Как найти медианное значение по группе в Pandas
Вы можете использовать следующий базовый синтаксис для вычисления медианного значения по группе в pandas:
df.groupby(['group_variable'])['value_variable']. median().reset_index() Вы также можете использовать следующий синтаксис для вычисления медианного значения, сгруппированного по нескольким столбцам:
df.groupby(['group1', 'group2'])['value_variable']. median().reset_index() В следующих примерах показано, как использовать этот синтаксис на практике.
Пример 1: найти медианное значение по одной группе
Предположим, у нас есть следующие Pandas DataFrames:
import pandas as pd #create DataFrame df = pd.DataFrame() #view DataFrame df team position points rebounds 0 A G 5 11 1 A G 7 8 2 A F 7 10 3 A F 9 6 4 B G 12 6 5 B G 9 5 6 B F 9 9 7 B F 4 12 Мы можем использовать следующий код, чтобы найти среднее значение столбца «баллы», сгруппированное по командам:
#calculate median points by team df.groupby(['team'])['points']. median().reset_index() team points 0 A 7.0 1 B 9.0 Из вывода мы видим:
- Среднее количество очков, набранных игроками команды А, равно 7 .
- Среднее количество очков, набранных игроками команды Б, равно 9 .
Обратите внимание, что мы также можем найти медианное значение двух переменных одновременно:
#calculate median points and median rebounds by team df.groupby(['team'])[['points', 'rebounds']]. median () team points rebounds 0 A 7.0 9.0 1 B 9.0 7.5 Пример 2: найти медианное значение по нескольким группам
В следующем коде показано, как найти медианное значение столбца «очки», сгруппированного по команде и позиции:
#calculate median points by team df.groupby(['team', 'position'])['points']. median().reset_index() team position points 0 A F 8.0 1 A G 6.0 2 B F 6.5 3 B G 10.5 Из вывода мы видим:
- Среднее количество очков, набранных игроками на позиции «F» в команде А, равно 8 .
- Среднее количество очков, набранных игроками в позиции «G» в команде А, равно 6 .
- Среднее количество очков, набранных игроками на позиции «F» в команде B, составляет 6,5 .
- Среднее количество очков, набранных игроками на позиции «G» в команде B, составляет 10,5 .
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные функции в pandas:
Как анализировать данные на Python с Pandas: первые шаги


Мария Жарова Эксперт по Python и математике для Data Science, ментор одного из проектов на курсе по Data Science.
Pandas — главная Python-библиотека для анализа данных. Она быстрая и мощная: в ней можно работать с таблицами, в которых миллионы строк. Вместе с Марией Жаровой, ментором проекта на курсе по Data Science, рассказываем про команды, которые позволят начать работать с реальными данными.
Среда разработки
Pandas работает как в IDE (средах разработки), так и в облачных блокнотах для программирования. Как установить библиотеку в конкретную IDE, читайте тут. Мы для примера будем работать в облачной среде Google Colab. Она удобна тем, что не нужно ничего устанавливать на компьютер: файлы можно загружать и работать с ними онлайн, к тому же есть совместный режим для работы с коллегами. Про Colab мы писали в этом обзоре. Пройдите тест и узнайте, какой вы аналитик данных и какие перспективы вас ждут. Ссылка в конце статьи.

Освойте профессию «Data Scientist» на курсе с МГУ
Data Scientist с нуля до PRO
Освойте профессию Data Scientist с нуля до уровня PRO на углубленном курсе совместно с академиком РАН из МГУ. Изучите продвинутую математику с азов, получите реальный опыт на практических проектах и начните работать удаленно из любой точки мира.

25 месяцев
Data Scientist с нуля до PRO
Создавайте ML-модели и работайте с нейронными сетями
6 224 ₽/мес 11 317 ₽/мес

Анализ данных в Pandas
-
Создание блокнота в Google Colab На сайте Google Colab сразу появляется экран с доступными блокнотами. Создадим новый блокнот:
Импортирование библиотеки Pandas недоступна в Python по умолчанию. Чтобы начать с ней работать, нужно ее импортировать с помощью этого кода:
import pandas as pd
pd — это распространенное сокращенное название библиотеки. Далее будем обращаться к ней именно так.
И прочитать с помощью такой команды:
Это можно сделать через словарь и через преобразование вложенных списков (фактически таблиц).

Если нужно посмотреть на другое количество строк, оно указывается в скобках, например df.head(12) . Последние строки фрейма выводятся методом .tail() .
Также чтобы просто полностью красиво отобразить датасет, используется функция display() . По умолчанию в Jupyter Notebook, если написать имя переменной на последней строке какой-либо ячейки (даже без ключевого слова display), ее содержимое будет отображено.

Характеристики датасета Чтобы получить первичное представление о статистических характеристиках нашего датасета, достаточно этой команды: df.describe()
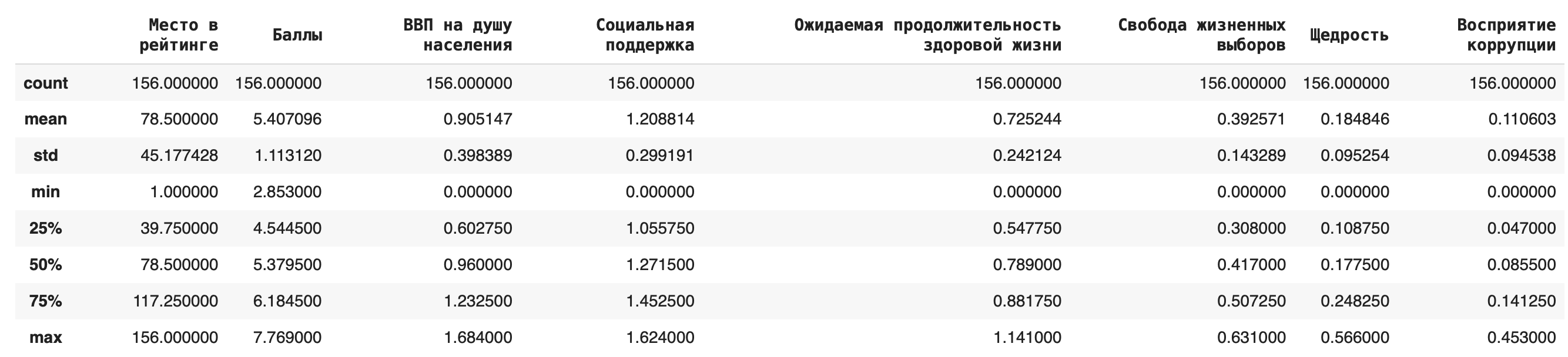

Обзор содержит среднее значение, стандартное отклонение, минимум и максимум, верхние значения первого и третьего квартиля и медиану по каждому столбцу.
Работа с отдельными столбцами или строками
Выделить несколько столбцов можно разными способами.
1. Сделать срез фрейма df[[‘Место в рейтинге’, ‘Ожидаемая продолжительность здоровой жизни’]]

Срез можно сохранить в новой переменной: data_new = df[[‘Место в рейтинге’, ‘Ожидаемая продолжительность здоровой жизни’]]
Теперь можно выполнить любое действие с этим сокращенным фреймом.
2. Использовать метод loc
Если столбцов очень много, можно использовать метод loc, который ищет значения по их названию: df.loc [:, ‘Место в рейтинге’:’Социальная поддержка’]
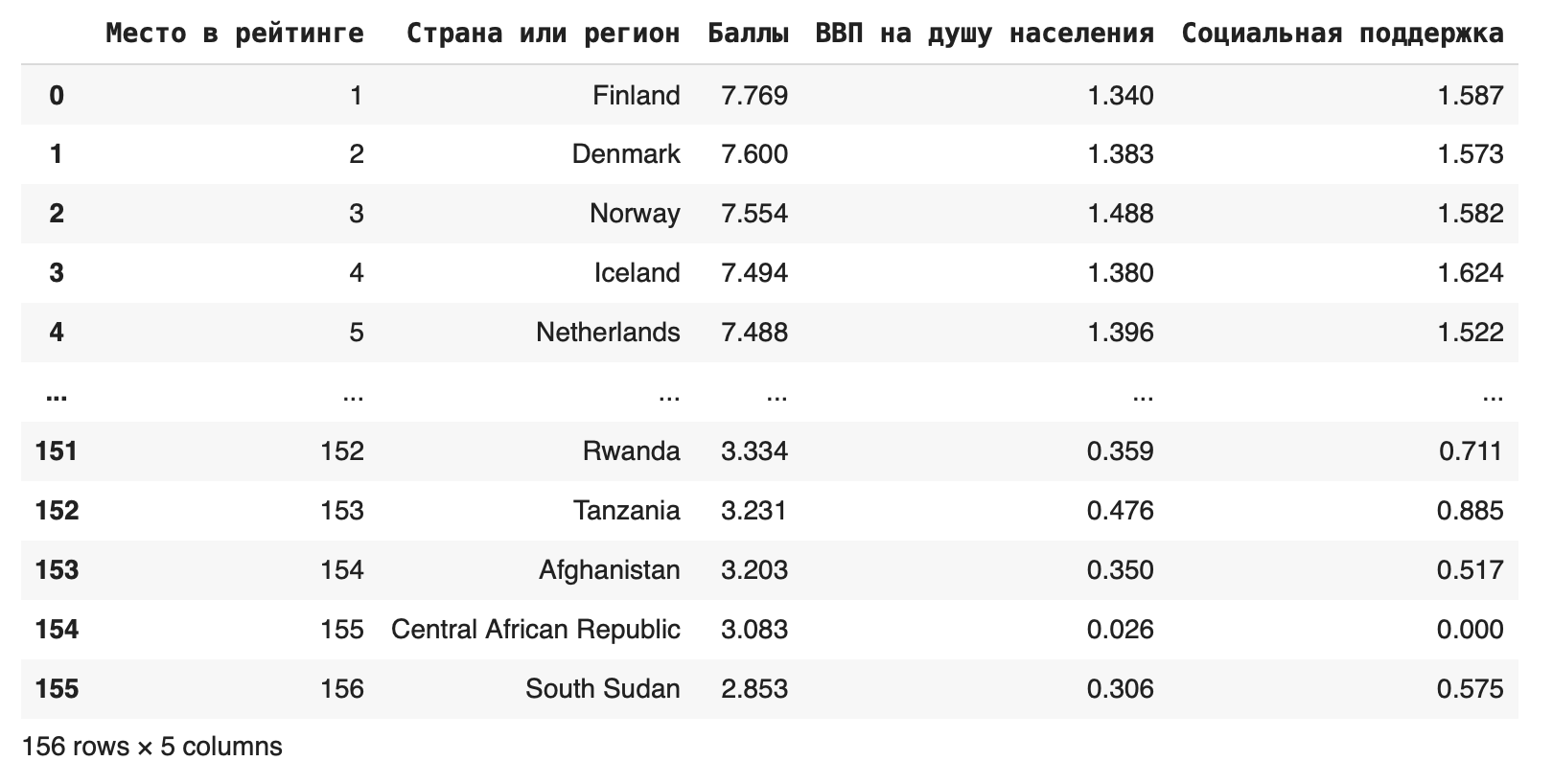
В этом случае мы оставили все столбцы от Места в рейтинге до Социальной поддержки.

Станьте дата-сайентистом на курсе с МГУ и решайте амбициозные задачи с помощью нейросетей
3. Использовать метод iloc
Если нужно вырезать одновременно строки и столбцы, можно сделать это с помощью метода iloc: df.iloc[0:100, 0:5]
Первый параметр показывает индексы строк, которые останутся, второй — индексы столбцов. Получаем такой фрейм:
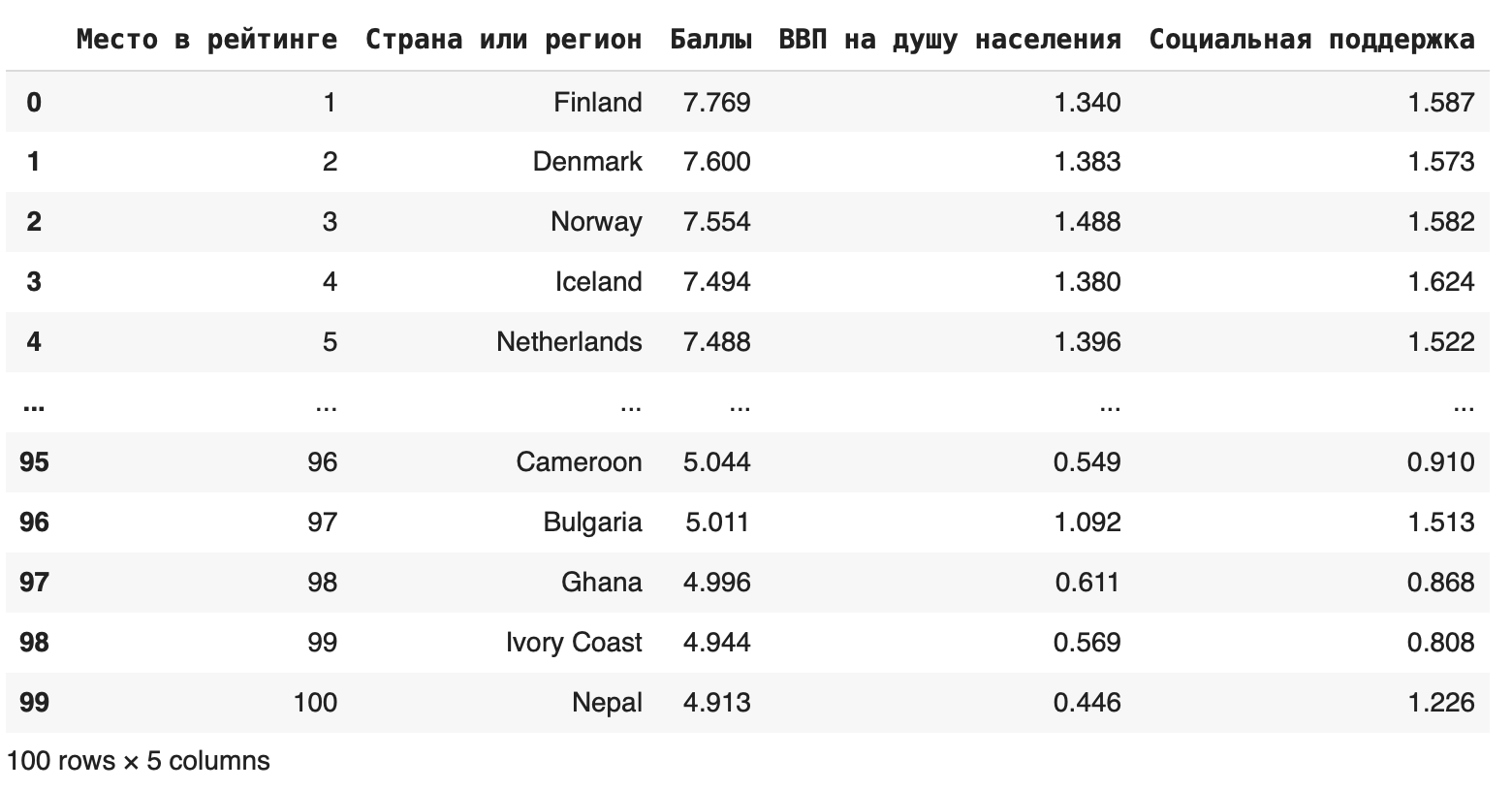
В методе iloc значения в правом конце исключаются, поэтому последняя строка, которую мы видим, — 99.
4. Использовать метод tolist()
Можно выделить какой-либо столбец в отдельный список при помощи метода tolist(). Это упростит задачу, если необходимо извлекать данные из столбцов: df[‘Баллы’].tolist()
Часто бывает нужно получить в виде списка названия столбцов датафрейма. Это тоже можно сделать с помощью метода tolist(): df.columns.tolist()

Добавление новых строк и столбцов
В исходный датасет можно добавлять новые столбцы, создавая новые «признаки», как говорят в машинном обучении. Например, создадим столбец «Сумма», в который просуммируем значения колонок «ВВП на душу населения» и «Социальная поддержка» (сделаем это в учебных целях, практически суммирование этих показателей не имеет смысла): df[‘Сумма’] = df[‘ВВП на душу населения’] + df[‘Социальная поддержка’]

Можно добавлять и новые строки: для этого нужно составить словарь с ключами — названиями столбцов. Если вы не укажете значения в каких-то столбцах, они по умолчанию заполнятся пустыми значениями NaN. Добавим еще одну страну под названием Country: new_row = df = df.append(new_row, ignore_index=True)
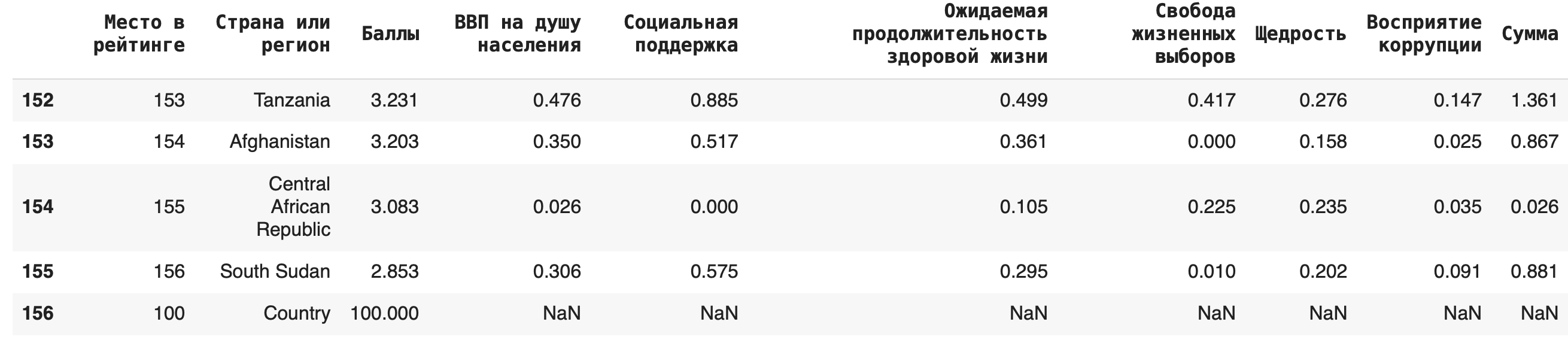
Важно: при добавлении новой строки методом .append() не забывайте указывать параметр ignore_index=True, иначе возникнет ошибка.
Иногда бывает полезно добавить строку с суммой, медианой или средним арифметическим) по столбцу. Сделать это можно с помощью агрегирующих (aggregate (англ.) — группировать, объединять) функций: sum(), mean(), median(). Для примера добавим в конце строку с суммами значений по каждому столбцу: df = df.append(df.sum(axis=0), ignore_index = True)
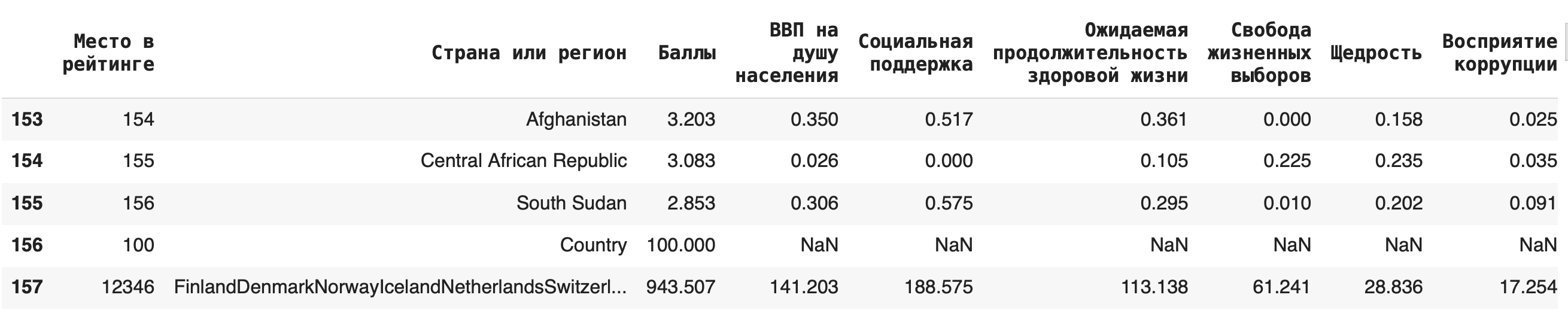
Удаление строк и столбцов
Удалить отдельные столбцы можно при помощи метода drop() — это целесообразно делать, если убрать нужно небольшое количество столбцов. df = df.drop([‘Сумма’], axis = 1)
В других случаях лучше воспользоваться описанными выше срезами.
Обратите внимание, что этот метод требует дополнительного сохранения через присваивание датафрейма с примененным методом исходному. Также в параметрах обязательно нужно указать axis = 1, который показывает, что мы удаляем именно столбец, а не строку.
Соответственно, задав параметр axis = 0, можно удалить любую строку из датафрейма: для этого нужно написать ее номер в качестве первого аргумента в методе drop(). Удалим последнюю строчку (указываем ее индекс — это будет количество строк): df = df.drop(df.shape[0]-1, axis = 0)
Копирование датафрейма
Можно полностью скопировать исходный датафрейм в новую переменную. Это пригодится, если нужно преобразовать много данных и при этом работать не с отдельными столбцами, а со всеми данными: df_copied = df.copy()
Уникальные значения
Уникальные значения в какой-либо колонке датафрейма можно вывести при помощи метода .unique(): df[‘Страна или регион’].unique()
Чтобы дополнительно узнать их количество, можно воспользоваться функцией len(): len(df[‘Страна или регион’].unique())
Подсчет количества значений
Отличается от предыдущего метода тем, что дополнительно подсчитывает количество раз, которое то или иное уникальное значение встречается в колонке, пишется как .value_counts(): df[‘Страна или регион’].value_counts()

Группировка данных
Некоторым обобщением .value_counts() является метод .groupby() — он тоже группирует данные какого-либо столбца по одинаковым значениям. Отличие в том, что при помощи него можно не просто вывести количество уникальных элементов в одном столбце, но и найти для каждой группы сумму / среднее значение / медиану по любым другим столбцам.
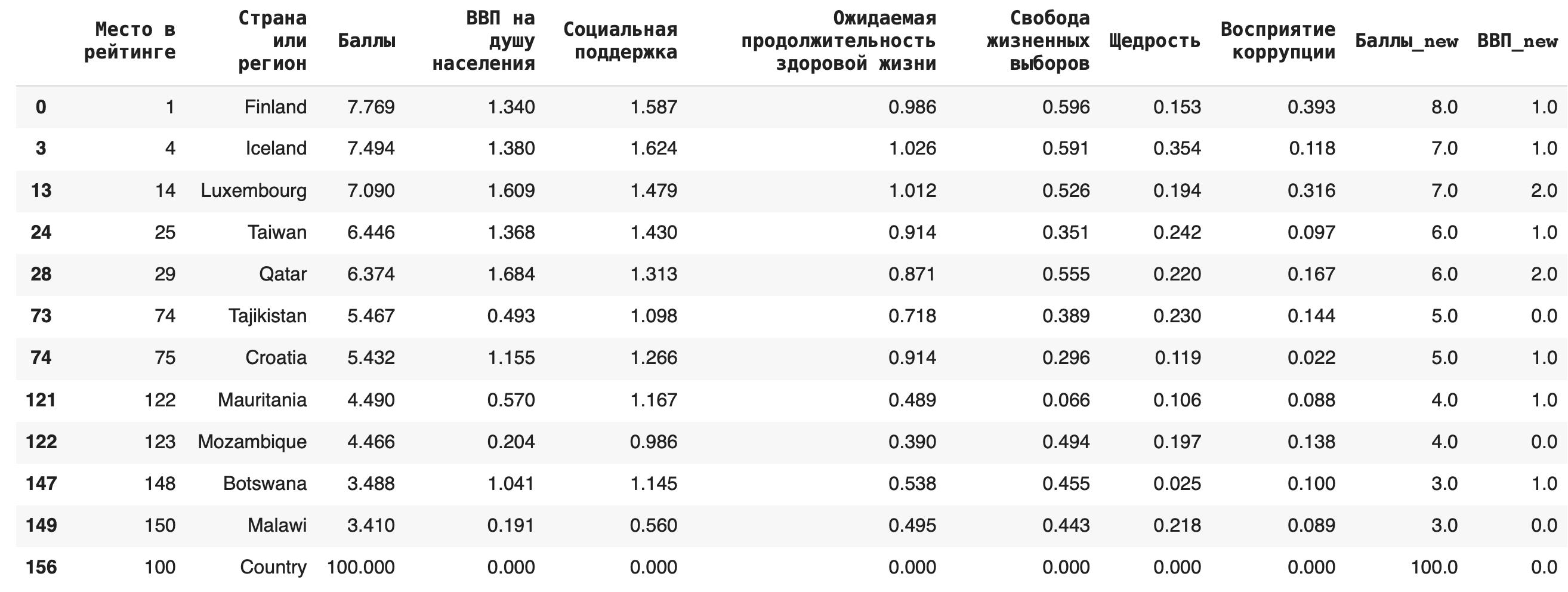
Рассмотрим несколько примеров. Чтобы они были более наглядными, округлим все значения в столбце «Баллы» (тогда в нем появятся значения, по которым мы сможем сгруппировать данные): df[‘Баллы_new’] = round(df[‘Баллы’])
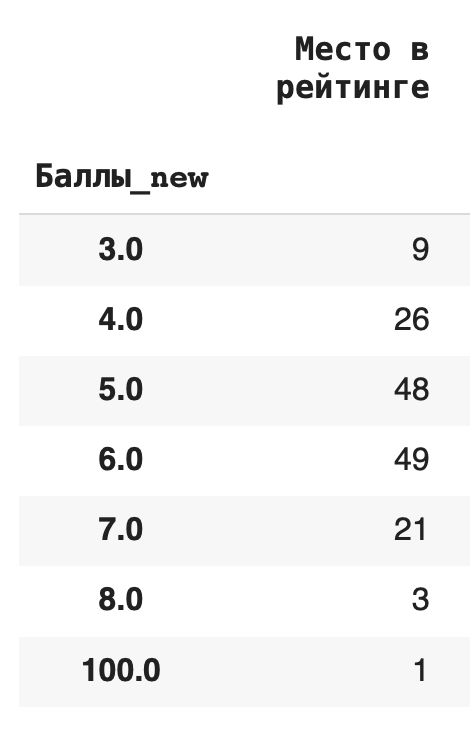
1) Сгруппируем данные по новому столбцу баллов и посчитаем, сколько уникальных значений для каждой группы содержится в остальных столбцах. Для этого в качестве агрегирующей функции используем .count(): df.groupby(‘Баллы_new’).count()
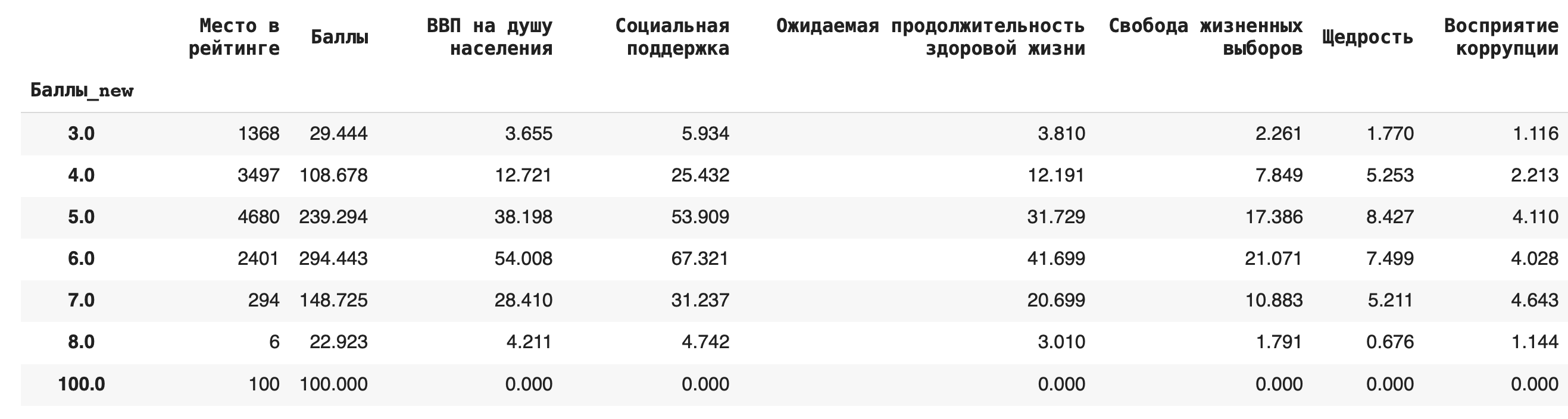
Получается, что чаще всего страны получали 6 баллов (таких было 49):
2) Получим более содержательный для анализа данных результат — посчитаем сумму значений в каждой группе. Для этого вместо .count() используем sum(): df.groupby(‘Баллы_new’).sum()
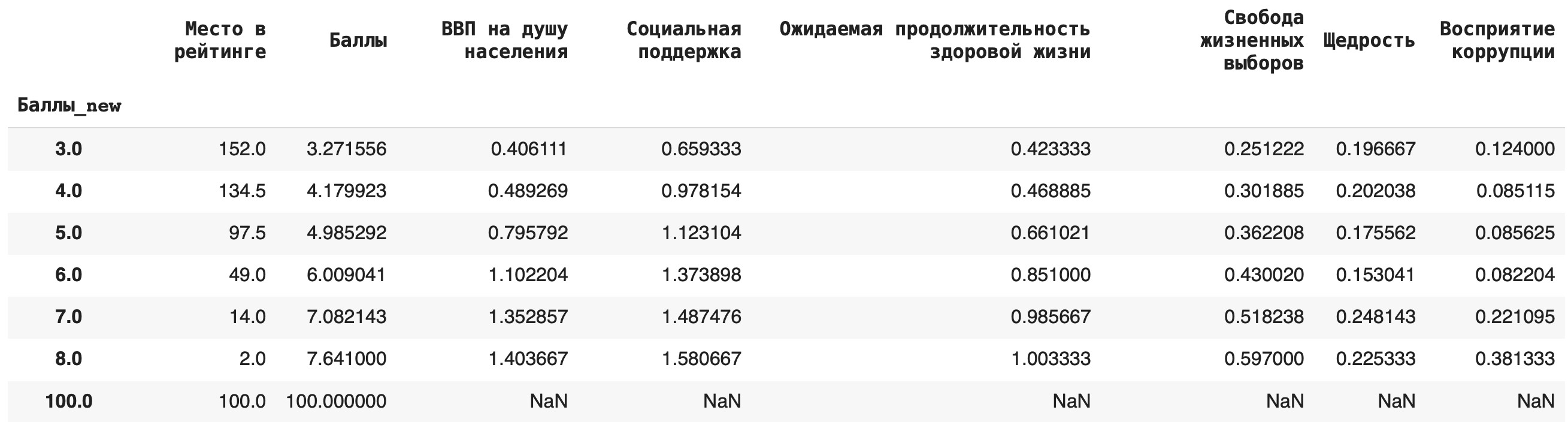
3) Теперь рассчитаем среднее значение по каждой группе, в качестве агрегирующей функции в этом случае возьмем mean(): df.groupby(‘Баллы_new’).mean()
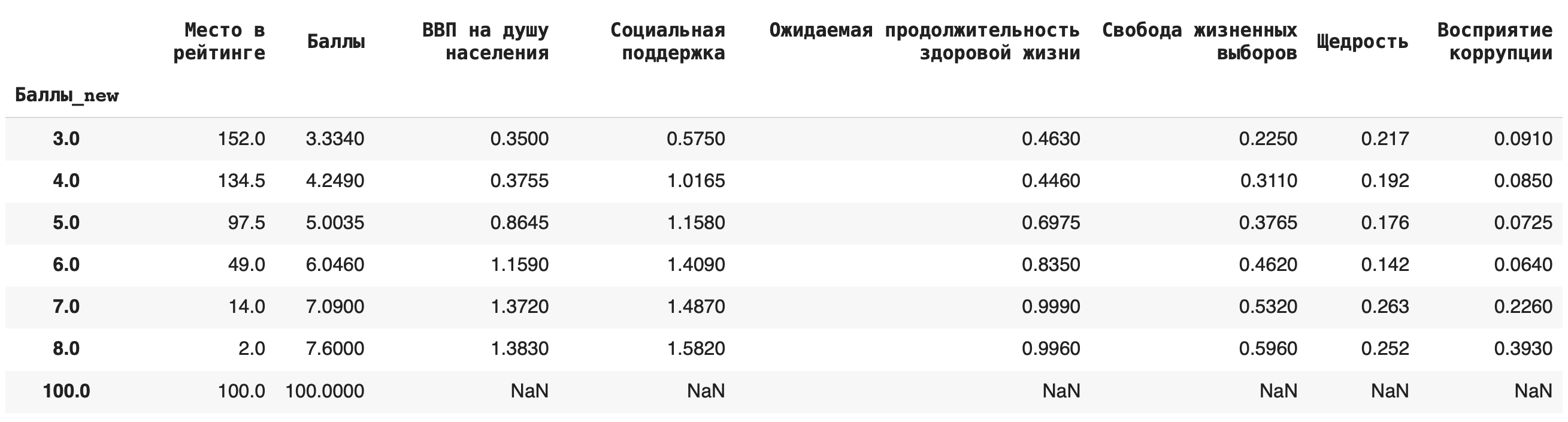
4) Рассчитаем медиану. Для этого пишем команду median(): df.groupby(‘Баллы_new’).median()
Это самые основные агрегирующие функции, которые пригодятся на начальном этапе работы с данными.
Вот пример синтаксиса, как можно сагрегировать значения по группам при помощи сразу нескольких функций:
df_agg = df.groupby(‘Баллы_new’).agg(< 'Баллы_new': 'count', 'Баллы_new': 'sum', 'Баллы_new': 'mean', 'Баллы_new': 'median' >)
Сводные таблицы
Бывает, что нужно сделать группировку сразу по двум параметрам. Для этого в Pandas используются сводные таблицы или pivot_table(). Они составляются на основе датафреймов, но, в отличие от них, группировать данные можно не только по значениям столбцов, но и по строкам.
В ячейки такой таблицы помещаются сгруппированные как по «координате» столбца, так и по «координате» строки значения. Соответствующую агрегирующую функцию указываем отдельным параметром.
Разберемся на примере. Сгруппируем средние значения из столбца «Социальная поддержка» по баллам в рейтинге и значению ВВП на душу населения. В прошлом действии мы уже округлили значения баллов, теперь округлим и значения ВВП: df[‘ВВП_new’] = round(df[‘ВВП на душу населения’])
Теперь составим сводную таблицу: по горизонтали расположим сгруппированные значения из округленного столбца «ВВП» (ВВП_new), а по вертикали — округленные значения из столбца «Баллы» (Баллы_new). В ячейках таблицы будут средние значения из столбца «Социальная поддержка», сгруппированные сразу по этим двум столбцам: pd.pivot_table(df, index = [‘Баллы_new’], columns = [‘ВВП_new’], values = ‘Социальная поддержка’, aggfunc = ‘mean’)
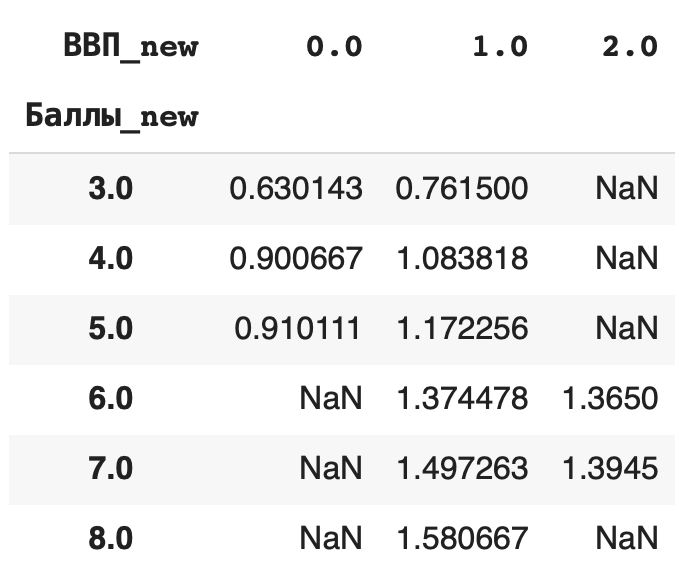
Сортировка данных
Строки датасета можно сортировать по значениям любого столбца при помощи функции sort_values(). По умолчанию метод делает сортировку по убыванию. Например, отсортируем по столбцу значений ВВП на душу населения: df.sort_values(by = ‘ВВП на душу населения’).head()
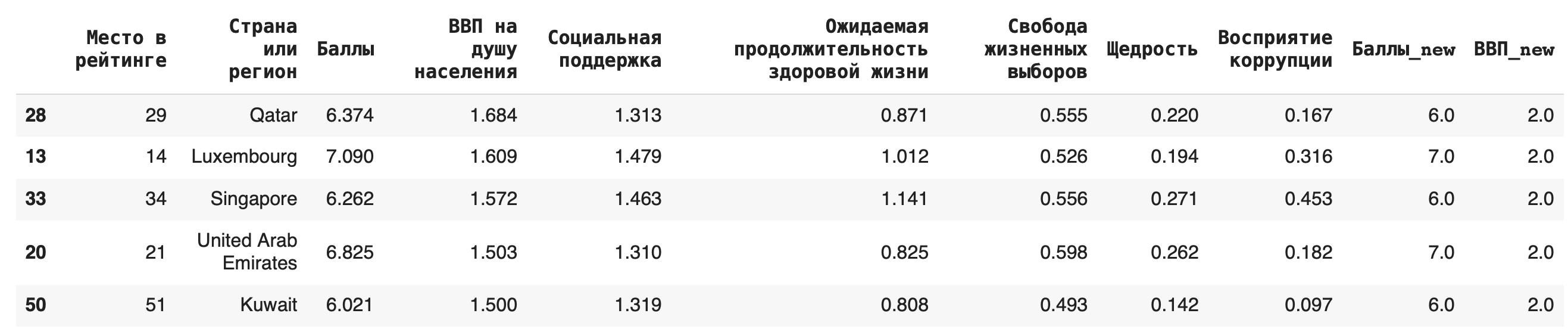
Видно, что самые высокие ВВП совсем не гарантируют высокое место в рейтинге.
Чтобы сделать сортировку по убыванию, можно воспользоваться параметром ascending (от англ. «по возрастанию») = False: df.sort_values(by = ‘ВВП на душу населения’, ascending=False)
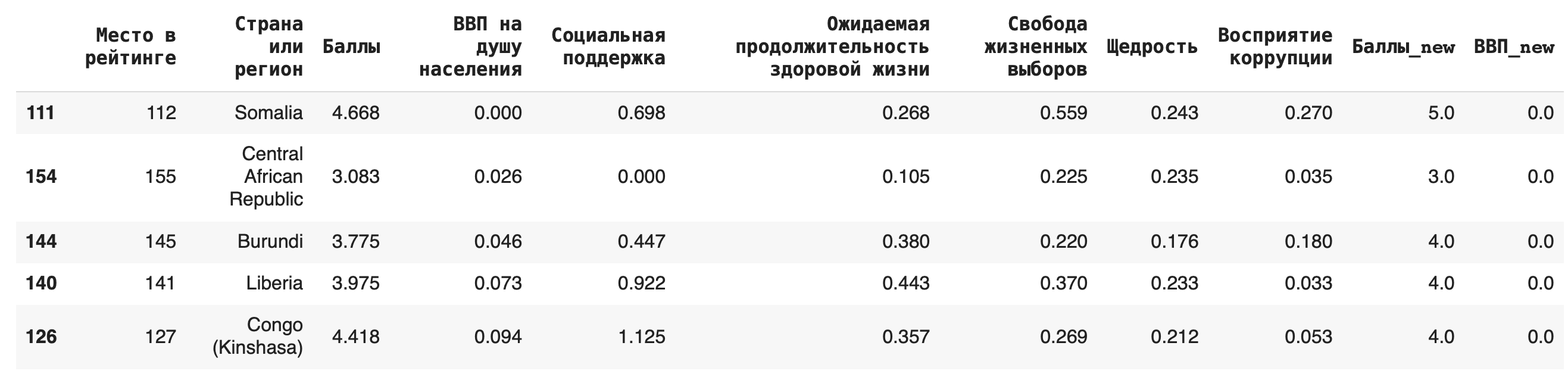
Фильтрация
Иногда бывает нужно получить строки, удовлетворяющие определенному условию; для этого используется «фильтрация» датафрейма. Условия могут быть самые разные, рассмотрим несколько примеров и их синтаксис:
1) Получение строки с конкретным значением какого-либо столбца (выведем строку из датасета для Норвегии): df[df[‘Страна или регион’] == ‘Norway’]

2) Получение строк, для которых значения в некотором столбце удовлетворяют неравенству. Выведем строки для стран, у которых «Ожидаемая продолжительность здоровой жизни» больше единицы:
df[df[‘Ожидаемая продолжительность здоровой жизни’] > 1]
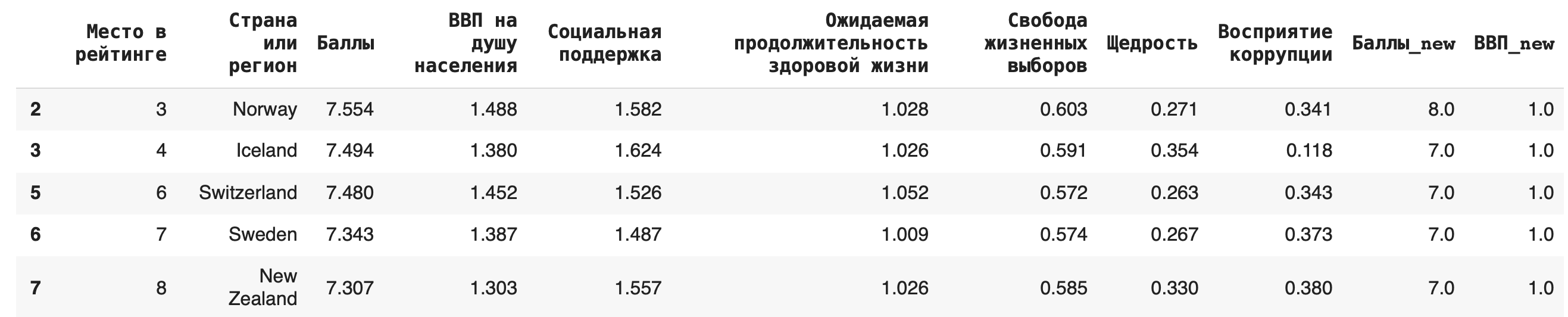
3) В условиях фильтрации можно использовать не только математические операции сравнения, но и методы работы со строками. Выведем строки датасета, названия стран которых начинаются с буквы F, — для этого воспользуемся методом .startswith():
df[df[‘Страна или регион’].str.startswith(‘F’)]

4) Можно комбинировать несколько условий одновременно, используя логические операторы. Выведем строки, в которых значение ВВП больше 1 и уровень социальной поддержки больше 1,5: df[(df[‘ВВП на душу населения’] > 1) & (df[‘Социальная поддержка’] > 1.5)]

Таким образом, если внутри внешних квадратных скобок стоит истинное выражение, то строка датасета будет удовлетворять условию фильтрации. Поэтому в других ситуациях можно использовать в условии фильтрации любые функции/конструкции, возвращающие значения True или False.
Применение функций к столбцам
Зачастую встроенных функций и методов для датафреймов из библиотеки бывает недостаточно для выполнения той или иной задачи. Тогда мы можем написать свою собственную функцию, которая преобразовывала бы строку датасета как нам нужно, и затем использовать метод .apply() для применения этой функции ко всем строкам нужного столбца.
Рассмотрим пример: напишем функцию, которая преобразует все буквы в строке к нижнему регистру, и применим к столбцу стран и регионов: def my_lower(row): return row.lower() df[‘Страна или регион’].apply(lower)

Очистка данных
Это целый этап работы с данными при подготовке их к построению моделей и нейронных сетей. Рассмотрим основные приемы и функции.
1) Удаление дубликатов из датасета делается при помощи функции drop_duplucates(). По умолчанию удаляются только полностью идентичные строки во всем датасете, но можно указать в параметрах и отдельные столбцы. Например, после округления у нас появились дубликаты в столбцах «ВВП_new» и «Баллы_new», удалим их: df_copied = df.copy() df_copied.drop_duplicates(subset = [‘ВВП_new’, ‘Баллы_new’])
Этот метод не требует дополнительного присваивания в исходную переменную, чтобы результат сохранился, — поэтому предварительно создадим копию нашего датасета, чтобы не форматировать исходный.
Строки-дубликаты удаляются полностью, таким образом, их количество уменьшается. Чтобы заменить их на пустые, можно использовать параметр inplace = True. df_copied.drop_duplicates(subset = [‘ВВП_new’, ‘Баллы_new’], inplace = True)
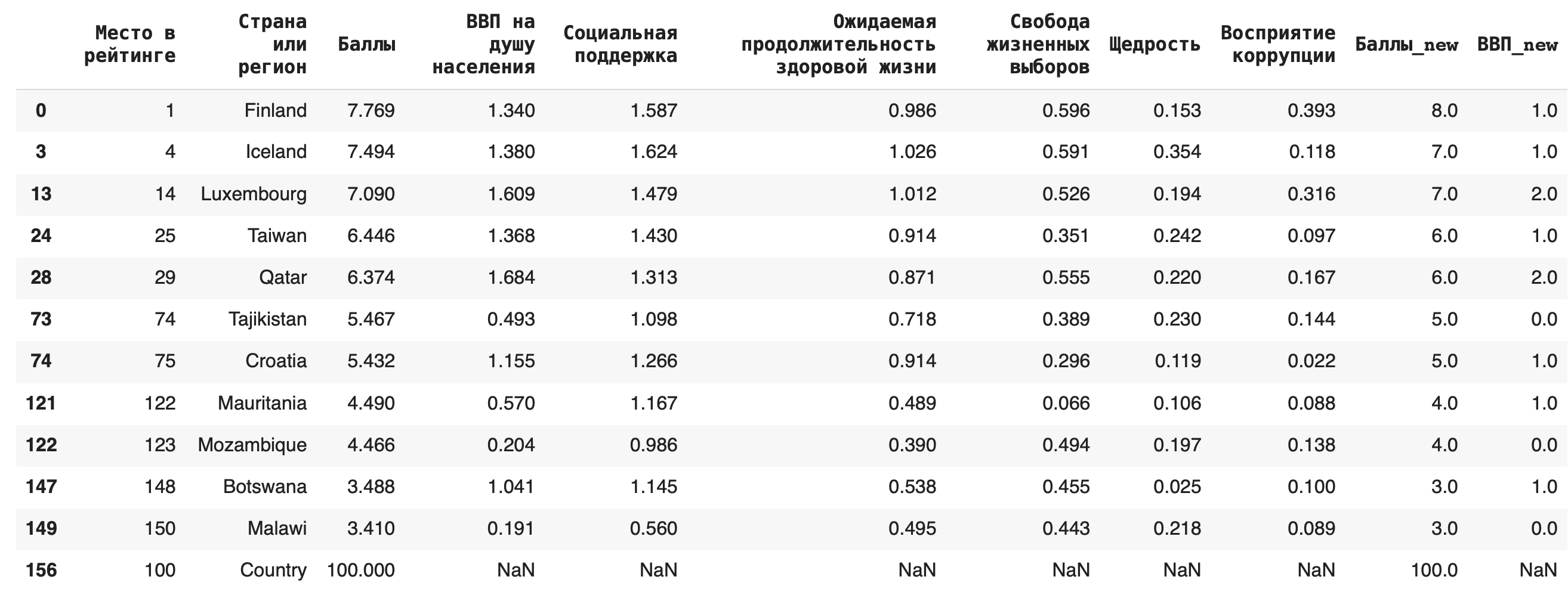
2) Для замены пропусков NaN на какое-либо значение используется функция fillna(). Например, заполним появившиеся после предыдущего пункта пропуски в последней строке нулями: df_copied.fillna(0)
3) Пустые строки с NaN можно и вовсе удалить из датасета, для этого используется функция dropna() (можно также дополнительно указать параметр inplace = True): df_copied.dropna()
Построение графиков
В Pandas есть также инструменты для простой визуализации данных.
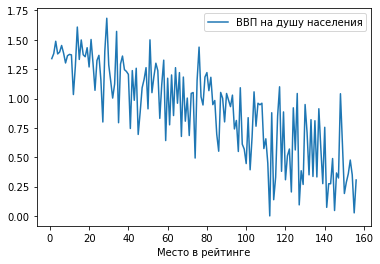
1) Обычный график по точкам.
Построим зависимость ВВП на душу населения от места в рейтинге: df.plot(x = ‘Место в рейтинге’, y = ‘ВВП на душу населения’)
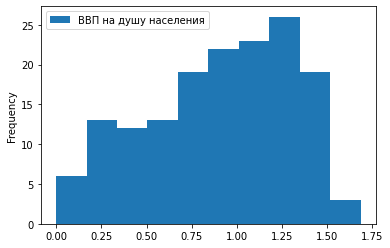
2) Гистограмма.
Отобразим ту же зависимость в виде столбчатой гистограммы: df.plot.hist(x = ‘Место в рейтинге’, y = ‘ВВП на душу населения’)
3) Точечный график.
df.plot.scatter(x = ‘Место в рейтинге’, y = ‘ВВП на душу населения’)
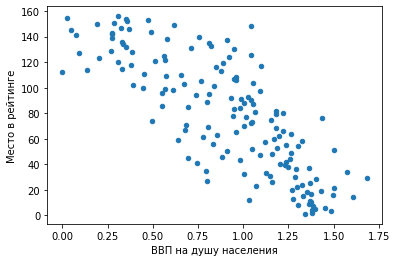
Мы видим предсказуемую тенденцию: чем выше ВВП на душу населения, тем ближе страна к первой строчке рейтинга.
Сохранение датафрейма на компьютер
Сохраним наш датафрейм на компьютер: df.to_csv(‘WHR_2019.csv’)
Теперь с ним можно работать и в других программах.
Блокнот с кодом можно скачать здесь (формат .ipynb).
Основы статистики с Python: описательная статистика
Изучаем основы описательной статистики с Python, на примере датасета от Kaggle с описаниями 130 тысяч марок вина.
Область статистики часто понимают неправильно, однако она играет важную роль в повседневной жизни. Корректно составленная статистика позволяет извлечь знания из неопределённого и сложного реального мира, однако при неправильном применении она может нанести вред или ввести в заблуждение. Для того, чтобы отличить правду от лжи, важно чётко понимать методы статистики и значение различных статистических измерений.
В этой статье мы поговорим о:
- определении статистики;
- описательной статистике:мерах центральной тенденции;мерах разброса.
Нам не понадобятся глубокие знания статистики, однако понадобится хотя бы минимальное знание Python. Если вы не встречались с циклами for и списками, будет лучше сначала ознакомиться с ними.
Не знаете с какой стороны подойти к Python? Тогда почитайте о том, с чего начать изучение Python.
Загружаем данные
Мы будем обсуждать статистику, используя реальные данные, взятые с платформы Kaggle из датасета Wine Reviews. Сами данные были извлечены с сайта Wine Enthusiast.
Предположим, вы — ученик сомелье. Вы нашли интересный датасет и хотели бы сравнить различные вина, воспользовавшись статистикой для описания данных и сделав для себя несколько выводов.
Код, представленный ниже, загружает датасет wine-data.csv в переменную wines в виде списка списков. В статье мы будем вести статистику на примере этой переменной:
import csv with open("wine-data.csv", "r", encoding="latin-1") as f: wines = list(csv.reader(f)) Давайте посмотрим на первые пять строк данных, указанных в таблице, чтобы понять, с какими значениями мы работаем:
Что именно представляет собой статистика?
Это вопрос с подвохом. Статистика включает в себя много всего, поэтому попытка кратко описать её неизбежно приведёт к упущению некоторых деталей. Тем не менее нам нужно с чего-то начинать.
Область статистики можно рассматривать как научную среду для работы с данными. Это определение включает все задачи, связанные со сбором, анализом и интерпретацией данных. Также статистика может относиться к отдельным измерениям, которые представляют собой сводную информацию по данным или определенные их аспекты. В этой статье мы постараемся провести грань между научной областью статистики и непосредственными измерениями.
И первым шагом будет логичный вопрос: а что такое «данные»? К счастью, это определение дать проще. Данные — это совокупность наблюдений за миром, которая может иметь множество вариаций, от качественных до количественных. Исследователи собирают данные, полученные в ходе экспериментов, предприниматели собирают данные своих клиентов, а игровые компании собирают данные о поведении игроков
Эти примеры указывают на ещё один важный аспект: наблюдения обычно связаны с генеральной совокупностью, представляющей интерес. Возвращаясь к предыдущему примеру: исследователь может рассматривать группу пациентов с определённым состоянием. Для наших данных генеральной совокупностью будет набор отзывов о винах. Чётко определив генеральную совокупность, мы можем применить методы статистики и извлечь знания из полученных результатов.
Но почему нас интересуют генеральные совокупности? Полезно иметь возможность сравнивать и противопоставлять их, чтобы проверить наши идеи. Например, мы хотели бы узнать, что пациенты, получающие новое лечение, выздоравливают быстрее тех, кто получает плацебо, но кроме того мы хотели бы доказать это количественно. Здесь на помощь приходит статистика, которая предоставляет точный подход к данным и даёт возможность принимать решения, основанные на реальных событиях, а не на догадках.
- статистика — наука о данных;
- данные — набор наблюдений за интересующей нас генеральной совокупностью;
- статистика предоставляет конкретный способ сравнения генеральных совокупностей с помощью чисел, а не неоднозначных описаний.
Описательная статистика
Когда у нас есть набор наблюдений, полезно свести признаки наших данных в одно определение. Этим занимается описательная статистика. Как следует из названия, описательная статистика описывает конкретное свойство данных, которые она обобщает. Такую статистику можно разделить на две категории: меры центральной тенденции и меры разброса.
Меры центральной тенденции
Меры центральной тенденции — показатели, представляющие собой ответ на вопрос: «На что похожа середина данных?». Слово «середина» звучит неточно, так как существует множество определений для её описания. Далее мы обсудим, как каждая новая мера меняет наше определение «середины».
Данная характеристика описывает среднее значение в наборе данных. Вычислить её довольно просто: сложите все значения и разделите полученную сумму на количество значений.
В случае со средним значением «серединой» датасета будет среднее арифметическое его значений. Среднее значение отражает типичный показатель в наборе данных. Если мы случайно выберем один из показателей, то, скорее всего, получим значение, близкое к среднему.
Вычислить среднее значение на Python просто. Давайте выясним, чему равна средняя оценка вина в нашем датасете:
# Извлекаем оценки из датасета scores = [float(w[4]) for w in wines] # Складываем все оценки sum_score = sum(scores) # Ищем количество оценок num_score = len(scores) # Считаем среднее значение avg_score = sum_score/num_score print(avg_score) # выводит 87.8884184721394 Это среднее значение говорит нам, что «типичная» оценка в датасете равна примерно 87,8. Соответственно, большинство вин имеют высокий рейтинг, если предположить, что оценивают по шкале от 0 до 100. Тем не менее нужно учесть, что Wine Enthusiast не публикует отзывы с рейтингом ниже 80.
Есть разные типы среднего значения, но это — наиболее распространённая форма. Оно называется средним арифметическим, так как интересующие нас значения складываются.
Следующая мера центральной тенденции, о которой пойдёт речь, — медиана. Медиана, как и среднее значение, нужна для определения типичного значения в наборе данных, но при этом не требует вычислений.
Чтобы найти медиану, данные нужно расположить в порядке возрастания. Медианой будет значение, которое совпадает с серединой набора данных. Если количество значений чётное, то берётся среднее двух значений, которые «окружают» середину.
Стандартной библиотекой Python не предусмотрен поиск медианы, но мы можем написать свою реализацию, следуя описанному алгоритму. Попробуем найти медиану цен на вина:
# Извлекаем цены prices = [float(w[5]) for w in wines if w[5] != ""] # Находим их количество num_wines = len(prices) # Сортируем в порядке возрастания sorted_prices = sorted(prices) # Ищем индекс среднего элемента middle = (num_wines / 2) + 0.5 # Находим медиану print(sorted_prices[middle]) # 24 Медианная цена бутылки вина составляет 24$. Это предполагает, что как минимум у половины вин в датасете цена равна или ниже 24$. Неплохо! А что насчёт среднего значения? Учитывая, что и медиана, и среднее значение отражают типичное значение, можно предположить, что они должны быть примерно одинаковы:
print(sum(prices)/len(prices)) # 33.13 Средняя цена в 33,13$ на порядок выше медианной. Как это произошло? Разница между медианой и средним значением существует из-за робастности (выбросоустойчивости).
Как вы помните, среднее значение можно найти, сложив все значения и разделив сумму на их количество, в то время как медиана ищется простой перестановкой значений. Если в данных есть выбросы — значения, которые гораздо выше или ниже остальных, — это может негативно повлиять на среднее значение. Таким образом, среднее значение не робастно, а медиана — напротив, выбросоустойчива.
Давайте взглянем на максимальную и минимальную цену в наших данных:
min_price = min(prices) max_price = max(prices) print(min_price, max_price) # 4.0, 2300.0 Теперь мы знаем, что в данных есть выбросы. Выбросы могут отражать интересные события или ошибки в нашем наборе данных, поэтому важно уметь определять их наличие. Сравнение медианы и моды — один из способов определить наличие выбросов, хотя визуализация обычно позволяет сделать это быстрее.
Это последняя мера центральной тенденции, о которой пойдёт речь. Мода определяется как значение, которое наиболее часто встречается в наборе данных. Мода не так очевидно соответствует понятию «середины» как среднее значение или медиана, но это соответствие абсолютно обосновано: если значение появляется в данных неоднократно, оно приблизит среднее значение к моде. Чем чаще появляется значение, тем сильнее оно влияет на среднее. Таким образом, мода показывает наиболее значимый фактор, формирующий среднее значение.
Как и в случае с медианой, встроенной функции для поиска моды у Python нет. Зато мы можем вычислить её сами, посчитав количество повторений различных цен и выбрав самую частую:
# Создаём пустой словарь, в котором будем считать количество появлений цен price_counts = <> for p in prices: if p not in price_counts: counts[p] = 1 else: counts[p] += 1 # Проходимся по словарю и ищем максимальное количество повторений maxp = 0 mode_price = None for k, v in counts.items(): if maxp < v: maxp = v mode_price = k print(mode_price, maxp) # 20.0, 7860Прим.перев. На самом деле, с версии Python 3.4 можно найти и моду.
Мода относительно близка к медиане, поэтому можно уверенно сказать, что и мода, и медиана отражают средние значения цен на вино.
Меры центральной тенденции полезны для описания среднего значения данных. Тем не менее они не показывают, насколько большой разброс присутствует в данных. Здесь на помощь приходят меры разброса данных.
Меры разброса данных
Меры разброса отвечают на вопрос: «Как сильно варьируются мои данные?». В мире существует не так много вещей, которые остаются в одном и том же состоянии при каждом наблюдении. Эта изменчивость делает мир нечётким и неопределённым, поэтому полезно иметь показатели, которые могут обобщить эту «нечёткость».
Размах
Наша первая мера разброса — размах. Из всех измерений, которые мы рассмотрим далее, его вычислить проще всего. Для этого нужно просто вычесть из наибольшего значения в наборе данных наименьшее.
Мы нашли максимальную и минимальную цены, когда искали медиану, поэтому сейчас можем использовать их:
price_range = max_price - min_price print(price_range) # 2296.0 Итак, размах равен 2296, но что это значит? Когда мы рассматриваем результаты различных измерений, очень важно делать это в контексте наших данных. Наша медианная цена была 24$, а размах равен 2296$. Размах на два порядка больше медианы, что указывает на сильный разброс данных. Возможно, будь у нас ещё один винный датасет, мы могли бы сравнить размахи, чтобы понять, как они отличаются. В ином случае сам по себе размах не слишком полезен.
Мы скорее хотели бы узнать, как сильно данные отличаются от типичного значения. Здесь нам помогут стандартное отклонение и дисперсия случайной величины.
Стандартное отклонение тоже является мерой разброса данных. Оно помогает узнать, как сильно данные отличаются от типичного значения. Иными словами, оно говорит о том, как сильно данные отличаются от среднего арифметического. Отношение к среднему арифметическому хорошо видно при расчёте отклонения:
Поговорим немного о строении уравнения. Как вы помните, среднее арифметическое рассчитывается путём сложения всех значений и деления на их количество. Уравнение стандартного отклонения похоже, но используется, чтобы найти, на сколько в среднем значения отклоняются от типичного, и включает дополнительную операцию с извлечением корня.
В некоторых источниках можно увидеть в качестве знаменателя n вместо n-1 . Такие детали выходят за рамки нашей статьи, но знайте, что использование n-1 считается более корректным. Можете прочитать интуитивное объяснение коррекции Бесселя.
Мы хотим посчитать стандартное отклонение, чтобы более полно описать цены вин и их оценки, поэтому напишем свою функцию. Поиск кумулятивной суммы вручную выглядел бы довольно громоздко, но циклы for в Python всё упрощают. Мы пишем свою функцию, чтобы показать, что на Python легко заниматься такой статистикой. Тем не менее в библиотеке numpy тоже реализовано вычисление стандартного отклонения через функцию std :
def stdev(nums): diffs = 0 avg = sum(nums)/len(nums) for n in nums: diffs += (n - avg)**(2) return (diffs/(len(nums)-1))**(0.5) print(stdev(scores)) # 3.2223917589832167 print(stdev(prices)) # 36.32240385925089 Такие результаты вполне ожидаемы. Оценки варьируются от 80 до 100, поэтому можно предположить, что стандартное отклонение будет небольшим. С другой стороны, отклонение в ценах гораздо выше из-за выбросов. Чем больше стандартное отклонение, тем больше рассеяны данные вокруг среднего значения, и наоборот.
Далее мы увидим, что дисперсия тесно связана со стандартным отклонением.
Часто стандартное отклонение и дисперсию связывают вместе и делают это не без причины. Вот уравнение дисперсии, ничего не напоминает?
Дисперсия и стандартное отклонение — почти одно и то же! Дисперсия — просто квадрат стандартного отклонения. Более того, обе величины отражают одну и ту же вещь — меру разброса, хотя стоит отметить, что единицы измерения разные. В каких бы единицах ни измерялись ваши данные, единицы измерения отклонения будут такими же, а у дисперсии они будут возведены в квадрат.
Многие новички в статистике задают вопрос: «Зачем возводить отклонение в квадрат? Разве нельзя избавится от отрицательных слагаемых при помощи модуля?». Избавление от отрицательных значений — хорошая причина для возведения в квадрат, но не единственная. Как и на среднее значение, на дисперсию и стандартное отклонение влияют выбросы. Очень часто нас интересуют выбросы, поэтому возведение в квадрат позволяет выделить эту особенность. Если вы знакомы с математическим анализом, то поймете, что наличие экспоненциального выражения позволяет найти точку минимального отклонения.
Чаще всего при статистическом анализе нам понадобятся только среднее значение и стандартное отклонение, однако дисперсия по-прежнему важна в других академических областях. Меры центральной тенденции и разброса позволяют нам систематизировать данные и извлечь из них знания.
- описательная статистика используется для систематизации и количественного описания данных;
- среднее значение указывает на типичное значение в нашем наборе данных. Оно не робастно;
- медиана является центральным значением в ряду данных. Она робастна;
- мода — значение, которое появляется наиболее часто;
- размах — это разность между максимальным и минимальным значениями в наборе данных;
- дисперсия и стандартное отклонение являются средним расстоянием от среднего арифметического значения.
Как рассчитать медиану в Pandas (с примерами)
Вы можете использовать функцию median() , чтобы найти медиану одного или нескольких столбцов в кадре данных pandas:
#find median value in specific column df['column1']. median () #find median value in several columns df[['column1', 'column2']]. median () #find median value in every numeric column df.median () В следующих примерах показано, как использовать эту функцию на практике со следующими пандами DataFrame:
#create DataFrame df = pd.DataFrame() #view DataFrame df player points assists rebounds 0 A 25 5 11 1 B NA 7 8 2 C 15 7 10 3 D 14 9 6 4 E 19 12 6 5 F 23 9 5 6 G 25 9 9 7 H 29 4 12 Пример 1: найти медиану одного столбца
В следующем коде показано, как найти медианное значение одного столбца в кадре данных pandas:
#find median value of *points* column df['points']. median () 23.0 Среднее значение в столбце очков равно 23 .
Обратите внимание, что по умолчанию функция median() игнорирует любые отсутствующие значения при вычислении медианы.
Пример 2: найти медиану нескольких столбцов
В следующем коде показано, как найти медианное значение нескольких столбцов в кадре данных pandas:
#find median value of *points* and *rebounds* columns df[['points', 'rebounds']]. median () points 23.0 rebounds 8.5 dtype: float64 Пример 3. Найдите медиану всех числовых столбцов
В следующем коде показано, как найти медианное значение всех числовых столбцов в кадре данных pandas:
#find median value of all numeric columns df.median () points 23.0 assists 8.0 rebounds 8.5 dtype: float64