Пересечение списков, совпадающие элементы двух списков
В данной задаче речь идет о поиске элементов, которые присутствуют в обоих списках. При этом пересечение списков и поиск совпадающих (перекрывающихся) элементов двух списков будем считать несколько разными задачами.
Если даны два списка, в каждом из которых каждый элемент уникален, то задача решается просто, так как в результирующем списке не может быть повторяющихся значений. Например, даны списки:
[5, 4, 2, ‘r’, ‘ee’] и [4, ‘ww’, ‘ee’, 3]
Областью их пересечения будет список [4, ‘ee’] .
Если же исходные списки выглядят так:
[5, 4, 2, ‘r’, 4, ‘ee’, 4] и [4, ‘we’, ‘ee’, 3, 4] ,
то списком их совпадающих элементов будет [4, ‘ee’, 4] , в котором есть повторения значений, потому что в каждом из исходных списков определенное значение встречается не единожды.
Начнем с простого — поиска области пересечения. Cначала решим задачу «классическим» алгоритмом, не используя продвинутые возможностями языка Python: будем брать каждый элементы первого списка и последовательно сравнивать его со всеми значениями второго.
a = [5, [1, 2], 2, 'r', 4, 'ee'] b = [4, 'we', 'ee', 3, [1, 2]] c = [] for i in a: for j in b: if i == j: c.append(i) break print(c)
Результат выполнения программы:
[[1, 2], 4, 'ee']
Берется каждый элемент первого списка (внешний цикл for ) и последовательно сравнивается с каждым элементом второго списка (вложенный цикл for ). В случае совпадения значений элемент добавляется в третий список c . Команда break служит для выхода из внутреннего цикла, так как в случае совпадения дальнейший поиск при данном значении i бессмыслен.
Алгоритм можно упростить, заменив вложенный цикл на проверку вхождения элемента из списка a в список b с помощью оператора in :
a = [5, [1, 2], 2, 'r', 4, 'ee'] b = [4, 'we', 'ee', 3, [1, 2]] c = [] for i in a: if i in b: c.append(i) print(c)
Здесь выражение i in b при if по смыслу не такое как выражение i in a при for . В случае цикла оно означет извлечение очередного элемента из списка a для работы с ним в новой итерации цикла. Тогда как в случае if мы имеем дело с логическим выражением, в котором утверждается, что элемент i есть в списке b . Если это так, и логическое выражение возвращает истину, то выполняется вложенная в if инструкция, то есть элемент i добавляется в список c .
Принципиально другой способ решения задачи – это использование множеств. Подходит только для списков, которые не содержат вложенных списков и других изменяемых объектов, так как встроенная в Python функция set() в таких случаях выдает ошибку.
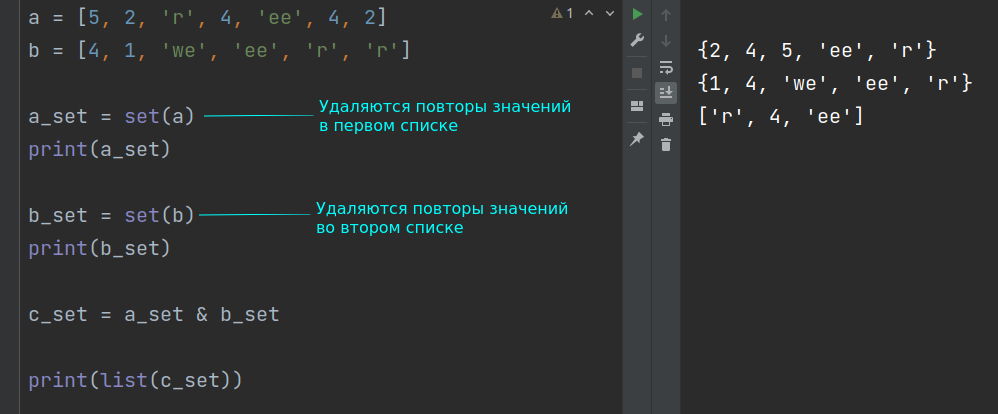
a = [5, 2, 'r', 4, 'ee'] b = [4, 1, 'we', 'ee', 'r'] c = list(set(a) & set(b)) print(c)
['ee', 4, 'r']
Выражение list(set(a) & set(b)) выполняется следующим образом.
- Сначала из списка a получают множество с помощью команды set(a) .
- Аналогично получают множество из b .
- С помощью операции пересечения множеств, которая обозначается знаком амперсанда & , получают третье множество, которое представляет собой область пересечения двух исходных множеств.
- Полученное таким образом третье множество преобразуют обратно в список с помощью встроенной в Python функции list() .
Множества не могут содержать одинаковых элементов. Поэтому, если в исходных списках были повторяющиеся значения, то уже на этапе преобразования этих списков во множества повторения удаляются, а результат пересечения множеств не будет отличаться от того, как если бы в исходных списках повторений не было.
Однако если мы вернемся к решению задачи без использования множеств и добавим в первый список повтор значения, то получим некорректный результат:
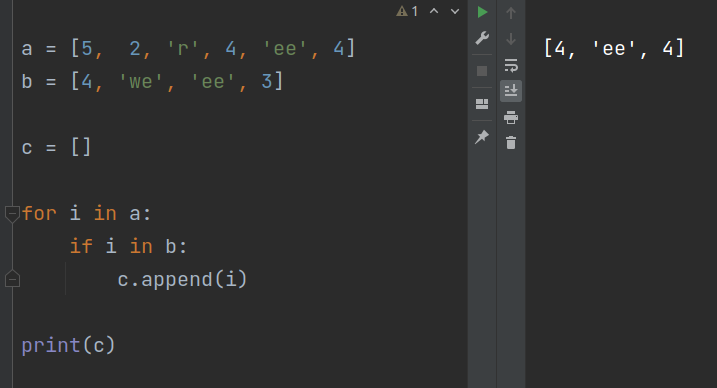
В список пересечения попадают оба равных друг другу значения из первого списка. Это происходит потому, что когда цикл извлекает, в данном случае, вторую 4-ку из первого списка, выражение i in b также возвращает истину, как и при проверке первой 4-ки. Следовательно, выражение c.append(i) выполняется и для второй четверки.
Чтобы решить эту проблему, добавим дополнительное условие в заголовок инструкии if . Очередной значение i из списка a должно не только присутствовать в b , но его еще не должно быть в c . То есть это должно быть первое добавление такого значения в c :
a = [5, 2, 'r', 4, 'ee', 4] b = [4, 'we', 'ee', 3] c = [] for i in a: if i in b and i not in c: c.append(i) print(c)
[4, 'ee']
Теперь усложним задачу. Пусть если в обоих списках есть по несколько одинаковых значений, они должны попадать в список совпадающих элементов в том количестве, в котором встречаются в списке, где их меньше. Или если в исходных списках их равное количетво, то такое же количество должно быть в третьем. Например, если в первом списке у нас три 4-ки, а во втором две, то в третьем списке должно быть две 4-ки. Если в обоих исходных по две 4-ки, то в третьем также будет две.
Алгоритмом решения такой задачи может быть следующий:
- В цикле будем перебирать элементы первого списка.
- Если на текущей итерации цикла взятого из первого списка значения нет в третьем списке, то только в этом случае следует выполнять все нижеследующие действия. В ином случае такое значение уже обрабатывалось ранее, и его повторная обработка приведет к добавлению лишних элементов в результирующий список.
- С помощью спискового метода count() посчитаем количество таких значений в первом и втором списке. Выберем минимальное из них.
- Добавим в третий список количество элементов с текущим значением, равное ранее определенному минимуму.
a = [5, 2, 4, 'r', 4, 'ee', 1, 1, 4] b = [4, 1, 'we', 'ee', 'r', 4, 1, 1] c = [] for item in a: if item not in c: a_item = a.count(item) b_item = b.count(item) min_count = min(a_item, b_item) # c += [item] * min_count for i in range(min_count): c.append(item) print(c)
[4, 4, 'r', 'ee', 1, 1]
Если значение встречается в одном списке, но не в другом, то метод count() другого вернет 0. Соответственно, функция min() вернет 0, а цикл с условием i in range(0) не выполнится ни разу. Поэтому, если значение встречается в одном списке, но его нет в другом, оно не добавляется в третий.
При добавлении значений в третий список вместо цикла for можно использовать объединение списков с помощью операции + и операцию повторения элементов с помощью * . В коде выше данный способ показан в комментарии.
X Скрыть Наверх
Решение задач на Python
Списки¶
Разработчики Python имели широкий выбор, когда реализовывали списки как структуру данных. Каждое их решение оказывает влияние на скорость выполнения операций со списками. Чтобы принять верное решение, они смотрели на то, для чего пользователи используют списки чаще всего, и оптимизировали реализацию таким образом, чтобы наиболее распространённые операции совершались очень быстро. Конечно, разработчики так же старались сделать быстрыми и менее используемые операции, но при поиске компромиссов производительность последних приносилась в жертву более распространённым.
Двумя наиболее частыми операциями над списками являются индексация и присваивание на заданную позицию. Обе они занимают равное количество времени, вне зависимости от того, насколько велик список. Когда операции не зависят от размера списка (как названные выше), говорят, что они имеют \(O(1)\)
Другим часто встречающимся программистским заданием является увеличение списка. Существует два способа продлить список. Вы можете использовать метод добавления или оператор конкатенации. Первый является \(O(1)\) , но вот второй имеет \(O(k)\) , где \(k\) — размер списка, который будет присоединён. Польза от этой информации в том, что она помогает сделать ваши программы более эффективными, выбирая правильный инструмент для работы.
Давайте рассмотрим четыре разных способа сгенерировать список из n чисел, начинающийся с нуля. Сначала мы попробуем цикл for и создадим список с помощью конкатенации. Затем используем для этого метод append . Далее попытаемся создать список, используя генераторы списков. И, наконец, используем для этого, возможно, самый очевидный способ — функцию range , обёрнутую в конструктор списка. Листинг 3 показывает код для всех этих четырёх способов.
Листинг 3
def test1(): l = [] for i in range(1000): l = l + [i] def test2(): l = [] for i in range(1000): l.append(i) def test3(): l = [i for i in range(1000)] def test4(): l = list(range(1000))
Чтобы получить время, требуемое для выполнения каждой функции, мы используем модуль Python timeit . Он разработан для того, чтобы разработчики могли делать кроссплатформенные синхронные измерения, запуская функции в согласованной среде и используя механизмы синхронизации, максимально схожие между собой для разных операционных систем.
Чтобы использовать timeit , вам нужно создать объект Timer , чьими параметрами являются два оператора Python. Первый из них сообщает, что вам нужно время; второй — что тест будет проводиться один раз. Модуль timeit замерит время, необходимое для выполнения операции, несколько раз. По умолчанию он попытается запустить операцию один миллион раз. Когда это будет сделано, время вернётся, как число с плавающей запятой, представляющее собой общее количество секунд. Однако, поскольку оператор вычислялся миллион раз, то вы можете прочитать результат, как количество микросекунд, затраченных на выполнение одного теста. Так же в timeit можно передать именованный параметр number , который позволит вам конкретизировать, сколько раз нужно запустить оператор. Следующий фрагмент показывает, как долго занимает запуск каждой тестовой функции тысячу раз.
t1 = Timer("test1()", "from __main__ import test1") print("concat ",t1.timeit(number=1000), "milliseconds") t2 = Timer("test2()", "from __main__ import test2") print("append ",t2.timeit(number=1000), "milliseconds") t3 = Timer("test3()", "from __main__ import test3") print("comprehension ",t3.timeit(number=1000), "milliseconds") t4 = Timer("test4()", "from __main__ import test4") print("list range ",t4.timeit(number=1000), "milliseconds") concat 6.54352807999 milliseconds append 0.306292057037 milliseconds comprehension 0.147661924362 milliseconds list range 0.0655000209808 milliseconds
В эксперименте выше мы замеряли время для функций test1() , test2() и так далее. Оператор начальной установки может показать вам очень необычным, так что давайте разберём детали. Возможно, вы хорошо знакомы с операторами from и import` , но они обычно используются в начале файлов программ на Python. В этом случае, оператор from __main__ import test1 импортирует функцию test1 из пространства имён __main__ в пространство имён, где ставит свой временн*о*й эксперимент timeit . Это делается, чтобы запускать тесты в среде с отсутствующими бродячими переменными, которые вы могли ненароком создать и которые могут повлиять на производительность функции непредвиденным образом.
Из эксперимента выше совершенно ясно, что операция append с 0.30 миллисекундами быстрее, чем конкатенация с её 6.54 миллисекундами. Также мы видим время, требуемое для двух дополнительных методов создания списков: использования конструктора списка с вызовом range и генератора списков. Интересно, что последний в два раза быстрее, чем цикл for с операцией append .
Наше последнее наблюдение в этом маленьком эксперименте заключается в том, что все времена, которые вы видите выше, содержат некоторые издержки при фактическом вызове тестовой функции. Однако, мы можем предположить, что для всех четырёх случаев эта величина одинакова, так что мы по-прежнему имеем адекватное сравнение операций. Поэтому правильно говорить не “конкатенация занимает 6.54 миллисекунд”, а “тестовая функция конкатенации выполняется 6.54 миллисекунд”. В качестве упражнения, вы можете провести временн*о*й тест для пустой функции и вычесть его результат из чисел выше.
После того, как мы увидели, как конкретно может быть измерена производительность, вы можете посмотреть в таблицу 2, чтобы узнать эффективность в терминах “большого О” для основных операций над списками. После вдумчивого размышления над ней, вы можете заинтересоваться двумя разными временами для pop . Когда этот метод вызывается для конца списка, это занимает \(O(1)\) . Но когда pop вызывают для первого или любого другого элемента из середины списка, он имеет \(O(n)\) . Причина кроется в том, как в Python выбрана реализация списков. Когда элемент берётся из начала списка, то все прочие элементы смещаются на одну позицию вперёд. Сейчас это может показаться вам глупым, но если вы посмотрите на таблицу 2, то увидите, что эта же реализация позволяет операции индексации иметь \(O(1)\) . Это один из тех компромиссов, которые разработчики Python сочли разумными.
| Операция | Эффективность |
|---|---|
| index [] | O(1) |
| Присваивание по индексу | O(1) |
| append | O(1) |
| pop() | O(1) |
| pop(i) | O(n) |
| insert(i,item) | O(n) |
| оператор del | O(n) |
| итерирование | O(n) |
| вхождение (in) | O(n) |
| срез [x:y] | O(k) |
| удалить срез | O(n) |
| задать срез | O(n+k) |
| обратить | O(n) |
| конкантенация | O(k) |
| сортировка | O(n log n) |
| размножить | O(nk) |
В качестве способа демонстрации этих различий в производительности, давайте проведём другой эксперимент с использованием модуля timeit . Нашей целью будет возможность проверки производительности операции pop на списке известного размера, когда программа выталкивает элемент из конца списка, и ещё раз — когда программа вталкивает элемент из начала списка. Мы также произведём замеры времени на списках разной длины. Что мы ожидаем увидеть, так это то, что временн*а*я зависимость у выталкивания из конца списка остаётся одинаковой при увеличении списка, в то время как выталкивание из начала списка будет расти вместе с его длиной.
Листинг 10 демонстрирует попытку замерить разницу между двумя использованиями pop . Как видно из первого примера, выталкивание с конца занимает 0.0003 миллисекунды, в то время как на выталкивание из начала требуется 4.82 миллисекунды. Для списка в два миллиона элементов коэффициент будет 16 000.
Есть ещё несколько замечаний относительно листинга 4. Первое — это оператор from __main__ import x . Несмотря на то, что мы не определяли функцию, мы хотим иметь возможность использовать список-объект x в нашем тесте. Этот подход позволяет нам замерять время только для единственной pop -операции и получать для неё наиболее точное значение. Поскольку замеры повторяются тысячу раз, то также важно отметить, что список уменьшается в размерах на единицу за каждую итерацию. Но поскольку изначально в нём два миллиона элементов, то общий объём уменьшится примерно на \(0.05\%\)
Листинг 4
popzero = timeit.Timer("x.pop(0)", "from __main__ import x") popend = timeit.Timer("x.pop()", "from __main__ import x") x = list(range(2000000)) popzero.timeit(number=1000) 4.8213560581207275 x = list(range(2000000)) popend.timeit(number=1000) 0.0003161430358886719
Пока наш первый тест показывает, что pop(0) действительно медленнее pop() . Но он не подтверждает заявление, что pop(0) является \(O(n)\) , в то время как pop() — \(O(1)\) . Чтобы доказать это, нам нужно рассмотреть производительность обоих вызовов на диапазоне размеров списков. Листинг 5 содержит этот тест.
Листинг 5
popzero = Timer("x.pop(0)", "from __main__ import x") popend = Timer("x.pop()", "from __main__ import x") print("pop(0) pop()") for i in range(1000000,100000001,1000000): x = list(range(i)) pt = popend.timeit(number=1000) x = list(range(i)) pz = popzero.timeit(number=1000) print("%15.5f, %15.5f" %(pz,pt))
На рисунке 3 показаны результаты нашего эксперимента. Вы можете видеть, как список становится всё длиннее и длиннее, а время, необходимое для pop(0) — больше и больше, тогда как график для pop остаётся плоским. Это в точности то, что мы ожидали увидеть от алгоритмов с \(O(n)\) и \(O(1)\)
Некоторым источником ошибок в нашем маленьком эксперименте стал тот факт, что на компьютере запущены и другие процессы, которые могут замедлять код. Несмотря на то, что мы старались минимизировать влияние прочих происходящих в компьютере вещей, с ними связаны некоторые флуктуации времён. Именно поэтому цикл выполняет тест тысячу раз — в первую очередь, чтобы статистически собрать достаточно информации для утверждения о надёжности измерений.
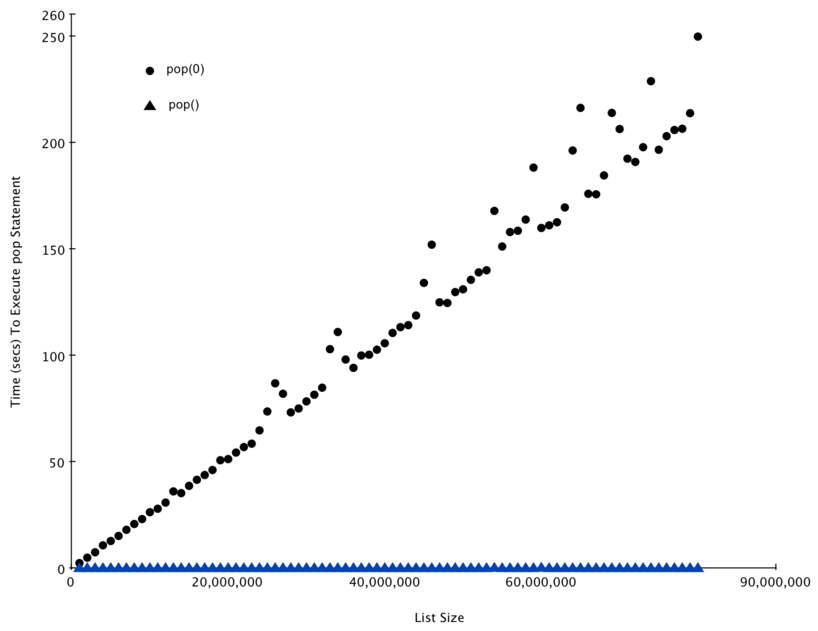
Рисунок 3: Сравнение производительности pop и pop(0)
readers online now | | Back to top
© Copyright 2014 Brad Miller, David Ranum. Created using Sphinx 1.2.3.
Списки в Python: что это такое и как с ними работать
Рассказали всё самое важное о списках для тех, кто только становится «змееустом».

Иллюстрация: Оля Ежак для Skillbox Media

Дмитрий Зверев
Любитель научной фантастики и технологического прогресса. Хорошо сочетает в себе заумного технаря и утончённого гуманитария. Пишет про IT и радуется этому.
Сегодня мы подробно поговорим о, пожалуй, самых важных объектах в Python — списках. Разберём, зачем они нужны, как их использовать и какие удобные функции есть для работы с ними.
В статье есть всё, что начинающим разработчикам нужно знать о списках в Python:
- Что это такое
- Как создавать списки в Python
- Какие с ними можно выполнять операции
- Как работать совстроенными функциями
- Какие вPython есть методы управления элементами
Что такое списки
Список (list) — это упорядоченный набор элементов, каждый из которых имеет свой номер, или индекс, позволяющий быстро получить к нему доступ. Нумерация элементов в списке начинается с 0: почему-то так сложилось в C, а C — это база. Теорий на этот счёт много — на «Хабре» даже вышло большое расследование 🙂
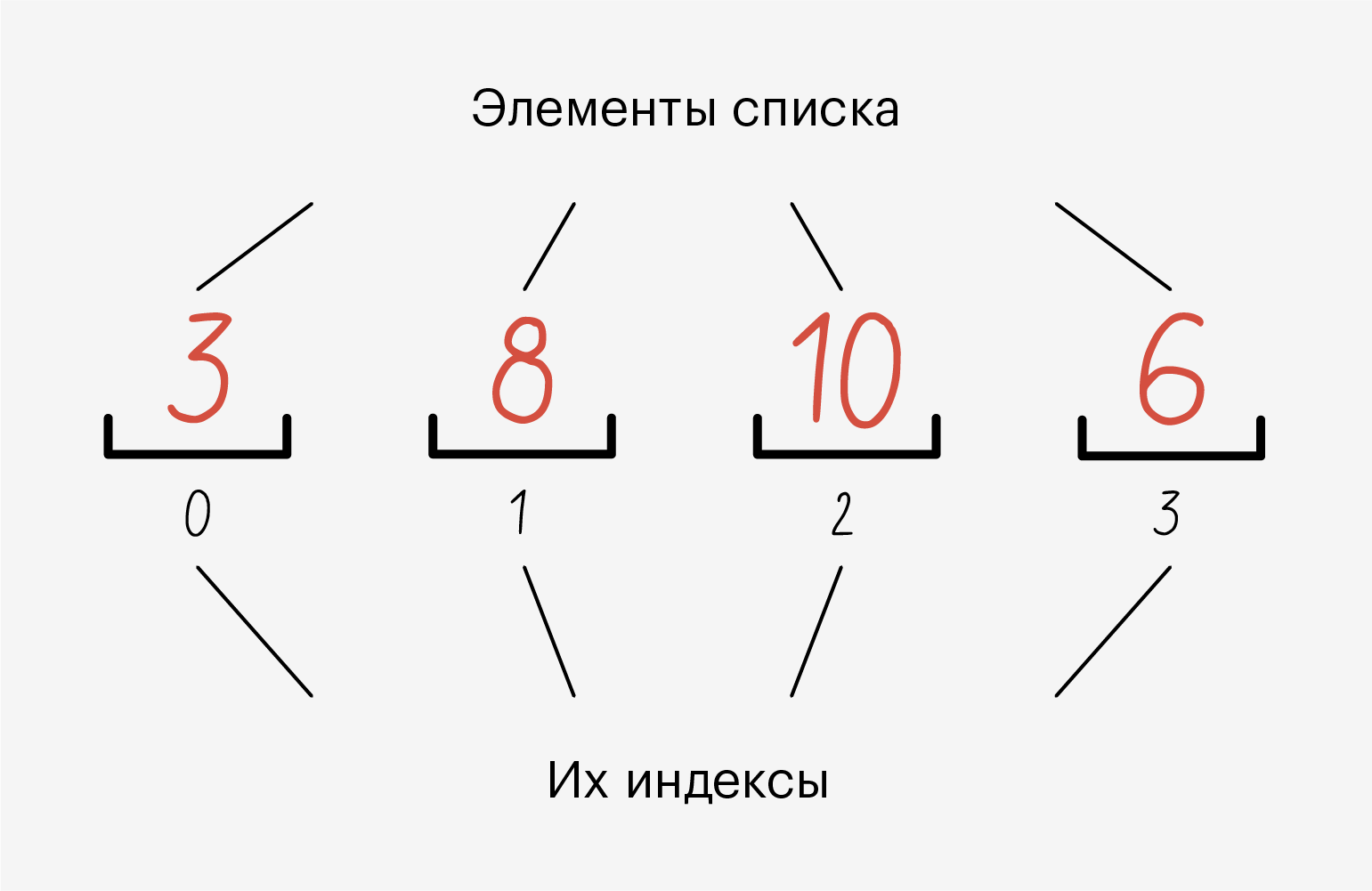
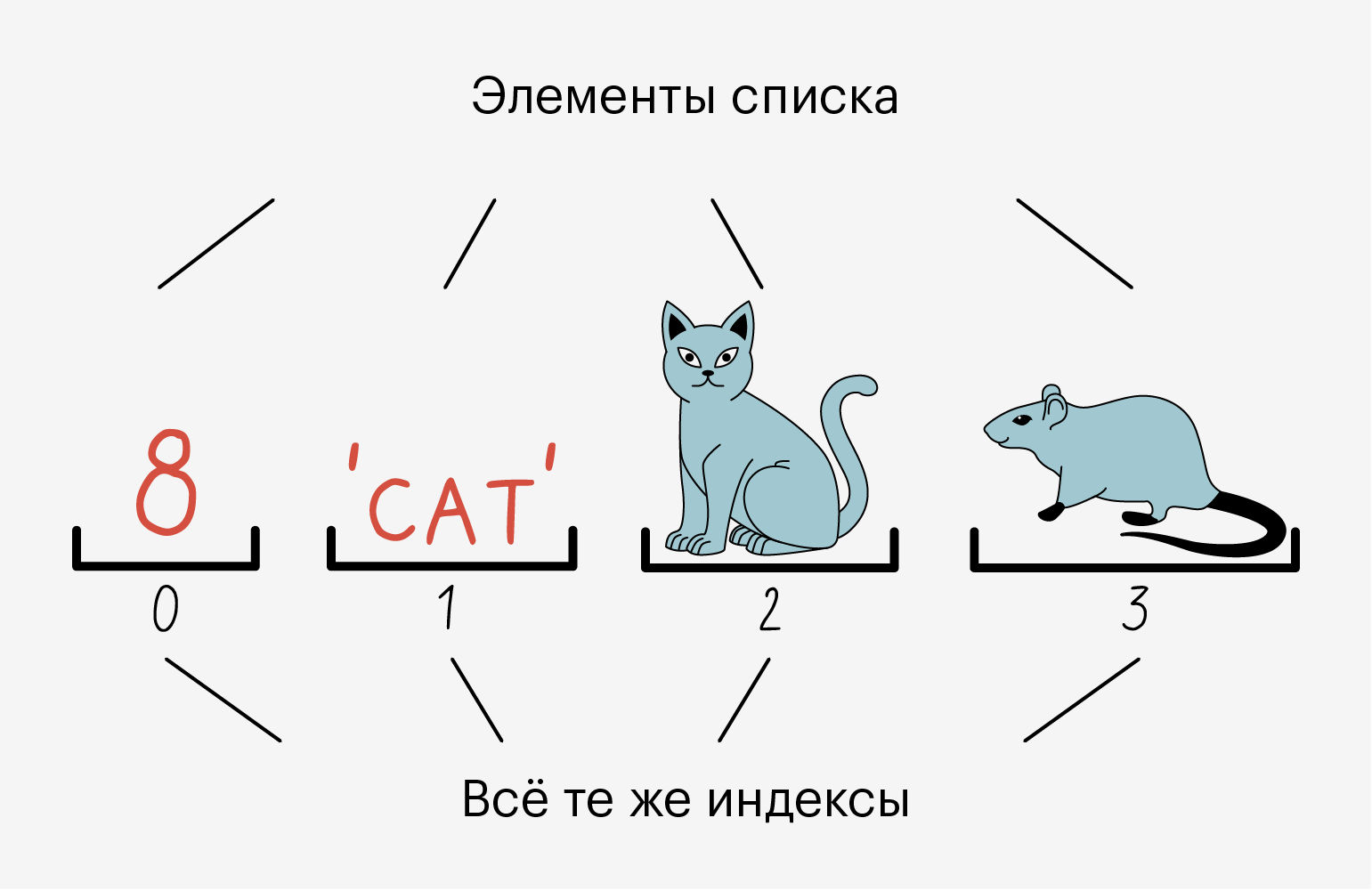
В одном списке одновременно могут лежать данные разных типов — например, и строки, и числа. А ещё в один список можно положить другой и ничего не сломается:
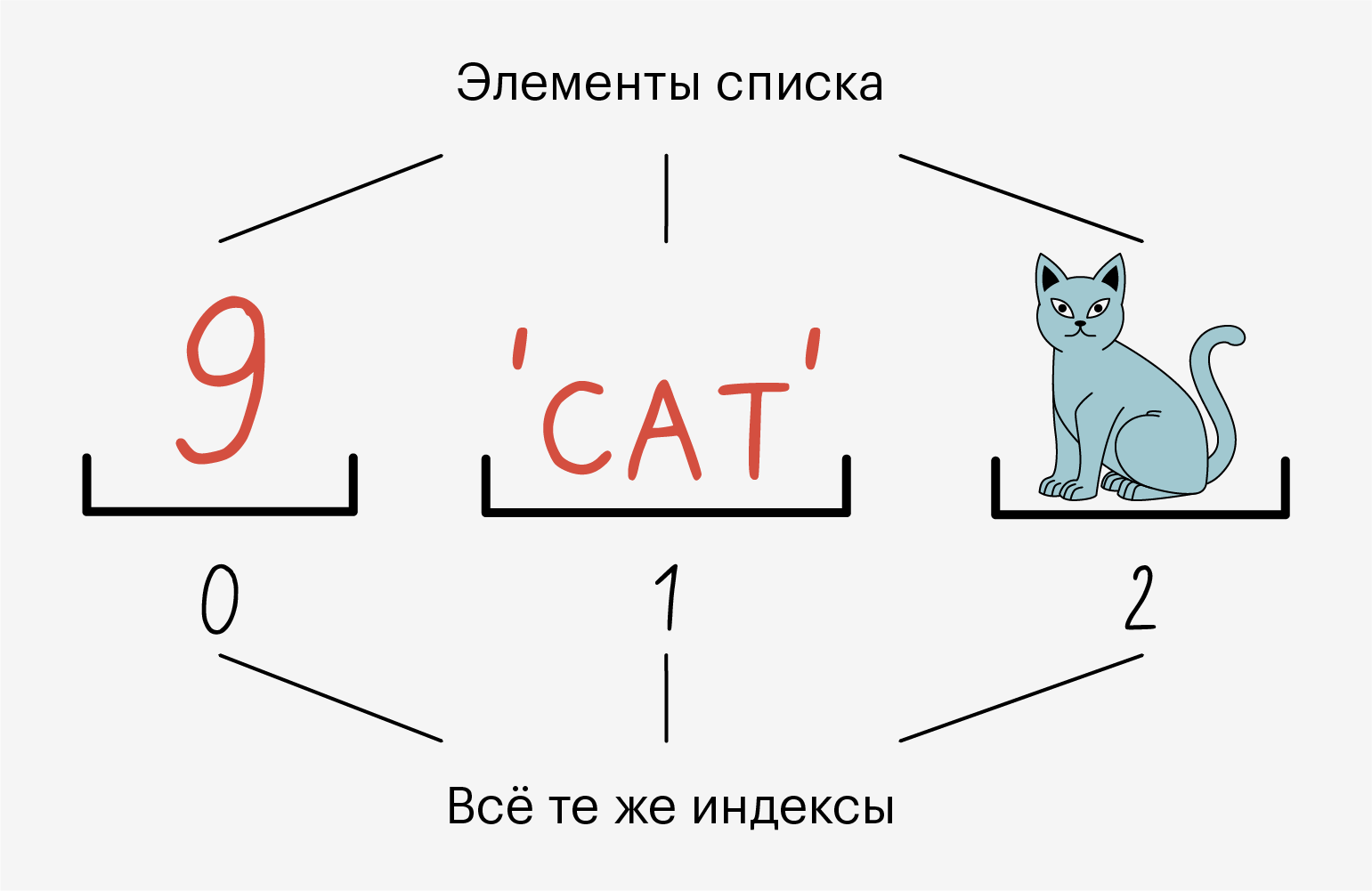
Все элементы в списке пронумерованы. Мы можем без проблем узнать индекс элемента и обратиться по нему.
Списки называют динамическими структурами данных, потому что их можно менять на ходу: удалить один или несколько элементов, заменить или добавить новые.
Когда мы создаём объект list, в памяти компьютера под него резервируется место. Нам не нужно переживать о том, сколько выделяется места и когда оно освобождается, — Python всё сделает сам. Например, когда мы добавляем новые элементы, он выделяет память, а когда удаляем старые — освобождает.
Под капотом списков в Python лежит структура данных под названием «массив». У массива есть два важных свойства: под каждый элемент он резервирует одинаковое количество памяти, а все элементы следуют друг за другом, без «пробелов».
Однако в списках Python можно хранить объекты разного размера и типа. Более того, размер массива ограничен, а размер списка в Python — нет. Но всё равно мы знаем, сколько у нас элементов, а значит, можем обратиться к любому из них с помощью индексов.
И тут есть небольшой трюк: списки в Python представляют собой массив ссылок. Да-да, решение очень элегантное — каждый элемент такого массива хранит не сами данные, а ссылку на их расположение в памяти компьютера!
Как создать список в Python
Чтобы создать объект list, в Python используют квадратные скобки — []. Внутри них перечисляют элементы через запятую:

Операции со списками
Если просто хранить данные в списках, то от них будет мало толку. Поэтому давайте рассмотрим, какие операции они позволяют выполнить.
Индексация
Доступ к элементам списка получают по индексам, через квадратные скобки []:
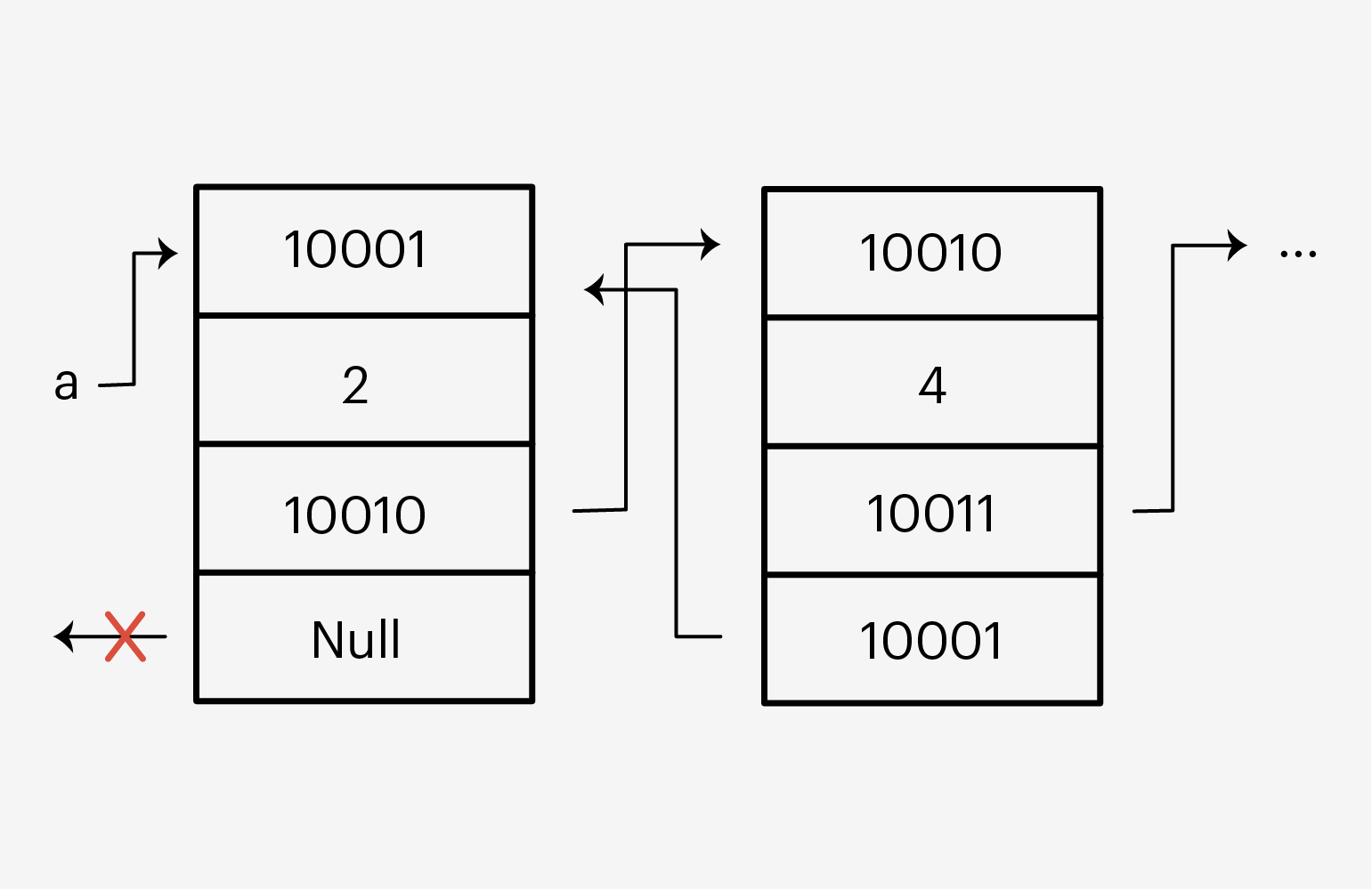
Каждый элемент списка имеет четыре секции: свой адрес, данные, адрес следующего элемента и адрес предыдущего. Если мы получили доступ к какому-то элементу, мы без проблем можем двигаться вперёд-назад по этому списку и менять его данные.
Поэтому, когда мы присвоили списку b список a, то на самом деле присвоили ему ссылку на первый элемент — по сути, сделав их одним списком.
Объединение списков
Иногда полезно объединить два списка. Чтобы это сделать, используют оператор +:

insert()
Добавляет новый элемент по индексу:

clear()
Удаляет все элементы из списка и делает его пустым:
a = [1, 2, 3] a.clear() print(a) >>> []
index()
Возвращает индекс элемента списка в Python:
a = [1, 2, 3] print(a.index(2)) >>> 1
Если элемента нет в списке, выведется ошибка:
a = [1, 2, 3] print(a.index(4)) Traceback (most recent call last): File "", line 1, in ValueError: 4 is not in list
pop()
Удаляет элемент по индексу и возвращает его как результат:
a = [1, 2, 3] print(a.pop()) print(a) >>> 3 >>> [1, 2]
Мы не передали индекс в метод, поэтому он удалил последний элемент списка. Если передать индекс, то получится так:
a = [1, 2, 3] print(a.pop(1)) print(a) >>> 2 >>> [1, 3]
count()
Считает, сколько раз элемент повторяется в списке:
a = [1, 1, 1, 2] print(a.count(1)) >>> 3
sort()
a = [4, 1, 5, 2] a.sort() # [1, 2, 4, 5]
Если нам нужно отсортировать в обратном порядке — от большего к меньшему, — в методе есть дополнительный параметр reverse:
a = [4, 1, 5, 2] a.sort(reverse=True) # [5, 4, 2, 1]
reverse()
Переставляет элементы в обратном порядке:
a = [1, 3, 2, 4] a.reverse() # [4, 2, 3, 1]
copy()
a = [1, 2, 3] b = a.copy() print(b) >>> [1, 2, 3]
Для того чтобы быстро находить нужные методы во время работы, пользуйтесь этой шпаргалкой:
| Метод | Что делает |
|---|---|
| a.append(x) | Добавляет элемент x в конец списка a. Если x — список, то он появится в a как вложенный |
| a.extend(b) | Добавляет в конец a все элементы списка b |
| a.insert(i, x) | Вставляет элемент x на позицию i |
| a.remove(x) | Удаляет в a первый элемент, значение которого равно x |
| a.clear() | Удаляет все элементы из списка a и делает его пустым |
| a.index(x) | Возвращает индекс элемента списка |
| a.pop(i) | Удаляет элемент по индексу и возвращает его |
| a.count(x) | Считает, сколько раз элемент повторяется в списке |
| a.sort() | Сортирует список. Чтобы отсортировать элементы в обратном порядке, нужно установить дополнительный аргумент reverse=True |
| a.reverse() | Возвращает обратный итератор списка a |
| a.copy() | Создаёт поверхностную копию списка. Для создания глубокой копии используйте метод deepcopy из модуля copy |
Что запомнить
Лучше не учить это всё, а применять на практике. А ещё лучше — попытаться написать каждый метод самостоятельно, не используя никакие встроенные функции.
Сколько бы вы ни писали код на Python, всё равно придётся подсматривать в документацию и понимать, какой метод что делает. И для этого есть разные удобные сайты — например, полный список методов можно посмотреть на W3Schools.
Больше интересного про код в нашем телеграм-канале. Подписывайтесь!
Читайте также:
- Как изучить Python самостоятельно и бесплатно: алгоритм
- Тест: сможете отличить Zen of Python от философии Лао-цзы?
- Rust: зачем он нужен, где применяется и за что его все любят
Быстрое вычитание списков
В случае, когда количество элементов списков A и B высоко (порядка 100 000 и выше), способ естественно работает очень медленно. Возможно ли реализовать подобный поиск быстрее? Если да, то как именно?
Отслеживать
Denis Leonov
задан 22 мар 2017 в 6:45
Denis Leonov Denis Leonov
550 4 4 золотых знака 11 11 серебряных знаков 24 24 бронзовых знака
4 ответа 4
Сортировка: Сброс на вариант по умолчанию
i in B это O(m) операция для списков ( m = len(B) ). Поэтому ваш код это O(n * m) алгоритм ( n = len(A) ), то есть для длин списков ~ 100_000 (10 5 ) ваша реализация вычитания списков займёт порядка 10_000_000_000 (10 10 ) операций. Если при работе с чуть бОльшими списками в телефоне вдруг всё начинает тормозить, когда для маленьких списков всё летает, то одно из вероятных объяснений, что программист использовал квадратичный алгоритм вместо линейного (или квази-линейного).
Можно значительно улучшить производительность (если все элементы списка хэшируются) с помощью set() :
Bset = frozenset(B) C = [item for item in A if item not in Bset] # C = A - B item in Bset это O(1) операция (в среднем). Поэтому C список вычисляется за O(n + m) (линейный алгоритм), что значительно лучше O(n * m) для больших B .
Обратите внимание, что set(A) не вызывается, иначе получатся результаты отличные от кода в вашем вопросе, если в A есть повторяющиеся элементы или если вы хотите исходный порядок в A сохранить:
>>> A = "abracadabra" >>> B = ['a', 'b', 'c'] >>> Bset = frozenset(B) >>> [item for item in A if item not in Bset] ['r', 'd', 'r'] Обратите внимание, ‘r’ встречается дважды в результате и относительный порядок ‘r’ и ‘d’ сохранён.
Если элементы не являются хэшируемыми (к примеру вложенные списки), то можно отсортировать B и использовать двоичный поиск, чтобы определить присутствует ли элемент в отсортированной последовательности:
from bisect import bisect_left def contains(sorted_seq, item): i = bisect_left(sorted_seq, item) return i != len(sorted_seq) and sorted_seq[i] == item >>> A = map(list, "abracadabra") >>> B = [['a'], ['b'], ['c']] >>> Bsorted = sorted(B) >>> [item for item in A if not contains(Bsorted, item)] [['r'], ['d'], ['r']] Это O((n + m) * log m) алгоритм. log() функция достаточно медленно растёт, к примеру, log10(10 5 ) == 5 Поэтому не измеряя производительность, сложно сказать какой код (на основе set или sorted) быстрее на заданных входных списках, платформе.
Если дополнительно порядок элементов в B списке не определён ( sorted() не работает) и можно только сравнивать элементы напрямую ( a == b ), то придётся использовать O(n * m) алгоритм аналогичный приведённому в вопросе:
>>> A = [1, "a", 1] >>> B = [[], 1] >>> [item for item in A if item not in B] ['a'] Как set(B) так и sorted(B) не работают в этом случае.
Стоит заметить, что C в примере ( [‘a’] ) не содержит единицу хотя она встречается два раза в A списке и только один раз в B .
Чтобы учесть число повторений в B :
C = [] for item in A: try: B.remove(item) except ValueError: C.append(item) # item not in B В этом случае C == [‘a’, 1] , а не [‘a’] . Код разрушает B . Алгоритм также O(n * m) .
Для хэшируемых элементов, чтобы учесть количество повторений элементов в B , можно в этом случае collections.Counter использовать как мультимножество:
from collections import Counter A = "abracadabra" B = ['a', 'b', 'c'] Bcount = Counter(B) C = [] for item in A: if Bcount[item] == 0: C.append(item) else: Bcount[item] -= 1 Результат C == [‘r’, ‘a’, ‘a’, ‘d’, ‘a’, ‘b’, ‘r’, ‘a’] отличается от C == [‘r’, ‘d’, ‘r’] полученного выше алгоритмом, который не учитывает количество повторений в B .
Если порядок элементов в результате не важен, то можно упростить код:
C = list((Counter(A) - Counter(B)).elements()) Возможный результат: C == [‘b’, ‘r’, ‘r’, ‘a’, ‘a’, ‘a’, ‘a’, ‘d’] . С точностью до порядка элементов внутри C , он совпадает с предыдущим примером. Оба алгоритма линейные — О(m + n) .
Так как порядок не сохраняется, то имеет смысл использовать просто:
C = Counter(A) - Counter(B) # -> Counter() так как иначе использование списка для C может создать впечатление, что порядок элементов учитывается.
Если не нужно учитывать ни порядок ни количество повторений, то разницу списков можно найти, используя set (множество — разновидность @Alban ответа):
C = set(A).difference(B) # ->
Видно, что в зависимости от желаемого определения вычитания для списков, разность разные значения принимает:
A = "abracadabra" B = ['a', 'b', 'c'] # C = A - B # -> # нет порядка, нет повторений # -> Counter() # нет порядка # -> ['r', 'd', 'r'] # порядок сохранён, но без учёта повторений в B # -> ['r', 'a', 'a', 'd', 'a', 'b', 'r', 'a'] # порядок + с учётом повторений в B В разных ситуациях разные определения могут быть полезны. Явной очевидной предпочтительной семантики здесь нет — вероятно поэтому операция вычитания ( A — B ) не определена для списков в Питоне.