изменить значение данных в столбце в датафрейме в R
У меня есть датафрейм с 4 столбцами, в котором один из столбцов содержит данные, допустим, a, b, c, d, e. Всего 582 строки с этими значениями. Мне нужно заменить в последнем столбце «a» и «b» на 1, а «c», «d», «e» на 0 и создать новый шестой столбец, в котором присутствуют только эти 0 и 1 (для последующей логистической регрессии). Как я могу это сделать? Дали подсказку, что можно с помощью dplyr, но пока нет представления.
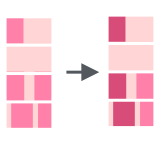
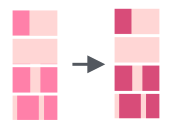
Нужно создать столбец Е, где заменить значения из столбца D на 0 и 1 так что: a, b = 1; c, d, e = 0 чтобы получилось так:
A B C D E R1 3 1 2 a 1 R2 2 2 1 c 0 R3 1 3 4 c 0 R4 4 3 5 e 0 R5 5 4 2 d 0 R6 3 1 1 b 1 R7 4 4 3 a 1 R8 2 2 2 b 1
Отслеживать
задан 29 окт 2021 в 15:46
57 6 6 бронзовых знаков
Пожалуйста, уточните вашу конкретную проблему или приведите более подробную информацию о том, что именно вам нужно. В текущем виде сложно понять, что именно вы спрашиваете.
5 Работа со строками
Мы будем пользоваться в основном пакетами stingr и stringi , так как они в большинстве случаях удобнее. К счастью функции этих пакетов легко отличить от остальных: функции пакет stringr всегда начинаются с str_ , а функции пакета stringi — c stri_ .
5.2 Как получить строку?
- следите за кавычками
"the quick brown fox jumps over the lazy dog"## [1] "the quick brown fox jumps over the lazy dog" 'the quick brown fox jumps over the lazy dog'## [1] "the quick brown fox jumps over the lazy dog" "the quick 'brown' fox jumps over the lazy dog"## [1] "the quick 'brown' fox jumps over the lazy dog" 'the quick "brown" fox jumps over the lazy dog'## [1] "the quick \"brown\" fox jumps over the lazy dog"- пустая строка
character(3)- преобразование
typeof(4:7)## [1] "integer" as.character(4:7)## [1] "4" "5" "6" "7"- встроенные векторы
letters## [1] "a" "b" "c" "d" "e" "f" "g" "h" "i" "j" "k" "l" "m" "n" "o" "p" "q" "r" "s" ## [20] "t" "u" "v" "w" "x" "y" "z" LETTERS## [1] "A" "B" "C" "D" "E" "F" "G" "H" "I" "J" "K" "L" "M" "N" "O" "P" "Q" "R" "S" ## [20] "T" "U" "V" "W" "X" "Y" "Z" month.name## [1] "January" "February" "March" "April" "May" "June" ## [7] "July" "August" "September" "October" "November" "December"- помните, что функции data.frame() , read.csv() , read.csv2() , read.table() из базового R всегда по-умолчанию преобразуют строки в факторы, и чтобы это предотвратить нужно использовать аргумент stringsAsFactors . Это много обсуждалось в сообществе R, можно, например, почитать про это вот этот блог пост Роджера Пенга.
str(data.frame(letters[6:10], LETTERS[4:8]))## 'data.frame': 5 obs. of 2 variables: ## $ letters.6.10.: chr "f" "g" "h" "i" . ## $ LETTERS.4.8. : chr "D" "E" "F" "G" . str(data.frame(letters[6:10], LETTERS[4:8], stringsAsFactors = FALSE))## 'data.frame': 5 obs. of 2 variables: ## $ letters.6.10.: chr "f" "g" "h" "i" . ## $ LETTERS.4.8. : chr "D" "E" "F" "G" . Но этом курсе мы учим использовать сразу tibble() , read_csv() , read_csv2() , read_tsv() , read_delim() из пакета readr (входит в tidyverse ).
- Создание рандомных строк
set.seed(42) stri_rand_strings(n = 10, length = 5:14)## [1] "uwHpd" "Wj8ehS" "ivFSwy7" "TYu8zw5V" ## [5] "OuRpjoOg0" "p0CubNR2yQ" "xtdycKLOm2k" "fAGVfylZqBGp" ## [9] "gE28DTCi0NV0a" "9MemYE55If0Cvv"- Перемешивает символы внутри строки
stri_rand_shuffle("любя, съешь щипцы, — вздохнёт мэр, — кайф жгуч")## [1] ",цо м,пюзгу сл аиъ—в кжряд,ыщьчебэн х—штё фй" stri_rand_shuffle(month.name)## [1] "aJayunr" "eyrbraFu" "achMr" "Aplri" "ayM" "Jnue" ## [7] "uJly" "usuAgt" "tpebermSe" "tOecrbo" "oeNembvr" "Dmceerbe"- Генерирует псевдорандомный текст 1
stri_rand_lipsum(nparagraphs = 2)## [1] "Lorem ipsum dolor sit amet, donec sit nunc urna sed ultricies ac pharetra orci luctus iaculis, ac tincidunt cum. Neque eu semper at sociosqu hendrerit. Eu aliquet lacus, eu hendrerit donec aliquam eros. Risus nibh, quam in sit facilisi ipsum. Amet sem sed donec sed molestie scelerisque tincidunt. Nisl donec et facilisis interdum non sed dolor purus. In ipsum dignissim torquent velit nec aliquam pellentesque. Ac, adipiscing, neque et at torquent, vestibulum ullamcorper. Ad dictumst enim velit non nulla felis habitant. Egestas placerat consectetur, dictum nostra sed nec. Erat phasellus dolor libero aliquam viverra. Vestibulum leo et. Suscipit egestas in in montes, sapien gravida? Conubia purus varius ut nec feugiat." ## [2] "Risus eleifend magnis neque diam, suspendisse ullamcorper nulla adipiscing malesuada massa, nisi sociosqu velit id et. Aliquam facilisis et aenean. Parturient vel ac in convallis, massa diam nibh. Nulla interdum cursus et. Natoque amet, ut praesent. Tortor ultrices a consectetur, augue natoque class faucibus? Ut sed arcu elementum magna. Dignissim ac facilisi quis ut nisl eu, massa."5.3 Соединение и разделение строк
Соединенить строки можно используя функцию str_c() , в которую, как и в функции с() , можно перечислять элементы через запятую:
tibble(upper = rev(LETTERS), smaller = letters) %>% mutate(merge = str_c(upper, smaller))Кроме того, если хочется, можно использовать особенный разделитель, указав его в аргументе sep :
tibble(upper = rev(LETTERS), smaller = letters) %>% mutate(merge = str_c(upper, smaller, sep = "_"))Аналогичным образом, для разделение строки на подстроки можно использовать функцию separate() . Это функция разносит разделенные элементы строки в соответствующие столбцы. У функции три обязательных аргумента: col — колонка, которую следует разделить, into — вектор названий новых столбец, sep — разделитель.
tibble(upper = rev(LETTERS), smaller = letters) %>% mutate(merge = str_c(upper, smaller, sep = "_")) %>% separate(col = merge, into = c("column_1", "column_2"), sep = "_")Кроме того, есть инструмент str_split() , которая позволяет разбивать строки на подстроки, но возвращает список.
str_split(month.name, "r")## [[1]] ## [1] "Janua" "y" ## ## [[2]] ## [1] "Feb" "ua" "y" ## ## [[3]] ## [1] "Ma" "ch" ## ## [[4]] ## [1] "Ap" "il" ## ## [[5]] ## [1] "May" ## ## [[6]] ## [1] "June" ## ## [[7]] ## [1] "July" ## ## [[8]] ## [1] "August" ## ## [[9]] ## [1] "Septembe" "" ## ## [[10]] ## [1] "Octobe" "" ## ## [[11]] ## [1] "Novembe" "" ## ## [[12]] ## [1] "Decembe" ""5.4 Количество символов
5.4.1 Подсчет количества символов
tibble(mn = month.name) %>% mutate(n_charactars = str_count(mn))5.4.2 Подгонка количества символов
Можно обрезать строки, используя функцию str_trunc() :
tibble(mn = month.name) %>% mutate(mn_new = str_trunc(mn, 6))Можно решить с какой стороны обрезать, используя аргумент side :
tibble(mn = month.name) %>% mutate(mn_new = str_trunc(mn, 6, side = "left")) tibble(mn = month.name) %>% mutate(mn_new = str_trunc(mn, 6, side = "center"))Можно заменить многоточие, используя аргумент ellipsis :
tibble(mn = month.name) %>% mutate(mn_new = str_trunc(mn, 3, ellipsis = ""))Можно наоборот “раздуть” строку:
tibble(mn = month.name) %>% mutate(mn_new = str_pad(mn, 10))Опять же есть аргумент side :
tibble(mn = month.name) %>% mutate(mn_new = str_pad(mn, 10, side = "right"))Также можно выбрать, чем “раздувать строку”:
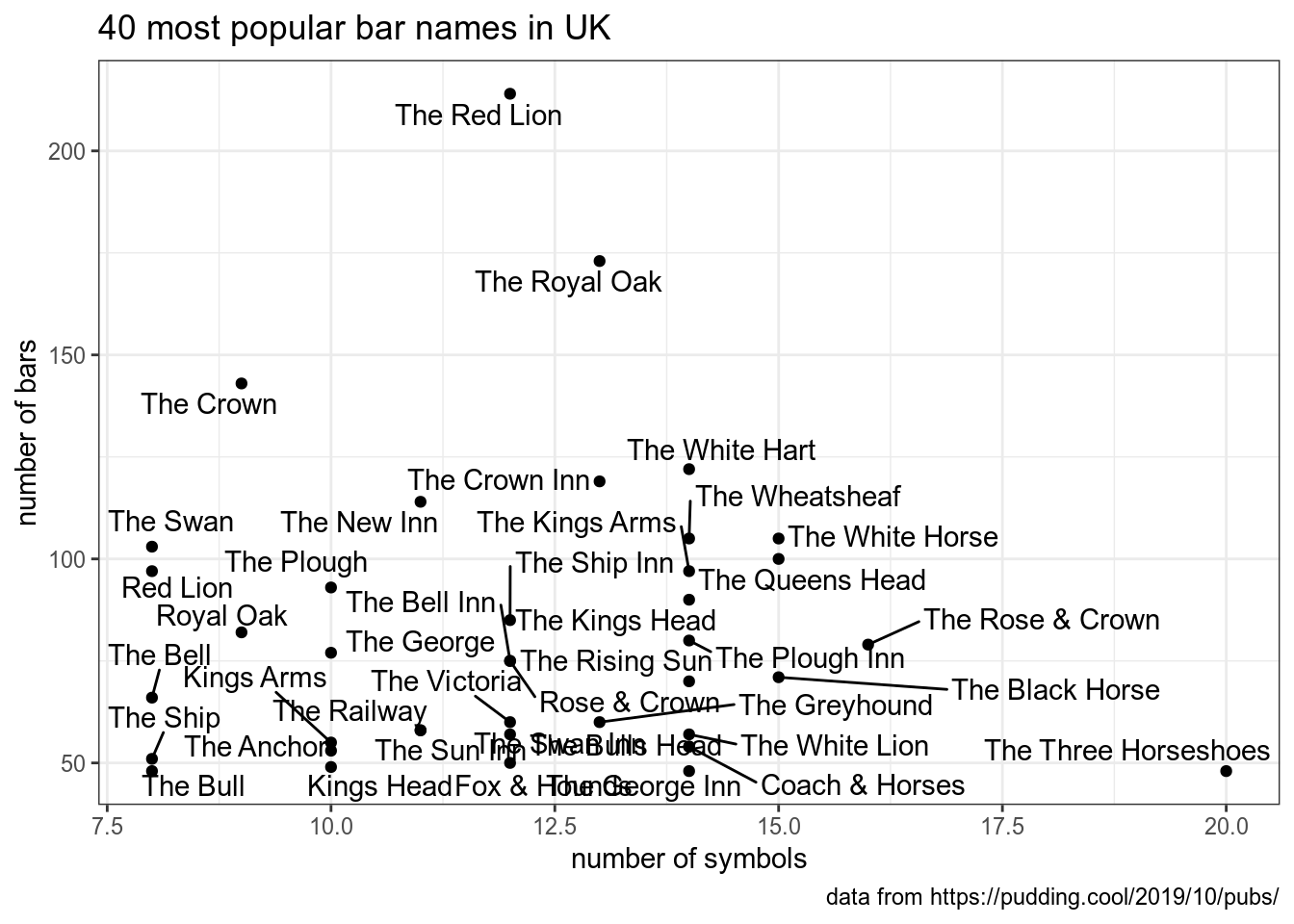
tibble(mn = month.name) %>% mutate(mn_new = str_pad(mn, 10, pad = "."))На Pudding вышла статья про английские пабы. Здесь лежит немного обработанный датасет, которые они использовали. Визуализируйте 40 самых частотоных названий пабов в Великобритании, отложив по оси x количество символов, а по оси y – количество баров с таким названием.
�� Датасет скачался, что дальше? ➡ Перво-наперво следует создать переменную, в которой бы хранилось количество каждого из баров.
�� А как посчитать количество баров? ➡ Это можно сделать при помощи функции count() .
�� Бары пересчитали, что дальше? ➡ Теперь нужно создать новую переменную, где бы хранилась информация о количестве символов.
�� Все переменные есть, теперь рисуем? ➡ Не совсем. Перед тем как рисовать нужно отфильтровать 50 самых популярных.
�� Так, все готово, а какие geom_() ? ➡ На графике geom_point() и geom_text_repel() из пакета ggrepel .
�� А-а-а-а! could not find function «geom_text_repel» ➡ А вы включили библиотеку ggrepel ? Если не включили, то функция, естественно будет недоступна.
�� А-а-а-а! geom_text_repel requires the following missing aesthetics: label» ➡ Все, как написала программа: чтобы писать какой-то текст в функции aes() нужно добавить аргумент label = pub_name . Иначе откуда он узнает, что ему писать?
�� Фуф! Все готово! ➡ А оси подписаны? А заголовок? А подпись про источник данных?
5.5 Сортировка
Для сортировки существует базовая функция sort() и функция из stringr str_sort() :
unsorted_latin c("I", "♥", "N", "Y") sort(unsorted_latin)## [1] "♥" "I" "N" "Y" str_sort(unsorted_latin)## [1] "♥" "I" "N" "Y" str_sort(unsorted_latin, locale = "lt")## [1] "♥" "I" "Y" "N" unsorted_cyrillic c("я", "i", "ж") str_sort(unsorted_cyrillic)## [1] "i" "ж" "я" str_sort(unsorted_cyrillic, locale = "ru_UA")## [1] "ж" "я" "i"Список локалей на копмьютере можно посмотреть командой stringi::stri_locale_list() . Список всех локалей вообще приведен на этой странице. Еще полезные команды: stringi::stri_locale_info и stringi::stri_locale_set .
Не углубляясь в разнообразие алгоритмов сортировки, отмечу, что алгоритм по-умолчанию хуже работает с большими данными:
set.seed(42) huge sample(letters, 1e7, replace = TRUE) head(huge)## [1] "q" "e" "a" "y" "j" "d" system.time( sort(huge) )## user system elapsed ## 7.359 0.024 7.383 system.time( sort(huge, method = "radix") )## user system elapsed ## 0.330 0.028 0.358 system.time( str_sort(huge) )## user system elapsed ## 6.566 0.072 6.679 huge_tbl tibble(huge) system.time( huge_tbl %>% arrange(huge) )## user system elapsed ## 3.404 0.064 3.468Предварительный вывод: для больших данных – sort(. method = «radix») .
5.6 Поиск подстроки
Можно использовать функцию str_detect() :
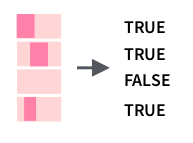
tibble(mn = month.name) %>% mutate(has_r = str_detect(mn, "r"))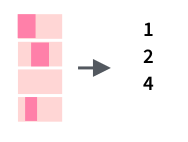
Кроме того, существует функция, которая возвращает индексы, а не значения TRUE / FALSE :
tibble(mn = month.name) %>% slice(str_which(month.name, "r"))Также можно посчитать количество вхождений какой-то подстроки:
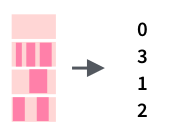
tibble(mn = month.name) %>% mutate(has_r = str_count(mn, "r"))5.7 Изменение строк
5.7.1 Изменение регистра
latin "tHe QuIcK BrOwN fOx JuMpS OvEr ThE lAzY dOg" cyrillic "лЮбЯ, сЪеШь ЩиПцЫ, — вЗдОхНёТ мЭр, — кАйФ жГуЧ" str_to_upper(latin)## [1] "THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG" str_to_lower(cyrillic)## [1] "любя, съешь щипцы, — вздохнёт мэр, — кайф жгуч" str_to_title(latin)## [1] "The Quick Brown Fox Jumps Over The Lazy Dog"5.7.2 Выделение подстроки
Подстроку в строке можно выделить двумя способами: по индексам функцией str_sub() , и по подстроке функцией str_png() .
tibble(mn = month.name) %>% mutate(mutate = str_sub(mn, start = 1, end = 2))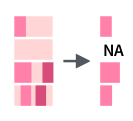
tibble(mn = month.name) %>% mutate(mutate = str_extract(mn, "r"))По умолчанию функция str_extract() возвращает первое вхождение подстроки, соответствующей шаблону. Также существует функция str_extract_all() , которая возвращает все вхождения подстрок, соответствующих шаблону, однако возвращает объект типа список.
str_extract_all(month.name, "r")## [[1]] ## [1] "r" ## ## [[2]] ## [1] "r" "r" ## ## [[3]] ## [1] "r" ## ## [[4]] ## [1] "r" ## ## [[5]] ## character(0) ## ## [[6]] ## character(0) ## ## [[7]] ## character(0) ## ## [[8]] ## character(0) ## ## [[9]] ## [1] "r" ## ## [[10]] ## [1] "r" ## ## [[11]] ## [1] "r" ## ## [[12]] ## [1] "r"5.7.3 Замена подстроки
Существует функция str_replace() , которая позволяет заменить одну подстроку в строке на другую:
tibble(mn = month.name) %>% mutate(mutate = str_replace(mn, "r", "R"))Как и другие функции str_replace() делает лишь одну замену, чтобы заменить все вхождения подстроки следует использовать функцию str_replace_all() :
tibble(mn = month.name) %>% mutate(mutate = str_replace_all(mn, "r", "R"))5.7.4 Удаление подстроки
Для удаления подстроки на основе шаблона, используется функция str_remove() и str_remove_all()
tibble(month.name) %>% mutate(mutate = str_remove(month.name, "r")) tibble(month.name) %>% mutate(mutate = str_remove_all(month.name, "r"))5.7.5 Транслитерация строк
В пакете stringi сууществует достаточно много методов транслитераций строк, которые можно вывести командой stri_trans_list() . Вот пример использования некоторых из них:
stri_trans_general("stringi", "latin-cyrillic")## [1] "стринги" stri_trans_general("сырники", "cyrillic-latin")## [1] "syrniki" stri_trans_general("stringi", "latin-greek")## [1] "στριγγι" stri_trans_general("stringi", "latin-armenian")## [1] "ստրինգի"Вот два датасета:
- список городов России
- частотный словарь русского языка [Шаров, Ляшевская 2011]
Определите сколько городов называется обычным словом русского языка (например, город Орёл)? Не забудьте поменять ё на е.
�� Датасеты скачались, что дальше? ➡ Надо их преобразовать к нужному виду и объединить.
�� А как их соединить? Что у них общего? ➡
В одном датасете есть переменная city , в другом – переменная lemma . Все города начинаются с большой буквы, все леммы с маленькой буквы. Я бы уменьшил букву в датасете с городами, сделал бы новый столбец в датасете с городами (например, town ), соединил бы датасеты и посчитал бы сколько в результирующем датасете значений town .
�� А как соеднить? ➡ Я бы использовал dict %>% . %>% inner_join(cities) . Если в датасетах разные названия столбцов, то следует указывать какие столбцы, каким соответствуют: dict %>% . %>% inner_join(cities, by = c(«lemma» = «city»))
�� Соединилось вроде… А как посчитать? ➡ Я бы, как обычно, использовал функцию count() .
5.8 Регулярные выражения
Большинство функций из раздела об операциях над векторами ( str_detect() , str_extract() , str_remove() и т. п.) имеют следующую структуру:
- строка, с которой работает функция
- образец (pattern)
Дальше мы будем использовать функцию str_view_all() , которая позволяет показывать, выделенное образцом в исходной строке.
str_view_all("Я всегда путаю с и c", "c") # я ищу латинскую c5.8.1 Экранирование метасимволов
a "Всем известно, что 4$\\2 + 3$ * 5 = 17$? Да? Ну хорошо (а то я не был уверен). [|>^<|]" str_view_all(a, "$") str_view_all(a, "\\$") str_view_all(a, "\\.") str_view_all(a, "\\*") str_view_all(a, "\\+") str_view_all(a, "\\?") str_view_all(a, "\\(") str_view_all(a, "\\)") str_view_all(a, "\\|") str_view_all(a, "\\^") str_view_all(a, "\\[") str_view_all(a, "\\]") str_view_all(a, "\\) str_view_all(a, "\\>") str_view_all(a, "\\\\")5.8.2 Классы знаков
- \\d – цифры. \\D – не цифры.
str_view_all("два 15 42. 42 15. 37 08 5. 20 20 20!", "\\d") str_view_all("два 15 42. 42 15. 37 08 5. 20 20 20!", "\\D")- \\s – пробелы. \\S – не пробелы.
str_view_all("два 15 42. 42 15. 37 08 5. 20 20 20!", "\\s") str_view_all("два 15 42. 42 15. 37 08 5. 20 20 20!", "\\S")- \\w – не пробелы и не знаки препинания. \\W – пробелы и знаки препинания.
str_view_all("два 15 42. 42 15. 37 08 5. 20 20 20!", "\\w") str_view_all("два 15 42. 42 15. 37 08 5. 20 20 20!", "\\W")- произвольная группа символов и обратная к ней
str_view_all("Умей мечтать, не став рабом мечтанья", "[оауиыэёеяю]") str_view_all("И мыслить, мысли не обожествив", "[^оауиыэёеяю]")- встроенные группы символов
str_view_all("два 15 42. 42 15. 37 08 5. 20 20 20!", "[0-9]") str_view_all("Карл у Клары украл кораллы, а Клара у Карла украла кларнет", "[а-я]") str_view_all("Карл у Клары украл кораллы, а Клара у Карла украла кларнет", "[А-Я]") str_view_all("Карл у Клары украл кораллы, а Клара у Карла украла кларнет", "[А-я]") str_view_all("The quick brown Fox jumps over the lazy Dog", "[a-z]") str_view_all("два 15 42. 42 15. 37 08 5. 20 20 20!", "[^0-9]")
- выбор из нескольких групп
str_view_all("Карл у Клары украл кораллы, а Клара у Карла украла кларнет", "лар|рал|арл")- произвольный символ
str_view_all("Везет Сенька Саньку с Сонькой на санках. Санки скок, Сеньку с ног, Соньку в лоб, все — в сугроб", "[Сс].н")- знак начала и конца строки
str_view_all("от топота копыт пыль по полю летит.", "^о") str_view_all("У ежа — ежата, у ужа — ужата", "жата$")- есть еще другие группы и другие обозначения уже приведенных групп, см. ?regex

5.8.3 Квантификация
- ? – ноль или один раз
str_view_all("хорошее длинношеее животное", "еее?")- * – ноль и более раз
str_view_all("хорошее длинношеее животное", "ее*")- + – один и более раз
str_view_all("хорошее длинношеее животное", "е+") str_view_all("хорошее длинношеее животное", "е")- – n раз и более
str_view_all("хорошее длинношеее животное", "е")- – от n до m . Отсутствие пробела важно: – правильно, – неправильно.
str_view_all("хорошее длинношеее животное", "е")- группировка символов
str_view_all("Пушкиновед, Лермонтовед, Лермонтововед", "(ов)+") str_view_all("беловатый, розоватый, розововатый", "(ов)+")- жадный vs. нежадный алоритмы
str_view_all("Пушкиновед, Лермонтовед, Лермонтововед", "в.*ед") str_view_all("Пушкиновед, Лермонтовед, Лермонтововед", "в.*?ед")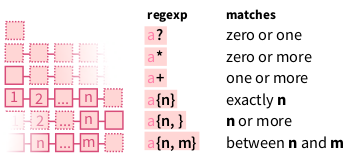
5.8.4 Позиционная проверка (look arounds)
Позиционная проверка – выглядит достаточно непоследовательно даже в свете остальных регулярных выражений.
Давайте найдем все а перед р:
str_view_all("Карл у Клары украл кораллы, а Клара у Карла украла кларнет", "а(?=р)")А теперь все а перед р или л:
str_view_all("Карл у Клары украл кораллы, а Клара у Карла украла кларнет", "а(?=[рл])")Давайте найдем все а после р
str_view_all("Карл у Клары украл кораллы, а Клара у Карла украла кларнет", "(?<=р)а")А теперь все а после р или л:
str_view_all("Карл у Клары украл кораллы, а Клара у Карла украла кларнет", "(?<=[рл])а")Также у этих выражений есть формы с отрицанием. Давайте найдем все р не перед а:
str_view_all("Карл у Клары украл кораллы, а Клара у Карла украла кларнет", "р(?!а)")А теперь все р не после а:
str_view_all("Карл у Клары украл кораллы, а Клара у Карла украла кларнет", "(?)Запомнить с ходу это достаточно сложно, так что подсматривайте сюда:
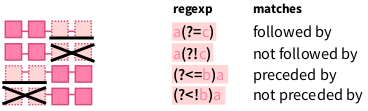
Вот отсюда можно скачать файл с текстом стихотворения Н. Заболоцкого “Меркнут знаки задиака”. Посчитайте долю женских (ударение падает на предпоследний слог рифмующихся слов) и мужских (ударение падает на последний слог рифмующихся слов) рифм в стихотворении.
�� Датасеты скачивается с ошибкой, почему? ➡ Дело в том, что исходный файл в формате .txt , а не .csv . Его нужно скачивать, например, командой read_lines()
�� Ошибка: . applied to an object of class «character» ➡
Скачав файл Вы получили вектор со строками, где каждая элимент вектора – строка стихотворения. Создайте tibble() , тогда можно будет применять стандартные инструменты tidyverse .
�� Хорошо, tibble() создан, что дальше? ➡ Дальше нужно создать переменную, из которой будет понятно, мужская в каждой строке рифма, или женская.
�� А как определить, какая рифма? Нужно с словарем сравнивать? ➡ Формально говоря, определять рифму можно по косвенным признакам. Все стихотворение написано четырехстопным хореем, значит в нем либо 7, либо 8 слогов. Значит, посчитав количество слогов, мы поймем, какая перед нами рифма.
�� А как посчитать гласные? ➡ Нужно написать регулярное выражение… вроде бы это тема нашего занятия…
�� Гласные посчитаны. А что дальше? ➡ Ну теперь нужно посчитать, сколько каких длин (в количестве слогов) бывает в стихотворении. Это можно сделать при помощи функции count() .
�� А почему у меня есть строки длины 0 слогов ➡ Ну, видимо, в стихотворении были пустые строки. Они использовались для разделения строф.
�� А почему у меня есть строки длины 6 слогов ➡ Ну, видимо, Вы написали регулярное выражение, которое не учитывает, что гласные буквы могут быть еще и в начале строки, а значит написаны с большой буквы.
В ходе анализа данных чаще всего бороться со строками и регулярными выражениями приходится в процессе обработки неаккуратнособранных анкет. Предлагаю обработать переменные sex и age такой вот неудачно собранной анкеты и построить следующий график:
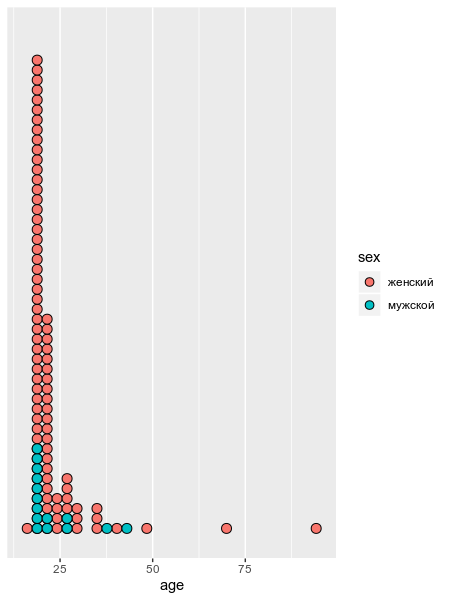
�� А что это за geom_. () ? ➡ Это geom_dotplot() с аргументом method = «histodot» и с удаленной осью y при помощи команды scale_y_continuous(NULL, breaks = NULL)
�� Почему на графике рисутеся каждое значение возраста? ➡ Если Вы все правильно преобразовали, должно помочь преобразование строковой переменной age в числовую при помощи функции as.integer().
5.9 Определение языка
Для определения языка существует два пакета cld2 (вероятностный) и cld3 (нейросеть).
udhr_24 read_csv("https://raw.githubusercontent.com/agricolamz/DS_for_DH/master/data/article_24_from_UDHR.csv")## Parsed with column specification: ## cols( ## article_text = col_character() ## ) udhr_24 cld2::detect_language(udhr_24$article_text)## [1] "ru" "en" "fr" "es" "ar" "zh" cld2::detect_language(udhr_24$article_text, lang_code = FALSE)## [1] "RUSSIAN" "ENGLISH" "FRENCH" "SPANISH" "ARABIC" "CHINESE" cld3::detect_language(udhr_24$article_text)## [1] "ru" "en" "fr" "es" "ar" "zh" cld2::detect_language("Ты женат? Говорите ли по-английски?")## [1] "bg" cld3::detect_language("Ты женат? Говорите ли по-английски?")## [1] NA cld2::detect_language("Варкалось. Хливкие шорьки пырялись по наве, и хрюкотали зелюки, как мюмзики в мове.")## [1] "ru" cld3::detect_language("Варкалось. Хливкие шорьки пырялись по наве, и хрюкотали зелюки, как мюмзики в мове.")## [1] "ru" cld2::detect_language("Варчилось… Хлив'язкі тхурки викрули, свербчись навкрузі, жасумновілі худоки гривіли зехряки в чузі.")## [1] "uk" cld3::detect_language("Варчилось… Хлив'язкі тхурки викрули, свербчись навкрузі, жасумновілі худоки гривіли зехряки в чузі.")## [1] "uk" cld2::detect_language_mixed("Многие в нашей команде OpenDataScience занимаются state-of-the-art технологиями машинного обучения: DL-фреймворками, байесовскими методами машинного обучения, вероятностным программированием и не только.")## $classificaton ## language code latin proportion ## 1 RUSSIAN ru FALSE 0.87 ## 2 ENGLISH en TRUE 0.11 ## 3 UNKNOWN un TRUE 0.00 ## ## $bytes ## [1] 353 ## ## $reliabale ## [1] TRUE cld3::detect_language_mixed("Многие в нашей команде OpenDataScience занимаются state-of-the-art технологиями машинного обучения: DL-фреймворками, байесовскими методами машинного обучения, вероятностным программированием и не только.")5.10 Расстояния между строками
Существует много разных метрик для измерения расстояния между строками (см. ?`stringdist-metrics` ), в примерах используется расстояние Дамерау — Левенштейна. Данное расстояние получается при подсчете количества операций, которые нужно сделать, чтобы перевести одну строку в другую.
- вставка ab → aNb
- удаление aOb → ab
- замена символа aOb → aNb
- перестановка символов ab → ba
library(stringdist)## ## Attaching package: 'stringdist'## The following object is masked from 'package:tidyr': ## ## extract stringdist("корова","корова") stringdist("коровы", c("курица", "бык", "утка", "корова", "осел"))## [1] 4 6 6 1 5 amatch(c("быки", "коровы"), c("курица", "бык", "утка", "корова", "осел"), maxDist = 2)## [1] 2 4- Lorem ipsum — классический текст-заполнитель на основе трактата Марка Туллия Цицерона “О пределах добра и зла”. Его используют, чтобы посмотреть, как страница смотриться, когда заполнена текстом↩︎
Загружаем, устанавливаем…
Онлайн IDE для R — на тот случай, если у вас не установлен R:
- https://rstudio.cloud
- Создайте папку, где будут храниться ВСЕ материалы курса. Например: Мы будем ее называть рабочей директорией. В эту папку помещайте ВСЕ файлы с кодом (с расширением .R).
- Внутри папки linmodr создайте папку data , где будут храниться все файлы с данными для анализа.
В итоге у вас должно получиться примерно это:
C:\linmodr\ C:\linmodr\data\Настройка RStudio
Все настройки RStudio находятся в меню Tools -> Global Options
- Восстановление рабочего пространства из прошлого сеанса — это лучше отменить, т.к. обычно переменные-призраки очень мешают. На вкладке General убираем галочку Restore .RData into workspace at startup , и меняем Save workspace to .RData on exit — Never
- Перенос длинных строк в окне кода — это удобно. На вкладке Code ставим галочку рядом с опцией Soft-wrap R source files
Комментарии
Комментарии в текстах программ обозначаются символом #
# это комментарии, они не будут выполнятьсяПолезные клавиатурные сокращения в RStudio
- Ctrl + Shift + C — закомментировать/раскомментировать выделенный фрагмент кода
- Ctrl + Enter — отправляет активную строку из текстового редактора в консоль, а если выделить несколько строк, то будет выполнен этот фрагмент кода.
- Tab или Ctrl + Space — нажмите после того как начали набирать название функции или переменной, и появится список автоподстановки. Это помогает печатать код быстро и с меньшим количеством ошибок.
Как получить помощь
- В RStudio можно поставить курсор на слово setwd и нажать F1
- Перед названием функции можно напечатать знак вопроса и выполнить эту строку ?setwd
- Можно воспользоваться функцией help()
help("setwd")R как калькулятор, математические операции
1024/2## [1] 512## [1] 1 2 3 4 5 6 7 8 9 10## [1] 136## [1] 16 sqrt(27)## [1] 5.196152Переменные
Переменные — это такие контейнеры, в которые можно положить разные данные и даже функции.
Имена переменных могут содержать латинские буквы обоих регистров, символы точки . и подчеркивания _ , а так же цифры. Имена переменных должны начинаться с латинских букв. Создавайте понятные и “говорящие” имена переменных.
var_1 1024 / 2 1238 * 3 -> var_2 var_2## [1] 3714Как выбрать название переменной?
- a — плохо, и даже b , с , или х . Но в некоторых случаях допустимо:)
- var1 — плохо, но уже лучше
- var_1 — плохо, но уже лучше
- shelllength — говорящее, но плохо читается
- shell_length , wing_colour или leg_num — хорошие говорящие и читабельные названия
Векторы — одномерные структуры данных
Данные в R можно хранить в виде разных объектов.
В результате выполнения следующих команд числа. Одно выражение — одно значение.
## [1] 23 sqrt(25)На самом деле, эти величины — просто векторы единичной длины
Векторы — один объект, внутри которого несколько значений.
Некоторые способы создания векторов:
- Оператор: используется для создания целочисленных векторов, где значения следуют одно за другим без пропусков
1:10 # от одного до 10## [1] 1 2 3 4 5 6 7 8 9 10 -5:3 # от -5 до 3## [1] -5 -4 -3 -2 -1 0 1 2 3- Функция seq() создает последовательности из чисел
seq(from = 1, to = 5, by = 0.5)## [1] 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0- Функция c() — от англ. concatenate. Следите, чтобы было английское си, а не русское эс:).
?c # посмотрите хелп к функцииФункция c принимает несколько (произвольное количество) аргументов, разделенных запятыми. Она собирает из них вектор.
c(2, 4, 6)## [1] 2 4 6 c(-9.3, 0, 2.17, 21.3)## [1] -9.30 0.00 2.17 21.30Векторы можно хранить в переменных для последующего использования
vect_num -11:12 # численный вектор от -11 до 12 сохранен в переменной vect_num vect_num_1 c(1.3, 1.7, 1.2, 0.9, 1.6, 1.4) # численный вектор, сохранен в переменной vect_num_1Адресация внутри векторов
При помощи оператора [] , можно обратится к некоторым элементам вектора. В квадратных скобках вам нужно указать один или несколько порядковых номеров элементов
vect_num[1] # первый элемент в векторе vect_num## [1] -11 vect_num[10] # 10-й элемент vect_num[22]## [1] 10Если вам нужно несколько элементов, то их нужно передать квадратным скобкам в виде вектора. Например, нам нужны элементы с 3 по 5. Вот вектор, который содержит значения 3, 4 и 5.
## [1] 3 4 5Если мы его напишем в квадратных скобках, то добудем элементы с такими порядковыми номерами
vect_num[3:5]## [1] -9 -8 -7Аналогично, если вам нужны элементы не подряд, то передайте вектор с номерами элементов, который вы создали при помощи функции c() c(2, 4, 6) # это вектор содержащий 2, 4 и 6, поэтому
vect_num[c(2, 4, 6)] # возвращает 2-й, 4-й и 6-й элементы## [1] -10 -8 -6 vect_num[c(1, 10, 20)] # возвращает 1-й, 10-й и 20-й элементы## [1] -11 -2 8Вектор — одномерный объект. У его элементов только один порядковый номер (индекс). Поэтому при обращении к элементам вектора нужно указывать только одно число или один вектор с адресами.
vect_num[c(1, 2, 5)] # возвращает 1-й, 3-й и 5-й элементы## [1] -11 -10 -7Но R выдаст ошибку, если при обращении к вектору, вы не создавали вектор, а просто перечислили номера элементов через запятую.
vect_num[1, 3, 5] # ошибка vect_num[15, 9, 1] # ошибка vect_num[c(15, 9, 1)] # правильно## [1] 3 -3 -11При помощи функции c() можно объединять несколько векторов в один вектор
c(1, 1, 5:9)## [1] 1 1 5 6 7 8 9 c(vect_num, vect_num)## [1] -11 -10 -9 -8 -7 -6 -5 -4 -3 -2 -1 0 1 2 3 4 5 6 7 ## [20] 8 9 10 11 12 -11 -10 -9 -8 -7 -6 -5 -4 -3 -2 -1 0 1 2 ## [39] 3 4 5 6 7 8 9 10 11 12 c(100, vect_num)## [1] 100 -11 -10 -9 -8 -7 -6 -5 -4 -3 -2 -1 0 1 2 3 4 5 6 ## [20] 7 8 9 10 11 12Добываем 1, 3, 5 и с 22 по 24 элементы
vect_num[c(1, 3, 5, 22:24)]## [1] -11 -9 -7 10 11 12Типы данных в R
Числовые данные
Уже видели в прошлом разделе.
Текстовые данные
Каждый текстовый элемент (говорят “строка” — string или character) должен быть окружен кавычками — двойными или одинарными.
"это текст"## [1] "это текст" 'это тоже текст'## [1] "это тоже текст"Текстовые значения можно объединять в вектора.
Это текстовый вектор
rainbow c("red", "orange", "yellow", "green", "blue", "violet") rainbow # весь вектор## [1] "red" "orange" "yellow" "green" "blue" "violet"Добываем первый и последний элементы
В данном случае я точно знаю, что их 6, мне нужны 1 и 6.
rainbow[c(1, 6)]## [1] "red" "violet"Добываем элементы с 3 по 6
Если у вас вдруг слишком короткий вектор в этом задании, то можно склеить новый из двух
double_rainbow c(rainbow, rainbow) double_rainbow## [1] "red" "orange" "yellow" "green" "blue" "violet" "red" "orange" ## [9] "yellow" "green" "blue" "violet" rainbow[3:6] # элементы с 3 по 6## [1] "yellow" "green" "blue" "violet"Логические данные
TRUE # истина## [1] TRUE FALSE # ложь## [1] FALSEДля ленивых — можно сокращать первыми заглавными буквами. Но лучше так не делать, чтобы читать программы было легче.
c(T, T, T, T, F, F, T, T)## [1] TRUE TRUE TRUE TRUE FALSE FALSE TRUE TRUE c(TRUE, TRUE, TRUE, FALSE, FALSE, TRUE)## [1] TRUE TRUE TRUE FALSE FALSE TRUEЕще логический вектор
short_logical_vector c(FALSE, TRUE)Создаем длинный логический вектор.
Чтобы создавать длинные вектора из повторяющихся элементов, можно использовать функцию rep()
rep(x = 1, times = 3) # 1 повторяется 3 раза## [1] 1 1 1 rep(x = "red", times = 5) # "red" повторяется 5 раз## [1] "red" "red" "red" "red" "red" rep(x = TRUE, times = 2) # TRUE повторяется 2 раза## [1] TRUE TRUEВ R названия аргументов функций можно не указывать, если вы используете аргументы в том же порядке, что прописан в help к этой функции.
rep(TRUE, 5) # TRUE повторяется 5 раз, аргументы без названий## [1] TRUE TRUE TRUE TRUE TRUEСоздаем логический вектор, где TRUE повторяется 3 раза, FALSE 3 раза и TRUE 4 раза. Результат сохраняем в переменной vect_log
vect_log c(rep(TRUE, 3), rep(FALSE, 3), rep(TRUE, 4)) vect_log## [1] TRUE TRUE TRUE FALSE FALSE FALSE TRUE TRUE TRUE TRUEПрименение логических векторов для фильтрации данных
Логические векторы создаются при проверке выполнения каких либо условий, заданных при помощи логических операторов ( > , < , == , != , >= ,
Вспомните, у нас был вот такой текстовый вектор
double_rainbow## [1] "red" "orange" "yellow" "green" "blue" "violet" "red" "orange" ## [9] "yellow" "green" "blue" "violet"Задача 1. Допустим, мы хотим из этого вектора извлечь только желтый цвет.
Мы можем создать логический вектор, в котором TRUE будет только для 3-го и 9-го элементов
f_yellow double_rainbow == "yellow" f_yellow## [1] FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSEЭтот логический вектор-фильтр мы можем использовать для извлечения данных из double_rainbow
double_rainbow[f_yellow]## [1] "yellow" "yellow"Задача 2. Допустим, мы хотим извлечь из double_rainbow желтый и синий Желтый фильтр у нас уже есть, поэтому мы создадим фильтр для синего.
f_blue double_rainbow == "blue"Выражение “желтый или синий” можно записать при помощи логического “или” ( | )
f_yellow | f_blue## [1] FALSE FALSE TRUE FALSE TRUE FALSE FALSE FALSE TRUE FALSE TRUE FALSEЗадача решена, мы извлекли желтый и синий цвета.
double_rainbow[f_yellow | f_blue]## [1] "yellow" "blue" "yellow" "blue"То же самое можно было бы записать короче.
В одну строку — совершенно нечитабельно:
double_rainbow[double_rainbow == "yellow" | double_rainbow == "blue"]## [1] "yellow" "blue" "yellow" "blue"Фильтр отдельно — читается лучше:
f_colours double_rainbow == "yellow" | double_rainbow == "blue" double_rainbow[f_colours]## [1] "yellow" "blue" "yellow" "blue"У нас был числовой вектор
vect_num## [1] -11 -10 -9 -8 -7 -6 -5 -4 -3 -2 -1 0 1 2 3 4 5 6 7 ## [20] 8 9 10 11 12Задача 3. Давайте извлечем из числового вектора vect_num только значения больше 0
vect_num[vect_num > 0]## [1] 1 2 3 4 5 6 7 8 9 10 11 12Задача 4. Давайте извлечем из вектора vect_num все числа, которые либо меньше или равны -8, либо больше или равны 8
f_5_8 (vect_num -8) | (vect_num >= 8) vect_num[f_5_8]## [1] -11 -10 -9 -8 8 9 10 11 12Факторы
Факторы — это способ хранения дискретных (=категориальных данных). Например, если вы поймали 10 улиток и посмотрели их цвет. У большого количества улиток небольшое счетное количество возможных цветов.
snail_colours c("red", "green", "green", "green", "yellow", "yellow", "yellow", "yellow") snail_colours # это текстовый вектор.## [1] "red" "green" "green" "green" "yellow" "yellow" "yellow" "yellow"Но цвет “желтый” обозначает одно и то же для каждой из улиток. Поэтому в целях экономии места можно записать цвета этих улиток в виде вектора, в котором численным значениям будут сопоставлены “этикетки” (называются “уровни” — levels) — названия цветов. Мы можем создать “фактор” цвет улиток.
factor(snail_colours)## [1] red green green green yellow yellow yellow yellow ## Levels: green red yellowуровни этого фактора
- 1 — green,
- 2 — red,
- 3 — yellow
По умолчанию, R назначает порядок уровней по алфавиту. Можно изменить порядок (см. help(«factor») ). Нам это пригодится позже
double_rainbow # текстовый вектор## [1] "red" "orange" "yellow" "green" "blue" "violet" "red" "orange" ## [9] "yellow" "green" "blue" "violet"Создаем фактор из текстового вектора и складываем его в переменную
f_double_rainbow factor(double_rainbow)Как узнать, что за данные хранятся в переменной?
Чтобы узнать, что за данные хранятся в переменной, используйте функцию class()
class(f_double_rainbow)## [1] "factor" class(vect_log)## [1] "logical" class(vect_num)## [1] "integer" class(rainbow)## [1] "character"Встроенные константы в R
Встроенные константы в R: NA, NULL, NAN, Inf
- NA — англ “not available”. Когда объект был, но его свойство не измерили или не записали.
- NULL — пусто — просто ничего нет
- NaN — “not a number”
- Inf — “infinity” — бесконечность
Вот текстовый вектор с пропущенным значением
rainbow_1 c("red", "orange", NA, "green", "blue", "violet")Кстати, если попросили добыть из вектора номер элемента, которого там точно нет, то R выдаст NA, потому, что такого элемента нет
rainbow_1[198]## [1] NAПоэкспериментируем с векторами. Проверим, как работают арифметические операции
vect_num + 2## [1] -9 -8 -7 -6 -5 -4 -3 -2 -1 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 vect_num * 2## [1] -22 -20 -18 -16 -14 -12 -10 -8 -6 -4 -2 0 2 4 6 8 10 12 14 ## [20] 16 18 20 22 24 vect_num * (-2)## [1] 22 20 18 16 14 12 10 8 6 4 2 0 -2 -4 -6 -8 -10 -12 -14 ## [20] -16 -18 -20 -22 -24 vect_num ^2## [1] 121 100 81 64 49 36 25 16 9 4 1 0 1 4 9 16 25 36 49 ## [20] 64 81 100 121 144Теперь посмотрим на встроенные константы в действии.
Создаем новый вектор для экспериментов
NAs_NANs c(1, 3, NA, 7, 0, 22:24)Вот так он выглядит
NAs_NANs## [1] 1 3 NA 7 0 22 23 24Что произойдет с NA?
NAs_NANs + 2 # останется NA## [1] 3 5 NA 9 2 24 25 26 NAs_NANs * 0 # останется NA## [1] 0 0 NA 0 0 0 0 0 NAs_NANs / 0 # останется NA## [1] Inf Inf NA Inf NaN Inf Inf InfНо в последнем случае вы увидите
- Inf при делении чисел на ноль
- NaN при делении нуля на ноль
NaN получится, если взять корень из отрицательного числа
sqrt(-1)## Warning in sqrt(-1): NaNs produced## [1] NaNФункции в R
Вы уже видели массу функций, их легко узнать по скобкам после ключевого слова. Познакомимся еще с несколькими и научимся писать пользовательские функции. Пользовательские функции позволяют автоматизировать повторяющиеся действия и делают код легко читаемым.
NAs_NANs## [1] 1 3 NA 7 0 22 23 24Длину вектора можно вычислить при помощи функции length()
length(NAs_NANs)Сумму элементов вектора при помощи функции sum()
sum(NAs_NANs)## [1] NAУпс! Почему-то получилось NA
Чтобы узнать, почему и как это исправить — посмотрите в help(«sum») . Выяснится, что у функции sum() есть аргумент na.rm , который по умолчанию принимает значение FALSE , то есть NA не учитываются при подсчете суммы.
Если мы передадим функции sum аргумент na.rm = TRUE , то получится правильная сумма
sum(NAs_NANs, na.rm = TRUE)## [1] 80Та же история с функцией mean
mean(NAs_NANs, na.rm = TRUE)## [1] 11.42857Попробуем написать пользовательскую функцию mmean() , которая будет по умолчанию считать среднее значение элементов в векторе с учетом пропущенных значений ( NA )
mmean function(x) mean(x, na.rm = TRUE) >В этом коде: — mmean — переменная, название функции. В эту переменную мы складываем функцию, которую создает функция function() — function() — функция, которая делает функции. В скобках перечисляются аргументы (названия переменных, которые мы передаем в функцию, чтобы она что-то сделала с ними) — < >— в фигурных скобках тело функции — последовательность действий, которую нужно сделать с аргументами
У больших функций бывает еще инструкция return() , которая сообщает, что именно должна возвращать наша функция. Вот как выглядела бы наша функция с этой инструкцией
mmean function(x) res mean(x, na.rm = TRUE) return(res) >Проверим нашу функцию при помощи встроенной функции
mean(vect_num, na.rm = TRUE)## [1] 0.5 mmean(vect_num)## [1] 0.5Фрейм данных R: как создать, добавить, выбрать и подмножество
A фрейм данных представляет собой список векторов одинаковой длины. Матрица содержит только один тип данных, тогда как фрейм данных принимает разные типы данных (числовые, символьные, факторные и т. д.).
Как создать фрейм данных
Мы можем создать фрейм данных в R передав переменные a,b,c,d в функцию data.frame(). Мы можем R создать фрейм данных, назвать столбцы с помощью name() и просто указать имена переменных.
data.frame(df, stringsAsFactors = TRUE)
аргументы:
- df: это может быть матрица для преобразования в фрейм данных или набор переменных для объединения.
- строкиAsFactors: преобразовать строку в фактор по умолчанию
Мы можем создать фрейм данных в R для нашего первого набора данных, объединив четыре переменные одинаковой длины.
# Create a, b, c, d variables aВывод:
## a b c d ## 1 10 book TRUE 2.5 ## 2 20 pen FALSE 8.0 ## 3 30 textbook TRUE 10.0 ## 4 40 pencil_case FALSE 7.0Мы видим, что заголовки столбцов имеют те же имена, что и переменные. Мы можем изменить имя столбца в R с помощью функции name(). Посмотрите пример создания фрейма данных R ниже:
# Name the data frame names(df)Вывод:
## ID items store price ## 1 10 book TRUE 2.5 ## 2 20 pen FALSE 8.0 ## 3 30 textbook TRUE 10.0 ## 4 40 pencil_case FALSE 7.0# Print the structure str(df)Вывод:
## 'data.frame': 4 obs. of 4 variables: ## $ ID : num 10 20 30 40 ## $ items: Factor w/ 4 levels "book","pen","pencil_case". 1 2 4 3 ## $ store: logi TRUE FALSE TRUE FALSE ## $ price: num 2.5 8 10 7По умолчанию фрейм данных возвращает строковые переменные в качестве фактора.
Срез фрейма данных
Можно разрезать значения кадра данных. Мы выбираем строки и столбцы для возврата в скобки, которым предшествует имя фрейма данных.
Фрейм данных состоит из строк и столбцов df[A, B]. A представляет строки, а B — столбцы. Мы можем разрезать, указав строки и/или столбцы.
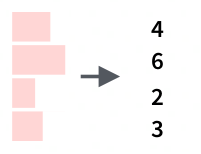
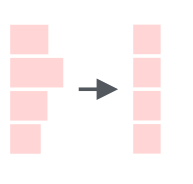
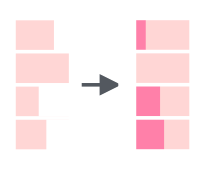
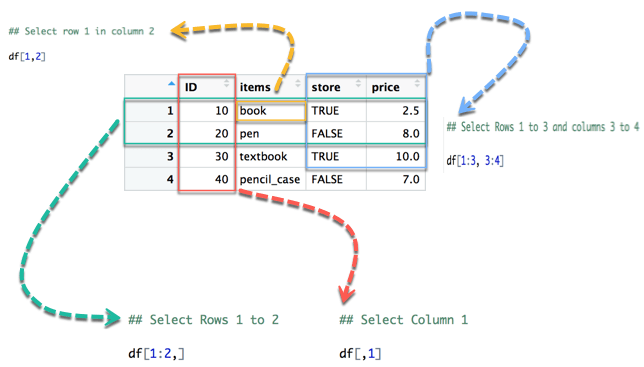
На рисунке 1 левая часть представляет собой ряды и правая часть - это столбцы. Обратите внимание, что символ : означает в. Например, 1:3 предполагает выбор значений от 1 в 3.
На диаграмме ниже мы показываем, как получить доступ к другому выбору фрейма данных:

- Желтая стрелка выбирает строка 1 д обзор 2
- Зеленая стрелка выбирает строки 1 - 2
- Красная стрелка выбирает обзор 1
- Синяя стрелка выбирает строки 1 - 3 и столбцы 3 - 4
Обратите внимание: если мы оставим левую часть пустой, R выберет все строки. По аналогии, если мы оставим правую часть пустой, R выберет все столбцы.
Мы можем запустить код в консоли:
## Select row 1 in column 2 df[1,2]
Вывод:
## [1] book ## Levels: book pen pencil_case textbook
## Select Rows 1 to 2 df[1:2,]
Вывод:
## ID items store price ## 1 10 book TRUE 2.5 ## 2 20 pen FALSE 8.0
## Select Columns 1 df[,1]
Вывод:
## [1] 10 20 30 40
## Select Rows 1 to 3 and columns 3 to 4 df[1:3, 3:4]
Вывод:
## store price ## 1 TRUE 2.5 ## 2 FALSE 8.0 ## 3 TRUE 10.0
Также можно выбрать столбцы по их именам. Например, приведенный ниже код извлекает два столбца: идентификатор и хранилище.
# Slice with columns name df[, c('ID', 'store')]
Вывод:
## ID store ## 1 10 TRUE ## 2 20 FALSE ## 3 30 TRUE ## 4 40 FALSE
Добавить столбец во фрейм данных
Вы также можете добавить столбец во фрейм данных. Вам нужно использовать символ $, чтобы добавить переменную фрейма данных R и добавить столбец в фрейм данных в R.
# Create a new vector quantityВывод:
## ID items store price quantity ## 1 10 book TRUE 2.5 10 ## 2 20 pen FALSE 8.0 35 ## 3 30 textbook TRUE 10.0 40 ## 4 40 pencil_case FALSE 7.0 5Примечание. Количество элементов в векторе должно быть равно количеству элементов в кадре данных. Выполнение следующегоwing оператор добавления столбца в фрейм данных R
quantityВыдает ошибку:
Error in ` lt;-.data.frame`(`*tmp*`, quantity, value = c(10, 35, 40)) replacement has 3 rows, data has 4Выберите столбец фрейма данных
Иногда нам нужно сохранить столбец фрейма данных для будущего использования или выполнить операцию над столбцом. Мы можем использовать знак $ для выбора столбца из фрейма данных.
# Select the column ID df$IDВывод:
## [1] 1 2 3 4Подмножество фрейма данных
В предыдущем разделе мы выбрали весь столбец без условия. Это возможно подмножество в зависимости от того, было ли определенное условие истинным.
Мы используем функцию subset().
subset(x, condition) arguments: - x: data frame used to perform the subset - condition: define the conditional statementМы хотим вернуть только товары с ценой выше 10, мы можем сделать:
# Select price above 5 subset(df, subset = price > 5)Вывод:
ID items store price 2 20 pen FALSE 8 3 30 textbook TRUE 10 4 40 pencil_case FALSE 7
- Агрегатная функция R: пример суммирования и Group_by()
- R Select(), Filter(), Arrange(), конвейер с примером
- Диаграмма рассеяния в R с использованием ggplot2 (с примером)
- boxсюжет() в R: как сделать BoxГрафики в RStudio [Примеры]
- Гистограмма и гистограмма в R (с примером)
- T-тест в программировании на R: один образец и парный T-тест [Пример]
- Учебное пособие по R ANOVA: односторонний и двусторонний (с примерами)
- Учебное пособие по R Random Forest с примером