По какому принципу образуется порядок элементов в unordered_map?
Само название структуры подразумевает, что элементы в ней не отсортированы, но если перезапускать все время программу и выводить циклом элементы, то они всегда будут в одном порядке. Например вот код из этой книги
struct coord < int x; int y; >; bool operator==(const coord &l, const coord &r) < return l.x == r.x && l.y == r.y; >namespace std < template <>struct hash < using argument_type = coord; using result_type = size_t; result_type operator()(const argument_type &c) const < return static_cast(c.x) + static_cast(c.y); > >; > int main() < std::unordered_mapm , 1>, , 2>, , 3>>; for (const auto & [key, value] : m) < std::cout "; > std::cout
Хэш формируется из сложения x и y , поэтому я думал, что по итоговому хэшу и будет выстроен порядок, но оказалось, что это так не работает. Порядок вывода всегда такой:
Как это работает?
Отслеживать
задан 11 июл 2021 в 16:53
175 9 9 бронзовых знаков
Это не сортировка, но порядок связан с хеш-значением. Причем опять же — это не значит, что элементы отсортированы по хешу.
11 июл 2021 в 16:56
2 ответа 2
Сортировка: Сброс на вариант по умолчанию
Для того, что бы ответить на вышеуказанный вопрос, для начала нужно понять, а как собственно устроен unordered_map изнутри. Есть два способа реализации, но самый простой и легкий из них — метод цепочек. Вроде он и применяется в стандартной библиотеке.
Сами данные хранятся в векторе списков. То есть так
class my_umap < std::vector>> m_data; >; когда нужно вставить элемент, то от индекса рассчитывается хеш (в нашем случае функция хеша должна уметь преобразовывать тип ключа в некое число в диапазоне 0..m_data.size()-1 . Обычно, хеш функция просто возвращает обычный int , а потом используется деление по модулю с помощью % . По полученному числу находится элемент вектора, в который в список и добавляется необходимый элемент (да, предварительно, проверяется, а нет ли такого элемента ещё).
Функция итерации по мапе обычно делается по простому — проходимся по всем элементам массива (вектора) и выводим элементы списка (опять же, в естественном порядке).
Теперь стает понятно, что при выводе элементов порядок будет определятся хеш функцией и тем, как элементы были вставлены в пределах одного и того же значения хеш функции.
Хеш функции обычно такие, что одному и тому же значению входного значения соответствует одно и тоже выходное значение (иначе это все работать не будет). Но с другой стороны, хеш функция старается максимально равномерно «размазать» значения хеша. Поэтому, если два значения (например, два int ) упорядочены по возрастанию, то значения хеш функции (идеальной конечно) будет упорядочены с вероятностью 50 на 50 (да, они могут совпасть, поэтому, наверно на самом деле это будет 49-49-2 или что то другое, похожее).
Чем же определяется хеш? его может явно задать программист, а может использоваться реализация от компилятора. Важно то, что с большущей вероятностью (если код не менялся), она не поменяется, а значит, значения хеша, которые определяют элемент вектора, будут те же.
Рекомендую попробовать написать свою реализацию unordered_map (того, что я написал выше уже достаточно для этого) и все вопросы пропадут сами собой.
Некоторые языки (например, golang) любят рандомизировать немного хеш функцию от запуска к запуску (для мнимой безопасности), тем самым доставляя кучу приятных впечатлений для молодых программистов.
Есть ещё одна реализация unordered_map — открытая адресация, но он немного сложнее, как по мне в реализции.
Вглубь std::unordered_map: магические числа
Все любители кодокопания заканчивают либо хорошо, либо плохо. Мне повезло. Поэтому я решила написать свою первую статью на Хабре.

Как всё начиналось
Мой друг игрался со вставкой в unordered_map и заметил странную закономерность в изменении параметра bucket_count с ростом числа элементов в таблице.
Unordered map в C++ представляет собой хэш-таблицу. Хэш-таблица даёт околоконстантное время операций за счёт того, что каждый элемент хранится по своему уникальному индексу, вычисляемому через хэш-функцию. При вычислении индекса значение хэш-функции (коротко — хэш) масштабируется на размер таблицы, поэтому он не должен меняться при выполнении операций. Совпадение индексов называется коллизией. Есть несколько стратегий обработки коллизий. В std::unordered_map используется bucket hashing.
Заключается она в том, что элементы с одинаковым хэшем кладутся в соответствующий этому хэшу сегмент (bucket). При возрастании числа коллизий скорость операций с таблицей падает, поэтому необходимо производить рехэширование (rehashing) — увеличивать число сегментов и пересчитывать все хэши элементов, соответственно перевыделять память для таблицы и вставлять их заново. Это дорогостоящая по времени и памяти операция, поэтому приходится искать компромисс между числом коллизий и частотой рехэширования.
Эксперимент показал, что рехэширование происходит при вставке соответственно 14го, 30го, 60го, 128го, 258го, 542го, 1110го, 2358го и так далее. Это дал следующий код:
#include #include int main () < std::unordered_map umap; // заполняем таблицу 2000 элементами - парами чисел for (int i = 0; i < 2000; i++) < // выводим число элементов и число сегментов на каждой итерации std::cout ); > > Получается, размеры таблицы образуют последовательность 13, 29, 59, 127, 257, 541, 1109, 2357, . Но откуда берутся эти числа?
(Здесь сразу стоит оговориться, что кто знает, тому очевидно. Интерес представляет внутренняя структура того, как это реализовано.)
Начинаем копать
Первая часть изысканий делается через встроенную в IDE возможность перехода к определениям функций. insert нам даёт:

Отлично. Мы обнаружили, что unordered_map ссылается на _M_h. Следующие пара шагов нам дают:
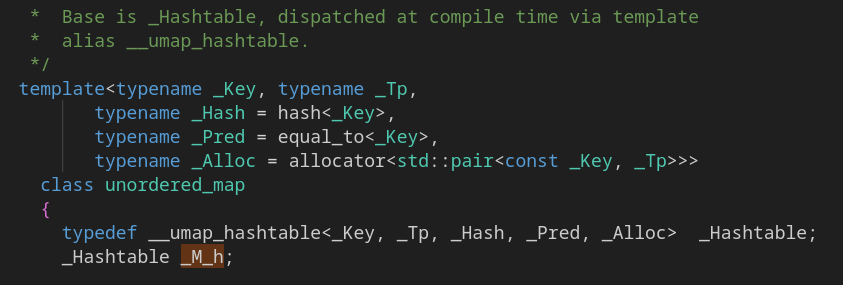
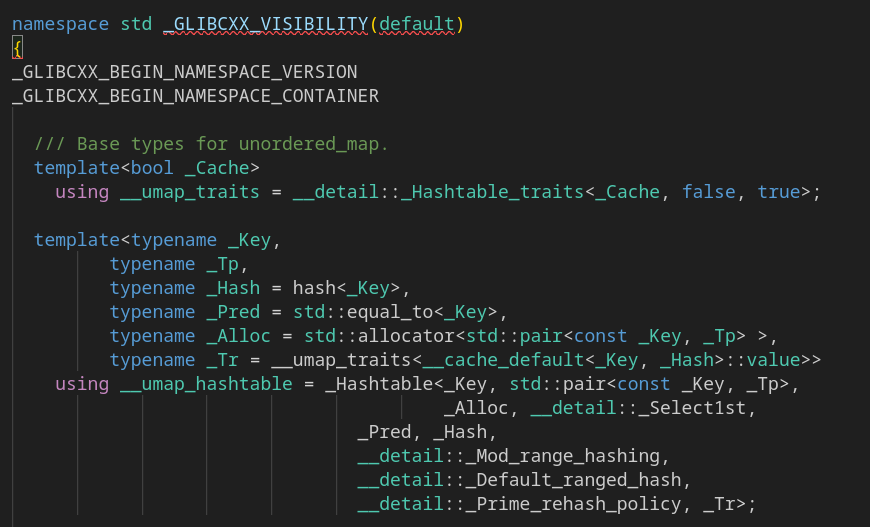
Это шаблон базового типа unordered_map. Там есть параметр, кончающийся на rehash_policy. Звучит как то, что нас интересует! Видно, что параметр определён в std::_detail. Объявим
std::__detail::_Prime_rehash_policy p;Перейдём к определению (используя «Go to definition»). Оно в файле под именем hashtable_policy.h. Лишний раз подтверждает связь хэш-таблицы и unordered_map.
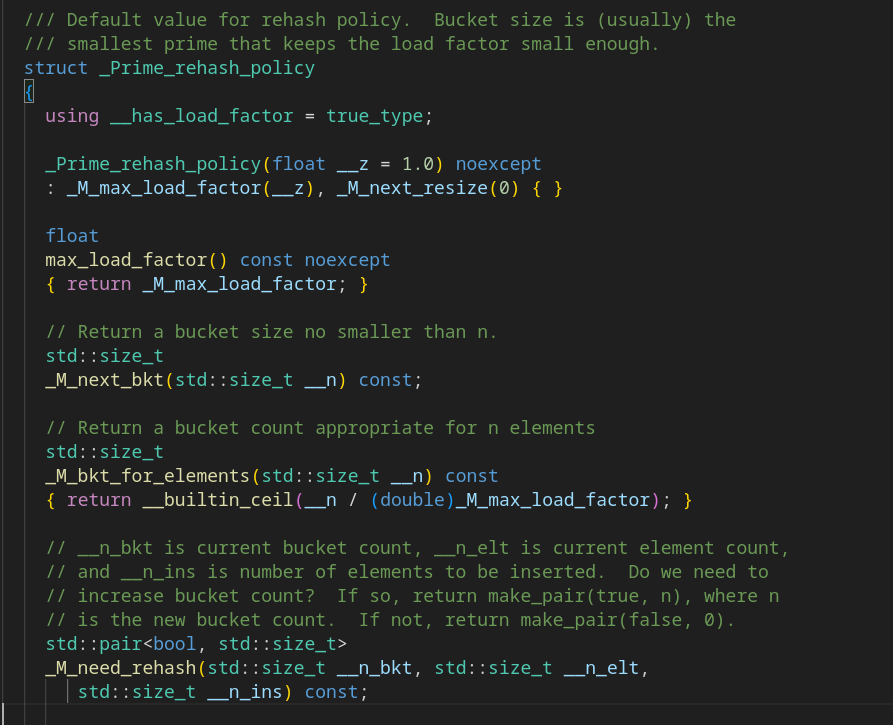
Теперь мы знаем, какие функции дают наши «магические числа». К сожалению, определений в этом файле не нашлось.
Долгожданная реализация
Гугл выдаёт следующее: хэдер с аналогичным названием, но из TR1 (проект-расширение C++ между C++03 и C++11, ставший частью последнего): https://gcc.gnu.org/onlinedocs/libstdc++/libstdc++-html-USERS-4.2/hashtable__policy_8h-source.html
Рассмотрим функцию need_rehash, которая определяет новое количество сегментов (а закон его расчёта мы и ищём):
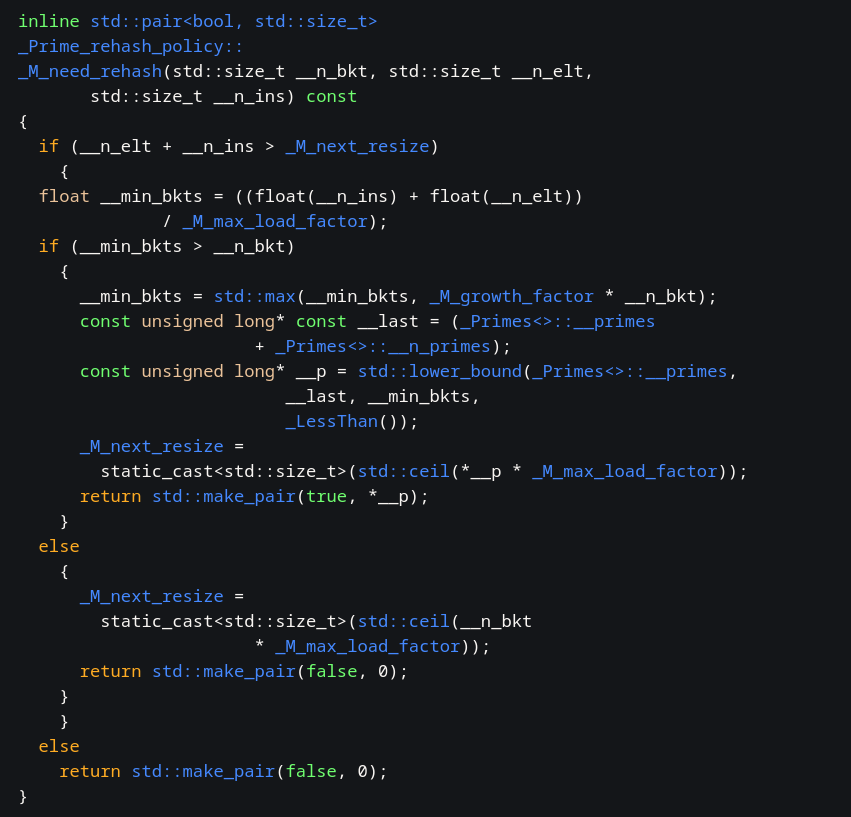
Наш случай — когда функция возвращает true (произойдёт rehashing). Параметр _M_growth_factor, он же _S_growth_factor в новой версии, по дефолту равен 2 (находится поиском по файлу), т.е. размер предварительно удваивается. _M_max_load_factor в дефолтном конструкторе равен 1. Шаблонный класс unordered_map использует именно дефолтные параметры, проверяется это эмпирически с помощью дебаггера.
Двоичный поиск по некоторому массиву _Primes<>::__primes нам даёт первое простое, большее удвоенного размера массива + числа вставленных элементов (1), и устанавливает в него параметр _M_next_resize, определяющий новое число сегментов.
Для первых 6 членов ряда всё ок: (13+1)*2 = 28 -> 29, аналогично 59 и 127. Но (257+1)*2+1 = 517, ближайшее простое — 521, а у нас — 541. Аналогично 1109 и 2357 не соответствуют расчётам.
На этом моменте я конкретно задумалась, но к счастью, моё внимание привлёк огромный массив чисел в начале файла. Это и есть тот самый _Primes<>::__primes:
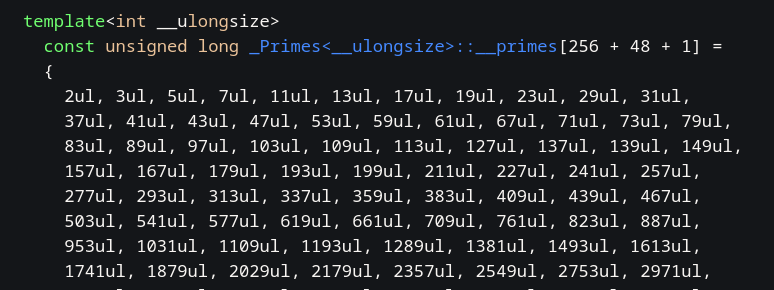
Согласно этому массиву, всё работает верно (это легко проверить). Ура. Мы нашли разгадку.
Заключение
Мы получили, что искомая последовательность формируется по принципу «ближайшее простое, большее 2(n+1), где n — предыдущий член последовательности». С оговоркой на то, что простые числа берутся из некоторого заданного массива. Почему он именно такой — неизвестно. Предположу, что часть простых пропущена из соображений памяти.
Также, невыясненным остался вопрос, почему при вставке одного элемента число сегментов возрастает сразу до 13. Может быть, вы знаете?
Жду замечаний и предложений в комментариях 🙂
P.S. Судя по тому, что новая библиотека работает как код из tr1, tr1 действительно был внесён в новый стандарт.
Когда map быстрее чем unordered
У меня даже вопроса нету. Одни эмоции. Нет, речь не о том что хеш сколлизился и мапа выродилась в лист.
Привожу пример кода, в котором простой map Быстрее(!) чем unsortered_map.
#include ctime> #include unordered_map> #include map> size_t hash_combine( size_t lhs, size_t rhs) < lhs ^= rhs + 0x9e3779b9 + ( lhs 6) + ( lhs >> 2); return lhs; > class hashme < public: size_t operator( )( const std::pairint, int> & x) const < return hash_combine( x.first, x.second); > >; int main( ) < // std::map< std::pair, int > qwe; std::unordered_map std::pairint, int>, int, hashme > qwe; for ( int i = 0; i 25; ++i) < qwe.insert( std::make_pair std::pairint, int>, int >( std::make_pair int, int >( i + 0, i + 1), i + 2)); > unsigned int start_time = clock( ); for ( int m = 0; m 20000; ++m) < for ( int i = 0; i 25; ++i) < qwe.find( std::make_pair int, int >( i + 0, i + 1)); > > printf( "-- %d --\n", clock( ) - start_time); return 0; >
Малое количество элементов в мапе наряду с вычислением hash-функции на каждый find, делают map быстрее чем unordered_map.
Такое условие — малое количество элементов в мапе и частый вызов find — отнють не сферический конь, а пример из реальной программы.
Это прекрасный пример, где мап лучше заменить на vector и делать бинарный поиск.
Но куда интересней, что разные компиляторы на разных компах дают разные результаты.
VisualStudio13 unsortered_map 10100 попугаев; map — 14800 попугаев
VisualStudio10 unsortered_map 22000 попугаев; map — 12500 попугаев
Когда я пришёл домой и опробовал это на ноутбуке — я получил противоположный результат: на vs13 Медленней чем на vs10.
Так что жопорукость vs10 отметаем, хотя vs10 — ужасен, но для данной задачи — дело не в нём.
Вариант «собрал под дебагом» тоже отметается — собирал повсякому — результат соизмеримо-одинаковый.
Так что если увидите в коде поиск по мапе или по вектору — не спешите строчить в говнокод. Unordered_map не всегда лучше.
#1
15:30, 24 мар 2015
Это просто к тому что VS очень сильно отстает по качеству stl библиотек . попробуй ещё на gcc
- Frankinshtein
- Постоялец
#2
15:35, 24 мар 2015
А если 10 и 13 сравнить еще между собой по твоим тестам что получится?
Как работает unordered map
Я правильно понял, что есть массив длины n, в качестве индекса для ключа k служит число hash(k)%N, где hash — какая-то хэш-функция?
Сообщ. #6 , 28.04.13, 09:43
Senior Member
Рейтинг (т): 24
Цитата ChaoCheese @ 27.04.13, 13:39
Я правильно понял, что есть массив длины n, в качестве индекса для ключа k служит число hash(k)%N, где hash — какая-то хэш-функция?
Ага, иногда бывают коллизии, когда для разных ключей получается один и тот же индекс. Это тоже рашаемо разными способами.
0 пользователей читают эту тему (0 гостей и 0 скрытых пользователей)
0 пользователей:
- Предыдущая тема
- C/C++: Общие вопросы
- Следующая тема
- Форум на Исходниках.RU
- Программирование
- C/C++
- C/C++: Общие вопросы