Бесплатные аналоги FreeOCR
FreeOCR — это программа для сканирования и распознавания, включающая в себя движок Tesseract free ocr, также известный как графический интерфейс Tesseract.
Он включает в себя установщик Windows и очень прост в использовании. FreeOCR поддерживает многостраничные TIFF, факсимильные документы, а также большинство типов изображений, включая сжатые TIFF, которые механизм Tesseract сам по себе не может прочитать.
Может работать с форматами PDF, а также совместим со сканерами TWAIN.
Бесплатный механизм распознавания текста Tesseract — это находящийся в открытом доступе продукт, выпущенный Google. Он был разработан в Hewlett Packard Laboratories в период с 1985 по 1995 год. В 1995 году вошел в тройку лучших на конкурсе OCR, организованном Университетом Невады.
FreeOCR 5.4.1
![]()
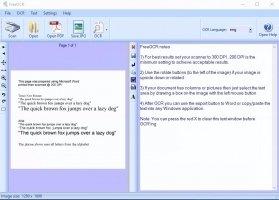
FreeOCR – программа, способная распознать отсканированный текст. Она умеет работать не только с сохраненными на жестком диске файлами, но и со сканерами, причем для начала работы необходимо только подключить устройство к компьютеру.
Возможности FreeOCR
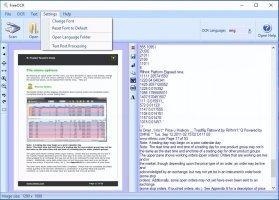
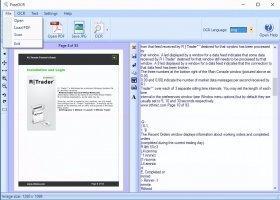
При первом запуске FreeOCR нуждается в доступе к Интернету для скачивания полной версии установочного файла со всеми доступными словарями и базами. Русский язык интерфейса отсутствует, что не мешает использовать программу. Стандартного ленточного меню нет, разработчики заменили его большими иконками с основными действиями. Окно программы состоит из двух частей. В одной отображается отсканированный или загруженный с жесткого диска документ, требующий распознания, в другой – результат распознавания.
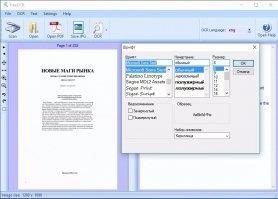
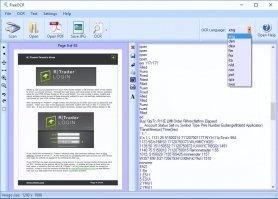
Программа поддерживает несколько языков: русский, французский, испанский, итальянский, немецкий и английский, причем больший упор сделан на последний. Без скачивания словарей придется выбирать язык распознавания вручную каждый раз, но скачав словари и указав путь к ним (все это делается за несколько кликов в настройках программы), можно автоматизировать работу программы.
Преимущества программы
- настройки полностью отсутствуют, работа программы максимально автоматизирована;
- интуитивно понятное меню с несколькими кнопками и надписями под ними;
- возможность экспорта распознанного текста в документ Word одним нажатием кнопки;
- работа с локальными файлами и возможность сканирования документов непосредственно из окна программы;
- поддержка всех основных графических форматов файлов (в том числе и PDF);
- отличное качество распознавания, особенно при работе с англоязычными текстами;
- шифрование и дешифрование текста;
- предварительный просмотр полученного результата;
- отображение информации о документе.
Недостатки программы
- нет русского языка интерфейса;
- недостаточно качественное распознавание текстов на других языках, кроме английского;
- программа плохо справляется с текстами, содержащими математические и специальные символы, такие тексты приходится проверять и править вручную, хотя эта проблема актальная и для платных аналогов.
Аналоги FreeOCR
FreeOCR — это программа для сканирования и распознавания, включающая в себя движок Tesseract free ocr, также известный как графический интерфейс Tesseract.
Он включает в себя установщик Windows и очень прост в использовании. FreeOCR поддерживает многостраничные TIFF, факсимильные документы, а также большинство типов изображений, включая сжатые TIFF, которые механизм Tesseract сам по себе не может прочитать.
Может работать с форматами PDF, а также совместим со сканерами TWAIN.
Бесплатный механизм распознавания текста Tesseract — это находящийся в открытом доступе продукт, выпущенный Google. Он был разработан в Hewlett Packard Laboratories в период с 1985 по 1995 год. В 1995 году вошел в тройку лучших на конкурсе OCR, организованном Университетом Невады.
Бесплатный сервис Free Online OCR

Free Online OCR — бесплатный онлайн сервис для распознавания текста. К достоинствам аналога ABBYY FineReader относятся хорошее качество распознавания текста; неограниченное количество загрузок; работа с 70 языками, в том числе русским; распознавание текста, содержащего сразу несколько языков; отсутствие регистрации. Free Online OCR предоставляет возможность выделять, а также разворачивать часть документа, предназначенную для дальнейшей обработки. Распознает следующие форматы: JPEG, JFIF, PNG, GIF, BMP, PBM, PGM, PPM и PCX. Работает с такими форматами сжатия как Unix compress, bzip2, bzip и gzip; со следующими мультистраничными документами: TIFF, PDF и DjVu. Распознает файлы DOCX и ODT с изображениями. Работает с ZIP архивами. Результат может быть получен в виде простого текста (TXT), документа Microsoft Word (DOC) и PDF-файла Adobe Acrobat.
Для настройки распознавания вы можете повернуть страницу, выбрать область распознавания и выставить опцию обработки текста с колонками.
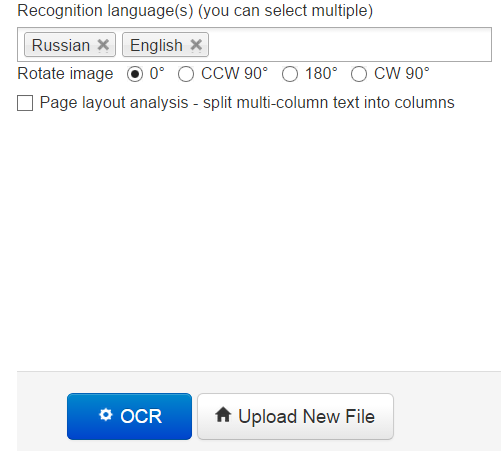
Отсканированный текст сервис распознаёт хорошо, если в нём не присутствуют изображения.


Но если текст содержит картинки или сфотографирован не в самом хорошем качестве, то результат далёк от корректного.


Free Online OCR — хороший сервис для распознавания хорошо отсканированных страниц, которые содержат только текст.