База данных простых чисел
Давеча снова увлекся простыми числами. Манит меня их тайна.
Написал алгоритм, похожий на решето Эратосфена. За 3 часа программа нашла 700 тысяч первых простых чисел. А мне надо хотя бы 14 миллионов простых чисел, чтобы перемножив их, получить число с количеством десятичных цифр, равным 100 миллионам штук.
Из статьи «Еще раз о поиске простых чисел», написанной пользователем Bodigrim, узнал о существовании быстрой программы primegen, которая работает используя решето Аткина. Установил ее в виртуальной машине LUbuntu (VirtualBox). Действительно, primegen очень быстро работает!
Тогда встал вопрос, как сохранить 14 миллионов простых чисел? Можно просто каждое простое число записать в файл как int32. А если простое число будет больше мощности 32-х бит?
Пришла в голову идея записывать в файл не сами числа, а расстояния между ними. А расстояние между соседними простыми числами всегда должно быть небольшим, предположил, что уместится в один байт.
Осталось узнать максимально-возможное расстояние для определенного диапазона чисел. Поскольку разница между простыми числами всегда есть четное число (кроме расстояния между 2 и 3), то разделим расстояние на 2.
В программе primegen в исходном файле primes.c вместо вывода числа на экран реализовал алгоритм подсчета статистики по кол-ву расстояний между числами:
int RastCount_Index = 0; int RastCount[1000]; for(i=0;i < 1000; i++) RastCount[i] = 0; for (;;) < u = primegen_next(&pg) - p; p += u; if (p >high) break; for (i = 0;u;++i) < u += digits[i]; if (u >= 200) < digits[i] = u % 10; u = u / 10; >else < digits[i] = mod10[u]; u = div10[u]; >> if (i > len) len = i; int LetsRast, index; LetsRast = 0; index = 0; char r[40], r_old[40]; for (i = 0;i < 40; i++) < r[i] = 0; r_old[i] = 0; >for (i = len - 1;i >= 0;--i) < if (! LetsRast) if (digits_old[i] != digits[i]) LetsRast = 1; if (LetsRast) < r[index] = '0' + digits[i]; r_old[index] = '0' + digits_old[i]; index++; >> int ri, ri_old, Rast; ri = atoi(r); ri_old = atoi(r_old); Rast = (ri - ri_old) >> 1; RastCount[Rast]++; if (Rast > RastCount_Index) RastCount_Index = Rast; for (i = len-1;i >= 0; i--) digits_old[i] = digits[i]; > for(i = 0; i
В терминале выполнил:
./primes 1 1000000000 Через 10 секунд отобразился список:
0 = 1 (расстояние между числами 2 и 3)
1 = 3424507
…
141 = 1
Таким образом, 141 — максимально-возможное расстояние по простое число значением до 1 миллиарда.
Написал код записи в файл:
FILE* fd; fd = fopen("primes.bin", "w+"); unsigned char b1[1]; b1[0] = Rast; fwrite(b1,1,1,fd); fclose(fd); Запустил до 300 миллионов:
./primes 1 300000000В файле primes.bin получил 16 миллионов первых простых чисел. Сжал архиватором 7-Zip, файл ужался до 9 Мб.
P.S. Есть идея, как еще сильнее сжать БД простых чисел. Надо простые числа разделить на 4 группы по последней десятичной цифре: 1, 3, 7, 9. Расстояние между числами делить на 10. Так же сформировать 4 файла. При этом возможно, что для значений расстояния можно будет отвести не 8 бит, а меньше, тогда придется реализовать формирование байтового буфера из, например, 5-битных расстояний.
Хотя в наш век Гигабайтных емкостей это не сильно принципиально.
Простые числа из диапазона 1000000-1004999.
1000003 1000033 1000037 1000039 1000081 1000099 1000117 1000121 1000133 1000151 1000159 1000171 1000183 1000187 1000193 1000199 1000211 1000213 1000231 1000249 1000253 1000273 1000289 1000291 1000303 1000313 1000333 1000357 1000367 1000381 1000393 1000397 1000403 1000409 1000423 1000427 1000429 1000453 1000457 1000507 1000537 1000541 1000547 1000577 1000579 1000589 1000609 1000619 1000621 1000639 1000651 1000667 1000669 1000679 1000691 1000697 1000721 1000723 1000763 1000777 1000793 1000829 1000847 1000849 1000859 1000861 1000889 1000907 1000919 1000921 1000931 1000969 1000973 1000981 1000999 1001003 1001017 1001023 1001027 1001041 1001069 1001081 1001087 1001089 1001093 1001107 1001123 1001153 1001159 1001173 1001177 1001191 1001197 1001219 1001237 1001267 1001279 1001291 1001303 1001311 1001321 1001323 1001327 1001347 1001353 1001369 1001381 1001387 1001389 1001401 1001411 1001431 1001447 1001459 1001467 1001491 1001501 1001527 1001531 1001549 1001551 1001563 1001569 1001587 1001593 1001621 1001629 1001639 1001659 1001669 1001683 1001687 1001713 1001723 1001743 1001783 1001797 1001801 1001807 1001809 1001821 1001831 1001839 1001911 1001933 1001941 1001947 1001953 1001977 1001981 1001983 1001989 1002017 1002049 1002061 1002073 1002077 1002083 1002091 1002101 1002109 1002121 1002143 1002149 1002151 1002173 1002191 1002227 1002241 1002247 1002257 1002259 1002263 1002289 1002299 1002341 1002343 1002347 1002349 1002359 1002361 1002377 1002403 1002427 1002433 1002451 1002457 1002467 1002481 1002487 1002493 1002503 1002511 1002517 1002523 1002527 1002553 1002569 1002577 1002583 1002619 1002623 1002647 1002653 1002679 1002709 1002713 1002719 1002721 1002739 1002751 1002767 1002769 1002773 1002787 1002797 1002809 1002817 1002821 1002851 1002853 1002857 1002863 1002871 1002887 1002893 1002899 1002913 1002917 1002929 1002931 1002973 1002979 1003001 1003003 1003019 1003039 1003049 1003087 1003091 1003097 1003103 1003109 1003111 1003133 1003141 1003193 1003199 1003201 1003241 1003259 1003273 1003279 1003291 1003307 1003337 1003349 1003351 1003361 1003363 1003367 1003369 1003381 1003397 1003411 1003417 1003433 1003463 1003469 1003507 1003517 1003543 1003549 1003589 1003601 1003609 1003619 1003621 1003627 1003631 1003679 1003693 1003711 1003729 1003733 1003741 1003747 1003753 1003757 1003763 1003771 1003787 1003817 1003819 1003841 1003879 1003889 1003897 1003907 1003909 1003913 1003931 1003943 1003957 1003963 1004027 1004033 1004053 1004057 1004063 1004077 1004089 1004117 1004119 1004137 1004141 1004161 1004167 1004209 1004221 1004233 1004273 1004279 1004287 1004293 1004303 1004317 1004323 1004363 1004371 1004401 1004429 1004441 1004449 1004453 1004461 1004477 1004483 1004501 1004527 1004537 1004551 1004561 1004567 1004599 1004651 1004657 1004659 1004669 1004671 1004677 1004687 1004723 1004737 1004743 1004747 1004749 1004761 1004779 1004797 1004873 1004903 1004911 1004917 1004963 1004977 1004981 1004987
| Еще диапазоны назад: | Еще диапазоны вперед: |
|---|---|
| 990000 (+4999) | 1010000 (+4999) |
| 985000 (+4999) | 1015000 (+4999) |
| 980000 (+4999) | 1020000 (+4999) |
| 975000 (+4999) | 1025000 (+4999) |
| 970000 (+4999) | 1030000 (+4999) |
База данных простых чисел до ста миллиардов на коленке
Самый известный алгоритм для нахождения всех простых чисел, не больших заданного, – решето Эратосфена. Он замечательно работает для чисел до миллиардов, может быть, до десятков миллиардов, если аккуратно написан. Однако каждый, кто любит развлекаться с простыми числами, знает, что их всегда хочется иметь под рукой как можно больше. Как-то раз мне для решения одной задачи на хакерранке понадобилась in-memory база данных простых чисел до ста миллиардов. При максимальной оптимизации по памяти, если в решете Эратосфена представлять нечетные числа битовым массивом, его размер будет около 6 гигабайт, что в память моего ноутбука не влезало. Существует модификация алгоритма, гораздо менее требовательная по памяти (делящая исходный диапазон чисел на несколько кусков и обрабатывающая по одному куску за раз) – сегментированное решето Эратосфена, но она сложнее в реализации, и результат целиком в память все равно не влезет. Ниже предлагаю вашему вниманию алгоритм почти такой же простой, как и решето Эратосфена, но дающий двукратную оптимизацию по памяти (то есть, база данных простых чисел до ста миллиардов будет занимать около 3 гигабайт, что уже должно влезать в память стандартного ноутбука).
Для начала вспомним, как работает решето Эратосфена: в массиве чисел от 1 до N вычеркиваются числа, делящиеся на два, потом числа, делящиеся на 3, и так далее. Оставшиеся после вычеркивания числа и будут простыми:
2 3 . 5 . 7 . 9 . 11 . 13 . 15 . 17 . 19 . 21 . 23 . 25 . 27 . 29 . 2 3 . 5 . 7 . . . 11 . 13 . . . 17 . 19 . . . 23 . 25 . . . 29 . 2 3 . 5 . 7 . . . 11 . 13 . . . 17 . 19 . . . 23 . . . . . 29 . Код на c#
class EratospheneSieve < private bool[] Data; public EratospheneSieve(int length) < Data = new bool[length]; for (int i = 2; i < Data.Length; i++) Data[i] = true; for (int i = 2; i * i < Length; i++) < if (!Data[i]) continue; for (int d = i * i; d < Length; d += i) Data[d] = false; >> public int Length => Data.Length; public bool IsPrime(int n) => Data[n]; > На моем ноутбуке до миллирарда считает 15 секунд и потребляет гигабайт памяти.
Алгоритм, который мы будем использовать, называется Wheel Factorization. Чтобы понять его суть, напишем натуральные числа табличкой по 30 штук в ряд:
0 1 2 3 4 5 . 26 27 28 29 30 31 32 33 34 35 . 56 57 58 59 60 61 62 63 64 65 . 86 87 88 89 .
И вычеркнем все числа, делящиеся на 2, 3, и 5:
. 1 . . . . . 7 . . . 11 . 13 . . . 17 . 19 . . . 23 . . . . . 29 . 31 . . . . . 37 . . . 41 . 43 . . . 47 . 49 . . . 53 . . . . . 59 . 61 . . . . . 67 . . . 71 . 73 . . . 77 . 79 . . . 83 . . . . . 89 . Видно, что в каждом ряду вычеркиваются числа на одних и тех же позициях. Так как мы вычеркивали только составные числа (за исключением, собственно, чисел 2, 3, 5), то простые числа могут быть только на невычеркнутых позициях.
Так как в каждом ряду таких чисел восемь, это дает нам идею представлять каждую тридцатку чисел одним байтом, каждый из восьми бит которого будет обозначать простоту числа на соответствующей позиции. Это совпадение не только эстетически красиво, но и сильно упрощает реализацию алгоритма!

Техническая реализация
Во-первых, наша цель – дойти до ста миллиардов, поэтому четырехбайтными числами уже не обойтись. Поэтому наш алгоритм будет выглядеть как-то так:
class Wheel235 < private byte[] Data; public Wheel235(long length) < . >public bool IsPrime(long n) < . >. > Для простоты реализации, будем округлять length вверх до ближайшего числа, делящегося на 30. Тогда
class Wheel235 < private byte[] Data; public Wheel235(long length) < // ensure length divides by 30 length = (length + 29) / 30 * 30; Data = new byte[length/30]; . >public long Length => Data.Length * 30L; . > Далее, нам нужны два массива: один переводит индекс 0..29 в номер бита, второй, наоборот, номер бита в позицию в тридцатке. Используя эти массивы и немного битовой арифметики, мы строим однозначное соответствие между натуральными числами и битами в массиве Data. Для простоты мы используем только два метода: IsPrime(n), позволяющий узнать, является ли число простым, и ClearPrime(n), устанавливающий соответствующий бит в 0, маркируя число n как составное:
class Wheel235 < private static int[] BIT_TO_INDEX = new int[] < 1, 7, 11, 13, 17, 19, 23, 29 >; private static int[] INDEX_TO_BIT = new int[] < -1, 0, -1, -1, -1, -1, -1, 1, -1, -1, -1, 2, -1, 3, -1, -1, -1, 4, -1, 5, -1, -1, -1, 6, -1, -1, -1, -1, -1, 7, >; private byte[] Data; . public bool IsPrime(long n) < if (n private void ClearPrime(long n) < int bit = INDEX_TO_BIT[n % 30]; if (bit < 0) return; Data[n / 30] &= (byte)~(1 > Заметим, что, если число делится на 2, 3 или 5, то номер бита будет -1, что означает, что число заведомо составное. Ну и, конечно, мы обрабатываем специальный случай n
Теперь, собственно, сам алгоритм, который практически дословно повторяет решето Эратосфена:
public Wheel235(long length) < length = (length + 29) / 30 * 30; Data = new byte[length / 30]; for (long i = 0; i < Data.Length; i++) Data[i] = byte.MaxValue; for (long i = 7; i * i < Length; i++) < if (!IsPrime(i)) continue; for (long d = i * i; d < Length; d += i) ClearPrime(d); >>
Соответственно, целиком получившийся класс:
выглядит так
class Wheel235 < private static int[] BIT_TO_INDEX = new int[] < 1, 7, 11, 13, 17, 19, 23, 29 >; private static int[] INDEX_TO_BIT = new int[] < -1, 0, -1, -1, -1, -1, -1, 1, -1, -1, -1, 2, -1, 3, -1, -1, -1, 4, -1, 5, -1, -1, -1, 6, -1, -1, -1, -1, -1, 7, >; private byte[] Data; public Wheel235(long length) < // ensure length divides by 30 length = (length + 29) / 30 * 30; Data = new byte[length / 30]; for (long i = 0; i < Data.Length; i++) Data[i] = byte.MaxValue; for (long i = 7; i * i < Length; i++) < if (!IsPrime(i)) continue; for (long d = i * i; d < Length; d += i) ClearPrime(d); >> public long Length => Data.Length * 30L; public bool IsPrime(long n) < if (n >= Length) throw new ArgumentException("Number too big"); if (n private void ClearPrime(long n) < int bit = INDEX_TO_BIT[n % 30]; if (bit < 0) return; Data[n / 30] &= (byte)~(1 > Есть только одна маленькая проблемка: этот код не работает для чисел, больших примерно 65 миллиардов! При попытке её запустить с такими числами программа падает с ошибкой:
Unhandled Exception: System.OverflowException: Array dimensions exceeded supported range. Проблема в том, что в c# массивы не могут иметь больше 2^31 элементов (видимо, потому что внутренняя имплементация использует четырехбайтный индекс массива). Один из вариантов – вместо массива byte[] создавать, например, массив long[], но это немного усложнит битовую арифметику. Для простоты мы пойдем другим путем, создав специальный класс, симулирующий нужный массив, держащий внутри два коротких массива. Заодно мы ему дадим возможность сохранять себя на диск, чтобы можно было один раз вычислить простые числа, и потом пользоваться базой повторно:
class LongArray < const long MAX_CHUNK_LENGTH = 2_000_000_000L; private byte[] firstBuffer; private byte[] secondBuffer; public LongArray(long length) < firstBuffer = new byte[Math.Min(MAX_CHUNK_LENGTH, length)]; if (length >MAX_CHUNK_LENGTH) secondBuffer = new byte[length - MAX_CHUNK_LENGTH]; > public LongArray(string file) < . >public long Length => firstBuffer.LongLength + (secondBuffer == null ? 0 : secondBuffer.LongLength); public byte this[long index] < get =>index < MAX_CHUNK_LENGTH ? firstBuffer[index] : secondBuffer[index - MAX_CHUNK_LENGTH]; set < if (index < MAX_CHUNK_LENGTH) firstBuffer[index] = value; else secondBuffer[index - MAX_CHUNK_LENGTH] = value; >> public void Save(string file) < . >>
Наконец, объединим все шаги в
окончательный вариант алгоритма
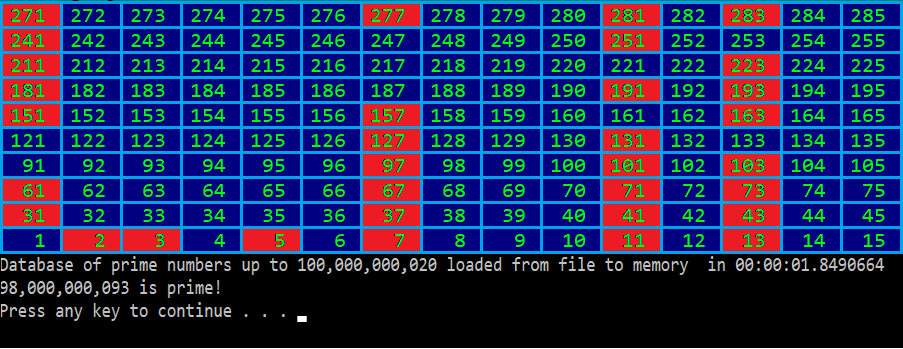
class Wheel235 < class LongArray < const long MAX_CHUNK_LENGTH = 2_000_000_000L; private byte[] firstBuffer; private byte[] secondBuffer; public LongArray(long length) < firstBuffer = new byte[Math.Min(MAX_CHUNK_LENGTH, length)]; if (length >MAX_CHUNK_LENGTH) secondBuffer = new byte[length - MAX_CHUNK_LENGTH]; > public LongArray(string file) < using(System.IO.FileStream stream = System.IO.File.OpenRead(file)) < long length = stream.Length; firstBuffer = new byte[Math.Min(MAX_CHUNK_LENGTH, length)]; if (length >MAX_CHUNK_LENGTH) secondBuffer = new byte[length - MAX_CHUNK_LENGTH]; stream.Read(firstBuffer, 0, firstBuffer.Length); if(secondBuffer != null) stream.Read(secondBuffer, 0, secondBuffer.Length); > > public long Length => firstBuffer.LongLength + (secondBuffer == null ? 0 : secondBuffer.LongLength); public byte this[long index] < get =>index < MAX_CHUNK_LENGTH ? firstBuffer[index] : secondBuffer[index - MAX_CHUNK_LENGTH]; set < if (index < MAX_CHUNK_LENGTH) firstBuffer[index] = value; else secondBuffer[index - MAX_CHUNK_LENGTH] = value; >> public void Save(string file) < using(System.IO.FileStream stream = System.IO.File.OpenWrite(file)) < stream.Write(firstBuffer, 0, firstBuffer.Length); if (secondBuffer != null) stream.Write(secondBuffer, 0, secondBuffer.Length); >> > private static int[] BIT_TO_INDEX = new int[] < 1, 7, 11, 13, 17, 19, 23, 29 >; private static int[] INDEX_TO_BIT = new int[] < -1, 0, -1, -1, -1, -1, -1, 1, -1, -1, -1, 2, -1, 3, -1, -1, -1, 4, -1, 5, -1, -1, -1, 6, -1, -1, -1, -1, -1, 7, >; private LongArray Data; public Wheel235(long length) < // ensure length divides by 30 length = (length + 29) / 30 * 30; Data = new LongArray(length / 30); for (long i = 0; i < Data.Length; i++) Data[i] = byte.MaxValue; for (long i = 7; i * i < Length; i++) < if (!IsPrime(i)) continue; for (long d = i * i; d < Length; d += i) ClearPrime(d); >> public Wheel235(string file) < Data = new LongArray(file); >public void Save(string file) => Data.Save(file); public long Length => Data.Length * 30L; public bool IsPrime(long n) < if (n >= Length) throw new ArgumentException("Number too big"); if (n private void ClearPrime(long n) < int bit = INDEX_TO_BIT[n % 30]; if (bit < 0) return; Data[n / 30] &= (byte)~(1 > В результате мы получили класс, который может вычислить простые числа, не превосходящие ста миллиардов, и сохранить результат на диск (у меня этот код на ноутбуке работал 50 минут; размер созданного файла получился примерно 3 гигабайта, как и ожидалось):
long N = 100_000_000_000L; Wheel235 wheel = new Wheel235(N); wheel.Save("./primes.dat");
А потом зачитать с диска и использовать:
DateTime start = DateTime.UtcNow; Wheel235 loaded = new Wheel235("./primes.dat"); DateTime end = DateTime.UtcNow; Console.WriteLine($"Database of prime numbers up to loaded from file to memory in "); long number = 98_000_000_093L; Console.WriteLine($" is <(loaded.IsPrime(number) ? "prime" : "not prime")>!");
- простые числа
- оптимизация
- решето эратосфена
- битовый массив
- числовые алгоритмы
- теория чисел
- Высокая производительность
- Алгоритмы
- C#
- Математика
Таблица простых чисел – онлайн калькулятор
Онлайн калькулятор для получения списка или таблицы простых чисел в заданном промежутке – от миллионов до миллиардов и намного больше. Имеется возможность поиска простых чисел, имеющих более 16-ти разрядов в десятичной системе исчисления, используя длинную арифметику.
Онлайн калькулятор
Найти простые числа в промежутке:
Результат вычислений
Вычисления были прерваны пользователем!
Затраченное время: 0 мс. Число найденных чисел: 168.
Таблица простых чисел в промежутке от 1 до 1000
| 2 | 3 | 5 | 7 | 11 | 13 | 17 | 19 | 23 | 29 | 31 | 37 |
| 41 | 43 | 47 | 53 | 59 | 61 | 67 | 71 | 73 | 79 | 83 | 89 |
| 97 | 101 | 103 | 107 | 109 | 113 | 127 | 131 | 137 | 139 | 149 | 151 |
| 157 | 163 | 167 | 173 | 179 | 181 | 191 | 193 | 197 | 199 | 211 | 223 |
| 227 | 229 | 233 | 239 | 241 | 251 | 257 | 263 | 269 | 271 | 277 | 281 |
| 283 | 293 | 307 | 311 | 313 | 317 | 331 | 337 | 347 | 349 | 353 | 359 |
| 367 | 373 | 379 | 383 | 389 | 397 | 401 | 409 | 419 | 421 | 431 | 433 |
| 439 | 443 | 449 | 457 | 461 | 463 | 467 | 479 | 487 | 491 | 499 | 503 |
| 509 | 521 | 523 | 541 | 547 | 557 | 563 | 569 | 571 | 577 | 587 | 593 |
| 599 | 601 | 607 | 613 | 617 | 619 | 631 | 641 | 643 | 647 | 653 | 659 |
| 661 | 673 | 677 | 683 | 691 | 701 | 709 | 719 | 727 | 733 | 739 | 743 |
| 751 | 757 | 761 | 769 | 773 | 787 | 797 | 809 | 811 | 821 | 823 | 827 |
| 829 | 839 | 853 | 857 | 859 | 863 | 877 | 881 | 883 | 887 | 907 | 911 |
| 919 | 929 | 937 | 941 | 947 | 953 | 967 | 971 | 977 | 983 | 991 | 997 |
Ход вычислений
Выполняется поиск простых чисел
Число найденных простых чисел:
Описание калькулятора
Выбор промежутка
После ввода натуральных чисел , будет осуществляться поиск простых чисел на отрезке .
При выборе промежутка необходимо учесть следующее.
- Приблизительное количество простых чисел, не превосходящих определяется по асимптотической формуле:
.
Тогда примерное количество простых чисел в промежутке :
.
Задание слишком большого промежутка может привести к переполнению памяти, используемой браузером для вывода результатов. - Первые 9592 простых чисел (до 99991 ) заложены в памяти программы. Остальные вычисляются колесным методом.
- Время вычислений растет с увеличением значений исследуемых натуральных чисел, входящих в промежуток .
- Калькулятор позволяет выполнять расчеты с использованием длинной арифметики при N 2 > 9007199254740991 . Однако время, затраченное на исследование одного натурального числа, сильно увеличивается, и составляет около 1 секунды для чисел, не сильно превышающих 9007199254740991 .
- Теоретически, максимально возможное значение равно 81129638414606663681390495662081 .
Дополнительные настройки
Число столбцов таблицы
Если ввести значение 0, то число столбцов таблицы рассчитывается автоматически.
Порядок колеса N
При фильтрации колесным методом, из ряда натуральных чисел удаляются элементы, делящиеся без остатка на первые N простых чисел.
См. Колесный метод фильтрации простых чисел
Задержка τ для отображения хода вычислений
Если время расчета превышает 1 секунду, то, после полной обработки исследуемого числа, происходит остановка расчетов, чтобы браузер отобразил текущие результаты во всплывающем окне хода вычислений. Через промежуток времени τ исследования чисел возобновляются. Если браузер не успевает показать прогресс вычислений, то можно увеличить τ, чтобы дать больше времени на отображения обработанных результатов. Прерывание расчетов происходит только после полной обработки текущего числа. До тех пор, пока этого не произойдет, изменений в окне хода вычислений не будет. Поэтому при расчете больших чисел возможно увеличение времени между обновлениями в окне хода вычислений.
Применяемый метод поиска простых чисел
Стандартный метод и его оптимизация
Пусть мы хотим найти все простые числа из промежутка . Самое легкое – взять каждое натуральное число из этого промежутка: , и проверить, является ли оно простым. Для этого нужно найти остатки от деления числа на все натуральные числа , не превышающие . Если все остатки не равны нулю, то число простое. Если хотя бы один остаток равен нулю: , то делится на . Поэтому не является простым.
Можно сократить объем вычислений, если в качестве перебирать не все натуральные числа, а только простые. Тогда для исследования числа нам потребуется вычислить не более остатков . Недостатком такой оптимизации является то, что для этого нужно хранить в памяти компьютера значений простых чисел , не превосходящих . Этот метод позволяет сократить объем вычислений, но при больших требуется большой объем памяти, что может привести к существенному снижению производительности вычислительной машины.
В этом калькуляторе использован другой способ оптимизации вычислений, основанный на фильтрации рядов и . Так, все четные числа, кроме двойки, не являются простыми. Поэтому из рядов и можно исключить четные числа. Тогда объем вычислений сократится более чем в два раза. Но также можно исключить числа, которые делятся на 3, 5, и так далее. Такая фильтрация выполняется с помощью колесного метода.
Колесный метод фильтрации простых чисел
Колесный метод – это метод построения ряда натуральных чисел, из которого исключены числа, делящиеся без остатка на первые простых чисел .
Числа, образующие колесо – это первые простых чисел .
Порядок колеса – это число первых простых чисел , образующих колесо.
Примориал – это произведение первых простых чисел:
.
Спицы колеса – Это множество натуральных чисел, каждое из которых меньше примориала, и не делится без остатка ни на одно число множества :
.
Число спиц в колесе определяется по формуле:
.
Элементы ряда определяются по формуле:
(1) .
Таким образом, для построения колесным методом отфильтрованного ряда, содержащего все простые числа, мы выполняем следующие шаги.
1) Выбираем порядок колеса .
2) Определяем значения спиц .
3) Определяем значения элементов ряда по формуле (1).
4) Добавляем к ряду числа, образующие колесо, .
Пример. Для имеем.
Числа, образующие колесо: .
Примориал: .
Число спиц колеса: .
Значения спиц:
.
Прибавляя к ним примориал, мы получим значения элементов следующего оборота колеса. И так далее, последовательно прибавляя к новым значениям примориал, получаем элементы ряда натуральных чисел, из которых исключены элементы, делящиеся на 2,3,5,7.
Доля чисел, прошедших фильтр равна доле чисел в колесе:
.
Таким образом, используя колесный метод с , из ряда натуральных чисел мы убираем 77,14% чисел, которые делятся на 2, 3, 5, 7 и, следовательно, не являются простыми.
Эффективность колесного метода
Чем меньше доля чисел, прошедших фильтр, тем меньше операций нам нужно выполнить для получения списка простых чисел в заданном промежутке. Эта доля уменьшается при увеличении порядка колеса. Однако увеличение порядка приводит к увеличению числа спиц и, следовательно, к увеличению занимаемого ими объема памяти. Оказывается, что с ростом , доля чисел, прошедших фильтр снижается незначительно, в то время как объем занимаемой памяти растет очень сильно, быстрее экспоненты. Для выполнения расчетов, наиболее подходящими, являются значения порядка колеса от 4 до 6, .
В приведенной ниже таблице приведены значения числа спиц и доли чисел в колесе при разных значениях порядка .
| Порядок колеса | Примориал | Число спиц | Доля чисел, прошедших фильтр |
|---|---|---|---|
| 1 | 2 | 1 | 0,5 |
| 2 | 6 | 2 | 0,3333 |
| 3 | 30 | 8 | 0,2667 |
| 4 | 210 | 48 | 0,2286 |
| 5 | 2 310 | 480 | 0,2078 |
| 6 | 30 030 | 5 760 | 0,1918 |
| 7 | 510 510 | 92 160 | 0,1805 |
| 8 | 9 699 690 | 1 658 880 | 0,1710 |
| 9 | 223 092 870 | 36 495 360 | 0,1636 |
| 10 | 6 469 693 230 | 1 021 870 080 | 0,1579 |
Использованная литература.
Поиск простых чисел. Учебные материалы по информатике для школьников при мехмате 54 школы г. Москвы.
Автор: Олег Одинцов . Опубликовано: 26-08-2022