Получение данных c веб-сайта без API в 3 строки кода на Python
Рассказываем о том, как можно сэкономить время и нервы при автоматизации процесса получения данных с веб-сайтов без соответствующего API-интерфейса.
Предположим, что в поисках данных, необходимых для вашего проекта, вы натыкаетесь на такую веб-страницу:
Вот они — все необходимые данные для вашего проекта.
Но что же делать, если нужные вам данные находятся на сайте, который не предоставляет API для их получения? Конечно же, можно потратить несколько часов и написать обработчик, который получит эти данные и преобразует их в нужный для вашего приложения формат.
Но есть и более простое решение — это библиотека Pandas и ее встроенная функция read_html() , которая предназначена для получения данных с html-страниц.
import pandas as pd tables = pd.read_html("http://apps.sandiego.gov/sdfiredispatch/") print(tables[0]) Прим. перев. В данной статье используется версия Pandas 0.20.3
Да, все настолько просто. Pandas находит html-таблицы на странице и возвращает их как новый объект DataFrame .
Теперь попробуем указать Pandas, что первая (а точнее нулевая) строка таблицы содержит заголовки столбцов, а также попросим ее сформировать datetime -объект из строки, находящейся в столбце с датой и временем.
import pandas as pd calls_df, = pd.read_html("http://apps.sandiego.gov/sdfiredispatch/", header=0, parse_dates=["Call Date"]) print(calls_df) На выходе мы получим следующий результат:
Call Date Call Type Street Cross Streets Unit 0 2017-06-02 17:27:58 Medical HIGHLAND AV WIGHTMAN ST/UNIVERSITY AV E17 1 2017-06-02 17:27:58 Medical HIGHLAND AV WIGHTMAN ST/UNIVERSITY AV M34 2 2017-06-02 17:23:51 Medical EMERSON ST LOCUST ST/EVERGREEN ST E22 3 2017-06-02 17:23:51 Medical EMERSON ST LOCUST ST/EVERGREEN ST M47 4 2017-06-02 17:23:15 Medical MARAUDER WY BARON LN/FROBISHER ST E38 5 2017-06-02 17:23:15 Medical MARAUDER WY BARON LN/FROBISHER ST M41 Теперь все эти данные находятся в DataFrame -объекте. Если же нам нужны данные в формате json, добавим еще одну строчку кода:
import pandas as pd calls_df, = pd.read_html("http://apps.sandiego.gov/sdfiredispatch/", header=0, parse_dates=["Call Date"]) print(calls_df.to_json(orient="records", date_format="iso")) В результате вы получите данные в формате json с правильным форматированием даты по стандарту ISO 8601:
[ < "Call Date": "2017-06-02T17:34:00.000Z", "Call Type": "Medical", "Street": "ROSECRANS ST", "Cross Streets": "HANCOCK ST/ALLEY", "Unit": "M21" >, < "Call Date": "2017-06-02T17:34:00.000Z", "Call Type": "Medical", "Street": "ROSECRANS ST", "Cross Streets": "HANCOCK ST/ALLEY", "Unit": "T20" >, < "Call Date": "2017-06-02T17:30:34.000Z", "Call Type": "Medical", "Street": "SPORTS ARENA BL", "Cross Streets": "CAM DEL RIO WEST/EAST DR", "Unit": "E20" >// и т.д. ] При желании данные можно сохранить в CSV или XLS:
import pandas as pd calls_df, = pd.read_html("http://apps.sandiego.gov/sdfiredispatch/", header=0, parse_dates=["Call Date"]) calls_df.to_csv("calls.csv", index=False) Выполните код и откройте файл calls.csv . Он откроется в приложении для работы с таблицами:
И, конечно же, Pandas упрощает анализ:
calls_df.describe() Call Date Call Type Street Cross Streets Unit count 69 69 69 64 69 unique 29 2 29 27 60 top 2017-06-02 16:59:50 Medical CHANNEL WY LA SALLE ST/WESTERN ST E1 freq 5 66 5 5 2 first 2017-06-02 16:36:46 NaN NaN NaN NaN last 2017-06-02 17:41:30 NaN NaN NaN NaN calls_df.groupby("Call Type").count() Call Date Street Cross Streets Unit Call Type Medical 66 66 61 66 Traffic Accident (L1) 3 3 3 3 И обработку данных:
calls_df["Unit"].unique() Результат метода unique :
array(['E46', 'MR33', 'T40', 'E201', 'M6', 'E34', 'M34', 'E29', 'M30', 'M43', 'M21', 'T20', 'E20', 'M20', 'E26', 'M32', 'SQ55', 'E1', 'M26', 'BLS4', 'E17', 'E22', 'M47', 'E38', 'M41', 'E5', 'M19', 'E28', 'M1', 'E42', 'M42', 'E23', 'MR9', 'PD', 'LCCNOT', 'M52', 'E45', 'M12', 'E40', 'MR40', 'M45', 'T1', 'M23', 'E14', 'M2', 'E39', 'M25', 'E8', 'M17', 'E4', 'M22', 'M37', 'E7', 'M31', 'E9', 'M39', 'SQ56', 'E10', 'M44', 'M11'], dtype=object) Теперь вы знаете, как с помощью Python и Pandas можно быстро получить данные с практически любого сайта, не прилагая особых усилий. Освободившееся время предлагаем посвятить чтению других интересных материалов по Python на нашем сайте.
Парсинг сайта с помощью PYTHON + SELENIUM

В этой статье, на примере моей задачи, рассмотрим, как можно извлечь большой объем данных с сайта ГИББД и с помощью какого инструмента. Это может быть полезно для финансовых компаний, которые принимают автомобили в качестве залога. Итак, мне необходимо было получить информацию о владельцах и периодах владения автомобилями, чтобы определить были ли изменения в конкретном периоде. Данная информация есть на официальном сайте ГИБДД.рф. На входе было дано 70 тысяч VIN номеров автомобилей, по которым и возможно было сделать эту выгрузку.

Поскольку я ранее не занимался парсингом, то решил проанализировать различные Интернет-ресурсы для поиска необходимого алгоритма, однако, для поставленной мне задачи отсутствовало готовое решение, в связи с чем мне пришлось делать всё самому. В ходе анализа я обнаружил библиотеку «requests» для передачи POST запросов, но понял, что она не подходит, поскольку на сайте «ГИБДД.РФ» есть элементы JS, а значит, что VIN номер не передать через адресную строку.
В ходе дальнейшего поиска решения для поставленной задачи я обнаружил библиотеку «Selenium», которая позволяет имитировать действия пользователя на сайте, в том числе с элементами JS.
Для ее установки используется команда: -pip install selenium .
При использовании браузера «Google Сhrome» для работы с вышеуказанной библиотекой необходима имеющаяся в свободном доступе программа «Webdriver Сhrome».
Проблемы:
На мой взгляд, особую сложность при парсинге подобных сайтов вызывает изучение вариантов различного поведения самого сайта при отправке запросов. В моём случае – это появление видеорекламы (которое можно закрыть спустя определенное время), либо фоторекламы (которое проходит само), то есть своеобразный аналог капчи. Проблематика заключалась в необходимости анализа периодичности появления рекламы, ее разновидности и способах обхода вышеуказанной рекламы.
Алгоритм действий:
Импортируем все необходимые библиотеки:
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys import pandas as pd import time from bs4 import BeautifulSoup from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as ECЗадаём опции для webdriver, запускаем его и переходим на нужную нам страницу проверки авто:
option = Options() option.add_argument("--disable-infobars") browser = webdriver.Chrome('C:\webdr\chromedriver.exe',chrome_options=option) # 'https://xn--90adear.xn--p1ai/check/auto' – ГИБДД.РФ browser.get('https://xn--90adear.xn--p1ai/check/auto')Открывается новое окно webdriver, после чего запускается сайт со следующим содержанием:

Затем осуществляем поиск нужных нам элементов через код страницы (правой кнопкой мыши – посмотреть код). В нашем случае это элемент с вводом VIN номера и кнопка с запросом.
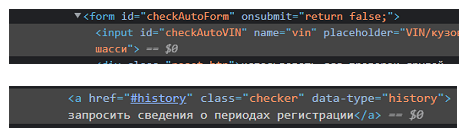
Находим идентификатор элемента id=”checkAutoVIN” и имя class =”checker”. Осуществляем поиск данных элементов, затем вставляем нужный VIN в соответствующую строку:
elem = browser.find_element(By.ID, 'checkAutoVIN' ) elem.send_keys('5GRGXXXXXXX129289' + Keys.RETURN)и нажимаем на кнопку:
share = browser.find_element(By.CLASS_NAME, 'checker' ) share.click()Первая проблема – появляется видеореклама, при просмотре которой через 4 секунды появляется крестик справа.

Находим код этого крестика на странице:

С помощью функции “WebDriverWait” ждём появления этого крестика и нажимаем на него, если это видеореклама.
WebDriverWait(browser, 10).until(EC.element_to_be_clickable((By.CLASS_NAME, "close_modal_window"))).click()В случае появления фоторекламы вышеуказанный код выдаст ошибку, которую я решил с помощью конструкции try – except (она пригодится ещё много раз).В случае появления фоторекламы необходимо дождаться ее самопроизвольного закрытия:

time.sleep(4) В дальнейшем для парсинга страницы необходимо воспользоваться библиотекой “ BeautifulSoup”.

elements = soup.find_all(attrs=>) elements1=soup.find_all(attrs=>) elements2=soup.find_all(attrs=>) elements3=soup.find_all(attrs=>) elements4=soup.find_all(attrs=>) elements5=soup.find_all(attrs=>) Для заполнения полученной информацией создадим пустую таблицу:
df = pd.DataFrame()Учитываем, что периодов владений автомобилем может быть несколько. В таком случае в каждом из найденных элементов будет несколько записей (элементы сохраняются в виде списка). Каждый новый период добавим с тем же VIN номером в новую строку:
for j in range(len(elements1)): df1 = df1.append(, ignore_index=True)На первый взгляд кажется, что для решения поставленной задачи необходимо только запустить цикл по всем VIN номерам, однако обнаружились следующие проблемы. После проверки 5 VIN номеров сайт начинает сильно затормаживаться. Чтобы это избежать, я установил счетчик и когда он достигает значение 5 – обнуляем его и инициализируем webdriver заново. В ходе данной работы я установил, что для корректной работы цикла важно не закрывать предыдущий webdriver ( browser.quit() ), поскольку при его закрытии в следующем проходе цикла возникает ошибка.
Также счётчик помог мне понять, что реклама появляется при первом запросе, при условии, что VIN номер есть в базе ГИБДД.
Учитываем указанную информацию и вводим новую переменную ermes , и при парсинге добавляем условие, что, если эта переменная равна ‘По указанному VIN не найдена информация о регистрации транспортного средства.’, то проделываем операцию с пережиданием или закрытием рекламы.
elementserr=soup.find_all(attrs=>) if elementserr[0].text=='По указанному VIN не найдена информация о регистрации транспортного средства.': ermes=elementserr[0].textСледующая проблема – иногда запрос выполняется с ошибкой. В таком случае необходимо нажимать кнопку запроса информации до тех пор, пока запрос выполнится без ошибки:
while elementserr[0].text=='При получении ответа сервера произошла ошибка.': share.click() time.sleep(4)Для успешного завершения поставленной задачи остается лишь взять все VIN номера и сделать по ним цикл:
vin=pd.read_excel(r'C:\Users\grvla\Desktop\Парс.xlsx')Таким образом, разработанный мной парсер работает стабильно, прерывания возможны, но крайне редко (оставлял на пару дней). В случае прерывания, будем запускать цикл заново, пропуская те значения, которые есть в итоговой таблице:
sh=0 ermes='' for i in vin.vins: if i in df.VIN.unique(): continueВ качестве ключевых выводов хочу отметить:
- Разработанный парсинг не могут забанить по ip, поскольку демонстрируется реклама. Мы же просто имитируем деятельность человека на сайте. Его можно запустить сразу на многих компьютерах, что ускорит результат работы. Количество полученных VIN-номеров в день – 7-8 тысяч. То есть на 10 компьютерах 70 тысяч VIN -номеров можно пропарсить за один день.
- Библиотека Selenium позволяет имитировать действия пользователя в браузере. Это помогает автоматизировать сбор данных практически с любого сайта, в котором нет капчи. С её помощью возможна работа с сайтами, в которых есть элементы javascript, с чем не справляются другие библиотеки для парсинга. Достаточно простой для написания код.
- Python
- Программирование
Web Parsing. Основы на Python
Рассмотрим еще один практический кейс парсинга сайтов с помощью библиотеки BeautifulSoup: что делать, если на сайте нет готовой выгрузки с данными и нет API для удобной работы, а страниц для ручного копирования очень много?
Недавно мне понадобилось получить данные с одного сайта. Готовой выгрузки с информацией на сайте нет. Данные я вижу, вот они передо мной, но не могу их выгрузить и обработать. Возник вопрос: как их получить? Немного «погуглив», я понял, что придется засучить рукава и самостоятельно парсить страницу (HTML). Какой тогда инструмент выбрать? На каком языке писать, чтобы с ним не возникло проблем? Языков программирования для данной задачи большой набор, выбор пал на Python за его большое разнообразие готовых библиотек.
Примером для разбора основ возьмем сайт с отзывами banki_ru и получим отзывы по какому-нибудь банку.
Задачу можно разбить на три этапа:
- Загружаем страницу в память компьютера или в текстовый файл.
- Разбираем содержимое (HTML), получаем необходимые данные (сущности).
- Сохраняем в необходимый формат, например, Excel.
Инструменты
Для начала нам необходимо отправлять HTTP-запросы на выбранный сайт. У Python для отправки запросов библиотек большое количество, но самые распространённые urllib/urllib2 и Requests. На мой взгляд, Requests — удобнее, примеры буду показывать на ней.
А теперь сам процесс. Были мысли пойти по тяжелому пути и анализировать страницу на предмет объектов, содержащих нужную информацию, проводить ручной поиск и разбирать каждый объект по частям для получения необходимого результата. Но немного походив по просторам интернета, я получил ответ: BeautifulSoup – одна из наиболее популярных библиотек для парсинга. Библиотеки найдены, приступаем к самому интересному: к получению данных.
Загрузка и обработка данных
Попробуем отправить запрос HTTP на сайт, чтобы получить первую страницу с отзывами по какому-нибудь банку и сохранить в файл, для того, чтобы убедиться, получаем ли мы нужную нам информацию.
import requests from bs4 import BeautifulSoup bank_id = 1771062 #ID банка на сайте banki.ru url = ‘https://www.banki.ru/services/questions-answers/?id=%d&p=1’ % (bank_id) # url страницы r = requests.get(url) with open(‘test.html’, ‘w’) as output_file: output_file.write(r.text)
После исполнения данного скрипта получится файл text.html.
Открываем данный файл и видим, что необходимые данные получили без проблем.
Теперь очередь для разбора страницы на нужные фрагменты. Обрабатывать будем последние 10 страниц плюс добавим модуль Pandas для сохранения результата в Excel.
Подгружаем необходимые библиотеки и задаем первоначальные настройки.
import requests from bs4 import BeautifulSoup import pandas as pd bank_id = 1771062 #ID банка на сайте banki.ru page=1 max_page=10 url = ‘https://www.banki.ru/services/questions-answers/?id=%d&p=%d’ % (bank_id, page) # url страницы
На данном этапе необходимо понять, где находятся необходимые фрагменты. Изучаем разметку страницы с отзывами и определяем, какие объекты будем вытаскивать из страницы.
Подробно покопавшись во внутренностях страницы, мы увидим, что необходимые данные «вопросы-ответы» находятся в блоках , соответственно, сколько этих блоков на странице, столько и вопросов.
result = pd.DataFrame() r = requests.get(url) #отправляем HTTP запрос и получаем результат soup = BeautifulSoup(r.text) #Отправляем полученную страницу в библиотеку для парсинга tables=soup.find_all(‘table’, <'class': 'qaBlock'>) #Получаем все таблицы с вопросами for item in tables: res=parse_table(item)
Приступая к получению самих данных, я кратко расскажу о двух функциях, которые будут использованы:
- Find(‘table’) – проводит поиск по странице и возвращает первый найденный объект типа ‘table’. Вы можете искать и ссылки find(‘table’) и рисунки find(‘img’). В общем, все элементы, которые изображены на странице;
- find_all(‘table’) – проводит поиск по странице и возвращает все найденные объекты в виде списка
У каждой из этих функций есть методы. Я расскажу от тех, которые использовал:
- find(‘table’).text – этот метод вернет текст, находящийся в объекте;
- find(‘a’).get(‘href’) – этот метод вернет значение ссылки
Теперь, уже обладая этими знаниями и навыками программирования на Python, написал функцию, которая разбирает таблицу с отзывом на нужные данные. Каждые стадии кода дополнил комментариями.
def parse_table(table):#Функция разбора таблицы с вопросом res = pd.DataFrame() id_question=0 link_question=» date_question=» question=» who_asked=» who_asked_id=» who_asked_link=» who_asked_city=» answer=» question_tr=table.find(‘tr’,<'class': 'question'>) #Получаем сам вопрос question=question_tr.find_all(‘td’)[1].find(‘div’).text.replace(‘
‘,’\n’).strip() widget_info=question_tr.find_all(‘div’, ) #Получаем ссылку на сам вопрос link_question=’https://www.banki.ru’+widget_info[0].find(‘a’).get(‘href’).strip() #Получаем уникальным номер вопроса id_question=link_question.split(‘=’)[1] #Получаем того кто задал вопрос who_asked=widget_info[1].find(‘a’).text.strip() #Получаем ссылку на профиль who_asked_link=’https://www.banki.ru’+widget_info[1].find(‘a’).get(‘href’).strip() #Получаем уникальный номер профиля who_asked_id=widget_info[1].find(‘a’).get(‘href’).strip().split(‘=’)[1] #Получаем из какого города вопрос who_asked_city=widget_info[1].text.split(‘(‘)[1].split(‘)’)[0].strip() #Получаем дату вопроса date_question=widget_info[1].text.split(‘(‘)[1].split(‘)’)[1].strip() #Получаем ответ если он есть сохраняем answer_tr=table.find(‘tr’,<'class': 'answer'>) if(answer_tr!=None): answer=answer_tr.find_all(‘td’)[1].find(‘div’).text.replace(‘
‘,’\n’).strip() #Пишем в таблицу и возвращаем res=res.append(pd.DataFrame([[id_question,link_question,question,date_question,who_asked,who_asked_id,who_asked_link,who_asked_city,answer]], columns = [‘id_question’,’link_question’,’question’,’date_question’,’who_asked’,’who_asked_id’,’who_asked_city’,’who_asked_link’,’answer’]), ignore_index=True) #print(res) return(res)
Функция возвращает DataFrame, который можно накапливать и экспортировать в EXCEL.
result = pd.DataFrame() r = requests.get(url) #отправляем HTTP запрос и получаем результат soup = BeautifulSoup(r.text) #Отправляем полученную страницу в библиотеку для парсинга tables=soup.find_all(‘table’, <'class': 'qaBlock'>) #Получаем все таблицы с вопросами for item in tables: res=parse_table(item) result=result.append(res, ignore_index=True) result.to_excel(‘result.xlsx’)
В результате мы научились парсить web-сайты, познакомились с библиотеками Requests, BeautifulSoup, а также получили пригодные для дальнейшего анализа данные об отзывах с сайта banki.ru. А вот и сама результирующая таблица.
Приобретенные навыки можно использовать для получения данных с других сайтов и получать обобщенную и структурированную информацию с бескрайних просторов Интернета.
Я надеюсь, моя статья была полезна. Спасибо за внимание.
Почему стоит научиться «парсить» сайты, или как написать свой первый парсер на Python

Для начала давайте разберемся, что же действительно означает на первый взгляд непонятное слово — парсинг. Прежде всего это процесс сбора данных с последующей их обработкой и анализом. К этому способу прибегают, когда предстоит обработать большой массив информации, с которым сложно справиться вручную. Понятно, что программу, которая занимается парсингом, называют — парсер. С этим вроде бы разобрались.
Перейдем к этапам парсинга.
- Поиск данных
- Извлечение информации
- Сохранение данных
И так, рассмотрим первый этап парсинга — Поиск данных.
Так как нужно парсить что-то полезное и интересное давайте попробуем спарсить информацию с сайта work.ua.
Для начала работы, установим 3 библиотеки Python.
pip install beautifulsoup4
Без цифры 4 вы ставите старый BS3, который работает только под Python(2.х).
pip install requests
pip install pandas
Теперь с помощью этих трех библиотек Python, можно проанализировать нашу веб-страницу.
Второй этап парсинга — Извлечение информации.
Попробуем получить структуру html-кода нашего сайта.
Давайте подключим наши новые библиотеки.
import requests from bs4 import BeautifulSoup as bs import pandas as pd И сделаем наш первый get-запрос.
URL_TEMPLATE = "https://www.work.ua/ru/jobs-odesa/?page=2" r = requests.get(URL_TEMPLATE) print(r.status_code) Статус 200 состояния HTTP — означает, что мы получили положительный ответ от сервера. Прекрасно, теперь получим код странички.
print(r.text) Получилось очень много, правда? Давайте попробуем получить названия вакансий на этой страничке. Для этого посмотрим в каком элементе html-кода хранится эта информация.
Комірник
У нас есть тег h2 с классом «add-bottom-sm», внутри которого содержится тег a. Отлично, теперь получим title элемента a.
soup = bs(r.text, "html.parser") vacancies_names = soup.find_all('h2', class_='add-bottom-sm') for name in vacancies_names: print(name.a['title']) Хорошо, мы получили названия вакансий. Давайте спарсим теперь каждую ссылку на вакансию и ее описание. Описание находится в теге p с классом overflow. Ссылка находится все в том же элементе a.
Some information about vacancy.
Получаем такой код.
vacancies_info = soup.find_all('p', class_='overflow') for name in vacancies_names: print('https://www.work.ua'+name.a['href']) for info in vacancies_info: print(info.text) И последний этап парсинга — Сохранение данных.
Давайте соберем всю полученную информацию по страничке и запишем в удобный формат — csv.
import requests from bs4 import BeautifulSoup as bs import pandas as pd URL_TEMPLATE = "https://www.work.ua/ru/jobs-odesa/?page=2" FILE_NAME = "test.csv" def parse(url = URL_TEMPLATE): result_list = r = requests.get(url) soup = bs(r.text, "html.parser") vacancies_names = soup.find_all('h2', class_='add-bottom-sm') vacancies_info = soup.find_all('p', class_='overflow') for name in vacancies_names: result_list['href'].append('https://www.work.ua'+name.a['href']) result_list['title'].append(name.a['title']) for info in vacancies_info: result_list['about'].append(info.text) return result_list df = pd.DataFrame(data=parse()) df.to_csv(FILE_NAME) После запуска появится файл test.csv — с результатами поиска.