Делаем сессии из лога событий с помощью Pandas
Волею судеб передо мной встала необходимость разбить большущий лог событий на сессии. Не буду приводить полный лог, а покажу упрощенный пример:
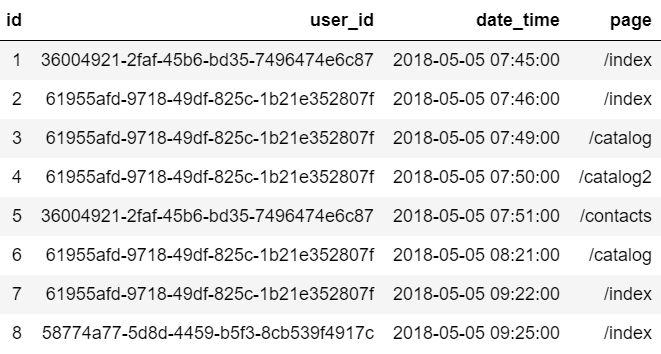
Структура данных лога представляет собой:
- id — порядковый номер события в логе
- user_id — уникальный идентификатор пользователя, совершившего событие (при решении реальной задачи анализа лога в качестве user_id может выступать IP-адрес пользователя или, например, уникальный идентификатор cookie-файла)
- date_time — время совершения события
- page — страница, на которую перешел пользователь (для решения задачи эта колонка не несет никакой пользы, я привожу её для наглядности)
Задача состоит в том, чтобы разбить последовательность событий (просмотров страниц) на вот такие блоки, которые будут сессиями:
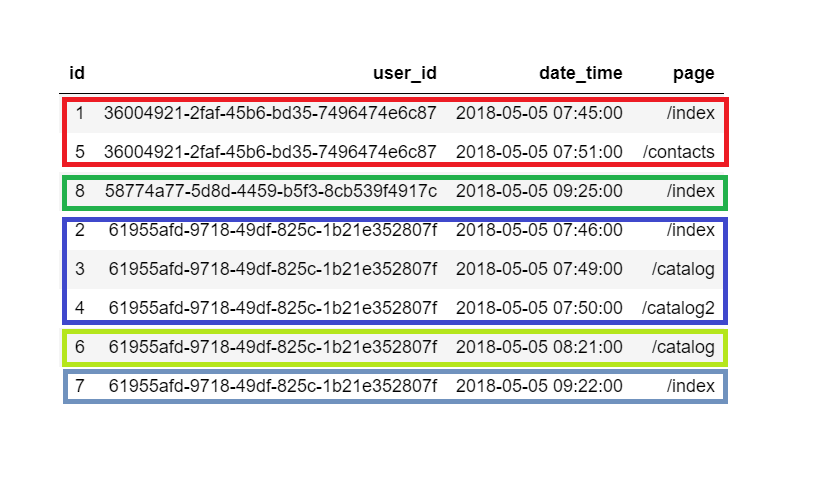
Говоря «разбить», я не имею в виду разделить и сохранить в виде разных массивов данных или ещё что-то подобное. Тут речь идёт о том, чтобы каждому событию сопоставить номер сессии, в которую это событие входит.
Критерий сессии в моем случае — она живет полчаса после предыдущего совершенного события. Например, в строке 6 пользователь перешел на страницу /catalog в 8:21, а следующую страницу /index (строка 7) посмотрел в 9:22. Разница между просмотром страниц составляет 1 час 1 минуту, а значит эти просмотры относятся к разным сессиям этого пользователя.
Все это дело я буду делать на Питоне при помощи Pandas в Jupyter Notebook. Вот ссылка на ноутбук.
Алгоритм
Итак, у нас есть ’event_df’ — это датафрейм, в котором содержатся данные о событиях в привязке к пользователям:
1 События сгенерированные разными пользователями идут в хронологическом порядке. Для удобства отсортируем их по user_id, тогда события каждого пользователя будут идти последовательно:
event_df = event_df.sort_values('user_id')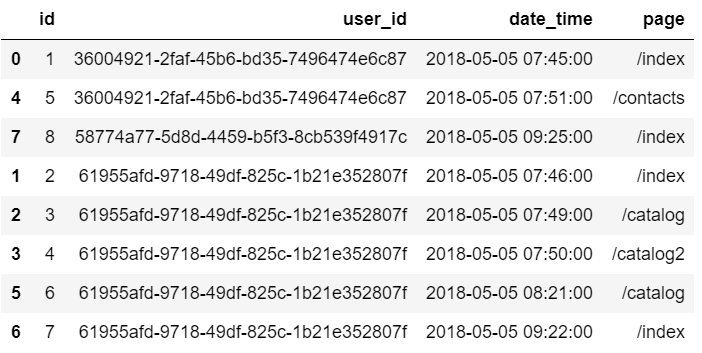
2 В колонке ’diff’ для каждого события отдельного пользователя посчитаем разницу между временем посещения страницы и временем посещения предыдущей страницы. Если страница была первой для пользователя, то значение в колонке ’diff’ будет NaT, т. к. нет предыдущего значения
Обратите внимание, что совместно с функцией diff я использую для группировки пользователей groupby, чтобы считать разницу между временными метками отдельных пользователей. Без использования groupby мы бы просто брали все временные метки и считали бы между ними разницу, что было бы неправильно, так как события относятся к разным пользователям.
event_df['diff'] = event_df.groupby('user_id')['date_time'].diff(1)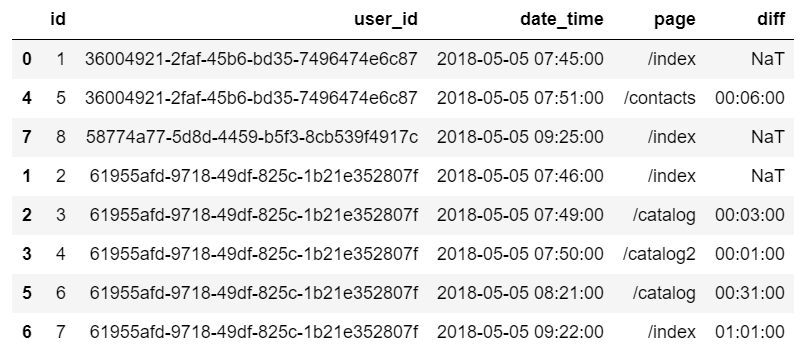
Кое-что уже проклевывается. Мы нашли такие события, которые будут начальными точками для сессий:
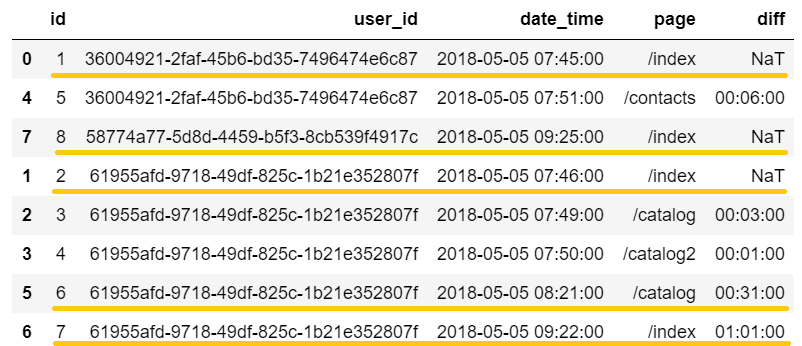
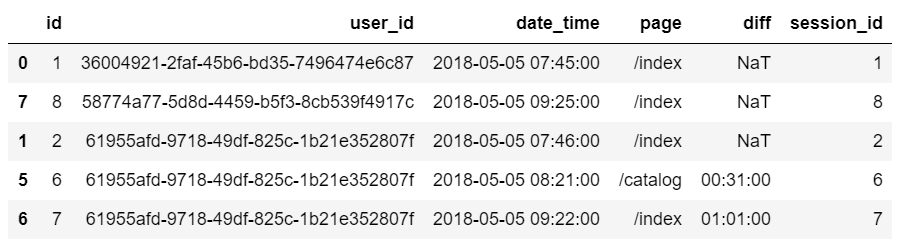
3 Из основного датафрейма ’event_df’ создадим вспомогательный датафрейм ’session_start_df’. Этот датафрейм будет содержать события, которые будут считаться первыми событиями сессий. К таким событиям относятся все события, которые произошли спустя более чем 30 минут после предыдущего, либо события, которые были первыми для пользователя (NaT в колонке ’diff’).
Также создадим во вспомогательном датафрейме колонку ’session_id’, которая будет содержать в себе id первого события сессии. Она пригодится, чтобы корректно отобразить идентификатор сессии, когда будем объединять данные из основного и вспомогательного датафреймов.
sessions_start_df = event_df[(event_df['diff'].isnull()) | (event_df['diff'] > '1800 seconds')] sessions_start_df['session_id'] = sessions_start_df['id']Вспомогательный датафрейм ’session_start_df’ выглядит так:
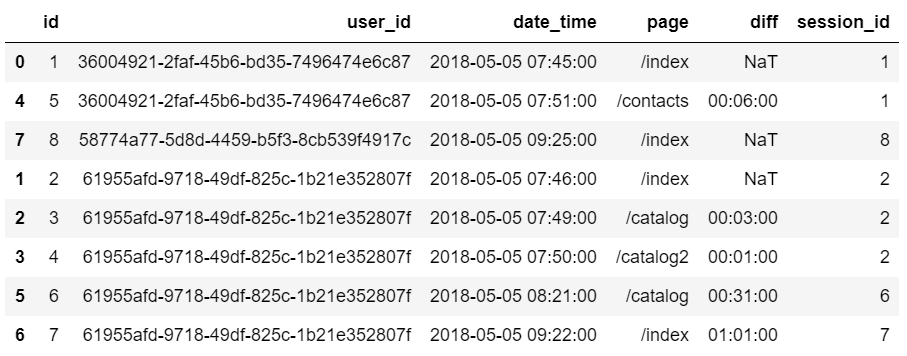
4 С помощью функции merge_asof объединим между собой данные основного и вспомогательного датафреймов. Эта функция позволяет объединить данные двух датафреймов схожим образом с левым join’ом, но не по точному соответствию ключей, а по ближайшему. Примеры и подробности в документации.
Для корректной работы функции merge_asof оба датафрейма должны быть отсортированы по ключу, на основе которого будет происходить объединение. В нашем случае это колонка ’id’.
Обратите внимание, что из датафрейма ’session_start_df’ я выбираю только колонки ’id’, ’user_id’ и ’session_id’, так как остальные колонки особо не нужны.
event_df = event_df.sort_values('id') sessions_start_df = sessions_start_df.sort_values('id') event_df = pd.merge_asof(event_df,sessions_start_df[['id','user_id','session_id']],on='id',by='user_id')В итоге получаем вот такой распрекрасный объединенный датафрейм, в котором в колонке ’session_id’ указан уникальный идентификатор сессии:
Дополнительные манипуляции
1 Найдем события, которые были первыми в сессиях. Это будет полезно, если мы захотим определить страницы входа.
Обнаружить эти события предельно просто: их идентификаторы будут равны идентификаторам сессии. Для этого создадим колонку ’is_first_event_in_session’, в которой сравним между собой значения колонок ’id’ и ’session_id’.
event_df['is_first_event_in_session'] = event_df['id'] == event_df['session_id']2 Вычислим время, проведенное на странице, руководствуясь временем посещения следующей страницы
Для этого сначала считаем разницу между предыдущей и следующей страницей внутри сессии. Мы уже делали такое вычисление, когда считали разницу между временем посещения страниц пользователем. Только тогда мы группировали по ’user_id’, а теперь будем по ’session_id’.
event_df['time_on_page'] = event_df.groupby(['session_id'])['date_time'].diff(1)Но diff со смещением в 1 строку считает разницу между посещением последующей страницы относительно предыдущей, поэтому время пребывания на предыдущей странице будет записано в строку следующего события:
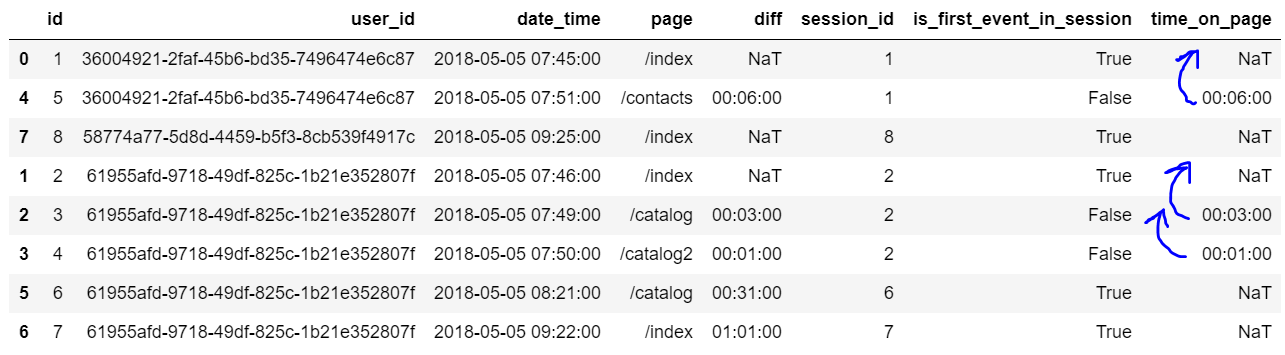
Нам нужно сдвинуть значение столбца ’time_on_page’ на одну строку вверх внутри отдельно взятой сессии. Для этого нам пригодится функция shift.
event_df['time_on_page'] = event_df.groupby(['session_id'])['time_on_page'].shift(-1)Получили то, что нужно:
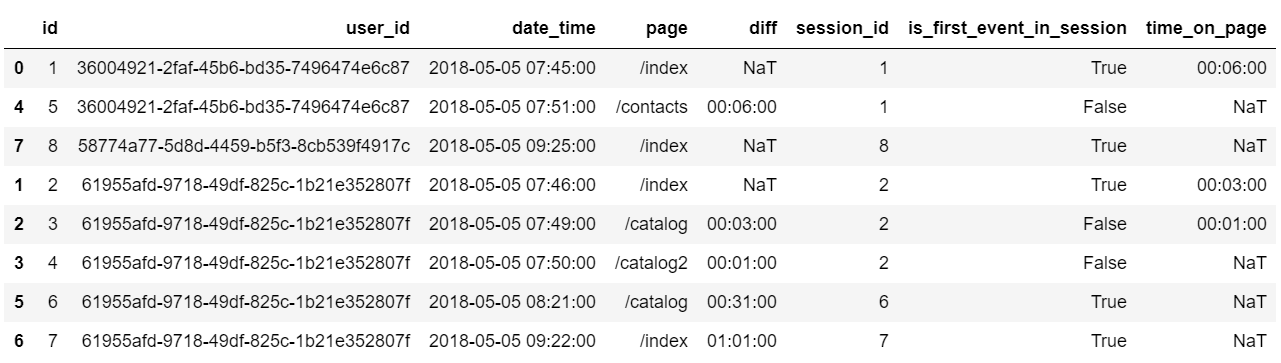
Значения в столбце ’time_on_page’ имеют специфический тип datetime64, который не всегда удобен для арифметических операций, поэтому преобразуем ’time_on_page’ в секунды.
event_df['time_on_page'] = event_df['time_on_page'] / np.timedelta64(1, 's')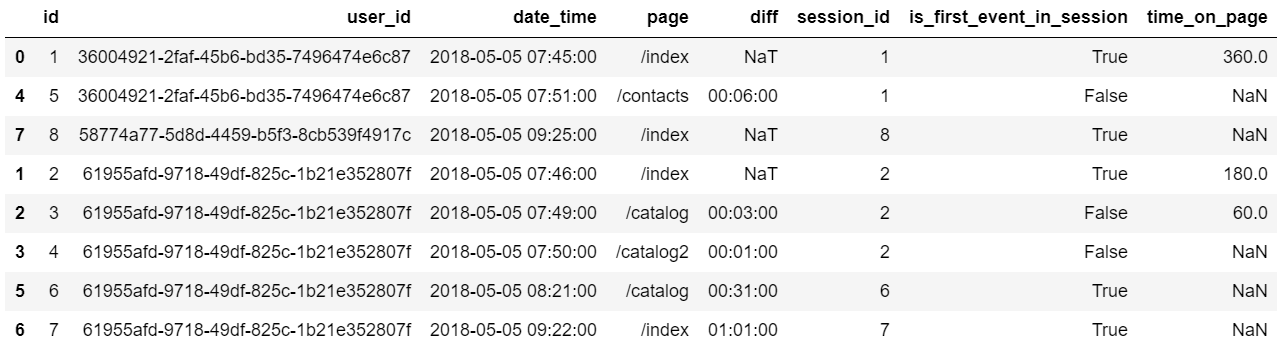
3 На основе полученных данных очень просто посчитать различные агрегаты
event_df['user_id'].nunique() # Количество пользователей event_df['session_id'].nunique() # Количество сессий event_df['id'].count() # Количество просмотров страниц (событий) event_df['time_on_page'].mean() # Среднее время просмотра страниц
Заключение
Таким образом, используя несколько не самых очевидных функций в Pandas (например, merge_asof мне довелось применять впервые), можно формировать сессии на основе лога событий. Логом событий могут выступать логи сервера, какой-нибудь клик-стрим в SaaS-сервисах, сырые данные систем веб-аналитики.
Удачи и новых аналитических достижений!
Вступайте в группу на Facebook и подписывайтесь на мой канал в Telegram, там публикуются интересные статьи про анализ данных и не только.
pandas. Изменить значение int на дату

Есть Excel файл с выгрузкой из системы, кривоватая.. Во-первых, все колонки с датами выгружаются с «зеленым треугольником» (как неопределенный формат). Во-вторых, если дата исходного заказа отсутствует она выгружается, как 00000000.. Помогите заменить 00000000 на пустую ячейку, а даты превратить в формат дат. Pandas изначально их воспринимает как int С другими колонками, где нет 00000000 получилось справиться так:
order_df['ord_Date'] = pd.to_datetime(order_df['ord_Date'].str[:4] + '-' + order_df['ord_Date'].str[4:6] + '-' + order_df['ord_Date'].str[6:8]) Сразу оговорюсь, функция pd.to_datatime выдавала некорректные значения. Например, дата (с «зеленым треугольником») 20220707 после обработки функцией превращалась в 1970-01-01 00:00:00.020220707. Установка разных форматов дат тоже не дала результата. Пробовала через if, не работает:
if order_df.ord_Orig_Date == 0: order_df['ord_Orig_Date'] = None else: order_df['ord_Orig_Date'] = pd.to_datetime(order_df['ord_Orig_Date'].str[:4] + '-' + order_df['ord_Orig_Date'].str[4:6] + '-' + order_df['ord_Orig_Date'].str[6:8]) Ошибка: ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all() Пробовала через Numpy, не работает:
order_df['ord_Orig_Date'] = np.where(order_df['ord_Orig_Date'] != 0, pd.to_datetime(order_df['ord_Orig_Date'].str[:4] + '-' + order_df['ord_Orig_Date'].str[4:6] + '-' + order_df['ord_Orig_Date'].str[6:8]), None) Ошибка: AttributeError: Can only use .str accessor with string values!. Did you mean: ‘std’? Пробовала и так:
order_df['ord_Orig_Date'] = np.where(order_df['ord_Orig_Date'] != 0, pd.to_datetime(order_df['ord_Orig_Date'].astype(str).str[:4] + '-' + order_df['ord_Orig_Date'].astype(str).str[4:6] + '-' + order_df['ord_Orig_Date'].astype(str).str[6:8]), None) Ошибка: File «», line 3, in raise_from dateutil.parser._parser.ParserError: day is out of range for month: 0— present at position 0
Что нового в pandas 1.0?


В конце января 2020 вышло большое обновление библиотеки pandas – 1.0. Представляем вам обзор изменений и дополнений, которые по нашему мнению являются интересными и заслуживают внимания.
- pd.NA
- Типы pandas для работы со строками и boolean-значениями
- Инструмент конвертирования типов
- Конвертор в markdown
- Еще изменения и дополнения…
Мажорный релиз 1.0 принес с собой улучшения существующих инструментов, новые дополнения (они пока имеют статус экспериментальных), ряд изменений в API, которые ломают обратную совместимость, багфиксы и изменения, увеличивающие производительность библиотеки.
pd.NA
Первое, с чего хотелось бы начать – это pd.NA – “значение”, которое pandas будет использовать для обозначения отсутствующих данных.
В предыдущих версиях pandas для обозначения отсутствующих данных использовались следующие значения: NaN, NaT и None. NaN – это отсутствующее значение в столбце с числовым типом данных, оно является аббревиатурой от Not a Number (пришло из numpy: np.NaN). NaT – это отсутствующее значение для данных типа DateTime, аббревиатура от Not a Time (является частью библиотеки pandas). None используется если тип данных object, такой тип имеют, например, элементы типа str (пришло из Python).
Рассмотрим работу с отсутствующими данными на примерах:
> d = <"A":[None, "test2", "test3"], "B": [1.01, np.nan, 3.45], "C": [date(2019, 1, 29), datetime.now(), None], "D":[1, 2, None]>> df = pd.DataFrame(d)

Если создать набор данных с целыми числами, не указывая явно тип, то будет использовано значение по умолчанию:
> pd.Series([4, 5, None]) 0 4.0 1 5.0 2 NaN dtype: float64
Если тип указать, то в pandas 1.0 будет использован pd.NA:
>pd.Series([4, 5, None], dtype="Int64") 0 4 1 5 2 dtype: Int64
Либо можно задать pd.NA напрямую:
> pd.Series([4, 5, pd.NA], dtype="Int64") 0 4 1 5 2 dtype: Int64
Для строковых и boolean значений это работает аналогично:
> pd.Series([None, "test2", "test3"]) 0 None 1 test2 2 test3 dtype: object > pd.Series([None, "test2", "test3"], dtype='string') 0 1 test2 2 test3 dtype: string > pd.Series([True, False, None]) 0 True 1 False 2 None dtype: object > pd.Series([True, False, None], dtype='boolean') 0 True 1 False 2 dtype: boolean
Типы pandas для работы со строками и boolean-значениями
Появился тип StringDtype для работы со строковыми данными (до этого строки хранились в object-dtype NumPy массивах). При создании структуры pandas необходимо указать тип StringDtype либо string:
> pd.Series([None, "test2", "test3"], dtype=pd.StringDtype()) 0 1 test2 2 test3 dtype: string > pd.Series([None, "test2", "test3"], dtype='string') 0 1 test2 2 test3 dtype: string
Также добавлен тип BooleanDtype для хранения boolean значений. В предыдущих версиях столбец данных типа bool не мог содержать отсутствующие значения, тип BooleanDtype поддерживает эту возможность:
> pd.Series([False, True, None], dtype=pd.BooleanDtype()) 0 False 1 True 2 dtype: boolean > pd.Series([False, True, None], dtype='boolean') 0 False 1 True 2 dtype: boolean
Инструмент конвертирования типов
Метод convert_dtypes поддерживает работу с новыми типами:
> d = <"A":[None, "test2", "test3"], "B": [1, np.nan, 3], "C": [True, False, None], "D":[1, 2, None]>> df = pd.DataFrame(d) > df_conv = df.convert_dtypes() > df

> df_conv

> df.dtypes A object B float64 C object D float64 dtype: object > df_conv.dtypes A string B Int64 C boolean D Int64 dtype: object
Конвертор в markdown
В pandas 1.0 добавлен метод to_markdown() для конвертирования структур pandas в markdown таблицы:
> d = <"A":[None, "test2", "test3"], "B": [1, np.nan, 3], "C": [True, False, None], "D":[1, 2, None]>> df = pd.DataFrame(d) > print(df.to_markdown()) | | A | B | C | D | |---:|:------|----:|:------|----:| | 0 | | 1 | True | 1 | | 1 | test2 | nan | False | 2 | | 2 | test3 | 3 | | nan | > s = pd.Series([None, "test2", "test3"], dtype='string') > print(s.to_markdown()) | | 0 | |---:|:------| | 0 | | | 1 | test2 | | 2 | test3 |
Еще изменения и дополнения…
- Ускорение работы функций rolling.apply и expanding.apply;
- Возможность игнорирования индекса при сортировке DataFrame:
> df = pd.DataFrame() > df

> df.sort_values("A")

> df.sort_values("A", ignore_index=True)

- Более информативный info()
> d = <"A":[None, "test2", "test3"], "B": [1, np.nan, 3], "C": [True, False, None], "D":[1, 2, None]>> df = pd.DataFrame(d).convert_dtypes() > df.info() RangeIndex: 3 entries, 0 to 2 Data columns (total 4 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 A 2 non-null string 1 B 2 non-null Int64 2 C 2 non-null boolean 3 D 2 non-null Int64 dtypes: Int64(2), boolean(1), string(1) memory usage: 212.0 bytes
Более подробно про остальные изменения и дополнения можете прочитать на официальной странице сайта pandas.
P.S.
Вводные уроки по “Линейной алгебре на Python” вы можете найти соответствующей странице нашего сайта . Все уроки по этой теме собраны в книге “Линейная алгебра на Python”.
Если вам интересна тема анализа данных, то мы рекомендуем ознакомиться с библиотекой Pandas. Для начала вы можете познакомиться с вводными уроками. Все уроки по библиотеке Pandas собраны в книге “Pandas. Работа с данными”.
Как удалить строки со значениями NaN в Pandas
Часто вас может заинтересовать удаление строк, содержащих значения NaN, в кадре данных pandas. К счастью, это легко сделать с помощью функции pandas dropna() .
В этом руководстве показано несколько примеров использования этой функции в следующих pandas DataFrame:
import numpy as np import scipy.stats as stats #create DataFrame with some NaN values df = pd.DataFrame() #view DataFrame df rating points assists rebounds 0 NaN NaN 5.0 11 1 85.0 25.0 7.0 8 2 NaN 14.0 7.0 10 3 88.0 16.0 NaN 6 4 94.0 27.0 5.0 6 5 90.0 20.0 7.0 9 6 76.0 12.0 6.0 6 7 75.0 15.0 9.0 10 8 87.0 14.0 9.0 10 9 86.0 19.0 5.0 7 Пример 1. Удаление строк с любыми значениями NaN
Мы можем использовать следующий синтаксис, чтобы удалить все строки, которые имеют любые значения NaN:
df.dropna () rating points assists rebounds 1 85.0 25.0 7.0 8 4 94.0 27.0 5.0 6 5 90.0 20.0 7.0 9 6 76.0 12.0 6.0 6 7 75.0 15.0 9.0 10 8 87.0 14.0 9.0 10 9 86.0 19.0 5.0 7 Пример 2. Удаление строк со всеми значениями NaN
Мы можем использовать следующий синтаксис, чтобы удалить все строки, содержащие все значения NaN в каждом столбце:
df.dropna (how='all') rating points assists rebounds 0 NaN NaN 5.0 11 1 85.0 25.0 7.0 8 2 NaN 14.0 7.0 10 3 88.0 16.0 NaN 6 4 94.0 27.0 5.0 6 5 90.0 20.0 7.0 9 6 76.0 12.0 6.0 6 7 75.0 15.0 9.0 10 8 87.0 14.0 9.0 10 9 86.0 19.0 5.0 7 В этом конкретном DataFrame не было строк со всеми значениями NaN, поэтому ни одна из строк не была удалена.
Пример 3. Удаление строк ниже определенного порога
Мы можем использовать следующий синтаксис, чтобы удалить все строки, которые не имеют определенного, по крайней мере , определенного количества значений, отличных от NaN:
df.dropna (thresh= 3 ) rating points assists rebounds 1 85.0 25.0 7.0 8 2 NaN 14.0 7.0 10 3 88.0 16.0 NaN 6 4 94.0 27.0 5.0 6 5 90.0 20.0 7.0 9 6 76.0 12.0 6.0 6 7 75.0 15.0 9.0 10 8 87.0 14.0 9.0 10 9 86.0 19.0 5.0 7 В самой первой строке исходного DataFrame не было по крайней мере 3 значений, отличных от NaN, так что это была единственная строка, которая была удалена.
Пример 4. Удаление строки со значениями Nan в определенном столбце
Мы можем использовать следующий синтаксис, чтобы удалить все строки, которые имеют значение NaN в определенном столбце:
df.dropna (subset=['assists']) rating points assists rebounds 0 NaN NaN 5.0 11 1 85.0 25.0 7.0 8 2 NaN 14.0 7.0 10 4 94.0 27.0 5.0 6 5 90.0 20.0 7.0 9 6 76.0 12.0 6.0 6 7 75.0 15.0 9.0 10 8 87.0 14.0 9.0 10 9 86.0 19.0 5.0 7 Пример 5: сброс индекса после удаления строк с NaN
Мы можем использовать следующий синтаксис для сброса индекса DataFrame после удаления строк со значениями NaN:
#drop all rows that have any NaN values df = df.dropna () #reset index of DataFrame df = df.reset_index(drop=True) #view DataFrame df rating points assists rebounds 0 85.0 25.0 7.0 8 1 94.0 27.0 5.0 6 2 90.0 20.0 7.0 9 3 76.0 12.0 6.0 6 4 75.0 15.0 9.0 10 5 87.0 14.0 9.0 10 6 86.0 19.0 5.0 77 Вы можете найти полную документацию по функции dropna() здесь .