Как найти все повторяющиеся элементы в списке и количество повторов?
Стоимость составления списка-счетчика: нужно n раз вставить в словарь значения. Вставка состоит из двух операций: сначала проверка, есть ли такой номер в словаре и, собственно, вставка — все вместе O(1) среднем или O(n) в худшем для редких случаев, когда у всех элементов одинаковый хеш. То есть стоимость составления счетчика — O(n) в среднем, O(n^2) в худшем.
Следущий шаг — отфильтровать только нужное. В худшем случае нужно пройти по всему счетчику — снова n операций по O(1) или в худшем O(n) — взять из словаря, сравнить с единицей, записать в новый словарь. В среднем O(n).
Итого O(n) в среднем или для специально подготовленных данных O(n^2) в худшем.
Результаты бенчмарков
Обновление с большим массивом: Минутка замеров:
import timeit non_Counter = \ """counter = <> for elem in A: counter[elem] = counter.get(elem, 0) + 1""" setup = "import random\n" \ "A = [random.randint(0, 100) for r in range(10**6)]" print(timeit.repeat(non_Counter, setup=setup, number=10)) non_Counter = """Counter(A)""" setup = "import random\n" \ "from collections import Counter\n"\ "A = [random.randint(0, 100) for r in range(10**6)]\n" print(timeit.repeat(non_Counter, setup=setup, number=10)) non_Counter = \ """counter = defaultdict(int) for elem in A: counter[elem] += 1""" setup = "import random\n" \ "from collections import defaultdict\n" \ "A = [random.randint(0, 100) for r in range(10**6)]" print(timeit.repeat(non_Counter, setup=setup, number=10)) [2.461800295429222, 2.456825704148736, 2.50377292183442] [0.7278253601108151, 0.7268121314832463, 0.7283143209274385] [1.3038446032438102, 1.3117127258723897, 1.3013156371393428] Как видно из результатов, быстрее всех решение с Counter.
Почему такие результаты
Объяснение проигрыша наивного решения со словарем:
Для того, чтобы получить значение из словаря, необходим хеш переменной elem . Значение хеша необходимо дважды: для того, чтобы получить предыдущее значение и для того, чтобы установить новое. Очевидно, вычислять два хеша — производить двойную работу. Замеры:
non_Counter = \ """ args = [None, None] for elem in A: hash(elem) hash(elem)""" setup = "import random\n" \ "A = [random.randint(0, 100) for r in range(10**6)]\n" \ "counter = <>" print(timeit.repeat(non_Counter, setup=setup, number=10)) [1.4283945417028974, 1.433934455438878, 1.4188164931286842] Как видно, лишнее вычисление съедает 0.7 секунд или 30% от общего времени. К сожалению, нет стандартной возможности получить значение из словаря по значению хеша. В классе Counter функция подсчета написана на более низком уровне (https://github.com/python/cpython/blob/3.11/Modules/_collectionsmodule.c#L2284) и вызывает функции _PyDict_GetItem_KnownHash, _PyDict_SetItem_KnownHash, что значительно экономит время.
Также каждый раз при вызове метода get(elem, 0) вызывается инструкция LOAD_ATTR, которая должна найти нужный метод по имени. Так как метод не изменится, можно вынести его поиск за цикл. Трюк старый, надо с ним быть внимательнее в новых версиях интерпретатора, может это более не работает:
getter = counter.get for elem in A: counter[elem] = getter(elem, 0) + 1 [1.917134484341348, 1.9207427770511107, 1.9153613342431033] Удалось сэкономить еще 0.6 секунд.
Отслеживать
ответ дан 8 июн 2016 в 17:31
6,399 4 4 золотых знака 35 35 серебряных знаков 57 57 бронзовых знаков
Использование .get() , filter(lambda) некрасиво выглядит. Если вам profiler говорит, что подсчёт элементов является узким местом и Counter() не достаточно быст для ваших целей, то в этом случае можно попробовать collections.defaultdict , тогда код выглядит как: for elem in A: counter[elem] += 1 и dups =
9 июн 2016 в 19:45
@jfs, я когда писал ответ даже не задумывался, что можно пробовать оптимизировать такие простые вещи. А оказалось, что по оптимизации строки counter[elem] = counter.get(elem, 0) + 1 можно целую статью написать с объяснениями, экспериментами и выкладками dis . Даже если перед циклом написать getter = counter.get , то производительность возрастает на 20%. Ну как так-то?
9 июн 2016 в 19:56
Меня смущает тот факт, что используется неидиоматичный код, без хорошей на то причины. И мне хорошо известно, что много вариантов по микрооптимизации можно придумать (нажмите на ссылку из моего предыдущего комментария)—я не понимаю к чему тут оптимизировать, но если вас это интересует, то я вижу в ответе пример кода ( filter(lambda) ), который одновременно некрасивый и медленный (я привёл пример, как более идиоматично и эффективно данную задачу решить в прошлом комментарии).
9 июн 2016 в 20:03
@jfs, согласен, if count > 1 выглядит лучше — изменил.
9 июн 2016 в 21:18
Хорошо, что filter(lambda) убрали. Что мешает .items() вызывать, чтобы избежать counter[elem] как показано в моём первом комментарии? 2- Если вы о сложности операций упоминаете, то в худшем случае (для специально сконструированного ввода) квадратичное поведение может быть у словаря, а не линейное. В среднем (для случайного ввода) поведение линейное амортизированное. 3- Измерение производительности является тяжёлой задачей, поэтому не стоит большого внимания полученным цифрам придавать, если вы не провели работу по учёту многих, многих факторов. Переместите counter = .. из setup.
10 июн 2016 в 10:52
Есть же уже готовый Counter в модуле collections.
from collections import Counter c = Counter([10, 10, 23, 10, 123, 66, 78, 123]) print(c) Отслеживать
ответ дан 8 июн 2016 в 17:43
20.4k 4 4 золотых знака 25 25 серебряных знаков 52 52 бронзовых знака
стоит отсеять уникальные элементы:
9 июн 2016 в 19:25
захотелось сравнить производительность для массива состоящего из 1.000.000 элементов:
from collections import Counter import pandas as pd # random list (length: 1.000.000) l = np.random.randint(1,100, 10**6).tolist() # pandas DF df = pd.DataFrame() # dict solution def dct(A): counter = <> for elem in A: counter[elem] = counter.get(elem, 0) + 1 return 1, counter)> In [79]: %timeit Counter(l) 10 loops, best of 3: 48 ms per loop сам по себе Counter — достаточно быстрый, но нам еще надо будет отфильтровать результат .
In [80]: %timeit dct(l) 10 loops, best of 3: 178 ms per loop In [81]: %timeit df.val.value_counts().reset_index().query('val > 1').rename(columns=) 100 loops, best of 3: 14.4 ms per loop In [71]: df = pd.DataFrame() In [72]: %paste (df.val .value_counts() .reset_index() .query('val > 1') .rename(columns=) ) ## -- End pasted text -- Out[72]: val count 0 10 3 1 123 2 Отслеживать
ответ дан 9 июн 2016 в 16:47
MaxU — stand with Ukraine MaxU — stand with Ukraine
149k 12 12 золотых знаков 59 59 серебряных знаков 132 132 бронзовых знака
Хм, Counter — потомок dict , и подсчет он ведет точно таким методом: mapping[elem] = mapping.get(elem, 0) + 1 , и метод get не переопределен. Единственный момент, что есть типа реализация этой строки на С и если она импортируется, то используется именно она. Что они там могли написать?
9 июн 2016 в 18:27
Ага, так вот же настоящий счетчик для Counter — hg.python.org/cpython/file/tip/Modules/… — там какой-то адок — я обновлю свой ответ с поясненем, почему Counter быстрее.
9 июн 2016 в 18:37
@m9_psy, спасибо за ссылку — немного запутанно, но интересно
9 июн 2016 в 20:01
#!/usr/bin/env python from itertools import groupby L = [10, 10, 23, 10, 123, 66, 78, 123] duplicates = <> for el, group in groupby(sorted(L)): count = len(list(group)) if count > 1: duplicates[el] = count # element -> number of occurrences print(duplicates) # ->
Если список неотсортирован, то сортировка это O(n * log n) операция. На практике следует измерять производительность разных вариантов, если производительность этого кода имеет значение в вашем случае (так как для небольшого n , O(n * log n) операция может быть быстрее O(n) операции, такой как с использованием Counter() ).
Отслеживать
ответ дан 9 июн 2016 в 19:56
52.3k 11 11 золотых знаков 108 108 серебряных знаков 312 312 бронзовых знаков
Если скорость выполнения не важна, то можно сделать так:
def test(lst): return 1> print(test([10, 10, 23, 10, 123, 66, 78, 123])) Отслеживать
ответ дан 8 июн 2016 в 18:16
user194374 user194374
Один из способов решения этой задачи — использовать словарь. Можно создать словарь, в котором каждому элементу списка соответствует количество его повторений, и в цикле перебрать элементы списка, добавляя их в словарь.
Вот пример такой функции:
def count_repeats(lst): """ Возвращает словарь, в котором каждому элементу списка lst соответствует количество его повторений. """ repeats = <> for item in lst: if item in repeats: repeats[item] += 1 else: repeats[item] = 1 return repeats # Пример использования функции lst = [10, 10, 23, 10, 123, 66, 78, 123] repeats = count_repeats(lst) print(repeats) #
Функция count_repeats принимает на вход список lst , перебирает его элементы и добавляет их в словарь repeats . Если элемент уже есть в словаре, то увеличивается значение соответствующей пары ключ-значение, если же элемента еще нет в словаре, то добавляется пара с ключом равным этому элементу и значением 1 .
Вы можете использовать эту функцию, чтобы найти повторяющиеся элементы в списке и количество их повторений.
Вы также можете использовать функцию Counter из модуля collections, чтобы посчитать количество повторений элементов списка. Эта функция возвращает словарь, в котором каждому элементу списка соответствует количество его повторений.
Вот пример кода, который использует функцию Counter:
from collections import Counter def count_repeats(lst): """ Возвращает словарь, в котором каждому элементу списка lst соответствует количество его повторений. """ return Counter(lst) # Пример использования функции lst = [10, 10, 23, 10, 123, 66, 78, 123] repeats = count_repeats(lst) print(repeats) # Counter() В этом коде сначала импортируется модуль collections и функция Counter , а затем определяется функция count_repeats , которая принимает список lst и возвращает результат вызова функции Counter на этом списке.
Вы также можете использовать функцию most_common из модуля collections , чтобы найти топ-N самых часто встречающихся элементов в списке. Эта функция принимает список и число N, и возвращает список кортежей, каждый из которых содержит элемент и количество его повторений.
Вот пример кода, который использует функцию most_common :
from collections import Counter def find_top_repeats(lst, n): """ Возвращает топ-N самых часто встречающихся элементов в списке lst. """ return Counter(lst).most_common(n) # Пример использования функции lst = [10, 10, 23, 10, 123, 66, 78, 123] top_repeats = find_top_repeats(lst, 2) print(top_repeats) # [(10, 3), (123, 2)] В этом коде сначала импортируется модуль collections и функция Counter , а затем определяется функция find_top_repeats , которая принимает список lst и число n , и возвращает результат вызова функции most_common
Если вам нужно найти только уникальные элементы в списке, то можете использовать функцию set. Эта функция создает множество из элементов списка, удаляя повторяющиеся элементы. Множество не содержит повторяющихся элементов, поэтому вы можете использовать его, чтобы найти уникальные элементы в списке.
Вот пример кода, который использует функцию set :
def find_unique(lst): """ Возвращает список уникальных элементов в списке lst. """ return list(set(lst)) # Пример использования функции lst = [10, 10, 23, 10, 123, 66, 78, 123] unique = find_unique(lst) print(unique) # [66, 78, 10, 123, 23] В этом коде определяется функция find_unique , которая принимает список lst и возвращает список уникальных элементов. Для этого список преобразуется в множество
Если вам нужно найти только уникальные элементы в списке и посчитать их количество, то можете соединить два предыдущих подхода: сначала использовать функцию set для нахождения уникальных элементов, а затем функцию count_repeats для подсчета их количества.
Вот пример кода, который реализует этот подход:
def count_unique(lst): """ Возвращает словарь, в котором каждому уникальному элементу списка lst соответствует количество его повторений. """ repeats = <> for item in set(lst): repeats[item] = lst.count(item) return repeats # Пример использования функции lst = [10, 10, 23, 10, 123, 66, 78, 123] unique_counts = count_unique(lst) print(unique_counts) #
В этом коде определяется функция count_unique , которая принимает список lst и возвращает словарь, в котором каждому уникальному элементу списка
Проверить уникальность элементов списка
В списке чисел проверить, все ли элементы являются уникальными, то есть встречается ли каждое число только один раз.
Решение задачи на языке программирования Python
Решить данную задачу на языке Python можно несколькими способами. Классический вариант — брать по очереди элементы списка и сравнить каждый со стоящими за ним. При первом же совпадении элементов делается вывод, что в списке есть одинаковы элементы и работа программы завершается.
Еще одним способом решения может быть использование типа данных «множества» ( set ). Как известно, в множествах не может быть одинаковых элементов. При преобразовании списка во множество в нем одинаковые элементы будут представлены единожды, то есть дубли удалятся. Если после этого сравнить длину исходного списка и множества, то станет ясно, есть ли в списке одинаковые элементы. Если длины совпадают, значит все элементы списка уникальны. Если нет, значит, были одинаковые элементы.
Допустим, исходный список генерируется таким кодом:
from random import random N = 10 arr = [0] * N for i in range(N): arr[i] = int(random() * 50) print(arr)
Пример решения классическим способом:
for i in range(N-1): for j in range(i+1, N): if arr[i] == arr[j]: print("Есть одинаковые") quit() print("Все элементы уникальны")
Здесь j принимает значения от следующего элемента за тем, для которого ищется совпадение, до последнего в списке. Сравнивать элемент с индексом i с элементами, стоящими впереди него, не надо, т. к. эти сравнения уже выполнялись на предыдущих итерациях внешнего цикла.
Решение задачи с помощью множества:
setarr = set(arr) if len(arr) == len(setarr): print("Все элементы уникальны") else: print("Есть одинаковые")
Функция set преобразует список во множество.
Примеры выполнения кода:
[2, 4, 1, 2, 45, 38, 26, 11, 49, 25] Есть одинаковые
[44, 49, 21, 19, 23, 27, 34, 9, 41, 31] Все элементы уникальны
В Python у списков есть метод count , который подсчитывает количество элементов списка, чьи значения совпадают с переданным в метод значением. Таким образом мы можем решить задачу, перебирая элементы списка и передавая каждый в метод count(item) . Если хотя бы однажны метод вернет число больше 1, значит в списке имеются повторы значений.
from random import randrange N = 10 arr = [randrange(50) for i in range(N)] print(*arr) for item in arr: if arr.count(item) > 1: print("Есть одинаковые") break else: print("Все элементы уникальны")
В программе выше ветка else цикла for срабатывает только в случае, если работа цикла не была прервана с помощью оператора break .
В более сложном варианте данной задачи может требоваться определить неуникальные элементы, то есть выявить значения, которые встречаются в списке более одного раза, а не просто сказать, есть повторы или нет. Здесь мы не можем использовать прерывание цикла, так как в списке может повторяться и другое значение. Также не можем для всех элементов списка вызывать count() , так как в этом случае метод будет вызываться повторно для уже учтенных ранее значений. Например, результат работы такой программы
from random import randrange N = 10 arr = [randrange(50) for i in range(N)] print(*arr) for item in arr: count = arr.count(item) if count > 1: print(f"Элемент встречается раз")
может выглядеть так:
9 36 43 21 48 6 19 13 3 48 Элемент 48 встречается 2 раз Элемент 48 встречается 2 раз
Чтобы исключить из перебора повторы значений, мы можем преобразовать список во множество. После этого перебирать в цикле элементы множества, которые уникальны.
from random import randrange N = 10 arr = [randrange(50) for i in range(N)] print(*arr) setarr = set(arr) for item in setarr: count = arr.count(item) if count > 1: print(f"Элемент встречается раз")
X Скрыть Наверх
Решение задач на Python
Пересечение списков, совпадающие элементы двух списков
В данной задаче речь идет о поиске элементов, которые присутствуют в обоих списках. При этом пересечение списков и поиск совпадающих (перекрывающихся) элементов двух списков будем считать несколько разными задачами.
Если даны два списка, в каждом из которых каждый элемент уникален, то задача решается просто, так как в результирующем списке не может быть повторяющихся значений. Например, даны списки:
[5, 4, 2, ‘r’, ‘ee’] и [4, ‘ww’, ‘ee’, 3]
Областью их пересечения будет список [4, ‘ee’] .
Если же исходные списки выглядят так:
[5, 4, 2, ‘r’, 4, ‘ee’, 4] и [4, ‘we’, ‘ee’, 3, 4] ,
то списком их совпадающих элементов будет [4, ‘ee’, 4] , в котором есть повторения значений, потому что в каждом из исходных списков определенное значение встречается не единожды.
Начнем с простого — поиска области пересечения. Cначала решим задачу «классическим» алгоритмом, не используя продвинутые возможностями языка Python: будем брать каждый элементы первого списка и последовательно сравнивать его со всеми значениями второго.
a = [5, [1, 2], 2, 'r', 4, 'ee'] b = [4, 'we', 'ee', 3, [1, 2]] c = [] for i in a: for j in b: if i == j: c.append(i) break print(c)
Результат выполнения программы:
[[1, 2], 4, 'ee']
Берется каждый элемент первого списка (внешний цикл for ) и последовательно сравнивается с каждым элементом второго списка (вложенный цикл for ). В случае совпадения значений элемент добавляется в третий список c . Команда break служит для выхода из внутреннего цикла, так как в случае совпадения дальнейший поиск при данном значении i бессмыслен.
Алгоритм можно упростить, заменив вложенный цикл на проверку вхождения элемента из списка a в список b с помощью оператора in :
a = [5, [1, 2], 2, 'r', 4, 'ee'] b = [4, 'we', 'ee', 3, [1, 2]] c = [] for i in a: if i in b: c.append(i) print(c)
Здесь выражение i in b при if по смыслу не такое как выражение i in a при for . В случае цикла оно означет извлечение очередного элемента из списка a для работы с ним в новой итерации цикла. Тогда как в случае if мы имеем дело с логическим выражением, в котором утверждается, что элемент i есть в списке b . Если это так, и логическое выражение возвращает истину, то выполняется вложенная в if инструкция, то есть элемент i добавляется в список c .
Принципиально другой способ решения задачи – это использование множеств. Подходит только для списков, которые не содержат вложенных списков и других изменяемых объектов, так как встроенная в Python функция set() в таких случаях выдает ошибку.
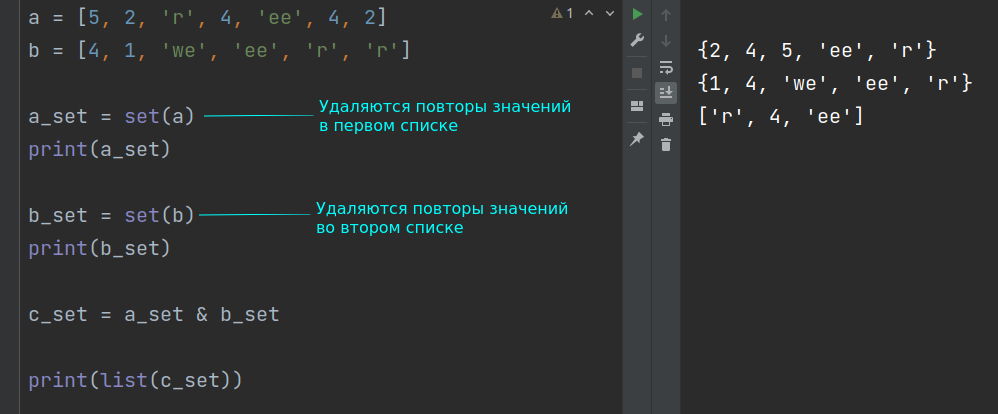
a = [5, 2, 'r', 4, 'ee'] b = [4, 1, 'we', 'ee', 'r'] c = list(set(a) & set(b)) print(c)
['ee', 4, 'r']
Выражение list(set(a) & set(b)) выполняется следующим образом.
- Сначала из списка a получают множество с помощью команды set(a) .
- Аналогично получают множество из b .
- С помощью операции пересечения множеств, которая обозначается знаком амперсанда & , получают третье множество, которое представляет собой область пересечения двух исходных множеств.
- Полученное таким образом третье множество преобразуют обратно в список с помощью встроенной в Python функции list() .
Множества не могут содержать одинаковых элементов. Поэтому, если в исходных списках были повторяющиеся значения, то уже на этапе преобразования этих списков во множества повторения удаляются, а результат пересечения множеств не будет отличаться от того, как если бы в исходных списках повторений не было.
Однако если мы вернемся к решению задачи без использования множеств и добавим в первый список повтор значения, то получим некорректный результат:
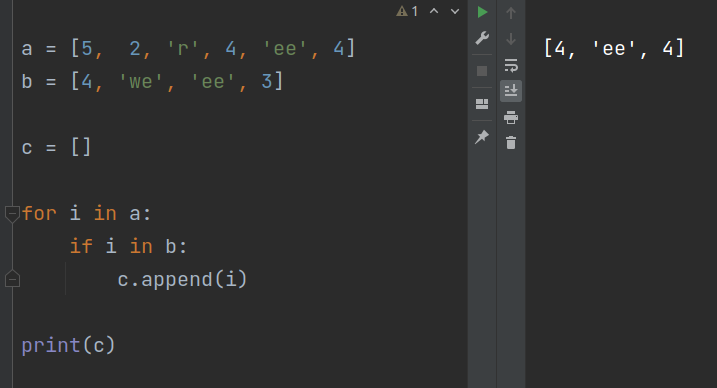
В список пересечения попадают оба равных друг другу значения из первого списка. Это происходит потому, что когда цикл извлекает, в данном случае, вторую 4-ку из первого списка, выражение i in b также возвращает истину, как и при проверке первой 4-ки. Следовательно, выражение c.append(i) выполняется и для второй четверки.
Чтобы решить эту проблему, добавим дополнительное условие в заголовок инструкии if . Очередной значение i из списка a должно не только присутствовать в b , но его еще не должно быть в c . То есть это должно быть первое добавление такого значения в c :
a = [5, 2, 'r', 4, 'ee', 4] b = [4, 'we', 'ee', 3] c = [] for i in a: if i in b and i not in c: c.append(i) print(c)
[4, 'ee']
Теперь усложним задачу. Пусть если в обоих списках есть по несколько одинаковых значений, они должны попадать в список совпадающих элементов в том количестве, в котором встречаются в списке, где их меньше. Или если в исходных списках их равное количетво, то такое же количество должно быть в третьем. Например, если в первом списке у нас три 4-ки, а во втором две, то в третьем списке должно быть две 4-ки. Если в обоих исходных по две 4-ки, то в третьем также будет две.
Алгоритмом решения такой задачи может быть следующий:
- В цикле будем перебирать элементы первого списка.
- Если на текущей итерации цикла взятого из первого списка значения нет в третьем списке, то только в этом случае следует выполнять все нижеследующие действия. В ином случае такое значение уже обрабатывалось ранее, и его повторная обработка приведет к добавлению лишних элементов в результирующий список.
- С помощью спискового метода count() посчитаем количество таких значений в первом и втором списке. Выберем минимальное из них.
- Добавим в третий список количество элементов с текущим значением, равное ранее определенному минимуму.
a = [5, 2, 4, 'r', 4, 'ee', 1, 1, 4] b = [4, 1, 'we', 'ee', 'r', 4, 1, 1] c = [] for item in a: if item not in c: a_item = a.count(item) b_item = b.count(item) min_count = min(a_item, b_item) # c += [item] * min_count for i in range(min_count): c.append(item) print(c)
[4, 4, 'r', 'ee', 1, 1]
Если значение встречается в одном списке, но не в другом, то метод count() другого вернет 0. Соответственно, функция min() вернет 0, а цикл с условием i in range(0) не выполнится ни разу. Поэтому, если значение встречается в одном списке, но его нет в другом, оно не добавляется в третий.
При добавлении значений в третий список вместо цикла for можно использовать объединение списков с помощью операции + и операцию повторения элементов с помощью * . В коде выше данный способ показан в комментарии.
X Скрыть Наверх
Решение задач на Python
Списки в Python

Введение в генераторы списков Генераторы списков являются мощным и компактным инструментом в Python, позволяющим создавать списки с помощью однострочных выражений.


При работе с данными в Python, часто возникает необходимость удалить дубликаты из списка. Дубликаты могут исказить результаты анализа данных, повторяющиеся

При работе с данными в Python, часто возникает необходимость найти повторяющиеся элементы в списке. Это может быть полезно для анализа данных, поиска дубликатов

Добавление элемента в начало списка является распространенной операцией при работе с данными в Python. В некоторых случаях порядок элементов имеет значение

программировании часто возникает необходимость заменить определенный элемент в списке на другое значение. Это может быть полезно, когда мы хотим обновить

Python — это язык программирования, который предоставляет множество встроенных функций и методов для работы со списками. Функции и методы списков

Введение Списки в Python — это универсальная структура данных, которая позволяет хранить и организовывать коллекции элементов. Списки являются одним

Python предоставляет удобные средства для работы со списками, включая вычисление среднего арифметического элементов списка. Среднее арифметическое —

В Python есть несколько способов вывести список в обратном порядке, и это может пригодиться при работе с данными в различных задачах. Например, если вы

Python — это высокоуровневый язык программирования, который часто используется для работы со списками. При выводе списков в Python по умолчанию скобки