How do I export Cypher Favorites recorded in the browser
Cypher Favorites are common Cypher statements which one can save to the left panel of the Neo4j browser. A Favorite is created by entering the Cypher at the top prompt and then clicking the Favorite icon to the right as depicted:

After clicking on the Favorite Icon, the title of the Cypher statement (in this case ‘my favorite Cypher’) will be added to the left panel of the browser. For example:

These favorites are stored in local browser storage and as such are centric to the user/browser who has recorded those favorites. Additionally, if one clears their browser cache, recorded favorites will be removed.
To export favorites, use the Developer Console of Google Chrome and connect to the Neo4j browser URL.
- Launch Google Chrome and connect to the Neo4j browser on http://localhost:7474
- Access the Developer Console, https://developer.chrome.com/devtools/docs/console within Google Chrome
- Use the keyboard shortcut Command + Option + J (Mac) or Control + Shift + J (Windows/Linux).
var res = JSON.parse(localStorage.getItem('neo4j.documents')) for (x in res)

Is this page helpful?
Разбираемся в типах NoSQL СУБД
В этой статье мы познакомимся с 4 основными типами NoSQL баз данных: ключ-значение, документоориентированной, колоночной и графовой.
В этой статье мы познакомимся с разными типами NoSQL СУБД.
Всего есть 4 основных типа:
- Хранилище «ключ-значение» — в нём есть большая хеш-таблица, содержащая ключи и значения. Примеры: Riak, Amazon DynamoDB;
- Документоориентированное хранилище — хранит документы, состоящие из тегированных элементов. Пример: CouchDB;
- Колоночное хранилище — в каждом блоке хранятся данные только из одной колонки. Примеры: HBase, Cassandra;
- Хранилище на основе графов — сетевая база данных, которая использует узлы и рёбра для отображения и хранения данных. Пример: Neo4J.
База данных типа «ключ-значение»
Отсутствие схемы в базах данных «ключ-значение», например, Riak, — это как раз то, что вам нужно для хранения данных. Ключ может быть синтетическим или автосгенерированным, а значение может быть представлено строкой, JSON, блобом (BLOB, Binary Large Object, большой двоичный объект) и т.д.
Такие базы данных как правило используют хеш-таблицу, в которой находится уникальный ключ и указатель на конкретный объект данных. Существует понятие блока (bucket) — логической группы ключей, которые не группируют данные физически. В разных блоках могут быть идентичные ключи.
Производительность сильно вырастает за счёт кеширующих механизмов, которые работают на основе маппингов. Чтобы прочитать значение, вам нужно знать как ключ, так и блок, поскольку на самом деле ключ является хешем (блок + ключ).
В модели «ключ-значение» нет ничего сложного, так как реализовать её проще простого. Не лучший способ, если вам нужно только обновить часть значения или сделать запрос к базе данных.
Если поразмыслить о теореме CAP, то становится довольно очевидно, что такие хранилища хороши в плане доступности (Availability) и устойчивости к разделению (Partition tolerance), но явно проигрывают в согласованности данных (Consistency).
Пример: посмотрим на набор данных, представленных таблицей ниже. Здесь ключ — это название страны, а значение — список адресов в этой стране:
База данных такого типа позволяет читать и записывать значения с помощью ключа следующим образом:
- Get(key) возвращает значение, связанное с переданным ключом;
- Put(key, value) связывает значение с ключом;
- Multi-get(key1, key2, . keyN) возвращает список значений, связанных с переданным ключами;
- Delete(key) удаляет запись для ключа из хранилища.
И хотя базы данных типа «ключ-значение» могут пригодиться в определённых ситуациях, они не лишены недостатков. Первый заключается в том, что модель не предоставляет стандартные возможности баз данных вроде атомарности транзакций или согласованности данных при одновременном выполнении нескольких транзакций. Такие возможности должны предоставляться самим приложением.
Второй недостаток в том, что при увеличении объёмов данных, поддержание уникальных ключей может стать проблемой. Для её решения необходимо как-то усложнять процесс генерации строк, чтобы они оставались уникальными среди очень большого набора ключей.
Riak и Dynamo от Amazon — самые популярные СУБД данных такого типа.
Документоориентированная база данных
Данные, представленные парами ключ-значение, сжимаются как хранилище документов схожим с хранилищем «ключ-значение» образом, с той лишь разницей, что хранимые значения (документы) имеют определённую структуру и кодировку данных. XML, JSON и BSON — некоторые из стандартных распространённых кодировок.
В следующем примере можно увидеть данные в виде «документа» который отображает названия определённых магазинов. Обратите внимание, что, хотя все три примера содержат местоположение, они отображают его по-разному:
Одним из ключевых различий между хранилищем «ключ-значение» и документоориентированным является то, что последний включает метаданные, связанные с хранимым содержимым, что даёт возможность делать запросы на основе содержимого. Например, в указанном примере можно попробовать найти все документы, в которых «City» равно «Noida», что вернёт все документы, связанные с магазинами в этом городе.
Apache CouchDB — пример документоориентированной СУБД. CouchDB использует JSON для хранения данных, JavaScript в качестве языка запросов с использованием MapReduce и HTTP для API. Данные и отношения не хранятся в таблицах так, как в традиционных реляционных базах данных, а по сути являются набором независимых документов.
Тот факт, что такие базы данных работают без схемы, делает простой задачей добавление полей в JSON-документы без необходимости сначала заявлять об изменениях.
Couchbase и MongoDB — самые популярные документоориентированные СУБД.
Колоночная база данных
В колоночных NoSQL базах данных данные хранятся в ячейках, сгруппированных в колонки, а не в строки данных. Колонки логически группируются в колоночные семейства. Колоночные семейства могут состоять из практически неограниченного количества колонок, которые могут создаваться во время работы программы или во время определения схемы. Чтение и запись происходит с использованием колонок, а не строк.
В сравнении с хранением данных в строках, как в большинстве реляционных баз данных, преимущества хранения в колонках заключаются в быстром поиске/доступе и агрегации данных. Реляционные базы данных хранят каждую строку как непрерывную запись на диске. Разные строки хранятся в разных местах на диске, в то время как колоночные базы данных хранят все ячейки, относящиеся к колонке, как непрерывную запись, что делает операции поиска/доступа быстрее.
Пример: получение списка заголовков нескольких миллионов статей будет трудоёмкой задачей при использовании реляционных баз данных, так как для извлечения заголовков придётся проходить по каждой записи. А можно получить все заголовки с помощью только одной операции доступа к диску.
- Колоночное семейство — структура, которая может легко группировать колонки и суперколонки;
- Ключ — постоянное имя записи. У ключей может быть разное количество колонок, поэтому база данных может расширяться неравномерно;
- Пространство ключей — определяет самый внешний уровень организации, как правило, имя приложения/базы данных.
- Колонка — имеет упорядоченный список элементов — кортежей с именами и значениями.
Самыми известными примерами являются Google BigTable и HBase с Cassandra, вдохновлённые BigTable.
BigTable представляет собой высокопроизводительное, сжатое и проприетарное хранилище данных от Google. У него есть следующие атрибуты:
- Разреженность — некоторые ячейки могут быть пустыми;
- Распределённость — данные разделены между многими узлами;
- Постоянство — хранится на диске;
- Многомерность — более 1 измерения;
- Сопоставление — ключ и значение;
- Отсортированность — сопоставления обычно не сортируются, но этот случай — исключение.
Двумерная таблица, состоящая из строк и колонок, является частью реляционной системы баз данных.
Эту таблицу можно представить в виде BigTable-сопоставления следующим образом:
< 3PillarNoida: < city: Noida pincode: 201301 >, details: < strength: 250 projects: 20 >> < 3PillarCluj: < address: < city: Cluj pincode: 400606 >, details: < strength: 200 projects: 15 >>, < 3PillarTimisoara: < address: < city: Timisoara pincode: 300011 >, details: < strength: 150 projects: 10 >> < 3PillarFairfax : < address: < city: Fairfax pincode: VA 22033 >, details: < strength: 100 projects: 5 >> - Внешние ключи «3PillarNoida», «3PillarCluj», «3PillarTimisoara» и «3PillarFairfax» являются аналогами строк.
- «address» и «details» — колоночные семейства.
- В колоночном семействе «address» есть колонки «city» и «pincode».
- В колоночном семействе «details» есть колонки «strength» и «projects».
На колонки можно ссылаться с помощью колоночного семейства.
Графовая база данных
В графовой базе данных вы не найдёте строгого формата SQL или представления таблиц и колонок, вместо этого используется гибкое графическое представление, которое идеально подходит для решения проблем масштабируемости. Графовые структуры используются вместе с рёбрами, узлами и свойствами, что обеспечивает безиндексную смежность. При использовании графового хранилища данные могут быть легко преобразованы из одной модели в другую.
- Такие базы данных используют рёбра и узлы для представления данных.
- Узлы связаны между собой определённым отношениями, представленными рёбрами между ними.
- У узлов и отношений есть некоторые свойства.
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Далее описаны некоторые особенности графовой базы данных на основе примера ниже:
Помеченный, направленный, атрибутированный мультиграф: граф содержит узлы, которые помечены определёнными свойствами и которые имеют связи друг с другом, что представлено направленными рёбрами. Например, связь «Элис знает Боба» выражена ребром с некоторыми свойствами.
Хотя реляционные базы данных могут скопировать поведение графовых, рёбрам потребуется соединение (JOIN), что дорого обойдётся.
Любой рейтинг «Рекомендовано вам», который можно увидеть на разных сайтах, зачастую составляется исходя из того, как другие пользователи оценили продукт. Графовые базы данных отлично подходят для такого случая.
InfoGrid и Infinite Graph — самые популярные графовые базы данных. InfoGrid позволяет соединять множество рёбер (Relationships) и узлов (MeshObjects), что упрощает представление набора информации со сложными взаимными ссылками.
InfoGrid предлагает два типа баз данных:
- MeshBase — подходящий вариант для автономного развёртывания;
- NetMeshBase — подойдёт для больших распределённых графов и имеет дополнительные возможности для взаимодействия с другими похожими NetMeshBase.
ORM — отвратительный анти-паттерн
От автора перевода: Написанный далее текст может не совпадать с мнением автора перевода. Все высказывания идут от лица оригинального автора, просьба воздержаться от неоправданных минусов. Оригинальная статья выпущена в 2014 году, поэтому некоторые фрагменты кода могут быть устаревшими или «нежелаемыми».
Вступление
ORM — это ужасный анти-паттерн, который нарушает все принципы объектно-ориентированного программирования, разбирая объекты на части и превращая их в тупые и пассивные пакеты данных. Нет никаких оправданий существованию ORM в любом приложении, будь то небольшое веб-приложение или система корпоративного размера с тысячами таблиц и манипуляциями CRUD с ними. Какова альтернатива? Объекты, говорящие на языке SQL (SQL-speaking objects).
Как работают ORM
Object-relational mapping (ORM) — это способ (он же шаблон проектирования) доступа к реляционной базе данных с помощью объектно-ориентированного языка (например, Java). Существует несколько реализаций ORM почти на каждом языке, например: Hibernate для Java, ActiveRecord для Ruby on Rails, Doctrine для PHP и SQLAlchemy для Python. В Java ORM даже стандартизирован как JPA.
Во-первых, рассмотрим на примере как работает ORM. Давайте использовать Java, PostgreSQL и Hibernate. Допустим, у нас есть единственная таблица в базе данных, называемая post:
+-----+------------+--------------------------+ | id | date | title | +-----+------------+--------------------------+ | 9 | 10/24/2014 | How to cook a sandwich | | 13 | 11/03/2014 | My favorite movies | | 27 | 11/17/2014 | How much I love my job | +-----+------------+--------------------------+Теперь мы хотим манипулировать этой таблицей CRUD-методами из нашего Java-приложения (CRUD расшифровывается как create, read, update и delete). Для начала мы должны создать класс Post (извините, что он такой длинный, но это лучшее, что я могу сделать):
@Entity @Table(name = "post") public class Post < private int id; private Date date; private String title; @Id @GeneratedValue public int getId() < return this.id; >@Temporal(TemporalType.TIMESTAMP) public Date getDate() < return this.date; >public String getTitle() < return this.title; >public void setDate(Date when) < this.date = when; >public void setTitle(String txt) < this.title = txt; >>Перед любой операцией с Hibernate мы должны создать SessionFactory:
SessionFactory factory = new AnnotationConfiguration() .configure() .addAnnotatedClass(Post.class) .buildSessionFactory();Эта фабрика будет выдавать нам “сеансы” каждый раз, когда мы захотим работать с объектами Post. Каждая манипуляция с сеансом должна быть заключена в этот блок кода:
Session session = factory.openSession(); try < Transaction txn = session.beginTransaction(); // your manipulations with the ORM, see below txn.commit(); >catch (HibernateException ex) < txn.rollback(); >finally
Когда сеанс будет готов, вот так мы получаем список всех записей из этой таблицы:
List posts = session.createQuery("FROM Post").list(); for (Post post : (List) posts)
Я думаю, вам ясно, что здесь происходит. Hibernate — это большой, мощный движок, который устанавливает соединение с базой данных, выполняет необходимые SELECT запросы и извлекает данные. Затем он создает экземпляры класса Post и заполняет их данными. Когда объект приходит к нам, он заполняется данными, и чтобы получить доступ к ним, необходимо использовать геттеры, как пример getTitle() выше.
Когда мы хотим выполнить обратную операцию и отправить объект в базу данных, мы делаем все то же самое, но в обратном порядке. Мы создаем экземпляр класса Post, заполняем его данными и просим Hibernate сохранить его:
Post post = new Post(); post.setDate(new Date()); post.setTitle("How to cook an omelette"); session.save(post);Так работает почти каждая ORM. Основной принцип всегда один и тот же — объекты ORM представляют собой немощные/анемичные (прямой перевод слова anemic) оболочки с данными. Мы разговариваем с ORM фреймворком, а фреймворк разговаривает с базой данных. Объекты только помогают нам отправлять запросы в ORM framework и понимать его ответ. Кроме геттеров и сеттеров, у объектов нет других методов. Они даже не знают, из какой базы данных они пришли.
Вот как работает object-relational mapping.
Что в этом плохого, спросите вы? Все!
Что не так с ORM?
Серьезно, что не так? Hibernate уже более 10 лет является одной из самых популярных библиотек Java. Почти каждое приложение в мире с интенсивным использованием SQL использует его. В каждом руководстве по Java будет упоминаться Hibernate (или, возможно, какой-либо другой ORM, такой как TopLink или OpenJPA) для приложения, подключенного к базе данных. Это стандарт де-факто, и все же я говорю, что это неправильно? Да.
Я утверждаю, что вся идея, лежащая в основе ORM, неверна. Его изобретение было, возможно, второй большой ошибкой в ООП после NULL reference.
ORM, вместо того чтобы инкапсулировать взаимодействие с базой данных внутри объекта, извлекает его, буквально разрывая на части прочный и сплоченный живой организм.
На самом деле, я не единственный, кто говорит что-то подобное, и определенно не первый. Многое на эту тему уже опубликовано очень уважаемыми авторами, в том числе OrmHate автора Martin Fowler (не против ORM, но в любом случае стоит упомянуть), Object-Relational Mapping is the Vietnam of Computer Science от Jeff Atwood, The Vietnam of Computer Science автора Ted Neward, ORM Is an Anti-Pattern от Laurie Voss и многие другие.
Однако мои аргументы отличаются от того, что они говорят. Несмотря на то, что их доводы практичны и обоснованны, например, “ORM работает медленно” или “обновление базы данных затруднено”, они упускают главное. Вы можете увидеть очень хороший, практический ответ на эти практические аргументы, от Bozhidar Bozhanov в его блоге ORM Haters Don’t Get It.
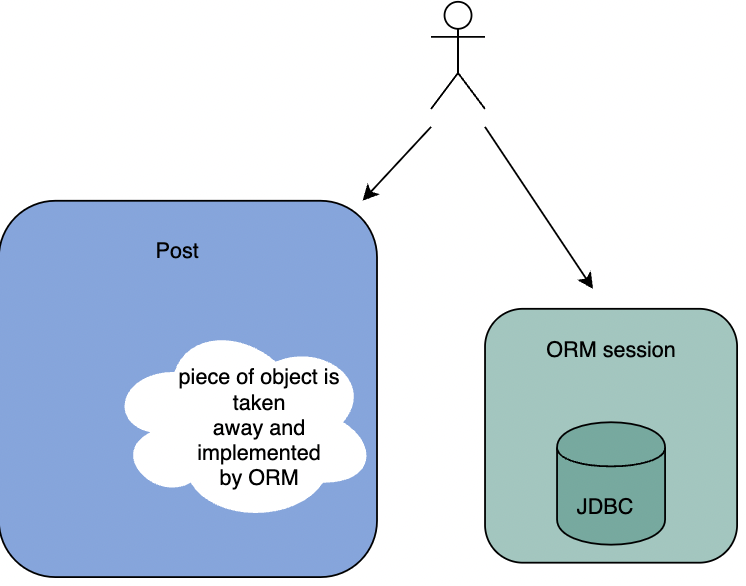
Суть в том, что ORM вместо того, чтобы инкапсулировать взаимодействие с базой данных внутри объекта, извлекает его, буквально разрывая на части прочный и сплоченный живой организм. Одна часть объекта хранит данные, в то время как другая, реализованная внутри механизма ORM ( sessionFactory ), знает, как обращаться с этими данными, и передает их в реляционную базу данных. Посмотрите на эту картинку; она иллюстрирует, что делает ORM.
Я, будучи читателем сообщений, должен иметь дело с двумя компонентами: 1) ORM и 2) возвращенный мне объект “ob-truncated”. Предполагается, что поведение, с которым я взаимодействую, должно предоставляться через единую точку входа, которая является объектом в ООП. В случае ORM я получаю такое поведение через две точки входа — механизм ORM и “предмет”, который мы даже не можем назвать объектом.
Из-за этого ужасного и оскорбительного нарушения объектно-ориентированной парадигмы у нас есть много практических проблем, уже упомянутых в уважаемых публикациях. Я могу добавить еще только несколько.
SQL Не Скрыт. Пользователи ORM должны говорить на SQL (или его диалекте, например, HQL). Смотрите пример выше; мы вызываем session.CreateQuery(«FROM Post») , чтобы получить все сообщения. Несмотря на то, что это не SQL, он очень похож на него. Таким образом, реляционная модель не инкапсулируется внутри объектов. Вместо этого он доступен для всего приложения. Каждому, с каждым объектом, неизбежно приходится иметь дело с реляционной моделью, чтобы что-то получить или сохранить. Таким образом, ORM не скрывает и не переносит SQL, а загрязняет им все приложение.
Трудно протестировать. Когда какой-либо объект работает со списком записей, ему необходимо иметь дело с экземпляром SessionFactory . Как мы можем замокать эту зависимость? Мы должны создать имитацию этого? Насколько сложна эта задача? Посмотрите на приведенный выше код, и вы поймете, насколько подробным и громоздким будет этот модульный тест. Вместо этого мы можем написать интеграционные тесты и подключить все приложение к тестовой версии PostgreSQL. В этом случае нет необходимости имитировать SessionFactory , но такие тесты будут довольно медленными, и, что еще более важно, наши объекты, не имеющие ничего общего с базой данных, будут протестированы на экземпляре базы данных. Ужасный замысел.
Позвольте мне еще раз повторить. Практические проблемы ORM — это всего лишь последствия. Фундаментальный недостаток заключается в том, что ORM разрывает объекты на части, ужасно и оскорбительно нарушая саму идею того, что такое объект.
SQL-speaking объекты

Какова альтернатива? Позвольте мне показать вам это на примере. Давайте попробуем спроектировать класс Post. Нам придется разбить его на два класса: Post и Posts , единственное и множественное число. Я уже упоминал в одной из своих предыдущих статей, что хороший объект — это всегда абстракция реальной сущности. Вот как этот принцип работает на практике. У нас есть две сущности: таблица базы данных и строка таблицы. Вот почему мы создадим два класса. Posts будет представлять таблицу, а Post будет представлять строку.
Как я также упоминал в этой статье, каждый объект должен работать по контракту и реализовывать интерфейс. Давайте начнем наш дизайн с двух интерфейсов. Конечно, наши объекты будут неизменяемыми. Вот как будут выглядеть Posts :
interface Posts < Iterableiterate(); Post add(Date date, String title); >Вот как будет выглядеть один Post :
interface Post
Вот так мы будем перечислять все записи в таблице базы данных:
Posts posts = // we'll discuss this right now for (Post post : posts.iterate())
Вот так создаётся новый Post :
Posts posts = // we'll discuss this right now posts.add(new Date(), "How to cook an omelette");Как вы видите, теперь у нас есть настоящие объекты. Они отвечают за все операции, и они прекрасно скрывают детали их реализации. Нет никаких транзакций, сеансов или фабрик. Мы даже не знаем, действительно ли эти объекты взаимодействуют с PostgreSQL или они хранят все данные в текстовых файлах. Все, что нам нужно от Posts — это возможность перечислить все записи для нас и создать новую. Детали реализации идеально скрыты внутри. Теперь давайте посмотрим, как мы можем реализовать эти два класса.
Я собираюсь использовать jcabi-jdbc в качестве оболочки JDBC, но вы можете использовать что-то другое, например jOOQ, или просто JDBC, если хотите. На самом деле это не имеет значения. Важно то, что ваши взаимодействия с базой данных скрыты внутри объектов. Давайте начнем с Posts и реализуем его в классе PgPosts (“pg” означает PostgreSQL):
final class PgPosts implements Posts < private final Source dbase; public PgPosts(DataSource data) < this.dbase = data; >public Iterable iterate() < return new JdbcSession(this.dbase) .sql("SELECT id FROM post") .select( new ListOutcome( new ListOutcome.Mapping() < @Override public Post map(final ResultSet rset) < return new PgPost( this.dbase, rset.getInt(1) ); >> ) ); > public Post add(Date date, String title) < return new PgPost( this.dbase, new JdbcSession(this.dbase) .sql("INSERT INTO post (date, title) VALUES (?, ?)") .set(new Utc(date)) .set(title) .insert(new SingleOutcome(Integer.class)) ); > >Далее давайте реализуем интерфейс Post в классе PgPost :
final class PgPost implements Post < private final Source dbase; private final int number; public PgPost(DataSource data, int id) < this.dbase = data; this.number = id; >public int id() < return this.number; >public Date date() < return new JdbcSession(this.dbase) .sql("SELECT date FROM post WHERE .set(this.number) .select(new SingleOutcome(Utc.class)); > public String title() < return new JdbcSession(this.dbase) .sql("SELECT title FROM post WHERE .set(this.number) .select(new SingleOutcome(String.class)); > >Вот как будет выглядеть сценарий полного взаимодействия с базой данных с использованием только что созданных нами классов:
Posts posts = new PgPosts(dbase); for (Post post : posts.iterate()) < System.out.println("Title: " + post.title()); >Post post = posts.add( new Date(), "How to cook an omelette" ); System.out.println("Just added post #" + post.id());Вы можете увидеть полный практический пример здесь. Это веб—приложение с открытым исходным кодом, которое работает с PostgreSQL, используя точный подход, описанный выше, — объекты, говорящие на SQL.
Как насчет производительности?
Я слышу, как вы спрашиваете: “А как же производительность?” В этом сценарии, приведенном несколькими строками выше, мы совершаем множество избыточных обходов базы данных. Сначала мы извлекаем идентификаторы записей с помощью SELECT id , а затем, чтобы получить их заголовки, мы выполняем дополнительный вызов SELECT title для каждой записи. Это неэффективно или, проще говоря, слишком медленно.
Не беспокойтесь, это объектно-ориентированное программирование, а это значит, что оно гибкое! Давайте создадим декоратор PgPost , который будет принимать все данные в своем конструкторе и кэшировать их внутри навсегда:
final class ConstPost implements Post < private final Post origin; private final Date dte; private final String ttl; public ConstPost(Post post, Date date, String title) < this.origin = post; this.dte = date; this.ttl = title; >public int id() < return this.origin.id(); >public Date date() < return this.dte; >public String title() < return this.ttl; >>Обратите внимание: этот декоратор ничего не знает о PostgreSQL или JDBC. Он просто декорирует объект типа Post и предварительно кэширует дату и заголовок. Как обычно, этот декоратор также неизменяем.
Теперь давайте создадим другую реализацию Posts , которая будет возвращать “постоянные” объекты:
final class ConstPgPosts implements Posts < // . public Iterableiterate() < return new JdbcSession(this.dbase) .sql("SELECT * FROM post") .select( new ListOutcome( new ListOutcome.Mapping() < @Override public Post map(final ResultSet rset) < return new ConstPost( new PgPost( ConstPgPosts.this.dbase, rset.getInt(1) ), Utc.getTimestamp(rset, 2), rset.getString(3) ); >> ) ); > >Теперь все записи, возвращаемые iterate() этого нового класса, предварительно снабжены датами и заголовками, полученными за одно обращение к базе данных.
Используя декораторы и несколько реализаций одного и того же интерфейса, вы можете создать любую функциональность, которую пожелаете. Что наиболее важно, так это то, что, хотя функциональность расширяется, сложность дизайна не возрастает, потому что классы не увеличиваются в размерах. Вместо этого мы вводим новые классы, которые остаются сплоченными и прочными, потому что они маленькие.
Что касается транзакций
Каждый объект должен иметь дело со своими собственными транзакциями и инкапсулировать их так же, как запросы SELECT или INSERT . Это приведет к вложенным транзакциям, что вполне нормально при условии, что сервер базы данных их поддерживает. Если такой поддержки нет, создайте объект транзакции для всего сеанса, который будет принимать “вызываемый” класс. Например:
final class Txn < private final DataSource dbase; public T call(Callable callable) < JdbcSession session = new JdbcSession(this.dbase); try < session.sql("START TRANSACTION").exec(); T result = callable.call(); session.sql("COMMIT").exec(); return result; >catch (Exception ex) < session.sql("ROLLBACK").exec(); throw ex; >> >Затем, когда вы хотите обернуть несколько манипуляций с объектами в одну транзакцию, сделайте это следующим образом:
new Txn(dbase).call( new Callable() < @Override public Integer call() < Posts posts = new PgPosts(dbase); Post post = posts.add( new Date(), "How to cook an omelette" ); post.comments().post("This is my first comment!"); return post.id(); >> );Этот код создаст новую запись и опубликует комментарий к ней. Если один из вызовов завершится неудачей, вся транзакция будет откачена.
Мне этот подход кажется объектно-ориентированным. Я называю это “объектами, говорящими на SQL”, потому что они знают, как разговаривать на SQL с сервером базы данных. Это их мастерство, идеально заключенное в их границах.
Разработка системы заметок с нуля. Часть 3: знакомство с Neo4j, работа над микросервисами CategoryService и APIService
Основы работы с графовой базой данных Neo4j на примере системы заметок, а также продолжение разработки проекта с микросервисной архитектурой.
Мы продолжаем разрабатывать систему заметок с нуля. В третьей части серии материалов мы познакомимся с графовой базой Neo4j, напишем CategoryService и реализуем клиента к новому сервису в APIService.
В первой части мы спроектировали систему и посмотрели, какие сервисы требуются для построения микросервисной архитектуры.
Во второй части мы спроектировали и разработали RESTful API Service на Golang cо Swagger и авторизацией.
Теперь разработаем сервис управления категориями CategoryService. Категории мы делаем в виде дерева с большой вложенностью, в теории — бесконечной. Сервис будем разрабатывать на языке Python, а в качестве хранилища используем Neo4j.
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Подробности в видео и текстовой расшифровке под ним.
Запуск графовой базы данных Neo4j
Neo4j — это высокопроизводительная NoSQL база данных, основанная на принципе графов. В ней нет такого понятия, как таблицы со строго заданными полями. Она оперирует гибкой структурой в виде нод и связей между ними.
Запускать Neo4j мы будем в Docker. Готовые образы на есть hub.docker.com. Они делятся на два вида: Enterprise и Community-версии. Нам надо выбрать тег образа, который будем использовать.
Важно: никогда не используйте тег latest, чтобы избежать ситуаций, когда вы запустите обновление контейнера, он обновится на последнюю версию, и у вас все сломается. Это связано с тем, что последнее обновление может содержать несовместимые изменения с вашей текущей версией. Например, у GitLab есть целая политика обновления как мажорных, так и минорных версий. Обновиться с 11 на 13 версию сразу не получится, придётся пройти длинный путь последовательных обновлений: 11.5.0 -> 11.11.8 -> 12.0.12 -> 12.10.14 -> 13.0.12 -> 13.2.3.
Но вернёмся к Neo4j. В официальной документации есть статья про запуск в Docker-контейнере. Возьмём оттуда команду docker run и преобразуем её в простой docker-compose.
docker run \ --name testneo4j \ -p7474:7474 -p7687:7687 \ -d \ -v $HOME/neo4j/data:/data \ -v $HOME/neo4j/logs:/logs \ -v $HOME/neo4j/import:/var/lib/neo4j/import \ -v $HOME/neo4j/plugins:/plugins \ --env NEO4J_AUTH=neo4j/test \ neo4j:latest Версия docker-compose — 3.9. Затем идёт определение сервисов. У нас будет сервис Neo4j. Укажем, чтобы он всегда рестартовал, если упадет. Образ мы будем использовать с тегом 4.2.3. Далее — имя контейнера. Указываем порты, которые мы пробрасываем на хостовую машину. На порте 7474 будет доступен веб-интерфейс по протоколу HTTP, а 7687 используется для общения с Neo4j по протоколу BOLT. Далее пробрасываем volumes. Кроме тех, что указаны в команде, я ещё пробросил /var/lib/neo4j/conf , чтобы был доступ в файлу конфигурации neo4j.conf .
По умолчанию Neo4j создает пользователя neo4j с паролем neo4j и при первом входе требует сменить пароль. Этот этап можно пропустить, задав пароль через переменную среду NEO4J_AUTH .
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Готовый файл запускаем командой^
docker-compose -f /path/to/docker-compose.yml Дополнительно нам понадобятся процедуры APOC, которые расширяют функционал запросов к Neo4j. Для этого идём в репозиторий этих процедур, скачиваем jar-файл apoc-4.2.0.2-all.jar и кладём в наш volume ./export/neo4j/plugins.
Работа через веб-интерфейс Neo4j
После установки Neo4j открываем веб-интерфейс, который висит на порте 7474. Коннектимся к дефолтной базе Neo4j. Вводим пароль, который указали в compose-файле. Нас встречает красивый интерфейс с тёмной темой. Он состоит из нескольких секций:
- Editor — здесь вводим команды на языке Cypher, чтобы работать с графом. Хоткей Shift + Enter позволяет вводить команду в несколько строк. Чтобы запустить выражение, нажмите Ctrl + Enter (CMD + Enter). Также ведётся полная история всех введённых команд.
- Stream — для отображения результата выполненной команды. Для каждой выполненной команды создаётся отдельный Stream.
- Code отображает все полученные и отправленные данные от сервера.
- Sidebar отображает мета-дату базы данных и основную информацию. Сохранённые скрипты можно раскидать по папкам. Также тут размещены ссылки на документацию и информация о лицензии.
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Основные команды языка Cypher
Язык Cypher создан специально для взаимодействия с графами. Он является декларативным, похож на SQL и использует паттерны, чтобы описать граф. Давайте разберёмся с основными командами, которые нам нужны.
CREATE (u:User ) Это команда создания ноды, которая будет представлять пользователя. CREATE — это ключевое слово, после него идет определение ноды в круглых скобках, u — это алиас, который мы можем использовать в запросе, он не сохраняется в базу. Далее через двоеточие указываем лейбл, их можно указать несколько. Они сохраняются в базе и могут быть использованы для идентификации. После лейблов в фигурных скобках в формате JSON указываются свойства ноды.
Выполняем команду, нажимая Cmd + Enter. Создаётся новое окно стрима, где отображается результат работы нашей команды. В данном случае в стриме будет отчёт о том, что было создано.
Теперь давайте найдём нашу ноду. Пишем ключевое слово MATCH, далее определяем, какие ноды ищем и возвращаем по алиасу.
MATCH (u:User:Human) RETURN u Теперь создадим ещё одну ноду и отношение с нодой пользователя.
MATCH (u:User) WHERE u.id = 1 CREATE (c:Category < name: "Category 1", id: apoc.create.uuid()>) CREATE (u)-[r:OWN]->(c) RETURN c.id Пишем ключевое слово MATCH и ноду, далее идёт ключевое слово WHERE — ищем пользователя с После нахождения мы можем создать новую ноду:
- Пишем CREATE.
- Формализуем ноду «Категории».
- Указываем свойство id и вызываем функцию APOC, которая генерирует UUID. Чтобы она работала, мы копировали ранее jar-файл.
После создания ноды создаём отношение:
- Добавляем ключевое слово CREATE.
- Пишем ноду нашего юзера.
- Создаём отношение.
- Возвращаем id созданной категории.
Отношение состоит из 3 элементов: направление отношения по отношению к пользователю, алиас и лейбл, направление отношения по отношению к ноде категории. То есть мы можем создать отношение как от юзера к категории, так и от категории к юзеру. У отношений также могут быть свойства. Они задаются в формате JSON. Это крайне удобно для сложных структур. Например, можно было для отношений пользователя к группам и категорий к подкатегориям сделать свойства отношения created_date.
Чтобы посмотреть, как Neo4j обрабатывает наш запрос, добавим ключевое слово EXPLAIN или PROFILE.
PROFILE MATCH (n) RETURN n EXPLAIN MATCH (n) RETURN n Мы увидим план запроса, который можно проанализировать, чтобы понять, насколько он хорош или плох.
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Посмотреть историю команд можно командой :history , очистить все стримы — командой :clear .
Давайте создадим ещё немного нод и отношений, чтобы можно было выполнить запрос на поиск всех нод и всех отношений:
MATCH (n) RETURN n У нас получилось создать две ноды пользователей с одинаковым полем id, так как уникальным идентификатором по умолчанию является внутренний идентификатор ноды , который генерирует сам Neo4j.
Запросы, которые будут использоваться в нашем сервисе
Создание ноды пользователя мы рассмотрели. Но мы будем делать это вместе с командой создания рутовой категории следующим образом:
MERGE (u:User ) CREATE (c:Category < name: "Category 22", id: apoc.create.uuid()>) CREATE (u)-[r:OWN]->(c) RETURN c.id Используем ключевое слово MERGE, которое создаст новую ноду, если пользователя с таким id нет, или найдёт все ноды с таким id. Создаём новую ноду «Категории» и связь между нодой пользователя и категории. В результате мы видим два JSONа и две созданные ноды с одинаковым названием, потому что первый запрос на матчинг пользователя нашёл двух пользователей с id равным единице и создал две категории и два отношения.
Рутовая категория — это категория, которая имеет связь с пользователем. Под категорией я имею в виду категории, которые не связаны с пользователем.
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Теперь нам нужен запрос на создание ноды подкатегории и отношения с рутовой категорией:
MATCH (cs:Category) WHERE cs.id = "de8dc382-67bb-454c-9873-fd969eec1535" CREATE (c:Category < name: "Category 1.2", id: apoc.create.uuid()>) CREATE (cs)-[r:CHILD]->(c) RETURN c.id Находим ноду категории по идентификатору. Далее создаём категорию и отношение между категориями. Для связи используем лейбл CHILD, а не OWN как для отношения между нодами пользователя и рутовой категории.
Нам также нужен запрос, который вернёт дерево всех нод категорий со всеми подкатегориями пользователя:
MATCH path = (u:User)-[*]->(c) WHERE NOT (c)-->() AND u.id = "77803c1a-8c1a-492a-89be-f219735b2aef" RETURN path Мы ищем от стартовой ноды, пока не дойдём до ноды, у которой нет выходных связей. В MATCH мы пишем path =. Таким образом мы создаём объект с типом Path, в котором находятся все найденные ноды. Это упрощает возврат всего графа всех категорий. Этот запрос отлично выводит граф в Neo4j в браузере, но для кода нам нужен на выходе древовидный JSON. Для этого соберём path в список и отдадим его функции apoc.convert.toTree, чтобы получить выходной древовидный JSON. Но перед его выводом удалим вторую ноду пользователя по внутреннему идентификатору:
MATCH (u:User) WHERE ID(u) = 26 DETACH DELETE u Теперь модифицируем нашу команду для получения дерева категорий. Добавляем ключевое слово WITH, собираем наш путь в список нод и вызываем функцию apoc.convert.toTree, передавая на вход список нод. В результате получаем древовидный JSON.
MATCH path = (u:User)-[*]->(c) WHERE NOT (c)-->() AND u.id = "77803c1a-8c1a-492a-89be-f219735b2aef" WITH collect(path) AS ps CALL apoc.convert.toTree(ps) yield value RETURN value Ещё нам нужно проверять наличие родительское категории, чтобы понимать, сможем ли мы создать подкатегорию. Сделать это можно при помощи следующего запроса:
OPTIONAL MATCH (n:User) RETURN n IS NOT NULL AS Predicate В результате выполнения запроса вернётся true или false.
Также нам нужно каскадно удалять категории. Чтобы сделать это, мы ищем все ноды от стартовой категории, которую хотим удалить, убираем связи и удаляем их.
MATCH path = (c:Category)-[*]->(cc:Category) WHERE c.id = "95bec604-5da2-4297-b792-5a866e292df4" DETACH DELETE path Во время разработки мне очень пригодился запрос на удаление всех нод. Ключевое слово DETACH позволяет удалять связанные ноды каскадно.
MATCH (n) DETACH DELETE n Создание CategoryService
Писать будем на Python.
Маленький disclaimer: я на Python пишу в таком же стиле, как на Java, так как Java был моим первым языком программирования. Знаю, что это не дзен и что так не принято, но такой код легче тестировать, в нём меньше ошибок, он более читаемый.
Сначала создадим venv и установим нужные библиотеки. Будем использовать:
- Flask как минималистичный веб-фреймоворк.
- Flask-CORS для возможности обращения с разных доменов.
- Flask-RESTful, чтобы было удобнее создавать классы с ресурсами. Этот проект забросили, если знаете достойную замену, напишите, пожалуйста, в комментариях.
- Flask-Injector для реализации паттерна Dependency Injection, чтобы не было глобальных импортов.
- PyYAML для работы с форматом данных YAML.
Начнём с главного файла app.py и с конфига приложения.
- Создаём класс конфига. Почти везде я буду использовать слоты для классов. Это уменьшает вес объектов, но лишает объекты свойства dict, об этом нужно помнить.
- Конфиг мы будем вычитывать из YAML-файла. Поэтому в конструкторе получаем путь до файла и сразу вызываем функцию read, которая вычитает файл.
- Проверяем, что такой файл есть. Если его нет, то выбрасываем ошибку.
- В контексте открываем файл и вычитываем содержимое. Тут же парсим его при помощи библиотеки PyYAML.
- Проходимся по содержимому.
- Далее мы будем вызывать метод setattr, чтобы засетить слоты в нашем классе. Если ключ есть в слотах, мы сеттим этот атрибут.
Создадим YAML-файл с конфигурацией. В нашем конфиге будет переменная debug. Она нужна для разработки, например, дополнительного логирования или перехвата ошибок.
Для констант создаём файл constants.py. Там мы будем хранить все константы приложения, например, путь до конфиг-файла и путь до папки с логами.
Возвращаемся к app.py. Следующий важный компонент — это логирование.
- Создаём дефолтный логер с уровнем DEBUG.
- Создаём FileHandler, чтобы наши логи попадали в файл.
- Формат записи в логе мы определяем при помощи форматтера. У него особый язык, который описан в документации.
- Добавляем в логер наш хендлер.
- Создаём основной объект нашего приложения app, настраиваем его, а конфиг сеттим внутрь нашего объекта. Это позволит конфигурировать сам Flask через наш конфиг.
- Оборачиваем объект приложения объектом Api из библиотеки Flask-RESTful. Теперь мы сможем регистрировать ресурсы в объекте api.
- Оставляем место, где у нас будет injector для Dependency Injection.
- Пишем глобальную обработку ошибок.
Метод errorhandler будет перехватывать все исключения типа AppException и вызывать функцию app_exception_handler. Теперь нам нужно создать такой класс исключения. Наследовать его будем от класса Exception. Также мы сделаем систему ошибок в нашем приложении. AppException в конструкторе будет принимать на себя параметр exc_data, который может являться enum AppError и состоит из полей error: сообщение об ошибке, error_code — код ошибки и developer_message — сообщение для разработчика.
Различные кастомные обработчики я обычно называю помощниками. Поэтому создаю пакет helpers и там в файле flask.py реализую функцию обработки AppException. Также, если приложение не в дебаг-режиме, то мы перехватываем вообще все исключения, даже те, которые не обрабатываем. Например, где-нибудь мы поделим на 0 и не обработаем. Это нужно для продакшен-режима, когда пользователь не должен видеть разные HTML-страницы с ошибками или трейсы. Для этого создаём функцию uncaught_exception_handler, которая пишет в лог и вызывает функцию обработки AppException с ошибкой системы. У нас её как раз нет, поэтому возвращаемся и реализовываем enum AppError, добавляем в него SYSTEM_ERROR.
Мы будем добавлять в enum ошибки по мере их появления. Запускаем приложение и проверяем, что в конфиге есть все наши настройки.
Разработка DAO-слоя для доступа к Neo4j
Мы будем реализовывать классический DAO-паттерн. Будет абстрактный класс Storage, который является по сути интерфейсом с абстрактными методами, и конкретная реализация с Neo4j. Это позволит не привязываться к конкретному хранилищу. Если возникнет необходимость его сменить, это можно будет сделать, создав ещё одну реализацию и изменив класс в контейнере зависимостей.
В классе с реализацией для Neo4j мы создаём объект Graph и передаём ему параметры для подключения. Для понимания того, что надо передать классу, чтобы присоединиться, есть два пути: смотреть в документацию или в исходники. Оба имеют право на жизнь.
Выполнение любого запроса для Neo4j — это исполнение команды Cypher. Создаём метод execute_cypher и все методы реализуем одинаково: вызываем метод execute_cypher и возвращаем прочитанные данные из курсора. С первого взгляда выглядит как костыль. Но это условность, которая даёт гибкость в смене хранилища, при этом проблем с реализацией или тестируемостью нет.
Далее создаём ресурсы категорий. Библиотека Flask-RESTful даёт возможность создавать ресурсы в виде классов с методами get, post, put, delete. Создав метод get, понимаем, что нам нужен сервис управления категориями, а создав класс сервиса, понимаем, что ему нужен DAO для доступа к категориям. Создаём класс-интерфейс CategoryDAO, который мы и будем инжектить, и реализацию этого класса под Neo4j.
Пришло время запросов, которые мы рассмотрели ранее.
- Идём в Neo4j и ещё раз проверяем, что запросы работают корректно.
- Переносим запрос поиска всех категорий пользователя из Neo4j в код сервиса. Попутно везде проставляем возвращаемые значения, где забыли.
- Возвращаемся в сервис, добавляем в конструктор логер и реализуем метод получения категорий.
- Разбираемся с методами сервиса и DAO-слоя. Основная логика простая: сервис вызывает метод DAO и получает данные, с которыми он может что-то сделать и вернуть.
Надо протестировать хотя бы получение всех категорий. Но для этого нам надо в сервисе получить реализацию интерфейса CategoryDAO. Это значит, что пришло время Dependency Injection.
- В основном файле app.py создаём объект Injector, который на вход принимает массив.
- Создаём объект FlaskInjector, которому отдаём наш объект app и созданный Injector.
- Создаём отдельный файл di.py.
- В файле di.py создаём классы модулей для наших зависимостей.
В случае со StorageModule для создания объекта Neo4jStorage нам нужны данные подключения к Neo4j из конфига. Поэтому в конструкторе передаем конфиг, а в методе configure уже используем его для создания экземпляра класса Neo4jStorage и биндим интерфейс Storage на объект нашей реализации. Также указываем параметр scope со значением singleton, то есть один объект на все приложение. Кроме того, там можно указать request, и тогда объект будет создаваться на каждый запрос к API. Таким же способом биндим интерфейс CategoryDAO на реализацию Neo4jCategoryDAO. Далее создаём подобный модуль для логера, чтобы и его можно было инжектить в конструкторе классов.
Заполняем массив Injector в файле app.py нашими модулями и проставляем декоратор @inject над конструкторами, куда инжектим наши классы. В ресурсах мы инжектим CategoryService, в CategoryService инжектим CategoryDAO, а в реализации Neo4jCategoryDAO инжектим Storage.
У нас будет два ресурса: CategoriesResource и CategoryResource.
- Реализуем метод GET у ресурса списка категорий.
- Вызываем сервис категорий, чтобы получить список категорий пользователя.
- Протестируем этот метод. Создаём HTTP скетч и делаем запрос.
- Первый тест сразу покажет все ошибки и опечатки. После исправлений проходимся в дебаге по всему процессу и смотрим, что происходит.
- Мы успешно получили данные из Neo4j. Парсим полученные данные от стораджа.
Тут надо отметить, что ключ value — это стандартный ключ, генерируемый Neo4j, а вот ключ own — это уже связь между пользователем и его рутовой категорией. У категории есть ключ child, что обозначает связь между рутовой категорией и подкатегорий.
Чтобы распарсить древовидный JSON, нам очевидно нужна рекурсивная функция.
- Создаём функцию _parse_categories и понимаем, что нам не хватает модели Category.
- Создаём пакет model в DAO и в нем организуем три файла: base.py для базовой модели методов, dto.py для реализации паттерна DTO и model.py для данных из БД.
DTO — это паттерн для оперирования входными данными от пользователя. Они упаковываются в класс DTO. Сервисы работают с ними, а модель — это уже полное представление данных из БД. Реализовывать модели и DTO будем на data-классах.
При реализации модели Category есть один нюанс. Так как категория содержит в себе подкатегории, то модель должна содержать поле с массивом это же класса. Python так не позволяет сделать, так как он не видит этого класса, для него он не создан. Обойти это можно строковой аннотацией и объектом List из пакета Typing. Все классы будем наследовать от базового класса Base. У него будут общие методы, например, преобразование объекта в словарь, исключая пустые поля. Это нужно, чтобы в итоговом JSON не было пустых полей.
DTO создаются на каждое действие пользователя. В нашем случае это Create, Update и Delete. Разные DTO содержат разные данные и разные обязательные поля. Например, для CreateCategoryDTO не нужен uuid категории, так как его еще не существует. В вот для Delete и Update uuid категории обязательно нужен.
Возвращаемся к парсингу категорий. Тут всё просто.
- Проходим по списку, собираем категорию.
- Если у категории есть дети, рекурсивно вызываем функцию, чтобы получить список категорий детей категории.
- Доделываем метод get_categories у сервиса категорий.
- Делаем проверку на то, что пользователь, чьи категории запрашиваются, существует, иначе отдаем 404 и ошибку USER_NOT_FOUND.
- Реализуем методы создания, обновления и удаления категории. Я вызываю несуществующие методы, чтобы понять, какие методы будут нужны. Также попутно дополняю DTO-классы необходимыми полями, после чего массово объявляю все нужные методы в интерфейсе CategoryDAO и потом реализую эти методы в DAO-реализации для Neo4j.
- Запросы всё так же тестируем в веб-интерфейсе Neo4j. Графы выглядят очень красиво, а язык Cypher крайне удобен, нет проблем с запросами бесконечной вложенности.
Есть информация, что Neo4j падает при 1 миллионе нод и 500 связей между ними. Я не тестировал, но думаю, что если применить масштабирование и/или шардирование, то эту проблему можно решить.
После реализации всех методов в DAO возвращаемся к ресурсам.
Получаем user_uuid из Query Path. Запускаем и проверяем получение всех категорий без указания user_uuid. Получаем код 500 вместо 404. Cтандартная ошибка вместо нашего User not found. Начинаю разбираться, почему ошибка не моя:
- Проверяю функции обработки ошибок.
- Понимаю, что в ошибке не хватает HTTP-кода возврата.
- Нахожу ошибку в классе исключения. Я не забирал данные из переданной ошибки в исключении.
- После исправления я всё-таки перехватил ошибку. Но метод jsonify упал с ошибкой, так как не смог сериализовать объект AppException. Поэтому передаем в jsonify не сам объект, а вызываем у него magic-метод dict. Теперь всё хорошо, кроме HTTP-кода.
Проблема была в месте присваивания HTTP-кода в классе AppException. Ошибка корректная. Теперь проверяем получение всех категорий с заданным user_uuid. Видим, что все объекты получены корректно. Но теперь код падает на сериализации списка категорий. Проблема в том, что стандартный сериализатор JSON не знает, что делать с классом Category, надо ему рассказать об этом.
Создаём в пакете helpers файл json.py. В нём создаём класс CustomJSONEncoder с методом default. Здесь мы пытаемся создать универсальный сериализатор, который будет уметь сериализовать строки, энамы, словари, итерируемые объекты, объекты со слотами или без слотов, но с объектом dict. Функция должна рекурсивной, чтобы сериализатор корректно работал с вложенными объектами. Поэтому выделяем код в отдельный метод to_dict и рекурсивно вызываем на каждый объект внутри объекта, а метод to_dict вызываем в методе default. Проверяем еще раз — успех. Мы получили древовидный JSON.
Тут можно спросить, зачем я десериализую JSON от Neo4j в объекты, а потом опять сериализую его в JSON, чтобы отдать клиенту. Ответ простой: если потребуется реализовать какую-то логику по обогащению данных или изменится структура в хранилище, структура и модели данных не изменятся, а значит не изменится и контракт сервиса. В материале про микросервисы я уже объяснял, что очень важно проектировать сервисы таким образом, чтобы их контракты не менялись даже при изменении логики работы самого сервиса.
Методы создания, обновления и удаления категории
Далее реализуем метод post для создания категории. Я не хочу вручную получать данные из body и создавать DTO. Поэтому применяю маршалинг. Пишу декоратор masrshal_with, в котором указываю, что вернёт метод, и декоратор use_kwargs, для которого указываю, какую DTO я жду на входе. То есть этот декоратор возьмет body из запроса и провалидирует его относительно data-класса, который я ему задал в параметрах.
Чтобы это работало, нужно реализовать метод to_schema во всех DTO. Для этого в классе Base реализуем метод to_schema. Воспользуемся библиотекой marshmallow_dataclass и методом class_schema. Теперь в сигнатуре метода хендлера я могу объявить аргумент валидируемой DTO. В методе post создания категории мы ничего не возвращаем, кроме заголовка Location с URI до созданной категории. Из этого заголовка будет легко получить uuid созданной категории. Пишем тест на создание рутовой категории (то есть без параметра parent_uuid) и проверяем. Видим, что наша DTO десерелиазована и все данные на месте. Главное, что категория создана. Теперь пишем тест на создание подкатегории, указывая parent_uuid в body, и проверяем, что такая категория была создана.
Теперь создаём ресурс для работы с конкретной категорией, а также методами patch для обновления и delete для удаления. Пишем для них тесты, проверяем функционал. Также добавим наследования классов ресурсов от класса MethodResource. Это нужно для корректной работы декораторов и возможности последующей генерации swagger-файла на основе кода. Запускаем тест и получаем ошибку в формате HTML. Давайте обработаем такие ошибки отдельно. Создаём функцию handle_request_parse_error с декоратором parser.error_handler. В случае такой ошибки выполняем функцию abort и передаём ей ошибки схемы валидации. Повторяем тест и получаем JSON с ошибкой валидации схемы. Далее финальное тестирование, фиксим опечатки. Сервис готов.
Ещё можно сделать валидацию пользовательских данных, например, проверку формата uuid для полей user_uuid и parent_uuid. Также можно провалидировать имя категории, чтобы это была строка, ограничить её по длине, нормализовать и сделать ограничение на спецсимволы.
Доработка APIService
Теперь нужно сделать реализацию клиента к новому CategoryService в нашем APIService.
- Создаём папку rest в pkg.
- Создаём файл client.go, в котором у нас будут общие структуры для общения с RESTful-сервисом.
- Добавляем FilterOptions — это структура для возможности фильтрации список, которая состоит из поля, оператора и значений.
- Делаем метод BuildURL, который будет формировать итоговый URL из базового URL ресурса, к которому мы обращаемся, и фильтров, которые, по сути, являются ключами и значениями Query Path. В BuildURL мы парсим базовый URL, добавляем в него ключи и значения из фильтров.
- Создаём метод ToStringWF у фильтра, чтобы склеить оператор и значения.
- Добавляем структуру ошибки API с полями Error, ErrorCode и DeveloperMessage. Это те же поля, что были в классе AppError в CategoryService.
- В internal создаём папку client.
- В директории client создаём папку category и файл client.go.
- В директории category создаём файлы model.go и service.go.
- В файле model.go описываем структуру «Категории». Здесь уже нет проблемы с указанием собственного класса в полях класса, как это было в Python.
- Применяем паттерн DTO и создаём DTO-модели.
Код можно немного зарефакторить. Идея следующая: в папке rest будет общий клиент для всех RESTful-сервисов в файле client.go, а в файле url.go — уже построение общего URL и структуры API.
- Базовый клиент состоит из URL, HTTP-клиента и мьютекса для многопоточной работы.
- Создаём метод SendRequest, который будет отправлять запрос и возвращать ответ.
- Лочим мьютекс.
- Запускаем отложенный анлок при помощи defer.
- Проверяем, есть ли HTTP-клиент.
- Выставляем заголовки, которые при желании можно получать на входе в функцию.
- Выполняем запрос.
- Проверяем статус-код у ответа. Если он плохой, то пытаемся прочитать из тела ответа ошибки. Также не забываем запустить отложенное закрытие тела ответа, так как это поток.
- Реализуем метод Close, который обнуляет HTTP-клиент.
Теперь реализуем клиента к сервису категорий.
- Создаём функцию NewClient, которая на вход получает URL сервиса.
- Реализуем все нужные нам методы: получение, создание, обновление и удаление категорий.
Реализация довольно простая: получаем на вход нужные параметры, контекст и фильтры, дополняем фильтры нашей логикой. В случае получения категорий добавляем туда параметр user_uuid. Далее билдим URL и запрос, добавляем в запрос контекст и отправляем запрос. Закрытие тела в методе SendRequest надо делать, только если статус-код плохой. Иначе мы не вычитаем тело в нашем методе. Вычитываем тело ответа, ожидая там увидеть список категорий. Здесь нужно запустить отложенное закрытие потока тела ответа. Затем возвращаем список категорий. Добавляем щепотки логирования и реализуем остальные методы.
В Golang контекст является агрегацией действий и процессов. Он позволяет отменить их все. Например, пользователь сделал запрос, вы его получили, запустили в общем контексте два запроса и ещё несколько фоновых операций. В процессе работы пользователь отменил запрос. Нам нужно отменить операции. Чтобы не закрывать их все руками, вы просто вызываете метод Cancel у контекста. Все сделанные запросы также прервут своё выполнение.
В методах CreateCategory, UpdateCategory и DeleteCategory мы используем библиотеку structs, которая позволяет нам сгенерировать map из входной DTO-структуры. Полученный map мы маршалим. Получаем байты, которые отдаём запросу в виде буфера через конструкцию bytes.NewBuffer.
Когда клиент готов, добавляем его в структуру нашего хендлера категорий. В самом хенделере пишем код, который вызывает методы клиента сервиса категорий.
Во всех хендлерах, если вызов метода клиента категорий привел к ошибке, я отдаю код ответа «418 I’m a teapot». Использую его, чтобы обозначить, что запрос не выполнился из-за ошибки в коде, а не проблемы среды или недоступности БД. Также при получении списка категорий я начал реализовывать маршалинг структуры массива категорий и неожиданно понял, что просто так делаю сериализацию и десериализацию списка категорий.
В APIService я точно не буду обрабатывать данные списка категорий, а просто отдам их клиенту. Поэтому я вовремя одумался и зарефакторил код клиента, чтобы отдавать массив байт. В клиенте я их вычитываю методом ReadAll из пакета ioutil, а в хендлере сразу отдаю клиенту методом w.Write. Также удалил модель Category, так как она не нужна. При создании категории по всем правилам REST я отдаю заголовок Location с uuid созданной категории. Я мог бы не парсить заголовок от CategoryService, так как ендпоинты совпадают, но они могут перестать совпадать. Чтобы избежать багов, я решил распарсить сразу.
Также из контекста я забираю значение по ключу httprouter.ParamsKey и кастую в httprouter.Params. Значение в контекст кладёт библиотека роутера, которую я использую. Это удобный и быстрый способ получить значения из Query Path. В методах удаления и обновления категории я отдаю код ответа «204 No Content», а при создании категории отдаю «201 Created». Также в методе генерации токена доступа JWT я захардкодил UUID пользователя, который был создан в БД, чтобы протестировать решение. Этот хардкод уберётся, когда появится UserService.
В точке входа app.go я создаю клиента к CategoryService. Мне нужен URL до API сервиса. Его мы будем забирать из конфига, поэтому добавим эту настройку в конфиг, в код и в YAML- файл. Далее пишем тесты на все ручки хендлера и запускаем.
В следующей части мы займёмся разработкой микросервисов NoteService, TagService и UserService.