Каковы алгоритмы сжатия данных?
Сжать данные без потерь – извечная проблема всех программистов. Несмотря на доступность информационных носителей достаточного объема и передачи данных на высокой скорости, сжатие в некоторых случаях просто незаменимо. К примеру, при пересылке документации по электронной почте, или для экономии трафика. Если существует необходимость в публикации документов на сайте, сжатие данных будет как нельзя кстати. Когда добавление или замена средств хранения затруднительны, встает вопрос экономии пространства на дисках.
Принципы сжатия данных
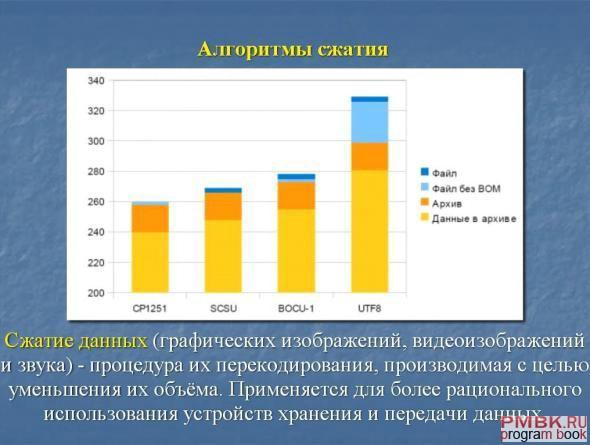
В основе любого метода сжатия лежит простой логический принцип. Допустим, элементы, которые встречаются довольно часто, кодируются коротко, а те, которые встречаются реже — обозначают длинными кодами. Значит, для хранения данных потребуется места меньше, чем для представления кодов одной длины: подробнее об этом можно узнать на http://pmbk.ru.
Running –простейший алгоритм. Например, строка текста имеет в конце много пробелов, то есть избыточность информации очевидна. Чтобы сжать строку следует сжать пробелы, упаковав их по методу повторения символов. Таким образом, первый байт фактически остается пробелом, а второй указывает на то, что при восстановлении строки следует развернуть предыдущий файл.
Huffman. Несмотря на то, что изначально кажется, что создать файл меньшего размера из исходного без исключения повторов или кодировки последовательности — нереальная задача, алгоритм Хоффмана доказывает обратное. Входной файл следует читать два раза: первый раз подсчитываются частоты вхождения символов , второй – кодировка.
LZW – алгоритм кодирования последовательность символов, которые не одинаковые. При повторении строк в файле, их можно закодировать в таблицу. Преимущество такого алгоритма – отсутствие необходимости включения таблицы кодировки в сжатые файлы. В отличие от алгоритма Хоффмана, сжатие LZW – однопроходная операция.
Сжатие без потерь: основные методы
Основными вариантами построения алгоритмов сжатия являются следующие группы:
1. Преобразование потока. Происходит описание новых несжатых данных через обработанные. Кодирование символов осуществляется исключительно на основе уже обработанных данных. Второе и последующие вхождения подстроки следует заменить ссылками на первое вхождение.
2. Статическое сжатие. В данной группе могут использоваться блочные и адаптивные методы. При блочном сжатии статистика блока данных исчисляется отдельно и добавляется к уже сжатому блоку (арифметическое кодирование). В случае с адаптивным сжатием вероятности вычисления новых данных основываются на данных, уже обработанных при кодировании.
3. Преобразование блока. Данный метод сжатия основан на следующем действии: входящая информация разбивается поблочно, а затем трансформируется в единое целое. Иногда методы с перестановкой блоков могут уменьшить объем данных. Тем не менее, подобная обработка улучшает структуру данных.
Виды сжатия данных
Сжатие можно разделить на группы — с потерями и без потерь. Если важна вся информация до последнего бита, то используют исключительно сжатие без потерь. К примеру, необходимо сохранение или восстановление текстового документа. Когда не требуется особая точность восстановления, можно использовать алгоритмы, которые реализуют сжатие с потерями.
Алгоритмы сжатия данных: от базовых принципов до современных методов
Сжатие данных – ключевой аспект. Эффективные алгоритмы сжатия помогают уменьшить объем данных, сэкономив пропускную способность сети и улучшив производительность хранения. В этой статье мы рассмотрим базовые принципы, классификацию, а также некоторые современные методы алгоритмов сжатия данных.
Если вы еще не начали карьеру в IT, приходите на наш бесплатный вебинар, чтобы узнать, как начать зарабатывать с помощью зерокодинга и нейросетей!
Основные принципы сжатия данных
- Удаление избыточности (Redundancy)
Избыточность в данных возникает из-за повторяющейся информации. Они удаляют эту избыточность, концентрируясь на выделении общих паттернов или повторяющихся последовательностей.
- Модель представления данных
Она основывается на создании моделей, которые представляют исходные данные более эффективно. Это включает замену повторов на короткие паттерны или методы кодирования через словари.
Алгоритмы кодирования преобразуют данные в другую форму для уменьшения их размера. Есть арифметическое, Хаффмана, и Лемпеля-Зива.
Типы алгоритмов
- Словарные
Словарные основаны на использовании словаря, который содержит часто встречающиеся последовательности данных. Один из известных методов – LZ77, где повторяющиеся блоки данных заменяются ссылками на предыдущие вхождения в словаре.
- Блочные и потоковые
Они делят файл на блоки и сжимают их независимо друг от друга, в то время как потоковые методы работают непрерывно, обрабатывая данные как один поток. Представителем блочных методов является Burrows-Wheeler Transform (BWT), а потоковых – Run-Length Encoding (RLE).
Применяется к определенным типам данных в файле. Например, JPEG использует частичное сжатие для изображений, сосредотачиваясь на уменьшении размера блоков с цветовой информацией.
Классификация
Алгоритмы сжатия можно классифицировать на две основные категории: без потерь (lossless) и с потерями (lossy).
Без потерь
Один из наиболее распространенных. Он присваивает переменные длины кода символам в зависимости от их частоты встречаемости.
Основан на замене повторяющихся последовательностей на специальные коды. LZ77 и LZ78 — основные вариации.
С потерями
- JPEG (Joint Photographic Experts Group)
Используется для изображений. Удаляет некоторую информацию, невидимую для человеческого глаза.
- MP3 (MPEG Audio Layer III)
Применяется к аудиофайлам. Использует психоакустические модели для удаления неслышимых компонентов аудиосигнала.
Современные методы
Используется в форматах ZIP и PNG. Сочетает в себе Лемпеля-Зива и Хаффмана.
Разработанный Google. Эффективно сжимает текстовые данные и используется на веб-серверах для ускорения передачи данных.
Применение
- Хранение и передача данных
Основное применение – уменьшение объема данных для экономии места на носителях и ускорения передачи по сетям. Например, формат ZIP используется для упаковки файлов и сэкономленного пространства на жестком диске.
- Изображение и аудио
С потерями можно использовать, например в форматах JPEG и MP3 широко применяется для уменьшения размера файлов, с умеренной потерей качества.
Алгоритмы без потерь, такие как метод Хаффмана, находят свое применение в сжатии текстовых данных, где каждый символ важен.
Заключение
Алгоритмы сжатия данных – часть технологий для повышения эффективности использования мощностей. Выбор конкретного алгоритма зависит от требований конкретного применения.
Сжатие без потерь: как это работает
Мы уже разобрались с тем, как оцифровывается звук. Одна из проблем — если качественно его оцифровывать, то нам нужно очень много данных, а это значит большие файлы, большой расход места на диске, дорогие флешки, много трафика в интернете. Хочется, чтобы файлики были поменьше.
Для этого используется сжатие — различные алгоритмы, которые творят с данными свою магию и на выходе получаются данные меньшего объёма.
Сжатие с потерями и без потерь
Есть два принципиальных вида сжатия — с потерями и без.
Сжатие с потерями означает, что в процессе мы лишились части информации. Алгоритмы сжатия с потерями стараются сделать так, чтобы мы потеряли только те данные, которые нам не слишком важны.
Представьте, что сжатие с потерями — это краткий пересказ произведения из школьной программы: школьнику не так важны описания природы и авторский стиль, ему главное сюжет. Краткий пересказ сохранил только важное, но передал это намного быстрее.
Сжатие без потерь — это когда мы уменьшаем размер файла, при этом не теряя в качестве. Для этого используются интересные математические приёмы и кодирование. Главная мысль — чтобы при раскодировании все данные остались на месте.
Алгоритмы сжатия без потерь
Есть два основных варианта: алгоритм Хаффмана или LZW. LZW используется повсеместно, но объяснить его довольно сложно, он неинтуитивный и требует целой лекции. Гораздо приятнее объяснить алгоритм Хаффмана.
Алгоритм Хаффмана берёт файл, разбивает его на фрагменты, с которыми ему удобно работать, а потом смотрит, насколько часто встречается каждый фрагмент. Самые частые слова этот алгоритм обозначает коротким кодом, а самые редкие — кодом подлиннее. Так как самые частые слова занимают теперь гораздо меньше места, то и готовый файл становится меньше.
Но есть и минус: иногда нужно хранить эту таблицу соответствий слов и кода прямо в этом же файле, а она может сама по себе получиться большой. Чаще всего алгоритм Хаффмана применяется для сжатия текстовых файлов и видео без потерь.
Вот пример: берём песню Beyonce — All The Single Ladies. Там есть два таких пассажа:
All the single ladies
All the single ladies
All the single ladies
Now put your hands up
If you like it then you shoulda put a ring on it
If you like it then you shoulda put a ring on it
Don’t be mad once you see that he want it
If you like it then you shoulda put a ring on it
Здесь 281 знак. Мы видим, что некоторые строчки повторяются. Закодируем их:
ТАБЛИЦА СЖАТИЯ
\a\ All the single ladies
\b\ Now put your hands up
\c\ If you like it then you shoulda put a ring on it
\d\ Don’t be mad once you see that he want it
ТЕКСТ ПЕСНИ
Вместе таблицей сжатия этот текст теперь занимает 187 знаков — мы сжали текст почти на треть благодаря тому, что он довольно монотонный.
Сжатие без потерь на примере аудио
В среднем минута несжатого аудио занимает 10 мегабайт. Это довольно много: если у вас, например, часовая запись концерта, то она будет занимать полгигабайта. С другой стороны, в этой записи захвачены все нюансы звука, есть много высоких частот и вообще красота.
Для таких ситуаций используют сжатие без потерь: оно уменьшает файл в 2–3 раза, не искажая звук. Алгоритмы, которые сжимают аудио, называются кодеками. FLAC и Apple Lossless — два популярных кодека для сжатия аудио без потерь.
Сравните сами размер и качество двухминутного аудио:
Оригинал — без сжатия, формат WAV, 23 мегабайта
Сжатие без потерь — формат FLAC с теми же параметрами, что и WAV, 10 мегабайт
Где ещё применяется сжатие без потерь
В архиваторах. Задача программ-архиваторов — упаковать выбранные файлы так, чтобы архив занимал как можно меньше места, при этом не повреждая то, что внутри. Например, текстовая версия «Войны и мира» может занимать 4 мегабайта, а заархивированная — 100 килобайт, в 40 раз меньше.
В программировании. Есть специальные упаковщики, которые берут готовую программу и оптимизируют код так, чтобы он занимал меньше места, но сохранил свою работоспособность. Например:
- Удаляют комментарии
- Сокращают до минимума названия переменных и функций
- Удаляют символы, которые нужны были человеку для удобочитаемости
Что дальше
В следующей части разберём, как работает сжатие с потерями и почему благодаря этому у нас есть ТикТок и Ютуб.
Алгоритмы — основа разработки
Изучите алгоритмы, чтобы легко проходить ИТ-собеседования и делать более совершенный софт. Старт — бесплатно. После обучения — помощь с трудоустройством.
Получите ИТ-профессию
В «Яндекс Практикуме» можно стать разработчиком, тестировщиком, аналитиком и менеджером цифровых продуктов. Первая часть обучения всегда бесплатная, чтобы попробовать и найти то, что вам по душе. Дальше — программы трудоустройства.
Простым языком о том, как работает сжатие файлов
Сжатие файлов помогает эффективно хранить и быстро передавать данные. В статье простым языком рассказываем, какие есть виды сжатия и для чего они подходят.
Сжатие файлов позволяет быстрее передавать, получать и хранить большие файлы. Оно используется повсеместно и наверняка хорошая вам знакомо: самые популярные расширения сжатых файлов — ZIP, JPEG и MP3. В этой статье кратко рассмотрим основные виды сжатия файлов и принципы их работы.
Что такое сжатие?
Сжатие файла — это уменьшение его размера при сохранении исходных данных. В этом случае файл занимает меньше места на устройстве, что также облегчает его хранение и передачу через интернет или другим способом. Важно отметить, что сжатие не безгранично и обычно делится на два основных типа: с потерями и без потерь. Рассмотрим каждый из них по отдельности.
Сжатие с потерями
Такой способ уменьшает размер файла, удаляя ненужные биты информации. Чаще всего встречается в форматах изображений, видео и аудио, где нет необходимости в идеальном представлении исходного медиа. MP3 и JPEG — два популярных примера. Но сжатие с потерями не совсем подходит для файлов, где важна вся информация. Например, в текстовом файле или электронной таблице оно приведёт к искажённому выводу.
MP3 содержит не всю аудиоинформацию из оригинальной записи. Этот формат исключает некоторые звуки, которые люди не слышат. Вы заметите, что они пропали, только на профессиональном оборудовании с очень высоким качеством звука, поэтому для обычного использования удаление этой информации позволит уменьшить размер файла практически без недостатков.
Аналогично файлы JPEG удаляют некритичные части изображений. Например, в изображении с голубым небом сжатие JPEG может изменить все пиксели на один или два оттенка синего вместо десятков.
Чем сильнее вы сжимаете файл, тем заметнее становится снижение качества. Вы, вероятно, замечали такое, слушая некачественную музыку в формате MP3, загруженную на YouTube. Например, сравните музыкальный трек высокого качества с сильно сжатой версией той же песни.
Сжатие с потерями подходит, когда файл содержит больше информации, чем нужно для ваших целей. Например, у вас есть огромный файл с исходным (RAW) изображением. Целесообразно сохранить это качество для печати изображения на большом баннере, но загружать исходный файл в Facebook будет бессмысленно. Картинка содержит множество данных, не заметных при просмотре в социальных сетях. Сжатие картинки в высококачественный JPEG исключает некоторую информацию, но изображение выглядит почти как оригинал.
При сохранении в формате с потерями, вы зачастую можете установить уровень качества. Например, у многих графических редакторов есть ползунок для выбора качества JPEG от 0 до 100. Экономия на уровне 90 или 80 процентов приводит к небольшому уменьшению размера файла с незначительной визуальной разницей. Но сохранение в плохом качестве или повторное сохранение одного и того же файла в формате с потерями ухудшит его.
Посмотрите на этот пример.
Оригинальное изображение, загруженное с Pixabay в формате JPEG. 874 КБ:
Результат сохранения в формате JPEG с 50-процентным качеством. Выглядит не так уж плохо. Вы можете заметить артефакты по краям коробок только при увеличении. 310 КБ:
Исходное изображение, сохранённое в формате JPEG с 10-процентным качеством. Выглядит ужасно. 100 КБ:
Где используется сжатие с потерями
Как мы уже упоминали, сжатие с потерями отлично подходит для большинства медиафайлов. Это крайне важно для таких компаний как Spotify и Netflix, которые постоянно транслируют большие объёмы информации. Максимальное уменьшение размера файла при сохранении качества делает их работу более эффективной.
Сжатие без потерь
Сжатие без потерь позволяет уменьшить размер файла так, чтобы в дальнейшем можно было восстановить первоначальное качество. В отличие от сжатия с потерями, этот способ не удаляет никакую информацию. Рассмотрим простой пример. На картинке ниже стопка из 10 кирпичей: два синих, пять жёлтых и три красных.
Вместо того чтобы показывать все 10 блоков, мы можем удалить все кирпичи одного цвета, кроме одного. Используя цифры, чтобы показать, сколько кирпичей каждого цвета было, мы представляем те же данные используя гораздо меньше кирпичей — три вместо десяти.
Это простая иллюстрация того, как осуществить сжатие без потерь. Та же информация сохраняется более эффективным способом. Рассмотрим реальный файл: mmmmmuuuuuuuoooooooooooo. Его можно сжать до гораздо более короткой формы: m5u7o12. Это позволяет использовать 7 символов вместо 24 для представления одних и тех же данных.
Где используется сжатие без потерь
ZIP-файлы — популярный пример сжатия без потерь. Хранить информацию в виде ZIP-файлов более эффективно, при этом когда вы распаковываете архив, там присутствует вся оригинальная информация. Это актуально для исполняемых файлов, так как после сжатия с потерями распакованная версия будет повреждена и непригодна для использования.
Другие распространённые форматы без потерь — PNG для изображений и FLAC для аудио. Форматы видео без потерь встречаются редко, потому что они занимают много места.
Сжатие с потерями vs сжатие без потерь
Теперь, когда мы рассмотрели обе формы сжатия файлов, может возникнуть вопрос, когда и какую следует использовать. Здесь всё зависит от того, для чего вы используете файлы.
Скажем, вы только что откопали свою старую коллекцию компакт-дисков и хотите оцифровать её. Когда вы копируете свои компакт-диски, имеет смысл использовать формат FLAC, формат без потерь. Это позволяет получить мастер-копию на компьютере, которая обладает тем же качеством звука, что и оригинальный компакт-диск.
Позже вы, возможно, захотите загрузить музыку на телефон или старый MP3-плеер. Здесь не так важно, чтобы музыка была в идеальном качестве, поэтому вы можете конвертировать файлы FLAC в MP3. Это даст вам аудиофайл, который по-прежнему достаточно хорош для прослушивания, но не занимает много места на мобильном устройстве. Качество MP3, преобразованного из FLAC, будет таким же, как если бы вы создали сжатый MP3 с оригинального CD.
Тип данных, представленных в файле, также может определять, какой вид сжатия подходит больше. В PNG используется сжатие без потерь, поэтому его хорошо использовать для изображений, в которых много однотонного пространства. Например, для скриншотов. Но PNG занимает гораздо больше места, когда картинка состоит из смеси множества цветов, как в случае с фотографиями. В этом случае с точки зрения размера файлов лучше использовать JPEG.
Проблемы во время сжатия файлов
Бесполезно конвертировать формат с потерями в формат без потерь. Это пустая трата пространства. Скажем, у вас есть MP3-файл весом в 3 МБ. Преобразование его в FLAC может привести к увеличению размера до 30 МБ. Но эти 30 МБ содержат только те звуки, которые имел уже сжатый MP3. Качество звука от этого не улучшится, но объём станет больше.
Также стоит иметь в виду, что преобразовывая один формат с потерями в аналогичный, вы получаете дальнейшее снижение качества. Каждый раз, когда вы применяете сжатие с потерями, вы теряете больше деталей. Это становится всё более и более заметно, пока файл по существу не будет разрушен. Помните также, что форматы с потерями удаляют некоторые данные и их невозможно восстановить.
Заключение
Мы рассмотрели как сжатие файлов с потерями, так и без потерь, чтобы увидеть, как они работают. Теперь вы знаете, как можно уменьшить размер файла и как выбрать лучший способ для этого.
Алгоритмы, которые определяют, какие данные выбрасываются в методах с потерями и как лучше хранить избыточные данные при сжатии без потерь, намного сложнее, чем описано здесь. На эту тему можно почитать больше информации здесь, если вам интересно.