Сложность операций в Python
Здесь приведены показатели сложности (по времени) для различных операций в текущей версии CPython. Данные для более старых, либо более новых версий, а также других реализаций могут отличаться, однако, в целом, можно предполагать, что они не медленнее, чем в O(log n).
| Привязка к переменной | O(1) | name = 3 | |
| Операции над целыми | O(1) | 1+2 10==11 | Простые операции над относительно небольшими числами (до 12 цифр). |
Сложность различных типов
- Словарь (dict)
- Список (list)
- Множество (set)
- Двунаправленная очередь (deque)
На заметку
Дополнительную информацию о сложности алгоритмов можно найти в главе «Анализ» интерактивной книги «Problem Solving with Algorithms and Data Structures using Python». Книга доступна на русском: «Решение задач при помощи алгоритмов и структур данных в Питоне».
Синонимы поиска: Сложность операций в Python, complexity
Статьи раздела
| Сложность операций со множествами | Здесь описана сложность исполнения основных операций над множествами. |
| Сложность операций со словарями | Здесь описана сложность исполнения основных операций над словарями. |
| Сложность операций со списками | Здесь описана сложность исполнения основных операций над списками. |
Сколько стоят операции над list, set и dict в Python? Разбираемся с временной сложностью
Временная сложность алгоритма часто обозначается нотацией «О» большое. Разбираемся, что это и какова сложность операций над коллекциями в Python.
Автор перевода Иван Капцов
Программисту, работающему с данными, крайне важно выбирать правильные структуры данных для решения поставленной задачи, ведь выбор неправильного типа данных плохо влияет на производительность приложения. В этой статье объясняется нотация «О» большое и сложность ключевых операций структур данных в CPython.
Что означает нотация «O» большое?
В алгоритме выполняется ряд операций. Эти операции могут включать в себя итерацию по коллекции, копирование элемента или всей коллекции, добавление элемента в коллекцию, вставку элемента в начало или конец коллекции, удаление элемента или обновление элемента в коллекции.
«O» большое служит обозначением временной сложности операций алгоритма. Она показывает, сколько времени потребуется алгоритму для вычисления требуемой операции. Можно также измерить пространственную сложность (сколько места занимает алгоритм), но в этой статье мы сосредоточимся на временной.
Проще говоря, нотация «O» большое — это способ измерения производительности операции на основе размера ввода, известного как n.
Значения нотации «О» большое
На письме временная сложность алгоритма обозначается как O(n), где n — размер входной коллекции.
O(1)
Обозначение константной временной сложности. Независимо от размера коллекции, время, необходимое для выполнения операции, константно. Это обозначение константной временной сложности. Эти операции выполняются настолько быстро, насколько возможно. Например, операции, которые проверяют, есть ли внутри коллекции элементы, имеют сложность O(1).
O(log n)
Обозначение логарифмической временной сложности. В этом случае когда размер коллекции увеличивается, время, необходимое для выполнения операции, логарифмически увеличивается. Эту сложность имеют потенциально оптимизированные алгоритмы поиска.
O(n)
Обозначение линейной временной сложности. Время, необходимое для выполнения операции, прямо и линейно пропорционально количеству элементов в коллекции. Это обозначение линейной временной сложности. Это что-то среднее с точки зрения производительности. Например, если мы хотим суммировать все элементы в коллекции, нужно будет выполнить итерацию по коллекции. Следовательно, итерация коллекции является операцией O(n).
O(n log n)
Обозначение квазилинейной временной сложности. Скорость выполнения операции является квазилинейной функцией числа элементов в коллекции. Временная сложность оптимизированного алгоритма сортировки обычно равна O(n log n).
O(n^2)
Обозначение квадратичной временной сложности. Время, необходимое для выполнения операции, пропорционально квадрату элементов в коллекции.
O(n!)
Обозначение факториальной временной сложности. Каждая операция требует вычисления всех перестановок коллекции, следовательно требуемое время выполнения операции является факториалом размера входной коллекции. Это очень медленно.
Нотация «O» большое относительна. Она не зависит от машины, игнорирует константы и понятна широкой аудитории, включая математиков, технологов, специалистов по данным и т. д.
Благоприятные, средние и худшие случаи
При вычислении временной сложности операции можно получить сложность на основе благоприятного, среднего или худшего случая.
Благоприятный случай. Как следует из названия, это сценарий, когда структуры данных и элементы в коллекции вместе с параметрами находятся в оптимальном состоянии. Например, мы хотим найти элемент в коллекции. Если этот элемент оказывается первым элементом коллекции, то это лучший сценарий для операции.
Средний случай. Определяем сложность на основе распределения значений входных данных.
Худший случай. Структуры данных и элементы в коллекции вместе с параметрами находятся в наиболее неоптимальном состоянии. Например, худший случай для операции, которой требуется найти элемент в большой коллекции в виде списка — когда искомый элемент находится в самом конце, а алгоритм перебирает коллекцию с самого начала.
Коллекции Python и их временная сложность
Список (list)
Список является одной из самых важных структур данных в Python. Можно использовать списки для создания стека или очереди. Списки — это упорядоченные и изменяемые коллекции, которые можно обновлять по желанию.
Операции списка и их временная сложность
Вставка: O(n).
Получение элемента: O(1).
Удаление элемента: O(n).
Проход: O(n).
Получение длины: O(1).
Множество (set)
Множества также являются одними из наиболее используемых типов данных в Python. Множество представляет собой неупорядоченную коллекцию. Множество не допускает дублирования, и, следовательно, каждый элемент в множестве уникален. Множество поддерживает множество математических операций, таких как объединение, разность, пересечение и так далее.
Операции с множествами и их временная сложность
Проверить наличие элемента в множестве: O(1).
Отличие множества A от B: O(длина A).
Пересечение множеств A и B: O(минимальная длина A или B).
Объединение множеств A и B: O(N) , где N это длина (A) + длина (B).
Словарь (dict)
Словарь — это коллекция пар ключ-значение. Ключи в словаре уникальны, чтобы предотвратить коллизию элементов. Это чрезвычайно полезная структура данных.
Словари индексируются по ключам, которые могут быть строками, числами или даже кортежами со строками, числами или кортежами. Над словарём можно выполнить ряд операций, таких как сохранение значения для ключа, извлечение элемента на основе ключа, или итерация по элементам и так далее.
Операции со словарями и их временная сложность
Здесь мы считаем, что ключ используется для получения, установки или удаления элемента.
Получение элемента: O(1).
Установка элемента: O(1).
Удаление элемента: O(1).
Проход по словарю: O(n).
Эмпирическая оценка алгоритмов на Python
Ниже представлен перевод главы из книги Python Algorithms: Mastering Basic Algorithms in the Python Language (Expert’s Voice in Open Source).
В этой книге описывается проектирование алгоритмов (и тесно связанный с ним анализ алгоритмов). Но в разработке есть также и другой немаловажный процесс, жизненно необходимый при создании крупных реальных проектов, это — оптимизация алгоритмов. С точки зрения такого разделения, проектирование алгоритма можно рассматривать как способ достижения заданного асимптотического времени работы (с помощью разработки эффективного алгоритма), а оптимизацию — как процесс уменьшения скрытых временных затрат при сохранении асимптотической сложности алгоритма.
Хотя я могу дать несколько советов по алгоритмам проектирования в Python, может быть трудно предсказать, какие именно хитрости и хаки дадут вам лучшую производительность в конкретной задаче, над которой вы работаете, или для вашего оборудования или версии Python. (Это именно тот вид особенностей асимптотики, который нужно избегать.) А в некоторых случаях такие хитрости и хаки могут вовсе не потребоваться, потому что ваша программа и так достаточно быстра. Самое простое, что вы можете делать в большинстве случаев, это просто пробовать и смотреть. Если у вас есть идея твика или хака, то просто опробуйте его! Реализуйте твик и запустите несколько тестов. Есть ли улучшения? А если твик делает ваш код менее читаемым, а прирост производительности мал, то подумайте — а стоит ли оно того?
Хотя есть теоретические аспекты так называемой экспериментальной алгоритмики (то есть, экспериментальной оценки алгоритмов и их реализации), которые выходят за рамки этой книги, я дам вам несколько практических советов, которые, могут быть очень полезны.
Совет 1: Если возможно, то не беспокойтесь об этом
Беспокойство об асимптоматической сложности может быть очень важным. Иногда это разница между решением и его отсутствием. Однако, постоянные составляющие времени исполнения часто совсем не критичны. Попробуйте простую реализацию алгоритма для начала, и убедитесь, что она работатет стабильно. Работает — не трогай.
Совет 2: Для измерения времени выполнения используйте timeit
timeit это модуль предназначенный для измерения времени исполнения. Хотя для получения действительно надежных данных вам потребуется выполнить кучу работы, для практических целей timeit вполне сгодится. Например:
>>> import timeit
>>> timeit.timeit(«x = 2 + 2»)
0.034976959228515625
>>> timeit.timeit(«x = sum(range(10))»)
0.92387008666992188
timeit можно использовать прямо из командной строки, например:
$ python -m timeit -s»import mymodule as m» «m.myfunction()»
Существует одна вещь, с которой вы должны быть осторожны при использовании timeit: побочные эффекты, которые будут влиять на повторное исполнение timeit. Функция timeit будет запускать ваш код несколько раз, чтобы увеличить точность, и если прошлые запуски влияют на последующие, то вы окажетесь в затруднительном положении. Например, если вы измеряете скорость выполнения чего-то типа mylist.sort(), список будет отсортирован только в первый раз. Во время остальных тысяч запусков список уже будет отсортированным и это даст нереально маленький результат.
Больше об этом модуле и как он работает можно найти в стандартной документации библиотеки.
Совет 3: Чтобы найти узкие места, используйте профайлер
Часто, для того чтобы понять, какие части программы требуют оптимизации, делаются разные догадки и предположения. Такие предположения нередко оказываются ошибочными. Вместо того, чтобы гадать, воспользуйтесь профайлером. В стандартной поставке Python идет
несколько профайлеров, но рекомендуется использовать cProfile. Им так же легко пользоваться, как timeit, но он дает больше подробной информации о том, на что тратится время при выполнении программы. Если основная функция вашей программы называется main, вы можете использовать профайлер следующим образом:
import cProfile
cProfile.run(‘main()’)
Такой код выведет на печать отчет о времени исполнения различных функций программы. Если в вашей системе нет модуля cProfile, используйте profile вместо него. Больше информации об этих модулях можно найти в документации. Если же вам не так интересны детали реализации, а просто нужно оценить поведение алгоритма на конкретном наборе данных, воспользуйтесь модулем trace из стандартной библиотеки. С его помощью можно посчитать, сколько раз будут выполнены то или иное выражение или вызов в программе.

Совет 4. Показывайте результаты графически
Визуализация может стать прекрасным способом, чтобы понять что к чему. Для исследования производительности часто применяются графики (например, для оценки связи количества данных и времени исполнения) и коробчатые диаграммы, отображающие распределение временных затрат при нескольких запусках. Примеры можно увидеть на рисунке. Отличная библиотека для построения графиков и диаграмм из Python — matplotlib (можно взять на http://matplotlib.sf.net).
Совет 5. Будьте внимательны в выводах, основанных на сравнении времени исполнения
Этот совет довольно расплывчатый, потому что существует много ловушек, в которые можно попасть, делая выводы о том, какой способ лучше, на основании сравнения времени исполнения. Во-первых, любая разница, которую вы видите, может определяться случайностью. Если вы используете специальные инструменты вроде timeit, риск такой ситуации меньше, потому что они повторяют измерение времени вычисления выражения несколько раз (или даже повторяют весь замер несколько раз, выбирая лучший результат). Таким образом, всегда будут случайные погрешности и если разница между двумя реализациями не превышает некоторой погрешности, нельзя сказать, что эти реализации различаются (хотя и то, что они одинаковы, тоже нельзя утверждать).
Проблема усложняется, если вы сравниваете больше двух реализаций. Количество пар для сравнения увеличивается пропорционально квадрату количества сравниваемых версий (это объяснено в гл. 3), сильно увеличивая вероятность того, что как минимум две из версий будут казаться слегка различными. (Это называется проблемой множественного сравнения). Существуют статистические решения этой проблемы, но самый простой способ — повторить эксперимент с двумя подозрительными версиями. Возможно, потребуется сделать это несколько раз. Они по-прежнему выглядят похожими?
Во-вторых, есть несколько моментов, на которые нужно обращать внимание при сравнении средних величин. Как минимум, вы должны сравнивать средние значения реального времени исполнения. Обычно, чтобы получить показательные числа при измерении производительности, время исполнения каждой программы нормируется делением на время исполнения какого-нибудь стандартного, простого алгоритма. Действительно, это
может быть полезным, но в ряде случаев сделает бессмысленными результаты замеров. Несколько полезных указаний на эту тему можно найти в статье «How not to lie with statistics: The correct way to summarize benchmark results» Fleming and Wallace. Также можно почитать Bast and Weber’s «Don’t compare averages,» или более новую статью Citron et al., «The harmonic or geometric mean: does it really matter?»
И в-третьих, возможно, ваши выводы нельзя обобщать. Подобные измерения на другом наборе входных данных и на другом железе могут дать другие результаты. Если кто-то будет пользоваться результаты ваших измерений, необходимо последовательно задокументировать, каким образом вы их получили.
Совет 6: Будьте осторожны, делая выводы об асимптотике из экспериментов
Если вы хотите что-то сказать окончательно об асимптотике алгоритма, то необходимо проанализировать ее, как описано ранее в этой главе. Эксперименты могут дать вам намеки, но они очевидно проводятся на конечных наборах данных, а асимптотика — это то, что происходит при сколь угодно больших размерах данных. С другой стороны, если только вы не работаете в академической сфере, цель асимптотического анализа — сделать какой-то вывод о поведении алгоритма, реализованного конкретным способом и запущенного на определенном наборе данных, а это значит, что измерения должны быть соответствующими.
Предположим, вы подозреваете, что алгоритм работает c квадратичной сложностью времени, но вы не в состоянии окончательно доказать это. Можете ли вы использовать эксперименты для поддержки вашего подозрения? Как уже говорилось, эксперименты (и проектирование алгоритмов) имеют дело в основном с постоянными коэффициентами, но есть способ. Основной проблемой является то, что ваша гипотеза на самом деле не проверяема (через эксперименты). Если вы утверждаете, что алгоритм имеет сложность О(n²), то данные не могут это ни подтвердить, ни опровергнуть. Тем не менее, если вы сделаете вашу гипотезу более конкретной, то она станет проверяемой. Вы могли бы, например, обоснованно на некоторых данных положить, что время работы программы никогда не будет превышать 0.24n²+0.1n+0.03 секунд в вашем окружении. Это проверяемые (или, более точно, опровергаемые) гипотезы. Если вы делаете много измерений, и так и не можете найти контр-примеры, значит ваша гипотеза в какой-то степени верна. Занятная деталь — это, косвенно, подтверждает квадратичную сложность алгоритма.
6.1. Теория¶
Во время своей работы программы используют различные структуры данных и алгоритмы, в связи с чем обладают разной эффективностью и скоростью решения задачи. Дать оценку оптимальности решения, реализованного в программе, поможет понятие вычислительной сложности алгоритмов.
6.1.1. Основные понятия¶
Вычислительная сложность (алгоритмическая сложность) — понятие, обозначающее функцию зависимости объема работы алгоритма от размера обрабатываемых данных.
Вычислительная сложность пытается ответить на центральный вопрос разработки алгоритмов: как изменится время исполнения и объем занятой памяти в зависимости от размера входных данных?. С помощью вычислительной сложности также появляется возможность классификации алгоритмов согласно их производительности.
В качестве показателей вычислительной сложности алгоритма выступают:
-
Временная сложность (время выполнения).
Временная сложность алгоритма — это функция от размера входных данных, равная количеству элементарных операций, проделываемых алгоритмом для решения экземпляра задачи указанного размера. Временная сложность алгоритма зачастую может быть определена точно, однако в большинстве случаев искать точное ее значение бессмысленно, т.к. работа алгоритма зависит от ряда факторов, например, скорости процессора, набора его инструкций и т.д.
Асимптотическая сложность оценивает сложность работы алгоритма с использованием асимптотического анализа. Алгоритм с меньшей асимптотической сложностью является более эффективным для всех входных данных.
6.1.2. Асимптотические нотации¶
Асимптотическая сложность алгоритма описывается соответствующей нотацией:
- О-нотация, \(O\) («О»-большое): описывает верхнюю границу времени (время выполнения «не более, чем…»);
- Омега-нотация, \(\Omega\) («Омега»-большое): описывает нижнюю границу времени (время выполнения «не менее, чем…»).
говорит о том, что алгоритм имеет квадратичное время выполнения относительно размера входных данных в качестве верхней оценки («О большое от эн квадрат»).
Каждая оценка при этом может быть:
- наилучшая: минимальная временная оценка;
- наихудшая: максимальная временная оценка;
- средняя: средняя временная оценка.
При оценке, как правило, указывается наихудшая оценка.
Допустим, имеется задача поиска элемента в массиве. При полном переборе слева направо:
- наилучшая оценка: \(O(1)\) , если искомый элемент окажется в начале списка;
- наихудшая оценка: \(O(N)\) , если искомый элемент окажется в конце списка;
- средняя оценка: \(O \left ( \cfrac\right ) = O(N)\) .
6.1.2.1. Верхняя оценка и \(O\) -нотация¶
Наиболее часто используемой оценкой сложности алгоритма является верхняя (наихудшая) оценка, которая обычно выражается с использованием нотации O-большое.
Выделяют следующие основные категории алгоритмической сложности в \(O\) -нотации:
- Постоянное время: \(O(1)\) .
- Время выполнения не зависит от количества элементов во входном наборе данных.
- Пример: операции присваивания, сложения, взятия элемента списка по индексу и др.
- Линейное время: \(O(N)\) .
- Время выполнения пропорционально количеству элементов в коллекции.
- Пример: найти имя в телефонной книге простым перелистыванием, почистить ковер пылесосом и т.д.
- Логарифмическое время: \(O(\log)\) .
- Время выполнения пропорционально логарифму от количества элементов в коллекции.
- Пример: найти имя в телефонной книге (используя двоичный поиск).
- Линейно-логарифмическое время: \(O(N \log)\) .
- Время выполнения больше чем, линейное, но меньше квадратичного.
- Пример: обработка \(N\) телефонных справочников двоичным поиском.
- Квадратичное время: \(O(N^)\) .
- Время выполнения пропорционально квадрату количества элементов в коллекции.
- Пример: вложенные циклы (сортировка, перебор делителей и т.д.).
На Рисунке 6.1.1 приведен график роста \(O\) -большое.
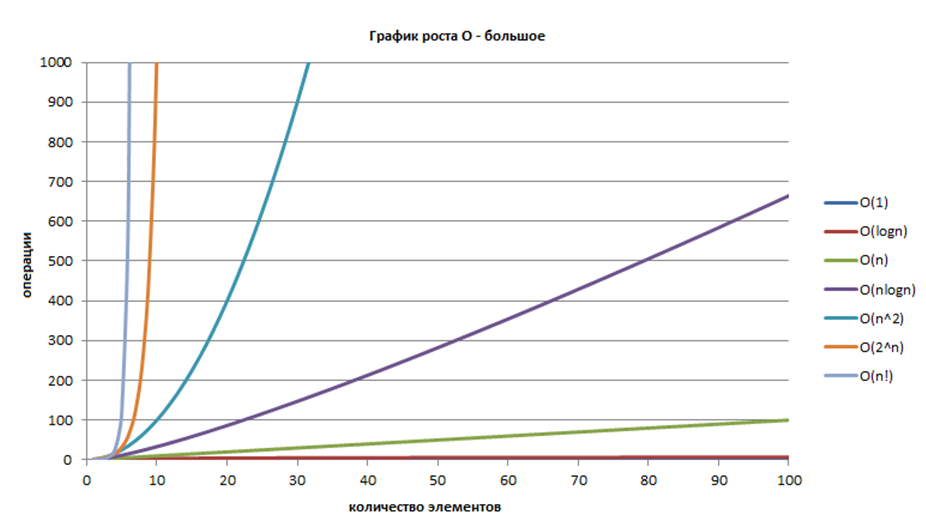
Рисунок 6.1.1 — График роста \(O\) -большое 6 ¶
6.1.3. Оценка сложности алгоритмов¶
Для оценки вычислительной сложности алгоритмов необходимо знать и учитывать сложности:
- используемых структур данных;
- совокупности различных операций.
6.1.3.1. Операции над структурами данных¶
В Python имеются коллекции (структуры данных), операции над которыми имеют определенную сложность.
6.1.3.1.1. Список и кортеж¶
Большинство операций со списком/кортежем имеют сложность \(O(N)\) (Таблица 6.1.1).
Таблица 6.1.1 — Асимптотические сложности для списка или кортежа ¶
Зависит от длины аргумента
Зависит от длины аргумента
Направление сортировки не играет роли
6.1.3.1.2. Множество¶
По сравнению со списком/кортежем множества большую часть операций выполняют со сложностью \(O(1)\) (Таблица 6.1.2).
Таблица 6.1.2 — Асимптотические сложности для множества ¶
В отличие от списка, где \(O(N)\)
В отличие от списка, где \(O(N)\)
В отличие от списка, где \(O(N)\)
Аналогично s = set()
Зависит от длины аргумента
6.1.3.1.3. Словарь¶
Большинство операций словарей имеет сложность \(O(1)\) (Таблица 6.1.3).
Таблица 6.1.3 — Асимптотические сложности для словаря ¶
Аналогично s = <> или dict()
Зависит от длины аргумента
Для всех методов: keys(), values(), items()
Важно выбирать структуру данных, которая была бы оптимальной для конкретной задачи.
Например, если приложения будет осуществлять частый поиск информации, словарь даст большую эффективность, при этом, если необходимо просто хранить упорядоченный набор данных — словарь или кортеж подойдут лучше.
6.1.3.2. Закон сложения и умножения для \(O\) -нотации¶
Для оценки сложности совокупности операций используются законы сложения и умножения.
- Закон сложения: итоговая сложность двух последовательных действий равна сумме их сложностей:
\[O(f(n)) + O(g(n)) = O(f(n) + g(n))\]
- итоговая сложность алгоритма оценивается наихудшим из слагаемых:
\[O(N) + O(\log
- в итоговой сложности константы отбрасываются
\[O(N) + O(N) + O(N) = 3 \cdot O(N) = O(N)\]
- при ветвлении берется наихудший вариант
if test: # O(t) block 1 # O(b1) else: block 2 # O(b2)
\[O(N) = O(t) + max(O(b1), O(b2))\]
- Закон умножения: итоговая сложность двух вложенных действий равна произведению их сложностей:
\[O(f(n)) + O(g(n)) = O(f(n) \cdot g(n))\]
# Общая O(N^2) for i in range(N): # O(N) for j in range(N): # O(N)
6.1.4. Сравнение производительности работы алгоритмов¶
Как правило существует не один алгоритм, позволяющий решить требуемую задачу, поэтому при разработке алгоритма необходимо учитывать его вычислительную сложность.
В Листинге 6.1.1 приведен пример решений одной и той же задачи, используя алгоритмы с разной алгоритмической сложностью.
Листинг 6.1.1 — Примеры определения сложности алгоритмов | скачать ¶
# 3 алгоритма, выполняющих одну и ту же задачу - проверку, что # все значения списка различны - но имеющие разную вычислительную сложность import random import time def timeit(func, *args, **kw): """Выполнить функицю 'func' с параметрами '*args', '**kw' и вернуть время выполнения в мс.""" time_start = time.time() res = func(*args, **kw) time_end = time.time() return (time_end - time_start) * 1000.0, res def is_unique_1(data): """Вернуть 'True', если все значения 'data' различны. Алгоритм 1: Пробежимся по списку с первого до последнего элемента и для каждого из них проверим, что такого элемента нет в оставшихся справа элементах. Сложность: O(N^2). """ for i in range(len(data)): # O(N) if data[i] in data[i+1:]: # O(N) - срез + in: O(N) + O(N) = O(N) return False # O(1) - в худшем случае не выполнится return True # O(1) def is_unique_2(data): """Вернуть 'True', если все значения 'data' различны. Алгоритм 2: Отсортируем список. Затем, если в нем есть повторяющиеся элементы, они будут расположены рядом — т.о. необходимо лишь попарно их сравнить. Сложность: O(N Log N). """ copy = list(data) # O(N) copy.sort() # O(N Log N) - «быстрая» сортировка for i in range(len(data) - 1): # O(N) - N-1, округлим до O(N) if copy[i] == copy[i+1]: # O(1) - [i] и ==, оба по O(1) return False # O(1) - в худшем случае не выполнится return True # O(1) def is_unique_3(data): """Вернуть 'True', если все значения 'data' различны. Алгоритм 3: Создадим множество из списка, при создании автоматически удалятся дубликаты если они есть. Если длина множества == длине списка, то дубликатов нет. Сложность: O(N). """ aset = set(data) # O(N) return len(aset) == len(data) # O(1) - 2 * len (O(1)) + == O(1) # Проверка res = [["i", "1 (мс.)", "2 (мс.)", "3 (мс.)"]] for i in (100, 1000, 10000, 20000, 30000): # Из 100000 чисел выбираем 'i' случайных data = random.sample(range(-100000, 100000), i) res.append([i, timeit(is_unique_1, data)[0], timeit(is_unique_2, data)[0], timeit(is_unique_3, data)[0]]) print("10> 10> 10> 10>".format(*res[0])) for r in res[1:]: print("10> 10.2f> 10.2f> 10.2f>".format(*r)) # ------------- # Пример вывода: # # i 1 (мс.) 2 (мс.) 3 (мс.) # 100 0.00 0.00 0.00 # 1000 15.01 0.00 0.00 # 10000 1581.05 5.00 2.00 # 20000 7322.86 12.01 2.00 # 30000 35176.36 25.02 8.01
При написании алгоритмов стремитесь выбирать решение, обладающее наименьшей вычислительной сложностью.
Sebesta, W.S Concepts of Programming languages. 10E; ISBN 978-0133943023.
Саммерфилд М. Программирование на Python 3. Подробное руководство. — М.: Символ-Плюс, 2009. — 608 с.: ISBN: 978-5-93286-161-5.
Лучано Рамальо. Python. К вершинам мастерства. — М.: ДМК Пресс , 2016. — 768 с.: ISBN: 978-5-97060-384-0, 978-1-491-94600-8.
Теоретическая оценка вычислительной сложности алгоритма в среднем, лучшем и худшем случаях, оцените асимптотическую сложность
подскажите, пожалуйста, как оценить сложность этого алгоритма. Алгоритм заменяет нули на предыдущее не нулевое значение.
a = [3,1,4,0,0,0,0,0,5,0,4,0] b = [] for i in a: b.append(i if i else b[-1]) print (b) Я только третий день начала изучать питон, не очень понимаю.
Отслеживать
48.6k 17 17 золотых знаков 56 56 серебряных знаков 100 100 бронзовых знаков
задан 19 мая 2023 в 9:09
11 1 1 бронзовый знак
1 ответ 1
Сортировка: Сброс на вариант по умолчанию
Ваш вопрос к пайтону особо отношения не имеет. Это относится к теме о сложности алгоритмов. В данном случае у вас сложность О(n) — линейная сложность. Естественно, как определять сложность алгоритмов в рамках одного ответа, объяснить невозможно. Поэтому рекомендую почитать литературу или погуглить тему «Оценка сложности алгоритмов».
Отслеживать
ответ дан 19 мая 2023 в 9:17
1,550 2 2 золотых знака 4 4 серебряных знака 15 15 бронзовых знаков
Не совсем так. В зависимости от реализации list.append() сложность может меняться от линейной до квадратичной
19 мая 2023 в 9:27
Возможно, я не по пайтон, не в курсе как в пайтоне append реализовано, но подозреваю что реализовать должны были с линейной сложность по аналогии с остальными языками
19 мая 2023 в 9:34
@had0uken если у append линейная сложность, то в целом алгоритм будет иметь квадратичную сложность. Для python у append сложность примерно константная, «но не совсем» (при росте списка в какой-то момент возникнет необходимость перемещения его в больший блок памяти). В целом, если говорить про разные языки, то лучше не полагаться, что во всех языках сложность добавления элемента в конец константная.
19 мая 2023 в 10:30
Вот тут в исходниках есть пояснение, по какому принципу выполняется ресайз блока памяти списка (в том числе при append): github.com/python/cpython/blob/… . Я так сходу сложность с учетом необходимости перемещения данных не оценю, но она явно не константная, скорее линейная с довольно маленьким множителем, либо логарифмическая в лучшем случае. Нужно смотреть, по по какому принципу растет размер выделяемого блока, вроде бы не совсем линейно (4 — 8 — 16 — 24 в линию не ложатся).
Сложность операций в Python
Здесь приведены показатели сложности (по времени) для различных операций в текущей версии CPython. Данные для более старых, либо более новых версий, а также других реализаций могут отличаться, однако, в целом, можно предполагать, что они не медленнее, чем в O(log n).
| Привязка к переменной | O(1) | name = 3 | |
| Операции над целыми | O(1) | 1+2 10==11 | Простые операции над относительно небольшими числами (до 12 цифр). |
Сложность различных типов
- Словарь (dict)
- Список (list)
- Множество (set)
- Двунаправленная очередь (deque)
На заметку
Дополнительную информацию о сложности алгоритмов можно найти в главе «Анализ» интерактивной книги «Problem Solving with Algorithms and Data Structures using Python». Книга доступна на русском: «Решение задач при помощи алгоритмов и структур данных в Питоне».
Синонимы поиска: Сложность операций в Python, complexity
Статьи раздела
| Сложность операций со множествами | Здесь описана сложность исполнения основных операций над множествами. |
| Сложность операций со словарями | Здесь описана сложность исполнения основных операций над словарями. |
| Сложность операций со списками | Здесь описана сложность исполнения основных операций над списками. |
Сколько стоят операции над list, set и dict в Python? Разбираемся с временной сложностью
Временная сложность алгоритма часто обозначается нотацией «О» большое. Разбираемся, что это и какова сложность операций над коллекциями в Python.
Автор перевода Иван Капцов
Программисту, работающему с данными, крайне важно выбирать правильные структуры данных для решения поставленной задачи, ведь выбор неправильного типа данных плохо влияет на производительность приложения. В этой статье объясняется нотация «О» большое и сложность ключевых операций структур данных в CPython.
Что означает нотация «O» большое?
В алгоритме выполняется ряд операций. Эти операции могут включать в себя итерацию по коллекции, копирование элемента или всей коллекции, добавление элемента в коллекцию, вставку элемента в начало или конец коллекции, удаление элемента или обновление элемента в коллекции.
«O» большое служит обозначением временной сложности операций алгоритма. Она показывает, сколько времени потребуется алгоритму для вычисления требуемой операции. Можно также измерить пространственную сложность (сколько места занимает алгоритм), но в этой статье мы сосредоточимся на временной.
Проще говоря, нотация «O» большое — это способ измерения производительности операции на основе размера ввода, известного как n.
Значения нотации «О» большое
На письме временная сложность алгоритма обозначается как O(n), где n — размер входной коллекции.
O(1)
Обозначение константной временной сложности. Независимо от размера коллекции, время, необходимое для выполнения операции, константно. Это обозначение константной временной сложности. Эти операции выполняются настолько быстро, насколько возможно. Например, операции, которые проверяют, есть ли внутри коллекции элементы, имеют сложность O(1).
O(log n)
Обозначение логарифмической временной сложности. В этом случае когда размер коллекции увеличивается, время, необходимое для выполнения операции, логарифмически увеличивается. Эту сложность имеют потенциально оптимизированные алгоритмы поиска.
O(n)
Обозначение линейной временной сложности. Время, необходимое для выполнения операции, прямо и линейно пропорционально количеству элементов в коллекции. Это обозначение линейной временной сложности. Это что-то среднее с точки зрения производительности. Например, если мы хотим суммировать все элементы в коллекции, нужно будет выполнить итерацию по коллекции. Следовательно, итерация коллекции является операцией O(n).
O(n log n)
Обозначение квазилинейной временной сложности. Скорость выполнения операции является квазилинейной функцией числа элементов в коллекции. Временная сложность оптимизированного алгоритма сортировки обычно равна O(n log n).
O(n^2)
Обозначение квадратичной временной сложности. Время, необходимое для выполнения операции, пропорционально квадрату элементов в коллекции.
O(n!)
Обозначение факториальной временной сложности. Каждая операция требует вычисления всех перестановок коллекции, следовательно требуемое время выполнения операции является факториалом размера входной коллекции. Это очень медленно.
Нотация «O» большое относительна. Она не зависит от машины, игнорирует константы и понятна широкой аудитории, включая математиков, технологов, специалистов по данным и т. д.
Благоприятные, средние и худшие случаи
При вычислении временной сложности операции можно получить сложность на основе благоприятного, среднего или худшего случая.
Благоприятный случай. Как следует из названия, это сценарий, когда структуры данных и элементы в коллекции вместе с параметрами находятся в оптимальном состоянии. Например, мы хотим найти элемент в коллекции. Если этот элемент оказывается первым элементом коллекции, то это лучший сценарий для операции.
Средний случай. Определяем сложность на основе распределения значений входных данных.
Худший случай. Структуры данных и элементы в коллекции вместе с параметрами находятся в наиболее неоптимальном состоянии. Например, худший случай для операции, которой требуется найти элемент в большой коллекции в виде списка — когда искомый элемент находится в самом конце, а алгоритм перебирает коллекцию с самого начала.
Коллекции Python и их временная сложность
Список (list)
Список является одной из самых важных структур данных в Python. Можно использовать списки для создания стека или очереди. Списки — это упорядоченные и изменяемые коллекции, которые можно обновлять по желанию.
Операции списка и их временная сложность
Вставка: O(n).
Получение элемента: O(1).
Удаление элемента: O(n).
Проход: O(n).
Получение длины: O(1).
Множество (set)
Множества также являются одними из наиболее используемых типов данных в Python. Множество представляет собой неупорядоченную коллекцию. Множество не допускает дублирования, и, следовательно, каждый элемент в множестве уникален. Множество поддерживает множество математических операций, таких как объединение, разность, пересечение и так далее.
Операции с множествами и их временная сложность
Проверить наличие элемента в множестве: O(1).
Отличие множества A от B: O(длина A).
Пересечение множеств A и B: O(минимальная длина A или B).
Объединение множеств A и B: O(N) , где N это длина (A) + длина (B).
Словарь (dict)
Словарь — это коллекция пар ключ-значение. Ключи в словаре уникальны, чтобы предотвратить коллизию элементов. Это чрезвычайно полезная структура данных.
Словари индексируются по ключам, которые могут быть строками, числами или даже кортежами со строками, числами или кортежами. Над словарём можно выполнить ряд операций, таких как сохранение значения для ключа, извлечение элемента на основе ключа, или итерация по элементам и так далее.
Операции со словарями и их временная сложность
Здесь мы считаем, что ключ используется для получения, установки или удаления элемента.
Получение элемента: O(1).
Установка элемента: O(1).
Удаление элемента: O(1).
Проход по словарю: O(n).
6.1. Теория¶
Во время своей работы программы используют различные структуры данных и алгоритмы, в связи с чем обладают разной эффективностью и скоростью решения задачи. Дать оценку оптимальности решения, реализованного в программе, поможет понятие вычислительной сложности алгоритмов.
6.1.1. Основные понятия¶
Вычислительная сложность (алгоритмическая сложность) — понятие, обозначающее функцию зависимости объема работы алгоритма от размера обрабатываемых данных.
Вычислительная сложность пытается ответить на центральный вопрос разработки алгоритмов: как изменится время исполнения и объем занятой памяти в зависимости от размера входных данных?. С помощью вычислительной сложности также появляется возможность классификации алгоритмов согласно их производительности.
В качестве показателей вычислительной сложности алгоритма выступают:
-
Временная сложность (время выполнения).
Временная сложность алгоритма — это функция от размера входных данных, равная количеству элементарных операций, проделываемых алгоритмом для решения экземпляра задачи указанного размера. Временная сложность алгоритма зачастую может быть определена точно, однако в большинстве случаев искать точное ее значение бессмысленно, т.к. работа алгоритма зависит от ряда факторов, например, скорости процессора, набора его инструкций и т.д.
Асимптотическая сложность оценивает сложность работы алгоритма с использованием асимптотического анализа. Алгоритм с меньшей асимптотической сложностью является более эффективным для всех входных данных.
6.1.2. Асимптотические нотации¶
Асимптотическая сложность алгоритма описывается соответствующей нотацией:
- О-нотация, \(O\) («О»-большое): описывает верхнюю границу времени (время выполнения «не более, чем…»);
- Омега-нотация, \(\Omega\) («Омега»-большое): описывает нижнюю границу времени (время выполнения «не менее, чем…»).
говорит о том, что алгоритм имеет квадратичное время выполнения относительно размера входных данных в качестве верхней оценки («О большое от эн квадрат»).
Каждая оценка при этом может быть:
- наилучшая: минимальная временная оценка;
- наихудшая: максимальная временная оценка;
- средняя: средняя временная оценка.
При оценке, как правило, указывается наихудшая оценка.
Допустим, имеется задача поиска элемента в массиве. При полном переборе слева направо:
- наилучшая оценка: \(O(1)\) , если искомый элемент окажется в начале списка;
- наихудшая оценка: \(O(N)\) , если искомый элемент окажется в конце списка;
- средняя оценка: \(O \left ( \cfrac\right ) = O(N)\) .
6.1.2.1. Верхняя оценка и \(O\) -нотация¶
Наиболее часто используемой оценкой сложности алгоритма является верхняя (наихудшая) оценка, которая обычно выражается с использованием нотации O-большое.
Выделяют следующие основные категории алгоритмической сложности в \(O\) -нотации:
- Постоянное время: \(O(1)\) .
- Время выполнения не зависит от количества элементов во входном наборе данных.
- Пример: операции присваивания, сложения, взятия элемента списка по индексу и др.
- Линейное время: \(O(N)\) .
- Время выполнения пропорционально количеству элементов в коллекции.
- Пример: найти имя в телефонной книге простым перелистыванием, почистить ковер пылесосом и т.д.
- Логарифмическое время: \(O(\log)\) .
- Время выполнения пропорционально логарифму от количества элементов в коллекции.
- Пример: найти имя в телефонной книге (используя двоичный поиск).
- Линейно-логарифмическое время: \(O(N \log)\) .
- Время выполнения больше чем, линейное, но меньше квадратичного.
- Пример: обработка \(N\) телефонных справочников двоичным поиском.
- Квадратичное время: \(O(N^)\) .
- Время выполнения пропорционально квадрату количества элементов в коллекции.
- Пример: вложенные циклы (сортировка, перебор делителей и т.д.).
На Рисунке 6.1.1 приведен график роста \(O\) -большое.
Рисунок 6.1.1 — График роста \(O\) -большое 6 ¶
6.1.3. Оценка сложности алгоритмов¶
Для оценки вычислительной сложности алгоритмов необходимо знать и учитывать сложности:
- используемых структур данных;
- совокупности различных операций.
6.1.3.1. Операции над структурами данных¶
В Python имеются коллекции (структуры данных), операции над которыми имеют определенную сложность.
6.1.3.1.1. Список и кортеж¶
Большинство операций со списком/кортежем имеют сложность \(O(N)\) (Таблица 6.1.1).
Таблица 6.1.1 — Асимптотические сложности для списка или кортежа ¶
Зависит от длины аргумента
Зависит от длины аргумента
Направление сортировки не играет роли
6.1.3.1.2. Множество¶
По сравнению со списком/кортежем множества большую часть операций выполняют со сложностью \(O(1)\) (Таблица 6.1.2).
Таблица 6.1.2 — Асимптотические сложности для множества ¶
В отличие от списка, где \(O(N)\)
В отличие от списка, где \(O(N)\)
В отличие от списка, где \(O(N)\)
Аналогично s = set()
Зависит от длины аргумента
6.1.3.1.3. Словарь¶
Большинство операций словарей имеет сложность \(O(1)\) (Таблица 6.1.3).
Таблица 6.1.3 — Асимптотические сложности для словаря ¶
Аналогично s = <> или dict()
Зависит от длины аргумента
Для всех методов: keys(), values(), items()
Важно выбирать структуру данных, которая была бы оптимальной для конкретной задачи.
Например, если приложения будет осуществлять частый поиск информации, словарь даст большую эффективность, при этом, если необходимо просто хранить упорядоченный набор данных — словарь или кортеж подойдут лучше.
6.1.3.2. Закон сложения и умножения для \(O\) -нотации¶
Для оценки сложности совокупности операций используются законы сложения и умножения.
- Закон сложения: итоговая сложность двух последовательных действий равна сумме их сложностей:
\[O(f(n)) + O(g(n)) = O(f(n) + g(n))\]
- итоговая сложность алгоритма оценивается наихудшим из слагаемых:
\[O(N) + O(\log
- в итоговой сложности константы отбрасываются
\[O(N) + O(N) + O(N) = 3 \cdot O(N) = O(N)\]
- при ветвлении берется наихудший вариант
if test: # O(t) block 1 # O(b1) else: block 2 # O(b2)
\[O(N) = O(t) + max(O(b1), O(b2))\]
- Закон умножения: итоговая сложность двух вложенных действий равна произведению их сложностей:
\[O(f(n)) + O(g(n)) = O(f(n) \cdot g(n))\]
# Общая O(N^2) for i in range(N): # O(N) for j in range(N): # O(N)
6.1.4. Сравнение производительности работы алгоритмов¶
Как правило существует не один алгоритм, позволяющий решить требуемую задачу, поэтому при разработке алгоритма необходимо учитывать его вычислительную сложность.
В Листинге 6.1.1 приведен пример решений одной и той же задачи, используя алгоритмы с разной алгоритмической сложностью.
Листинг 6.1.1 — Примеры определения сложности алгоритмов | скачать ¶
# 3 алгоритма, выполняющих одну и ту же задачу - проверку, что # все значения списка различны - но имеющие разную вычислительную сложность import random import time def timeit(func, *args, **kw): """Выполнить функицю 'func' с параметрами '*args', '**kw' и вернуть время выполнения в мс.""" time_start = time.time() res = func(*args, **kw) time_end = time.time() return (time_end - time_start) * 1000.0, res def is_unique_1(data): """Вернуть 'True', если все значения 'data' различны. Алгоритм 1: Пробежимся по списку с первого до последнего элемента и для каждого из них проверим, что такого элемента нет в оставшихся справа элементах. Сложность: O(N^2). """ for i in range(len(data)): # O(N) if data[i] in data[i+1:]: # O(N) - срез + in: O(N) + O(N) = O(N) return False # O(1) - в худшем случае не выполнится return True # O(1) def is_unique_2(data): """Вернуть 'True', если все значения 'data' различны. Алгоритм 2: Отсортируем список. Затем, если в нем есть повторяющиеся элементы, они будут расположены рядом — т.о. необходимо лишь попарно их сравнить. Сложность: O(N Log N). """ copy = list(data) # O(N) copy.sort() # O(N Log N) - «быстрая» сортировка for i in range(len(data) - 1): # O(N) - N-1, округлим до O(N) if copy[i] == copy[i+1]: # O(1) - [i] и ==, оба по O(1) return False # O(1) - в худшем случае не выполнится return True # O(1) def is_unique_3(data): """Вернуть 'True', если все значения 'data' различны. Алгоритм 3: Создадим множество из списка, при создании автоматически удалятся дубликаты если они есть. Если длина множества == длине списка, то дубликатов нет. Сложность: O(N). """ aset = set(data) # O(N) return len(aset) == len(data) # O(1) - 2 * len (O(1)) + == O(1) # Проверка res = [["i", "1 (мс.)", "2 (мс.)", "3 (мс.)"]] for i in (100, 1000, 10000, 20000, 30000): # Из 100000 чисел выбираем 'i' случайных data = random.sample(range(-100000, 100000), i) res.append([i, timeit(is_unique_1, data)[0], timeit(is_unique_2, data)[0], timeit(is_unique_3, data)[0]]) print("10> 10> 10> 10>".format(*res[0])) for r in res[1:]: print("10> 10.2f> 10.2f> 10.2f>".format(*r)) # ------------- # Пример вывода: # # i 1 (мс.) 2 (мс.) 3 (мс.) # 100 0.00 0.00 0.00 # 1000 15.01 0.00 0.00 # 10000 1581.05 5.00 2.00 # 20000 7322.86 12.01 2.00 # 30000 35176.36 25.02 8.01
При написании алгоритмов стремитесь выбирать решение, обладающее наименьшей вычислительной сложностью.
Sebesta, W.S Concepts of Programming languages. 10E; ISBN 978-0133943023.
Саммерфилд М. Программирование на Python 3. Подробное руководство. — М.: Символ-Плюс, 2009. — 608 с.: ISBN: 978-5-93286-161-5.
Лучано Рамальо. Python. К вершинам мастерства. — М.: ДМК Пресс , 2016. — 768 с.: ISBN: 978-5-97060-384-0, 978-1-491-94600-8.