Обход защиты от парсинга
Парсинг – это процесс автоматического сбора информации в интернете. Может показаться, что получение доступа к данным не будет проблемой даже у автоматизированных инструментов, но это не так. Сегодня мы расскажем, как компании защищают свои сайты от парсинга и как обойти эту защиту.
Самый распространённый способ использования парсера в сфере интернет-коммерции – это ценовой анализ и мониторинг рынка. Не все конкуренты хотят давать вам такую возможность, у них есть множество способов незаметного распознавания ботов и парсеров, но каждую защиту можно обойти.
Механизмы защиты от парсеров
Защита от ботов создана для блокировки их работы на сайте, они могут отличать парсеры от реальных людей несколькими способами, это позволяет смягчать DDOS атаки и мошеннических схем, но в нашем случае мы просто собираем информацию и не хотим причинять никакого вреда.
Суть любой защиты заключается в разделении запросов роботов и реальных людей, в этом разделе мы рассмотрим все способы, которыми можно отследить парсеры на веб-сайтах.
Проверка заголовка
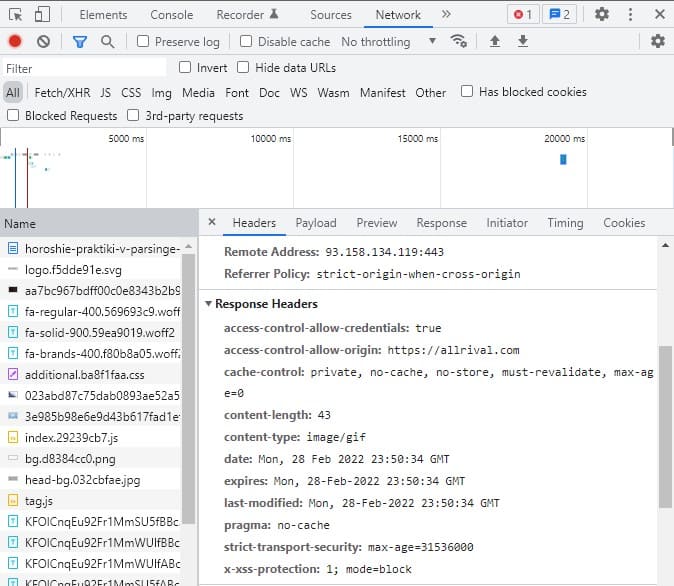
Вместе с запросом на сервер браузер так же отправляет заголовок, который выглядит по-разному для каждого браузера. Например, так выглядит заголовок Chrome. Парсер можно легко распознать, если шаблон заголовка не соответствует обычному браузеру.
Отпечатки TCP/IP
Более сложный способ распознание парсеров – это обнаружение отпечатков TCP/IP. TCP – это один из основных протоколов интернета, отвечающий за транспортировку данных, он так же оставляет множество сопутствующих параметров, например, начальное состояние окна. Если эти значения параметров не будут совпадать, доступ будет ограничен. Например, отправка запроса от имени Chrome с сервера на linux ожидаемый TTL будет отличаться от актуального.

Блокировка IP
Если один IP-адрес будет неоднократно уличён в отправке нечеловеческих запросов, то его могут просто заблокировать. Это ограничение легко обходится при помощи прокси серверов, или других инструментов, изменяющих ваш ip.

Геоблокировка
Некоторые сайты могут блокировать запрос, который исходит из определённого региона. Похожая проблема может возникнуть, если в зависимости от региона меняется контент. Эти сложности так же легко решаются при помощи прокси.
Обнаружение парсера на фронтэнде
Помимо обнаружения парсера на серверной части, его так же могут распознать и во внешнем интерфейсе.
JavaScript
Этот язык программирования вшит в каждый браузер, он позволяет современным сайтам корректно отображаться и функционировать. Если ваш парсер не может корректно рендерить JS, то его будет легко обнаружить. Всё может дойти до того, что сайт может заставлять выполнять ваш парсер простые арифметические операции, просто что бы проверить возможность работы с JS. JavaScript так же можно использовать для AJAX запросов и отложений загрузки. Что бы не быть раскрытым, запросы парсера должны отправляться с обработкой JS. В противном случае кроме блокировки вы рискуете не увидеть часть контента.
Отпечатки браузера
Отпечаток браузера – это комбинация из свойств и атрибутов, создающих его портрет. Он содержит информацию об ОС, устройствах, акселерометре, WebGL, хосте и о многом другом. Если в этом наборе информации будут присутствовать не состыковки, парсер могут заблокировать.

Captcha и Recaptcha
Сейчас происходит постоянная гонка визуальных головоломок и искусственного интеллекта, и если раньше алгоритмы машинного обучения не могли справиться с их решением, то сейчас капчи приходится делать всё более и более сложными. Всё доходит до того, что вместо решения загадок сайты смотрят на поведение пользователей, которое в корне отличается от поведения машины. Движение мыши и щелчки, поиск пути к нужной информации, время, проведённое на странице и начинают показывать капчи только после ряда действий. Поэтому вместо борьбы с капчами, вы просто можете понять, что вызывает их появление.
Как обойти блокировки сайтов при парсинге?
В настоящее время многие компании используют парсинг, чтобы получить множество различных преимуществ. Независимо от того, находитесь ли вы в сфере онлайн-торговли и хотите стать более конкурентоспособными, или вы хотите предоставлять услуги другим компаниям, сбор данных может стать способом увеличения прибыли однозначно в каждом случае.
К сожалению, многие компании даже имея в штате программистов или системных администраторов не рассматривают самостоятельный парсинг как очень желанный вид деятельности. Последовательная отправка большого количества запросов на ресурсы может заблокировать работу, что неизбежно приведет к приостановке деятельности по сбору данных.
Если вы хотите узнать больше о том, как и почему это происходит, и узнать, как обойти блокировки, вы находитесь на правильном пути.
Парсинг товаров: проблемы блокировки
Понимание того, как обойти блокировки в процессе парсинга , имеет решающее значение для успеха. Парсинг данных — это не то, к чему вы должны относиться легкомысленно, поскольку на пути действительно возникнет много проблем, которые необходимо решать последовательно, а думать о них заранее. Если вы запустите проект по сборку данных, не зная, как обойти блокировки, вы рискуете быстро зайти в тупик. Особенно это относится к крупным сайтам электронной коммерции из-за объема данных, которые вам необходимо получить. Таким образом, опытные парсеры понимают, что в любом проекте по сбору данных есть несколько общих проблем.
Структура сайта не установлена в самом начале
Макеты сайтов постоянно меняются. Эти изменения помогают им оптимизировать взаимодействие с пользователем, привлечь больше клиентов и увеличить продажи. Если структура целевого сайта изменяется , скрипты или плагины подготовленные для парсинга не могут выполнить автоматическую перенастройку, и парсер может дать сбой или вернуть неполный набор данных . И то, и другое фатально для вашей операции по сбору данных.
Недостаточно места для хранения полученных данных
Масштабная операция по сбору данных обеспечивает внушительные результаты. Тем не менее, результаты — это большие куски данных, которые вам нужно где-то хранить. Есть две проблемы, связанные с емкостью хранения: может быть недостаточно для хранения собранных данных объема хранилища или инфраструктура данных может быть плохо проанализирована, что делает экспорт слишком неэффективным. Плохое управление данными может привести к критическим проблемам , прежде чем вы начнете беспокоиться о том, как обойти блокировки.
Поддержание качества данных
Целостность данных может быть легко нарушена во время самого процесса сбора информации. Таким образом, проверка первых полученных данных становится обязательной и предварительной частью любого проекта по парсингу. Вам нужно будет установить четкие параметры по качеству данных. После этого проверка данных может быть инициирована путем создания правил, обеспечивающих соответствие полученной информации требованиям по качеству.
Анти-парсер технологии и враждебная среда
Электронная коммерция — прибыльная отрасль. Таким образом, многие интернет-магазины тратят много денежных средств на то, чтобы держать ботов, включая различные сканеры по отлову всяких нежелательных элементов на сайте. Чтобы сделать это, они внедряют различные технологии защиты от копирования данных, которые варьируются от CAPTCHA и reCAPTCHA и прочих возможных вариантов блокировок. Поэтому понимание того, как парсить сайт без блокировки, становится важной частью любой операции по сбору данных.
В любом случае, если сайт распознает автоматические запросы, ваш IP может быть заблокирован на пару дней или даже заблокирован навсегда. Это особенно неудобно для тех, кто использует статические IP-адреса. Поэтому покупка и использование прокси адресов становится неотъемлемой частью любого проекта.
Что такое враждебная среда?
Враждебное среда или окружение относится к технологиям Javascript и Ajax, которые сильно затрудняют парсинг. Определенные элементы, которые содержат важную информацию, могут быть просто недоступны для многих парсеров, которые вы найдете бесплатно. Поэтому специфические обходные пути или сценарии должны быть обязательно реализованы дополнительно для доступа к этим данным.
Парсинг сайтов может заблокировать вас
В то время как для некоторых начинающих блокирование их сайтами может быть слишком знакомым, для новичков это может иметь серьезные последствия. Без правильной настройки и отраслевых знаний каждый заблокированный IP будет чрезвычайно дорогостоящим. Поэтому выяснение того, как сайты блокируют ботов и как обходить блокировки, является первым шагом для любого новичка.
Почему сайты блокируют ботов?
Боты, которые используются вами без понимания того, как сканировать сайты без блокировки, часто мгновенно блокируются. Увеличение посещаемости сайта за счет ботов во время парсинга выглядит безобидно. Тем не менее, боты могут отправлять значительно больше запросов в секунду, чем обычный пользователь, и сильно нагружать серверы, на которых размещается сайт. Если он пересекает определенный порог, сайт может стать слишком медленным или полностью отключиться.
Для многих сайт — это всего лишь одна ссылка в цепочке, приносящей доход. Боты-парсеры и различные сканеры могут отправлять слишком много запросов и подвергать серверы такой нагрузке, что это может привести к закрытию сайта. Даже небольшие задержки могут стоить потенциального дохода от клиентов, поскольку такой расклад ни одного пользователя не устроит, дальше они могут просто закрыть этот сайт и купить желаемый продукт у конкурента. Таким образом, многие сайты используют технологии предотвращения парсингу, чтобы избежать любых возможных замедлений, которые могут вызвать боты.
Как сайты распознают ботов?
Существуют различные алгоритмы и спецификации, которые различают пользователей и пользователей-ботов. Мы также упомянули CAPTCHA и reCAPTCHA как самые популярные антибот-технологии. Выпущена новая версия reCAPTCHA 3, и она еще более эффективна при обнаружении ботов . Таким образом, понимание того, как обходить блокировки, становится все более важным, так как частота запретов может увеличиться и та же капча может выстреливать при каждом запросе данных, представляете как вы обрадуетесь?
Другие решения могут отслеживать количество запросов с одного IP-адреса. Особенно это актуально при периодическом мониторинге цен .Также есть анализаторы, которые могут сопоставить местоположение вашего IP-адреса с языком и часовым поясом и обнаружить несоответствия.
Все эти технологии создают сеть безопасности, и они работают 24/7. Обход этих ограничений во многом является преимущественным. Разблокировка определенного IP-адреса практически невозможна, поэтому лучше не блокировать его.
Как обойти блокировки при парсинге?
Блокировок можно избежать, если понять, как сайты защищают себя. Существуют очень специфические методы и технологии, которые могут помочь вам собрать данные с крупных маркетплейсов например, не забанив их, не заблокировав и даже не обнаружив за использованием парсеров.
Ознакомьтесь с политикой сайта (если таковая имеется на сайте)
Крупные сайты позволяют в некоторой степени сбор данных. Чтобы не выходить за пределы, вы должны сделать две вещи: проверить официальную Политику сайта в области сбора данных, если таковая имеется на сайте, и просмотреть файл robots.txt на сайте (это делается как правило через слеш после адреса — www.site-donor.ru/ROBOTS.TXT ). В robots.txt вы сможете увидеть, что вам разрешено собирать (закрытые страницы будут помечены). Пребывание в согласованных пределах значительно уменьшит или даже полностью исключит возможность блокировки вашего парсера.
Работайте с надежным прокси-провайдером
Прокси-серверы являются основным инструментом для обхода блокировок на сайте. Если вы решите использовать прокси-серверы для получения данных от более сложных сайтов, обязательно выберите надежного прокси-провайдера. Лучшие провайдеры используют первоклассную ИТ-инфраструктуру, технологии безопасности и шифрования для обеспечения постоянной пропускной способности и времени безотказной работы. Любое время простоя прокси-серверов вызывает проблемы и задержки, отнеситесь к этом серьезно. Очень подробно о прокси рассказано в нашей статье .
Кроме того, с надежным поставщиком прокси вы получите доступ к поддержке клиентов и получите профессиональную помощь при внедрении прокси в повседневных операциях по парсингу. Это может оказаться очень полезным, когда вы хотите повысить или понизить свою деятельность, избегая при этом риска блокировки сайтами.
Кроме того, хорошие прокси-провайдеры должны поддерживать такие функции, как фиксированные записи портов, управление временем сеанса и широкий спектр возможных местоположений. Определенный контент может отображаться только в определенных регионах или странах (например, США). В этом случае использование прокси-сервера США позволит собирать любое содержимое данных.
Использовать реальных пользовательских агентов
Интернет-магазины размещаются на серверах, и эти серверы становятся умнее с каждым днем. Серверы теперь могут анализировать заголовок HTTP-запроса, сделанного вашими ботами. Этот заголовок, называемый пользовательским агентом, содержит различную информацию от ОС и программного обеспечения до типа приложения и его версии.
Серверы могут обнаруживать подозрительные пользовательские агенты
Чтобы избежать блокировки, вы всегда должны использовать реальных пользовательских агентов. Реальные пользовательские агенты содержат популярные конфигурации HTTP-запросов, которые отправляются реальными посетителями. Кроме того, рекомендуется ротация пользовательских агентов путем разработки большого набора жизнеспособных вариантов. Если пользовательские агенты не перебираются автоматически сменяя друг друга с каждым запросом, сайты могут обнаружить, что большая часть входящего трафика (массы запросов) подозрительно похожа, и, по крайней мере, временно заблокировать определенный набор пользовательских агентов.
Используемые пользовательские агенты обычно прописываются прокси-провайдером. Не забывайте проверять технические характеристики прокси-серверов, чтобы убедиться, что они соответствуют вашим требованиям.
Обход защиты от парсинга на PHP
Если вы будете парсить более-менее серьезные сайты — вы можете столкнутся с защитой от парсинга. Например, если парсить какой-то сайт достаточно длительное время и слать запросы к нему очень часто — этот сайт может вас заблокировать по ip и выдать капчу.
Основной принцип обхода защиты от парсинга — ваш парсер должен вести себя так, как вел бы себя человек, зашедший на сайт. В следующих уроках мы будем разбирать основные приемы.
Трепачёв Дмитрий © 2012-2024
t.me/trepachev_dmitry
Как обойти защиту от парсинга с помощью Python?
При попытке парсить КиноПоиск постоянно запрашивает капчу. Как сделать так, чтобы оно ее даже не предлагало? Я не хочу ее обходить с помощью нейроннок, так как не всегда правильно будет разпозновать. Использовал Requests и Selenium, с обеими не получается, указывал user-agent. Что ещё надо указывать или использовать чтобы обойти всю эту защиту?
- Вопрос задан более трёх лет назад
- 2274 просмотра
1 комментарий
Средний 1 комментарий