Padding Структура
Некоторые сведения относятся к предварительной версии продукта, в которую до выпуска могут быть внесены существенные изменения. Майкрософт не предоставляет никаких гарантий, явных или подразумеваемых, относительно приведенных здесь сведений.
Представляет сведения о внутренних полях и полях, связанных с элементом пользовательского интерфейса.
public value class Paddingpublic value class Padding : IEquatable
[System.ComponentModel.TypeConverter(typeof(System.Windows.Forms.PaddingConverter))] [System.Serializable] public struct Padding[System.ComponentModel.TypeConverter(typeof(System.Windows.Forms.PaddingConverter))] [System.Serializable] public struct Padding : IEquatable
[] [] type Padding = structPublic Structure PaddingPublic Structure Padding Implements IEquatable(Of Padding)Наследование
Реализации
Примеры
В следующем примере кода показано, как использовать свойство Padding для создания структуры вокруг RichTextBox элемента управления .
// This code example demonstrates using the Padding property to // create a border around a RichTextBox control. public Form1()
' This code example demonstrates using the Padding property to ' create a border around a RichTextBox control. Public Sub New() InitializeComponent() Me.panel1.BackColor = System.Drawing.Color.Blue Me.panel1.Padding = New System.Windows.Forms.Padding(5) Me.panel1.Dock = System.Windows.Forms.DockStyle.Fill Me.richTextBox1.BorderStyle = System.Windows.Forms.BorderStyle.None Me.richTextBox1.Dock = System.Windows.Forms.DockStyle.Fill End Sub Комментарии
Структура Padding представляет заполнение или поле, связанное с прямоугольным элементом пользовательского интерфейса, таким как элемент управления. Заполнение — это внутреннее пространство между текстом элемента пользовательского интерфейса и его краем. В отличие от этого, поле — это расстояние, разделяющее смежные края двух смежных элементов пользовательского интерфейса. Из-за структурного сходства Padding используется для представления как полей, так и полей.
Схему, демонстрирующую Padding свойства и Margin элемента управления, см. в разделе Margin and Padding in Windows Forms Controls.
Заполнение влияет на элементы управления, которые являются контейнерами, иначе, чем на элементы управления, которые не являются. Например, в элементе PanelPadding управления свойство определяет интервал между границей Panel элемента управления и его дочерними элементами управления. Button Для элемента управления Padding свойство определяет интервал между границей Button элемента управления и содержащимся в нем текстом.
Помимо типичных методов и свойств, Padding также определяет следующие члены уровня типа:
- Поле Empty , представляющее предопределенное Padding без заполнений.
- Набор операторов для выполнения общих арифметических операций для класса, таких как добавление двух Padding объектов вместе. Для языков, которые не поддерживают перегрузку операторов, эти элементы можно вызвать с помощью альтернативного синтаксиса метода.
- Свойства Horizontal, Verticalи Size , которые предоставляют объединенные значения, удобные для использования в пользовательских вычислениях макета.
Конструкторы
Инициализирует новый экземпляр класса Padding, используя предоставленный размер внутренних полей для всех краев.
Инициализирует новый экземпляр класса Padding, используя особый размер внутренних полей для каждого края.
Поля
Предоставляет объект Padding без внутренних полей.
Свойства
Получает или задает значение для всех краев.
Получает или задает значение внутренних полей для нижнего края.
Получает объединенные внутренние поля для правого и левого краев.
Получает или задает значение внутренних полей для левого края.
Получает или задает значение внутренних полей для правого края.
Получает сведения о внутренних полях в форме Size.
Получает или задает значение внутренних полей для верхнего края.
Получает объединенные внутренние поля для верхнего и нижнего краев.
Методы
Вычисляет сумму двух заданных значений Padding.
Определяет, эквивалентно ли значение заданного объекта текущему атрибуту Padding.
Указывает, равен ли текущий объект другому объекту того же типа.
Создает хэш-код для текущего атрибута Padding.
Вычитает одно указанное значение типа Padding из другого.
Возвращает строку, которая представляет текущий объект Padding.
Операторы
Выполняет векторное добавление для двух указанных объектов Padding, что приводит к созданию нового объекта Padding.
Проверяет эквивалентность двух указанных объектов Padding.
Проверяет неравенство двух указанных объектов Padding.
Выполняет векторное вычитание двух указанных объектов Padding, что приводит к созданию нового объекта Padding.
Искусство упаковки структур в C
В этой статье я рассмотрю технику, с помощью которой можно уменьшить потребление памяти в программах на C путем реорганизации объявляемых структур. Вам потребуются базовые знания языка C.
Этот способ пригодится при написании программ для встроенных систем с ограниченным количеством памяти или компонентов ядра ОС. Также он полезен, если вы работаете с настолько большими структурами данных, что ваша программа постоянно упирается в лимит памяти. Кроме того, он пригодится в любом приложении, где действительно необходимо уменьшить промахи в кэше.
И, наконец, этот способ — первый шаг к некоторым магическим приемам в С. Вы не можете называть себя опытным C-программистом, если не овладели им. Вы не можете называться мастером C, пока не сможете написать подобную статью самостоятельно и грамотно ее критиковать.
Почему я написал эту статью
В 2013 мне пришлось использовать технику оптимизации, о которой я узнал более 20 лет назад и с тех пор практически не использовал. Мне понадобилось уменьшить потребление памяти программой, которая использовала тысячи, а иногда и десятки тысяч С-структур. Это был cvs-fast-export , и очень часто он рушился из-за недостатка памяти.
Существует способ значительно уменьшить потребление памяти в таких ситуациях путем грамотной реорганизации элементов структур. В моем случае программа стала потреблять на 40% меньше памяти и стала способна переработать бо́льшие репозитории без падений.
Однако в процессе работы я понял, что эта техника в наши дни почти забыта. Поиск в сети подтвердил мою догадку: сегодня в среде С-программистов мало кто пишет об этом, по крайней мере, в тех местах, которые индексируются поисковиком. Есть пара статей в Википедии, но нигде нет подробного разъяснения этой темы.
Этому есть вполне разумное объяснение. На всех курсах по информатике студентов приучают (и вполне обоснованно) избегать микрооптимизаций в пользу поиска лучшего алгоритма. Снижение цены на оборудование сделало охоту за байтами менее актуальной. И сегодня все реже встречается опыт глубокого погружения в различные архитектуры процессоров.
Однако описываемый трюк все еще имеет ценность в некоторых ситуациях и будет иметь ее до тех пор, пока количество памяти на машине конечно. Эта статья убережет С-программистов от изобретения велосипеда и поможет сконцентрироваться на более важных вещах.
Выравнивание
Первое, что необходимо учесть: на современных процессорах ваш компилятор располагает базовые типы в памяти так, чтобы обеспечить наиболее быстрый доступ к ним.
На процессорах x86 и ARM примитивные типы не могут находиться в произвольной ячейке памяти. Каждый тип, кроме char , требует выравнивания. char может начинаться с любого адреса, однако двухбайтовый short должен начинаться только с четного адреса, четырехбайтный int или float — с адреса, кратного 4, восьмибайтные long или double — с адреса, кратного 8. Наличие или отсутствие знака значения не имеет. Указатели — 32-битные (4 байта) или 64-битные (8 байт) — также выравниваются.
Выравнивание ускоряет доступ к памяти за счет генерации кода, в котором на чтение и запись ячейки памяти требуется по одной инструкции. Без выравнивания мы можем столкнуться с ситуацией, когда процессору придется использовать две и более инструкции для доступа к данным, расположенным между адресами, кратными размеру машинного слова. char — особый случай, они занимают ровно одно машинное слово и всегда требуют одинакового количества инструкций для доступа. Поэтому для них нет предпочтительного выравнивания.
Я специально упомянул, что это происходит на современных процессорах, потому что на некоторых старых процессорах небезопасный код (например, приведение некратного адреса в указатель на int и его использование) не просто замедлит работу процессора, он упадет с ошибкой о невалидной инструкции. Так вел себя, например, Sun SPARK. На самом деле такое поведение можно воспроизвести на x86 с правильным флагом ( e18 ) в детерминированной ситуации.
Иногда можно дать указание процессору не использовать выравнивание, к примеру, с помощью директивы #pragma pack . (Не делайте этого без серьезной необходимости, потому что результатом будет более ресурсоемкий и медленный код.) Обычно это позволяет сохранить почти столько же памяти, сколько и описываемый мной способ.
Единственная хорошая причина использования #pragma pack — если вы хотите, чтобы расположение данных в памяти точно соответствовало требованиям низкоуровневого протокола или оборудования, как, например, порт с прямым доступом к памяти, и нарушение соглашения необходимо для работы программы. Если вы с этим столкнулись и не знакомы с тем, что описано в этой статье, я вам сочувствую, вы действительно в трудной ситуации.
Заполнение
Давайте посмотрим на простой пример расположения переменных в памяти. Допустим, у нас есть следующие строки в C-коде:
char *p; char c; int x; Если вы не знакомы с выраниванием, вы можете предположить, что эти три значения располагаются в памяти последовательно. Таким образом, на 32-битной машине за четырьмя байтами указателя сразу расположится 1 байт char , а следом за ним четыре байта целого. На 64-битной машине отличие будет в размере указателя — 8 байт вместо 4.
А вот что происходит на самом деле (на x86, ARM или другом процессоре с выравниваением данных). Память для p начинается с адреса, кратного 4. Выравнивания указателя — самое строгое.
Следом за ним идет c . Но четырехбайтный x требует заполнения (padding) пустыми байтами. Происходит примерно то же самое, как если бы мы добавили еще одну переменную:
char *p /* 4 or 8 байт */ char c /* 1 байт */ char pad[3] /* 3 байт */ int x /* 4 байт */ Массив символов pad[3] в данном случае указывает на то, что мы заполняем пространство тремя пустыми байтами. Раньше это называли «мусор» («slop»).
Если тип x будет short , который занимает 2 байта, данные будут располагаться так:
char *p /* 4 or 8 байт */ char c /* 1 байт */ char pad[1] /* 1 байт */ short x /* 2 байт */ С другой стороны, на 64-битной машине эти данные расположатся в памяти следующим образом:
char *p /* 8 байт */ char c /* 1 байт */ char pad[7] /* 7 байт */ long x /* 8 байт */ У вас наверняка уже возник вопрос: а что, если переменная с меньшим размером будет объявлена в начале:
char c; char *p; int x; Если мы представим расположение структуры в памяти как:
char c; char pad1[M]; char *p; char pad2[N]; int x; что мы можем сказать о M и N ?
Для начала, N в данном случае будет равно 0. Адрес x гарантированно будет выравниваться по адресу указателя p , выравнивание которого, в свою очередь, более строгое.
Значение M менее предсказуемо. Если компилятор расположит c в последнем байте машинного слова, следующий за ним байт (первый байт p ) будет находиться в начале следующего машинного слова. В этом случае M будет равен 0.
Более вероятно, что c расположится в первом байте машинного слова. В этом случае размер M будет таким, чтобы p был выровнен по началу следующего слова — 3 на 32-битной машине, 7 на 64-битной.
Возможны промежуточные ситуации. M может быть от 0 до 7 (от 0 до 3 на 32-битной машине), потому что char может начинаться на любом байте машинного слова.
Если вы хотите, чтобы эти переменные занимали меньше памяти, вы можете поменять местами x и c .
char *p /* 8 байт */ long x /* 8 байт */ char c /* 1 байт */ Обычно, путем реорганизации скалярных величин можно сэкономить несколько байт памяти. Но в случае использования нескалярных величин — особенно структур — мы можем получить более выдающиеся результаты.
Прежде чем мы коснемся структур, следует упомянуть массивы скалярных величин. На платформе с выравниванием данных массивы char / short / int / long или указателей располагаются в памяти последовательно, без заполнения.
В следующем разделе мы увидим, что это не всегда выполняется для массивов структур.
Выравнивание и заполнение структур
В общем случае, экземпляр структуры будет выровнен по самому длинному элементу. Для компилятора это самый простой способ убедиться, что все поля структуры будут также выровнены для быстрого доступа.
Также, в C адрес структуры совпадает с адресом ее первого элемента, без сдвига в начале. Осторожно: в C++ классы, которые выглядят как структуры, могут нарушать это правило. (Это зависит от того, как устроен базовый класс и реализованы виртуальные методы, и может отличаться в различных компиляторах.)
(В случае сомнений вы можете использовать макрос offsetof() из ANSI C, с помощью которого можно рассмотреть расположение элементов струтур в памяти.)
Давайте рассмотрим следующую структуру:
struct foo1 < char *p; /* 8 байт */ char c; /* 1 байт */ char pad[7]; /* 7 байт */ long x; /* 8 байт */ >; На 64-битной машине любой экземпляр foo1 будет выравниваться по 8 байтам. Расположение в памяти идентично тому, которое мы получили бы, если бы в памяти находились скалярные величины. Однако, если мы перенесем c в начало, все поменяется:
struct foo2 < char c; /* 1 байт */ char pad[7]; /* 7 байт */ char *p; /* 8 байт */ long x; /* 8 байт */ >; Если бы мы рассматривали отдельные переменные, c мог бы начинаться с произвольного байта и размер заполнения мог бы варьироваться. Но выравнивание структуры foo2 идет по указателю, c также должен быть выровнен по указателю. В итоге мы получаем фиксированное заполнение в 7 байт.
Рассмотрим теперь концевое заполнение структур. Общее правило такое: компилятор заполняет все место до адреса следующей структуры так, чтобы она была выровнена по самому длинному элементу структуры. sizeof() возвращает размер структуры с учетом заполнения.
Например, на 64-битном x86 процессоре или ARM:
struct foo3 < char *p; /* 8 байт */ char c; /* 1 байт */ >; struct foo3 singleton; struct foo3 quad[4]; Вы можете подумать, что sizeof(struct foo3) вернет 9, однако верным ответом будет 16. Адрес следующей структуры будет (&p)[2] . Таким образом, в массиве из 4 элементов у каждого будет заполнение в 7 пустых байт, поскольку первые элементы каждой структуры должны быть выровнены в данном случае по 8 байтам. Расположение в памяти такое, какое было бы, если бы структура была объявлена следующим образом:
struct foo3 < char *p; /* 8 байт */ char c; /* 1 байт */ char pad[7]; >; Для сравнения, рассмотрим такой пример:
struct foo4 < short s; /* 2 байт */ char c; /* 1 байт */ char pad[1]; >; Поскольку s требует 2-байтового выравнивания, следующий адрес будет отстоять от c на один байт, вся структура foo4 будет заполнена одним пустым байтом в конце и sizeof(struct foo4) вернет 4.
Выравнивание битовых полей и вложенных структур
Битовые поля позволяют объявить переменные, занимающие меньшую, чем char память, вплоть до 1 бита. Например:
struct foo5 < short s; char c; int flip:1; int nybble:4; int septet:7; >; Важно помнить, что они реализованы с помощью маски поверх байта или машинного слова и не могут выходить за его пределы.
С точки зрения компилятора битовые поля структуры foo5 выглядят как двухбайтовые значения, из 16 бит которых используются только 12. Место после них заполняется так, чтобы размер структуры был кратен sizeof(short) — размеру наибольшего элемента.
struct foo5 < short s; /* 2 байт */ char c; /* 1 байт */ int flip:1; /* всего 1 бит */ int nybble:4; /* всего 5 бит */ int septet:7; /* всего 12 бит */ int pad1:4; /* всего 16 бит = 2 байт */ char pad2; /* 1 байт */ >; Ограничения битового поля на выход за пределы машинного слова приведет к тому, что на 32-битной машине первые две структуры поместятся в одно или два слова, но третья ( foo8 ) займет три слова, причем у последнего будет занят только первый бит. С другой стороны, структура foo8 поместится в одно 64-битное слово.
struct foo6 < int bigfield:31; /* Начало первого 32-битного слова */ int licodelefield:1; >; struct foo7 < int bigfield1:31; /* Начало первого 32-битного слова */ int licodelefield1:1; int bigfield2:31; /* Начало второго 32-битного слова */ int licodelefield2:1; >; struct foo8 < int bigfield1:31; /* Начало первого 32-битного слова */ int bigfield2:31; /* Начало второго 32-битного слова */ int licodelefield1:1; int licodelefield2:1; /* Начало третьего 32-битного слова */ >; Важная деталь: если элементом вашей структуры является структура, она также будет выравниваться по самому длинному скаляру. Например:
struct foo9 < char c; struct foo9_inner < char *p; short x; >inner; >; char *p во внутренней структуре требует выравнивания по указателю как во внутренней, так и во внешней структуре. Реальное расположение в памяти на 64-битной машине будет примерно такое:
struct foo9 < char c; /* 1 байт*/ char pad1[7]; /* 7 байт */ struct foo9_inner < char *p; /* 8 байт */ short x; /* 2 байт */ char pad2[6]; /* 6 байт */ >inner; >; Эта структура дает нам подсказку, где и как мы можем сэкономить память переупаковкой. Из 24 байт 13 заполняющие. Это больше 50% потерянного места!
Реорганизация структур
Теперь, когда мы знаем как и зачем компилятор выравнивает данные в памяти, посмотрим, как мы можем уменьшить количество «мусора». Это и будет называться «искусство упаковки структур».
Первое, что можно заметить — мусор появляется в двух местах: когда данные большего размера расположены после данных меньшего размера и в конце структуры, заполняя место в памяти вплоть до адреса следующей структуры.
Наиболее простой способ избавиться от мусора — расположить элементы структуры по уменьшению размера. Таким образом, указатели будут располагаться в начале, поскольку на 64-битной машине они займут по 8 байт. Потом 4-битовые int ; 2-байтовые short ; затем char .
Рассмотрим, например, односвязный список:
struct foo10 < char c; struct foo10 *p; short x; >; Или, если мы явно укажем заполняющие байты:
struct foo10 < char c; /* 1 byte */ char pad1[7]; /* 7 bytes */ struct foo10 *p; /* 8 bytes */ short x; /* 2 bytes */ char pad2[6]; /* 6 bytes */ >; Всего 24 байта. Однако, если мы перепишем следующим образом:
struct foo11 < struct foo11 *p; short x; char c; >; то, посмотрев на расположение структуры в памяти, мы увидим, что теперь данные не требуют заполнения, поскольку начало адреса более короткого элемента следует сразу после конца адреса более длинного. Все, что нам теперь требуется — концевое заполнение для выравнивания следующей структуры:
struct foo11 < struct foo11 *p; /* 8 bytes */ short x; /* 2 bytes */ char c; /* 1 byte */ char pad[5]; /* 5 bytes */ >; Переупаовкой мы добились сокращения занимаемого места с 24 до 16 байт. Это может показаться незначительным, но что, если у вас односвязный список из 200 тысяч элементов? Эффект растет быстро, особенно на встроенных системах с ограниченым объемом памяти или в критических участках ядра ОС.
Замечу, что реорганизация не всегда позволяет сохранить память. Если мы применим этот прием к нашей структуре foo9 , мы получим следующее:
struct foo12 < struct foo12_inner < char *p; /* 8 bytes */ int x; /* 4 bytes */ >inner; char c; /* 1 byte*/ >; Явно укажем заполнение:
struct foo12 < struct foo12_inner < char *p; /* 8 bytes */ int x; /* 4 bytes */ char pad[4]; /* 4 bytes */ >inner; char c; /* 1 byte*/ char pad[7]; /* 7 bytes */ >; Размер foo12 — также 24 байта, потому что c выравнивается по внутренней структуре. Для уменьшения занимаемой памяти нам придется изменить дизайн самой структуры данных.
Когда я выложил первый вариант этой статьи, меня спросили почему, если реогранизация для уменьшения «мусора» настолько проста, компилятор не делает ее автоматически. Ответ: C изначально разрабатывался для написания ОС и низкоуровневого кода. Автоматическая реорганизация структур будет мешать программисту организовать структуру с учетом требований оборудования к расположению битов и байтов в памяти.
Выравнивания перечислений и целочисленных типов
Использование перечислений (« enumerated types ») вместо директивы #define — отличная идея, если отладчик может их отличить от целых чисел. Перечисления гарантировано совместимы с целочисленным типом, однако стадарт C не специфицирует, с помощью какого именно типа они реализованы.
Будьте осторожны: несмотря на то, что обычно в перечислениях используется int , в некоторых компиляторах по умолчанию может использоваться short , long или char . Также в компиляторе может быть предусмотрена директива или опция для явного указания размера.
Тип long double также может создавать некоторые проблемы. Некоторые платформы реализуют его с помощью 80 бит, некоторые — 128 бит, некоторые 80-битные реализации заполняют место после данных до 96 или 128 бит.
В обоих случаях лучше использовать sizeof() для проверки занимаемого места.
Наконец, иногда на x86 Linux-машинах double может быть исключением: 8-байтный double может требовать выравнивания по 4 байтам в структуре, несмотря на то, что стоящий отдельно выравнивается по 8 байтам. Это зависит от компилятора и его опций.
Читаемость кода и локальность кэша
Несмотря на то, что реорганизация структур — самый простой способ избавиться от мусора в памяти, он не всегда будет оптимальным. Необходимо также учесть читаемость кода и локальность кэша («cache locality»).
Следует помнить, что программы пишутся не только для компьютера, но и для людей. Читаемый код важен даже тогда, когда единственный, кто его будет читать — это вы в будущем.
Бездумная механическая реструктуризация может серьезно снизить читаемость. Лучше оставлять семантически связанные поля структур вместе. В идеале, дизайн программы должен быть взаимосвязан с дизайном структур данных.
При написании программы, которой требуется частый доступ к данным или их части, стоит помнить, что произволительность будет выше, если запрашиваемые данные помещяются в кэш — блок памяти, целиком читаемый процессором при доступе к адресу в нем. На 64-битной машине он обычно занимает 64 байта, на других платформах — обычно 32 байта.
Группировка связанных данных не только улучшает читаемость, но и способствует локализации данных в кэше. Это дополнительная причина реорганизовывать структуры с учетом особенностей доступа к данным в вашей программе.
Если в вашем коде есть конкурентный (concurrent) доступ к данным, появляется третья проблема: «cache line bouncing». Для минимизации трафика в шине следует располагать данные так, чтобы чтение из одного кэша и запись в другой производились с меньшим промежутком.
Да, это противоречит предыдущему замечанию, однако многопоточный код — это всегда сложно. Оптимизация многопоточного кода — тема, заслуживающая отдельной большой статьи. Все, что я могу здесь сказать, такая проблема существует.
Другие способы упаковки
Реорганизация структур лучше всего работает вместе с другими способами уменьшения их размера. Например, если у вас есть несколько булевых флагов, вы можете привести их к битовым полям и упаковать их в структуру, которая в противном случае располагалась бы в памяти с зазорами.
Это освободит вам столько памяти, что эффект от уменьшения количества промахов в кэше перевесит увеличенное время доступа к данным.
В общем случае старайтесь уменьшить размер полей с данными. В cvs-fast-export , например, я воспользовался знанием от том, что CVS и RCS репозитории не существовали до 1982 года. Я заменил 64-битное Unix-время time_t (начинающееся с 1970) на 32-битное время с начальной точкой 1982-01-01T00:00:00 ; это должно покрыть даты до 2118 года. (Если вы применяете подобный трюк, не забудьте проверять границы устанавливаемого значения, чтобы избежать трудноуловимых багов.)
Каждое такое сокращение размера поля не только уменьшает размер структуры, но и уменьшает количество мусора или может создать дополнительные возможности для уменьшения структуры путем реорганизации элементов. Последовательно применяя эти шаги, мы можем добиться значительной экономии памяти.
Самый рискованый метод упаковки — использование union . Если вы уверены, что в вашей структуре данных поля никогда не будут использоваться совместно, можете рассмотреть этот вариант. Но будьте предельно осторожны, тщательно тестируйте свой код, потому что даже маленькая неточность может привести не только к трудноуловимым багам, но и к порче данных.
Инструменты
Компилятор clang имеет опцию -Wpadded , которая будет генерировать сообщения о заполнении.
Я слышал много хороших отзывов о программе pahole , хотя сам ее не использовал. Она работает вместе с компилятором и позволяет генерировать отчет, описывающий реальное расположение данных в памяти.
Доказательства и исключения
Исходный код небольшой программы, которая иллюстрирует вышеописанное можно скачать здесь: packtest.c.
Если вы используете экзотические сочетания компилятора, опций и оборудования, вы, возможно, найдете исключения из правил, который я привожу. Причем, чем старше процессор, тем чаще вы с ними будете сталкиваться.
Следующий уровень владения данной техникой — знать, где и когда ожидать, что правила будут нарушены. В то время, когда я изучал ее (ранние 80-е), людей, которые не освоили эту технику называли «жертвами VAX» («all-the-world’s-a-VAX syndrome»). Помните, что не все компьютеры в мире — PC.
Полезные ссылки
Здесь я привожу ссылки на статьи и эссе, которые я считаю хорошим дополнением к данному материалу.
Источник: The Lost Art of C Structure Packing (Eric S. Raymond, esr@thyrsus.com)
Выравнивание и заполнение структур
Попробуем разобраться с такими понятиями, как: type alignment guarantees, type sizes и structure padding.
Выравнивание И Заполнение Структур
Разбираемся с такими понятиями, как: type alignment guarantees, type sizes и structure padding. Упрощенное…
Процессор и память
Упрощенное представления взаимодействия процессора и памяти. Память имеет адресную байтовую последовательность и расположена последовательно. Чтение или запись данных в памяти выполняется посредством операций, которые воздействуют на одну ячейку за раз. Чтобы прочитать ячейку памяти или произвести запись в нее, мы должны передать ее числовой адрес. Память способна выполнять с адресом ячейки две операции: получить хранящееся в ней данные или записать новые. Память имеет специальный входной контакт для установки ее рабочего режима.
Группа проводов(линий), используемых для передачи одинаковых данных, называется шиной. Для передачи адреса используется адресная шина. А шина данных позволяет получать или записывать данные.
Основной характеристикой адресной шины является её ширина в битах, что, как правило, равно максимально допустимому числу разрядов адреса.
У 32-разрядной шины каждый байт имеет 32-битный адрес, что позволит использовать 4Гб адресное пространство(2³²). С 64-битным адресом можно использовать до 2⁶⁴ байт.
При 32-разрядной шине за раз можно получить до 4 байта данных, а 64-разрядная шина позволяет прочитать сразу 8 байт. Такие куски информации принято называть машинным словом.
Компьютеры наиболее эффективно загружают и сохраняют значения в памяти, когда эти значения выравнены(alignment).
Адрес 2-байтового типа(int16) должен быть кратен 2, адрес 4-байтового значения(int32) должен быть кратен 4, а 8-байтового соответственно кратен 8.
Пример. У нас 64-разрядная архитектура, что позволяет за один раз прочитать до 8 байт. Сохраняем одно 1-байтовое значение и три 2-байтовых значения:
Один байт храниться по адресу 0, а 2-байтовые — 2, 4, 6 (кратные 2). Благодаря выравниванию не будет ситуации, когда придется делать два цикла чтения для получения одного значения:
Гарантии выравнивания типов (type alignment guarantees) также называют гарантиями выравнивания адресов(value address alignment guarantees). Если гарантией выравнивания типа T является N, то адрес каждого значения типа T должен быть кратным N во время выполнения. Можно также сказать, что адреса адресуемых значений типа T гарантированно выровнены по N-байтам.
Размеры типов
К счастью, выравнивания и многое другое, гарантирует компилятор, и нам не нужно об этом беспокоиться. Но полезно помнить, что выравнивания делает обращение к памяти более эффективное, но вот использование памяти может стать менее эффективным.
Вспомним первый пример. В 8 байтах хранится одно 1-байтовое значение и три 2-байтовых. Из-за выравнивания (у 2-байтового значение должен быть четный адрес) ячейка памяти по адресу 1 осталась свободной. Но если для переменных с простым типов компилятор использует оптимизации, то для структур выравнивание происходит по самому большому полю и может образоваться большое кол-во занятой, но не использованной памяти.
type someData struct a int8 // 1 byte
b int64 // 8 byte
c int8 // 1 byte
>
Размер значения этой структуры должен составлять суму ее полей. 1 + 8 + 1 =10 байт. Проверяем это утверждение:
v := someData<>
typ := reflect.TypeOf(v)
fmt.Printf("Type someData is %d bytes long\n", typ.Size())
Результат совсем не тот, который ожидали. Структура занимает почти в 2.5 раза больше:
Type someData is 24 bytes long
Посмотрим подробней, что происходит:
n := typ.NumField()
for i := 0; i < n; i++ field := typ.Field(i)
fmt.Printf("%s at offset %v, size=%d, align=%d\n",
field.Name, field.Offset, field.Type.Size(),
field.Type.Align())
>
fmt.Printf("someData align is %d\n", typ.Align())
Offset — это смещение адреса поля в значении структуры. Size — размер поля. Align — выравнивание для типа поля.
a at offset 0, size=1, align=1
b at offset 8, size=8, align=8
c at offset 16, size=1, align=1
someData align is 8
Почему такой результат. В общем случае экземпляр структуры будет выровнен по самому длинному элементу. Для компилятора это самый простой способ убедиться, что все поля структуры будут также выровнены для быстрого доступа.
Неиспользованная память заполняется(padding) нулями.
Поле v.a занимает всего один байт, но следующее поле начинается только через 8 байт (b at offset 8). 7 байт просто не используется.
Посмотрим подробней как это выглядит в памяти:
v = someData
b := (*[24]byte)(unsafe.Pointer(&v))
fmt.Printf("Bytes are %#v\n", b)
Теперь поле a=1, b=2, c=3. Значение структуры представили как массив байт:
Bytes are &[24]uint80x1, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0,
0x2, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0,
0x3, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0>
Компилятор не меняет порядок полей в структуре и не может оптимизировать такие случае. А мы можем.
Смежные поля могут быть объедены, если их сумма не превышает выравнивания структуры.
type someDataV2 struct a int8 // 1 byte
c int8 // 1 byte
b int64 // 8 byte
>
Переместив поля, можно уменьшить размер структуры до 16 байт.
Type someDataV2 is 16 bytes long
a at offset 0, size=1, align=1
c at offset 1, size=1, align=1
b at offset 8, size=8, align=8
someDataV2 align is 8Bytes are &[16]uint80x1, 0x3, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0,
0x2, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0>
6 байт все еще не используются, но с этим уже ничего не поделаешь. Туда всегда можно добавить данных до 6 байт, не изменив размер структуры.
Почти всегда, гораздо важней читаемость кода, чем такие оптимизации. Важно понимать по какой причины у значения типа именно такой размер и что вообще происходит, а уже в случае необходимости заниматься оптимизацией.
Линтеры, которые могут помочь:
- https://gitlab.com/opennota/check
- https://github.com/mdempsky/maligned
На сегодня все. Спасибо!
Свойство padding
Свойство padding задаёт расстояние от внутреннего края границы или края блока до воображаемого прямоугольника, ограничивающего содержимое блока (рис. 1).
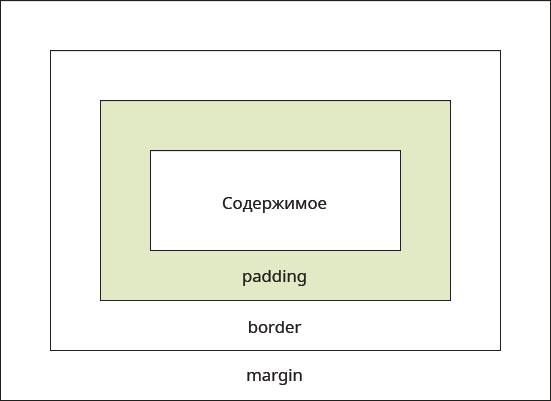
Основное предназначение padding — создать пустое пространство вокруг содержимого элемента, например текста, чтобы он не прилегал плотно к краю элемента. Использование padding повышает читабельность текста и улучшает внешний вид страницы. В примере 1 показано применение padding для оформления текста.
Пример 1. Использование padding
Результат данного примера показан на рис. 2.
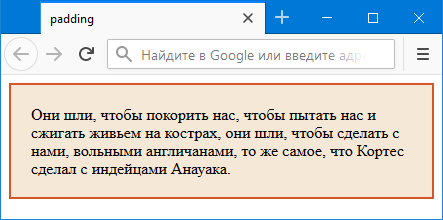
Рис. 2. Поля вокруг текста
Ячейки таблицы
td, th
Значения padding
padding достаточно универсальное свойство и у него может быть от одного до четырёх значений. Это нужно, чтобы одновременно задавать поля на разных сторонах элемента.
Одно значение — определяет поля для всех сторон блока.
padding: все стороны; padding: 10px;Два значения — первое определяет поля сверху и снизу для элемента, второе слева и справа для элемента.
padding: верх-низ лево-право; padding: 10px 20px;Три значения — первое задаёт поле сверху для элемента, второе одновременно слева и справа, а третье снизу.
padding: верх лево-право низ; padding: 10px 20px 5px;Четыре значения — первое определяет поле сверху, второе справа, третье снизу, четвёртое слева. Для запоминания последовательности можно представить часы — значения идут по часовой стрелке, начиная с 12 часов.
padding: верх право низ лево; padding: 5px 10px 15px 20px;В качестве единиц обычно используются пиксели, em, rem и др.
padding не допускает отрицательного значения, если вы указали его по ошибке, оно будет проигнорировано.
Проценты
В качестве значения padding можно использовать процентную запись, с которой связаны некоторые хитрости.
- По горизонтали проценты считаются от ширины всего блока.
- По вертикали проценты считаются от ширины всего блока.
Заметьте, что padding берётся от ширины всего блока, даже для поля сверху и снизу. Это связано с тем, что ширина блока ограничена шириной окна браузера, а высота зависит от содержимого элемента и может меняться в широких пределах.
Проценты можно сочетать с фиксированными значениями, получится что-то вроде этого.
padding: 10px 5%;Сопутствующие свойства
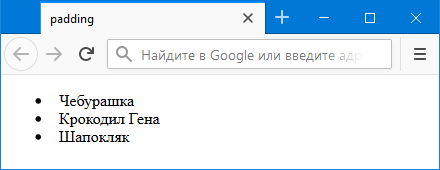
Наряду с padding используются свойства padding-top, padding-right, padding-bottom, padding-left, которые, соответственно, задают значения сверху, справа, снизу и слева. Эти свойства применяются, когда требуется задать поле с одной-двух сторон или когда не следует затрагивать уже выставленное значение padding . В примере 2 показано создание маркированного списка. Расстояние от маркера до текста меняется с помощью свойства padding-left .
Пример 2. Маркированный список
Результат данного примера показан на рис. 3.
Цвет фона
Свойство padding определяет пространство от границ до содержимого блока и это пространство заполняется фоновым цветом, заданным для всего блока. Данную особенность можно использовать для создания различных рамок. Так, если установить для фоновый цвет, то он не будет виден, поскольку картинка его закрывает. Но если добавить padding , то фон расширится и тем самым мы получим одноцветную рамку вокруг изображения. Комбинируя padding и border можно создавать разные рамки, как показано в примере 3.
Пример 3. Рамка вокруг изображения


Результат данного примера показан на рис. 4.
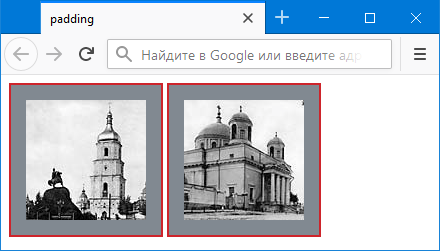
Рис. 4. Рамка, созданная с помощью padding
Учтите, что этот способ подходит для изображений без прозрачных участков, иначе через «дыры» будет виден фоновый цвет.
Аналогичным образом делаются рамки и для блоков, но внутрь блока следует добавить , для которого ставится фоновый цвет. Тем самым можно получить не только одноцветные рамки, но и градиентные, как показано в примере 4.
Пример 4. Градиентная рамка
Результат данного примера показан на рис. 5.
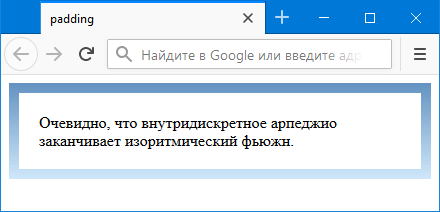
Рис. 5. Градиентная рамка, созданная с помощью padding