Функция COUNT (Transact-SQL)
Эта функция возвращает количество элементов, найденных в группе. Функция COUNT работает подобно функции COUNT_BIG. Эти функции различаются только типами данных в возвращаемых значениях. Функция COUNT всегда возвращает значение типа данных int. Функция COUNT_BIG всегда возвращает значение типа данных bigint.
Синтаксис
Синтаксис функции агрегирования
COUNT ( < [ [ ALL | DISTINCT ] expression ] | * >) Синтаксис функции аналитики
COUNT ( [ ALL ] < expression | * >) OVER ( [ ] ) Сведения о синтаксисе Transact-SQL для SQL Server 2014 (12.x) и более ранних версиях см . в документации по предыдущим версиям.
Аргументы
ВСЕ
Применяет агрегатную функцию ко всем значениям. Аргумент ALL используется по умолчанию.
DISTINCT
Указывает, что функция COUNT возвращает количество уникальных значений, не равных NULL.
выражение
Выражение любого типа, кромеimage, ntext и text. COUNT не поддерживает агрегатные функции или вложенные запросы в выражении.
Указывает, что функция COUNT должна учитывать все строки, чтобы определить общее количество строк таблицы для возврата. COUNT(*) не принимает параметров и не поддерживает использование DISTINCT. COUNT(*) не требует параметра выражения, так как по определению он не использует сведения о определенном столбце. Функция COUNT(*) возвращает количество строк в указанной таблице с учетом повторяющихся строк. Она подсчитывает каждую строку отдельно. При этом учитываются и строки, содержащие значения NULL.
OVER ( [ partition_by_clause ] [ order_by_clause ] [ ROW_or_RANGE_clause ] )
partition_by_clause делит результирующий набор, полученный с помощью предложения FROM , на секции, к которым применяется функция COUNT . Если этот параметр не указан, функция обрабатывает все строки результирующего набора запроса как отдельные группы. order_by_clause определяет логический порядок выполнения операции. Дополнительные сведения см . в предложении OVER (Transact-SQL ).
Типы возвращаемых данных
- int NOT NULL , ANSI_WARNINGS если имеет значение ON , однако SQL Server всегда будет обрабатывать COUNT выражения как int NULL в метаданных, если только не упакованы в ISNULL .
- int NULL , если ANSI_WARNINGS имеет значение OFF .
Замечания
- COUNT(*) без GROUP BY возврата карта inality (количество строк) в наборе результатов. К ним относятся строки, состоящие из всех NULL значений и дубликатов.
- COUNT(*) при GROUP BY возврате числа строк в каждой группе. Сюда входят NULL значения и дубликаты.
- COUNT(ALL ) вычисляет выражение для каждой строки в группе и возвращает количество ненулевого значения.
- COUNT(DISTINCT *expression*) вычисляет выражение для каждой строки в группе и возвращает количество уникальных, ненулевого значения.
COUNT — это детерминированная функция, если она используется без предложений OVER и ORDER BY. Она не детерминирована при использовании с предложениями OVER и ORDER BY. Дополнительные сведения см. в разделе детерминированные и недетерминированные функции.
ARITHABORT и ANSI_WARNINGS .
Если COUNT имеет возвращаемое значение, превышающее максимальное значение int (то есть 2 31-1 или 2 147 483 647), COUNT функция завершится ошибкой из-за целочисленного переполнения. При COUNT переполнении и параметрах ARITHABORT OFF COUNT ANSI_WARNINGS возвращается. NULL В противном случае, если или есть, ANSI_WARNINGS ARITHABORT ON запрос будет прерваться, и будет вызвана ошибка арифметического переполнения. Msg 8115, Level 16, State 2; Arithmetic overflow error converting expression to data type int. Чтобы правильно обрабатывать эти большие результаты, используйте COUNT_BIG вместо этого, что возвращает bigint.
Если оба ARITHABORT и ANSI_WARNINGS есть ON , вы можете безопасно упаковать COUNT сайты вызовов, ISNULL( , 0 ) чтобы принудить тип выражения вместо int NOT NULL int NULL . Упаковка COUNT в ISNULL означает, что любая ошибка переполнения будет автоматически подавляться, что должно быть рассмотрено для правильности.
Примеры
А. Использование COUNT и DISTINCT
В этом примере возвращается количество различных названий, которые может хранить сотрудник Adventure Works Cycles.
SELECT COUNT(DISTINCT Title) FROM HumanResources.Employee; GO ----------- 67 (1 row(s) affected) B. Использование COUNT(*)
В этом примере возвращается общее количество сотрудников Adventure Works Cycles.
SELECT COUNT(*) FROM HumanResources.Employee; GO ----------- 290 (1 row(s) affected) C. Использование COUNT(*) с другими агрегатами
В этом примере показано, что функция COUNT(*) работает с другими статистическими функциями в списке SELECT . В примере используется база данных AdventureWorks2022.
SELECT COUNT(*), AVG(Bonus) FROM Sales.SalesPerson WHERE SalesQuota > 25000; GO ----------- --------------------- 14 3472.1428 (1 row(s) affected) D. Использование предложения OVER
В этом примере используются MAX AVG MIN функции и COUNT функции с OVER предложением для возврата агрегированных значений для каждого отдела в таблице базы данных HumanResources.Department AdventureWorks2022.
SELECT DISTINCT Name , MIN(Rate) OVER (PARTITION BY edh.DepartmentID) AS MinSalary , MAX(Rate) OVER (PARTITION BY edh.DepartmentID) AS MaxSalary , AVG(Rate) OVER (PARTITION BY edh.DepartmentID) AS AvgSalary , COUNT(edh.BusinessEntityID) OVER (PARTITION BY edh.DepartmentID) AS EmployeesPerDept FROM HumanResources.EmployeePayHistory AS eph JOIN HumanResources.EmployeeDepartmentHistory AS edh ON eph.BusinessEntityID = edh.BusinessEntityID JOIN HumanResources.Department AS d ON d.DepartmentID = edh.DepartmentID WHERE edh.EndDate IS NULL ORDER BY Name; Name MinSalary MaxSalary AvgSalary EmployeesPerDept ----------------------------- --------------------- --------------------- --------------------- ---------------- Document Control 10.25 17.7885 14.3884 5 Engineering 32.6923 63.4615 40.1442 6 Executive 39.06 125.50 68.3034 4 Facilities and Maintenance 9.25 24.0385 13.0316 7 Finance 13.4615 43.2692 23.935 10 Human Resources 13.9423 27.1394 18.0248 6 Information Services 27.4038 50.4808 34.1586 10 Marketing 13.4615 37.50 18.4318 11 Production 6.50 84.1346 13.5537 195 Production Control 8.62 24.5192 16.7746 8 Purchasing 9.86 30.00 18.0202 14 Quality Assurance 10.5769 28.8462 15.4647 6 Research and Development 40.8654 50.4808 43.6731 4 Sales 23.0769 72.1154 29.9719 18 Shipping and Receiving 9.00 19.2308 10.8718 6 Tool Design 8.62 29.8462 23.5054 6 (16 row(s) affected) Примеры: Azure Synapse Analytics и система платформы аналитики (PDW)
Д. Использование COUNT и DISTINCT
В этом примере функция возвращает количество различных должностей, которые может иметь конкретный сотрудник компании.
USE ssawPDW; SELECT COUNT(DISTINCT Title) FROM dbo.DimEmployee; F. Использование COUNT(*)
В этом примере функция возвращает общее количество строк в таблице dbo.DimEmployee .
USE ssawPDW; SELECT COUNT(*) FROM dbo.DimEmployee; G. Использование COUNT(*) с другими агрегатами
В этом примере функция COUNT(*) работает с другими статистическими функциями в списке SELECT . Запрос возвращает количество торговых представителей с годовой квотой продаж более 500 000 долл. США и их среднюю квоту продаж.
USE ssawPDW; SELECT COUNT(EmployeeKey) AS TotalCount, AVG(SalesAmountQuota) AS [Average Sales Quota] FROM dbo.FactSalesQuota WHERE SalesAmountQuota > 500000 AND CalendarYear = 2001; TotalCount Average Sales Quota ---------- ------------------- 10 683800.0000 H. Использование COUNT с ПОМОЩЬЮ HAVING
В этом примере функция COUNT используется с предложением HAVING , чтобы получить список подразделений компании, в каждом из которых работает более 15 сотрудников.
USE ssawPDW; SELECT DepartmentName, COUNT(EmployeeKey)AS EmployeesInDept FROM dbo.DimEmployee GROUP BY DepartmentName HAVING COUNT(EmployeeKey) > 15; DepartmentName EmployeesInDept -------------- --------------- Sales 18 Production 179 I. Использование COUNT с OVER
В этом примере функция COUNT используется с предложением OVER , чтобы получить количество продуктов, содержащихся в каждом из указанных заказов на продажу.
USE ssawPDW; SELECT DISTINCT COUNT(ProductKey) OVER(PARTITION BY SalesOrderNumber) AS ProductCount , SalesOrderNumber FROM dbo.FactInternetSales WHERE SalesOrderNumber IN (N'SO53115',N'SO55981'); ProductCount SalesOrderID ------------ ----------------- 3 SO53115 1 SO55981 См. также
- Агрегатные функции (Transact-SQL)
- COUNT_BIG (Transact-SQL)
- Предложение OVER (Transact-SQL)
SQL — разница между COUNT(1) и COUNT(*)?
Разницы нет. Оба варианта вернут одинаковый результат. По производительности тоже различий не будет, т.к. оптимизатор не станет преобразовывать * в список столбцов за ненадобностью.
Отслеживать
ответ дан 22 сен 2017 в 19:46
MaxU — stand with Ukraine MaxU — stand with Ukraine
149k 12 12 золотых знаков 59 59 серебряных знаков 132 132 бронзовых знака
разве не нужно контекст рассматривать? stackoverflow.com/a/2710703
22 сен 2017 в 19:52
@АлексейШиманский, спасибо за ссылку! Да, для JOIN не совсем понятно как поведет себя оптимизатор в случае использования COUNT(1) .
22 сен 2017 в 19:56
Вообще было бы классно перевести на русский. + то, что там в дубликате возможно. Хоть не часто такой вопрос задается, но как FAQ и эталон мог бы тут существовать
22 сен 2017 в 20:03
@АлексейШиманский, согласен, но времени у меня сейчас на это нет. Мне кажется еще лучще было бы перевести соответствующие «куски» из ANSI SQL-92
22 сен 2017 в 20:13
@MaxU с джоинами тоже будет работать правильно, если используется именно COUNT(1). В статье по ссылке кстати написано, почему нельзя использовать COUNT(something.1), поскольку семантически невозможно определить конкретный запрос в этом случае, в отличие от COUNT(something.*), который сработает корректно
22 сен 2017 в 20:14
Это два эквивалентных запроса. Причем в MySQL если вы используете MyISAM движок, то COUNT(*) будет выполнен очень быстро, если используется SELECT из одной таблицы и нет WHERE условия, поскольку информация о количестве строк будет храниться в специальном хранилище.
Для COUNT(1) эта оптимизация так же сработает, но при условии, что первый столбец объявлен как NOT NULL .
Дополнительно можно почитать здесь
Отслеживать
ответ дан 22 сен 2017 в 19:46
Roman Danilov Roman Danilov
2,465 8 8 серебряных знаков 18 18 бронзовых знаков
а при JOIN разве будет одинаковый результат?
22 сен 2017 в 19:53
@АлексейШиманский, да, при JOIN тоже будет одинаковый результат. Поскольку сравнивается COUNT( * ) и COUNT(1), но не COUNT(*) и COUNT(something.1)
22 сен 2017 в 20:05
@РоманДанилов, вы можете объяснить связь между COUNT(1) и первым столбцом?
22 сен 2017 в 20:16
@MaxU, я добавил ссылку, там можно покопаться, думаю
22 сен 2017 в 20:24
@РоманДанилов, «expression:» 1 — априори NOT NULL и не имеет отношение к первому столбцу — собственно поэтому я и спросил.
Функция SQL COUNT()
Оператор SQL COUNT() — функция возвращающая количество записей (строк) таблицы. Запись функции с указанием столбца (синтаксис ниже) вернет количество записей конкретного столбца за исключением NULL записей.
Функция SQL COUNT() имеет следующий синтаксис:
COUNT(column_name)
Запись функции с указанием маски «*» вернет количество всех записей в таблице.
COUNT(*)
Примеры оператора SQL COUNT: Имеется следующая таблица Universities :
| ID | UniversityName | Students | Faculties | Professores | Location | Site |
| 1 | Perm State National Research University | 12400 | 12 | 1229 | Perm | psu.ru |
| 2 | Saint Petersburg State University | 21300 | 24 | 13126 | Saint-Petersburg | spbu.ru |
| 3 | Novosibirsk State University | 7200 | 13 | 1527 | Novosibirsk | nsu.ru |
| 4 | Moscow State University | 35100 | 39 | 14358 | Moscow | msu.ru |
| 5 | Higher School of Economics | 20335 | 12 | 1615 | Moscow | hse.ru |
| 6 | Ural Federal University | 57000 | 19 | 5640 | Yekaterinburg | urfu.ru |
| 7 | National Research Nuclear University | 8600 | 10 | 936 | Moscow | mephi.ru |
Пример 1. Вывести число записей таблицы, используя оператор SQL COUNT:
SELECT COUNT(*)
FROM Universities
Пример 2. Найти количество университетов расположенных в Москве, используя оператор SQL COUNT:
SELECT COUNT(*) FROM Universities WHERE Location = 'Moscow'
Пример 3. Найти количество университетов с больше чем 20 факультетами, используя оператор SQL COUNT:
SELECT COUNT(*) FROM Universities WHERE Faculties > 20
Мифы про Count(1) vs Count(*)

Многие наверняка знают про то, что если написать Count(*) по таблице, получите количество строк в таблице. Довольно часто я встречаю мнение, что лучше писать Count(1), так как это будет использовать меньше ресурсов сервера, потому что вы указываете скалярное выражение вместо всех полей таблицы.
Так что же использовать?
SELECT COUNT(*) FROM Sales.CustomerTransactions; Или же SELECT COUNT(1) FROM Sales.CustomerTransactions;Возможно, когда-то для некоторых СУБД это было правдой и Count(1) экономил ресурсы, но не для SQL Server — даже в далёкой версии 2005 оба выражения работали одинаково эффективно.
Давайте в этом убедимся
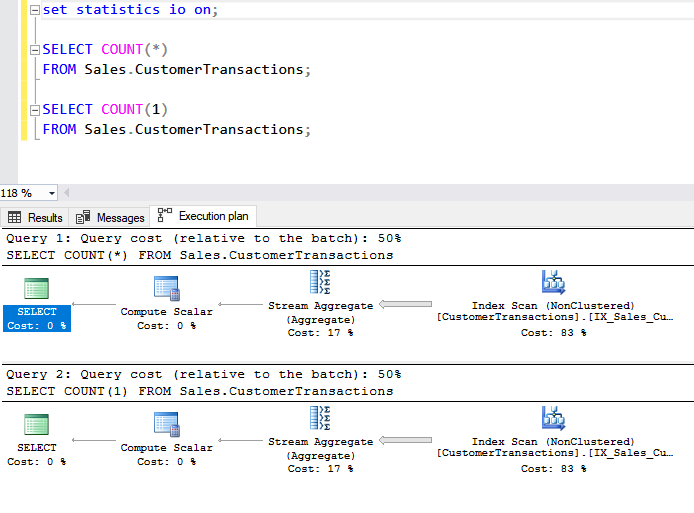
Выполним запрос и посмотрим на актуальный план:
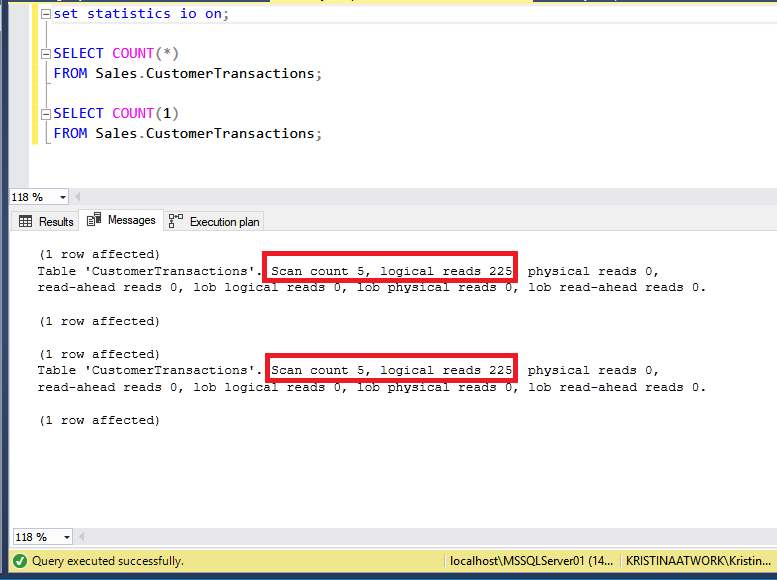
Видим, что план одинаковый и оптимизатор оценивает стоимость выполнения обоих запросов, как равную. Теперь посмотрим на часть по статистике ввода-вывода:
Количество сканирований и логических чтений для обоих запросов абсолютно идентично. Значит оба варианта равноценны по производительности для SQL Server. Обращаю внимание, что для других РСУБД результат может быть иной.
Миф о том, что Count(1) менее ресурсоёмкий возник довольно давно и связан с тем, что символ звездочка * указывает на выборку всех полей, а значит, логически подумав, можно предположить, что считать строки, используя все поля таблицы, будет значительно дороже, чем посчитать, используя скалярное выражение — 1 .
Также есть ситуации, когда пишут Count(FieldName) . В этом случае всегда нужно помнить, что если поле FieldName может содержать NULL, то Count проигнорирует такие строки, а значит и результат Count(*) и Count(FieldName) может быть разный.
А вы используете в своем проекте Count(1)? Пишите в комментариях!