Рекомендации по работе с Power Query
В этой статье содержатся некоторые советы и рекомендации, которые помогут вам получить большую часть возможностей обработки данных в Power Query.
Выбор правильного соединителя
Power Query предлагает большое количество соединителей данных. Эти соединители варьируются от таких источников данных, как TXT, CSV и Excel, до баз данных, таких как Microsoft SQL Server, и популярных служб SaaS, таких как Microsoft Dynamics 365 и Salesforce. Если источник данных не отображается в окне получения данных , можно всегда использовать соединитель ODBC или OLEDB для подключения к источнику данных.
Используя лучший соединитель для задачи, вы получите лучший опыт и производительность. Например, использование соединителя SQL Server вместо соединителя ODBC при подключении к базе данных SQL Server не только обеспечивает более эффективное взаимодействие с данными , но и соединитель SQL Server также предлагает функции, которые могут повысить производительность и производительность, такие как свертывание запросов. Чтобы узнать больше о свертке запросов, перейдите к свертке запросов Power Query.
Каждый соединитель данных соответствует стандартному интерфейсу, как описано в разделе «Получение данных». Этот стандартизованный интерфейс имеет этап с именем «Предварительная версия данных». На этом этапе вы предоставляете понятное окно, чтобы выбрать данные, которые вы хотите получить из источника данных, если соединитель разрешает его, и простой предварительный просмотр этих данных. Вы даже можете выбрать несколько наборов данных из источника данных в окне навигатора , как показано на следующем рисунке.
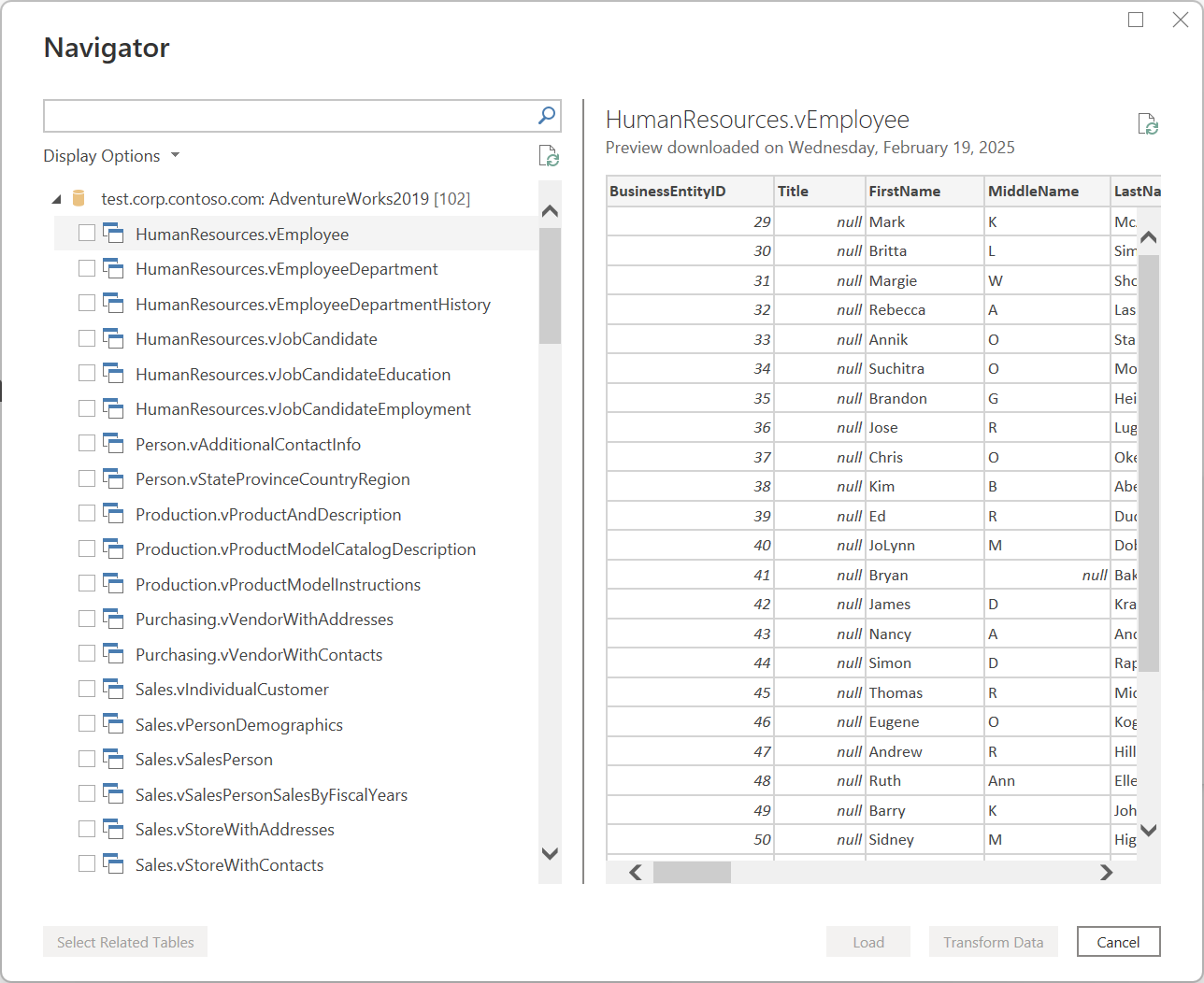
Чтобы просмотреть полный список доступных соединителей в Power Query, перейдите к Подключение дорам в Power Query.
Фильтрация рано
Всегда рекомендуется фильтровать данные на ранних этапах запроса или как можно раньше. Некоторые соединители будут использовать свои фильтры с помощью свертывания запросов, как описано в свертке запросов Power Query. Кроме того, рекомендуется отфильтровать все данные, которые не относятся к вашему делу. Это позволит вам лучше сосредоточиться на задаче, показывая только данные, соответствующие в разделе предварительного просмотра данных.
Вы можете использовать меню автоматического фильтра, отображающее отдельный список значений, найденных в столбце, для выбора значений, которые необходимо сохранить или отфильтровать. Вы также можете использовать панель поиска, чтобы найти значения в столбце.
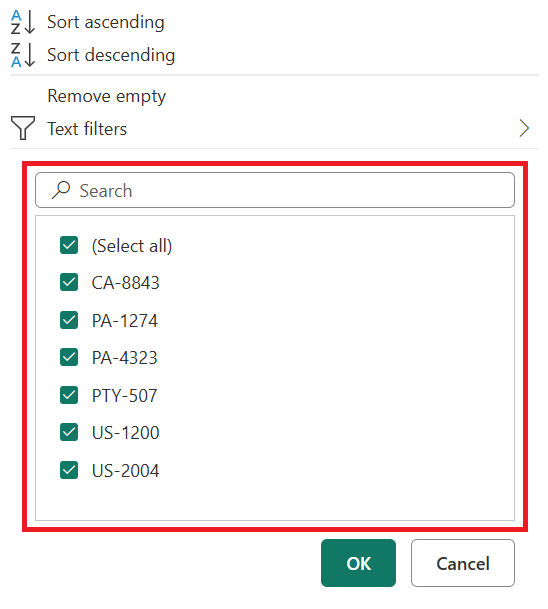
Вы также можете воспользоваться такими фильтрами, как «В предыдущем » для даты, даты и времени или даже столбца часового пояса.
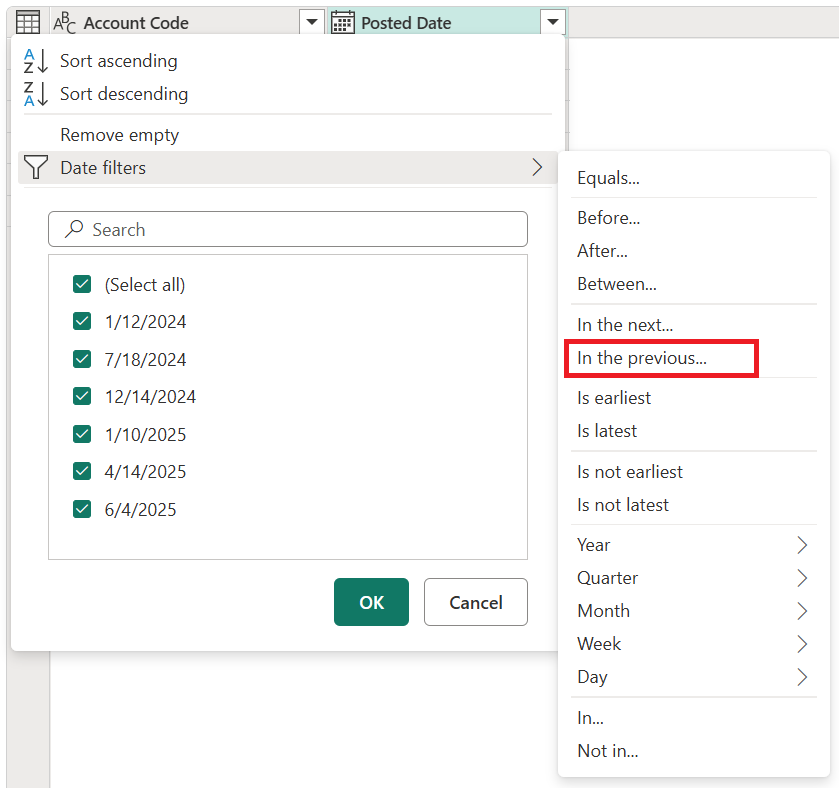
Эти фильтры, относящиеся к типу, помогут вам создать динамический фильтр, который всегда будет получать данные, которые будут отображаться на предыдущем x количестве секунд, в минутах, часах, днях, неделях, месяцах, кварталах или годах, как показано на следующем рисунке.
Дополнительные сведения о фильтрации данных на основе значений из столбца см. в разделе «Фильтр по значениям».
Последнее время выполнения дорогостоящих операций
Некоторые операции требуют чтения полного источника данных для возврата любых результатов и, таким образом, будут медленно просматриваться в Редактор Power Query. Например, если выполнить сортировку, возможно, первые несколько отсортированных строк находятся в конце исходных данных. Таким образом, чтобы возвращать результаты, операция сортировки должна сначала считывать все строки.
Другие операции (например, фильтры) не должны считывать все данные перед возвратом результатов. Вместо этого они работают над данными в режиме потоковой передачи. Данные «потоки» и результаты возвращаются по пути. В Редактор Power Query таких операций достаточно прочитать исходные данные, чтобы заполнить предварительную версию.
По возможности сначала выполняйте такие операции потоковой передачи и выполняйте все более дорогие операции. Это поможет свести к минимуму время ожидания предварительной версии для отображения при каждом добавлении нового шага в запрос.
Временное использование подмножества данных
Если добавление новых шагов в запрос в Редактор Power Query медленно, попробуйте сначала выполнить операцию «Сохранить первые строки» и ограничить количество строк, с которыми вы работаете. После добавления всех необходимых шагов удалите шаг «Сохранить первые строки».
Использование правильных типов данных
Некоторые функции в Power Query контекстно относятся к типу данных выбранного столбца. Например, при выборе столбца даты доступные параметры в группе столбцов даты и времени в меню «Добавить столбец«. Но если столбец не имеет набора типов данных, эти параметры будут серыми.

Аналогичная ситуация возникает для фильтров, относящихся к типу, так как они относятся к определенным типам данных. Если в столбце нет правильного типа данных, эти фильтры, относящиеся к типу, не будут доступны.
Важно всегда работать с правильными типами данных для столбцов. При работе с структурированными источниками данных, такими как базы данных, сведения о типе данных будут доставлены из схемы таблицы, найденной в базе данных. Но для неструктурированных источников данных, таких как TXT и CSV-файлы, важно задать правильные типы данных для столбцов, поступающих из этого источника данных. По умолчанию Power Query предлагает автоматическое обнаружение типов данных для неструктурированных источников данных. Дополнительные сведения об этой функции и о том, как она может помочь в типах данных.
Дополнительные сведения о важности типов данных и их работе см. в разделе «Типы данных».
Изучение данных
Прежде чем приступить к подготовке данных и добавлению новых шагов преобразования, рекомендуется включить средства профилирования данных Power Query, чтобы легко обнаруживать сведения о данных.
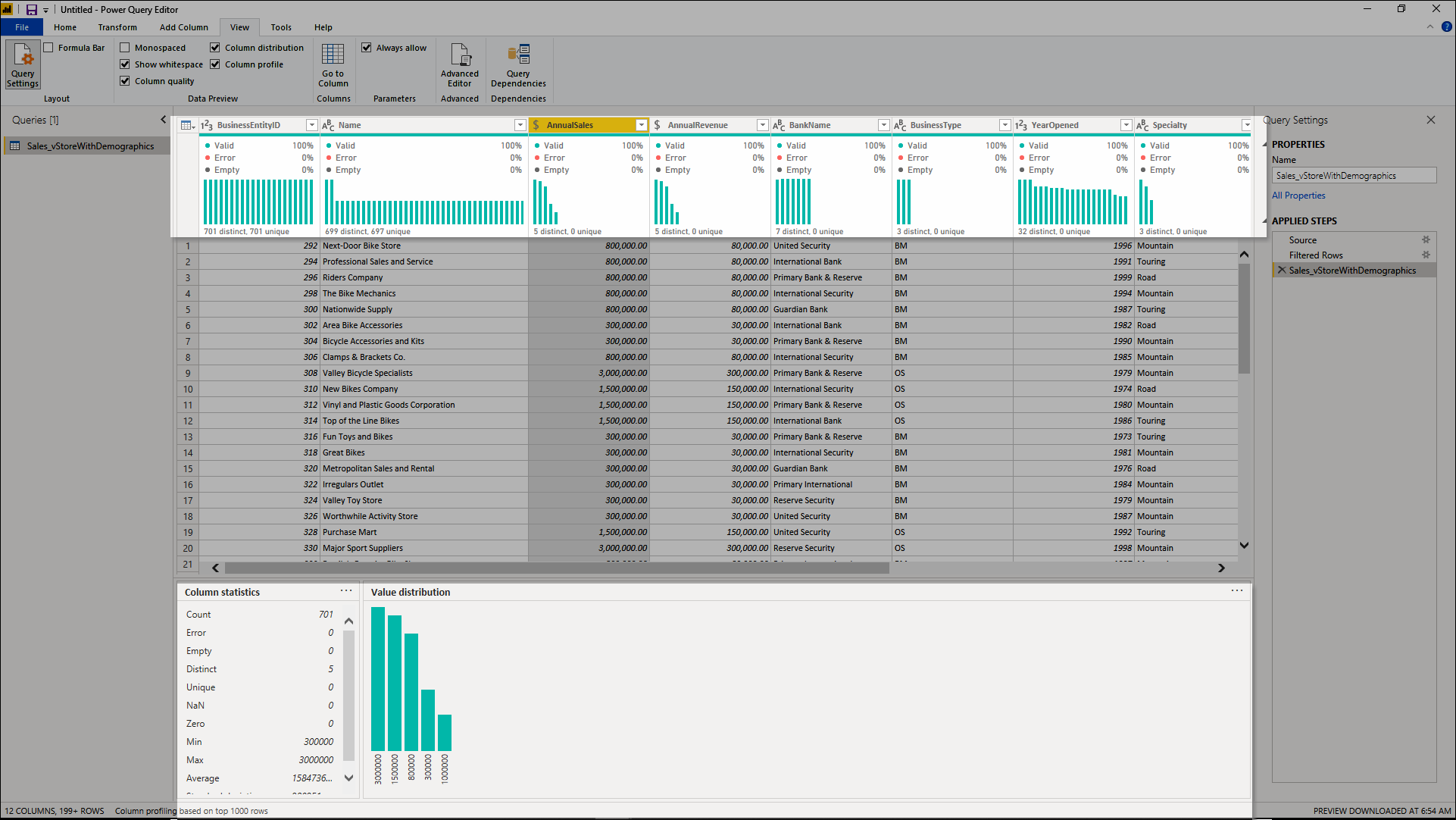
Эти средства профилирования данных помогают лучше понять данные. Эти средства предоставляют небольшие визуализации, отображающие сведения на основе столбцов, например:
- Качество столбца— предоставляет небольшую линейчатую диаграмму и три индикатора с представлением количества значений в столбце, входящих в категорию допустимых, ошибок или пустых значений.
- Распределение столбцов — предоставляет набор визуальных элементов под именами столбцов, демонстрирующих частоту и распределение значений в каждом столбце.
- Профиль столбца— предоставляет более тщательное представление столбца и статистику, связанную с ней.
Вы также можете взаимодействовать с этими функциями, что поможет подготовить данные.
Дополнительные сведения о средствах профилирования данных см. в разделе «Средства профилирования данных».
Документируйте работу
Рекомендуется задокументировать запросы, переименовав или добавив описание в действия, запросы или группы, как показано в соответствии с вашими данными.
Хотя Power Query автоматически создает имя шага для вас в области примененных шагов, вы также можете переименовать шаги или добавить описание в любой из них.
Дополнительные сведения обо всех доступных функциях и компонентах, найденных в области примененных шагов, см. в разделе «Использование списка примененных шагов».
Подход к модульной работе
Полностью можно создать один запрос, содержащий все преобразования и вычисления, которые могут потребоваться. Но если запрос содержит большое количество шагов, возможно, рекомендуется разделить запрос на несколько запросов, где один запрос ссылается на следующий. Цель этого подхода заключается в том, чтобы упростить и разделить этапы преобразования на небольшие части, чтобы они легче понять.
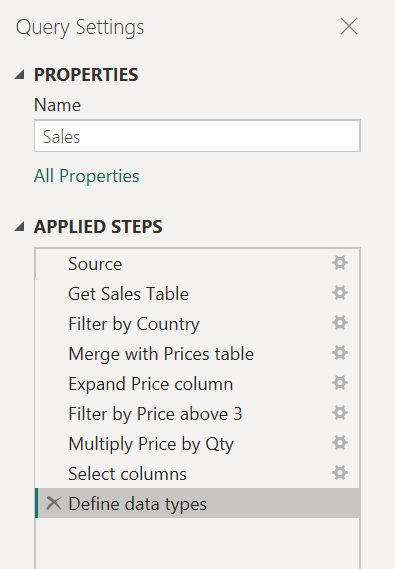
Например, предположим, что у вас есть запрос с девятью шагами, показанными на следующем рисунке.
Этот запрос можно разделить на два на шаге «Слияние с ценами «. Таким образом, проще понять шаги, которые были применены к запросу о продажах перед слиянием. Чтобы выполнить эту операцию, щелкните правой кнопкой мыши шаг «Слияние с ценами » и выберите параметр «Извлечь предыдущую «.
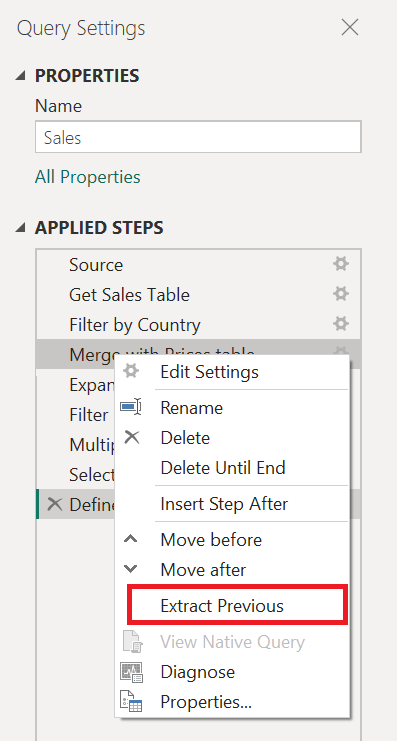
Затем появится диалоговое окно, чтобы указать новое имя запроса. Это позволит эффективно разделить запрос на два запроса. Перед слиянием один запрос будет иметь все запросы. Другой запрос будет иметь начальный шаг, который будет ссылаться на новый запрос и остальные шаги, которые вы выполнили в исходном запросе из шага «Слияние с ценами » вниз.
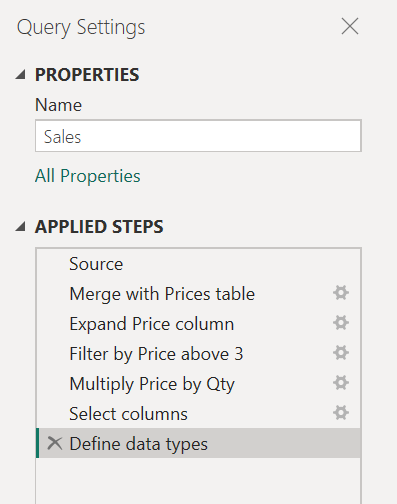
Вы также можете использовать ссылку на запросы, как показано в соответствии. Но это хорошая идея держать ваши запросы на уровне, который не кажется ошеломляющим на первый взгляд с таким количеством шагов.
Чтобы узнать больше о ссылке на запросы, перейдите к разделу «Общие сведения о области запросов».
Создание групп
Отличный способ организовать работу— использовать группы в области запросов.
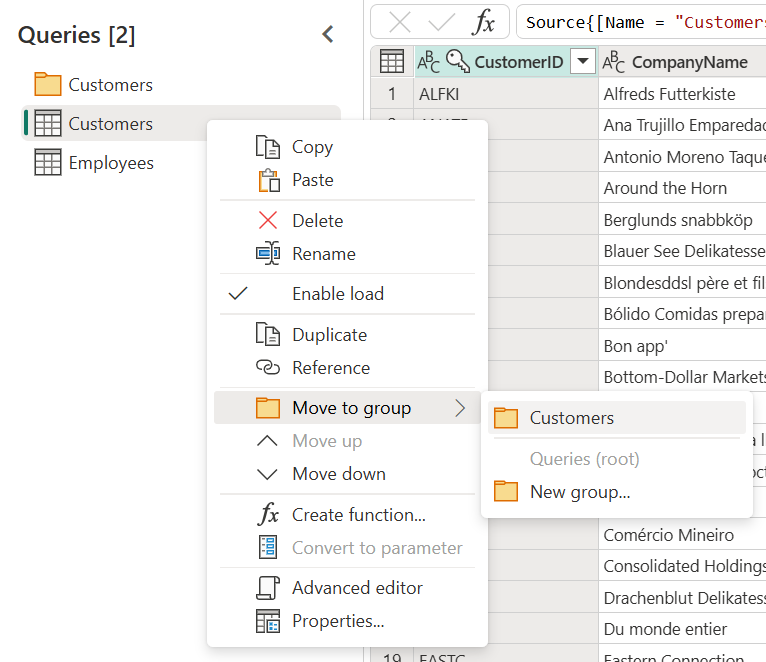
Единственной целью групп является поддержание организации работы, выступая в качестве папок для запросов. Вы можете создавать группы в группах, если вам нужно. Перемещение запросов между группами так же легко, как перетаскивание.
Попробуйте дать группам понятное имя, которое имеет смысл для вас и вашего дела.
Дополнительные сведения обо всех доступных функциях и компонентах, найденных в области запросов, см. в разделе » Общие сведения о области запросов».
Запросы для проверки правописания в будущем
Убедитесь, что вы создаете запрос, который не будет иметь никаких проблем во время будущего обновления является главным приоритетом. В Power Query есть несколько функций, которые позволяют сделать запрос устойчивым к изменениям и обновлять даже при изменении некоторых компонентов источника данных.
Рекомендуется определить область запроса о том, что он должен делать, и что он должен учитывать с точки зрения структуры, макета, имен столбцов, типов данных и любого другого компонента, который вы считаете соответствующими область.
Ниже приведены некоторые примеры преобразований, которые помогут вам сделать запрос устойчивым к изменениям:
-
Если запрос содержит динамическое число строк с данными, но фиксированное число строк, которые служат нижним колонтитулов, которые следует удалить, можно использовать функцию «Удалить нижние строки».
Примечание. Чтобы узнать больше о фильтрации данных по позиции строки, перейдите к разделу «Фильтрация таблицы по позиции строки».
Примечание. Чтобы узнать больше о выборе или удалении столбцов, перейдите к разделу «Выбор или удаление столбцов».
Примечание. Дополнительные сведения о параметрах для отмены сводных столбцов см. в разделе «Отмена сводных столбцов».
Примечание. Чтобы узнать больше о работе и работе с ошибками, перейдите к разделу «Работа с ошибками».
Использование параметров
Создание динамических и гибких запросов — это рекомендация. Параметры в Power Query помогают сделать запросы более динамическими и гибкими. Параметр служит способом легко хранить и управлять значением, которое можно повторно использовать различными способами. Но чаще используется в двух сценариях:
- Аргумент шага. Параметр можно использовать в качестве аргумента нескольких преобразований, управляемых из пользовательского интерфейса.
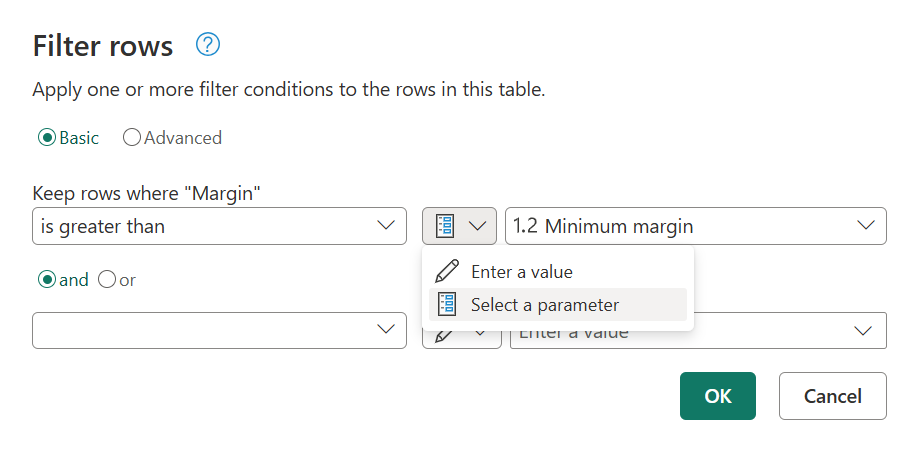
- Аргумент пользовательской функции— вы можете создать новую функцию из запроса и ссылаться на параметры в качестве аргументов пользовательской функции.
Основными преимуществами создания и использования параметров являются:
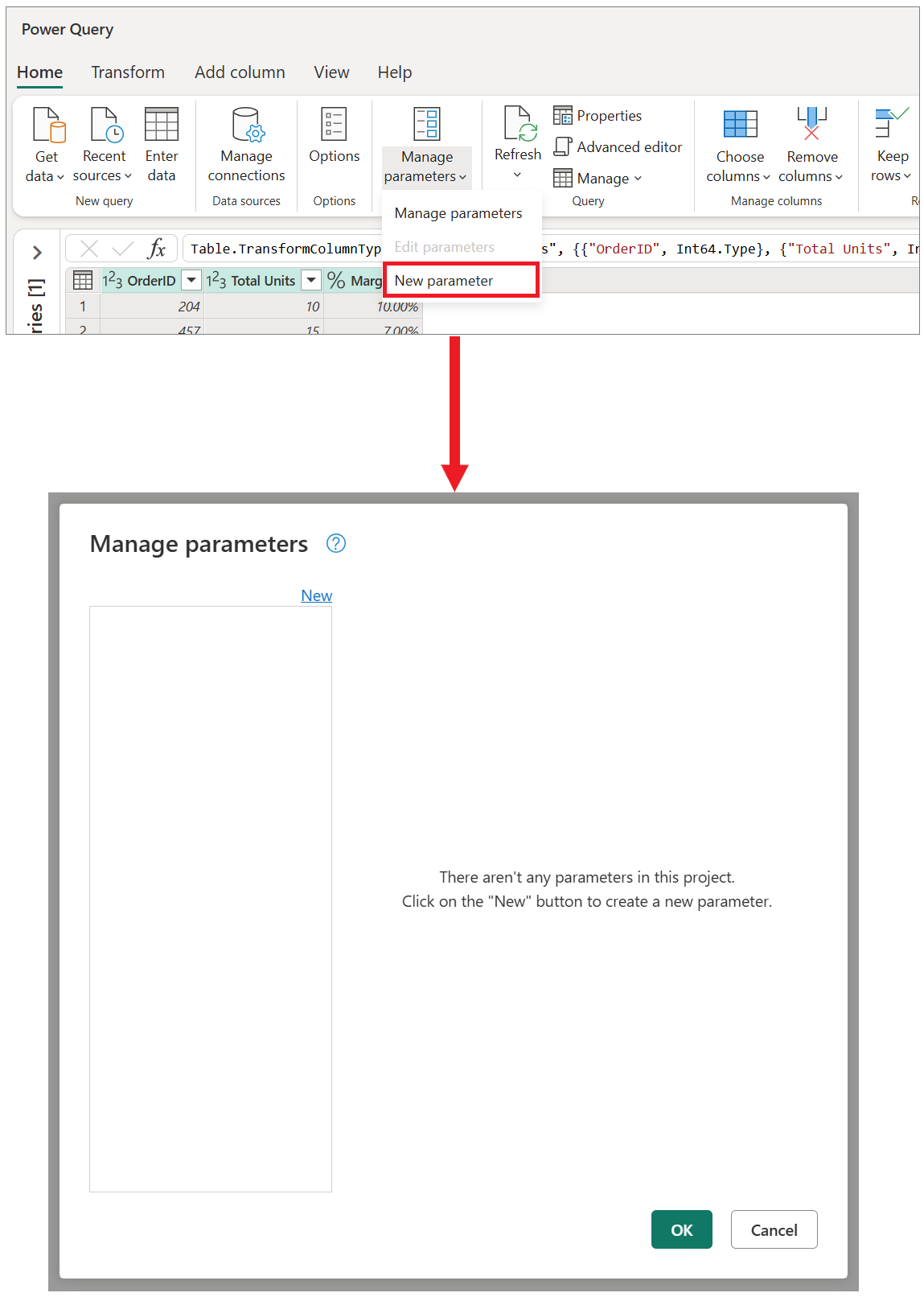
- Централизованное представление всех параметров с помощью окна «Управление параметрами «.
- Повторное использование параметра в нескольких шагах или запросах.
- Упрощает создание пользовательских функций.
Можно даже использовать параметры в некоторых аргументах соединителей данных. Например, можно создать параметр для имени сервера при подключении к базе данных SQL Server. Затем этот параметр можно использовать в диалоговом окне базы данных SQL Server.
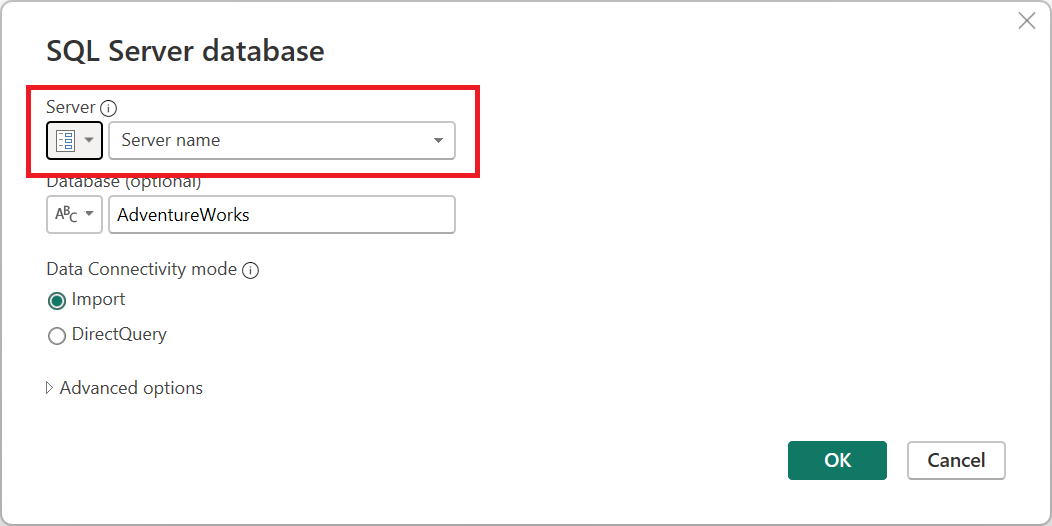
Если изменить расположение сервера, необходимо обновить параметр для имени сервера, а запросы будут обновлены.
Дополнительные сведения о создании и использовании параметров см. в разделе «Использование параметров».
Создание повторно используемых функций
Если вы найдете себя в ситуации, когда необходимо применить один набор преобразований к разным запросам или значениям, создайте пользовательскую функцию Power Query, которую можно повторно использовать столько раз, сколько вам может быть полезно. Пользовательская функция Power Query — это сопоставление из набора входных значений с одним выходным значением и создается из собственных функций и операторов M.
Например, предположим, что у вас есть несколько запросов или значений, требующих одного набора преобразований. Вы можете создать пользовательскую функцию, которая позже может быть вызвана в запросах или значениях выбранного варианта. Эта настраиваемая функция экономит время и помогает управлять набором преобразований в центральном расположении, которое можно изменить в любой момент.
Пользовательские функции Power Query можно создавать из существующих запросов и параметров. Например, представьте запрос, имеющий несколько кодов в виде текстовой строки, и вы хотите создать функцию, которая декодирует эти значения.
Сначала у вас есть параметр, имеющий значение, которое служит примером.
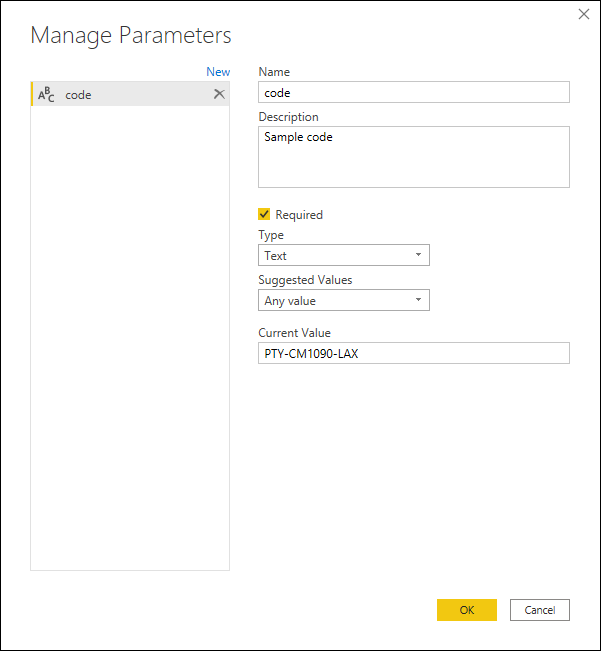
В этом параметре создается новый запрос, в котором применяются необходимые преобразования. В этом случае необходимо разделить код PTY-CM1090-LAX на несколько компонентов:
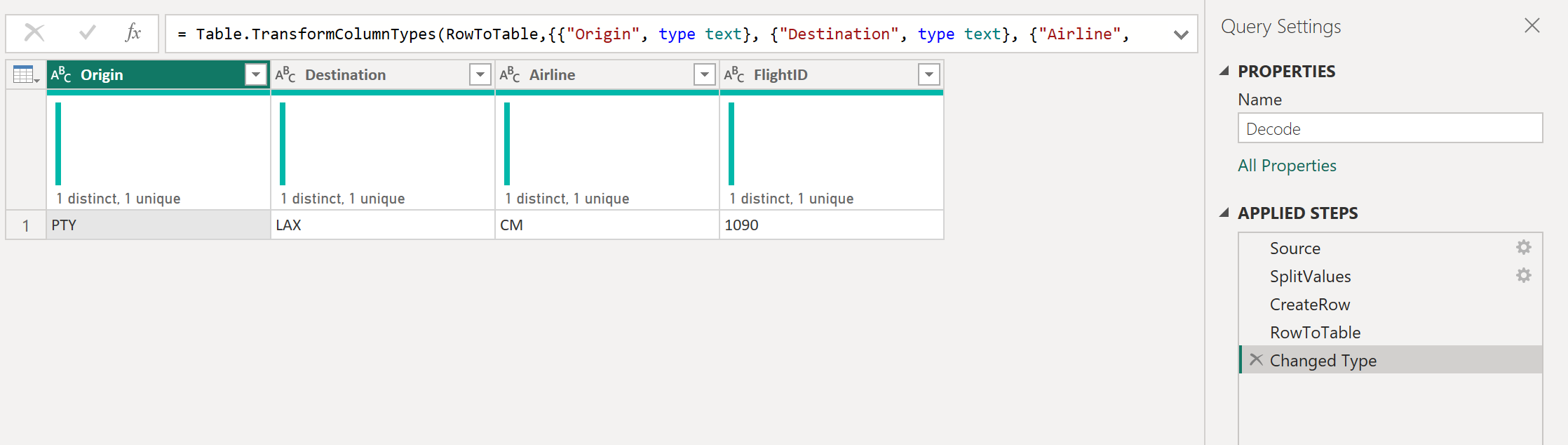
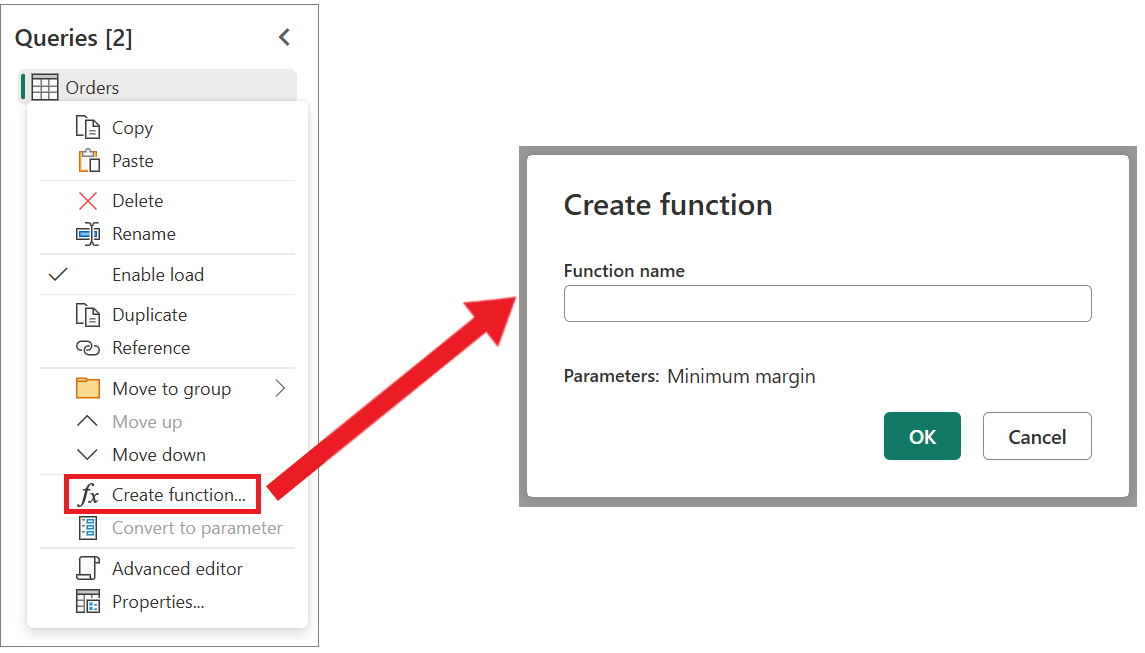
Затем этот запрос можно преобразовать в функцию, щелкнув правой кнопкой мыши запрос и выбрав «Создать функцию«. Наконец, можно вызвать пользовательскую функцию в любой из запросов или значений, как показано на следующем рисунке.
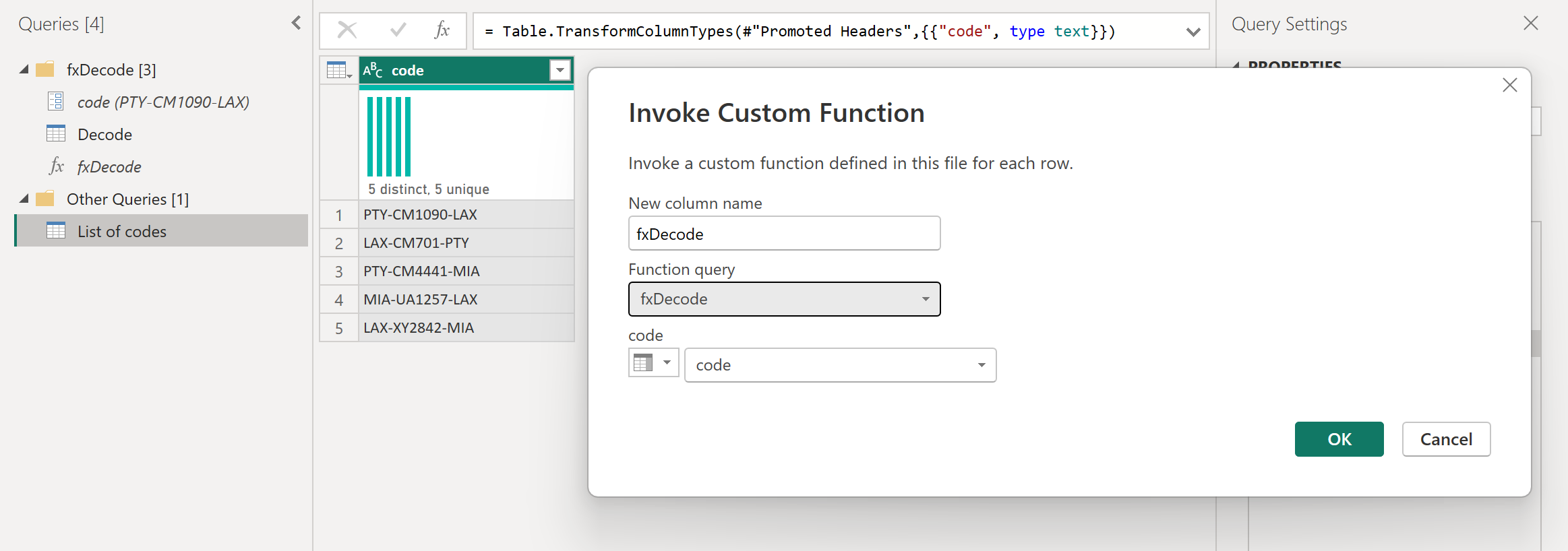
После нескольких преобразований вы увидите, что достигли нужных выходных данных и использовали логику для такого преобразования из пользовательской функции.
Дополнительные сведения о создании и использовании пользовательских функций в Power Query см. в статье «Пользовательские функции».
Как ускорить функцию объединения в повер квери
Argument ‘Topic id’ is null or empty
Сейчас на форуме
© Николай Павлов, Planetaexcel, 2006-2023
info@planetaexcel.ru
Использование любых материалов сайта допускается строго с указанием прямой ссылки на источник, упоминанием названия сайта, имени автора и неизменности исходного текста и иллюстраций.
| ООО «Планета Эксел» ИНН 7735603520 ОГРН 1147746834949 |
ИП Павлов Николай Владимирович ИНН 633015842586 ОГРНИП 310633031600071 |
Использование пользовательских функций
Если вы найдете себя в ситуации, когда необходимо применить один набор преобразований к разным запросам или значениям, создайте пользовательскую функцию Power Query, которую можно повторно использовать столько раз, сколько вам может быть полезно. Пользовательская функция Power Query — это сопоставление из набора входных значений с одним выходным значением и создается из собственных функций и операторов M.
Хотя вы можете вручную создать собственную пользовательскую функцию Power Query с помощью кода, как показано в разделе «Общие сведения о функциях Power Query M», пользовательский интерфейс Power Query предлагает функции для ускорения, упрощения и улучшения процесса создания и управления пользовательской функцией.
В этой статье рассматривается этот интерфейс, предоставляемый только через пользовательский интерфейс Power Query, и как получить большую часть из него.
В этой статье описывается, как создать пользовательскую функцию с помощью Power Query с помощью распространенных преобразований, доступных в пользовательском интерфейсе Power Query. В нем рассматриваются основные понятия для создания пользовательских функций и ссылки на дополнительные статьи в документации по Power Query для получения дополнительных сведений о конкретных преобразованиях, на которые ссылается эта статья.
Создание пользовательской функции из ссылки на таблицу
Следующий пример был создан с помощью рабочего стола, найденного в Power BI Desktop, а также можно использовать интерфейс Power Query, найденный в Excel для Windows.
Вы можете следовать этому примеру, скачав примеры файлов, используемых в этой статье, со следующей ссылкой для скачивания. Для простоты эта статья будет использовать соединитель папок. Дополнительные сведения о соединителе папок см. в папке . Цель этого примера — создать пользовательскую функцию, которую можно применить ко всем файлам в этой папке, прежде чем объединять все данные из всех файлов в одну таблицу.
Начните с использования соединителя папок, чтобы перейти к папке, в которой находятся файлы, и выберите «Преобразовать данные » или «Изменить«. Это позволит вам воспользоваться интерфейсом Power Query. Щелкните правой кнопкой мыши двоичное значение в поле «Содержимое» и выберите параметр «Добавить как новый запрос«. В этом примере вы увидите, что выбор был сделан для первого файла из списка, который будет файлом за апрель 2019.csv.
Этот параметр фактически создаст новый запрос с шагом навигации непосредственно в этот файл в виде двоичного файла, и имя этого нового запроса будет путь к файлу выбранного файла. Переименуйте этот запрос в пример файла.
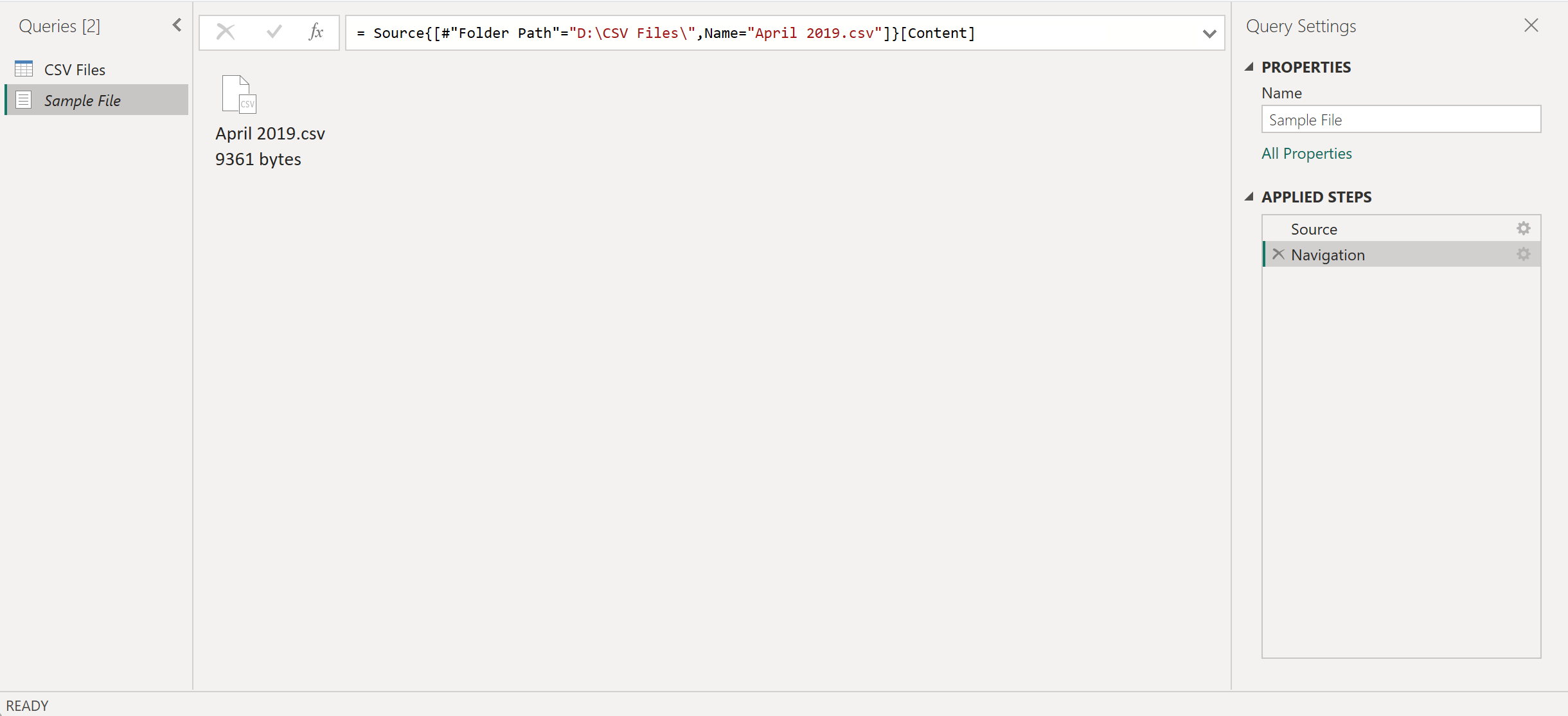
Создайте новый параметр с именем параметра файла. Используйте запрос примера файла в качестве текущего значения, как показано на следующем рисунке.
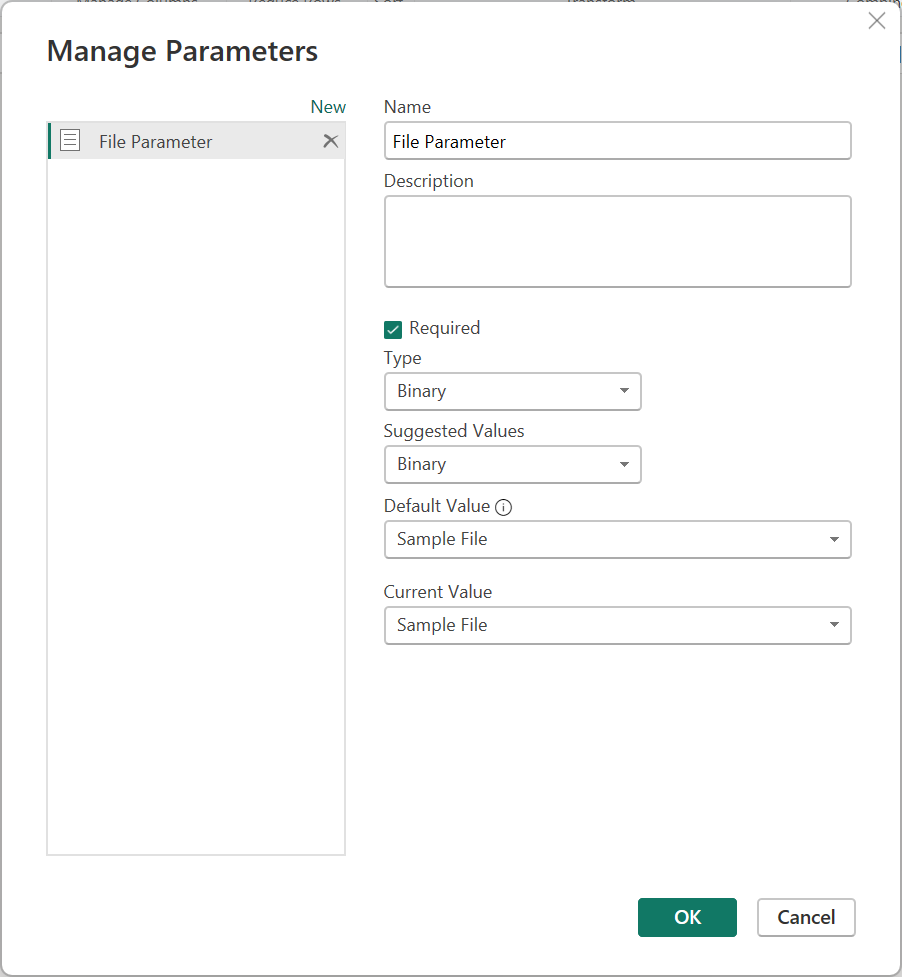
Мы рекомендуем ознакомиться со статьей о параметрах , чтобы лучше понять, как создавать параметры в Power Query и управлять ими.
Пользовательские функции можно создавать с помощью любого типа параметров. Для любой пользовательской функции не требуется использовать двоичный файл в качестве параметра.
Тип двоичного параметра отображается только в раскрывающемся меню «Параметры» в раскрывающемся меню «Параметры » при наличии запроса, который оценивается в двоичный файл.
Можно создать пользовательскую функцию без параметра. Обычно это видно в сценариях, когда входные данные можно выводить из среды, в которой вызывается функция. Например, функция, которая принимает текущую дату и время среды и создает определенную текстовую строку из этих значений.
Щелкните правой кнопкой мыши параметр файла в области «Запросы«. Выберите параметр «Ссылка«.
Переименуйте только что созданный запрос из параметра файла (2) в преобразование примера файла.
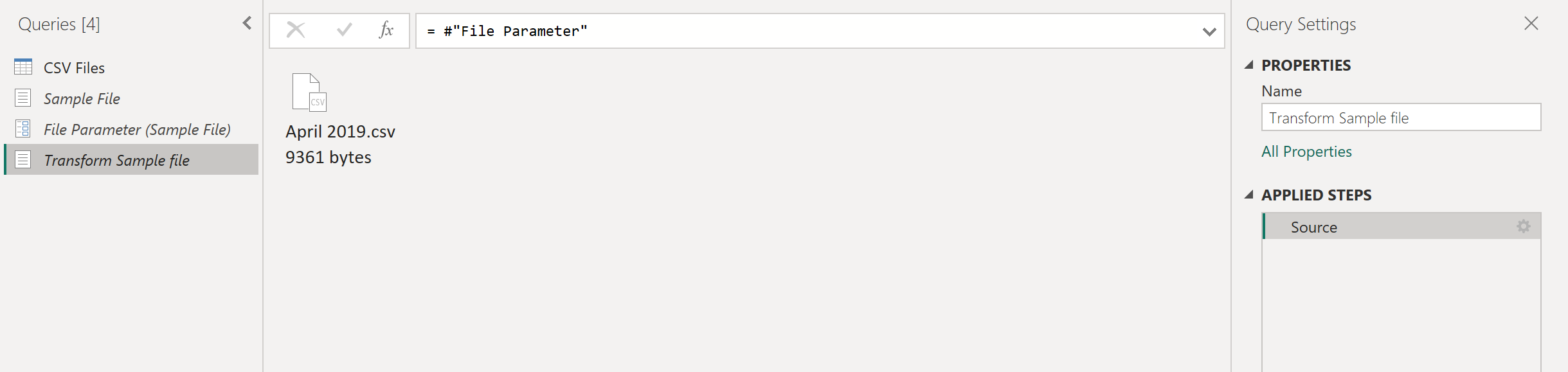
Щелкните правой кнопкой мыши этот новый запрос преобразования примера файла и выберите параметр «Создать функцию «.
Эта операция фактически создаст новую функцию, которая будет связана с запросом примера файла преобразования. Все изменения, внесенные в запрос на пример файла преобразования, автоматически реплика в настраиваемую функцию. Во время создания этой новой функции используйте файл преобразования в качестве имени функции.
После создания функции вы увидите, что для вас будет создана новая группа с именем функции. Эта новая группа будет содержать следующее:
- Все параметры, на которые ссылались в запросе на образец файла преобразования.
- Запрос примера файла преобразования, известный как пример запроса.
- Созданная функция, в данном случае файл преобразования.

Применение преобразований к образцу запроса
Создав новую функцию, выберите запрос с именем «Преобразование примера файла«. Этот запрос теперь связан с функцией преобразования файлов , поэтому любые изменения, внесенные в этот запрос, будут отражены в функции. Это то, что называется понятием примера запроса, связанного с функцией.
Первое преобразование, которое должно произойти с этим запросом, — это то, что будет интерпретировать двоичный файл. Вы можете щелкнуть двоичный файл правой кнопкой мыши в области предварительного просмотра и выбрать параметр CSV, чтобы интерпретировать двоичный файл как CSV-файл .
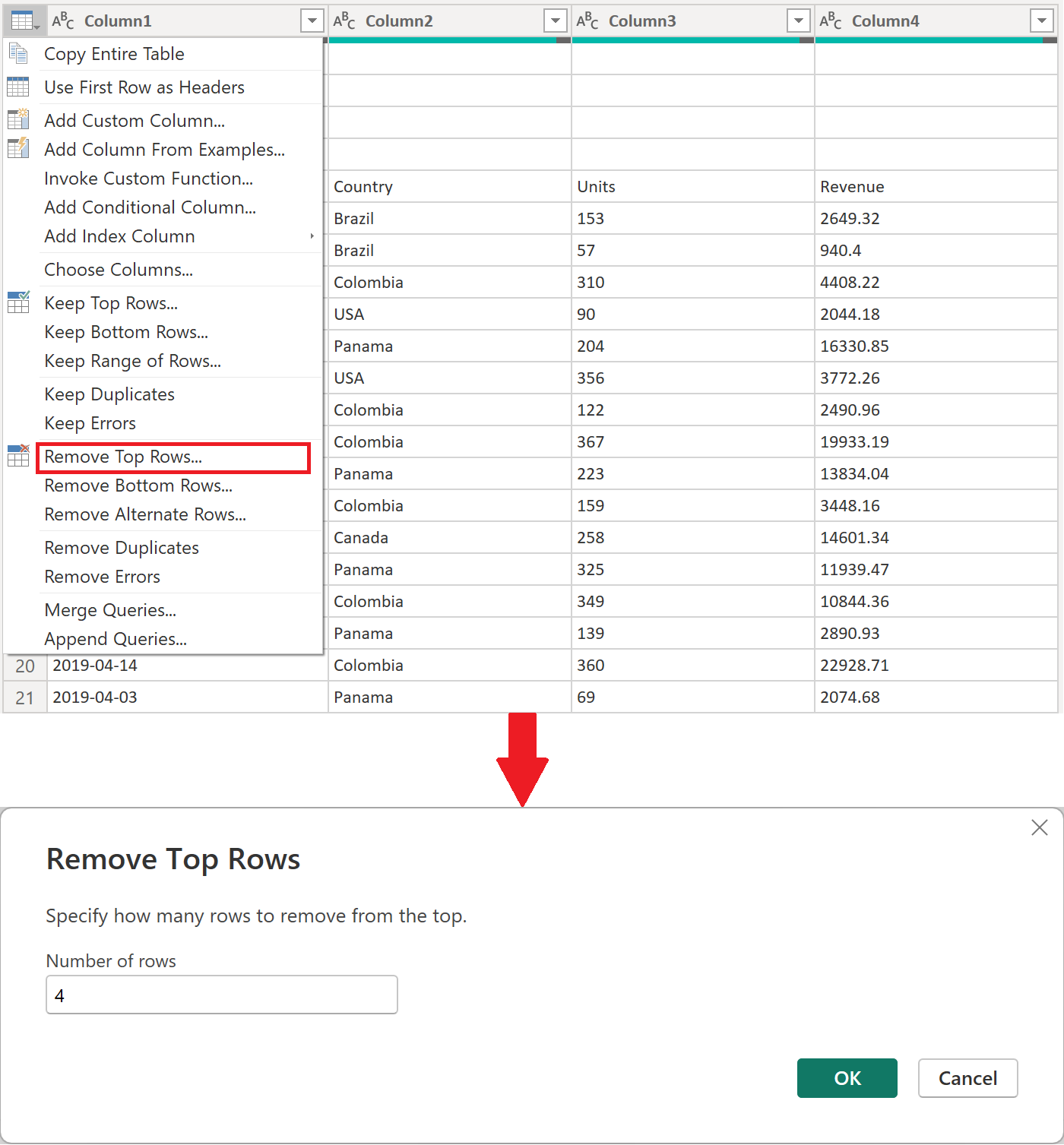
Формат всех CSV-файлов в папке одинаков. Все они имеют заголовок, охватывающий первые четыре строки. Заголовки столбцов расположены в строке пять, а данные начинаются с шести строк вниз, как показано на следующем рисунке.
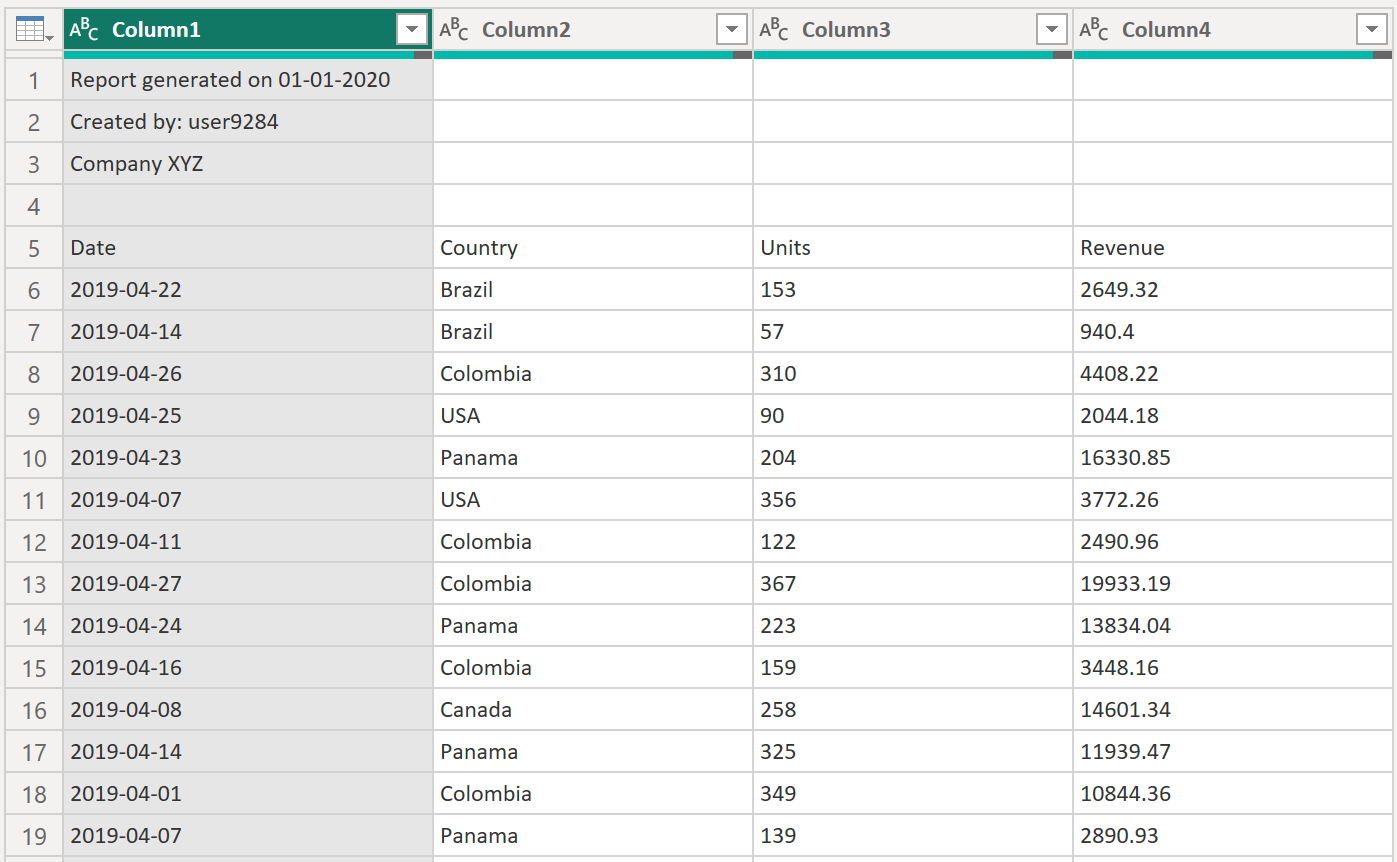
Ниже приведен следующий набор шагов преобразования, которые необходимо применить к файлу примера преобразования:
-
Удалите первые четыре строки. Это действие позволит избавиться от строк, которые считаются частью раздела заголовка файла.
Примечание. Чтобы узнать больше о том, как удалить строки или отфильтровать таблицу по позиции строки, перейдите к разделу «Фильтр по позиции строки».
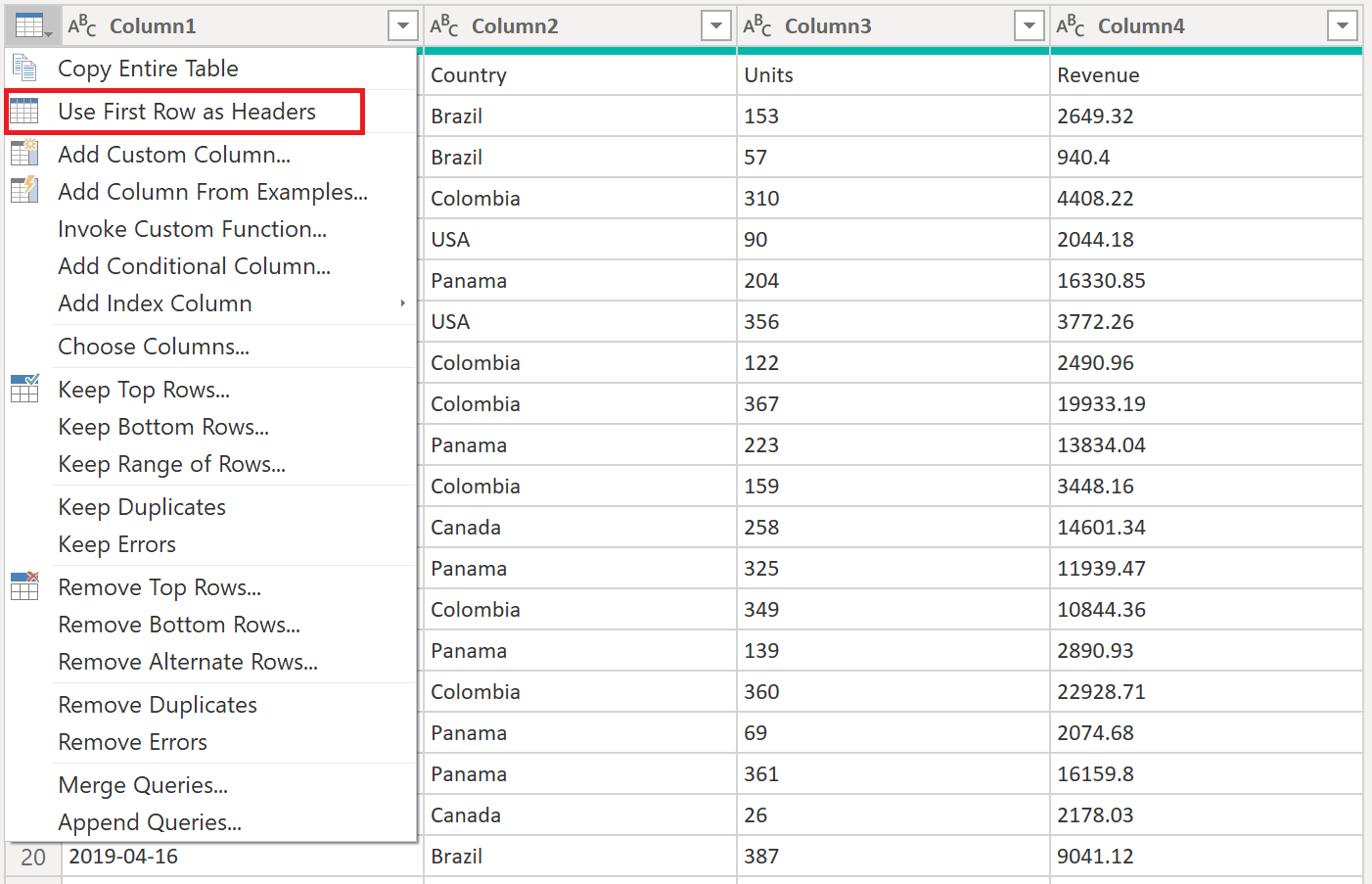
Power Query по умолчанию автоматически добавит новый шаг «Измененный тип » после продвижения заголовков столбцов, которые автоматически будут обнаруживать типы данных для каждого столбца. Запрос примера файла преобразования будет выглядеть следующим образом.
Дополнительные сведения о повышении и понижении заголовков см. в разделе «Повышение или понижение заголовков столбцов».
Функция файла преобразования зависит от шагов, выполняемых в запросе на пример файла преобразования. Однако если вы попытаетесь вручную изменить код для функции преобразования файлов , вы будете приветствовать предупреждение, которое считывает The definition of the function ‘Transform file’ is updated whenever query ‘Transform Sample file’ is updated. However, updates will stop if you directly modify function ‘Transform file’.
Вызов пользовательской функции в качестве нового столбца
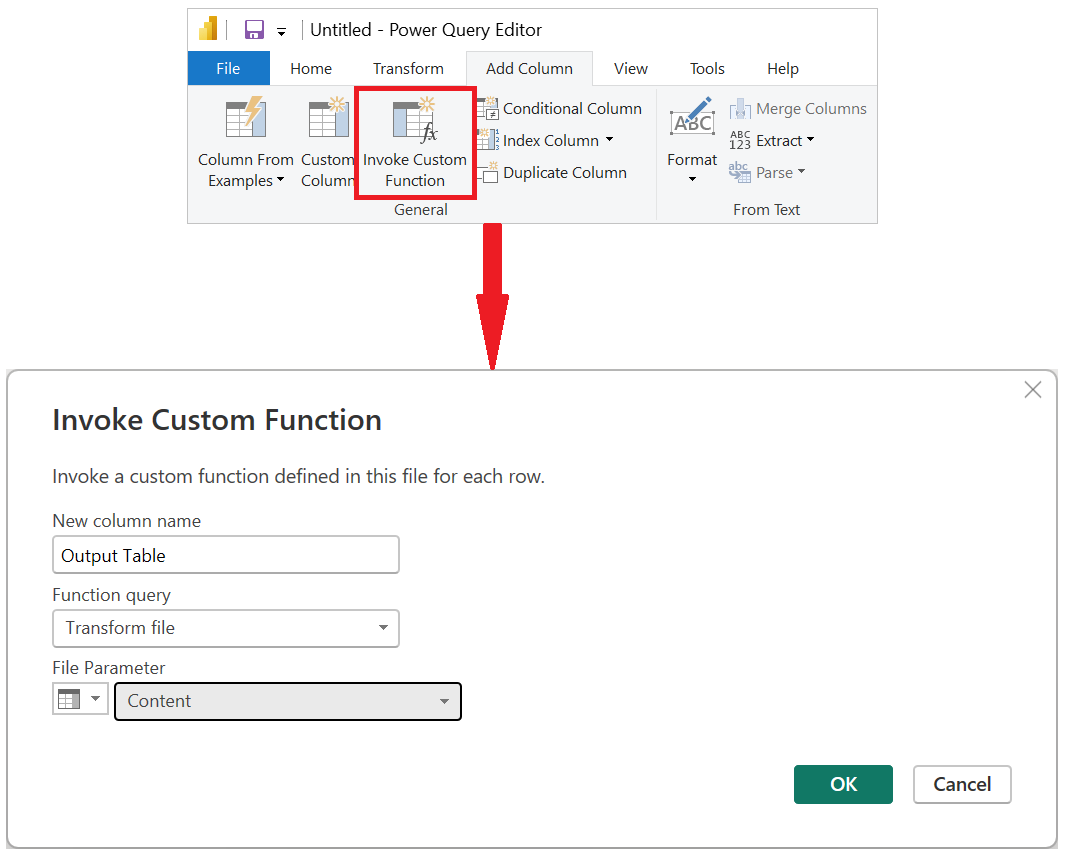
После создания пользовательской функции и всех шагов преобразования, которые были включены, вы можете вернуться к исходному запросу, где у вас есть список файлов из папки. На вкладке «Добавить столбец » на ленте выберите «Вызвать настраиваемую функцию » из группы «Общие «. В окне «Вызов настраиваемой функции» введите в качестве имени нового столбца таблицу вывода. Выберите имя функции, файл преобразования в раскрывающемся списке запроса функции. После выбора функции в раскрывающемся меню будет отображаться параметр функции, и вы можете выбрать столбец из таблицы, который будет использоваться в качестве аргумента для этой функции. Выберите столбец Content в качестве значения или аргумента, который необходимо передать для параметра файла.
После нажатия кнопки «ОК» будет создан новый столбец с именем выходной таблицы . Этот столбец содержит значения таблицы в своих ячейках, как показано на следующем рисунке. Для простоты удалите все столбцы из этой таблицы, кроме имени и выходной таблицы.
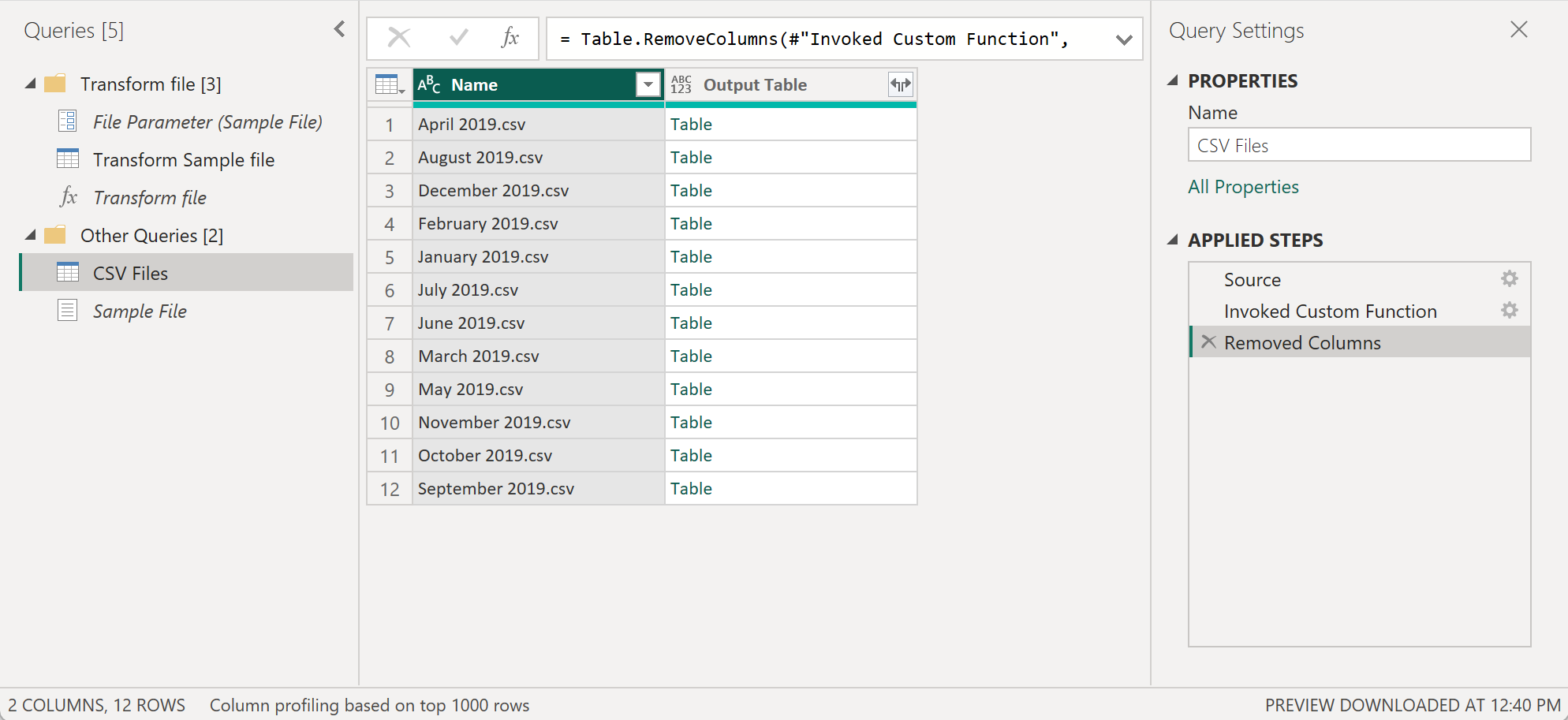
Чтобы узнать больше о выборе или удалении столбцов из таблицы, перейдите к разделу «Выбор или удаление столбцов».
Функция была применена к каждой строке из таблицы, используя значения из столбца Content в качестве аргумента для функции. Теперь, когда данные были преобразованы в фигуру, которую вы ищете, можно развернуть столбец выходной таблицы , как показано на рисунке ниже, без использования префикса для развернутых столбцов.
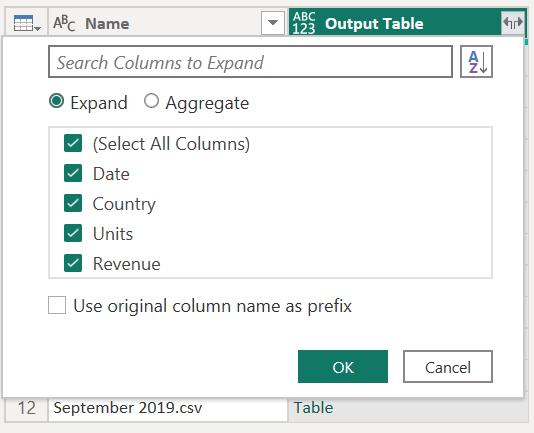
Вы можете убедиться, что у вас есть данные из всех файлов в папке, проверка значения в столбце «Имя» или «Дата«. В этом случае можно проверка значения из столбца Date, так как каждый файл содержит только данные за один месяц от заданного года. Если вы видите несколько файлов, это означает, что вы успешно объединили данные из нескольких файлов в одну таблицу.
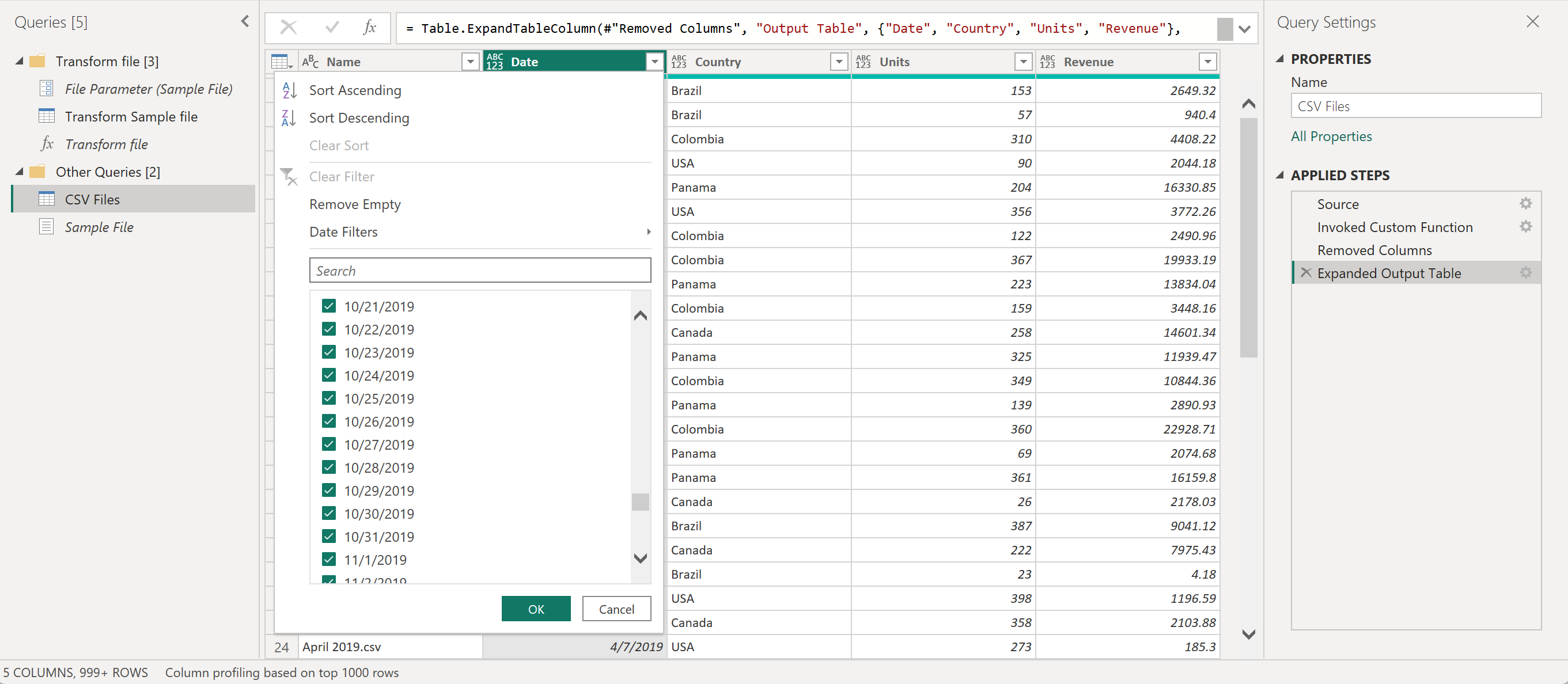
То, что вы читали до сих пор, является фундаментальным процессом, который происходит во время работы с файлами объединения, но делается вручную.
Мы рекомендуем также ознакомиться со статьей об обзоре файлов объединения и объединить CSV-файлы , чтобы более подробно понять, как работает взаимодействие с файлами в Power Query и роль, которую играют пользовательские функции.
Добавление нового параметра в существующую пользовательскую функцию
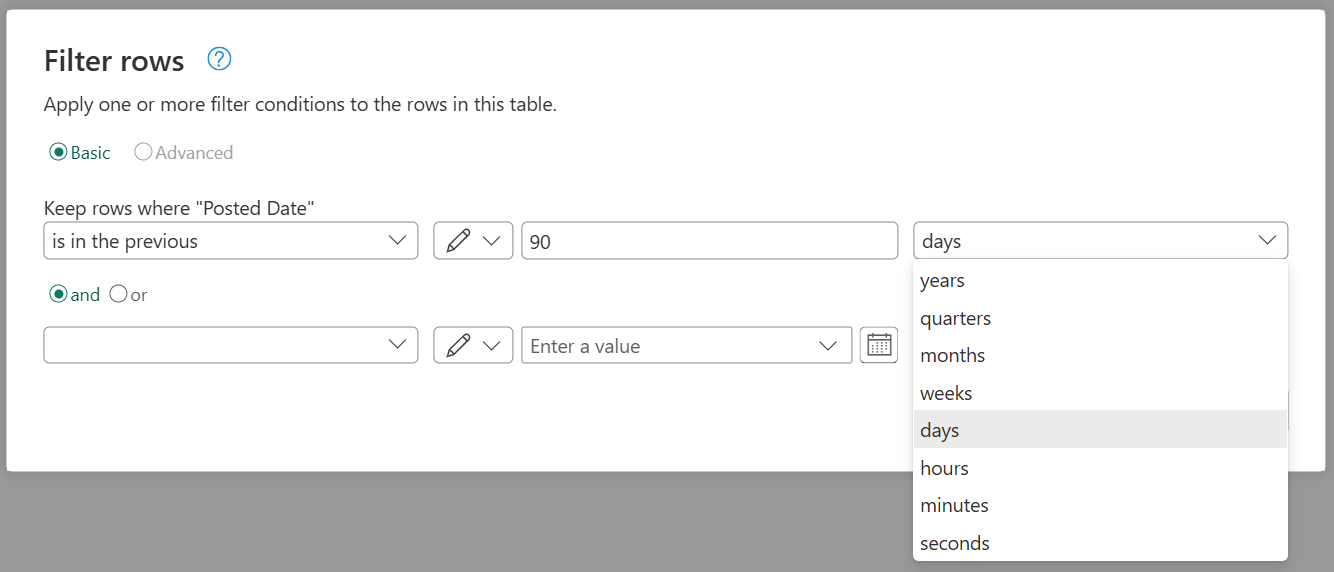
Представьте, что есть новое требование на основе того, что вы создали. Новое требование требует, чтобы перед объединением файлов отфильтровывали данные внутри них, чтобы получить только строки, в которых страна равна Панаме.
Чтобы сделать это требование, создайте новый параметр с именем Market с текстовым типом данных. В поле «Текущее значение» введите значение Панама.
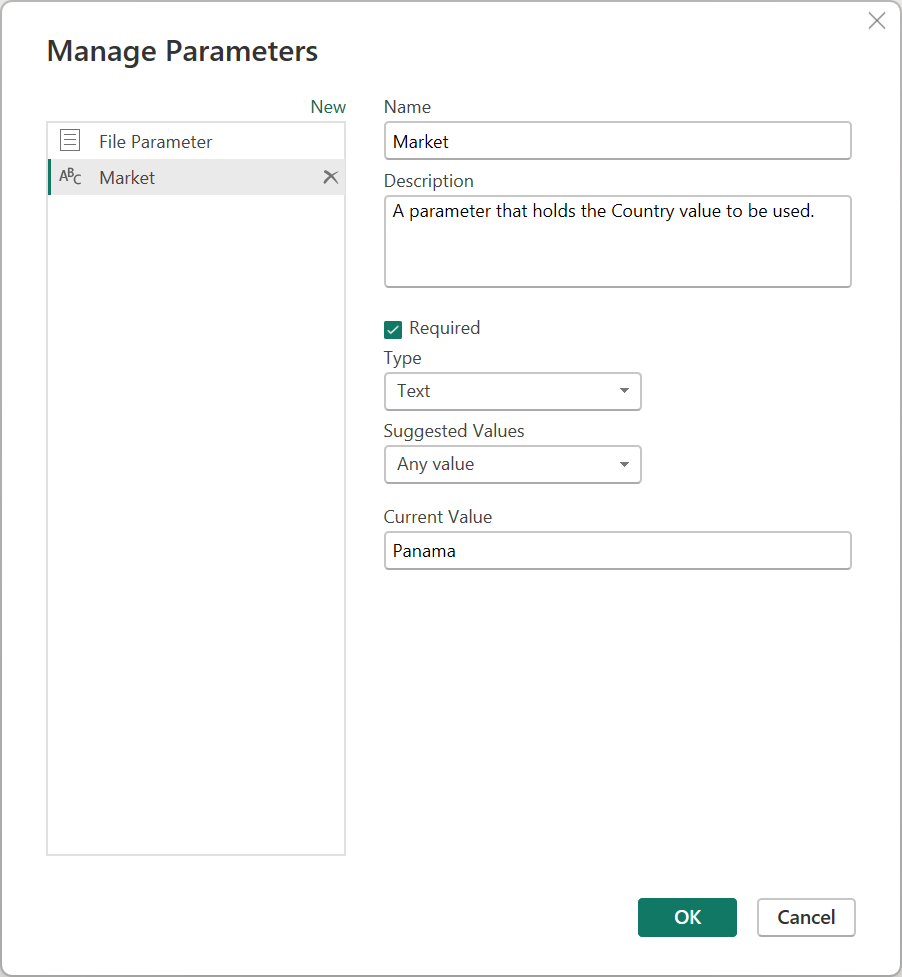
В этом новом параметре выберите запрос «Преобразовать пример файла » и отфильтруйте поле «Страна » с помощью значения из параметра Market .
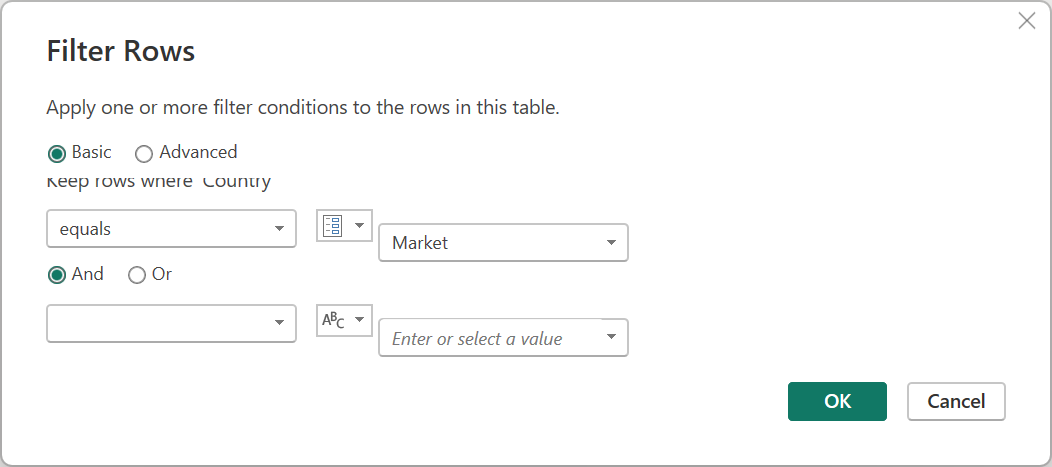
Дополнительные сведения о том, как фильтровать столбцы по значениям, перейдите к разделу «Фильтрация значений».
Применение этого нового шага к запросу автоматически обновит функцию файла преобразования, которая теперь потребует двух параметров на основе двух параметров, которые использует образец файла преобразования.
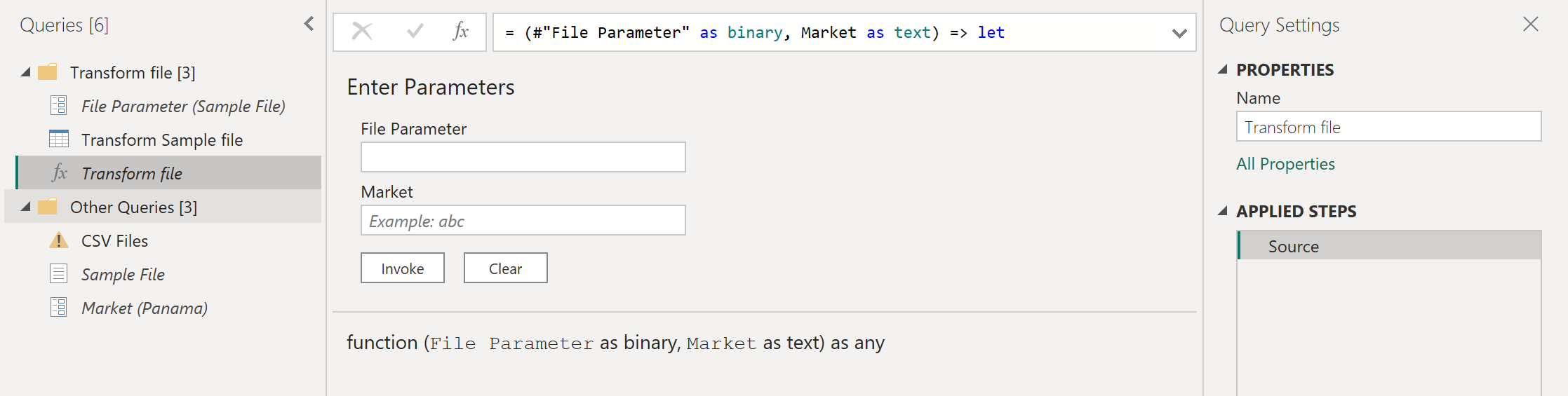
Но запрос CSV-файлов содержит знак предупреждения рядом с ним. Теперь, когда функция была обновлена, требуется два параметра. Таким образом, шаг, в котором вызывается функция, приводит к ошибкам, так как только один из аргументов был передан в функцию преобразования файла во время шага вызываемой пользовательской функции .
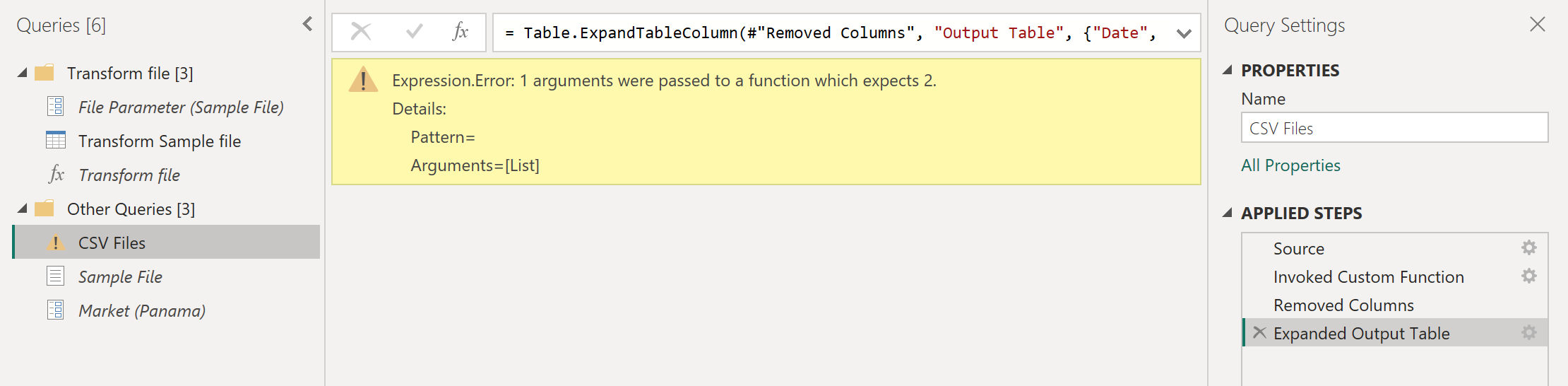
Чтобы устранить ошибки, дважды щелкните «Вызвать настраиваемую функцию» в разделе «Примененные действия«, чтобы открыть окно «Вызвать пользовательскую функцию«. В параметре Market вручную введите значение Панама.
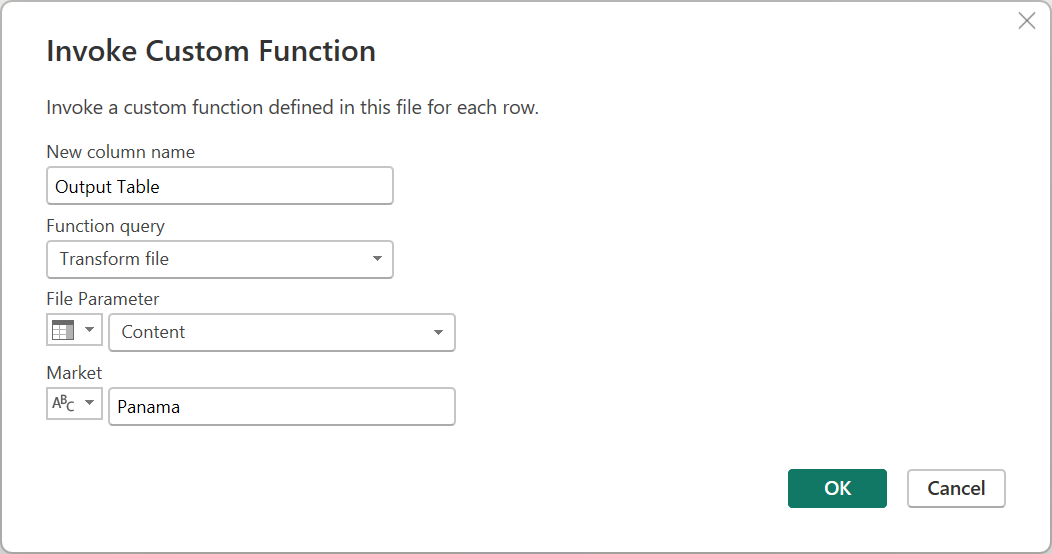
Теперь вы можете проверка запрос, чтобы проверить, что только строки, в которых страна равна Панаме, отображаются в окончательном результирующем наборе запроса CSV-файлов.
Создание пользовательской функции из повторно используемых фрагментов логики
Если у вас несколько запросов или значений, требующих одного набора преобразований, можно создать пользовательскую функцию, которая выступает в качестве многократно используемых фрагментов логики. Позже эту настраиваемую функцию можно вызвать в запросах или значениях выбранного варианта. Эта настраиваемая функция может сэкономить время и помочь вам в управлении набором преобразований в центральном расположении, которое можно изменить в любой момент.
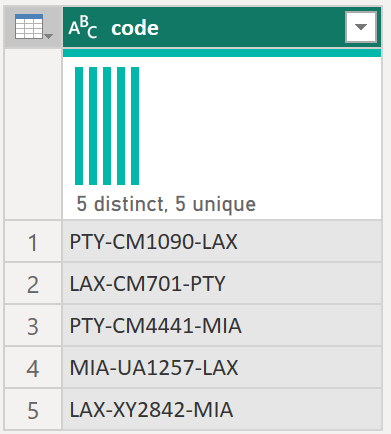
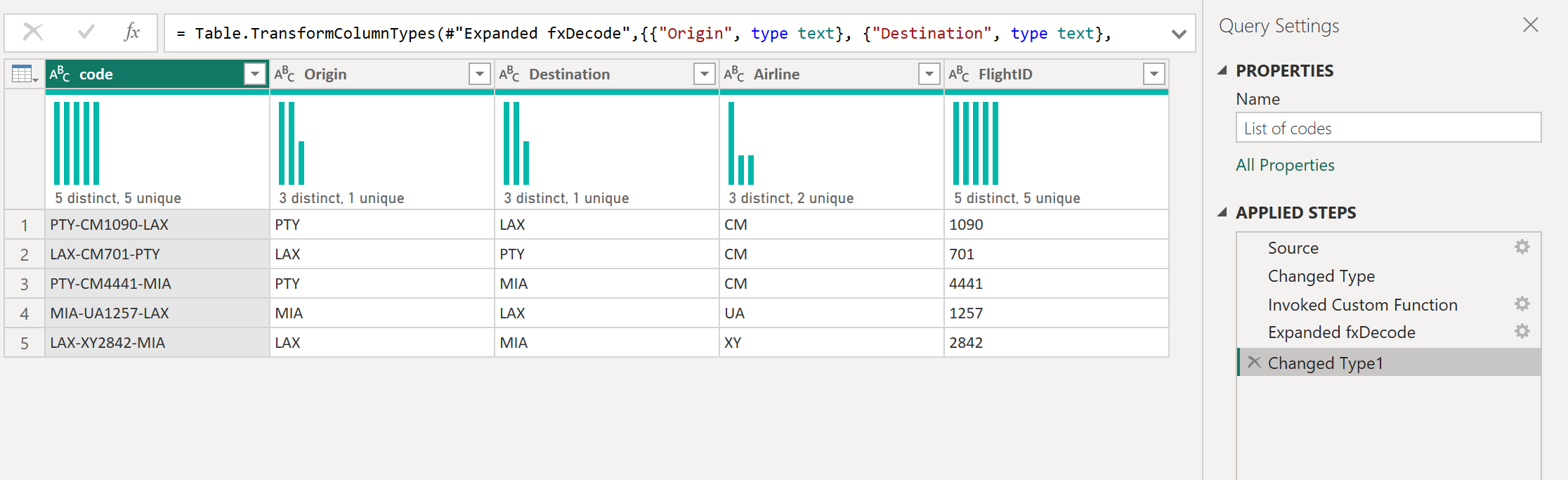
Например, представьте запрос, имеющий несколько кодов в виде текстовой строки, и вы хотите создать функцию, которая декодирует эти значения, как показано в следующей таблице.
| кодом |
|---|
| PTY-CM1090-LAX |
| LAX-CM701-PTY |
| PTY-CM4441-MIA |
| MIA-UA1257-LAX |
| LAX-XY2842-MIA |
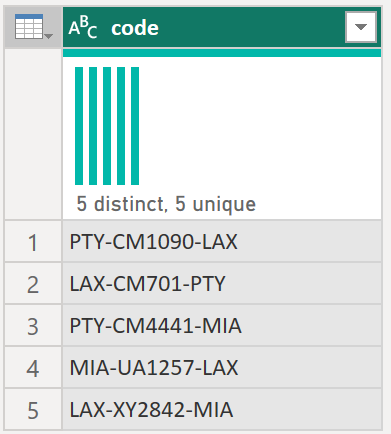
Сначала у вас есть параметр, имеющий значение, которое служит примером. В этом случае это будет значение PTY-CM1090-LAX.
В этом параметре создается новый запрос, в котором применяются необходимые преобразования. В этом случае необходимо разделить код PTY-CM1090-LAX на несколько компонентов:
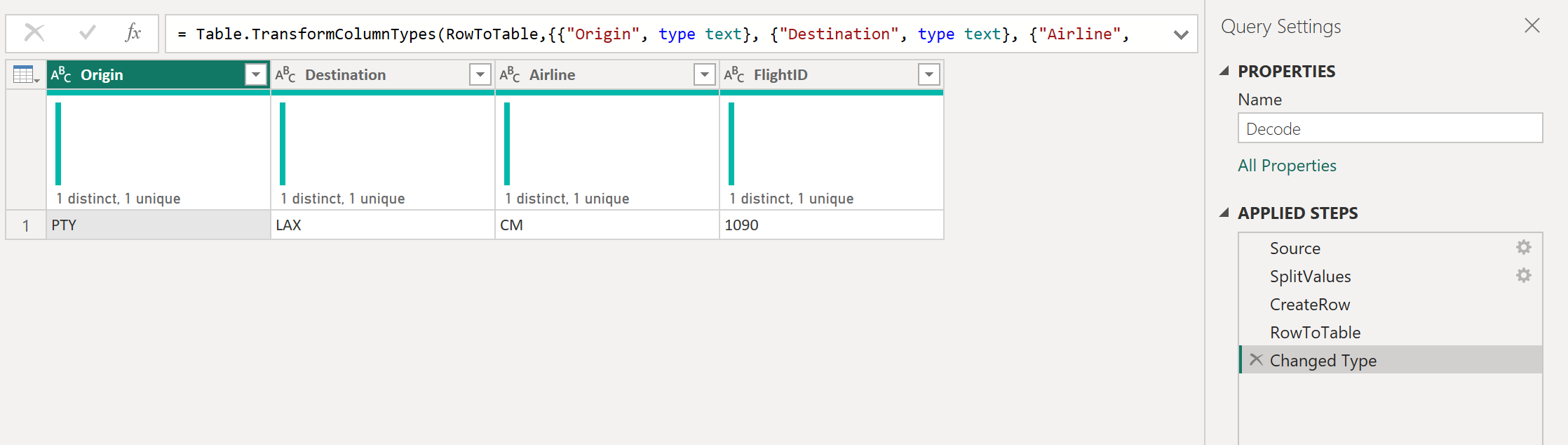
Ниже показан код M для этого набора преобразований.
let Source = code, SplitValues = Text.Split( Source, "-"), CreateRow = [Origin= SplitValues, Destination= SplitValues, Airline=Text.Start( SplitValues,2), FlightID= Text.End( SplitValues, Text.Length( SplitValues ) - 2) ], RowToTable = Table.FromRecords( < CreateRow >), #"Changed Type" = Table.TransformColumnTypes(RowToTable,, , , >) in #"Changed Type" Дополнительные сведения о языке формул Power Query M см. на языке формул Power Query M.
Затем этот запрос можно преобразовать в функцию, щелкнув правой кнопкой мыши запрос и выбрав «Создать функцию«. Наконец, можно вызвать пользовательскую функцию в любой из запросов или значений, как показано на следующем рисунке.
После нескольких преобразований вы увидите, что достигли нужных выходных данных и использовали логику для такого преобразования из пользовательской функции.
Объединение несовпадающих таблиц в Power Query
Несовпадающие таблицы в контексте этой главы — это таблицы, которые описывают одни и те же семантические сущности и факты, но имеют различающиеся названия столбцов. Например:
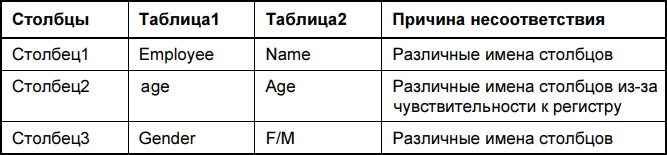
Рис. 1. Пример несоответствия имен столбцов
Скачать заметку в формате Word или pdf, примеры в формате архива (внутри несколько файлов Excel без поддержки макросов)
В большинстве случаев Power Query объединяет таблицы в новую таблицу, которая включает расширенный набор всех столбцов из исходных таблиц. Каждая строка из первой таблицы копируется в объединенную таблицу, причем пустые значения отображаются в столбцах, находящихся только во второй таблице. Каждая строка из второй таблицы будет скопирована таким же образом с пустыми значениями в столбцах, которые являются исключительными для первой таблицы. Это называется разделением данных. Вместо объединения значений из двух таблиц в один столбец Power Query сохраняет исходные столбцы с унаследованными несвязанными данными.
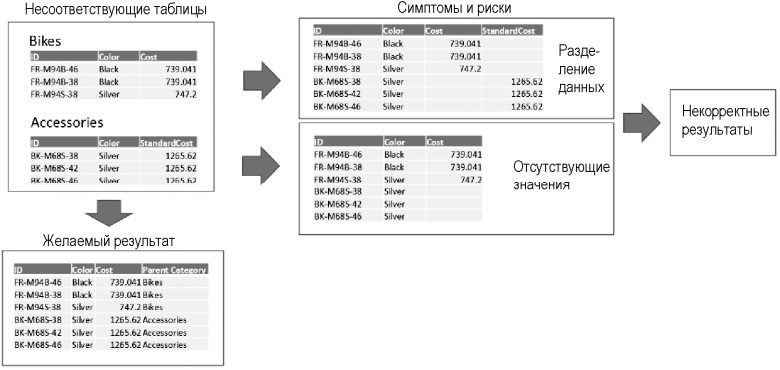
Рис. 2. Несоответствующие таблицы
Устранение несоответствующих названий столбцов
Загрузить файлы: C04E01 — Accessories.xlsx и C04E01 — Bikes.xlsx. Стоимость товара указана в столбце Cost для Bikes и в столбце StandardCost в таблице Accessories. Откройте новую рабочую книгу в Excel и импортируйте две исходные книги в режиме Только создать подключение. В редакторе PQ выберите запрос Accessories и выполните команду Добавить запросы –> Добавить запросы в новый. Обратите внимание, что в новом запросе Добавить1 столбцы Cost и StandardCost включены в объединенные результаты:
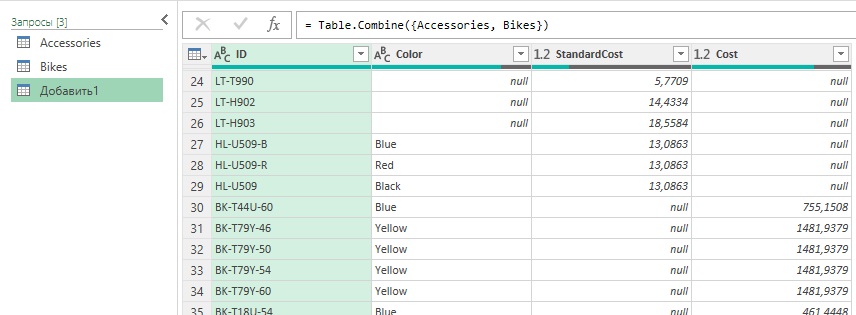
Рис. 3. Объединенный запрос; чтобы увеличить изображение кликните на нем правой кнопкой мыши и выберите Открыть картинку в новой вкладке
Выберите запрос Accessories и переименуйте столбец StandardCost на Cost. Теперь, при повторном выборе запроса Append1 видно, что столбцы объединены корректно.
Объединение несоответствующих таблиц из одной папки
Допустим четверо менеджеров ведут запасы товаров. При попытке объединить их данные обнаруживается, что они используют разные имена столбцов:

Рис. 4. Имена столбцов в четырех категориях продуктов
Загрузите файлы C04E02 — Accessories.xlsx, C04E02 — Bikes.xlsx, C04E02 — Components.xlsx, C04E02 — Clothing.xlsx в отдельную папку. В Excel откройте новую рабочую книгу, пройдите Данные –> Получить данные –> Из файла –> Из папки. В окне Обзор выберите папку, в которой сохранили эти 4 файла (я назвал ее Товары) и нажмите Открыть, хотя ни один файл не выбран. В следующем окне файлы из папки будут представлены четырьмя строками. Пройдите Объединить –> Объединить и преобразовать данные. В окне Объединить файлы раскрывающееся меню Пример файла позволяет выбрать один из исходных файлов и применить его формат и заголовки ко всем файлам в папке:
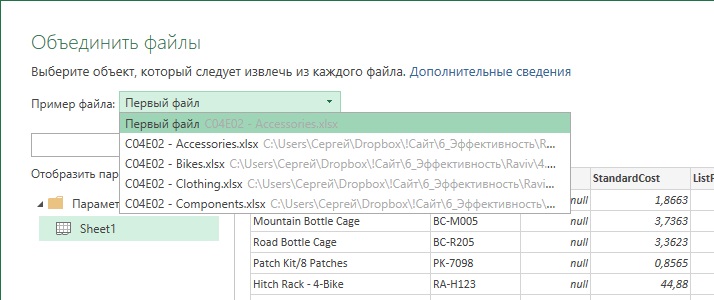
Рис. 5. Выбор файла для заголовков
Оставьте выбор по умолчанию, выделите Sheet1 и кликните Ok.
В окне редактора PQ прокрутите вниз, пока строки не изменятся от Accessories до Bikes. Ряд столбцов содержат нулевые значения. В редакторе PQ перейдите на панель Запросы и выберите запрос Преобразовать пример файла. Он играет роль примера запроса. Этот запрос сгенерирован в результате объединения файлов из папки. После выбора примера запроса можно увидеть на главной панели редактора PQ, что данные из таблицы Accessories отображаются правильно.
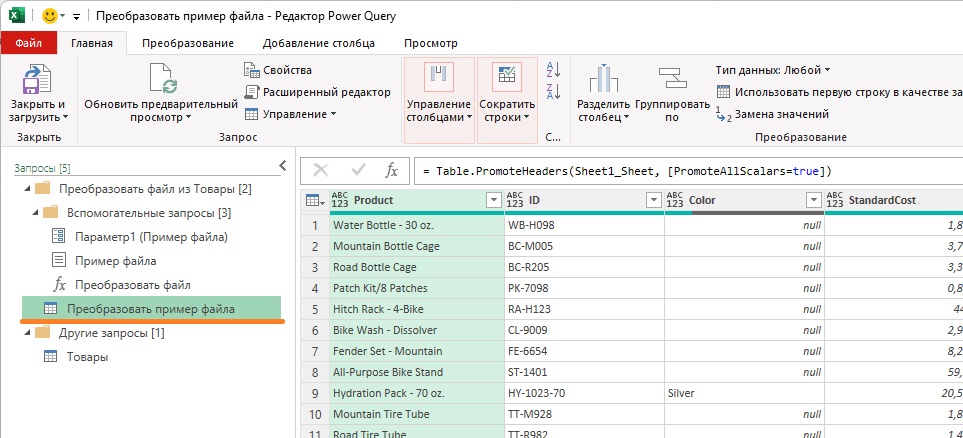
Рис. 6. Запрос Преобразовать пример файла
При объединении файлов из папки Power Query создает:
- функцию Преобразовать файл,
- пример файла,
- Параметр 1 (Пример файла) и
- запрос Преобразовать пример файла
- запрос Товары; этот запрос будет назван по имени папки, из которой вы ведете импорт.
Эти элементы помогают объединять несколько файлов из папки на основе выбранных данных. Основное преобразование для каждого файла реализовано в функции. Для того чтобы настроить преобразование для каждого файла, можно вносить изменения в пример запроса. Эти изменения распространяются на функцию и применяются ко всем файлам. Всякий раз при объединении файлов из папки найдите запрос, который начинается с Преобразовать пример файла. Этот запрос рассматривает как изменение каждого файла, так и его добавление.
Предположение об одинаковом порядке столбцов
В редакторе PQ выберите запрос Преобразовать пример файла и переименуйте его в Products Sample. На панели Примененные шаги удалите последний шаг Повышенные заголовки. После этого объединенная таблица будет иметь общие столбцы с именами Column1, Column2, Column3 и т.д. Если все таблицы имеют одинаковую последовательность столбцов, то данные в добавленной таблице будут корректными.
Выберите запрос Товары и просмотрите объединенную таблицу. Обратите внимание, что при переходе от Accessories к Bikes данные отражаются корректно. Правда появилась ошибка Столбец «Product» таблицы не найден. На панели Примененные шаги удалите последний шаг Измененный тип. Теперь в объединенной таблице отсутствуют пропущенные значения. Можно убедиться в этом, выполнив прокрутку снова и удостоверившись, что включены все значения в таблице Accessories.
Теперь можно повысить первую строку до уровня заголовка, выбрав команду Использовать первую строку в качестве заголовков. Осталось избавиться от промежуточных заголовков. На панели Запросы выберите запрос Products Sample. Пройдите Добавление столбца –> Столбец индекса. Имена столбцов каждой таблицы имеют индекс ноль. Вернитесь к запросу Товары и отфильтруйте строки с нулевым индексом. Для этого кликните мышью на элементе управления фильтром в последнем столбце, который помечен символом 0. Снимите галочку напротив значения 0, нажмите Ok.
Удалите первый столбец (столбец «C04E02 — Accessories.xlsx») и последний столбец (столбец 0). Можно также повысить надежность скрипта, изменив удаление столбца с именем «C04E02 — Accessories.xlsx» на удаление первого столбца. Измените код:
= Table . RemoveColumns ( #»Строки с примененным фильтром»,
= Table . RemoveColumns ( #»Строки с примененным фильтром»,
Теперь можно загрузить объединенную таблицу на лист Excel и приступать к анализу.
Простая нормализация
= #»Повышенные заголовки
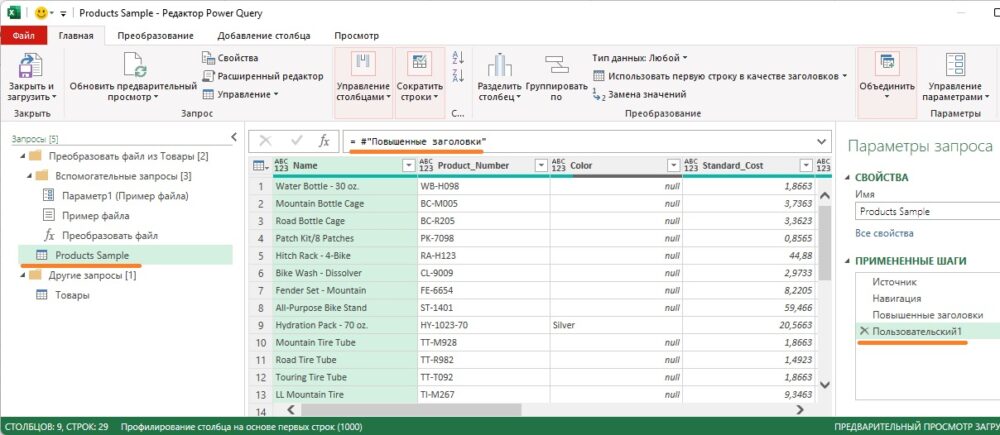
Рис. 7. Код М, соответствующий щелчку на значке fx Шаг Повышенные заголовки был последним шагом на панели Примененные шаги перед тем, как выполнен щелчок на кнопке fx. #»Повышенные заголовки – переменная, используемая для вывода этого шага. Поскольку данная переменная возвращает таблицу с несовпадающими именами столбцов, к ней можно применить функцию Table.TransformColumnNames с помощью метода Text.Lower, что позволит задать строчные буквы в именах столбцов. Для этого измените формулу в строке на:
= Table . TransformColumnNames ( #»Повышенные заголовки», Text.Lower)
= Пользовательский 1
= Table . TransformColumnNames ( Пользовательский 1 ,
each Replacer . ReplaceText ( _ , «_» , » » ) )
Нажмите Enter и обратите внимание на то, что все имена столбцов теперь содержат пробелы вместо подчеркивания. Выберите запрос Товары и удалите последний шаг Измененный тип. Заметьте, что все файлы корректно сведены вместе, без каких-либо дополнительных признаков пропущенных значений.
Таблица преобразования

К сожалению, простой нормализации может не хватить для исправления разношерстных заголовков. Для обозначения одного по сути столбца разные менеджеры используют 4 заголовка: ID, Product_Number, Product_num и Product Number. Нормализовать имена этих столбцов с помощью простых операций над текстом нельзя. Вместо этого можно сформировать таблицу преобразования исходных имен в нормализованные. Рис. 8. Таблица преобразования исходных имен в нормализованные Все несоответствия, которые вы будете выявлять при работе с исходными файлами, удобно отражать в таблице во внешней книге Excel. Постепенно будут появляться новые несоответствия, и формироваться новые строки таблицы преобразования. При подключении таблицы преобразования к запросам не нужно редактировать запрос для нормализации новых несоответствующих имен столбцов. Вместо этого просто добавьте в таблицу преобразования новые строки и обновите отчет. Рассмотрим несколько методов, позволяющих работать с таблицами преобразования.
Методика транспонирования
Для нормализации несовпадающих столбцов с помощью таблицы преобразования необходимо временно преобразовать имена столбцов в таблицу с одним столбцом, объединить таблицу преобразования, заменить несоответствующие имена столбцов требуемыми целевыми и преобразовать имена столбцов обратно в заголовки. Загрузите файл C04E04 — Conversion Table.xlsx с таблицей преобразования. Загрузите файлы C04E04 — Accessories.xlsx, C04E04 — Bikes.xlsx, C04E04 — Components.xlsx, C04E04 — Clothing.xlsx в отдельную папку, например Products. Откройте новую книгу в Excel и пройдите Данные –> Получить данные –> Из файла –> Из книги. Выберите файл C04E04 — Conversion Table.xlsx. Нажмите Импорт. В окне Навигатор выберите Header_Conversion. Кликните Загрузить –> Загрузить в…, выберите опцию Только создать подключение. Теперь, при наличии таблицы преобразований в качестве нового запроса, можно загрузить содержимое папки Products. Пройдите Данные –> Получить данные –> Из файла –> Из папки. Выберите папку Products и нажмите Открыть, хотя ни один файл не выбран. В следующем окне файлы из папки будут представлены четырьмя строками. Пройдите Объединить –> Объединить и преобразовать данные. В окне Объединить файлы выделите Sheet1 и кликните Ok. На панели Запросы выберите Преобразовать пример файла и переименуйте его в Products Sample. Напомним, что этот запрос является примером обработки одного файла из папки. Введенные здесь изменения повлияют на таблицу, добавленную в запросе Products. Переименуйте запрос Products в Appended Products. Пройдите Главная –> Закрыть и загрузить. Сохраните рабочую книгу Excel. Затем создайте три ее копии; они пригодятся при выполнении следующих заданий. Первый способ нормализации имен столбцов основан на команде Преобразование –> Транспонировать. С помощью транспонирования каждая ячейка в столбце X и строке Y будет помещена в столбец Y и строку X. При манипулировании значениями имен столбцов выполнить это в редакторе Power Query гораздо проще, если имена столбцов представлены вертикально в столбце. Однако при попытке транспонирования таблицы обнаруживается, что исходные имена столбцов не сохраняются после преобразования. Для сохранения имен столбцов необходимо понизить имена столбцов до первой строки, а затем транспонировать таблицу. Для этого откройте сохраненную книгу и запустите редактор Power Query. Например, пройдя Данные –> Получить данные –> Запустить редактор Power Query. На панели Запросы выберите запрос Products Sample, удалите шаг Повышенные заголовки. Теперь заголовки примера таблицы находятся в первой строке. Пройдите Преобразование –> Транспонировать. Теперь столбец Column1 включает имена столбцов, которые необходимо нормализовать. ![]() Рис. 9. Запрос Products Sample после транспонирования столбцов в строки При выбранном запросе Products Sample пройдите Главная –> Объединить запросы. Будьте внимательны, ранее мы использовали команду Добавить запросы. В окне Слияние выберите столбец Column1 в таблице Products Sample (1), в раскрывающемся меню выберите запрос Header_Conversion (2), выберите столбец Source (3):
Рис. 9. Запрос Products Sample после транспонирования столбцов в строки При выбранном запросе Products Sample пройдите Главная –> Объединить запросы. Будьте внимательны, ранее мы использовали команду Добавить запросы. В окне Слияние выберите столбец Column1 в таблице Products Sample (1), в раскрывающемся меню выберите запрос Header_Conversion (2), выберите столбец Source (3): 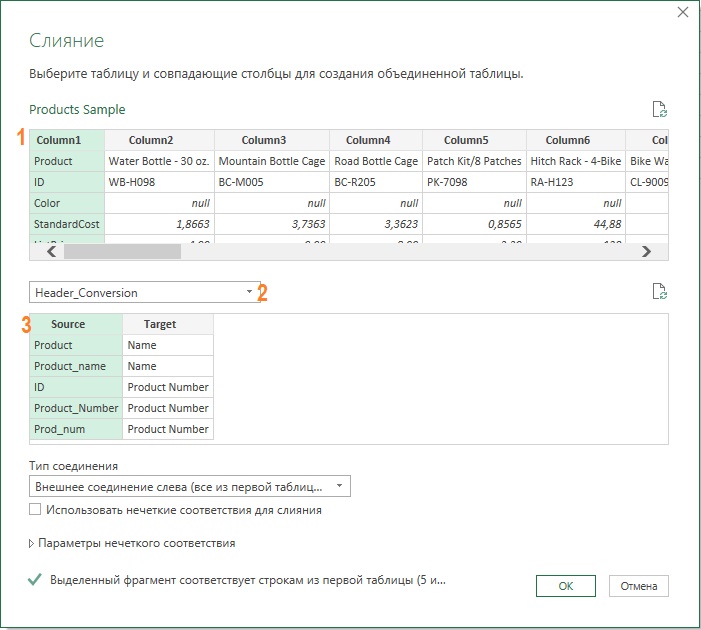 Рис. 10. Окно Слияние Проверьте, что Тип соединения выбран Внешнее соединение слева, кликните Ok. В запрос Products Sample добавится новый столбец Header_ Conversion с объектами таблицы (Table). Разверните столбец Header_Conversion щелкнув мышью на элементе управления справа от его заголовка, и установив опции:
Рис. 10. Окно Слияние Проверьте, что Тип соединения выбран Внешнее соединение слева, кликните Ok. В запрос Products Sample добавится новый столбец Header_ Conversion с объектами таблицы (Table). Разверните столбец Header_Conversion щелкнув мышью на элементе управления справа от его заголовка, и установив опции: 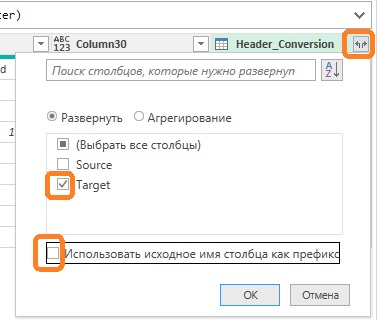 Рис. 11. Окно Развернуть Столбец Header_Conversion преобразуется в столбец Target:
Рис. 11. Окно Развернуть Столбец Header_Conversion преобразуется в столбец Target: 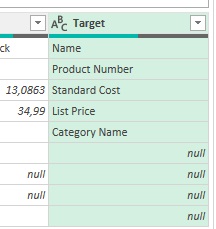 Рис. 12. Столбец Target Значение null означает, что запрос Header_ Conversion не содержал значений для замены, т.е. исходные заголовки в столбце Column1 отвечают требованиям. Добавим условный столбец для копирования целевых значений из строк, которые должны быть нормализованы, и исходных значений из прочих строк. Пройдите Добавление столбца –> Условный столбец. Настройте параметры:
Рис. 12. Столбец Target Значение null означает, что запрос Header_ Conversion не содержал значений для замены, т.е. исходные заголовки в столбце Column1 отвечают требованиям. Добавим условный столбец для копирования целевых значений из строк, которые должны быть нормализованы, и исходных значений из прочих строк. Пройдите Добавление столбца –> Условный столбец. Настройте параметры: 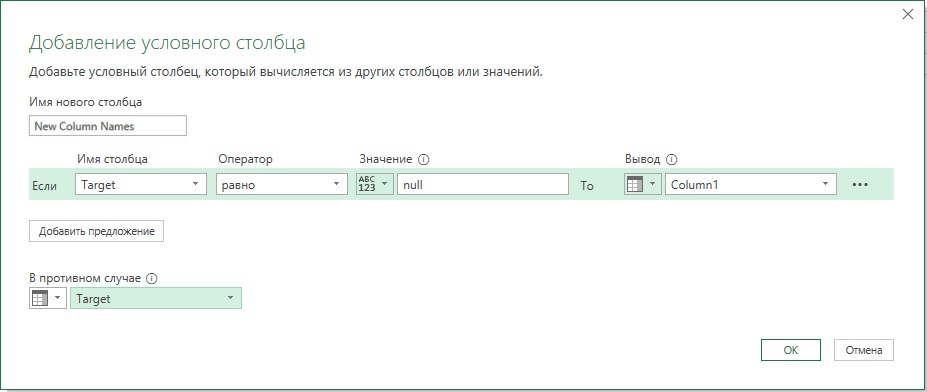 Рис. 13. Окно Добавление условного столбца
Рис. 13. Окно Добавление условного столбца
Удалите столбцы Column1 и Target. Переместите столбец New Column Names на место первого столбца таблицы. Просто перетащите и опустите его с правой на левую сторону или воспользуйтесь советом. Если в таблице много столбцов, а нужно переместить столбец в начало, вместо перетаскивания столбца можно выделить столбец и на вкладке Преобразование выбрать команду Переместить –> В начало. Также можно щелкнуть правой кнопкой мыши на заголовке столбца и выбрать в контекстном меню команду Переместить –> В начало. Пришло время транспонировать таблицу обратно. Выполните Преобразование –> Транспонировать, и Преобразование –> Использовать первую строку в качестве заголовков. Перейдите к запросу Appended Products и удалите последний шаг Измененный тип. Изучите запрос Appended Products в редакторе PQ или на листе Excel. Объединение должно быть выполнено корректно, несмотря на несоответствие в заголовках в четырех исходных файлах.
Отмена свертывания, слияние и повторное сведение

Метод транспонирования работает только при небольших наборах данных. Power Query поддерживает таблицы с 16 384 столбцами. Так что у вас не получится транспонировать таблицу с более чем 16 384 строками. Даже если испробовать этот метод на 15 000 строках, потребление памяти и низкая частота обновления наводят на мысль о необходимости альтернативного метода. Откройте копию файла, сохраненного ранее. Напомню, мы остановились на шаге, когда переименовали запрос Products в Appended Products. Запустите редактор Power Query. Выберите запрос Products Sample. Пройдите Добавление столбца –> Столбец индекса. Кликните правой кнопки мыши на столбце индекса и выберите Отменить свертывание других столбцов. Power Query создаст новую таблицу с тремя столбцами: Индекс, Атрибут и Значение. В столбце Индекс сохраняется исходный идентификатор строки, что поможет далее вернуть таблицу в исходное состояние. Столбец Атрибут включает имя столбца, а столбец Значение содержит исходные значения, которые имелись в таблице. Теперь можно выполнить подстановку в столбце Атрибут. Рис. 14. Отменить свертывание других столбцов Примените последовательность слияния, описанную выше. Пройдите Главная –> Объединить запросы. Настройте окно Слияние, как на рис. 10. Разверните столбец Header_Conversion, как показано на рис. 11. Добавьте условный столбец с параметрами, как на рис. 13. Удалите столбцы Атрибут и Target. Переместите столбец New Column Names на место второго столбца таблицы. Для отмены развертывания выберите столбец New Column Names, пройдите Преобразование –> Столбец сведения. В окне Столбец сведения выберите Значение (вместо Индекс), откройте раздел Расширенные параметры. Установите Не агрегировать, кликните Ok. Удалите столбец Индекс. Перейдите к запросу Appended Products, удалите шаг Измененный тип. Наслаждайтесь качественно скомбинированной таблицей!