RMarkdown, R и ggplot
Данная статья не является ни документацией, ни рассказывает что-то принципиально новое, её стоит рассматривать как обзорную или как шпаргалку.
Преамбула
Конференция это прежде всего доклады, и далеко не последнее место занимает то, как оформлены слайды доклада.
Безусловно, есть докладчики, которые могут не смотря ни на что, провести доклад даже без единого слайда, но всё же они как правило хорошо дополняют повествование. Одним достаточно накидать мемасиков в доклад и дело готово, другим обязательно надо вставить код, причём на ассемблере (кто не в курсе ещё — JPoint — это конференция по java), и есть ещё те, кому надо показать графики. Впрочем, встречается и их комбинация.
Пожалуй известные средства для создания слайдов это:
- PowerPoint, и вариации в лице LibreOffice Impress, Apple KeyNote
- облачные вариации с тем же подходом — Google Slides
- LaTeX
- и относительно новый (для меня) RMarkdown
И если первые два по своей сути представляют бинарные форматы, а облачные Google Slides и ко ещё требуют наличие интернета, что является некоторым неприятным ограничением (во время поездок и перелётов), то последние два — и оффлайновые, и исключительно текстовые, а значит можно хранить историю всех изменений в git/hg/на ваш вкус. Кроме того, область применения далеко не ограничена только слайдами.
LaTeX формат с историей — много написано и сказано, а вот RMarkdown молодой, даже немного хипстерский, но без подворотов.
Markdown
Markdown это облегченный язык разметки, созданный с целью написания максимально читаемого и удобного для правки текста. Markdown является и лёгким для понимания, и легким для чтения даже без каких-либо трансформаций.
Сравните сами: _курсив_ это курсив, **сильное выделение** это сильное выделение, и многое другое — более подробно описано в Markdown cheatsheet.
Markdown поддерживают github, habrahabr, sublime, jira (имеет схожий синтаксис), и многие другие.
R
R — язык программирования для статистической обработки данных и работы с графикой.
Как правило это останавливает — это очень сложно, это математика, и это не надо — но никто же заставляет использовать всю доступную функциональность, пожалуй самый простой и наглядный — это графики и визуализация.
Хотя часто для того, чтобы построить какой-либо график используют Excel, он с большим трудом справляется, когда количество данных приближается уже к миллиону. Тогда как для R это не является какой-то сложной задачей.
Данные и графики
Оставим за кадром баталию, что же лучше — таблицы или графики. Вопрос вкуса.
Для построения графиков используем расширение ggplot2.
Дополнено: Нам необходим сам R и RStudio, например для MacOS / Homebrew:
$ brew tap homebrew/science
$ brew install r
$ brew сask install rstudio
устанавливаем модуль в RStudio для R :
install.packages("ggplot2")Но чтобы строить графики нужны данные, и разумно хранить их отдельно от представления, например, в csv формате — опять же — простой текстовый формат.
Мои данные — это результаты полученные при помощи jmh для моего доклада Внутрь VM сквозь замочную скважину hashCode. Мне нравится стиль, используемый Алексеем Шипилёвым: записывать результаты benchmark’а в виде комментария в начале файла — grep-n-sed и мы имеем csv-файл.
pos,alloc,value,error 10,single-threaded,2.836,0.285 20,java,9.878,2.676 28,epsilon,75.289,23.667 30,sync,186.672,21.195 40,cas,74.721,0.192 50,tlab,8.506,1.849 55,javaHashCode,60.270,12.318 57,readHashCode,7.296,0.316Формируем таблицу данных (data frame) из csv-файла — по-умолчанию, считается, что в файле есть заголовок — это нам поможет при обращении к отдельным колонкам
``` df = read.csv(file = "csv/allocations.csv") ```если хотим отфильтровать, н-р, по конкретным значениям в колонке alloc
Бары / столбики
Для начала необходимо задать схему соответствия переменных (aes) из таблицы данных — отображать будем значение от типа, в нашем случае типа аллокации, цвет бара будет выбран также на основе типа аллокации.
ggplot(data=df, aes(x=alloc, y=value, fill=alloc))Отображать будем в виде столбиков ( bar chart ) + geom_bar()
ggplot(data=df, aes(x=alloc, y=value, fill=alloc)) + geom_bar(stat="identity")повернём систему координат (из вертикальных в горизонтальные бары) опцией + coord_flip()
ggplot(data=df, aes(x=alloc, y=value, fill=alloc)) + geom_bar(stat="identity") + coord_flip()добавим ошибку изменений + geom_errorbar() (помните, у нас в csv-файле есть колонка error):
ggplot(data=df, aes(x=alloc, y=value, fill=alloc)) + geom_bar(stat="identity") + coord_flip() + geom_errorbar(aes(ymin = value - error, ymax = value + error), width=0.5, alpha=0.5)для наглядности стоит добавить значения рядом с баром + geom_text() (логично, что текстом будет value)
ggplot(data=df, aes(x=alloc, y=value, fill=alloc)) + geom_bar(stat="identity") + coord_flip() + geom_errorbar(aes(ymin = value - error, ymax = value + error), width=0.5, alpha=0.5) + geom_text(aes(label=value))добавим лоска подписи + geom_text():
- используем функцию для изменения подписи значение ± ошибка — label=base::sprintf(«%0.2f ± %0.2f», value, error) (привет старый добрый sprintf и шаблоный форматирования %f!)
- поиграемся с горизонтальным hjust и вертикальным vjust расположением подписи
- изменим размер шрифта size и начертание fontface подписи
- подкрутим тему + theme_classic()
- уберём легенду + theme(legend.position=»none»)
- добавим подписи + labs(title =…, x =…, y = ..) и шрифты для осей + theme(axis.text.y = ..)
и для придания финального лоска
- специфицируем цвета + scale_fill_manual()
- удалим зазор между вертикальной осью и баром + scale_y_continuous() и немного расширим диапазон значений, чтобы и ошибка помещалась, и подпись
- и ещё зафиксируем порядок баров, согласно колонке pos: x=reorder(alloc, -pos)
ggplot(data=df, aes(x=reorder(alloc, -pos), y=value, fill=alloc)) + geom_bar(stat="identity") + coord_flip() + geom_errorbar(aes(ymin = value - error, ymax = value + error), width=0.5, alpha=0.5) + geom_text(aes(label=base::sprintf("%0.2f ± %0.2f", value, error)), hjust=-0.1, vjust=-0.4, size=5, fontface = "bold") + scale_fill_manual(values=c(java'='#a9a518','sync'='#fa8074', 'cas'='#00b3f6', 'tlab'='#e67bf3')) + labs(title = "@Threads( 4 )", x = "", y = "ns/op") + theme_classic() + scale_y_continuous(limits=c(0, max(df$value) + 40), expand = c(0, 0)) + theme(axis.text.y = element_text(size = 16, face = "bold")) + theme(axis.title = element_text(size = 16, face = "bold")) + theme(legend.position="none")tip: можно сохранить график в файл + ggsave(«allocations.svg»), но не стоит злоупотреблять векторным форматом, если на графике много точек — сохраняйте в растр, н-р png.
install.packages("svglite")Отдельно стоит отметить цветовую палитру, используемую по-умолчанию: выбираемые цвета хорошо различимы даже для людей с ослабленым цветовосприятием.
Не используйте сочетание красный/зелёный даже если вы используете всего два цвета, чтобы выделить, что лучше/хуже — эти цвета слабо различимы для людей с ослабленым цветовосприятием.
tip: colorbrewer2 поможет выбрать в т.ч. безопасные цвета.
Точки
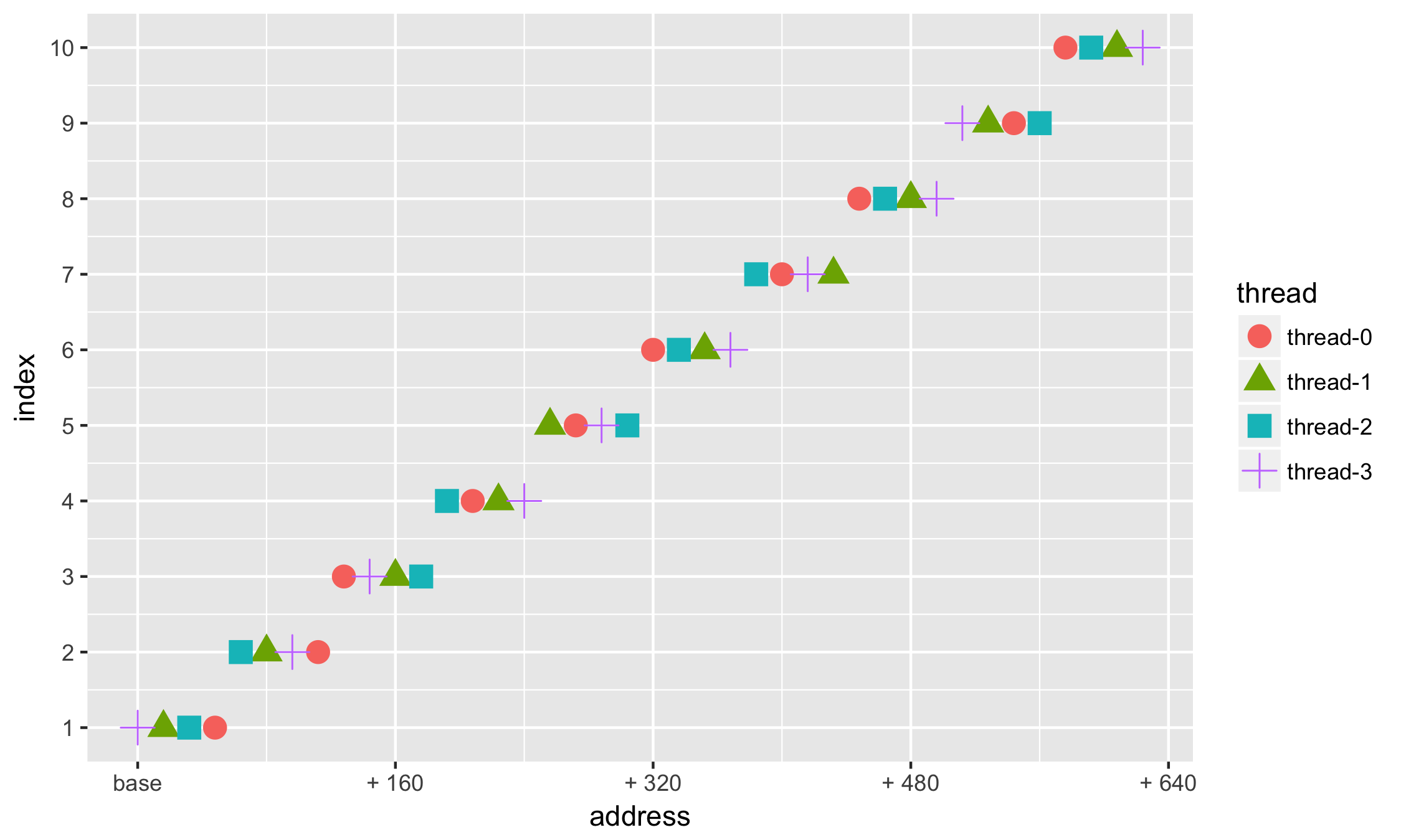
Есть некоторое распределение адресов по нитям
step,thread,address 1,thread-0,807437816 1,thread-1,807437784 1,thread-2,807437800 . - отобразим отдельно по точкам + geom_point
- чтобы можно было различить одну нить от другой, укажем не только цветовую aes(. colour = thread. ) дифференциацию, но и на основе формы маркераaes(. shape = thread. ) —
ggplot(data=df, aes(x = address, y = index, group=thread, colour=thread, shape=thread)) +
geom_point(size=2)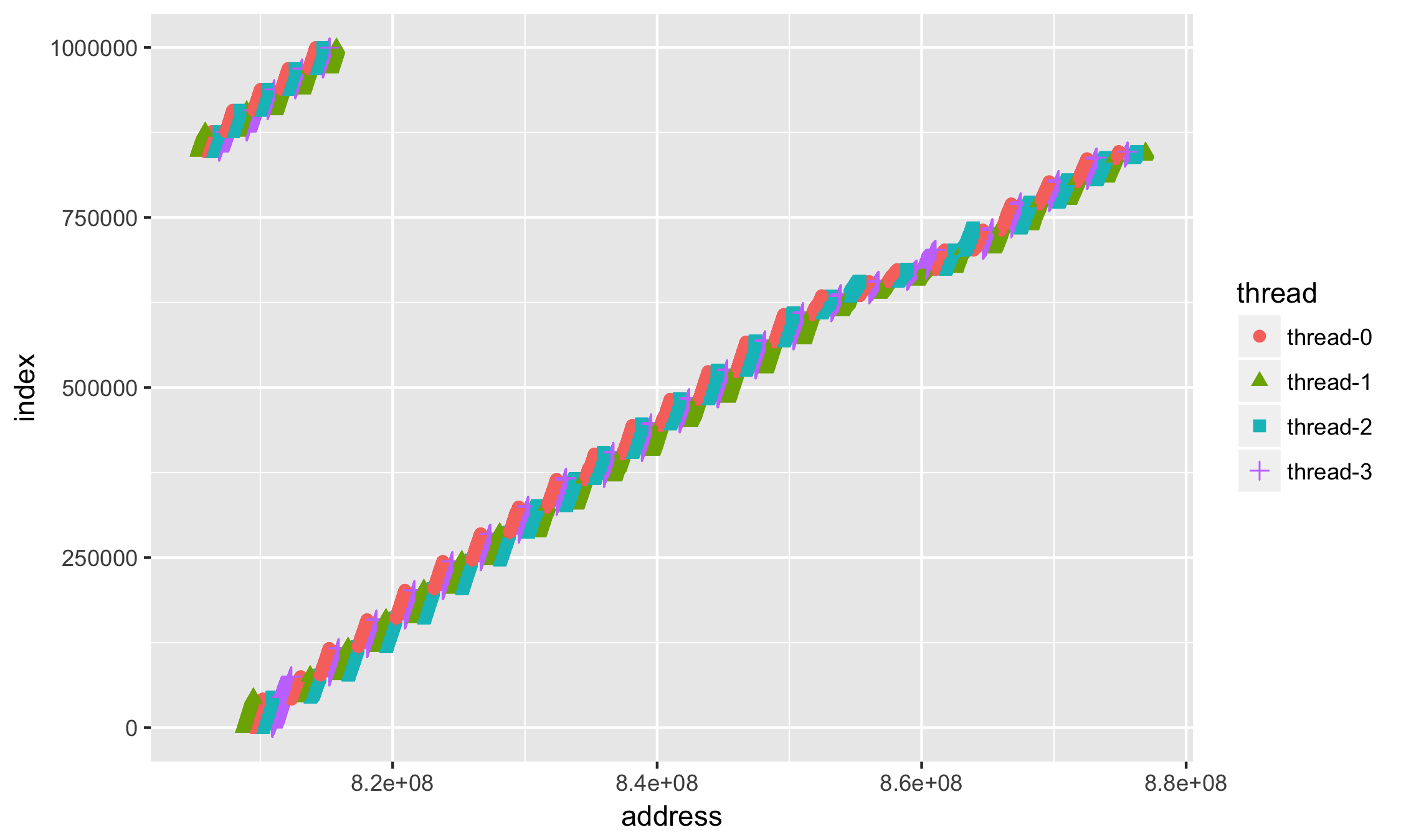
Первое, что бросается в глаза (кроме того, что много данных) — это значения адресов в научной нотации. Как-то привычней иметь дело с адресами в 16-тиричной системе: добавим форматирование значений по оси X +scale_x_continuous():
ggplot(data=df, aes(x = address, y = index, group=thread, colour=thread, shape=thread)) + geom_point(size=2) + scale_x_continuous( labels = function(n)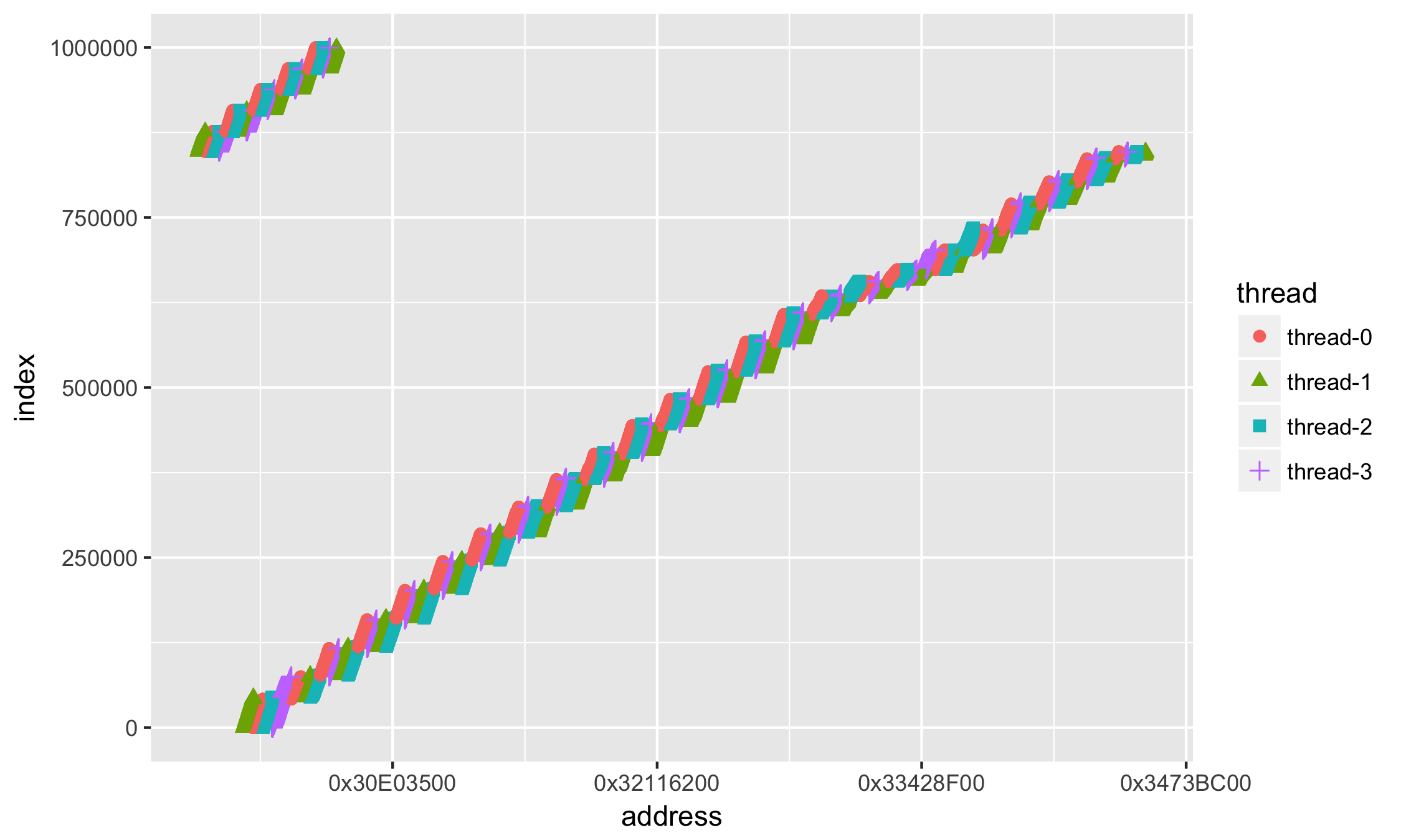
Лучше, но всё равно как-то сложно и мало понятно.
Поскольку мы можем задавать любую функцию, то почему бы не отображать смещение относительно некоторого базового, н-р минимального, адреса:
min_address = min(df$address) ggplot(data=df, aes(x = address, y = index, group=thread, colour=thread, shape=thread)) + geom_point(size=2) + scale_x_continuous( labels = function(n)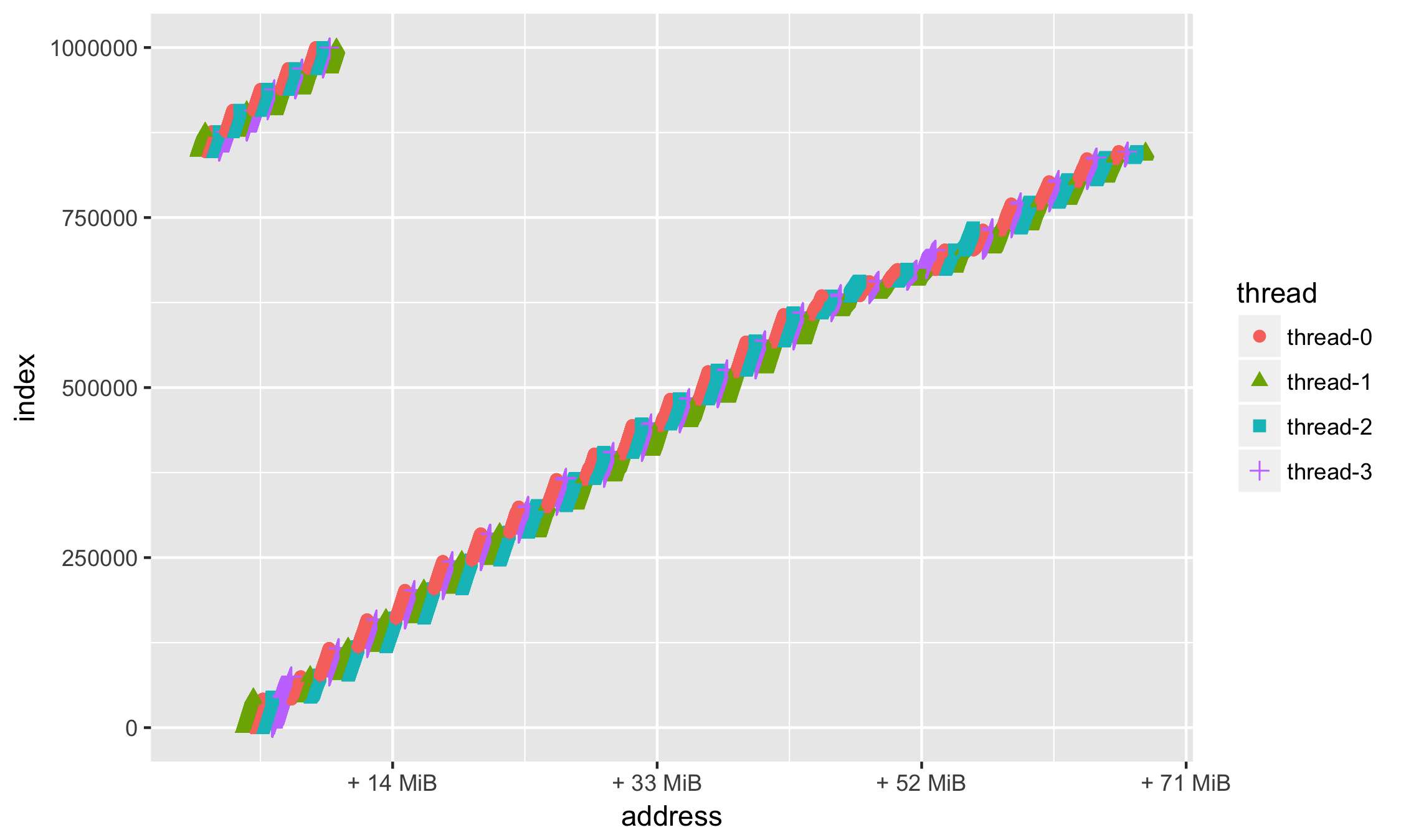
Опять же в силу привычки — поставим метки (breaks =) по целым числам — а именно 16, 32, 48, 64Мб:
ggplot(data=df, aes(x = address, y = index, group=thread, colour=thread, shape=thread)) + geom_point(size=2) + scale_x_continuous( labels = function(n)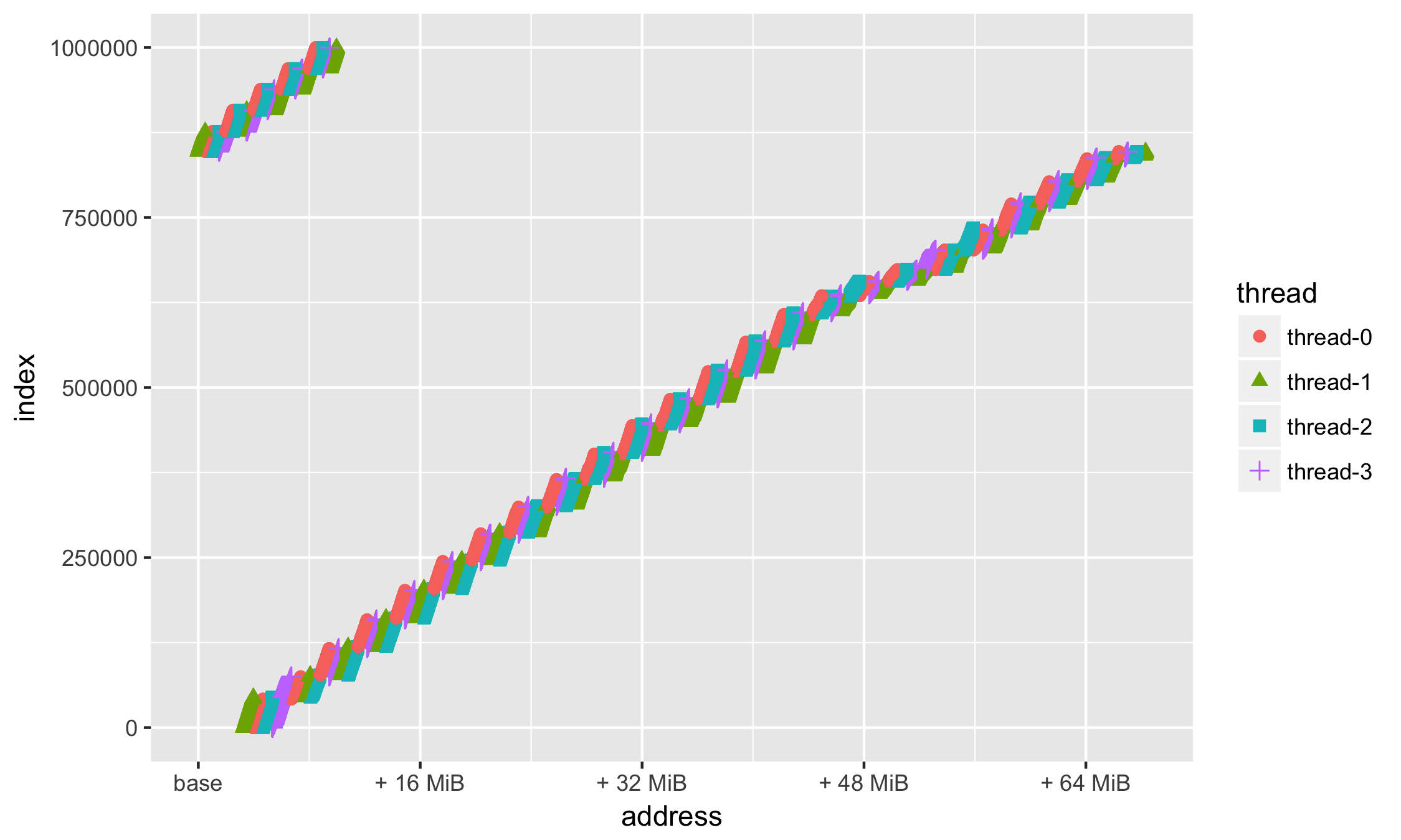
Данных много — хотим взглянуть на небольшую её часть
- ограничим набор данных по количеству nrows при загрузке read.csv(. )
- добавим метки в нужных местах на оси Y: + scale_y_continuous(breaks = c(. ))
Гистограмма
И конечно же — гистограмма, частотное распределение. Очень грубо это можно описать как количество элементов попадающих в диапазон значений. Н-р, для ряда [1, 2, 3, 1, 1] — гистограмма будет выглядеть как [3, 1, 1] — т.к элемент 1 встретился 3 раза, а элементы 2 и 3 по одному разу.
addressHashCode = read.csv(file = "csv/addressHashCode.csv") defaultHashCode = read.csv(file = "csv/defaultHashCode.csv") ggplot() + geom_histogram(data=addressHashCode, aes(x=hashCode, fill="address"), alpha=0.7, bins = 500) + geom_histogram(data=defaultHashCode, aes(x=hashCode, fill="MXSRng"), alpha=0.7, bins = 500) +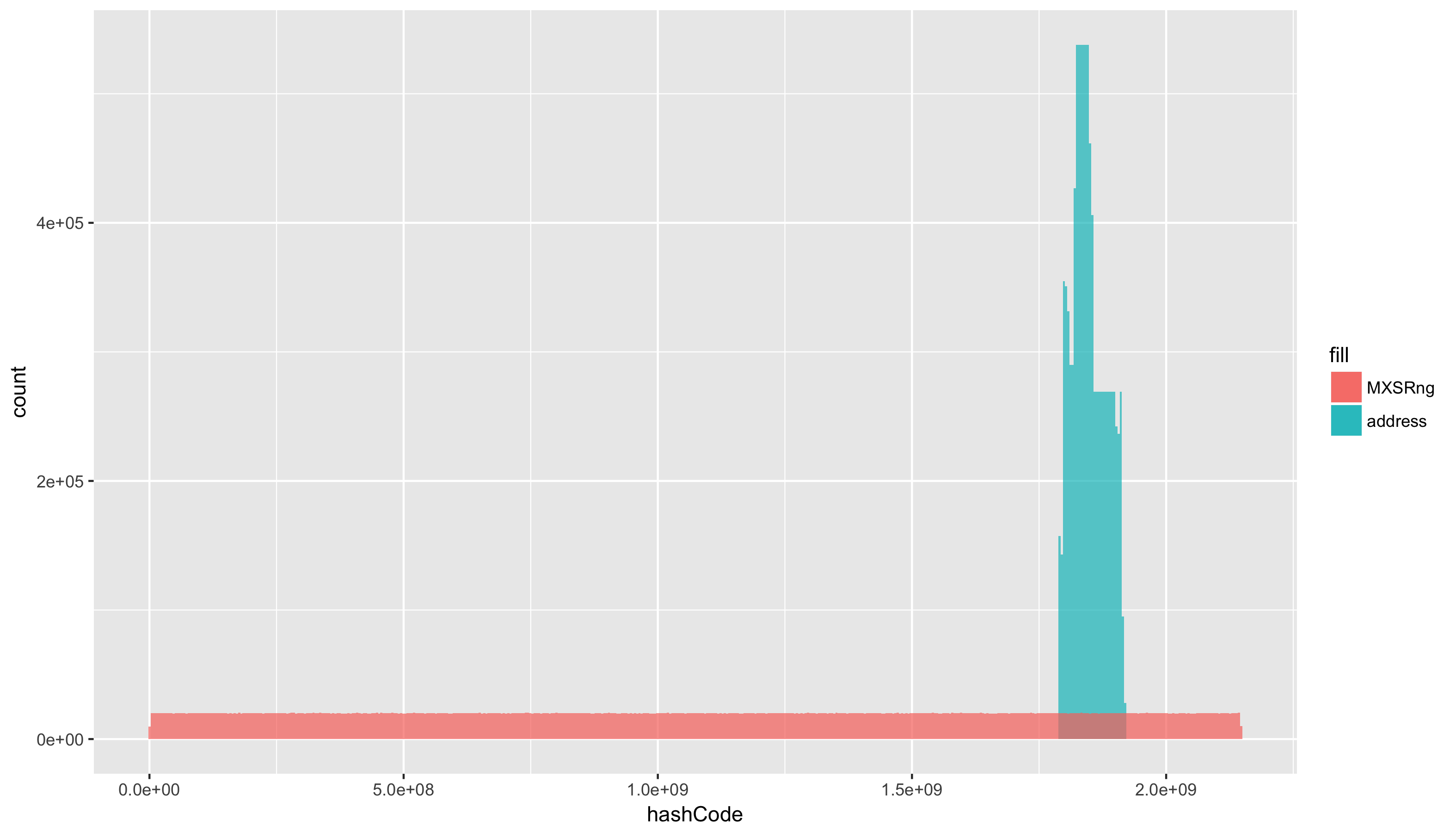
Добавляем уже известные опции до придания нужного вида:
ggplot() + geom_histogram(data=addressHashCode, aes(x=hashCode, fill="address"), alpha=0.7, bins = 500) + geom_histogram(data=defaultHashCode, aes(x=hashCode, fill="MXSRng"), alpha=0.7, bins = 500) + scale_fill_manual(name="тип hashCode:", labels=c("address"="адрес", "MXSRng"="MXS-гпсч"), values=c("address" ="#003dae", "MXSRng" = "#ae003d")) + labs(title = sprintf("количество коллизий по адресу: %s k, по MXS-гпсч: %s k", round( sum(duplicated(addressHashCode)) / 1000, 1), round( sum(duplicated(defaultHashCode)) / 1000, 1)), x = "hashCode") + theme_classic() + theme(axis.title.y=element_blank()) + scale_y_continuous(labels = function(n)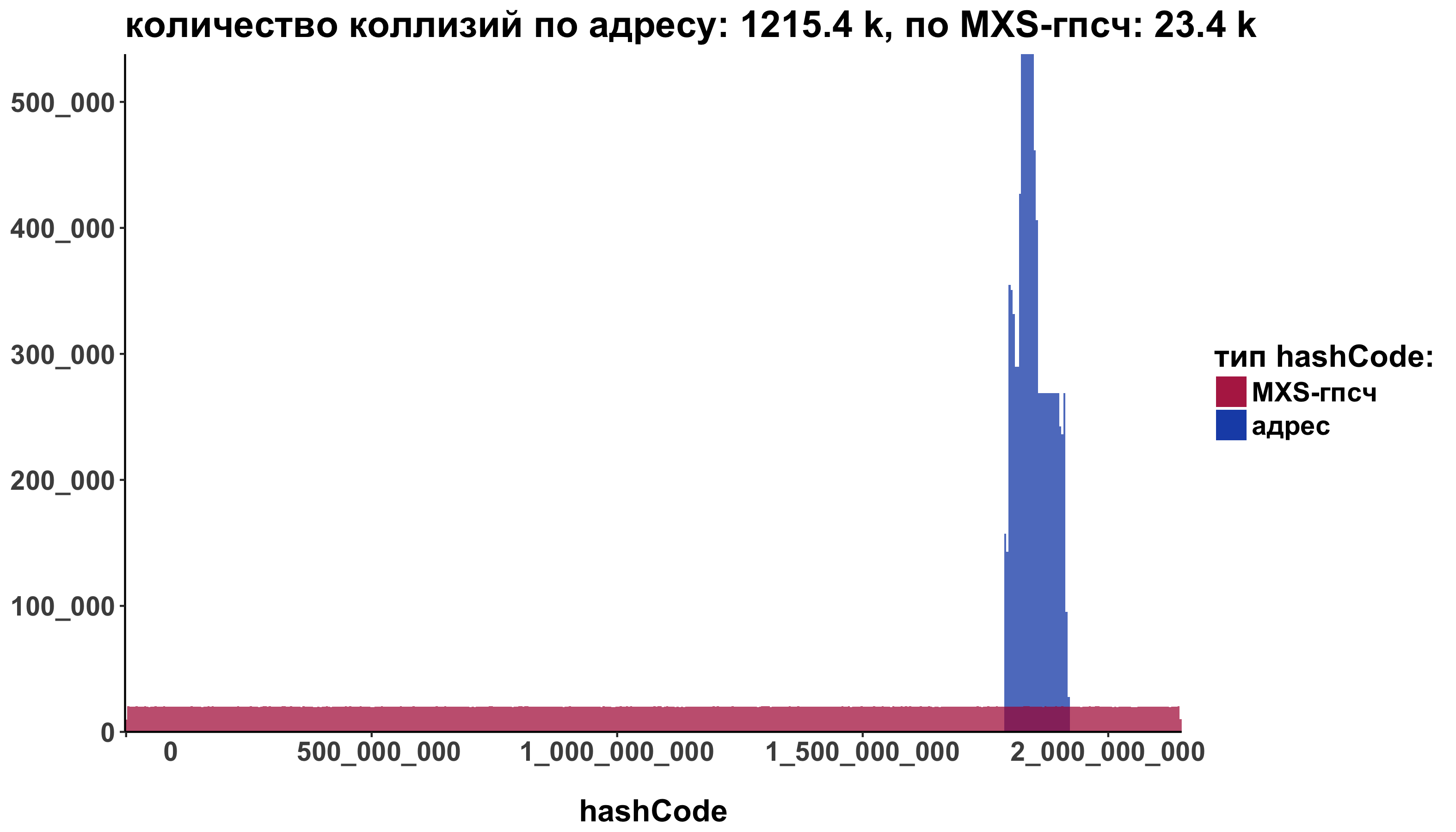
# install.packages('png') img
RMarkdown
Не надо быть большим капитаном, чтобы сообразить, что RMarkdown это R + Markdown.
Устанавливаем модуль для R :
install.packages("rmarkdown")И со словами HTML знаю, LaTeX люблю рендерим RMarkdown:
rmarkdown::render("path_to_file.Rmd", encoding = "UTF-8")
В заголовке досаточно указать, например:
output: pdf_document
для этого в заголовке достаточно поменять output:
16 R Markdown и Quarto
После подсчета описательных статистик, создания графиков и, в особенности, интерактивных визуализаций, возникает вопрос о том, как представить полученные результаты.
R Markdown представляет такую возможность. С помощью R Markdown в документе можно совмещать код, результаты его исполнения и написанный текст. Кроме того, можно вставлять картинки, ссылки, видео и многое другое. В чем-то R Markdown напоминает Jupyter Notebook знакомый всем питоноводом, но это сходство, скорее, функциональное (и то, и то позволяет превращать сухой текст скрипта в красивый документ), их устройство значительно различается.
R Markdown представляет собой текстовый документ специального формата .Rmd, который можно скомпилировать в самые различные документы:
- Документы в форматах Word, ODT, RTF, PDF (с использованием LaTeX), HTML, в том числе:
- Онлайн-книги (bookdown)
- Научные статьи (papaja)
Формат вывода легко настроить и поменять по ходу работы, что позволяет гибко изменять формат документа на выходе.
16.2 Начало работы в R Markdown
Для работы с R Markdown у RStudio есть специальные инструменты, которые позволяют не только удобно писать и компилировать R Markdown документы, но и превращают R Markdown в удобную среду для работы с R вместо обычных R-скриптов.
Чтобы начать работать с R Markdown, нужно создать новый .Rmd файл с помощью File - New File - R Markdown.. . Перед вами появится меню выбора формата R Markdown документа, названия и имени автора.
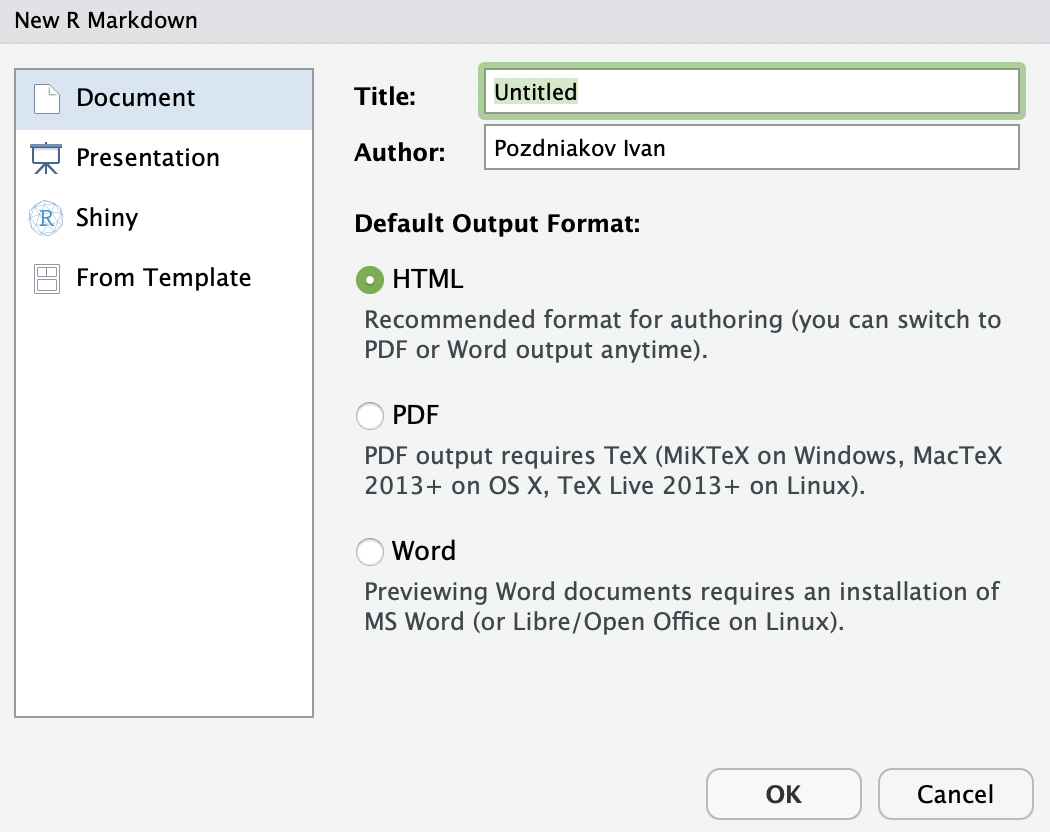
Выбирайте что угодно, все это можно потом изменить вручную.
Если пакет rmarkdown у вас еще не установлен, то он будет автоматически установлен. Кроме того, если вы выбрали в качестве формата PDF (презентацию или документ), то вам понадобится еще установить LaTeX на компьютер. Это тоже можно сделать с помощью специального пакета:
install.packages('tinytex') tinytex::install_tinytex() # install TinyTeX.Rmd файл, который вы создадите таким образом, будет создан из шаблона, который демонстрирует основной функционал R Markdown. В отличие от работы с R скриптом, перед вами будет немного другой набор кнопок. Самая важная из новых кнопок — это кнопка Knit (с клубком и спицей рядом), нажав на которую, начнется “вязание” (knitting) финального документа, то есть его компиляция. Если компиляция завершится успешно, то перед вами появится скомпилированный документ в том формате, который вы выбрали.
16.3 Структура R Markdown документа
R Markdown документ состоит из трех базовых элементов:
- YAML-шапки 1
- Текста с использованием разметки Markdown
- Чанков (chunks) с кодом
Разберем их по порядку.
- YAML-шапка находится в самом верху документа и отделена тремя дефисами ( --- ) сверху и снизу. В нем содержится, во-первых, мета-информация о документе, которая будет отображена на титульном листе/слайде, во-вторых, информация о формате документа, который будет “связан”. Пример YAML-шапки:
--- title: "Классное название для документа" author: "Поздняков Иван" date: "15 11 2020" output: html_document ---- Текст с использование синтаксиса Markdown идет сразу после YAML-шапки и составляет основную часть .Rmd документа. Markdown (не путать с R Markdown!) — это популярный и очень удобный язык разметки. Markdown используется повсюду: в ReadMe страницах на GitHub, как способ ведения записей во многих программах для заметок и даже в Telegram! Например, вот так можно задавать полужирный шрифт и курсив:
Вот так мы делаем **полужирный**, а вот так мы делаем *курсив.*В результате мы получим следующую строчку:
Вот так мы делаем полужирный, а вот так мы делаем курсив.
Далее мы разберем подробнее синтаксис Markdown.
- Чанки с кодом содержат в себе код на языке R или другом языке программирования, которые будут исполнены, а результат которых будет отображен прямо под чанком с кодом. Чанк с кодом отделяется ``` с обоих сторон и содержит . Это означает, что внутри находится код на R, который должен быть выполнен:
В итоговом документе чанк будет выглядеть так:
Краткое руководство по Маркдауну
Официальное руководство по синтаксису Markdown мне кажется слишком длинным и не слишком наглядным, поэтому я составил краткое руководство, которое поможет выучить или повторить синтаксис Маркдауна за час.
Кроме традиционного Маркдауна у разработчиков получил распространение дополненный и улучшеный вариант языка — Github Flavoured Markdown, сокращенно GFM.
Основные отличия GFM и чистого Маркдауна:
- добавили таблицы, которых не было в оригинальном Маркдауне;
- добавили альтернативный синтаксис для вставки блоков кода: теперь можно не ставить 4 пробела перед каждой строкой кода, также можно явно указать язык кода;
- добавили зачеркнутый текст.
# GitHub-Flavored Markdown ## Краткое руководство Абзацы создаются при помощи пустой строки. Если вокруг текста сверху и снизу есть пустые строки, то текст превращается в абзац. Чтобы сделать перенос строки вместо абзаца, нужно поставить два пробела в конце предыдущей строки. Заголовки отмечаются диезом `#` в начале строки, от одного до шести. Например: # Заголовок первого уровня # ## Заголовок h2 ### Заголовок h3 #### Заголовок h4 ##### Заголовок h5 ###### Заголовок h6 В декоративных целях заголовки можно «закрывать» с обратной стороны. ### Списки Для разметки неупорядоченных списков можно использовать или `*`, или `-`, или `+`: - элемент 1 - элемент 2 - элемент . Вложенные пункты создаются четырьмя пробелами перед маркером пункта: * элемент 1 * элемент 2 * вложенный элемент 2.1 * вложенный элемент 2.2 * элемент . Упорядоченный список: 1. элемент 1 2. элемент 2 1. вложенный 2. вложенный 3. элемент 3 4. Donec sit amet nisl. Aliquam semper ipsum sit amet velit. Suspendisse id sem consectetuer libero luctus adipiscing. На самом деле не важно как в коде пронумерованы пункты, главное, чтобы перед элементом списка стояла цифра (любая) с точкой. Можно сделать и так: 0. элемент 1 0. элемент 2 0. элемент 3 0. элемент 4 Список с абзацами: * Раз абзац. Lorem ipsum dolor sit amet, consectetur adipisicing elit. * Два абзац. Donec sit amet nisl. Aliquam semper ipsum sit amet velit. Suspendisse id sem consectetuer libero luctus adipiscing. * Три абзац. Ea, quis, alias nobis porro quos laborum minus sed fuga odio dolore natus quas cum enim necessitatibus magni provident non saepe sequi? Четыре абзац (Четыре пробела в начале или один tab). ### Цитаты Цитаты оформляются как в емейлах, с помощью символа `>`. > This is a blockquote with two paragraphs. Lorem ipsum dolor sit amet, > consectetuer adipiscing elit. Aliquam hendrerit mi posuere lectus. > Vestibulum enim wisi, viverra nec, fringilla in, laoreet vitae, risus. > > Donec sit amet nisl. Aliquam semper ipsum sit amet velit. Suspendisse > id sem consectetuer libero luctus adipiscing. Или более ленивым способом, когда знак `>` ставится перед каждым элементом цитаты, будь то абзац, заголовок или пустая строка: > This is a blockquote with two paragraphs. Lorem ipsum dolor sit amet, consectetuer adipiscing elit. Aliquam hendrerit mi posuere lectus. Vestibulum enim wisi, viverra nec, fringilla in, laoreet vitae, risus. > > Donec sit amet nisl. Aliquam semper ipsum sit amet velit. Suspendisse id sem consectetuer libero luctus adipiscing. В цитаты можно помещать всё что угодно, в том числе вложенные цитаты: > ## This is a header. > > 1. This is the first list item. > 2. This is the second list item. > > > Вложенная цитата. > > Here's some example code: > > return shell_exec("echo $input | $markdown_script"); ### Исходный код В чистом Маркдауне блоки кода отбиваются 4 пробелами в начале каждой строки. Но в GitHub-Flavored Markdown (сокращенно GFM) есть более удобный способ: ставим по три апострофа (на букве Ё) до и после кода. Также можно указать язык исходного кода. ` ` `html nav class="nav nav-primary"> ul> 0 комментариев Комментарии Войти ul> nav> ` ` ` Самое приятное, что в коде не нужно заменять угловые скобки `< >` и амперсанд `&` на их html-сущности. ### Инлайн код Для вставки кода внутри предложений нужно заключать этот код в апострофы (на букве Ё). Пример: ``. Если внутри кода есть апостроф, то код надо обрамить двойными апострофами: ``There is a literal backtick (`) here.`` ### Горизонтальная черта `hr` создается тремя звездочками или тремя дефисами. *** ### Ссылки Это встроенная [ссылка с title элементом](http://example.com/link "Я ссылка"). Это — [без title](http://example.com/link). А вот [пример][1] [нескольких][2] [ссылок][id] с разметкой как у сносок. Прокатит и [короткая запись][ ] без указания id. [1]: http://example.com/ "Optional Title Here" [2]: http://example.com/some [id]: http://example.com/links (Optional Title Here) [короткая запись]: http://example.com/short Вынос длинных урлов из предложения способствует сохранению читабельности исходника. Сноски можно располагать в любом месте документа. ### Emphasis Выделять слова можно при помощи `*` и `_`. Одним символ для наклонного текста, два символа для жирного текста, три — для наклонного и жирного одновременно. Например, это _italic_ и это тоже *italic*. А вот так уже __strong__, и так тоже **strong**. А так ***жирный и наклонный*** одновременно. ### Зачеркивание В GFM добавлено зачеркивание текста: две тильды `~` до и после текста. ~~Зачеркнуто~~ ## Картинки Картинка без `alt` текста  Картинка с альтом и тайтлом:  Запомнить просто: синтаксис как у ссылок, только перед открывающей квадратной скобкой ставится восклицательный знак. Картинки «сноски»: ![Картинка][image1] ![Картинка][image2] ![Картинка][image3] [image1]: http://placehold.it/250x100 [image2]: http://placehold.it/200x100 [image3]: http://placehold.it/150x100 Картинки-ссылки: [](http://example.com/) ## Использование HTML внутри Markdown Mожно смешивать Markdown и HTML. Если на какие-то элементы нужно поставить классы или атрибуты, смело используем HTML: > Выделять слова можно при помощи * и _ . Например, это italic и это тоже italic. А вот так уже strong, и так тоже strong. Можно и наоборот, внутри HTML-тегов использовать Маркдаун. section class="someclass"> ### Пример Маркдауна внутри HTML Выделять слова можно при помощи `*` и `_` . Например, это _italic_ и это тоже *italic*. А вот так уже __strong__, и так тоже **strong**. section> ### Таблицы В чистом Маркдауне нет синтаксиса для таблиц, а в GFM есть. First Header | Second Header ------------- | ------------- Content Cell | Content Cell Content Cell | Content Cell Для красоты можно и по бокам линии нарисовать: | First Header | Second Header | | ------------- | ------------- | | Content Cell | Content Cell | | Content Cell | Content Cell | Можно управлять выравниванием столбцов при помощи двоеточия. | Left-Aligned | Center Aligned | Right Aligned | |:------------- |:---------------:| -------------:| | col 3 is | some wordy text | **$1600** | | col 2 is | centered | $12 | | zebra stripes | are neat | ~~$1~~ | Внутри таблиц можно использовать ссылки, наклонный, жирный или зачеркнутый текст. Для всего остального есть обычный HTML.7 Представление данных: rmarkdown
Достаточно важной частью работы с данными является их представление. Мы рассмотрим наиболее распространенный варианты: rmarkdown , flexdashboard и shiny . Смотрите книжку (Xie, Allaire, and Grolemund 2019) (https://bookdown.org/yihui/rmarkdown/) или cheatsheet.
7.1 rmarkdown
rmarkdown – это пакет, который позволяет соединять R команды и их исполнения в один документ. В результате можно комбинировать текст и исполняемый код, что в свою очередь позволяет делать: * докумунты в формате .html , .pdf (используя , мы почти не будем это обсуждать), .docx * презентации в формате .html , .pdf (используя пакет beamer ) .pptx -презентации * набор связанных .html документов (полноценный сайт или книга)
7.1.1 Установка
Как и все пакеты rmarkdown можно установить из CRAN
install.packages("rmarkdown")7.1.2 Составляющие rmarkdown -документа
- yaml шапка (факультативна)
- обычный текст с markdown форматированием (расширенный при помощи Pandoc)
- блоки кода (не обязательно на языке R), оформленные с двух сторон тройным бэктиком ``` (у меня на клавиатуре этот знак на букве ё).
7.1.3 Пример rmarkdown -документа
Создайте файл .Rmd в какой-нибудь папке (в RStudio, это можно сделать File > New file > R Markdown ). Скомпелировать файл можно командой:
rmarkdown::render("ваш_файл.Rmd")
или кнопкой . Вот пример кода:
--- output: html_document --- ## Данные В документе можно вставлять R код ``` summary(iris) ``` ## График И строить графики ``` library(tidyverse) iris %>% ggplot(aes(Sepal.Length, Sepal.Width))+ geom_point() ```Создайте и скомпелируйте свой rmarkdown -документ с заголовком, текстом и кодом.
7.1.4 Markdown
Универсальны язык разметки, работает во многих современных он-лайн системах создания текста.
7.1.4.1 Заголовки
## Заголовок уровня 2 #### Заголовок уровня 47.1.4.2 Форматирование
_италик_ или *другой италик* __жирный__ или **другой жирный** ~~зачеркивание~~италик или другой италик
жирный или другой жирный
7.1.4.3 Списки
* кролик * заяц * заяц серый 1. машины 1. автобус 2. самолеты + можно еще ставить плюс - и минус- кролик
- заяц
- заяц серый
- машины
- автобус
- можно еще ставить плюс
- и минус
7.1.4.4 Ссылки и картинки
[Ссылка 1](https://agricolamz.github.io/2018_ANDAN_course_winter/2_ex.html) [Можно вставить ссылку потом, а пока отсавить метку][1] Или даже просто голую [метку].  Опять же можно вставить только метку ![][2] [1]: https://agricolamz.github.io/2018_ANDAN_course_winter/2_ex.html [метку]: https://agricolamz.github.io/2018_ANDAN_course_winter/2_ex.html [2]: https://raw.githubusercontent.com/agricolamz/2018_ANDAN_course_winter/master/rmarkdown.pngИли даже просто голую метку.

Опять же можно вставить только метку
7.1.4.5 Код
Код нужно оформалять вот так `rmarkdown::render()`Код нужно оформалять вот так rmarkdown::render()
``` friends = ['john', 'pat', 'gary', 'michael'] for i, name in enumerate(friends): print "iteration is ".format(iteration=i, name=name) ```collection = ['hey', 5, 'd'] for x in collection: print(x)hey 5 dЕсли хочется использовать результат работы кода в тексте, нужно в начале поставить язык, который будет исполнять код, например, в
Фигурные скобки не обязательны, но тогда RStudio подсветит.
7.1.4.6 Цитаты
> Цитаты нужно офрмлять так. > Это попадет в тот же фрагмент. > А вот тут произошел разрыв. Кстати, здесь тоже можно использовать *markdown*.Цитаты нужно офрмлять так. Это попадет в тот же фрагмент.
А вот тут произошел разрыв. Кстати, здесь тоже можно использовать markdown.
7.1.4.7 Разрыв страницы
7.1.4.8 HTML
- Чистый HTML
- Еще можно писать в HTML.
- и Markdown в HTML
- даже работает **правильно**. Но можно использовать и теги.
Чистый HTML Еще можно писать в HTML. и Markdown в HTML даже работает правильно. Но можно использовать и теги.
7.1.4.9 Таблицы
Еще есть целая наука как делать таблицы в Markdown, но я предпочитаю использовать он-лайн генератор.
7.1.5 Pandoc
Pandoc это программа, созданная Дж. МакФарлэйном (J. MacFarlane), которая позволяет переходить из разных текстовых форматов в другие, а также смешивать их. Я покожу лишь несколько полезных расширений.
7.1.5.1 Верхние и нижние индексы
2^10^ C~n~^k^7.1.5.2 Нумерованные примеры
(@) Славный пример номер раз. (@) Славный пример номер два. (@three) Славный пример номер три, у которого есть *имя*. Я могу сослаться на пример (@three)!- Славный пример номер раз.
- Славный пример номер два.
- Славный пример номер три, у которого есть имя.
Я могу сослаться на пример (3)!
7.1.5.3 Сноски
Вот и сноска[^1] [^1]: Сноска, сноска, сноска.7.1.5.4 Математика: \(\LaTeX\)
$\LaTeX$ код может быть в тексте $\frac<\pi>>$ или отдельной строчкой: $$\frac<\pi>>$$\(\LaTeX\) код может быть в тексте \(\frac<\pi>>\) или отдельной строчкой:
7.1.6 Code chunks
Фрагменты кода имеют свои наборы свойств, который можно записывать в фигурных скобках.
7.1.6.1 Язык программирования
``` summary(cars) ``` ``` x = "my string" print(x.split(" ")) ```summary(cars)speed dist Min. : 4.0 Min. : 2.00 1st Qu.:12.0 1st Qu.: 26.00 Median :15.0 Median : 36.00 Mean :15.4 Mean : 42.98 3rd Qu.:19.0 3rd Qu.: 56.00 Max. :25.0 Max. :120.00x = "my string" print(x.split(" "))['my', 'string']7.1.6.2 Появление и исполнение кода
И код, и результат ``` plot(mtcars$mpg) ``` Только результат ``` plot(mtcars$mpg) ``` Только код ``` plot(mtcars$mpg) ``` Исполняется, но не показывается ни код, ни результат ``` a <- mtcars$mpg ``` Обратимся к переменной, созданной в фрагменте с аргументом `include = FALSE` ```a ```7.1.6.3 Другие полезные аргументы
Существует достаточно много аргументов, которые можно перечислить в фигурных скобках в фрагменте кода, вот некоторые из них:
- error : показывать ли ошибки.
- warning : показывать ли предупреждения.
- message : показывать ли сообщения (например, при подключении пакетов).
- comment : по умолчанию, результат работы кода предваряется знаком ## , используйте NA , чтобы их не было, или любую другую строку.
- cache : сохранить ли результат работы фрагмента кода. Очень полезно, если происходят какие-то операции, занимающая много времени. Сохранив результат, не нужно будет тратить время, на пересчет, при каждой новой компиляции.
- fig.width , fig.height (по умолчанию, 7)
Все эти аргументы можно перечислить в функции knitr::opts_chunk$set(. ) :
7.1.6.4 Pets or livestock?
В RMarkdown каждому фрагменту кода можно дать имя (но избегайте пробелов и точек):
``` library(tidyverse) diamonds %>% count(carat, color) %>% ggplot(aes(carat, n, color = color))+ geom_point() ```Maëlle Salmon написал отличный пост, почему полезно именовать фрагменты кода:
- проще ориентироваться
- код более читаемый
- ошибки при компеляции показывают имя, а не номер
- если фрагмент кэшировался, то добавление одного фрагменты перед ним, не заставит все пересчитываться
- в blogdown можно ссылаться
7.1.7 YAML шапка
Факультативная YAML шапка обычно содержит метаданные документа, и аргументы, необходимые для работы некоторых дополнений.
--- title: "Мой RMarkdown" author: Славный Автор date: 20 ноября 2019 ---7.1.7.1 Тип получившегося файла
- output: html_document (по умолчанию)
- output: word_document
- output: pdf_document (но нужно договориться с \(\LaTeX\) ом на вашем компьютере)
- output: ioslides_presentation
- output: slidy_presentation
- output: slidy_presentation
- output: beamer_presentation
7.1.7.2 Библиография
Существует несколько сопособов вставлять библиографию в RMarkdown. Я раскажу, как использовать пакет Bibtex (как видно из названия, сделанный для \(\LaTeX\) ). Для начала нужно создать файл с раширением .bib, в который записать все источники, которые будут использоваться (библиографию в формате BibTeX выдает, например, GoogleScholar):
@book, author=, year=, publisher= > @article, author=, journal=, volume=, number=, pages=, year=, publisher= >На следующем шаге нужно добавить название файла с раширением .bib в YAML шапку:
--- bibliography: bibliography.bib ---После этого, можно использовать сслыки в тексте
В своей работе @gordon02 раскрыл.В своей работе Gordon, Barthmaier, and Sands (2002) раскрыл…
Об этом можно узнать из [@ladefoged96; @gordon02], но .Об этом можно узнать из (Ladefoged and Maddieson 1996; Gordon, Barthmaier, and Sands 2002) , но …
В своей работе [@gordon02] раскрыл.В своей работе (Gordon, Barthmaier, and Sands 2002) раскрыл…
Об этом можно узнать из [см. @gordon02, с. 33--35; а также @ladefoged96, гл. 1].Об этом можно узнать из (см. Gordon, Barthmaier, and Sands 2002, с. 33–35; а также Ladefoged and Maddieson 1996, гл. 1) …
Список литературы автоматически появляется в конце.
7.1.7.3 Оглавление и пр.
Существует сразу несколько аргументов, отвечающих за оглавление.
- toc вставлять ли оглавление
- toc_depth глубина иерархии, которую отражать в огловлении
- toc_float должно ли оглавление все время следовать за текстом
- collapsed должно ли оглавление быть все время полностью раскрыто
- collapsed должно ли оглавление быть все время полностью раскрыто
- number_sections автоматическая нумерация секций
- code_folding (hide) — делать ли кнопочку, показывающую/скрывающую весь код
- theme одна из Bootstrap тем
- highlight : “default”, “tango”, “pygments”, “kate”, “monochrome”, “espresso”, “zenburn”, “haddock” или “textmate”
--- html_document: theme: spacelab highlight: pygments toc: yes toc_position: right toc_depth: 3 toc_float: yes smooth_scroll: false ---7.1.7.4 Отображение датафреймов
- df_print: default
- df_print: kable
- df_print: tibble
- df_print: paged
--- output: html_document: df_print: paged ---7.1.8 Где хостить .html ?
Полученные .html можно разместить в интернете:
- на каком-то вашем хосте
- опубликовать на бесплатном хостинке Rpubs
- опубликовать на гитхабе и включить Github Pages
Теперь создайте документ index.Rmd, в котором напишите код на R и на Python, вставьте картинку, сноску, ссылку на литературу, таблицу и оглавление. Скомпелируйте .html документ и опубликуйте его на Github, пройдя по этой ссылке. Cделайте Github Pages и заполните README.md файл.
7.2 Бывают и другие способы представления данных
- flexdashboard – динамические дэшборды
- shiny – динамические сайты, которые позволяют взаимодействовать с пользователем
- posterdown – постеры в RMarkdown
- pagedown – содержит много шаблонов: для книги, статьи, постера, резюме, визитки… да хоть приглашение на свадьбу можно сделать.
Ссылки на литературу
Gordon, M., P. Barthmaier, and K. Sands. 2002. “A Cross-Linguistic Acoustic Study of Voiceless Fricatives.” Journal of the International Phonetic Association 32 (2): 141–74.
Ladefoged, P., and I. Maddieson. 1996. The Sounds of the World’s Languages. Oxford Publishers.
Xie, Yihui, Joseph J Allaire, and Garrett Grolemund. 2019. R Markdown: The Definitive Guide. Chapman; Hall/CRC.
- Сноска, сноска, сноска.↩︎