Профилирование в программировании: какой профилировщик выбрать

Профайлер или профилировщик в программировании — это специализированный программный инструмент, который выполняет процесс профилирования. Профилирование — это процесс, при котором собираются характеристики работоспособности какой-то программы. Характеристики работы программы нужны для того, чтобы оценить насколько эффективно работает исследуемая программа и выявить ее «слабые» участки.
Простыми словами, профилировщик — это программа, которая следит за другими программами, во время их исполнения. Процесс профилирования связан не только с программированием, но и с другими сферами, где нужно «отслеживать» определенные показатели определенных программ. Например, профилирование активно используется в трейдерстве, когда специальные профилировщики отслеживают работу других программ, участвующих в построении графиков торговых серверов.
Сегодня нас интересует, что такое профилировщик в программировании. Описание работы таких программ в других сферах оставим для следующих статей.
Профилировщик в программировании — что это?
- измерение времени, затраченного на ту или иную функцию;
- измерение потраченных системных ресурсов на ту или иную функцию;
- изменения программы в зависимости от воздействия на нее со стороны пользователей;
- как запустилась и как прекратила работать программа;
- были ли «зависания» в программе и из-за чего;
- и др.
Программы-профилировщики
- «gprof». Многоплатформенный и многофункциональный профилировщик.
- «VТune». Программный продукт компании Intel на платной основе.
- «Single Event API». Программный продукт компании Intel на бесплатной основе.
- «CodeAnalyst». Универсальный профилировщик компании AMD.
- «AQtime». Профилировщик для операционной системы Windows.
- «Instruments». Профилировщик для операционной системы MacOS.
- «Perf». Профилировщик для операционной системы Linux.
- «dotMemory». Профилировщик памяти разных систем.
Заключение
Профилировщик — это программа, которая «отслеживает» показатели других программ. На самом деле, это довольно специфический инструмент, который используется в особых случаях. Не каждый разработчик профилирует собственные программы, но каждый разработчик должен знать, что такой процесс существует и имеются соответствующие инструменты.
Мы будем очень благодарны
если под понравившемся материалом Вы нажмёте одну из кнопок социальных сетей и поделитесь с друзьями.
Профилирование программ
Профилирование позволяет оценить время, затрачиваемое на выполнение отдельных операций в программе. Профилирование можно выполнять как для всего кода, так и для его фрагментов.

Для начала рассмотрим профилирование фрагментов кода.
В случае работы в Jupyter notebook можно использовать так называемые “магические команды”. Для того, чтобы узнать время выполнения одной строки, нужно в её начале разместить магическую команду %time. В приведенном ниже примере в последней ячейке тетрадки создается матрица размером 10000×10000, заполненная случайными вещественными числами

Как видно, на это потребовалось 1,27 секунды. Отметим, что повторный запуск аналогичной команды потребовал уже 1,63 секунды.
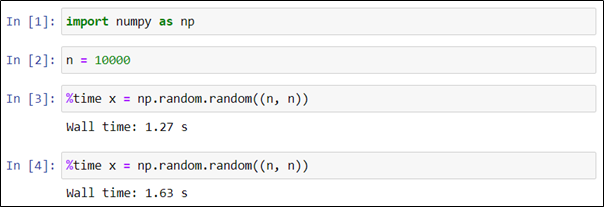
Чтобы оценить время выполнения кода в каждой из строк какой-либо ячейки, необходимо использовать магическую команду %time в каждой строке. В приведенном ниже примере создаются и перемножаются две матрицы размером 5000×5000, заполненные случайными вещественными числами.
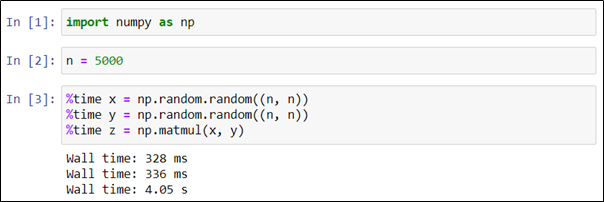
Если же нужно оценить время выполнения ячейки в целом, необходимо использовать команду %%time. Генерация двух матриц и их перемножение потребовали в сумме 4,7 секунды.
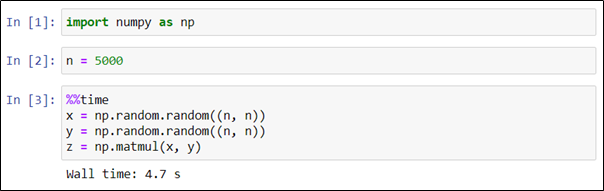
Описанные приемы позволяют получить лишь начальное представление о быстродействии кода. Как известно, единичного эксперимента недостаточно для того, чтобы составить адекватное представление о поведении исследуемой системы. Проведем серию экспериментов и возьмем среднее значение в качестве оценки времени выполнения кода. Для этого будем использовать команду %%timeit с ключом -r, задающим количество вычислительных экспериментов.
В следующем примере мы так же генерируем и перемножаем две матрицы в серии из пяти экспериментов.
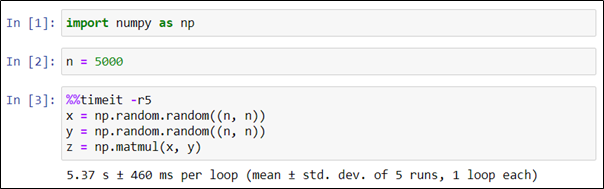
Как видно, среднее значение времени в серии экспериментов (5,37 секунды) отличается от времени единичного эксперимента, проведенного ранее (4,7 секунды).
Рассмотрим еще один пример профилирования кода.
В некоторых случаях имеет смысл сравнить несколько возможных вариантов реализации кода, чтобы выбрать из них наиболее производительный.
Известно, что значение функции “синус” для значений аргумента, близких к нулю, можно представить в виде суммы ряда Маклорена, а приближенное значение вычислить как сумму его первых двух слагаемых.

Исследуем два способа вычисления приближенного значения синуса, отличающихся способом вычисления второго слагаемого: в одном случае через трехкратное перемножение аргумента, в другом — через операцию возведения в степень. Для измерения времени снова воспользуемся командой timeit.
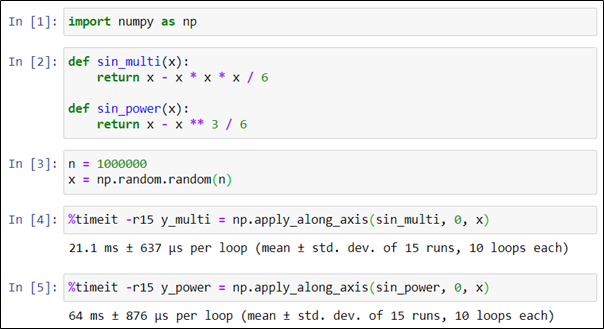
Несмотря на то, что математически эти варианты полностью эквивалентны, вариант с расчетом через перемножение аргументов приблизительно в три раза быстрее варианта с возведением в степень. Этот результат был бы совершенно не очевиден без профилирования.
Перейдем к профилированию кода программы в целом.
Представим, что есть программа min_distance_naive.py, вычисляющая наименьшее расстояние между точками на плоскости и началом координат. Координаты точек представлены матрицей размерности 1000000×2, записанной в файле points.npy. Ключевой фрагмент кода — функция min_dist_naive.
import numpy as np def min_dist_naive(points, base): r_min = float('inf') for p in points: r = ((p[0] - base[0]) ** 2 + (p[1] - base[1]) ** 2) ** (1 / 2) r_min = min(r, r_min) return r_min points = np.load('points.npy') origin = (0, 0) min_dist = min_dist_naive(points, origin) print(min_dist)Для запуска этой программы необходимо в командной строке выполнить следующую команду:
python min_distance_naive.pyДля запуска профилирования дополним эту команду ключом -m cProfile указывающим, что для профилирования нужно использовать модуль cPython, и ключом -s time, указывающим, что результаты профилирования нужно упорядочить по времени.
python -m cPython -s time min_distance_naive.py > naive.txtВесь вывод, в том числе результаты профилирования, будут записаны в текстовый файл naive.txt. Анализ этого файла показывает, что время выполнения программы составило 4,369 с., суммарное время выполнения функции поиска минимального расстояния составило 4,132 с.

Теперь попробуем ускорить выполнение кода. Поскольку алгоритм решения задачи построен вокруг сравнения между собой большого количества расстояний, то, принимая во внимание монотонность функции извлечения квадратного корня, можно исключить эту функцию и сравнивать между собой квадраты расстояний. В соответствии с этой идеей несколько доработаем исходную функцию, исключив из цикла операцию извлечения квадратного корня.
import numpy as np def min_dist_optim(points, base): r_min = float('inf') for p in points: r = (p[0] - base[0]) ** 2 + (p[1] - base[1]) ** 2 r_min = min(r, r_min) r_min = r_min ** (1 / 2) return r_min points = np.load('points.npy') origin = (0, 0) min_dist = min_dist_optim(points, origin) print(min_dist)Запустим профилирование доработанной программы.
python -m cPython -s time min_distance_optimized.py > optimized.txtОбратимся к результатам профилирования.

В этом случае время выполнения функции составило 3,772 с.
По результатам многократного профилирования обоих вариантов и статистической обработки полученных экспериментальных данных, включающей в том числе сравнение выборок с помощью t-критерия Уэлча, получен статистически значимый результат, свидетельствующий о том, что модифицированная функция приблизительно на 8% быстрее исходной. Таким образом, профилирование помогает выявить узкие места в коде с точки зрения производительности, сравнить разные варианты реализации алгоритмов, и в конечном счете ускорить выполнение программ. Код приведенных примеров, а также экспериментальные данные можно найти в репозитории.
- профилирование
- программ
- Python
- Программирование
- Машинное обучение
Профилирование уже запущенных программ
Все мы пользуемся профайлерами. Традиционная схема работы с ними такова, что приходится изначально запускать программу «под профайлером» а затем, после окончания ее работы, анализировать сырой дамп с помощью дополнительных утилит.
А что делать если мы не имея root’а хотим запрофилировать уже работающую программу, которая долго работала «как надо», а сейчас что-то пошло не так. И хотим это сделать быстро. Знакомая ситуация?
Тогда рассмотрим наиболее популярные профайлеры и принципы их работы. А затем профайлер, который решает именно указанную задачу.
Популярные профайлеры
Если вы знаете принципиально другой — напишите о нем в комментах. А пока рассмотрим эти 4:
I. gprof
Старый-добрый UNIX профайлер который, по словам Кирка МакКузика, был написан Биллом Джоем для анализа производительности подсистем BSD. Собственно, профайлер «предоставляется» компилятором — он должен расставить контрольные точки в начале и в конце каждой функции. Разница между двумя этими точками и будет временем ее исполнения.
Стоит отметить, что gprof в данном случе точно «знает» и то, сколько раз была вызвана каждая функция. И хотя это может быть необходимым в некоторых ситуациях, это также имеет отрицательный эффект — overhead от замеров может быть сравним или даже больше чем само тело функции. Поэтому, например, для при компиляции C++-кода используют оптимизации приводящие к inline.
Так или иначе, но gprof не работает с уже запущеными программами.
II. Callgrind
Callgrind является частью Valgrind’а — отличного фреймворка для построения средств динамического анализа кода. Valgrind запускает программу «в песочнице», фактически используя виртуализации. Callgrind производит профилирование основываясь на брейкпоинтах на инструкциях типа call и ret. Он значительно замедляет анализируемый код, как правило, от 5 до 20 раз. Таким образом, для анализа на больших данных в runtime он, как правило, не годен.
Однако инструмент очень популярен, и простой формат графа вызовов поддерживается отличными средствами визуализации, например, kcachegrind.
III. OProfile
OProfile is a system-wide profiler for Linux systems, capable of profiling all running code at low overhead.
OProfile является общесистемным профайлером. Т.е. он не нацелен на работу с отдельными процессами, профилируя вместо этого всю систему. OProfile собирает метрики считывая не системный таймер, как gprof или callgrind, а счетчики CPU. Поэтому для запуска демона он требует привелегий.
Однако это незаменимое средство когда Вам необходимо разобраться с работой всей системы, всего сервера сразу. И особенно незаменимое при профилировании области ядра.
Новая версия OProfile 0.9.8
Для версий 0.9.7 и в более ранних профайлер состоял из драйвера ядра и демона для сбора данных. С версии 0.9.8 этот метод заменен на использование Linux Kernel Performance Events (требует ядро 2.6.31 или более свежее). Релиз 0.9.8 также включает в себя программу ‘operf’, позволяющую непривилегированным пользователям профилировать отдельные процессы.
IV. Google perftools
Этот профайлер является частью набора Google perftools. Я не нашел на хабре его обзора, поэтому очень кратко опишу.
Набор включает серию библиотек нацеленых на ускорение и анализ C/C++ — приложений. Центральной частью является аллокатор tcmalloc, который помимо ускорения распределения памяти несет средства для анализа классических проблем — memory leaks и heap profile.
Второй частью является libprofiler, который позволяет собирать статистику использования CPU. Важно остановиться на том, как он это делает. Несколько раз в секунду (по-умолчанию 100) программа прерывается на сигнал таймера. В обработчике этого сигнала раскручивается стек и запоминаются все указатели инструкций. По-окончанию сырые данные сбрасываются в файл, по которому уже можно строить статистику и граф вызовов.
Здесь некоторые детали того как это делается
1. По-умолчанию сигналом таймера выбирается таймер ITIMER_PROF, который тикает лишь при использовании программой CPU. Ведь, как-правило, нам не очень интересно где была программа ожидая ввод с клавиатуры или поступления данных по сокету. А если все же интересно, используйте env CPUPROFILE_REALTIME=1
2. Стек вызова раскручивается либо с помощью libunwind, либо вручную (что требует —fno-omit-framepointer, всегда работает на x86).
3. Имена функций впоследствии узнаются с помощью addr2line(1)
4. Как и прочие средства Google perftools, профайлер может быть слинкован явно, а может быть и предзагружен средствами LD_PRELOAD .
Интересен принцип действия — программа прерывается лишь N раз в секунду, где N достаточно мало. Это т.н. сэмплирующий профайлер. Его преимущество в том, что он не оказывает существенного влияния на анализируемую программу, сколько бы мелких функций там не вызывалось. Ввиду особенностей работы, он, однако, не позволяют ответить на вопрос «сколько раз вызывалась данная функция».
В случае с google profiler есть еще несколько неприятностей:
- этот профайлер также не предназначен для работы с уже работающими программами
- последние версии не работают с fork(2), порой затрудняя его использование в демонах
Crxprof
Как и обещал, теперь про другой профайлер, который написан именно для решения обозначенной выше проблемы — легкое профилирование уже запущенных процессов.
Он собирает стек вызовов и выводит наиболее «горячие» части в консоль по нажатию ENTER. Также он умеет сохранять граф вызова в упомянутом ранее формате callgrind. Работает быстро, и как любой другой сэмплирующий профайлер не зависит от сложности вызовов в профилируемой программе.
Некоторые детали работы
В основном, crxprof работает также как perftools, но использует внешнее профилирование через ptrace(2). Подобно perftools он использует libunwind для раскрутки стека, а вместо тяжелой работы по преобразованию в имена функций, вместо addr2line(1) используется libbfd.
Несколько раз в секунду программа останавливается (SIGSTOP) и с помощью libunwind «снимается» стек вызова. Загрузив при старте crxprof карту функций профилируемой программы и связанных с ней библиотек, мы можем быстро найти какой функции пренадлежит каждый отделый IP (instruction pointer).
Параллельно выстраивается граф вызова, полагая что есть некая центральная функция — точка входа. Обычно это __libc_start_main из библиотеки libc.
Исходный код доступен на github. Т.к. утилита создавалась для меня и моих коллег, я вполне допускаю что она может не соответствовать Вашему use-case’у. Так или иначе, спрашивайте.
Соберем crxprof и посмотрим на пример его использования.
Сборка
Что необходимо: Linux (2.6+), autoconf+automake, binutils-dev (включает libbfd), libunwind-dev (у меня он называется libunwind8-dev).
Для сборки выполняем:
autoreconf -fiv ./configure make sudo make install Если libunwind установлен в нестандартное место, используйте:
./configure --with-libunwind=/path/to/libunwind Профилирование
Для этого просто запустите
crxprof pid И все! Теперь используйте ENTER для вывода профайла в консоль, и ^C для завершения. Crxprof также выведет профайл и по выходу программы.
crxprof: ptrace(PTRACE_ATTACH) failed: Operation not permitted
Если вы видите эту ошибку, значит ptrace на вашей системе «залимитирован». (Ubuntu ?)
Подробней можно прочитать здесь
Если кратко, то либо пускайте с sudo, либо (лучше) выполните в консоли:
$ echo 0 | sudo tee /proc/sys/kernel/yama/ptrace_scope Как все unix-утилиты, crxprof выводит usage при вызове с ключом —help. Подробную информацию см. в man crxprof .
crxprof —help
Usage: crxprof [options] pid Options are: -t|--threshold N: visualize nodes that takes at least N% of time (default: 5.0) -d|--dump FILE: save callgrind dump to given FILE -f|--freq FREQ: set profile frequency to FREQ Hz (default: 100) -m|--max-depth N: show at most N levels while visualizing (default: no limit) -r|--realtime: use realtime profile instead of CPU -h|--help: show this help --full-stack: print full stack while visualizing --print-symbols: just print funcs and addrs (and quit)
Реальный пример
Для того чтобы привести реальный, но не сложный пример я использую этот код на C. Скомпилируем, запустим его и попросим crxprof сохранить граф вызова функций (4054 — pid профилируемой программы):
$ crxprof -d /tmp/test.calls 4054 Reading symbols (list of function) reading symbols from /home/dkrot/work/crxprof/test/a.out (exe) reading symbols from /lib/x86_64-linux-gnu/libc-2.15.so (dynlib) reading symbols from /lib/x86_64-linux-gnu/ld-2.15.so (dynlib) Attaching to process: 6704 Starting profile (interval 10ms) Press ENTER to show profile, ^C to quit 1013 snapshot interrputs got (0 dropped) main (100% | 0% self) \_ heavy_fn (75% | 49% self) \_ fn (25% | 25% self) \_ fn (24% | 24% self) Profile saved to /tmp/test.calls (Callgrind format) ^C--- Exit since ^C pressed - main() вызывает heavy_fn() (и это самый «тяжелый» путь)
- heavy_fn() вызывает fn()
- main() также вызывает fn() непосредственно
- heavy_fn() занимает половину времени CPU
- fn() занимает оставшееся время CPU
- main() сама по себе не потребляет ничего

Визуализация делается по схеме «наибольшие поддеревья — первыми». Таким образом, даже для больших реальных программ можно использовать простую визуализацию в консоли, что должно быть удобно на серверах.
Для визуализации сложных графов вызова удобно использовать KCachegrind:
$ kcachegrind /tmp/test.calls Картинка, которая получилась у меня, представлена справа.
Вместо заключения, напомню что профайлером пока пользуются лишь несколько моих коллег и я сам. Надеюсь, он будет также полезен и Вам.
Профилирование (компьютерное программирование) — Profiling (computer programming)
В программная инженерия, профилирование («профилирование программы», « профилирование программного обеспечения «) — это форма динамического анализа программы, которая измеряет, например, пространственную (память) или временную сложность программы, использование определенных инструкций, или частота и продолжительность вызовов функций. Чаще всего информация о профилировании служит для помощи оптимизации программы.
Профилирование достигается посредством инструментария либо исходного кода программы, либо его двоичной исполняемой формы с помощью инструмента, называемого профилировщиком ( или профилировщик кода). Профилировщики могут использовать ряд различных методов, таких как методы на основе событий, статистические, инструментальные и имитационные методы.
- 1 Сбор событий программы
- 2 Использование профилировщиков
- 3 История
- 4 Типы профилировщиков на основе выходных данных
- 4.1 Плоский профилировщик
- 4.2 Профилировщик графа вызовов
- 4.3 Профилировщик с учетом ввода
- 5.1 Профилировщики на основе событий
- 5.2 Статистические профилировщики
- 5.3 Инструменты
- 5.4 Инструменты интерпретатора
- 5.5 Гипервизор / Симулятор
Сбор событий программы
Профилировщики используют широкий спектр методов для сбора данных, включая аппаратные прерывания, инструментарий кода, имитация набора команд, операционная система перехватчики и счетчики производительности. Профилировщики используются в процессе проектирования производительности.
Использование профилировщиков

Графический вывод профилировщика CodeAnalyst.
Инструменты анализа программы чрезвычайно важны для понимания поведения программы. Компьютерные архитекторы нуждаются в таких инструментах, чтобы оценить, насколько хорошо программы будут работать на новых архитектурах. Разработчикам программного обеспечения нужны инструменты для анализа своих программ и выявления критических участков кода. Составители компиляторов часто используют такие инструменты, чтобы узнать, насколько хорошо выполняется их алгоритм планирования инструкций или предсказания переходов.
Результатом профилировщика может быть:
- Статистическая сводка наблюдаемых событий (профиль )
/ * ------------ источник ------------- ------------ count * / 0001 IF X = "A" 0055 0002 THEN DO 0003 ADD 1 to XCOUNT 0032 0004 ELSE 0005 IF X = "B" 0055
- Поток записанных событий (a trace )
- Постоянное взаимодействие с гипервизором (например, непрерывный или периодический мониторинг через экранный дисплей)
Профилировщик может применяться к отдельному методу или в масштабе модуля или программы, чтобы идентифицировать узкие места производительности с помощью сделать очевидным длительный код. Профилировщик можно использовать для понимания кода с точки зрения синхронизации с целью его оптимизации для обработки различных условий выполнения или различных нагрузок. Результаты профилирования могут быть получены компилятором, который обеспечивает оптимизацию на основе профиля. Результаты профилирования могут использоваться для разработки и оптимизации отдельного алгоритма; алгоритм сопоставления подстановочных знаков Краусса является примером. Профилировщики встроены в некоторые системы управления производительностью приложений, которые собирают данные профилирования, чтобы получить представление о рабочих нагрузках транзакций в распределенных приложениях.
История
Инструменты анализа производительности существовали на платформах IBM / 360 и IBM / 370 с начала 1970-х годов, обычно они основывались на прерываниях таймера, которые записывали слово состояния программы (PSW) с установленными интервалами таймера для обнаружения «горячих точек» в исполняемом коде. Это был ранний пример выборки (см. Ниже). В начале 1974 года имитаторы набора команд допускали полную трассировку и другие функции мониторинга производительности.
Анализ программ на основе профилировщика в Unix восходит к 1973 году, когда системы Unix включали в себя базовый инструмент, prof , в котором перечислены все функции и время выполнения программы. В 1982 году gprof расширил концепцию до полного анализа графа звонков.
В 1994 году Амитабх Шривастава и Алан Юстас из Digital Equipment Corporation опубликовала документ, описывающий ATOM (инструменты анализа с OM). Платформа ATOM преобразует программу в собственный профилировщик: во время компиляции он вставляет код в программу, которую нужно проанализировать. Этот вставленный код выводит данные анализа. Этот метод — изменение программы для анализа самой себя — известен как «инструментарий ».
В 2004 году газеты gprof и ATOM вошли в список 50 самых влиятельных статей PLDI за 20-летний период, закончившийся в 1999 году.
Типы профилировщика на основе выходных данных
Плоский профилировщик
Плоские профилировщики вычисляют среднее время вызовов по вызовам и не разбивают время вызовов на основе вызываемого или контекста.
Профилировщик графа вызовов
График вызовов Профилировщики показывают время вызовов и частоту функций, а также задействованные цепочки вызовов в зависимости от вызываемого. В некоторых инструментах полный контекст не сохраняется.
Профилировщик, чувствительный к вводу
Профилировщики, чувствительные к вводу, добавляют дополнительное измерение к профилировщикам с плоским графиком или графиком вызовов, связывая показатели производительности с характеристиками рабочих нагрузок ввода, такими как размер ввода или вводимые значения. Они генерируют диаграммы, которые характеризуют масштабирование производительности приложения в зависимости от вводимых данных.
Детализация данных в типах профилировщиков
Профилировщики, которые также являются самими программами, анализируют целевые программы, собирая информацию об их выполнении. В зависимости от детализации данных и того, как профилировщики собирают информацию, они подразделяются на профилировщики на основе событий или статистические профилировщики. Профилировщики прерывают выполнение программы для сбора информации, что может привести к ограниченному разрешению в измерениях времени, к чему следует относиться с недоверием. Базовый блок профилировщики сообщают о количестве машинных тактовых циклов, выделенных на выполнение каждой строки кода, или о времени, основанном на их сложении; время, сообщаемое для каждого базового блока, может не отражать разницу между кешем попаданиями и промахами.
Профилировщики на основе событий
Перечисленные здесь языки программирования имеют профилировщики на основе событий:
- Java : API JVMTI (интерфейс инструментов JVM), ранее называвшийся JVMPI (интерфейс профилирования JVM), предоставляет средства профилирования для перехвата таких событий, как вызовы, загрузка класса, выгрузка, вход в поток. leave.
- .NET : может присоединить агент профилирования в качестве COM-сервера к CLR с помощью Profiling API. Как и Java, среда выполнения затем предоставляет агенту различные обратные вызовы для перехвата таких событий, как метод JIT / enter / leave, создание объекта и т. Д. Особенно мощный, поскольку агент профилирования может переписывать байт-код целевого приложения произвольным образом.
- Python : профилирование Python включает модуль профиля, hotshot (который основан на графике вызовов), и использование функции sys.setprofile для перехвата таких событий, как c_ , python_ .
- Ruby : Ruby также использует интерфейс, аналогичный Python для профилирования. Flat-profiler в profile.rb, module и ruby-prof присутствует C.-extension.
Статистические профилировщики
Некоторые профилировщики работают по выборке. Профилировщик выборки проверяет стек вызовов целевой программы через регулярные промежутки времени, используя прерывания операционной системы. Профили выборки обычно менее точны в числовом отношении и конкретны, но позволяют целевой программе работать почти на полной скорости.
Полученные данные не точны, а являются статистическим приближением. «Фактическая величина ошибки обычно составляет более одного периода выборки. Фактически, если значение в n раз превышает период выборки, ожидаемая ошибка в нем равна квадратному корню из n периодов выборки».
На практике выборочные профилировщики часто могут предоставить более точную картину выполнения целевой программы, чем другие подходы, поскольку они не так навязчивы для целевой программы и, следовательно, не имеют так много побочных эффектов (например, как в кэшах памяти или конвейерах декодирования команд). Кроме того, поскольку они не так сильно влияют на скорость выполнения, они могут обнаруживать проблемы, которые в противном случае были бы скрыты. Они также относительно невосприимчивы к переоценке стоимости небольших, часто называемых рутинных операций или «жестких» циклов. Они могут показать относительное количество времени, проведенного в пользовательском режиме по сравнению с режимом ядра с прерываниями, таким как обработка системного вызова.
Тем не менее, код ядра для обработки прерываний влечет за собой незначительную потерю циклов ЦП, переадресацию использования кеша и неспособен различать различные задачи, возникающие в непрерывном коде ядра (активность микросекундного диапазона).
Специальное оборудование может выйти за рамки этого: ARM Cortex-M3 и интерфейс JTAG некоторых недавних процессоров MIPS имеют регистр PCSAMPLE, который производит выборку программного счетчика в поистине необнаруживаемой манере, позволяя ненавязчиво сборник плоского профиля.
Некоторые часто используемые статистические профилировщики для Java / управляемого кода: SmartBear Software AQtime и Microsoft CLR Profiler. Эти профилировщики также поддерживают профилирование собственного кода вместе с Shark (OSX) от Apple Inc. (OSX), OProfile (Linux), Intel VTune и Parallel Amplifier (часть Intel Parallel Studio ), а также Oracle Performance Analyzer и другие.
Инструментарий
Этот метод эффективно добавляет инструкции к целевой программе для сбора необходимой информации. Обратите внимание, что инструментирование программы может вызвать изменения производительности, а в некоторых случаях может привести к неточным результатам и / или heisenbugs. Эффект будет зависеть от того, какая информация собирается, от уровня сообщаемых деталей синхронизации и от того, используется ли базовое профилирование блоков в сочетании с инструментами. Например, добавление кода для подсчета каждого вызова процедуры / подпрограммы, вероятно, будет иметь меньший эффект, чем подсчет того, сколько раз выполняется каждый оператор. Некоторые компьютеры имеют специальное оборудование для сбора информации; в этом случае влияние на программу минимально.
Инструментарий является ключом к определению уровня контроля и временного разрешения, доступного профилировщикам.
- Руководство : Выполняется программистом, например добавив инструкции для явного расчета времени выполнения, просто подсчитайте события или вызовы измерений API-интерфейсов, таких как стандарт измерения отклика приложений.
- Уровень автоматического источника : инструменты добавлены в исходный код с помощью автоматического инструмента в соответствии с политикой инструментария.
- Промежуточный язык : инструментарий, добавленный к сборке или декомпилированный байткодами, обеспечивающими поддержку нескольких исходных языков более высокого уровня и предотвращение (несимвольных) проблем с перезаписью двоичного смещения.
- С помощью компилятора
- Двоичная трансляция : инструмент добавляет инструментарий к скомпилированному исполняемому файлу.
- инструментарий времени выполнения : непосредственно перед выполнением код инструментирован. Программа полностью контролируется и контролируется инструментом.
- Внедрение во время выполнения : Более легкий, чем инструментарий во время выполнения. Код изменяется во время выполнения для перехода к вспомогательным функциям.
Инструментарий интерпретатора
- Параметры отладки интерпретатора могут включать сбор показателей производительности, когда интерпретатор встречает каждый целевой оператор. Интерпретаторы байт-кода , управляющей таблицы или JIT — это три примера, которые обычно полностью контролируют выполнение целевого кода, что обеспечивает чрезвычайно широкие возможности сбора данных. 232>Гипервизор / Симулятор
- Гипервизор : данные собираются путем запуска (обычно) неизмененной программы под гипервизором. Пример: SIMMON
- Simulator и Hypervisor : данные собираются интерактивно и выборочно путем запуска неизмененной программы в имитаторе набора команд.
См. Также
- Эффективность алгоритмов
- Бенчмарк
- Производительность Java
- Список инструментов анализа производительности
- PAPI — переносимый интерфейс (в виде библиотеки) для аппаратных счетчиков производительности на современных микропроцессорах.
- Разработка производительности
- Прогноз производительности
- Настройка производительности
- Проверка времени выполнения
- Профильная оптимизация
- Статический анализ кода
- Археология программного обеспечения
- Время выполнения в наихудшем случае (WCET)
Ссылки
Внешние ссылки
- Статья «Потребность в скорости — Устранение узких мест производительности » по анализу времени выполнения Java-приложений с использованием.
- Профилирование кода, созданного и интерпретируемого во время выполнения, с использованием VTune Performance Анализатор