Недетерминированный конечный автомат
В NDFA для определенного входного символа машина может перейти в любую комбинацию состояний в машине. Другими словами, точное состояние, в которое перемещается машина, не может быть определено. Следовательно, он называется недетерминированным автоматом . Поскольку оно имеет конечное число состояний, машина называется недетерминированным конечным автоматом или недетерминированным конечным автоматом .
Формальное определение NDFA
NDFA может быть представлен 5-кортежем (Q, ∑, δ, q 0 , F), где –
- Q – конечное множество состояний.
- ∑ – это конечный набор символов, называемых алфавитами.
- δ – функция перехода, где δ: Q × ∑ → 2 Q (Здесь набор мощности Q (2 Q ) был взят, потому что в случае NDFA из состояния может произойти переход к любой комбинации состояний Q)
- q 0 – начальное состояние, из которого обрабатывается любой вход (q 0 ∈ Q).
- F – множество конечных состояний / состояний Q (F ⊆ Q).
Q – конечное множество состояний.
∑ – это конечный набор символов, называемых алфавитами.
δ – функция перехода, где δ: Q × ∑ → 2 Q
(Здесь набор мощности Q (2 Q ) был взят, потому что в случае NDFA из состояния может произойти переход к любой комбинации состояний Q)
q 0 – начальное состояние, из которого обрабатывается любой вход (q 0 ∈ Q).
F – множество конечных состояний / состояний Q (F ⊆ Q).
Графическое представление NDFA: (так же, как DFA)
NDFA представлен орграфами, которые называются диаграммой состояний.
- Вершины представляют состояния.
- Дуги, помеченные входным алфавитом, показывают переходы.
- Начальное состояние обозначается пустой единственной входящей дугой.
- Конечное состояние обозначено двойными кружками.
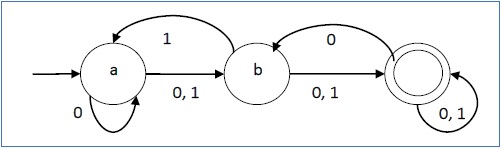
Пусть недетерминированный конечный автомат будет →
Функция перехода δ, как показано ниже –
| Современное состояние | Следующее состояние для ввода 0 | Следующее состояние для ввода 1 |
|---|---|---|
| а, б | б | |
| б | с | а, с |
| с | До нашей эры | с |
Его графическое представление будет следующим:
ДФА против НДФА
В следующей таблице перечислены различия между DFA и NDFA.
| DFA | NDFA |
|---|---|
| Переход из состояния в одно конкретное следующее состояние для каждого входного символа. Следовательно это называется детерминированным . | Переход из состояния может быть в несколько следующих состояний для каждого входного символа. Следовательно это называется недетерминированным . |
| Пустые строковые переходы не видны в DFA. | NDFA разрешает переходы пустой строки. |
| Отклонение разрешено в DFA | В NDFA откат не всегда возможен. |
| Требуется больше места. | Требует меньше места. |
| DFA принимает строку, если она переходит в конечное состояние. | NDFA принимает строку, если хотя бы один из всех возможных переходов заканчивается в конечном состоянии. |
Акцепторы, классификаторы и преобразователи
Акцептор (Распознаватель)
Автомат, который вычисляет булеву функцию, называется акцептором . Все состояния акцептора либо принимают, либо отклоняют введенные ему входные данные.
классификатор
Классификатор имеет более двух конечных состояний и выдает один выход при его завершении.
преобразователь
Автомат, который производит выходные данные на основе текущего входа и / или предыдущего состояния, называется преобразователем . Преобразователи могут быть двух типов –
- Мили Машина – выход зависит как от текущего состояния и текущего ввода.
- Moore Machine – Выход зависит только от текущего состояния.
Мили Машина – выход зависит как от текущего состояния и текущего ввода.
Moore Machine – Выход зависит только от текущего состояния.
Приемлемость DFA и NDFA
DFA / NDFA принимает строку, если DFA / NDFA, начиная с начального состояния, заканчивается после полного чтения строки в состоянии принятия (любом из конечных состояний).
Строка S принимается DFA / NDFA (Q, ∑, δ, q 0 , F), если
Язык L принятый DFA / NDFA:
Строка S ′ не принимается DFA / NDFA (Q, ∑, δ, q 0 , F), если
Язык L ′ не принят DFA / NDFA (дополнение к принятому языку L)
Давайте рассмотрим DFA, показанный на рисунке 1.3. Из DFA, приемлемые строки могут быть получены.
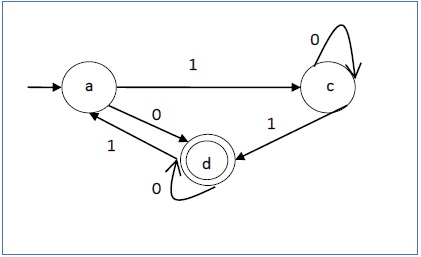
Строки, принятые вышеуказанным DFA:
Строки, не принятые вышеуказанным DFA:
С чем едят конечный автомат
Машина Тьюринга и машина состояний, детерминированный и недетерминированный конечный автомат, конечный автомат Мура и конечный автомат Мили. Голова кругом от всех этих понятий. Как во всем этом разобраться новичку? Тем более, что и у бывалых спецов бывает такая каша в голове из этих понятий. Чего только стоит вебинар от Яндекс Практикум на тему «Конечные автоматы в реальной жизни». Именно случайный просмотр этого вебинара сподвиг меня написать статью. Я обратил внимание, что даже более опытные лекторы ловко жонглируют всеми этими понятиями или подменяют одни другими в своих лекциях. С этим можно просто смириться, или дойти до безумия, разбираясь что к чему. И как со всем этим жить начинающему ардуинщику, если про конечные автоматы в программировании трубят из каждого утюга, а добраться до истины самостоятельно непросто?
Не гарантирую, что после прочтения статьи все сразу станет на свои места, но, как минимум, постараемся выудить из всей этой «каши» что-то полезное для себя. Так что усаживайтесь по удобнее, тема не простая, под катом будет много текста.
❯ Во всем виноваты математики
Да, именно так. Математика — это наука с долгой историей. Наука очень увлекательная, и поэтому она затягивает все большее количество умов. И каждому математику в душе хочется стать новым Пифагором, Евклидом, Лобачевским. А для этого необходимо постоянно расширять поле деятельности. Как только появляется какое-то новое научное направления, математики тут же жадно накидываются на него и изобретают свои новые теории.
Язык у математиков весьма своеобразный, совершенно непредназначенный для того, чтобы на нем разговаривать. Вот почему неподготовленному человеку в этих теориях сложно разобраться. К тому же, новые теории всегда строятся на уже имеющихся, происходит заимствование знакомых ранее понятий и адаптация их к новым условиям. От того путаницы становится все больше, остается ждать, пока все это как следует устоится.
Такая же участь ждала и электронику на заре ее развития. На ранних парах электроника была нераздельно связана со словом «радио» (радиоэлектроника), и ориентирована на радиосвязь. Новое прикладное применение обрела для себя тригонометрия, подтянулась теория сигналов, преобразования Фурье и еще много чего интересного.
❯ Комбинационные логические схемы
С развитием электроники от нее стали откалываться новые направления. Одно из таких — вычислительная техника. И тут математики тоже не остались в стороне. Хорошим подспорьем стала дискретная математика, от которой перешли к математической теории вычислительной техники.
К компьютерам вычислительная техника пришла далеко не сразу. Сперва появились комбинационные логические схемы. К таким схема можно отнести знакомые всем базовые логические вентили НЕ, И, ИЛИ, Исключающее ИЛИ и другие их комбинации. Шифраторы и дешифраторы можно считать более сложным вариантом комбинационных схем.
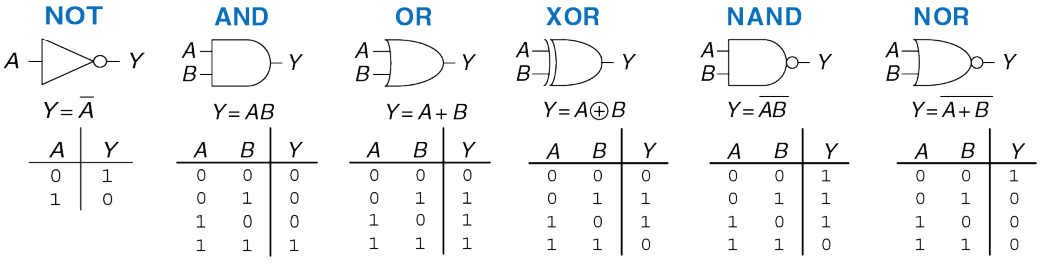
Особенность комбинационных схем заключается в том, что значение на выходе схемы зависит только от комбинации входных сигналов в текущий момент времени. Такие схемы не пригодны для сложных применений, так как не имеют элементов памяти. Описание работы комбинационных схем может быть выполнено в виде таблицы истинности или в виде логического выражения.
❯ Последовательностные логические схемы
Для реализации более сложных вычислений появились последовательностные логические схемы, значения на выходе которых зависят как от текущих входных значений, так и от предыдущих. Для этого последовательностные логические схемы содержат память. Эти схемы могут явно запоминать предыдущие значения определенных входов, или могут сжимать их в меньшее количество информации, называемое состоянием системы. Состояние системы содержит всю необходимую информацию о прошлом, необходимую для определения будущего поведения схемы.
В общем случае к последовательностным схемам можно отнести все схемы, которые не являются комбинационными. То есть последовательностные логические схемы – это те, значение выхода которых нельзя однозначно определить, зная лишь текущие значения входов.

Примером последовательностных логических схем могут служить защелки или различные типы триггеров. Они способны запоминать всего один бит информации. Объединение нескольких триггеров позволяет получить более сложные схемы параллельных, параллельно-последовательных, последовательно-параллельных и прочих регистров, которые способны хранить уже несколько бит.
❯ Конечный автомат Мура и Мили
Поведение некоторых последовательностных схем может быть весьма сложным, для описания их работы простые таблицы истинности уже не подходят. Чтобы упростить анализ сложных последовательностных логических схем, появилась теория цифровых автоматов для построения математических моделей, использующая понятие абстрактный автомат (Abstract Machine).
Абстрактный автомат — это математическая абстрактная модель дискретного устройства, имеющего один вход и один выход, в каждый момент находится в одном состоянии из множества возможных.
Частным случаем этой теории являются автоматы Мура и Мили, позволяющие описать функционирование цифровых систем, которые нашла широкое применение для синтеза сложных последовательностных схем на основе ПЛИС. А математические «иероглифы», которыми обильно сдобрена теория, стали хорошим подспорьем для языков описания аппаратуры подобных SystemVerilog или VHDL.
Автоматы Мура и Мили названы в честь своих изобретателей, ученых, разработавших теорию автоматов и математическую базу для них в фирме Bell Labs.

Эдвард Форест Мур (1925–2003) опубликовал свою первую статью «Gedankenexperiments on Sequential Machines» («Мысленные эксперименты с последовательностными автоматами») в 1956 году.

Джордж Мили (1927–2010) опубликовал «Method of Synthesizing Sequential Circuits» («Метод синтеза последовательностных схем») в 1955 году. Впоследствии он написал первую операционную систему для компьютера IBM 704. Позже он перешел на работу в Гарвардский Университет.

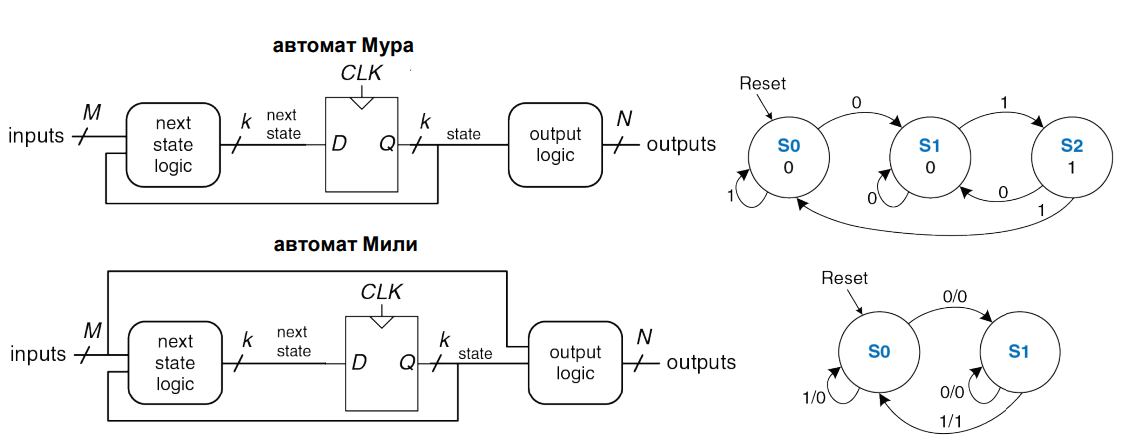
Схема конечного автомата содержит память для запоминания допустимых состояний. Выход схемы памяти вместе с входным сигналом поступает на входную схему формирования переходов, которая формирует новое значение в ячейке памяти (определяет следующее состояние). Также выход схемы памяти формирует выходной сигнал.
Если выходной сигнал полностью определяется значением ячейки памяти, то схему называют автомат Мура.
В ряде случаев в формировании выходного сигнала может задействоваться не только ячейка памяти, но и входной сигнал. Это позволяет сократить количество необходимых состояний. Такая схема называется автомат Мили.
Основная разница между конечными автоматами Мура и Мили в том, что у автомата Мура обычно больше (Moore – more) состояний, чем у автомата Мили, решающего ту же задачу.

Описание переходов между состояниями для автоматов удобно выражать в виде диаграмм, выполненных в виде графов. Если состояния имеют единственную последовательность переключений, то такой автомат называется детерминированным. Если из одного состояния возможно выполнить несколько переходов, то автомат называется недетерменированным.
Цифровой автомат также может однозначно описываться таблицей переходов и таблицей выходов, которые связывают состояния ячеек памяти и входных сигналов. В каждой ячейке таблицы переходов размещаются следующие значения памяти, которые получаются под воздействием входного сигнала при текущем состоянии.
❯ Машина Тьюринга
И вот, наконец вычислительная техника вплотную приблизилась к появлению компьютеров, для которых уже недостаточно было только разработать схему, но и требовалось разработать программное обеспечение. Естественно, что это потребовало новых математических теорий.
Машина Тьюринга была предложена для формализации понятия алгоритма, и является расширением или частным случаем конечного автомата. Сам Алан Тьюринг использовал понятие «вычислительная машина» («computing machine»).

Отдельно останавливаться на самом Тьюринге нет смысла, личность его достаточно известна. Чего стоит только один фильм «Игра в имитацию» с великолепным Бенедиктом Камбербэдчем. Кто не смотрел — крайне рекомендую.
Машина Тьюринга разрабатывалась для того, чтобы ответить на вопрос: «есть ли конкретный метод или механический процесс, который можно применить к математическому утверждению и он ответит, доказуемо ли это утверждение» — которым задавался известный математик Макс Ньюман на своих лекциях в Кембридже.
Нужно понимать, что математикам для работы совершенно не требовалось физически строить машину Тьюринга, а было достаточно ее формализованного описания. То есть машина существует как список правил, по которым она могла бы работать.
Кроме машины Тьюринга появлялись и другие аналогичные теории. К примеру, всего на три месяца позже независимо от машины Тьюринга вышла публикация о машине Поста. Работа над ней велась независимо. Машина Поста также используется в научных трудах благодаря ее простоте.

Гениальность машины Тьюринга заключается в простой идее, что на одной и той же вычислительной машине можно реализовать совершенно разные устройства. Во многом благодаря ей в математике зародилась теория сложности вычислений.
В интернете вы можете встретить достаточное количество программных реализаций машины Тьюринга. Но, на мой взгляд, это не имеет большого прикладного смысла. К счастью, на сегодняшний день существуют другие более эффективные программные решения.
❯ Конечные автоматы в программировании
И так, мы уже увидели, как конечные автоматы используются в математике и электронике. Третье направление, где используется теория конечных автоматов — это программирование. Но не нужно думать, что используется оно в чистом виде.

Идея рассматривать программу в терминах конечного автомата сама по себе не новая. Но наиболее активно свое развитие она получила в начале 90-х годов прошлого века. Одним из основоположников данной идеи является профессор Университета ИТМО Анатолий Абрамович Шалыто. Идея заключается в том, чтобы программировать с использованием понятия «состояние». Сперва для названия этого подхода появился термин «Switch-технологии«, так как операторы множественного выбора в традиционных языках подходили для смены состояний программы больше всего. Позже, в конце 90-х термин «Switch-технологии» был заменен на «автоматное программирование«.
Теория автоматного программирования — это, прежде всего, отдельное направление в программировании, которое заимствовало некоторые термины и определения из теории автоматического управления, но при этом строится как самостоятельная теория. Для реализации автоматных программ можно использовать диаграммы Мура и таблицы состояний, но сама реализация конечного автомата в автоматном программировании будет отличаться от схемотехнической.
Автоматное программирование можно рассматривать как самостоятельную парадигму. Есть мнение, что оно должно исправить недостатки ООП, и может использоваться как дополнение к нему.
Но, так как специализированные языки для автоматного программирования еще не получили такого распространения, как традиционные языки, точно отделить автоматные программы от программ, написанных более традиционными способами, достаточно сложно. На эту тему идут постоянные споры.
Хочу заметить, что в англоязычном интернете упоминаний о работе Шалыто я не нашел. А Finite State Machine рассматривается как модель для разработки и электрических схем и программных алгоритмов. Каких-то отдельных названий для программирования конечных автоматов я тоже не встречал, обычно так и пишут: «программирование конечного автомата«. Хотя, мне лично такое название, как «автоматное программирование«, кажется удобным для обращения. На Хабре есть интересная статья, посвященная работе Анатолия Абрамовича, советую почитать.
Но, несмотря на всю неоднозначность, все же рекомендую ознакомиться с работами Шалыто, в частности с его книгой «Автоматное программирование«. В ней содержится много полезных прикладных решений. Еще есть сайт автора на эту тему.
Программирование в стиле конечных автоматов получило широкое распространение в системах автоматизированного управления, разработке компьютерных игр, текстовых интерпретаторах, все чаще используется в веб-программировании. Написано большое количество готовых библиотек, реализующих конечные автоматы, на разных языках и для разных систем программирования.
Хорошим примером языка программирования, специализированного на автоматном стиле, является язык последовательных функциональных схем SFC (Sequential Function Chart).
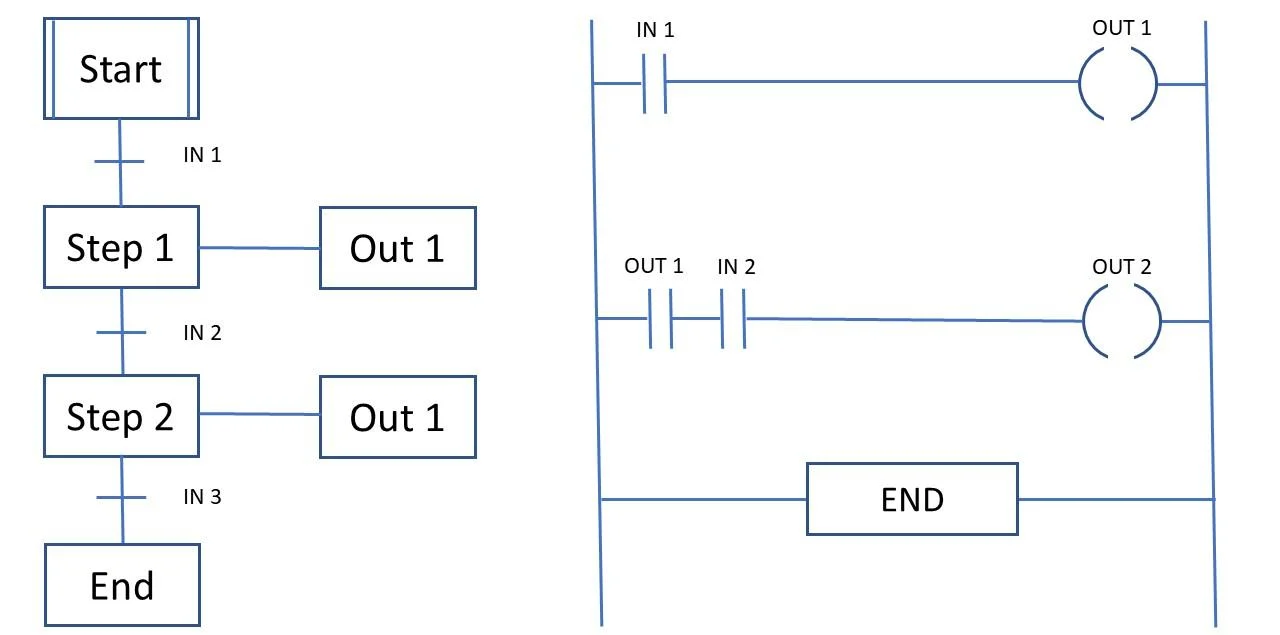
SFC — язык программирования стандарта IEC61131-3, предназначенный для программирования промышленных контроллеров. Широко используется в SCADA/HMI пакетах для программирования промышленных логических контроллеров PLC. Является графическим языком, программа описывается в виде схематической последовательности шагов, объединенных переходами, подобно диаграмме состояний.
Стоит отметить, что подходы, используемые автоматным программированием, очень удобны в разработке программ для микроконтроллеров.
❯ Заключение
И все-таки, почему же с конечными автоматами получается такая каша? Мне кажется, что это связано с большим объемом знаний по данной тематике. Не все они имеют прямое отношение к программированию. Да и такая высокая формализация в программировании, как в синтезе электрических схем, скорее всего не нужна. Или все-таки нужна, но программисты обычно не уделяют этому вопросу достаточного внимания?

В общем, можно говорить о том, что такие понятия как: конечный автомат или конечный автомат состояний, и машина состояний или State Mashine, или Finite State Machine (FSM)- являются синонимами. Это связанно с особенностями терминологии на русском и английском языках.
Надеюсь, что дальнейшее изучение теории цифровых автоматов станет для вас значительно проще.

- timeweb_статьи
- конечный автомат
- автомат Мура и Мили
- finite state machine
- FSM
- математика
- логические схемы
- радиоэлектроника
- Тьюринг
- scada разработка программирование
Детерминированные конечные автоматы
Ещё раз напомним, что детерминированным конечным автоматом (далее ДКА) называется произвольное отображение \(t:S\times A\to S\), для которого множества \(S\) и \(A\) конечны. Множество \(S\) называется множеством состояний автомата, а \(A\) — алфавитом.
Обработка текста
Пусть \(a=a_0a_1a_2\ldots\) — текст (то есть последовательность элементов множества \(A\)). По тексту и начальному состоянию \(s_0\) можно построить последовательность \(s_0s_1s_2\ldots\) по следующему правилу:
Последний элемент этой последовательности называется результатом работы автомата на тексте \(a\). Функция вычисления результата работы автомата может выглядеть, например, так:
def run_dfa(dfa, s0, text): s = s0 for a in text: s = dfa(s, a) return s Иногда начальное состояние \(s_0\) включают в понятие автомата, но мы это делать не будем.
Примеры автоматов
Поиск символа
При помощи конечного автомата можно тривиально определить, входит ли некоторый символ в текст:
def search_for_char_dfa(x): return (lambda s, a: (s or a == x)) У такого автомата два состояния: True и False .
Подсчёт количества символов
Можно подсчитать количество символов по какому-нибудь модулю:
def count_chars_modulo(x, n): def dfa(s, a): if a == x: return (s+1)%n return s return dfa Можно также просто подсчитать количество символов (но такой автомат уже не будет конечным):
def count_chars(x, n): def dfa(s, a): if a == x: return s+1 return s return dfa Поиск последовательности
Вот такой автомат определяет, есть ли в тексте последовательность xy :
def find_xy(s, a): if s == 2: return s if s == 1: if a == 'y': return 2 return 0 if a == 'x': return 1 return 0 Если автомат остановился в состоянии 2 , это означает, что искомая последовательность присутствует в тексте.
Моделирование автомата словарём
Во всех вышеприведённых примерах автомат моделировался явными условными переходами. Для сколько-нибудь крупных автоматов такой способ, очевидно, неудобен. Существенно удобнее строить автомат по его графику, закодированному словарём:
def dfa_from_dict(d): return (lambda s,a: d[s][a]) Кодировка словарём, в частности, позволяет строить автомат из более простых, не жертвуя производительностью (построение автомата из нескольких функций приводит к неприятному эффекту линейной зависимости времени поиска состояния от количества использованных функций).
Автомат Кнута-Морриса-Пратта
В качестве иллюстрации процедуры последовательного построения автомата приведём распространённый алгоритм поиска подтекста внутри текста. А именно, построим автомат, который определяет, какой наидлиннейший префикс искомого текста совпадает с хвостом входного текста. Например, для искомого текста foobar и входного текста barfoo автомат должен выдать foo (ну или 3, если называть состояния длиной найденного префикса).
Интересное свойство такого автомата (в отличие от автоматов со схожими, но немного другими определениями) — его можно построить рекуррентным образом:
def kmp_add_char(kmp_dict, x): n = len(kmp_dict) - 1 kmp_dict[n+1] = <> old = kmp_dict[n][x] kmp_dict[n][x] = n+1 for a in kmp_dict[old]: kmp_dict[n+1][a] = kmp_dict[old][a] def kmp_dfa(alphabet, needle): kmp_dict = > for a in alphabet: kmp_dict[0][a] = 0 for x in needle: kmp_add_char(kmp_dict, x) return dfa_from_dict(kmp_dict) Корректность
Докажем, что этот автомат (если его запускать, начиная с состояния 0) удовлетворяет сформулированному нами определению. Точнее, приведём краткий набросок доказательства (аккуратное «лобовое» доказательство довольно сложно).
Будем вести индукцию по длине искомого текста. Предположим, что для всех текстов needle длины, меньшей \(N\), автомат kmp_dfa(alphabet,needle) делает то, что нужно (а именно, выдаёт самое большое k , для которого needle[:k] совпадает с хвостом входного текста).
Если \(N=0\), то наш автомат всегда выдаёт 0, что, очевидно, удовлетворяет его определению. Если \(N\gt0\), проведём индукцию по длине входного текста.
С пустым входным текстом всё хорошо. Если же в тексте есть хотя бы один символ, этот текст можно представить в виде T+x , где x — этот самый последний символ. По индуктивному предположению, обработав текст T , автомат остановится в состоянии, соответствующем наиболее длинному хвосту T , являющемуся префиксом needle . При этом автомат мог остановиться в одном из трёх состояний:
- одно из первых \(N-2\) состояний
- состояние \(N-1\)
- состояние \(N\)
Посмотрим, как среагирует автомат на последний символ x . В первом случае мы находимся в пределах автомата для слова needle[:N-1] , который по предположению внешней индукции делает то, что нужно. Во втором случае тоже всё хорошо: если x == needle[N-1] , то мы перейдём в состояние \(N\); если же нет, то мы опять в пределах автомата для слова needle[:N-1] .
Единственный нетривиальный случай — если мы сейчас в состоянии \(N\). Тут нужно разобрать два подслучая.
Подслучай первый: после обработки символа x длина префикса остаётся N . Но так бывает только тогда, когда needle состоит из одинаковых символов, равных x . Нетрудно проверить, что для такого автомата переход из состояния N по символу x ведёт в N .
Подслучай второй: длина префикса изменяется. Но тогда автомат должен остановиться в том же состоянии, в котором остановился бы автомат для needle[:N-1] . Отмотаем на два шага назад: мы окажемся в состоянии, отличном от N (и в том же, в котором бы остановился автомат для needle[:N-1] ). А теперь обратно пройдём на два шага вперёд. По построению мы окажемся там же, где оказался бы автомат для needle[:N-1] .
2.2.3. Детерминированные и недетерминированные конечные автоматы
Различают детерминированные и недетерминированные конечные автоматы. КА называется недетерминированным (НДКА), если в диаграмме его состояний из одной вершины исходит несколько дуг с одинаковыми пометками. Например, КА из примера 2.2.2 является НДКА. Хотя НДКА располагает, на первый взгляд, большими возможностями, чем детерминированный КА, классы языков, которые они допускают, в действительности совпадают.
По описанию НДКА всегда можно построить описание детерминированного КА (ДКА). При этом НДКА А
1) с входным алфавитом V,
3) и функцией переходов
преобразуется в ДКА А’, у которого:
1) Заключительные состояния F’ — все подмножества Q, содержащие хотя бы одно заключительное состояние автомата А.
Пример 2.2.3. Пусть регулярный язык порождается грамматикой G = , у которой N = , Т = , S = ,
Построим НДКА А = , qQ, F>. Имеем
3) F = , отображение представлено на рис.2.3 в виде диаграммы состояний.
Рис 2.3. Диаграмма состояний НДКА из примера 2.2.3
Построим эквивалентный ему ДКА А’ = ‘, q0‘, F’>.
Возможно создание нескольких вариантов ДКА, распознающих язык L'(G’).
В первом случае компонентами ДКА будут:
Q’ = , , >; остальные 4 состояния можно отбросить, так как ни в одно из них автомат попасть не может;
функцию переходов ‘ можно задать с помощью следующих команд:
Представление ‘ показано как в виде диаграммы состояний (рис 2.4), так и в виде матрицы переходов:
Рис 2.4. Диаграмма состояний ДКА
Построим по описанию ДКА А’ регулярную грамматику G’ = . Для этого дадим новые обозначения элементам множества Q’ :
Во втором случае компонентами ДКА будут:
функцию переходов ‘ можно задать с помощью следующих команд:
диаграмма состояний для этого варианта приведена на рис.
Рис 2.5. Диаграмма состояний ДКА
Для практических целей необходимо, чтобы конечный распознаватель играл более активную роль и сам определял момент окончания входной последовательности символов с выдачей сообщения о правильности или ошибочности входной цепочки. Для этих целей входная цепочка считается ограниченной справа концевым маркером ├. Тогда для конечного автомата из примера 2.2.2 получаем:
А в диаграмму состояний КА вводятся интерпретированные состояния, будем обозначать эти состояния соответственно:
Z — «допустить входную цепочку»,
О — «запомнена ошибка во входной цепочке»,
Е — «отвергнуть входную цепочку».
Состояния Z и Е являются заключительными, и в них КА переходит при прочтении концевого маркера соответственно после обработки правильной или ошибочной входной цепочки. Состояние О является промежуточным, в него КА переходит из любого допустимого состояния КА при обнаружении ошибки во входной цепочке и остается в нем до поступления концевого маркера ├, после чего осуществляется переход в состояние Е — «отвергнуть входную цепочку».
Ниже приведена модифицированная диаграмма состояний конечного распознавателя из примера 2.2.2 (рис. 2.6)
Рис. 2.6. Модифицированная диаграмма состояний КА для распознавания идентификаторов ( — не буква)
Этой диаграмме состояний соответствует матрица переходов: