не менять формат логов
Пересылаю логи Apache на удаленный сервер syslog-ng, где они записываются в файл.
Можно ли не менять формат лога при записи, на удаленном сервере syslog-ng добавляет дату и ip?
WinLin2 ★★
05.02.20 16:50:05 MSK
template apache_access_log < template("$MSG\n"); >; destination apache_access_log < file('/var/log/$HOST/apache/access.log' template(apache_access_log)); >; spirit ★★★★★
( 05.02.20 17:44:22 MSK )
Ответ на: комментарий от spirit 05.02.20 17:44:22 MSK
Исходный лог на сервере Apache:
111.222.111.222 — — [05/Feb/2020:20:35:10 +0300] «GET / HTTP/1.0» 200 4692
Лог на сервере syslog-ng:
без template:
Feb 5 20:15:42 10.1.1.1 111.222.111.222 — — [05/Feb/2020:20:15:42 +0300] «GET / HTTP/1.0» 200 4692
template:
— — [05/Feb/2020:20:35:10 +0300] «GET / HTTP/1.0» 200 4692
Обрезается адрес клиента.
WinLin2 ★★
( 05.02.20 20:49:22 MSK ) автор топика
Ответ на: комментарий от WinLin2 05.02.20 20:49:22 MSK
Правильная настройка такая:
template(«$PROGRAM $MESSAGE\n»)
Elasticsearch + Kibana (но без Logstash)
При изучении состояния продакшен сервера и поиска возможных ошибок и их причин используются логи приложения. Всё, что в коде выглядит как log.info/debug/error/trace, потом чаще всего попадает в один или несколько файлов, размер которых может достигать нескольких гигабайт в сутки, если слишком увлекаться логированием, например, всех SQL запросов и параметров (show_sql=true). Чтобы такие файлы не блокировали приложение, логи ротируются: файл обрезается до, скажем, 1гб, архивируется, а приложение продолжает писать логи в старый файл, но уже пустой. Такие файлы скапливаются и получают добавку к имени: .1.log.gz, .2.log.gz и так далее до заданного лимита по количеству или сроку давности.

Что же делать если нужно исследовать ошибку, случившуюся два-три дня назад? Опцию открывать файлы по одному в редакторе я не рассматриваю, ведь за неделю может легко накопиться десять или сотня таких файлов. На помощь приходит команда grep/zgrep: пишем незамысловатые команды наподобие Думаю, вы уловили идею: чтобы понять, как обрабатывался один запрос к сервису, нужно распарсить файл, разбить по потокам и разделить на части от строчки «СТАРТ» до строчки «ФИНИШ». Эти части уже можно было бы загрузить в elasticsearch, но не каждую строчку в отдельности.
Распарсить подобные логи на Java несложно, а вот как и можно ли вообще сделать такое в logstash, я не уверен. Поэтому я оставил logstash до лучших времен и подключился к elasticsearch напрямую. Существует проект Spring Data Elasticsearch, который упрощает задачу, но на текущий момент он не поддерживает elasticsearch последней версии, поэтому я использую готовый REST клиент, являющийся частью elasticsearch. При загрузке данных такими блоками можно кроме самого текста выделять важные параметры: время обработки, права доступа, успешно или ошибка, какие-то существенные данные для анализа. После этого по данным параметрам можно будет осуществлять поиск и агрегацию, строить красивые графики и диаграммы. Да, эти параметры приходится доставать из лога с помощью регулярных выражений. Зато не нужно никак менять работающее приложение, достаточно научиться скачивать логи с продакшен сервера.
В качестве примера я проведу небольшое исследование производительности работы с файлами. Программа будет создавать новый файл, записывать в него данные и вычитывать, измеряя затраченное время, а потом удалять файл. Информация о каждом полном цикле будет сохраняться в одной записи в elasticsearch, что в его терминологии называется документом. Всё это будет происходить в многопоточном режиме и количество потоков будет увеличиваться со временем. После чего я покажу базовые способы работы c этими данными в Kibana.
Код тут. Нужно установить Kibana и Elasticsearch 7 версии. Для этого достаточно распаковать архивы и запустить. Вот как это выглядит у меня:
C:\dev\ELK\kibana-7.5.2-windows-x86_64\bin\kibana.bat C:\dev\ELK\elasticsearch-7.5.2\bin\elasticsearch.bat
Теперь нужно научиться сохранять данные в elasticsearch. Он принимает данные в формате JSON, поэтому определим DTO класс:
public class WriteReadBenchmarkResult private String id; private String threadName; private int nThreads; private long writeMillis; private long readMillis; private long fileSizeBytes; private boolean failed = false; private String errorMessage = ""; @JsonFormat(shape = JsonFormat.Shape.STRING, pattern = "yyyy-MM-dd'T'HH:mm:ssZ"); private OffsetDateTime timestamp = OffsetDateTime.now(); //. getters, setters
Ничего особенного, кроме специфического формата для даты, чтобы elasticsearch определил это поле как время, а не как строку.
Обращаться к elasticsearch будем с помощью High level REST client. Создаём экземпляр клиента с настройками по умолчанию:
@Bean public RestHighLevelClient client() final CredentialsProvider credentialsProvider = new BasicCredentialsProvider(); credentialsProvider.setCredentials( AuthScope.ANY, new UsernamePasswordCredentials("elastic", "changeme")); RestClientBuilder builder = RestClient.builder(new HttpHost("127.0.0.1", 9200, "http")) .setHttpClientConfigCallback(httpClientBuilder -> httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider)); RestHighLevelClient client = new RestHighLevelClient(builder); return client; >
Сохраняем коллекцию DTO объектов. Сразу использую bulk операцию, потому что, как правило, в реальности количество записей будет исчисляться миллионами. Индекс «samples-writrateread» в elasticsearch создастся автоматически.
for (WriteReadBenchmarkResult writeReadBenchmarkResult : batch) IndexRequest indexSingleRequest = new IndexRequest("samples-writrateread"); indexSingleRequest.id(writeReadBenchmarkResult.getId()); indexSingleRequest.source(mapper.writeValueAsString(writeReadBenchmarkResult), XContentType.JSON); bulkRequest.add(indexSingleRequest); > BulkResponse bulkResponse = client.bulk(bulkRequest, RequestOptions.DEFAULT);
Теперь запустим тест, чтобы загрузить данные для анализа. Код в FileWriteReadRandomTaskIT, он довольно длинный, но ничего примечательного. Просто записываем в файл около 30 мегабайт, вычитываем и удаляем. Повторяем операцию 300 раз, а потом увеличиваем количество потоков на 1 и всё по новой. В тестовом запуске получилось пройти от 1 до 29 потоков за пару часов. Теперь переходим к изучению этой информации в Kibana.
Сначала нужно указать на тот индекс, который мы использовали, создав index pattern. Например, по ссылке http://localhost:5601/app/kibana#/management/kibana/index_pattern?_g=(). Либо в левой панели самый нижний значок — настройки. На шаге два (Step 2 of 2: Configure settings) выбираем timestamp, чтобы все наши данные имели временную метку, всё остальное происходит по умолчанию само. А именно: Kibana определяет набор полей и их типы. Например, поле readMillis — число, а значит его можно сравнивать, суммировать, находить максимумы и минимумы.
Я не показываю детально работу с интерфейсом Kibana, думаю для этого эффективнее всего установить и начать нажимать на все кнопки подряд, а также посмотреть пару самых простых сценариев на Youtube. Первое время я пользовался только текстовым поиском, а когда немного освоился, то начал пробовать фильтры, диаграммы и графики.
Итак, поиск. В терминах Kibana — Discover. Всегда нужно указать временные рамки. Пустой запрос означает все данные, простой текст означает индексный поиск по текстовым полям, а указание полей позволяет точно искать записи («nThreads:8» — всё, что запускалось в 8 потоков). Посмотрим все операции и медленные чтения.
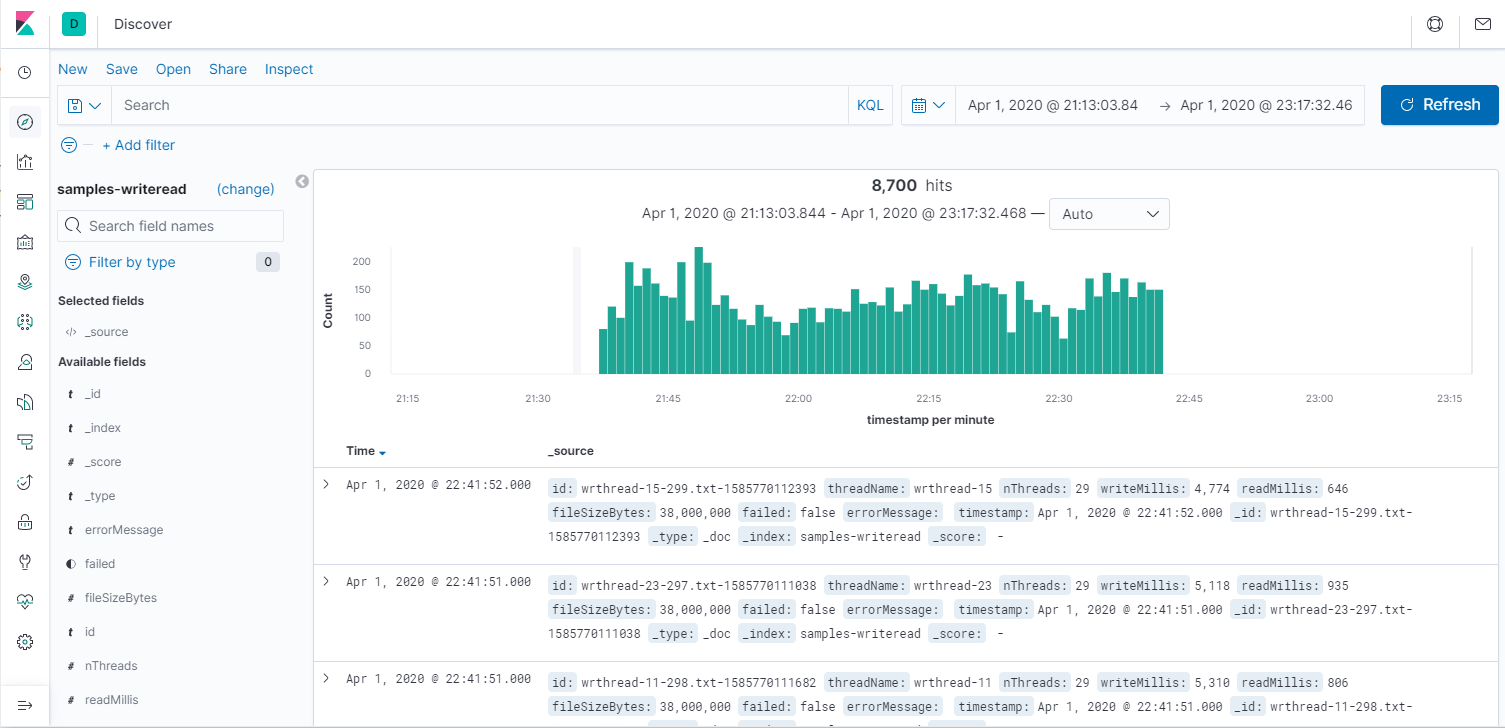
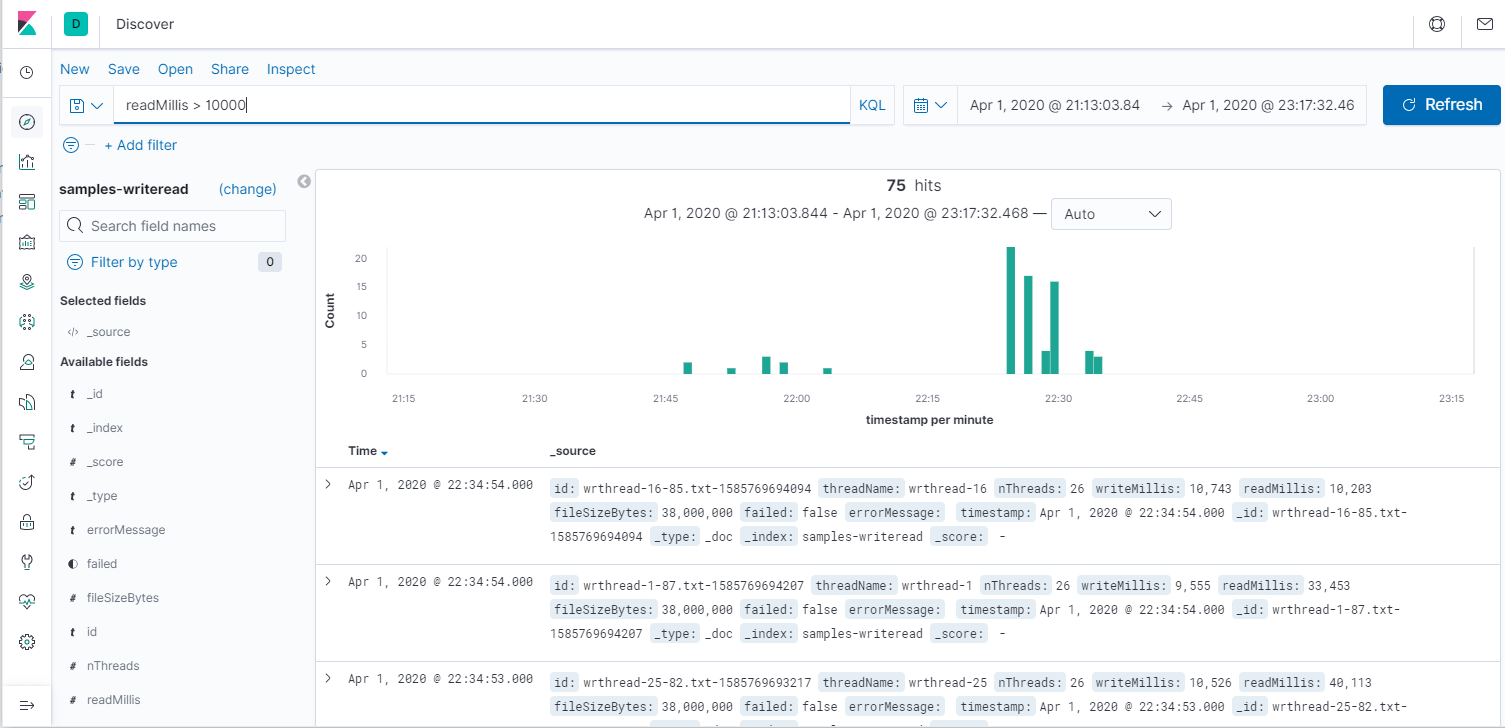
По сравнению в анализом данных командой grep, это уже космос. Давайте теперь посмотрим средние значения на графике. Для этого идём в Visualization -> Lines. Ось Х — Date histogram, то есть агрегация за промежуток времени: секунда, минута, день. Ось Y — Average/Min/Max/Count и и прочее. Первый график за всё время, второй — его начало (от 1 до 10 потоков.) На графике среднее время чтения и записи за 30 секунд, а также количество потоков, но я не смог его масштабировать, поэтому приходится наводить мышкой и на скриншотах не видно. Третий график — Count, показывает пропускную способность системы.
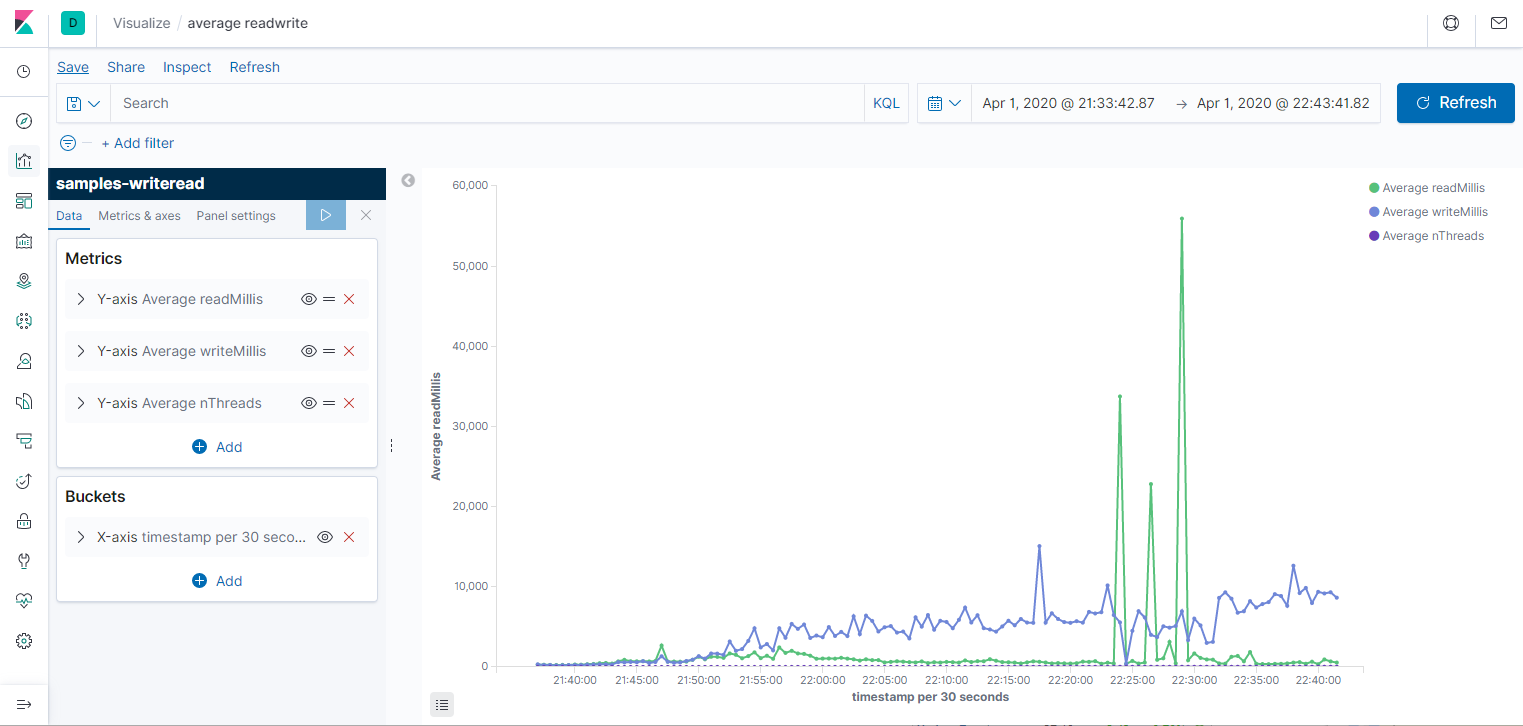
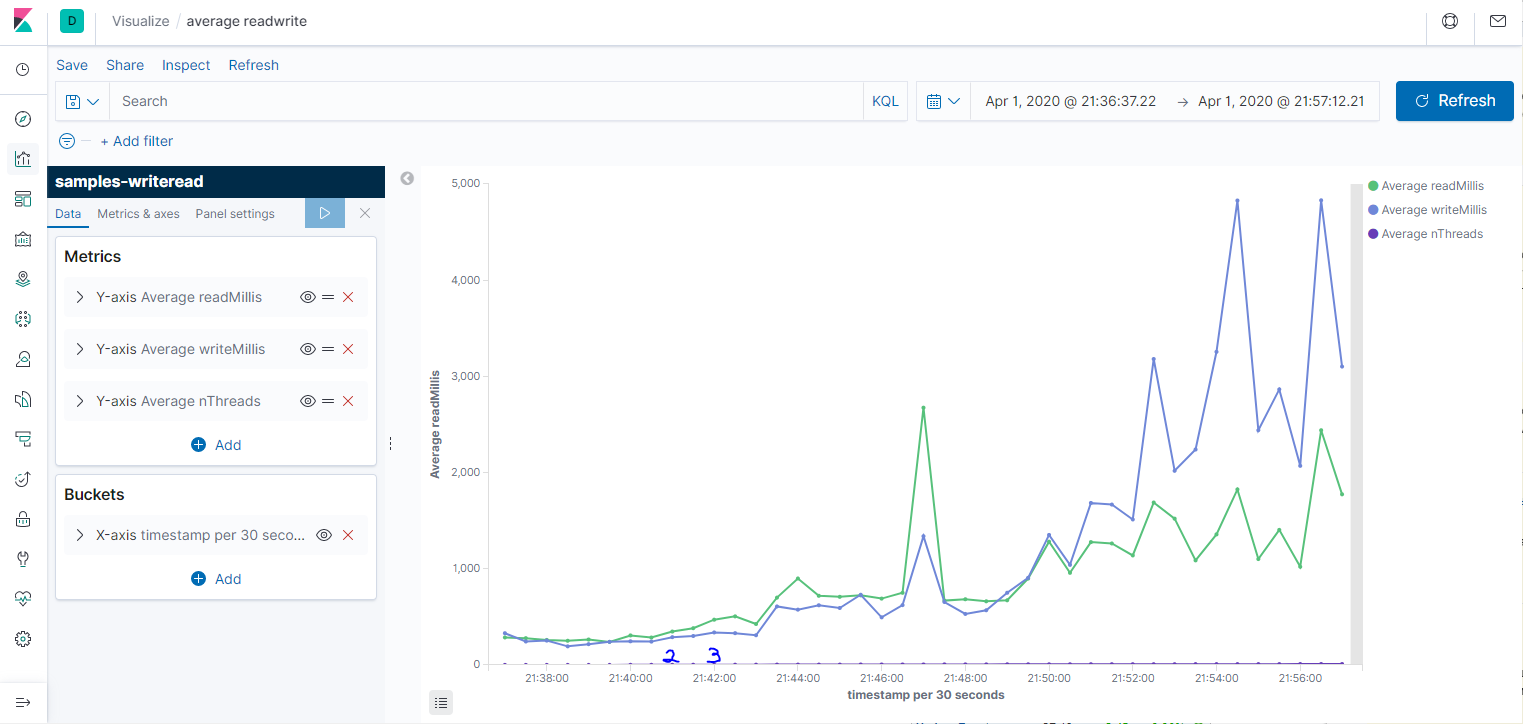
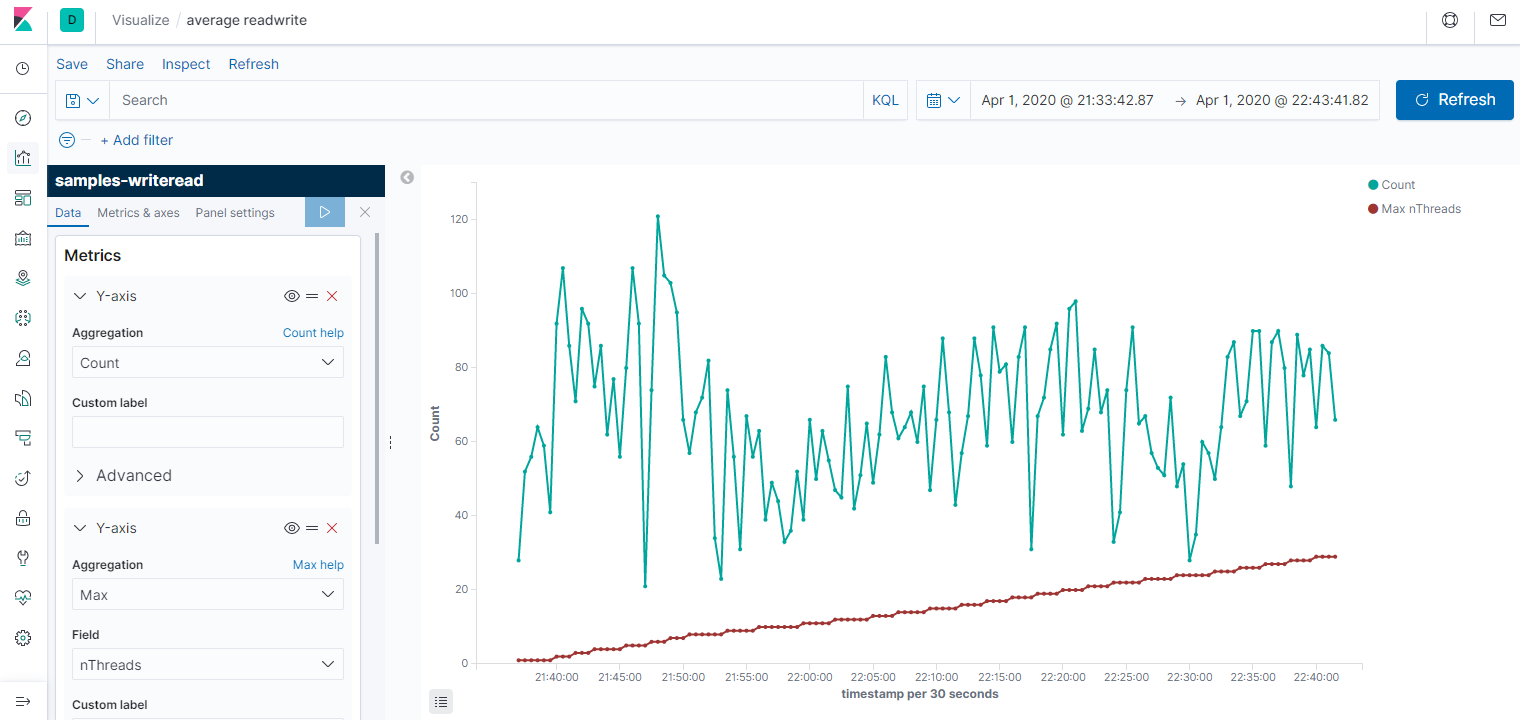
Делаю несколько выводов: во-первых, параметры недостаточно стабильны, чтобы им можно было серьёзно доверять. Во-вторых, с количеством потоков заметно растёт время записи и чтения. Время записи в среднем растёт сильнее. В третьих, при большом количестве потоков происходили очень неприятные пики до 170 секунд на чтение (если смотреть max, а не average). Возможно, ноутбук нагрузился какой-то запланированной работой в это время. Третий график вообще намекает на то, что степень параллелизма никак не влияет на пропускную способность.
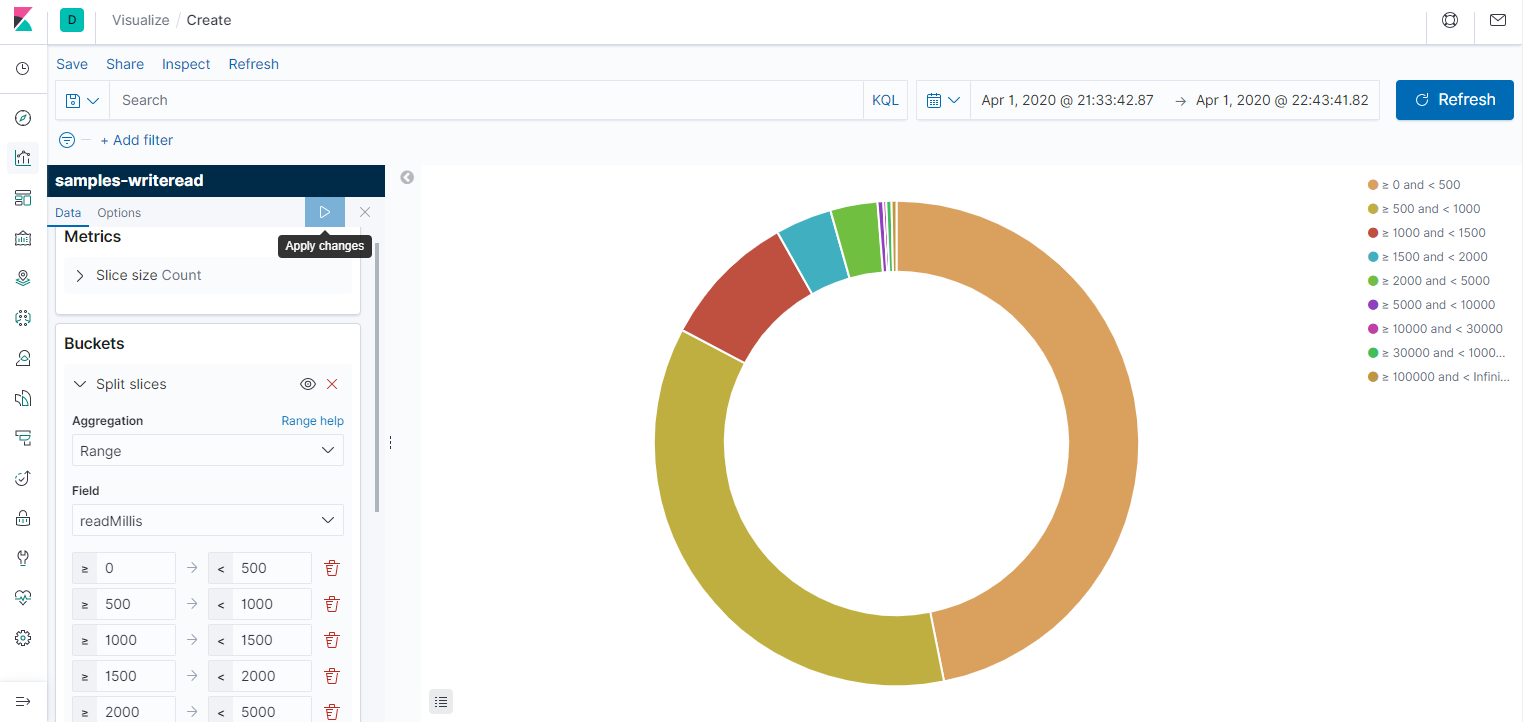
Результат ожидаемый. Если бы вместо жёсткого диска производилась работа с сетью, особенно с источником, который отвечает долго, но размер ответа небольшой, то пропускная способность росла бы почти линейно хоть до 100 потоков. Хотя результатом может стать DDOS источника данных. Думаю, ускорение можно было бы получить, если бы вместо одного жёсткого диска работа бы велась с несколькими. Так или иначе, цель — знакомство с elasticsearch и kibana, а такое мини-исследование производится просто ради спортивного интереса. Напоследок покажу диаграмму типа Pie, просто она мне нравится. Видно, что большинство чтений укладывается в секунду, а из них половина — в полсекунды.
Заключение
В первую очередь, я думаю, elasticsearch + kibana в таком использовании будут полезны тем, кто часто использует команду grep по однотипным логам. Обычно это старые системы, в которых нет времени или необходимости использовать готовые полнофункциональные решения, где всё уже интегрировано и настроено. Второе применение — это произвести более глубокий анализ данных, в особенности, логов, минимальными усилиями.
Странная «ошибка при обработке запроса»

Доброго времени суток.
Подскажите, при попытке просмотреть список таблиц какой-либо базы или при попытке открыть содержимое таблиц выдаётся ошибка «Ошибка при обработке запроса \n Код Ошибки: 200\n Текст ошибки: ОК»:
Такая ошибка вылетает, если таблиц сравнительно много. Если таблиц немного или в таблице немного данных, то ошибка отсутствует. pma обновлён до последней версии.
С чем это может быть связано и как это исправить?
2 Ответ от Hanut 2013-07-16 12:11:21
Re: Странная «ошибка при обработке запроса»
Код 200 означает, что запрос вернул результаты. Посмотрите как ведут себя альтернативные браузеры. Пока не уверен, что проблема в phpMyAdmin.
3 Ответ от sanam 2013-07-16 14:33:28
Re: Странная «ошибка при обработке запроса»
Именно потому, что 200 это как бы и не ошибка, всё это очень странно. Браузеры пробовались разные, как и операционные системы.
4 Ответ от Hanut 2013-07-17 09:43:39
Re: Странная «ошибка при обработке запроса»
Пока только могу предложить откатиться на более раннюю версию phpMyAdmin. Воссоздать ошибку у меня не получается.
5 Ответ от flash11 2013-10-25 11:39:01
Re: Странная «ошибка при обработке запроса»
Добрый день.
Возникает аналогичная проблема на версиях 4.0.8 и 3.5.8.2.
На сервере nginx + apache. Как мне показалось, если nginx не использовать, то работает нормально.
Причем подобная ошибка выскакивает произвольно на любом запросе. К примеру, можно 9 раз кликнуть на таблицу и все будет ок, а на 10-й выскочит ошибка.
Конфиг nginx на всякий случай:
server < listen 80; server_name firmware; charset utf-8; access_log /var/log/nginx/firmware.access.log; error_log /var/log/nginx/firmware.error.log warn; client_max_body_size 1m; set $www_root "/Users/user/www/firmware/www"; location ~* ^.+\.(jpg|jpeg|gif|png|ico|css|zip|tgz|gz|rar|bz2|doc|xls|exe|pdf|ppt|txt|tar|wav|bmp|rtf|js)$ < root $www_root; >location ~ /\.ht < deny all; >location / < proxy_pass http://127.0.0.1:88; proxy_set_header Host $host; >>6 Ответ от Hanut 2013-10-25 11:51:08
Re: Странная «ошибка при обработке запроса»
flash11 сказал:
Возникает аналогичная проблема на версиях 4.0.8 и 3.5.8.2.
В логах сервера ошибок нет? Надо посмотреть что передает Ajax в браузер при такой ошибке. Лучше всего это посмотреть в Firefox через Firebug.
7 Ответ от flash11 2013-10-25 13:01:49 (изменено: flash11, 2013-10-25 13:04:59)
Re: Странная «ошибка при обработке запроса»
В ответ приходит JSON вида Но очевидно, что он не полный, т.е. почему-то обрезан. Вероятно, из-за этого он не может быть обработан в js, и возникает описанная ошибка.
Вот неполный кусок того, что пришло:
\u0422\u0430\u0431\u043b\u0438\u0446\u0430  \n\n\n \u0414\u0435\u0439\u0441\u0442\u0432\u0438\u0435\n\n
\n\n\n \u0414\u0435\u0439\u0441\u0442\u0432\u0438\u0435\n\nВ логах сервера ошибок нет.
Apache log (логи): как настроить и анализировать журналы веб-сервера
Для эффективного управления веб-сервером необходимо получить обратную связь об активности и производительности сервера, а также о всех проблемах, которые могли случиться. Apache HTTP Server обеспечивает очень полную и гибкую возможность ведения журнала. В этой статье мы разберём, как настроить логи Apache и как понимать, что они содержат.
HTTP-сервер Apache предоставляет множество различных механизмов для регистрации всего, что происходит на вашем сервере, от первоначального запроса до процесса сопоставления URL-адресов, до окончательного разрешения соединения, включая любые ошибки, которые могли возникнуть в процессе. В дополнение к этому сторонние модули могут предоставлять возможности ведения журналов или вставлять записи в существующие файлы журналов, а приложения, такие как программы CGI, сценарии PHP или другие обработчики, могут отправлять сообщения в журнал ошибок сервера.
В этой статье мы рассмотрим модули журналирования, которые являются стандартной частью http сервера.
Логи Apache в Windows
В Windows имеются особенности настройки имени файла журнала — точнее говоря, пути до файла журнала. Если имена файлов указываются с начальной буквы диска, например "C:/", то сервер будет использовать явно указанный путь. Если имена файлов НЕ начинаются с буквы диска, то к указанному значению добавляется значение ServerRoot — то есть «logs/access.log» с ServerRoot установленной на "c:/Server/bin/Apache24", будет интерпретироваться как "c:/Server/bin/Apache24/logs/access.log", в то время как "c:/logs/access.log" будет интерпретироваться как "c:/logs/access.log".
Также особенностью указания пути до логов в Windows является то, что нужно использовать слэши, а не обратные слэши, то есть "c:/apache" вместо "c:\apache". Если пропущена буква диска, то по умолчанию будет использоваться диск, на котором размещён httpd.exe. Рекомендуется явно указывать букву диска при абсолютных путях, чтобы избежать недоразумений.
Apache error: ошибки сервера и сайтов
Путь до файла журнала с ошибками указывается с помощью ErrorLog, например, для сохранения ошибок в папке "logs/error.log" относительно корневой папки веб-сервера:
ErrorLog "logs/error.log"
Если не указать директиву ErrorLog внутри контейнера , сообщения об ошибках, относящиеся к этому виртуальному хосту, будут записаны в этот общий файл. Если в контейнере вы указали путь до файла журнала с ошибками, то сообщения об ошибках этого хоста будут записываться там, а не в этот файл.
С помощью директивы LogLevel можно установить уровень важности сообщений, которые должны попадать в журнал ошибок. Доступные варианты:
Журнал ошибок сервера, имя и местоположение которого задаётся директивой ErrorLog, является наиболее важным файлом журнала. Это место, куда Apache httpd будет отправлять диагностическую информацию и записывать любые ошибки, с которыми он сталкивается при обработке запросов. Это первое место, где нужно посмотреть, когда возникает проблема с запуском сервера или работой сервера, поскольку он часто содержит подробности о том, что пошло не так и как это исправить.
Журнал ошибок обычно записывается в файл (обычно это error_log в системах Unix и error.log в Windows и OS/2). В системах Unix также возможно, чтобы сервер отправлял ошибки в системный журнал или передавал их программе.
Формат журнала ошибок определяется директивой ErrorLogFormat, с помощью которой вы можете настроить, какие значения записываются в журнал. По умолчанию задан формат, если вы его не указали. Типичное сообщение журнала следующее:
[Fri Sep 09 10:42:29.902022 2011] [core:error] [pid 35708:tid 4328636416] [client 72.15.99.187] File does not exist: /usr/local/apache2/htdocs/favicon.ico
Первый элемент в записи журнала — это дата и время сообщения. Следующим является модуль, создающий сообщение (в данном случае ядро) и уровень серьёзности этого сообщения. За этим следует идентификатор процесса и, если необходимо, идентификатор потока процесса, в котором возникло условие. Далее у нас есть адрес клиента, который сделал запрос. И, наконец, подробное сообщение об ошибке, которое в этом случае указывает на запрос о несуществующем файле.
В журнале ошибок может появиться очень большое количество различных сообщений. Большинство выглядит похожим на пример выше. Журнал ошибок также будет содержать отладочную информацию из сценариев CGI. Любая информация, записанная в stderr (стандартный вывод ошибок) сценарием CGI, будет скопирована непосредственно в журнал ошибок.
Если поместить токен %L в журнал ошибок и журнал доступа, будет создан идентификатор записи журнала, с которым вы можете сопоставить запись в журнале ошибок с записью в журнале доступа. Если загружен mod_unique_id, его уникальный идентификатор запроса также будет использоваться в качестве идентификатора записи журнала.
Во время тестирования часто бывает полезно постоянно отслеживать журнал ошибок на наличие проблем. В системах Unix вы можете сделать это, используя:
tail -f error_log
Apache access: логи доступа к серверу
Журнал доступа к серверу записывает все запросы, обработанные сервером. Расположение и содержимое журнала доступа контролируются директивой CustomLog. Директива LogFormat может быть использована для упрощения выбора содержимого журналов. В этом разделе описывается, как настроить сервер для записи информации в журнал доступа.
Различные версии Apache httpd использовали разные модули и директивы для управления журналом доступа, включая mod_log_referer, mod_log_agent и директиву TransferLog. Директива CustomLog теперь включает в себя функциональность всех старых директив.
Формат журнала доступа легко настраивается. Формат указывается с использованием строки формата, которая очень похожа на строку формата printf в стиле C. Некоторые примеры представлены в следующих разделах. Полный список возможного содержимого строки формата смотрите здесь: https://httpd.apache.org/docs/current/mod/mod_log_config.html
Общий формат журнала (Common Log)
Типичная конфигурация для журнала доступа может выглядеть следующим образом.
LogFormat "%h %l %u %t \"%r\" %>s %b" common CustomLog logs/access_log common
В первой строке задано имя (псевдоним) common, которому присвоено в качестве значения строка "%h %l %u %t \"%r\" %>s %b".
Строка формата состоит из директив, начинающихся с символа процента, каждая из которых указывает серверу регистрировать определённый фрагмент информации. Литеральные (буквальные) символы также могут быть помещены в строку формата и будут скопированы непосредственно в вывод журнала. Символ кавычки (") должен быть экранирован путём размещения обратной косой черты перед ним, чтобы он не интерпретировался как конец строки формата. Строка формата также может содержать специальные управляющие символы "\n"для новой строки и "\t" для обозначения таба (табуляции).
В данной строке значение директив следующее:
- %h — имя удалённого хоста. Будет записан IP адрес, если HostnameLookups установлен на Off, что является значением по умолчанию.
- %l — длинное имя удалённого хоста (от identd, если предоставит). Это вернёт прочерк если не присутствует mod_ident и IdentityCheck не установлен на On.
- %u — удалённый пользователь, если запрос был сделан аутентифицированным пользователем. Может быть фальшивым, если возвращён статус (%s) 401 (unauthorized).
- %t — время получения запроса в формате [18/Sep/2011:19:18:28 -0400]. Последнее показывает сдвиг временной зоны от GMT
- \"%r\" - первая строка запроса, помещённая в буквальные кавычки
- %>s — финальный статус. Если бы было обозначение %s, то означало бы просто статус — для запросов, которые были внутренне перенаправлены это обозначало бы исходный статус.
- %b — размер ответа в байтах, исключая HTTP заголовки. В формате CLF, то есть '-' вместо 0, когда байты не отправлены.
Директива CustomLog устанавливает новый файл журнала, используя определённый псевдоним. Имя файла для журнала доступа относительно ServerRoot, если оно не начинается с косой черты (буквы диска).
Приведённая выше конфигурация будет сохранять записи журнала в формате, известном как Common Log Format (CLF). Этот стандартный формат может создаваться многими различными веб-серверами и считываться многими программами анализа журналов. Записи файла журнала, созданные в CLF, будут выглядеть примерно так:
127.0.0.1 - frank [10/Oct/2000:13:55:36 -0700] "GET /apache_pb.gif HTTP/1.0" 200 2326
Каждая часть этой записи журнала описана ниже.
127.0.0.1 (%h)
Это IP-адрес клиента (удалённого хоста), который сделал запрос к серверу. Если для HostnameLookups установлено значение On, сервер попытается определить имя хоста и зарегистрировать его вместо IP-адреса. Однако такая конфигурация не рекомендуется, поскольку она может значительно замедлить работу сервера. Вместо этого лучше всего использовать постпроцессор журнала, такой как logresolve, для определения имён хостов. Указанный здесь IP-адрес не обязательно является адресом машины, на которой сидит пользователь. Если между пользователем и сервером существует прокси-сервер, этот адрес будет адресом прокси, а не исходной машины.
- (%l)
«Дефис» в выходных данных указывает на то, что запрошенная часть информации недоступна. В этом случае информация, которая недоступна, является идентификационной информацией клиента RFC 1413, определённой с помощью id на клиентском компьютере. Эта информация крайне ненадёжна и почти никогда не должна использоваться, кроме как в жёстко контролируемых внутренних сетях. Apache httpd даже не будет пытаться определить эту информацию, если для IdentityCheck не установлено значение On.
frank (%u)
Это идентификатор пользователя, запрашивающего документ, как определено HTTP-аутентификацией. Такое же значение обычно предоставляется сценариям CGI в переменной среды REMOTE_USER. Если код состояния для запроса равен 401, то этому значению не следует доверять, поскольку пользователь ещё не аутентифицирован. Если документ не защищён паролем, эта часть будет "-", как и предыдущая.
[10/Oct/2000:13:55:36 -0700] (%t)
Время получения запроса. Формат такой:
Можно отобразить время в другом формате, указав %t в строке формата журнала, где формат такой же, как в strftime(3) из стандартной библиотеки C, или один из поддерживаемых специальных токенов. Подробности смотрите в строках формате строки mod_log_config.
"GET /apache_pb.gif HTTP/1.0" (\"%r\")
Строка запроса от клиента указана в двойных кавычках. Строка запроса содержит много полезной информации. Во-первых, клиент использует метод GET. Во-вторых, клиент запросил ресурс /apache_pb.gif, и в-третьих, клиент использовал протокол HTTP/1.0. Также возможно зарегистрировать одну или несколько частей строки запроса независимо. Например, строка формата "%m %U%q %H" будет регистрировать метод, путь, строку запроса и протокол, что приведёт к тому же результату, что и "%r".
200 (%>s)
Это код состояния, который сервер отправляет обратно клиенту. Эта информация очень ценна, потому что она показывает, привёл ли запрос к успешному ответу (коды начинаются с 2), к перенаправлению (коды начинаются с 3), к ошибке, вызванной клиентом (коды начинаются с 4), или к ошибкам в сервер (коды начинаются с 5). Полный список возможных кодов состояния можно найти в спецификации HTTP (RFC2616 раздел 10).
2326 (%b)
Последняя часть указывает размер объекта, возвращаемого клиенту, не включая заголовки ответа. Если контент не был возвращён клиенту, это значение будет "-". Чтобы записать «0» без содержимого, вместо %b используйте %B.
Логи комбинированного формата (Combined Log)
Другая часто используемая строка формата называется Combined Log Format. Может использоваться следующим образом.
LogFormat "%h %l %u %t \"%r\" %>s %b \"%i\" \"%i\"" combined CustomLog log/access_log combined
Этот формат точно такой же, как Common Log Format, с добавлением ещё двух полей. Каждое из дополнительных полей использует директиву начинающуюся с символа процента %i, где заголовок может быть любым заголовком HTTP-запроса. Журнал доступа в этом формате будет выглядеть так:
127.0.0.1 - frank [10/Oct/2000:13:55:36 -0700] "GET /apache_pb.gif HTTP/1.0" 200 2326 "http://www.example.com/start.html" "Mozilla/4.08 [en] (Win98; I ;Nav)"
Дополнительными полями являются:
"http://www.example.com/start.html" (\"%i\")
Referer — это часть заголовок HTTP-запроса, которая называется также Referer. В этой строке содержится информация о странице, с которой клиент был прислан на данный сайт. (Это должна быть страница, которая ссылается или включает /apache_pb.gif).
"Mozilla/4.08 [en] (Win98; I ;Nav)" (\"%i\")
Заголовок HTTP-запроса User-Agent. Это идентифицирующая информация, которую клиентский браузер сообщает о себе.

Настройки логов в Apache по умолчанию
По умолчанию в главном конфигурационном файле Apache прописаны следующие настройки логов:
LogFormat "%h %l %u %t \"%r\" %>s %b \"%i\" \"%i\"" combined LogFormat "%h %l %u %t \"%r\" %>s %b" common LogFormat "%h %l %u %t \"%r\" %>s %b \"%i\" \"%i\" %I %O" combinedio CustomLog "logs/access.log" common
Как можно увидеть, установлены три псевдонима: combined, common и combinedio. При этом по умолчанию используется common. При желании вы без труда сможете переключиться на combined или настроить формат строки лога под свой вкус.
Например, если вы предпочитаете, чтобы в файле лога доступа также присутствовала информация о пользовательском агенте и реферере, то есть Combined Logfile Format, то вы можете использовать следующую директиву:
CustomLog "logs/access.log" combined