Ошибка в преобразовании ISO-8859-1 в UTF8 [дубликат]
html, который возвращает POST имеет кодировку ISO-8859-1, при попытке преобразования в UTF-8 выпадает в ошибку.
import requests url = "http://___" payload='some text' headers = r=requests.request("POST", url, headers=headers, data=payload) r.encoding html=r.text.encode('ISO-8859-1').decode('UTF-8') ‘utf-8’ codec can’t decode byte 0xcf in position 226: invalid continuation byte
Если поискать пример конкретного текста, то можно увидеть такое:
from bs4 import BeautifulSoup soup = BeautifulSoup(r.text, 'html.parser') div=soup.find('div', ) mystr=div.find_all('td')[0].get_text() print(mystr) Âàðèàíòû íàèìåíîâàíèÿ ïðîäóêöèè
Отслеживать
задан 7 июл 2021 в 19:31
97 9 9 бронзовых знаков
Просто r.content передавайте вместо r.text (байты вместо неправильно декодированного текста), тогда bs сам по мета-тегам определит правильную кодировку: soup = BeautifulSoup(r.content, ‘html.parser’)
8 июл 2021 в 5:06
И еще, перед получением текста из ответа можно кодировку заменить: r.encoding = ‘cp1251’ print(r.text)
8 июл 2021 в 5:14
1 ответ 1
Сортировка: Сброс на вариант по умолчанию
У меня перекодировалось при таком составе кодировок:
text = 'Âàðèàíòû íàèìåíîâàíèÿ ïðîäóêöèè' print(text.encode('CP1252').decode('CP1251', errors='ignore')) # Варианты наименования продукции Могу посоветовать в спорных случаях в список свести себе все варианты поддерживаемых кодировок с https://docs.python.org/3/library/codecs.html#standard-encodings. И в цикле их все попробовать с распечаткой применить. Так найдете нужную комбинацию кодировок.
Отслеживать
ответ дан 7 июл 2021 в 21:34
Andy Pavlov Andy Pavlov
3,884 10 10 серебряных знаков 16 16 бронзовых знаков
- python
- кодировка
- requests
-
Важное на Мете
Связанные
Похожие
Дизайн сайта / логотип © 2024 Stack Exchange Inc; пользовательские материалы лицензированы в соответствии с CC BY-SA . rev 2024.1.3.2953
Нажимая «Принять все файлы cookie» вы соглашаетесь, что Stack Exchange может хранить файлы cookie на вашем устройстве и раскрывать информацию в соответствии с нашей Политикой в отношении файлов cookie.
Как поменять кодировку с iso-8859-1 на windows-1251?
Ситуация такая: я получаю запрос, который пользователь вводит в строку поиска и применяю функцию preg_split. После чего кодировка слов меняется и судя по функции mb_detect_encoding на iso-8859-1. Можно ли как то изменить кодировку на windows-1251?
Пробовала iconv не работает
Читала еще, что mb_detect_encoding может неправильно определить кодировку, тогда как можно определить правильно?
Выдает такой символ �, прочитала, что это UTF-8, но при применении iconv строка становится пустой
- Вопрос задан более трёх лет назад
- 5275 просмотров
1 комментарий
Оценить 1 комментарий
ISO-8859
ISO-8859 — семейство кодовых страниц, разработанное совместными усилиями IEC. По состоянию на 2006 г. это семейство состоит из 15 кодовых страниц.
Общая информация
Поскольку кодировки ISO-8859 разрабатывались как средства для обмена информацией, а не как средства обеспечения высококачественной типографики, то в них не включены такие символы, как парные кавычки, тире различной длины, лигатуры и т. п. (хотя там всё же присутствуют такие символы как неразрывный пробел и символ мягкого переноса). Зато довольно много места (область 0x80—0x9F) зарезервировано под «верхние управляющие символы», предназначенные для управления терминалами.
Поскольку различные страницы ISO-8859 разрабатывались совместно, они обладают некоторой взаимной совместимостью. Например, все семь символов расширенной латиницы, используемые в немецком языке, стоят на одинаковых позициях во всех кодовых страницах, включающих эти символы. Страницы Latin-1—Latin-4 обладают ещё большей степенью совместимости: каждый символ, представленный в любых двух из этих страниц, стоит в них на одинаковых позициях.
Применение
Кодировки серии ISO-8859 применяются главным образом на веб-страниц (поскольку большинство веб-серверов используют UNIX).
В системах Microsoft Windows используются кодировки Windows, некоторые из которых совместимы с ISO-8859, но включают больше графических символов за счёт использования области 0x80—0x9F.
Части ISO-8859
ISO 8859-1 (Latin-1) Расширенная латиница, включающая символы большинства западноевропейских языков (английский, датский, ирландский, исландский, испанский, итальянский, немецкий, норвежский, португальский, ретороманский, фарерский, шведский, шотландский (гэльский) и частично голландский, финский, французский), а также некоторых восточноевропейских (албанский) и африканских языков (африкаанс, суахили). В Latin-1 отсутствуют знак евро и заглавная буква Ÿ. Эта кодовая страница считается кодировкой по умолчанию для электронной почты. Также этой кодовой странице соответствуют первые 256 символов Юникода. ISO 8859-2 (Latin-2) Расширенная латиница, включающая символы центральноевропейских и восточноевропейских языков (боснийский, венгерский, польский, словацкий, словенский, хорватский, чешский). В Latin-2, как и в Latin-1, отсутствуют знак евро. ISO 8859-3 (Latin-3) Расширенная латиница, включающая символы южноевропейских языков (мальтийский, турецкий и эсперанто). ISO 8859-4 (Latin-4) Расширенная латиница, включающая символы североевропейских языков (гренландский, эстонский, латвийский, литовский и саамские языки). ISO 8859-5 (Latin/Cyrillic) Кириллица, включающая символы славянских языков (белорусский, болгарский, македонский, русский, сербский и частично украинский). ISO 8859-6 (Latin/Arabic) Символы, используемые в арабском языке. Символы других языков с письмом на основе арабского не поддерживаются. Для корректного отображения текста в кодировке ISO-8859-6 требуется поддержка двунаправленного письма и контекстно-зависимых форм символов. ISO 8859-7 (Latin/Greek) Символы современного греческого языка. Может использоваться также для записи древнегреческих текстов в монотонической орфографии. ISO 8859-8 (Latin/Hebrew) Символы современного иврита. Используется в двух вариантах: с логическим порядком следования символов (требует поддержки двунаправленного письма) и с визуальным порядком следования символов. ISO 8859-9 (Latin-5) Вариант Latin-1, в котором редко используемые символы исландского языка заменены на турецкие. Используется для турецкого и курдского языков. ISO 8859-10 (Latin-6) Вариант Latin-4, более удобный для скандинавских языков. ISO 8859-11 (Latin/Thai) Символы тайского языка. ISO 8859-12 (Latin/Devanagari) Символы письма деванагари. В 1997 работа над ISO-8859-12 была официально прекращена, и эта кодировка так и не была принята как стандарт. ISO 8859-13 (Latin-7) Вариант Latin-4, более удобный для балтийских языков. ISO 8859-14 (Latin-8) Расширенная латиница, включающая символы кельтских языков, таких как шотландский (гэльский) и бретонский. ISO 8859-15 (Latin-9) Вариант Latin-1, в котором редко используемые символы заменены на необходимые для полной поддержки финского, французского и эстонского языков. Кроме того, в Latin-9 был добавлен знак евро. ISO 8859-16 (Latin-10) Расширенная латиница, включающая символы южноевропейских и восточноевропейских (албанский, венгерский, итальянский, польский, румынский, словенский, хорватский), а также некоторых западноевропейских языков (ирландский в новой орфографии, немецкий, финский, французский). Как и в Latin-9, в Latin-10 был добавлен знак евро.
| Кодовые таблицы символов в ISO-8859 |
|---|
| ISO 8859-1 | ISO 8859-2 | ISO 8859-3 | ISO 8859-4 | ISO 8859-5 | ISO 8859-6 | ISO 8859-7 | ISO 8859-8 ISO 8859-9 | ISO 8859-10 | ISO 8859-11 | ISO 8859-12 | ISO-8859-13 | ISO 8859-14 | ISO 8859-15 | ISO 8859-16 |
Wikimedia Foundation . 2010 .
Использование UTF-8 в HTTP заголовках

Как известно, HTTP 1.1 — это текстовой протокол передачи данных. HTTP сообщения закодированы, используя ISO-8859-1 (которую условно можно считать расширенной версией ASCII, содержащей умляуты, диакритику и другие символы, используемые в западноевропейских языках). При этом в теле сообщений можно использовать другую кодировку, которая должна быть обозначена в заголовке «Content-Type». Но что делать, если нам необходимо задать non-ASCII символы не в теле сообщения, а в самих заголовках? Наверное, самый распространенный кейс — это проставление имени файла в «Content-Disposition» заголовке. Это, казалось бы, довольно распространенная задача, но ее реализация не так очевидна.
TL;DR: Используйте кодировку, описанную в RFC 6266, для «Content-Disposition» и преобразуйте текст в латиницу (транслит) в остальных случаях.
Небольшая вводная в кодировки
В статье упоминаются и используются кодировки US-ASCII (часто именуемую просто ASCII), ISO-8859-1 и UTF-8. Это небольшая вводная в эти кодировки. Раздел предназначен для разработчиков, которые редко или совсем не работают с кодировками и успели подзабыть их. Если вы к ним не относитесь, то смело пропускайте раздел.
ASCII — это простая кодировка, содержащая 128 символов и включающая весь английский алфавит, цифры, знаки препинания и служебные символы.

7 бит достаточно, чтобы представить любой ASCII символ. Слово «test» будет представлено в HEX представлении, как 0x74 0x65 0x73 0x74. Первый бит у всех символов всегда 0, поскольку символов в кодировке 128, а байт предоставляет 2^8 = 256 вариантов.
ISO-8859-1 — кодировка, предназначенная для западноевропейских языков. Содержит французскую диакритику, немецкие умляуты и т.д.

Кодировка содержит 256 символов и, таким образом, может быть представлена одним байтом. Первая половина (128 символов) полностью совпадает с ASCII. Таким образом, если первый бит = 0, то это обычный ASCII символ. Если 1, то это символ, специфичный для ISO-8859-1.
UTF-8 — одна из самых известных кодировок наравне с ASCII. Способна кодировать 1.112.064 символов. Размер каждого символа варьируется от 1-го до 4-х байт (раньше допускались значения до 6 байт).


Программа, работающая с этой кодировкой, определяет по первым битам, как много байтов входит в символ. Если октет начинается с 0, то символ представлен одним байтом. 110 — два байта, 1110 — три байта, 11110 — 4 байта.
Как и в случае с ISO-8859-1, первые 128 символов полностью соответствуют ASCII. Поэтому тексты, использующие только ASCII символы, будут абсолютно идентичны в бинарном представлении, вне зависимости от того, использовалась ли для кодирования US-ASCII, ISO-8859-1 или UTF-8.
Использование UTF-8 в теле сообщения
Прежде чем перейти к заголовкам, давайте быстро взглянем, как использовать UTF-8 в теле сообщений. Для этого используется заголовок «Content-Type».

Если «Content-Type» не задан, то браузер должен обрабатывать сообщения, как будто они написаны в ISO-8859-1. Браузер не должен пытаться отгадать кодировку и, тем более, игнорировать «Content-Type». Но, что реально отобразится в ситуации, когда «Content-Type» не передан, зависит от реализации браузера. Например, Firefox сделает согласно спецификации и прочитает сообщение, будто оно было закодировано в ISO-8859-1. Google Chrome, напротив, будет использовать кодировку операционной системы, которая для многих российских пользователей равна Windows-1251. В любом случае, если сообщение было в UTF-8, то оно будет отображено некорректно.

Проставляем UTF-8 сообщение в значение заголовка
С телом сообщения все достаточно просто. Тело сообщения всегда следует после заголовков, поэтому здесь не возникает технических проблем. Но как быть с заголовками? В спецификации недвусмысленно заявляется, что порядок заголовков в сообщении не имеет значения. Т.е. задать кодировку в одном заголовке через другой заголовок не представляется возможным.
Что будет, если просто взять и записать UTF-8 значение в значение заголовка? Мы видели, что такой трюк с телом сообщения приведет к тому, что значение будет просто прочитано в ISO-8859-1. Логично было бы предположить, что то же самое произойдет с заголовком. Но это не так. Фактически, во многих, если не в большинстве, случаях такое решение будет работать. Сюда включаются старые айфончики, IE11, Firefox, Google Chrome. Единственным из находящихся у меня под рукой браузеров, когда я писал эту статью, который не захотел работать с таким заголовком, является Edge.

Такое поведение не зафиксировано в спецификациях. Возможно, разработчики браузеров решили облегчить жизнь разработчиков и автоматически определять, что в заголовках сообщение закодировано в UTF-8. В общем-то, это не является такой сложной задачей. Смотрим на первый бит: если 0, то ASCII, если 1 — то, возможно, UTF-8.
Нет ли в этом случае пересечения с ISO-8859-1? На самом деле, практически нет. Возьмем для примера UTF-8 символ из 2-х октетов (русские буквы представлены двумя октетами). Символ в бинарном представлении будет иметь вид: 110xxxxx 10xxxxxx. В HEX представлении: [0xC0-0x6F] [0x80-0xBF]. В ISO-8859-1 этими символами едва ли можно закодировать что-то, несущее смысловую нагрузку. Поэтому риск того, что браузер неправильно расшифрует сообщение, очень мал.
Однако, при попытке использовать этот способ можно столкнуться с техническими проблемами: ваш веб-сервер или фреймворк может просто не разрешить записывать UTF-8 символы в значение заголовка. Например, Apache Tomcat вместо всех UTF-8 символов проставляет 0x3F (вопросительный знак). Разумеется, это ограничение можно обойти, но, если само приложение бьет по рукам и не дает что-то сделать, то, возможно, вам и не нужно это делать.
Но, независимо от того, разрешает ли вам ваш фреймворк или сервер записать UTF-8 сообщения в заголовок или нет, я не рекомендую этого делать. Это не задокументированное решение, которое в любой момент времени может перестать работать в браузерах.
Транслит
Я думаю, что использовать транслит — eto bolee horoshee reshenie. Многие крупные популярные русские ресурсы не брезгуют использовать транслит в названиях файлов. Это гарантированное решение, которое не сломается с выпуском новых браузеров и которое не надо тестировать отдельно на каждой платформе. Хотя, разумеется, надо подумать, как преобразовывать весь спектр возможных символов, что может быть не совсем тривиально. Например, если приложение рассчитано на российскую аудиторию, то в имя файла могут попасть татарские буквы ә и ң, которые надо как-то обработать, а не просто заменять на «?».
RFC 2047
Как я уже упомянул, томкат не позволил мне проставить UTF-8 в заголовке сообщения. Отражена ли эта особенность поведения в Java docs для сервлетов? Да, отражена:
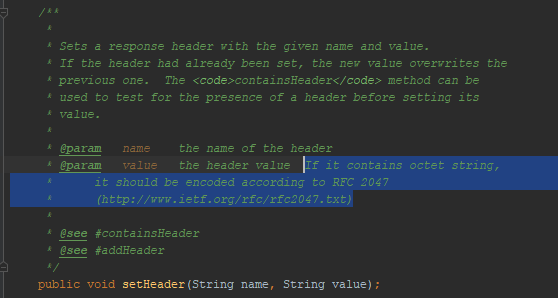
Упоминается RFC 2047. Я пробовал кодировать сообщения, используя этот формат, — браузер меня не понял. Этот метод кодировки не работает в HTTP. Хотя работал раньше. Вот, например, тикет на удаление поддержки этой кодировки из Firefox.
RFC 6266
В тикете, ссылка на который содержится в предыдущем разделе, есть упоминания, что даже после прекращения поддержки RFC 2047, все еще есть способ передавать UTF-8 значения в названии скачиваемых файлов: RFC 6266. На мой взгляд, это самое правильно решение на сегодняшний день. Многие популярные интернет ресурсы используют его. Мы в CUBA Platform также используем именно этот RFC для генерации «Content-Disposition».
RFC 6266 — это спецификация, описывающая использование “Content-Disposition” заголовка. Сам способ кодировки подробно описан в другой спецификации — RFC 8187.

Параметр “filename” содержит название файла в ASCII, “filename*” — в любой необходимой кодировке. При наличии обоих атрибутов “filename” игнорируется во всех современных браузерах (включая IE11 и старые версии Safari). Совсем старые браузеры, напротив, игнорируют “filename*”.
При использовании данного способа кодирования в параметре сначала указывается кодировка, после » идет закодированное значение. Видимые символы из ASCII кодирования не требуют. Остальные символы просто пишутся в hex представлении, со стоящим «%» перед каждым октетом.
Что делать с другими заголовками?
Кодирование, описанное в RFC 8187, не является универсальным. Да, можно поместить в заголовок параметр с * префиксом, и это, возможно, будет даже работать для некоторых браузеров, но спецификация предписывает не делать так.
В каждом случае, где в заголовках поддерживается UTF-8, на настоящий момент есть явное упоминание об этом в релевантном RFC. Помимо «Content-Disposition» данная кодировка используется, например, в Web Linking и Digest Access Authentication.
Следует учесть, что стандарты в этой области постоянно меняются. Использование описанной выше кодировки в HTTP было предложено лишь в 2010. Использование данной кодировки именно в «Content-Disposition» было зафиксировано в стандарте в 2011. Несмотря на то, что эти стандарты находятся лишь на стадии «Proposed Standard», они поддержаны повсеместно. Вариант, что в будущем нас ожидают новые стандарты, которые позволят более унифицировано работать с различными кодировками в заголовках, не исключен. Поэтому остается только следить за новостями в мире стандартов HTTP и уровня их поддержки на стороне браузеров.