Hashset java как работает
Интерфейс Set расширяет интерфейс Collection и представляет набор уникальных элементов. Set не добавляет новых методов, только вносит изменения в унаследованные. В частности, метод add() добавляет элемент в коллекцию и возвращает true, если в коллекции еще нет такого элемента.
Обобщенный класс HashSet представляет хеш-таблицу. Он наследует свой функционал от класса AbstractSet , а также реализует интерфейс Set .
Хеш-таблица представляет такую структуру данных, в которой все объекты имеют уникальный ключ или хеш-код. Данный ключ позволяет уникально идентифицировать объект в таблице.
Для создания объекта HashSet можно воспользоваться одним из следующих конструкторов:
- HashSet() : создает пустой список
- HashSet(Collection col) : создает хеш-таблицу, в которую добавляет все элементы коллекции col
- HashSet(int capacity) : параметр capacity указывает начальную емкость таблицы, которая по умолчанию равна 16
- HashSet(int capacity, float koef) : параметр koef или коэффициент заполнения, значение которого должно быть в пределах от 0.0 до 1.0, указывает, насколько должна быть заполнена емкость объектами прежде чем произойдет ее расширение. Например, коэффициент 0.75 указывает, что при заполнении емкости на 3/4 произойдет ее расширение.
Класс HashSet не добавляет новых методов, реализуя лишь те, что объявлены в родительских классах и применяемых интерфейсах:
import java.util.HashSet; public class Program < public static void main(String[] args) < HashSetstates = new HashSet(); // добавим в список ряд элементов states.add("Germany"); states.add("France"); states.add("Italy"); // пытаемся добавить элемент, который уже есть в коллекции boolean isAdded = states.add("Germany"); System.out.println(isAdded); // false System.out.printf("Set contains %d elements \n", states.size()); // 3 for(String state : states) < System.out.println(state); >// удаление элемента states.remove("Germany"); // хеш-таблица объектов Person HashSet people = new HashSet(); people.add(new Person("Mike")); people.add(new Person("Tom")); people.add(new Person("Nick")); for(Person p : people) < System.out.println(p.getName()); >> > class Person < private String name; public Person(String value)< name=value; >String getName() >
Как работает hashset в java
HashSet в Java — это реализация интерфейса Set , который использует хэш-таблицы для хранения элементов коллекции. HashSet не гарантирует порядок элементов при их переборе, и не допускает хранение дублирующихся элементов.
Основные операции, которые можно выполнить с HashSet :
- добавление элемента: add()
- удаление элемента: remove()
- проверка наличия элемента: contains()
- очистка коллекции: clear()
- получение размера коллекции: size()
HashSet реализован как хэш-таблица , где элементы хранятся в виде ключей, а значения не используются.
- При добавлении элемента, HashSet рассчитывает его хэш-код и добавляет в таблицу с соответствующим индексом.
- Если в таблице уже есть элемент с таким же хэш-кодом , то выполняется проверка на равенство.
- Если элементы равны, то новый элемент не добавляется в коллекцию, иначе он добавляется в таблицу.
При работе с HashSet важно правильно определить методы hashCode() и equals() для класса, который будет храниться в коллекции. Это позволит корректно выполнять поиск и удаление элементов. Если класс не переопределит методы hashCode() и equals() , то будут использоваться реализации по умолчанию, которые могут не давать ожидаемых результатов при работе с HashSet
Интерфейс Set и классы HashSet, LinkedHashSet

Он расширяет Collection и определяет поведение коллекций, не допускающих дублирования элементов. Таким образом, метод add() возвращает false , если делается попытка добавить дублированный элемент в набор.
Интерфейс не определяет никаких собственных дополнительных методов.
Интерфейс Set заботится об уникальности хранимых объектов, уникальность определятся реализацией метода equals() . Поэтому если объекты создаваемого класса будут добавляться в Set , желательно переопределить метод equals() .
Ниже представлена ветка иерархии интерфейса Set :
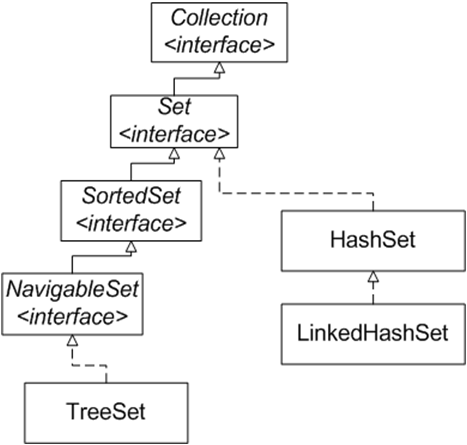
2. Класс HashSet
Класс HashSet реализует интерфейс Set и создает коллекцию, которая хранит элементы в хеш-таблице.
Хеш-таблица
Что же такое хеш-таблица? Элементы хеш-таблицы хранятся в виде пар ключ-значение. Ключ определяет ячейку (или бакет) для хранения значения. Содержимое ключа служит для определения однозначного значения, называемого хеш-кодом.
Мы можем считать, что хеш-код это ID объекта, хотя он необязательно должен быть уникальным. Этот хеш-код служит далее в качестве индекса, по которому сохраняются данные, связанные с ключом.
Вычисление хеш-кода
Рассмотрим пример вычисления хеш-кодов:
A(1) + l(12) + e(5) + x(24)
B(2) + o(15) + b(2)
D(4) + i(9) + r(18) + k(11)
F(6) + r(18) + e(5) + d(4)

Допустим, чтобы получить хеш-код, я сопоставляю каждый символ из ключа с номером этого символа в алфавите и получаю их сумму. Таким образом «Bob» попадает в бакет 19, «Fred» в бакет 33. Как видно из примера, для ключей «Alex» и «Dirk» получается одинаковый хеш-код, что тоже допустимо. Такая ситуация называется коллизией, два значения попадают в один бакет с номером 42.
Каким образом происходит обратный процесс — поиск элемента в хеш-таблице? У нас есть ключ объекта, по которому мы вычисляем хеш-код и определяем бакет, в котором находится наш объект. Но что делать если в бакете находится не один, а несколько элементов? Конечно, же это не значит, что хеш-таблица вернет любой объект из бакета. Если объектов в бакете несколько, далее с помощью метода equals() определяется нужный объект.
Контракт между методами hashCode() и equals()
Как Вы уже поняли, методы hashCode() и equals() тесно связаны между собой. Поэтому существуют специальный контракт написания методов hashCode() и equals() :
- Для одного и того же объекта, хеш-код всегда будет одинаковым.
- Если объекты одинаковые, то и хеш-коды одинаковые (но не наоборот).
- Если хеш-коды равны, то входные объекты не всегда равны.
- Если хеш-коды разные, то и объекты гарантированно будут разные.
На самом деле, корректным, но не эффективным может быть такое определение хеш-кода:
@Override public int hashCode()
Это определение метода hashCode() соответствует контракту, но он разместит все объекты класса в один бакет, что нивелирует все достоинства хеш-таблицы.
Создание метода hashCode()
Эффективным алгоритмом для определения хеш-кода объекта является такой алгоритм, который ровным слоем распределяет объекты по хеш-таблице. Вообще создание такого алгоритма, это достаточно сложный процесс, на котором защищают докторские диссертации. Но хорошей новостью является то, что на самом деле Вам не нужно придумывать свой алгоритм.
В средствах разработки, в частности в IntelliJ IDEA, существует генератор, который сгенерирует Вам метод hashCode() . Обычно все пользуются этим вариантом создания метода.
Конструкторы класса HashSet
Давайте рассмотрим конструкторы класса HashSet:
- HashSet() — начальная емкость по умолчанию (initialCapacity) – 16, коэффициент загрузки по умолчанию (loadFactor) – 0,75.
- HashSet(int initialCapacity) — коэффициент загрузки – 0,75.
- HashSet(int initialCapacity, float loadFactor)
- HashSet(Collection collection) – конструктор, добавляющий элементы из другой коллекции.
В конструкторах можно указывать такие параметры как начальная емкость и коэффициент загрузки. Давайте разберемся что это и для чего они нужны.
Начальная емкость (initial capacity) – это изначальное количество ячеек (buckets) в хэш-таблице. Если все ячейки будут заполнены, их количество увеличится автоматически.
Коэффициент загрузки (load factor) – это показатель того, насколько заполненным может быть HashSet до того момента, когда его емкость автоматически увеличится. Когда количество элементов в HashSet становится больше, чем capacity * loadfactor , хэш-таблица ре-хэшируется (заново вычисляются хэшкоды элементов, и таблица перестраивается согласно полученным значениям) и количество buckets в ней увеличивается в два раза.
Коэффициент загрузки, равный 0,75, в среднем обеспечивает хорошую производительность. Если этот параметр увеличить, тогда уменьшится нагрузка на память (так как это уменьшит количество операций ре-хэширования и перестраивания), но это повлияет на операции добавления и поиска. Чтобы минимизировать время, затрачиваемое на ре-хэширование, нужно правильно подобрать параметр начальной емкости.
Достоинства и недостатки класса HashSet
Выгода от хеширования состоит в том, что оно обеспечивает постоянство время выполнения операций add() , contains() , remove() и size() , даже для больших наборов. Сложность выполнения операций будет О(1). В худшем случае (если в хэш-таблице только один bucket) сложность выполнения будет O(n) для Java 7 и О(log n) для Java 8.
Недостаток класса HashSet (или можно даже сказать особенность) в том, что он не гарантирует упорядоченности элементов, поскольку процесс хеширования сам по себе обычно не приводит к созданию отсортированных множеств.
Пример использования класса HashSet
Рассмотрим пример использования класса HashSet :
import java.util.HashSet; import java.util.Set; public class HashSetDemo < public static void main(String[] args) < Setset = new HashSet<>(); set.add("Харьков"); set.add("Киев"); set.add("Львов"); set.add("Кременчуг"); set.add("Харьков"); System.out.println(set); > >3. Класс LinkedHashSet
Класс LinkedHashSet языка Java расширяет HashSet , не добавляя никаких новых методов.
LinkedHashSet поддерживает связный список элементов набора в том порядке, в котором они вставлялись. Это позволяет организовать упорядоченную итерацию вставки в набор. Но это приводит к тому что класс LinkedHashSet выполняет операции дольше чем класс HashSet .
Рассмотрим пример использования класса LinkedHashSet :
import java.util.LinkedHashSet; import java.util.Set; public class LinkedHashSetDemo < public static void main(String[] args) < Setset = new LinkedHashSet<>(); set.add("Бета"); set.add("Aльфa"); set.add("Этa"); set.add("Гaммa"); set.add("Эпсилон"); set.add("Oмeгa"); System.out.println(set); > > - Интерфейс Collection
- Структуры данных
- Интерфейс List и класс ArrayList
- Интерфейс SortedSet и класс TreeSet
- Интерфейсы Comparable и Comparator
- Интерфейс NavigableSet
- Интерфейс Queue и классы
- Интерфейс Iterator
- Интерфейс ListIterator
- Отображения Map
- Класс Collections
- Backed Collections
- Legacy Classes
- Задания
Множества: Set, HashSet, LinkedHashSet, TreeSet
HashSet, TreeSet и LinkedHashSet относятся к семейству Set. В множествах Set каждый элемент хранится только в одном экземпляре, а разные реализации Set используют разный порядок хранения элементов. В HashSet порядок элементов определяется по сложному алгоритму. Если порядок хранения для вас важен, используйте контейнер TreeSet, в котором объекты хранятся отсортированными по возрастанию в порядке сравнения или LinkedHashSet с хранением элементов в порядке добавления.
Множества часто используются для проверки принадлежности, чтобы вы могли легко проверить, принадлежит ли объект заданному множеству, поэтому на практике обычно выбирается реализация HashSet, оптимизированная для быстрого поиска.
В Android 11 (R) обещают добавить несколько перегруженных версий метода of(), которые являются частью Java 8.
HashSet
Название Hash. происходит от понятия хэш-функция. Хэш-функция — это функция, сужающая множество значений объекта до некоторого подмножества целых чисел. Класс Object имеет метод hashCode(), который используется классом HashSet для эффективного размещения объектов, заносимых в коллекцию. В классах объектов, заносимых в HashSet, этот метод должен быть переопределен (override).
Имеет два основных конструктора (аналогично ArrayList):
// Строит пустое множество public HashSet() // Строит множество из элементов коллекции public HashSet(Collection c)
Методы
- public Iterator iterator()
- public int size()
- public boolean isEmpty()
- public boolean contains(Object o)
- public boolean add(Object o)
- public boolean addAll(Collection c)
- public Object[] toArray()
- public boolean remove(Object o)
- public boolean removeAll(Collection c)
- public boolean retainAll(Collection c) — (retain — сохранить). Выполняет операцию «пересечение множеств».
- public void clear()
- public Object clone()
Методы аналогичны методам ArrayList за исключением того, что метод add(Object o) добавляет объект в множество только в том случае, если его там нет. Возвращаемое методом значение — true, если объект добавлен, и false, если нет.
Перейдём к практике. Как это ни странно, но в жизни встречаются несколько Барсиков, Мурзиков и прочих Рыжиков. Несмотря на одинаковые имена, каждый кот неповторим. Надеюсь, с этим никто не спорит. Но пихать имена котов в множество HashSet не стоит, так как в множестве может храниться только одно имя и двух Мурзиков тут не записать. Другое дело — страны. Не может быть двух Франций, двух Англий, двух Россий (даже партия такая есть Единая Россия, впрочем мы отвлеклись).
Итак, создадим множество стран.
public void onClick(View view) < HashSetcountryHashSet = new HashSet<>(); countryHashSet.add("Россия"); countryHashSet.add("Франция"); countryHashSet.add("Гондурас"); countryHashSet.add("Кот-Д'Ивуар"); // любимая страна всех котов // Получим размер HashSet mInfoTextView.setText("Размер HashSet Кот-Д'Ивуар"); после России, то всё-равно размер останется прежним. Убедиться в этом можно, если вызвать метод iterator(), который позволяет получить всё множество элементов:
public void onClick(View view) < HashSetcountryHashSet = new HashSet<>(); countryHashSet.add("Россия"); countryHashSet.add("Кот-Д'Ивуар"); // любимая страна всех котов countryHashSet.add("Франция"); countryHashSet.add("Гондурас"); countryHashSet.add("Кот-Д'Ивуар"); // кот попросил добавить ещё раз для надёжности Iterator iterator = countryHashSet.iterator(); while (iterator.hasNext()) < mInfoTextView.setText(mInfoTextView.getText() + iterator.next() + ", "); >>
Несмотря на наше упрямство, мы видим только четыре добавленных элемента.
Стоит отметить, что порядок добавления стран во множество будет непредсказуемым. HashSet использует хэширование для ускорения выборки. Если вам нужно, чтобы результат был отсортирован, то пользуйтесь TreeSet.
Преобразовать в массив и вывести в ListView
Следующий пример - задел на будущее. Когда вы узнаете, что такое ListView, то вернитесь к этому уроку и узнайте, как сконвертировать множество в массив и вывести результат в компонент ListView (Список):
public void onClick(View view) < ArrayAdapteradapter; HashSet countryHashSet = new HashSet<>(); countryHashSet.add("Россия"); countryHashSet.add("Кот-Д'Ивуар"); // любимая страна всех котов countryHashSet.add("Франция"); countryHashSet.add("Гондурас"); // Конвертируем HashSet в массив String[] myArray = <>; myArray = countryHashSet.toArray(new String[countryHashSet.size()]); // Выводим массив в ListView final ListView listView = (ListView) findViewById(R.id.listView); adapter = new ArrayAdapter<>(this, android.R.layout.simple_list_item_1, myArray); listView.setAdapter(adapter); >
Продолжим опыты. Поработаем теперь с числами.
public void onClick(View view) < Random random = new Random(30); SetnumberSet = new HashSet<>(); for(int i = 0; i
Здесь мы ещё раз убеждаемся, что повторное добавление числа не происходит. В цикле случайным образом выбирается число от 0 до 9 тысячу раз. Естественно, многие числа должны были повториться при таком сценарии, но во множество каждое число попадёт один раз.
При этом данные не сортируются, так как расположены как попало.
Специально для Android был разработан новый класс ArraySet, который более эффективен.
ArraySet = HashSet
LinkedHashSet
Класс LinkedHashSet расширяет класс HashSet, не добавляя никаких новых методов. Класс поддерживает связный список элементов набора в том порядке, в котором они вставлялись. Это позволяет организовать упорядоченную итерацию вставки в набор.
TreeSet
Переделанный пример для вывода случайных чисел в отсортированном порядке. HashSet не может гарантировать, что данные будут отсортированы, так как работает по другому алгоритму. Если сортировка для вас важна, то используйте TreeSet.
public void onClick(View view) < Random random = new Random(30); SortedSetnumberSet = new TreeSet<>(); for(int i = 0; i
Со строками это выглядит нагляднее:
public void onClick(View view) < SortedSetcountrySet = new TreeSet<>(); countrySet.add("Россия"); countrySet.add("Франция"); countrySet.add("Гондурас"); countrySet.add("Кот-Д'Ивуар"); // любимая страна всех котов mInfoTextView.setText(countrySet.toString()); >
Названия стран выведутся в алфавитном порядке.
Класс TreeSet создаёт коллекцию, которая для хранения элементов применяет дерево. Объекты сохраняются в отсортированном порядке по возрастанию.
SortedSet
В примере с TreeSet использовался интерфейс SortedSet, который позволяет сортировать элементы множества. По умолчанию сортировка производится привычным способом, но можно изменить это поведение через интерфейс Comparable.
Кроме стандартных методов Set у интерфейса есть свои методы.
- Comparator comparator()
- subSet(Object fromElement, Object toElement)
- tailSet(Object fromElement)
- headSet(Object toElement)
- Object first()
- Object last()
SortedSet animalSet = new TreeSet(); animalSet.add("Antilope"); animalSet.add("Fox"); animalSet.add("Goat"); animalSet.add("Dog"); animalSet.add("Elephant"); animalSet.add("Bear"); animalSet.add("Hippo"); animalSet.add("Cat"); Iterator iterator = animalSet.iterator(); while(iterator.hasNext()) < // Antilope Bear Cat Dog Elephant Fox Goat Hippo mInfoTextView.append(iterator.next().toString() + " "); >Log.i(TAG, animalSet.subSet("Dog", "Hippo").toString()); // [Dog, Elephant, Fox, Goat] Log.i(TAG, animalSet.tailSet("Dog").toString()); // [Dog, Elephant, Fox, Goat, Hippo] Log.i(TAG, animalSet.headSet("Dog").toString()); // [Antilope, Bear, Cat] Log.i(TAG, animalSet.first()); // Antilope Log.i(TAG, animalSet.last()); // Hippo