Как создать Pandas DataFrame из серии (с примерами)
Часто вы можете захотеть создать pandas DataFrame из одной или нескольких серий pandas.
В следующих примерах показано, как создать pandas DataFrame, используя существующие ряды в качестве строк или столбцов DataFrame.
Пример 1: создание Pandas DataFrame с использованием серий в качестве столбцов
Предположим, у нас есть следующие три серии панд:
import pandas as pd #define three Series name = pd.Series(['A', 'B', 'C', 'D', 'E']) points = pd.Series([34, 20, 21, 57, 68]) assists = pd.Series([8, 12, 14, 9, 11]) Мы можем использовать следующий код для преобразования каждой серии в DataFrame, а затем объединить их все в один DataFrame:
#convert each Series to a DataFrame name_df = name. to_frame (name='name') points_df = points. to_frame (name='points') assists_df = assists. to_frame (name='assists') #concatenate three Series into one DataFrame df = pd.concat([name_df, points_df, assists_df], axis= 1 ) #view final DataFrame print(df) name points assists 0 A 34 8 1 B 20 12 2 C 21 14 3 D 57 9 4 E 68 11 Обратите внимание, что каждая из трех серий представлена в виде столбцов в окончательном кадре данных.
Пример 2: создание Pandas DataFrame с использованием серий в качестве строк
Предположим, у нас есть следующие три серии панд:
import pandas as pd #define three Series row1 = pd.Series(['A', 34, 8]) row2 = pd.Series(['B', 20, 12]) row3 = pd.Series(['C', 21, 14]) Мы можем использовать следующий код для объединения каждой серии в кадр данных pandas, используя каждую серию в качестве строки в кадре данных:
#create DataFrame using Series as rows df = pd.DataFrame([row1, row2, row3]) #create column names for DataFrame df.columns = ['col1', 'col2', 'col3'] #view resulting DataFrame print(df) col1 col2 col3 0 A 34 8 1 B 20 12 2 C 21 14 Обратите внимание, что каждая из трех серий представлена в виде строк в окончательном кадре данных.
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные операции в Python:
Pandas Базовый №2. Создание DataFrame 2
В этом уроке мы научимся создавать DataFrame еще несколькими способами:
- Создать DataFrame из одномерного массива numpy
- Создать DataFrame из двумерного массива numpy
- Создать DataFrame из Series
- Создать DataFrame из Series и словаря
Решение
Сначала нужно импортировать нужные модули.
import numpy as np import pandas as pdСоздать DataFrame из массива numpy
Создаем датафрейм с помощью pandas.DataFrame. В качестве первого параметра передаем np.arange, второй параметр — имена столбцов.
# Создаем DataFrame из одномерного массива numpy pd.DataFrame(np.arange(1, 5), columns=['num'])Создать DataFrame из двумерного массива numpy
В функцию np.array нужно передать список списков. В каждом списке первый элемент будет являться значением для первого столбца, а второй элемент будет являться значением второго столбца.
# Создаем DataFrame из двумерного массива numpy jp_albums = pd.DataFrame(np.array([[1980, 'British Steel'], [1981, 'Point of Entry'], [1982, 'Screaming for Vengeance'], [1984, 'Defenders of the Faith']]), columns=['year', 'album'])Создать DataFrame из нескольких Series
При создании DataFrame из списка Series нельзя сразу задать имена столбцов.
# Создаем DataFrame из Series albums_1 = pd.Series([1986, 'Turbo']) albums_2 = pd.Series([1988, 'Ram it Down']) jp_albums_2 = pd.DataFrame([albums_1, albums_2]) jp_albums_2.columns = ['year', 'album']Создавать DataFrame из словаря серий
Каждая Series — это значения одного столбца.
# Создать DataFrame из Series и словаря albums_3_name = pd.Series(['Painkiller', 'Jugulator']) albums_3_year = pd.Series([1990, 1997]) jp_albums_3 = pd.DataFrame()Что если в одном из столбцов значения есть не для каждой строки
В данном примере для столбца nsongs значения есть не для всех строк. В таком случае в параметре index нужно указать индексы строк, которые нужно заполнить.
# Как произойдет заполнение albums_4_name = pd.Series(['Demolition', 'Angel of Retribution']) albums_4_year = pd.Series([2001, 2005]) albums_4_nsongs = pd.Series([13], index=[0]) jp_albums_4 = pd.DataFrame()Примененные функции
- numpy.arange
- pandas.DataFrame
- numpy.array
- pandas.Series
Курс Pandas Базовый
| Номер урока | Урок | Описание |
|---|---|---|
| 1 | Pandas Базовый №1. Создание DataFrame и запись в CSV | Познакомимся с объектом DataFrame. Научимся его создавать двумя разными способами и научимся записывать его в файл. |
| 2 | Pandas Базовый №2. Создание DataFrame 2 | Изучим еще несколько способов создания объекта DataFrame. В этом уроке мы создадим DataFrame из массива numpy, Series, словаря Series. |
| 3 | Pandas Базовый №3. Отбор строк и столбцов, Размерность, Импорт CSV | Получить информацию о размере DataFrame, отбор строк и столбцов, индексация. |
| 4 | Pandas Базовый №4. Операции со столбцами DataFrame | Операции со столбцами в Pandas. Переименование столбцов, добавление новых столбцов, изменить существующий столбец, удаление столбцов. |
| 5 | Pandas Базовый №5. Операции со строками | Объединение по вертикали методами append и concat, Создание строк вручную, Удаление строк методом drop, Фильтрация строк условием или срезом. |
| 6 | Pandas Базовый №6. Индексы | Зачем нужны индексы, Как задать индекс, Как пользоваться индексами. |
| 7 | Pandas Базовый №7. Категории | Что такое категориальные переменные. |
Как создать pandas DataFrame
DataFrame — это специальная структура данных в очень популярной Python библиотеки pandas. Работа с библиотекой pandas часто заключается в том что нужно создать из данных DataFrame, а дальше что-то делать с этими данными, лежащими в DataFrame.
Есть несколько способов создать DataFrame.
Создать DataFrame из данных, записанных в коде программы
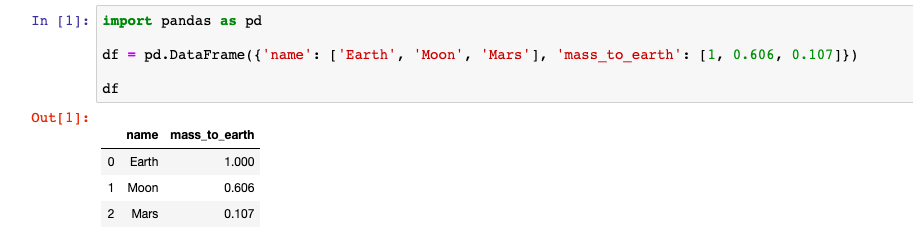
Самый простой способ создать DataFrame — это передать конструктору словарь. Ключи станут названиями колонок, а значения (в которых содержатся списки) станут данными в этих колонках.
import pandas as pd df = pd.DataFrame() Вот пример как это выглядит в Jupyter Notebook:
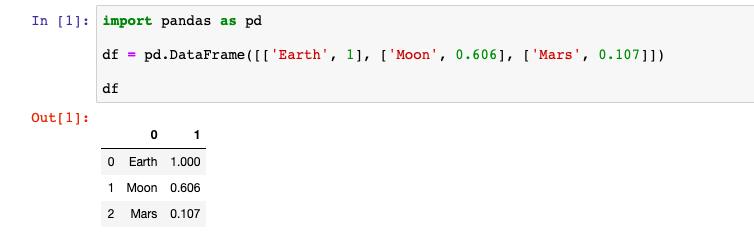
Но не всегда удобно задавать данные по столбцам. Можно создать DataFrame и из данных, которые разбиты по строкам. Для этого в конструктор нужно передать список в котором содержатся данные для строк. Вот пример создания DataFrame с данными как из прошлого примера, но по строкам, а не по столбцам:
df = pd.DataFrame([['Earth', 1], ['Moon', 0.606], ['Mars', 0.107]]) Но при такой записи система не знает как нужно называть столбцы, поэтому названия столбцов становятся числа начиная с нуля. В этих данных две колонки, поэтому они называются ноль и один:
Для того чтобы вместо чисел были осмысленные названия колонок нужно указать список названий в именованном аргументе columns:
df = pd.DataFrame([['Earth', 1], ['Moon', 0.606], ['Mars', 0.107]], columns=['name', 'mass_to_earth']) Но запись данных в коде программы подходит только для очень простых ситуаций, когда данных немного. Обычно данные в DataFrame загружаются из какого-то внешнего источника, например из файла из из базы данных.
Создать DataFrame из csv файла
Вот содержимое файла solar-system.csv:
name,mass_to_earth Earth,1 Moon,0.606 Mars,0.107 Csv — это очень распространенный формат (расшифровывается как «comma separated values»,— «значения разделенные запятыми»). В файле solar-system.csv в первой строчке находится заголовок с названиями столбцов, все остальные строки — это данные. Разделитель между элементами это символ запятая. Для того чтобы загрузить данные из этого файла в DataFrame нужно сказать:
df = pd.read_csv('solar-system.csv') Но иногда формат csv файла выглядит несколько иначе. Бывает что в качестве разделителя используется не запятая, а какой-то другой символ, например точка с запятой или символ табуляции (в это случае файл иногда бывает с расширением .tsv — «tab separated values»). read_csv можно указать какой разделитель использовать:
df = pd.read_csv('solar-system.tsv', sep='\t') Бывает что в csv файле нет заголовка, в первой строке сразу идут данные. В таком случае нужно передать None в именованный параметр header:
df = pd.read_csv('solar-system.csv', header=None) Но в такой ситуации система не будет знать какие названия столбцов использовать и будут использованы цифры начиная с нуля. Для того чтобы установить имена колонок нужно передать параметр names:
df = pd.read_csv('solar-system.csv', header=None, names=['name', 'mass_to_earth']) Создать DataFrame из jsonl файла
Кроме csv еще есть достаточно популярный формат для хранения данных в текстовых файла — jsonl. JSON Lines. При использовании этого формата в каждой строчке файла содержится однострочный json. Это формат лучше чем csv, так как строго регламентирует что должно быть разделителем и как нужно экранировать.
Вот пример содержимого файла solar-system.jsonl:
Для того чтобы загрузить его в DataFrame нужно сказать:
pd.read_json('solar-system.jsonl', lines=True) Создать DataFrame из результата sql запроса
Вот пример кода, который загружает в DataFrame таблицу с результатом sql запроса из sqlite базы данных:
import sqlite3 import pandas as pd cnx = sqlite3.connect(r'/data/db.db') df = pd.read_sql_query("SELECT * FROM users", cnx) Создать DataFrame из файла в интернете
Иногда необходимо создать DataFrame с данными которые лежат где-то в интернете. Например, создать DataFrame из csv файла, который лежит на GitHub.
pandas.read_csv умеет рабоать не только с локальными файлами, но и с файлами, которые лежат в интернете. Вот как загрузить в DataFrame данные про страны из файла по ссылке:
import pandas as pd url = 'https://raw.githubusercontent.com/lukes/ISO-3166-Countries-with-Regional-Codes/master/all/all.csv' df = pd.read_csv(url) Дальше
Создание DataFrame в Pandas путем построчного добавления
В работе с библиотекой pandas для Python часто возникает необходимость создания и последующего заполнения DataFrame построчно. Допустим, есть цель создать пустой DataFrame с определенными именами столбцов, а затем добавить в него строки со значениями.
Сначала создается пустой DataFrame с нужными столбцами. Например, так:
import pandas as pd df = pd.DataFrame(columns=['A', 'B', 'C'])
Затем требуется добавить строку с данными в этот DataFrame. Возможно, первое, что приходит на ум, это использовать метод _set_value() , который позволяет добавить значение в конкретную ячейку DataFrame.
df = df._set_value(index=len(df), col='A', value=1)
Однако, этот подход работает только для одного поля за раз, что не всегда удобно. Да и сам метод _set_value() считается внутренним и его использование не рекомендуется.
Более предпочтительный способ — использование метода append() , который позволяет добавить целую строку за один раз.
new_row = df = df.append(new_row, ignore_index=True)
В этом случае new_row — это словарь, где ключи — это названия столбцов, а значения — это данные, которые должны быть добавлены в эти столбцы. Параметр ignore_index=True говорит pandas игнорировать индекс словаря и присвоить новой строке следующий по порядку индекс.
Таким образом, при работе с pandas и построчным добавлением данных в DataFrame более предпочтительно использовать метод append() . Он позволяет добавлять сразу несколько значений, что делает его более удобным и эффективным.