Web Scraping

Web Scraping — это автоматическое извлечение данных с веб-страниц в соответствии с заданными параметрами.
Специальная программа сканирует сайт и копирует его данные: тексты, изображения, аудиофайлы и так далее. Затем систематизирует их и сохраняет, к примеру, в таблицу формата CSV. Таким образом, можно выгрузить целый каталог интернет-магазина, библиотеку или любую другую базу данных. Конечно, если она находится в открытом веб-доступе.
Свяжите сервисы между собой без программистов за 5 минут!
Используейте ApiX-Drive для самостоятельной интеграции разных сервисов между собой. Доступно 350+ готовых интеграций.
- Автоматизируйте работу интернет магазина или лендинга
- Расширяйте возможности за счет интеграций
- Не тратьте деньги на программистов и интеграторов
- Экономьте время за счет автоматизации рутинных задач
Бесплатно протестируйте работу сервиса прямо сейчас и начните экономить до 30% времени! Перейти
Web Scraping не всегда используют для заранее выбранных ресурсов. Так, бывают ситуации, когда нужно собрать конкретные типы данных, но на каких сайтах они находятся — неизвестно. В таких случаях используют поискового бота, или краулера. Он ищет нужные данные в интернете, а после этого сообщает о них скрейперу — программе, которая непосредственно занимается извлечением. Краулеры и скрейперы разрабатывают индивидуально под нужды каждого конкретного проекта.
Некоторые ресурсы сами предоставляют быстрый доступ к данным через API. Например, интернет-магазин таким образом может делиться снимками и характеристиками товаров из своего каталога с партнерами. Если же подобной функциональности не предусмотрено, на помощь приходит Web Scraping.
Настроить интеграцию без программистов ApiX-Drive
Статьи о маркетинге, автоматизации и интеграциях в нашем Блоге
Что такое веб-скрейпинг и как он работает
Что такое web-scraping и зачем он нужен. Как он работает и чем отличается от парсинга. Насколько законно извлекать данные с сайта и как их применять. Какие сервисы лучше использовать для безопасного веб-скрейпинга: список проверенных инструментов.
Веб‑скрейпинг — технология, которая может быть полезной для SEO‑продвижения сайта.
Рассказываем, каким бывает веб‑скрейпинг, как он работает и как с его помощью получить полезные данные, а также какие инструменты использовать для скрейпинга и как защититься от его незаконной и вредной формы.
Что такое веб‑скрейпинг
Веб‑скрейпинг (web scraping, буквально «выскребание, соскабливание веба») — автоматизированный процесс извлечения данных с сайта.
Когда мы находим на сайте какую‑то информацию и копируем её к себе в документ, то, по сути, занимаемся скрейпингом, но в очень маленьком объёме.
В рамках веб‑скрейпинга данные собираются автоматически в больших объёмах — с помощью ботов. Под ботом имеется в виду любая программа, собирающая данные с веб‑сайтов. Это может быть готовая программа, которую надо установить на компьютер, веб‑приложение или самописный сервис.
Боты‑скрейперы получают HTML‑код интересующих страниц сайта, разбирают его по определенным правилам, заданным для скрейпинга, и таким образом превращают любую нужную информацию с сайта в читаемый формат.
Чем скрейпинг отличается от парсинга данных
Скрейпинг и парсинг легко спутать, потому что эти понятия часто используют как взаимозаменяемые. Разобраться можно, если узнать дословный перевод слов to scrape и to parse.
Скрейпинг (от глагола to scrape — «соскребать, собирать») — автоматизированный сбор данных, как мы уже писали.
Парсинг (от глагола to parse — «разбирать») — процесс, на котором из скачанных данных извлекается нужная информация и превращается в нужный нам читаемый формат. Проще говоря, второй этап веб‑скрейпинга.
В статье мы не будем углубляться в термины, а расскажем о процессе полностью, называя его «веб‑скрейпинг».
Зачем нужен веб‑скрейпинг
У скрейпинга много сфер применения:
- Отслеживание цен на товары в интернет‑магазинах
Собирая информацию о ценах на разных платформах (сайтах, маркетплейсах), можно вовремя корректировать цены и обходить конкурентов.
- Извлечение описаний товаров и услуг
Это поможет улучшить свои описания товаров и услуг с опорой на тексты конкурентов.
- Мониторинг новостей и объявлений
Инструмент для отслеживания интересных тем и создания актуального контента.
- Сбор данных для аналитики
С помощью скрейпинга можно собрать лайки, репосты, комментарии в одну таблицу и оценить эффективность своего контента или даже провести маркетинговое исследование.
Вы наверняка видели подобные исследования в интернете:


Для них нужно довольно много данных — вручную такое не собрать. И здесь снова понадобится веб‑скрейпинг.
- Извлечение контактной информации
С помощью скрейпинга можно получить адреса электронной почты, телефоны, прочие контактные данные и свести в одну таблицу — она пригодится для ретаргетинга.
- Мониторинг репутации бренда
Скрейпинг также используется для отслеживания упоминаний о бренде/продукте, чтобы компания могла вовремя реагировать на изменение тональности упоминаний.
Какой бывает веб‑скрейпинг
Законность или незаконность той или иной формы сбора данных зависит от юрисдикции: то, что разрешено в одной стране, может быть запрещено в другой. Мы рассказываем о скрейпинге с точки зрения того, что мы и наши читатели — в России.
Условно скрейпинг делится на хороший и плохой.
Законный (хороший)
- Работа ботов поисковых систем. Они просматривают сайт, анализируют его контент и индексируют.
Этот вид скрейпинга нужен, чтобы сайт попал в результаты выдачи. Без этого пользователи не увидят наш сайт.
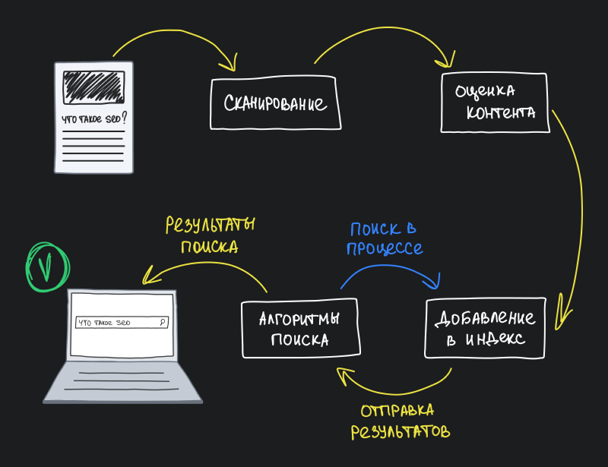
Подробно о ботах поисковых систем, процессах сканирования, фильтрации и индексации мы рассказываем во втором модуле нашего бесплатного курса по SEO.
- Сбор данных агрегаторов / сайтов сравнения цен. Они используют ботов для извлечения цен и описаний продуктов, создавая сравнения сайтов похожих продавцов.
В результате мы можем видеть информацию с разных сайтов в одном каталоге:

- Маркетинговые (и не только) исследования. При создании таких исследований компании задействуют ботов, которые извлекают сообщения из соцсетей и форумов и затем сводят их в один документ.
Пример такого исследования мы привели выше, в разделе «Зачем нужен веб‑скрейпинг».
Незаконный (плохой)
Формально парсинг и скрейпинг в России не запрещены. Но некоторые виды скрейпинга условно считаются плохими, и сайты стараются их пресекать:
Сайты активно защищаются от сбора данных о ценах: конкуренты часто скрейпят друг друга, снижая свои цены и вызывая таким образом ценовой демпинг.
Чаще всего такое происходит в отраслях, где товары можно легко и быстро сопоставить, а цена играет решающую роль при покупке. То есть это не дешёвые товары повседневного спроса, а то, что человек считает крупной покупкой: авиа‑ и ж/д‑билеты, туристические путёвки, электроника и бытовая техника.
От этой формы скрейпинга нужно активно защищаться, поскольку огромное количество созданного вручную контента можно легко вытащить с вашего сайта и скопировать на другой ресурс.
❗️Получается, что и боты, которые собирают данные с сайтов, условно делятся на «плохих» и «хороших». Есть пара признаков, по которым их можно узнать:
- «Хорошие» боты действуют согласно директивам из файла robots.txt. В этом файле веб‑мастер прописывает, как обходить конкретные страницы сайта — например, какие индексировать, какие нет. «Плохие» боты игнорируют robots.txt и ходят по всем страницам сайта.
- «Хороший» бот обычно ссылается на организацию, которая «послала» его исследовать страницы. Запись (referer), показывающая, к какой организации бот относится, обычно прописана в HTTP‑заголовке бота. «Плохие» боты имитируют естественный трафик, ничего не указывая, будто на сайт зашёл человек.
От «плохих» ботов сайты защищаются с помощью различных технологий: распознавание репутации IP, введение прогрессивных задач, проверка HTTP‑заголовка, анализ поведения посетителей. Подробнее об этом в следующем разделе.
Нам важно про это знать не только ради защиты своего сайта, но и чтобы самим не оказаться «плохим» ботом. О том, как безопасно извлекать данные и не попадать под блокировки, в разделе «Как безопасно извлекать данные с сайта».
Как защититься от веб‑скрейпинга
Есть несколько способов. Чаще всего их используют вместе:
- Анализировать поведение посетителей сайта
Обычно ботов от реальных посетителей отличает то, что они делают много запросов за короткий период времени, а ещё просматривают страницы в нелогичном порядке — не как человек.
Когда попытки доступа к сайту определены как принадлежащие боту, они блокируются.
IP‑адрес — уникальный адрес конкретного компьютера (как номер телефона). Сайты хранят информацию об IP‑адресах, с которых к ним обращались.
IP‑адреса, которые в прошлом использовались для подозрительной активности, рассматриваются очень внимательно, и их доступ к сайту может быть заблокирован.
- Проверять HTTP‑заголовки
Поможет база HTTP‑заголовков браузеров, которые обращались к сайту и были опознаны как вредоносные: все следующие запросы проверяются через эту базу данных.
- Давать на выполнение прогрессивные задачи
Такие задачи предлагают выполнить пользователям, которые заходят с подозрительного IP‑адреса.
Самый простой пример — CAPTCHA (капча — «найдите все светофоры на картинке» и прочие). Боты не умеют её проходить, потому что для выполнения такой задачи нужно подключить логику или совершить осмысленные действия, что подвластно только человеку.
Благодаря прогрессивным задачам реальные посетители могут пользоваться сайтом неограниченно, а боты — нет. Правда, скрейпинг становится всё совершеннее и всё легче обходит простые прогрессивные задачи, которые, в свою очередь, тоже постоянно усложняются.
Как безопасно извлекать данные с сайта
Получается, когда мы скрейпим данные чужого сайта, нам нужно обойти защиты, о которых мы написали выше.
Вот как это сделать (можно использовать один способ, комбинировать несколько или задействовать все сразу):
- Установить корректный User‑Agent
При посещении сайта клиентское приложение — браузер — посылает серверу информацию о себе, которая начинается со строки User‑agent:’. Там содержится информация о приложении, его версии, ОС компьютера и языке.
В этой строке нужно корректно указать всю требуемую информацию, потому что запросы от неизвестных браузеров часто блокируют.
О нём мы писали выше. Укажите в HTTP‑заголовке запроса, с какого сайта вы пришли, чтобы вас пропустили. Вот как это выглядит:
- Подключить программу для решения прогрессивных задач (CAPTCHA)
Например, 2Captcha. Сервис платный — от 44 рублей за 1 000 решённых задач, подключается через API.
- Задать случайные интервалы между запросами к сайту
Пользователи не заходят на сайт тысячу раз в минуту и не сидят на сайте 24 часа в сутки. Если вы самостоятельно написали бот для веб‑скрейпинга, нужно указать, как часто ему заходить на сайт — в идеале так, как это делает обычный человек. Приложения для скрейпинга, о которых мы рассказываем ниже, делают это по умолчанию.
Прокси‑серверы помогают имитировать, будто запросы к сайту приходят с разных IP‑адресов, а не с одного и того же. Специальные сервисы для скрейпинга автоматически предусматривают ротацию IP.
Инструменты для веб‑скрейпинга
Часто программисты пишут конкретных ботов с конкретными функциями под конкретную задачу, но есть и более простые, специализированные инструменты для веб‑скрейпинга. Мы расскажем именно о них.
Большинство сервисов работают по одной и той же схеме: нужно зарегистрироваться и подтвердить адрес электронной почты, а затем можно начинать скрейпить.
Сам скрейпинг прост в управлении: нужно ввести адрес сайта и выбрать элементы, которые необходимо собрать. Приложение сделает всё за вас и даст возможность посмотреть результаты в читаемом формате. Весь процесс проходит онлайн.
Некоторые сервисы предлагают скачать их API (программу) для скрейпинга. Как правило, на сайте приложения всегда есть инструкция по установке и использованию.
Некоторые сервисы предлагают персональные решения — они сделают всю работу за вас. Для этого надо связаться с менеджментом конкретной компании.
Бесплатное расширение для Chrome. Можно собирать разные типы данных и экспортировать их в CSV, XLS или JSON.
Сервис с бесплатным тарифом для небольших проектов; для более сложных — от 75 долларов в месяц. Позволяет скачивать данные и хранить их в облаке, работает на Mac и Windows.
Обеспечивает ротацию IP и проходит CAPTCHA. Есть демоверсия — её нужно запросить на сайте.
Десктопная программа. Выберите данные, которые нужно собирать, и ждите. Данные можно выгрузить в формате JSON, Excel и API.
Бесплатно можно получить 200 страниц с данными. Платные тарифы начинаются от 189 долларов в месяц.
Сервис позволяет скрейпить одновременно несколько типов данных, формируя их в задачи и выполняя поочерёдно. Можно сделать шаблон для быстрого сбора однотипных данных. Есть 30‑дневный бесплатный пробный период.
Сервис скрейпинга сайтов и соцсетей. Для каждого типа данных — например, сырого HTML, информации с сайтов недвижимости или торговли — предоставляются разные API, они специализированы для определенного сектора.
Например, API для скрейпинга сырого HTML извлекает HTML‑код страниц. API для ритейла позволяет просматривать страницы товаров и извлекать цены, описания и прочее. API для недвижимости даёт возможность просматривать площадь, местоположения, цены.
Задачи в приложении оплачиваются кредитами — в бесплатной версии у вас будет 100 кредитов. Когда они закончатся, придётся заплатить от 39 евро в месяц за 100 000 кредитов.
Как и предыдущий, этот сервис предоставляет для скачивания API для скрейпинга. 1 000 запросов — бесплатно, платные тарифы — от 20 долларов в месяц.
Здесь решения создаются под каждый конкретный бизнес. Стоимость — от 40 долларов в месяц за один сайт.
Как в Datahut, здесь вам подберут персональное решение. Datamam, например, обойдется в 5 000+ долларов за полноценный сбор данных.
Выводы
- Веб‑скрейпинг — это автоматизированный сбор данных сайтов. Парсинг — это часть веб‑скрейпинга, процесс приведения собранных данных в читаемый вид.
- Скрейпинг нужен, чтобы анализировать цены конкурентов и эффективность своего контента, мониторить репутацию в соцсетях, корректировать описания товаров и услуг, искать идеи для эффективного контента.
- Скрейпинг бывает хорошим — например, работа поисковых роботов — и плохим, когда сбор данных используется для кражи контента или ценового демпинга.
- Чтобы защититься от скрейпинга данных, требуется анализировать поведение пользователей, проверять IP, HTTP‑заголовки запросов, ставить CAPTCHA.
- Чтобы пройти через защиты сайтов, нужно установить корректный User Agent, добавить в заголовок запроса referer, установить интервалы между запросами к сайту, использовать прокси для изменения IP‑адреса и подключить программу прохождения CAPTCHA.
- Для обхода защиты используют специальные сервисы. Это может быть веб‑приложение или десктопная программа, а ещё есть компании, которые занимаются скрейпингом на заказ.
Web Scraping – что это такое и зачем он нужен
Каталог товаров, спортивная статистика, цены на офферы… Что-то знакомое, правда? Эти и другие вещи собирают с помощью специальных софтов или вручную в документы. Там информация структурирована; нет необходимости разбираться что и где.
Если вас заинтересовал такой метод, подумайте о веб-скрейпинге.
Что такое веб-скрейпинг?
Web scraping – процесс сбора данных с помощью программы, то есть в автоматическом режиме. В русскоязычном пространстве этот процесс называют парсингом. А программу – парсером. Точно так же как за бугром говорят to scrape web page, у нас – парсить страницу. Так что если изучаете материал на английском, не переводите как “скрабить”, “скрабы” и так далее 🙂
Как работает веб-скрейпинг?
Запускаете программу и загружаете в нее адреса страниц. А еще наполняете софт ключевыми словами и фразами, блоками и числами, которые нужно собрать. Эта программка заходит на указанные сайты и копирует в файл все, что найдет. Это может быть файл CSV-формата или Excel-таблица.
Когда программа закончит работу, вы получите файл, в котором вся информация будет структурирована.
Для чего он нужен?
С помощью веб-скрейпинга собирают нужные данные. Например, у вас новостное агентство и вы хотите проанализировать тексты своих конкурентов на конкретную тематику. Какую лексику они используют? Как подают информацию? Конечно, найти такие статьи можно вручную, но проще настроить программу и поручить эту задачу ей.
Или так: вы любитель литературы и сейчас страшно хотите найти информацию о болгарских поэтах. На болгарском. В болгарском интернете информации о болгарской литературе в принципе мало, и поэтому штудировать каждый сайт – долго. В таком случае есть смысл обратиться к парсеру. Загоняете в программу ключевые слова и фразы, по которым она будет искать материал о поэтах, – и ждете, пока софт завершит работу.
То есть парсить информацию могут все, кто захочет. В основном этим занимаются те, кому нужно проанализировать контент конкурентов.
Зачем нужны прокси для веб-скрейпинга?
В web data scraping вы не обойдетесь без прокси. Есть две причины использовать промежуточные серверы.
- Вы преодолеете лимиты на количество запросов на сайт
Если обновляете страницу определенное количество раз, на ней срабатывает антифрод-система. Сайт начинает воспринимать ваши действия как DDoS-атаку. Итог – доступ к странице закрывается, вы не можете зайти на нее.
Парсер делает огромное количество запросов на сайт. Поэтому в любой момент его работу может остановить антифрод-система. Чтобы успешно собрать информацию, используйте даже несколько IP-адресов. Все зависит от того, какое количество запросов необходимо сделать.
- Обойдете защиту от скрапинга на некоторых ресурсах
Некоторые сайты защищаются от веб-скрейпинга как могут. А прокси помогают эту защиту обойти. Например, вы парсите информацию из буржевых сайтов, а у них стоит защита. Когда программа захочет скопировать содержимое страниц в таблицу, она сможет это сделать, но ресурс отдаст вам информацию на русском – не на английском.
Чтобы обойти такую антифрод-систему, используют прокси того же сервера, на котором расположен сайт. Например, парсить инфу с американского веб-ресурса нужно с американским IP.
Какие прокси использовать?
Покупайте платные прокси. Благодаря ним вы обойдете антифрод-системы сайтов. Бесплатные не дадут вам этого сделать: веб-ресурсы уже давно занесли бесплатные айпи в блэклисты. И если сделаете огромное количество запросов с публичного адреса, в какой-то момент произойдет следующее:
- страница закроет доступ: выдаст ошибку подключения.
- сайт попросит ввести капчу.
Во втором случае вы сможете спокойно скрайпить и дальше, но нужно будет при каждом новом обращении к странице вводить капчу.
Иногда достаточно одного запроса, чтобы сайт закрыл доступ или попросил ввести капчу. Так что вывод один: только платные промежуточные серверы.
Купить недорогие прокси для веб-скрейпинга вы можете на нашем сайте. Если не будет получаться настроить его или возникнут другие вопросы – пишите. Саппорт онлайн 24/7. Отвечает в течение 5 минут.
А сколько их должно быть?
Точно сказать, сколько использовать прокси для веб-скрейпинга, нельзя. У каждого сайта свои требования, а у каждого парсера в зависимости от задачи будет свое количество запросов.
300-600 запросов в час с одного айпи-адреса – вот примерные лимиты сайтов. Будет хорошо, если отыщете ограничение для ресурсов с помощью тестов. Если у вас нет такой возможности – берите среднее арифметическое: 450 запросов в час с одного IP.
К каким программам обратиться?
Инструментов для парсинга много. Они написаны на разных языках программирования: Ruby, PHP, Python. Есть программы с открытым кодом, где пользователи вносят изменения в алгоритм, если нужно.
Для вас – самые популярные программы для веб-скрейпинга:
Найдите подходящий софт для себя. А еще лучше – попробуйте несколько и выберите из них лучший.
А это законно?
Если боитесь собирать данные с сайтов, не стоит. Парсинг – это законно. Все, что находится в открытом доступе, можно собирать.
Например, вы можете спокойно спарсить электронные почты и номера телефонов. Это личная информация, но если пользователь сам публикует ее, претензий уже не может быть.
Заключение
Благодаря веб-скрапингу пользователи собирают каталоги товаров, цены на эти товары, спортивную статистику, даже целые тексты. Парсинг без блокировки – это реально: достаточно просто закупиться IP-адресами и менять их.
Web scraping что это
Если вы когда-либо копировали и вставляли информацию с веб-сайта, вы выполняли ту же функцию, что и любой веб-скрайпер, только в очень маленьком объёме. В отличие от обычного, ручного извлечения данных, веб-скрапер автоматически извлекает огромные массивы данных.
Веб-скрапинг представляет собой процесс извлечения и очистки данных с веб-сайта. Помимо банального удобства веб-скрапинга, его истинная сила заключается в том, какую пользу могут принести полученные благодаря нему данные. Многие успешные компании используют данные, полученные с помощью веб-скрапинга для улучшения своей деятельности, принимая эффективные решения для своего бизнеса, вплоть до индивидуального подхода в обслуживании клиентов.
В этой статье простым языком описано, что из себя представляет веб-скрапинг и из каких шагов состоит этот процесс.
Основы веб-скрапинга
На самом деле всё очень просто. Работа веб-скрапера состоит из двух частей: программа проходит по сайту и определяет, что нужно выгрузить, а затем выгружает запрошенные данные.
В случае, когда применяется web-crawling, программа проходит по сети для индексирования страниц и поиска нужного контента с помощью искусственного интеллекта, а затем происходит выгрузка нужных данных. Первая чать программы как бы ведёт вторую через сеть, в то время как она автоматически выгружает всё необходимое.
Эффективный веб-скрапинг: Три шага
1. Вначале IT-специалист пишет программу для веб-скрапинга под конкретный проект. Невозможно написать универсальную программу, которая будет качественно осуществлять веб-скрапинг для любой задачи, везде есть свои нюансы, которые необходимо проработать в программном коде.
2. После запуска программы, данные чаще всего извлекаются в формате HTML, затем происходит очистка данных, то есть преобразование в нормальный, подходящий для анализа вид. В сырых данных часто присутствуют шум, пропуски и другие неприятные вещи, с которыми необходимо поработать.
3. В конечном счете, данные преобразуются в подходящий формат, в зависимости от специфики проекта. Некоторые компании используют сторонние приложения или базы данных для просмотра и обработки данных по своему выбору, в то время как другие предпочитают данные в простом формате — например XLS, CSV и другие.