Использование критерия Like для поиска данных
Условия или оператор Like используются в запросе для поиска данных, которые соответствуют определенному шаблону. Например, в нашей базе данных есть таблица «Клиенты», как по примеру ниже, и нам нужно найти только клиентов, живущих в городах, названия которых начинаются с «B». Вот как мы создадим запрос и будем использовать условия Like:
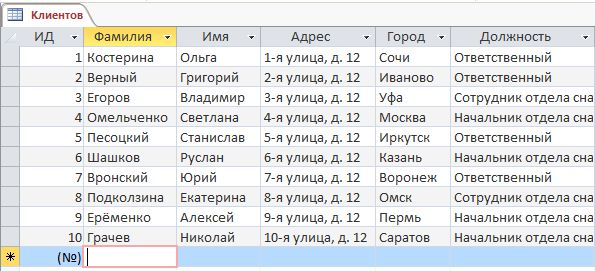
«Клиенты»:
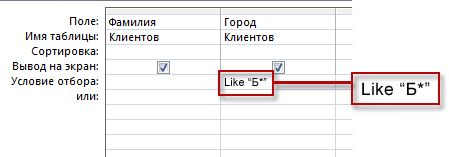
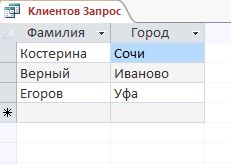
В результатах запроса будут отбираться только клиенты из названий городов, названия которых начинаются с буквы «B».
Дополнительные информацию об использовании критериев см. в этой теме.
Использование оператора Like в SQL в синтаксис
Если вы предпочитаете синтаксис SQL (язык SQL), вот как это сделать:
- Откройте таблицу «Клиенты» и на вкладке «Создание» нажмите кнопку «Конструктор запросов».
- На вкладке «Главная» нажмите кнопку «>SQL», а затем введите следующий синтаксис:
SELECT [Last Name], City FROM Customers WHERE City Like “B*”;
- Щелкните Выполнить.
- Щелкните вкладку запроса правой кнопкой мыши и выберите >«Закрыть».
Дополнительные сведения см. в SQL Access: основные понятия, лексика и синтаксис, а также о том, как изменять SQL для более четкого получения результатов запроса.
Примеры шаблонов условий Like и результатов
Условия или оператор Like удобны при сравнении значения поля с строкным выражением. Следующий пример возвращает данные, которые начинаются с буквы P, за которой идут любая буква от A до F и три цифры:
Like “P[A-F]###”
Вот несколько способов использования like для различных шаблонов:
Если ваша база данных имеет
соответствие, вы увидите
Если в базе данных нет
совпадений, вы увидите
Какой оператор позволяет делать запросы к базе
27 сентября 2023
Скопировано
SQL (от англ. Structured Query Language) — это структурированный язык запросов, созданный для того, чтобы получать из базы данных необходимую информацию. Если описать схему работы SQL простыми словами, то специалист формирует запрос и направляет его в базу. Та в свою очередь обрабатывает эту информацию, «понимает», что именно нужно специалисту, и отправляет ответ.

Освойте профессию «Аналитик данных»
Данные хранятся в виде таблиц, они структурированы и разложены по строкам и столбцам, чтобы ими легче было оперировать. Такой способ хранения информации называют реляционными базами данных (от англ. relation — «отношения»). Название указывает на то, что объекты в такой базе связаны определенными отношениями.
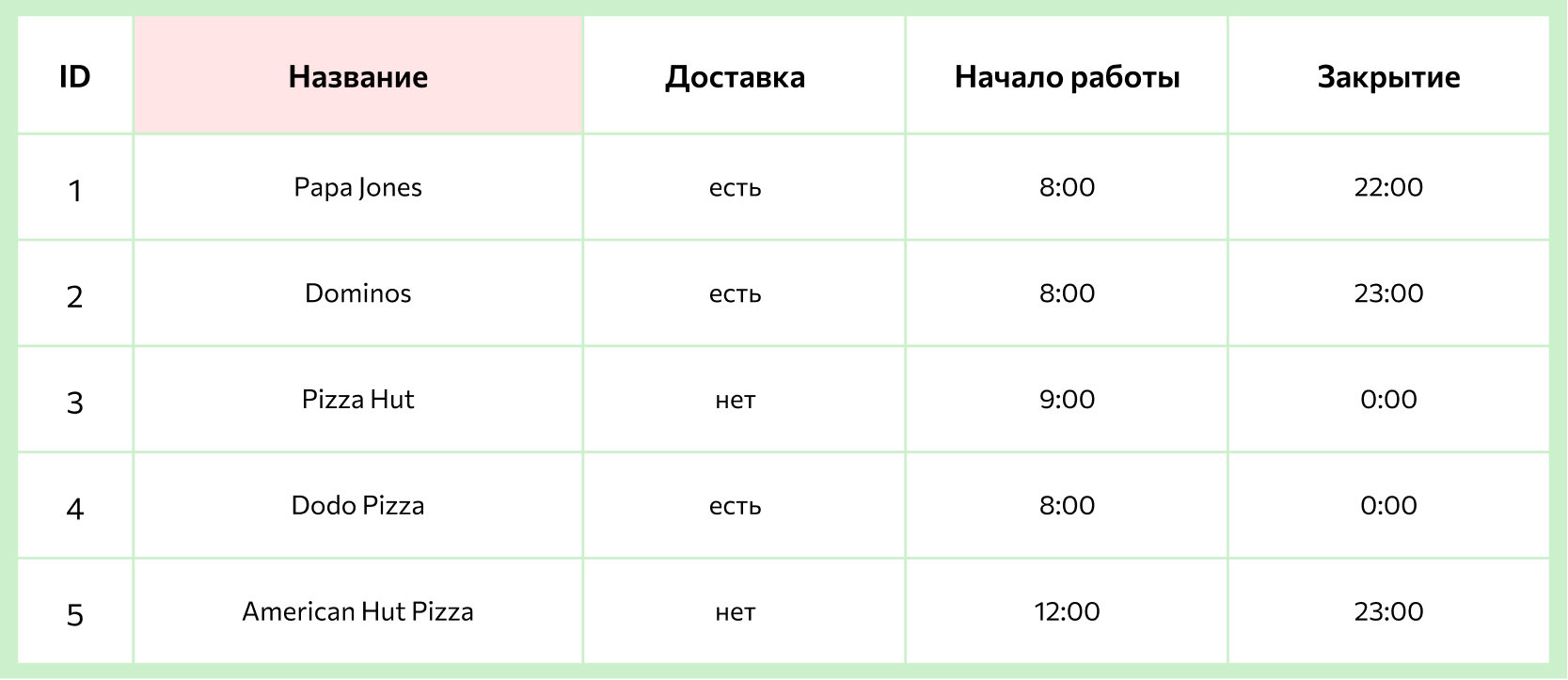
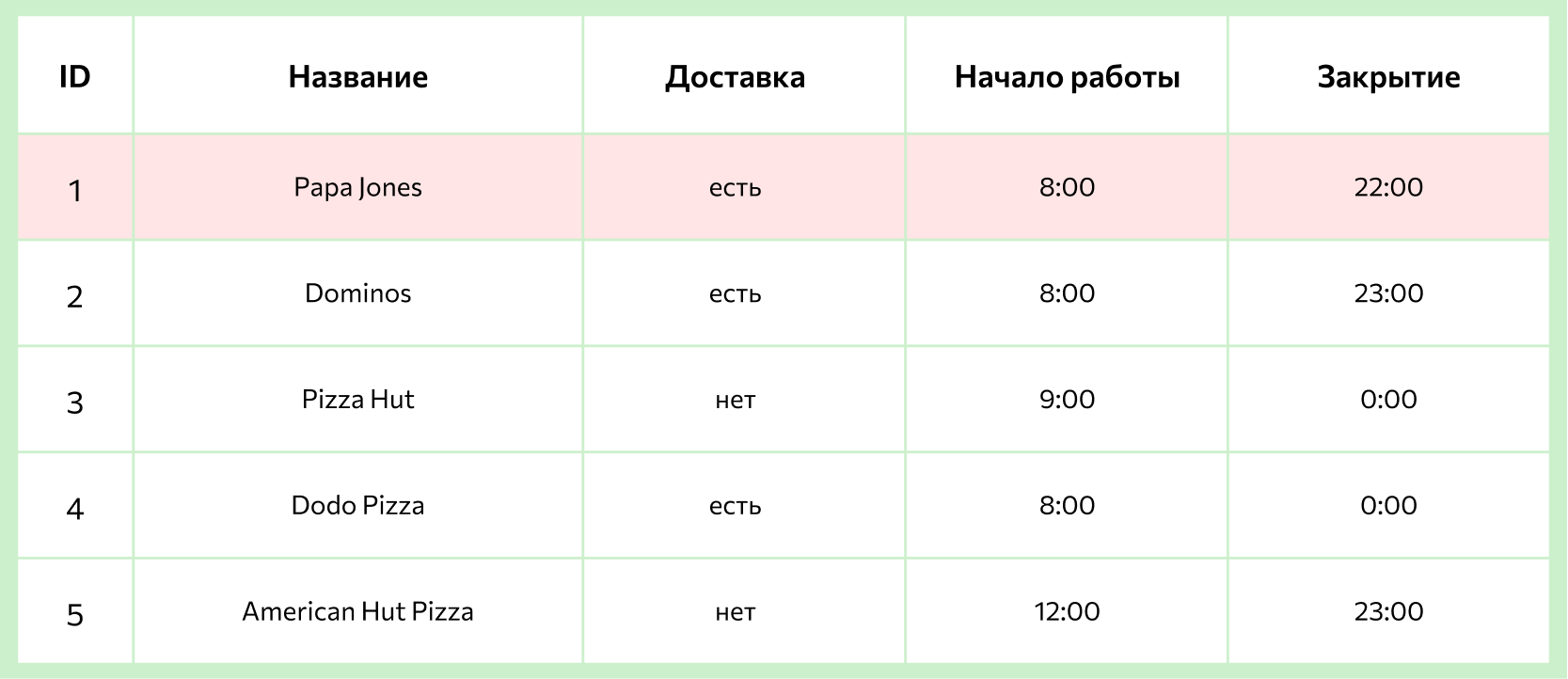
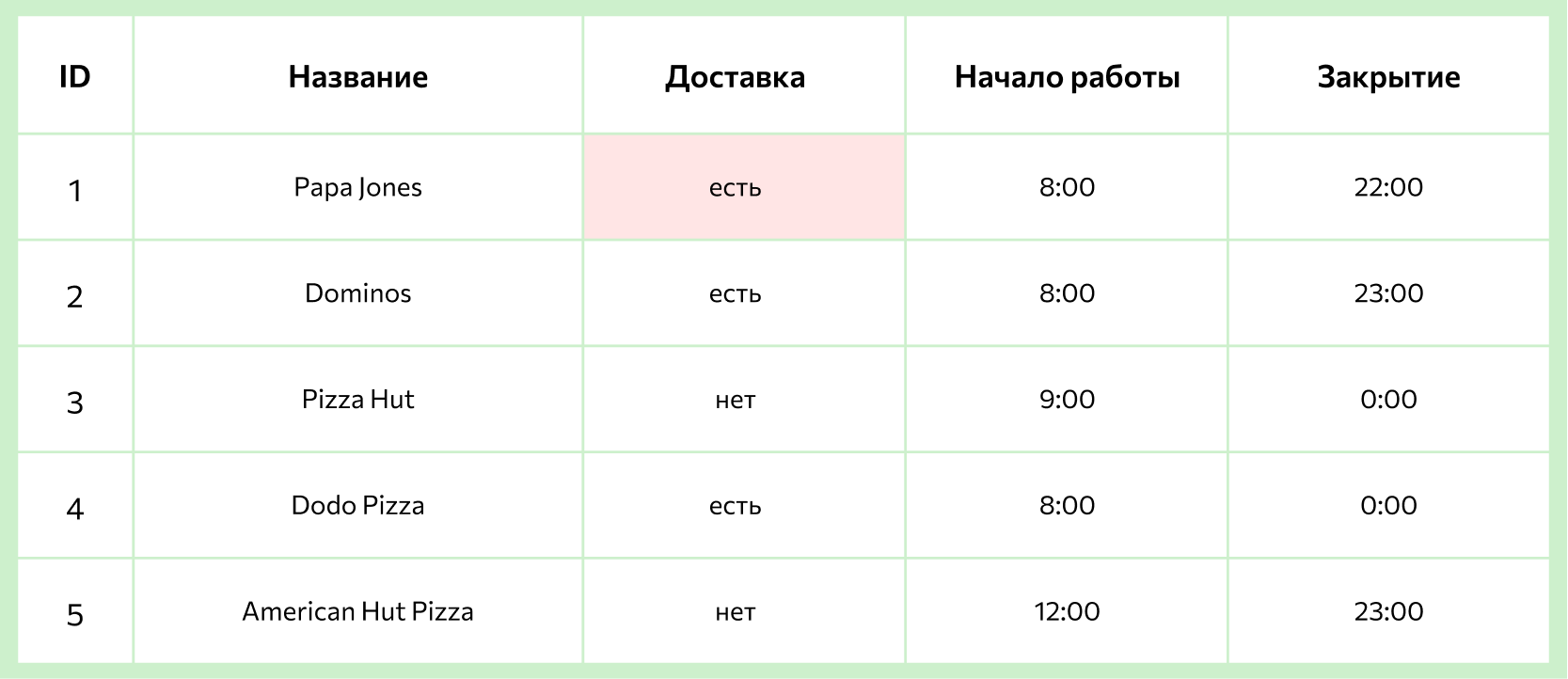
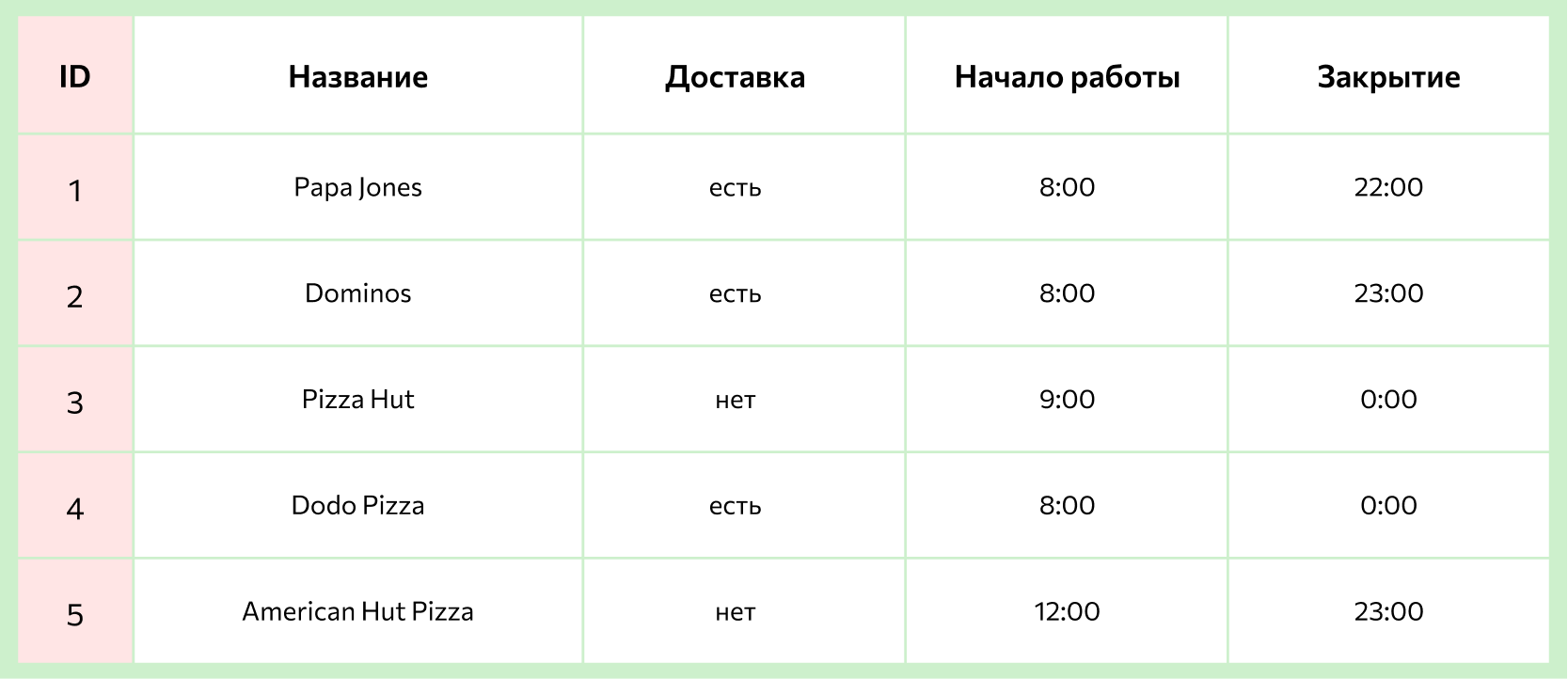
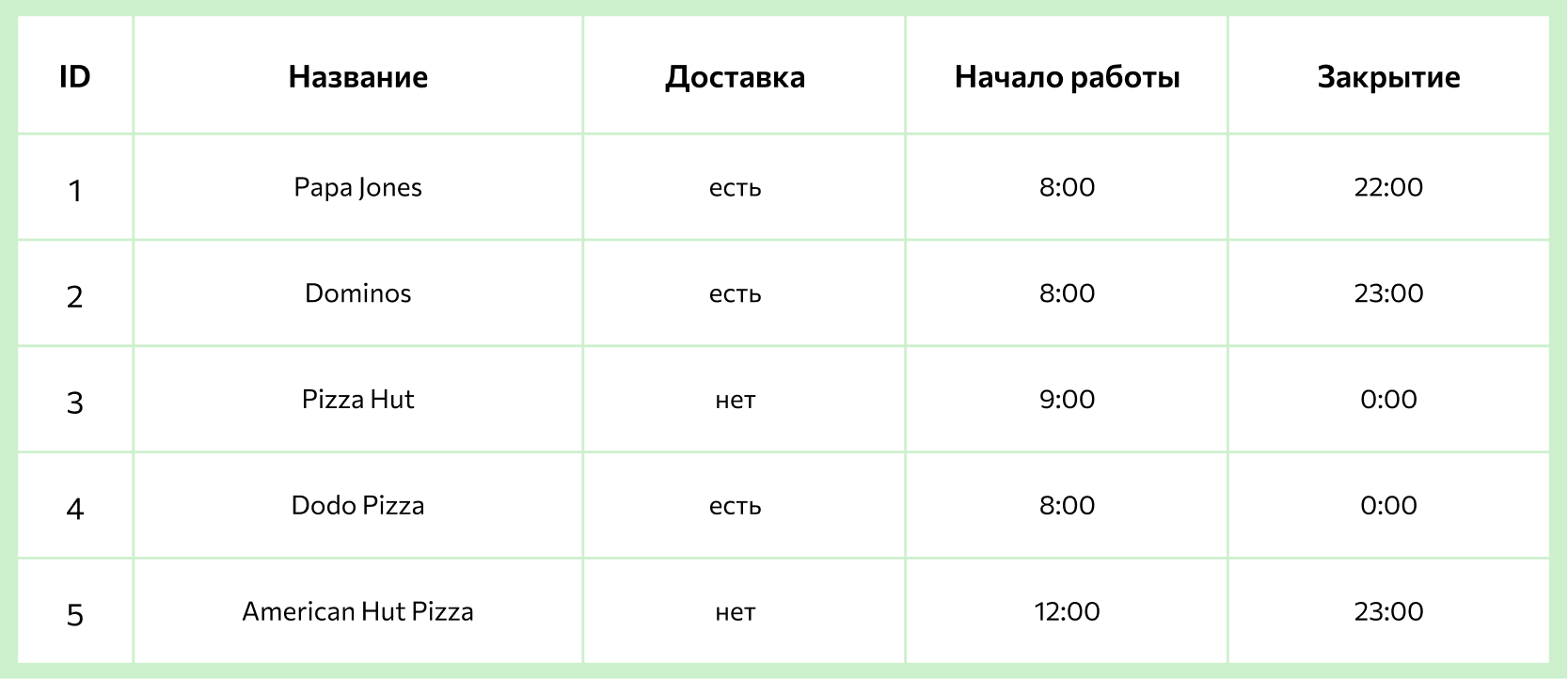
Например, у маркетолога есть база, в которой собрана информация обо всех пиццериях в городе: названия, ассортимент, цены, график работы и прочее. Во время анализа конкурентов он решил выяснить, сколько пиццерий готовят пиццу с ананасами и оформляют доставку после 23:00. Для того чтобы получить такой список из базы, достаточно написать грамотный SQL-запрос.
Профессия / 12 месяцев
Аналитик данных
Находите закономерности и делайте выводы, которые помогут бизнесу

Для чего нужен SQL
SQL — это не язык программирования, поэтому написать приложение или сайт с его помощью не получится, но при этом внутренняя работа сайта (backend) невозможна без запросов. Поиск информации в Google — это тоже модель использования SQL. Пользователь задает параметры, которые его интересуют, и отправляет запрос на сервер; затем происходит магия и в поисковой выдаче появляются результаты, соответствующие именно этому запросу.
SQL используют разные виды специалистов:
- Аналитикиипродуктовые маркетологи. Знание SQL помогает этим специалистам не зависеть от программистов, а самостоятельно получать и обрабатывать данные.
- Разработчикиитестировщики. С помощью SQL они могут самостоятельно проектировать базы для быстрой и надежной работы с данными, улучшать с их помощью сайты и приложения.
- Руководители и менеджеры. SQL позволит специалистам на руководящих постах самостоятельно обращаться к базам, контролировать работу компании и в реальном времени получать данные о положении дел.
Читайте также Востребованные IT-профессии 2023 года: на кого учиться онлайн
Как работают запросы
Чтобы разобраться, как именно работает магия запроса, давайте представим его путь от пользователя до нужных ему данных:
Пользователь → Клиент → Запрос → Система управления → База данных → Таблица с базами данных
Данные для работы с SQL хранятся в таблицах. Как именно они устроены — разберемся ниже; пока же просто представим их. На пути от пользователя к таблице находится несколько посредников:
- Клиент — способ введения запроса. В случае с Google, например, клиентом будет поисковая строка браузера, в которую пользователь вводит сформулированный запрос.
- Система управления базами данных (СУБД) — комплекс программ, которые позволяют управлять данными. Эта система помогает таблицам понять, чего хочет пользователь, а пользователю — что ему отвечают таблицы.
- База данных — система хранения таблиц, в которой они связаны между собой. База данных сама по себе не умеет манипулировать информацией — это просто хранилище, где у каждого объекта есть свое место.

Станьте аналитиком данных и получите востребованную специальность
Что такое база данных в SQL
SQL-запросы обращаются к данным в виде таблиц, то есть к реляционным базам данных. Упрощенный вариант такой базы — это таблицы Excel, в которых информация также упорядочена в столбцы и строки.
Основные понятия реляционной модели:
1. Отношение — это сама таблица, она двумерная и состоит из столбцов и строк.
2. Атрибут — столбец в таблице, который содержит один конкретный параметр: название, тип, дату, стоимость или другую характеристику.
3. Домен — это допустимые значения для каждого атрибута. Например, в столбце «Имя» или «Название» значения должны представлять собой набор буквенных символов, но они не могут начинаться с «ь» или «ъ» и не могут быть записаны числами.
4. Кортеж (строка или запись) — это табличная строка с порядковым номером, в которой содержится информация об одном конкретном объекте.
5. Значение — элемент таблицы, который находится на пересечении столбцов и строк.
6. Ключ — это самый важный столбец в таблице, за счет этих значений и происходит взаимодействие в реляционной базе данных, он связывает таблицы между собой.
Ключи бывают нескольких видов:
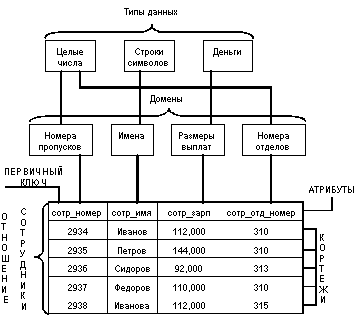
- Первичный ключ — идентификатор, такой как индекс или артикул.
- Потенциальный ключ — другое уникальное значение, которое может служить идентификатором.
- Внешний ключ — столбец-ссылка, используется для объединения двух таблиц, каждое значение внешнего ключа обязательно соответствует первичному ключу в другой таблице.
Например, для решения задачи — выбрать все пиццерии, которые смогут доставить пиццу с ананасами после 23:00, — кроме основной таблицы с графиками работы понадобятся также таблицы с ассортиментом каждого заведения, а также таблицы с составом каждой пиццы (чтобы понять, есть ли в ней ананасы). Все эти таблицы будут связаны между собой с помощью ключей.


Станьте дата-сайентистом: изучите науку о данных с преподавателями Сеченовского университета и практикуйтесь на реальных кейсах
SQL-операторы
Работать с данными помогают операторы — определенные слова или символы, которые используются для выполнения конкретной операции — например, для выбора из множества по конкретному параметру. Если нам нужно из всех видов пиццы отсортировать те, в которых есть пармезан, — нужно использовать оператор SELECT (выбор в соответствии с условием).
Операторы в SQL делятся на несколько групп в соответствии с задачами, которые они решают.
DDL (Data Definition Language) — операторы определения данных. Они работают с объектами, то есть с целыми таблицами. Если базу нужно дополнить таблицей с новыми данными или, наоборот, убрать одну из таблиц с ошибочными данными — используется этот набор операторов.
- CREATE — создание объекта в базе данных
- ALTER — изменение объекта
- DROP — удаление объекта
DML (Data Manipulation Language) — операторы манипуляции данными. Эти операторы уже работают с содержимым таблиц — строками, атрибутами и значениями. С их помощью можно вносить изменения в конкретное значение. Например, заменить поле в колонке «Фамилия» в строке с данными сотрудницы компании посте того, как она вышла замуж. Или удалить строку с данными уволенного сотрудника.
- SELECT — выбор данных в соответствии с условием
- INSERT — добавление новых данных
- UPDATE — изменение существующих данных
- DELETE — удаление данных
DCL (Data Control Language) — оператор определения доступа к данным. Он определяет, кто из пользователей может отправлять запросы к базе, менять объекты и значения. Например, можно отозвать доступ у сотрудника, перешедшего в другой отдел, а также открыть доступ к базе новому маркетологу или разработчику.
- GRANT — предоставление доступа к объекту
- REVOKE — отзыв ранее выданного разрешения
- DENY — запрет, который является приоритетным над разрешением
TCL (Transaction Control Language) — язык управления транзакциями. Транзакции — это набор команд, которые выполняются поочередно. Если все команды выполнены, транзакция считается успешной, а если где-то произошла ошибка — транзакция откатывается назад, отменяя все выполненные команды. Наглядный пример такой транзакции — оплата онлайн, когда банк просит сначала ввести сумму и получателя, затем проверить и подтвердить операцию, а после ввести одноразовый код. На каждом из этих этапов оплату можно отменить и транзакция откатится назад.
- BEGIN TRANSACTION — обозначение начала транзакции
- COMMIT TRANSACTION — изменение команд внутри транзакции
- ROLLBACK TRANSACTION — откат транзакции
- SAVE TRANSACTION — указание промежуточной точки сохранения внутри транзакции
Виды СУБД
Сами по себе таблицы или база данных не способны выполнять операции, а в СУБД можно создавать новые таблицы, удалять ненужные данные, настраивать ключи и обрабатывать запросы. Основные задачи СУБД:
- поддержка языков баз данных;
- непосредственное управление данными;
- управление буферами оперативной памяти;
- управление транзакциями;
- резервное копирование и восстановление после сбоев.
Существуют разные виды таких систем, которые разрабатывает и техногиганты, вроде Google, Microsoft и Amazon, и более нишевые студии. Разработчики стремятся сделать свой продукт лучше, чтобы их система быстрее и качественнее других обрабатывала данные. Из-за этого появились разные виды языка SQL — так называемые SQL-диалекты. У каждой СУБД диалект имеет что-то общее со всеми, а также свои особенности, которые не будут работать в другой системе.
СУБД могут быть коммерческими или иметь открытый код. Системы управления с открытым кодом можно бесплатно использовать в проектах, а также дополнять их документацию и совершенствовать процесс работы с системой. Коммерческие СУБД имеют платный доступ к полным версиям — как правило, такие используют крупные корпорации.
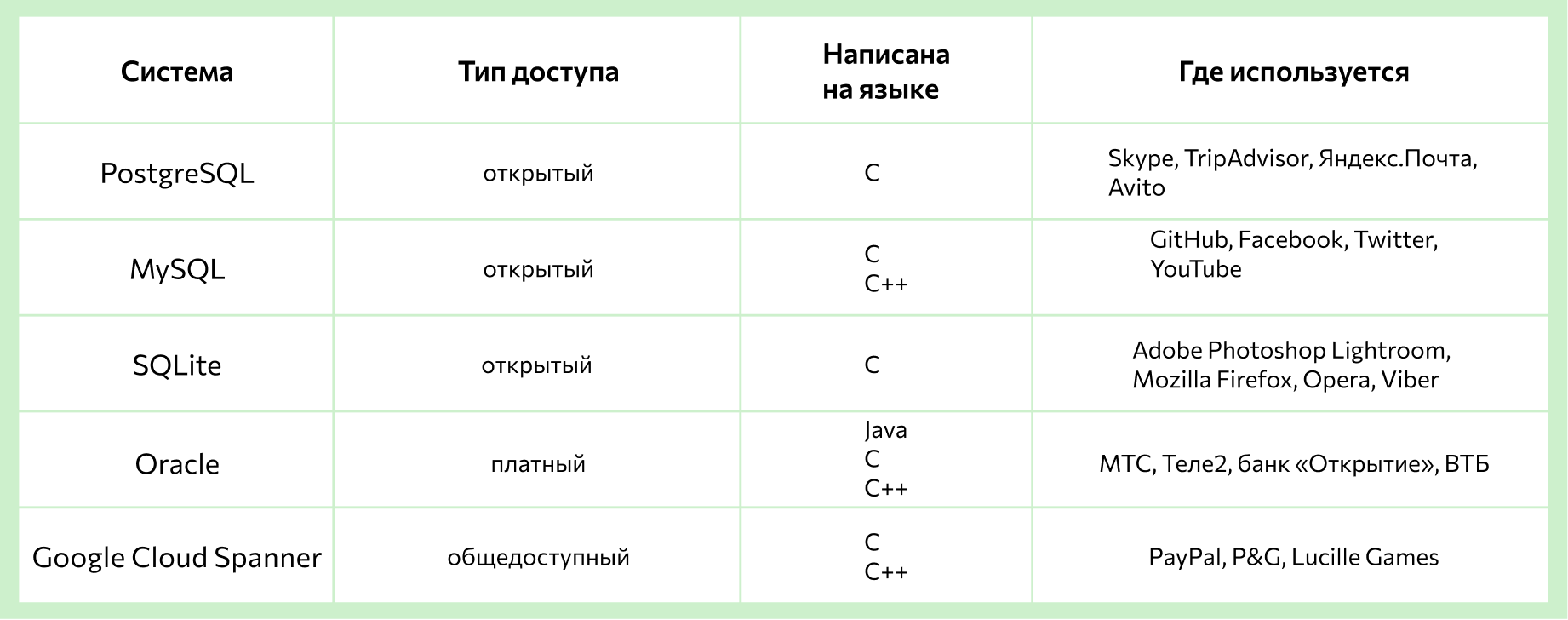
- PostgreSQL — это объектно-ориентированная система, то есть она обрабатывает данные как абстрактные объекты. Каждый объект, в отличие от простых табличных значений, может иметь собственные характеристики и уникальные методы взаимодействия с другими объектами. Это позволяет PostgreSQL обрабатывать более сложные структуры данных и выполнять более сложные процедуры. Например, Яндекс.Почта в свое время перешла на эту систему, чтобы поддерживать стабильное соединение десятков тысяч пользователей к одной базе.
- MySQL — простая в изучении и функциональная система, которая работает с сайтами и веб-приложениями. Чаще всего используется в системах управления контентом сайтов (CMS), на сайтах с возможностью регистрации пользователей, в корпоративных системах CRM, в планировщиках, чатах и форумах. MySQL считается одним из самых безопасных и высокоскоростных решений, которое существует на рынке.
- SQLite — это облегченная встраиваемая версия СУБД. В ней нет возможности поделиться правами доступа, как во многих других системах, но благодаря своему устройству эта система быстрая и мощная. SQLite подходит для обработки запросов на сайтах с низким и средним трафиком, а также в однопользовательских мобильных приложениях и играх. Преимущество такой системы — файловая структура, то есть база в SQLite состоит из одного файла, поэтому ее очень легко переносить.
- Oracle — одна из первых СУБД, которая появилась еще в 1977 году и развивается до сих пор. Это кроссплатформенная система, которая может работать на Windows, Linux, MacOS, мобильных и других ОС. Система используется в крупных коммерческих проектах. Например, в России с Oracle сотрудничают операторы МТС и Теле2, банк «Открытие» и ВТБ.
- Google Cloud Spanner — это облачная система управления данными, которую Google разработал для управления собственными сервисами, например AdWords и Google Play. В 2017 году систему сделали общедоступной. Cloud Spanner относят к категории NewSQL — это системы, которые совмещают в себе преимущества реляционных и нереляционных СУБД.
Как начать работу с SQL
Для начала работы с SQL достаточно разбираться в основах Excel, чтобы понимать принцип работы запросов, а также иметь базовый уровень английского на уровне A1-A2. Эти навыки необходимы, чтобы понимать синтаксис SQL:
- SELECT — выбери данные
- FROM — вот отсюда
- JOIN — добавь еще эти таблицы
- WHERE — при таком условии
- GROUP BY — сгруппируй данные по этому признаку
- ORDER BY — отсортируй данные по этому признаку
- LIMIT — нужно такое количество результатов
- ; — конец предложения
Системы для работы с SQL имеют схожую структуру: есть редактор запросов, результат запросов и список таблиц, которые используются для обработки.
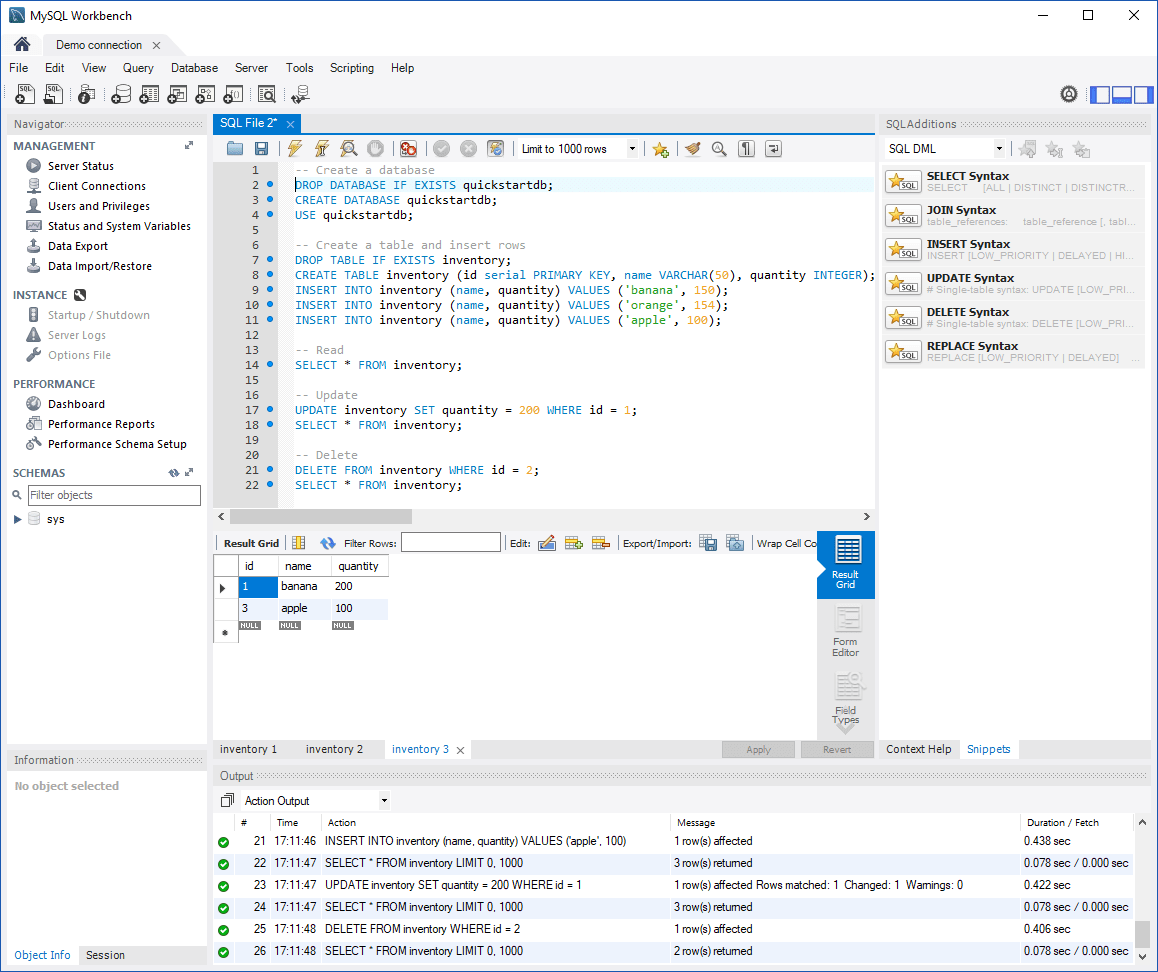
Самостоятельно начать изучение SQL можно с просмотра уроков на YouTube и чтения тематических статей в профильных медиа. Для более системного усвоения информации и экономии времени, потраченного на обучение, лучше записаться на курсы к опытным преподавателям, где вы сразу попадете в профессиональное сообщество и будете получать поддержку менторов.
Аналитик данных
Аналитики влияют на рост бизнеса. Они выясняют, какой товар и в какое время больше покупают. Считают юнит-экономику. Оценивают окупаемость рекламной кампании. Поэтому компании ищут и переманивают таких специалистов.
Работа с запросами в MySQL
Базы данных являются ключевым компонентом многих веб-сайтов и приложений и лежат в основе хранения и обмена данными в Интернете. Одним из наиболее важных аспектов управления базой данных является практика извлечения данных из базы данных, будь то на разовой основе или частью процесса, который был закодирован в приложении. Существует несколько способов получения информации из базы данных, но один из наиболее часто используемых методов выполняется путем отправки запросов через командную строку.
В системах управления реляционными базами данных запрос — это любая команда, используемая для извлечения данных из таблицы. В языке структурированных запросов (SQL) запросы почти всегда выполняются с помощью оператора SELECT.
В этом руководстве мы обсудим основной синтаксис SQL-запросов, а также некоторые из наиболее часто используемых функций и операторов. Мы также будем практиковаться в создании запросов SQL с использованием некоторых примеров данных в базе данных MySQL.
MySQL — это система управления реляционными базами данных с открытым исходным кодом. MySQL, одна из наиболее распространенных баз данных SQL, отдает приоритет скорости, надежности и удобству использования. Как правило, она соответствует стандарту ANSI SQL, хотя в некоторых случаях MySQL выполняет операции не так, как признанный стандарт.
Подготовка окружения
В целом, команды и концепции, представленные в этом руководстве, могут использоваться в любой операционной системе на базе Linux, на которой работает любое программное обеспечение базы данных SQL. Тем не менее, он был написан специально для сервера Ubuntu 18.04. Для настройки вам понадобится следующее:
- Сервер с Ubuntu 18.04
- Установленный на сервере MySQL
Если сервер создается в NetAngels, то при создании сервера мы рекомендуем выбрать Ubuntu 18.04 Bionic LAMP
Создание образца базы данных
Прежде чем мы сможем начать делать запросы в SQL, мы сначала создадим базу данных и пару таблиц, а затем заполним эти таблицы некоторыми примерами данных. Это позволит вам получить практический опыт, когда вы начнете делать запросы позже.
Для примера базы данных, которую мы будем использовать в этом руководстве, представьте следующий сценарий:
Вы и несколько ваших друзей празднуете свои дни рождения друг с другом. В каждом случае члены группы направляются в местный боулинг, участвуют в дружеском турнире, а затем все направляются к вам, где вы готовите любимое блюдо для именинника.
Теперь, что эта традиция продолжается некоторое время, вы решили начать отслеживать записи с этих турниров. Кроме того, чтобы упростить планирование обедов, вы решаете создать запись о днях рождения ваших друзей и их любимых блюдах, сторонах и десертах. Вместо того чтобы хранить эту информацию в физической книге, вы решаете использовать свои навыки работы с базами данных, записав ее в базу данных MySQL.
Если вы создали сервер в NetAngels на основе образа Ubuntu 18.04 Bionic LAMP, то откройте приглашение MySQL выполнив от пользователя root команду:
Примечание: Если зайти в MySQL таким образом не удается, то для аутентификации с использованием пароля используйте команду:
Затем создайте базу данных, запустив:
CREATE DATABASE `birthdays`; Затем выберите эту базу данных, набрав:
USE birthdays; Затем создайте две таблицы в этой базе данных. Мы будем использовать первую таблицу, чтобы отслеживать записи ваших друзей в боулинге. Следующая команда создаст таблицу под названием «tourneys» со столбцами для «name» каждого из ваших друзей, количества турниров, которые они выиграли («wins»), их лучший результат за все время и каков размер обувь для боулинга, которую они носят ( размер ):
CREATE TABLE tourneys ( name varchar(30), wins real, best real, size real ); Как только вы запустите команду CREATE TABLE и заполните ее заголовками столбцов, вы получите следующий вывод:
Query OK, 0 rows affected (0.00 sec) Заполните таблицу ‘tourneys’ некоторыми примерами данных:
INSERT INTO tourneys (name, wins, best, size) VALUES ('Dolly', '7', '245', '8.5'), ('Etta', '4', '283', '9'), ('Irma', '9', '266', '7'), ('Barbara', '2', '197', '7.5'), ('Gladys', '13', '273', '8'); Вы получите такой вывод:
Query OK, 5 rows affected (0.01 sec) Records: 5 Duplicates: 0 Warnings: 0 После этого создайте еще одну таблицу в той же базе данных, которую мы будем использовать для хранения информации о любимых блюдах ваших друзей на день рождения. Следующая команда создает таблицу с именем dinners и столбцами для«имя» каждого из ваших друзей, их «дата рождения», их любимое «блюдо», их любимое «гарнир» и их любимый «десерт»:
CREATE TABLE dinners ( name varchar(30), birthdate date, entree varchar(30), side varchar(30), dessert varchar(30) ); Аналогично для этой таблицы вы получите отзыв, подтверждающий успешное выполнение команды:
Query OK, 0 rows affected (0.01 sec) Заполните эту таблицу также некоторыми примерами данных:
INSERT INTO dinners (name, birthdate, entree, side, dessert) VALUES ('Dolly', '1946-01-19', 'steak', 'salad', 'cake'), ('Etta', '1938-01-25', 'chicken', 'fries', 'ice cream'), ('Irma', '1941-02-18', 'tofu', 'fries', 'cake'), ('Barbara', '1948-12-25', 'tofu', 'salad', 'ice cream'), ('Gladys', '1944-05-28', 'steak', 'fries', 'ice cream'); Query OK, 5 rows affected (0.00 sec) Records: 5 Duplicates: 0 Warnings: 0 Как только эта команда завершится успешно, вы закончили настройку базы данных. Далее мы рассмотрим основную структуру команд запросов SELECT.
Понимание операторов SELECT
Как упоминалось во введении, SQL-запросы почти всегда начинаются с оператора SELECT . SELECT используется в запросах, чтобы указать, какие столбцы из таблицы должны быть возвращены в наборе результатов. Запросы также почти всегда включают FROM , который используется для указания таблицы, к которой будет обращаться оператор.
Как правило, SQL-запросы следуют этому синтаксису:
SELECT column_to_select FROM table_to_select WHERE certain_conditions_apply; Например, следующий оператор вернет весь столбец name из таблицы dinners :
SELECT name FROM dinners; +---------+ | name | +---------+ | Dolly | | Etta | | Irma | | Barbara | | Gladys | +---------+ 5 rows in set (0.00 sec) Вы можете выбрать несколько столбцов из одной таблицы, разделяя их имена запятыми, например:
SELECT name, birthdate FROM dinners; +---------+------------+ | name | birthdate | +---------+------------+ | Dolly | 1946-01-19 | | Etta | 1938-01-25 | | Irma | 1941-02-18 | | Barbara | 1948-12-25 | | Gladys | 1944-05-28 | +---------+------------+ 5 rows in set (0.00 sec) Вместо того, чтобы называть конкретный столбец или набор столбцов, вы можете следовать за оператором SELECT со звездочкой ( * ), которая служит заполнителем, представляющим все столбцы в таблице. Следующая команда возвращает каждый столбец из таблицы tourneys :
SELECT * FROM tourneys; +---------+------+------+------+ | name | wins | best | size | +---------+------+------+------+ | Dolly | 7 | 245 | 8.5 | | Etta | 4 | 283 | 9 | | Irma | 9 | 266 | 7 | | Barbara | 2 | 197 | 7.5 | | Gladys | 13 | 273 | 8 | +---------+------+------+------+ 5 rows in set (0.00 sec) WHERE используется в запросах для фильтрации записей, которые удовлетворяют указанному условию, и любые строки, которые не удовлетворяют этому условию, исключаются из результата. Предложение WHERE обычно соответствует следующему синтаксису:
. . . WHERE column_name comparison_operator value Оператор сравнения в предложении WHERE определяет способ сравнения указанного столбца со значением. Вот некоторые распространенные операторы сравнения SQL:
| Оператор | Что он делает |
|---|---|
| = | тесты для равенства |
| != | тесты для неравенства |
| тесты для больше | |
| = | тесты для больше чем или равный к |
| BETWEEN | проверяет лежит ли в заданном диапазоне |
| IN | проверяет содержатся ли строки в наборе значений |
| EXISTS | тесты на соответствие строки существует при заданных условиях |
| LIKE | проверяет совпадает ли значение с указанной строкой |
| IS NULL | тесты для `NULL` значения |
| IS NOT NULL | тесты для всех других значений, чем `NULL` |
Например, если вы хотите найти размер обуви Ирмы, вы можете использовать следующий запрос:
SELECT size FROM tourneys WHERE name = 'Irma'; +------+ | size | +------+ | 7 | +------+ 1 row in set (0.00 sec) SQL допускает использование подстановочных знаков, и это особенно удобно при использовании в предложениях WHERE. Знаки процента ( % ) представляют ноль или более неизвестных символов, а подчеркивания ( _ ) представляют один неизвестный символ. Они полезны, если вы пытаетесь найти конкретную запись в таблице, но не уверены, что эта запись. Чтобы проиллюстрировать это, скажем, что вы забыли любимое блюдо нескольких своих друзей, но вы уверены, что это конкретное блюдо начинается с буквы “t”. Вы можете найти его имя, выполнив следующий запрос:
SELECT entree FROM dinners WHERE entree LIKE 't%'; +--------+ | entree | +--------+ | tofu | | tofu | +--------+ 2 rows in set (0.00 sec) Основываясь на вышеприведенном выводе, мы видим, что блюдо — это тофу.
Могут быть случаи, когда вы работаете с базами данных, в которых есть столбцы или таблицы с относительно длинными или трудно читаемыми именами. В этих случаях вы можете сделать эти имена более читабельными, создав псевдоним с ключевым словом AS . Псевдонимы, созданные с помощью AS , являются временными и существуют только на время запроса, для которого они созданы:
SELECT name AS n, birthdate AS b, dessert AS d FROM dinners; +---------+------------+-----------+ | n | b | d | +---------+------------+-----------+ | Dolly | 1946-01-19 | cake | | Etta | 1938-01-25 | ice cream | | Irma | 1941-02-18 | cake | | Barbara | 1948-12-25 | ice cream | | Gladys | 1944-05-28 | ice cream | +---------+------------+-----------+ 5 rows in set (0.00 sec) Здесь мы сказали SQL отображать столбец name как n , столбец birthdate как b , а столбец sert как d .
Примеры, которые мы рассмотрели до этого момента, включают в себя некоторые из наиболее часто используемых ключевых слов и предложений в запросах SQL. Они полезны для базовых запросов, но они бесполезны, если вы пытаетесь выполнить вычисление или получить скалярное значение (одно значение, а не набор из нескольких различных значений) на основе ваших данных. Это где агрегатные функции вступают в игру.
Агрегатные функции
Часто при работе с данными необязательно просматривать сами данные. Скорее, вам нужна информация о данных. Синтаксис SQL включает в себя ряд функций, которые позволяют интерпретировать или выполнять вычисления для ваших данных, просто выполнив запрос «SELECT». Они известны как aggregate functions.
Функция COUNT считает и возвращает количество строк, соответствующих определенным критериям. Например, если вы хотите узнать, сколько ваших друзей предпочитают тофу для своего дня рождения, вы можете выполнить этот запрос:
SELECT COUNT(entree) FROM dinners WHERE entree = 'tofu'; +---------------+ | COUNT(entree) | +---------------+ | 2 | +---------------+ 1 row in set (0.00 sec) Функция AVG возвращает среднее (среднее) значение столбца. Используя наш пример таблицы, вы можете найти средний лучший результат среди ваших друзей с помощью этого запроса:
SELECT AVG(best) FROM tourneys; +-----------+ | AVG(best) | +-----------+ | 252.8 | +-----------+ 1 row in set (0.00 sec) SUM используется для поиска общей суммы данного столбца. Например, если вы хотите посмотреть, сколько игр вы и ваши друзья играли в боулинг за эти годы, вы можете выполнить этот запрос:
SELECT SUM(wins) FROM tourneys; +-----------+ | SUM(wins) | +-----------+ | 35 | +-----------+ 1 row in set (0.00 sec) Обратите внимание, что функции AVG и SUM будут работать правильно только при использовании с числовыми данными. Если вы попытаетесь использовать их для нечисловых данных, это приведет к ошибке или просто к «0», в зависимости от того, какую СУБД вы используете:
SELECT SUM(entree) FROM dinners; +-------------+ | SUM(entree) | +-------------+ | 0 | +-------------+ 1 row in set, 5 warnings (0.00 sec) MIN используется для поиска наименьшего значения в указанном столбце. Вы можете использовать этот запрос, чтобы увидеть, какой худший общий рекорд в боулинге (с точки зрения количества побед):
SELECT MIN(wins) FROM tourneys; +-----------+ | MIN(wins) | +-----------+ | 2 | +-----------+ 1 row in set (0.00 sec) Аналогично, MAX используется для поиска наибольшего числового значения в данном столбце. Следующий запрос покажет лучший общий результат в боулинге:
SELECT MAX(wins) FROM tourneys; +-----------+ | MAX(wins) | +-----------+ | 13 | +-----------+ 1 row in set (0.00 sec) В отличие от SUM и AVG , функции MIN и MAX могут использоваться как для числовых, так и для буквенных типов данных. При запуске в столбце, содержащем строковые значения, функция MIN будет отображать первое значение в алфавитном порядке:
SELECT MIN(name) FROM dinners; +-----------+ | MIN(name) | +-----------+ | Barbara | +-----------+ 1 row in set (0.00 sec) Аналогично, при запуске в столбце, содержащем строковые значения, функция MAX покажет последнее значение в алфавитном порядке:
SELECT MAX(name) FROM dinners; +-----------+ | MAX(name) | +-----------+ | Irma | +-----------+ 1 row in set (0.00 sec) Агрегатные функции умеют больше того, что было описано в этом разделе. Они особенно полезны при использовании с предложением GROUP BY , которое рассматривается в следующем разделе, а также с несколькими другими предложениями запроса, которые влияют на сортировку наборов результатов.
Управление запросами
В дополнение к предложениям FROM и WHERE , есть несколько других предложений, которые используются для манипулирования результатами запроса SELECT . В этом разделе мы объясним и предоставим примеры для некоторых из наиболее часто используемых предложений запросов.
Одним из наиболее часто используемых предложений запроса, помимо FROM и WHERE , является предложение GROUP BY . Обычно он используется, когда вы выполняете статистическую функцию для одного столбца, но в отношении сопоставления значений в другом.
Например, скажем, вы хотели знать, сколько ваших друзей предпочитают каждый из трех блюд, которые вы делаете. Вы можете найти эту информацию с помощью следующего запроса:
SELECT COUNT(name), entree FROM dinners GROUP BY entree; +-------------+---------+ | COUNT(name) | entree | +-------------+---------+ | 1 | chicken | | 2 | steak | | 2 | tofu | +-------------+---------+ 3 rows in set (0.00 sec) Предложение ORDER BY используется для сортировки результатов запроса. По умолчанию числовые значения сортируются в порядке возрастания, а текстовые значения сортируются в алфавитном порядке. Чтобы проиллюстрировать это, следующий запрос перечисляет столбцы name и birthdate , но сортирует результаты по дате рождения:
SELECT name, birthdate FROM dinners ORDER BY birthdate; +---------+------------+ | name | birthdate | +---------+------------+ | Etta | 1938-01-25 | | Irma | 1941-02-18 | | Gladys | 1944-05-28 | | Dolly | 1946-01-19 | | Barbara | 1948-12-25 | +---------+------------+ 5 rows in set (0.00 sec) Обратите внимание, что поведение по умолчанию ORDER BY состоит в сортировке набора результатов в порядке возрастания. Чтобы изменить это и отсортировать набор результатов в порядке убывания, закройте запрос с помощью DESC :
SELECT name, birthdate FROM dinners ORDER BY birthdate DESC; +---------+------------+ | name | birthdate | +---------+------------+ | Barbara | 1948-12-25 | | Dolly | 1946-01-19 | | Gladys | 1944-05-28 | | Irma | 1941-02-18 | | Etta | 1938-01-25 | +---------+------------+ 5 rows in set (0.00 sec) Как уже упоминалось ранее, предложение WHERE используется для фильтрации результатов на основе определенных условий. Однако, если вы используете предложение WHERE с агрегатной функцией, оно вернет ошибку, как в случае со следующей попыткой выяснить, какие стороны являются фаворитами по крайней мере трех ваших друзей:
SELECT COUNT(name), side FROM dinners WHERE COUNT(name) >= 3; ERROR 1111 (HY000): Invalid use of group function Предложение HAVING было добавлено в SQL для обеспечения функциональности, аналогичной функциональности предложения WHERE, а также совместимости с агрегатными функциями. Полезно думать о разнице между этими двумя пунктами как о том, что WHERE применяется к отдельным записям, в то время как HAVING применяется к групповым записям. С этой целью каждый раз, когда вы вводите предложение HAVING , также должно присутствовать предложение GROUP BY .
Следующий пример — еще одна попытка найти, какие гарниры являются фаворитами как минимум трех ваших друзей, хотя этот вернет результат без ошибок:
SELECT COUNT(name), side FROM dinners GROUP BY side HAVING COUNT(name) >= 3; +-------------+-------+ | COUNT(name) | side | +-------------+-------+ | 3 | fries | +-------------+-------+ 1 row in set (0.00 sec) Агрегатные функции полезны для суммирования результатов определенного столбца в данной таблице. Однако во многих случаях необходимо запросить содержимое более чем одной таблицы. Мы рассмотрим несколько способов сделать это в следующем разделе.
Запрос нескольких таблиц
Чаще всего база данных содержит несколько таблиц, каждая из которых содержит разные наборы данных. SQL предоставляет несколько разных способов выполнения одного запроса для нескольких таблиц.
Предложение JOIN может использоваться для объединения строк из двух или более таблиц в результате запроса. Это достигается путем нахождения связанного столбца между таблицами и соответствующей сортировки результатов в выходных данных.
Операторы SELECT , которые включают предложение JOIN , обычно следуют этому синтаксису:
SELECT table1.column1, table2.column2 FROM table1 JOIN table2 ON table1.related_column=table2.related_column; Обратите внимание, что поскольку предложения JOIN сравнивают содержимое нескольких таблиц, в предыдущем примере указывается, из какой таблицы выбрать каждый столбец, предшествуя имени столбца с именем таблицы и точкой. Вы можете указать, из какой таблицы должен быть выбран столбец, например, для любого запроса, хотя это не обязательно при выборе из одной таблицы, как мы делали в предыдущих разделах. Давайте рассмотрим пример, используя наш образец Dата.
Представьте, что вы хотите купить каждому из ваших друзей пару ботинок для боулинга в качестве подарка на день рождения. Поскольку информация о датах рождения и размерах обуви ваших друзей хранится в отдельных таблицах, вы можете запросить обе таблицы по отдельности, а затем сравнить результаты для каждой из них. Тем не менее, с помощью предложения JOIN вы можете найти всю необходимую информацию с помощью одного запроса:
SELECT tourneys.name, tourneys.size, dinners.birthdate FROM tourneys JOIN dinners ON tourneys.name=dinners.name; +---------+------+------------+ | name | size | birthdate | +---------+------+------------+ | Dolly | 8.5 | 1946-01-19 | | Etta | 9 | 1938-01-25 | | Irma | 7 | 1941-02-18 | | Barbara | 7.5 | 1948-12-25 | | Gladys | 8 | 1944-05-28 | +---------+------+------------+ 5 rows in set (0.00 sec) Предложение JOIN , используемое в этом примере, без каких-либо других аргументов, является предложением inner JOIN . Это означает, что он выбирает все записи, которые имеют совпадающие значения в обеих таблицах, и печатает их в наборе результатов, в то время как все несоответствующие записи исключаются. Чтобы проиллюстрировать эту идею, давайте добавим новую строку в каждую таблицу, у которой нет соответствующей записи в другой:
INSERT INTO tourneys (name, wins, best, size) VALUES ('Bettye', '0', '193', '9'); INSERT INTO dinners (name, birthdate, entree, side, dessert) VALUES ('Lesley', '1946-05-02', 'steak', 'salad', 'ice cream'); Затем повторно запустите предыдущий оператор SELECT с предложением JOIN:
SELECT tourneys.name, tourneys.size, dinners.birthdate FROM tourneys JOIN dinners ON tourneys.name=dinners.name; +---------+------+------------+ | name | size | birthdate | +---------+------+------------+ | Dolly | 8.5 | 1946-01-19 | | Etta | 9 | 1938-01-25 | | Irma | 7 | 1941-02-18 | | Barbara | 7.5 | 1948-12-25 | | Gladys | 8 | 1944-05-28 | +---------+------+------------+ 5 rows in set (0.00 sec) Обратите внимание, что, поскольку в таблице «tourneys» нет записи для Лесли, а в таблице «dinners» нет записи для Бетти, эти записи отсутствуют в этих выходных данных.
Тем не менее, можно вернуть все записи из одной из таблиц, используя предложение outer JOIN . В MySQL предложения JOIN записываются как LEFT JOIN или RIGHT JOIN .
Предложение LEFT JOIN возвращает все записи из« левой »таблицы и только совпадающие записи из правой таблицы. В контексте внешних объединений левая таблица — это таблица, на которую ссылается условие FROM , а правая таблица — любая другая таблица, на которую ссылается после оператора JOIN .
Выполните предыдущий запрос еще раз, но на этот раз используйте предложение LEFT JOIN :
SELECT tourneys.name, tourneys.size, dinners.birthdate FROM tourneys LEFT JOIN dinners ON tourneys.name=dinners.name; Эта команда будет возвращать каждую запись из левой таблицы (в данном случае, «турниры»), даже если в правой таблице нет соответствующей записи. Каждый раз, когда в правой таблице нет подходящей записи, она возвращается как NULL или просто пустое значение, в зависимости от вашей RDBMS:
+---------+------+------------+ | name | size | birthdate | +---------+------+------------+ | Dolly | 8.5 | 1946-01-19 | | Etta | 9 | 1938-01-25 | | Irma | 7 | 1941-02-18 | | Barbara | 7.5 | 1948-12-25 | | Gladys | 8 | 1944-05-28 | | Bettye | 9 | NULL | +---------+------+------------+ 6 rows in set (0.00 sec) Теперь выполните запрос еще раз, на этот раз с предложением RIGHT JOIN :
SELECT tourneys.name, tourneys.size, dinners.birthdate FROM tourneys RIGHT JOIN dinners ON tourneys.name=dinners.name; Это вернет все записи из правой таблицы ( dinners ). Поскольку дата рождения Лесли записана в правой таблице, но для нее нет соответствующей строки в левой таблице, столбцы name и size вернутся как значения NULL в этой строке:
+---------+------+------------+ | name | size | birthdate | +---------+------+------------+ | Dolly | 8.5 | 1946-01-19 | | Etta | 9 | 1938-01-25 | | Irma | 7 | 1941-02-18 | | Barbara | 7.5 | 1948-12-25 | | Gladys | 8 | 1944-05-28 | | NULL | NULL | 1946-05-02 | +---------+------+------------+ 6 rows in set (0.00 sec) Обратите внимание, что левые и правые объединения могут быть записаны как LEFT OUTER JOIN или RIGHT OUTER JOIN , хотя подразумевается часть «OUTER» в предложении. Аналогично, указание INNER JOIN даст тот же результат, что и простое написание JOIN .
В качестве альтернативы использованию JOIN для запроса записей из нескольких таблиц, вы можете использовать предложение UNION .
Оператор UNION работает немного иначе, чем предложение JOIN : вместо того, чтобы печатать результаты из нескольких таблиц в виде уникальных столбцов с использованием одного оператора SELECT , UNION объединяет результаты двух операторов SELECT в один столбец.
Чтобы проиллюстрировать, запустите следующий запрос:
SELECT name FROM tourneys UNION SELECT name FROM dinners; Этот запрос удалит все повторяющиеся записи, что является поведением по умолчанию оператора UNION :
+---------+ | name | +---------+ | Dolly | | Etta | | Irma | | Barbara | | Gladys | | Bettye | | Lesley | +---------+ 7 rows in set (0.00 sec) Чтобы вернуть все записи (включая дубликаты), используйте оператор UNION ALL :
SELECT name FROM tourneys UNION ALL SELECT name FROM dinners; +---------+ | name | +---------+ | Dolly | | Etta | | Irma | | Barbara | | Gladys | | Bettye | | Dolly | | Etta | | Irma | | Barbara | | Gladys | | Lesley | +---------+ 12 rows in set (0.00 sec) Имена и количество столбцов в таблице результатов отражают имя и количество столбцов, запрошенных первым оператором SELECT. Обратите внимание, что при использовании UNION для запроса нескольких столбцов из более чем одной таблицы каждый оператор SELECT должен запрашивать одинаковое количество столбцов, соответствующие столбцы должны иметь одинаковые типы данных, а столбцы в каждом операторе SELECT должны быть в том же порядке. В следующем примере показано, что может произойти, если вы используете предложение UNION для двух операторов SELECT , которые запрашивают разное количество столбцов:
SELECT name FROM dinners UNION SELECT name, wins FROM tourneys; ERROR 1222 (21000): The used SELECT statements have a different number of columns Другой способ запроса нескольких таблиц — использование subqueries. Подзапросы (также известные как inner или nested query) — это запросы, заключенные в другой запрос. Это полезно в тех случаях, когда вы пытаетесь отфильтровать результаты запроса по сравнению с результатами отдельной агрегатной функции.
Чтобы проиллюстрировать эту идею, скажем, вы хотите знать, кто из ваших друзей выиграл больше матчей, чем Барбара. Вместо того, чтобы узнать, сколько матчей выиграла Барбара, а затем выполнить другой запрос, чтобы узнать, кто выиграл больше игр, вы можете рассчитать обе с помощью одного запроса:
SELECT name, wins FROM tourneys WHERE wins > ( SELECT wins FROM tourneys WHERE name = 'Barbara' ); +--------+------+ | name | wins | +--------+------+ | Dolly | 7 | | Etta | 4 | | Irma | 9 | | Gladys | 13 | +--------+------+ 4 rows in set (0.00 sec) Подзапрос в этом операторе был выполнен только один раз; нужно было только найти значение из столбца wins в той же строке, что и Barbara в столбце name , а данные, возвращаемые подзапросом и внешним запросом, не зависят друг от друга. Однако существуют случаи, когда внешний запрос должен сначала прочитать каждую строку в таблице и сравнить эти значения с данными, возвращенными подзапросом, чтобы получить требуемые данные. В этом случае подзапрос называется коррелированным подзапросом.
Следующее утверждение является примером коррелированного подзапроса. Этот запрос пытается выяснить, кто из ваших друзей выиграл больше игр, чем в среднем для тех, у кого одинаковый размер обуви:
SELECT name, size FROM tourneys AS t WHERE wins > ( SELECT AVG(wins) FROM tourneys WHERE size = t.size ); Чтобы запрос завершился, он должен сначала собрать столбцы name и size из внешнего запроса. Затем он сравнивает каждую строку из этого набора результатов с результатами внутреннего запроса, который определяет среднее количество побед для людей с одинаковыми размерами обуви. Поскольку у вас есть только два друга с одинаковым размером обуви, в наборе результатов может быть только одна строка:
+------+------+ | name | size | +------+------+ | Etta | 9 | +------+------+ 1 row in set (0.00 sec) Как упоминалось ранее, подзапросы могут использоваться для запроса результатов из нескольких таблиц. Чтобы проиллюстрировать это одним последним примером, скажем, вы хотели устроить неожиданный ужин для лучшего боулера группы. Вы можете узнать, кто из ваших друзей имеет лучший рекорд в боулинге, и вернуть любимое блюдо по следующему запросу:
SELECT name, entree, side, dessert FROM dinners WHERE name = (SELECT name FROM tourneys WHERE wins = (SELECT MAX(wins) FROM tourneys)); +--------+--------+-------+-----------+ | name | entree | side | dessert | +--------+--------+-------+-----------+ | Gladys | steak | fries | ice cream | +--------+--------+-------+-----------+ 1 row in set (0.00 sec) Обратите внимание, что этот оператор не только включает подзапрос, но также содержит подзапрос в этом подзапросе.
Заключение
Выдача запросов является одной из наиболее часто выполняемых задач в области управления базами данных. Существует ряд инструментов администрирования баз данных, таких как phpMyAdmin или pgAdmin, которые позволяют выполнять запросы и визуализировать результаты, но с помощью операторов SELECT это все еще широко распространенный рабочий процесс, который также может предоставить вам больший контроль.
Рекомендуемые статьи:
- Оптимальные настройки mysql для Битрикс
- PhpMyAdmin — как создать пользователя и базу данных
- Резервное копирование Mysql
- Перенос пользователей в MySQL между серверами
- Как сбросить пароль MariaDB 10 на сервере с Debian
SQL-запросы: базовые команды и примеры

Чтобы создать таблицу, используют команду CREATE TABLE, новую запись — INSERT.

Анастасия Хамидулина
Автор статьи
14 июня 2022 в 15:01
SQL — язык структурированных запросов. Его создали в 1974 году, чтобы хранить и обрабатывать данные. Все реляционные СУБД — системы управления базами данных — используют его в качестве препроцессора для обработки команд. Сами же базы данных представляют наборы таблиц, где запись — это строка.
SQL в работе используют разработчики и тестировщики, чтобы улучшать сайт или приложение через грамотную работу с базами данных. Тестировщики таким образом помогают бизнесу принимать эффективные решения на основе данных. Маркетологи — глубже анализировать поведение пользователей.
Инженер-тестировщик: новая работа через 9 месяцев
Получится, даже если у вас нет опыта в IT

Виды SQL-запросов
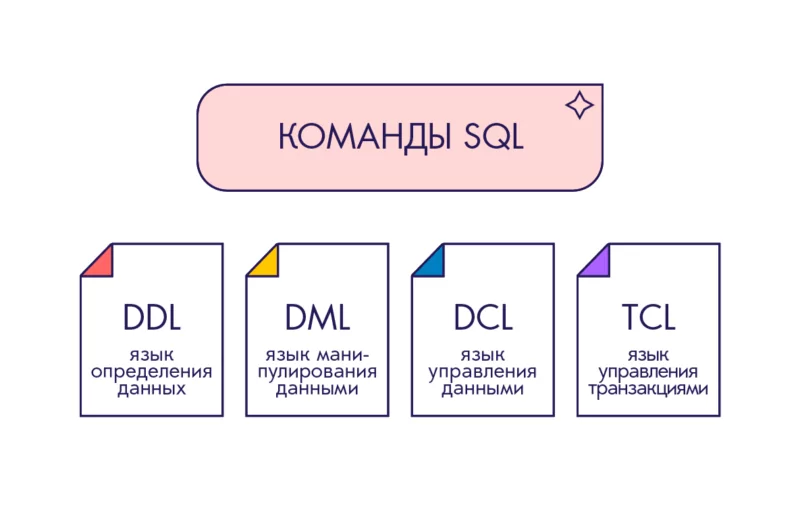
Ключевые слова этого языка делят на четыре логические группы.
1️⃣ DDL
Data Definition Language — язык определения данных. В него входят ключевые слова CREATE, DROP, RENAME и другие, которые относят к определению и манипулированию структурой базы данных. Их используют, чтобы создавать базы данных и описывать структуру, устанавливать, как размещать данные.
2️⃣ DML
Data Manipulation Language — язык манипулирования данными. В этой группе — запросы SELECT, INSERT, UPDATE, DELETE и другие. Их используют, чтобы изменять, получать, обновлять и удалять данные из базы.
3️⃣ DCL
Data Control Language — язык управления данными. К этой группе относят запросы разрешений, прав и различных ограничивающих доступ настроек. Например, GRANT или DENY.
4️⃣ TCL
Transaction Control Language — язык управления транзакциями. В эту группу входят все запросы, которые относят к управлению транзакциями и их жизненными циклами. Например, BEGIN TRANSACTION, ROLLBACK TRANSACTION, COMMIT TRANSACTION.
Особенности языка изучите на курсе «Аналитик данных». Под руководством наставников научитесь делать таблицы и составлять запросы для анализа. Сможете соединять и обрабатывать несколько таблиц, использовать оконные функции.
Структура SQL-запросов
Запросы на языке SQL последовательны: логика их составления почти не отличается от обычного предложения. Например, вы хотите отфильтровать записи, чтобы получить только те, где в первом столбце значение равно единице. А после получить значения второго и третьего столбцов в выборке. Предложение на такую команду будет следующее:
Выбрать Столбец2, Столбец3 из Таблица1, где Столбец1 равен одному
На SQL это выглядит похоже:
SELECT (Column2, Column3) FROM Table1 WHERE Column1 = 1
Простые запросы SQL
Ключевые слова
Их используют, чтобы составить запросы:
Это ключевое слово отфильтровывает записи. Мы использовали его в абстрактном примере:
SELECT (Column2, Column3) FROM Table1 WHERE Column1 = 1
Группирует записи выборки по значениям указанных столбцов. Это ключевое слово должно следовать после WHERE.
✔️ AND, OR и BETWEEN
AND или OR расширяют выборку, создаваемую с помощью WHERE. Либо сужают ее, если указать дополнительные значения. Ключевое слово BETWEEN позволяет указать диапазон значений, чтобы создать выборку.
Лимитирует количество значений выборки. Например, по указанным фильтрам получено 100 значений, а нужны только первые 10. Тогда применяют синтаксис LIMIT 10.
На курсе «Анализ данных» несколько уроков посвящены тому, чтобы делать простые запросы на выборку, фильтрацию и сортировку данных, очищать и подготавливать их для анализа. На практике научитесь составлять разные комбинации, чтобы решать реальные задачи. Создадите проекты для портфолио, а если успешно окончите курс, получите диплом установленного образца.
Команды
С них начинаются запросы.
Предположим, нам необходимо создать базу данных, чтобы хранить информацию о прочитанных книгах, извлекать и изменять данные. В примерах мы будем использовать самую простую СУБД — sqlite3 в среде Linux. Создайте базу данных командой sqlite3 demo.db — и сразу попадете в командную строку программы:
sqlite3 demo.db SQLite version 3.27.2 2019-02-25 16:06:06 Enter ".help" for usage hints. sqlite>
�� CREATE TABLE
Чтобы создать таблицу, используют команду CREATE TABLE. Если создаете таблицу с прочитанными книгами, вероятно, понадобятся три столбца: id, название и автор.
sqlite> CREATE TABLE Books (id INTEGER PRIMARY KEY, title CHAR(255), author CHAR(255)); sqlite> .tables Books
Команда .tables отображает список таблиц.
�� INSERT
Команда создает новые записи. Добавим три книги в нашу таблицу:
sqlite> INSERT INTO Books(title, author) VALUES . > ("Язык SQL", "Неизвестный автор"), . > ("SQL. Сборник рецептов", "Энтони Молинаро"), . > ("Книга №3", "Без автора");
Указываем, в какие столбцы нужно вставить данные, игнорируя столбец id: он помечен как первичный ключ. Будет автоматически инкрементироваться, генерируя уникальные значения. В примере вставляем несколько записей за один запрос.
�� SELECT
Извлекает записи из таблицы:
sqlite> SELECT * FROM Books; 1|Язык SQL|Неизвестный автор 2|SQL. Сборник рецептов|Энтони Молинаро 3|Книга №3|Без автора
Каждая запись будет на новой строке, а значения столбцов — разделены вертикальной линией. Если, например, нужны не все, а определенные столбцы, то звездочку замените на названия столбцов через запятую:
sqlite> SELECT title, author FROM Books; Язык SQL|Неизвестный автор SQL. Сборник рецептов|Энтони Молинаро Книга №3|Без автора
�� UPDATE
Изменяет существующие записи. Чтобы использовать эту команду, укажите уникальный идентификатор изменяемой записи. Либо характеристику, по которой можно получить одну запись или группу из нескольких записей. Обновим авторов у первой и последней записи:
sqlite> UPDATE Books . > SET author = "Unknown" . > WHERE OR sqlite> SELECT title, author FROM Books; Язык SQL|Unknown SQL. Сборник рецептов|Энтони Молинаро Книга №3|Unknown
�� DELETE
Удаляет записи из таблицы по поисковому запросу. Удалим книгу с id, равным двум:
sqlite> DELETE FROM Books WHERE sqlite> SELECT * FROM Books; 1|Язык SQL|Unknown 3|Книга №3|Unknown
�� DROP TABLE
Удаляет таблицы из базы данных. Создадим и удалим демонстрационную таблицу:
sqlite> CREATE TABLE Demo (id INTEGER PRIMARY KEY, text TEXT); sqlite> sqlite> .tables Books Demo sqlite> sqlite> DROP TABLE Demo; sqlite> sqlite> .tables Books
�� ALTER TABLE
Команда в сочетании с другими ключевыми словами изменяет названия таблиц или добавляет новые столбцы. Изменим название нашей таблицы Books:
sqlite> ALTER TABLE Books RENAME TO MyBooks; sqlite> sqlite> .tables MyBooks
Добавим в нее новый столбец is_finished с булевым значением:
sqlite> ALTER TABLE MyBooks ADD COLUMN is_finished BOOLEAN; sqlite> UPDATE MyBooks . > SET is_finished = True; sqlite> sqlite> SELECT * FROM MyBooks; 1|Язык SQL|Unknown|1 3|Книга №3|Unknown|1
Агрегатные функции
Их используют, чтобы проводить дополнительные вычисления внутри полученной выборки:
✔️ COUNT(название_столбца) — возвращает количество строк выборки, где значение столбца не NULL.
✔️ SUM(название_столбца) — вычисляет и возвращает сумму значений в указанном столбце.
✔️ AVG(название_столбца) — вычисляет и возвращает среднее значение по столбцу.
✔️ MIN(название_столбца) — возвращает наименьшее значение для указанного столбца.
✔️ MAX(название_столбца) — возвращает наибольшее значение указанного столбца.
Научиться работе со всеми видами агрегатных функций можно на курсе «Анализ данных». Сможете взаимодействовать с синтаксисом и операторами для создания, модификации и удаления таблиц в SQL. В конце обучения у вас будет резюме, портфолио и диплом о профессиональной переподготовке. Это поможет устроиться на хорошую работу.
Вложенные подзапросы
Это SQL-запрос внутри другого SQL-запроса. Подзапросы помогают, если выборку фильтруют по значениям, которые тоже можно отфильтровать. Например, получим названия футбольных команд — участников соревнований с 2010 по 2020 годы:
SELECT DISTINCT club_name FROM clubs WHERE game_year = 2010 AND club_id IN (SELECT club_id FROM clubs WHERE game_year = 2020 );
Ключевое слово DISTINCT убирает из выборки дублирующиеся результаты.