6 бесплатных ресурсов для практики в SQL

SQL (structured query language) — это язык структурированных запросов в таблицы баз данных (БД). Он обеспечивает соединение с БД, а также поиск и обновления информации. SQL используют бэкендеры, аналитики и тестировщики.
Рассказываем, где бесплатно потренироваться в написании SQL-запросов.
SQLZoo
Рекомендуем тем, кто начинает изучать язык. На сайте 9 разделов с задачами по sql. Их решение займет 18–20 часов. Среди тем — вложенные запросы или обработка значений null. Также доступны разборы решений. В SQLZoo есть справочник терминов.

SQLTest
В SQLTest можно изменять или замещать значения и масштабировать их. Это позволяет имитировать взаимодействие с БД произвольного количества пользователей или запросов. Сервис генерирует запросы к базе данных SQL Server и поддерживает MySQL и Oracle.
SQLTest доступен в десктопной и облачной версии.
Pgexercises
Сайт состоит из 80 упражнений для работы с объектно-реляционной системой PostgreeSQL. Доступен один набор данных, который состоит из 3 таблиц: members, booking и facilities. Упражнения начинаются с предложений select и where, затем рассматриваются оконные функции и рекурсивные запросы. Курс разделен на блоки:
- Простые запросы SQL;
- Присоединение и подзапросы;
- Изменения данных;
- Агрегация;
- Работа с метками времени;
- Операции с рядами;
- Рекурсивные запросы.
SQL Fiddle
SQL Fiddle — сервис с открытым исходным кодом. Сайт позволяет делиться информацией с другими пользователями.
Он поддерживает БД Oracle, SQLite, MySQL. Также есть возможность экспортировать данные в разных форматах: иерархические файлы (например, XML-документы), текстовые и таблицы.
курсы по теме:
SQL для аналитики и разработки
Учебная схема
Многие примеры начального курса могут быть выполнены онлайн, для этого вам потребуется просто перейти по заданной ссылке и заполнить некоторые поля.
Итак, большинство примеров и практических заданий вы сможете выполнить на онлайн-сервисах.
Первый сервис предоставляет компания ORACLE для разработки, я уже зарегистрировал там аккаунт, и сейчас там уже есть все таблицы, которые нам потребуются в учебе.
Также там есть все необходимые заполненные данные для выполнения учебных задач и запросов.
Вам достаточно пройти по ссылке
и ЗАПОЛНИТЬ регистрационную информацию.
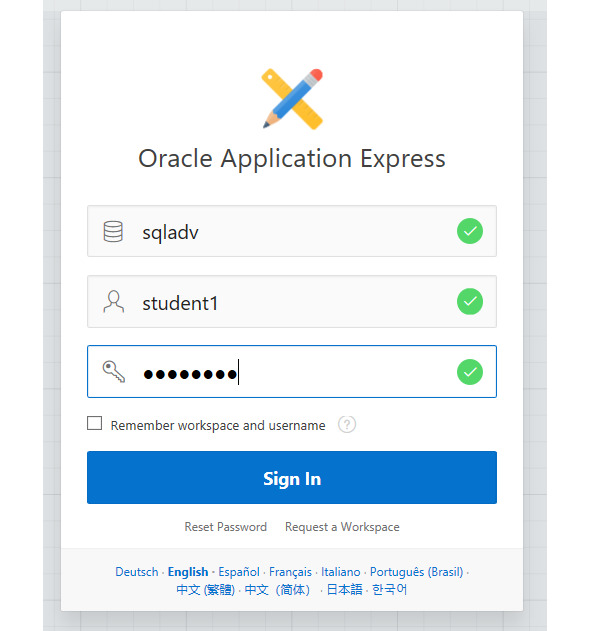
Рисунок 1. Форма авторизации в APPEX
Первое поле сверху мы заполняем SQLADV, во второе поле мы вносим имя пользователя student1 и заполняем пароль – также student1.
Также будут работать учетные записи: student2/, student2, student3/, student3… student11/, student11).
Перед вами откроется среда разработки.
Выберите пункт меню SQL Workshop, а дальше SQL ComMANd.
Пред вами откроется среда выполнения SQL-запросов.
Напишите следующий учебный запрос:
SELECT * FROM AUTO;
Нажмите кнопку RUN SQL, и далее в нижней части экрана должен появиться результат выполнения запроса.
Это и будет тот сервис, которым вы в основном сможете пользоваться для выполнения практических заданий.
Данный ресурс предоставлен компанией ORACLE в рекламных маркетинговых целях.
Если не устраивает данный сервис или почему-то этот сервис у вас не работает, тогда существует второй способ.
Вы можете воспользоваться сервисом SQL-Фидель.
Учебная схема, по которой необходимо заниматься, состоит из нескольких таблиц, которые заполнены соответствующими данными.
Введите в поле браузера ссылку
Выберите тип базы данных ORACLE 11 g r2.
Далее вам потребуется загрузить учебную схему, по которой мы будем заниматься. Скрипт учебной схемы находится по следующей ссылке в текстовом документе:
Скопируйте содержимое скрипта в поле в левой части экрана и нажмите кнопку BuildSchema.
После чего уже в правой части экрана SQLFIDlle вы сможете писать необходимые запросы и выполнять учебные задания.
Учебные запросы в SQLFIDdle пишутся в текстовом поле в правой части экрана.
После создания схемы напишите следующий учебный запрос:
SELECT * FROM MAN
Нажмите RUN SQL, в нижней части экрана должен появиться результат выполнения запроса.
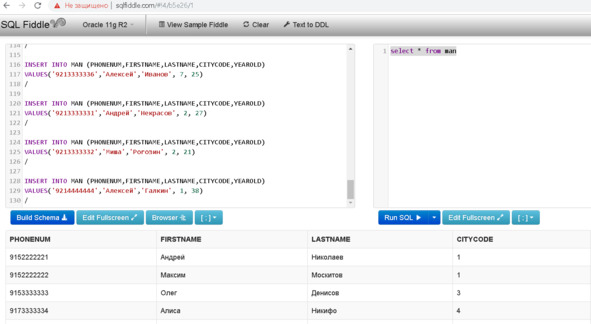
Рисунок 2. Пробный запрос SQLFIDlle
Если все получилось, то вы можете приступать к учебе.
Данный текст является ознакомительным фрагментом.
Язык запросов SQL
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
База данных — централизованное хранилище данных, обеспечивающее хранение, доступ, первичную обработку и поиск информации.
Базы данных разделяются на:
- Иерархические
- Сетевые
- Реляционные
- Объектно-ориентированные
SQL (Structured Query Language) — представляет из себя структурированный язык запросов (перевод с английского). Язык ориентирован на работу с реляционными (табличными) базами данных. Язык прост и, по сути, состоит из команд (интерпретируемый), посредством которых можно работать с большими массивами данных (базами данных), удаляя, добавляя, изменяя информацию в них и осуществляя удобный поиск.
Для работы с SQL кодом необходима система управления базами данных (СУБД), которая предоставляет функционал для работы с базами данных.
Система управления базами данных (СУБД) — совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями.
Обычно, для обучения используется СУБД Microsoft Access, но мы будем использовать более распространенную в веб сфере систему — MySQL. Для удобства будет использовать веб-интерфейс phpmyadmin или онлайн сервис для построения sql запросов sql fiddle, принцип работы с которыми описан ниже.
Важно: При работе с реляционными или табличными базами данных строки таблицы будем называть записями, а столбцы — полями.
Каждый столбец должен иметь свой тип данных, т.е. должен быть предназначен для внесения данных определенного типа. Типы данных в MySQL описаны в одном из уроков данного курса.
Составляющие языка SQL
Язык SQL состоит из следующих составных частей:
- язык манипулирования данными (Data Manipulation Language, DML);
- язык определения данных (Data Definition Language, DDL);
- язык управления данными (Data Control Language, DCL).
1.
Язык манипулирования данными состоит из 4 главных команд:
- выборка данных из БД — SELECT
- вставка данных в таблицу БД — INSERT
- обновление (изменение) данных в таблицах БД — UPDATE
- удаление данных из БД — DELETE
2.
Язык определения данных используется для создания и изменения структуры базы данных и ее составных частей — таблиц, индексов, представлений (виртуальных таблиц), а также триггеров и сохраненных процедур.
Мы будем рассматривать лишь несколько из основных команд языка. Ими являются:
- создание базы данных — CREATE DATABASE
- создание таблицы — CREATE TABLE
- изменение таблицы (структуры) — ALTER TABLE
- удаление таблицы — DROP TABLE
3.
Как сделать sql запрос в phpmyadmin
- Запустить ярлык start denwer .
- В адресной строке браузера набрать http://localhost/tools/phpmyadmin .
- В левой части окна выбрать интересующую базу данных или создать ее (если еще не создана). Создание базы данных в phpmyadmin рассмотрено ниже.
- Если известна таблица, с которой будет работать запрос — в левой части окна выбрать эту таблицу.
- Выбрать вкладку SQL и начать вводить запрос.

Создание базы данных в phpmyadmin
Для начала необходимо выполнить первые два пункта из предыдущего задания.
Затем:
- в открывшемся веб-интерфейсе выбрать вкладку Базы данных;
- в поле Создать базу данных ввести название базы;
- щелкнуть по кнопке Создать;
- теперь для продолжения работы в phpMyAdmin в созданной базе данных можно перейти к уроку создания таблиц.

Работа в сервисе sql fiddle
Онлайн проверка sql запросов возможна при помощи сервиса sqlFiddle.
Самый простой способ организации работы состоит из следующих этапов:

-
В верхней части рабочей области сервиса выбираем язык: SQLite(WebSQL);
Открывшаяся рабочая область разделена визуально на 3 окна: левое — для кода создания таблиц и заполнения их данными, правое — для кода запросов, нижнее — для отображения результатов запросов.



Еще пример:
Теперь некоторые пункты рассмотрим подробнее.
Создание таблиц:
Пример: создайте сразу три таблицы (teachers, lessons и courses); добавьте по нескольку значений в каждую таблицу.
* для тех, кто незнаком с синтаксисом — просто скопировать полностью код и вставить в левое окошко сервиса
* урок по созданию таблиц в языке SQL далее
/*teachers*/ CREATE TABLE `teachers` ( `id` INT(11) NOT NULL, `name` VARCHAR(25) NOT NULL, `code` INT(11), `zarplata` INT(11), `premia` INT(11), PRIMARY KEY (`id`) ); INSERT INTO teachers VALUES (1, 'Иванов',1,10000,500), (2, 'Петров',1,15000,1000) ,(3, 'Сидоров',1,14000,800), (4,'Боброва',1,11000,800); /*lessons*/ CREATE TABLE `lessons` ( `id` INT(11) NOT NULL, `tid` INT(11), `course` VARCHAR(25), `date` VARCHAR(25), PRIMARY KEY (`id`) ); INSERT INTO lessons VALUES (1,1, 'php','2015-05-04'), (2,1, 'xml','2016-13-12'); /*courses*/ CREATE TABLE `courses` ( `id` INT(11) NOT NULL, `tid` INT(11), `title` VARCHAR(25), `length` INT(11), PRIMARY KEY (`id`) ); INSERT INTO courses VALUES (1,1, 'php',54), (2,1, 'xml',72), (3,2, 'sql',25);
/*teachers*/ CREATE TABLE `teachers` ( `id` int(11) NOT NULL, `name` varchar(25) NOT NULL, `code` int(11), `zarplata` int(11), `premia` int(11), PRIMARY KEY (`id`) ); insert into teachers values (1, ‘Иванов’,1,10000,500), (2, ‘Петров’,1,15000,1000) ,(3, ‘Сидоров’,1,14000,800), (4,’Боброва’,1,11000,800); /*lessons*/ CREATE TABLE `lessons` ( `id` int(11) NOT NULL, `tid` int(11), `course` varchar(25), `date` varchar(25), PRIMARY KEY (`id`) ); insert into lessons values (1,1, ‘php’,’2015-05-04′), (2,1, ‘xml’,’2016-13-12′); /*courses*/ CREATE TABLE `courses` ( `id` int(11) NOT NULL, `tid` int(11), `title` varchar(25), `length` int(11), PRIMARY KEY (`id`) ); insert into courses values (1,1, ‘php’,54), (2,1, ‘xml’,72), (3,2, ‘sql’,25);

В результате получим таблицы с данными:
Отправка запроса:
Для того чтобы протестировать работоспособность сервиса, добавьте в правое окошко код запроса.
Пример: при помощи запроса выберите все данные из таблицы teachers, касаемые учителя с фамилией Иванов
SELECT * FROM `teachers` WHERE `name` = 'Иванов';
SELECT * FROM `teachers` WHERE `name` = ‘Иванов’;
На дальнейших уроках SQL будет использоваться та же схема, поэтому необходимо будет просто копировать схему и вставлять в левое окно сервиса.
Онлайн визуализации схемы базы данных
Для онлайн визуализации схемы базы данных можно воспользоваться сервисом https://dbdesigner.net/:
- Создать свой аккаунт (войти в него, если уже есть).
- Щелкнуть по кнопке Go to Application.
- Меню Schema ->Import.
- Скопировать и вставить в появившееся окно код создания и заполнения таблиц базы данных
SQL для аналитики — рейтинг прикладных задач с решениями
Привет, Хабр! У кого из вас black belt на sql-ex.ru, признавайтесь? На заре своей карьеры я немало времени провел на этом сайте, практикуясь и оттачивая навыки. Должен отметить, что это было увлекательное и вознаграждающее путешествие. Пришло время воздать должное.
В этой публикации я собрал топ прикладных задач и мои подходы к их решению в терминах SQL. Каждая задача снабжена кусочком данных и кодом, с которым можно интерактивно поиграться на SQL Fiddle.
SQL is intergalactic data speak. SQL — это межгалактический язык данных
— Michael Stonebraker
Моя цель — показать подходы и самые распространенные проблемы на понятных и доступных примерах. Конечно, СУБД, на которой решается задача имеет значение. Поддержка функций и синтаксиса варьируется. В SQL Fiddle я задействовал PostgreSQL, Oracle, SQL Server. Для решения серьезных аналитических задач сегодня я чаще всего использую специальные СУБД, такие как Redshift, Vertica, BigQuery, Clickhouse, Snowflake.
Уверен, неискушенные пользователи смогут многое для себя почерпнуть. Продвинутых же пользователей призываю поделиться своими наиболее интересными задачами и поучаствовать в обсуждении.
Конкатенация значений из нескольких строк в одну через разделитель
Когда это может быть полезно? К примеру, если исходный набор данных хранит каждый тег, присвоенный сделке, в отдельной строке (это же получится при соединении таблиц лидов и тегов), и есть необходимость собрать все теги, обойдясь при этом без дублирования строк по каждой сделке.
Формулировка задачи: Для каждого лида вывести список тегов, разделенных запятой в одном столбце
Пример решения:
select lead_id ,string_agg(tag, ', ') as tags from leads group by lead_id ;Аналитические функции при сохранении всех строк выборки
Речь пойдет о так называемых analytic functions, которые оперируют над партициями данных (окна, windows), возвращая результат для каждой строки. В отличие от aggregate functions, “схлопывающих” строки, оконные функции оставляют все строки выборки.
Окно определяется спецификацией (выражение OVER) и основывается на трех основных концепциях:
- Разбиение строк на группы (выражение PARTITION BY)
- Порядок сортировки строк в каждой группе (выражение ORDER BY)
- Рамки, которые определяют ограничения по количеству строк относительно каждой строки (выражение ROWS)
Таких функций существует немало, от аналитических: всем известные SUM, AVG, COUNT, менее известные LAG, LEAD, CUMEDIST, и до ранжирующих: RANK, ROWNUMBER, NTILE. Я же приведу несколько простых примеров часто встречающихся запросов:
- Ко всем транзакциям пользователя вывести дату первой покупки
- К каждой транзакции добавить дату предыдущей транзакции пользователя
- Показать сумму покупок пользователя нарастающим итогом
- Присвоить всем транзакциям пользователя / продавца / отделения порядковый номер
Пример решения:
select salesid ,dateid ,sellerid ,buyerid ,qty ,first_value(dateid) over (partition by buyerid order by dateid) as first_purchase_dt ,lag(dateid) over (partition by buyerid order by dateid) as previous_purchase_dt ,sum(qty) over (partition by buyerid order by dateid rows between unbounded preceding and current row) as moving_qty ,row_number() over (partition by buyerid order by dateid) as order_number from winsales ;Работа с NULL и применение логики ветвления IF-THEN-ELSE в SQL
Про COALESCE / NVL знают все, и нет смысла останавливаться на них подробно. Зато с NVL2 и NULLIF знакомы уже не так много людей.
NULLIF сравнивает два значения и возвращает NULL, если аргументы равны. По сути эта функция — обратна к NVL / COALESCE. Формулировка задачи:
- Как обработать ошибку деления на 0 (divide by zero error)
- Как выводить NULL вместо пустых строк (‘’)
Пример решения:
select lead_id ,nullif(tag, '') as tag from leads ;NVL2 в свою очередь вернет одно из значений, в зависимости от того, является ли входной аргумент NULL или NOT NULL. Например, если в таблице транзакций есть ссылка на invoiceid, значит транзакция в сегменте B2B, и ее следует пометить соответствующим образом.
Пример решения:
select "transaction_id" ,"ts" ,"invoice_id" ,nvl2("invoice_id", 1, 0) as "is_b2b" from transactions ;Но больше всего мне нравится функция DECODE. Она в буквальном смысле позволяет расшифровать значения согласно заданной вами логике:
DECODE ( expression, search, result [, search, result ]… [ ,default ] ).
Формулировка задачи: Присвоить численному коду (или, например, битовой маске) текстовые наименования.
Пример решения:
select "transaction_id" ,decode("status", 0, 'charge', 1, 'authorize', 2, 'settle', 'void') as "status" from transactions ;Опережая вопрос, конечно, эту же логику можно выразить через всем известное выражение CASE. Задача показать что-то интересное, и чем меньше кода — тем красивее, на мой взгляд.
Дедупликация данных
Это классика. Задачу часто спрашивают на собеседованиях в формулировке “как удалить дубли / копии строк”, и решить ее можно несколькими способами. Я привык мыслить в терминах историзации данных в Хранилище, и удаление мне ни к чему, поэтому для решения задачи я воспользуюсь ранжирующей функцией ROWNUMBER().
Формулировка задачи: Выбрать самую актуальную запись с учетом статуса (успешная / отмененная транзакция) и временнОй метки
Пример решения:
with decoded as ( select "transaction_id" ,"is_successful" ,"ts" ,decode("is_successful", 'true', 0, 'false', 1, 2) as "order_is_successful" from transactions ), ordered as ( select "transaction_id" ,"is_successful" ,"ts" ,row_number() over(partition by "transaction_id" order by "order_is_successful" asc, "ts" desc) as rn from decoded ) select "transaction_id" ,"is_successful" ,"ts" from ordered where rn = 1 ;Некоторые СУБД, например, Teradata позволяют сделать запрос короче при помощи выражения QUALIFY:
select * from students_db.exam_results qualify row_number() over (partition by subject order by marks desc) = 1 ;Анализ временных рядов
Просто не могу обойти это стороной. ВременнАя шкала — это, безусловно, одно из наиболее часто используемых измерений. Отчетность зачастую строится вокруг измерения метрик и их динамики относительно периодов: неделя, месяц, время суток и т.д.
Замечательно, если ваша BI система умеет работать с различными абсолютными и относительными фреймами, и наружу выставляет красивый визуальный интерфейс. Еще лучше, если в ваш инструментарий аналитика входит пара наиболее используемых функций:
- Получение текущей даты (+ время) — CURRENTDATE, CURRENTTIMESTAMP
- Разница между событием и текущим временем — DATEDIFF
- Подсчет времени истечения срока действия события — DATEADD
- Дата начала недели, в которой произошло событие — DATETRUNC
- Конвертация Unix Timestamp (epoch) в человекочитаемый формат
Пример решения:
select ts ,_metadata_ts_epoch ,convert(date, getdate()) as current_dt ,current_timestamp as current_ts ,datediff(minute, ts, getdate()) as minutes_since_ts ,dateadd(hour, 36, ts) as ts_expiration_ts ,dateadd(week, datediff(week, 0, ts), 0) as ts_week ,dateadd(S, (_metadata_ts_epoch / 1000), '1970-01-01') as _metadata_ts from transactions ;Анализ истории со Slowly Changing Dimensions (SCD)
В основе Хранилища Данных лежит принцип историзации. Иначе говоря — это возможность получить состояние той или иной сущности на определенный момент времени, а также проследить цепочку событий и изменений атрибутов и показателей. Существует несколько способов организации хранения истории. Один из наиболее популярных подходов — запись новой строки на любое изменение атрибутного состава, с указанием даты начала и окончания действия каждой строки. Есть несколько задач, с которыми вы с большой долей вероятности можете встретиться.
Формулировка задачи: Какой статус был у клиентов на 3-й день месяца?
Пример решения:
select client_id ,status from clients where '2021-02-03' >= valid_from and '2021-02-03' < coalesce(valid_to, '2100-01-01') ;Формулировка задачи: Как в течение недели росло количество активных клиентов?
select c.dt ,h.status ,count(distinct h.client_id) from calendar c left join clients h on c.dt >= valid_from and c.dt < coalesce(valid_to, '2100-01-01')::date where true and c.dt between '2021-02-01' and '2021-02-07' and h.status in ('active') group by c.dt ,h.status order by 1, 3 desc ;С помощью такого подхода можно подсчитать долю неактивных контрагентов на каждую дату за последний месяц. При этом неактивным считается контрагент, не совершивший ни одной транзакции за предыдущие 7 дней на каждую дату. Вот так может выглядеть визуализация решения задачи на дашборде:
Использование выражения CASE в агрегирующих функциях
Агрегирующие функции могут принимать в качестве аргумента результат оценки выражения CASE. Таким образом можно к агрегируемым строкам применить псевдофильтр. Это напоминает мне использование формулы СУММЕСЛИ из старого доброго Excel, только для реляционных баз данных. Смотрите сами:
- Подсчитать все лиды и выручку
- Подсчитать количество лидов со статусом success
- Подсчитать выручку лидов с тегом python
Пример решения:
select dt ,count(1) as leads_total ,sum(case status when 'success' then 1 else 0 end) as leads_success ,sum(case when tags like '%python%' then 1 else 0 end) as leads_python ,sum(amount) as amount_total ,sum(case status when 'success' then amount else 0 end) as amount_success from leads group by dt order by dt ;Парсинг колонки с разделением на отдельные атрибуты
Чаще всего так поступают в условиях внешних ограничений, когда иного выхода нет. Например, при ограниченном наборе полей в CRM системе. Или при передаче нескольких UTM-меток в одной строковой переменной. Еще так могут делать люди, которые не слышали про нормализацию данных.
Формулировка задачи: Выделить закодированные в названии кампании атрибуты в отдельные колонки: сеть, регион, категория, температура, бренд.
Пример решения:
select campaign ,split_part(campaign, '-', 1) as network ,split_part(campaign, '-', 2) as region ,split_part(campaign, '-', 3) as category ,nullif(split_part(campaign, '-', 4), 'None') as temperature ,split_part(campaign, '-', 5) as brand from campagins ;Чуть более сложная ситуация с парсингом UTM-меток, а именно UTMContent, которая по сути является контейнером для произвольного набора атрибутов, разделенных любым символом. Поэтому стоит быть последовательным и аккуратным при формировании таких меток, хотя зачастую инженер вынужден работать с тем, что есть.
Формулировка задачи: Разбить строку UTMContent на отдельные атрибуты cid, gid, aid, kwd с соблюдением соответствия ключ-значение. Каждое значение предваряется наименованием ключа, все значения разделены вертикальной строкой (|).
Пример решения:
select substring("UTMContent" from '%cid_#"%#"_gid%' FOR '#' ) AS cid ,substring("UTMContent" from '%gid_#"%#"_aid%' FOR '#' ) AS gid ,substring("UTMContent" from '%aid_#"%#"_dvc%' FOR '#' ) AS aid ,substring("UTMContent" from '%kwd_#"%#"_pos%' FOR '#' ) AS kwd from utm ;FULL JOIN для соединений без потери строк
Уверен, что все знают про FULL JOIN, но кто хоть иногда использует этот тип соединения? Это незаменимый подход в ситуациях, когда я хочу сохранить все исходные строки с каждой стороны джоина. Иначе говоря, недопустимо терять факты трат денежных средств, даже если для них не нашлось соответствующих лидов в таблицах CRM.
А теперь представьте ситуацию, когда таблиц больше двух. Это может быть веб-аналитика, выгрузки из рекламных кабинетов, CRM. В этом случае я дополнительно формирую мета-колонки isrowmatched (нашлось ли совпадение - да / нет) и roworigin (источник данных для конкретной строки).
Формулировка задачи: Подготовить витрину-трекер для сквозной аналитики лидов из CRM и трат из Рекламных Кабинетов (Яндекс.Директ, Google Adwords, Facebook).
Пример решения:
select coalesce(c.hash_key, l.hash_key) as hash_key ,coalesce(c.dt, l.dt) as dt ,coalesce(c.campaign_id, l.campaign_id) as campaign_id -- costs ,coalesce(c.platform, null) as platform ,coalesce(c.clicks, 0) as clicks ,coalesce(c.costs, 0) as costs -- leads ,coalesce(l.leads, 0) as leads ,coalesce(l.amount, 0) as amount -- meta ,case when c.dt is not null then c.platform when l.dt is not null then 'crm' end as meta_row_origin ,case when c.hash_key = l.hash_key then 1 else 0 end as meta_is_row_match from costs as c full join leads as l on l.hash_key = c.hash_key ;Пример упрощен и умозрителен. Однако этой задаче я посвятил одну из своих предыдущих публикаций: Сквозная Аналитика на Azure SQL + dbt + Github Actions + Metabase и недавнее выступление на вебинаре: Путь Инженера Аналитики: Решение для Маркетинга. Тема заслуживает отдельного внимания.
Разбиение пользовательских событий на сессии
Сессионизация - весьма интересная и сложная задача, сочетающая в себе сразу комплекс инженерных и аналитических решений. С ростом популярности и востребованности всевозможных трекеров, таких как Google Analytics, Snowplow, Amplutide кратно возрастает спрос на решение подобного рода задач.
Для чего это можно использовать? Прежде всего, для того, чтобы перейти от анализа хитов (кликов) к полноценному анализу пользовательского взаимодействия и поведения. Во-вторых, улучшение UX и качества сервисов, проведение A/B тестирования. Наконец, поиск паттернов, определенных сегментов пользователей, в том числе fraud monitoring (защита от мошенничества и ботов).
Чуть подробнее про дефиницию сессии от Google Analytics: How a web session is defined in Universal Analytics. Резюмируя, сессия - это набор пользовательских действий в рамках заданного промежутка времени. Сессия завершается при следующих событиях:
- 30 минут бездействия
- Начало новых суток
- Смена источника трафика (возврат на сайт по клику на новый рекламный баннер)
Базовая задача сессионизации сводится к следующему: превратить последовательность кликов из лога веб-сервера в набор сессий.
Попробуем декомпозировать и решить задачу по частям:
- Шаг 1. Для каждого пользователя берем идентификатор просмотра, время просмотра, источник трафика (хеш-сумма). Хеш-сумма берется от текстовой конкатенации атрибутов источника трафика: utm_source + utm_medium + utm_campaign. При этом обрабатываются null-значения в любом из столбцов (заменяются на литерал 'null'). По хеш-сумме легко проверить смену источника трафика.
select user_id ,hit_id ,ts ,md5(concat(coalesce(utm_source, 'null'), coalesce(utm_medium, 'null'), coalesce(utm_campaign, 'null'))) as utm_hash from hits_raw
- Шаг 2. Для каждого хита выводим предыдущий хит и соответствующее ему время. Окно - по пользователю, сортировка по времени хита:
select user_id ,hit_id ,ts ,lag(ts, 1) over (partition by user_id order by ts) as lag_ts ,utm_hash ,lag(utm_hash, 1) over (partition by user_id order by ts) as lag_utm_hash from hits- Шаг 3. Рассчитываем, является ли каждый хит началом новой сессии. Это проверка на выполнение любого из трех указанных выше условий окончания сессии:
select user_id ,hit_id ,ts ,lag_ts ,case when utm_hash <> lag_utm_hash then 1 when date_part('day', ts - lag_ts) <> 0 then 1 when date_part('hour', ts - lag_ts) * 60 + date_part('minute', ts - lag_ts) > 30 then 1 else 0 end as is_new_session -- ,date_part('day', ts - lag_ts) as days_diff -- ,date_part('hour', ts - lag_ts) * 60 + -- date_part('minute', ts - lag_ts) as minutes_diff ,utm_hash ,lag_utm_hash from lags- Шаг 4. Присваиваем каждой сессии уникальный идентификатор. Для этого сначала необходимо пронумеровать сессии одного пользователя монотонно возрастающими числами. Затем построить уникальный суррогатный ключ сессии: к номеру сессии добавить идентификатор пользователя, взять хеш-сумму:
select user_id ,hit_id ,ts ,is_new_session ,sum(is_new_session) over (partition by user_id order by ts rows between unbounded preceding and current row) as session_index ,md5(concat(user_id, sum(is_new_session) over (partition by user_id order by ts rows between unbounded preceding and current row))) as session_id from new_sessionsВ реальном мире всё сложнее
Помимо логики, выраженной в SQL, не меньшее значение имеет ряд других факторов:
- СУБД, с которой вы работаете: то, какие функции и возможности она поддерживает, формат хранения данных: в виде колонок или строк
- Фактически используемый план выполнения запроса: алгоритмы соединения таблиц, локальность операций, наличие статистических данных у оптимизатора
- Используемые физические и логические модели данных: индексы, материализованные представления, кеш, предварительно отсортированные данные
На занятиях курса Data Engineer я и мои коллеги готовим объемлющий и интересный контент, затрагивающий множество тем, связанных с архитектурой аналитических приложений, внутренним устройством систем обработки больших данных и развертыванием ML.
Советую посетить ближайшие открытые вебинары:
- ML в Spark, 11 февраля в 20:00
- MPP-базы данных, 17 февраля в 20:00
Оставляйте ваши комментарии и вопросы, предлагайте собственные примеры задач и подходы к решению.