Аналитик Big Data — чем занимается, и что нужно знать, чтобы им стать?
Совместно с GeekBrains рассказываем, что нужно знать, чтобы стать аналитиком Big Data — даже если у вас нету опыта работы.
Аналитик Big Data нужен, чтобы собирать, хранить и извлекать из огромного количества данных полезную информацию, которую различные компании могут использовать в своих целях.
Факультет Аналитики Big Data онлайн-университета GeekBrains помог нам разобраться, что нужно знать, чтобы стать аналитиком больших данных.
Работа с базами данных — язык запросов SQL
Самый первый и главный навык аналитика больших данных — это умение этими данными оперировать. SQL — язык, который позволяет создавать и менять базы данных, а также выбирать из них нужную информацию, сортировать и фильтровать её. Для аналитика это то же самое, что для математика умение складывать и вычитать числа.
Освоение баз данных можно разбить на такие темы:
- синтаксис SQL;
- CRUD-операции;
- представления, сортировка, фильтрация и объединение данных;
- хранимые процедуры и функции, транзакции, триггеры;
- оптимизация запросов.
Сбор данных и программирование
После того, как вы научились работать с базами данных, нужно понять, как эти данные собирать. Бродить по сайтам, вручную искать и копировать информацию — не вариант. Мы говорим о данных, которые исчисляются терабайтами (не просто же так эти данные называются большими) и обновляются в сети с огромной скоростью. Руками это всё перебрать будет тяжело, не так ли? Для этого нужно уметь работать с API, или даже самому писать парсеры для веб-скрейпинга.
Ещё нужно учесть, что большие данные — это видео, картинки, текст, геоданные и много прочего, собранного в одну неструктурированную солянку. То есть такой датасет очень разнообразен, из-за чего применить универсальное, уже существующее решение для его обработки может быть сложно. Поэтому часто приходится создавать своё, учитывая при этом все особенности конкретной ситуации.
Самые распространённые языки программирования для обработки и визуализации данных — это Python (с библиотеками NumPy, pandas, matplotlib и др.) и R. Но знание дополнительных языков, таких как Java, MATLAB и других, всегда будет в плюс. Так вы будете знать преимущества и недостатки каждого из них и в разных ситуациях сможете подобрать наиболее подходящий.
Для изучения Python и Java мы уже создали дорожные карты, которые помогут изучить эти языки программирования с нуля.
Организация хранения и работы с данными
Большие данные хранить на одном компьютере невозможно. Количество информации так велико, что приходится создавать целые распределённые системы.
Экосистема Hadoop — одна из них, и считается основой для аналитика Big Data. Это набор разных утилит и библиотек для хранения и обработки данных, которые распределены по сотням узлов. Большая часть из этих инструментов написана на Java или Scala, но поддерживаются API на Python.
Экосистема состоит из четырёх модулей:
- набор утилит и библиотек Hadoop Common;
- распределённая файловая система HDFS;
- система управления кластером YARN;
- Hadoop MapReduce.
Математика и анализ данных
Если обработка данных требует от специалиста Big Data хорошей технической подготовки, то для анализа потребуются знания из теории вероятностей (случайные события, дискретные и непрерывные случайные величины, законы распределения и т.д.), а также математической статистики (описательная статистика, проверка гипотез, корреляция величин).
Всё это нужно, чтобы из датасета выделить какие-то полезные данные. А для этого, в свою очередь, понадобится хорошее понимание алгоритмов анализа данных:
- линейной регрессии и градиентного спуска;
- масштабирования признаков;
- логистической регрессии;
- построения дерева решений и случайного леса;
- градиентного бустинга (алгоритм AdaBoost);
- классификации и кластеризации.
Большие данные и машинное обучение идут тандемом — линейная алгебра используется для создания статистической модели и прогнозирования. На основе этого строятся рекомендательные системы. Например такие, как у Netflix или Spotify. Всё вышесказанное подводит нас к следующему пункту.
Аналитику Big Data нужно понимать потребности бизнеса
Быть на «ты» с технологиями безусловно важно, но бизнесу всё равно, как вы будете собирать и обрабатывать данные. Ему нужны инсайты, с помощью которых компании выйдут на новые рынки и определят предпочтения клиентов.
Первый шаг в этом направлении — научиться сознательно спрашивать себя: «Какая информация может помочь клиенту и как он может её применить»? А вот чтобы ответить на эти вопросы, понадобится вникнуть в основы бизнес-аналитики:
- BI-системы;
- OLAP-кубы;
- витрины данных;
- управление данными и прогнозирование;
- умение составлять и интерпретировать отчёты.
Стать аналитиком Big Data — сложная задача, особенно, если у вас нет предыдущего опыта разработки или работы со статистикой. Но сложно — не значит невозможно. Упорство, труд и терпение обязательно приведут вас к этой профессии. Старайтесь посещать конференции, общаться и обмениваться опытом.
Также существует курс с обширной программой от Факультета Аналитики Big Data онлайн-университета GeekBrains, где люди без опыта становятся настоящими аналитиками. У вас тоже получится!
Big Data: что нужно знать о технологии, изменившей мир

Откуда супермаркет через дорогу знает, какие продукты закончились у вас дома, и почему именно их предлагает купить со скидкой? Как стриминговый сервис понимает, что вам понравится новый сериал? Ответ — с помощью анализа больших данных. В последние годы произошел настоящий бум этой технологии, и сегодня на ней завязаны многие, даже обыденные, процессы.
Что такое большие данные

© Gettyimages
Сегодня вряд ли кого-то можно удивить тем, что почти каждый интернет-сервис за считанные секунды угадывает желания пользователя: предлагает подходящие товары, фильмы, музыку и другие виды контента. Без анализа больших данных такое было бы невозможно. Как именно это работает?
Big Data — это большие массивы данных, которые обрабатывают с помощью специальных автоматизированных инструментов и используют для сбора статистики, принятия или обоснования решений, составления прогнозов. По сути, это набор неперсонализированных данных, которые вместе образуют обезличенный портрет пользователя с набором определенных социально-демографических характеристик.
По мере развития интернета и информационных технологий в целом данные накапливаются все в большем объеме. Крупнейшие в мире операторы данных — Google, Microsoft, IBM, Oracle, Amazon и другие — первыми обратили внимание на то, что в них есть потенциал для изучения и практического использования. Они стали активно собирать данные пользователей, анализировать их и применять для улучшения собственных сервисов. Таким образом анализ больших данных открыл перед компаниями возможность анализировать привычки своих клиентов и использовать полученную информацию при разработке различных стратегий развития. Кроме того, в крупнейших вузах мира стали появляться направления по изучению Big Data, а на рынке труда — профильные специалисты.
Где и как собирают Big Data

© Gettyimages
Чтобы от больших данных была польза, необходимо где-то их собирать и обрабатывать. Основные источники Big Data сегодня — поисковики, соцсети и блоги, а также данные компаний, в особенности из сфер e-commerce, телекоммуникаций, foodtech, fintech, сервисов доставки и такси, стриминговых сервисов. Кроме того, большие данные формируются с помощью статистических данных (медицинских, городских, метеорологических, географических и др.), данных «интернета вещей» (IoT) и девайсов.
Вся эта информация хранится в дата-центрах с мощнейшими серверами, которые обеспечивают ее быструю и качественную обработку. Помимо физических серверов, зачастую используются облачные хранилища — так называемые Data Lake («озера данных»), а также платформы Hadoop и Spark на основе открытого кода, созданные специально для хранения и обработки Big Data. Благодаря появлению инструментов, которые значительно упрощают обработку Big Data и снижают стоимость их хранения, аналитика на их основе стала еще более востребованной.
Сценарии применения больших данных

© Gettyimages
Потенциал аналитики больших данных настолько велик, что сегодня ее можно использовать во множестве сценариев и практически во всех сферах. Среди областей, в которых аналитика на основе больших данных сегодня находит применение чаще всего, — промышленность, ретейл, медицина, телекоммуникации.
В промышленности анализ больших данных позволяет предсказывать аварии и оптимизировать производство. Внедрив на предприятии решение на базе «интернета вещей», то есть «умных» датчиков, компания начинает собирать данные, с помощью которых мониторит и анализирует состояние оборудования, предотвращает возможные сбои, моделирует производственные процессы, изучает их эффективность, рассчитывает наиболее экономные модели потребления ресурсов.
Так, например, «умные» датчики на атомных или гидроэлектрических станциях в режиме реального времени мониторят работу большинства систем, основываясь на множестве имеющихся данных. При обнаружении отклонений от нормы датчики моментально срабатывают, позволяя человеку вовремя среагировать и устранить неполадки.
Главная ценность использования больших данных в производстве — оптимизация издержек и снижение себестоимости продукции.
С помощью больших данных производитель может прогнозировать спрос на свою продукцию, ориентируясь на продажи за прошлые периоды, сезонность спроса, условия на рынке, изменения стоимости расходных материалов и т.д. Все эти данные содержатся в общей базе и дают представление обо всем, что может повлиять на производство.
В ретейле большие данные помогают компаниям лучше понимать своих клиентов, оптимизировать логистику и точнее прогнозировать продажи.
Компании анализируют покупки потребителей, выявляют закономерности, которые позволяют точнее рассчитывать спрос на продукцию. Добавляя к этим данным информацию о самих покупателях, которая есть у розничных компаний, ретейлеры делают клиентам персонализированные предложения. А с помощью геоаналитики розничные компании принимают решение об экспансии в другие регионы и точнее рассчитывают логистические цепочки.
К примеру, внедрение инструментов анализа больших данных крупнейшей в мире сети оптово-розничной торговли Walmart позволило увеличить объем выручки от онлайн-продаж с 10% до 15%. Другой пример использования больших данных в этой сфере — улучшение системы рекомендаций. Так, новая рекомендательная система Amazon, основанная на Big Data, стала генерировать треть выручки компании.
Важность использования Big Data в медицине обусловлена тем, что через систему здравоохранения проходит практически каждый житель Земли, а, значит, данные о нем могут дополнить общую картину и помочь медучреждениям работать более эффективно.
Например, анализ больших данных дает возможность исследовать эффективность лечения и профилактики заболеваний. Кроме того, он позволяет разрабатывать новые методы оздоровления населения, прогнозировать спрос на лекарственные препараты, проводить массовый скрининг с целью предотвращения эпидемий.
Электронные медицинские карты являются одним из основных источников данных реальной клинической практики. Централизованный сбор обезличенных медицинских записей в «озера данных», обработка информации, ее структурирование, анализ и изучение позволяют получить огромное количество ценных данных, необходимых для решения различных задач в области здравоохранения, например, для оценки распространенности заболеваний, проведения исследований, использования данных в качестве доказательной базы.
Аналогично ретейлу в телекоме большие данные позволяют собирать более детальную информацию о потребителях и использовать ее, чтобы улучшать предложения по услугам, разрабатывать новые тарифы и сервисы, прогнозировать продажи и т.д.
Одна из самых интересных и полезных областей применения больших данных в телекоммуникациях — предотвращение фрода. Благодаря технологии машинного обучения операторы способны отслеживать спам-звонки и таким образом ограждать абонентов от навязчивой рекламы.
Телеком-операторы — одни из самых крупных владельцев больших данных, что позволяет им предлагать услуги по анализу и обработке Big Data для компаний из других сфер. Например, МегаФон, как одна из ведущих телекоммуникационных компаний, имеет многолетний опыт работы с Big Data. Благодаря партнерам аналитические инструменты МегаФона анализируют данные 98% населения страны.
Ваш гид по профессиям, связанным с данными
Помимо разработки программ, недавно в мире ИТ появилось большое направление работы с большими данными. У компаний есть множество источников данных, теперь нужно научиться извлекать из них полезные знания.
В этом руководстве — введение в эту сферу, основные понятия и разбор карьерных перспектив для тех, кто думает стать дата-сайентистом или инженером данных.
Что такое бигдата
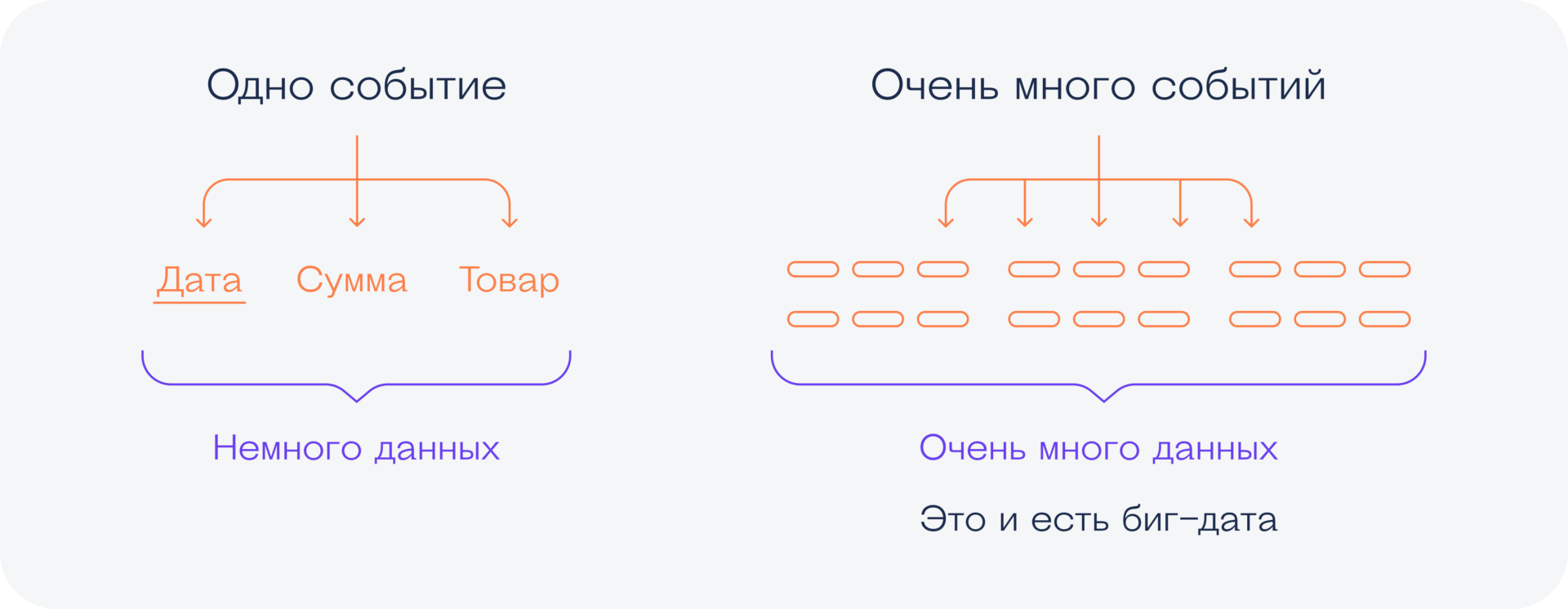
Big data, или «большие данные», — это термин, обозначающий огромные массивы данных, которые накапливаются в каких-то больших системах.
Например, человек в Москве совершает 5–6 покупок по карте в день, это около 2 тысяч покупок в год. В стране таких людей, допустим, 80 миллионов. За год это 160 миллиардов покупок. Данные об этих покупках — бигдата.
В банках какой-то страны каждый день совершаются сотни тысяч операций: платежи, переводы, возвраты и так далее. Данные о них хранятся в центральном банке страны — это бигдата.
Ещё бигдата: данные о звонках и СМС у мобильного оператора; данные о пассажиропотоке на общественном транспорте; связи между людьми в соцсетях, их лайки и предпочтения; посещения сайтов; данные о покупках в конкретном магазине; данные с шагомеров и тайм-трекеров; скачанные приложения; открытые вами файлы и программы.
Какие-то из этих данных уже накоплены и требуют анализа. Какие-то накапливаются прямо сейчас, и бизнес хочет принимать на основе этих данных правильные решения: кому что предлагать, какие продукты выпускать, какие скидки делать, как подстраивать предложение под спрос и т. д. Тут на сцену выходят специалисты по данным: сайентисты, инженеры и аналитики.
Что такое Data Science
Дата-сайентисты — люди, которые занимаются большими данными: придумывают, как получать из них полезные выводы быстро и желательно автоматически.
В каком-то смысле это аналитики — то есть вы говорите им: «Ребята, вот данные, нужно по ним получить ответ на такой-то вопрос».
Но также дата-сайентисты работают намного шире. Они должны:
- Разбираться в источниках данных.
- Понимать, как собирать данные и готовить их для анализа.
- Уметь извлекать знания из данных — как аналитики.
- Уметь автоматизировать извлечение данных и выводов — через визуализацию, алгоритмы и нейросети.
- В идеале — вообще создавать автономные системы принятия решений на основе данных, чтобы все данные собирались автоматически, а выводы поставлялись бесперебойно и не требовали участия человека.
Идеальный проект для дата-сайентиста — система рекомендация товаров на основании данных о том, как человек сидит в нашей соцсети. Представьте, сколько измерений данных можно из этого извлечь — начиная с его анкеты, заканчивая скоростью его скролла. И насколько сложно по массе всех его данных научиться автоматически отбирать нужные ему товары нужных рекламодателей. Вот это — прямо золотой пример задачи сайентиста.
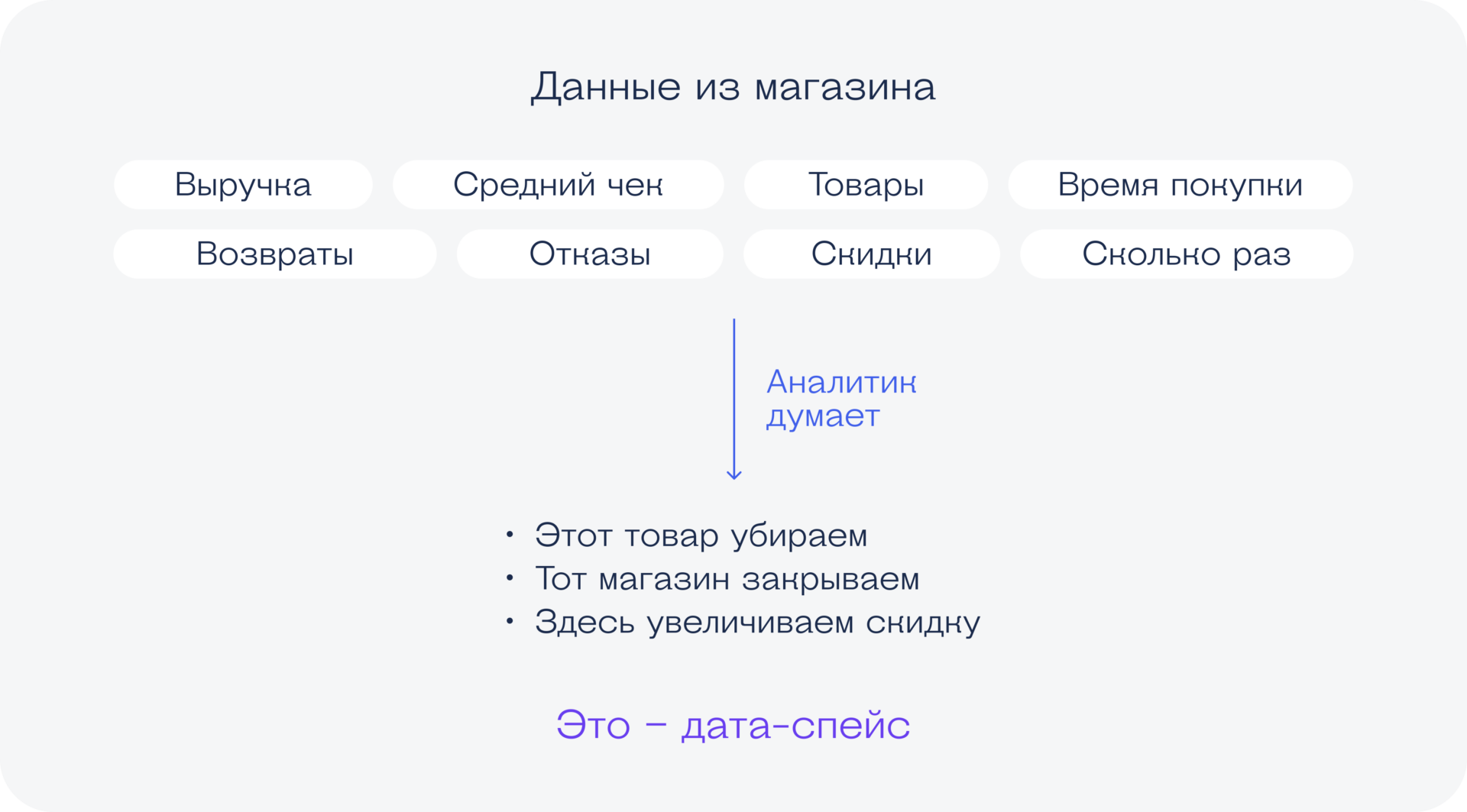
Ещё пример: мы управляющая компания магазина «Пятёрочка». По всей стране у нас открыты магазины. Мы можем попросить дата-сайентиста создать такую систему, которая показывала бы, какие магазины можно безболезненно закрыть, не упав по выручке ниже определённого порога. Гипотеза в том, что некоторые «Пятёрочки» стоят слишком плотно друг к другу, а людям столько точек не нужно. Вот сайентист должен будет придумать, как постоянно и системно отвечать на этот вопрос.
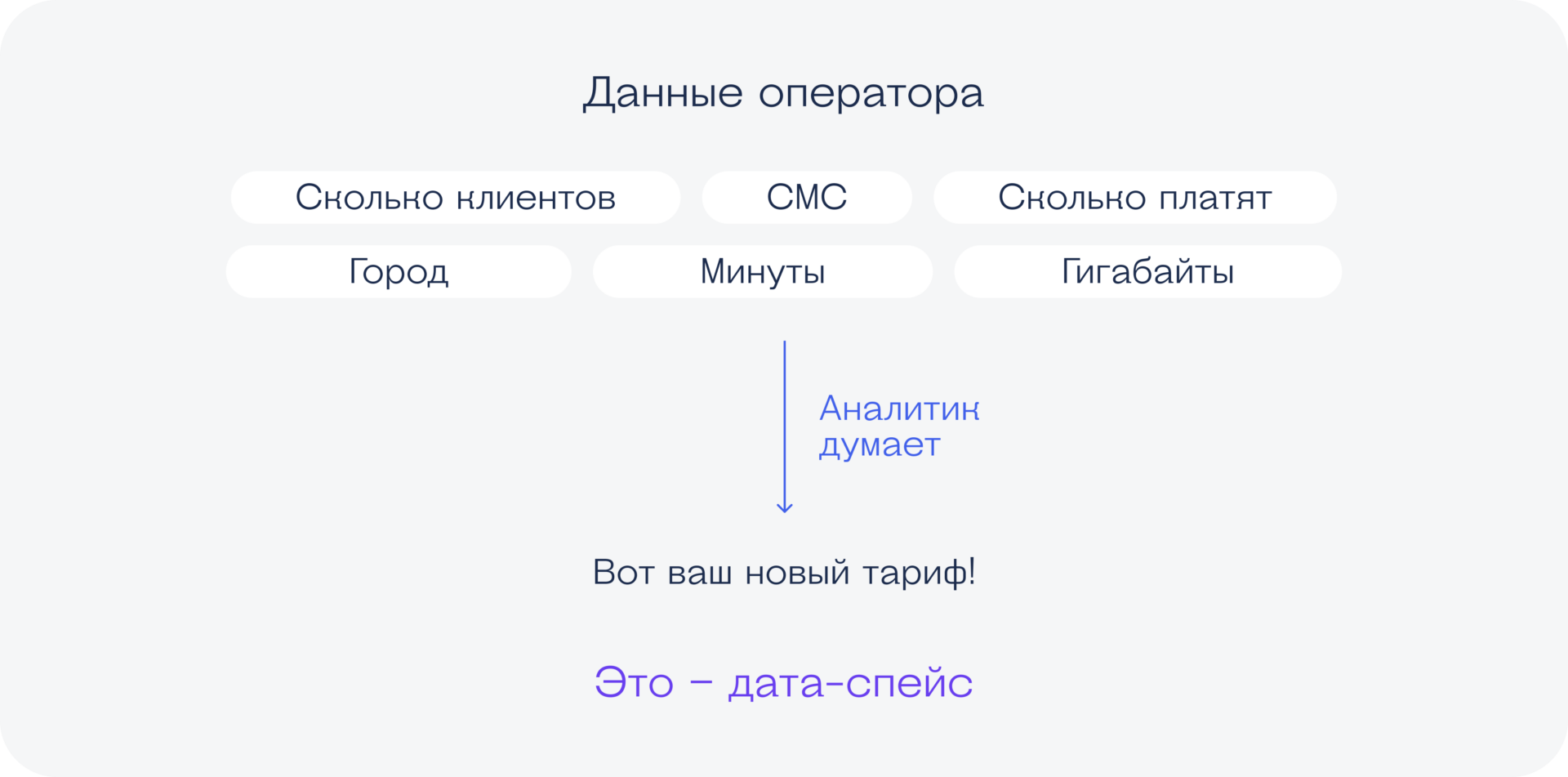
Ещё пример. Мы мобильный оператор. Мы хотим выпускать тарифы, которые опережают желания потребителей. Мы отдаём нашу клиентскую базу и данные о поведении клиентов дата-сайентисту, и тот создаёт для нас модель, которая предсказывает следующий актуальный тариф для нужных нам людей. Алгоритм как-то следит за поведением абонентов, выявляет тенденции, строит выводы: «Вот этой группе людей нужно +30 гигабайт, они за это готовы заплатить ещё 300 ₽».
Что такое нейросети и как они связаны с дата-сайенсом
Один из прорывных инструментов дата-сайентиста — нейросети. Это не единственный инструмент, но важный.
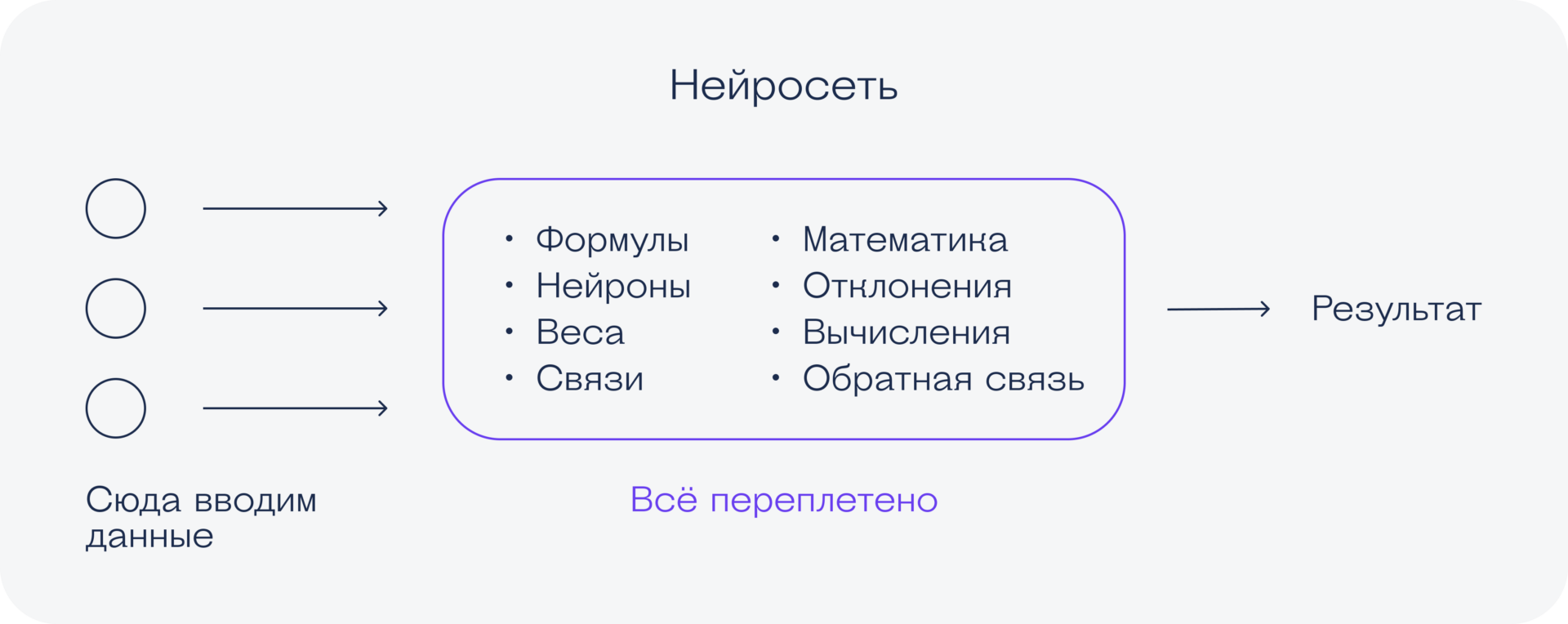
Нейросеть — это сложная база данных, в которых ячейки связаны между собой формулами. Данные поступают с одного конца базы данных, обрабатываются через множество формул и выдаются с другого конца.
Если нейронка правильно «обучена», то эти данные могут быть полезны в народном хозяйстве. Настройка этих формул — задача специалиста по машинному обучению или дата-сайентиста.
Примеры, зачем может быть полезна нейросеть для бизнеса и трудоустройства:
- На основе предыдущих покупок человека предсказать, что ему может быть интересно дальше.
- Выявить мошеннические схемы, отмывание денег, попытки взлома наших систем сложными методами.
- На основании исторических данных о погоде предсказать завтрашнюю.
- Подогнать текст, вёрстку или дизайн сайта под предпочтения и поведение конкретного клиента (автоматически).
- На основании данных о взаимодействии менеджеров и клиентов подобрать идеальные пары, чтобы клиентам было приятно звонить в вашу компанию.
Можно представить, что правильно обученная нейросеть — это очень быстрый прогнозист. Он ошибается в 2% случаев, но в 98% случаев он заменяет живого человека, который строит гипотезы и предполагает будущее.
Где научиться писать нейросети:
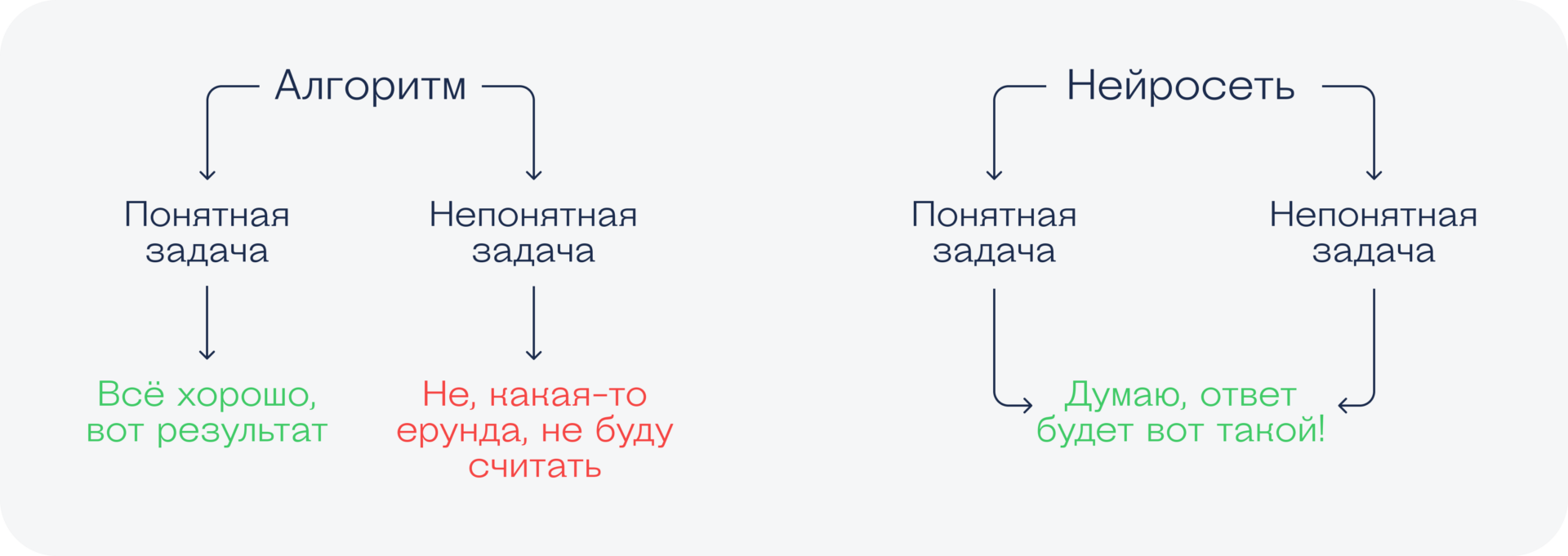
Чем нейросети отличаются от обычных алгоритмов
Вот самое простое отображение структуры нейросети. Слева ячейки ввода данных, справа ячейки вывода данных, а между ними — какой-то скрытый слой, в котором нейросеть совершает свои математические вычисления. Пока что это может быть непонятно, но мы ещё расскажем об этом отдельно.
В классических алгоритмах разработчики сразу прописывают правильную последовательность действий, которые дают какой-то предсказуемый результат. Например, разработчик пишет программу для расчёта площади квартиры по чертежу, и там пошагово описаны все действия: умножь, сложи, вычти и т. д. Если посмотреть на этот алгоритм, будет понятно его устройство, в него можно внести изменения.
Нейросетям вместо алгоритмов дают много заранее правильно решённых задач. Например, десять тысяч планов квартир с уже прописанными площадями. И нейросеть начинает угадывать, какой результат от неё ожидают. Отдельный алгоритм говорит ей, правильно она угадала или нет, и со временем она учится угадывать всё более правильно.
По ходу обучения у нейросети формируются связи, которые позволяют ей угадывать полезный результат. Какие это связи, никто не понимает: мы можем их пронаблюдать, но не всегда можем понять принцип, по которым они формируются.
Что такое Machine Learning
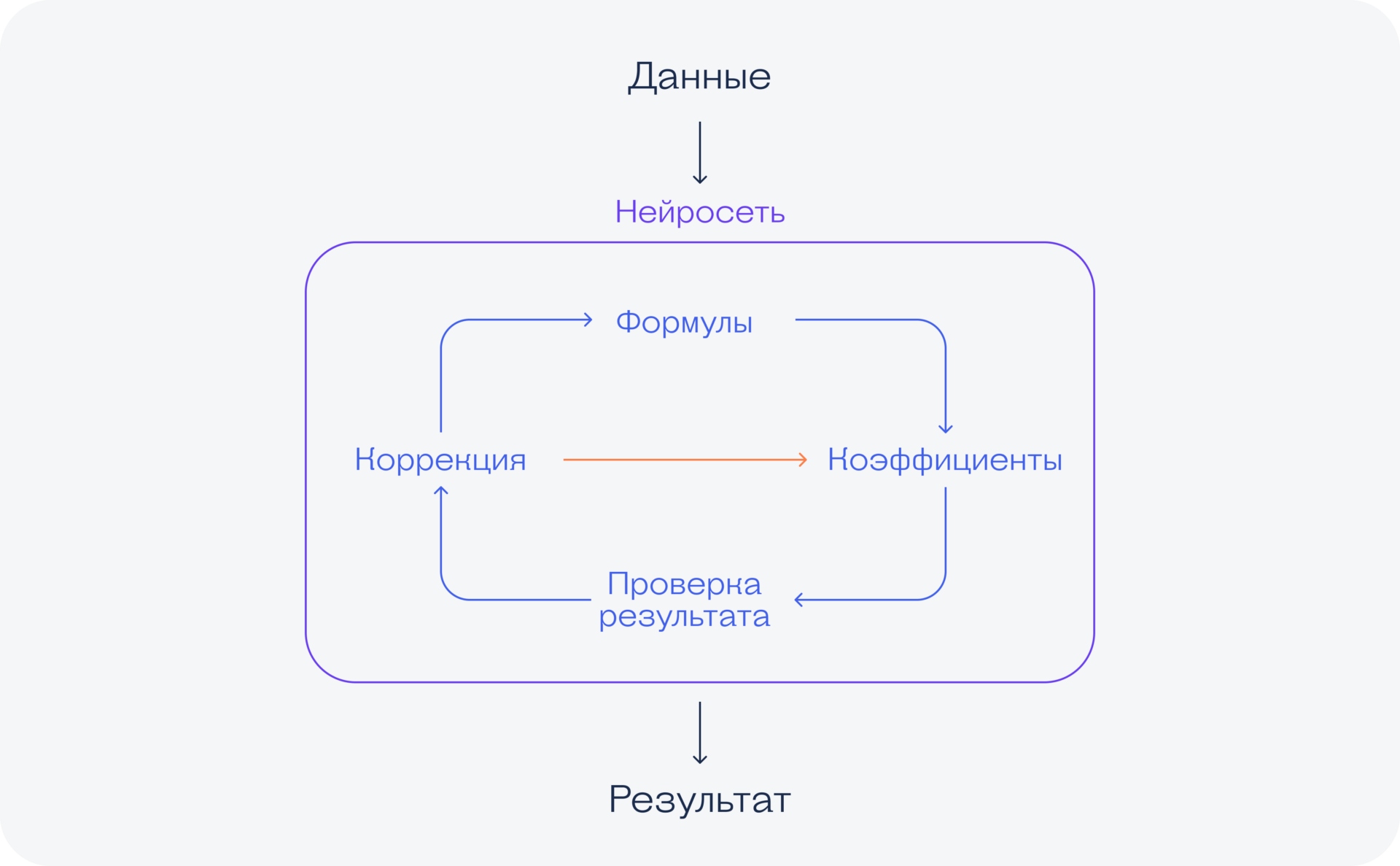
Machine Learning («машинное обучение») — это когда нейросеть учат работать правильно, чтобы она могла заранее отличить хороший свой ответ от плохого и дать только хороший ответ.
Суть обучения нейросети — задать нужные формулы, чтобы при вводе определённого типа данных мы получали достаточно качественные результаты вычислений.
Обучение происходит на большом массиве данных: закидываем в нейросеть много задач с одного конца и много правильных ответов к этим задачам с другого конца. С помощью специального математического колдовства нейронка учится выдавать правильные ответы не только на эти задачи, но и на другие похожего вида.
Почему о дате и нейросетях всегда говорят через запятую
Эти сферы действительно тесно переплетены. Нейросети очень нужны для решения человеческих задач по автоматизации, а для работы нейросетей нужно очень много данных. В свою очередь, благодаря нейросетям можно извлекать новые данные о поведении людей и работе механизмов. И так по кругу: больше данных, больше нейросетей, ещё больше данных и т. д.
В итоге аналитики, сайентисты и дата-инженеры тянут на себе всё это хозяйство: и собирают данные, и автоматизируют, и обучают, и тестируют. Всё рядом, всё похоже, всё пересекается.
Профессии в бигдате
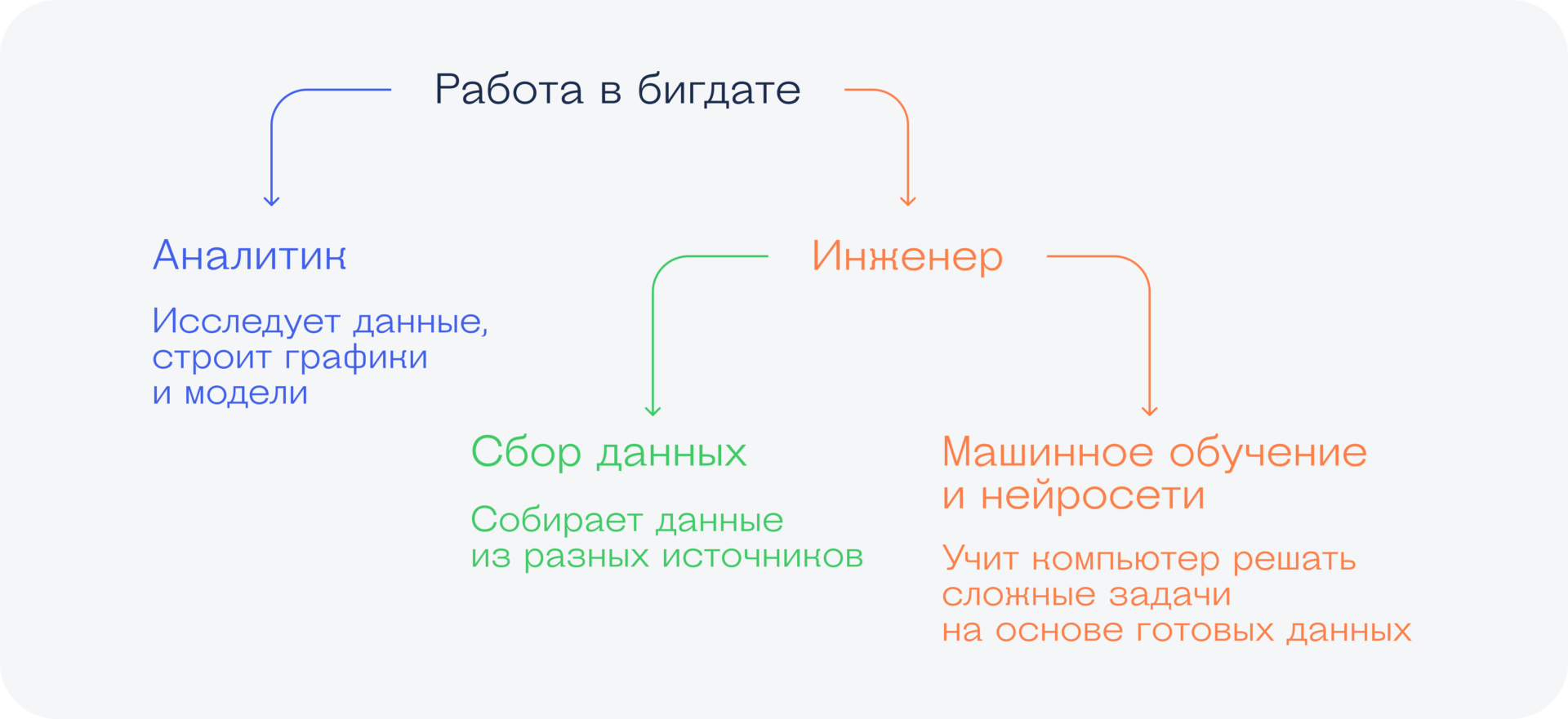
Бигдата — это несколько направлений в ИТ. У них общая основа, но различаются инструменты и подход к работе. И хотя люди постоянно переходят из одной сферы в другую, а термины ещё не устоялись до конца, всё равно для порядка нужно как-то их разделить:
- Аналитики работают с уже собранными данными — приводят их в порядок, анализируют, строят графики и модели. Иногда говорят, что аналитик занимается разовыми задачами.
- Инженеры и дата-сайентисты занимаются сбором данных и машинным обучением. Можно с некоторой уверенностью сказать, что инженер больше про сбор, а сайентист про обучение, но это очень условное разделение.
Чем отличаются аналитики от дата-сайентистов
На самом деле разделение — чистая условность. Но можно представить так:
- Работа дата-сайентиста в том, чтобы создать механизм обработки и анализа данных. Это может быть алгоритм на Python, обученная нейросетевая модель, какой-то механизм получения и очистки данных.
- Работа аналитика в том, чтобы задать правильные вопросы и получить полезные ответы. Для этого он может использовать механизмы, созданные сайентистами, или какие-то ещё инструменты.
- Если не лезть в машинное обучение, то аналитик и дата-сайентист — это очень похожие профессии. Но если речь про машинное обучение, то там обычно дата-сайентисты знают гораздо больше математики и намного лучше разбираются в сложном программировании.
Чем занимаются аналитики данных
Задача аналитика — обработать большой массив информации и сделать на его основе какие-то выводы. Примеры:
- какой товар и по каким причинам продаётся лучше всего в такой-то период;
- в какое время лучше всего привозить свежую выпечку, чтобы она не залёживалась на прилавке до вечера;
- какие метрики влияют на прибыль и выручку от клиента, а какие нет;
- какую промоакцию провести в этом месяце, чтобы она имела смысл для клиента и была коммерчески целесообразной.
В общем случае — «Какое решение лучше всего принять, исходя из имеющихся данных?»
Чтобы презентовать результаты своей работы в понятном виде, аналитики используют сервисы визуализации данных, например Tableau. А чтобы получать результаты — техники и методы анализа; чем дольше работаешь, тем больше в них вникаешь.
Типичный запрос для аналитика в торговой компании будет звучать так: «Нам кажется, что нужно показывать клиентам из Сочи рекламу надувных игрушек для бассейна, а жителям из Сибири — рекламу лыж. Реклама и того и другого будет стоить нам 50 млн рублей в год. Есть какие-то данные, чтобы обосновать или опровергнуть эту гипотезу? Помоги нам не потерять эти 50 млн». Можно сказать, что запрос очевидный и интуитивно понятный, но готовы ли мы поставить 50 млн на свою интуицию?
Аналитик помогает посмотреть на разные вопросы в разрезе реальных данных, а не интуитивных догадок. Это могут быть данные из прошлого или даже прогнозы, построенные на каких-то моделях. Главное — аналитик не подгоняет данные под нужные выводы, а показывает реальность: «Вот о чём говорят данные».
Где научиться:
Чем занимаются инженеры по сбору данных
Инженер — это технический специалист, который помогает решить вопросы обработки, сбора и хранения данных так, чтобы всем остальным это было удобно, данные не потерялись и вообще всё было хорошо.
Эту работу может сделать и аналитик, и инженер машинного обучения, но иногда сбор становится отдельной задачей. В этом случае инженер:
- пишет скрипт, который будет собирать информацию из нужных источников;
- настраивает базу данных;
- следит за правильностью собранных данных и корректирует скрипт, если что-то идёт не так;
- фильтрует данные, чтобы в базу попадало меньше мусора.
Для этого достаточно общих знаний из бигдаты плюс знание API того сервиса, откуда забираем данные. Но этому всё равно нужно учиться — сложно будет прийти в такой проект, если знаешь только базы данных или у тебя начальные навыки программирования на Python.
Где научиться:
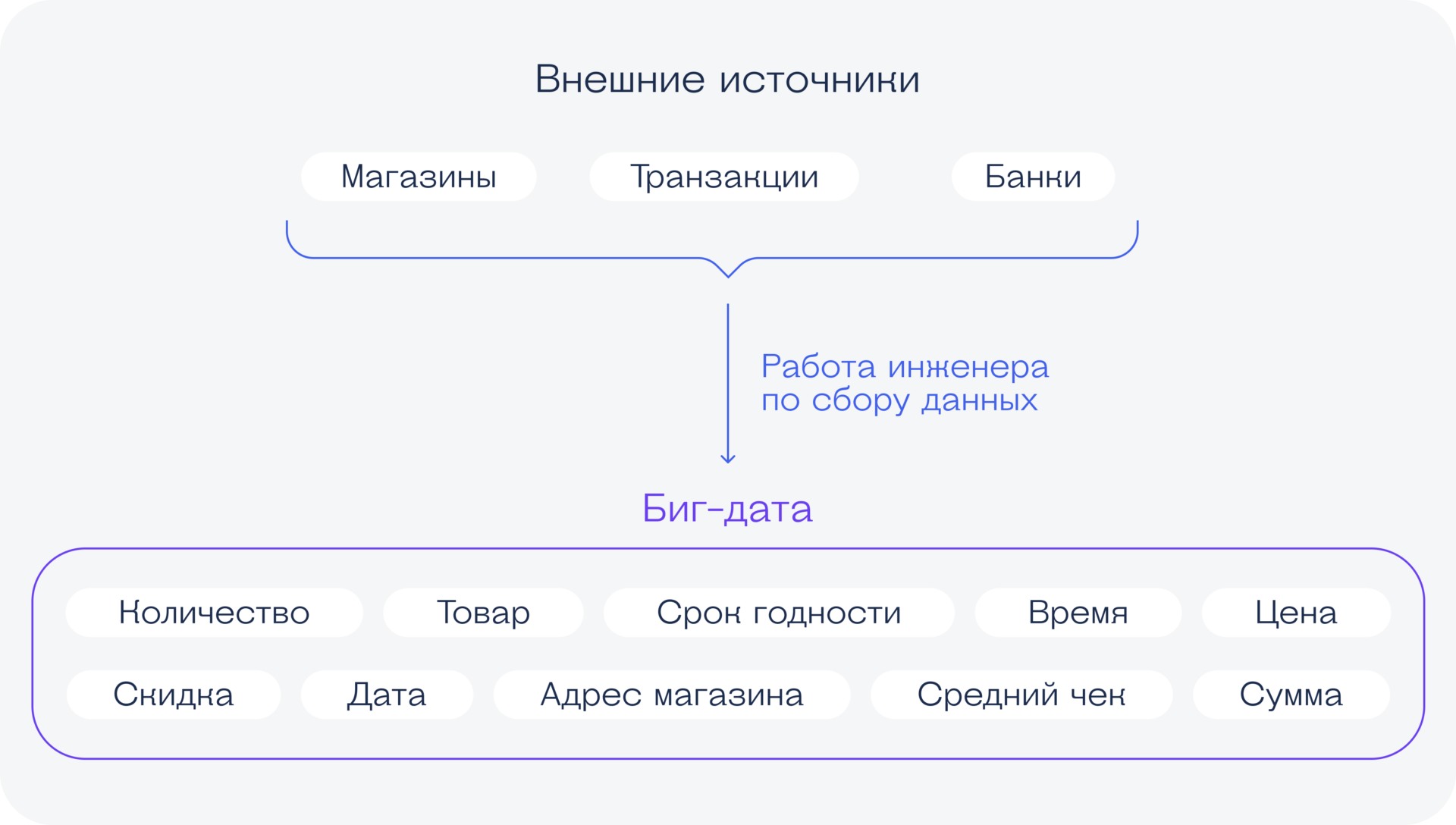
Что делают специалисты по Data Science
У этих ребят задачи технически намного сложнее, потому что они чаще всего работают с нейросетями — обучают их или программируют самостоятельно. Для этого надо знать много математики:
- теорию вероятностей,
- статистику,
- математическую логику,
- матан,
- численные методы,
- работу с векторами и матрицами,
- теорию рядов.
Кроме этого, будущим дата-сайентистам дают углублённые знания Python и учат их работе с нейросетями. Это значит — много программирования, библиотеки, фреймворки, API, базы данных, тестирование и облачные вычисления. В итоге всё это позволяет разработчикам создавать нейросети, заниматься компьютерным зрением, искусственным интеллектом, голосовыми помощниками и вообще быть впереди компьютерной науки.
Где научиться:
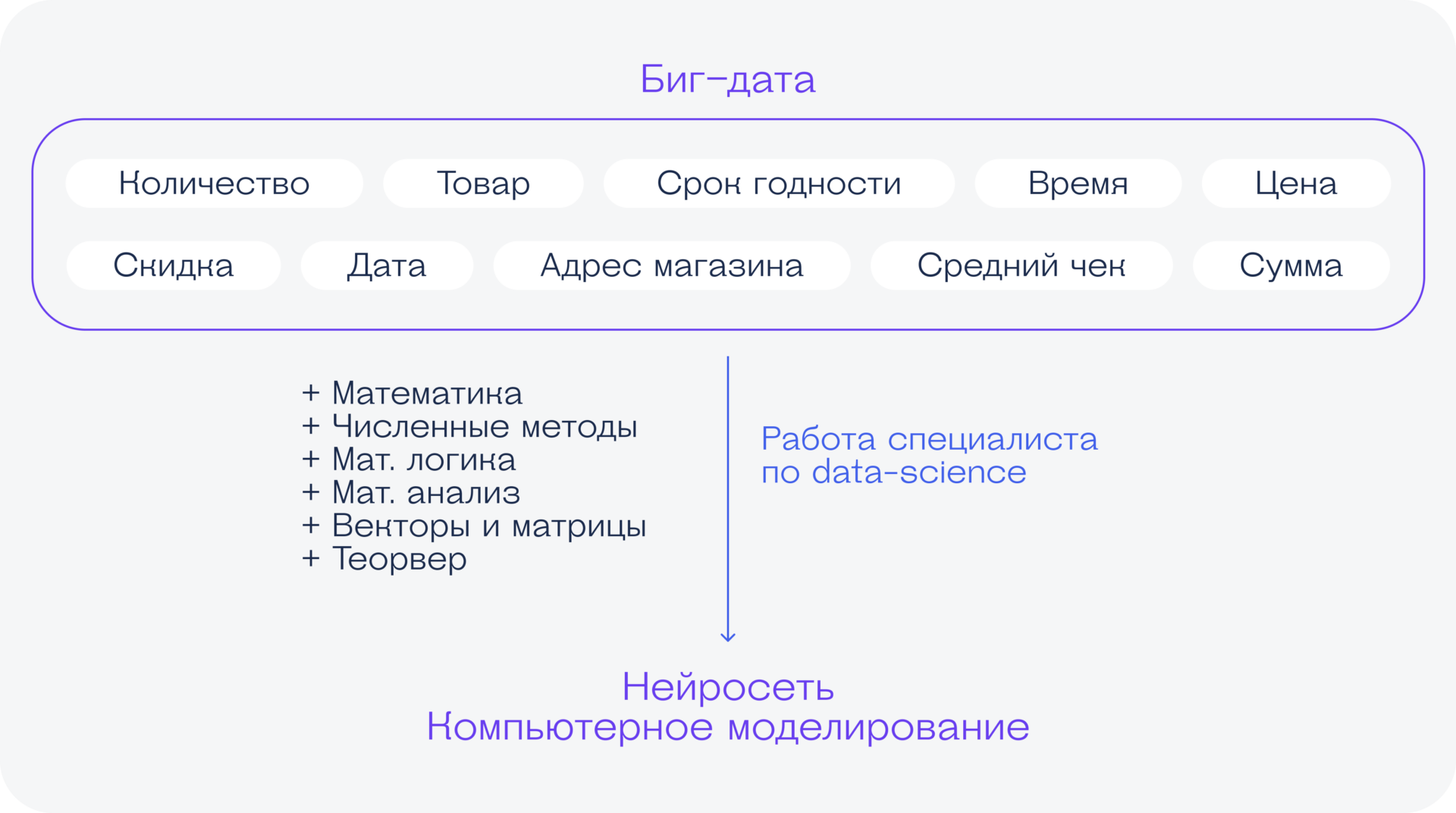
Что нужно знать, чтобы полноценно заниматься бигдатой
Вот начальный список навыков, знаний и умений, которые нужны для старта в работе.
Математическая логика, линейная алгебра и высшая математика. Без этого не получится построить модель, найти закономерности или предсказать что-то новое. Для начала работы аналитиком можно знать это на базовом уровне.
Есть те, кто говорит, что это всё не нужно и главное — писать код и красиво делать отчёты, но они лукавят. Чтобы обучить нейронку, нужна математика и формулы; чтобы найти закономерности в данных — нужна математика и статистика; чтобы сделать отчёт на основе большой выборки данных — ну вы поняли. Математика рулит.
Знание машинного обучения. Работа дата-сайентиста — анализ данных огромного размера, и вручную это сделать нереально. Чтобы было проще, они поручают это компьютерам. Поручить такую задачу — значит настроить готовую нейросеть или обучить свою. Поручить программисту обычно это нельзя — слишком много нужно будет объяснить и проконтролировать.
Программирование на Python и R. Python — идеальный язык для машинного обучения и нейросетей. На нём можно быстро написать любую модель для первоначальной оценки гипотезы, поиска общих данных или простой аналитики.
R — язык программирования для статического анализа. Если вам нужно прикинуть, как лайки на странице зависят от количества просмотров или до какого места читатель гарантированно долистывает статью (чтобы поставить туда баннер), — R вам поможет. Но если вы не знаете математику — не поможет.
Умение получать данные. Не всем везёт настолько, что они сразу получают готовые наборы данных для обработки. Чаще всего нужно самим выяснить, где, откуда, как и сколько брать данных. Здесь обычные программисты им уже могут помочь — спарсить сайт, выкачать большую базу данных или настроить сбор статистики на сервере.
Визуализация. Ещё один важный навык в этой профессии — умение наглядно показать результаты работы. Какой толк в графиках, если никто, кроме автора, не понимает, что там нарисовано? Задача дата-сайентиста — представить данные наглядным образом, чтобы зрителю было легче сделать нужный вывод.
Минимальная база для старта в машин-лёрнинге
Если из всех направлений вы планируете выбрать машинное обучение, то вот что нужно знать на старте — без этого не получится полноценно разобраться в предмете:
Python — основной язык программирования нейросетей и анализа данных. Сначала изучите его, потом беритесь за всё остальное.
Библиотеки машинного обучения — Pytorch и TensoFflow. С ними будет в сто раз легче, чем делать всё самому с нуля.
Виды и различия нейросетей: свёрточные, рекуррентные, цепи Маркова и все остальные. Не бывает «просто нейросети» — каждая сеть построена по определённой архитектуре и решает конкретные задачи.
Векторы и матрицы. Большинство нейросетей — это работа с матрицами, большими и маленькими, простыми и сложными, бинарными или комплексными.
Очистка данных. Если за основу взять непроверенные, неподготовленные и неочищенные данные, то нейросеть будет работать плохо и выдавать неправильные решения.
Почему школьной математики не хватит для полноценного дата-сайенса
В школе нам дают базу и основу, чтобы мы имели представление о предмете и могли посчитать разные несложные штуки. Для работы с бигдатой этого недостаточно: у больших данных есть свои математические законы, которые нужно знать.
Кроме обычной математики, хорошему дата-сайентисту нужно знать много из институтского курса физмата: матан, теорию вероятности, дифференциальное исчисление и прочие направления математики. Даже если вы не пишете нейросети, для работы аналитиком тоже требуется высшая математика — например, выяснить, с каким отклонением коррелируют данные на графике с результатами теоретических прогнозов или насколько можно доверять собранным статистическим данным. Школьной математики для этого точно будет недостаточно.
При программировании нейросетей иногда даже знаний дата-сайентиста будет недостаточно. Например, для распознавания точных форм объекта на фотографии нужно уметь работать с кривыми, заданными различными формулами, считать пространственные координаты и определять глубину объекта. Всё это — отдельные области математики, без которых не получится собрать нужную нейросеть.
Где подтянуть математику:
Примеры и задачи из жизни аналитиков
Антон Леонов, аналитик в X5 Retail Group
Часть наших задач можно описать так: есть какой-то отчёт, нам нужно сделать так, чтобы он формировался автоматически и с нужными данными. Вот пара примеров:
�� В разных магазинах могут различаться ходовые и неходовые товары. Например, в одном магазине любят печенье «Юбилейное», а в другом его почти не берут. Мы хотим понимать по каждому конкретному магазину, сколько закупили, сколько продали, сколько списали каждой позиции. Затем мы смотрим, какие товары двигаются хуже, и даём сигнал людям на местах, например, устроить промо определённых товаров в тех магазинах, где с ними есть проблемы.
�� Сейчас мы автоматизируем отчётность, которая идёт руководителям сетей. Раньше коллеги руками собирали эксель-файл, затем руками переносили данные на слайды — не очень надёжный подход. Мы делаем систему, которая сама ходит за данными, а потом их визуализирует, руками делать ничего не нужно, ошибок меньше.
Бывает так, что данные есть в какой-то устаревшей системе. Тогда нужно провести реверс-инжиниринг, разобраться, как она работает. Или не хватает бизнес-требований, тогда мы их пишем самостоятельно.
Анастасия Никулина, дата-сайентист Росбанка
В 2019 году мне предложили работать в рекламном агентстве OMD OM Group — так я выросла до мидла и решила полностью погрузиться в дата-сайенс.
В агентстве мы анализировали соцсети, собирали пользовательские данные и помогали маркетологам создавать эффективную рекламу — мы делали так, чтобы объявления доходили до целевой аудитории. Чтобы мужчины не получали предложений о женской косметике, а девушки — препараты от облысения (это шутка: реклама бывает разной и зависит от многих факторов).
Тагир Хайрутдинов, главный аналитик в «Альфа-Банке»
Кто такой аналитик? Это человек, который на основании данных может помочь бизнесу ответить на вопросы. На основании этих цифр бизнес будет принимать решения, важные для себя. Круто ощущать себя тем человеком, который подходит к какой-то задаче с разных сторон. Смотрит, считает какие-то метрики, думает в целом, как работает продукт. И этим можно даже влиять на продукт с какой-то стороны.
У аналитиков очень нетривиальные задачи. Если ты разработчик, ты пишешь код, ты занимаешься разработкой. А если ты аналитик, например в «Озоне», то в один день к тебе придёт продакт и скажет: «Слушай, у нас есть гипотеза, что при поиске приложение показывает в феврале в поисковой выдаче по запросу „куртка“ один и тот же товар человеку, который живёт в Сочи, и человеку, который живёт в Сибири. Логично бы сибиряку показывать пуховик на минус 30, а чуваку из Сочи показывать ветровку или весеннюю куртку. Звучит очевидно, но нужно проверить цифрами, сможешь?».
И ты сидишь, и ты думаешь, пытаешься проанализировать, как можно подойти к этой задаче, как можно посчитать, как можно на основании цифр показать, что это действительно так. А может, это окажется не так — и это тоже результат.
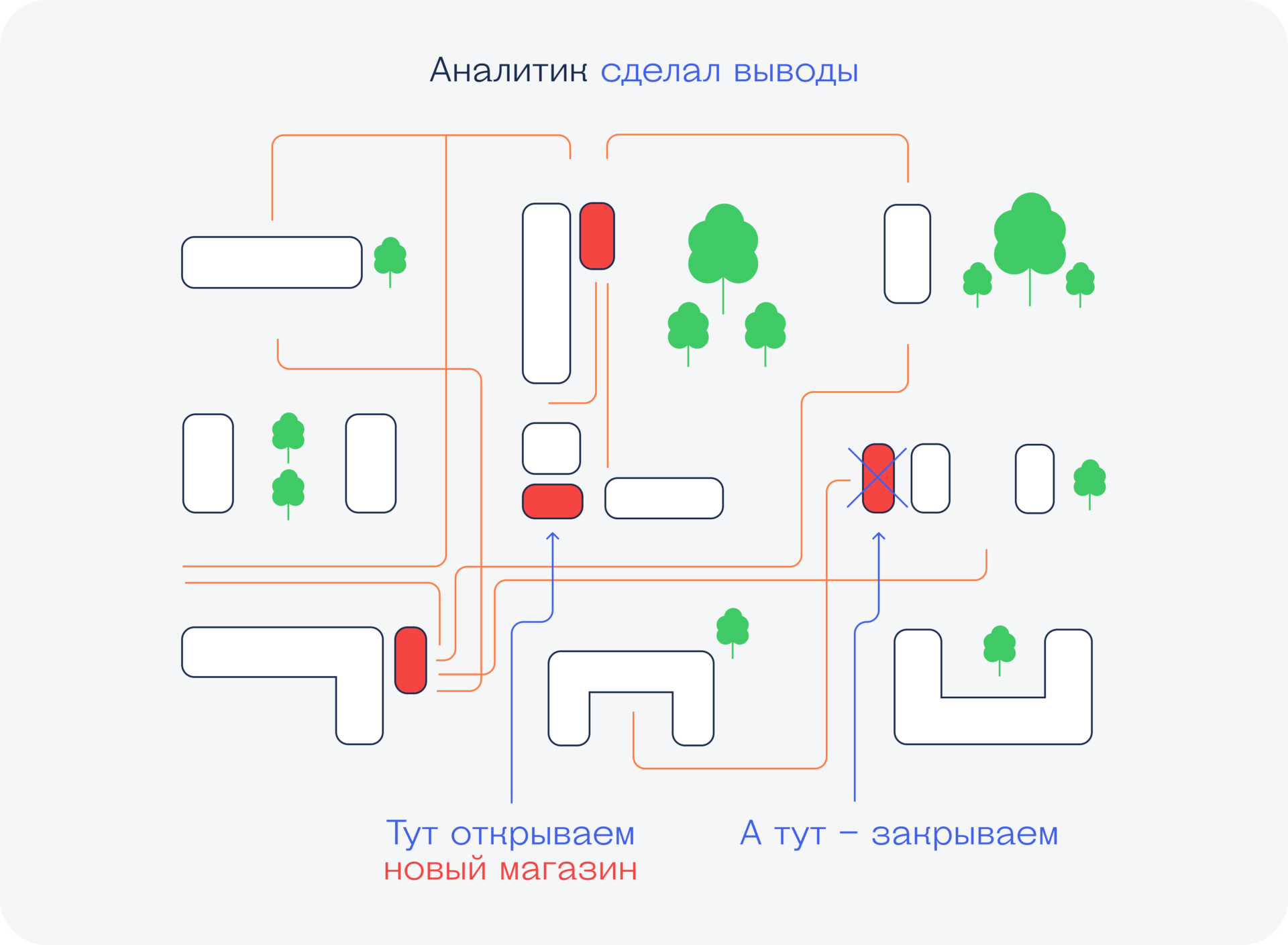
Фантазийный пример: Data Science и аналитика для принятия решения об открытии магазина
Возьмём пример, где данные, аналитика и модели предсказаний могут стоить компании миллионы, а экономить (или зарабатывать) сотни миллионов.
Иногда, стоя на перекрёстке, можно увидеть вокруг несколько магазинов одной и той же сети: «Пятёрочки», «Дикси» или любые другие. Некоторые думают, что в этом нет никакого смысла: зачем строить новый магазин, когда через дорогу есть точно такой же?
Вот как к этому вопросу могли бы подойти магазины, работай они с данными профессионально. Сейчас будет упрощённая модель, но по сути верная.
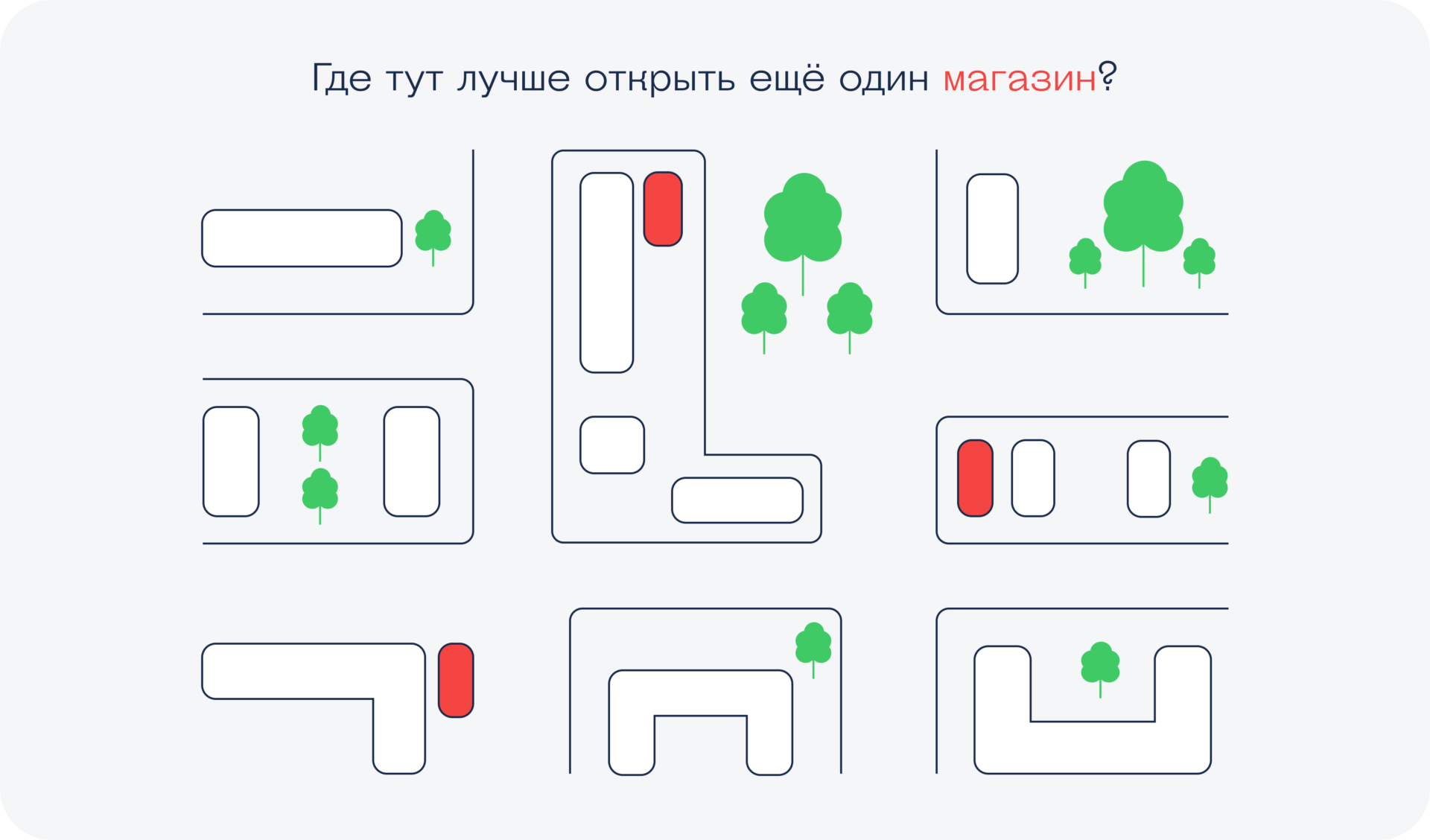
Магазин типа «Пятёрочки» надо открывать там, где ходят люди. Никто специально не поедет в соседний район ради продуктового магазина, поэтому для начала нужно ответить на такие вопросы:
- Где в этом районе ходят люди?
- По каким маршрутам?
- Сколько их в разное время?
- А где точно не ходят?
Чтобы это узнать, можно воспользоваться бигдатой: собрать её или заполучить. Для этого зовут инженера по сбору данных, который находит оптимальный способ найти нужную информацию, например:
- У сотового оператора.
- Поставить Wi-Fi- и Bluetooth-точки в разных местах нужного района.
- Поставить камеры с распознаванием лиц.
Всё это может придумать и в какой-то степени реализовать дата-инженер.
После того как мы получили карту перемещений, её нужно проанализировать и найти те точки, где проходит максимальное количество пешеходов. В идеале — найти такие места, где пешеходный поток не заходит в магазины конкурентов или где их вообще нет. Это уже задача аналитика данных.
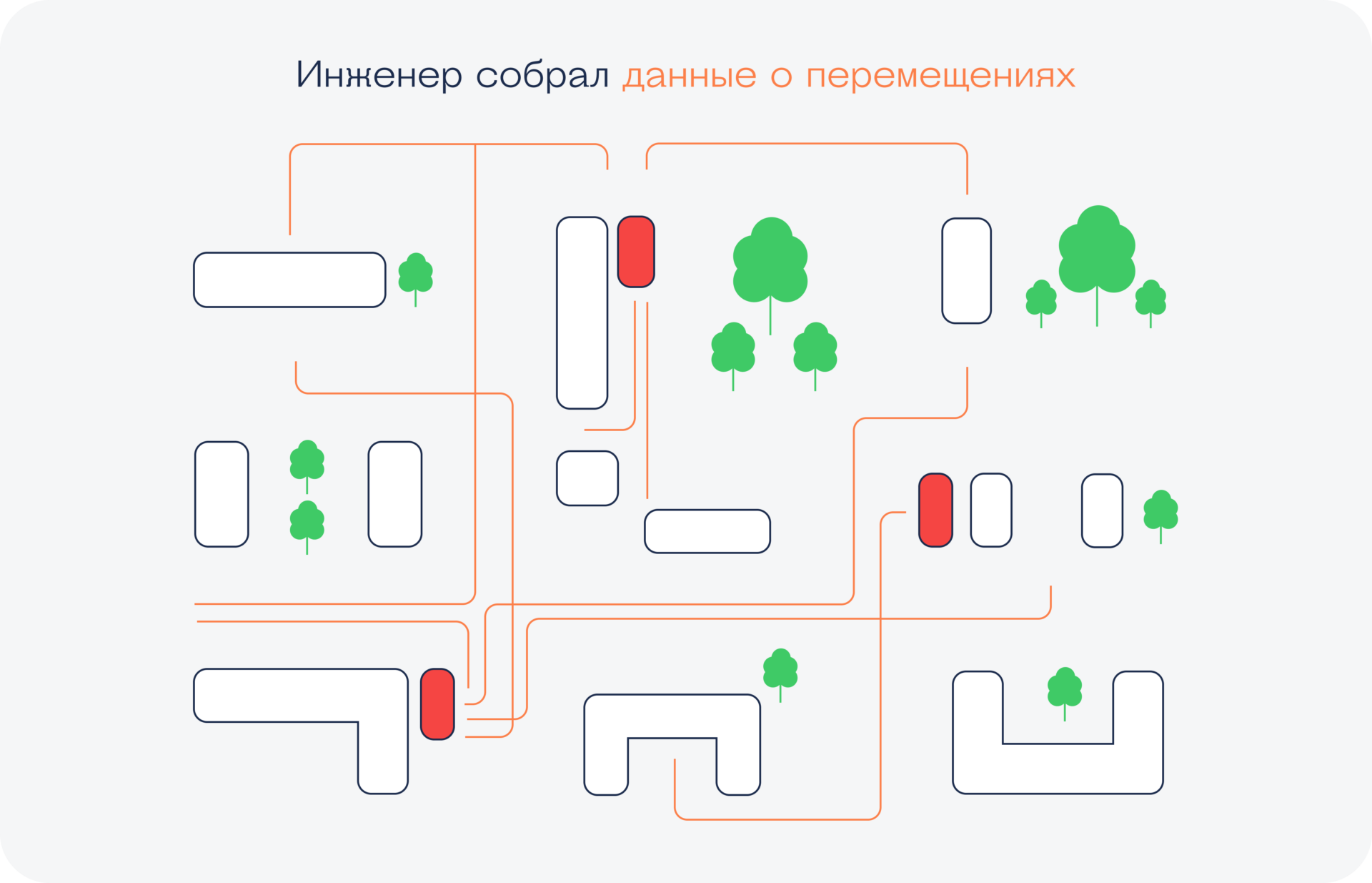
Открываем магазины в нужных местах (поможет аналитик данных)
Задача розничной сети — получить как можно больше прибыли с каждого района в городе. Это значит — открыть столько магазинов, сколько это физически возможно и прибыльно.
Допустим, мы уже открыли много магазинов в каждом районе города. Задача аналитика — спуститься с уровня города на уровень жилого квартала. Кажется, что если один магазин уже стоит во дворе, то на соседней улице нет смысла открывать такой же — достаточно перейти через дорогу. Но это не всегда так.
Через некоторое время после открытия первого магазина мы снова начинаем смотреть на пешеходные потоки — как они изменились. Иногда мы предполагаем, что люди будут переходит через дорогу, чтобы зайти в наш магазин, но на деле это часто не так. Обычно бывает, что магазин притягивает одну часть пешеходов, а другая ходит сама по себе. Можно ли эту часть переманить?
На этом этапе мы ставим перед аналитиком такую задачу — найти место на другой стороне улицы, где больше всего проходит тех людей, кто не заходит в наш первый магазин. Снова собираем много данных, анализируем их и находим нужное место.
Иногда может так получиться, что с одного перекрёстка видно сразу несколько таких одинаковых магазинов. Это значит, что в этом районе есть несколько независимых основных пешеходных маршрутов. И те, кто ходит в «Пятёрочку» за углом, обычно не ходят в «Пятёрочку» у светофора — это дольше и совсем не по пути.
Вопросы и ответы
Что лучше выбрать — Data Science или Machine Learning?
На старте лучше заняться Data Science — это проще, меньше математики, и первые ощутимые результаты там можно получить гораздо быстрее.
Сколько времени реально надо, чтобы освоить минимум и попробовать себя в профессии
Если реально — то месяца 3–4 плотной работы и изучения нового. Причём нужный минимум можно освоить за 2–3 недели, а остальное время уйдёт на практику и проверку усвоенных знаний. Одно дело, когда ты что-то знаешь в теории, и другое — когда можешь сам запустить это у себя на компьютере.
Ещё вариант — снизить нагрузку и заниматься фоново, пару часов в день после работы или учёбы. В этом случае полугода будет достаточно, чтобы попробовать себя в деле и понять, хотите ли вы этим заниматься дальше на профессиональном уровне или нет.
Какая техника нужна для работы с бигдатой
На самом деле заниматься машинным обучением можно почти на любом компьютере — другое дело, насколько быстро будет там работать нейросеть.
Вся работа в дата-сайенсе делится на две части: написание кода и работа нейросети — обучение, калибровка, запуск и отладка. Для написания кода достаточно любого текстового редактора, а для всего остального действует такое правило: чем мощнее, тем лучше.
Если есть возможность, лучше заниматься бигдатой на компьютерах с видеокартами Nvidia — у них есть поддержка технологии CUDA, которая здорово ускоряет все вычисления. Ещё видеокарта сама по себе позволяет быстро вычислять простейшие операции с матрицами — в этом ей помогают большое количество ядер и скоростная память.
Ещё вариант — использовать мощности Google Colab, специального сервиса для облачной работы с машинным обучением и бигдатой. На бесплатных версиях есть свои ограничения, но, когда вы с ними столкнётесь, к этому времени вы уже будете сильно в теме.
Можно ли перейти в бигдату из обычного программирования
Да, если подтянуть математику и алгоритмы нейросетей. Тем, кто уже знает программирование, будет намного проще заняться бигдатой, чем стартовать с нуля. Многие программисты из тех, что сейчас занимаются искусственным интеллектом, начинали как обычные Python-разработчики.
Куда идти учиться
Самый простой способ ворваться в бигдату — прийти в Практикум на курсы. Учиться можно двумя способами:
- долго и с равномерной нагрузкой в нормальном темпе;
- быстро и суперинтенсивно на буткемпе.
Обучение в обычном темпе длится от 6 до 9 месяцев, на буткемпе — в 2–3 раза быстрее. На выходе у вас портфолио с учебными проектами, навыки для работы в отрасли и помощь карьерного центра.
Если нужны конкретные курсы — держите:
Если интересно, как вообще устроены такие курсы, почитайте наш разбор обучения в Практикуме. Там всё как раз на примере курсов про бигдату.
Что дальше
Работа с большими данными — это перспективное направление, которое будет актуально ещё много лет. Всё дело в том, что данных становится всё больше и с ними нужно как-то уметь работать. На основе выводов из данных компании принимают решения, которые помогут развиваться их бизнесу, поэтому хорошие специалисты по работе с данными сейчас в цене.
Если вы ещё не решили, что выбрать в бигдате, — попробуйте себя в каждой роли:
- соберите бигдату на основе разных источников;
- проанализируйте её и попробуйте сделать выводы;
- постройте простую нейросеть, которая сможет предсказывать результаты при разных входных параметрах.
Что из этого понравится больше всего — на том и остановитесь для начала. А как разберётесь поглубже, сможете сами принять верное для себя решение.
Получите ИТ-профессию
В «Яндекс Практикуме» можно стать разработчиком, тестировщиком, аналитиком и менеджером цифровых продуктов. Первая часть обучения всегда бесплатная, чтобы попробовать и найти то, что вам по душе. Дальше — программы трудоустройства.
Big Data: что это и где применяется?
Почему все вокруг говорят про большие данные? Какие именно данные считаются большими? Где их искать, зачем они нужны, как на них заработать? Объясняем простыми словами, что такое «Биг Дата», вместе с экспертом SkillFactory — ведущим автором курса по машинному обучению, старшим аналитиком в «КиноПоиске» Александром Кондрашкиным.

Освойте профессию «Data Scientist» на курсе с МГУ
Data Scientist с нуля до PRO
Освойте профессию Data Scientist с нуля до уровня PRO на углубленном курсе совместно с академиком РАН из МГУ. Изучите продвинутую математику с азов, получите реальный опыт на практических проектах и начните работать удаленно из любой точки мира.

25 месяцев
Data Scientist с нуля до PRO
Создавайте ML-модели и работайте с нейронными сетями
6 224 ₽/мес 11 317 ₽/мес

Что такое большие данные?
Big Data («Биг Дата», большие данные) — огромные наборы разнообразных данных. Огромные, потому что их объемы такие, что простой компьютер не справится с их обработкой, а разнообразные — потому что эти данные разного формата, неструктурированные и содержат ошибки. Большие данные быстро накапливаются и используются для разных целей. Big Data — это не обычная база данных, даже если она очень большая. Вот отличия:
Не большие данные
Большие данные
База записей о тысячах работников корпорации. Информация в такой базе имеет заранее известные характеристики и свойства, ее можно представить в виде таблицы, как в Excel.
Журнал действий сотрудников. Например, все данные, которые создает во время работы колл-центр, где работает 500 человек.
Информация об именах, возрасте и семейном положении всех 2,5 миллиардов пользователей Фейсбук* — это всего лишь очень большая база данных.
Переходы по ссылкам, отправленные и полученные сообщения, лайки и репосты, движения мыши или касания экранов смартфонов всех пользователей Фейсбук*.
Архив записей городских камер видеонаблюдения.
Данные системы видеофиксации нарушений правил дорожного движения с информацией о дорожной ситуации и номерах автомобилей нарушителей; информация о пассажирах метро, полученная с помощью системы распознавания лиц, и о том, кто из них числится в розыске.

Объем информации в мире увеличивается ежесекундно, и то, что считали большими данными десятилетие назад, теперь умещается на жесткий диск домашнего компьютера. 60 лет назад жесткий диск на 5 мегабайт был в два раза больше холодильника и весил около тонны. Современный жесткий диск в любом компьютере вмещает до полутора десятков терабайт (1 терабайт равен 1 млн мегабайт) и по размерам меньше обычной книги. В 2021 году большие данные измеряют в петабайтах. Один петабайт равен миллиону гигабайт. Трехчасовой фильм в формате 4K «весит» 60‒90 гигабайт, а весь YouTube — 5 петабайт или 67 тысяч таких фильмов. 1 млн петабайт — это 1 зеттабайт. Пройдите наш тест и узнайте, какой вы Data Scientist. Ссылка в конце статьи.
Как работает технология Big Data?
- социальные;
- машинные;
- транзакционные.
Все, что человек делает в сети, — источник социальных больших данных. Каждую секунду пользователи загружают в Инстаграм* 1 тыс. фото и отправляют более 3 млн электронных писем. Ежесекундный личный вклад каждого человека — в среднем 1,7 мегабайта.
Другие примеры социальных источников Big Data — статистики стран и городов, данные о перемещениях людей, регистрации смертей и рождений и медицинские записи.
Большие данные также генерируются машинами, датчиками и «интернетом вещей». Информацию получают от смартфонов, умных колонок, лампочек и систем умного дома, видеокамер на улицах, метеоспутников.
Транзакционные данные возникают при покупках, переводах денег, поставках товаров и операциях с банкоматами.

Станьте дата-сайентистом на курсе с МГУ и решайте амбициозные задачи с помощью нейросетей
Как обрабатывают большие данные?
Массивы Big Data настолько большие, что простой Excel с ними не справится. Поэтому для работы с ними используют специальное ПО.
Его называют «горизонтально масштабируемым», потому что оно распределяет задачи между несколькими компьютерами, одновременно обрабатывающими информацию. Чем больше машин задействовано в работе, тем выше производительность процесса.
Такое ПО основано на MapReduce, модели параллельных вычислений. Модель работает так:
- сначала данные фильтруются по условиям, которые задает исследователь, сортируются и распределяются между отдельными компьютерами (узлами);
- затем узлы параллельно рассчитывают свои блоки данных и передают результат вычислений на следующую итерацию.
MapReduce — не конкретная программа, а скорее алгоритм, с помощью которого можно решить большинство задач обработки больших данных.
Примеры ПО, которое основывается на MapReduce:
- Hadoop — набор программ с открытым исходным кодом для хранения файлов, планирования и совместной работы с данными. Система разработана так, чтобы при сбое на одном узле нагрузка сразу перераспределялась на другие, не прерывая вычисления.
- Apache Spark — набор библиотек, которые позволяют выполнять вычисления в оперативной памяти и многократно обращаться к результатам расчетов. Его применяют для решения широкого круга задач, от простой обработки и фильтрации данных до машинного обучения.
Специалисты по большим данным используют оба инструмента: Hadoop для создания инфраструктуры данных и Spark для обработки потоковой информации в реальном времени.
Где применяется аналитика больших данных?
Большие данные нужны в маркетинге, перевозках, автомобилестроении, здравоохранении, науке, сельском хозяйстве и других сферах, в которых можно собрать и обработать нужные массивы информации.
Бизнесу большие данные нужны, чтобы:
- Оптимизировать процессы — например, крупные банки используют большие данные, чтобы обучать чат-бота — программу, которая заменит живого сотрудника по простым вопросам и при необходимости переключит на специалиста.
- Делать прогнозы — анализируя большие данные о продажах, компании могут предсказать поведение клиентов и покупательский спрос на товары в зависимости от времени года или ситуации в мире.
- Строить модели — с помощью анализа данных о прибыли и издержках компания может построить модель для прогнозирования выручки.
Анализ больших данных позволяет бизнесу не только систематизировать информацию, но и находить неочевидные причинно-следственные связи.
Продажи товаров
Онлайн-маркетплейс Amazon запустил решение для рекомендаций товаров, работающую на машинном обучении. Она учитывает не только поведение и предыдущие покупки пользователя, но и время года, ближайшие праздники и остальные факторы, важные для бизнеса. После того как эта система заработала, рекомендации начали генерировать 35% всех продаж сервиса.
В супермаркетах «Лента» с помощью больших данных анализируют информацию о покупках и предлагают персонализированные скидки на товары. К примеру, говорят в компании, система по данным о покупках может понять, что клиент изменил подход к питанию, и начнет предлагать ему подходящие продукты.
Американская сеть Kroger использует большие данные для персонализации скидочных купонов, которые получают покупатели по электронной почте. После того как их сделали индивидуальными, подходящими конкретным покупателям, доля покупок только по ним выросла с 3,7 до 70%.
Найм сотрудников
Крупные компании, в том числе российские, стали прибегать к помощи роботов-рекрутеров, чтобы на начальном этапе поиска сотрудника отсеять тех, кто не заинтересован в вакансии или не подходит под нее. Так, компания Stafory разработала робота Веру, которая сортирует резюме, делает первичный обзвон и выделяет заинтересованных кандидатов. PepsiCo заполнила 10% нужных вакансий только с помощью робота.
Банки
Обработка больших данных помогает защищать клиентов от мошенников. Именно с помощью этих технологий обнаруживают аномалии в поведении пользователя, нетипичные для него покупки или переводы. Уже в 2017 году Visa с помощью анализа данных ежегодно предотвращала мошенничества на $2 млрд.
Автомобилестроение
В 2020 году у автоконцерна Toyota возникла проблема: нужно было понять причину большого числа аварий по вине водителей, перепутавших педали газа и тормоза. Компания собрала данные со своих автомобилей, подключенных к интернету, и на их основе определила, как именно люди нажимают на педали.
Оказалось, что сила и скорость давления различаются в зависимости от того, хочет человек затормозить или ускориться. Теперь компания разрабатывает новый сервис, который будет определять манеру давления на педали во время движения и сбросит скорость автомобиля, если водитель давит на педаль газа, но делает это так, будто хочет затормозить.
Медицина
Американские ученые научились с помощью больших данных определять, как распространяется депрессия. Исследователь Мунмун Де Чаудхури и ее коллеги загрузили в прогностическую модель сообщения из Twitter, Фейсбук* с геометками. Сообщения отбирали по словам, которые могут указывать на депрессивное и подавленное состояние. Расчеты совпали с официальными данными.
Госструктуры
Большие данные просто необходимы госструктурам. С их помощью ведется не только статистика, но и слежка за гражданами. Подобные технологии используют во многих странах: известен новый сервис PRISM, которыми пользуются ФБР и ЦРУ для сбора персональных данных из соцсетей и продуктов Microsoft, Google и Apple. В России информацию о пользователях и телефонных звонках собирает решение СОРМ.
Маркетинг
Работа с большими данными нужна и в этой сфере. Социальные большие данные помогают группировать пользователей по интересам и персонализировать для них рекламу. Людей ранжируют по возрасту, полу, интересам и месту проживания. Те, кто живут в одном регионе, бывают в одних и тех же местах, смотрят видео и читают статьи на похожие темы, скорее всего, заинтересуются одними и теми же товарами.
При этом регулярно происходят скандалы, связанные с использованием больших данных в маркетинге. Так, в 2018 году стриминговую платформу Netflix обвинили в расизме из-за того, что она показывает пользователям разные постеры фильмов и сериалов в зависимости от их пола и национальности.
Медиа
С помощью анализа больших данных в медиа измеряют аудиторию. В этом случае Big Data может даже повлиять на политику редакции. Так, издание Huffington Post использует решение, которое в режиме реального времени показывает статистику посещений, комментариев и других действий пользователей, а также готовит аналитические отчеты.
Новый сервис в Huffington Post оценивает, насколько эффективно заголовки привлекают внимание читателя, разрабатывает методы доставки контента определенным категориям пользователей. Например, выяснилось, что родители чаще читают статьи со смартфона и поздно вечером в будни, после того как уложили детей спать, а по выходным они обычно заняты, — в итоге контент для родителей публикуется на сайте в удобное для них время.
Логистика
Анализ больших данных помогает оптимизировать перевозки, сделать доставку быстрее и дешевле. В компании DHL работа с большими данными коснулась так называемой проблемы последней мили, когда необходимость проехать через дворы и найти парковку перед тем, как отдать заказ, съедает в общей сложности 28% от стоимости доставки. В компании стали анализировать «последние мили» с помощью информации с GPS и данных о дорожной обстановке. В результате удалось сократить затраты на топливо и время доставки груза.
Внутри компании большие объемы данных помогают отслеживать качество работы сотрудников, соблюдение контрольных сроков, правильность их действий. Для анализа используют машинные данные, например со сканеров посылок в отделениях, и социальные — отзывы посетителей отделения в приложении, на сайтах и в соцсетях.
Обработка фото
До 2016 года не было технологии нейросетей на мобильных устройствах, это даже считали невозможным. Прорыв в этой области (в том числе благодаря российскому стартапу Prisma) позволяет нам сегодня пользоваться огромным количеством фильтров, стилей и разных эффектов на фотографиях и видео.
Аренда недвижимости
Сервис Airbnb с помощью технологий Big Data изменил поведение пользователей. Однажды выяснилось, что посетители сайта по аренде недвижимости из Азии слишком быстро его покидают и не возвращаются. Оказалось, что они переходят с главной страницы на «Места поблизости» и уходят смотреть фотографии без дальнейшего бронирования.
Компания детально проанализировала поведение пользователей и заменила ссылки в разделе «Места поблизости» на самые популярные направления для путешествий в азиатских странах. В итоге конверсия в бронирования из этой части планеты выросла на 10%.
*деятельность компании Meta Platforms Inc., которой принадлежит Инстаграм / Фейсбук, запрещена на территории РФ в части реализации данной (-ых) социальной (-ых) сети (-ей) на основании осуществления ею экстремистской деятельности
Кто работает с большими данными?
Дата-сайентисты специализируются на анализе Big Data. Они ищут закономерности, строят модели и на их основе прогнозируют будущие события.
Например, исследователь больших объемов данных может использовать статистику по снятиям денег в банкоматах, чтобы разработать математическую модель для предсказания спроса на наличные. Эта система подскажет инкассаторам, сколько денег и когда привезти в конкретный банкомат.
Чтобы освоить эту профессию, необходимо понимание основ математического анализа и знание языков программирования, например Python или R, а также умение работать с SQL-базами данных.
Аналитик данных использует тот же набор инструментов, что и дата-сайентист, но для других целей. Его задачи — делать описательный анализ, интерпретировать и представлять данные в удобной для восприятия форме. Он обрабатывает данные и выдает результат, составляя аналитические отчеты, статистику и прогнозы.
С Big Data также работают и другие специалисты, для которых это не основная сфера работы:
- дизайнеры интерфейсов, анализирующие данные поведенческих исследований для создания пользовательских интерфейсов;
- NLP-инженеры, которые разрабатывают программы для чат-ботов и автоматизации колл-центров, анализируя естественный язык;
- маркетологи-аналитики, которые исследуют массив данных для выстраивания маркетинговой политики и персонализации рекламы;
- инженеры и программисты на предприятиях, занимающиеся обработкой объема данных.
Дата-инженер занимается технической стороной вопроса и первый работает с информацией: организует ее сбор, хранение и первоначальную обработку.
Дата-инженеры помогают исследователям, создавая ПО и алгоритмы для автоматизации задач. Без таких инструментов большие данные были бы бесполезны, так как их объемы невозможно обработать. Для этой профессии важно знание Python и SQL, уметь работать с фреймворками, например со Spark.
Александр Кондрашкин о других профессиях, в которых может понадобиться Big Data: «Где-то может и product-менеджер сам сходить в Hadoop-кластер и посчитать что-то несложное, если обладает такими навыками. Наверняка есть множество backend-разработчиков и DevOps-инженеров, которые настраивают хранение и сбор данных от пользователей».
Востребованность больших данных и специалистов по ним
Востребованность больших данных растет: по исследованиям 2020 года, даже при пессимистичном сценарии объем рынка Big Data в России к 2024 году вырастет с 45 млрд до 65 млрд рублей, а при хорошем развитии событий — до 230 млрд.
Компании все чаще прибегают к анализу больших данных, так как те, кто этого не делает, замечают упущенную выгоду: The Bell приводит пример корпорации Caterpillar. В 2014 году ее дистрибьюторы ежегодно упускали от $9 до $18 млрд прибыли только из-за того, что не внедряли технологии обработки Биг Дата. Теперь 3,5 млн единиц техники компании оборудованы датчиками, которые собирают информацию о ее состоянии и степени износа ключевых деталей, что позволяет лучше управлять затратами на техобслуживание.
Вместе с популярностью больших данных растет запрос и на тех, кто может эффективно с ними работать. В середине 2020 года Академия больших данных MADE от Mail.ru Group и HeadHunter провели исследование и выяснили, что специалисты по анализу данных уже являются одними из самых востребованных на рынке труда в России. За четыре года число вакансий в этой области увеличилось почти в 10 раз
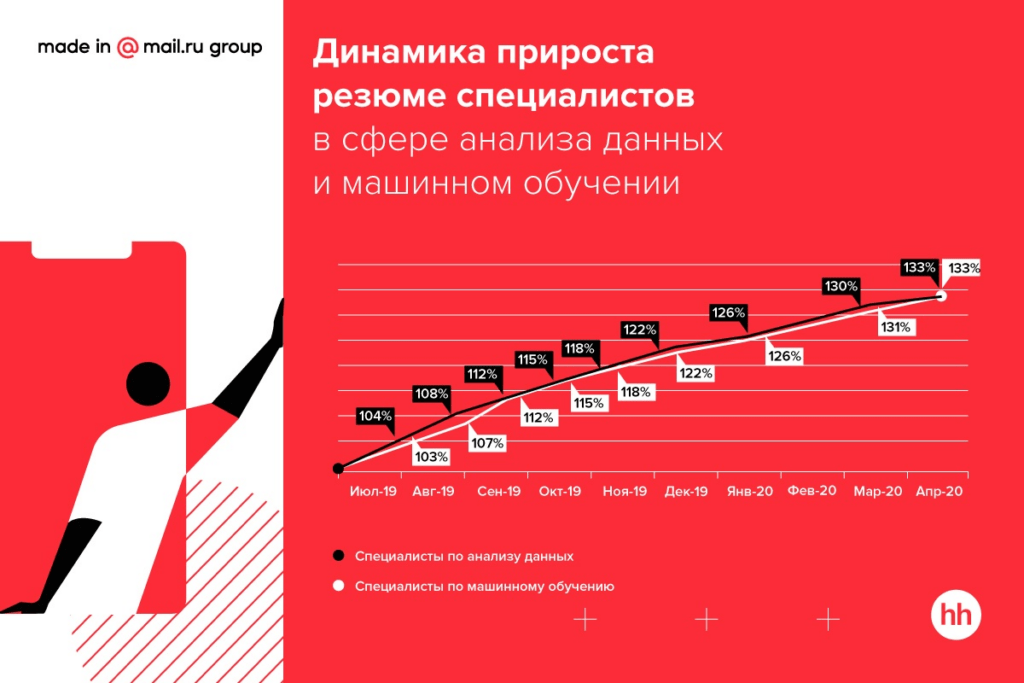
Более трети вакансий для специалистов по анализу данных (38%) приходится на IT-компании, финансовый сектор (29%) и сферу услуг для бизнеса (9%). В сфере машинного обучения IT-компании публикуют 55% вакансий на рынке, 10% приходит из финансового сектора и 9% — из сферы услуг.
Как начать работать с большими данными?
Проще будет начать, если у вас уже есть понимание алгоритмов и хорошее знание математики, но это не обязательно. Например, Оксана Дереза была филологом и для нее главной трудностью в Data Science оказалось вспомнить математику и разобраться в алгоритмах, но она много занималась и теперь анализирует данные в исследовательском институте.
Еще несколько историй людей, которые успешно освоили data-профессию.
Если у вас нет математических знаний, на курсе SkillFactory «Data Science с нуля» вы получите достаточную подготовку, чтобы работать с большими данными. За год вы научитесь получать данные из веб-источников или по API, визуализировать данные с помощью Pandas и Matplotlib, применять методы математического анализа, линейной алгебры, статистики и теории вероятности для обработки данных и многое другое.
Чтобы стать аналитиком данных, вам пригодится знание Python и SQL — эти навыки очень популярны в вакансиях компаний по поиску соответствующей позиции. На курсе «Аналитик данных» вы получите базу знаний основных инструментов аналитики (от Google-таблиц до Python и Power BI) и закрепите их на тренажерах.
Важно определиться со сферой, в которой вы хотите работать. Студентка SkillFactory Екатерина Карпова, рассказывает, что после обучения ей была важна не должность, а сфера (финтех), поэтому она сначала устроилась консультантом в банк «Тинькофф», а теперь работает там аналитиком.
FAQ
Что понимается под Big Data?
Big Data — это большие объемы данных, которые невозможно обработать и анализировать с помощью стандартных средств.
Что такое Big Data и где это используется?
Технологии Big Data применяются во многих сферах, таких как банковское дело, здравоохранение, розничная торговля, производство, научные исследования и др.
Для чего нужны Big Data?
Технологии Big Data используются для анализа больших объемов данных, выявления скрытых закономерностей, определения потребностей клиентов и оптимизации бизнес-процессов.
Что такое работа с Big Data?
Работа с Big Data — это анализ больших объемов данных с помощью специальных технологий, которые позволяют обрабатывать и анализировать данные быстро и эффективно.
Что нужно знать для работы с Big Data?
Для работы с Big Data необходимо знание базовых технологий, таких как Hadoop, Spark, NoSQL и др.
Кто работает с Big Data?
С Big Data работают аналитики данных, разработчики, инженеры данных, специалисты по машинному обучению и др.
Что является примером больших данных?
Примеры больших данных включают в себя данные о клиентах, данные о продажах для бизнеса, данные о посетителях веб-сайтов, данные о здоровье и др.
Где хранятся Big Data?
Big Data хранятся на серверах в облаке или на серверах компаний, которые занимаются обработкой данных.
Где учат работе с Big Data?
Учиться Big Data можно на онлайн-курсах, в университетах, технических колледжах и других учебных заведениях.
Какой язык программирования используется в Big Data?
В Big Data используется язык программирования Java, Python, R, Scala и др.
Можно ли стать аналитиком данных без образования?
Да, можно. Для этого нужно изучить базовые принципы и технологии работы с данными, учиться на курсах и в онлайн-школах, получать опыт работы в сфере аналитики данных.