Модели облачных сервисов: разница между IaaS, SaaS, PaaS и примеры
Облачные вычисления (cloud computing) – это способ обеспечения удаленного доступа к вычислительным ресурсам через интернет. Основа облачных технологий — это физические серверы, которые работают в единой системе. Эти серверы делятся на виртуальные машины (ВМ). Как и у физического сервера, у каждой машины есть процессор, оперативная память, хранилище данных и т.д. Однако в отличии от «железных» серверов, конфигурация ВМ в облаке не ограничена параметрами физических компонентов. Например, в виртуальную машину можно в любой момент добавить оперативную память или уменьшить количество используемых процессорных ядер. Это возможно потому, что ВМ использует ресурсы нескольких «железных» серверов одновременно.
Облака используют для ряда корпоративных задач: на их основе развертывают интернет-магазины, базы данных, системы управления предприятием, почтовые серверы и т.д. Иными словами, облако – виртуальная ИТ-инфраструктура, в которой можно развернуть любые системы и приложения компании.
Почему компании выбирают облачные решения? Вот несколько причин:
- Доступность через интернет вне зависимости от времени и местонахождения;
- Не нужно тратиться на системных администраторов, обновления аппаратного обеспечения и ПО – всё это на стороне провайдера;
- Быстрая масштабируемость за счет использования виртуальных ресурсов;
- Разные уровни пользовательского доступа и разрешений;
- Комплексное обслуживание и техподдержка.
IaaS, PaaS, SaaS и XaaS – это модели облачных технологий, которые предоставляются пользователю в аренду; разница между ними заключается в уровне решаемых задач. В рамках модели IaaS клиент получает вычислительные мощности облака; на базе этой инфраструктуры строятся программные решения. PaaS – модель, которая предоставляет облачные ресурсы и набор предустановленных инструментов. Пользователь SaaS получает готовое решение, которое остается только применить; скорее всего, вы не раз сталкивались с SaaS-услугами в повседневной жизни. Эти модели так или иначе соответствуют определению XaaS, то есть «все как услуга».
IaaS – база, на которой строятся программные решения компании
Что такое IaaS? (Инфраструктура как услуга)
IaaS (англ. Infrastructure-as-a-Service) – модель облачных вычислений, которая включает в себя все основы: серверную инфраструктуру, коммуникации, хранилища и т.д. В эту услугу входит сама облачная инфраструктура и обслуживание аппаратуры — поддержкой занимается IaaS-провайдер.
В чем преимущества IaaS:
- Экономия бюджета за счет передачи расходов на инфраструктуру провайдеру;
- Данные размещаются в дата-центре провайдера, где они защищены системами безопасности на физическом и на программном уровне;
- Простое масштабирование по мере роста компании.
IaaS для бизнеса – база, на которой строятся программные решения компании. Провайдер IaaS предоставляет меньше услуг, чем в последующих моделях. В зависимости от потребностей компании, это может быть плюсом. Если у вас есть собственная стратегия разработки IT-решений, эта модель предоставит наибольшую свободу для ее реализации. На основе IaaS развертывают как отдельные приложения, так и все ИТ-инструменты компании – ERP-системы, терминальные серверы, удаленные офисы, базы данных и т.д.
Администрирование и мониторинг IaaS-системы реализуются с помощью виртуального интерфейса. В нем вы управляете конфигурацией IaaS, добавляете предустановленное ПО и подключаете дополнительные сервисы.
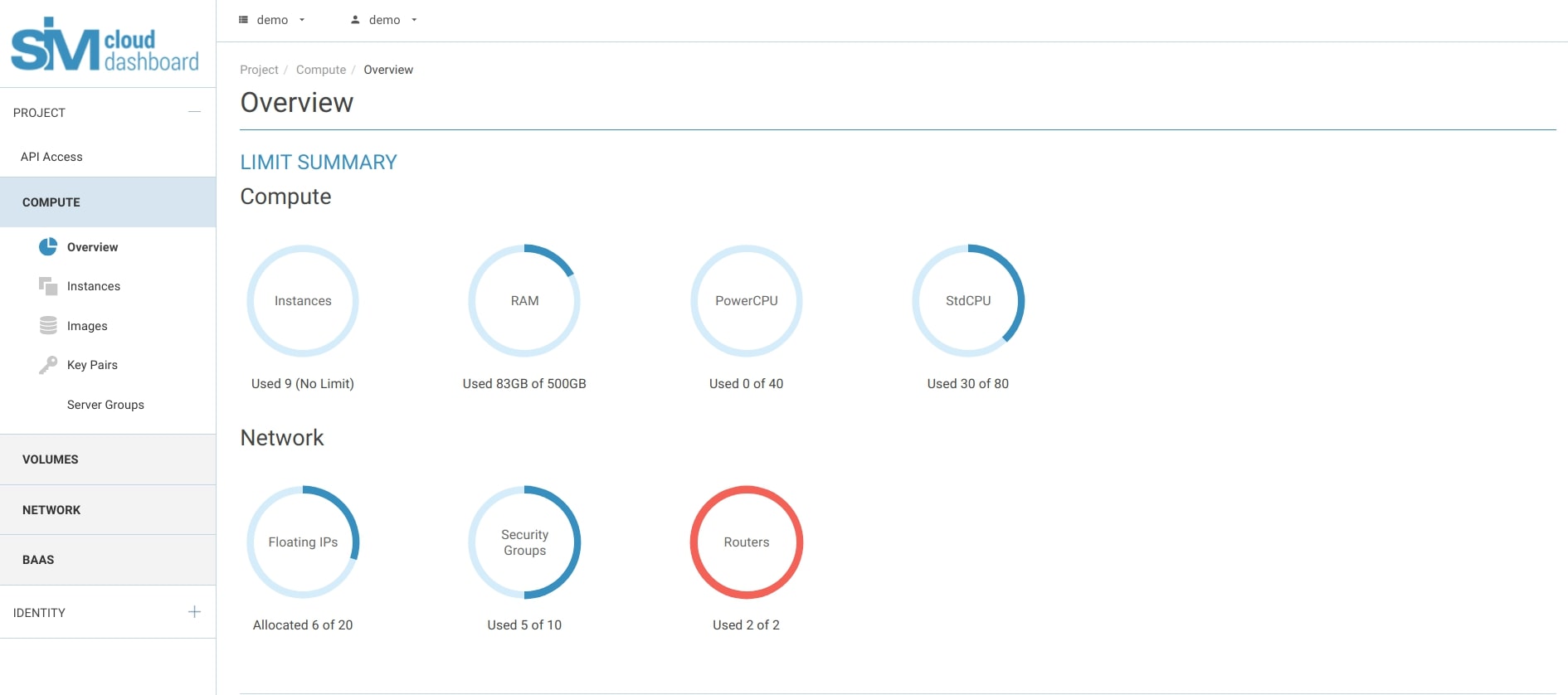
Мониторинг системы в виртуальном интерфейсе SIM-Cloud IaaS
Если для проекта нужны дополнительные ресурсы, достаточно добавить их в панели управления. Например, вы можете увеличить объем хранилища или выбрать комбинацию «процессор + оперативная память». Если компания не пользуется всеми мощностями облака, так же просто уменьшить объем ресурсов и платить меньше. Кроме того, условия содержания инфраструктуры и поддержка – ответственность провайдера. Компании не нужно арендовать помещение под ЦОД, обеспечивать серверы электропитанием, устанавливать системы охлаждения и .т.д. Таким образом, аренда IaaS позволяет тратить меньше времени и средств на IT.
Выбор IaaS требует ответственной подготовки. При выборе облака для бизнеса, оцените решение по этим параметрам:
- Обеспечена ли отказоустойчивость облака за счет дублирования компонентов?
- Как провайдер защищает данные клиентов?
- Соответствует ли дата-центр провайдера классу Tier III или выше?
- Какие гарантии дает провайдер в рамках SLA (соглашения об уровне услуг)?
- Доступна ли тех. поддержка провайдера круглосуточно и без выходных?
- Какие дополнительные XaaS-услуги предоставляет провайдер?
Узнайте больше о критериях выбора IaaS; мы сравнили технические характеристики SIM-Cloud с облаками Microsoft Azure и Amazon Web Services
XaaS («Anything-as-a-Service») – услуги для использования в облаке. «X» в аббревиатуре обозначает переменную, то есть такой услугой может быть что угодно. В контексте облачных инфраструктур этой аббревиатурой часто обозначают дополнения к IaaS-облаку. Популярный пример – BaaS («Backup-as-a-Service»), услуга автоматизированного резервного копирования данных в облаке.
Значения аббревиатур XaaS-услуг отличаются в зависимости от провайдера и контекста. Например, «MaaS» может обозначать как «Mobility-as-a-Service» («мобильность как услуга»), так и «Malware-as-a-Service» («вредоносное ПО как услуга»).
PaaS избавляет от необходимости заниматься задачами, которые уже решил провайдер
Что такое PaaS (Платформа как услуга)?
PaaS (англ. Platform-as-a-Service) – сервисная модель, в которой провайдер предлагает виртуальную инфраструктуру для разработки и развертывания приложений с предустановленными настройками. Например, платформой может быть почтовый сервер, система управления базой данных, веб-сервер, среда разработки и тестирования, резервный сервер и др.
- Провайдер PaaS-услуг берет на себя обновления, исправления и обслуживание программного обеспечения;
- Клиенту не нужно инвестировать в оборудование и ПО – все необходимое предоставляет провайдер;
- Гибкость при развертывании платформы: инфраструктура разработки, тестирования и развертывания полностью управляется провайдером PaaS.
PaaS во многом схож с IaaS, однако клиенты PaaS-провайдера не имеют возможности масштабировать инфраструктуру. То есть, например, отключить неиспользуемые мощности пользователь не может. Разница между услугами IaaS и PaaS состоит в том, что в рамках модели «платформа-как-сервис» вы получаете вычислительную инфраструктуру и стек решений, но не влияете на конфигурацию платформы.
Важный плюс модели PaaS — стандартизированный инструментарий для разработчиков. Например, это может значительно облегчить работу команды, которая занята одним проектом.
Примеры PaaS-решений: Google App Engine, VMWare Cloud Foundry, IBM Bluemix и др.
PaaS предоставляет меньше возможностей управления облачным сервисом, чем IaaS, но этим же избавляет от необходимости заниматься задачами, которые уже решил провайдер. Выбор между IaaS и PaaS – вопрос того, соответствуют ли эти решения запросам бизнеса.
SaaS – отличный выбор, если предоставляемая услуга решает поставленные задачи, ведь вам остается только применить готовые решения
Что такое SaaS (Программное обеспечение как услуга)?
SaaS (англ. Software-as-a-Service) – ПО как сервис, подразумевает использование клиентом приложений, развернутых на платформе провайдера. SaaS – простая вещь, которой вы, скорее всего, пользуетесь в повседневной жизни. Клиентами модели обслуживания SaaS часто становятся конечные пользователи, например, сервисов электронной почты, онлайн-кинотеатров, облачных хранилищ файлов малого объема, мессенджеров и т.д. Социальные сети также работают по модели SaaS.
Корпоративные клиенты SaaS-провайдеров используют приложения для видеоконференций, ERP- и CRM-системы, системы автоматизации бизнес-процессов, приложения для управления проектами и тайм-менеджмента, сервисы электронной почты и т.д. Многие примеры SaaS-решений вам наверняка будут знакомы: Gmail, Jira, Bitrix, WordPress, Citrix и др.
SaaS – отличный выбор, если предоставляемая услуга решает поставленные задачи, ведь вам остается только применить готовые решения. Если же нужен специализированный подход, для которого понадобится разработка собственных инструментов, вам подойдет одна из двух предыдущих моделей.
К какой модели обслуживания относится google colab
1 ФГБОУ ВО «Грозненский государственный нефтяной технический университет имени академика М.Д. Миллионщикова»
В данной статье рассматриваются инструменты для создания системы распознавания речи малораспространённых языков, в частности чеченского языка. Технологии распознавания речи – одна из актуальных проблем современного цифрового общества. Данные технологии в программной реализации дают возможность вычислительным системам воспринимать устную речь, интерпретировать ее и генерировать в текстовом формате. Инструментарий распознавания речи уже стала частью нашей повседневной жизни, но пока все еще ограничивается относительно простыми отработанными командами. Учитывая современные тенденции, технология распознавания речи будет быстрорастущим (и меняющим мир) подмножеством обработки сигналов на долгие годы. Программная разработка предназначена для автоматизации сбора входных данных и их качественной обработки для реализации системы эффективной обратной связи с потребителем товаров и услуг в call-центре. Поставленная задача разработки программного приложения для записи и проверки аудиозаписей на чеченском языке решена технологией машинного обучения в анализе больших аудиоданных. Описаны разработка интерфейса для анализа и мониторинга работы Call-центра, проектирование приложения сбора данных для записи и проверки аудиозаписей на чеченском языке.

машинное обучение
чеченский язык
автоматизированные системы
распознавание речи
дуальная модель распознавания
большие данные
стенографирование
обучение модели
1. Дронов В.А. Django: Практика создания Web-сайтов на Python. СПб.: БХВ-Петербург, 2021. 704 с.
2. Стюарт Р., Норвиг П. Искусственный интеллект: современный подход, 4-е издание. Том 1. Решение проблем: знания и рассуждения. М.: Диалектика-Вильямс, 2021. 704 с.
3. Вольский В.В. Веселова О.В. Золкина Н.К. Оператор call-центра: от найма до увольнения. Тверь: Софитель, 2008. 200 с.
4. Гринберг М. Разработка веб-приложений с использованием Flask на языке Python. М.: ДМК-Пресс, 2016. 272 с.
5. Ляпунов С.М., Алымов А.С. Методология анализа текста с помощью составления частотных словарей по частям речи // Научный альманах. 2017. № 10–3 (36). С. 203–206.
6. Малявко А.А. Параллельное программирование на основе технологий openmp, cuda, opencl, mpi. М.: ЮРАЙТ-Восток, 2021. 136 с.
В последнее десятилетие наблюдается бурное развитие сферы машинного обучения в анализе больших данных. Различные организации внедряют технологии, основанные на машинном обучении. Они решают задачи автоматизации, ведения статистики и анализа деятельности. Крупные IT-компании предоставляют доступ к проприетарному программному обеспечению, функционирующему на их собственных серверах. Это является проблемой для организаций, в которых действуют особые требования к защите конфиденциальной информации. Кроме того, стоимость пользования такими услугами может быть достаточно высокой, что может служить препятствием для использования этих технологий для малых организаций.
Другая проблема – это отсутствие системы распознавания малораспространённых языков, в частности чеченского языка. Для носителей таких языков нет возможности перевести записанную речь в текст. Пример ситуаций, при которых это критично – общение с туристами, коммуникация с людьми с ограниченными возможностями, работа региональных клиентских сервисов и т.д.
В данной статье будут рассмотрены инструменты для создания системы распознавания речи на русском и чеченском языках, а также описана разработка интерфейса для анализа и мониторинга работы колл-центра.
Для сбора данных, необходимых при реализации услуг в call-центре, который является системой эффективной обратной связи с потребителем товаров и услуг (заказчиком), ставится задача разработки программного приложения для записи и проверки аудиозаписей на чеченском языке.
Технология распознавания речи позволяет компьютерам принимать устную речь, интерпретировать ее и генерировать из нее текст. Она уже стала частью нашей повседневной жизни, но пока все еще ограничивается относительно простыми командами. Учитывая современные тенденции, технология распознавания речи будет быстрорастущим (и меняющим мир) подмножеством обработки сигналов на долгие годы.
Для организации работы контакт-центров необходимо обеспечить отдел определенным оборудованием, в список которого входит: сервер, VoIP–шлюзы, GSM-шлюзы, IP-телефоны, гарнитура для операторов. Ключевая задача сервера в данном случае – это функция управления телефонными вызовами и распределения звонков между операторами центра. Все входящие и исходящие звонки предполагается осуществлять на основе внедрения в телекоммуникации серверного оборудования.
В случае если организация хочет проводить анализ и мониторинг содержания записей, она должна выделить персонал, который будет монотонно прослушивать записи и заполнять анкеты для каждого из них. Для этого необходимо использовать информационную систему для сбора этих анкет и анализа их результатов.
Другая значительная проблема – региональный язык. В данном случае чеченский язык. В настоящее время отсутствуют автоматизированные системы распознавания чеченской речи.
Существует потребность в разработке такой системы, которая должна соответствовать следующим требованиям:
– должна функционировать оффлайн;
– иметь дуальную модель распознавания;
– должна распознавать чеченский язык.
Система, описываемая в данной статье, решает одну из проблем – стенографирование аудиозаписей. Для анализа диалога требуется разработать алгоритмы для поиска и фильтрации диалогов, анализа корпоративной этики, появления конфликтной ситуации и др.
Для решения поставленной задачи нужно решить следующие задачи:
– определить систему для разработки системы распознавания и перевода речи в текст (проблема «Speech2Text») дуальной языковой модели – русской и чеченской;
– разработать решения для сбора аудиоданных чеченского языка;
– разработать приложение для мониторинга работы call-центра, а именно – стенографирование разговоров для дальнейшего анализа аудио.
Материалы и методы исследования
Среди систем, предназначенных для разработки системы перевода речи в текст, наиболее распространены практики применения следующих инструментов:
CMU Sphinx сейчас является крупнейшим проектом по распознаванию человеческой речи, в инструментарий которого входят следующие программы и библиотеки [1]:
– Kaldi – это набор инструментов для распознавания речи на основе математических функций, предназначена для исследований в области распознавания речи;
– Deepspeech – система, предпочтительная в применении для дуальной модели, так как предлагает «end to end» – модель для распознавания двух языков.
В связи с возникшей ситуацией необходимости формирования огромного набора данных Deepspeech была выбрана в качестве подсистемы для распознавания чеченской речи в случае, если русский язык распознан с низким значением convenience – то есть уверенности в адекватном отображении [2].
Для обучения систем распознавания речи используются наборы данных со следующей структурой: аудиофайл с частотой 16 кГц, моноканальный, в формате wav; документ в формате csv/tsv со следующими данными – id, название аудиофайла, id пользователя, дата, количество подтверждений.
В открытом доступе отсутствует набор данных на чеченском языке, в связи с чем возникла необходимость разработки программного приложения для сбора данных. Размещение данного приложения рекомендовано на собственном сервере в связи с высокой себестоимостью использования способа аренды больших объёмов памяти.
Для мониторинга деятельности call-центра были определены ключевые показатели эффективности, к которым относятся:
– индекс потребительской лояльности (NPS) – отражает вероятность того, что потребитель порекомендует товар или услуги другому человеку;
– среднее время обработки контакта (AHT) показывает, насколько быстро операторы обрабатывают контакты с абонентами.
Скорость обработки данных, в свою очередь, тесно связана с экономическими показателями деятельности call-центра. В общем случае, чем быстрее операторы работают, тем меньшее количество таких сотрудников необходимо, и, следовательно, тем меньший фонд оплаты труда потребуется для содержания такого офиса.
Среднее время обработки контакта AHT складывается из четырех компонентов:
– Ring Time – время, отсчет которого начинается с момента, когда автомат распределения нагрузки извлекает вызов из очереди и направляет его на рабочее место;
– Talk Time – время разговора без учета времени постановки абонента на удержание;
– Hold Time – время постановки абонента на удержание;
– Wrap-Up Time – время поствызовной обработки. Оно начинается в момент завершения соединения и заканчивается, когда система открывает доступ к оператору для следующего контакта [3].
Кроме вышеперечисленных критериев, будет преимуществом в данной разработке определять следующие показатели, влияющие на эффективность работы системы: эмоциональная окраска записи, класс обращений, уровень корпоративной этики, определение признаков конфликтной ситуации.
Наиболее популярными решениями, с точки зрения оптимальной работы, для call-центров являются следующие:
При выборе платформы для реализации программного решения были проанализированы современные решения этой проблемы и обоснованно сделан оптимальный выбор «Оки-Токи», который является профессиональным облачным сервисом для организации работы контакт-центра. Главным достоинством этого решения является то, что «Оки-Токи» работает из браузера без дополнительного программного обеспечения и оборудования.
Платформа рассчитана поддерживать до 500 операторов и 1000 линий одновременно, а также ее надёжность обеспечивается резервным копированием и хранением данных в разных странах мира. При этом интеграция осуществляется с внешними системами через технологию Webhooks и API.
Отметим также основной функционал, который будет использован в решении нашей проблемной задачи распознавания речи и обработки данных:
– мультиканальная обработка обращений;
– проектирование сценария для IVR и операторов, с помощью различных ин- струментов;
– поддержка черных, белых и VIP списков для каждого проекта;
– интеграции и сценарии работы в чатах (Facebook, WhatsApp и др.);
– обработка обращений в личном каби- нете;
– автоматический callback по утраченным звонкам;
– импорт и экспорт телефонной базы в CRM;
– настройка разных воронок продаж под разные проекты, используя библиотеку шаблонов и сценариев;
– автоматическая проверка загруженных контактов на уникальность, а также на наличие ошибок;
– хранение истории взаимодействий с клиентом (звонки, переписки, чаты);
– управление доступами к контактам;
MANGO OFFICE – функциональное и производительное решение среди российских облачных сервисов телефонии. Описание основных возможностей данного продукта для реализации описываемой системы можно сконцентрировать на следующем перечне:
– подключение номеров и других каналов связи – многоканальные номера, единые номера, FMC-связь, виджеты звонков, мультиканальный чат, рассылки;
– внутренние коммуникации и совместная работа – адресная книга сотрудников, мессенджер, конференции;
– работа с входящими обращениями – переадресация, создание групп сотрудников, распределение звонков по операторам, голосовое меню, голосовая почта;
– работа с исходящими звонками – адресная книга контрагентов, автоподстановка номера, плагины;
– стандартизация и автоматизация бизнес-процессов – готовые интеграции с популярными бизнес-приложениями, Google Apps, конструктор API, записи разговоров, облачное хранилище.
Кроме того, выбор Mango Office в данном исследовательском проекте обоснован его универсальным набором инструментов мониторинга, анализа и контроля: статистика и мониторинг, дашборд руководителя, доска мотивации, аналитика продаж, аналитика обслуживания, речевая аналитика.
Разработанная система распознавания чеченской речи в общем виде состоит из модулей, сформированных для исполнения функционала независимо друг от друга. Поэтому программные средства для каждого из них собственные, для которых можно привести краткую характеристику основных инструментов, использованных в данной разработке:
1) основной язык программирования – Python. Python с динамической типизаций и автоматическим управлением памяти [4];
2) JavaScript – это язык программирования, который в данном проекте использовался для добавления интерактивности веб-страницам;
3) Jupyter Notebook – удобный интерпретатор для использования языка Python, обычного текста, математических выражений и визуального представления данных;
4) Google Colab – Colaboratory, или сокращенно Colab – продукт компании Google Research, который особенно хорошо подходит для машинного обучения, анализа данных и образования;
5) Flask – фреймворк для создания веб-приложений на языке программирования Python, использующий набор инструментов Werkzeug, а также шаблонизатор Jinja2 [5];
6) CUDA – программно-аппаратная архитектура параллельных вычислений, которая позволяет существенно увеличить вычислительную производительность благодаря использованию графических процессоров фирмы Nvidia [6].
Результаты исследования и их обсуждение
Сервер на данный момент выполняет 2 функции:
– обработка API запросов для распознавания речи;
– сохранение аудиозаписей для сбора набора данных.
При завершении обучения модели распознавания речи данную функцию следует отключить, поэтому доступ в Интернет при интеграции сервиса не требуется.
Для обучения моделей использовались 3 рабочие станции и облачные вычисления.
На рабочую станцию для вычислений должна быть установлена операционная система Ubuntu версии 18.04 и библиотека cuDNN (рис. 1).
Рис. 1. Тест работы видеокарты в симуляции nbody
Для тестирования системы обучения нейронной сети следует использовать небольшой набор данных из 10 минут записей (рис. 2).
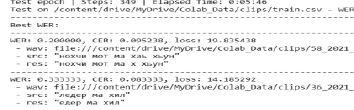
Рис. 2. Тест модели
Рис. 3. Главная страница amdar
Рис. 4. Страница для записи
Созданы обработчики по следующим маршрутам: «/» – главная страница, отображает приветствие и счётчик записей (рис. 3). На этой странице размещается общая информация о проекте, для каких целей создано, а также текущий прогресс.
На рис. 4 представлен интерфейс базовой пользовательской страницы «/Records», с необходимыми атрибутами: микрофоном, текстом и инструкцией.
Для работы описываемого в этой статье программного приложения рекомендовано использовать WPS-сервер и достаточно большой объём доступной памяти для создания и обработки банка данных. Для хранения файлов может декларироваться минимальный порог количественной характеристики объема хранилища – от 1.5 Тбайта в RAID-массиве.
Заключение
Рассмотрим приложение для работы пользователя, а именно мониторинга и анализа работы call-центра, которое разработано с помощью фреймворка Django на языке Python. Программа позволяет загрузить информацию о новых записях в виде JSON-файла, данные из которых будут автоматически сохраняться в локальной базе данных SQLite.
Предусмотрена возможность поиска записей. В разделе «Общая статистика» выводится общая статистика диалогов по операторам. Показатели эффективности описывают уровень соблюдения корпоративной этики, которая описывается супервайзером в отдельном для этого разделе со списком слов и выражений. В отдельном окне прописывается показатель использования рекомендуемых слов и выражений, и все эти показатели приводятся по дням работы конкретного оператора.
Сводная статистика выводится в отдельном разделе, при которой в разделе «Мониторинг слов» формируются списки слов, а именно рекомендуемые слова и слова по предлагаемым услугам. На основе этого текста производится расчёт статистики. Отдельно можно посмотреть список активных операторов в разделе «Операторы», откуда можно совершить переходы на страницу для их редактирования.
Данное приложение уже выполняет основную функцию стенографирования и каталогизации бесед операторов. Модель, используемая для распознавания дуальной модели речи, будет улучшена при получении достаточного количества набора данных, для формирования банка которых запущено и функционирует веб-приложение.
Работа в Google Colab: преимущества и недостатки
О чем речь? Google Colab – облачная среда для работы с Python в браузере. Удобна тем, что бесплатная, дает возможность «колдовать» над кодом нескольким разработчикам, оставлять комментарии или замечания.
На что обратить внимание? Несмотря на все плюсы, минусы тоже присутствуют. Бесплатный тариф дарит возможность работать над кодом лишь 12 часов. По истечении этого времени все исчезнет, придется начинать все заново. Чтобы снять ограничение, нужно оплатить Pro-подписку, которая доступна ограниченному количеству стран.
В статье рассказывается:
- Что такое Google Colab
- Что такое CPU, GPU и TPU
- Преимущества и недостатки Google Colab
- Как работать с Google Colab
- Часто задаваемые вопросы о Google Colab
Пройди тест и узнай, какая сфера тебе подходит:
айти, дизайн или маркетинг.
Бесплатно от Geekbrains
Что такое Google Colab
Google Colab (Colaboratory) представляет собой бесплатную среду, позволяющий писать код в jupyter notebook. Эта система является облачной, что позволяет вести коллективную работу над одним проектом. С помощью программы можно получить доступ к графическим процессорам GPU и TPU. Их мощности задействуются для анализа искусственного интеллекта и разработки приложений на базе нейросетей.
Colab помогает писать код на Python. Разработка и выполнение осуществляются прямо в браузере. Пользователю нужно лишь предоставить доступ к Google-аккаунту.
С помощью Colab можно использовать в одном файле исполняемый код, html-разметку, изображения. Все эти элементы будут храниться на Google-диске. При этом пользователь может поделиться своими файлами. При помощи настроек доступа можно разрешить просматривать и корректировать данные, а также оставлять комментарии для других разработчиков.
Облачная среда часто используется специалистами по обработке информации и программистами, которые занимаются созданием нейросетей. Colab позволяет решать следующие задачи:
- сортировка информации;
- создание визуализаций;
- машинное обучение;
- разработка систем для big data;
- формирование прогнозов;
- создание руководств.
Узнай, какие ИТ — профессии
входят в ТОП-30 с доходом
от 210 000 ₽/мес
Павел Симонов
Исполнительный директор Geekbrains
Команда GeekBrains совместно с международными специалистами по развитию карьеры подготовили материалы, которые помогут вам начать путь к профессии мечты.
Подборка содержит только самые востребованные и высокооплачиваемые специальности и направления в IT-сфере. 86% наших учеников с помощью данных материалов определились с карьерной целью на ближайшее будущее!
Скачивайте и используйте уже сегодня:

Павел Симонов
Исполнительный директор Geekbrains
Топ-30 самых востребованных и высокооплачиваемых профессий 2023
Поможет разобраться в актуальной ситуации на рынке труда
Подборка 50+ бесплатных нейросетей для упрощения работы и увеличения заработка
Только проверенные нейросети с доступом из России и свободным использованием
ТОП-100 площадок для поиска работы от GeekBrains
Список проверенных ресурсов реальных вакансий с доходом от 210 000 ₽
Получить подборку бесплатно
Уже скачали 25514
Что такое CPU, GPU и TPU
GPU и TPU — это графические процессоры, которые могут задействоваться пользователями Google Colab абсолютно бесплатно. Эти устройства позволяют сводить базовую аналитику данных, а также проводить сложные исследования, связанные с машинным обучением.
CPU представляет собой центральный процессор компьютера, отвечающий за выполнение операций с данными. Его можно применять для решения практически любых задач.
GPU — это графический процессор компьютера. Его скорость обработки данных выше, чем у CPU, так как он выполняет задачи параллельно, а не последовательно. Предназначен для работы с графикой. Как правило, используется для 3D-моделирования и монтажа.
TPU представляет собой тензорный процессор, созданный компанией Google. Применяется для тренировки нейросетей. Демонстрирует высочайшую производительность даже при больших объемах вычислительных задач.
Все это оборудование стоит недешево. Google Colaboratory предоставляет доступ к устройствам, которые можно бесплатно эксплуатировать в течение 12 часов. По истечении этого срока вся информация будет полностью удалена. Если пользователь будет бездействовать на протяжении 30 минут, то интерактивная среда отключит блокноты. Это позволяет убрать лишнюю нагрузку с процессоров.
У пользователя есть возможность продлить время работы Colab, увеличить объем памяти в два раза и получить приоритетный доступ к TPU. Однако в этом случае придется купить Google Collab Pro за $9,99 в месяц. Кроме того, нужно учитывать, что на данный момент Pro-подписка доступна только для жителей Канады и США.
Преимущества и недостатки Google Colab
Для начала рассмотрим преимущества Google Colab:
- Возможность использования Python-библиотек для проведения онлайн-анализа информации. Эта функция также есть в Google-документах.
- Простой и понятный интерфейс. Работать с Colab очень удобно. При этом все вычисления выполняются крайне быстро.
- Вход в аккаунт с любых устройств. Если же пользователь хочет повысить уровень конфиденциальности, то лучше воспользоватьсяjupyter notebook (командная оболочка для интерактивных вычислений на Python).
- Интеграция с GitHub. Сотрудничество с крупнейшим разработчиком ПО позволяет использовать любое хранилище. Для этого ему нужно предоставить профиль на сервисе.
- Возможность оставлять комментарии и редакторские заметки. Если выбран общий доступ, то другие пользователи смогут просмотреть все содержимое блокнота. К примеру, текст, код,комментарии и выходные данные. Чтобы в блокноте сохранялся только код без результатов исполнения, потребуется перейти в меню «Изменить», потом в «Настройки блокнота», а затем поставить галочку «Исключить выходные данные кодовой ячейки при сохранении блокнота».
Глава 2. Модели и системы параллельного программирования
Данная глава представляет некий обзор популярных сред обработки данных используемых для анализа Больших данных в окружениях высокопроизводительных вычислений и центров обработки данных. Она обсуждает и перечисляет примеры различных инфраструктур, разработанных для обслуживания пяти V Больших данных. Данная глава также предоставляет образцы приложений для демонстрации возможностей программирования различных понятий обработки Больших данных.
Обзор
Высокопроизводительная обработка Больших данных стимулирует трансформацию ведения дел и масштабный рост научных исследований, например, медицинских наук. Для обеспечения этого были разработаны платформы обработки данных, которые могут обслуживать большие объёмы данных за разумное время для предоставления ценных сведений. Чтобы быть более точным, платформы Больших данных должны обладать возможностью вычисления огромных объёмов данных из различных ресурсов, управляя при этом данными, которые могут быть структурированы неточно. Большие данные также нуждаются в системах, которые способны обрабатывать и анализировать потоки неограниченных или непрерывных данных в режиме реального времени. Таким образом, для удовлетворения каждого из таких тонких и уникальных требований, в последние годы были предложены различные среды обработки Больших данных. Мы подразделяем их на пять широких категорий, что отражено на Рисунке 2.1.
Рисунок 2.1

Модели программирования для распределённой обработки данных
Каждая из представленных на Рисунке 2.1 среда обработки данных пяти различных типов отличается тем способом, которым они обрабатывают данные. Среды пакетной обработки, такие как Hadoop MapReduce (Dean and Ghemawat, 2008) и Spark (Zaharia et al., 2016) широко применяются в структурах автономной аналитики данных, которые разрабатываются для обработки больших неизменных наборов данных поверх распределённых файловых систем. С другой стороны, реляционные базы данных, способные выполнять обработку запросов в структурированных данных (например, MySQL (MySQL, 2020)) и неструктурированных данных (скажем, HBase (Apache Software Foundation, 2021f)), предоставили ценные догадки о данных за последние десятилетия. Были предложены решения, выходящие за рамки подобной MapReduce аналитики, для действенной обработки графов крупного масштаба, которые, как правило, выступают итеративными рабочими нагрузками. В связи с растущим значением систем на основе Искусственного интеллекта (ИИ), специализированных и оптимизированных систем Машинного и Глубокого обучения, они осуществили эволюцию, например TensorFlow (Google, 2021b), Caffe2 (Markham and Jia, 2017) и BigDL (Wang et al., 2018). По мере развития высокопроизводительных ускорителей и сетевых сред, различные производители оборудования, такие как Intel, NVIDIA и Mellanox < Прим. пер.: последняя в 2019- 2020 поглощена nVidia > также вкладывают средства в «вертикальную интеграцию» своих технологий с платформами Больших данных и делают их доступными в виде стеков программного обеспечения (ПО) производителей. Такие стеки тонко настроены для обеспечения высокой производительности на оборудовании конкретного производителя.
В данной главе мы изучим самые основы этих пяти парадигм Больших данных и обсудим широко применяемые среды следуя каждому из этих различных подходов. В то же самое время мы также обсудим популярные решения, которые пользуются вертикальной интеграцией аппаратных средств/ программного обеспечения.
Среды пакетной обработки
Пакетная обработка обладает самой длинной историей для систем понятий модели программирования Больших данных. Она включает в себя вычисления в больших статических наборах данных и возвратом, причём, вероятно, с применением нескольких циклов конвейеров, получаемых результатов по завершению вычислений. Hadoop MapReduce и Spark это две наиболее популярные платформы пакетной обработки из доступных в наши дни.
Apache Hadoop MapReduce
Hadoop (Apache Software Foundation, 2021e) это популярная реализация с открытым исходным кодом модели программирования MapReduce Dean and Ghemawat (2008). HDFS от Shvachko et al. (2010) выступает первоначальным источником данных и ПО промежуточного уровня хранения для кластера Hadoop. Кластер Hadoop составляется из двух типов узлов: NameNode и DataNode. NameNode управляет пространством имён своей файловой системы, а DataNode хранят реальные данные. NameNode обладает процессом JobTracker, а все DataNode могут исполнять один или более процессов TaskTracker. Эти процессы, все вместе, действуют в виде архитектуры хозяин — подчинённый для некого задания MapReduce. Задание MapReduce, в целом, состоит из трёх этапов: map, shuffle/merge/sort и reduce (соответствие, перетасовка/ слияние/ сортировка и понижение). Рисунок 2.3 отражает имеющийся поток этих различных этапов.
Рисунок 2.2

Обзор обработки данных с применением MapReduce
JobTracker это служба внутри Hadoop, которая отвечает за распределение имеющихся индивидуальных задач некого задания в конкретные узлы своего кластера. Таким образом, отдельный JobTracker координирует несколькими TaskTracker для разрешения успешного исполнения задания MapReduce. Каждый TaskTracker запускает один или более MapReduce в соответствии со значением числа расщеплений (split) данных определяемого входными наборами данных в соответствующей распределённой файловой системе. Функция map() преобразовывает первоначальные записи в непосредственные результаты и сохраняет их в своей локальной файловой системе. Каждый из таких файлов сохраняется так, чтобы имелся один раздел данных на ReduceTask. Затем соответствующий JobTracker запускает ReduceTask как только из его MapTasks доступны выводы «map». TaskTracker способен охватывать несколько одновременных MapTasks или ReduceTasks. Каждый MapTasks or ReduceTasks начинает выполнять выборку выводов map из завершившегося MapTasks. Этот этап представляет собой период shuffle/ merge (перетасовки/ слияния) при котором имеющиеся в различных местоположениях выводы map отправляются и принимаются через запросы и отклики. При получении таких данных из разных мест запускается алгоритм сортировки слиянием (sort- merge) для объединения таких блоков данных, которые затем будут представлены соответствующей операции «reduce» (понижения). Далее каждая ReduceTask загружает и обрабатывает объединённые выходные данные при помощи определяемой пользователем функции reduce() . Окончательный результат затем сохраняется в HDFS. Данный поток данных отображён на Рисунке 2.3.
Рисунок 2.3

Обзор обработки данных с применением Hadoop MapReduce
В типичном кластере Hadoop (версии 1.x), его хозяин, или JobTracker, отвечает за приём заданий обработки данных от клиентов и составление их расписания при выполнении управления глобальными ресурсами. Hadoop 2.x улучшает имеющиеся ограничения масштабируемости вводя разделение для узла и всеобщего управления ресурсами. Для достижения этого Hadoop 2.x вводит YARN (Yet Another Resource Negotiator) (Vavilapalli et al., 2013), в качестве некого шага в направлении проектирования MapReduce 2.0. YARN делит возможности управления ресурсами и планирования JobTracker в Hadoop 1.x, добавляя два новых компонента. Глобальный Resource Manager (Диспетчер ресурсов) отвечает за назначение ресурсов для всех исполняемых в кластере Hadoop заданий, в то время как Node Manager (Диспетчер узлов) аналогичен TaskTracker из самой ранней версии Hadoop MapReduce (версия 1.x) с одним Node Manager, запускаемом в каждом из узлов. Application Master (Хозяин приложения) запускается для каждого нового задания в своём кластере. Такой Application Master координирует свои действия с Resource Manager и Node Managers для выполнения соответствующих задач.
С другой стороны, самая последняя среда Hadoop 3.x вносит серьёзные изменения в схемы хранения в HDFS (обсуждаются в разделе 2.2.1 Главы 3). В Hadoop 3.x также внесены небольшие изменения для повышения масштабируемости и надёжности имеющегося сервера временной шкалы, отвечающего за сохранение текущих и исторических сведений о приложениях в YARN.
Образец WordCount с применением MapReduce
Для иллюстрации модели программирования MapReduce с точки зрения проектирования приложения, мы предоставим простой пример WordCount. Это пример WordCount подсчитывает значение числа уникальных слов в неком наборе данных документа, состоящего из текстовых файлов. Код этого приложения WordCount представлен в Листинге 2.1. Как мы видим, MapReduce требует, чтобы мы определили некий класс Mapper , который задаёт функцию map() для вычисления в индивидуальных отдельных блоках данных HDFS, а также определяемую пользователем функцию reduce() , реализуемую через расширение имеющегося класса Reduce для слияния результатов, получаемых от вычисленных задач map.
Хранящийся в HDFS набор данных разделён между имеющимися задачами map имея в виду планирование с учётом местоположения. Как видно из данного кода, функция map() , которая включает соответствующую задачу map, создаёт кортеж (word,count) для каждого встречающегося из соответствующих назначенных ему блоков данных HDFS слова. Такие кортежи перетасовываются в соответствующих задачах понижения, в которых они сортируются и сливаются таким образом, что они группируются по ключу. После перетасовки и сортировки вызывается функция reduce() для подсчёта количества вхождений каждого слова. Содержащий слова и соответствующие им счётчики вывод запоминается в файле вывода, записываемого в HDFS.
Листинг 2.1. Приложение Hadoop WordCount
import java.io.I0Exception; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount < public static class TokenizerMapper extends Mapper< private final static IntWritable one = new IntWritable (1); private Text word = new Text (); public void map( Object key, Text value, Context context ) throws I0Exception, InterruptedException < StringTokenizer itr = new StringTokenizer (value.toString ()); while (itr.hasMoreTokens ()) < word.set (itr.nextToken ()); context.write (word, one); >> > public static class IntSumReducer extends Reducer < private IntWritable result = new IntWritable (); public void reduce ( Text key , Iterable values , Context context ) throws I0Exception, InterruptedException < int sum = 0; for (IntWritableval : values) < sum += val.get ( ); >result.set(sum); context.write(key, result); > > public static void main( String [] args) throws Exception < Configuration conf = new Configuration (); Job job = Job.getInstance (conf , "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion (true) ? 0 : 1); >>
Apache Spark
Spark (Apache Software Foundation, 2021k) от Zaharia et al. (2016) это среда кластерных вычислений с открытым исходным кодом, которая изначально была разработана в лаборатории AMPLab Калифорнийского университета в Беркли. Он был разработан для определённых типов рабочих нагрузок кластерных вычислений, а именно — итерационных рабочих нагрузок, таких как алгоритмы Машинного обучения, которые повторно применяют набор рабочих данных для параллельных операций и интерактивного интеллектуального анализа данных. Для оптимизации таких типов рабочих нагрузок Spark применяет понятие кластерного вычисления в оперативной памяти, когда наборы данных можно кэшировать в оперативной памяти для уменьшения задержки доступа к ним. Архитектура Spark основана на понятии устойчивых распределённых наборов данных (RDD, resilient distributed datasets). В целом, RDD представляют собой отказоустойчивый набор объектов, распределённых по некому множеству узлов, которые способны обрабатываться параллельно. Такие коллекции создаются путём считывания данных из ПО промежуточного уровня или получаются как выходные данные иного задания Spark. Они устойчивы, поскольку их можно восстанавливать, когда какая- то часть набора данных будет утрачена, посредством повторного вычисления преобразованного распределённого набора данных.
Всякое приложение Spark разбивает свою работу на множество RDD и запускает процесс для каждого из таких обрабатываемых блоков данных. Таким образом, задание Spark состоит из независимого набора процессов, координируемых объектом SparkContext, который создаётся приложением пользователя и носит название программы драйвера. Для простоты совместимости SparkContext был разработан для работы как в автономном режиме, так и с имеющимися популярными диспетчерами кластеров, например с Apache Mesos и Hadoop YARN. В автономном режиме его среда состоит из одного хозяина Spark и нескольких рабочих процессов Spark, как это отражено на Рисунке 2.4. Spark также пользуется ZooKeeper для обеспечения высокой доступности. Как только диспетчер кластера распределяет ресурсы между приложениями, Spark получает исполнителей в своих рабочих узлах, которые отвечают за исполнение вычислений и хранение данных для своего приложения. Код этого приложения затем отправляется его исполнителям. Наконец, SparkContext отправляет соответствующим исполнителям задачи для запуска. По окончанию выполнения задачи будут исполняться в своих работниках, а результаты будут возвращаться в соответствующую программу драйвер. Поскольку в данной главе основное внимание уделяется сторонам сетевого взаимодействия Spark, мы рассматриваем только автономный Диспетчер кластера.
Рисунок 2.4

Обзор архитектуры Spark
Зависимости в Spark
Выполняемые исполнителем задачи состоят из двух типов операций, причём оба они поддерживаются RDD^ действие, которое выполняет вычисление набора данных и возвращает значение своему драйверу, а также преобразование, которое создаёт новый набор данных из уже имеющегося набора данных. Операция преобразования определяет определяет зависимый от обработки направленный ациклический граф (DAG, directed acyclic graph) среди RDD.
Как показано на Рисунке 2.5, эти зависимости бывают двух видов: узкие зависимости (например, map, filter), когда каждый раздел родительского RDD используется не более чем одним разделом дочернего RDD и широкими зависимостями (например, GroupByKey, join), когда несколько дочерних разделов могут зависеть от одного и того же раздела родительского RDD. Широкие зависимости предполагают перемещение данных по сетевой среде. Таким образом, широкие зависимости требуют интенсивного обмена данными и являются потенциально узким местом для большинства приложений Spark.
Рисунок 2.5
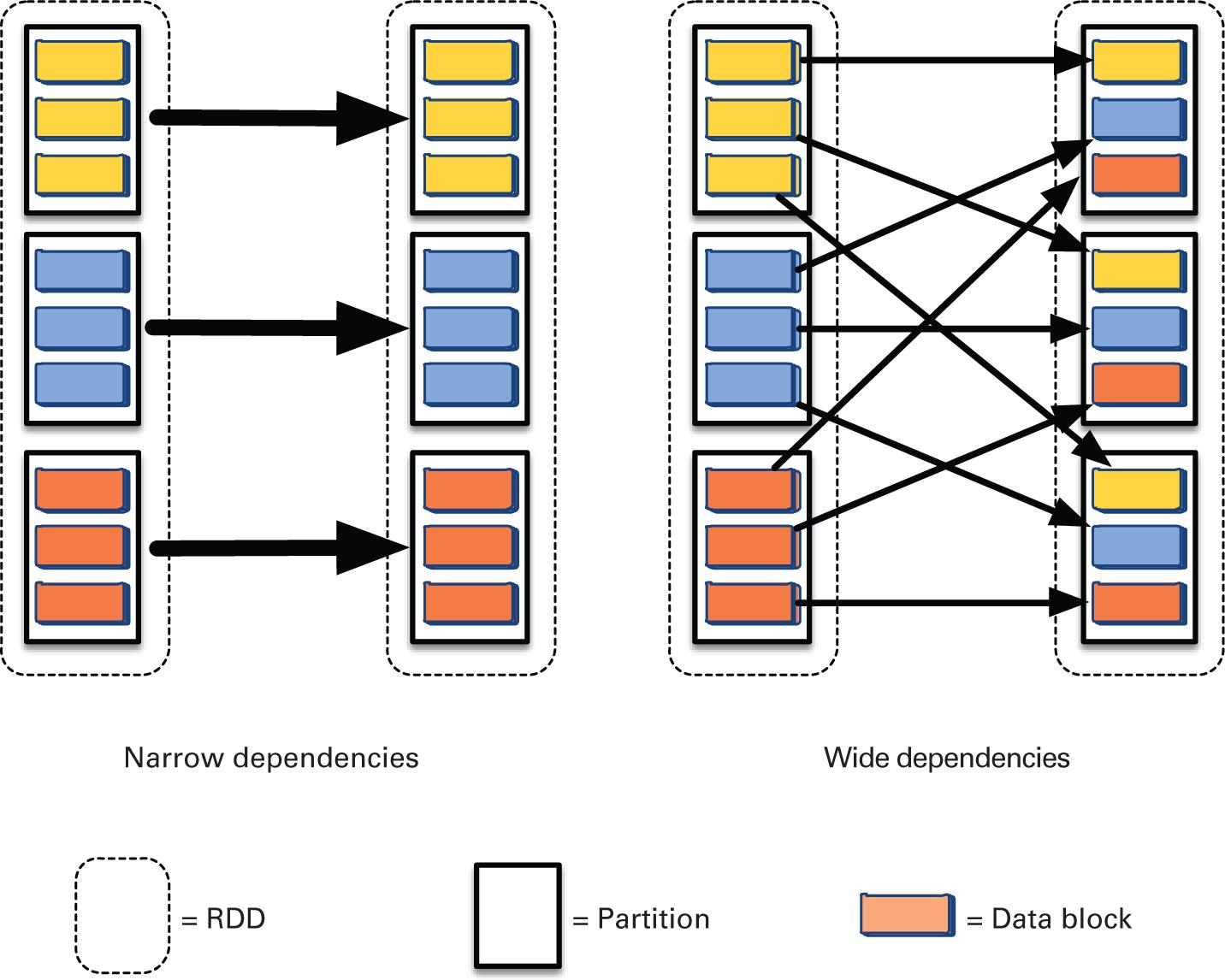
Зависимости Spark
Хотя Spark и имеет сходство с , он представляет собой новую среду кластерных вычислений с некоторыми едва уловимыми отличиями. Поскольку RDD позволяют выполнять вычисления в оперативной памяти и способны гибко храниться в постоянном хранилище, они делают возможным разработку более действенных конвейеров для итерационных рабочих нагрузок, которым, в отличие от Hadoop MapReduce, не требуется считывать входные данные из внешней системы хранения для каждой итерации.
Образец WordCount с применением Spark
Для иллюстрации подобной MapReduce модели программирования Spark, мы представляем простой пример WordCount, предлагаемый при помощи Hadoop MapReduce. Код для этого приложения представлен на Листинге 2.2.
Листинг 2.2. Приложение Spark WordCount
JavaRDD textFile = sc.textFile ("hdfs :/// user/ wordfiles"); JavaPairRDD counts = textFile .flatMap(s —> Arrays.asList(s.split (" ")). iterator ()) .mapToPair(word —> new Tuple2 <>(word , I)) .reduceByKey((a , b) —> a + b ); counts.saveAsTextFile ("hdfs : //. ");
Как можно понять из данного кода, в отличие от Hadoop MapReduce, Spark требует всего три строки кода для реализации одного и того же приложения. Входной RDD определяется для преобразования входных текстовых файлов в список слов, а преобразование узкого map применяется к входному RDD для определения кортежей (word,count) со счётчиком единица. Широкое преобразование reduceByKey применяется к преобразованному при помощи map RDD для подсчёта количества вхождений для слов. Как и в Hadoop, получаемые на выходе данные записываются в располагаемый в HDFS текстовый файл.
Хотя в этом примере представлены API-интерфейсы Scala Spark, он также предоставляет API-интерфейсы Java. Что ещё более значимо, важно отметить, что приложению Spark WordCount требуется значительно меньше строк (сокращение до 90 процентов), чем приложению, разработанному с применением API MapReduce. Такая эффективность объясняется способностью Spark абстрагировать данные в RDD.
Dryad
Dyrad (Microsoft, 2021b) это простая и мощная седа параллельного программирования для написания приложений обработки данных крупного масштаба, исполняемых в компьютерах с большим числом ядер, причём от небольших кластеров, до крупных ЦОД, в которых размещаются тысячи вычислительных узлов. Это, в частности, механизм распределённого выполнения общего назначения для параллельных приложений с крупной грануляцией данных. Приложение Dyrad формирует граф потока данных, объединяя вычислительные «вершины» с коммуникационными «каналами». Он запускает своё приложение путём исполнения своих вершин данного графа на наборе доступных компьютеров, при необходимости взаимодействуя через файлы, сокеты TCP/IP и общую память. Множество вершин планируются на множестве ядер или поверх множества компьютеров (или узлов) для достижения параллельности. Для оптимального применения доступных ресурсов приложение Dyrad способно определять значение размера и размещение данных в процессе исполнения и изменять свой граф потока данных по мере осуществления вычислений.
DataMPI
DataMPI Team (2021) это действенная и гибкая коммуникационная библиотека, которая предоставляет интерфейс взаимодействия на основе пары ключ- значение для расширения возможностей MPI под разработку параллельных научных приложений в кластерах высокопроизводительных вычислений для обработки Больших данных (Lu, Fan, et al., 2014). Она предпринимает попытку соединения двух разных областей высокопроизводительных вычислений и Больших данных, которые требуют массивных вычислительных мощностей для обработки данных. Применяя действенные технологии коммуникации, которые пользуются высокоскоростными сетевыми технологиями, DataMPI способна ускорять возникающие новые вычислительные приложения, интенсивно применяющие данные. В настоящее время DataMPI поддерживает несколько режимов для различных приложений работы с Большими данными, такими как MapReduce, потоковая обработка и итеративные рабочие нагрузки, что позволяет одной программе работать с множеством приложений данных.
Вертикально интегрированные решения
Как уже обсуждалось в Разделах 2.1 и 2.2, среды на основе MapReduce обладают этапом перетасовки с интенсивным применением сетевой среды, которая распределяет выходные данные этапа map с этапом reduce. С развитием высокопроизводительных сетевых сред (которые подробно обсуждаются в Главе 4), обеспечивающих передачу данных с малой задержкой, такие гиганты программного обеспечения как Mellanox (теперь часть NVIDIA (Mellanox, 2021)), для оптимизации перемещения данных по сетевой среды для платформы Hadoop MapReduce на основе Hadoop-A (Wang et al., 2011). Mellanox UDA (Mellanox, 2011) предложили программные стеки производителей, например, Ускорители неструктурированных данных (UDA, Unstructured Data Accelerator) это программно подключаемый модуль, который ускоряет работу сетевых сред Hadoop и расширяет возможности масштабирования кластеров Hadoop, в которых выполняются приложения, интенсивно использующие анализ данных. Кластеры Hadoop на основе плат адаптеров Mellanox InfiniBand и десятигигабитного Ethernet RoCE (подробно обсуждаемых в главе 4.4) теперь способны передавать данные между серверами с применением нового протокола перемещения данных, который сочетает RDMA с оптимизированным алгоритмом сортировки слиянием. В том же духе Intel также выпустила HPC-дистрибутив Apache Hadoop для оптимизации производительности параллельных файловых систем, таких как Lustre (обсуждается в главе 3.2.1).
Для более новой и широко применяемой сегодня платформы Apache Spark компания Mellanox выпустила вертикально интегрированное решение, известное как подключаемый модуль Spark-RDMA (Mellanox, 2018), которое ускоряет выборку данных по сети с использованием технологии RDMA/RoCE для улучшения общего время выполнения задания.
Среды обработки в потоках
Обработка данных в потоке это система понятий, при которой приложения будут непрерывно обрабатывать данные в их движении. Иначе говоря, пока эти данные вырабатываются в качестве потока, как последовательность событий, приложения будут получать и обрабатывать их в режиме реального времени. В современных центрах обработки данных (ЦОД) существует множество приложений обработки данных в потоках, таких как обработка финансовых сделок, событий датчиков, действий пользователей в вебсайтах и т.п.. Действенная обработка потоковых данных это нетривиальная задача. Таким образом, в данном сообществе предлагается большое число систем потоковой обработки данных. В этом разделе описываются некоторые популярные образцы систем потоковой обработки.
Apache Storm
Apache Storm (Apache Software Foundation, 2021l) это одна из самых первых сред для решения задач обработки Больших данных в реальном масштабе времени. Это распределённая, отказоустойчивая система обработки данных. Всякий кластер хранения состоит из узла (узлов) Nimbus и узла (узлов) Supervisor. Общая архитектура конвейера Storm показана на Рисунке 2.6.
Рисунок 2.6
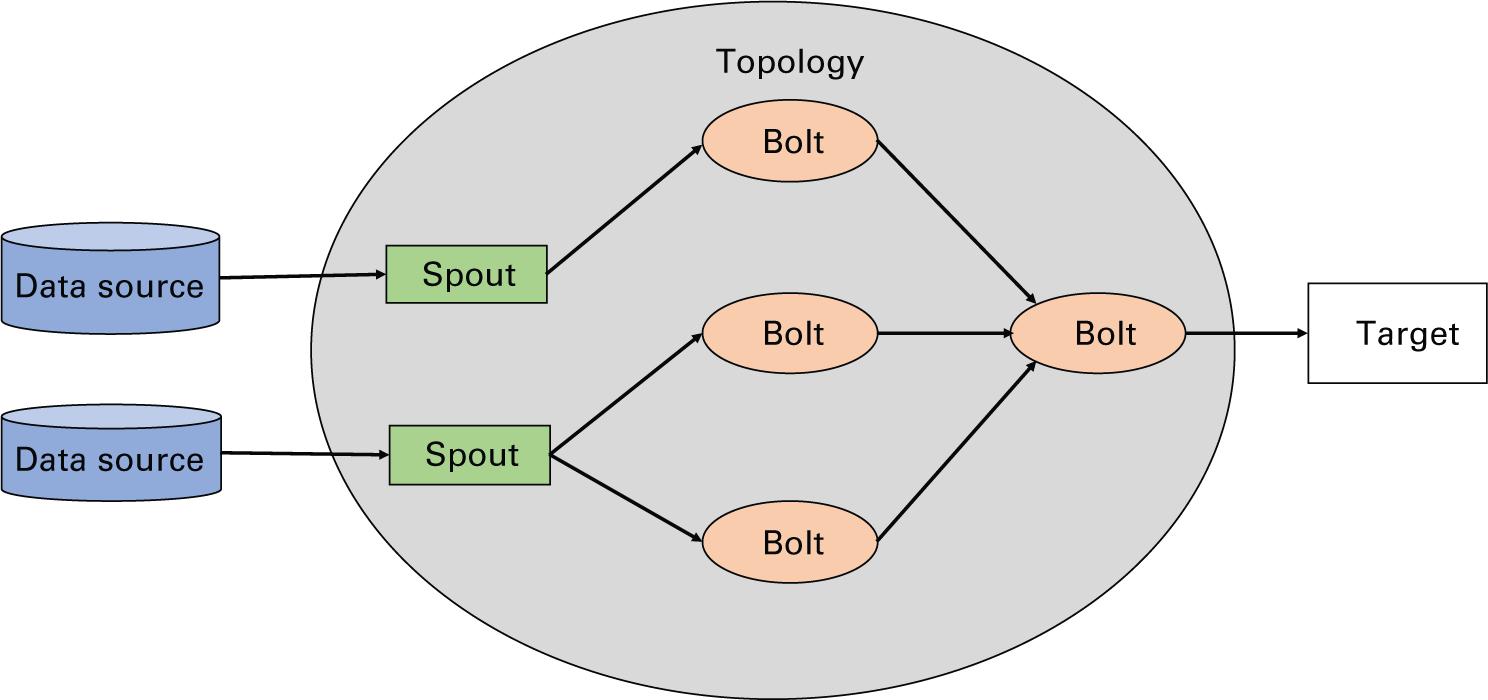
Обзор потоковой обработки с применением Apache Storm
Как отражено на Рисунке 2.6, каждое принимаемое Storm задание описывается как топология , представляющая различные источники потоков, называемых желобами (spouts) и преобразованиями, именуемыми болтами (bolts), которые применяются к имеющимся потокам (Toshniwal et al., 2014). Пользователь представляет топологию Nimbus, который затем выделяет какое- то подмножество этой топологии каждому узлу Supervisor в своём кластере. И Nimbus, и Supervisor в Storm не обладают состоянием, а потому для координации между ними и для отработки сбоев применяется ZooKeeper. Каждый узел кластера записывает в ZooKeeper своё состояние. В случае сбоя некого узла его можно запустить повторно, получая его состояние от ZooKeeper и возобновляя его роль в топологии. Storm предлагает семантику доставки сообщений хотя бы однократно, что означает, что сообщения в его топологии могут доставляться более одного раза и само приложение обязано отрабатывать дубликаты.
Потоковая обработка Apache Spark
Apache Spark Streaming (Apache Software Foundation, 2021t) это уровень обработки потока поверх механизма обработки данных Spark. Основным элементом обработки в Spark Streaming выступает Дискретизированный поток (DStream, Discretized Stream) (Zaharia et al., 2013), который представляет собой абстракцию набора RDD для совместной обработки. Однако, в отличие от Storm, Spark следует политике микропакетов для потоковой обработки, согласно которой поступающие в системы потоковые данные сначала, перед их обработкой системой, собираются небольшими пакетами, носящими название DStream. Такая политика микропакетов по своей сути добавляет существенную задержку в общем конвейере данных, поскольку, хотя сообщения и поступают в систему в режиме реального времени, они не обрабатываются до тех пор, пока не будет достигнуто время действия пакета. Однако Spark Streaming предлагает в точности одну семантику доставки, а потому самому предложению не нужно беспокоиться о дубликатах. Кроме того, наличие одного и того же базового ядра Spark означает, что логика потоков может быть запросто интегрирована с прочими модулями Spark, такими как пакетная обработка, обработка в графах или Машинное обучение.
Apache Heron
Apache Heron (Apache Software Foundation, 2021g) это среда обработки в потоках, промышленно применяемая в Twitter (Kulkarni et al., 2015) и в значительной степени вдохновлённая Storm. Задания Heron, носящие название топологий, также работают с моделью DAG (направленного ацикличного графа), состоящей из желобов и болтов. Она предлагает полную совместимость со Storm при заявлении в два- пять раз большей действенности. С целью отладки Heron изолированно исполняет желоба и болты. Она применяет строгие ограничения на потребление ресурсов, так что применяемые топологией ресурсы не должны превышать количество, доступное во время исполнения. При возникновении попытки потребления большего объёма ресурсов, такой контейнер будет дросселирован, что приведёт к замедлению его топологии. Когда некая топология замедляется по причине некоторых медленных контейнеров, применяется механизм обратного давления, позволяющий топологии корректировать свою скорость соответствующим образом, чтобы сводит к минимуму потерю данных. Клиент записывает топологии при помощи API Heron, которые отправляются планировщику. Планировщик предоставляет необходимый объём ресурсов и порождает в разных узлах контейнеры. Контейнер хозяина обрабатывает поступающую топологию и отправляет своё местоположение на основании пары хост- порт недолговечному ZooKeeper, который занимается координацией между прочими контейнерами. Во всех подчинённых контейнерах исполняются диспетчеры потоков, диспетчеры метрик, а также экземпляры желобов/ болтов. Диспетчер потока управляет потоком данных по всей топологии. Экземпляр Heron в таких контейнерах исполняет логику обработки желобов или болтов. Поток (thread, тред) шлюза в экземплярах взаимодействует с диспетчером потоков (stream manager) для отправки и получения сообщений. Он передаёт их треду исполнения задачи, который и применяет логику обработки.
Apache Fink
Apache Flink (Apache Software Foundation, 2021d) предоставляет некую универсальную архитектуру как для пакетной обработки данных, так и для обработки данных в реальном масштабе времени, трактуя их все в качестве потоков (streams) (Carbone et al., 2015). Единственное отличие задания обработки пакета будет состоять в том, что оно будет представлять собой ограниченный поток данных, в то время как задание обработки данных в реальном масштабе времени будет неограниченным потоком данных. На рисунке 2. отражена архитектура Apache Fink.
Рисунок 2.7
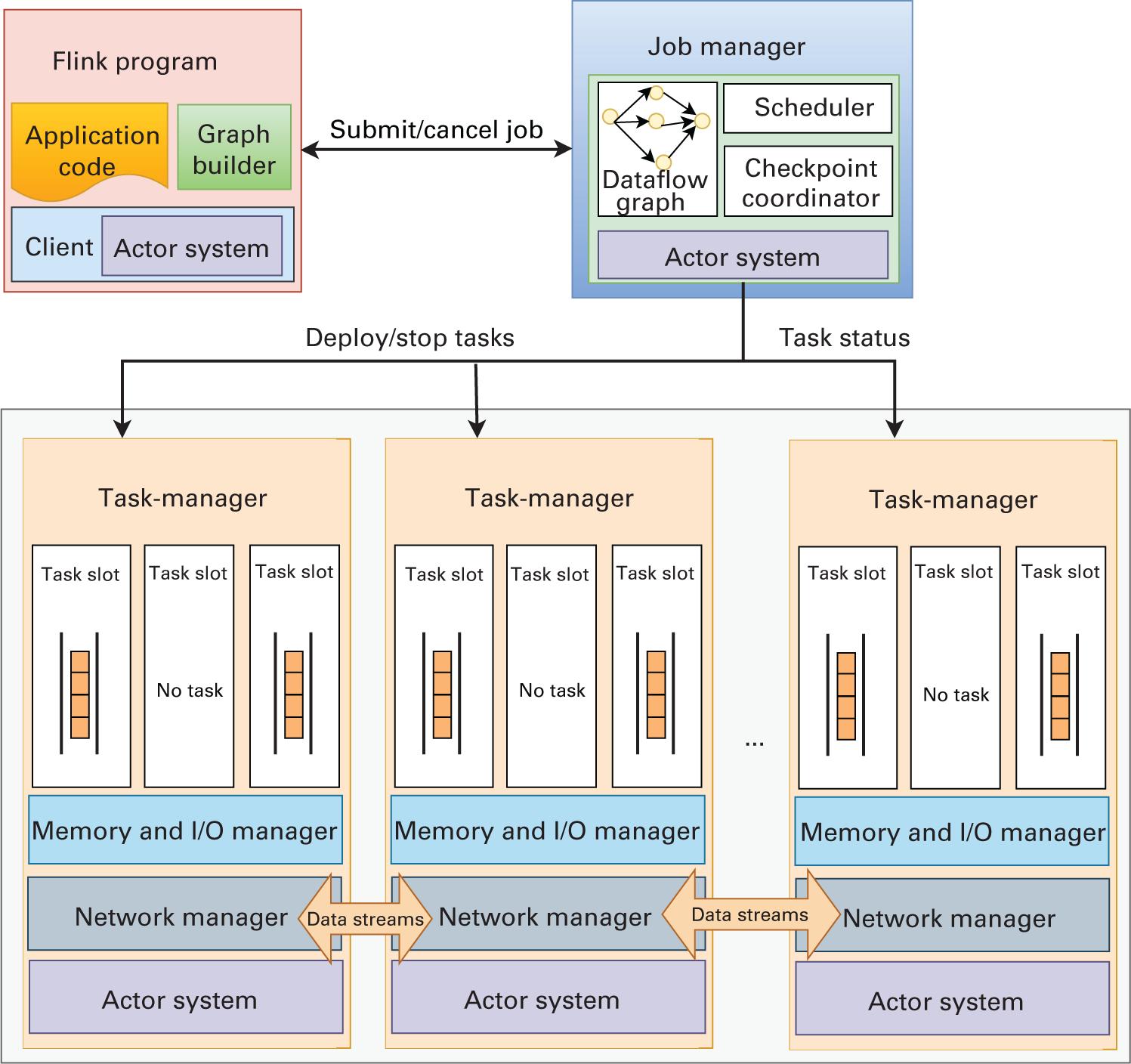
Обзор потоковой обработки с применением Apache Flink
Fink обладает лежащим в её основе уровне, обеспечивающим оптимизацию различных операций объединения, перетасовки и разбиения на разделы, что ускоряет обработку данных. В отличие от Spark, Fink также изначально естественным образом поддерживает и итерации в своём конвейере данных, а это означает, что получаемые в результате итерации данные можно просто возвращать в его конвейер для последующих итераций. Такая функциональная возможность превращает его в чрезвычайно подходящий под итерационные рабочие нагрузки и нагрузок Машинного обучения. Как отражено на Рисунке 2., написанная на Flink программа передаётся JobManager, который выступает в качестве хозяина всего кластера Fink целиком. Такой JobManager разбивает соответствующее задание на более мелкие компоненты и планирует их исполнение в различных TaskManager в своём кластере. Эти TaskManager отвечают за выполнение своих задач и оправку получаемых результатов обратно своему JobManager при обмене с прочими TaskManager в процессе обработки.
Среды обработки запросов
Поддержка необузданных запросов к большим объёмам данных превращается во всё более важную в ряде областей программного обеспечения. Среды обработки запросов представляют собой некий подкласс сред Больших данных, ориентированных на предоставление возможностей анализа данных на гигантских объёмах как структурированных, так и не структурированных данных. Их основная цель — абстрагироваться от мелких подробностей хранения и извлечения данных и предоставлении упрощённого и выразительного языка запросов для анализа данных. В то время как пакетная обработка большое значение придаёт пропускной способности и объёму данных, обработка запросов делает акцент как на задержке, так и на пропускной способности. Обычные системы баз данных были разработаны для структурированных данных и предоставляли чётко определённый язык запросов для взаимодействия со своей базой данных. Напротив, растущая тенденция состоит в том, чтобы обладать системами, которые способны поддерживать запросы и хранение произвольных данных. Типичные среды обладают архитектурой с группой исполнителей — обычно распределённых по большому числу серверов — для обработки запросов клиентов. Синхронизацией занимается некая служба координации (обычно централизованная). Хранение и распределение данных зависят от принятой модели организации данных; их примеры включают распределённые таблицы ил просто распределённые двоичные объекты. В последующих разделах описаны некоторые популярные образцы сред обработки запросов.
MySQL
MySQL (Oracle, 2021) это популярное решение базы данных с открытым исходным кодом от Oracle. Она выставляет традиционный интерфейс языка структурированных запросов (SQL, Structured Query Language) для запроса и извлечения данных. MySQL это некая реализация системы управления реляционной базой данных, которая предоставляет пользователям данные в форме таблиц (или отношений). Высокая стабильность, хорошая поддержка программного обеспечения и высокая доступность выступают основными причинами популярности MySQL. Однако по причине своей высоко структурированной реляционной архитектуры MySQL не может действенно обрабатывать не структурированные данные. Более того, часто подвергалась сомнению масштабируемость MySQL. По этим причинам пользователи всё чаще и чаще применяют среды NoSQL и NewSQL.
Hive
Apache Hive (Apache Software Foundation, 2021h) это решение складирования данных, которое предоставляет подобный SQL интерфейс для хранящихся в Apache Hadoop данных. Hive применяет компилятор запросов для преобразования получаемого запроса в план исполнения. Анализируя такой запрос, компилятор преобразовывает его в DAG (направленный ацикличный граф), который затем применяется для определения задач MapReduce для запроса данных. Сохраняя данные в масштабируемой HDFS и применяя концепцию MapReduce, Hive наследует масштабируемость лежащей в его основе инфраструктуры. Благодаря дополнительным функциональным возможностям, таким как сжатие, индексирование и множество форматов хранения, Hive быстро превратился в предпочтительное решение складирования данных.
HBase
Apache HBase (Apache Software Foundation, 2021f) это распределённая не реляционная база данных с открытым исходным кодом, основанная на Bigtable Google. HBase хранит и работает с данными, находящимися в оперативной памяти, для достижения отказоустойчивости полагаясь на HDFS. Данные хранятся в виде ориентированных на столбцы пар ключ- значение. Хотя HBase сама по себе не предоставляет сложного интерфейса запросов, такие проекты как Apache Phoenix, а также ряд академических работ реализовали подобный SQL слой для HBase. Эти работы обычно создают первичные и вторичные индексы под каждую таблицу данных для ускорения обработки запросов и применения концепции MapReduce для исполнения соответствующего плана запроса. HBase превратилась в популярную для хранения безбрежных объёмов данных. До недавнего времени она применялась Facebook для реализации их платформы обмена сообщениями.
Spark SQL
Spark SQL (Apache Software Foundation, 2021r) это модуль для Apache Spark, привносящий поддержку SQL для анализа хранящихся в RDD данных. Он позволяет разработчикам совмещать запросы SQL с традиционной аналитикой Spark, создавая мощные конвейеры в одном приложении. Spark SQL преобразует запросы во внутренний код на основе MapReduce применяя генератор кода и оптимизатор на основе затрат, что обеспечивает быструю и масштабируемую обработку запросов. Кроме того, он обеспечивает полную отказоустойчивость промежуточного запроса и даже способен импортировать имеющиеся данные из таблиц Hive или Parquet.
Вертикально интегрированные решения
С растущими вычислительными возможностями и возможностями оперативной памяти автономных ускорителей, таких как графические процессоры (GPU, graphics processor units, подробнее обсуждаемых в Главе 4), сообщество аналитиков GPU и сообщество Больших данных совместно провели работу над такими решениями как BlazingSQL (BlazingSQL, 2021). BlazingSQL это механизм SQL с ускорением на графическом процессоре, полностью построенный поверх RAPIDS AI NVIDIA (NVIDIA, 2021n). На основе его представления столбцами данных, принятого в Apache Arrow (Apache Software Foundation, 2021b), был создан GPU DataFrame (cuDF) (RAPIDS, 2021), который способен хранить данные в одном непрерывном блоке для оптимальной обработки в своём GPU. Благодаря такому cuDF, в BlazingSQL для выполнения операций сданными в диапазоне от простой сортировки вплоть до аналитических операций, таких как агрегирование и соединение применяется библиотека cuDF на основе CUDA (Complete Unified Device Architecture) RAPIDS AI.
Среды обработки в графах
В диапазоне от защиты против мошенничества до прогнозирования новых тенденций, социальные графы выступают центром для выделения выразительных взаимосвязей в данных. Обработка таких графов требует массивных вычислительных мощностей и индивидуальных сред. В идущих далее разделах описаны некоторые популярные образцы сред обработки графов.
GraphX
GraphX (Gonzalez et al., 2014) это специализированная встроенная среда обработки графов, созданная на основе Apache Spark. Она предназначена для прозрачного применения присущих Spark возможностей отказоустойчивости, которые обеспечивают паритет функциональных возможностей и производительности с прочими специализированными средами графов. Операции на графах реализуются с применением основных операций потоков данных, таких как соединение, сопоставление и группировка ( join, map и group-by). Существующие приложения могут реализовываться поверх GraphX с применением его API на основе оператора графов Pregel.
Pregel
Pregel (Malewicz et al., 2010) это система для обработки графов крупного масштаба. Лежащая в его основе модель выражает программы в качестве последовательности итераций с вершинами, обменивающимися сообщениями и изменяющими топологию графа на протяжении итерации. Pregel предоставляет упрощённый API C++, в котором приложения способны определять свои индивидуальные подпрограммы для вычислений и видоизменений. Таким образом, могут быть легко реализованы алгоритмы произвольного графа в произвольных представлениях графа.
Giraph
Apache Giraph (Apache Software Foundation, 2021q) это среда с итерациями для обработки на графах с высокой масштабируемостью. Например, в настоящее время Facebook применяет её для анализа социальных графов, формируемых пользователями и их связями (Ching et al., 2015). Giraph возник в виде конкурента с открытым исходным кодом для Pregel, разработанной в Google архитектуры обработки на графах. Обе системы вдохновлены моделью массивных синхронных параллельных распределённых вычислений (Valiant, 1990), впервые предложенной Лесли Валиантом. Помимо базовой модели Pregel, Giraph добавляет ряд функциональных возможностей, включая вычисления хозяина, сегментированные агрегаторы, ориентированный на периферию ввод и вычисления вне ядра, и это лишь некоторые из имеющихся. С растущим сообществом пользователей по всему миру и быстрым циклом разработки Giraph является очевидным выбором для раскрытия потенциала структурированных наборов данных в массовом масштабе.
GraphLab
GraphLab (Low et al., 2012, 2014) это среда для реализации действенных алгоритмов параллельного Машинного обучения. Она основана на абстракции MapReduce, компактно выражая асинхронные итерационные алгоритмы с разряженными вычислительными зависимостями, обеспечивая при этом согласованность данных. Она предоставляет модель данных для захвата зависимостей данных и вычислений, а также модель параллельного доступа, обеспечивающую последовательную согласованность < Прим. пер.: подробнее о моделях согласованности в нашем переводе Внутреннее устройство баз данных Алекса Петрова (С), 2019, O’Reilly Media > и структуру агрегирования управления глобальным состоянием. Модель данных GraphLab предназначена для преодоления недостатков существующих моделей (MapReduce, DAG и систолической — конвейерной) при выражении итерационных алгоритмов. Как и Giraph, GraphLab разрабатывается как написанный на C++ проект с открытым исходным кодом. Различные тематические исследования успешно продемонстрировали, что она способна на порядки превосходить прочие абстракции.
GraphBLAS
Перпендикулярно методам итеративной обработки ряд работ в области обработки данных на графах сосредоточены на применении подходов линейного программирования на основе матриц для действенного отделения задач разработчиков аппаратного/ программного обеспечения от собственно логики приложения. GraphBLAS (Buluç et al., 2017a,b) это одна из подобных попыток, которая математически определяет набор операций на графах ядра, которые могут применяться для реализации широкого класса алгоритмов на графах в различных средах программирования. Она применяет настраиваемые представления в диапазоне от целых чисел разного размера до побитного хранения. Такие проекты, как SuiteSparse (Davis, 2019), IBM GraphBLAS (IBM, 2018), GraphBLAST (C. Yang et al., 2019) и тому подобные реализуют сам стандарт GraphBLAS. Аналогично, такие хранилища данных как Redis, интегрировали GraphBLAS в свои системы при помощи модулей, подобных RedisGraph (Redis, 2021a).
Вертикально интегрированные решения
При росте популярности графических процессоров (подробнее обсуждаемых в Главе 4), сообщество аналитиков GPU также вложилось в аналитику графов по причине растущей потребности в современной работе с графами крупного масштаба. Существенным достижением в данном направлении выступает вертикально интегрированное библиотечное решение на основе NVIDIA’s RAPIDS AI (NVIDIA, 2021n). Библиотека RAPIDS cuGraph (NVIDIA, 2021b) это набор графических алгоритмов с ускорением на графическом процессоре. Для действенной передачи данных она работает на уровне Python под GPU DataFrames (RAPIDS, 2021).
Среды Машинного обучения и Глубинного обучения
Благодаря повсеместному распространению огромных вычислительных мощностей в последние годы огромных успехов добился ИИ (AI, artificial intelligence — Искусственный интеллект). Применение ИИ широко варьируется от беспилотных автомобилей до содействия в медицинских исследованиях по выявлению ранних стадий рака. ИИ применяет Машинное обучение, Глубинное обучение и прочие методы для решения реальных задач. Машинное обучение — это область ИИ, которая сосредотачивается на предоставлении системам возможности учиться и совершенствоваться без программирования в явном виде. Глубинное обучение это подмножество Машинного обучения, которому уделяется большое внимание по причине его точности логического вывода.
В сообществе было предложено множество сред и инструментов машинного и глубокого обучения, таких как Caffe (Jia et al., 2014), Facebook Caffe2 (Markham and Jia, 2017), Microsoft Cognitive Toolkit (Seide and Agarwal, 2016), Intel BigDL (Wang et al., 2018), Google TensorFlow (Abadi, Agarwal, et al., 2016), MLlib for Apache Spark (Meng et al., 2016), PyTorch (Paszke et al., 2019), MXNet (Chen et al., 2015), и многие другие. В этом разделе мы обсудим некоторые популярные и действенные разработанные среды.
Google TensorFlow
Google TensorFlow (Google, 2021b) одна из самых популярных сред для выполнения распределённого Машинного обучения и Глубинного обучения. В последнее время она набирает обороты в сообществах Больших данных, Глубинного обучения и высокопроизводительных вычислений.
Среда TensorFlow (Abadi et al., 2016) была разработана командой Google Brain Team в ноябре 2015. TensorFlow применяет графы потоков данных для обучения распределённой Глубинной нейронной сети. Граф потоков данных состоит из узлов, представляющих математические операции и рёбер, обозначающих многомерные массивы данных (т.е. тензоры), передаваемые между узлами. Саму модель исполнения распределённого TensorFlow можно отнести к четырём отдельным компонентам: клиенту, хозяину, набору исполнителей и нескольким серверам параметров. Рисунок 2.8 иллюстрирует взаимодействие между этими компонентами. Вычислительный граф строится клиентской программой TensorFlow, написанной пользователем. Этот клиент затем создаёт сеанс для своего хозяина и отправляет определения своего графа в виде буфера протокола. После этого хозяин делегирует и координирует выполнение (после подрезки и оптимизации) полученных подчинённых графов множеству распределённых процессов исполнителей и процессов серверов параметров. Каждый из этих процессов может применять неоднородные среды. Например, для окончательного выполнения своих задач можно пользоваться сочетанием ЦПУ, GPU и/ или тензорного процессора (TPU) (Google, 2021a).
Рисунок 2.8
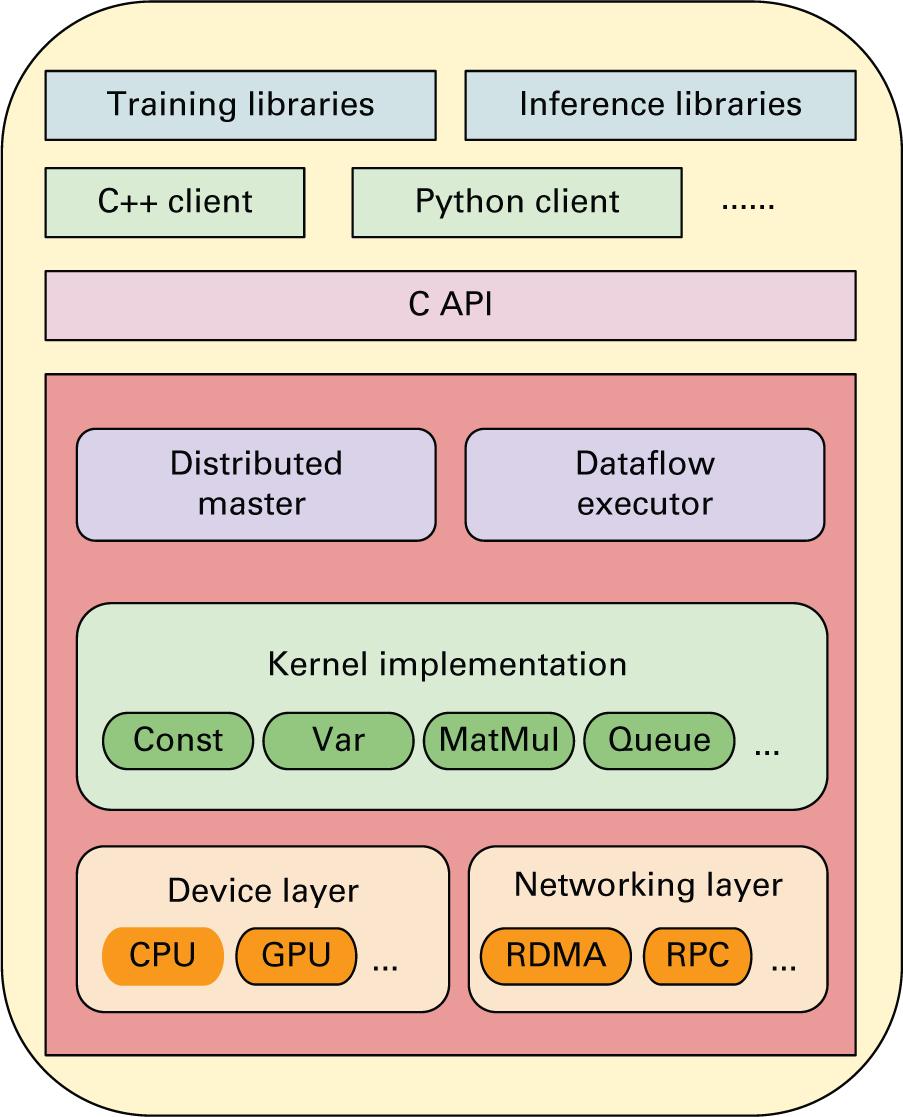
Обзор стека TensorFlow
Имеющиеся серверы параметров отвечают за обновление и хранение установленных параметров модели, в то время как исполнители отправляют оптимизированные обновления своей модели и получают обновлённую модель от соответствующих серверов параметров. Такой процесс обмена параметрами (или передача тензора) это основная фаза взаимодействия, а применяемый по умолчанию TensorFlow с открытым исходным кодом для их обработки способен поддерживать различные каналы взаимодействия, например, gRPC, gRPC+Verbs и gRPC+MPI, как это отображено на Рисунке 2.9.
Рисунок 2.9
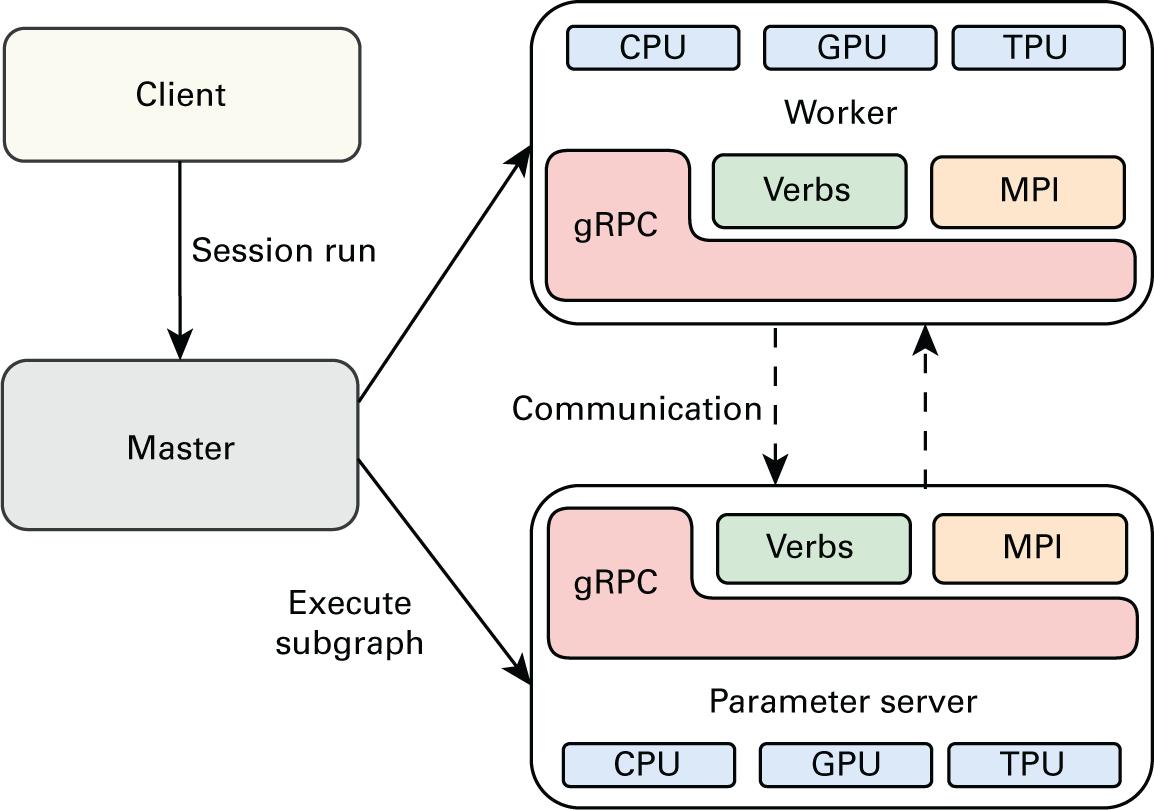
Обзор распределённой среды TensorFlow
Для достижения одновременности, распределённый TensorFlow поддерживает как обучение одновременности данных, так и обучение распараллеливанию модели (Abadi et al., 2016). При обучении одновременности данных, TensorFlow распараллеливает имеющиеся вычисления градиента для минипакета по элементам минипакета. Такая техника реплицирует имеющийся граф TensorFlow (который выполняет большую часть вычислений) по различным узлам, причём каждая реплика работает с отличающимся набором данных. Эти градиенты сочетаются после каждой итерации вычислений таких реплицированных моделей. Затем может применяться обновление параметров, причём, как синхронно, так и асинхронно. Тем самым, это будет иметь то же самое действие, что и осуществление последовательного вычисления на графе с накопляемым размером минипакета, но намного быстрее. С другой стороны, при параллельном обучении модели для одного и того же пакета данных, разные части вычисления этого графа распределяются по различным узлам.
PyTorch Facebook
PyTorch (Paszke et al., 2019) это библиотека Машинного обучения с открытым исходным кодом для Python, основанная на Torch (поддерживается Ronan and Soumith (2021); разработана Collobert et al. (2002)), применяемая для таких приложений как обработка естественного языка. Разработанный исследовательской группой ИИ Facebook, PyTorch пользуется тензорными вычислениями, которые, как и NumPy (NumPy, 2021), представляют собой многомерные массивы, которые можно вычислять и обрабатывать на графических процессорах. В отличие от большинства сред Глубинного обучения, NumPy не следует символическому подходу, а сосредотачивается на расширяемости и низких накладных расходах за счёт определения строго повелительных программ. Такая применяемая PyTorch техника дифференцирования носит название автоматического дифференцирования. Некий регистратор записывает какие операции были выполнены и воспроизводит их в обратном порядке для вычисления необходимых градиентов. Данный метод, носящий название модуля автоматической градации PyTorch, в особенности мощен при построении нейронных сетей в отношении экономии времени в одной эпохе за счёт вычисления приращений параметров на самом прямом проходе. Такая система автоматической градации упрощает определение вычислительных графов и получение градиентов. Для обёртывания необработанных и низкоуровневых возможностей автоматической градации, PyTorch определяет соответствующий модуль torch.nn в помощи разработчикам приложений для облегчения определения сложных нейронных сетей.
Apache MXNet
Apache MXNet (Chen et al., 2015) это среда Глубинного обучения, которая обеспечивает действенность и удобство для определения Глубинных нейронных сетей. Данная среда с открытым исходным кодом представляет нейронные сети как смесь декларативных символьных выражений и повелительных (императивных) тензорных вычислений, а также предоставляет гибкие интерфейсы API для построения/ оптимизации пользовательский сетевых сред. Обычно она применяется для распараллеливания данных, то есть любые устройства ЦПУ или GPU должны содержать все операции этого графа вычислений. MXNet пользуется NDArray в качестве основного инструмента для хранения преобразованных данных. Для оценки MXNet представляет связанное символьное выражение в виде вычислительного графа и преобразует его для оптимизации эффективности. Для распределённого обучения она пользуется структуру на основе сервера параметров, применяя хранилище ключ- значение для синхронизации данных между устройствами.
Spark MLlib
Spark MLlib (Meng et al., 2016) это библиотека Машинного обучения Apache Spark, которая поддерживает распространённые алгоритмы Машинного обучения, например, регрессию, классификацию, кластеризацию и совместную фильтрацию в среде Spark. Она также предоставляет утилиты и инструменты для сопровождения таких алгоритмов, включая обработку данных, сохранность, конвейерную обработку и т.п. MLib поддерживает локальные векторы и матрицы на одном компьютере и применяет RDD Spark для определения распределённых матриц. Применяя API на основе RDD, локальные векторы и матрицы представляются в виде простых моделей данных, которые служат общедоступными интерфейсами. Лежащие в основе операции линейной алгебры предоставляются библиотекой линейной алгебры Breeze.
Вертикально интегрированные решения
Программное обеспечение производителей оборудования в наши дни играет огромную роль в сообществе Машинного обучения, в особенности по причине потребности для осуществления крупномасштабного Машинного и Глубинного обучения в ускорителях, таких как графические процессоры. Среди них наиболее популярным вертикально интегрированным решением выступает cuML, основанное на популярной коллекции библиотек ИИ NVIDIA RAPIDS. cuML (NVIDIA, 2021c) это набор библиотек, включающих алгоритмы Машинного обучения и математические примитивные функции с применением интерфейсов API, совместимых с API-интерфейсами, используемыми в прочих проектах RAPIDS. Эти реализации на основе графического процессора способны обрабатывать массивные наборы данных в десять-пятьдесят раз быстрее, чем их аналоги на ЦПУ. Исследователи данных, аналитики и разработчики программного обеспечения применяют cuML для выполнения типичных задач табличного Машинного обучения (ML) на графических процессорах без необходимости изучать программирование CUDA. Python API cuML удобен для пользователя, поскольку он очень похож на scikit-learn.
С появлением ускорителей Google, таких как TPU (обсуждаемых в Разделе 2.4 Главы 4), TensorFlow также можно считать вертикально интегрированным решением для Машинного обучения.
Взаимодействие инструментов Больших данных
Поскольку обработка Больших данных не всегда проста, был предпринят ряд попыток интеграции простых в применении компонентов персонала в конвейер обработки данных. Они включают в себя применение интерактивных инструментов визуализации, также носящими название записных книжек, для понимания и анализа массивных наборов данных. Такие инструменты позволяют учёным и бизнес- аналитикам действенно определять закономерности необработанных данных и применять получаемые результаты для обеспечения крупномасштабной обработки данных с применением прочих сред Больших данных. К примеру, специалисты по анализу данных выполняют извлечение функциональных особенностей или обучение на небольшом подмножестве набора данных при помощи интерактивных инструментов визуализации Больших данных для выбора и уточнения своих алгоритмов машинного обучения обработки своих данных в полном масштабе. В данном разделе мы обсудим некоторые из большого числа доступных интерактивных инструментов с открытым исходным кодом размещаемых в Интернете.
Инструменты с открытым исходным кодом
Jupyter (Project Jupyter, 2021) это самая популярная записная книжка, применяемая учёными для интерактивных вычислений. Она позволяет аналитикам данных и учёным интегрировать программный код, результаты вычислений, текстовые пояснения и графические представления в единый документ. Она поддерживает такие языки программирования как Python, R и Julia и способна сочетаться с графическими библиотеками, например, Plotly (Plotly, 2021), а также с инструментами манипуляции данных, такими как Pandas (NumFOCUS, 2021). Аналогично, Apache Zeppelin (Apache Software Foundation, 2021m) это записная книжка на основе веб- интерфейса, которая сочетает в себе функциональные возможности исследования данных, визуализации, совместного применения, а также совместной работы с SQL, Scala и тому подобным и способна взаимодействовать со средами Больших данных, например, с Hive и SparkSQL. Кроме того, такие как D3.js (Bostock, 2020) библиотеки JavaScript также упрощают обработку Больших данных.
Размещаемые и коммерческие инструменты визуализации
Поскольку интерактивные и совместные вычисления превращаются в важный продукт, различные организации вкладывают средства в размещение инструментария для аналитики данных. К ним относятся Deepnote (Deepnote, 2021), Google Colab (Bisong, 2019) и Databricks Collaborative Notebooks (Databricks, 2021), которые поддерживают сквозную разработку моделей Машинного обучения на протяжении всего жизненного цикла. Дополнительно к этому также доступны и такие инструменты машинного обучения как TensorBoard (Tensorflow, 2021), которые разработаны в качестве управляемой службы для отслеживания совместной работы над экспериментами с TensorFlow.
Перпендикулярно этому, специально для бизнес- аналитики, популярными инструментами визуализации выступает ПО визуализации Tableau (Chabot, 2009; Apache Software Foundation, 2021n), PowerBI (Powell, 2017) и тому подобные.
Инструменты мониторинга и диагностики
В дополнение к средам обработки Больших данных жизненно важно обладать инструментами мониторинга и диагностики, которые позволяют отлаживать и отслеживать производительность таких сред. Хотя каждая из обсуждаемых в данной главе сред предоставляет встроенные инструменты диагностики в том или ином виде, в данном разделе мы обсудим некоторые из большого числа популярных внешних инструментов, которые можно применять для управления и мониторинга в распределённых кластерах, встречающихся как в литературе, так и в крупномасштабном применении, с такими средами как Hadoop и Spark.
Starfish
По причине своей природной простоты в настройке, такие платформы как Hadoop в значительной степени полагаются на пользователей для установки верного диапазона параметров настройки под оптимизацию общей производительности системы. Для систематического сопровождения настройки производительности Hadoop такие академические проекты как Starfish (Herodotou et al., 2011) предоставляют собой платформу, которая сочетает в себе автоматизацию запросов к базе данных на основе затрат, статический и динамический анализ программ, динамическую выборку данных и профилирование времени исполнения, а также статистическую машину, обучение глубокому пониманию влияния различных конфигураций кластера на производительность. Программы MapReduce могут применять это без какой-либо дополнительной настройки и с минимальными затратами на выполнение задания.
Dynatrace
Dynatrace (Dynatrace, 2021b) это основанная на Искусственном интеллекте программная платформа для мониторинга и оптимизации производительности и разработки приложений, инфраструктуры и практики пользователя. Она анализирует как текущие, так и исторические данные для обеспечения углублённого анализа выходных данных кластера. Анализируя зависимости внутри своего стека приложений, она способствует выявлению проблемных компонентов. Специально для Больших данных Dynatrace автоматически идентифицирует компоненты Hadoop (Dynatrace, 2021c) и Spark (Dynatrace, 2021a) и отображает основные статистические данные и временную карту для каждого из них.
Sparklint
Поскольку производительность выступает ключом к обработке данных в таких средах как Spark, крайне важно отслеживать и регулировать задания Spark для повышения эффективности. Такие проекты с открытым исходным кодом как Sparklint (Groupon, 2017) поддерживают мониторинг и настройку, предоставляя расширенные метрики и улучшенную визуализацию применения ресурсов приложения Spark для содействия выявления провалов эффективности. О анализирует отдельные рабочие процессы Spark на наличие завышенного или не сбалансированного применения ресурсов, неточного разделения данных и не оптимального местоположения исполнителей при помощи API метрик Spark и настраиваемого ожидания событий. Его можно быстро добавлять к любому заданию Spark и он предоставляет данные для просмотра через веб — интерфейс, а также вносит предложения по общим проблемам производительности, просто изменяя конфигурацию имеющегося кластера.
Datadog
В особенности для облачного решения, такие службы управления приложениями на основе программного обеспечения, как Datadog (Datadog, 2021), применяются для отслеживания серверов, баз данных, инструментов и ресурсов в режиме реального времени. Она предоставляет возможности для сквозного мониторинга инфраструктуры Hadoop, включая Hadoop MapReduce и HDFS (Mouzakitis, 2016), Hive (Gottschling, 2019), Flink (Tai, 2020) и тому подобные.
Выводы
Обработка Больших данных охватывает различные подходы, включая пакетную обработку, обработку в потоках, обработку на графах, а также Машинное, Глубинное обучение. Такие модели обработки данных привели к разработке различных систем аналитики и обработки в диапазоне от самых ранних систем пакетной обработки, таких как Google Bigtable, до современных сред общего назначения, таких как Apache Spark и ориентированных на ИИ сред, подобных, TensorFlow. Эти системы и среды обработки Больших данных превращаются в важные строительные блоки современной инфраструктуры анализа данных крупного масштаба, разворачиваемой в различных областях от бизнес- аналитики до медицинских изысканий.
Обычно такие системы и среды обработки Больших данных хорошо оптимизированы для стандартных кластеров. Однако в недавнем прошлом появились тенденции к применению современных кластеров высокопроизводительных вычислений для развёртывания таких сред. Такие кластеры высокопроизводительных вычислений оснащены передовыми аппаратными архитектурами, такими как высокоскоростные интерконнекты, графические процессоры, программируемые вентильные матрицы (FPGA, field programmable gate arrays), NVRAM, NVMe-SSD и тому подобное, которые предлагают вычислительную мощность для соответствия растущей скорости Больших данных. Это открыло множество новых возможностей исследований и задач для аналитиков данных и сообществ высокопроизводительных вычислений, чтобы изучать больше альтернатив проектирования, которые могли бы содействовать максимизации значения времени окупаемости больших наборов данных. Эта глава призвана помочь читателям получить краткое представление о традиционных системах обработки данных и общих сценариях их применения. Опираясь на эти знания, в своих следующих главах мы подробно обсуждаем задачи применения таких платформ в средах высокопроизводительных вычислений, необходимость кодирования этих платформ для полного использования ими преимуществ современных аппаратных архитектур, а также соответствующих подходов, предлагаемых для обеспечения высокой производительности аналитики данных.