Как конвертировать файл word в PDF/XPS и в Adobe PDF через код на Python?
Имеется документ word, необходимо чтобы при запуске программы определенный документ конвертировался в указанное расширение. Как так сделать?
Отслеживать
13.4k 1 1 золотой знак 8 8 серебряных знаков 23 23 бронзовых знака
задан 8 сен 2021 в 11:30
Андрей Александров Андрей Александров
560 2 2 серебряных знака 11 11 бронзовых знаков
8 сен 2021 в 14:02
Можно привести пример с объяснением на русском?
8 сен 2021 в 15:51
1 ответ 1
Сортировка: Сброс на вариант по умолчанию
Как вариант (перед этим только нужно pip install docx2pdf):
from docx2pdf import convert convert("input.docx") И ваш файл (лежащий рядом с файлом скрипта) input.docx превратиться в output.pdf (и так же будет рядом с файлом скрипта).
Работа с PDF-файлами в Python: чтение и разбор
Сегодня формат переносимых документов (PDF) относится к наиболее часто используемым форматам данных. В 1990 году структура документа PDF была определена Adobe. Идея, лежащая в основе формата PDF, заключается в том, что передаваемые данные / документы выглядят одинаково для обеих сторон, участвующих в процессе коммуникации — для создателя, автора или отправителя и получателя. PDF является преемником формата PostScript и стандартизирован как ISO 32000-2: 2017 .
Обработка PDF документов
Для Linux существуют мощные инструменты командной строки, такие как pdftk и pdfgrep. Как разработчик, вы с огромным энтузиазмом создаете свое собственное программное обеспечение, основанное на Python и использующее свободно доступные библиотеки PDF.
Эта статья — начало небольшой серии, в которой будут рассмотрены эти полезные библиотеки Python. В первой части мы сосредоточимся на манипулировании существующими PDF-файлами. Вы узнаете, как читать и извлекать содержимое (как текст, так и изображения), вращать отдельные страницы и разбивать документы на отдельные страницы. Вторая часть будет посвящена добавлению водяных знаков на основе наложений. Третья часть будет посвящена исключительно написанию / созданию PDF-файлов, а также удалению и повторному объединению отдельных страниц в новый документ.
Инструменты и библиотеки
Спектр доступных решений для связанных с Python инструментов, модулей и библиотек PDF немного сбивает с толку, и требуется время, чтобы понять, что к чему и какие проекты поддерживаются постоянно. На основании нашего исследования это те кандидаты, которые соответствуют современным требованиям:
PyPDF2 : библиотека Python для извлечения информации и содержимого документов, постраничного разделения документов, объединения документов, обрезки страниц и добавления водяных знаков. PyPDF2 поддерживает как незашифрованные, так и зашифрованные документы.
PDFMiner : полностью написан на Python и хорошо работает для Python 2.4. Для Python 3 используйте клонированный пакет PDFMiner.six . Оба пакета позволяют анализировать и преобразовывать PDF-документы. Это включает в себя поддержку PDF 1.7, а также языков CJK (китайский, японский и корейский) и различные типы шрифтов (Type1, TrueType, Type3 и CID).
PDFQuery : он описывает себя как «быструю и удобную библиотеку очистки PDF», которая реализована как оболочка для PDFMiner, lxml и pyquery . Его цель состоит в том, чтобы «надежно извлекать данные из наборов PDF-файлов, используя как можно меньше кода».
tabula-py : Это простая оболочка Python для tabula-java , которая может читать таблицы из PDF-файлов и преобразовывать их в Pandas DataFrames. Это также позволяет вам конвертировать файл PDF в файл CSV / TSV / JSON.
pdflib для Python: расширение библиотеки Poppler, которое предлагает для него привязки Python. Это позволяет вам анализировать и конвертировать PDF документы. Не следует путать его коммерческий клон с таким же именем.
PyFPDF : библиотека для создания документов PDF под Python. Портировано из библиотеки FPDF PHP, известной замены PDFlib-расширения со множеством примеров, сценариев и производных.
PDFTables : коммерческий сервис, предлагающий извлечение из таблиц в виде документа PDF. Предлагает API, позволяющий использовать PDFTables в качестве SAAS.
PyX — графический пакет Python: PyX — это пакет Python для создания файлов PostScript, PDF и SVG. Он сочетает в себе абстракцию модели чертежа PostScript с интерфейсом TeX / LaTeX. Сложные задачи, такие как создание 2D и 3D графиков в готовом для публикации качестве, построены из этих примитивов.
ReportLab : амбициозная промышленная библиотека, в основном ориентированная на точное создание PDF-документов. Доступна свободно как версия с открытым исходным кодом, так и коммерческая улучшенная версия с именем ReportLab PLUS.
PyMuPDF (он же «fitz»): привязки Python для MuPDF, который является облегченным средством просмотра PDF и XPS. Библиотека может получать доступ к файлам в форматах PDF, XPS, OpenXPS, epub, комиксах и художественных книгах, а также известна своей высокой производительностью и высоким качеством рендеринга.
pdfrw : чистый анализатор PDF на основе Python для чтения и записи PDF. Он точно воспроизводит векторные форматы без растеризации. Вместе с ReportLab он помогает повторно использовать части существующих PDF-файлов в новых PDF-файлах, созданных с помощью ReportLab.
| Библиотека | Используется для |
|---|---|
| PyPDF2 | чтение |
| PyMuPDF | чтение |
| PDFlib | чтение |
| PDFTables | чтение |
| Табула-ру | чтение |
| PDFMiner.six | чтение |
| PDFQuery | чтение |
| pdfrw | Чтение, Запись / Создание |
| ReportLab | Запись / Создание |
| дарохранительница | Запись / Создание |
| PyFPDF | Запись / Создание |
Ниже мы сосредоточимся на PyPDF2 и PyMuPDF и объясним, как извлечь текст и изображения самым простым способом. Чтобы понять использование PyPDF2, помогло сочетание официальной документации и множества примеров, доступных на других ресурсах. Напротив, официальная документация PyMuPDF намного понятнее и значительно быстрее при использовании библиотеки.
Извлечение текста с помощью PyPDF2
PyPDF2 может быть установлен как обычный программный пакет, так и с использованием pip3 (для Python3). Тесты здесь основаны на пакете для предстоящего выпуска Debian GNU / Linux 10 «Buster». Имя пакета Debian является python3-pypdf2 .
В листинге 1 PdfFileReader сначала импортируется класс. Затем, используя этот класс, он открывает документ и извлекает информацию о документе, используя метод getDocumentInfo() , количество используемых страниц getDocumentInfo() и содержимое первой страницы.
Обратите внимание, что PyPDF2 начинает считать страницы с 0, и поэтому вызов pdf.getPage(0) извлекает первую страницу документа. В конце концов, извлеченная информация печатается в stdout .
Листинг 1: Извлечение информации и содержимого документа.
#!/usr/bin/python from PyPDF2 import PdfFileReader pdf_document = "example.pdf" with open(pdf_document, "rb") as filehandle: pdf = PdfFileReader(filehandle) info = pdf.getDocumentInfo() pages = pdf.getNumPages() print (info) print ("number of pages: %i" % pages) page1 = pdf.getPage(0) print(page1) print(page1.extractText())
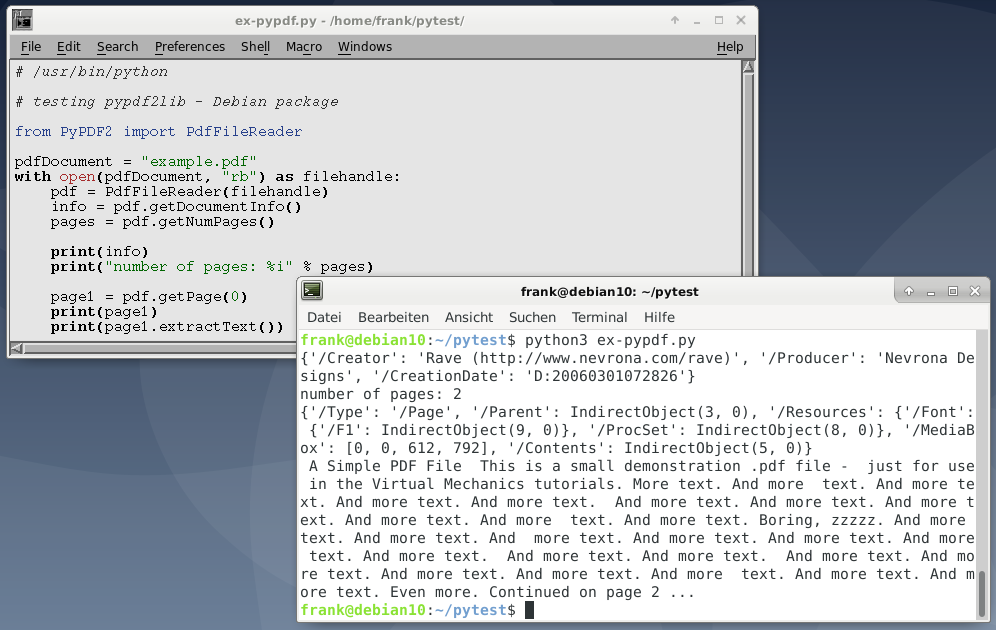
Как показано на рисунке 1 выше, извлеченный текст печатается на постоянной основе. Здесь нет ни абзацев, ни разделений предложений. Как указано в документации по PyPDF2, все текстовые данные возвращаются в том порядке, в котором они представлены в потоке содержимого страницы, и их использование может привести к неожиданностям. Это в основном зависит от внутренней структуры документа PDF и от того, как поток инструкций PDF был создан процессом записи PDF.
Извлечение текста с помощью PyMuPDF
PyMuPDF доступен на веб-сайте PyPi, и вы устанавливаете пакет с помощью следующей команды в терминале:
$ pip3 install PyMuPDF
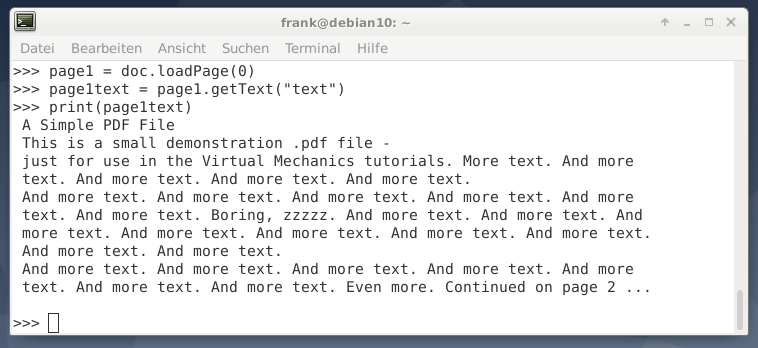
Отображение информации о документе, печать количества страниц и извлечение текста из документа PDF выполняется аналогично PyPDF2 (см. Листинг 2 ). Импортируемый модуль имеет имя fitz и возвращается к предыдущему имени PyMuPDF.
Листинг 2: Извлечение содержимого из документа PDF с использованием PyMuPDF.
#!/usr/bin/python import fitz pdf_document = "example.pdf" doc = fitz.open(pdf_document): print ("number of pages: %i" % doc.pageCount) print(doc.metadata)page1 = doc.loadPage(0) page1text = page1.getText("text") print(page1text)
Приятной особенностью PyMuPDF является то, что он сохраняет исходную структуру документа без изменений — целые абзацы с разрывами строк сохраняются такими же, как в PDF-документе (см. Рисунок 2 ).
Извлечение изображений из PDF с помощью PyMuPDF
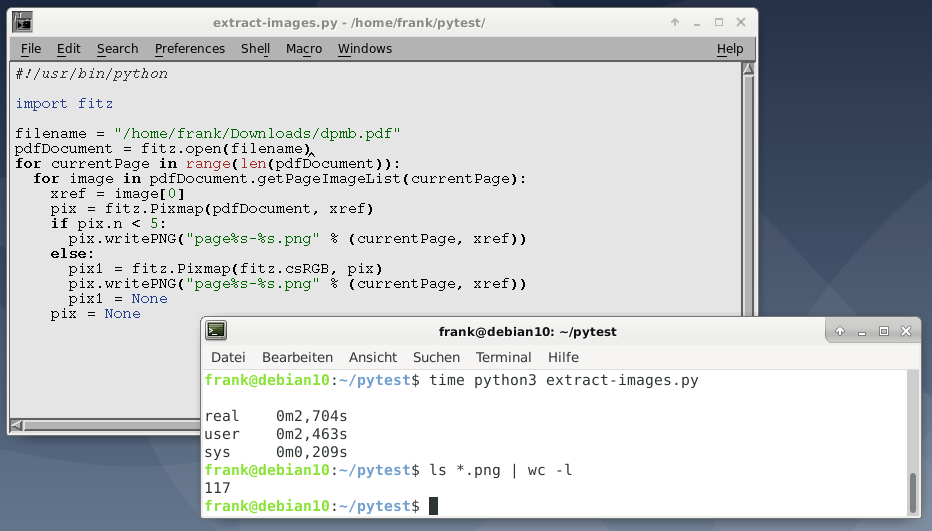
PyMuPDF упрощает извлечение изображений из документов PDF с использованием метода getPageImageList() . Листинг 3 основан на примере из вики-страницы PyMuPDF и извлекает и сохраняет все изображения из PDF в формате PNG постранично. Если изображение имеет цветовое пространство CMYK, оно будет сначала преобразовано в RGB.
Листинг 3: Извлечение изображений.
#!/usr/bin/python import fitz pdf_document = fitz.open("file.pdf") for current_page in range(len(pdf_document)): for image in pdf_document.getPageImageList(current_page): xref = image[0] pix = fitz.Pixmap(pdf_document, xref) if pix.n < 5: # this is GRAY or RGB pix.writePNG("page%s-%s.png" % (current_page, xref)) else: # CMYK: convert to RGB first pix1 = fitz.Pixmap(fitz.csRGB, pix) pix1.writePNG("page%s-%s.png" % (current_page, xref)) pix1 = None pix = None
Запустив этот скрипт Python на 400-страничном PDF, он извлек 117 изображений менее чем за 3 секунды, что удивительно. Отдельные изображения хранятся в формате PNG. Чтобы сохранить исходный формат и размер изображения вместо преобразования в PNG, взгляните на расширенные версии сценариев в вики PyMuPDF .
Разделение PDF-файлов на страницы с помощью PyPDF2
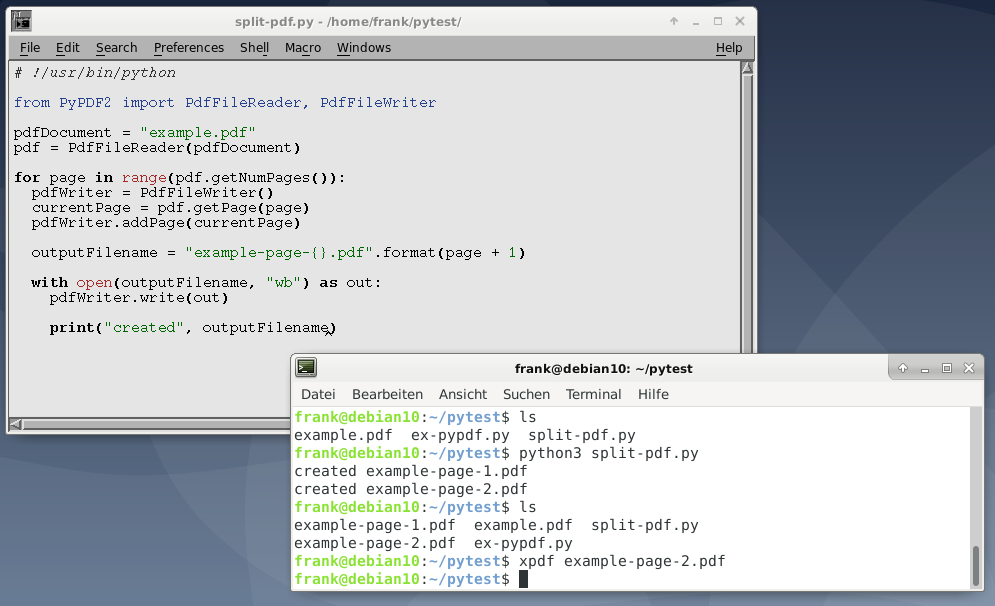
Для этого примера, в первую очередь необходимо импортировать классы PdfFileReader и PdfFileWriter . Затем мы открываем файл PDF, создаем объект для чтения и перебираем все страницы, используя метод объекта для чтения getNumPages .
Внутри цикла for мы создаем новый экземпляр PdfFileWriter , который еще не содержит страниц. Затем мы добавляем текущую страницу к нашему объекту записи, используя метод pdfWriter.addPage() . Этот метод принимает объект страницы, который мы получаем, используя метод PdfFileReader.getPage() .
Следующим шагом является создание уникального имени файла, что мы делаем, используя исходное имя файла плюс слово «page» плюс номер страницы. Мы добавляем 1 к текущему номеру страницы, потому что PyPDF2 считает номера страниц, начиная с нуля.
Наконец, мы открываем новое имя файла в режиме (режиме wb ) записи двоичного файла и используем метод write() класса pdfWriter для сохранения извлеченной страницы на диск.
Листинг 4: Разделение PDF на отдельные страницы.
#!/usr/bin/python from PyPDF2 import PdfFileReader, PdfFileWriter pdf_document = "example.pdf" pdf = PdfFileReader(pdf_document) for page in range(pdf.getNumPages()): pdf_writer = PdfFileWriter current_page = pdf.getPage(page) pdf_writer.addPage(current_page) outputFilename = "example-page-<>.pdf".format(page + 1) with open(outputFilename, "wb") as out: pdf_writer.write(out) print("created", outputFilename)
Найти все страницы, содержащие текст
Этот вариант использования довольно практичен и работает аналогично pdfgrep . Используя PyMuPDF, скрипт возвращает все номера страниц, которые содержат данную строку поиска. Страницы загружаются одна за другой, и с помощью метода searchFor() обнаруживаются все вхождения строки поиска. В случае совпадения соответствующее сообщение печатается на stdout .
Листинг 5: Поиск заданного текста.
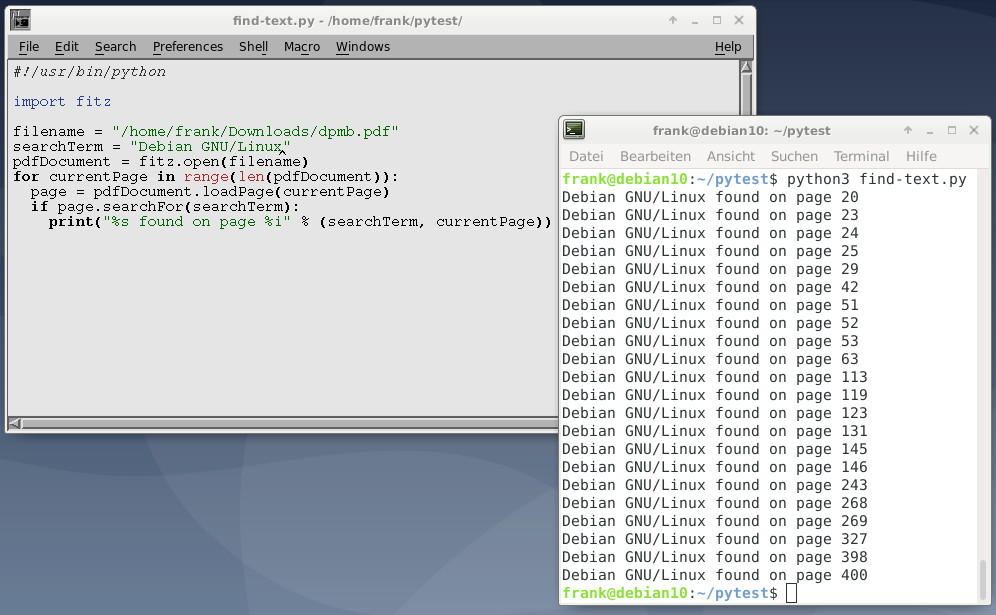
#!/usr/bin/python import fitz filename = "example.pdf" search_term = "invoice" pdf_document = fitz.open(filename): for current_page in range(len(pdf_document)): page = pdf_document.loadPage(current_page) if page.searchFor(search_term): print("%s found on page %i" % (search_term, current_page))
На рисунке 5 ниже показан результат поиска для термина «Debian GNU / Linux» в книге на 400 страниц.
Заключение
Методы, показанные здесь, довольно мощные. Сравнительно небольшое количество строк кода позволяет легко получить результат. Другие варианты использования рассматриваются во второй части (скоро!), Посвященной добавлению водяного знака в PDF.
PDFDocument
Позволяет управлять документами PDF, включая объединение и удаление страниц, поведение при открытии, добавление вложений и создание или изменение настроек безопасности документа.
Обсуждение
PDFDocumentOpen и PDFDocumentCreate являются двумя функциями, которые обеспечивают ссылку на объект PDFDocument .
Один из стандартных сценариев создания новых файлов PDF предназначен для создания атласов. Как правило, необходимо создать новый объект PDFDocument , присоединить к нему содержание других PDF-файлов и сохранить объект PDFDocument на диск. Другим стандартным сценарием является изменение содержания существующего файла PDF или его свойств. После того, как вы получили ссылку на PDFDocument , вы можете выполнить методы appendPages , insertPages или deletePages , а также использовать методы updateDocProperties и updateDocSecurity для изменения настроек PDF-файла.
Метод deletePages удобен для выгрузки только тех страниц, которые должны быть изменены. Обработка большого количества страниц занимает много времени. Если были изменены всего несколько страниц, быстрее удалить их, затем добавить измененные страницы с помощью метода insertPages .
В настоящий момент при использовании Python для настройки безопасности PDF документа, она ограничена шифрованием RC4 . Если вы настраиваете безопасность PDF в ArcGIS Pro , она ограничена шифрованием AES 256-bit . Это значит, что, если вы управляете документами PDF, используя Python, вы ограничены работой только с теми документами PDF, которые не защищены, либо документами с шифрованием RC4 .
Свойства
| Свойство | Описание | Тип данных |
| pageCount |
(только чтение)
Возвращает целое число, отображающее общее число страниц в документе PDF.
Обзор метода
Добавляет один документ PDF в конце другого.
Позволяет удалить одну или несколько страниц из документа PDF.
Позволяет вставлять содержимое одного документа PDF в начало или в середину другого PDF.
Сохраняет изменения, внесенные в текущий PDFDocument .
Позволяет обновлять метаданные документа PDF, а также указывать конкретное поведение, которое будет запускаться при открытии документа в приложениях Adobe Reader и Adobe Acrobat, например, исходный режим просмотра и вид образцов.
Обеспечивает механизм установки пароля, шифрования и ограничений безопасности для файлов PDF.
Методы
appendPages (pdf_path, )
Необходимо вставить строку с указанием расположения и имени присоединяемого документа PDF.
input_pdf_password
Строка, определяющая главный пароль для защищенного файла. Это должен быть главный пароль: пользовательский пароль не подойдет.
(Значение по умолчанию — None)
При присоединении документов PDF с различными настройками безопасности настройки выходного документа будут основаны на настройках главного документа, к которому будет присоединены страницы. Например, если документ, к которому будут присоединены страницы, не имеет защитного пароля, а присоединяемые страницы имеют, полученный документ не будет иметь защитного пароля.
Для добавления страницы в начало текущего документа PDF используйте insertPages .
deletePages (page_range)
page_range
Строка, задающая страницы для удаления. Для удаления одной страницы в строке указывается одно значение (например, "3" ). Несколько страниц можно удалить, задав их номера через запятую (например, "3, 5, 7" ). Кроме того, можно задать диапазоны страниц (например, "1, 3, 5-12" ).
Необходимо внимательно следить за удаляемыми страницами, т.к. после каждого удаления номера страниц в документе PDF автоматически пересчитываются. Например, страница 3 станет страницей 2 сразу после удаления страницы 1 или 2. Если страницы 1 и 2 удалены, страница 3 станет страницей 1. Необходимо учитывать эти особенности, если при использовании команды deletePages вы сразу же следом применяете команду insertPages вместе со значением before_page_number .
insertPages (pdf_path, , )
Необходимо вставить строку с указанием расположения и имени вставляемого документа PDF.
before_page_number
Целое число, определяющее номер страницы в ссылаемом PDFDocument , перед которым необходимо вставить новые страницы. Например, если before_page_value равно 1, вставляемая страница будет находиться перед всеми страницами.
(Значение по умолчанию — 1)
input_pdf_password
Строка, определяющая главный пароль для защищенного файла. Это должен быть главный пароль: пользовательский пароль не подойдет.
(Значение по умолчанию — None)
При использовании документов PDF с различными настройками безопасности настройки выходного документа будут основаны на настройках главного документа, в который будут вставляться страницы. Например, если документ, в который будут вставляться страницы, не имеет защитного пароля, а вставляемые страницы имеют, полученный документ не будет иметь защитного пароля.
Для добавления страницы в конец текущего документа PDF используйте appendPages .
saveAndClose ()
Метод saveAndClose следует использовать для сохраняемых изменений. Если скрипт завершает работу до исполнения saveAndClose , изменения не сохраняются. Если вы создаете новый файл с помощью PDFDocumentCreate , файл не появится на диске, пока не будет выполнена команда saveAndClose .
updateDocProperties (, , , , , )
Строка, задающая заголовок документа, свойство метаданных файла PDF.
(Значение по умолчанию — None)
pdf_author
Строка, задающая автора документа, свойство метаданных файла PDF.
(Значение по умолчанию — None)
pdf_subject
Строка, задающая тему документа, свойство метаданных файла PDF.
(Значение по умолчанию — None)
pdf_keywords
Строка, задающая ключевые слова документа, свойство метаданных файла PDF.
(Значение по умолчанию — None)
pdf_open_view
Строка или число, которые определяют поведение при просмотре файла PDF. Значение по умолчанию USETHUMBS задает автоматическое отображение панели «Страницы просмотрщика» при открытии файла PDF.
- VIEWER_DEFAULT — Заданный пользователем параметр, применяемый при открытии файла.
Создание и изменение PDF-файлов в Python
Узнать, как в Python можно создавать и модифицировать PDF-файлы, очень и очень полезно. PDF (Portable Document Format) — это один из самых распространенных форматов для документов в интернете. Файлы в формате PDF могут содержать текст, изображения, таблицы, разнообразные формы, а также различные мультимедийные форматы видео и анимации. Причем все это может быть вместе, в одном файле.
Подобное изобилие создает определенные трудности в работе с PDF-файлами. Ведь для открытия файла нужно декодировать множество различных типов данных! К счастью, в экосистеме Python есть несколько отличных пакетов для чтения, изменения и создания PDF- файлов.
Из этого руководства вы узнаете как:
- Считывать текст из PDF-файла
- Делить PDF-файл на несколько других
- Объединять PDF-файлы
- Вращать и обрезать страницы в PDF-файлах
- Шифровать и дешифровать PDF-файлы паролем
- Создавать PDF-файл с нуля.
Примеры кода и PDF-файлы, которые мы используем в данном руководстве, можно загрузить отсюда.
Извлечение текста из PDF-файла
В этом разделе вы узнаете, как читать PDF-файл и извлекать из него текст при помощи пакета PyPDF2 . Однако, для начала его надо установить при помощи менеджера pip.
$ python3 -m pip install PyPDF2
Проверить результат установки можно при помощи следующей команды:
$ python3 -m pip show PyPDF2 Name: PyPDF2 Version: 1.26.0 Summary: PDF toolkit Home-page: http://mstamy2.github.com/PyPDF2 Author: Mathieu Fenniak Author-email: biziqe@mathieu.fenniak.net License: UNKNOWN Location: c:\\users\\david\\python38-32\\lib\\site-packages Requires: Required-by:
Обратите особое внимание на версию пакета. На момент написания статьи последней версией пакета PyPDF2 была 1.26.0. Если вы используете IDE IDLE, для работы с только что установленным пакетом ее надо перезапустить.
Открываем PDF-файл
Начнем с того, что откроем PDF-файл и считаем из него некоторую информацию. Мы будем использовать файл Pride_and_Prejudice.pdf, расположенный в директории practice_files/ репозитория, ссылку на который мы дали выше.
Импортируем класс PdfFileReader из пакета PyPDF2 :
from PyPDF2 import PdfFileReader
Для создания нового экземпляра класса PdfFileReader нам потребуется информация о пути к файлу, который мы хотим открыть. Будем использовать для этого модуль pathlib .
from pathlib import Path pdf_path = ( Path.home() / "creating-and-modifying-pdfs" / "practice_files" / "Pride_and_Prejudice.pdf" )
Сейчас переменная pdf_path содержит путь к файлу Pride_and_Prejudice.pdf, в котором находится книга Джейн Остин «Гордость и предубеждение».
Примечание: возможно вам придется изменить этот путь в соответствии с расположением директории creating-and-modifying-pdfs/ на вашем компьютере.
Теперь мы создаем экземпляр класса PdfFileReader :
pdf = PdfFileReader(str(pdf_path))
Нам пришлось конвертировать содержимое переменной pdf_path в строку, так как класс PdfFileReader не знает, как работать с объектами pathlib.Path .
Вспомним, что в Python все открытые файлы должны быть закрыты до завершения работы программы. Так вот, объект PdfFileReader все это делает за вас, и вам не нужно беспокоиться об открытии и закрытии файлов!
Заметим, что создав экземпляр класса PdfFileReader , мы можем его использовать для получения информации о PDF-файле. Например, метод .getNumPages () возвращает количество страниц, содержащихся в файле PDF:
pdf.getNumPages() # результат: 234
Заметим, что метод .getNumPages() написан в так называемом «верблюжем регистре» (lowerCamelCase или, иначе говоря, MixedCase), в то время как PEP8 рекомендует «змеиный регистр» (примерно так — lower_case_with_underscores). Верблюжий регистр PEP8 советует использовать в именах классов. Но имейте в виду, что PEP8 это свод рекомендаций, а не правил. Как бы то ни было, верблюжий регистр здесь вполне приемлем.
Примечание: Пакет PyPDF2 вышел из пакета pyPdf, который был написан в 2005 году, всего через 4 года после публикации PEP8. К этому времени появилось много программистов, которые мигрировали из других языков, где верблюжий регистр был обычным делом.
Также мы можем получить некоторую информацию о документе с помощью атрибута .documentInfo :
pdf.documentInfo
Объект, возвращенный атрибутом .documentInfo , выглядит как словарь, но это не совсем так. Все его значения можно также получить атрибутивным образом, обратившись к ним через точку (‘ . ‘).
Например, чтобы получить заголовок, воспользуемся атрибутом .title :
pdf.documentInfo.title 'Pride and Prejudice, by Jane Austen'
Объект, полученный при помощи атрибута .documentInfo , содержит метаданные PDF-файла, которые задаются при его создании.
Класс PdfFileReader содержит все методы и атрибуты, необходимые вам для доступа к данным PDF-файла. Давайте рассмотрим, что и как можно сделать с этим файлом!
Извлекаем текст из страницы
Страницы PDF-файла представлены в пакете PyPDF2 классом PageObject . Мы используем экземпляры класса PageObject для взаимодействия со страницами в PDF-файле. Но нам не нужно непосредственно создавать собственные экземпляры класса PageObject . Вместо этого к ним можно получить доступ через метод .getPage() объекта класса PdfFileReader .
Извлечь текст из единичной страницы PDF-файла можно в два шага:
- Получаем экземпляр класса PageObject при помощи метода PdfFileReader.getPage() .
- Извлекаем текст в виде строки с помощью метода .extractText() , который есть у каждого экземпляра класса PageObject .
В файле Pride_and_Prejudice.pdf 234 страницы. Каждая страница проиндексирована от 0 до 233. Мы можем получить экземпляр класса PageObject , представляющий конкретную страницу, передав индекс страницы в PdfFileReader.getPage() :
first_page = pdf.getPage(0)
Метод .getPage() возвратит экземпляр класса PageObject :
type(first_page) # результат
Теперь мы можем извлечь текст при помощи метода PageObject.extractText() :
first_page.extractText() '\\n \\nThe Project Gutenberg EBook of Pride and Prejudice, by Jane Austen\\n \\n\\nThis eBook is for the use of anyone anywhere at no cost and with\\n \\nalmost no restrictions whatsoever. You may copy it, give it away or\\n \\nre\\n-\\nuse it under the terms of the Project Gutenberg License included\\n \\nwith this eBook or online at www.gutenberg.org\\n \\n \\n \\nTitle: Pride and Prejudice\\n \\n \\nAuthor: Jane Austen\\n \\n \\nRelease Date: August 26, 2008 [EBook #1342]\\n\\n[Last updated: August 11, 2011]\\n \\n \\nLanguage: Eng\\nlish\\n \\n \\nCharacter set encoding: ASCII\\n \\n \\n*** START OF THIS PROJECT GUTENBERG EBOOK PRIDE AND PREJUDICE ***\\n \\n \\n \\n \\n \\nProduced by Anonymous Volunteers, and David Widger\\n \\n \\n \\n \\n \\n \\n \\nPRIDE AND PREJUDICE \\n \\n \\nBy Jane Austen \\n \\n\\n \\n \\nContents\\n \\n'
Заметим, что вывод на экран был отформатирован при размещении на этой странице. То, что вы увидите на своем экране, может несколько отличаться.
Каждый объект класса PdfFileReader имеет атрибут .pages , при помощи которого мы можем производить итерацию по всем страницам нашего PDF-файла.
Например, следующий цикл for выведет на экран текст со всех страниц файла Pride_and_Prejudice.pdf:
for page in pdf.pages: print(page.extractText())
Теперь давайте соберем наши знания воедино и напишем программу, которая извлекает весь текст из файла Pride_and_Prejudice.pdf и записывает его в текстовый файл (с расширением .txt).
Собираем все вместе
Откройте новое окно в вашем редакторе или IDE и напишете там следующий код:
from pathlib import Path from PyPDF2 import PdfFileReader # Не забудьте поменять путь на тот, что есть в вашем компьютере. pdf_path = ( Path.home() / "creating-and-modifying-pdfs" / "practice-files" / "Pride_and_Prejudice.pdf" ) # 1 pdf_reader = PdfFileReader(str(pdf_path)) output_file_path = Path.home() / "Pride_and_Prejudice.txt" # 2 with output_file_path.open(mode="w") as output_file: # 3 title = pdf_reader.documentInfo.title num_pages = pdf_reader.getNumPages() output_file.write(f"\\nNumber of pages: \\n\\n") # 4 for page in pdf_reader.pages: text = page.extractText() output_file.write(text)
Давайте разберем этот код:
- Сначала мы сохраняем новый экземпляр класса PdfFileReader в переменную pdf_reader . Мы также создаем объект Path , который указывает на файл Pride_and_Prejudice.txt в нашей домашней директории и сохраняем его в переменную output_file_path .
- Далее мы открываем файл, указатель на который сохранен в переменной output_file_path , в режиме записи, и присваиваем этому объекту имя output_file . Инструкция with гарантирует нам, что файл будет закрыт сразу же после выполнения этого блока кода.
- Затем, внутри блока with , мы записываем в текстовый файл заголовок (title) нашего PDF-файла и количество страниц — при помощи метода output_file.write() .
- И наконец, с помощью цикла for мы производим итерацию по всем страницам PDF-файла. На каждом шаге цикла в переменную page записывается элемент из объекта PageObject . Текст из каждой страницы извлекается при помощи метода page.extractText() и затем записывается в output_file .
Когда вы сохраните и запустите эту программу, она создаст файл Pride_and_Prejudice.txt в вашей домашней директории, в котором будет весь текст из файла Pride_and_Prejudice.pdf. Откройте его и убедитесь сами!
Проверка ваших знаний
Упражнение: Выведите текст из PDF файла.
В папке practice_files данного репозитория находится файл под названием zen.pdf. Создайте экземпляр класса PdfFileReader и используйте его для вывода на экран текста из первой страницы.
Решение:
Сначала определяем путь до PDF-файла:
# Вначале импортируем необходимые библиотеки и классы from pathlib import Path from PyPDF2 import PdfFileReader # Затем создаем объект Path для нашего PDF файла # Возможно, вам нужно изменить этот путь на вашем компьютере pdf_path = ( Path.home() / "creating-and-modifying-pdfs" / "practice_files" / "zen.pdf" )
Теперь создаем экземпляр класса PdfFileReader :
pdf_reader = PdfFileReader(str(pdf_path))
Не забывайте, что экземпляры класса PdfFileReader могут создаваться только со строковой переменной, которая содержит в себе путь к файлу. Объекты типа Path не подходят!
Теперь используем метод .getPage() , чтобы получить первую страницу:
first_page = pdf_reader.getPage(0)
Помним, что страницы индексируются начиная с 0 .
Затем используем метод .extractText() , чтобы извлечь текст:
text = first_page.extractText()
И наконец, выводим текст на экран:
print(text)
Если готовы, переходим ко второй секции.
Извлечение страниц из PDF-файла
В предыдущей секции мы научились извлекать весь текст из PDF-файла и сохранять его в текстовый файл. Сейчас мы научимся извлекать страницу или диапазон страниц из PDF-файла и сохранять ее или их в новый PDF-файл.
Для создания нового PDF-файла используется класс PdfFileWriter . Давайте рассмотрим этот класс и изучим шаги, необходимые для создания нового PDF-файла при помощи пакета PyPDF2 .
Используем класс PdfFileWriter
Класс PdfFileWriter создает новые PDF-файлы. Импортируем класс PdfFileWriter и создадим новый экземпляр с именем pdf_writer :
from PyPDF2 import PdfFileWriter pdf_writer = PdfFileWriter()
Объекты PdfFileWriter похожи на пустые PDF-файлы. Перед сохранением в файл надо добавить в них несколько страниц.
Давайте добавим пустую страницу:
page = pdf_writer.addBlankPage(width=72, height=72)
Параметры width и height являются обязательными и определяют размеры страницы в единицах под названием points (точки). Одна точка равна 1/72 дюйма. Таким образом мы создали пустую страницу размеров в один квадратный дюйм и добавили ее в объект pdf_writer (который является экземпляром класса PdfFileWriter ).
Метод .addBlankPage() возвращает новый экземпляр класса PageObject , представляющий собой страницу, которую мы добавили в объект класса PdfFileWriter :
type(page) # результат:
В этом примере мы присвоили значение экземпляра класса PageObject , возвращаемое методом .addBlankPage() , переменной Page , но на практике это обычно не требуется. То есть, обычно вызывается метод .addBlankPage() без присваивания возвращаемого значения чему-либо:
pdf_writer.addBlankPage(width=72, height=72)
Чтобы записать содержимое объекта pdf_writer в файл PDF, передаем объект файла в двоичном режиме записи в метод pdf_writer.write() :
from pathlib import Path with Path("blank.pdf").open(mode="wb") as output_file: pdf_writer.write(output_file)
Данный код создает файл под названием blank.pdf в нашей текущей рабочей директории. Если мы откроем этот файл в каком-нибудь редакторе, например в Adobe Acrobat, то увидим документ с единственной пустой страницей площадью в один дюйм.
Техническое замечание: Обратите внимание, что мы сохраняем PDF-файл, передавая объект файла методу .write() , принадлежащему объекту класса PdfFileWriter , а не методу .write() из стандартной библиотеки Python.
То есть, следующий код работать не будет:
with Path("blank.pdf").open(mode="wb") as output_file: output_file.write(pdf_writer)
Подобные ошибки часто ставят в тупик начинающих программистов, так что старайтесь их избегать.
Объекты класса PdfFileWriter могут записывать в новые PDF-файлы, но с их помощью нельзя создать ничего, кроме пустых страниц.
Это может казаться серьезным недостатком, но во многих случаях нам не нужно создавать новый контент. Зачастую мы просто работаем со страницами, извлеченными из других PDF файлов, открыв их при помощи класса PdfFileReader .
Примечание: мы научимся создавать PDF-файл с нуля дальше, в секции «Создание PDF-файла с нуля».
В вышеприведенном примере можно выделить три шага по созданию нового PDF-файла при помощи пакета PyPDF2 :
- Создаем экземпляр класса PdfFileWriter .
- Добавляем к нему одну или более страниц.
- Записываем его в файл, используя метод PdfFileWriter.write() .
Вы увидите этот шаблон много раз, когда мы будем изучать различные методы добавления страниц в экземпляр класса PdfFileWriter .
Извлекаем одну страницу из PDF-файла
Давайте снова вернемся к файлу Pride_and_Prejudice.pdf, с которым уже работали в прошлой секции. Мы откроем этот PDF-файл, извлечем первую страницу и создадим новый PDF-файл только с этой единственной страницей.
Для начала, импортируем классы PdfFileReader и PdfFileWriter из пакета PyPDF2 , а класс Path — из модуля pathlib .
from pathlib import Path from PyPDF2 import PdfFileReader, PdfFileWriter
Теперь откроем файл Pride_and_Prejudice.pdf при помощи экземпляра класса PdfFileReader :
# при необходимости поменяйте путь, в зависимости от расположения # файлов на вашем компьютере. pdf_path = ( Path.home() / "creating-and-modifying-pdfs" / "practice_files" / "Pride_and_Prejudice.pdf" ) input_pdf = PdfFileReader(str(pdf_path))
Передаем индекс 0 в метод .getPage() , чтобы получить объект класса PageObject , который будет представлять первую страницу:
first_page = input_pdf.getPage(0)
Теперь создаем новый экземпляр класса PdfFileWriter и добавляем к нему first_page при помощи метода .addPage() :
pdf_writer = PdfFileWriter() pdf_writer.addPage(first_page)
Метод .addPage() добавляет страницу ко множеству страниц объекта pdf_writer, точно так же, как это делает метод .addBlankPage() . Разница только в том, что методу .addPage() требуется существующий объект класса PageObject .
Теперь запишем содержимое pdf_writer в новый файл:
with Path("first_page.pdf").open(mode="wb") as output_file: pdf_writer.write(output_file)
Теперь мы имеем новый файл, сохраненный в нашей рабочей директории под названием first_page.pdf. Он содержит страницу обложки из файла Pride_and_Prejudice.pdf. Отлично!
Извлекаем несколько страниц из PDF-файла
Давайте извлечем первую главу из Pride_and_Prejudice.pdf и сохраним ее в новый PDF-файл.
Если вы откроете Pride_and_Prejudice.pdf при помощи любого редактора PDF, вы увидите, что первая глава находится на второй, третьей и четвертой страницах PDF-файла. Поскольку страницы индексируются, начиная с 0 , нам нужно извлечь страницы с индексами 1 , 2 и 3 .
Для начала настроим все, импортировав нужные нам классы и открыв файл PDF:
from PyPDF2 import PdfFileReader, PdfFileWriter from pathlib import Path pdf_path = ( Path.home() / "creating-and-modifying-pdfs" / "practice_files" / "Pride_and_Prejudice.pdf" ) input_pdf = PdfFileReader(str(pdf_path))
Наша цель — извлечь страницы с индексами 1 , 2 и 3 , добавить их в новый экземпляр класса PdfFileWriter , а затем записать их в новый PDF-файл.
Один из способов это сделать — при помощи цикла перебрать нужные нам индексы, начиная с 1 и заканчивая 3 , извлекая страницу на каждом шаге цикла и добавляя ее в экземпляр класса PdfFileWriter :
pdf_writer = PdfFileWriter() for n in range(1, 4): page = input_pdf.getPage(n) pdf_writer.addPage(page)
Цикл перебирает числа 1 , 2 и 3 , поскольку функция range (1, 4) не включает правую границу ( 4 ). На каждом этапе цикла страница с текущим индексом извлекается с помощью метода . getPage () и добавляется в объект pdf_writer с помощью метода .addPage () .
Теперь объект pdf_writer имеет три страницы, что можно проверить при помощи метода .getNumPages () :
pdf_writer.getNumPages() # результат: 3
И наконец, можно записать извлеченные страницы в новый PDF-файл:
with Path("chapter1.pdf").open(mode="wb") as output_file: pdf_writer.write(output_file)
Теперь можно открыть файл chapter1.pdf, который находится в текущей рабочей директории, и прочитать первую главу книги «Гордость и предубеждение».
Другой способ извлечь несколько страниц из PDF-файла — воспользоваться тем фактом, что атрибут PdfFileReader.pages поддерживает срезы. Давайте повторим предыдущий пример, используя атрибут .pages вместо циклического перемещения по нужному диапазону.
Начнем с инициализации нового объекта класса PdfFileWriter :
pdf_writer = PdfFileWriter()
Теперь переберем страницы из нужного диапазона, от 1 до 4 ,воспользовавшись срезом атрибута .pages :
for page in input_pdf.pages[1:4]: pdf_writer.addPage(page)
Не забывайте, что срез берется от первого элемента включительно до последнего, но не включая его. Таким образом, .pages[1:4] вернет итерируемую последовательность страниц с индексами 1 , 2 и 3 .
И наконец, запишем извлеченные страницы в новый PDF-файл:
with Path("chapter1_slice.pdf").open(mode="wb") as output_file: pdf_writer.write(output_file)
Теперь откроем файл chapter1_slice.pdf в нашем текущем рабочем каталоге и сравним его с файлом chapter1.pdf, который мы создали ранее. Они абсолютно одинаковы!
Иногда нам нужно извлечь все страницы из PDF-файла. Можно использовать способы, показанные выше, но PyPDF2 содержит другой удобный метод. Экземпляры класса PdfFileWriter имеют метод .appendPagesFromReader() , который можно использовать для добавления страниц из экземпляра класса PdfFileReader .
Чтобы использовать .appendPagesFromReader () , надо передать в него экземпляр класса PdfFileReader в качестве параметра. Например, следующий код копирует все страницы из PDF-файла «Гордость и предубеждение» в экземпляр PdfFileWriter :
pdf_writer = PdfFileWriter() pdf_writer.appendPagesFromReader(pdf_reader)
Объект pdf_writer теперь содержит все страницы из объекта pdf_reader !
Проверка ваших знаний
Упражнение: Извлеките последнюю страницу PDF-файла.
Извлеките последнюю страницу из файла Pride_and_Prejudice.pdf и сохраните ее в новый файл с именем last_page.pdf.
Решение:
Устанавливаем путь к файлу Pride_and_Prejudice.pdf:
# Вначале импортируем необходимые классы и библиотеки from pathlib import Path from PyPDF2 import PdfFileReader, PdfFileWriter # Создаем объект Path, который содержит путь до нужного файла. # На вашем компьютере он может быть другим pdf_path = ( Path.home() / "creating-and-modifying-pdfs" / "practice_files" / "Pride_and_Prejudice.pdf" )
Теперь создаем экземпляр класса PdfFileReader :
pdf_reader = PdfFileReader(str(pdf_path))
Не забывайте, что экземпляры класса PdfFileReader могут создаваться только со строковой переменной, которая содержит в себе путь к файлу. Объекты типа Path не подходят!
Используем атрибут .pages , чтобы получить доступ ко всем страницам в PDF-файле. К последней странице можно обратиться по индексу -1 :
last_page = pdf_reader.pages[-1]
Теперь можно создать экземпляр класса PdfFileWriter и добавить к нему последнюю страницу:
pdf_writer = PdfFileWriter() pdf_writer.addPage(last_page)
Наконец, запишем содержимое pdf_writer в файл last_page.pdf:
output_path = Path.home() / "last_page.pdf" with output_path.open(mode="wb") as output_file: pdf_writer.write(output_file)
Если готовы, продолжение следует!