Введение
Модель ветвления в системен контроля версий, в которой разработчики работают над кодом в единственной ветке под названием ‘trunk’ *. Эта модель позволяет не создавать другие долгоживущие ветки и описывает технику как именно это делать. Разработчики избегают merge конфликтов при слиянии кода, не ломают сборку, и живут долго и счастливо.
* master, в терминологии Git
Общие ветки вне mainline/master/trunk это плохо при любом релизном цикле:

Trunk-Based Development для небольших команд:

Масштабированный Trunk-Based Development:

Разработка, Требования и Предостережения

Trunk-Based Development это ключевой фактор Continuous Integration и, соответственно, Continuous Delivery. Когда каждый разработчик в команде вливает свой код в trunk несколько раз в день, то это позволяет легко выполнить ключевое требование Continuous Integration — все члены команды вливают свой код в trunk как минимум 1 раз в 24 часа. Это обеспечивает возможность сделать релиз кодовой базы по требованию и делает возможным Continuous Delivery.
Для того, чтобы определить границу между маленькой и большой Trunk-Based Development командами, нужно рассмотреть размер команды и скорость коммитов. Определение точного момента, когда команда разработки перестала быть маленькой и начала быть большой, лучше оставить тем, кто любит практиковаться в дебатах. Несмотря на это, любой член команды все равно делает полную “прединтеграционную” сборку (компиляция, прогон unit и интеграционных тестов) на своей рабочей станции прежде чем сделать commit/push кода в общую ветку.
Требования
- Вам следует сделать Trunk-Based Development вместо GitFlow и других моделей ветвления, которые поддерживают много долгоживущих веток
- Вы можете либо напрямую сделать commit/push в trunk (в маленькой команде), либо следовать Pull-Request подходу при условии что feature ветки имеют короткое время жизни и в feature ветке работает один человек.
Предостережения
- В зависимости от размера комманды и частоты коммитов, feature ветки с коротким временем жизни используются для code-review и проверки сборки (CI), но не для создания артефактов или выпуска. Все проверки должны проходить до того, как произойдет слияние кода в ветку trunk, т.к. от этой ветки зависят другие разработчики. Такие ветки позволяют разработчикам быть вовлеченными в более быстрое и непрерывное code review коллег и/или других разработчиков до того, как их код будет влит в общую ветку trunk. Очень маленькие команды могут вливать код напрямую в trunk.
- В зависимости от предполагаемой частоты релизов, у вас могут быть релизные ветки,которые создаются из ветки trunk в нужный момент. Ветки “застывают” до релиза (чтобы не было командной активности), и эти ветки удаляются через какое-то время после релиза. При другом подходе, релизных веток может не быть если команда разработки собирает релизы из trunk ветки и выбирает стратегию “правки по мере появления” для правки багов. Также, для того чтобы делать релизы из ветки trunk, команда должна обладать высокой пропускной способностью.
- Команде нужно будет освоить технику ветвления по абстракции для того, чтобы добиться изменений в работе, и использовать feature flags в каждодневной разработке для подстраховки и сохранения частоты релизов (больше крутых вещей — см. параллельная разработка последовательных релизов)
- Если у вас на проекте работает больше двух разработчиокв, вам потребуется поднять сервер для сборки и настроить проверку того, что код этих разработчиков не ломает сборку после того, как он был влит в trunk, а также до того, как он будет влит в trunk из feature ветки с коротким временем жизни.
- Команды разработки могут без проблем увеличивать или уменьшать число разработчиков (в trunk) без какого-либо негативного влияния на пропускную способность или качество. Доказательство? Их есть у меня. Google работает по Trunk-Based Development и у них есть 35000 разработчиков and QA автоматизаторов в этом единственном trunk монорепозитории, так что в их случае они могут добавлять или убирать разработчиков из монорепозитория по запросу.
- Люди, которые используют модель ветвления GitHub-flow, заметят, что подходы очень похожи, их единственное небольшое различе — то, откуда выпускается релиз.
- Люди, которые используют модель ветвления Gitflow, заметят что она очень сильно отличается. Так было со многими разработчиками, которые использовали популярные в прошлом модели ветвления — ClearCase, Subversion, Perforce, StarTeam, VCS.
- Многие публикации рекомендуют Trunk-Based Development, которую мы тут описываем. Эти публикации включают в себя, например, ‘Continuous Delivery’ и ‘DevOps Handbook’. Так что дальнейших споров про это быть не должно!
История
Trunk-Based Development это не новая модель ветвления. Слово ‘trunk’(ствол) является отсылкой к концепции растущего дерева, где самая толстая и длинная ветка это trunk(ствол), а остальные ветки отходят от неё и имеют более короткую длину.
В середине 90-х, когда в проектах выбирали модель ветвления, про эту модель знали мало и редко выбирали ее, а в 80-х она вообще рассматривалась только в теоретическом ключе. В круплейших организациях по разработке ПО, таких как Google и Facebook, эту модель ветвления практикуют на больших командах.
Более чем 30 лет различных улучшений в технологиях контроля версий, а также сопутствующих инструментов и техник, сделали Trunk-Based Development более (а иногда и менее) преобладающей в разработке, но это та самая модель ветвления, которой придерживались многие компании на протяжении многих лет.
Об этом сайте
Этот сайт это попытка собрать все факты, объяснения и техники для Trunk-Based Development, в одном месте, а также дополнить это 25 диаграммами для более глубокого понимания.
© 2017-2020: Paul Hammant, with contributions from friends. Site built with Hugo with Material theme, via Netlify. Contribute to this page
Trunk Based Development и Spring Boot, или ветвись оно все по абстракции
Закончилась осень, зима вступила в свои законные права, листья уже давно опали и перепутанные ветви кустарников наталкивают меня на мысли о моём рабочем Git репозитории… Но вот начался новый проект: новая команда, чистый, как только что выпавший снег репозиторий. «Тут все будет по другому» — думаю я и начинаю «гуглить» про Trunk Based Development.
Если у вас никак не получается поддерживать git flow, вам надоели кучи этих непонятных веток и правил для них, если в вашем проекте появляются ветки вида «develop/ivanov», то добро пожаловать под кат! Там я пробегусь по основным моментам Trunk Based Development и расскажу о том, как реализовать такой подход, используя Spring Boot.

Введение
Trunk Based Development (TBD) — это подход, при котором вся разработка ведется на основе единственной ветки trunk (ствол). Чтобы воплотить такой подход в жизнь, нам нужно следовать трем основным правилам:
1) Любые коммиты в trunk не должны ломать сборку.
2) Любые коммиты в trunk должны быть маленькими на столько, чтобы review нового кода не занимало более 10 минут.
3) Релиз выпускается только на основе trunk.
Договорились? Теперь давайте разбираться на примере.
Начало разработки

Initial commit
Я не придумал ничего лучше, как написать приложение «оповещатель», REST сервис которому мы передаем оповещение в виде json, а он уже оповещает конечного адресата. Для начала собираем наш проект на spring initializr. Я сделал Maven Project, язык Java 8, Spring Boot 2.4.0. Зависимости нам понадобятся следующие:
Название
Тип
Описание
Spring Configuration Processor
Generate metadata for developers to offer contextual help and «code completion» when working with custom configuration keys (ex.application.properties/.yml files).
JSR-303 validation with Hibernate validator.
Build web, including RESTful, applications using Spring MVC. Uses Apache Tomcat as the default embedded container.
Java annotation library which helps to reduce boilerplate code.
Инициализируем git репозиторий и пушим на GitHub или куда вам больше нравится. Основную ветку можно назвать по своему усмотрению: main, master или даже так и назвать — trunk, чтобы всем сразу было понятно, чем вы тут занимаетесь. Все. Посадили деревце. Теперь будем бережено его выращивать.
Первая фича
Напишем первую реализацию, которая будет отправлять сообщение на почту. Для начала опишем свойства нашего сервиса в виде ConfigurationProperties. У приложения пока будут только два свойства: sender-email — почтовый адрес отправителя и email-subject — тема письма в оповещении.
@Getter @Setter @Component @Validated //говорим, что свойства должны проверяться @ConfigurationProperties(prefix = "notification") public class NotificationProperties < @Email //проверяем что это почта @NotBlank //проверяем что поле заполнено private String senderEmail; @NotBlank private String emailSubject; >
Теперь сделаем компонент, который будет отправлять оповещения на почту, делаем просто заглушу, так как скорее всего в реальности этот компонент предоставлялся бы библиотекой.
Собственно реализация для данного примера нам вообще не понадобится.
EmailSender
@Slf4j @Component public class EmailSender < /** * Отправляет сообщение на почту понарошку */ public void sendEmail(String from, String to, String subject, String text)< log.info("Send email\nfrom: <>\nto: <>\nwith subject: <>\nwith\n text: <>", from, to, subject, text); > > Напишем простую модель для оповещения:
@Getter @Setter @Builder @AllArgsConstructor public class Notification
@Service @RequiredArgsConstructor public class NotificationService < private final EmailSender emailSender; private final NotificationProperties notificationProperties; public void notify(Notification notification)< String from = notificationProperties.getNotificationSenderEmail(); String to = notification.getRecipient(); String subject = notificationProperties.getNotificationEmailSubject(); String text = notification.getText(); emailSender.sendEmail(from, to, subject, text); >> И наконец контроллер:
@RestController @RequiredArgsConstructor public class NotificationController < private final NotificationService notificationService; @PostMapping("/notification/notify") public void notify(Notification notification)< notificationService.sendNotification(notification); >> Ещё нам конечно понадобится тесты, без них TBD не получится. Напишем тест для NotificationService:
@SpringBootTest class NotificationServiceTest < @Autowired NotificationService notificationService; @Autowired NotificationProperties properties; @MockBean EmailSender emailSender; @Test void emailNotification() < Notification notification = Notification.builder() .recipient("test@email.com") .text("some text") .build(); notificationService.notify(notification); ArgumentCaptoremailCapture = ArgumentCaptor.forClass(String.class); verify(emailSender, times(1)) .sendEmail(emailCapture.capture(),emailCapture.capture(),emailCapture.capture(),emailCapture.capture()); assertThat(emailCapture.getAllValues()) .containsExactly(properties.getSenderEmail(), notification.getRecipient(), properties.getEmailSubject(), notification.getText() ); > > И для NotificationController:
@WebMvcTest(controllers = NotificationController.class) class NotificationControllerTest < @Autowired MockMvc mockMvc; @Autowired ObjectMapper objectMapper; @MockBean NotificationService notificationService; @SneakyThrows @Test void testNotify() < ArgumentCaptornotificationArgumentCaptor = ArgumentCaptor.forClass(Notification.class); Notification notification = Notification.builder() .recipient("test@email.com") .text("some text") .build(); mockMvc.perform(post("/notification/notify") .contentType(MediaType.APPLICATION_JSON) .content(objectMapper.writeValueAsString(notification))) .andExpect(status().isOk()); verify(notificationService, times(1)).notify(notificationArgumentCaptor.capture()); assertThat(notificationArgumentCaptor.getValue()) .usingRecursiveComparison() .isEqualTo(notification); > > Написали, сделали rebase, прогнали сборку с тестами и запушили в trunk — эта последовательность должна войти в привычку и делаться как можно чаще.
Для настоящих проектов я очень рекомендую делать первый коммит именно таким, чтобы он был как можно меньше и удовлетворял нашему второму правилу — code review меньше чем за 10 минут.
Профили

Начнем с самого простого и известного приема — использование профилей. Для начала вам нужно включить все ваше воображение и представить, что нам вдруг понадобилось оповещать кого-то по расписанию. Ну что же сделаем отдельный класс под эту задачу.
@Component @EnableScheduling @RequiredArgsConstructor public class NotificationTask < private final NotificationService notificationService; private final NotificationProperties notificationProperties; @Scheduled(fixedDelay = 1000) public void notifySubscriber()< notificationService.notify(Notification.builder() .recipient(notificationProperties.getSubscriberEmail()) .text("Notification is worked") .build()); >> Теперь прогоним наши тесты и получим исключение для теста сервиса:
«org.mockito.exceptions.verification.TooManyActualInvocations».
Конечно, ведь в нашем тесте ожидался один вызов метода sendEmail, а получилось больше, так как теперь этот же метод вызывается в задаче.
Не порядок. Можно конечно выставить задаче initialDelay, чтобы тест успел запустится раньше чем задача, но это будет костыль. Вместо этого, как вы уже, наверное, догадались, мы применим профиль. Вынесем аннотацию @EnableScheduling в отдельную конфигурацию и добавим аннотацию @Profile, где скажем, что нужно запускать задачи всегда, кроме как в профиле «test».
@Profile("!test") @Configuration @EnableScheduling public class SchedulingConfig <> В тестовых ресурсах, в application.yaml добавим включение профиля:
spring: profiles: active: test notification: email-subject: Auto notification sender-email: robot@somecompany.com Теперь все должно заработать. В тестах задачи по расписанию больше не запускаются, но если просто запустить приложение из main метода, то задачи будут исправно тикать.
В своей работе я, в основном, использую профили именно для тестирования, но никто вам не запретит использовать их для своих целей, главное, как мне кажется, с ними не мельчить и не создавать их много.
Используйте профили тогда, когда вам нужно включать или выключать целый слой какой-либо логики, причем на постоянной основе, т.е. вы не планируете выкинуть эту возможность когда-нибудь потом. Примерами могут служить: безопасность, мониторинг или ,как в нашем случае, задачи по расписанию.
Для более точечного управления функциями приложения лучше использовать Feature flags, но этот способ мы рассмотрим уже после нашего первого релиза. Сделали rebase, прогнали сборку с тестами и запушили в trunk.
Первый релиз

Давайте немного отвлечемся от кодирования и посмотрим, что делать с релизами. В TBD описано два способа выпускать релизы: первый из релизной ветки, второй прямо из trunk. Здесь я разберу первый способ.
Первым делом нам нужно взять коммит из которого мы будем делать релиз, это может быть как последний коммит в trunk, так и коммит который вы сделали в прошлом, все зависит от того, из какой ревизии кода вы хотите сделать релиз.
Для git выкачать прошлый коммит можно так:
git checkout
Теперь создаем новую релизную ветку, обязательно ставим метку c версией, и пушим в удаленный репозиторий.
git checkout -b Release_1.0.0 git tag 1.0.0 git push -u origin Release_1.0.0 git push origin 1.0.0 Готово! Можно разворачивать код из этой ветки в staging, а затем и в production.
Теперь мы добавим ещё парочку правил, которые будем соблюдать при работе с релизными ветками:
1) Разработчики не ведут в релизной ветке какие-либо работы.
2) Релизная ветка не сливается с trunk.
3) Если нужен Hotfix, делаем Cherry-pick из trunk и добавляем метку с минорной версией.
Таким образом, релизная ветка как бы «замораживается» и нужна только для того, чтобы выпустить из неё релиз и хранить в себе код соответствующей версии приложения. Релизные ветки можно и даже нужно удалять как только они становятся не актуальным.
Feature flags

Для второй версии нашего приложения у нас стоит задача добавить немного аудита в нашу систему: теперь каждое оповещение должно сохраняться в базу данных. Только вот проблема в том, что не известно когда на production её развернут и подготовят. Тогда, чтобы никого не ждать и не откладывать то, что можно сделать сейчас, мы обернем данную функциональность в feature flag.
Этот прием позволит нам внедрить новую фичу уже в следующем релизе, а вот включить её можно будет как только появится возможность это сделать, а в случае, если, что-то пойдет не так, фичу можно будет снова выключить.
Добавляем зависимости для взаимодействия с базой данных. БД на production у нас будет например oracle (это не особо важно для примера), а для тестов будем использовать h2.
org.springframework.boot spring-boot-starter-data-jpa com.oracle.ojdbc ojdbc10 com.h2database h2
Теперь добавим отдельный класс, где будем описывать только свойства для включения разных фич. Примем конвенцию, что все свойства в этом классе должны быть boolean. Добавим туда флаг «persistence», который будет включать и выключать сохранение оповещений в базу.
@Getter @Setter @Component @ConfigurationProperties(prefix = "features.active") public class FeatureProperties
Сразу запишем в application.yaml в тестовых ресурсах features.active.persistence: on (spring сам поймет, что on==true).
Только не забудьте сначала скомпилировать проект, чтобы включилось автодополнение в свойствах приложения.
Нашу модель переделываем в Entity.
Notification (Entity)
@Entity @Getter @Setter @Builder @NoArgsConstructor @AllArgsConstructor public class Notification
public interface NotificationRepository extends CrudRepository
В NotificationService добавим NotificationRepository и FeatureProperties как зависимости, в конце метода notify вызовем метод репозитория save, обернув его в обычный if.
NotificationService (Feature flag)
@Service @RequiredArgsConstructor public class NotificationService < private final EmailSender emailSender; private final NotificationProperties notificationProperties; private final FeatureProperties featureProperties; @Nullable private final NotificationRepository notificationRepository; public void notify(Notification notification)< String from = notificationProperties.getSenderEmail(); String to = notification.getRecipient(); String subject = notificationProperties.getEmailSubject(); String text = notification.getText(); emailSender.sendEmail(from, to, subject, text); if(featureProperties.isPersistence())< notificationRepository.save(notification); >> > Забегая немного вперед, аннотация @Nullable для поля NotificationRepository нам нужна, чтобы Spring не падал с ошибкой UnsatisfiedDependencyException, если не найдет такой бин у себя в контексте.
Теперь можно запустить тесты и увидеть, что все они прошли, но если мы запустим наше приложение, то оно будет требовать указать url для базы данных и не будет запускаться.
Исправлять будем примерно так же как и для задач по расписанию. Создадим отдельную конфигурацию, где мы укажем, что автоконфигурация для базы данных должна быть исключена, если флаг features.active.persistence: off (spring сам поймет, что off==false).
@Configuration @ConditionalOnProperty(prefix = "features.active", name = "persistence", havingValue = "false", matchIfMissing = true) @EnableAutoConfiguration(exclude = < DataSourceAutoConfiguration.class, DataSourceTransactionManagerAutoConfiguration.class, HibernateJpaAutoConfiguration.class>) public class DataJpaConfig
Запускаем приложение с флагом features.active.persistence: off в свойствах. Приложение стартует, но не создает никаких бинов, связанных с работой базы данных.
Для того, чтобы управлять флагами в среде развертывания, можно указать spring через командную строку файл дополнительных свойств, например:
—spring.config.additional-location=file:/etc/config/features.yaml
Или передать с помощью аргументов VM, например:
-Dfeatures.active.persistence=true
Правил с флагами будет два:
1) После того, как функциональность полностью протестирована и стабильно работает, флаг этой функции нужно удалить.
2) Мест в коде, где идет ветвление по одному и тому же feature флагу, должно быть минимальное количество.
По второму правилу поясню подробнее. Если ваша новая функциональность, которую вы хотите обернуть в feature флаг, заставляет вас писать код вида: «if (flag) » в нескольких местах сразу, то вам стоит задуматься либо над дизайном вашей системы, либо о приеме «ветвления по абстракции», который как раз сейчас и разберем.
Branch by Abstraction

В третьей версии настало время расширять функциональность оповещений.
Теперь с клиентской части нашего приложения в сообщениях будет приходить тип оповещения: EMAIL, SMS или PUSH. Следовательно нам необходимо реализовать два дополнительных «отправщика» сообщений, а ещё логику в самом сервисе уведомлений, которая будет определять реализацию.
Это довольно серьезная доработка, поэтому мы не хотим с ней торопится, мы хотим тщательно проработать архитектуру решения, да так, чтобы в его развитии принимало как можно больше разработчиков. Поэтому мы не будет делать в Git отдельную ветку, в которой можно было бы хранить нестабильный код, а сделаем ветку внутри программы, с помощью ветвления по абстракции.
Рецепт от Мартина Фаулера прост:
1) Выделить интерфейс для заменяемой функциональности.
2) Заменить прямой вызов реализации в клиенте на обращение к интерфейсу.
3) Создать новую реализацию, которая реализует интерфейс.
4) Подменить старую реализацию на новую.
5) Удалить старую реализацию.
Первым делом нам нужно сделать интерфейс NotificationService вместо класса, а сам класс переименовать в EmailNotificationService. В Inellij IDEA это можно провернуть с помощью рефакторинга:
1) Правой кнопкой по классу, выбрать Refactor/Extract interface…
2) Выбрать опцию «Rename original class and use interface where possible».
3) В поле «Rename implementation class to» вписываем «EmailNotificationService».
4) В «Members to from interface» нажать галочку напротив метода «notify» .
5) Нажать кнопку «Refactor».
После этого все классы должны ссылаться на интерфейс NotificationService, а рядом в пакете появится EmailNotificationService, где будет старая реализация.
Сделали rebase, прогнали сборку с тестами и запушили в trunk.
После этого можно спокойно продолжать работу уже над новой реализацией. Добавим в модель поле с типом оповещения, пусть это просто Enum.
public enum NotificationType
Так же нам нужно будет добавить два новых компонента «отправителя»:
SmsSender и PushSender.
@Slf4j @Component public class SmsSender < /** * Отправляет сообщение на телефон */ public void sendSms(String phoneNumber, String text)< log.info("Send sms <>\nto: <>\nwith text: <>", phoneNumber, text); > > @Slf4j @Component public class PushSender < /** * Отправляет push уведомления */ public void push(String id, String text)< log.info("Push <>\nto: <>\nwith text: <>", id, text); > > Новую реализацию сервиса назовем MultipleNotificationService и для начала напишем «в лоб».
MultipleNotificationService — switch case
@Service @RequiredArgsConstructor public class MultipleNotificationService implements NotificationService < private final EmailSender emailSender; private final PushSender pushSender; private final SmsSender smsSender; private final NotificationProperties notificationProperties; private final NotificationRepository notificationRepository; @Override public void notify(Notification notification) < String from = notificationProperties.getSenderEmail(); String to = notification.getRecipient(); String subject = notificationProperties.getEmailSubject(); String text = notification.getText(); NotificationType notificationType = notification.getNotificationType(); switch (notificationType!=null ? notificationType : NotificationType.UNKNOWN) < case PUSH: pushSender.push(to, text); break; case SMS: smsSender.sendSms(to, text); break; case EMAIL: emailSender.sendEmail(from, to, subject, text); break; default: throw new UnsupportedOperationException("Unknown notification type: " + notification.getNotificationType()); >notificationRepository.save(notification); > > Запустив тесты, мы обнаружим, что NotificationServiceTest стал падать с ошибкой:
«expected single matching bean but found 2: emailNotificationService, multipleNotificationService».
Вылечить проблему можно, например, добавлением аннотации @Primary над старой реализацией сервиса — EmailNotificationService.
@Primary сделает бин приоритетным для инъекции, но в тоже время бины с тем же типом все равно создадутся в контексте и мы сможем внедрить новую реализацию в тест.
Другой вариант — просто убрать аннотацию @Service из новой реализации, тем самым исключив её из контекста, а для теста написать отдельную конфигурацию или вообще не писать Spring тест, а написать простой unit тест, где будем создавать компоненты сами через «new».
Я воспользуюсь первым вариантом и напишу отдельный Spring тест для новой реализации.
@SpringBootTest class MultipleNotificationServiceTest < @Autowired MultipleNotificationService multipleNotificationService; @Autowired NotificationProperties properties; @MockBean EmailSender emailSender; @MockBean PushSender pushSender; @MockBean SmsSender smsSender; @Test void emailNotification() < Notification notification = Notification.builder() .recipient("test@email.com") .text("some text") .notificationType(NotificationType.EMAIL) .build(); multipleNotificationService.notify(notification); ArgumentCaptoremailCapture = ArgumentCaptor.forClass(String.class); verify(emailSender, times(1)) .sendEmail(emailCapture.capture(),emailCapture.capture(),emailCapture.capture(),emailCapture.capture()); assertThat(emailCapture.getAllValues()) .containsExactly(properties.getSenderEmail(), notification.getRecipient(), properties.getEmailSubject(), notification.getText() ); > @Test void pushNotification() < Notification notification = Notification.builder() .recipient("id:1171110") .text("some text") .notificationType(NotificationType.PUSH) .build(); multipleNotificationService.notify(notification); ArgumentCaptorcaptor = ArgumentCaptor.forClass(String.class); verify(pushSender, times(1)) .push(captor.capture(),captor.capture()); assertThat(captor.getAllValues()) .containsExactly(notification.getRecipient(), notification.getText()); > @Test void smsNotification() < Notification notification = Notification.builder() .recipient("+79157775522") .text("some text") .notificationType(NotificationType.SMS) .build(); multipleNotificationService.notify(notification); ArgumentCaptorcaptor = ArgumentCaptor.forClass(String.class); verify(smsSender, times(1)) .sendSms(captor.capture(),captor.capture()); assertThat(captor.getAllValues()) .containsExactly(notification.getRecipient(), notification.getText()); > @Test void unsupportedNotification() < Notification notification = Notification.builder() .recipient("+79157775522") .text("some text") .build(); assertThrows(UnsupportedOperationException.class, () ->< multipleNotificationService.notify(notification); >); > > Сделали rebase, прогнали сборку с тестами, запушили в trunk, получили от команды по шапке за switch-case.
Реализовать логику красиво позволит шаблон «Стратегия», но тут есть проблема в том, что у всех компонент «отправителей» разные интерфейсы, собственно как скорее всего и будет в реальности, ведь обычно такие компоненты предоставляются внешними библиотеками. Решить проблему с разными интерфейсами можно с помощью шаблона «Адаптер». Расписывать подробно здесь не буду, статья всё таки о другом, но код вы можете посмотреть у меня на GitHub.
После того как сделали все красиво мы пробуем ещё раз: rebase, прогнали сборку с тестами, запушили в trunk.
На этот раз код не вызвал ни у кого негатива, и его можно включать в программу. Делать будем это с помощью все того же feature флага.
В класс с флагами добавляем новый:
boolean multipleSenders;
Над классом EmailNotificationService добавляем аннотацию с условием (ни в коем случае не удалять @Primary):
«Выключить, только, если флаг features.active.multiple-senders установлен (matchIfMissing) и равен false»
@ConditionalOnProperty(prefix = "features.active", name = "multiple-senders", havingValue = "false", matchIfMissing = true)Над MultipleNotificationService нужно добавить аннотацию с «зеркальным» условием:
«Включить, только, если флаг features.active.multiple-senders не установлен (matchIfMissing) или равен true»
@ConditionalOnProperty(prefix = "features.active", name = "multiple-senders", havingValue = "true", matchIfMissing = true)Таким образом, в тестах у нас окажутся обе реализации, а вот при запуске приложения будет работать только одна.
После того как новая версия будет обкатана, вместе с feature флагом нужно будет удалить и старую реализацию, а вот выделенный интерфейс лучше все таки оставить.
И снова rebase, прогнали сборку с тестами, запушили в trunk. Вся команда проверила ваш код и благополучно забыла, что у вас ещё есть задача по расписанию, которой не сказали с каким типом ей отправлять оповещения.
На production заметили, что оповещения по расписанию больше не запускаются, но благодаря feature флагу все сразу же откатили обратно.
Команде разработки выдали логи, она принялась за исправление, и параллельно начала обдумывать как правильно сделать Hotfix, улучшить code review и тестирование проекта, чтобы более не сталкиваться с подобными проблемами… но это уже совсем другая история, а нам пора подводить итоги.
Итоги
Trunk Based Development — отличная модель ветвления, которая наконец-то поможет вам избавится от кошмара слияния веток, позволит получить больше контроля над кодом, а команду сделать более дисциплинированной, превратит «теневое внедрение» из просто интересного приема в обыденность.
Trunk Based Development — очень гибкая методология, у неё есть несколько вариаций, из которых вы сможете выбрать наиболее подходящий вариант, и ,конечно, для её применения не обязательно использовать Spring Boot, но надеюсь я смог показать вам, что с ним это просто и удобно.
На этом всё, внизу будут все ссылки из статьи, спасибо за внимание!
Trunk-based Development

В процессе разработки кода программистам не обойтись без инструмента по версионности и контролю изменений. Одна из наиболее известных и популярных систем контроля версий — git (изменение кода можно зафиксировать и у этого изменения будет специальная метка). В результате вся история процесса разработки видна программистам, что очень удобно.
Однако когда команда ведёт работу над одним и тем же кодом, рекомендовано придерживаться следующих правил: — «не ломать» текущий рабочий код; — не мешать друг другу, работая в одной ветке.
Для решения проблем взаимодействия разработчиков друг с другом в git есть различные подходы, например, git-flow. Работа с ветками является одной из основных в git-flow и это один из главных его недостатков. Постоянные merge и конфликты при слиянии, а также сама суть в долгосрочных ветках могут сыграть злую шутку против разработчиков. И если говорить об итеративной разработке, то при больших промежутках времени между релизами с git-flow можно подружиться, но когда речь идёт о более частых релизах, всё становится гораздо сложнее.
В данной ситуации предпочтительнее выглядит Trunk-based Development — подход, который сегодня широко используется такими крупными компаниями, как Google и Facebook. Он также основан на ветвлении, однако второстепенные ветки имеют короткий срок жизни: от нескольких часов до нескольких дней. Из этого нюанса и вытекает концептуальная идея Trunk-based Development, которая заключается в том, что в конце работы с кодом в рамках временной ветки все изменения так или иначе должны попасть в основную master-ветвь.
Кроме того: — есть требования к контролю качества кода (в master-ветку попадает уже протестированный рабочий код, что повышает его стабильность, детали — здесь); — все релизы делаются только из master-ветки.
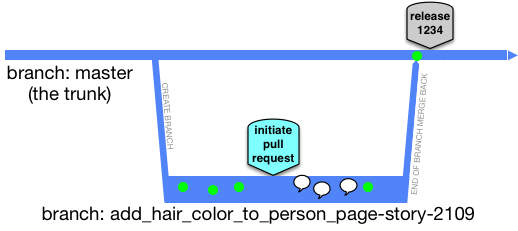
При этом взаимодействие между разработчиками в рамках временной ветки — вполне нормальное явление (можно делать brunch нашей задачи, получать комментарии, выполнять изменения и дополнения, возвращать исправленные фрагменты кода в мастер-ветку). Вот, пожалуй, и всё на сегодня. Если хотите получить более глубокие знания по инструментам синхронизации, записывайтесь на курсы OTUS по DevOps!
Trunk-based development — современный процесс разработки
Каждая команда разработчиков стремятся к гибкому и эффективному процессу разработки программного обеспечения. Есть много способов добиться этого. Разработка на основе магистралей — один из наиболее современных подходов, привлекающих внимание профессионалов. Давайте подробнее рассмотрим, что это такое, как это работает и какую пользу может принести вашей команде IT-специалистов.
Что такое Trunk-based development?
Тег video не поддерживается вашим браузером. Тег video не поддерживается вашим браузером.
Магистральная разработка — это практика управления. Модель ветвления системы управления версиями, ориентированная на одну ветвь кода, называемую магистралью. Разработка на основе Trunk направлена на то, чтобы магистраль всегда была готова к развертыванию. Разработчики совместно работают над небольшими частями кода, которые часто обновляются и объединяются в основную ветку.
Это гибкий и быстрый процесс — проверка кода эффективна, а разработка и слияние веток не должны занимать более нескольких дней. Trunk-based разработка близка идеям методологии DevOps, а также использует преимущества автоматизированного тестирования и интеграции.
Данная модель направлена на достижение CI/CD (непрерывная интеграция/непрерывная поставка) и повышение эффективности команды и качества продукта. При правильном развертывании подход может упростить процесс слияния и помочь избежать ада интеграции. Это полезно в ситуации, когда слияние проблематично, и новые части кода должны быть исправлены, отлажены, а иногда и полностью переписаны для интеграции в существующий код.
Разработка на основе магистрали противостоит традиционным моделям ветвления, которые требуют разработки долгоживущих ветвей. Этот процесс занимает гораздо больше времени, так как ветки более сложные. Кроме того, слияние трудностей может отбросить команду назад и замедлить прогресс.
Преимущества магистральной разработки
Подход на основе магистрали во многих отношениях облегчает жизнь разработчикам. Самое главное, чтобы слияние проходило максимально гладко. Рассмотрим подробнее преимущества магистральной модели.
Снижение сложности слияния
Сложное, трудоемкое, проблематичное слияние — это именно та проблема, на решение которой направлена разработка на основе магистралей. Уменьшение размера новых ветвей задач помогает сделать интеграцию более управляемой, экономя время, труд и деньги.
Разработка на основе магистралей — это один из способов создания конвейера CI/CD. Более медленный и менее гибкий подход значительно усложнил бы непрерывную интеграцию. В основную ветку поступает постоянный поток новых частей кода. Поэтому автоматизированное тестирование и интеграция являются обязательными.
Непрерывный обзор кода
Меньший размер недавно разработанных ветвей позволяет получить мгновенную обратную связь. Ветви также менее сложны, чем в традиционной модели, поэтому поиск источника проблемы и внесение необходимых изменений происходит быстрее и проще.
Нет дублирования работы
Поскольку команды часто развертывают свои ветки, меньше вероятность дублирования работы, даже если разные разработчики работают над одними и теми же проблемами. В результате команды остаются на одной странице, оставаясь в курсе всех изменений, происходящих в основной ветке.
Непрерывный выпуск кода
Согласно зачаткам транковой модели, основная ветвь всегда должна быть готова к развертыванию. Это возможно благодаря мгновенной обратной связи и постоянному исправлению новых частей кода. Автоматизированное тестирование также играет здесь значительную роль, делая процесс менее трудоемким.
Все вышеперечисленные преимущества объединяются, возможностью обеспечить плавный и эффективный процесс разработки программного обеспечения. Использование этой модели экономит время и труд и, следовательно, приводит к более рентабельной разработке.
Магистральная разработка против Gitflow

Важно отметить, что разработка на основе магистрали является преемником других практик, которые изначально изменили представление об управлении разработкой программного обеспечения. Одна из них — Gitflow. Именно рабочий процесс обеспечил современную стратегию управления ветвями. Однако он гораздо менее популярен, чем раньше, поскольку им сложно управлять, поддерживая конвейер CI/CD.
Gitflow — это модель ветвления, основанная на функциональных ветвях и множестве первичных ветвей. Подход использует более долгоживущие ветки, чем разработка на основе основной ветки, и их слияние откладывается до тех пор, пока функция не будет завершена.
Данный подход требует большего сотрудничества во время процесса слияния, что делает его более трудоемким. Также существует более высокий риск проблем по сравнению с разработкой на основе магистрали, а основная ветвь не всегда готова к развертыванию.
Gitflow против Trunk — когда их использовать?
Разработка на основе магистралей сейчас является обычной практикой среди команд разработчиков программного обеспечения, но Gitflow все еще может оказаться полезным в некоторых случаях. Например, Gitflow можно использовать в проектах с запланированным циклом выпуска.
Работа над одной функцией одновременно в течение длительного времени также может иметь свои преимущества. Например, можно проводить изолированные эксперименты. Более строгие правила Gitflow также обеспечивают качество кода — ветка может быть интегрирована в код только после того, как ее примут конкретные люди.
Когда разработка на основе магистралей полезна?
Разработка на основе магистралей — это особый стиль управления, который не подходит для каждого программного проекта. Принимая решение о том, использовать этот подход или нет, следует учитывать два фактора.
Во-первых, важно помнить, что этот стиль разработки означает быстрый прогресс. Команда должна быть к этому готова, поэтому должна быть прозрачная коммуникационная стратегия. Таким образом, разработчики находятся на одной странице и постоянно получают информацию об изменениях в ветве. Быстрый прогресс также означает, что команде нужно действовать быстро. Для магистрального подхода требуется мотивированная и компетентная команда разработчиков.
Еще одна вещь, о которой следует помнить, это то, что разработка на основе магистралей требует большого доверия к разработчикам. Существует короткий процесс проверки кода, поэтому каждый разработчик должен быть осторожен с изменениями, которые они фиксируют в ветке. Это означает, что этот стиль управления разработкой программного обеспечения, вероятно, не будет работать для проектов с открытым исходным кодом, где любой может открывать запросы на вытягивание.
Тем не менее, разработка на основе магистрали по-прежнему является хорошим выбором для многих ситуаций. Например, подход отлично подходит для стартапов и других команд, которые умеют сотрудничать и поддерживать высокую скорость разработки. Если вам интересно реализовать этот подход в своем проекте, ознакомьтесь с нашими услугами по разработке программного обеспечения на заказ .
Как заставить работать Trunk разработку?
Как только вы узнаете, что такое транковая разработка и когда ее использовать, вы должны узнать, как заставить ее работать для вашей команды. Здесь мы поделимся некоторыми передовыми практиками, которые сделают разработку на основе магистралей плавной и эффективной.
Это количество ветвей, которые обычно должны быть активны в системах контроля версий репозиториев приложений. Иногда это может отличаться из-за специфики проекта, но важно установить четкую цифру. Номером должно быть легко управлять, и он должен быть виден всем в команде.
Код не зависает
Избегание зависаний кода и пауз на этапах интеграции имеет решающее значение для успешной разработки на основе магистралей. В конвейере CI/CD должен быть постоянный поток обновлений. Поэтому конфликты слияния и зависания кода, которые мешают разработчикам отправлять код, должны происходить как можно реже.
Объединение раз в день
Частота слияний является важным показателем для разработки на основе магистралей. Среда должна побуждать каждого разработчика фиксировать в магистрали не реже одного раза в 24 часа. Это требование непрерывной интеграции.
Синхронный обзор кода
Эффективная проверка кода, которая не требует часов или дней для получения окончательного утверждения, является ключом к ежедневному слиянию. Разработчики не должны начинать новые части кода до тех пор, пока предыдущая часть не будет объединена — это поможет сохранить концентрацию команды. Чем короче задержка слияния, тем меньше вероятность возникновения проблем со слиянием.
Измерение успеха магистральной разработки
Чтобы отслеживать, соответствует ли ваша команда стандартам разработки на основе магистрали, вам нужны некоторые методы измерения. Эти метрики аналогичны вышеупомянутым рекомендациям и позволяют легко определить возможности для улучшения.

Факторы для тестирования включают в себя:
- количество активных ветвей в репозитории кода приложения (обычно три или меньше)
- количество периодов заморозки кода (должно быть равно нулю)
- частота объединения веток (не реже одного раза в сутки)
- время утверждения изменений кода (должно быть как можно короче)
Эти четыре контрольных точки помогут вашей команде не отставать от требований разработки на основе магистралей.
Разработка на основе магистралей — хороший инструмент для обеспечения бесперебойной разработки программного обеспечения. Эта практика направлена на экономию времени и труда разработчиков, минимизацию возможности слияния трудностей и использование автоматизации тестирования. У подхода есть определенные требования, и он не будет работать для каждого проекта, но при правильном развертывании Trunk может значительно улучшить команду. Кроме того, это эффективный с точки зрения затрат и времени подход к управлению версиями.
«Web Soft Shop & Technologies» — разработка корпоративного ПО на заказ.
Читайте анонсы наших статей:
Почитать наши архивные публикации можно и в Yandex Q