Data science что это

Data Science, то есть наука о работе с данными, это не просто новое модное слово в мире IT. Это то, что изменит мир программирования, бизнеса и даже потребителей не менее, чем в свое время его изменило изобретение парового двигателя и персонального компьютера. На самом деле, Data Science уже его меняет, свидетельство тому – множество стартапов в области больших данных и искусственного интеллекта.
Редакция AIN.UA объясняет на картинках, что же это такое и каким образом меняет наш мир. Помогает нам разобраться в этой теме Максим Орловский, ментор Cloud Business City (первый виртуальный бизнес-центр в облаке, который развивает Data Science проекты), PhD, MD, руководитель BICA Labs, CEO Кодрум, сооснователь BanQ Systems и спикер на грядущей конференции «Data Science, машинное обучение и нейросети». Максим изучает вопросы искусственного интеллекта и сопутствующих ему технологий с 1998 года.
Data Scientist

Data Scientist — это человек, который работает с большими объемами данных. Вот прям с огромными. Он умеет их добывать, анализировать, но главное — обрабатывать.
средняя зарплата
удовлетворенность
Что делает Data Scientist
Data Scientist — человек с отличными математическими и аналитическими способностями, и совсем необязательно это должен быть только программист. Зачастую это направление интересно специалистам по прикладной математике и статистике, а также аналитикам. Data Scientist понимает, в каком виде данные воспримет компьютер и предоставляет ему их. Таким образом, компьютер может извлечь ценную информацию из полученных данных и использовать ее во благо. Например, на Data Science основаны Self-driving cars, персонализированные интерфейсы, медицинская система IBM Watson, подсказки на ресурсах типа Aliexpress, Amazon, Netflix.
Data Scientist работает с данными из различных источников: собирает их, структурирует, выделяет и синтезирует. Для него важно обеспечивать выводы и действия, основанные на собранных данных. В своей работе специалист использует различные языки программирования — SAS, R и Python, а также аналитические методы. Работая с большими данными, нельзя обойтись без статистики, поэтому Data Scientist занимается еще и статистическими тестами и распределениями.
Data Scientist должен быть готов к упорной работе, ведь ему постоянно предстоит искать идеальную формулу для обучения искусственного интеллекта. К тому же, часто нет очевидного решения проблемы, поэтому среди всех алгоритмов специалистам приходится подыскивать подходящий под конкретную задачу.
Сколько получает Data Scientist
По классике: чем больше опыта у Data Scientist, тем выше его ставка. К тому же, размер зарплаты зависит еще и от региона — к примеру, в столичной компании ставка будет выше. А если вы еще и знаете Python, Java и Hadoop, то ваша средняя зарплата вырастет на 5-14%.
Что такое наука об изучении данных?
В большинстве организаций контроль над процессами Data Science обычно осуществляют руководители трех специальностей:
Бизнес-менеджеры: совместно с группой по изучению данных определяют задачу и разрабатывают стратегию анализа. Бизнес-руководитель может являться руководителем отдела (например, маркетингового, коммерческого или финансового) и возглавлять группу Data Science. Он координирует работу над проектом совместно с главой группы Data Science и ИТ-руководителем.
ИТ-менеджеры:ИТ-руководитель несет ответственность за инфраструктуру и архитектуру для выполнения операций по изучению данных. Он осуществляет постоянный мониторинг операций и ресурсов для обеспечения эффективности и безопасности. ИТ-руководитель также может нести ответственность за создание и обновление рабочей среды ИТ.
Менеджеры по изучению данных:контролируют работу группы по изучению данных и выполнение ею повседневных задач. Он несет ответственность за привлечение и обучение специалистов, а также планирование и мониторинг проекта.
Но самым важным игроком в этом процессе является специалист по анализу данных.
Что представляет собой специалист по Data Science?
Наука о данных возникла совсем недавно. Она зародилась на стыке статистического анализа и интеллектуального анализа данных. Журнал The Data Science Journal впервые был издан в 2002 году Международным советом по науке: комитетом по данным для науки и технологий. К 2008 году появились специалисты по анализу данных, и началось быстрое развитие этой отрасли. Несмотря на то, что все больше высших учебных заведений готовят специалистов по изучению данных, их по-прежнему не хватает.
В обязанности специалиста по анализу данных входят разработка стратегий анализа, подготовка данных для анализа, исследование, анализ и визуализация данных, разработка моделей на основе данных с использованием таких языков программирования, как Python и R, и внедрение моделей в приложения.
Специалист по изучению данных работает не один. Для эффективного изучения данных требуется команда из представителей различных специальностей. Помимо специалиста по изучению данных в нее должен входить бизнес-аналитик, который определяет задачу; специалист по обработке данных, который отвечает за подготовку данных и получение к ним доступа; архитектор ИТ-систем, который занимается обслуживанием необходимых процессов и инфраструктуры; а также разработчик приложений, который внедряет модели или результаты анализа в приложения и продукты.
Сложности при внедрении Data Science в организации
Несмотря на преимущества, которые изучение данных дает бизнесу, и большие объемы инвестиций в эту отрасль, не всем компаниям удается использовать свои данные с максимальной выгодой для себя. Нанятые специалисты приступают к разработке программ по изучению данных, однако сталкиваются с неудовлетворительной организацией процессов и вынуждены использовать разнородные, плохо сочетающиеся инструменты и программы. Чтобы обеспечить окупаемость инвестиций, необходимо более строгое централизованное руководство.
Отсутствие его создает множество проблем.
Специалисты по изучению данных не могут работать эффективно. Доступ к данным и ресурсам для анализа предоставляет ИТ-администратор, т. е. специалисты тратят время на ожидание. Получив доступ, команда специалистов по изучению данных может анализировать их, используя различные и, возможно, несовместимые инструменты. Например, модель может быть разработана с использованием языка R, однако приложение, в котором ее планируется использовать, написано на другом языке. Именно поэтому на внедрение моделей в приложения порой требуется несколько недель, а то и месяцев.
Разработчики приложений не могут использовать модели машинного обучения напрямую. Нередко разработчики приложений получают модели обучения, которые не готовы к развертыванию в приложения. Недостаток гибкости не дает развертывать модели во всех требуемых сценариях и вынуждает разработчиков приложений вносить исправления.
ИТ-администраторы тратят слишком много времени на оказание поддержки. Число инструментов на основе открытого кода постоянно растет, что означает увеличение нагрузки на администраторов. Например, специалисты по изучению маркетинговых данных и финансовых данных используют совершенно разные инструменты. Они также используют разные процессы, т. е. администраторам постоянно приходится вносить изменения и дополнения в инфраструктуру.
Бизнес-руководители не обладают нужным уровнем понимания проблемы. Процессы изучения данных не всегда интегрированы в процессы и системы для принятия бизнес-решений, и не все руководители разбираются в специфике этой деятельности на должном уровне. Им сложно понять, почему на разработку прототипа и внедрение его в производство требуется столько времени, а отсутствие быстрых результатов ведет к снижению финансирования.
Платформы для Data Science предоставляют новые возможности
Во многих компаниях осознали, что без интегрированной платформы отрасль Data Science неэффективна, небезопасна и непродуктивна. Так появились специализированные платформы для Data Science.. Они представляют собой программные центры, которые дают возможность устранить большинство проблем, связанных с Data Science, и помогают компаниям быстрее и эффективнее получать из данных полезную информацию.
Централизованная платформа машинного обучения дает возможность специалистам работать коллективно, используя наиболее привычные им инструменты на основе открытого исходного кода, и синхронизировать наработки с помощью системы контроля версий.
Преимущества платформы для Data Science
Платформа для Data Science сокращает потребление ресурсов и способствует внедрению инноваций. С ее помощью специалисты обмениваются материалами, результатами и отчетами. Она обеспечивает оптимизацию процессов за счет простого управления и использования лучших практик.
Лучшие платформы для Data Science позволяют:
- Сделать работу специалистов по анализу данных более продуктивной, помогая им ускорить разработку и быстрее создавать модели с меньшим количеством ошибок
- Упростить специалистам по анализу данных работу с большими объемами разнообразных данных
- Создавать надежные приложения искусственного интеллекта корпоративного класса, которые работают без ошибок, аудируемы и стабильны
Платформы для Data Science обеспечивают совместную работу таких специалистов, как эксперты по анализу данных, гражданские специалисты по Data Science, , специалисты по обработке данных, а также инженеры и специалисты по машинному обучению. Например, специалисты по изучению данных получают возможность развертывать модели в качестве API для легкой интеграции их в приложения. Доступ к инструментам, данным и инфраструктуре осуществляется без помощи ИТ-администратора.
Спрос на платформы для изучения данных растет в геометрической прогрессии. По ожиданиям экспертов, в ближайшее время этот сегмент рынка продолжит расти на более чем 39 % в год и к 2025 году будет оцениваться в 385 млрд долларов.
Что нужно специалисту по обработке данных на платформе
При выборе платформы для изучения данных необходимо учитывать следующие соображения:
Проектный интерфейс для облегчения совместной работы. Платформа должна помогать специалистам в работе над моделью, от проектирования до внедрения в производство, и обеспечивать доступ к данным и ресурсам в режиме самообслуживания.
Интеграция и гибкость. Убедитесь, что платформа поддерживает современные инструменты на основе открытого кода, наиболее популярные системы для управления версиями, такие как GitHub, GitLab и Bitbucket, а также интеграцию с другими ресурсами.
Возможности масштабирования. По мере развития бизнеса и увеличения команды платформа должна иметь возможность расширяться. Обращайте внимание на такие характеристики, как высокая доступность, эффективные средства управления доступом и поддержка большого числа одновременных пользователей.
Самообслуживание в Data Science. Выбирайте платформу, которая снимет нагрузку с администраторов и инженеров ИТ и поможет специалистам по анализу данных мгновенно развертывать среды, отслеживать работу над проектами и внедрять модели в производственной среде.
Обеспечение упрощенного развертывания. Развертывание и подготовка модели к работе является одним из наиболее важных этапов жизненного цикла машинного обучения, которому зачастую не уделяется должного внимания. Выбирайте сервисы, которые упрощают подготовку моделей к работе, будь то предоставление API или способа построения моделей, обеспечивающего их простую интеграцию.
Когда переход на платформу для Data Science является правильным решением
Ваша организация готова к внедрению платформы для Data Science, если Вы отмечаете, что:
- Имеются признаки понижения продуктивности и качества совместной работы
- Модели машинного обучения невозможно отслеживать или воспроизводить
- Модели никогда не доходят до производственной среды
Платформа для Data Science может оказаться действительно ценной для вашей компании. Платформа Oracle для изучения данных имеет широкий спектр сервисов, обеспечивающих комплексный подход к работе, призванный ускорить развертывание моделей и улучшить результаты анализа данных.
Что такое Data Science и зачем она нужна бизнесу
В сырых и неструктурированных данных скрыты полезные для бизнеса знания. Но извлечь их и правильно использовать — сложная и трудоемкая задача. Разбираемся, что это дает компаниям и как облегчить работу дата-сайентистами
Что такое Data Science
Data Science (DS) — это междисциплинарная область на стыке статистики, математики, системного анализа и машинного обучения, которая охватывает все этапы работы с данными. Она предполагает исследование и анализ сверхбольших массивов информации и ориентирована в первую очередь на получение практических результатов.
Каждый день человечество генерирует примерно 2,5 квинтиллиона байт различных данных. Они создаются буквально при каждом клике и пролистывании страницы, не говоря уже о просмотре видео и фотографий в онлайн-сервисах и соцсетях. Наука о данных появилась задолго до того, как их объемы превысили все мыслимые прогнозы. Отсчет принято вести с 1966 года, когда в мире появился Комитет по данным для науки и техники — CODATA. Его создали в рамках Международного совета по науке, который ставил своей целью сбор, оценку, хранение и поиск важнейших данных для решения научных и технических задач. В составе комитета работают ученые, профессора крупных университетов и представители академий наук из нескольких стран, включая Россию. Сам термин Data Science вошел в обиход в середине 1970-х с подачи датского ученого-информатика Петера Наура. Согласно его определению, эта дисциплина изучает жизненный цикл цифровых данных от появления до использования в других областях знаний. Однако со временем это определение стало более широким и гибким. В 2010-х годах объемы данных стали расти по экспоненте. Свою роль сыграл целый ряд факторов — от повсеместного распространения мобильного интернета и популярности соцсетей до всеобщей оцифровки сервисов и процессов. В итоге профессия дата-сайентиста быстро превратилась в одну из самых популярных и востребованных. Еще в 2012 году позицию дата-сайентиста журналисты назвали самой привлекательной работой XXI века (The Sexiest Job of the XXI Century).
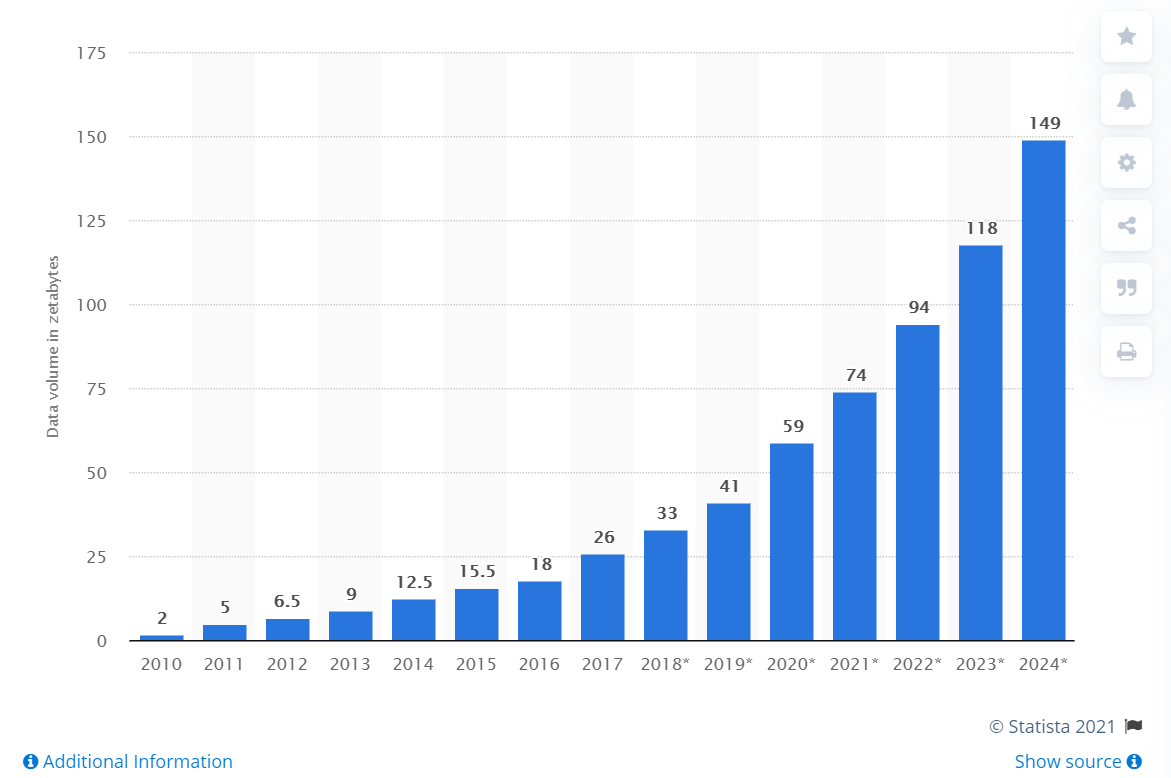
Объем данных, созданных, собранных и потребленных во всем мире с 2010 по 2024 год (в зеттабайтах) (Фото: Statista)
Развитие Data Science шло вместе с внедрением технологий Big Data и анализа данных. И хотя эти области часто пересекаются, их не следует путать между собой. Все они предполагают понимание больших массивов информации. Но если аналитика данных отвечает на вопросы о прошлом (например, об изменениях в поведениях клиентов какого-либо интернет-сервиса за последние несколько лет), то Data Science в буквальном смысле смотрит в будущее. Специалисты по DS на основе больших данных могут создавать модели, которые предсказывают, что случится завтра. В том числе и предсказывать спрос на те или иные товары и услуги.
Зачем Data Science бизнесу
Компании используют Data Science вне зависимости от размера бизнеса, показывает статистика Kaggle (профессиональная соцсеть специалистов по работе с данными). А по подсчетам IDC и Hitachi, 78% предприятий подтверждают, что количество анализируемой и используемой информации в последнее время значительно возросло. Бизнес понимает, что неструктурированная информация содержит очень важные для компании знания, способные повлиять на результаты бизнеса, отмечают авторы исследования.

- онлайн-торговля и развлекательные сервисы: рекомендательные системы для пользователей;
- здравоохранение: прогнозирование заболеваний и рекомендации по сохранению здоровья;
- логистика: планирование и оптимизация маршрутов доставки;
- digital-реклама: автоматизированное размещение контента и таргетирование;
- финансы: скоринг, обнаружение и предотвращение мошенничества;
- промышленность: предиктивная аналитика для планирования ремонтов и производства;
- недвижимость: поиск и предложение наиболее подходящих покупателю объектов;
- госуправление: прогнозирование занятости и экономической ситуации, борьба с преступностью;
- спорт: отбор перспективных игроков и разработка стратегий игры.
И это лишь самый краткий и поверхностный список использования Data Science. Количество различных кейсов с использованием «науки о данных» увеличивается с каждым годом в геометрической прогрессии.
Каждый интернет-пользователь и просто потребитель ежедневно десятки раз сталкивается с продуктами и решениями, в которых применяются инструменты Data Science. К примеру, аудио-сервис Spotify использует их, чтобы лучше подбирать треки для пользователей в соответствии с их предпочтениями. То же самое можно сказать о предложении фильмов и сериалах на видео-стримингах, таких как Netflix. А в Uber науку о данных рассматривают как инструмент для предиктивной аналитики, прогнозирования спроса, улучшения и автоматизации всех продуктов и клиентского опыта.

Конечно, дата-сайентисты не могут в точности предсказать будущее компании и учесть абсолютно все возможные риски. «Все модели неправильные, но некоторые из них полезны», — иронизировал по этому поводу британский статистик Джордж Бокс. Тем не менее, инструменты Data Science служат хорошей поддержкой для компаний, которые хотят принимать более информированные и обоснованные решения о своем будущем.
Как работают дата-сайентисты
Для работы с данными дата-сайентисты применяют целый комплекс инструментов — пакеты статистического моделирования, различные базы данных, специальное программное обеспечение. Но, главное, они используют технологии искусственного интеллекта и создают модели машинного обучения (нейросети), которые помогают бизнесу анализировать информацию, делать выводы и прогнозировать будущее.
Каждую такую нейросеть необходимо спланировать, построить, оценить, развернуть и только потом перейти к ее обучению. «Сейчас, по нашим оценкам, в процессе работы над ИИ-решениями только 30% времени специалистов уходит на обучение моделей. Все остальное — на подготовку к нему и другую рутину», — говорит CTO «Сбербанк Груп», исполнительный вице-президент и глава блока «Технологии» Давид Рафаловский.

Компания Anaconda, которая разрабатывает продукты для работы с данными, приводит еще более печальную статистику. Ее опросы показывают, что в среднем почти половину времени (45%) специалисты тратят на подготовку данных, то есть их загрузку и очистку. Еще примерно треть уходит на визуализацию данных и выбор модели. На обучение и развертывание остается всего 12% и 11% рабочего времени соответственно.
Дата-сайентисты в облаках
Облегчить и ускорить работу по сбору данных, построению и развертыванию моделей помогают специальные облачные платформы. Именно облачные платформы для машинного обучения стали самым актуальным трендом в Data Science. Поскольку речь идет о больших объемах информации, сложных ML-моделях, о готовых и доступных для работы распределенных команд инструментах, то дата-сайентистами понадобились гибкие, масштабируемые и доступные ресурсы.
Именно для дата-сайентистов облачные провайдеры создали платформы, ориентированные на подготовку и запуск моделей машинного обучения и дальнейшую работу с ними. Пока таких решений немного и одно из них было полностью создано в России. В конце 2020 года компания Cloud представила облачную платформу полного цикла разработки и реализации AI-сервисов — ML Space. Платформа содержит набор инструментов и ресурсов для создания, обучения и развертывания моделей машинного обучения — от быстрого подключения к источникам данных до автоматического развертывания обученных моделей на динамически масштабируемых облачных ресурсах Cloud.

Сейчас ML Space — единственный в мире облачный сервис, позволяющий организовать распределенное обучение на 1000+ GPU. Эту возможность обеспечивает собственный облачный суперкомпьютер Cloud — «Кристофари». Запущенный в 2019 году «Кристофари» является сейчас самым мощным российским вычислительным кластером и занимает 40 место в мировом рейтинге cуперкомпьютеров TOP500
Платформу уже используют команды разработчиков экосистемы Сбера. Именно с ее помощью было запущено семейство виртуальных ассистентов «Салют». Для их создания с помощью «Кристофари» и ML Space было обучено более 70 различных ASR- моделей (автоматическое распознавание речи) и большое количество моделей Text-to-Speech. Сейчас ML Space доступна для любых коммерческих пользователи, учебных и научных организаций.
«ML Space – это настоящий технологический прорыв в области работы с искусственным интеллектом. По нескольким ключевым параметрам ML Space уже превосходит лучшие мировые решения. Я считаю, что сегодня ML Space одна из лучших в мире облачных платформ для машинного обучения. Опытным дата-сайентистам она предоставляет новые удобные инструменты, возможность распределенной работы, автоматизации создания, обучения и внедрения ИИ-моделей. Компаниям и организациям, не имеющим глубокой ML-экспертизы, ML Space дает возможность впервые использовать искусственный интеллект в своих продуктах, приложениях и рабочих процессах», — уверен Отари Меликишвили, лидер продуктового вправления AI Cloud, компании Cloud.
Облака помогают рынку все шире использовать платформы для работы с данными, предлагая безграничные вычислительные мощности, подтверждают аналитики Mordor Intelligence.
По мнению экспертов из Anaconda, потребуется время, чтобы бизнес и сами специалисты созрели для широкого использования инструментов DS и смогли получить результаты. Но прогресс уже очевиден. «Мы ожидаем, что в ближайшие два-три года Data Science продолжит двигаться к тому, чтобы стать стратегической функцией бизнеса во многих отраслях», — прогнозирует компания.