CUDA: Работа с памятью. Часть I.
В процессе работы с CUDA я практически не касался вопросов об использовании памяти видеокарты. Настало время убрать этот пробел.
Так как тема весьма объемная, то я решил разделить её на несколько частей. В этой части я расскажу об основных видах памяти, доступных на видеокарте и приведу пример, как влияет выбор типа памяти на производительность вычислений на GPU.
Видеокарта и типы памяти
При использовании GPU разработчику доступно несколько видов памяти: регистры, локальная, глобальная, разделяемая, константная и текстурная память. Каждая из этих типов памяти имеет определенное назначение, которое обуславливается её техническими параметрами (скорость работы, уровень доступа на чтение и запись). Иерархия типов памяти представлена на рис. 1.

Рис. 1. Типы памяти видеокарты
- Регистровая память (register) является самой быстрой из всех видов. Определить количество регистров доступных GPU можно с помощью уже хорошо известной функции cudaGetDeviceProperties. Рассчитать количество регистров, доступных одной нити GPU, так же не составляет труда, для этого необходимо разделить общее число регистров на произведение количества нитей в блоке и количества блоков в гриде. Все регистры GPU 32 разрядные. В CUDA нет явных способов использования регистровой памяти, всю работу по размещению данных в регистрах берет на себя компилятор.
- Локальная память (local memory) может быть использована компилятором при большом количестве локальных переменных в какой-либо функции. По скоростным характеристикам локальная память значительно медленнее, чем регистровая. В документации от nVidia рекомендуется использовать локальную память только в самых необходимых случаях. Явных средств, позволяющих блокировать использование локальной памяти, не предусмотрено, поэтому при падении производительности стоит тщательно проанализировать код и исключить лишние локальные переменные.
- Глобальная память (global memory) – самый медленный тип памяти, из доступных GPU. Глобальные переменные можно выделить с помощью спецификатора __global__, а так же динамически, с помощью функций из семейства cudMallocXXX. Глобальная память в основном служит для хранения больших объемов данных, поступивших на device с host’а, данное перемещение осуществляется с использованием функций cudaMemcpyXXX. В алгоритмах, требующих высокой производительности, количество операций с глобальной памятью необходимо свести к минимуму.
- Разделяемая память (shared memory) относиться к быстрому типу памяти. Разделяемую память рекомендуется использовать для минимизации обращение к глобальной памяти, а так же для хранения локальных переменных функций. Адресация разделяемой памяти между нитями потока одинакова в пределах одного блока, что может быть использовано для обмена данными между потоками в пределах одного блока. Для размещения данных в разделяемой памяти используется спецификатор __shared__.
- Константная память (constant memory) является достаточно быстрой из доступных GPU. Отличительной особенностью константной памяти является возможность записи данных с хоста, но при этом в пределах GPU возможно лишь чтение из этой памяти, что и обуславливает её название. Для размещения данных в константной памяти предусмотрен спецификатор __constant__. Если необходимо использовать массив в константной памяти, то его размер необходимо указать заранее, так как динамическое выделение в отличие от глобальной памяти в константной не поддерживается. Для записи с хоста в константную память используется функция cudaMemcpyToSymbol, и для копирования с device’а на хост cudaMemcpyFromSymbol, как видно этот подход несколько отличается от подхода при работе с глобальной памятью.
- Текстурная память (texture memory), как и следует из названия, предназначена главным образом для работы с текстурами. Текстурная память имеет специфические особенности в адресации, чтении и записи данных. Более подробно о текстурной памяти я расскажу при рассмотрении вопросов обработки изображений на GPU.
Пример использования разделяемой памяти
Чуть выше я вкратце рассказал о различных типах памяти, которые доступны при программировании GPU. Теперь я хочу привести пример использования разделяемой памяти при операции транспонирования матрицы.
Перед тем, как приступить к написанию основного кода, приведу небольшой способ отладки. Как известно, функции из CUDA runtime API могут возвращать различные коды ошибок, но в предыдущий раз я ни как это не учитывал. Чтобы упростить себе жизнь можно использовать следующий макрос для отлова ошибок:
#define CUDA_CHECK_ERROR(err) \
if (err != cudaSuccess) < \
printf( «Cuda error: %s\n» , cudaGetErrorString(err)); \
printf( «Error in file: %s, line: %i\n» , __FILE__, __LINE__); \
> \
#endif
* This source code was highlighted with Source Code Highlighter .
Как видно, в случае, если определена переменная среды CUDA_DEBUG, происходит проверка кода ошибки и выводиться информация о файле и строке, где она произошла. Эту переменную можно включить при компиляции под отладку и отключить при компиляции под релиз.
Приступаем к основной задаче.
Для того чтобы увидеть, как влияет использование разделяемой памяти на скорость вычислений, так же следует написать функцию, которая будет использовать только глобальную память.
Пишем эту функцию:
// Функция транспонирования матрицы без использования разделяемой памяти
//
// inputMatrix — указатель на исходную матрицу
// outputMatrix — указатель на матрицу результат
// width — ширина исходной матрицы (она же высота матрицы-результата)
// height — высота исходной матрицы (она же ширина матрицы-результата)
//
__global__ void transposeMatrixSlow( float * inputMatrix, float * outputMatrix, int width, int height)
int xIndex = blockDim.x * blockIdx.x + threadIdx.x;
int yIndex = blockDim.y * blockIdx.y + threadIdx.y;
if ((xIndex < width) && (yIndex < height))
//Линейный индекс элемента строки исходной матрицы
int inputIdx = xIndex + width * yIndex;
//Линейный индекс элемента столбца матрицы-результата
int outputIdx = yIndex + height * xIndex;
outputMatrix[outputIdx] = inputMatrix[inputIdx];
>
>
* This source code was highlighted with Source Code Highlighter .
Данная функция просто копирует строки исходной матрицы в столбцы матрицы-результата. Единственный сложный момент – это определение индексов элементов матриц, здесь необходимо помнить, что при вызове ядра может быть использованы различные размерности блоков и грида, для этого и используются встроенные переменные blockDim, blockIdx.
Пишем функцию транспонирования, которая использует разделяемую память:
// Функция транспонирования матрицы c использования разделяемой памяти
//
// inputMatrix — указатель на исходную матрицу
// outputMatrix — указатель на матрицу результат
// width — ширина исходной матрицы (она же высота матрицы-результата)
// height — высота исходной матрицы (она же ширина матрицы-результата)
//
__global__ void transposeMatrixFast( float * inputMatrix, float * outputMatrix, int width, int height)
__shared__ float temp[BLOCK_DIM][BLOCK_DIM];
int xIndex = blockIdx.x * blockDim.x + threadIdx.x;
int yIndex = blockIdx.y * blockDim.y + threadIdx.y;
if ((xIndex < width) && (yIndex < height))
// Линейный индекс элемента строки исходной матрицы
int idx = yIndex * width + xIndex;
//Копируем элементы исходной матрицы
temp[threadIdx.y][threadIdx.x] = inputMatrix[idx];
>
//Синхронизируем все нити в блоке
__syncthreads();
xIndex = blockIdx.y * blockDim.y + threadIdx.x;
yIndex = blockIdx.x * blockDim.x + threadIdx.y;
if ((xIndex < height) && (yIndex < width))
// Линейный индекс элемента строки исходной матрицы
int idx = yIndex * height + xIndex;
//Копируем элементы исходной матрицы
outputMatrix[idx] = temp[threadIdx.x][threadIdx.y];
>
>
* This source code was highlighted with Source Code Highlighter .
В этой функции я использую разделяемую память в виде двумерного массива.
Как уже было сказано, адресация разделяемой памяти в пределах одного блока одинакова для всех потоков, поэтому, чтобы избежать коллизий при доступе и записи, каждому элементу в массиве соответствует одна нить в блоке.
После копирования элементов исходной матрицы в буфер temp, вызывается функция __syncthreads. Эта функция синхронизирует потоки в пределах блока. Её отличие от других способов синхронизации заключаеться в том, что она выполняеться только на GPU.
В конце происходит копирование сохраненных элементов исходной матрицы в матрицу-результат, в соответствии с правилом транспонирования.
Может показаться, что эта функция должна выполняться медленне, чем её версия без разделяемой памяти, где нет никаких посредников. Но на самом деле копирование из глобальной памяти в глобальную работает значительно медленее, чем связка глобальная память – разделяемая память – глобальная память.
Хочу заметить, что проверять границы массивов матриц стоит вручную, в GPU нет аппаратных средств для слежения за границами массивов.
Ну и напоследок напишем функцию транспонирования, которая исполняется только на CPU:
// Функция транспонирования матрицы, выполняемая на CPU
__host__ void transposeMatrixCPU( float * inputMatrix, float * outputMatrix, int width, int height)
for ( int y = 0; y < height; y++)
for ( int x = 0; x < width; x++)
outputMatrix[x * height + y] = inputMatrix[y * width + x];
>
>
>* This source code was highlighted with Source Code Highlighter .
Теперь необходимо сгенерировать данные для расчетов, скопировать их с хоста на девайс, в случае использования GPU, произвести замеры производительности и очистить ресурсы.
Так как эти этапы примерно такие же, что я описывал в предыдущий раз, то привожу этого фрагмента сразу:
#define GPU_SLOW 1
#define GPU_FAST 2
#define CPU 3
#define ITERATIONS 20 //Количество нагрузочных циклов
__host__ int main()
<
int width = 2048; //Ширина матрицы
int height = 1536; //Высота матрицы
int matrixSize = width * height;
int byteSize = matrixSize * sizeof ( float );
//Выделяем память под матрицы на хосте
float * inputMatrix = new float [matrixSize];
float * outputMatrix = new float [matrixSize];
//Заполняем исходную матрицу данными
for ( int i = 0; i < matrixSize; i++)
inputMatrix[i] = i;
>
//Выбираем способ расчета транспонированной матрицы
printf( «Select compute mode: 1 — Slow GPU, 2 — Fast GPU, 3 — CPU\n» );
int mode;
scanf( «%i» , &mode);
//Записываем исходную матрицу в файл
printMatrixToFile( «before.txt» , inputMatrix, width, height);
if (mode == CPU) //Если используеться только CPU
<
int start = GetTickCount();
for ( int i = 0; i < ITERATIONS; i++)
transposeMatrixCPU(inputMatrix, outputMatrix, width, height);
>
//Выводим время выполнения функции на CPU (в миллиекундах)
printf ( «CPU compute time: %i\n» , GetTickCount() — start);
>
else //В случае расчета на GPU
float * devInputMatrix;
float * devOutputMatrix;
//Выделяем глобальную память для храния данных на девайсе
CUDA_CHECK_ERROR(cudaMalloc(( void **)&devInputMatrix, byteSize));
CUDA_CHECK_ERROR(cudaMalloc(( void **)&devOutputMatrix, byteSize));
//Копируем исходную матрицу с хоста на девайс
CUDA_CHECK_ERROR(cudaMemcpy(devInputMatrix, inputMatrix, byteSize, cudaMemcpyHostToDevice));
//Конфигурация запуска ядра
dim3 gridSize = dim3(width / BLOCK_DIM, height / BLOCK_DIM, 1);
dim3 blockSize = dim3(BLOCK_DIM, BLOCK_DIM, 1);
cudaEvent_t start;
cudaEvent_t stop;
//Создаем event’ы для синхронизации и замера времени работы GPU
CUDA_CHECK_ERROR(cudaEventCreate(&start));
CUDA_CHECK_ERROR(cudaEventCreate(&stop));
//Отмечаем старт расчетов на GPU
cudaEventRecord(start, 0);
if (mode == GPU_SLOW) //Используеться функция без разделяемой памяти
for ( int i = 0; i < ITERATIONS; i++)
transposeMatrixSlow>>(devInputMatrix, devOutputMatrix, width, height);
>
>
else if (mode == GPU_FAST) //Используеться функция с разделяемой памятью
for ( int i = 0; i < ITERATIONS; i++)
transposeMatrixFast>>(devInputMatrix, devOutputMatrix, width, height);
>
>
//Отмечаем окончание расчета
cudaEventRecord(stop, 0);
float time = 0;
//Синхронизируемя с моментом окончания расчетов
cudaEventSynchronize(stop);
//Рассчитываем время работы GPU
cudaEventElapsedTime(&time, start, stop);
//Выводим время расчета в консоль
printf( «GPU compute time: %.0f\n» , time);
//Копируем результат с девайса на хост
CUDA_CHECK_ERROR(cudaMemcpy(outputMatrix, devOutputMatrix, byteSize, cudaMemcpyDeviceToHost));
//
//Чистим ресурсы на видеокарте
//
//Записываем матрицу-результат в файл
printMatrixToFile( «after.txt» , outputMatrix, height, width);
//Чистим память на хосте
delete[] inputMatrix;
delete[] outputMatrix;
* This source code was highlighted with Source Code Highlighter .
В случае если расчеты выполняются только на CPU, то для замера времени расчетов используется функция GetTickCount(), которая подключается из windows.h. Для замера времени расчетов на GPU используеться функция cudaEventElapsedTime, прототип которой имеет следующий вид:
- time – указатель на float, для записи времени между event’ами start и end (в миллисекундах),
- start – хендл первого event’а,
- end – хендл второго event’а.
- cudaSuccess – в случае успеха
- cudaErrorInvalidValue – неверное значение
- cudaErrorInitializationError – ошибка инициализации
- cudaErrorPriorLaunchFailure – ошибка при предыдущем асинхронном запуске функции
- cudaErrorInvalidResourceHandle – неверный хендл event’а
Так же я записываю исходную матрицу и результат в файлы через функцию printMatrixToFile. Чтобы удостовериться, что результаты верны. Код этой функции следующий:
__host__ void printMatrixToFile( char * fileName, float * matrix, int width, int height)
FILE* file = fopen(fileName, «wt» );
for ( int y = 0; y < height; y++)
for ( int x = 0; x < width; x++)
fprintf(file, «%.0f\t» , matrix[y * width + x]);
>
fprintf(file, «\n» );
>
fclose(file);
>
* This source code was highlighted with Source Code Highlighter .
Если матрицы очень большие, то вывод данных в файлы может сильно замедлить выполнение программы.
Заключение
В процессе тестирования я использовал матрицы размерностью 2048 * 1536= 3145728 элементов и 20 итераций в нагрузочных циклах. После результатов замеров у меня получились следующие результаты (рис. 2).

Рис. 2. Время расчетов. (меньше –лучше).
Как видно, GPU версия с разделяемой памятью выполняется почти в 20 раз быстрее, чем версия на CPU. Так же стоит отметить, что при использовании разделяемой памяти расчет выполняется примерно в 4 раза быстрее, чем без неё.
В своем примере я не учитываю время копирования данных с хоста на девайс и обратно, но в реальных приложениях их так же необходимо брать в расчет. Количество перемещений данных между CPU и GPU по-возможности необходимо свести к минимуму.
P.S. Надеюсь, вам понравился прирост производительности, который можно получить с помощью GPU.
Что такое GPU memory? Скачал сегодня программу GPU temp, там есть раздел с GPU memory.. и.
Омега ⟨ω⟩ Оракул (77222) Процессор видеокарты желательно что бы не релся выше 75 при полной загрузке, память до 60 максимум.
Похожие вопросы
Ваш браузер устарел
Мы постоянно добавляем новый функционал в основной интерфейс проекта. К сожалению, старые браузеры не в состоянии качественно работать с современными программными продуктами. Для корректной работы используйте последние версии браузеров Chrome, Mozilla Firefox, Opera, Microsoft Edge или установите браузер Atom.
Визуализация на GPU¶
Визуализация на GPU позволяет вам использовать для визуализации вашу графическую карту вместо центрального процессора. Это может сильно ускорить визуализацию, поскольку современные видеокарты спроектированы для выполнения множества однотипных вычислений. С другой стороны, они также имеют некоторые ограничения по визуализации сложных сцен из-за меньшего количества доступной памяти, а так же проблемы с отзывчивостью интерфейса, если одна и та же видеокарта используется как для обычной работы, так и для визуализации.
Cycles поддерживает два режима визуализации на GPU: CUDA, который предпочтителен для графических карт Nvidia, и OpenCL, который поддерживает визуализацию на графических картах AMD.
Конфигурирование¶
Для включения визуализации на GPU, откройте окно Параметры и на вкладке Система выберите используемое Устройство расчёта. Затем, для каждой сцены, в панели Визуализация вы сможете настроить использование визуализации на CPU или на GPU.
CUDA¶
Nvidia CUDA is supported for GPU rendering with Nvidia graphics cards. We support graphics cards starting from GTX 4xx (computing capability from 2.0 to 6.1).
Cycles требует установки самых свежих драйверов Nvidia, для всех операционных систем.
OpenCL¶
OpenCL is supported for GPU rendering with AMD graphics cards. (We only support graphics cards with GCN architecture 2.0 and above). To make sure your GPU is supported checkout this Wikipedia page.
Cycles требует установки самых свежих драйверов AMD, для всех операционных систем.
Поддерживаемые возможности и ограничения¶
Обзор поддерживаемых возможностей и сравнение технологий приведены в соответсвующем разделе .
Ограничения CUDA: Максимальное количество индивидуальных текстур ограничено 88 целочисленными текстурами ( PNG , JPEG и так далее) и 5 текстурами с плавающей запятой ( OpenEXR , 16-битный TIFF и прочие) на картах серии GTX 4xx/5xx. Более поздние карты не имеют такого ограничения.
Часто задаваемые вопросы¶
Почему Blender перестаёт отвечать во время визуализации?¶
Когда графическая карта занята визуализацией, она не может перерисовывать пользовательский интерфейс, из-за чего Blender перестаёт отвечать. Мы пытаемся обойти эту проблему, забирая контроль над GPU как можно чаще, но гарантировать полностью гладкую работу мы не можем, особенно на тяжёлых сценах. Это ограничение графических карт и для него не существует стопроцентно работающего решения, хотя мы и постараемся в будущем улучшить этот момент.
Если у вас есть возможность, лучше установить более одного GPU и использовать один из них для отображения, а остальные задействовать для визуализации.
Почему сцена, которая визуализируется на центральном процессоре, не визуализируется на видеокарте?¶
Для этого существует множество причин, но самая часто встречающаяся — на вашей видеокарте недостаточно памяти. На текущий момент мы можем визуализировать только те сцены, которые влезают в память видеокарты, которая обычно меньше памяти, доступной центральному процессору. Обратите внимание, что, например, изображения текстур размерами 8k, 4k, 2k и 1k занимают, соответственно, 256Мб, 64Мб, 16Мб и 4Мб памяти.
Мы намерены добавить систему для поддержки сцен больших, чем имеющаяся память видеокарты, но это будет не скоро.
Можно ли для визуализации использовать несколько видеокарт?¶
Да, перейдите в Параметры ‣ Система ‣ Устройство расчёта ( User Preferences ‣ System ‣ Compute Device Panel ) и настройте устройства по своему вкусу.
Могут ли несколько видеокарт увеличить доступную память?¶
Нет, каждая видеокарта имеет доступ только к своей собственной памяти.
Какой рендер быстрее: Nvidia или AMD, CUDA или OpenCL?¶
Currently Nvidia with CUDA is rendering fastest, but this really depends on the hardware you buy. Currently, CUDA and OpenCL are about the same in the newest mid-range GPUs. However, CUDA is fastest in the respect of high-end GPUs.
Сообщения об ошибках¶
Unsupported GNU version! gcc 4.7 and up are not supported! (Неподдерживаемая версия GNU! gcc 4.7 и старше не поддерживаются!)¶
On Linux, depending on your GCC version you might get this error. There are two possible solutions:
Use an alternate compiler
If you have an older GCC installed that is compatible with the installed CUDA toolkit version, then you can use it instead of the default compiler. This is done by setting the CYCLES_CUDA_EXTRA_CFLAGS environment variable when starting Blender.
Launch Blender from the command line as follows:
CYCLES_CUDA_EXTRA_CFLAGS="-ccbin gcc-x.x" blender
(Substitute the name or path of the compatible GCC compiler).
Remove compatibility checks
If the above is unsuccessful, delete the following line in /usr/local/cuda/include/host_config.h
#error -- unsupported GNU version! gcc 4.7 and up are not supported!
This will allow Cycles to successfully compile the CUDA rendering kernel the first time it attempts to use your GPU for rendering. Once the kernel is built successfully, you can launch Blender as you normally would and the CUDA kernel will still be used for rendering.
CUDA Error: Invalid kernel image (Ошибка CUDA: Неверное ядро изображения)¶
Если вы получили эту ошибку на 64-битной MS-Windows, убедитесь, что вы используете 64-битную сборку Blender, а не 32-битную.
CUDA Error: Kernel compilation failed (Ошибка CUDA: Сбой компиляции ядра)¶
Эта ошибка может возникнуть, если у вас новая карта Nvidia, которая пока ещё не поддерживается вашей версией Blender’а, а у вас установлен набор инструментов CUDA. В этом случае Blender может попытаться динамически собрать ядро для вашей графической карты и не преуспеть в этом.
В таком случае вы можете:
- Check if the latest Blender version (official or experimental builds) supports your graphics card.
- Если вы сами собирали Blender, попробуйте скачать и установить новейший набор инструментов для разработчика CUDA.
Обычным пользователям не требуется устанавливать набор инструментов CUDA, поскольку Blender уже поставляется со скомпилированными ядрами.
CUDA Error: Out of memory (Ошибка CUDA: Не хватает памяти)¶
Обычно эта ошибка означает, что для хранения сцены на видеокарте не хватает памяти. На текущий момент мы можем визуализовывать только те сцены, которые влезают в память видеокарты, которая обычно меньше памяти, доступной центральному процессору. Подробности смотрите выше.
The Nvidia OpenGL driver lost connection with the display driver (Драйвер Nvidia OpenGL потерял соединение с драйвером дисплея)¶
Если видеокарта используется как для обычной работы, так и для визуализации, MS-Windows имеет ограничение на время, которое видеокарта может посвятить вычислению визуализации. Если у вас есть особенно тяжёлые сцены, Cycles может занять слишком много времени видеокарты. Уменьшение размера плиток в панели .*Производительность* может облегчить эту проблему, но единственным реальным решением является использование отдельной видеокарты для визуализации.
Another solution can be to increase the time-out, although this will make the user interface less responsive when rendering heavy scenes. Learn More Here.
CUDA error: Unknown error in cuCtxSynchronize() (Ошибка CUDA: Неизвестная ошибка в cuCtxSynchronize())¶
An unknown error can have many causes, but one possibility is that it is a time-out. See the above answer for solutions.
© Copyright : This page is licensed under a CC-BY-SA 4.0 Int. License.
Потребление ресурсов

Чтобы узнать, сколько программа потребляет ОЗУ и насколько эффективно загружает процессорные ядра, можно использовать методы, описанные ниже.
Во время работы программы
Предварительно необходимо выяснить, на каких именно узлах работает задача. Это делается командой ‘qstat -f XXXX‘, где XXXX — номер выполняющейся задачи. Выделенные задаче узлы будут отображаться в строке ‘exec_host’:
user01@clu:~> qstat -f 389182
. exec_host = cn225/0*4+cn226/0*4+cn227/0*4+cn228/0*4 .
В данном случае задача работает на узлах cn225, cn226, cn227 и cn228. ‘0*4’ означает, что на каждом узле выделено по 4 ядра.
Метод 1
Данный способ наиболее нагляден, но применим только в том случае, если вычислительный узел монопольно занят одной задачей.
Открыть веб-интерфейс Ganglia. В левом верхнем углу в поле ‘Choose a Source’ выбрать поле, соответствующее модели используемых узлов:
BL2x220c-G6 для 8-ядерных, с именами cn101-cn196
BL2x220c-G7 для 12-ядерных, с именами cn201-cn296
SL390s-G7 для узлов с GPU, sl001-sl012
В появившемся рядом поле ‘Choose a Node’ выбрать интересующий узел. Будет отображена статистика использования ресурсов за некоторое прошедшее время. В первую очередь надо обращать внимание на использование Memory и CPU. Например, из приведённой ниже картинки видно, что задача, запустившаяся около 14:36, достаточно быстро загрузила все ядра до 90% и стабильно держит нагрузку на этом уровне, а потребление оперативной памяти с момента запуска постепенно увеличивается, и на данный момент (15:15) составляет около 9 ГБ:
Для обновления графиков необходимо нажать кнопку ‘Get Fresh Data’ в правом верхнем углу.
Метод 2
Зайти на используемый узел с помощью команды ‘ssh‘:
user01@clu:~> ssh cn225
user01@cn225:~>
Подобным образом можно зайти только на тот узел, на котором уже выполняется Ваша программа, запущенная планировщиком. Если же зайти на какой-то другой узел, то ssh-сессия будет принудительно закрыта в течении нескольких секунд.
Запустить команду ‘top‘:
user01@cn225:~> top
top - 22:56:25 up 1 day, 10:06, 1 user, load average: 4.43, 4.44, 4.45 Tasks: 349 total, 5 running, 344 sleeping, 0 stopped, 0 zombie Cpu(s): 31.8%us, 0.4%sy, 0.0%ni, 67.6%id, 0.2%wa, 0.0%hi, 0.0%si, 0.0%st Mem: 24684348k total, 23334268k used, 1350080k free, 119680k buffers Swap: 33559776k total, 0k used, 33559776k free, 7100712k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 25415 user01 20 0 3835m 3.7g 15m R 101 15.6 293:43.08 fluent_mpi.13.0 25417 user01 20 0 3776m 3.6g 15m R 101 15.3 293:58.96 fluent_mpi.13.0 25416 user01 20 0 3945m 3.8g 15m R 99 16.0 294:04.56 fluent_mpi.13.0 25418 user01 20 0 3961m 3.8g 15m R 99 16.1 293:17.68 fluent_mpi.13.0 9300 root 20 0 27060 8316 1168 S 2 0.0 5:37.87 pbs_mom 1 root 20 0 1064 412 348 S 0 0.0 0:01.92 init 2 root 15 -5 0 0 0 S 0 0.0 0:00.02 kthreadd .
В данном случае видно, что:
Работают 4 процесса пользователя user01, каждый из которых потребляет около 3.7 ГБ ОЗУ (столбец RES) и полностью загружает одно ядро (столбец %CPU).
Всеми процессами (включая операционную систему) на узле суммарно используется 23334268 КБ ОЗУ из имеющихся 24684348 КБ.
Виртуальная память (SWAP) на узле не используется.
Полное потребление памяти, включая виртуальную, отображается в столбце VIRT
Если число в столбце RES не имеет суффикса g или m, то это значение в килобайтах.
Чтобы прервать работу утилиты top, необходимо нажать Ctrl-C
Использование GPU
При выполнении вычислений на графических сопроцессорах cтепень загруженности GPU и памяти видеокарты можно узнать с помощью утилиты ‘nvidia-smi‘. Для этого необходимо:
Определить используемый задачей узел и GPU.
Командой ‘ssh’ зайти с интерфейсного сервера на соответствующий узел и выполнить следующую команду, заменив ‘X’ на идентификатор нужного GPU (или нескольких GPU, через запятую):
nvidia-smi --query-gpu=utilization.gpu,utilization.memory,memory.free,memory.used --format=csv -i X
При использовании узлов в очереди teslaq в качестве идентификатора GPU можно использовать его порядковый номер (от 0 до 2), определяемый из имени виртуального узла. Например, если интересует нагрузка на GPU задачей с номером 3437445, запросившей два ngpus:
Чтобы узнать выделенные задаче виртуальные узлы, выполнить на интерфейсном сервере:
qstat -f 3437445|tr -d '\n'' ''\t'|sed 's/Hold_Types.*//'|sed 's/.*exec_vnode=//'|tr -d \(\)|tr + '\n'|sed 's/:.*//'|sort
Допустим, эта команда выведет:
sl003[0] sl003[2]
Т.е. задача иcпользует GPU с номерами 0 и 2 на узле sl003.
Выполнить на интерфейсном сервере команду:
ssh sl003 nvidia-smi --query-gpu=utilization.gpu,utilization.memory,memory.free,memory.used --format=csv -i 0,2
При использовании очереди a6500g10q порядковый номер GPU не является уникальным идентификатором т.к. для каждой из работающих задач доступные GPU нумеруются последовательно, начиная с ноля. Вместо этого можно использовать идентификатор шины PCI:
Добавить в начало скрипта для qsub такую команду:
nvidia-smi --query-gpu=pci.bus_id --format=csv,noheader > $PBS_O_WORKDIR/$PBS_JOBID.id
В результате после запуска задачи в рабочей директории появится файл с именем вида ‘95054.vm-pbs.id’, содержащий что-то вроде ‘00000000:15:00.0’ (или несколько таких строк, если было запрошено несколько GPU).
Выполнить команду вида:
ssh a6500g10 nvidia-smi --query-gpu=utilization.gpu,utilization.memory,memory.free,memory.used --format=csv -i 00000000:15:00.0
В результате на экран будет выведено примерно такое:
utilization.gpu [%], utilization.memory [%], memory.free [MiB], memory.used [MiB] 33 %, 0 %, 1735 MiB, 30775 MiB
Обращаем внимание, что ‘utilization.memory’ — это интенсивность работы с памятью карты, а не степень её заполненности.
Может быть полезно выполнить ‘man mvidia-smi’ и изучить возможности утилиты. Например, можно запросить вывод статистики каждые 10 секунд, добавив команде параметр ‘-l 10’
После завершения программы
Выполнить команду ‘tracejob XXX‘, где ‘XXX’ — номер задачи. Эта команда анализирует логи PBS и выводит информацию, связанную с работой указанной задачи. По умолчанию обрабатываются данные только за последний день. Если задача закончилась несколько дней назад или Вы хотите получить данные, начиная с момента постановки задачи в очередь, то надо дополнительно указать параметр ‘-n ZZZ‘, где ‘ZZZ’ — количество дней, прошедших с данного момента, логи за которые должна проанализировать команда.
Пример: запрос информации по задаче с номером 482685 за два прошедших дня:
tracejob -n 2 482685
. 11/19/2013 06:05:04 A user=user01 group=users project=_pbs_project_default jobname=runs queue=bl2x220g7q ctime=1384777907 qtime=1384777907 etime=1384777907 start=1384777908 exec_host=cn263/0 exec_vnode=(cn263:mem=4194304kb:ncpus=1) Resource_List.mem=4gb Resource_List.ncpus=1 Resource_List.nodect=1 Resource_List.place=pack Resource_List.qlist=bl2x220g7q Resource_List.select=1:mem=4gb:ncpus=1:qlist=bl2x220g7q Resource_List.walltime=100:00:00 session=10647 end=1384815904 Exit_status=271 resources_used.cpupercent=98 resources_used.cput=10:33:16 resources_used.mem=1321292kb resources_used.ncpus=1 resources_used.vmem=2144544kb resources_used.walltime=10:33:17 run_count=1
Здесь видно, в частности, что задача:
Запросила 1 ядро (Resource_List.ncpus) и 4 ГБ ОЗУ (Resource_List.mem)
Но ОЗУ использовалась крайне неэффективно: resources_used.mem=1321292kb, т.е. примерно 1.26 ГБ из 4 ГБ запрошенных. Что означает, что 2.5 ГБ из зарезервированных PBS под эту задачу, не использовались и при этом были недоступны другим пользователям.
Время работы команды ‘tracejob’ зависит от временного интервала, за который запрашивается информация.
Если с момента завершения задачи прошло не очень много времени, то можно также открыть веб-интерфейс Ganglia и посмотреть на графики работы. Однако, чем больше прошло времени, тем сложнее будет по графикам определить период работы задачи.
Использование виртуальной памяти
В случае, если необходимо использовать больше ОЗУ, чем имеется у компьютера, операционная система сохраняет данные из каких-то неиспользуемых в данный момент областей оперативной памяти на жесткий диск в специальный файл (файл подкачки) или специальный раздел диска, обобщённо называемые ‘swap’ (английское ‘обмен’). Освободившаяся оперативная память используется по назначению. В случае, если потребуются данные, перенесённые в swap, то происходит аналогичная операция — часть данных из ОЗУ переносится на диск, а нужные данные с диска возвращаются в оперативную память. Подобный метод позволяет операционной системе и программам работать так, как будто на компьютере больше оперативной памяти, чем на самом деле. Поэтому такая память называется виртуальной.
К сожалению, скорость передачи данных у жесткого диска существенно меньше, чем у микросхем оперативной памяти. Поэтому интенсивное использование swap сильно замедляет работу.
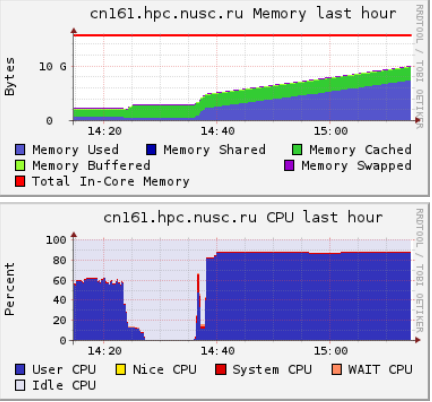
Рассмотрим типичные графики, полученные при помощи системы Ganglia с сервера, на котором работает задача, потребившая всю оперативную память (обозначена на первом графике синим) и интенсивно использующая swap (фиолетовый):
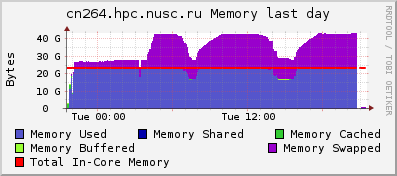
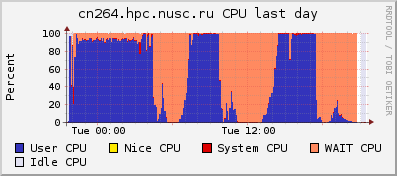
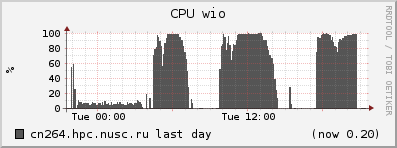
Видно, что в те моменты, когда потребление swap увеличивается, процессор вместо выполнения прикладных задач (‘User CPU’, загрузка процессора пользовательскими программами) простаивает в ожидании данных (‘Wait CPU’ и ‘CPU wio’; wio = wait in/out, ожидание ввода/вывода). То есть данная программа почти половину времени не работает, а ждёт обмена данными с жёстким диском. И если бы у сервера было больше оперативной памяти, программа работала бы почти в два раза быстрее.
Поэтому рекомендуется отслеживать потребление памяти вашими задачами и при необходимости что-то менять:
В случае, если программа пишется вами, в первую очередь надо подумать об оптимизации кода с целью уменьшения потребления ОЗУ.
Если известно, что при распараллеливании задачи каждый процесс, загружающий одно ядро, требует определённое количество ОЗУ и оно больше, чем имеется у сервера, то может иметь смысл занимать сервер полностью, но задействовать не все ядра. Например: у сервера 12 ядер и 24 ГБ ОЗУ, т.е. 2 ГБ на ядро; а задаче необходимо 3 ГБ на процесс. В таком случае можно занять сервер полностью (запросить 12 ядер) но задействовать только 24/3 = 8 ядер, запустив 8 процессов. Хотя более правильным будет позапускать задачу с использованием разного количества ядер и найти компромиссный вариант, обеспечивающий максимальное использование процессора.
Перенести запуск задач на сервера другого типа, имеющие больше ОЗУ либо больше ОЗУ на одно ядро.
Следует однако отметить, что само по себе использование виртуальной памяти и количество данных, находящихся в swap, не критичны для быстродействия. Если данные просто перенеслись на диск и долгое время никому не требовались, то и больших задержек не возникло. Гораздо важнее интенсивность работы с swap — как часто происходят обращения к жёсткому диску для чтения или записи. К сожалению, количества таких обращений на графиках Ganglia нет.
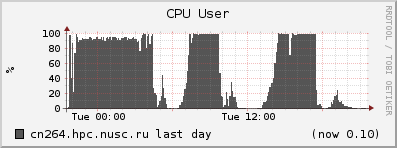
Ниже приведены графики задачи, которой использование виртуальной памяти не вредит — хотя в swap находится уже 24 ГБ данных, процессор всё равно загружен на 90%. Другое дело, что виртуальная память не бесконечна и если она закончится, то такая задача прервётся. Скорее всего, для такой задачи будет более правильным сразу сохранять в файл полученные результаты и освобождать память.