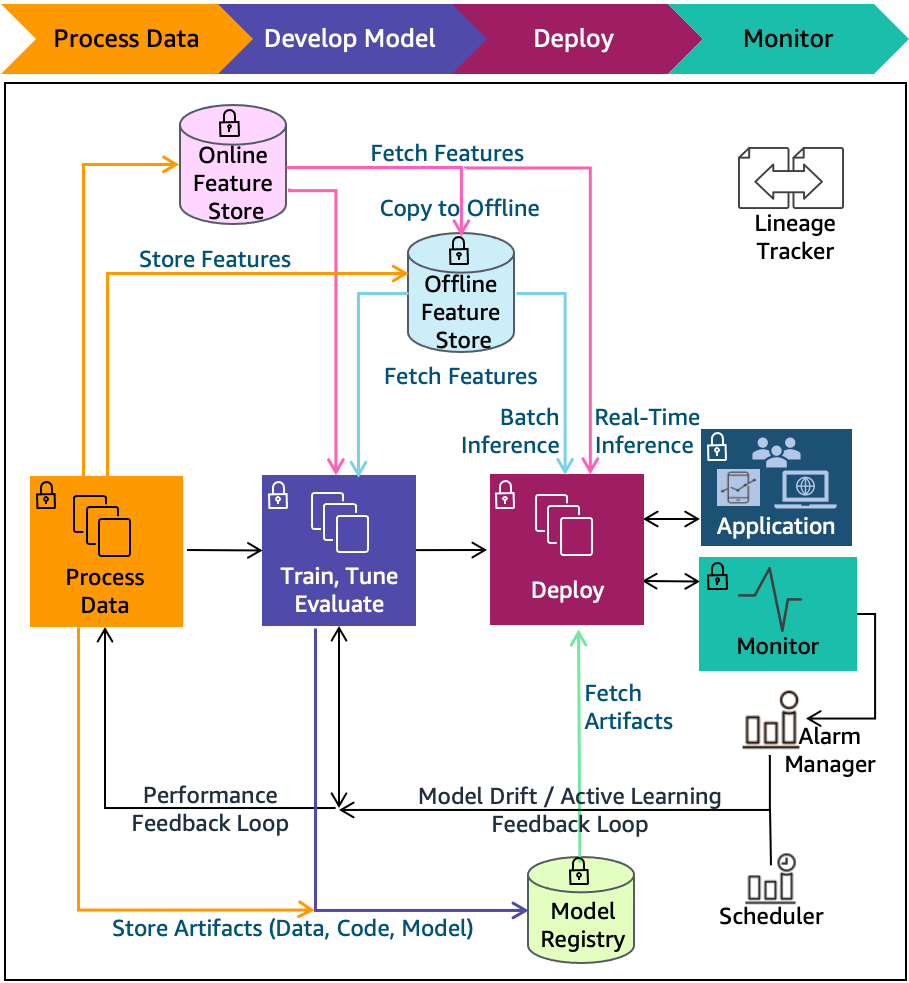
Выбор алгоритмов машинного обучения Azure
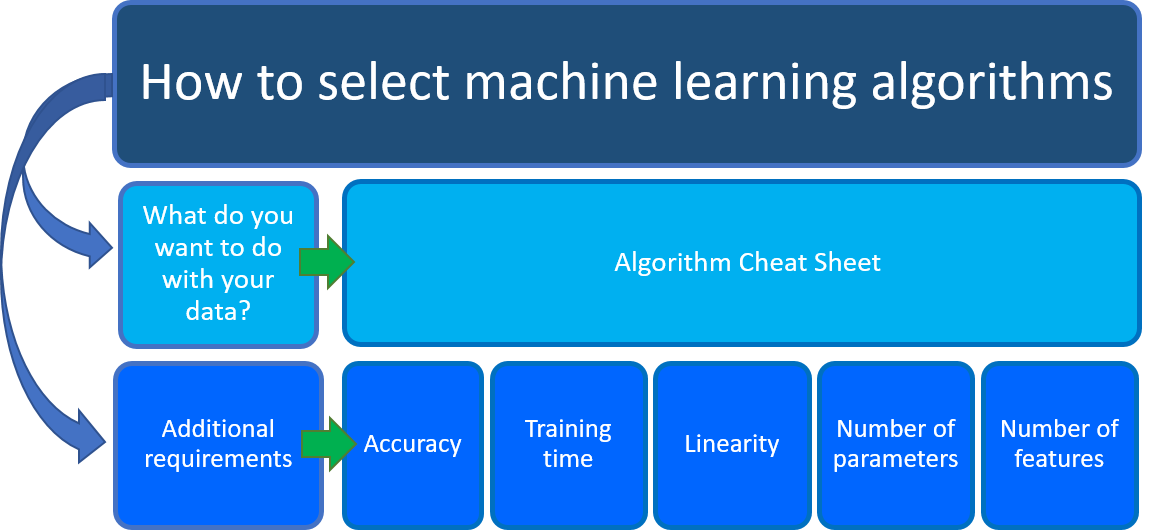
Распространенный вопрос: «Какой алгоритм машинного обучения следует использовать?» Выбранный алгоритм зависит, в основном, от двух различных аспектов сценария обработки и анализа данных:
- Что вы хотите сделать с данными? В частности, каков бизнес-вопрос, на который вы хотите ответить при обучении по прошлым данным?
- Каковы требования к сценарию обработки и анализа данных? В частности, какова точность, время обучения, линейность, количество параметров и функций, поддерживаемых вашим решением?
Конструктор поддерживает два типа компонентов, классические предварительно созданные компоненты (версии 1) и пользовательские компоненты (версия 2). Эти два типа компонентов несовместимы.
Классические предварительно созданные компоненты предоставляют предварительно созданные компоненты, главным образом для обработки данных и традиционных задач машинного обучения, таких как регрессия и классификация. Этот тип компонента по-прежнему поддерживается, но новые компоненты добавляться не будут.
Пользовательские компоненты позволяют упаковывать собственный код в качестве компонента. Она поддерживает совместное использование компонентов между рабочими областями и простой разработки в интерфейсах Studio, CLI версии 2 и ПАКЕТА SDK версии 2.
Для новых проектов мы настоятельно рекомендуем использовать настраиваемый компонент, совместимый с AzureML версии 2 и сохраняющий получение новых обновлений.
Эта статья относится к классическим предварительно созданным компонентам и не совместим с CLI версии 2 и пакетом SDK версии 2.
Бизнес-сценарии и краткий справочник по Машинному обучению
Краткий справочник по Машинному обучению Azure в первую очередь позволяет ответить на вопрос: что нужно сделать с данными? На листе Машинное обучение алгоритма найдите задачу, которую вы хотите выполнить, а затем найдите алгоритм конструктора Машинное обучение Azure для решения прогнозной аналитики.
Конструктор Машинного обучения предоставляет комплексный портфель алгоритмов, таких как лес решений с несколькими классами, системы рекомендаций, регрессия нейронных сетей, многоклассовая нейронная сеть и кластеризация методом k-средних. Каждый алгоритм предназначен для решения определенного типа проблем, связанных с машинным обучением. Полный список, а также описание работы каждого алгоритма и настройки параметров для оптимизации алгоритма см. в Справочнике по модулям и алгоритмам для конструктора Машинного обучения Azure.
Вместе с рекомендациями, приведенными в кратком справочнике по алгоритмам Машинного обучения, следует учитывать другие требования при выборе алгоритма Машинного обучения для принятия решения. Ниже приведены дополнительные факторы, которые следует учитывать, такие как точность, время обучения, линейность, количество параметров и функций.
Сравнение алгоритмов машинного обучения
Некоторые алгоритмы обучения делают определенные предположения о структуре данных или желаемых результатов. Если вы сможете найти тот алгоритм, который соответствует вашим потребностям, с ним вы сможете получить более точные результаты, более точные прогнозы и сократить время обучения.
В следующей таблице перечислены некоторые из наиболее важных характеристик алгоритмов из семейств классификации, регрессии и кластеризации.
| Алгоритм | Точность | Время обучения | Линейность | Параметры | Примечания |
|---|---|---|---|---|---|
| Семейство классификации | |||||
| Двухклассовая логистическая регрессия | Специалист | Быстро | Да | 4 | |
| Двухклассовый лес принятия решений | Отлично | Умеренно | No | 5 | Показывает меньшее время оценки. Предложение не работает с Многоклассовым классификатором «один — все» из-за более медленных оценок, вызванных блокировкой в накоплении прогнозов дерева |
| Двухклассовое увеличивающееся дерево принятия решений | Отлично | Умеренно | No | 6 | Большой объем памяти |
| Двухклассовая нейронная сеть | Специалист | Умеренно | No | 8 | |
| Двухклассовое усредненное восприятие | Специалист | Умеренно | Да | 4 | |
| Двухклассовый метод опорных векторов | Специалист | Быстро | Да | 5 | Подходит для больших наборов функций |
| Многоклассовая логистическая регрессия | Специалист | Быстро | Да | 4 | |
| Многоклассовый лес принятия решений | Отлично | Умеренно | No | 5 | Показывает меньшее время оценки |
| Мультиклассовое увеличивающееся дерево принятия решений | Отлично | Умеренно | No | 6 | Имеет тенденцию к повышению точности с небольшим риском меньшего объема |
| Многоклассовая нейронная сеть | Специалист | Умеренно | No | 8 | |
| Многоклассовый классификатор «один — все» | — | — | — | — | Просмотрите свойства выбранного двухклассового метода |
| Семейство регрессии | |||||
| Линейная регрессия | Специалист | Быстро | Да | 4 | |
| Регрессия леса принятия решений | Отлично | Умеренно | No | 5 | |
| Регрессия увеличивающегося дерева принятия решений | Отлично | Умеренно | No | 6 | Большой объем памяти |
| Регрессия нейронной сети | Специалист | Умеренно | No | 8 | |
| Семейство кластеризации | |||||
| Кластеризация методом k-средних | Отлично | Умеренно | Да | 8 | Алгоритм кластеризации |
Требования к сценарию обработки и анализа данных
После того как будет известно о том, что делать с данными, необходимо определить дополнительные требования для принятия решения.
Сделайте выбор и, возможно, найдите приемлемое решение для удовлетворения следующих требований.
- Правильность
- Время обучения
- Линейность
- Количество параметров
- Количество функций
Правильность
Точность машинного обучения позволяет измерить эффективность модели как пропорцию истинных результатов к общему числу вариантов. В конструкторе Машинного обучения компонент «Оценка модели» вычисляет набор отраслевых метрик оценки. Вы можете использовать этот компонент для измерения точности обученной модели.
Получение наиболее точного ответа возможно не всегда. Иногда достаточно приближенного ответа в зависимости от того, для чего он используется. В этом случае можно значительно сократить время обработки, придерживаясь более приближенных методов. Кроме того, приблизительные методы, как правило, позволяют избежать лжевзаимосвязи.
Существует три способа использования компонента «Оценка модели»:
- Создание оценок для обучающих данных для оценки модели
- Создание оценок для модели, но со сравнением этих оценок с показателями в зарезервированном проверочном наборе
- Сравнение оценок для двух различных, но связанных моделей с использованием одного набора данных
Полный список метрик и подходов, которые можно использовать для оценки точности моделей машинного обучения, см. в компоненте «Оценка модели».
Время обучения
Контролируемое обучение обозначает использование исторических данных для построения модели машинного обучения, которая позволяет снизить ошибки до минимума. Количество минут или часов, необходимых для обучения модели, сильно отличается для различных алгоритмов. Время обучения часто тесно связано с точностью — одно обычно сопутствует другому.
Кроме того, некоторые алгоритмы более чувствительны к количеству точек данных, чем другие. Можно выбрать конкретный алгоритм, так как имеется ограничение по времени, особенно если набор данных большой.
В конструкторе Машинного обучения создание и использование модели машинного обучения, как правило, состоит из трех этапов:
- Необходимо настроить модель, выбрав определенный тип алгоритма и определив ее параметры или гиперпараметры.
- Предоставьте помеченный набор данных, который содержит данные, совместимые с алгоритмом. Подключите данные и модель к компоненту «Обучение модели».
- После завершения обучения используйте обученную модель с одним из компонентов оценки, чтобы создать прогнозы на основе новых данных.
Линейность
Линейность в статистике и машинном обучении означает, что между переменной и константой в наборе данных существует линейная связь. Например, алгоритмы линейной классификации предполагают, что классы могут быть разделены прямой линией (или ее аналогом для большего числа измерений).
Линейность используется во многих алгоритмах машинного обучения. В конструкторе «Машинное обучение» Azure они включают:
- Многоклассовая логистическая регрессия
- Двухклассовая логистическая регрессия
- Поддержка векторных компьютеров
Алгоритмы линейной регрессии предполагают, что тренды данных следуют прямой линии. Это предположение полезно для решения некоторых проблем, но для других снижает точность. Несмотря на недостатки, линейные алгоритмы распространены в качестве первой стратегии. Обычно они алгоритмически просты и быстро осваиваются.
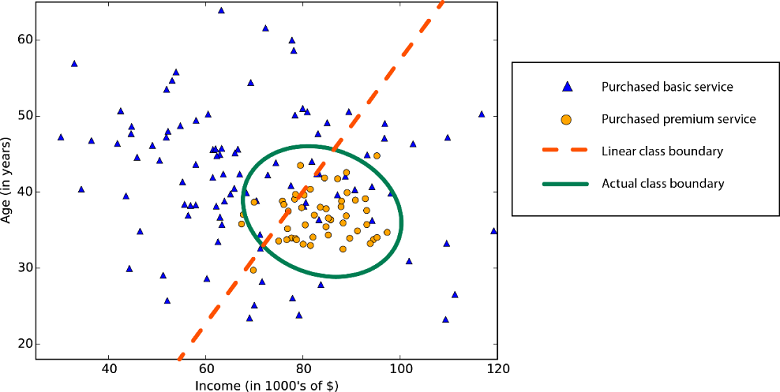
Граница нелинейного класса — использование алгоритма линейной классификации приведет к снижению точности.
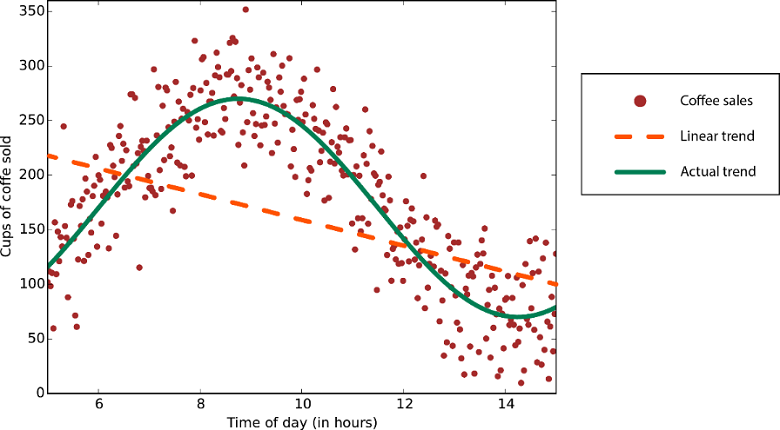
Данные с нелинейным трендом — использование метода линейной регрессии приведет к появлению гораздо большего количества ошибок, чем необходимо.
Количество параметров
Параметры являются теми регуляторами, которые специалист по данным поворачивает при настройке алгоритма. Это числа, которые влияют на поведение алгоритма, например чувствительность к ошибкам или количество итераций, либо на варианты поведения алгоритма. Время обучения и точность алгоритма иногда могут быть чувствительными к точности задания параметров. Как правило, алгоритмы с большим числом параметров требуют большого количества проб и ошибок, чтобы определить удачное сочетание параметров.
Кроме того, конструктор Машинного обучения содержит компонент «Настройка гиперпараметров модели». Цель этого компонента — определить оптимальные гиперпараметры для модели машинного обучения. Модуль создает и тестирует несколько компонентов, используя различные сочетания параметров. Он сравнивает метрики по всем моделям, чтобы получить сочетания параметров.
Хотя это отличный способ убедиться в том, что вы заполнили пространство параметров, с увеличением количества параметров экспоненциально возрастает время, необходимое для обучения модели. Плюсом является то, что наличие большого количества параметров обычно означает, что алгоритм имеет большую гибкость. Часто это позволяет достичь очень хорошей точности при условии, что вы можете найти правильное сочетание настроек параметров.
Количество функций
В машинном обучении компонент — это количественная переменная, которую вы пытаетесь проанализировать. Для некоторых типов данных количество функций может быть очень большим по сравнению с количеством точек данных. Это часто происходит с генетическими или текстовыми данными.
Большое количество функций для некоторых алгоритмов обучения может привести к тому, что они увязнут и время обучения станет недопустимо большим. Метод опорных векторов особенно хорошо подходит для сценариев с большим количеством функций. По этой причине они использовались во многих областях применения: от извлечения информации до классификации текста и изображения. Методы опорных векторов можно использовать как для задач классификации, так и регрессии.
Как правило, выбор признаков обозначает процесс применения статистических тестов к входным данным с учетом конкретных выходных данных. Цель состоит в том, чтобы определить столбцы, которые лучше других позволяют прогнозировать эти выходные данные. Компонент «Выбор признаков с помощью фильтра» в конструкторе Машинного обучения предоставляет несколько алгоритмов выбора признаков. Данный компонент включает такие методы корреляции, как корреляция Пирсона и значения хи-квадрат.
Кроме того, можно воспользоваться компонентом «Важность признака перестановки», чтобы вычислить набор оценок важности признаков для вашего набора данных. Используйте эти оценки при определении наиболее подходящих признаков в модели.
Следующие шаги
- Подробнее о конструкторе Машинного обучения Azure
- Описание всех алгоритмов машинного обучения, доступных в конструкторе Машинного обучения Azure, см. в Справочнике по алгоритмам и компонентам для конструктора Машинного обучения
- Сведения о связи между глубоким обучением, машинным обучением и искусственным интеллектом см. в статье Глубокое обучение и Машинное обучение
Что такое машинное обучение?

Машинное обучение – это наука о разработке алгоритмов и статистических моделей, которые компьютерные системы используют для выполнения задач без явных инструкций, полагаясь вместо этого на шаблоны и логические выводы. Компьютерные системы используют алгоритмы машинного обучения для обработки больших объемов статистических данных и выявления шаблонов данных. Таким образом, системы могут более точно прогнозировать результаты на основе заданного набора входных данных. Например, специалисты по работе с данными могут обучить медицинское приложение диагностировать рак по рентгеновским изображениям, сохраняя миллионы отсканированных изображений и соответствующие диагнозы.
Почему машинное обучение так важно?
Машинное обучение помогает компаниям стимулировать рост, открывать новые источники дохода и решать сложные проблемы. Данные являются важной движущей силой принятия бизнес-решений, но традиционно компании использовали данные из различных источников, таких как отзывы клиентов, сотрудников и финансов. Исследования в области машинного обучения автоматизируют и оптимизируют этот процесс. Используя ПО, которое анализирует очень большие объемы данных на высокой скорости, компании могут быстрее достигать результатов.
Где используется машинное обучение?
Ключевые области использования машинного обучения см. ниже.
Производство
Машинное обучение может поддерживать профилактическое обслуживание, контроль качества и инновационные исследования в производственном секторе. Технология машинного обучения также помогает компаниям улучшать логистические решения, включая активы, цепочки поставок и управление запасами. Например, крупномасштабная компания-производитель 3M использует AWS Machine Learning для инновации шлифовальной бумаги. Алгоритмы машинного обучения позволяют исследователям 3M анализировать, как незначительные изменения формы, размера и ориентации улучшают абразивность и долговечность. Эти предложения влияют на производственный процесс.
Здравоохранение и медико‑биологические разработки
Распространение носимых датчиков и устройств породило значительный объем данных о здоровье. Программы машинного обучения могут анализировать эту информацию и помогать врачам в диагностике и лечении в режиме реального времени. Исследователи машинного обучения разрабатывают решения, которые обнаруживают раковые опухоли и диагностируют глазные заболевания, что значительно влияет на показатели здоровья человека. Например, компания Cambia Health Solutions использовала машинное обучение AWS для поддержки стартапов в области здравоохранения с целью автоматизации и персонализации лечения беременных женщин.
Финансовые услуги
Проекты финансового машинного обучения улучшают аналитику рисков и регулирование. Технология машинного обучения может позволить инвесторам выявлять новые возможности путем анализа движений фондового рынка, оценки хедж-фондов или калибровки финансовых портфелей. Кроме того, это может помочь выявить кредитных клиентов с высоким уровнем риска и смягчить признаки мошенничества. Лидирующий поставщик финансового ПО Intuit использует подсистему AWS Machine Learning, Amazon Textract,чтобы обеспечить более персонализированное управление финансами и помочь конечным пользователям улучшить финансовое положение.
Розничная торговля
В розничной торговле машинное обучение может использоваться для улучшения обслуживания клиентов, управления запасами, дополнительных продаж и многоканального маркетинга. Например, Amazon Fulfillment (AFT) удалось сократить расходы на инфраструктуру на 40 %, используя модель машинного обучения для выявления неуместных запасов. Это позволяет выполнять обещание Amazon в отношении предоставления клиентам простого доступа к товару и своевременной доставки такого товара, несмотря на обработку миллионов поставок ежегодно.
Мультимедиа и развлечения
Компании в индустрии развлечений обращаются к машинному обучению, чтобы лучше понимать целевую аудиторию и предоставлять иммерсивный персонализированный контент по запросу. Алгоритмы машинного обучения используются для разработки трейлеров и другой рекламы, предоставления потребителям персонализированных рекомендаций по контенту и даже оптимизации производства.
Например, Disney использует глубокое обучение AWS для архивирования медиатеки. Инструменты машинного обучения AWS автоматически маркируют, описывают и сортируют медиаконтент, позволяя писателям и аниматорам Disney быстро искать персонажей Disney и знакомиться с ними.
Как работает машинное обучение?
Центральной идеей машинного обучения является существующая математическая связь между любой комбинацией входных и выходных данных. Модель машинного обучения не имеет сведений об этой взаимосвязи заранее, но может сгенерировать их, если будет предоставлено достаточное количество наборов данных. Это означает, что каждый алгоритм машинного обучения строится вокруг модифицируемой математической функции. Описание основополагающего принципа см. ниже.
- Мы «обучаем» алгоритм, давая ему следующие комбинации ввода-вывода [input / output (i,o)]: (2,10), (5,19) и (9,31).
- Алгоритм вычисляет соотношение между входом и выходом следующим образом: o = 3 × i + 4.
- Затем мы задаем ввод 7 и просим предсказать результат. Алгоритм может автоматически определить выход как 25.
Хотя это базовое понимание, машинное обучение фокусируется на том принципе, что все сложные точки данных могут быть математически связаны компьютерными системами, если у них достаточно данных и вычислительной мощности для обработки этих данных. Следовательно, точность выходных данных прямо пропорциональна величине входных данных.
Какие типы алгоритмов машинного обучения существуют?
Алгоритмы можно разделить на четыре стиля обучения в зависимости от ожидаемого результата и типа ввода.
- Машинное обучение с учителем
- Машинное обучение без учителя
- Машинное обучение с частичным привлечением учителя
- Машинное обучение с подкреплением
1. Машинное обучение с учителем
Специалисты по работе с данными предоставляют алгоритмам помеченные и определенные обучающие данные для оценки корреляций. Демонстрационные данные определяют как входные данные, так и выходные данные алгоритма. Например, изображения рукописных цифр аннотируются, чтобы указать, какому числу они соответствуют. Система обучения с учителем может распознавать кластеры пикселей и фигур, связанных с каждым числом, при наличии достаточного количества примеров. Со временем система распознает написанные от руки цифры, стабильно различая числа 9 и 4 или 6 и 8.
Сильные стороны машинного обучения с учителем – простота и легкость структуры. Такая система полезна при прогнозировании возможного ограниченного набора результатов, разделении данных на категории или объединении результатов двух других алгоритмов машинного обучения. Однако маркировка миллионов немаркированных наборов данных является сложной задачей. Давайте рассмотрим это подробнее.
Что такое маркировка данных?
Маркировка данных – это процесс категоризации входных данных с соответствующими им определенными выходными значениями. Помеченные обучающие данные необходимы для обучения с учителем. Например, миллионы изображений яблок и бананов должны быть помечены словами «яблоко» или «банан». Затем приложения машинного обучения могли бы использовать эти обучающие данные, чтобы угадывать название фрукта по изображению фрукта. Однако маркировка миллионов новых данных может быть трудоемкой и сложной задачей. Сервисы коллективной работы, такие как Amazon Mechanical Turk, могут в некоторой степени преодолеть это ограничение алгоритмов обучения с учителем. Эти сервисы обеспечивают доступ к большому количеству доступным рабочим ресурсам по всему миру, что упрощает сбор данных.
2. Машинное обучение без учителя
Алгоритмы обучения без учителя обучаются на неразмеченных данных. Такие алгоритмы просматривают новые данные, пытаясь установить значимые связи между входными и заранее определенными выходными данными. Они могут выявлять закономерности и классифицировать данные. Например, алгоритмы без учителя могут группировать новостные статьи с разных новостных веб-сайтов в общие категории, такие как спорт, криминал и т. д. Они могут использовать обработку естественного языка для понимания смысла и эмоций в статье. В розничной торговле обучение без учителя поможет найти закономерности в покупках клиентов и предоставить результаты анализа данных, такие как: покупатель, скорее всего, купит хлеб, если также купит масло.
Обучение без учителя полезно для распознавания образов, обнаружения аномалий и автоматического группирования данных по категориям. Поскольку обучающие данные не требуют маркировки, настройка проста. Эти алгоритмы также можно использовать для автоматической очистки и обработки данных для дальнейшего моделирования. Ограничение этого метода состоит в том, что он не может дать точных прогнозов. Кроме того, он не может самостоятельно выделять конкретные типы выходных данных.
3. Машинное обучение с частичным привлечением учителя
Как следует из названия, этот метод сочетает в себе обучение с учителем и без него. Этот метод основан на использовании небольшого количества размеченных данных и большого количества неразмеченных данных для обучения систем. Сначала размеченные данные используются для частичного обучения алгоритма машинного обучения. После этого частично обученный алгоритм сам размечает неразмеченные данные. Этот процесс называется псевдомаркировкой. Затем модель переобучается на результирующем наборе данных без явного программирования.
Преимущество этого метода в том, что вам не требуются большие объемы размеченных данных. Это удобно при работе с такими данными, как длинные документы, чтение и маркировка которых отнимает слишком много времени у человека.
4. Обучение с подкреплением
Обучение с подкреплением – это метод, в котором значения вознаграждения привязаны к различным шагам, которые должен пройти алгоритм. Таким образом, цель модели – накопить как можно больше призовых баллов и в конечном итоге достичь конечной цели. Большая часть практического применения обучения с подкреплением за последнее десятилетие была связана с видеоиграми. Передовые алгоритмы обучения с подкреплением добились впечатляющих результатов в классических и современных играх, часто значительно превосходя ручные аналоги.
Хотя этот метод лучше всего работает в неопределенных и сложных средах данных, он редко применяется в бизнес-контексте. Это неэффективно для четко определенных задач, и предвзятость разработчиков может повлиять на результаты. Поскольку специалист по работе с данными разрабатывает награды, они могут влиять на результаты.
Являются ли модели машинного обучения детерминированными?
Если выход системы предсказуем, то говорят, что она детерминирована. Большинство программных приложений предсказуемо реагируют на действия пользователя, поэтому можно сказать: что «если пользователь делает то-то, он получает то-то». Однако алгоритмы машинного обучения учатся на основе наблюдения и опыта. Поэтому они носят вероятностный характер. Утверждение теперь меняется на следующее: «если пользователь делает это, есть вероятность X %, что произойдет это».
В машинном обучении детерминизм – это стратегия, используемая при применении методов обучения, описанных выше. Любой из методов обучения (с учителем, без учителя и т. д.) можно сделать детерминированным в зависимости от желаемых бизнес-результатов. Вопрос исследования, поиск данных, структура и решения по хранению определяют, будет ли принята детерминированная или недетерминированная стратегия.
Детерминированный и вероятностный подходы
Детерминированный подход фокусируется на точности и объеме собранных данных, поэтому эффективность важнее неопределенности. С другой стороны, недетерминированный (или вероятностный) процесс предназначен для управления фактором случайности. Встроенные инструменты интегрированы в алгоритмы машинного обучения, чтобы помочь количественно определить, идентифицировать и измерить неопределенность во время обучения и наблюдения.
Что такое глубокое обучение?
Глубокое обучение – это метод машинного обучения, который моделируется мозгом человека. Алгоритмы глубокого обучения анализируют данные с логической структурой, аналогичной той, которую используют люди. Глубокое обучение использует интеллектуальные системы, называемые искусственными нейронными сетями, для обработки информации слоями. Данные проходят от входного слоя через несколько «глубоких» скрытых слоев нейронной сети, прежде чем попасть на выходной слой. Дополнительные скрытые слои поддерживают обучение, которое намного эффективнее, чем стандартные модели машинного обучения.
Что такое искусственная нейронная сеть?
Слои глубокого обучения представляют собой узлы искусственной нейронной сети (ИНС), которые работают как нейроны человеческого мозга. Узлы могут представлять собой комбинацию аппаратного и программного обеспечения. Каждый уровень в алгоритме глубокого обучения состоит из узлов ИНС. Каждый узел или искусственный нейрон соединяется с другим и имеет связанный с ним номер значения и пороговый номер. Узел отправляет номер своего значения в качестве входных данных узлу следующего слоя при активации. Он активируется, только если его выход превышает указанное пороговое значение. В противном случае никакие данные не передаются.
Что такое машинное зрение?
Компьютерное зрение – это реальное применение глубокого обучения. Точно так же, как искусственный интеллект позволяет компьютерам думать, компьютерное зрение позволяет им видеть, наблюдать и реагировать. Самоуправляемые автомобили используют компьютерное зрение, чтобы «читать» дорожные знаки. Камера автомобиля делает снимок знака. Это фото отправляется алгоритму глубокого обучения в машине. Первый скрытый слой обнаруживает края, следующий различает цвета, а третий слой идентифицирует детали алфавита на знаке. Алгоритм предсказывает, что на знаке написано СТОП, и автомобиль ответит срабатыванием тормозного механизма.
Машинное обучение и глубокое обучение – это одно и то же?
Глубокое обучение – это часть машинного обучения. Алгоритмы глубокого обучения можно рассматривать как непростую и математически сложную эволюцию алгоритмов машинного обучения.
Машинное обучение и искусственный интеллект – это одно и то же?
Короткий ответ: нет. Хотя термины «машинное обучение» и «искусственный интеллект» (ИИ) могут использоваться взаимозаменяемо, это не одно и то же. Искусственный интеллект – это общий термин для различных стратегий и методов, используемых для того, чтобы сделать машины более похожими на людей. ИИ включает в себя все, от умных помощников, таких как Alexa, до роботов-пылесосов и беспилотных автомобилей. Машинное обучение – одна из многих других ветвей искусственного интеллекта. Хотя машинное обучение – это ИИ, все действия ИИ нельзя назвать машинным обучением.
Машинное обучение и наука о данных – это одно и то же?
Нет, машинное обучение и наука о данных – это не одно и то же. Наука о данных – это область исследования, в которой используется научный подход для извлечения смысла и понимания из данных. Специалисты по работе с данными используют ряд инструментов для анализа данных, и машинное обучение является одним из таких инструментов. Специалисты по работе с данными понимают общую картину данных, таких как бизнес-модель, предметная область и сбор данных, в то время как машинное обучение — это вычислительный процесс, который работает только с необработанными данными.
Каковы преимущества и недостатки машинного обучения?
Мы предлагаем вашему вниманию возможности и ограничения машинного обучения.
Преимущества моделей машинного обучения:
- определение тенденций и закономерностей данных, которые может упустить человек;
- работа без вмешательства человека после настройки; например, машинное обучение в ПО для кибербезопасности может постоянно отслеживать и выявлять нарушения в сетевом трафике без участия администратора;
- результаты могут стать более точными с течением времени;
- обработка различных форматов данных в динамических, больших объемов и сложных сред данных.
Недостатки моделей машинного обучения:
- исходная подготовка является дорогостоящим и трудоемким процессом; трудоемкая реализация в отсутствии достаточного объема данных;
- ресурсоемкий процесс, требующий больших первоначальных инвестиций, если оборудование устанавливается собственными силами;
- без помощи специалиста может быть сложно правильно интерпретировать результаты и устранить неопределенность.
Как Amazon может содействовать машинному обучению?
AWS предоставляет машинное обучение в руки каждого разработчика, специалиста по данным и бизнес-пользователя. Сервисы Amazon Machine Learning предоставляют высокопроизводительную, экономически эффективную и масштабируемую инфраструктуру для удовлетворения потребностей бизнеса.
Работа только началась?
Овладейте машинным обучением с нашей помощью, используя учебные устройства: AWS DeepRacer, AWS DeepComposer и AWS DeepLens.
Архив данных уже существует?
Используйте маркировку данных Amazon SageMaker для встроенных рабочих процессов маркировки данных, поддерживающих видео, изображения и текст.
Системы машинного обучения уже имеются?
Используйте Amazon SageMaker Clarify для обнаружения смещений, а также Amazon SageMaker Debugger для мониторинга и оптимизации продуктивности.
Хотите внедрить глубокое обучение?
Используйте распределенное обучение Amazon SageMaker для автоматического обучения больших моделей глубокого обучения. Чтобы начать машинное обучение уже сегодня, зарегистрируйте бесплатный аккаунт!
Алгоритмы машинного обучения: основные понятия

Машинное обучение использует широкий спектр алгоритмов для перевода наборов данных в прогнозные модели. Какой алгоритм сработает лучше, зависит от решаемой задачи.
Машинное обучение получило широкое распространение, но и еще более широкое непонимание. Коротко изложим основные понятия машинного обучения, обсудим некоторые из наиболее распространенных алгоритмов машинного обучения и объясним, как эти алгоритмы связаны с другими частями мозаики создания прогнозных моделей из исторических данных.
Что такое алгоритмы машинного обучения?
Машинное обучение – это класс методов автоматического создания прогнозных моделей на основе данных. Алгоритмы машинного обучения превращают набор данных в модель. Какой алгоритм работает лучше всего (контролируемый, неконтролируемый, классификация, регрессия и т. д.), зависит от типа решаемой задачи, доступных вычислительных ресурсов и характера данных.
Алгоритмы обычно напрямую говорят компьютеру, что делать. Например, алгоритмы сортировки преобразуют неупорядоченные данные в данные, упорядоченные по некоторым критериям, часто в числовом или алфавитном порядке одного или нескольких полей данных.
Алгоритмы линейной регрессии «подгоняют» прямую линию к числовым данным, как правило, выполняя инверсии матрицы, чтобы минимизировать значение квадрата погрешности между линией и данными. Квадрат погрешности используется в качестве метрики, поскольку не важно, находится ли линия регрессии выше или ниже точек данных — принципиально только расстояние между построенной линией и исходными точками.
Алгоритмы нелинейной регрессии, которые «подгоняют» кривые (например, многочлены или экспоненты) к данным, немного сложнее: в отличие от задач линейной регрессии для них не существует детерминистских подходов. Вместо этого алгоритмы нелинейной регрессии реализуют тот или иной итерационный процесс минимизации, часто — некоторую вариацию метода самого крутого спуска.
Самый крутой спуск в общем случае предполагает вычисление квадрата погрешности и ее градиента при текущих значениях параметров, выбор размера шага (он же — скорость обучения), следование направлению градиента «вниз по склону», а затем пересчет квадрата погрешности и ее градиента при новых значениях параметров. В конце концов, если повезет, все сойдется. Варьируя алгоритм самого крутого спуска пытаются улучшить его характеристики сходимости.
Алгоритмы машинного обучения еще сложнее, чем нелинейная регрессия, отчасти потому, что машинное обучение обходится без ограничения на «подгонку» к определенной математической функции. Есть две основные категории задач, которые часто решаются с помощью машинного обучения: регрессия и классификация. Регрессия – для числовых данных (например, каков вероятный доход для человека с данным адресом и профессией). Классификация – для нечисловых данных (например, сможет ли заемщик выплатить кредит).
Задачи прогнозирования (например, какова будет цена открытия акций «Яндекса» завтра) являются подмножеством регрессионных задач для данных временных рядов. Задачи классификации иногда подразделяют на бинарные (да или нет) и мультикатегории (животные, фрукты или предметы мебели).
Контролируемое обучение против неконтролируемого
Независимо от этих типов существуют еще два вида алгоритмов машинного обучения: контролируемые (supervised) и неконтролируемые (unsupervised). В контролируемом обучении формируется обучающий набор данных с ответами, скажем, набор изображений животных вместе с именами животных. Целью обучения будет модель, которая сможет правильно распознавать изображения (то есть узнавать животных, включенных в набор обучения), которые она ранее не видела.
При неконтролируемом обучении алгоритм сам просматривает данные и пытается получить значимые результаты. Результатом может быть, например, набор групп значений, которые могут быть связаны внутри каждой группы. Алгоритм работает надежнее, когда такие группы не пересекаются.
Обучение превращает контролируемые алгоритмы в модели, оптимизируя их параметры, чтобы найти набор значений, который наилучшим образом соответствует данным. Алгоритмы часто основываются на вариантах самого крутого спуска, оптимизированных для конкретного случая; пример — стохастический градиентный спуск (SGD), который является по существу самым крутым спуском, выполненным многократно от случайных начальных точек. Учет факторов, которые корректируют направление градиента на основе импульса или регулируют скорость обучения в зависимости на основе прогресса от одного прогона данных (его называют эпохой) к следующему, позволяют подобрать оптимальные настройки SGD.
Очистка данных для машинного обучения
Такой вещи, как чистые данные, не существует. Чтобы быть полезными для машинного обучения, данные должны быть сильно отфильтрованы. Например, можно:
- Просмотреть данные и исключить все столбцы, в которых много недостающих данных.
- Просмотреть данные еще раз и выбрать столбцы, которые будут использованы для прогнозирования. (Если эту операцию повторять эту операцию несколько раз, то можно выбирать разные столбцы.)
- Исключить все строки, в которых отсутствуют данные в оставшихся столбцах.
- Исправить очевидные опечатки и объединить эквивалентные значения. Скажем, РФ, Российская Федерация и Россия могут быть собраны в одну категорию.
- Исключить строки с данными, которые находятся вне нужного диапазона. Например, если анализировать поездки на такси в пределах Москвы, вы захотите отфильтровать строки с широтами и долготами, которые находятся за пределами агломерации.
Можно сделать еще много чего, но это будет зависеть от собранных данных. Это может быть утомительно, но, если шаг очистки данных в конвейере машинного обучения предусмотрен, в дальнейшем по желанию его можно будет изменить или повторить.
Кодирование и нормализация данных для машинного обучения
Чтобы использовать категориальные данные для машинной классификации, необходимо преобразовать текстовые метки в другую форму. Существует два типа кодировок.
Первая – нумерация меток, каждое значение текстовой метки заменяется числом. Вторая – «единая горячая» (one-hot) кодировка, каждое значение текстовой метки превращается в столбец с двоичным значением (1 или 0). Большинство платформ машинного обучения имеют функции, которые выполняют кодировку самостоятельно. Как правило, предпочтительной является единая горячая кодировка, поскольку нумерация меток иногда может запутать алгоритм машинного обучения, заставляя думать, что коды упорядочены.
Чтобы использовать числовые данные для машинной регрессии, данные обычно требуется нормализовать. В противном случае при вычислении евклидовых расстояний наборы чисел с большими диапазонами могут начать неоправданно «доминировать», а оптимизация самого крутого спуска может не сходиться. Существует несколько способов нормализации данных для машинного обучения, включая минимаксную нормализацию, центрирование, стандартизацию и масштабирование до единичной длины. Этот процесс также часто называют масштабированием.
Что такое признаки в машинном обучении?
Признак – это индивидуальное измеримое свойство или характеристика наблюдаемого явления. Понятие «признак» связано с понятием независимой переменной, которая используется в статистических методах, таких как линейная регрессия. Векторы признаков объединяют все признаки одной строки в числовой вектор.
Часть искусства выбора функций состоит в том, чтобы выбрать минимальный набор независимых переменных, которые объясняют задачу. Если две переменные сильно коррелированы, их необходимо объединить в одну или удалить. Иногда люди анализируют главные компоненты, чтобы преобразовать коррелированные переменные в набор линейно некоррелированных переменных.
Некоторые преобразования, используемые для построения новых признаков или уменьшения размерности их векторов, просты. Например, вычтя год рождения из года смерти, получают возраст смерти, который является главной независимой переменной для анализа смертности и продолжительности жизни. В других случаях построение признаков может быть не столь очевидным.
Общие алгоритмы машинного обучения
Существуют десятки алгоритмов машинного обучения, варьирующихся по сложности от линейной регрессии и логистической регрессии до глубоких нейронных сетей и ансамблей (так называют комбинации других моделей).
Вот некоторые из наиболее распространенных алгоритмов:
- линейная регрессия, она же регрессия наименьших квадратов (для числовых данных);
- логистическая регрессия (для бинарной классификации);
- линейный дискриминантный анализ (для мультикатегорийной классификации);
- деревья решений (для классификации и регрессии);
- наивный байесовский классификатор (для классификации и регрессии);
- метод k-ближайших соседей, он же k-NN (для классификации и регрессии);
- обучение нейронной сети Кохонена, он же LVQ (для классификации и регрессии);
- метод опорных векторов, он же SVM (для двоичной классификации);
- «случайный лес» и методы бэггинга (для классификации и регрессии);
- методы бустинга, включая AdaBoost и XGBoost, являются ансамблями алгоритмов, которые создают серию моделей, где каждая новая модель пытается исправить ошибки предыдущей модели (для классификации и регрессии).
А где нейронные сети и глубокие нейронные сети, о которых так много говорят? Они, как правило, требуют больших вычислительных затрат, поэтому их следует использовать только для специализированных задач, таких как классификация изображений и распознавание речи, для которых не подходят более простые алгоритмы. («Глубокая» означает, что в нейронной сети много слоев.)
Гиперпараметры для алгоритмов машинного обучения
Алгоритмы машинного обучения обучаются на данных, чтобы найти лучший набор весов для каждой независимой переменной, которая влияет на прогнозируемое значение или класс. Сами алгоритмы имеют переменные, называемые гиперпараметрами. Они называются гиперпараметрами, потому что, в отличие от параметров, управляют работой алгоритма, а не определяемыми весами.
Наиболее важным гиперпараметром часто является скорость обучения, которая определяет размер шага, используемый при поиске следующего набора весов для оптимизации. Если скорость обучения слишком высока, крутейший спуск может быстро сойтись на плато или к неоптимальной точке. Если скорость обучения слишком низкая, спуск может остановиться и никогда полностью не сойтись.
Многие другие распространенные гиперпараметры зависят от используемых алгоритмов. Большинство алгоритмов имеют параметры остановки, такие как максимальное число эпох, максимальное время выполнения или минимальное улучшение от эпохи к эпохе. Определенные алгоритмы имеют гиперпараметры, которые управляют формой их поиска. Например, классификатор случайного леса имеет гиперпараметры для минимальных выборок на лист, максимальной глубины, минимальных выборок при расщеплении, минимальной массовой доли для листа и проч.
Некоторые платформы машинного обучения предусматривают автоматическую настройку гиперпараметров. По сути, системе следует сообщить, какие гиперпараметры надо изменить, и, возможно, какую метрику требуется оптимизировать, и система просматривает эти гиперпараметры столько запусков, сколько ей будет позволено. (Например, Google Cloud hyperparameter tuning извлекает соответствующую метрику из модели TensorFlow, поэтому вам не нужно ее указывать.)
Есть три подхода в оптимизации гиперпараметров: Байесовская оптимизация, поиск по решетке и случайный поиск. Как правило, самым эффективным подходом оказывается Байесовская оптимизация.
Можно предположить, что настройка как можно большего количества гиперпараметров даст лучший ответ. Однако, это может быть очень дорого. С опытом приходит понимание, какие гиперпараметры имеют наибольшее значение для исследуемых в каждом конкретном случае данных и выбранных алгоритмов.
Автоматизированное машинное обучение
Есть только один способ узнать, какой алгоритм или ансамбль алгоритмов даст лучшую модель в каждом случае, – попробовать все. Если также попробуете все возможные нормализации и варианты функций, неминуем с комбинаторным взрывом.
Пытаться все сделать вручную нецелесообразно, поэтому поставщики инструментов машинного обучения приложили много усилий для выпуска систем класса AutoML (так называемое автоматизированное машинное обучение). Лучшие из них сочетают в себе настройку параметров, подбор алгоритмов и нормализацию данных. Гиперпараметрическую настройку лучшей модели (или моделей) часто оставляют на потом.
Таким образом, алгоритмы машинного обучения – всего лишь часть мозаики машинного обучения. В дополнение к выбору алгоритма (вручную или автоматически) нужно будет иметь дело с оптимизаторами, очисткой данных, выбором функций, нормализацией и (необязательно) настройкой гиперпараметров.
Когда вы обработаете все это и построите модель, которая будет работать с вашими данными, придет время использовать модель, а затем обновлять ее по мере изменения условий. Однако управление моделями машинного обучения – уже совсем другая история.
В чем разница между машинным и глубоким обучением?
Машинное обучение – это наука об обучении компьютерной программы или системы выполнению задач без четких инструкций. Компьютерные системы используют алгоритмы машинного обучения для обработки больших объемов данных, выявления закономерностей данных и прогнозирования точных результатов для неизвестных или новых сценариев. Глубокое обучение – это подмножество машинного обучения, в котором используются специальные алгоритмические структуры, называемые нейронными сетями, смоделированные по образцу человеческого мозга. Методы глубокого обучения направлены на автоматизацию более сложных задач, для выполнения которых обычно требуется человеческий интеллект. Например, с помощью глубокого обучения можно описывать изображения, переводить документы или транскрибировать звуковой файл в текст.
В чем сходство между машинным и глубоким обучением?
Для выявления закономерностей в данных можно использовать как машинное, так и глубокое обучение. Они оба используют наборы данных для обучения алгоритмов, основанных на сложных математических моделях. Во время обучения алгоритмы находят взаимосвязи между известными выходами и входами. Затем модели могут автоматически генерировать или прогнозировать выходные данные на основе неизвестных входных данных. В отличие от традиционного программирования, процесс обучения также автоматизирован и требует минимального вмешательства человека.
Ниже приведены другие сходства между машинным и глубоким обучением.
Методы искусственного интеллекта
Как машинное, так и глубокое обучение являются подмножествами анализа данных и искусственного интеллекта (ИИ). Обе технологии могут выполнять сложные вычислительные задачи, для решения которых с помощью традиционных методов программирования в противном случае потребовалось бы много времени и ресурсов.
Статистическая основа
И глубокое, и машинное обучение используют статистические методы для обучения своих алгоритмов наборам данных. Эти методы включают регрессионный анализ, деревья решений, линейную алгебру и анализ функций. Как эксперты по машинному обучению, так и специалисты по глубокому обучению хорошо разбираются в статистике.
Большие наборы данных
Как машинное, так и глубокое обучение требуют больших наборов качественных обучающих данных для более точных прогнозов. Например, для модели машинного обучения требуется около 50–100 точек данных для каждой функции, в то время как модель глубокого обучения начинает работу с тысячами точек данных на функцию.
Широкая сфера применения и различные варианты использования
Решения по глубокому и машинному обучению выполняют сложные задачи во всех отраслях и областях применения. Для решения или оптимизации этих типов задач потребовалось бы значительно больше времени, если бы вы использовали традиционные методы программирования и статистики.
Требования к вычислительной мощности
Для обучения и запуска алгоритмов машинного обучения требуются значительные вычислительные мощности, а для глубокого обучения вычислительные требования еще выше из-за его повышенной сложности. Благодаря последним достижениям в области вычислительных мощностей и облачных ресурсов теперь возможно использовать обе технологии в личных целях.
Постепенное улучшение
По мере того как решения машинного и глубокого обучения обрабатывают больше данных, они становятся более точными при распознавании образов. Когда в систему добавляются входные данные, система совершенствуется, используя их в качестве точки данных для обучения.
Какие ограничения машинного обучения привели к развитию глубокого обучения?
Традиционное машинное обучение требует значительного взаимодействия человека через конструирование признаков для получения результатов. Например, если вы обучаете модель машинного обучения классифицировать изображения кошек и собак, вам необходимо вручную настроить ее для распознавания таких черт, как форма глаз, хвоста, ушей, контуры носа и т. д.
Поскольку целью машинного обучения является снижение необходимости вмешательства человека, методы глубокого обучения избавляют людей от необходимости маркировать данные на каждом этапе.
Хотя глубокое обучение существует уже много десятилетий, в начале 2000-х годов такие ученые, как Янн ЛеКун, Йошуа Бенджио и Джеффри Хинтон, изучили эту область более подробно. Исследователи совершенствовали глубокое обучение, тем не менее большие и сложные наборы данных в это время были ограничены, а вычислительные мощности, необходимые для обучения моделей, – дорогостоящими. За последние 20 лет эти условия улучшились, и глубокое обучение стало коммерчески выгодным.
Ключевые отличия машинного и глубокого обучения
Глубокое обучение – это часть машинного обучения. Вы можете считать его продвинутой техникой машинного обучения. Каждая из этих возможностей имеет широкий спектр применения. Однако решения для глубокого обучения требуют больше ресурсов – больших наборов данных, требований к инфраструктуре и последующих затрат.
Ниже приведены другие различия между машинным и глубоким обучением.
Предполагаемые варианты использования
Решение об использовании машинного или глубокого обучения зависит от типа данных, которые необходимо обработать. Машинное обучение выявляет закономерности на основе структурированных данных, таких как системы классификации и рекомендаций. Например, компания может использовать машинное обучение, чтобы предсказать, когда клиент откажется от подписки на основе предыдущих данных об оттоке клиентов.
С другой стороны, решения для глубокого обучения больше подходят для неструктурированных данных, где для извлечения функций требуется высокий уровень абстракции. Задачи глубокого обучения включают классификацию изображений и обработку естественного языка, где необходимо определить сложные взаимосвязи между объектами данных. Например, решение для глубокого обучения может анализировать упоминания в социальных сетях для определения настроений пользователей.
Подход к решению проблем
Традиционное машинное обучение обычно требует разработки функций, когда люди вручную выбирают и извлекают объекты из необработанных данных и присваивают им веса. И наоборот, решения для глубокого обучения выполняют проектирование функций с минимальным вмешательством человека.
Архитектура нейронной сети глубокого обучения по своей конструкции более сложна. Методы обучения решений для глубокого обучения основаны на принципе работы человеческого мозга, где нейроны представлены узлами. Глубокие нейронные сети состоят из трех или более уровней узлов, включая узлы входного и выходного уровней.
В глубоком обучении каждый узел нейронной сети автономно присваивает вес каждому объекту. Информация проходит через сеть в прямом направлении от входа к выходу. Затем вычисляется разница между прогнозируемым и фактическим выходом, и эта ошибка снова передается по сети для регулировки веса нейронов.
Вследствие процессов автоматического определения веса, глубины уровней архитектуры и используемых техник, для глубокого обучения модели нужно решать гораздо больше операций, чем для машинного обучения.
Методы обучения
Машинное обучение использует четыре основных метода обучения: под наблюдением, без него, с частичным наблюдением и с подкреплением. Другие методы обучения включают трансферное обучение и обучение под наблюдением.
Напротив, в алгоритмах глубокого обучения применяются несколько типов более сложных методов обучения: используются сверточные и рекуррентные нейронные сети, генеративно-состязательные сети и автокодировщики.
Производительность
Как для машинного, так и для глубокого обучения есть конкретные случаи использования, когда одна из технологий работает лучше другой.
Для более простых задач, таких как выявление новых входящих спам-сообщений, подходит машинное обучение, которое обычно превосходит решения глубокого обучения. Для более сложных задач, таких как распознавание медицинских изображений, решения для глубокого обучения превосходят решения машинного, поскольку они позволяют выявлять аномалии, невидимые человеческому глазу.
Участие человека
Решения как для машинного, так и для глубокого обучения требуют значительного участия человека в работе. Кто-то должен определить проблему, подготовить данные, выбрать и обучить модель, а затем оценить, оптимизировать и внедрить решение.
Людям легче интерпретировать модели машинного обучения, поскольку они основаны на более простых математических моделях, таких как деревья решений.
И наоборот, для детального анализа моделей глубокого обучения требуется значительное количество времени, поскольку модели математически сложны. При этом способ обучения нейронных сетей избавляет людей от необходимости маркировать данные. Вы можете еще больше снизить необходимость участия людей, выбрав предварительно обученные модели и платформы.
Требования к инфраструктуре
Поскольку модели глубокого обучения более сложны и требуют больших наборов данных, им требуется больше места для хранения и вычислительных мощностей, чем моделям машинного обучения. Данные и модели машинного обучения могут работать на одном инстансе или кластере серверов, а модель глубокого обучения часто требует высокопроизводительных кластеров и другой существенной инфраструктуры.
Из-за требований к инфраструктуре решений для глубокого обучения затраты на него могут значительно превышать затраты на машинное обучение. Использование локальной инфраструктуры может быть нецелесообразным или экономически неэффективным для запуска решений глубокого обучения. Для контроля расходов можно использовать масштабируемую инфраструктуру и полностью управляемые сервисы глубокого обучения.