Что такое Google Colab и кому он нужен
Блокнот Colab — это бесплатная интерактивная облачная среда для работы с кодом на языке Python от Google в браузере. Принцип у нее такой же, как у остальных онлайн-офисов компании: она позволяет одновременно с коллегами работать с данными. Рассказываем, в чем преимущества Colab для написания кода в каких сферах он может быть полезен разработчикам и не только.

Освойте профессию «Data Scientist» на курсе с МГУ
Data Scientist с нуля до PRO
Освойте профессию Data Scientist с нуля до уровня PRO на углубленном курсе совместно с академиком РАН из МГУ. Изучите продвинутую математику с азов, получите реальный опыт на практических проектах и начните работать удаленно из любой точки мира.

25 месяцев
Data Scientist с нуля до PRO
Создавайте ML-модели и работайте с нейронными сетями
6 224 ₽/мес 11 317 ₽/мес

Что такое Google Colab
Google Colab — сервис, созданный Google, который предоставляет возможность работать с кодом на языке Python через Jupyter Notebook, не устанавливая на свой компьютер дополнительных программ. В Google Colab можно применять различные библиотеки на Python, загружать и запускать файлы, анализировать данные и получать результаты в браузере. Этот сервис особенно полезен для разработчиков и студентов, изучающих программирование на Python.
Кому нужен Google Colab
- вообще всем, кто работает с Big Data;
- аналитикам данных (сортировать данные в файлах за долгий период, делать визуализацию или выстраивать закономерности);
- исследователям данных (разрабатывать и тестировать новые модели машинного обучения, составлять прогнозы);
- инженерам данных (разрабатывать ПО, системы для хранения больших данных).
В основе «Колаборатории» — блокнот Jupyter для работы с кодом на языке Python, только с базой на Google Диске, а не на компьютере. Здесь те же ячейки (cells), которые поддерживают текст, формулы, изображения, разметку HTML и не только. То есть можно заниматься программированием на языке Python и не качать лишние файлы, кучу библиотек, не перегружать машину и не переживать, что место на жестком диске вот-вот закончится. Единственное условие — нужно иметь Google-аккаунт.
Главная особенность «Колаборатории» — бесплатные мощные графические процессоры GPU и TPU, благодаря которым можно заниматься не только базовой аналитикой данных, но и более сложными исследованиями в области машинного обучения. С тем, что CPU вычисляет часами, GPU или TPU справляются за минуты или даже секунды.
Anaconda и Jupyter Notebook
Дата-сайентисты часто работают с Jupyter Notebook — инструментом, позволяющим запускать и отлаживать алгоритмы небольшими фрагментами. Это удобно для работы с данными: нужно запустить фрагмент кода в ячейке — посмотреть результаты — изменить код — снова запустить и так далее.
Одна из популярных программ, в составе которых есть Jupyter Notebook, — Anaconda. Кроме Jupyter на ваш компьютер будут установлены языки Python и R, а также больше 250 разных программ и библиотек для анализа данных и разработки моделей машинного обучения.
Такое разнообразие нужно не всегда. Также не всегда можно установить все локально. В этом случае помогает Google Colaboratory.
Читайте также 8 понятий из математической статистики, без которых не обойтись дата-сайентисту
CPU vs. GPU vs. TPU
CPU — центральный процессор — мозг компьютера, который выполняет операции с файлами. Настолько универсален, что может использоваться почти для всех задач: от записи фотографий на флешку до моделирования физических процессов.
GPU — графический процессор. Обрабатывает файлы быстрее, так как задачи выполняет параллельно, а не последовательно, как CPU. Он заточен исключительно под графику, поэтому на нем удобнее работать с изображением и видео, например заниматься 3D-моделированием или монтажом.
TPU — тензорный процессор, разработка Google. Он предназначен для тренировки нейросетей. У этого процессора в разы выше производительность при больших объемах вычислительных задач.
Сами процессоры дорогие, и не каждый может их себе позволить. Платформа Google Colaboratory дает возможность бесплатно и непрерывно пользоваться ими на протяжении 12 часов. Будьте внимательны: как только это время истечет, Colab сотрет все данные и файлы и придется начинать сначала.
Кроме того, Google отключает файлы блокнота после примерно 30 минут бездействия, чтобы не перегружать процессоры. Система Colab так устроена специально: например, многие факторы, в том числе время простоя, максимальная активность, общие ограничения на объем памяти иногда динамически меняются. Активным участникам ненадолго могут ограничить доступ к GPU, чтобы дать возможность использовать процессор другим.
Для чего используется Google Colab
- знакомство с TensorFlow — открытой библиотекой на Python для машинного обучения;
- разработка нейронных сетей;
- эксперименты с TPU;
- распространение исследований в области искусственного интеллекта;
- создание руководств.
Несколько таких примеров есть в открытом доступе прямо в Colab.
Эта гибкость в управлении ограничениями позволяет Colab оставаться бесплатным для всех пользователей. Ну а чтобы все не упало в самый неожиданный момент, можно оформить подписку на Colab Pro за $9,99 в месяц. Там и памяти в два раза больше, и времени работы, и к тому же приоритетный доступ к TPU. Правда, пока Pro-подписка есть только в Канаде и США.

Станьте дата-сайентистом: изучите науку о данных с преподавателями Сеченовского университета и практикуйтесь на реальных кейсах
Как начать работать с Google Colab
Все просто: на сайте Google Colab сразу появляется экран с доступными блокнотами. Можно создавать новый или загружать уже разработанный Python-код из Google Диска.
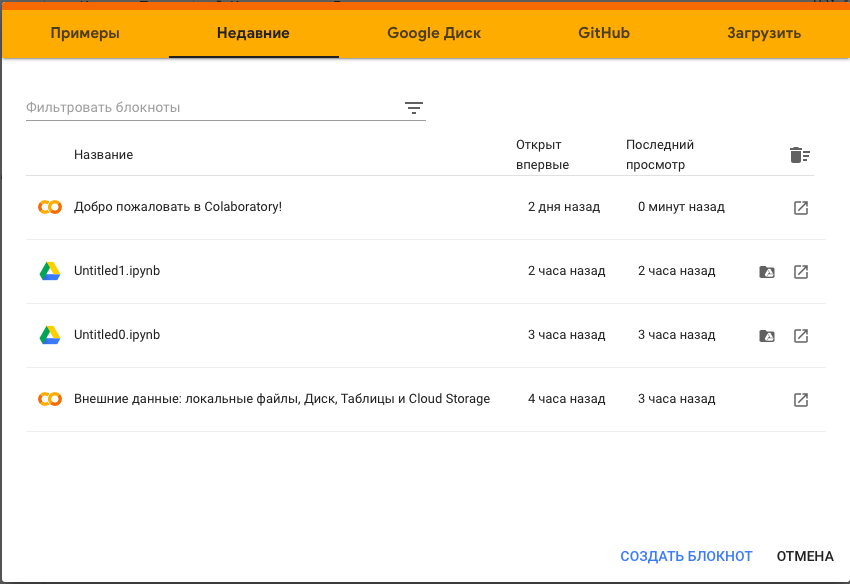
Чтобы работать с файлами и кодом в Google Colab с личного диска, нужно использовать команду mount() :
from google.colab import drive
drive.mount ('/content/drive')После запуска команды Colab предложит ввести код авторизации. Открыв URL, вы должны предоставить сервису доступ к своему аккаунту. Тогда он выдаст код, который нужно будет вставить в поле, нажать ВВОД, и Google Colab подключится к хранилищу.

Чтобы проверить, действительно ли Colab подключился, можно использовать команду !ls «/content/drive/My Drive» . Она покажет содержимое Google-диска.
Зачем использовать Google Colab
- Как и Google Документы, он дает возможность работать с Python-библиотеками для анализа данных онлайн.
- «Гугл Коллаб» предоставляет мощные процессоры для облачных вычислений. У него интуитивно понятный интерфейс, который позволяет не перегружать компьютер файлами и процессами и делать все вычисления быстро.
- Все блокноты под рукой. В Google Colab сохраняется доступ к аккаунту с файлами с любых устройств. Правда, если вы с осторожностью относитесь к своей конфиденциальности, Jupyter Notebook останется более предпочтительным вариантом.
- Сердце Colab — это совместное использование. При работе над проектом в команде Colab дает возможность свободно править, комментировать и редактировать код с разных аккаунтов, даже если вы сидите на жестком локдауне где-нибудь в Лондоне.
Еще одно достоинство Colab — интеграция с GitHub. Он открывает доступ к любому хранилищу, если ему предоставить профиль на сервисе.
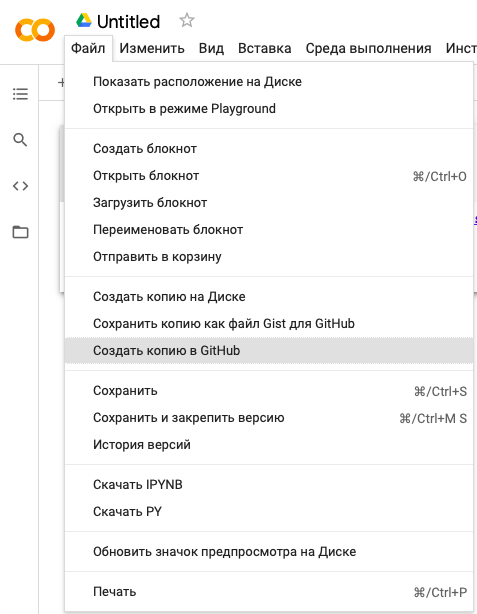
Кроме того, для определенных задач в Google Colab можно выбрать подходящий по мощности процессор. Необходимо просто сменить среду выполнения в нужной вкладке

и уже в настройках блокнота выбрать между GPU и TPU.

Не стоит работать с мощным процессором, когда не требуется работать с Big Data. Как мы уже говорили, Colab не любит, когда его ресурсы используются нерационально, поэтому любые перегрузки приведут к внезапному вылету из блокнота на неопределенное время.
Google Colab максимально упростил все процессы: в нем есть и базовые библиотеки (NumPy, scikit-learn, Pandas), и более сложные (вроде Keras, TensorFlow или PyTorch), не нужно ставить программы и среды самостоятельно, можно просто сразу писать код. Если же базовых библиотек Google Colab недостаточно, всегда можно добавить необходимые с помощью установщика PIP и работать дальше:
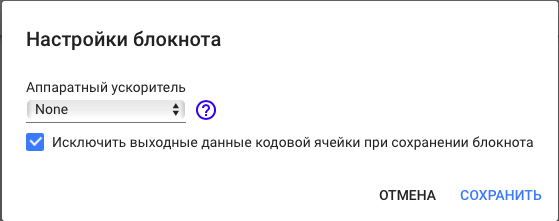
%pip install emojiВ Colab можно делиться файлами с другими, оставлять комментарии, редакторские заметки и в целом делать все, что доступно в тех же Google Документах. Поэтому при общем доступе к блокноту все его содержимое будет доступно другим пользователям (текст, код, комментарии, выходные данные). Последнее можно отключить: нужно выбрать «Настройки блокнота» в меню «Изменить».
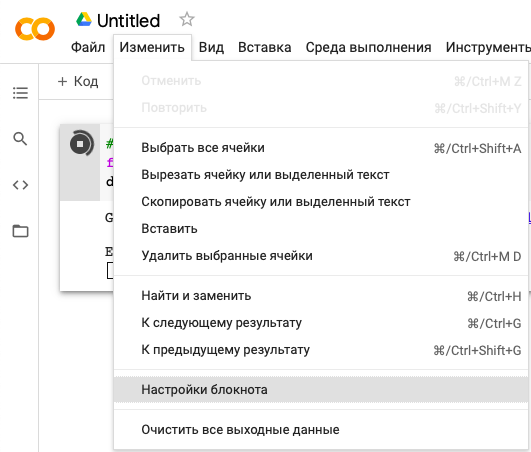
В появившемся окне Google Colab поставить галочку «Исключить выходные данные кодовой ячейки при сохранении блокнота», и тогда в блокноте сохранится только код, но не результаты его исполнения.
Вместе с тем открытый доступ к коду и его редактированию — отличная возможность найти интересные разработки по всему миру. У Google есть обширный репозиторий SeedBank, в котором можно исследовать множество блокнотов по Data Science или глубокому обучению, просто кликнув мышкой.
Облачные среды, похожие на Google Colab
Yandex DataSphere — в отличие от Google Colaboratory это платный блокнот, в котором тарифицируется фактическое время вычислений. При регистрации на пробный период (60 дней) выдается грант в размере 4000 ₽ для резидентов РФ и 50 $ для нерезидентов РФ. Особенности использования сервиса можно изучить в документации.
Kaggle Kernels — кроме Python, сервис Kaggle поддерживает R, интегрируется с Google Cloud Storage, BigQuery и AutoML. При этом время пользования процессорами – девять часов, на три меньше, чем у GC.
Azure Notebooks — как и Google Colaboratory, среда тоже поддерживает другие языки (R, F#). Сервисы Microsoft Azure также, как и Яндекса, тарифицируются за фактическое время использования.
CoCalc — предлагает и бесплатный, и платный (14 $) периоды. В расширенной версии больше памяти и времени простоя, приоритетный доступ к процессорам и техподдержке. Документация.
Что такое Google Colab и как оплатить Google Colab из России?

Дорогие друзья, в декабре 2022 года наблюдаются новости в оплате сервиса Google Colab.
Сервис Google Colab предложит вам подтвердить карту. Это будет выглядеть так:
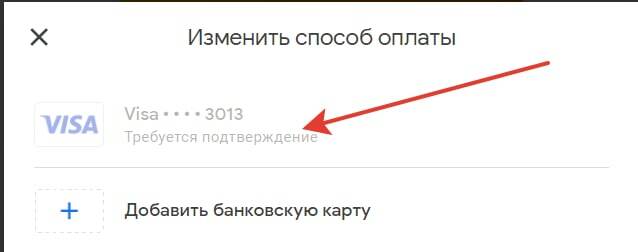
Потом вам нужно будет зайти по адресу: http://pay.google.com/
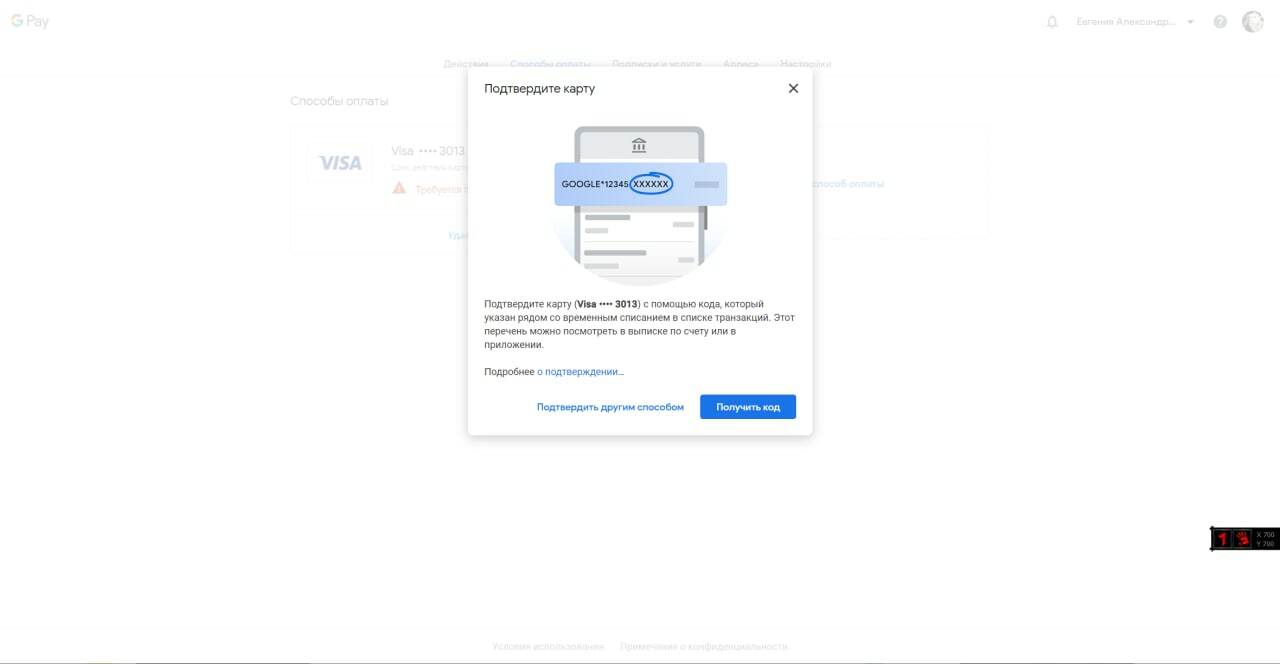
И подтвердить карту способом, как показано на скриншоте:
Данный код мы, естественно, вам сообщаем.
Обращайтесь в CheatPay, и мы с радостью поможем вам оплатить зарубежные сервисы!
Для начала разберемся, что же такое Google Colab или Блокнот Colab?
Это бесплатная интерактивная облачная среда для работы с кодом от Google. Принцип работы таков: она дает возможность в одно время с коллегами работать с данными.
Итак, далее мы расскажем в чем же плюсы Colab и в каких сферах он может сыграть на руку.
Кому будет полезен Google Colab
- каждому, кто работает с Big Data;
- аналитикам данных (сортировать данные за долгий период, делать визуализацию или выстраивать закономерности);
- исследователям данных (разрабатывать и тестировать новые модели машинного обучения, составлять прогнозы);
- инженерам данных (разрабатывать ПО, системы для хранения больших данных).
Основная фишка «Колаборатории» — бесплатные мощные графические процессоры GPU и TPU, с ними вы сможете заниматься и базовой аналитикой данных, и куда более сложными исследованиями в области машинного обучения. Google Colaboratory дает возможность бесплатно и непрерывно пользоваться этими процессорами 12 часов. Внимание: как когда время истечет, Colab удалит все ваши созданные данные, и вы будете вынуждены начинать заново.
Более того, Google отключает блокноты, если вы бездействуете 30 минут для того, чтобы не перегружать процессоры.
Для чего нужен Google Colab?
- знакомство с TensorFlow — открытой библиотекой для машинного обучения;
- разработка нейронных сетей;
- эксперименты с TPU;
- распространение исследований в области искусственного интеллекта;
- создание руководств.
Эта гибкость в управлении ограничениями дает возможность Colab оставаться бесплатным для всех пользователей. Также можно оформить подписку на Collab Pro всего за $9,99 в месяц. Преимущества подписки: памяти в два раза больше, времени работы также больше, и к тому же есть приоритетный доступ к TPU. Единственный минус — в настоящее время Pro-подписка может быть оформлена только в Канаде и США.
С чего начать работу?
Все элементарно: на сайте сервиса сразу же возникает экран с доступными для пользования блокнотами. Можно создать новый или загружать уже существующий Python-код из Google Диска.
Чтобы работать с файлами с личного диска, необходимо воспользоваться командой mount():
from google.colab import drive
drive.mount (‘/content/drive’)
После запуска данной команды сайт скажет вам ввести код авторизации. Открывая URL, вам нужно предоставить сервису доступ к своему аккаунту. Тогда он выдаст код, который нужно будет вставить в поле, нажать ВВОД, и Google Colab подключится к хранилищу.
Чтобы проверить, правда ли Colab подключился, нужно воспользоваться командой !ls «/content/drive/My Drive». Она покажет содержимое Google-диска.
4 причины воспользоваться Google Colab
- Сервис предоставляет возможность работы с Python-библиотеками для анализа данных онлайн.
- Colab использует мощные процессоры для облачных вычислений. У него довольно понятный интерфейс, что не позволяет перегружать компьютер, и все вычисления делаются оперативно.
- Все блокноты рядом. В Google Colab сохранится доступ к профилю с любого устройства.
- Лучшее, что дает Colab — это совместное пользование. При работе над проектом в команде Colab дает вам опцию свободно править, комментировать и редактировать код с разных профилей.
Более того, для каких-либо задач можно выбрать подходящий по мощности процессор. Необходимо просто сменить среду выполнения в нужной вкладке и уже в настройках блокнота выбрать между GPU и TPU.
Не стоит работать с мощным процессором кроме работы с Big Data. Как уже известно, Colab не приветствует, когда его ресурсы используются неразумно, поэтому любая перегрузка приведет к резкому вылету из блокнота на некоторое время.
В Google Colab есть и базовые библиотеки (NumPy, scikit-learn, Pandas), и более сложные (вроде Keras, TensorFlow или PyTorch), нет необходимости ставить программы и среды самим, можно просто сразу писать код. Если же базовых библиотек не хватает, вы всегда можете добавить необходимые с помощью установщика PIP и работать дальше.
В Colab можно поделиться работой с другими пользователями, оставлять комментарии, редакторские заметки и в целом делать все, что можно, например, в Google Документах. Поэтому при общем доступе к блокноту все, что там содержится, будет доступно другим пользователям (текст, код, комментарии, выходные данные). Последнее возможно выключить: необходимо выбрать «Настройки блокнота» в меню «Изменить».
В появившемся окне поставить галочку «Исключить выходные данные кодовой ячейки при сохранении блокнота», и тогда в блокноте сохранится только код, но не результаты его исполнения.
Также у Google есть обширный репозиторий SeedBank, в котором можно исследовать множество блокнотов по Data Science или глубокому обучению.
Как вы могли прочитать выше, в сервисе есть и платные функции, однако сейчас пользователи из России не могут оплатить данную платформу. Но не переживайте: наша команда CheatPay поможет вам в этом.
Как оплатить Google Colab из России
1) Вы переводите нам оплату
2) Открываете страницу оплаты сервиса у себя в аккаунте
3) Мы высылаем вам реквизиты карты зарубежного банка
4) Вы вбиваете платежные реквизиты карты зарубежного банка на странице оплаты
5) Готово! Наслаждайтесь пользованием сервиса!
Важный момент: при оплате данного сервиса рекомендуется включить VPN.
Обращайтесь к нам в CheatPay, и мы с радостью поможем вам оплатить зарубежные сервисы!
Google Colab | Подписка Colab Pro и Pro+ на 1 месяц

�� Cashback — после покупки за положительный отзыв вы получите подарочную карту.
�� Покупая данный товар вы получаете:
⭐ Подписку Colab Pro или Pro+ сроком 1 месяц на Ваш аккаунт.
⭐ Бесперебойную работу сервиса.
⭐ Возможность оформить подписку на Ваш старый или новый аккаунт.
⭐ Гарантию на купленный товар весь срок действия подписки.
�� Главные особенности подписок:
�� 100 вычислительных блоков в месяц (срок действия вычислительных блоков – 90 дней. При необходимости их можно докупить).
�� Более быстрые ГП (получите доступ к более мощным графическим процессорам).
�� Увеличенный объем памяти (получите доступ к оборудованию с большим объемом памяти).
�� Терминал (возможность использовать терминал с подключенной ВМ).
Colab Pro+ дает :
�� 500 вычислительных блоков в месяц (срок действия вычислительных блоков – 90 дней. При необходимости их можно докупить).
�� Выполнение в фоновом режиме (обновите блокноты, чтобы обрабатывать данные ещё в течение 24 часов, даже если вы закроете браузер).
�� Более быстрые ГП (получите доступ к более мощным графическим процессорам).
�� Увеличенный объем памяти (получите доступ к оборудованию с большим объемом памяти).
�� Терминал (возможность использовать терминал с подключенной ВМ).
Pay As You Go дает от 100 до 500 вычислительных блоков :
�� Подписка не требуется, платите только за то, что используете.
�� Более быстрые ГП (получите доступ к более мощным графическим процессорам).
�� Для оформления подписки после оплаты необходимо будет предоставить уникальный код об оплате товара и данные от аккаунта Google (логин:пароль) в форме «Переписка с продавцом» на странице покупки, для авторизации и последующей активации подписки.
�� Оформление производится путём оплаты премиума через официальный магазин на 1 месяц с банковской карты, на Вашу почту придёт чек об оплате и в информации о подписке отобразится оплаченный срок.
�� Что Вам делать после покупки?
1. После оплаты товара, уникальный код придет к вам на почту, его нужно будет сообщить мне в »Переписку с продавцом».
2️. Вместе с уникальным кодом, предоставьте пожалуйста данные для авторизации в аккаунт Google.
3️. Подождать, пока будет выполнен заказ.
4. Готово, Ваш премиум активирован!
5. Сделать небольшое доброе дело, а точнее оставить положительный отзыв (таким образом Вы улучшаете наш сервис и мотивируете становиться только лучше и лучше! )
Мы очень ценим Вашу обратную связь, поэтому заранее очень признательны Вам за уделенное время.
Дополнительная информация
При покупке Google Colab | Подписка Colab Pro и Pro+ на 1 месяц действует гарантия магазина Dimikey.
ML в облаке: как я попробовал Yandex DataSphere и почему его так непросто сравнить с Google Colab
Привет, Хабр! Меня зовут Дмитрий (@pagin), и я специализируюсь на вопросах ускорения и уменьшения свёрточных сетей. Моя основная работа — распознавание автомобилей и классификация транспорта, поэтому я обучаю много небольших CNN и часто пользуюсь облачными сервисами для ML. Раньше я использовал Google Colab и был в меру доволен. Но огорчался каждые 12 часов, когда ноутбук и окружение умирали. Недавно услышал про DataSphere от Yandex. Под катом расскажу про его отличия от Google Colab, опыт запуска обучения, особенности окружения и ценовую политику. Если любишь ресёрчить в ML и хочешь удобное рабочее пространство, то го под кат.
Чем я занимаюсь
Мы в TrafficData пилим ПО для оценки дорожного трафика. В процессе решаем задачу классификации транспорта на 23 типа. Топорный метод с обучением CNN на 23 класса заходит плохо из-за несбалансированности классов. Чтобы вы прочувствовали всю боль несбалансированности классов, вот распределение экземпляров на класс:

Однако есть дополнительная информация о том, что часть этих классов можно объединить в надклассы — все грузовые, все автопоезда или все автобусы. А ошибки внутри таких надклассов более предпочтительны, чем, например, между легковыми и грузовыми. Поэтому более правильное решение — одна CNN для определения надкласса и ещё 4 для уточнения подклассов. В таком случае и распределение экземпляров на класс становится более приятным:

Итого — 5 CNN по 500К весов, которые не так-то удобно учить одновременно на наших 2−3 свободных GPU. В таком контексте мне и подвернутся под руку Yandex DataSphere.
Yandex DataSphere: что это за зверь и как к нему подкатить
Разработчики Яндекса позиционируют DataSphere как платформу для исследований, разработки и эксплуатации сервисов в области анализа данных, машинного обучения и искусственного интеллекта. И тут нельзя сказать, что это ещё один «Облачный Jupyter Notebook», — решение оказывается гораздо шире. Для себя я нашёл встроенные механизмы версионирования (кода, переменных и состояний!), необычное решение выделения аппаратных ресурсов, кучу готовых сниппетов, фоновые операции, пригодность для продакшена и удобную среду для работы. Но обо всём по порядку.
Создание аккаунта и проекта
Итак, я зашёл на Yandex.Cloud. В консоли управления выбрал DataSphere. Дальше наткнулся на неочевидную вещь: чтобы создать рабочее пространство DataSphere, нужно выйти на уровень выше, зайти в биллинг и создать там свой платёжный аккаунт. Что хорошо, сейчас Яндекс даёт бонусные гранты, чтобы попробовать сервисы в Yandex.Cloud. DataSphere здесь относится ко второй строке (можно напробоваться на 3К):

После создания платёжного аккаунта достаточно зайти в DataSphere и нажать большую синюю кнопку Создать проект. Открываем проект и ждём, пока рабочее пространство будет создано. Иногда нужно подождать около 1–2 минут. Далее откроется интерфейс:

По вкладкам с первой странички лучше сразу пройтись, чтобы подробнее понять рабочие моменты. Впрочем, всё важное и интересное разберём прямо здесь.
Перенос, запуск и хранение проекта
Для начала работы со своим проектом нужно было перенести один .ipynb и заархивированный датасет на 5 ГБ (всего для работы в DataSphere доступно 300 ГБ). В DataSphere работает drag’n’drop файлов (или можно подключить свой Яндекс.Диск), причём скорость загрузки по ощущениям значительно выше, чем у Google Colab. И дальше — распаковать архив. Т. к. консольного доступа к ОС в DataSphere нет, я сделал всё через Python.
По библиотекам — практически всё любимое ML-щиками (от tensorflow до opencv) имеется. Мне пришлось накатить лишь seaborn для красоты и imgaug для аугментаций. Pip работает через символ процента:

В первый день работы встретил одну проблему. Я люблю разные необычные слои в CNN. Например, мне нравится экспериментировать с SeparableConv2D, реализация которых доступна в tensorflow.keras.layers. Этот слой присутствовал и в архитектуре, которую я использовал здесь. При компиляции CNN я получил малопонятный DeserializationException:

Пришлось потратить 10 минут, последовательно упрощая архитектуру, чтобы понять, что лишним был как раз SeparableConv2D. Неприятно, но терпимо. На моем ПК с таким же окружением всё ок, как и на Google Colab. О возможных причинах в следующем пункте.
Аппаратные ресурсы
Тут внимание и следим за руками. Способ работы с конфигурациями у DataSphere — особенная фича. Любой проект DataSphere стартует в бессерверном режиме. Выбор мощностей происходит уже при исполнении конкретной ячейки. По умолчанию ячейки будут исполняться в самой простой 4-ядерной конфигурации. Всего конфигураций 5:

Чтобы выполнить ячейку кода на другом железе, в начале ячейки нужно указать номер аппаратного набора, например — #!g1.1. На выделение ресурсов уходит 20−30 секунд. Правда, когда я запускал первый раз, пришлось ждать ≈5 минут. Я даже подумал, что-то сломалось, но позже поддержка Яндекса объяснила, что я попал на пиковую нагрузку, с которой уже справились.
Attention: Видимо, сервис набирает обороты и активных клиентов и отчасти защищается от майнеров, поэтому с 20.06.2021 доступ к конфигурациям g1.1 ограничен. Для доступа необходимо пополнить баланс до суммы 500 ₽ или отправить в поддержку запрос с описанием задачи. Зато теперь конфигурации g1.1 будут с большей вероятностью доступны.
По доступности аппаратных наборов. За 5 дней моих экспериментов всегда всё было доступно и выделялось. Лишь один раз g1.1 были недоступны и DataSphere попросил меня подождать несколько минут. И правда — потом подключилось.
Совершенно нормально и приветствуется, что разные ячейки выполняются на разных аппаратных конфигурациях. Все переменные и состояния между ними удачно передадутся. Ну не вау ли!
Не совсем вау. Насчёт проблемы из предыдущего пункта. Я не шарю во внутренних реализациях DataSphere, но по traceback могу предположить, что как раз эта фича с переносом состояний и стала причиной неработающего SeparableConv2D в нашем проекте. Ведь эти состояния нужно сериализовать в одном аппаратном окружении и десериализовать в другом. Но возможно, это лишь единичная проблема или просто я не прав насчёт DeserializationException. С другими слоями проблем я не встретил.
Тем не менее я запустил обучение в окружении DataSphere и, к сожалению, никак не смог полностью загрузить V100. Даже отключая аугментацию и нацеливая CPU полностью на формирование батчей, я не смог добиться утилизации GPU более 5−10 %. Просто очень оверхедная мощность GPU для нашей небольшой CNN. А вот если бы мы решились обучать в облаке нашу YOLOv4.5, то V100 как раз был бы к месту.
Фоновые операции
Фича, которую просто невозможно обойти стороной. Мне её очень не хватало в работе с Google Colab. Иной раз поставишь в Google Colab обучаться модель, а сам кукуешь. Вроде хочется провести эксперименты над другими моделями или датасетом в это время. Но для этого нужно заводить другой ноутбук, заново ставить окружение — короче, неприятно.
А здесь идея простая — можно запускать долгие операции (например, обучение моделей) в фоновом режиме, т. е. асинхронно. При этом можно продолжать работу с ноутбуком. Однако стоит иметь в виду, что:
- Запуск операций в фоновом режиме не гарантирует немедленный запуск исполнения.
- Фоновые операции в общем случае могут выполняться дольше, чем обычные операции.
- Фоновые операции могут выполняться на прерываемых виртуальных машинах и ресурсах.
- Фоновые операции тарифицируются по другим правилам.
И если первые три пункта здесь не очень радуют, то четвёртый приятный (подробнее через несколько абзацев).
Для текущей задачи фоновые операции мне не понадобились, т. к. датасет уже плотно исследован и нет необходимости в каких-то отдельных экспериментах. Я лишь убедился, что обучение успешно запускается в фоне и ячейки ноутбука доступны к выполнению.
Версионирование
DataSphere интегрирован с системой контроля данных DVC и системой контроля версий Git. Связка с Git сделана очень плотно — можно управлять практически без консоли. В верхнем и левом тулбарах есть специальные меню и область для просмотра и управления ветками. Интерфейс Git здесь не самый привычный, но приятный и понятный:

Отдельно стоит упомянуть про чекпоинты — код ячеек, вывод и значения переменных в определённый момент времени. Для них слева в тулбаре тоже есть своё меню. В любой момент можно переключиться на одно из предыдущих сохранённых состояний. Сохранить состояние можно самостоятельно, или оно сохранится автоматически при бездействии ВМ. Просто необходимый и уникальный инструмент для воспроизводимости экспериментов в ML. Что круто, ими можно поделиться вместе с ноутбуком.
Для нашего проекта Git был не нужен, т. к. скрипт обучения умещается в одну портянку.ipynb. Поэтому я лишь погипнотизировал предоставляемый интерфейс. А вот сохранение чекпоинтов пригодилось и сыграло на руку. Можно удобно распарсить датасет в переменную и затем сохранить состояние в чекпоинте. И при перезапуске обучения нужно лишь вернуть состояние этого чекпоинта. В моём случае это экономит приятные 4−5 минут. Т. е. не нужно снова бежать по 23 папкам, изменять разрешение изображений и составлять список объектов.
Ценовая политика
Тут тоже интересный подход. При работе с сервисом DataSphere вы платите за фактическое использование вычислительных ресурсов — посекундно тарифицируется время вычисления. То есть если ячейка закончила свои вычисления и CPU/GPU больше не загружен, то вы не платите ни цента. Вычисление общей стоимости происходит с помощью юнитов. Чем мощнее конфигурация, тем больше юнитов в секунду будет назначено:

И чтобы посчитать общую стоимость, необходимо время работы умножить на количество юнитов и на стоимость одного юнита. Скажу проще. 1 час работы самой слабой конфигурации — это 10,8 ₽. А 1 час работы g1.1 — это 194,4 ₽.
Стоимость фоновых операций высчитывается тоже с помощью юнитов. Но стоит отметить, что их выполнение значительно выгоднее. 1 час работы самой слабой конфигурации — это 2,7 ₽. А 1 час работы g1.1 — это 40,5 ₽. Ну и стоит затронуть вопрос трафика. Входящий не тарифицируется. Исходящий не тарифицируется до 10 ГБ.
У меня на полное обучение одной CNN в такой загрузке ушло ≈4 часа и было потрачено ≈600 ₽. И тут мне подумалось, что хочется ещё конфигурацию подешевле с GPU попроще. Ну хотя бы T4 или K80, как у Colab. Ведь загрузить V100 на 100 % — это задачка совсем непростая. Особенно когда ты просто учишь небольшие CNN.
Сравнение с Google Colab
Составляя сравнительную табличку, я ещё раз убедился, что в двух этих сервисах проще перечислить общее, чем различия. Тем не менее я постарался выделить наиболее важные моменты:
;Google Colab;Yandex DataSphere
Порог вхождения;5 минут;≈1 час. Нужно прочитать краткие справки, чтобы понять некоторые важные принципы работы Ценовая политика;Бесплатно;Оплачивается только фактическое время вычислений. Для слабых конфигураций и фоновых операций практически бесплатно. Для теста бонусом 3К Мощности;K80 в обычном. T4 и P100 в Pro. 2vCPU @2.2GHz;V100 + 4/8/32/80vCPU. Время жизни окружения;12 или 24 (Pro) часа;Всегда Версионирование;Результаты нужно сохранять на диск. Коммитить в репо вручную;Код, переменные и диск версионируются из коробки Смена GPU/CPU;Сессия заканчивается, данные теряются;Ничего не теряется (!) Пакеты;Новые установленные умирают в конце сессии;Окружение сохраняется Тема с корги и котиками;+;−

Тема с корги и котиками, которой так не хватает в Yandex DataSphere
Тут ещё для сравнения ценообразования — у Google Colab есть подписка за 10 $, где даётся приоритетный доступ к GPU и время жизни ноутбуков увеличивается до 24 часов! (На восклицательный знак смотреть с иронией.) Понятно, что, учитывая специфику DataSphere, подписка нам обошлась бы сильно дороже. И оплата только фактического времени вычислений освобождает нас от необходимости бежать выключать ноутбук после конца обучения. Но для себя я пока не понял, какой тип тарификации мне больше нравится.
У каждого сервиса есть свой ряд плюсов. Google Colab проще для старта, бесплатен, имеет более гибкий набор GPU и тему с корги. А DataSphere более гибок в выборе CPU, имеет удобное рабочее пространство, версионирование из коробки, сохранение окружения и фоновые операции. Как итог сложно сказать, что лучше или хуже. Но можно разделить сферы применения.
Если тебе срочно нужен облачный Jupyter для учёбы или коротких экспериментов и ты не собираешься к нему часто возвращаться, то Google Colab будет достаточно. А если ты хочешь перенести важную часть своей работы в облако, проводить там большие ресёрчи, делиться ими с коллегами и не переживать за сохранность данных, то предпочтительнее окажется DataSphere.