Как написать summary?
Summary (саммари) представляет собой пересказ какого-либо объемного материала. В этой статье мы поговорим, зачем summary пишется, какими особенностями отличается, какую имеет структуру, какие практические советы по написанию существуют.
Саммари — это сжатое изложение материала либо обобщение информации, которая изложена в каком-нибудь источнике. Также саммари — это:
— краткая выжимка основных идей/главного содержания;
— уход от излишней детализации и ненужных подробностей;
— упражнение, развивающее письменную речь в английском языке.
Иногда summary включает в себя дополнительные рекомендации относительно того, что можно сделать в контексте решения рассматриваемой проблемы.
Цель
Саммари необходимо писать в следующих целях:
— для обучения, если речь идет об иностранных языках;
— для предоставления заинтересованной стороне наиболее важной информации об интересующих вопросах/проблемах/тематике;
— для существенной экономии времени (далеко не каждый имеет возможность прочитать конспект на ста листах или неделю изучать какой-нибудь объемный текст).
Таким образом, изучив саммари, заинтересованное лицо будет знать суть материала, причем с основными источниками ему знакомиться не придется.
Структура
Структуризация позволяет написать материал более логично и последовательно. Говоря о структуре, мы подразумеваем наличие отдельных логических модулей, к примеру:
- Введение (презентуется тема, дается информация об авторе).
- Изложение (открывается основная идея, даются факты/примеры).
- Заключение (делаются выводы).
Также для summary характерно применение:
Советы и рекомендации
Рассмотрим практические советы общего плана, которые помогут все грамотно написать:
— внимательно прочтите оригинальный текст, ведь вам нужно четко понимать, о чем речь;
— выделите основную идею;
— отметьте факты и важные примеры — это позволит обозначить основные тезисы;
— излагайте материал сжато и кратко, сложная терминология не приветствуется.
Теперь рассмотрим советы о том, как писать саммари на английском:
1. При обучении вам могут поставить задачу написать summary двух видов: оценочное либо информативное, причем вы должны понимать, о каком виде пересказа идет речь. Первый случай — это аналогия с рецензиями к фильмам/книгам/передачам. Здесь надо не только изложить сюжет в краткой форме, но и высказать свое мнение, дать оценку работе автора/актера/режиссера. Здесь потребуется высокий уровень владения языком. Второй случай — это краткое изложение смысла какой-нибудь статьи. Данный вариант также называют реферированием.
2. Бегло ознакомьтесь с материалом, выявите основную мысль.
3. Перечитайте материал еще раз, но уже более вдумчиво. Разберите речевые обороты и незнакомые слова. Далее определите и выпишите ключевые фразы. Кратко сформулируйте суть каждого абзаца, составьте предварительный план.
4. Доработайте план. Очень часто некоторые абзацы без проблем объединяются в один. Тут важно учитывать не размер абзацев, а их смысл.
5. Старайтесь передать содержание любого пункта вашего плана несколькими предложениями (одним-двумя). Можно применять готовые фрагменты из источника либо перефразировать длинные фразы более кратко, но уже своими словами.
Фразы для summary
В современном английском языке есть много фраз и выражений, позволяющих излагать текст последовательно. Примеры:
- The article/problem is about/concerned with… (эта статья/проблема касается…)
- It’s a striking example of the… (это поразительный пример…)
- The author provides/gives the information on… (автор информирует о…)
- The author gives a detailed analysis of… (автор проводит детальный анализ…)
- In the first/second/third paragraph… (в первом/втором/третьем параграфе…)
- Firstly/Secondly/Thirdly…
- Afterwards… (после этого…)
- In addition… (в дополнение…)
- Moreover… (более того…)
- In the conclusion… (в заключение…)
- At the end… (в конце…)
- Finally… (наконец…)
Также вам может быть полезна таблица ниже:
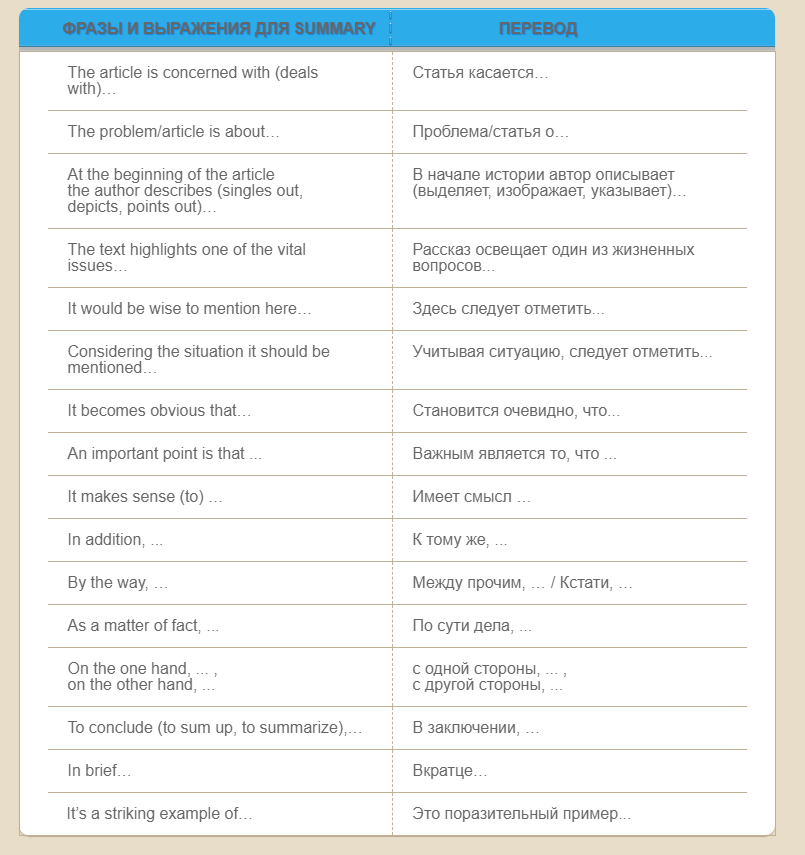
Итогом вашей деятельности должен стать краткий пересказ, который будет составлять не более четверти от первоначального объема. Надеемся, эта статья была вам полезна, и теперь вы знаете, как писать summary.
- https://inspeak.ru/articles/Leksika/Summary;
- https://irina-deryugina.ru/blog/summary.
summary.mlModel: сводка по модели Машинного обучения Microsoft R.
Объект модели, возвращаемый из анализа MicrosoftML.
top
Указывает число верхних коэффициентов, отображаемых в сводке для линейных моделей, таких как rxLogisticRegression и rxFastLinear. Сначала выполняется смещение, за которым следуют другие весовые коэффициенты, отсортированные по их абсолютным величинам в убывающем порядке. Если задано значение NULL , отображаются все ненулевые коэффициенты. В противном случае отображаются только первые коэффициенты top .
Дополнительные аргументы передаются в метод сводки.
Подробнее
Предоставляет сводку о вызове исходной функции —
набор данных, использованный для обучения модели, и статистические показатели для коэффициентов в модели.
Значение
Метод summary объектов анализа MicrosoftML возвращает список, включающий исходный вызов функции и используемые базовые параметры. Метод coef возвращает именованный вектор весовых коэффициентов, обрабатывая данные из объекта модели.
Для модели rxLogisticRegression в сводке также может применяться следующая статистика, если для параметра showTrainingStats задано значение TRUE .
training.size
Размер набора данных, используемого для обучения модели, относительно числа строк.
deviance
Отклонение модели, заданное -2 * ln(L) , где L — это вероятность получения наблюдений со всеми функциями, включенными в модель.
null.deviance
Нулевое отклонение, заданное -2 * ln(L0) , где L0 — это вероятность получения наблюдений без эффекта от функций. Нулевая модель включает смещение, если оно есть в модели.
aic
AIC (информационный критерий Akaike) определяется как 2 * k «+ deviance , где k — число коэффициентов модели. Смещение считается одним из коэффициентов. Критерий AIC — это мера относительного качества модели. Он влияет на компромиссное соотношение между степенью соответствия модели (измеряемой отклонением) и ее сложностью (измеряемой количеством коэффициентов).
coefficients.stats
Это кадр данных, содержащий статистику для каждого коэффициента в модели. Для каждого коэффициента отображаются следующие статистические данные. Смещение отображается в первой строке, а оставшиеся коэффициенты — в порядке возрастания p-значения.
- Estimate — рассчитанное значение коэффициента модели.
- StdError — это квадратный корень из дисперсии большой выборки оценки коэффициента.
- Z-оценка может проверить нулевую гипотезу, в которой говорится, что коэффициент должен быть равен нулю в отношении значимости коэффициента путем вычисления соотношения его оценки и его стандартной ошибки. При нулевой гипотезе, если не применяется регуляризация, оценка интересующего коэффициента соответствует нормальному распределению со средним значением 0 и стандартным отклонением, равным стандартной ошибке, вычисленной выше. Z-оценка выводит отношение между оценкой коэффициента и стандартной ошибкой коэффициента.
- Pr(>|z|) Это соответствующее p-значение для двустороннего теста z-оценки. В зависимости от уровня значимости к p-значению добавляется индикатор значимости. Если F(x) — это CDF стандартного нормального распределения N(0, 1) , тогда P(>|z|) = 2 — «2 * F(|z|) .
Авторы
См. также
Примеры
# Estimate a logistic regression model logitModel 0 testIris
Summary python что это
The fileinfo.py program should now make perfect sense.
Пример 3.40. fileinfo.py
"""Получение метаинформации, специфичной для файла данного типа. Создайте экземпляр соответствующего класса, передав конструктору имя файла. Возвращаемый объект ведет себя аналогично словарю с парами ключ-значение для каждой части метаинформации. import fileinfo info = fileinfo.MP3FileInfo("/music/ap/mahadeva.mp3") print "\\n".join(["%s=%s" % (k, v) for k, v in info.items()]) Или используйте функцию listDirectory для получения информации обо всех файлов в директории for info in fileinfo.listDirectory("/music/ap/", [".mp3"]): . Модуль может быть расширен путем доюавления классов для других типов файлов, например HTMLFileInfo, MPGFileInfo, DOCFileInfo. Каждый класс полностью отвечает за анализ файлов соответствующего типа; используйте MP3FileInfo в качестве примера. """ import os import sys from UserDict import UserDict def stripnulls(data): "очищает строку от символов пропуска и нулевых символов" return data.replace("\00", "").strip() class FileInfo(UserDict): "хранит метаинформацию о файле" def __init__(self, filename=None): UserDict.__init__(self) self["name"] = filename class MP3FileInfo(FileInfo): "хранит ID3v1.0 MP3 теги" tagDataMap = "title" : ( 3, 33, stripnulls), "artist" : ( 33, 63, stripnulls), "album" : ( 63, 93, stripnulls), "year" : ( 93, 97, stripnulls), "comment" : ( 97, 126, stripnulls), "genre" : (127, 128, ord)> def __parse(self, filename): "анализ ID3v1.0 тегов из MP3 файла" self.clear() try: fsock = open(filename, "rb", 0) try: fsock.seek(-128, 2) tagdata = fsock.read(128) finally: fsock.close() if tagdata[:3] == "TAG": for tag, (start, end, parseFunc) in self.tagDataMap.items(): self[tag] = parseFunc(tagdata[start:end]) except IOError: pass def __setitem__(self, key, item): if key == "name" and item: self.__parse(item) FileInfo.__setitem__(self, key, item) def listDirectory(directory, fileExtList): """возвращает список объектов с метаинформацией для всех файлов с указанным расширением""" fileList = [os.path.normcase(f) for f in os.listdir(directory)] fileList = [os.path.join(directory, f) for f in fileList \ if os.path.splitext(f)[1] in fileExtList] def getFileInfoClass(filename, module=sys.modules[FileInfo.__module__]): "оределяет класс, предназначеный для обработки файла, по расширению" subclass = "%sFileInfo" % os.path.splitext(filename)[1].upper()[1:] return hasattr(module, subclass) and getattr(module, subclass) or FileInfo return [getFileInfoClass(f)(f) for f in fileList] if __name__ == "__main__": for info in listDirectory("/music/_singles/", [".mp3"]): print "\n".join(["%s=%s" % (k, v) for k, v in info.items()]) print
Before diving into the next chapter, make sure you're comfortable doing all of these things:
- Importing modules using either import module or from module import
- Defining and instantiating classes
- Defining __init__ methods and other special class methods, and understanding when they are called
- Subclassing UserDict to define classes that act like dictionaries
- Defining data attributes and class attributes, and understanding the differences between them
- Defining private methods
- Catching exceptions with try. except
- Protecting external resources with try. finally
- Reading from files
- Assigning multiple values at once in a for loop
- Using the os module for all your cross-platform file manipulation needs
- Dynamically instantiating classes of unknown type by treating classes as objects and passing them around
Copyright © 2000, 2001, 2002 Марк Пилгрим
Copyright © 2001, 2002 Перевод, Денис Откидач
Python summary примеры использования
Python summary - 4 примера найдено. Это лучшие примеры Python кода для clld.util.summary, полученные из open source проектов. Вы можете ставить оценку каждому примеру, чтобы помочь нам улучшить качество примеров.
Related in langs
def test_summary(): from clld.util import summary # text consisting of unique words text = "This is a long text, which we want to summarize." assert summary(text[:20]) == text[:20] assert summary(text, len(text) - 1).endswith('. ') assert summary('One verylongword', 10) == 'One . ' assert summary('One verylongword', 2) == '. '
def test_summary(): from clld.util import summary # text consisting of unique words text = "This is a long text, which we want to summarize." assert summary(text[:20]) == text[:20] assert summary(text, len(text) - 1).endswith('. ') assert summary('One verylongword', 10) == 'One . ' assert summary('One verylongword', 2) == '. '
def atom_feed(request, feed_url): """ Proxy feeds so they can be accessed via XHR requests. We also convert RSS to ATOM so that the javascript Feed component can read them. """ ctx = try: res = requests.get(ctx['url'], timeout=(3.05, 1)) except Timeout: res = None if res and res.status_code == 200: d = feedparser.parse(res.content.strip()) ctx['title'] = getattr(d.feed, 'title', None) for e in d.entries: ctx['entries'].append(dict( title=e.title, link=e.link, updated=datetime.fromtimestamp(mktime(e.published_parsed)).isoformat(), summary=summary(e.description))) response = render_to_response('atom_feed.mako', ctx, request=request) response.content_type = 'application/atom+xml' return response