Volatile write cache ssd что это
Контент представлен пользователями ОК. Здесь вы найдете все, что нужно, чтобы быть в курсе последних новостей и тенденций в мире технологий. volatile write cache ssd что это – ОК место, где вы сможете найти ответы на все вопросы, связанные с гаджетами, а также прочитать интересные статьи, подготовленные нашими экспертами. Будьте в центре событий и следите за всеми новинками в области гаджетов. Изучайте контент, если вы искали volatile write cache ssd что это и интересуетесь этой увлекательной темой.
Часто ищут
- Лада
- Рукоделие
- Закуски
- Осень
- Селедочка
- Рецепты на скорую руку
- Лучшие фильмы
- Советы по готовке
- Стихи
- Продам
- Смешные картинки
- Москва
- Пирожки с картошкой
- Попугаи
- Юмор
- Выпечка
- Лайфхаки
- Советы по ремонту
- Как испечь торт
- Вредители
Общие сведения о кэше пула носителей
Локальные дисковые пространства, базовая технология виртуализации хранилища, лежащая в основе Azure Stack HCI и Windows Server, содержит встроенный кэш на стороне сервера, чтобы повысить производительность хранилища и снизить затраты. Это большой постоянный кэш для чтения и записи в режиме реального времени, который настраивается автоматически при развертывании. В большинстве случаев никакого ручного управления не требуется. Способ работы кэша зависит от типов имеющихся накопителей.
Типы накопителей и варианты развертывания
Локальные дисковые пространства в настоящее время работает с четырьмя типами дисков:
| Тип диска | Описание |
|---|---|
 |
PMem относится к постоянной памяти, новому типу хранилища с низкой задержкой и высокой производительностью. |
 |
NVMe (Non-Volatile Memory Express) — это твердотельные диски, подключенные непосредственно к шине PCIe. Распространенные форм-факторы: 2,5 дюйма U.2, плата расширения PCIe (AIC) и M.2. NVMe предлагает более высокую пропускную способность операций ввода-вывода и операций ввода-вывода с меньшей задержкой, чем любой другой тип диска, который мы поддерживаем сегодня, кроме PMem. |
 |
SSD — это твердотельные накопители, которые подключаются через обычные SATA или SAS. |
 |
HDD — это вращаемые магнитные жесткие диски, которые обеспечивают большую емкость хранилища по низкой цене. |
Их можно комбинировать различными способами, которые мы сгруппируем в две категории: «all-flash» и «hybrid». Развертывания со всеми жесткими дисками не поддерживаются.
В этой статье рассматриваются конфигурации кэша с NVMe, SSD и HDD. Сведения об использовании постоянной памяти в качестве кэша см. в статье Общие сведения об использовании и развертывании постоянной памяти.
Варианты развертывания только с флэш-накопителями
Развертывания с поддержкой всего флэш-накопителя нацелены на максимальную производительность хранилища и не включают жесткие диски.

Варианты гибридного развертывания
Гибридные развертывания предназначены для балансировки производительности и емкости или для максимальной емкости и включают HDD.

Гибридное развертывание не поддерживается в конфигурации с одним сервером. Все конфигурации неструктурированного типа одного хранилища (например, все NVMe или все SSD) являются единственным поддерживаемым типом хранилища для одного сервера.
Кэш-накопители выбираются автоматически
В развертываниях с несколькими типами дисков Локальные дисковые пространства автоматически использует для кэширования все диски самого быстрого типа. Остальные диски используются для хранения.
Скорость работы накопителя определяется согласно следующей иерархии.

Например, если у вас есть накопители NVMe и SSD, NVMe будут использоваться в качестве кэша для SSD.
Если у вас есть твердотельные накопители (SSD) и жесткие диски, SSD будут использоваться в качестве кэша для жестких дисков.
Диски кэша не обеспечивают использование емкости хранилища в кластере. Все данные, хранящиеся в кэше, хранятся и в других местах или будут храниться там после их переноса из кэша на устройство. Это означает, что общая емкость необработанного хранилища кластера является суммой только дисков емкости.
Если все накопители принадлежат к одному типу, кэш не настраивается автоматически. Вы можете вручную задать более износостойкие накопители в качестве кэша для менее износостойких накопителей того же типа. Соответствующие инструкции см. в разделе Ручная настройка.
В некоторых случаях использование кэша пула носителей не имеет смысла. Например, в развертываниях с все NVMe или SSD, особенно в очень небольших масштабах, отсутствие дисков, «затраченных» на кэш, может повысить эффективность хранилища и повысить производительность. Аналогичным образом, небольшие удаленные развертывания или развертывания филиалов могут иметь ограниченное пространство для дисков кэша.
Режим работы кэша задается автоматически
Поведение кэша определяется автоматически на основе типов дисков, которые кэшируются. При кэшировании для устройств флэш-памяти (например, при кэшировании NVMe для ssd) кэшируются только операции записи. При кэшировании для вращающихся дисков (например, кэширования SSD для жестких дисков) кэшируются операции чтения и записи.
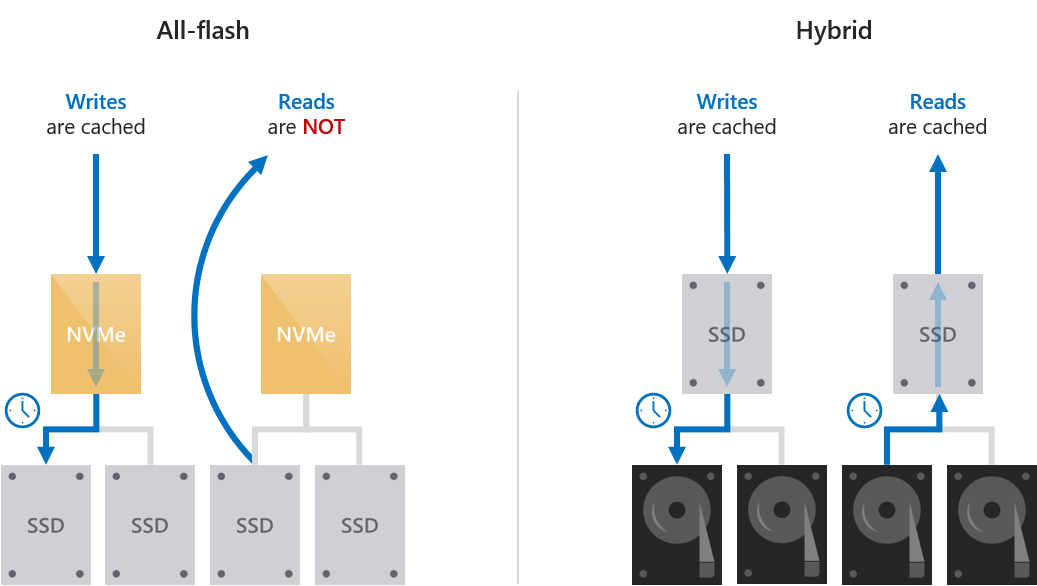
Кэширование только операций записи для развертываний только с флэш-накопителями
Кэширование можно использовать в сценарии с использованием всех флэш-накопителей, например использование NVMe в качестве кэша для ускорения производительности накопителей SSD. При кэшировании для развертываний на основе флэш-памяти кэшируются только операции записи. Это снижает нагрузку на дисках емкости, так как многие операции записи и повторной записи могут объединиться в кэше, а затем деактивироваться только по мере необходимости, уменьшая совокупный трафик на диски емкости и продлевая их срок службы. Поэтому для кэша рекомендуется выбирать более износостойкие и оптимизированные для записи накопители. Накопители-хранилища в целом могут иметь менее высокий ресурс записи.
Так как операции чтения не влияют на срок службы флэш-памяти и диски SSD обеспечивают низкую задержку чтения, операции чтения не кэшируются: они обслуживаются непосредственно с дисков емкости (за исключением случаев, когда данные были записаны так недавно, что они еще не были де-этапированы). Это позволяет ориентировать работу кэша исключительно на операции записи, повышая их эффективность.
Это приводит к тому, что характеристики записи (например, задержка записи) определяются кэш-накопителями, а характеристики чтения — накопителями-хранилищами. И те, и другие согласованы, предсказуемы и унифицированы.
Кэширование операций чтения и записи для гибридных развертываний
При кэшировании hdd кэшируются как операции чтения, так и записи, чтобы обеспечить задержку, подобную флэш-памяти (часто примерно в 10 раз лучше). Кэш чтения хранит недавно считанные и часто считываемые данные для организации быстрого доступа к ним и сведения к минимуму объема произвольных обращений к жестким дискам. (Из-за задержек во время операций поиска и раскрутки диска вызванные произвольными обращениями к жесткому диску потери времени и задержки имеют существенное значение.) Операции записи кэшируются, чтобы объединить последовательности запросов, а также объединить операции записи и перезаписи для снижения общего потока данных на накопители-хранилища.
Локальные дисковые пространства реализует алгоритм, который отменяет случайные операции записи перед их отменой, чтобы эмулировать шаблон ввода-вывода на диск, который кажется последовательным, даже если фактические операции ввода-вывода, поступающие от рабочей нагрузки (например, виртуальных машин), являются случайными. Это позволяет увеличить количество операций ввода-вывода в секунду и пропускную способность для жестких дисков.
Кэширование в развертываниях с помощью NVMe, SSD и HDD
При наличии дисков всех трех типов диски NVMe обеспечивают кэширование как для ssd, так и для жестких дисков. Режим работы соответствует описанному ранее: для накопителей SSD кэшируются только операции записи, для жестких дисков — операции чтения и записи. Работа по кэшированию жестких дисков равномерно распределяется среди кэш-накопителей.
Сводка
В этой таблице приведена сводная информация о том, какие накопители используются для кэширования, какие — для хранения данных и как осуществляется кэширование в каждом варианте развертывания.
| Развертывание | Кэш-накопители | Накопители-хранилища | Режим кэширования (по умолчанию) |
|---|---|---|---|
| Только NVMe | Нет (как вариант — настройка вручную) | NVMe | Только запись (если настроено) |
| Только SSD | Нет (как вариант — настройка вручную) | SSD | Только запись (если настроено) |
| NVMe + SSD | NVMe | SSD | Только на запись |
| NVMe + жесткий диск | NVMe | HDD | Чтение + запись |
| SSD + жесткий диск | SSD | HDD | Чтение + запись |
| NVMe + SSD + жесткий диск | NVMe | SSD + жесткий диск | Для жесткого диска — чтение + запись, для SSD — только запись |
Серверная архитектура
Кэш реализуется на уровне накопителя: отдельные кэш-накопители на одном сервере привязаны к одному или нескольким накопителям-хранилищам на том же сервере.
Поскольку кэш находится ниже остального стека программно-определяемого хранилища Windows, он не использует такие концепции, как дисковые пространства или отказоустойчивость, и не нуждается в них. Его можно рассматривать как создание «гибридных» (часть флэш-памяти, часть диска), которые затем представляются операционной системе. Как и в случае с реальным гибридным накопителем, перемещение в режиме реального времени «горячих» и «холодных» данных между более быстрыми и более медленными зонами физического носителя почти незаметно извне.
С учетом того, что устойчивость в локальных дисковых пространствах реализуется как минимум на уровне сервера (то есть, копии данных всегда записываются на разные сервера; не более одной копии на сервер), на данные в кэше распространяются те же преимущества устойчивости, что и на данные не в кэше.
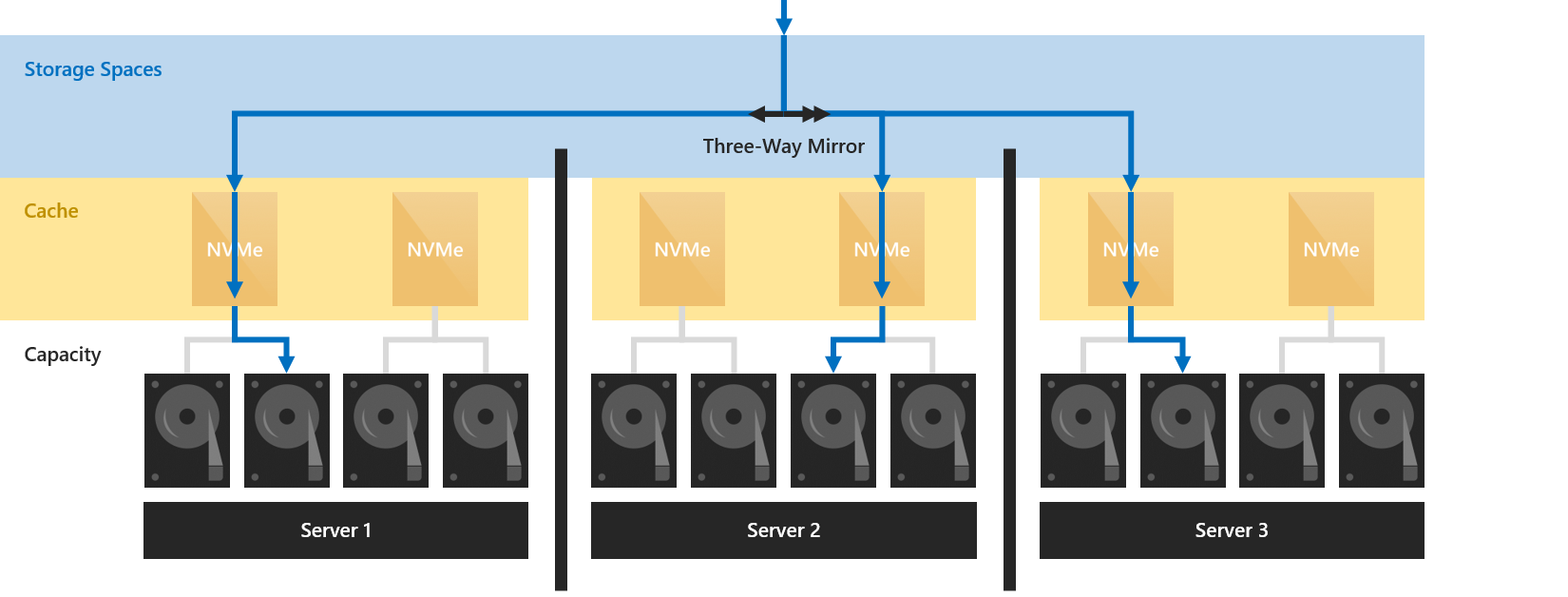
Например, при использовании трехстороннего зеркалирования три копии любых данных записываются на разные серверы и оказываются там в кэше. Вне зависимости от того, будут ли они позднее перенесены из кэша на устройство или нет, три эти копии всегда существуют.
Привязки к накопителям являются динамическими
Привязка кэш-накопителей к накопителям-хранилищам может иметь любой коэффициент — от 1:1 до 1:12 и так далее. Он настраивается динамически всякий раз, когда добавляются или удаляются накопители, например при увеличении масштаба системы или после сбоев. Это означает, что вы можете добавлять кэш-накопители или накопители-хранилища независимо друг от друга, когда это необходимо.
Рекомендуется делать число накопителей-хранилищ кратным числу кэш-накопителей для соблюдения симметрии. Например, если у вас четыре кэш-накопителя, то при наличии восьми накопителей-хранилищ (соотношение 1:2) производительность будет более постоянной, чем при наличии семи или девяти накопителей-хранилищ.
Обработка сбоев кэш-накопителей
При сбое в работе кэш-накопителя все операции записи, которые еще не были перенесены из кэша на устройство, теряются на локальном сервере, то есть существуют только в других копиях (на других серверах). Так же, как и при сбоях других накопителей, дисковые пространства могут выполнять автоматическое восстановление и делают это, обращаясь к сохранившимся копиям.
В течение небольшого периода времени накопители-хранилища, которые были привязаны к отказавшему кэш-накопителю, будут отображаться как неисправные. После повторной привязки кэша (выполняется автоматически) и завершения восстановления данных (выполняется автоматически) они снова будут отображаться как исправные.
Этот сценарий показывает, почему для поддержания работоспособности сервера требуется не менее двух кэш-накопителей на сервер.
Затем можно заменить кэш-накопитель, следуя стандартной процедуре замены любых накопителей.
Может потребоваться отключение питания для безопасной замены накопителя NVMe в виде дополнительной карты (AIC) или в форм-факторе M.2.
Связь с другими кэшами
Существует несколько других несвязанных друг с другом кэшей в стеке программно-определяемого хранилища Windows. Примерами могут служить кэш обратной записи дисковых пространств и кэш чтения в памяти общего тома кластера (CSV).
В Azure Stack HCI не следует изменять кэш обратной записи дисковые пространства по умолчанию. Например, не следует использовать такой параметр, как -WriteCacheSize в командлете New-Volume.
Решайте сами, использовать кэш CSV или нет. Он включен по умолчанию в Azure Stack HCI, но не конфликтует с кэшем, описанным в этом разделе. В некоторых рабочих сценариях он может повысить производительность. Дополнительные сведения см. в статье Использование кэша чтения CSV в памяти с Azure Stack HCI.
Настройка вручную
В большинстве случаев ручная настройка не требуется. В случае необходимости см. следующие разделы.
Если после настройки необходимо внести изменения в модель устройства кэша, измените документ о компонентах поддержки службы работоспособности, как описано в разделе Обзор службы работоспособности.
Указание модели кэш-накопителя
В развертываниях, где все накопители одного типа (например, только NVMe или SSD), кэш не настроен, поскольку Windows не может автоматически определить у накопителей одного типа такие характеристики, как ресурс записи.
Чтобы использовать более износостойкие накопители в качестве кэша для менее износостойких накопителей того же типа, используйте для указания нужной модели накопителя параметр -CacheDeviceModel командлета Enable-ClusterS2D. Все диски этой модели будут использоваться для кэширования.
Убедитесь, что строка модели указана в точности так, как она отображается в выходных данных командлета Get-PhysicalDisk.
Пример
Сначала получите список физических дисков:
Get-PhysicalDisk | Group Model -NoElement Вот пример выходных данных:
Count Name ----- ---- 8 FABRIKAM NVME-1710 16 CONTOSO NVME-1520 Затем введите следующую команду, указав модель устройства кэша:
Enable-ClusterS2D -CacheDeviceModel "FABRIKAM NVME-1710" Вы можете проверить, что назначенные накопители используются для кэширования, запустив командлет Get-PhysicalDisk в PowerShell и проверив свойство Usage — оно должно иметь значение «Journal».
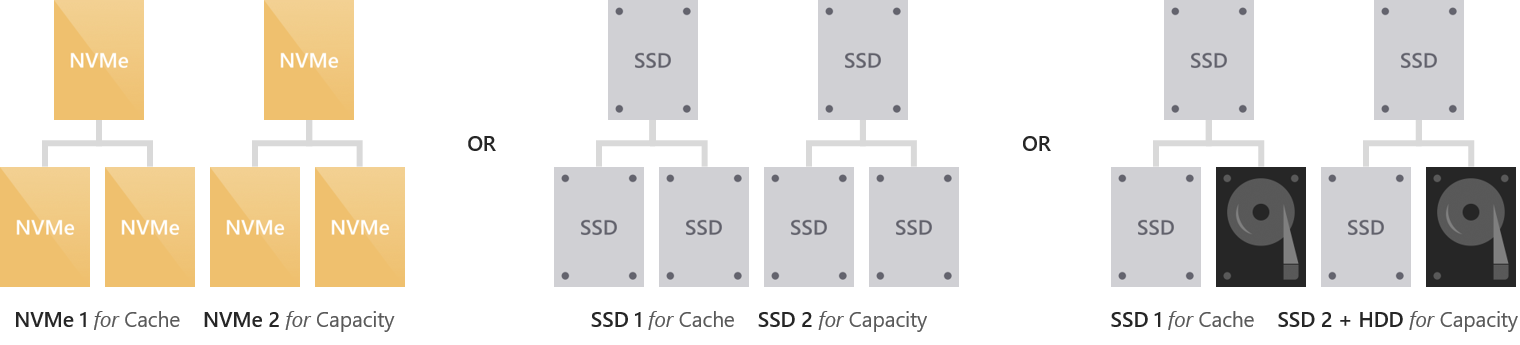
Варианты развертывания вручную
Ручная настройка поддерживает следующие варианты развертывания:
Установка режима работы кэша
Можно переопределить режим работы кэша по умолчанию. Например, можно включить кэширование операций чтения даже для развертываний только с использованием флэш-накопителей. Не рекомендуется менять режим работы, если вы не уверены, что режим работы по умолчанию не подходит для ваших рабочих нагрузок.
Чтобы переопределить поведение, используйте командлет Set-ClusterStorageSpacesDirect и его параметры -CacheModeSSD и -CacheModeHDD . Параметр CacheModeSSD задает поведение кэша при кэшировании ssd. Параметр CacheModeHDD задает поведение кэша при кэшировании hdd.
Вы можете использовать Командлет Get-ClusterStorageSpacesDirect , чтобы проверить, задано ли поведение.
Пример
Сначала получите параметры Локальные дисковые пространства:
Get-ClusterStorageSpacesDirect Вот пример выходных данных:
CacheModeHDD : ReadWrite CacheModeSSD : WriteOnly Затем сделайте следующее.
Set-ClusterStorageSpacesDirect -CacheModeSSD ReadWrite Get-ClusterS2D Вот пример выходных данных:
CacheModeHDD : ReadWrite CacheModeSSD : ReadWrite Изменение размера кэша
Размер кэша должен выбираться таким, чтобы в нем мог разместиться рабочий набор (активно читаемые и записываемые данные в любой момент времени) ваших приложений и рабочих нагрузок.
Это особенно важно в гибридных развертываниях с использованием жестких дисков. Если размер активного рабочего набора превышает размер кэша либо размер активного рабочего набора меняется слишком быстро, будет возрастать число промахов в кэше чтения и операции записи должны будут чаще переноситься из кэша на устройство, что будет негативно сказываться на общей производительности.
Для проверки показателя промахов в кэше можно использовать встроенную служебную программу Windows «Системный монитор» (PerfMon.exe). В частности, можно сравнить значение Cache Miss Reads/sec (Промахов в кэше чтения в секунду) из группы счетчиков Cluster Storage Hybrid Disk (Гибридный диск системы хранения данных кластера) с общим числом операций чтения в вашем развертывании. Каждый «гибридный диск» соответствует одному накопителю-хранилищу.
Например, два кэш-накопителя, привязанные к четырем накопителям-хранилищам, дадут четыре экземпляра объекта «гибридный диск» на сервер.
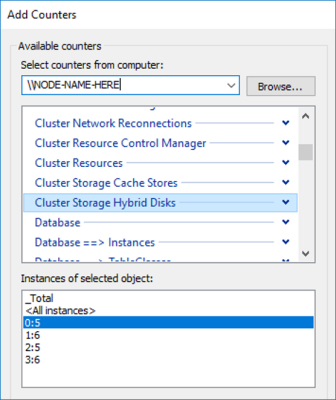
Универсальных правил нет, но если слишком много операций чтения не попадают в кэш, его размер может быть недостаточным. В этом случае рекомендуется добавить дополнительные кэш-накопители для увеличения размера кэша. Добавлять кэш-накопители и накопители-хранилища можно независимо друг от друга, когда это необходимо.
Дальнейшие действия
Дополнительные сведения о хранилище см. также:
- Отказоустойчивость и эффективность хранения
- Кворум кластеров и пулов
Бояринцев .NET

Подпишитесь на мой телеграм-канал, там я пишу о дотнете и веб-разработке.
Друзья:
//devdigest platform — новости и полезные статьи о дотнете.
Volatile, модели и барьеры памяти
November 13, 2019
Сегодня будем разбираться с volatile и всем, что с ним связано. Тема эта интересна тем, что чтобы полностью её понимать необходимо опуститься вплоть до уровня процессора и даже узнать чем отличаются разные процессорные архитектуры в плане работы с памятью. Так как материал объёмный и сложный, то не буду пытаться, что-то объяснить сам, а буду давать ссылки.
Что о volatile нам рассказал Рихтер
У Рихтера в книге для volatile отведёно 7 страниц и этого явно недостаточно, чтобы хорошенько разобраться с темой.
Компилятор C#, JIT-компилятор и даже сам процессор могут оптимизировать ваш код. В процессе оптимизации кода компилятором C#, JIT-компилятором и процессором гарантируется сохранение его назначения. То есть с точки зрения одного потока метод делает то, зачем мы его написали, хотя способ реализации может отличаться от описанного исходном коде. Однако при переходе к многопоточной конфигурации ситуация может измениться.
То есть, если у вас многопоточное приложение с разделяемыми несколькими потоками данными (например полями класса), то у вас нет гарантии того, что данные в эти разделяемые поля будут записаны одним потоком и прочитаны другим потоком именно в том порядке, в котором вы их написали в своём коде.
a = c; b = d; flag = true; .NET не гарантирует, что чтения и записи выше будут произведены именно в этом порядке, поэтому если вы хотите написать код, в котором один поток сначала читает какие-то данные и потом проставляет флаг в true, а второй поток проверяет значение флага и начинает работать только тогда, когда он выставлен в true, то без использования специальных средств у вас нет гарантий, что этот код будет работать так как вы его задумали.
Что же может сделать этот код работоспособным? — Методы Volatile.Write и Volatile.Read
Метод Volatile.Write заставляет записать значение в параметр location непосредственно в момент обращения. Бодее ранние загрузки и сохранения программы должны происходить до вызова этого метода. Метод Volatile.Read заставляет считать значение параметра address непосредственно в момент обращения. Более поздние загрузки и сохранения программы должны происходить после вызова этого метода.
Или ключевое слово volatile применённое к полям
JIT-компилятор гарантирует, что доступ к полям, помеченным данным ключевым словом, будет происходить в режиме волатильного чтения или записи, поэтому в явном виде вызывать статические методы Read и Write класса Volatile больше не требуется.
Volatile и Модель памяти
Разобраться в теме гораздо глубже поможет доклад Валерия Петрова Модель памяти .NET
Из доклада можно узнать:
- Почему процессоры переставляют выполняемые инструкции местами
- Какие оптимизации могут произвести с вашим кодом Компилятор/JIT/CPU
- Что такое модель памяти и при чём тут она
- Как работает ключевое слово volatile и методы Volatile.Write и Volatile.Read и как правильно их использовать
Кроме того, что в докладе очень доступная подача материала, мне нравится ещё и то, что Валерий для подтверждения своих слов приводит ссылки на пункты спецификации и цитаты из неё.
Также я нашёл презентацию Валерия Петрова, но видимо она сделана к какому-то другому докладу, потому что слайдов в ней намного больше и больше разного материала затронуто.
Хочется остановится на определении модели памяти.
In computing, a memory model describes the interactions of threads through memory and their shared use of the data. A memory model allows a compiler to perform many important optimizations. Compiler optimizations like loop fusion move statements in the program, which can influence the order of read and write operations of potentially shared variables. Changes in the ordering of reads and writes can cause race conditions. Without a memory model, a compiler is not allowed to apply such optimizations to multi-threaded programs in general, or only in special cases.
Моя “расслабленная” интерпретация этого определения: :
Модель памяти — это разрешения, которые есть у компилятора на проведение оптимизаций, которые могут повлиять на порядок операций чтения и записи, которые могут производиться с памятью, с которой работают несколько потоков одновременно, что в свою очередь может привести к багу в работе какого-либо потока, или если ещё более кратко — это возможные перестановки операций чтения и записи относительно их порядка в исходном коде.
На хабре также есть статья, которая довольно близка к докладу Валерия по кругу разбираемых вопросов:
В ней материал тоже подаётся вполне доступно, но есть несколько комментариев от меня:
- Написано, что в модели памяти .NET разрешены все перестановки кроме write-write — Валерий Петров упоминает, в своём докладе, что об этом часто пишут в статьях, но неизвестно откуда взялся этот факт и насколько он соответствует действительности, в спецификациях или каких-либо других источниках его подтверждение найти не удаётся.
- Материал непосредственно про барьеры памяти мне кажется изложен не очень понятно.
- В самом конце статьи в разделе “Производительность Thread.Volatile* и ключевого слово volatile” написано, что: “На большинстве платформ (точнее говоря, на всех платформах, поддерживаемых Windows, кроме умирающей IA64) все записи и чтения являются volatile write и volatile read соответственно. Таким образом, во время выполнения ключевое слово volatile не оказывает никакого влияния на производительность.” — текст неактуальный на данный момент, так как с тех пор появилась поддержка ARM-процессоров, а так как в статье, не были затронуты особенности разных процессорных архитектур в плане перестановок инструкций и то как на них влияет volatile, то этот параграф всё-равно будет непонятен неподготовленному читателю. Также лично мне не кажется удачной формулировка, что запись и чтения на платформах являются волатильными, но об этом позже.
Какие ещё есть статьи, которые, в принципе, можно пропустить
- Статья Джо Албахари Threading in C# PART 4: ADVANCED THREADING первая часть, которой посвящена неблокирующей синхронизации в общем и volatile в частности — есть утверждения, которые либо не понятны, либо которые я не знаю как подтвердить.
- Модель памяти C# в теории и на практике Игоря Островского — к этой статье тоже есть вопросы в плане используемых утверждений и формулировок.
- C# — The C# Memory Model in Theory and Practice, Part 2 — вторая часть статьи Игоря Островского про модель памяти, в этой статье разбираются три вида оптимизаций, которые может произвести с кодом компилятор, а также особенности работы volatile на архитектурах x86/x64, Itanium, ARM — материал про особенности конкретных архитектур может представлять интерес.
Если вы прочитали/прослушали материалы выше, то теперь вы знаете интересные факты о том, что в .NET
- Вызов Volatile.Write/Volatile.Read идентичны использованию ключевого слова volatile в плане получаемых эффектов на выполнение кода, а вот вызовы Thread.VolatileWrite/Thread.VolatileRead ведут себя по другому.
- Волатильная запись и последующее волатильное чтение могут быть переставлены местами (но это не только в .NET)
Барьеры памяти
По определению David Howells и David Howells в статье LINUX KERNEL MEMORY BARRIERS:
Independent memory operations are effectively performed in random order, but this can be a problem for CPU-CPU interaction and for I/O. What is required is some way of intervening to instruct the compiler and the CPU to restrict the order.
Memory barriers are such interventions. They impose a perceived partial ordering over the memory operations on either side of the barrier.
Such enforcement is important because the CPUs and other devices in a system can use a variety of tricks to improve performance, including reordering, deferral and combination of memory operations; speculative loads; speculative branch prediction and various types of caching. Memory barriers are used to override or suppress these tricks, allowing the code to sanely control the interaction of multiple CPUs and/or devices.
Или в моей расслабленной интерпретации: барьеры памяти — это инструкции, способные заставить компилятор и даже процессор прекратить выполнять оптимизации и гарантировать, что определённые операции чтения и записи могут остаться с какой-либо из сторон барьера памяти.
Использование ключевого слова volatile или методов Volatile.Read/Write — это один из способов установить барьер памяти, Thread.MemoryBarier — другой.
Статья на эту тему Memory Barriers in .NET Nadeem Afana.
Статья интересна тем, что рассматривает вопрос работы барьеров памяти довольно близко к тому, как они работают на уровне процессоров.
Мои замечания к статье:
- Автор тоже упоминает, что существует модель памяти .NET в которой запрещены перестановки запись-запись.
- Автор упоминает, что для lock, Interlocked и прочих вещей генерируется полный барьер памяти — ECMA-335 говорит нам другое в разделе I.12.6.5 Locks and threads.
Если статья вас заинтересовала, но некоторые слова вы не поняли, например, такие STORE Buffer и Cache Coherence, и есть желание разобраться дальше, то читайте статью Memory Barriers: a Hardware View for Software Hackers Paul E. McKenney (или русский перевод первой части статьи) — тут всё прямо с алгоритмами того, как процесс происходит внутри процессора.
Дополнительный материал по барьерам памяти
Волатильное чтение и запись на архитектуре процессора x86
Во многих статьях пишут, что на архитектуре процессора x86 все операции чтения и записи осуществляются как волатильное чтение и волатильная запись, поэтому использование волатильного чтения и записи в коде программы будет иметь влияние только на компилятор, но не на инструкции процессора. К сожалению, никто не даёт ссылок на источник этого утверждения, я попытался найти этот источник в итоге нашёл только описание модели памяти x86: Intel® 64 and IA-32 Architectures Software Developer’s Manual (раздел 8.2) и в нём нет формулировки про волатильное чтение и запись, есть только список разрешённых перестановок и фактически разрешена только перестановка запись и последующее чтение, что совпадает с разрешёнными перестановками при волатильных чтениях и записях (волатильная запись и последующее волатильное чтение могут быть переставлены) — видимо из-за этого совпадения разрешённых/запрещённых перестановок и возникла формулировка про то что операции чтения/записи на архитектуре x86 волатильные.
Что ещё можно прочитать
- ECMA-335 Common Language Infrastructure (CLI)
- ECMA-334 C# Language Specification
- What Every Programmer Should Know About Memory Ulrich Drepper
CrystalDiskInfo 8.8.1 добавил поддержку секторов размером 4K
CrystalDiskInfo – программа, предназначенная для проверки «здоровья» жестких дисков: техническое состояние, контроль температуры накопителей, мониторинг значений S.M.A.R.T. и позволяет строить их графики.
Программа понимает обычные HDD, твердотельные накопители SSD, гибридные накопители SSHD, а также внешние винчестеры, подключаемые по USB.
Запустив программу, CrystalDiskInfo выдает подробную информацию о встроенных в компьютер накопителях.
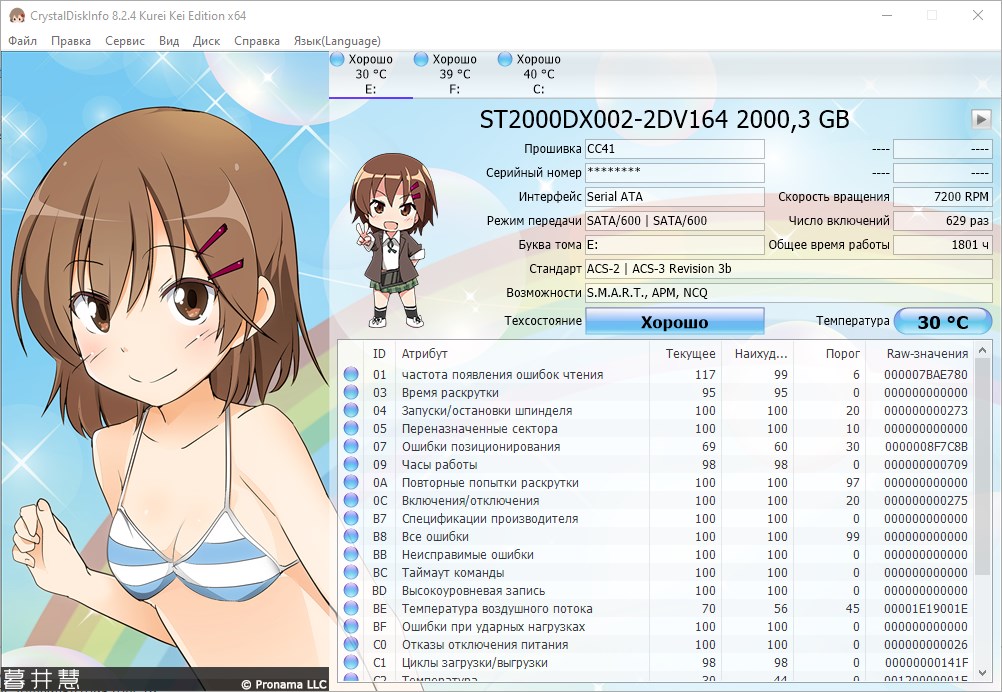
Утилита позволяет владельцу просмотреть модель винчестера, версию прошивки микроконтроллера, серийный номер, интерфейс подключения, скорость передачи данных, букву диска, объем буфера, объем NV-кэша, скорость вращения шпинделя, число включений, общее время работы и прочую важную информацию.
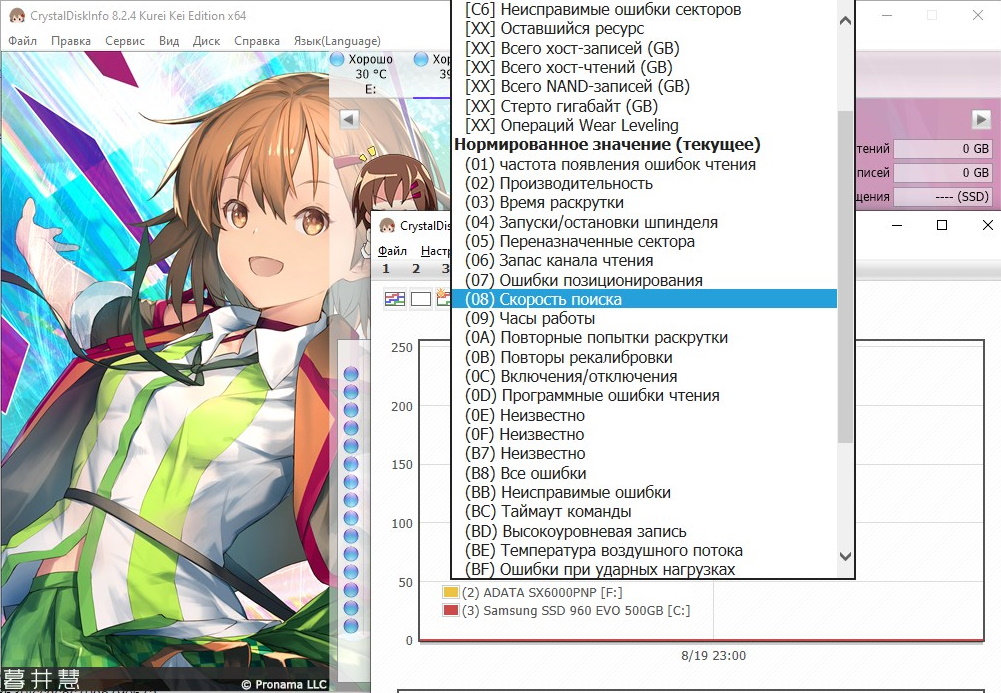
CrystalDiskInfo показывает подробные значения S.M.A.R.T., в том числе, текущие, наихудшие, пороговые и RAW-значения.
Утилита также может выводить в трее индикаторы с температурой каждого накопителя.
Программа полностью переведена на русский язык для удобства отечественному пользователю.
| Программа: | CrystalDiskInfo |
| Разработчик: | hiyohiyo (Япония) |
| Лицензия: | Freeware (бесплатно) |
| Поддержка версий Windows: | XP, Vista, 8, 8.1, 10 |
| Поддержка русского языка: | Есть (полная) |
| Размер инсталляционного файла: | 4,4 МБ |
Мониторинг улучшений CrystalDiskInfo 8.8.1:
- Улучшенная поддержка SATA SSD дисков:
- Kingston;
- WD;
- SanDisk;
- KIOXIA;
- SSSTC;
- Micron;
- Crucial;
- SK Hynix;
- Intel;
- Apacer;
- Transcend;
- TOSHIBA;
- Seagate;
- ADATA;