Net::HTTP — Универсальный базовый парсер с поддержкой многостраничного парсинга и обходом CloudFlare
 Net::HTTP – это универсальный парсер, который позволяет решать большинство нестандартных задач. Может быть использован как основа для для парсинга произвольного контента с любых сайтов. Позволяет скачать код страницы по ссылке, поддерживает многостраничный парсинг (переход по страницам), автоматическую работу с прокси, позволяет выполнить проверку успешного ответа по коду или по содержимому страницы.
Net::HTTP – это универсальный парсер, который позволяет решать большинство нестандартных задач. Может быть использован как основа для для парсинга произвольного контента с любых сайтов. Позволяет скачать код страницы по ссылке, поддерживает многостраничный парсинг (переход по страницам), автоматическую работу с прокси, позволяет выполнить проверку успешного ответа по коду или по содержимому страницы.
Кейсы по применению парсера
�� Аукцион доменов REG.RU
Парсинг аукциона свобождающихся доменов с возможностью фильтрации
�� Данные по SSL сертификату
Парсинг данных SSL сертификата доменов с сайта leaderssl.ru
�� Парсинг ресурса Booking.com
Получение результатов поиска квартир и отелей на сайте
�� Сбор характеристик товара
Пример парсинга неизвестного количества характеристик товара
�� Парсинг базы фильмов из IMDB
Получает данные о каждом фильме и записывает их в результат
�� Проверка наличия HTTPS
Пресет проверяет наличие HTTPS на сайте
Собираемые данные
- Контент
- Код ответа сервера
- Описание ответа сервера
- Заголовки ответа сервера
- Прокси, использованные при запросе
- Массив со всеми собранными страницами (используется при работе опции Use Pages)
Возможности
- Многостраничный парсинг (переход по страницам)
- Автоматическая работа с прокси
- Проверка успешного ответа по коду или по содержимому страницы
- Поддерживает сжатия gzip/deflate/brotli
- Определение и преобразование кодировок сайтов в UTF-8
- Обход защиты CloudFlare
- Выбор движка (HTTP или Chrome)
- Опция Check content – выполняет указанное регулярное выражение на полученной странице. Если выражение не сработало, страница будет загружена заново с другой прокси.
- Опция Use Pages – позволяет перебрать указанное количество страниц с определенным шагом. Переменная $pagenum содержит текущий номер страницы при переборе.
- Опция Check next page – необходимо указывать регулярное выражение, которое будет извлекать ссылку на следующую страницу (обычно кнопка «Вперёд»), если она существует. Переход между страницами осуществляется в рамках указанного лимита (0 — без ограничений).
- Опция Page as new query – переход на следующую страницу происходит в новом запросе. Позволяет убрать ограничение на количество страниц для перехода.
Варианты использования
- Скачивание контента
- Скачивание картинок
- Проверка кода ответа сервера
- Проверка наличия HTTPS
- Проверка наличия редиректов
- Вывод списка URL редиректов
- Получение размера страницы
- Сбор мета-тегов
- Извлечение данных из исходного кода страницы и/или заголовков
Запросы
В качестве запросов необходимо указывать ссылки на страницы, например:
http://lenta.ru/ http://a-parser.com/pages/reviews/ Варианты вывода результатов
A-Parser поддерживает гибкое форматирование результатов благодаря встроенному шаблонизатору Template Toolkit, что позволяет ему выводить результаты в произвольной форме, а также в структуированной, например CSV или JSON
Вывод контента
$data DOCTYPE html>html id="XenForo" lang="ru-RU" dir="LTR" class="Public NoJs uix_javascriptNeedsInit LoggedOut Sidebar Responsive pageIsLtr hasTabLinks hasSearch is-sidebarOpen hasRightSidebar is-setWidth navStyle_0 pageStyle_0 hasFlexbox" xmlns:fb="http://www.facebook.com/2008/fbml"> head> meta charset="utf-8" /> meta http-equiv="X-UA-Compatible" content="IE=Edge,chrome=1" /> meta name="viewport" content="width=device-width, initial-scale=1" /> base href="https://a-parser.com/" /> title>A-Parser - парсер для профессионалов SEOtitle> noscript>style>.JsOnly, .jsOnly display: none !important; >style>noscript> link rel="stylesheet" href="css.php?css=xenforo,form,public,parser_icons&style=9&dir=LTR&d=1612857138" /> link rel="stylesheet" href="css.php?css=facebook,google,login_bar,moderator_bar,nat_public_css,node_category,node_forum,node_list,notices,panel_scroller,resource_list_mini,sidebar_share_page,thread_list_simple,twitter,uix_extendedFooter&style=9&dir=LTR&d=1612857138" /> link rel="stylesheet" href="css.php?css=uix,uix_style&style=9&dir=LTR&d=1612857138" /> Код ответа сервера
$code Формат результата [% response.Redirects.0.Status || сode %] позволяет выводить статус 301, если в запросе присутствуют редиректы.
Получение данных о запросе
Переменная $response помогает получить о запросе и ответе сервера
$response.json\n "Time": 3.414, "connection": "keep-alive", "Decode": "Decode from utf-8(meta charset)", "cache-control": "max-age=3600,public", "last-modified": "Tue, 18 May 2021 12:42:56 GMT", "transfer-encoding": "chunked", "date": "Thu, 27 May 2021 14:18:42 GMT", "Status": 200, "content-encoding": "gzip", "Body-Length-Decoded": 1507378, "Reason": "OK", "Proxy": "http://51.255.55.144:25302", "content-type": "text/html", "Redirects": [], "server": "nginx", "Request-Raw": "GET / HTTP/1.1\r\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\r\nAccept-Encoding: gzip, deflate, br\r\nAccept-Language: en-US,en;q=0.9\r\nConnection: keep-alive\r\nHost: a-parser.com\r\nUpgrade-Insecure-Requests: 1\r\nUser-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)\r\n\r\n", "URI": "https://a-parser.com/", "HTTPVersion": "1.1", "Body-Length": 299312, "Decode-Mode": "auto-html", "etag": "W/\"60a3b650-170032\"", "Decode-Time": 0.003, "IP": "remote", "expires": "Thu, 27 May 2021 15:18:42 GMT" > Получение редиректов
https://google.it $response.Redirects.0.URI -> $response.URI https://google.it/ -> https://www.google.it/ JSON с редиректами
$response.Redirects.json ["x-powered-by":"PleskLin","connection":"keep-alive","URI":"http://a-parser.com/","location":"https://a-parser.com/","date":"Thu, 18 Feb 2021 09:16:36 GMT","HTTPVersion":"1.1","Status":301,"content-length":"162","Reason":"Moved Permanently","Proxy":"socks5://51.255.55.144:29683","content-type":"text/html","IP":"remote","server":"nginx","Request-Raw":"GET / HTTP/1.1\r\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\r\nAccept-Encoding: gzip, deflate, br\r\nAccept-Language: en-US,en;q=0.9\r\nConnection: keep-alive\r\nHost: a-parser.com\r\nUpgrade-Insecure-Requests: 1\r\nUser-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)\r\n\r\n">] Вывод статуса ответа сервера
$reason Время ответа сервера
$response.Time 1.457 Получение размера страницы
В качестве примера размер представлен в трех разных вариантах.
[% "data-length: " _ data.length _ "\n"; "Body-Length: " _ response.$'Body-Length'> _ "\n"; "Body-Length-Decoded: " _ response.$'Body-Length-Decoded'> _ "\n" %] data-length: 70257 Body-Length: 23167 Body-Length-Decoded: 75868 Обработка результатов
A-Parser позволяет обрабатывать результаты непосредственно во время парсинга, в этом разделе мы привели наиболее популярные кейсы для парсера Net::HTTP
Вывод заголовков H1-H6
Добавить регулярку (опция Использовать регулярку) (.+?) , в поле «Применить к» выбрать $pages.$i.data — Page content , в поле напротив регулярки выбрать модификаторы sg . В качестве типа результата будет автоматически выбран массив. В поле «Имя» указать headers , в «$1 to» указать tag , нажать на плюсик напротив и в «$2 to» указать content . В Формате результата использовать $p1.headers.format(‘$content\n’) .
eJx9VE1v2zAM/SsFkcMGBEFy2MW3NFiKDVnTNekpyEGNaUOLLGmSnDUw/N9H+ktO N/Rmko+PfCTlCoLwZ//k0GPwkBwqsM03JLD7miQPxuQK7zZSn/3di5a/S4QpWOE8 OoYfRigKpJiJUgWYVhCuFonEXNA5mXJQpmRbZ96uDoOT6Ml3Eapk2GI+n0P9QZrI 8WRKHWLO4gO44n4tOk4bZcxHKWUvhuRyy8kBSJMlByfDcdoh9i3cU8c6h977oMyr UJAEV2J9PPYsfm1cIXh4E7uYdZMcgjtxwb2hYCZVrOzXZD2KgqtMUhGQo7OsIfr0 eRbemEGkqQzSaKHaCjz7WLVbTALaEJY+ebprZwpyBWwI2HntuzvApLGjyp9tDiSZ UB6n4KnVtaBG0vcRGdCJYNzWcj/kr8DopVIbvKCKsIb/vpQqpUNZZpT0rUv8P2T7 D0c9yBuXokX/cdTDwNJY99sfMSs1G5OT8vS1WWYhA9l+1VxPAnNynhHtMLNHnllh HA5lOuauOr0Ni5qvKq5saaPrRsbNWm6dJ6MzmW+7S+2Rpd7TA9zqlSmsQtalS6Vo LR6f43ksfbcGNmKD75NXTQmW3r9DCMYo/33XtmqdpPP7wg0WNMlx1Y7yJJR6ed6M IxBPqjknz7QnutPc0AWRivo4/BGG/0g1/i8kVU1r+eWfWhBrYAj5aBieZs6P+S/t 6pW4 - Использование регулярных выражений
- Форматирование и представление результатов
Сбор мета-тегов
Добавить регулярку (опция Использовать регулярку) (
eJxtVO9v2jAQ/V8spBatg/XDvkRTJYqEtokRRtNPNJMscsk8/Gu2Q0FR/vfeJSGB bp/ie37v3Z3PTsUC93u/duAheBZtK2abNYtYBjkvZWB3zHLnwdH2lq0gRNHXJFkj 3jMqFk4WULMrfTBqA74VunYRbdGiAE8SHjhLaaeAIwpuvygIfPvrIf3wMGYdnrRm Re/QAdw5fkKw+a64IozkPY9KZCKAYmmdpj26ME5xamlk7yckmOQNcnszIvLLi74Z Dx5P/ACJQXYuJAzwAqMu5wi7ANo9+4wn4Uj98iwTQRjNZZuS6hnKeNbib0l6bZCL SyfAL5xRCAVoDAg8ncvdslET03mVjfZnq2FRzqWHO+ax1AXHQrL3O9iX48G42FI9 iFfM6JmUSziAHGiN/2MpZIbzneUo+tYJ/0+J//Go+/YuUx3AvTqsoXdposf4x6DK zNIU58OQQomAsZ+bUtOkPiG4B7D9ma2IpoyDPk3n3GXHK2xBZ8gcRjazA3TVxtVY rsGd0bkoYmzAiQzOzFIn+E5iPTfKSqC+dCkljsXDZrgeM9+NgYKhwPfieZPi6oUF Y6T//tSWap3A6/eZClR4kpdZO8sdl/J5s7zcYcOVwuB3CNZH0yn/2L7dyc6o6avY i6nQGRynjDwCFAZvF3ZYp/0j738F1cVTj6oaJ/bHr1sOtUcMxPCcPI6DRff1GzD1 gDE= - Использование регулярных выражений
- Форматирование и представление результатов
Варианты прохода по пагинации
Использование Use pages
Use pages. Данная функция позволяет проходить по пагинации с указанием наперед известного числа страниц. Для примера возьмем одну из категорий на сайте каталога товаров https://www.proball.ru/catalog/myachi/ . Вверху и внизу мы видим панель пагинации. При клике по пиктограмах с номерами страниц можно увидеть в строке браузера, как осуществляется передача параметра с номером страницы в конце запроса:
https://www.proball.ru/catalog/myachi/?PAGEN_1=1 Use pages — это своего рода счетчик, который фактически в переменную $pagenum подставляет по порядку номера, увеличивая их на то значение, которое мы укажем
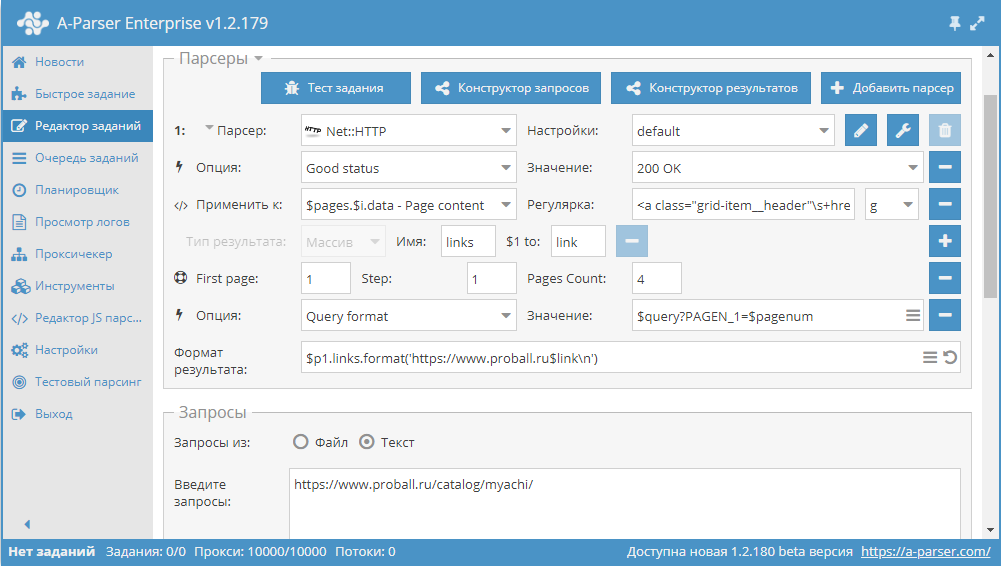
Как видно на скриншоте, в формате запроса парсера в нужном месте используется переменная $pagenum . Функция Use pages переберет и подставит в запрос все значения, фактически мы будем получать ссылки для запроса
https://www.proball.ru/catalog/myachi/?PAGEN_1=$pagenum где вместо переменной $pagenum будет подставлен номер страницы, начиная от 1 и до 4 с шагом 1. Таким образом, получается проход по страницах нужного диапазона. В этом заключается ограничение данного метода — нужно заранее знать количество страниц, которые есть в пагинации. Очевидно, что при одновременном парсинге нескольких категорий, количество страниц везде будет разное, и как выход, мы можем просто указать большее количество предполагаемых страниц. Но это не совсем правильно, поэтому есть более оптимальное решение, о котором речь пойдет дальше
eJx1VNtu2kAQ/ZVqhJSgUAhV+2I1jSgqvSgCmtAnjKKtPTZu1rubvXAR8r931jY2 pOmTvWfPXM7M7BzAMvNk5hoNWgPB8gCq/IcAnME5SxF6oJg2qP31EqZog+DbYjEn PMaEOW6hdwC7V0g2coNaZ7E3ymI6p1LGY1meN4w7oizfXV+vitYicsbK/B5N6Qh0 9RMsKWiKxgdhlsHK36S4I4OP7E3EmTE3IaQU6m1mMX98XCOLUYcQhuZqrTGh28v+ 1W03hE9Q2y6qgGkTpQaY1mxPYPmdstxjPBNPpiF65SUEp5lLZTMpzFFqXS7TSoWh 9xrHmecxDsGhEvVgUdW3/hxJJ3y930NR/L+Szw71PpE6Z/YkQqeEb+ejr1+mj8Ob jvcnXA7FatUkP6mMiKyG/VJYv/JzebG2VplgMNhut32l5W/GeV+7jieFobjothV4 YBtcSHKSZBxbeEKnumQdahT626P3bj8ym7MKVJn4arbZ/RLZcylFSOJ6ORmaiZY5 QRZ3tgb3RxXLWrMfCVfa/qxsIEgYN9gDQ6lOGCUSv7yhUdHMSj2rO0cNkWLE+R1u kLe00v9nl3GaKDNKyOh7bfg6ZfaPj6KRdxqKOrrVlENLiuWdTI/anxBVU42pR3Kp sXFQR6790otVKPxgtM0YqRY6S/Cs4OdgJEWSpbN62I5MJxa0FmZiLHPF0WcsHOc9 P+P3beNHpi6wP7QJvjQelyEorWZdgJWSmx8PVapKZzRYH5rmE/r6XA4iWgVcpoN8 z6J1NiBbQjCVNA1+c5XjQi9Hl/J6gDvFRIxUEasdFqti1ayyZuEdThZacKAHCH/M vOJ4VZ5BGJXHUBcgGBZ/AXULzRU= Использование Сheck next page
Сheck next page — это еще одна функция, которая позволяет организовать проход по пагинации. Особенность ее использования заключается в том, что для перехода на следующую страницу, нужно использовать регулярное выражение, которое будет возвращать ссылку на следующую страницу. Это более удобный и наиболее часто применяемый способ. Но применить его для https://www.proball.ru/catalog/myachi/ не получится, т.к. в коде нету ссылок на следующие страницы. Ссылки там генерируются скриптом. Поэтому возьмем в качестве примера сайт http://www.imdb.com/search/name?gender=female . Здесь есть пагинация как в начале так и в конце списка. Посмотрев и проанализировав исходный код, можно увидеть наличие ссылки, которая позволяет переходить на следующую страницу:
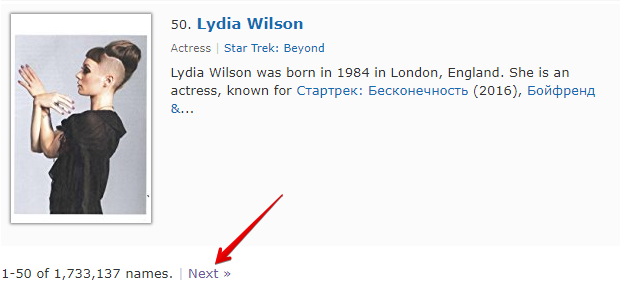
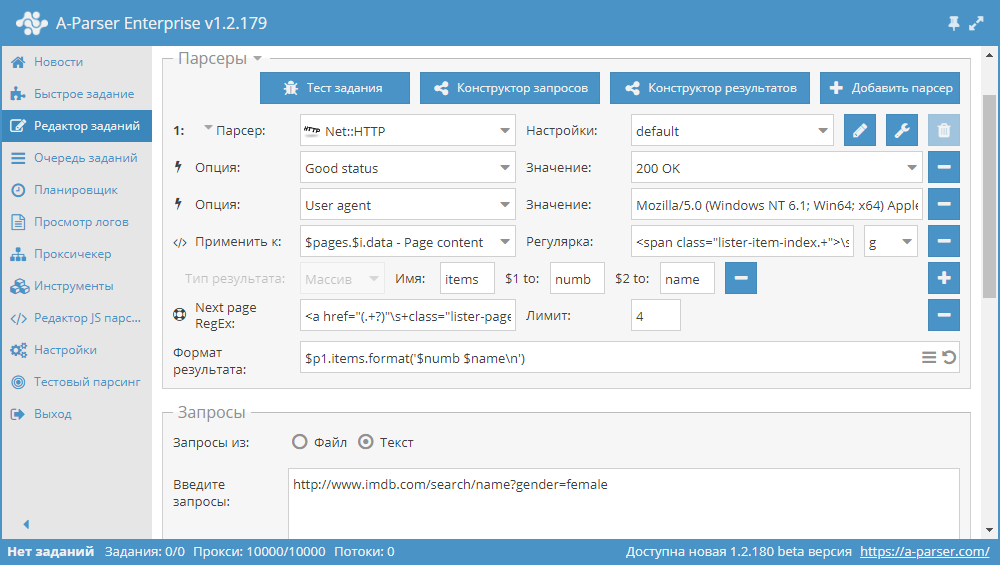
- в поле Next page RegEx запишем регулярное выражение
- в поле Лимит укажем количество страниц, которое нужно пройти
В примере указано 4 . Указав лимит, мы определяем, сколько страниц парсер должен пройти. В нашем случае будет пройдено 5 страниц, так как отсчет начинается с 0 . Если указать лимит 0 , то парсер будет работать до того времени, пока не пройдет все страницы в независимости от их количества. Это очень удобно использовать, когда нужно спарсить все результаты со всех страниц
eJx1VGFT2kAQ/SuZG2aUggGq4DSijnXG2qpAlY4fCM6cZANXL7n07iJYhv/e3RAS sO0XuH3ZvX1vd2+XzHLzYgYaDFjDvNGSJdmZeWwyg8lLDxZ2wKfA6izh2oAmpxHr gfW86+FwgHgAIU+lZfUls28JYKR6Ba1FQEEiQHuqVHCpMvuVyxRdRh+bzfHq/xEp ZjrAtLEtY9id+i2k5I2223T2H0UcqLlxekOn47ZOHLQ7RyfOonNUdS6SRMIjPN8I 22gfHruHHWf/5np4d1t3pHgB5wsKU1XncqZVBI32J7fpHjaPW26r1XYeeMi1yMPY FsVJaqyK7sFkWpleH7wR1mUKhurALWdj+jKFBQZ0TcJjZyK5Mac+k8JY1CQsRAdI HRZuzWdnvm8+7Lu18yodur7foBhCa10+ejob19Yeo6fueMuJn7E8zXDNbVoQygGu NX9DMPvv8YgwSm0KR+oji9PoGZGYHHbakVihYrPpxvtJ2DSky52ZhhDVrTUwIv5O MFXnIMZYh34y02fELAgEJeGSecvdDLciEjSAR2y1Go8LwldKR5zwStJyMzFumEH7 exUS4lRIh+/He9VS5QN/haHCoFBIKOErtPKyVLBvQF83t1Vdu7A7DNeZqWIlmx+x +JUVIVboi0ctwFzhQCFkIbuAwLcN6xGrZDZNSJrFfl/HMC/k0kCdGaR6xZFI8P4L itXcKt3P24IFU/GFlLfwCrJ0y+7/nAoZ4DO9CDHoax74b5f+X3esCnnbqfBtzjVy KJ0CdaumG+0vAElRjR4hkdJQXJBnzu/FTZNATENVNgOfawHtENwp+C44UXEopv18 bWw803iI66wfX6oINwAxjlMp67RO7svGX5i8wGSUBN8HX2YpkFax4JhVSppvD2uq iRY4WO2i+YjOrE28RmM+n7siCp7diYoaBriezBo0m+e40FDCaQgRz6ZxgqM3VTgU tHizqaHhMZQKFrgJAsCyWJ3CarwaFxu42NbLrT3sLVfYmJ9msPYhaeSBGNbIYCuY 11r9ASIaBUM= Как было сказано выше, есть возможность динамически ограничивать количество страниц в Use pages. Для этого нужно совместно использовать Use pages и Сheck next page. Дополним пример, который был рассмотрен при описании Use pages и добавим в него функцию Сheck next page:
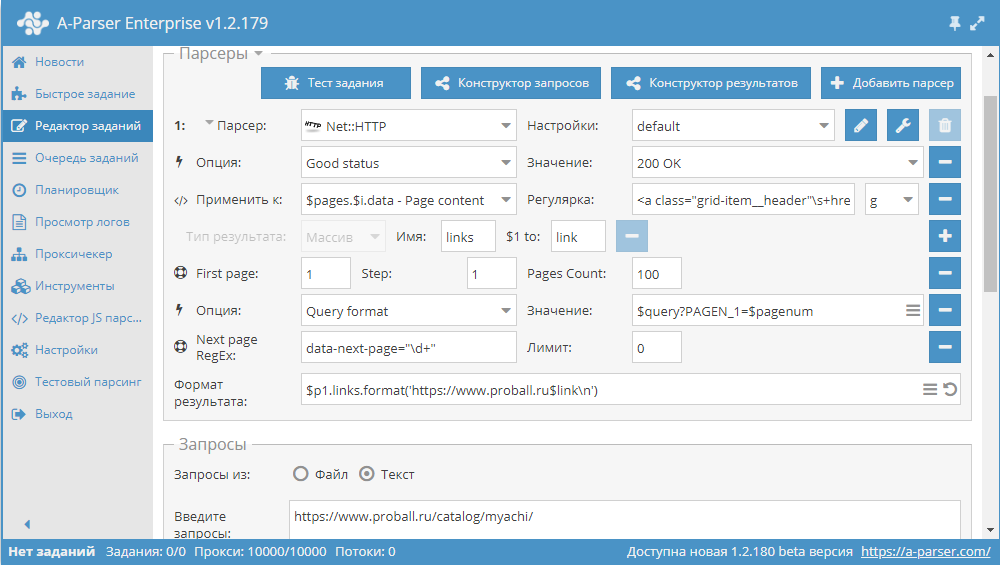
Эти две функции в паре работают следующим образом: Use pages обеспечивает проход по страницам, а Check next page проверяет, существует ли следующая. Как только Check next page не найдет следующей страницы, парсинг этой категории будет остановлен, не дожидаясь прохода по всему количеству, которое указано в Use pages. Совмещая эти функции, мы добавляем эффективности в работе парсера, экономя время и ресурсы
eJx1VNtuGjEQ/ZXKQkqiEC6V+rJqGtGo9KIIaEKfWBS5u7OLi9d2bC8EIf69M3uF XJ52fTyXM2fGs2eeu7WbWXDgHQsWe2aKfxaw3MGMp8C6zHDrwNL1gk3AB8GP+XyG eAwJz6Vn3T3zOwPoozdgrYjJScR4TrWOb3Vx3nCZo8ni42CwPLQeUe68zu7BFYGY LX+CBSZNwVES7jlb0k0Kz+jwmX+IJHfuOmQpproSHrLHxxXwGGzIwtBdriwkeHve u7y5CNkXVvnOy4Rpk6UCuLV8h2DxnfCMMCnU2jWGVHkBsWPm2nihlatLreRybals SFHjWJAdlyzYl0U9eDDVLZ0jnSvSezgYsMPhfS2fcrC7RNuM+6McnQK+mY2+f5s8 Dq87FFHlGXufaLSCaD2BZ191t45EQl8pxK8oxjVpGV+G7FUNJ/53IhNEnqgvl41g 45Im0jPDXiFmr2R+frby3rig399utz1j9V8uZc/mHTIKQ3V20ar+wDcw1xgkERJa eIynqk0d5Ax0W0e/6EVuc8K4ZEIdbNn9UeKpKFlptCUBBbix1RlCHgurwF1dxaJS mcYwL3x/lz4sSLh00GUOqY45Eolf3uB4Wu61nVZNQAG1Gkl5BxuQrVkR/2suJE6x GyXo9LNyfNtk+irGoSnvOBXO0NYih9Yo1nc6rWtfA5hGjQkhmbbQBKgyV3FxSxhQ NEJtM0amhU4Ingh+CkZaJSKdVuNdW+Zqjqtoqm51ZiQQY5VL2aV3dd82fuQqgenQ EnzpfFukoKGuVxTzWkv366GkaqzAwfrUNB/Rt+eyH+GrkDrtZzserUQffRGBVOM0 0LYsxgWfmC3K6zJ4NlzFgIoMD8vDstmdzYbdH23QYI/vnf1zs9KGSiILxFAbhy2g KP8Byg3yDQ== Использование макросов подстановок
Макросы подстановок позволяют реализовать последовательную подстановку значений из указанного диапазона
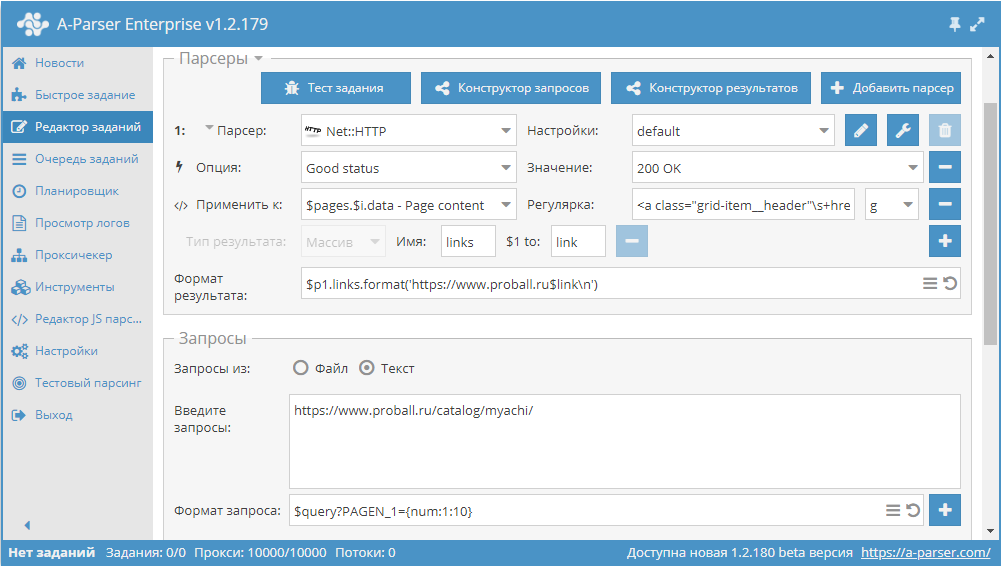
Данный пресет будет работать следующим образом. Указав в формате запроса шаблон:
$query?PAGEN_1= мы добавляем подстановку значений от 1 до 10 (диапазон можно указать любой) в сам запрос. Таким образом мы получаем запросы, оторые обеспечивают проход по нужному количеству страниц, вида:
https://www.proball.ru/catalog/myachi/?PAGEN_1=1 https://www.proball.ru/catalog/myachi/?PAGEN_1=2 . https://www.proball.ru/catalog/myachi/?PAGEN_1=10 Использование макросов подстановок для прохода по пагинации похоже на функцию Use pages и имеет такие же ограничения, то есть нужно указывать конкретный диапазон значений. Преимуществом данного метода можно считать то, что через макросы подстановок можно подставлять разные значения, как числовые, так и текстовые, например, слова или выражения. Таким образом мы можем более гибко вставлять нужные части в запросы или формировать сами запросы из частей, которые будут размещаться в разных файлах, если этого требует задание
eJxtVFtP2zAU/iuTVQkQXUsn7SUaQx2iu4i1HXRPTYW85CT1cGzPx+lFUf47x26a AOMp8Xcu3+dzccUcx0ecW0BwyKJlxUz4ZxH7yROr8WbH+sxwi2C9fcmm4KLo22Ix JzyFjJfSsX7F3N4ABekNWCtSIKNI6ZxrnV7rcN5wWZLL8sPFxaruIpISnS7uAEMi Zg8/0ZJIc0BPwh1nK2/JYUcBn/i7RHLEy5jlRPVeOCgeHtbAU7Axi2M8X1vIyHo6 OL86i9ln1sQuDoR5y9IA3Fq+JzB8p7zwmBTqEVtHf/MAsVW9WrXoRNuC+1L1zGgQ IgZZgE5P1s4ZjIbD7XY7MFb/4VIObNnzTnGsTs661Pd8AwtNSTIhoYMndGq09KgC 4K3H7GeDBDdecJoKJ7Ti8qDEy+zU/Vbiny84U5p86dcKwInVBUEOdq4B98dbLFkv nK/m468304fRZaXKIhpFo4val78M6X4d0rAo4xKhz5DUTzhpS19bqC2WO21nxksk vGJajaW8hQ3Izi1QfimFpO7hOKOg703g2y6z/3LU7Y2fU9Ecbi1p6JxSfavzYzke AUxboKlHCm2hTdAwN3lpPQwoP85df8amg14IfNGDl2CiVSbyWbMiR89SLWgHZ+pa F0aCV6xKKangCHfdLIyxKbA/dAJfB18HCpLVriZzWkv8cX+QaqygWfvYzgOhb4/q MKG1kzofFnuerMWQYgmBXNt9eCbCBPlBQs8BO8NVClQPZ0uoaUvaR6N9W6pnT0dU 1dSRvzg/+Pg7eQ/CqDhIPWDRqH4C36ybyg== Использование Page as query
Для уменьшения потребления памяти логику можно определить с помощью опции Page as query. При ее активации функции Check next page и Use pages будут каждую следующую страницу подставлять в запросы как отдельный самостоятельный запрос, тем самым не накапливая их контент в памяти. Page as query позволяет также определить, повышать ли уровень запроса Increase (аналогично работе инструмента tools.query.add), или нет Keep
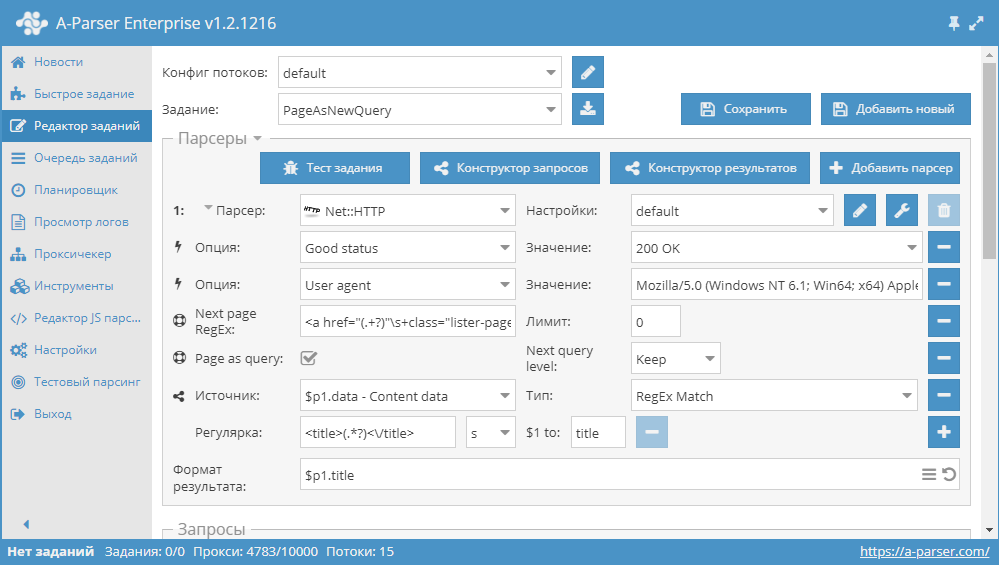
Скачать пример
eJx1VNty2jAQ/RWPJg/QEts0gUydpBnCDE0bAiQhkwfgQbHXoCJbriQDKcO/dyXM tc0LeFd7OXv2siSaqqnqSVCgFQkGS5LZbxKQHh1DQ3Vg/piDfCcVklGpQBqrAemA DoK7fr+H+ghimnNNKkui3zNAVzEDKVkE+MgilMdCRE1h5RnlOZoMvvj+aPWxR46Z ThFAqnc+5EH8YZxTr+b6TumVpZGYK6fTd+pu9dJBuX5+6Szq52WnkWUcXuHtnmmv dnbhntWd0v1d/6FdcTibgvMdwqkoO82JFAl4ta+u7575F1W3Wq05zzSmkhVuZB9i pplI1QZhOMEgHVhow9MeyCvqTCTE10NScj/flIdkOFSfQ06VQhVnSmNhGbqcpujr mB8rDgnGoFHETBLKSbA8zNBmCTNd8cnqY0zZccsKUFrmcBx9CpBZszbMADX+ajUa VQh2H3upWkIm1OQ7yaquZpqbEou3ZzqDvsC3mO2rWyh1aGJgnURUg3l1YxunVHb1 Qh8UuE5ghmmX9CVlvy2HqUBb/JQMVAt7hCoNNoBRvm/ADciJlQmGyK3v49qHBDHl CktWCLVFEUh0/MKwD1QL2S0YREZE2uDcsrEzs/Fvc8YjnPxGjE4/Csf/m3T/ibHa lrefCsd9LhHDNoqVbrsPO69ItMUYK4/esG5u2o+yaoo8Xc9BxbZwy1nHcJYICds0 ReQiO+54BqmZkl3LcE+2qoMyDtqyp1wSJXIZmgX2ESHV1HBfDKOEMSxscPOPm2Dn 5lvJ/XRTvhoOvbW4MeivnczsamF6uZ6y0QoDhiKN2bhb3IQNmjzt47Hqpk2R4Hob 7tKc84q5FU+7EWyootVG2JFw7Ny0KQy9m+uFMARXP5/XdGSSIaqaAZtgt/azFiFD yvnLU3v/hezGFoWJ1lngefP53GVJ9OaGIvEUUBlOvBT35AavG9J6HUNC7R6FuDRj geOM5RoWinu7Pc7LvasbLPEMkF+qt7YxtRoL1CFpCvtPgurqL0u6AK8= Возможные настройки
| Название параметра | Значение по умолчанию | Описание |
|---|---|---|
| Good status | All | Выбор какой ответ с сервера будет считается успешным. Если при парсинге будет другой ответ от сервера, то запрос будет повторен с другим прокси |
| Good code RegEx | Возможность указать регулярное выражения для проверки кода ответа | |
| Ban Proxy Code RegEx | Возможность банить прокси на время (Proxy ban time) на основе кода ответа сервера | |
| Method | GET | Метод запроса |
| POST body | Контент для передачи на сервер при использовании метода POST. Поддерживает переменные $query – URL запроса, $query.orig – исходный запрос и $pagenum — номер страницы при использовании опции Use Pages. | |
| Cookies | Возможность указать cookies для запроса. | |
| User agent | _Автоматически подставляется user-agent актуальной версии Chrome_ | Заголовок User-Agent при запросе страниц |
| Additional headers | Возможность указать произвольные заголовки запроса с поддержкой возможностей шаблонизатора и использованием переменных из конструктора запросов | |
| Read only headers | ☐ | Читать только заголовки. В некоторых случаях позволяет экономить трафик, если нет необходимости обрабатывать контент |
| Detect charset on content | ☐ | Распознавать кодировку на основе содержимого страницы |
| Emulate browser headers | ☑ | Эмулировать заголовки браузера |
| Max redirects count | 7 | Максимальное кол-во редиректов, по которым будет переходить парсер |
| Follow common redirects | ☑ | Позволяет делать редиректы http https и www.domain domain в пределах одного домена в обход лимита Max redirects count |
| Max cookies count | 16 | Максимальное число cookies для сохранения |
| Engine | HTTP (Fast, JavaScript Disabled) | Позволяет выбрать движок HTTP (быстрее, без JavaScript) или Chrome (медленнее, JavaScript включен) |
| Chrome Headless | ☐ | Если опция включена, браузер не будет отображаться |
| Chrome DevTools | ☐ | Позволяет использовать инструменты для отладки Chromium |
| Chrome Log Proxy connections | ☐ | Если опция включена, в лог будет выводиться информация по подключениям chrome |
| Chrome Wait Until | networkidle2 | Определяет, когда страница считается загруженной. Подробнее о значениях. |
| Use HTTP/2 transport | ☐ | Определяет, использовать ли HTTP/2 вместо HTTP/1.1. Например, Google и Majestic сразу банят, если использовать HTTP/1.1. |
| Don’t verify TLS certs | ☐ | Отключение валидации TLS сертификатов |
| Randomize TLS Fingerprint | ☐ | Данная опция позволяет обходить бан сайтов по TLS отпечатку |
| Bypass CloudFlare with Chrome | ☐ | Автоматический обход проверки CloudFlare |
| Bypass CloudFlare with Chrome Max Pages | 20 | Макс. кол-во страниц при обходе CF через Chrome |
| Bypass CloudFlare with Chrome Headless | ☑ | Если опция включена, браузер не будет отображаться во время обхода CF через Chrome |
Последнее обновление 28 дек. 2023 г.
- Обзор парсера
- Кейсы по применению парсера
- Собираемые данные
- Возможности
- Варианты использования
- Запросы
- Варианты вывода результатов
- Вывод контента
- Код ответа сервера
- Получение данных о запросе
- Получение редиректов
- JSON с редиректами
- Вывод статуса ответа сервера
- Время ответа сервера
- Получение размера страницы
- Вывод заголовков H1-H6
- Сбор мета-тегов
- Использование Use pages
- Использование Сheck next page
- Использование макросов подстановок
- Использование Page as query
HTTP запросы (+работа с куками, прокси, сессии)
Чтобы собрать данные с веб-страницы нужно выполнить HTTP запрос. В JavaScript API v2 А-Парсера реализован легкий в использовании метод выполнения HTTP запросов, который в ответ возвращает JSON объект в зависимости от указанных аргументов метода. Далее вы узнаете: как производится HTTP запрос, какие аргументы и опции имеет метод, результаты указанных опций, как указывать условие успешности HTTP запроса, и другое.
Также описаны методы позволяющие легко манипулировать куками, прокси и сессией в создаваемом парсере. После успешного выполнения HTTP запроса, или перед выполнением, вы можете установить/изменить данные прокси/кук/сессии для выполнения HTTP запросов или сохранить для выполнения другим потоком с помощью Менеджера сессий.
Данные методы наследуются от BaseParser и являются основой для создания собственных парсеров
await this.request(method, url[, queryParams][, opts])
await this.request(method, url, queryParams, opts)Получение HTTP ответа по запросу, в качестве аргументов указывается:
- method — метода запроса (GET, POST. )
- url — ссылка для запроса
- queryParams — хэш с get параметрами или хэш с телом post-запроса
- opts — хэш с опциями запроса
opts.check_content
check_content: [ условие1, условие2, . ] — массив условий для проверки получаемого контента, если проверка не проходит, то запрос будет повторен с другим прокси.
Возможности:
- использование в качестве условий строк (поиск по вхождению строки)
- использование в качестве условий регулярных выражений
- использование своих функций проверок, в которые передаются данные и хедеры ответа
- можно задать сразу несколько разных типов условий
- для логического отрицания поместите условие в массив, т.е. check_content: [‘xxxx’, [/yyyy/]] означает что запрос будет считаться успешным, если в полученных данных содержится подстрока xxxx и при этом регулярное выражение /yyyy/ не находит совпадений на странице
Для успешного запроса должны пройти все указанные в массиве проверки
Пример (в комментариях указано что нужно для того, чтобы запрос считался успешным):
let response = await this.request('GET', set.query, >, check_content: [ /|/, // на полученной странице должно сработать это регулярное выражение ['XXXX'], // на полученной странице не должно быть этой подстроки '