должна вернуть возможные варианты автодополнения в переменную COMPREPLY , которой шелл воспользуется, чтобы предоставить пользователю возможные варианты дополнения. В файле .bashrc надо определить эту функцию. Приведу пример из книги для приложения todo:
function get_todo_completions() < if [ -z $2 ] ; then # получаем список команд COMPREPLY=(`todo help -c`) else # получаем список возможных аргументов для команды, указанной в $2 COMPREPLY=(`todo help -c $2`) fi >complete -F get_todo_completions todo Теперь в программе надо реализовать следующее поведение (оставим это как легкое упражнение):
1) если вручную набрать в командной строке todo help -c , вы должны увидеть список команд приложения: list, add, complete, help (каждое на своей строке)
2) если набрать todo help -c complete — вы должны увидеть список всех дел, которые начаты, но еще не завершены (тех, к которым можно применить команду complete).
help -c [. ] — это служебная команда, её наличие можно не афишировать в краткой справке. Предполагается, что её будет использовать не пользователь, а тот скрипт в .bashrc .
В этом скрипте функция спрашивает у самого приложения, что можно подставить, исходя из того, что уже набрано (этот передается после опции help -с ). Программа отслеживает ситуацию, когда приложению указывают такой специальный набор параметров, и выводит список всех вариантов в стандартный вывод (как вы уже видели), откуда они направляются прямиком в переменную шелл-скрипта COMPREPLY .
Автор в книге пользуется собственной библиотекой GLI, которая автоматически отслеживает такой набор опций. Вы легко можете реализовать эту возможность и без помощи GLI. Как вы видите, здесь нет никакой магии.
Plays well with others
Не будем обсуждать вопрос о необходимости удобного взаимодействия программ, каждый, кто работал в Unix может сам оценить, насколько это важно. Главный вопрос — как добиться этого?
Коды возврата
Во-первых, используйте коды возврата. В случае успешного завершения программы — 0, в случае ошибки — различные ненулевые коды возврата. Это важно, потому что шелл-скрипты могут определить, нормально ли отработала программа, запросив статус последней завершенной программы из переменной $? . Чтобы вернуть статус возврата, в ruby используется метод exit(exit_status) .
Если разным ошибкам назначать разные коды возврата, то есть шанс, что другая программа, использующая вашу, сможет принять решение о том, можно ли устранить проблему, и стоит ли вообще на неё обращать внимание. Снаружи программы лучше видно, страшно ли, что программа «упала» или нет. Различные коды возврата — это как различные классы исключений, может у вас ошибка в том, что оперативной памяти нет, а может всего лишь сеть пропала на секунду и стоит попробовать ещё разок. Некоторые программы могут упасть одновременно от нескольких ошибок. Если у вас есть необходимость сообщить сразу о нескольких проблемах — воспользуйтесь битовыми масками. В сети есть рекомендации о том, какие коды возврата принято использовать для каких ошибок, об этом можно почитать на сайтах GNU (весьма общо) и FreeBSD (очень конкретно). Если не хочется заморачиваться кодами ошибки, сделайте хотя бы минимальное усилие — верните хоть какое-нибудь ненулевое значение в случае ошибки. Иначе другие программы даже не смогут узнать, нормально ли отработала ваша программа.
Кстати, вы можете запустить программу не только из шелл-скрипта, но и из ruby-скрипта. Есть несколько вариантов сделать это, например Kernel.system или IO.popen Подробнее про них почитайте в документации. Если вы вызываете другую программу с помощью system , то можете узнать её код возврата в аналогичной shell-у переменной $? .
Потоки ввод-вывода и поток ошибок. Пайпы
Главный способ взаимодействия программ, запускаемых из командной строки — пайпы (pipes). Пайп — это способ перенаправить вывод одной программы на вход другой. Обозначается пайп вертикальной чертой | . Например, в команде ls | sort , первая часть — ls не выводит ничего на экран, а вместо этого перенаправляет свой вывод на вход программе сортировки. А программа sort забирает текст из входного потока построчно и уже осортированный список выводит на экран. С одной стороны, ls и сама могла бы отсортировать файлы, но она для этого не предназначена. В то же время sort нужна именно для этой цели и имеет множество опций. Например, вы можете отсортировать строки не совсем лексиграфически, если названия начинаются с числа (иначе порядок будет следующим: 1.jpg, 10.jpg, 100.jpg, 2.jpg, . ). Или отсортировать в обратном порядке. Кроме того, с помощью специальных программ (типа awk, sed) перед сортировкой строки можно подправить (например, стереть префиксы). Следует отметить, что пайп может быть составлен из произвольного числа программ. Так ls | sort -n | tail выведет последний десяток строк списка файлов, отсортированного по номеру.
Подумайте о том, для чего в вашей программе могут понадобиться потоки ввода и вывода. Что вы пишете в поток вывода, а что — в поток ошибок. Разберемся сначала со вторым вопросом: чем отличаются потоки вывода(stdout) и ошибок(stderr)? Тем, что один поток идет в пайп, а другой — нет. Поток stderr используют для вывода не только ошибок, но и для вывода любой информации о процессе работы, такой как стадия выполнения программы, отладочная информация итп. Эта информация не должна попасть на вход другой программы, она нужна лишь для удобства пользователя. Поток stdout используется для всей остальной информации, такой как результат работы программы.
Необходимо подумать о формате вывода, поскольку с выводом вашей программы предстоит работать не только человеку, но и машине. Имеет смысл сделать опцию —format=
Указывать формат вывода при каждом запуске программы пользователю не захочется, а выбрать один на все случаи жизни тоже не всегда возможно. Есть трюк, который поможет автоматически определить, предназначен ли вывод для глаз человека или машины, а именно метод IO#tty? . Вызов $stdout.tty? скажет вам, направлен ли ваш вывод в терминал или нет. Если нет, значит вывод вашей программы направлен в пайп или перенаправлен в файл (следующим образом: ls > output.txt ). Для вывода, направленного в терминал, и для вывода в перенаправленный поток можно выбрать разные варианты форматирования по-умолчанию: options[:format] = $stderr.tty? ? ‘table’ : ‘csv’
А если вы захотите, например, вывести в файл результат в формате вывода, предназначенном для человека, просто укажите формат явно.
Теперь поговорим о входном потоке. Какие данные должна принимать программа из входного потока? Это, конечно, зависит от специфики программы. Давайте подумаем, какие данные могут прийти во входной поток? Очевидный ответ — те, которые есть на выходе у другой программы. Например, у меня есть программа, которая конвертирует файл матрицы в другой формат и записывает в файл с другим расширением. Имеет ли смысл принимать матрицы из входного потока? На мой взгляд, не имеет: каким образом и зачем эта матрица попадет во входной поток? Гораздо удобнее будет принимать пачку имен файлов, чтобы сразу обработать множество файлов. Это те данные, которые может выдать, например, команда ls.
Можно поспорить с этой точкой зрения, ведь можно написать скрипт, который будет перебирать список файлов и запускать программу несколько раз. Но тогда вы лишаетесь возможности сделать это прямо из командной строки одним перенаправлением ввода-вывода, вам придется писать цикл. Кроме того, некоторые программы долго стартуют и быстро работают, поэтому на сотню матриц вы можете потратить не одну секунду, а сто одну (увы, это вполне реальный — и даже оптимистичный — масштаб времени при использовании множественных запусков скрипта из гема на Windows-системе). Но, в любом случае, выбор за вами. Делайте то, что целесообразно и не забудьте описать это в мануале.
Кстати, пытается ли другая программа передать данные на вход вашего скрипта можно, вызвав уже знакомый нам метод $stdin.tty?
Сигналы
Наконец, заслуживает упоминания ещё один способ, посредством которого программы могут общаться (не беря в расчет сокеты и всё с ними связанное) — сигналы. Пусть у вас есть долгоиграющий процесс, например, веб-сервер, и вам необходимо попросить его прочитать новую конфгурацию, не перезагружаясь. Вы можете послать ему сигнал (обычно SIGHUP), а он, перехватив его, сделает то, о чем его просят. Или повесить обработчик на сигнал SIGINT, который будет аккуратно завершать работу программы по нажатию Ctrl+C. Всё это достигается методом Signal.trap . Этот метод принимает в качестве аргументов имя сигнала и блок, который выполняется, когда программе приходит указанный сигнал. Работает это (как и перенаправление потоков, кстати) во всех POSIX-системах, т.е. и в Unix, и в Windows. Возможно, однако, что набор поддержживаемых сигналов в Windows будет меньше, чем в Unix, так что если вы добиваетесь кросс-платформенности приложения, сигналы — место, подлежащее тщательному тестированию.
Вот — пример того, как сделать так, чтобы по нажатию Ctrl+C программа сначала подчищала за собой недоделанные файлы, а уже затем закрывалась, вернув код ошибки:
Signal.trap("SIGINT") do FileUtils.rm output_file exit 1 end Has sensible defaults but is configurable
Повторю, стандартные сценарии использования должны быть доступны без указания тысячи опций. Нестандартные сценарии не обязаны быть простыми в использовании, но должны быть все-таки доступными. Кроме того, набор опций-по-умолчанию должен быть настраиваемым.
Про стандартные сценарии всё понятно. Необходимо продумать, для чего программа будет использоваться и выбрать самые популярные параметры — параметрами по-умолчанию.
У всех пользователей потребности немного разные, так что подумайте о как можно большем числе вариантов использования вашего скрипта. Если ваше приложение будет выполнять одну задачу, но будет гибко настраиваться (в разумных пределах), пользователи скажут вам спасибо. Нестандартные сценарии должны быть, если они имеют применение. Не страшно, если для их выполнения придется указать множество опций — пользователь два раза подумает, для того ли предназначен ваш скрипт. Напомню о рекомендации делать редкие опции длинными и не предоставлять короткой версии для таких опций ( —use-nonstandard-mode вместо -u ).
На последнем пункте остановлюсь подробнее. Что значит «набор опций-по-умолчанию должен быть настраиваемым»? Представьте, что вашей программой пользуются множество людей и делают это часто. К примеру, вы написали утилиту для бэкапа БД. Ваш сисадмин пользуется утилитой каждый день и использует набор опций по-умолчанию (например, —no-scheme —gzip ), просто набирая db_backup my_db .
Но кроме админа программой пользуются ваши коллеги разработчики, у которых схема БД меняется каждый день. И они каждый день вынуждены писать db_backup —scheme my_db , им нельзя забыть этот ключик. Вы, возможно, будете правы, если скажете, что сисадминские настройки важнее и будут настройками по-умолчанию… но в действительности там будут ещё и опции —login , —password , —host , —force , и такой набор параметров уже сложно воспроизвести без ошибок даже сисадмину, у которого остальные настройки идут по-умолчанию. Не заставляйте ни сисадмина, ни программиста каждый раз вводить все эти параметры и думать о настройках, ведь можно сделать значения по-умолчанию конфигурируемыми.
Для этого служат файлы вида ~/.myapp.rc . В файле нет никакой магии, это лишь соглашение. Каждый пользователь в своём домашнем каталоге может создать файл с предпочтительными для него настройками по-умолчанию. В домашнем каталоге — чтобы разные пользователи могли задавать разные умолчания. Точка в начале файла — чтобы сделать его скрытым. Расширение .rc — дань традиции.
Что должно храниться в этом файле? Просто перечисление тех опций, которые отличаются от стандартных значений по умолчанию. Для этого конфигурационного файла крайне удобно использовать формат YAML. Приведу пример:
--- :gzip: false :force: true :user: "Bob" :password: "Secr3t!"Рассмотрим, как эти опции загрузить.
require 'yaml' require 'optparse' # опции по-умолчанию options = < :gzip =>true, :force => false > # путь к файлу конфигурации # (при тестировании его можно будет подменить, используя переменную окружения HOME) CONFIG_FILE = File.join(ENV['HOME'],'.db_backup.rc.yaml') if File.exists? CONFIG_FILE # загружаем опции из файла config_options = YAML.load_file(CONFIG_FILE) # и обновляем хэш опций по-умолчанию значениями из загруженного файла options.merge!(config_options) end # а теперь обрабатываем аргументы командной строки # этот парсер не допускает никаких типов опций, кроме перечисленных явно option_parser = OptionParser.new do |opts| # заголовок в строке подсказки. #__FILE__ указан как имя скрипта, чтобы при переименовании скрипта подсказка автоматически менялась opts.banner # встретив опцию -u или --username мы выполняем блок, передавая ему значение параметра opts.on("-u USER", "--username", "Database username, in first.last format") do |user| options[:user] = user end # обратите внимание на третий аргумент, он используется для строки подсказки opts.on("-p PASSWORD", "--password", "Database password") do |password| options[:password] = password end # здесь у опции нет параметра, так что это булева опция. Она либо есть, либо её нет. # Наличие опции --gzip вызывает блок и устанавливает значение true. # В отсутствие опции блок не вызывается, так что остается значение по-умолчанию # Чтобы задать опции значение false необходимо передать скрипту опцию --no-gzip opts.on("--[no-]gzip", "Compress or not the backup file") do |gzip| options[:gzip] = gzip end end # В следующей строке из массива вычленяются опции, описанные в объекте option_parser. # В результате в ARGV остаются только позиционные аргументы, # а переданные опции при обработке заполняют хэш options # (это явно прописано в блоках обработчиков) option_parser.parse!(ARGV) # считываем позиционные аргументы db_name = ARGV.shift Если у вас стоит задача настройки программного пакета — это делается таким же конфигурационным файлом. Только в хэше на этот раз должны быть как глобальные опции, так и опции каждой команды — во вложенном хэше.
--- :filename: ~/.todo.txt :url: http://jira.example.com :username: davec :password: S3cr3tP@ss :commands: :new: :f: true :group: Analytics Database :list: :format: pretty :done: <> Есть и другие способы записи данных в конфигурационный файл, YAML — просто один из самых легко читаемых. Так или иначе, настройка через конфигурационные файлы — широко используемая техника. Так настраиваются, например, утилиты gem и rspec, а также git.
Installs painlessly
Даже очень хорошее приложение никто не будет использовать, если процесс его установки слишком сложен. К счастью, в мире руби есть rubygems — менеджер пакетов, который позволяет устанавливать и обновлять программы в одну строчку:
gem install/update gemname
Гем — это пакет, который содержит исходные коды, а также информацию о номере версии и авторе, описание пакета, а также набор зависимостей (какие версии каких гемов используются вашей библиотекой или вашим приложением). По-умолчанию все гемы публикуются на сервере rubygems.org. Благодаря этому при установке гемов вам не надо искать, откуда скачать пакет, он находится на сервере общем для всех (разумеется, можно отдельно настроить корпоративный сервер гемов, чтобы не отдавать свои гемы в посторонние руки) и программа gem автоматически использует его для выкачивания гемов.
Когда вы выполняете команду gem install , менеджер пакетов ищет на сервере rubygems пакет с заданным названием и узнает, какие другие гемы (и каких определенных версий) ему требуются для работы. Затем он выкачивает все необходимые пакеты и устанавливает их, компилирует нативный код, делает возможным запуск файлов, указанных как исполняемые (это могут быть и руби-скрипты, не только бинарники). В системе один гем может стоять в любом числе версий, каждая версия может иметь свой набор версий зависимостей и не вызывать конфликтов. Например, если у вас стоит rails 2.3.8 и rails 3.2, каждый из них будет обращаться к своей версии activesupport-а, той, с которой он согласован.
Про то, как создавать гемы я писать не буду, об этом на хабре уже была отличная статья, если вы ещё не умеете этого делать — прямо сейчас оторвитесь от моей статьи и уделите полчаса своего времени этому вопросу. Это очень просто, очень удобно и жизненно необходимо, если вы собираетесь заниматься ruby и дальше.
Когда вы будете создавать свой гем, вам предстоит указывать номер версии. Есть весьма последовательное соглашение под названием «семантическое версионирование». Формат версий состоит из трех чисел: Major.Minor.Patch. Младшее число — патч-левел отвечает только за багфиксы. Среднее число меняется при изменениях API, являющихся обратно-совместимыми. И старшее число меняется при внесении изменений, рушащих обратную совместимость. Заметьте, не цифра, а число, так что номер версии легко может быть таким: 1.13.2.
Семантическое версионирование полезно тем, что в зависимостях можно указывать не точную версию гема, а версию с точностью до патч-левела или до minor-версии. Таким образом вы получаете возможность, ничего не делая с вашим собственным пакетом, получать исправления, устраняющие баги в пакетах зависимостей. Но в то же время вы имеете возможность запретить версиям зависимостей измениться слишком сильно, чтобы не получить с очередным апдейтом изменения API, несовместимые с вашим пакетом.
Теперь — пара слов про исполняемые файлы. Все файлы, которые вы поместили в папку bin своего гема, считаются исполняемыми (если для создания гема вы используете bundler в конфигурации по-умолчанию). При установке пакета в папке . /ruby/bin создается что-то вроде ссылок на эти файлы (на самом деле, создается специальный руби-скрипт, который знает, где искать исполняемый файл). Фокус в том, что эта папка при установке ruby попадает в переменную окружения PATH — и таким образом становится одним из мест поиска исполняемых файлов. Таким образом все исполняемые файлы из гема становятся доступными из любого места системы.
Под Windows процесс, как я понял, чуть сложнее — вокруг этого файла создается ещё и bat-обертка, которая передает управление самому скрипту. Впрочем, от программиста и от пользователя все эти детали скрыты.
Что должно быть в исполняемом файле?
Во-первых, хотя это и руби-скрипт, не нужно ему указывать указывать расширение .rb. Ни на Unix, ни на Windows. Это только будет сбивать пользователя, а для удачного запуска скрипта это совершенно необязательно.
Во-вторых, в первой строчке должно быть написано: #!/usr/bin/env ruby
Обратите внимание на то, что в этой строке путь не /usr/bin/ruby . Использование env позволяет обнаружить руби, даже если он расположен в другой папке, что просто необходимо при установленном rvm.
В-третьих, всю логику скрипта лучше вынести в отдельный файл, например lib/my_exec.rb, а из исполняемого файла получить её с помощью require. Подробнее прочитать об этом можно в статье про изготовление гемов, которую я упоминал выше. В итоге исполняемый файл выглядит так:
#!/usr/bin/env ruby require 'rubygems' # не нужно для ruby 1.9 и выше require 'your-gem' require 'your-gem/my_exec' Какие неприятности вас ждут, если вы решите не собирать свой гем-пакет? Ну, кроме очевидной лишней головной боли по контролю зависимостей, вас ждет ещё один неприятный сюрприз. Представьте, что вы написали скрипт и пишете в командной строке my_app value1 value2 . Какой список аргументов вы ожидаете? Вероятно, [‘value1’, ‘value2’] . Что в действительности вы имеете? В Unix всё будет, как вы и ожидаете. А запуская скрипт в Windows вы имеете пустой список аргументов, т.к. my_app не воспринимается в Windows, как программа, которая может получить аргументы (вместо неё аргументы обычно получает программа ruby.exe). Для того, чтобы скрипту передать аргументы, необходимо запускать скрипт, приписав в начале слово ruby. Т.е. каждый запуск программы будет выглядеть так: ruby my_app value1 value2 , а если вы забудете слово ruby, то имеете шансы даже не понять, почему ничего не работает.
Помните, я упоминал, что rubygems создает bat-обертку? Это нужно потому что bat-файл аргументы командной строки понимает и может передать их скрипту, вызвав скрипт надлежащим образом. Таким образом rubygems решает эту проблему. Но есть и ложка дёгтя: такой каскад вызовов существенно замедляет старт приложения. Иногда программа Hello World запускается пять секунд. После того как приложение запущено, всё работает с нормальной скоростью, но процесс запуска приложений неприятно долгий (насколько я понимаю, Windows-процессы вообще более тяжеловесны, чем Unix-процессы). Это может раздражать, когда вы после каждого изменения кода запускаете, например, rspec. Или каждые пять минут тратите пять секунд дожидаясь реакции git-а (который тоже страдает от этой проблемы, хоть и написан не на ruby). Но это цена, которую приходиться платить за совместимость программ с Windows, по-другому — никак.
Fails gracefully
Тут всё совсем просто.
Ваш скрипт упал. Выведите в stderr сообщение об ошибке, предложите возможные варианты решения (например, подскажите, какой аргумент пропущен или какие опции конфликтуют). Если надо, выведите справочную строку с описанием использования. И уж точно программа не должна пытаться выполнить какие-либо действия, если аргументов для их выполнения не хватает.
Ваш скрипт записывает что-то в файлы или, может, стирает файлы? Если да, убедитесь, что он не перезаписывает существующие файлы. Если файл существует, скрипт должен сказать об этом и попросить подтверждение модификации файла, либо предложить использовать ключ —force . Ну и пусть программа выведет сообщение о том, какой файл он перезаписала или удалила.
Пользователь указал странные опции? Попросите его подтвердить, что он имел ввиду ровно это. Представьте себе команду rm -rf * .log Этот случайный пробел будет вам очень дорого стоить, так что переспросите пользователя, если есть подозрения, что программа может вести себя излишне деструктивно.
Gets new features and bug fixes easily
Поддержка кода — слишком широкое понятие, чтобы его полноценно описать. В двух словах, делайте приложение модульным, разбивайте на отдельные файлы. Если необходимо, разбивайте на несколько отдельных гемов. Для того, чтобы устранять баги и не допускать новых, необходимо писать тесты. И вот тут могут быть проблемы…
Дело в том, что тестирование обычно предполагает изолированность тестов, а при работе с файловой системой (что часто является целью утилит) этого добиться непросто. Вам может понадобиться создавать, удалять и перезаписывать файлы, а также восстанавливать состояние файловой системы после каждого теста. Это всё может быть крайне неприятным и долгим делом (работа с HDD — вообще не быстрое дело). Есть по-меньшей мере два решения проблемы.
Первое решение — гем aruba, предоставляющий специфичные сценарии Cucumber для тестирования CLI. Сценарии для наполнения файлов содержимым, для очистки, для проверки существования файла, а также сценарии для запуска приложения с определенными аргументами, проверки кода возврата, содержимого потоков ввода-вывода итп.
Второе решение (которое лично мне нравится значительно больше) — обычные TestUnit или rspec-тесты вместе с гемом fakefs. Этот гем подменяет классы, работающие с файловой системой, и создают виртуальную файловую систему в оперативной памяти — со своей структурой папок, своими файлами с тем содержимым, которое вы пожелаете туда занести. Никаких mock-ов создавать не надо, весь класс File , Dir (и сопричастные) превращаются на время в один большой фэйк, так что код программы вообще не нужно менять, чтобы протестировать поведение. Никаких следов в файловой системе после работы не остаётся. Красота! Мы включаем режим фэйковой файловой системы, загружаем (не запускаем приложение, используя Kernel.system , а именно загружаем) скрипт из нашего файла lib/my_exec и проверяем результаты.
Как, не используя aruba, проверить, что программа выводит на экран? Для этого надо подменить потоки stdout и stderr на объекты класса StringIO . Тогда после работы программы можно будет проверить содержимое этих «потоков». Вы можете использовать готовое решение: out, err = MiniTest::Assertions.capture_io < . >из стандартной библиотеки тестирования, а можете сами попробовать написать код для перехвата содержимого потоков, он совсем не сложен.
Важное замечание! В руби есть две переменные для потоков ввода-вывода: константа STDOUT и глобальная переменная $stdout . Когда вы будете подменять потоки с помощью StringIO, пользуйтесь глобальной переменной, не пытайтесь поменять константу. Не то страшно, что вы увидите warning, но то, что это не даст ожидаемого эффекта. Вероятно, команды типа puts по-умолчанию завязаны именно на глобальную переменную, а константа лишь ссылается на неё.
Конечно, это замечание не касается случаев явного указания потока ( STDOUT.puts ‘smth’ ), и это, кстати, повод вообще не использовать константы STDOUT , STDIN и STDERR .
Есть ещё один момент. Мы ведь хотим, чтобы код тестирования был как можно больше приближен к реальности. Скрипт получает эти переменные в виде массива ARGV . А мы передаем аргументы в приложение строкой, а не массивом, так ведь? Перед нами встает вопрос: как из строки аргументов получить массив. Вспомните про упоминавшуюся выше библиотеку shellwords и разбейте строку на элементы методом String#shellsplit .
Теперь, когда у нас есть массив аргументов командной строки, мы можем, например, заменить содержимое ARGV этим массивом: ARGV.replace(new_array) .
Но лучше будет подменить массив, передаваемый методу OptionParser#parse! . Вместо ARGV ему достаточно передать наш новый массив OptionParser#parse!(new_array) , и он будет вычленять опции из него, а не из ARGV . Не забудьте, что позициональные аргументы надо будет выделять тоже из нового массива — после вычленения опций.
Отдельный вопрос — как тестировать корректную работу с файлами конфигурации. Автор советует сделать возможность переопределять настройки этих файлов через переменные окружения. Я лично считаю это неэлегантным и оставлю любопытному читателю возможность залезть в книгу и самостоятельно посмотреть связанные с этим рекомендации.
Delights users
Немного замечаний про красивости в формате вывода.
Таблицы
Предположим, что ваша утилита выводит список самых популярных блогеров: имя, количество постов, комментариев, френдов. Напрашивается очевидный формат вывода: нарисовать табличку. Решение столь же прямолинейное — воспользуйтесь гемом terminal-table.
Цвета
Ещё один вид красивостей вы встретите, если воспользуетесь одной из утилит для сравнения файлов. Вы увидите строчки с плюсиками и минусиками для добавленных и удаленных строк. Но кроме того эти строчки для удобства раскрашены в различные цвета: красный/зеленый. Раскрашивание цветов в консоли выполняется добавлением специальных эскейп-последовательностей в местах смены цвета. Два популярных решения — гемы rainbow и term-ansicolor. Используются они тоже весьма прямолинейно, почитайте их мануалы. Надо отметить, что — увы — не все терминалы нормально поддерживают работу с цветами. Стандартный Windows-терминал для некоторых программ вместо цветных строк выдает цифры кодирующие эти цвета, а для других работает корректно. Так что проверьте работу гемов в разных терминалах, прежде чем начинать использовать их в коде.
Дэвид Коупленд напоминает, что почти 10% людей страдают дальтонизмом. Из этого следует, что цвет должен лишь помогать ориентироваться в выводе программы, а не брать на себя функцию единственного канала передачи данных. Если в утилите diff убрать плюсики и минусики, то существенная часть людей потеряет возможность воспользоваться результатами работы. Поэтому в раскрашенном выводе должны быть и цвета, и другие данные, имея которые, цвета перестают быть необходимыми.
Важное замечание! Когда ваша утилита выдает текст в machine-readable формате — желательно, чтобы форматирование цветов было отключено. В противном случае сторона, принимающая входные данные, имеет шанс заработать «несварение желудка» от специальных символов в строке.
Интерактивное общение с пользователем
Ещё одна библиотека предназначена для обеспечения интерактивности. Readline, о котором я уже говорил. Итак, к вашим услугам: запоминание истории пользовательских ответов и автодополнение. Также в rubygems и thor есть специальные модули отвечающие за взаимодействие с пользователем и предоставляющие такие методы, как say и ask.
Какого типа бывают интерактивные приложения? Вспомните irb и rails console. Автор книги приводил ещё один пример: предположим, вам приходит крупный JSON-объект и вы хотите исследовать, что в нем есть. Для этого можно написать интерактивный просмотрщик JSON, который позволяет бродить по иерархии командами cd, ls, а также изменять его командами rm и mknode. Пример приведен исключительно для того, чтобы разбудить ваше воображение. Можете придумать ещё сотню применений интерактивным приложениям.
Берегите нервы пользователя
Представьте себя на месте пользователя, который выкачивает через мобильное соединение большой файл и не знает, сколько уже скачалось. Первые десять минут пользователь ждет, зная, что файл большой. А потом начинает кусать локти: а вдруг коннекта нет? а может программа зависла? а может файл настолько большой, что пользователю в конце месяца мобильный раз и навсегда отключат? В случае, если программа может работать долго, ей не помешало бы вывести строку состояния в stderr или в лог-файл (и не забудьте, что файловые операции буферизуются, так что время от времени делайте flush , а то имеете шансы увидеть результаты в лог-файле только после того, как программа завершит работу).
Будет нелепо отсчитывать каждый процент загрузки на новой строке! Вместо этого давайте будем переписывать одну строку, каждый раз меняя числа. В этом нам поможет спецсимвол \r — возврат каретки. Когда в строке встречается \r , курсор терминала как бы смещается в начало строки и начинает печатать символы поверх старых (осторожно, «хвост» старой строки автоматически не затирается). Будьте однако внимательны, метод puts нам не подойдет, т.к. он автоматически переводит курсор на новую строку. Нам нужен метод print , и вот пример его использования:
(0..100).each do |i| $stderr.print("\r#% done") sleep(0.1) end Стоит, правда, немного вас предостеречь: в окне терминала потоки stderr и stdout смешаны, так что вы можете начать затирать не те данные, которые нужно.
В заключение не могу не рассказать о нескольких популярных библиотеках.
Если вы хоть немного проработали с руби-проектами, наверняка уже встречали команду rake, а может и команду thor. Это — специализированные библиотеки, позволяющие при помощи специального DSL описать набор утилиток, как набор задачи автоматизации.
Rake — это улучшенный аналог программы make для ruby. Он заглядывает в Rakefile текущего или родительского каталога и ищет там описание задачи. Например, bundler создает для каждого нового гема Rakefile с набором задач: build, install, release, что позволяет инсталлировать и публиковать собственные гемы одной командой. Одной из отличительных фишек rake является система зависимостей между задачами — так rake release сначала выполнит задачу build и только затем release. К сожалению, передавать аргументы в rake то ли нельзя, то ли нетривиально. На хабре, кстати, уже был вводный пост про rake.
Thor — система похожая на rake. Она помимо прочего позволяет «устанавливать» задачи в систему. Подробнее лучше посмотреть в других источниках.
Я упоминаю об этих библиотеках, поскольку они могут облегчить вам жизнь, если вам не нужна никакая сложная обработка опций и аргументов. Простые программные пакеты вполне описываются в терминах этих двух известных библиотек. В частности, в Ruby on Rails они обе используются для задач типа запуска генераторов, миграций, очистки кэша приложения итп.
Большую часть повествования я использовал для разбора опций OptionParser из стандартной библиотеки ruby. Это весьма удобная библиотека, однако некоторые считают её довольно тяжеловесной и пишут обертки. Некоторые обертки концентрируются на том, чтобы упростить задание опций, некоторые — на том, чтобы сделать хэш опций доступным глобально итд. Если вам покажется, что OptionParser вас тормозит, можете подобрать одну из готовых оберток (список можно найти на сайте книги — см. начало статьи) или сделать свою.
Есть у OptionParser и другие недостатки: она не способна отличить глобальные опции от локальных в программном пакете (это разделение мы сами сделали; вообще говоря, оно ниоткуда не следует, кроме успешного применения концепции в некоторых крупных проектах, таких как git). Ещё одна особенность OptionParser-а (это не прописано в спецификации и я полагаю, что это баг) — то что отрицательные числа в аргументах он понимает как опции. Полагаю, что рано или поздно этот баг исправят, но если ваша программа принимает числовые аргументы — будьте осторожны и тщательно тестируйте программу.
Для построения программных пакетов автор книги Дэвид Коупленд сделал весьма неплохой гем GLI. Он различает глобальные опции, опции команды и распознает саму команду. Проект живой и периодически получает обновления.
Кроме того, не могу не упомянуть довольно сырой, но крайне любопытный проект — docopt. Это — библиотека, которая по строке подсказки генерирует парсер опций, тогда как OptionParser и родственные библиотеки делают наоборот. Эта библиотека изначально написана на python и портирована на довольно большое количество языков. Про её возможности можно почитать здесь. Думаю, при должном внимании сообщества, она может превратиться в крайне удобную и мощную библиотеку.
P.S. Помимо описанного мной в статье, рубисту, работающему с приложениями командной строки, есть смысл почитать про специальную переменную ARGF . Если все аргументы вашего скрипта — имена файлов, то ARGF — просто конкатенация содержимого всех файлов.
Двенадцатифакторная модель создания CLI-приложений
Современному пользователю сложно представить себе взаимодействие с операционной системой без мышки или пальца на экране. Интерфейс однозначно ассоциируется с чем-то графическим и оконным, основанным на пользовательском опыте миллионов людей за несколько десятилетий. Это очень удобно, однако в разработке софта есть ещё удалённые уголки Вселенной, где для решения сложных комплексных задач просто нет готовых решений с графическими интерфейсами. Тут на помощь приходит старая добрая командная строка (Command Line Interface, CLI). Поводом для перевода и публикации этой статьи стал интерес команды Artezio к повышению удобства, читаемости и возможности поддержки CLI в части разработки. В конце концов это такой же интерфейс как и графический, он тоже должен быть удобным. Мы очень надеемся, что эти знания окажутся полезными для читателей блога.

Интерфейс командной строки (Command line interface, CLI) – это отличный способ создания прикладных приложений. На их разработку требуется значительно меньше времени, чем на веб-приложения, при этом CLI-приложения предоставляют гибкость для решения технических задач ИТ-инженерам. В веб-приложениях вы можете выполнять действия, которые запрограммировал разработчик. А с помощью CLI вы можете с легкостью самостоятельно объединить несколько инструментов для выполнения сложных сценариев и комплексных задач. Для их использования требуются технические знания, но они прекрасно подходят и для задач администратора, опытного пользователя или создания продуктов для разработчиков.
В Heroku разработали методологию под названием «Двенадцатифакторное приложение». Это набор практик, предназначенных для создания легко поддерживаемых веб-приложений. Ниже похожий набор — 12 правил, которые стоит учитывать при разработке CLI-приложений. Следуя этим принципам, вы сможете создавать приложения для командной строки, которые понравятся пользователям.
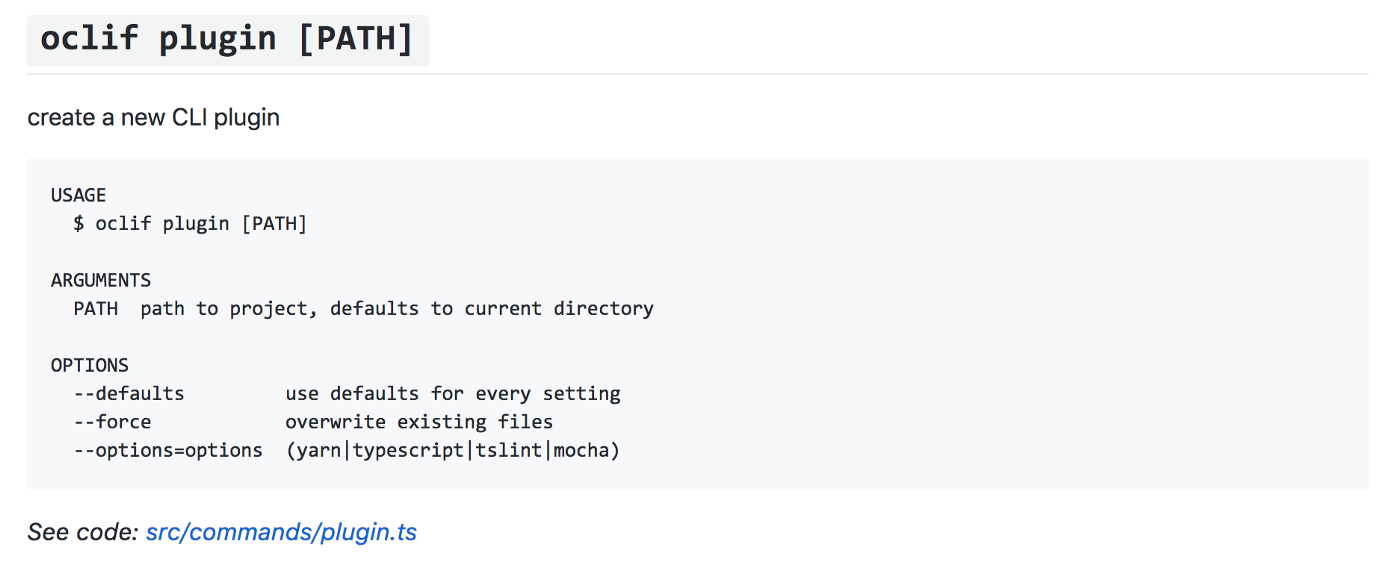
Мы также сделали CLI-фреймворк под названием oclif, разработанный с учетом этих принципов для создания интерфейсов командной строки в Node.
1. Хорошая справочная информация
Для CLI-приложений очень важно предоставить пользователям хорошую документацию. Намного важнее, чем при разработке веб-приложений, так как вы не можете подсказывать пользователю через интуитивно понятный графический интерфейс.
Хороший интерфейс командной строки умеет сам предоставлять справочную информацию о себе, а также обладает онлайн-документацией или файлом READMI. Это позволяет быстро разобраться прямо из командной строки, в то же время ваши пользователи могут и загуглить какой-то вопрос (кстати, убедитесь, что Google индексирует страницы с документацией).
Man-документация вам, скорее всего, не нужна (если только это не прямое требование ваших пользователей), она редко используется. Начинающие разработчики ничего о ней не знают, и к тому же она не работает под Windows. Оффлайн-поддержка не нужна, у вас уже есть help в CLI. При этом в нашем фреймворке в oclif мы планируем создать man-документацию. В случае фреймворка имеет смысл создать единое описание для всех интерфейсов.
Убедитесь, что все из вариантов ниже отображают справку в интерфейсе командной строки. Вы не знаете, что будет вводить пользователь, поэтому всё это должно показывать справку.
# list all commands $ mycli $ mycli --help $ mycli help $ mycli -h# get help for subcommand $ mycli subcommand --help $ mycli subcommand -h -h,--helpследует зарезервировать только в качестве флага для получения справки. Когда речь идет о subcommand help, вы не можете гарантировать, что help не является аргументом, который надо передать подкоманде. Лучше договориться об общем правиле и всегда показывать справку или ошибку с недопустимым аргументом. Есть приложение Heroku под названием “help”, которое не раз вызывало у меня эту проблему.
Автодополнение для Shell – еще один хороший способ помочь пользователям.
Что касается самой справки, покажите описание команды, аргументов, всех флагов и, самое важное, предоставьте примеры типичного применения CLI, даже если оно очевидно для вас. Это самая распространённая часть документации, на которую ссылаются пользователи.

Конечно же, создавая интерфейс командной строки с oclif, вы всё это получаете бесплатно: онлайн-документация, документация в CLI и автодополнение. Мы даже работаем над средством контроля качества кода, чтобы помочь вам везде применять описания.
2. Лучше использовать флаги, чем аргументы
CLI принимает два типа входных данных shell: флаги и аргументы. При использовании флагов строчка ввода будет чуть длиннее, но они делают CLI более понятным. Например, в Heroku CLI мы часто работали с командой heroku fork. Она копировала из исходного приложения в целевое. Изначально использовался следующий флаг и аргумент:
$ heroku fork FROMAPP --app TOAPPПри этом было сложно понять, что было исходным, а что ― целевым приложением. Мы стали использовать флаги для обоих случаев:
$ heroku fork --from FROMAPP --to TOAPPТак стало понятнее, что есть исходное, а что ― целевое приложение.
Обратите внимание, что мы удалили эту команду из Heroku CLI, но это хороший пример того, как аргументы могут сбивать с толку.
Иногда аргументы вполне можно использовать, когда они очевидны, например, $ rm file_to_remove. Есть хорошее правило: один тип аргумента – это хорошо, два типа – сомнительно, а три – бесполезно.
Для аргументов переменной длины можно применять несколько аргументов (например, $ rm field file2 file3). Но когда они разных типов, это сбивает пользователя с толку.
Для флагов гораздо проще написать логику автодополнения, так как вы точно знаете, каким должно быть значение.
В CLI, которые передают флаги любому другому процессу (например, heroku run), парсер флагов должен принимать — аргумент для обозначения того, что он должен прекратить парсинг и передать все в качестве аргумента. Это позволяет запустить команду heroku run -a myapp — myscript.sh -a arg1 (это демонстрирует, как –a может быть флагом для heroku run, а другая –a передается в динамические контейнеры).
3. Какую версию я использую?
Убедитесь, что вы можете узнать версию CLI при помощи:
$ mycli version # multi only $ mycli --version $ mycli –VЕсли только это не однокомандный CLI, у которого тоже есть флаг -v,—verbose, команда $ mycli –v аналогично должна отображать версию CLI. Запускать три разные команды, чтобы узнать версию CLI, затруднительно до тех пор, пока вы не найдёте нужную.
Команда версии – это основное место, где вы будете запрашивать у пользователей отладочную информацию, поэтому здесь хорошо размещать любой полезный материал, помимо номера версии, который может помочь вам определить проблемы.
Я также предлагаю отправлять строку версии как User-Agent, чтобы вы могли исправить ошибки на стороне сервера (предположим, ваш CLI использует какой-либо API).

4. Следите за потоками
Потоки stdout и stderr позволяют выводить сообщения пользователю, а также перенаправлять их содержимое в файл. Например:
$ myapp > foo.txt Warning: something went wrongПоскольку этот Warning находится в stderr, он не попадает в файл. Направляя Warningи в stdout, вы не только скроете их от пользователя, но и создадите проблемы для структурированных данных, таких, как JSON или бинарные файлы. Используйте stderr для ошибок и предупреждений, которые по умолчанию всегда будут отображаться на экране, даже если stdout будет перенаправлен.
Хотя не все в stderr является ошибкой. Например, вы можете использовать команду curl для загрузки файла, и вывод её прогресса будет находиться в stderr. Это позволяет вам перенаправить stdout, но при этом видеть прогресс.
Итак, stdout необходим для вывода, stderr – для сообщений.
Если вы запускаете подкоманду в CLI, убедитесь, что вы всегда передаете stderr этой подкоманды пользователю. В таком случае все ошибки всегда будут выводиться на экран пользователя.
5. Отслеживайте проблемы и нестандартные ситуации
В CLI проблемы возникают гораздо чаще, чем в веб-приложениях. Не имея UI для помощи пользователю, единственное, что мы можем сделать – показать ошибку. Это логичное поведение и неотъемлемая часть использования любого CLI.
Прежде всего, ваши ошибки должны быть информативными. Идеальное сообщение об ошибке должно содержать следующее:
- код ошибки,
- название ошибки,
- описание ошибки (опционально),
- способы её исправления,
- URL для получения дополнительной информации.
Например, если наш CLI выдал ошибку о проблеме с правами доступа к файлу, можно отобразить следующее сообщение:
$ myapp dump -o myfile.out Error: EPERM - Invalid permissions on myfile.out Cannot write to myfile.out, file does not have write permissions. Fix with: chmod +w myfile.outТолько подумайте, если бы каждый интерфейс командной строки был таким полезным, как здорово было бы быть программистом.
Всегда есть возможность возникновения необрабатываемых ошибок, ситуации, когда вы не предполагали, что пользователь может с этим столкнуться. Для этого позаботьтесь о возможности просмотреть полную информацию трассировки и отладочную информацию с переменными окружения.
В oclif мы используем отладочный модуль, который позволяет нам выводить операторы отладки, сгруппированные по компонентам, если установлена переменная окружения DEBUG. Мы ведем очень подробное логирование при включенной отладке, это невероятно полезно при исправлении ошибок.
Логи ошибок также могут быть полезными для анализа и исправления ошибок, но убедитесь, что в них имеются временные метки. Рекомендуем периодически очищать их, чтобы они не занимали место на диске, и убедитесь в отсутствии цветовой кодировки ANSI.
6. Выделяйся!
Современным CLI не стоит стесняться быть яркими. Используйте цвета/подсветку для выделения важной информации. Спиннеры, прогресс-бары, счётчики и индикаторы выполнения для отображения длительных задач отлично подойдут, чтобы проинформировать пользователя о ведущейся работе. Применяйте нотификации операционной системы, чтобы показать выполнение длительной задачи.
В то же время у вас должна быть возможность вернуться к классическим схемам отображения информации и понимание, когда стоит это сделать. Например, если stdout пользователя не подключен к TTY (обычно это означает, что он передается в файл), то не отображайте цвета в stdout (аналогично stderr).
Счетчики и индикаторы выполнения также не являются хорошей идеей, если это не TTY. Они отрисовываются из элементов кодировки ANSI, и, конечно, это работает только на экране. В файле они вам совершенно точно не пригодятся.
У пользователя могут быть причины, по которым он не хочет видеть вывод, сияющий как новогодняя ёлка. Учитывайте это, если установлен TERM=dumb, NO COLOR, или, если указано —no-color. Я бы также предложил добавить переменную окружения MYAPP_NOCOLOR=1 для конкретного приложения на случай, если они захотят отключить цвет только в вашем CLI.
7. Предоставьте интерфейс с диалогом, если это возможно
Для принятия входных параметров, если stdin является TTY, предоставьте возможность передать параметры в диалоговом интерфейсе с подсказками, а не заставляйте пользователя обязательно указывать флаг. При этом никогда не делайте диалоги обязательными. Пользователь должен иметь возможность автоматизировать ваш CLI в скрипте.
Ещё одно отличное место для добавления диалогов с подсказками – это подтверждение опасных действий. Например, если вы хотите удалить приложение Heroku, вам придётся снова ввести его имя для подтверждения:
Флажки и радиокнопки — отличный способ улучшить взаимодействие с CLI, когда вы хотите визуально представить параметры пользователю:
8. Используйте таблицы
Обратите внимание, что команда cli.table() из cli-ux@5 позволяет легко создавать таблицы, следуя этим правилам.
Таблицы – распространённый способ вывода данных в CLI. Важно, чтобы каждая строка вывода представляла собой одну «запись» данных. Никогда не выводите границы таблицы. Это неудобно и сложно для парсинга. Ниже пример того, что не стоит делать:

Если каждая строка соответствует одной записи, вы можете использовать команду wc для подсчёта строк или grep для фильтрации каждой строки:

Помните о ширине экрана. Отображайте лишь несколько основных столбцов по умолчанию, но разрешите пользователю передавать команду —columns со списком имён столбцов, указанных через запятую, чтобы добавить и другие данные.
Обрезайте строки, которые будут выходить за пределы текущей ширины экрана, если не задан параметр —no-truncate.
Показывайте заголовки столбцов по умолчанию, но разрешайте их скрывать, используя —no-headers.
Дайте возможность пользователям задавать команду —filter для фильтрации определённых столбцов (обычно это может выполнить grep, но флаг может фильтровать определённые значения ячеек).
Разрешите сортировку по столбцам с помощью —sort. Разрешите обратную сортировку, а также сортировку по множеству колонок.
Разрешите выводить файлы в формате csv или JSON. Отображение необработанных данных в виде JSON – это отличный способ вывода структурированных данных. Ими можно управлять с помощью jq. Хоть jq очень полезен, cut и awk – более простые инструменты, которые лучше работают с данными в csv.
9. Будьте быстрыми
CLI нужно быстро запускаться. Используйте $ time mycli для проверки CLI. Ниже примерный гайд:
Очевидно, если ваш CLI выполняет такую важную задачу, как загрузка большого файла или что-либо ограниченное возможностью процессора, выполнение не будет быстрым. В этом случае покажите прогресс-бар выполнения программы или хотя бы спиннер. Просто наличие спиннера создаст впечатление, что CLI быстрее, чем есть на самом деле.
oclif разработан с минимальным потреблением ресурсов. Прямо сейчас на моем компьютере оно составляет около 150 мс, что достаточно хорошо. Для этого не нужно иметь все файлы js в CLI, только команду, которая должна быть запущена. Таким образом, даже если у вас есть сотни команд, ресурсопотребление всё равно будут составлять 150 мс.
10. Стимулируйте доработки и дополнения со стороны пользователей
Сделайте ваш код открытым. Это позволяет пользователям изучать его и самостоятельно находить проблемы. Хорошая идея для сообщества – предлагать образец кода, если это может быть полезно другим. Это положительно скажется на имидже организаций.
Убедитесь также, что вы выбрали лицензию. GitHub и GitLab – это отличное место, где можно разместить ваш CLI, а READMI дает вам отличную возможность для обзора вашего CLI.
Напишите, как запустить CLI локально и выполнить наборы тестов. Предложите документ с рекомендациями по внесению дополнений, чтобы сообщить участникам, что вы ожидаете с точки зрения синтаксиса коммитов, качества кода, тестов и всего остального, что им важно знать.
Добавьте кодекс поведения, даже если вам кажется, что в этом нет необходимости. Для некоторых людей это имеет значение, и они чувствуют себя гораздо лучше, видя, что такой документ существует. Некоторые, возможно, даже не заметят его, но это будет полезно в случае, если кто-то ведёт себя грубо, а у вас будет документ с разъяснениями.
В oclif имеется система плагинов, которая предлагает отличный способ для дополнения вашего CLI. Эти плагины могут быть в дальнейшем включены в основной плагин для предоставления функционала всем пользователям.
11. Предоставьте чёткую информацию о подкомандах
Существуют два типа CLI: однокомандный и многокомандный. Однокомандный CLI – это базовый CLI вида UNIX, такой, как cp или grep. Многокомандный больше похож на git или npm, принимающий подкоманду в качестве первого аргумента.
Если CLI простой и выполняет только одну базовую задачу, он хорошо подходит для однокомандного CLI. Однако для большинства CLI лучше использовать подкоманды.
В любом случае, если пользователь не передает никаких аргументов в CLI, всегда лучше в ответ перечислить подкоманды (для многокомандного) или отобразить справку (для одногокомандного), а не выполнять какие-либо действия по умолчанию. Обычно пользователь делает это перед тем, как сделать что-либо еще.
Если вы начинаете использовать подкоманды, через какое-то время они превращаются в целые полезные подразделы (мы называем их topics (темами) в oclif). Git обычно отделяет тему от подкоманды пробелами:
$ git submodule add git@github.com:oclif/commandВ то же время мы используем двоеточие в Heroku CLI:
$ heroku domains:add www.myapp.comДвоеточие предпочтительнее, чтобы разграничить команду от аргументов, переданных команде. Пользователь быстро узнает, что аргумент 1 – это команда, и как получить о ней справку.
Проще говоря, есть и другая техническая причина, почему мы предпочитаем двоеточие. Для команд уровня тем, таких, как $ heroku domains, мы перечисляем все домены приложения. Если бы мы использовали пробелы для отделения команд от подкоманд и хотели бы, чтобы эта команда уровня темы принимала аргумент, то парсер не смог бы определить, является ли аргумент подкомандой или аргументом команды темы. Таким образом, использование пробелов для разделения приводит к тому, что вы не можете иметь команды уровня темы, которые также принимают аргумент.
12. Следуйте спецификации XDG
Спецификация XDG – это отличный стандарт, который стоит использовать, чтобы узнать, где размещать файлы. Если переменные окружения, такие, как XDG_CONFIG_HOME не говорят об обратном, используйте ~/.config/myapp для файлов конфигурации и ~/.local/share/myapp для файлов данных.
Для файлов кэша используйте ~/.cache/myapp для UNIX, но на MacOS лучше использовать по умолчанию ~/Library/Caches/myapp. На Windows можно применять %LOCALAPPDATA%\myapp.
Вместо вывода мы хотели бы вам предложить высказать свое мнение о применении описанных подходов. Насколько актуальным остается для вас и вашей компании поиск новых решений и инструментов программирования? Также мы хотим напомнить, что в Artezio открыто много вакансий для начинающих и опытных разработчиков, которым было бы интересно поучаствовать в интересных проектах и расширить свой кругозор благодаря новым знаниям и практикам. Полный список актуальный вакансий можно найти здесь.
- Блог компании ГК ЛАНИТ
- Программирование