Введение в графы и Neo4j. Обработка графов в Spark
Программисты автоматизируют мир. Начав с автоматизации подсчета денег, где табличные записи естественны, программисты стали заталкивать в таблички всё, до чего их допустили. И это работало. В прошлом веке. И это хорошо т.к. из глубин вековой давности мы получили SQL – языка запросов к табличке. SQL хватает почти всегда – он простой, логичный и все его знают. А когда не хватает, его расширяют. И дальше мы будем работать с расширениями и диалектами SQL.
В реальном мире всё несколько сложнее. В табличках представлять большие и сложные зависимости сложно и не эффективно по ресурсам (дисковое пространство,процессор, и главный ресурс – время). А какие данные не идеальны для табличек? Может, это лишние данные?
Важный граф
В математике есть понятие граф – набор вершин (узлы) и связей этих вершин (ребро).
Минимальный граф – это две вершины и одно ребро между ними. Например этим минимальным графом мы можем нарисовать семейную пару: М —- Ж. То есть граф – это естественные связи вещей и цепочки этих связей.
Например, записать структуру папок на компьютере в табличку. Для рубистов штук 5 гемов есть и только одно правильное решение – ltree + индексы. Кроме правильного есть идеальное решение: LDAP. А структуру организации в табличку? Тоже можно, но дурная затея, LDAP и тут выручает. И то и то деревья – есть корень и ветки, самая толстая ветка – ствол 🙂
Не видел в жизни ни одного графа
Да даже мой любимый git это граф. Выполните в любом своём репозитории:
git log --graph --abbrev-commit --decorate --date=relative --all И вы увидите дерево изменений.
Еще один граф – это родственные связи в Звездных Войнах (как вы помните, там только Император был сиротой): https://nplus1.ru/news/2016/02/10/star-wars-graph.
А еще на графах интернет держится. Например, алгоритм Дейкстры как раз решает задачу как бы быстрейший/кратчайший путь найти.
Когда у нас простой граф мы можем его нарисовать в табличках.
Графы кстати бывают разные. Граф, в котором связи направленные и не создают петель называется . направленный ацикличный граф https://en.wikipedia.org/wiki/Directed_acyclic_graph. Этот тип графа важен для понимания логики работы Spark-приложений, так же он помогает формализировать бизнес процессы и ускорять их.
Если б на почте РФ знали о таких графах, то почтой бы чаще пользовались и не надо было в отделениях торговать сигаретами и водкой. И раз уж мы вспомнили Apache Spark, то RDD представляет из себя дерево разных версий RDD (если вы не поняли о чем речь, то читаем публикации создателя Spark ).
Зависимости в приложении тоже граф, например ruby-erd может для руби приложения нарисовать.
Neo4j и простые запросы
А если у нас тысячи узлов? То тоже можем использовать таблички, только устанем. Вот тут на помощь приходит специализированный инструмент – графовые базы данных. Их много, но мы выберем Neo4j – она сама простая для начала и имеет прекрасный веб-интерфейс с визуализацией, а красивая картинка иногда информативнее тысячи слов.
Есть графовые «базы», использующие табличное хранение данных, но использующие графовую абстракцию – эта порнография работает только в специфичных условиях (в этих же условиях платят хорошо, потому запоминаем cassandra + titan или Spark).
Потихоньку начнем изучать Neo4j с данными, доступными каждому.
Сначала запустим Neo4j, что очень легко, как и всё в Java мире:
- Качаете архив neo4j-community-3.0.3 с официального сайта http://neo4j.com/
- Распаковываете tar -xzvf ./neo4j-community-3.0.3-unix.tar.gz
- Запускаете ./bin/neo4j start
А вообще, не надо. Останавливайте: ./bin/neo4j stop . Сделаем современно и молодежно.
docker run --publish=7474:7474 \ --publish=7687:7687 \ --volume=$HOME/neo4j/data:/data:rw,z \ --env=NEO4J_AUTH=none neo4j:3.0 А дальше самое интересное, причина почему стоит начинать с Neo4j: откройте в браузере http://localhost:7474/. Всё, вы – властелин графовой базы данных.
Интерактивная консоль и визуализация упростит старт. А еще мы отключили аутентификацию —env=NEO4J_AUTH=none . Для наших экспериментов она не нужна, а для боевых систем надо всё параноидально закрывать. Хотя это и смешно – закрывать и Docker 🙂
Так же там есть документация по возможностям системы и статистика по используемым ресурсам.
Создадим минимальный граф.
В данной статье главный диалект языка SQL зовётся “Кефир”: https://neo4j.com/developer/cypher-query-language/ 🙂
CREATE (c:M )-[:rel ]->(b:F ); И посмотрим на результат:
MATCH (n) RETURN n LIMIT 1000; .png)
Граф у нас направленный, даже в наш безумный век мужчина направлен к женщине. Любопытно, что направлением при поиске можно пренебречь:
MATCH p=(n)-->(b) return p A можно не пренебрегать:
MATCH (n)-[p]->(b) WHERE startNode(p).id='Male' return b, n; // вернется наш граф MATCH (n)-[p]->(b) WHERE startNode(p).id='Female' return b, n; // а тут уже пустой Еще мы можем выбрать самые сильные отношения, чего размениваться на короткие интрижки:
MATCH (n)-[p]->(b) WHERE p.weight > 1000 return b, n /// таких нет, но вы можете снизить порог фильтра Заметки по Кефировским запросам для игр на досуге.
Создаем ноды, если нет:
MERGE (c:M ); Создаем отношения, если их нет, и ноды если их нет:
MERGE (p:twivi13 ) MERGE (n:Real ) CREATE UNIQUE (p)-[r:rel ]-(n) return r Обновляем вес отношений, если они есть:
MATCH (n)-[p]->(b) WHERE b.id='Male' AND n.id='Female' SET p.weight = p.weight + 7 RETURN p Смотрим в Neo4j только сотню самых сильных отношений:
MATCH (n)-[p]-(b) RETURN p Order by p.weight DESC limit 100 Ищем вершины с более чем 2 связями:
MATCH (n) WHERE size((n)--())>2 RETURN n Ну и если захотим удалить:
MATCH (n) DETACH DELETE n Все классно, всё работает, всё просто. Но пользы ни какой.
Пишем приложения с Neo4j, Spark и данными Твиттера
Надо залить другие данные. И всплывает вопрос о том, как приложение вообще может общаться с Neo4j?
Есть поддержка формата для хипстеров HTTP API с JSON, в нём есть даже загрузка данных пачками. Так что с этой стороны все правильно, но зря.
Следующий вариант: протокол Bolt. Bolt бинарный, шифруемый и изобретен специально для Neo4j.
Каждое приложение должно придумать свой протокол, а то протоколов не хватает.
И раз уж есть такая возможность, то впихиваем все модные инструменты без разбору, особенно если в них нет нужды. И в модных инструментах выберем еще и модные названия: напишем приложение для Spark Streaming, которое будет читать твиттер, строить граф и обновлять связи в графе.
Есть прогноз что Spark Streaming через 5 лет будет не актуален, но сейчас за него платят. И он еще и не стриминг ни разу 🙂
Твиттер – доступный источник большого количества лишней информации. Можно даже считать его графом человеческой глупости. А вот задался бы кто целью проследить развитие идей – был бы наглядный аргумент за классическое образование (у меня его нет, о чем данная статья аж кричит).
Первым делом скачиваем исходники Spark на свою локальную машинку.
git clone https://github.com/apache/spark git checkout branch-1.6 И в одном из примеров узнаем как подключиться к твиттеру и как его читать. И других примеров там много – полезно просмотреть, пролистать, чтобы знать, что Spark уже умеет.
Если это первое ваше знакомство с твиттером с этой стороны, то ключики и токены брать тут https://apps.twitter.com. После модификации примера получиться может так:
package org.apache.spark.examples.streaming import org.apache.spark.streaming.Seconds, StreamingContext> import org.apache.spark.streaming.StreamingContext._ import org.apache.spark.SparkContext._ import org.apache.spark.streaming.twitter._ // да да - тут эклипс бы отрефакторил всё, но я на виме import org.apache.spark.streaming.twitter.TwitterUtils import org.apache.spark.storage.StorageLevel import org.apache.spark.SparkConf import org.neo4j.driver.v1._ object Twittoneo def main(args: Array[String]) StreamingExamples.setStreamingLogLevels() // а сюда я сначала настоящие ключи записал :) System.setProperty("twitter4j.oauth.consumerKey", "tFwPvX5s") System.setProperty("twitter4j.oauth.consumerSecret", "KQvGuGColS12k6Mer45jnsxI") System.setProperty("twitter4j.oauth.accessToken", "113404896-O323jjsnI6mi2o6radP") System.setProperty("twitter4j.oauth.accessTokenSecret", "pkyl20ZjhtbtMnX") val sparkConf = new SparkConf().setAppName("Twitter2Neo4j") val ssc = new StreamingContext(sparkConf, Seconds(5)) val stream = TwitterUtils.createStream(ssc, None) val actData = stream.map(status => // extract from twitter json only interesting fields val author:String = status.getUser.getScreenName.replaceAll("_", "UNDERSCORE") val ments:Array[String] = status.getUserMentionEntities.map(x => x.getScreenName.replaceAll("_", "UNDERSCORE") >) (author, ments) >) actData.foreachRDD(rdd => if(!rdd.isEmpty()) println("Open connection to Neo4jdb") val driver = GraphDatabase.driver( "bolt://localhost", AuthTokens.basic( "neo4j", "neo4j" )) try // collect called for execute all logic on driver // http://spark.apache.org/docs/latest/cluster-overview.html rdd.collect().foreach(x => x._2.foreach( target => val session = driver.session() // create relation if not exist // merge (p:twivi13 ) // merge (n:Real ) // create unique (p)-[r:rel ]-(n) return r // // pregix 'twi' and replacement _ to UNDESCORE require because Neo4j has many restrictions for label val relation = "MERGE (p:twi"+ x._1+" +x._1+"'>) MERGE (d:twi"+ target+" + target + "'>) CREATE UNIQUE (p)-[r:rel ]-(d) RETURN 1" println(relation) val result1 = session.run(relation) result1.consume().counters().nodesCreated(); session.close() >) >) > finally driver.close() println("Close Neo4j connection") > driver.close() > >) ssc.start() ssc.awaitTermination() > > Обратите внимание – neo4j-spark-connector нам сейчас не нужен, вместо него мы возьмем neo4j-java-driver, который отвечает только за связь java-приложения и Neo4j , без выгрузок и загрузок в естественные форматы RDD или GraphFrame. Но в след. статье они нам понадобятся для настоящей работы носящей гордое имя Big Data инженер.
Компилируем и ставим в локальный Maven репозиторий библиотеку neo4j-java-driver:
git clone git@github.com:neo4j/neo4j-java-driver.git cd neo4j-java-driver mvn clean package install Кладём наш код в src/main/scala/org/apache/spark/examples/streaming/Twitter2neo4j.scala . Находясь в папке examples добавляем в ./pom.xml :
org.neo4j.driver neo4j-java-driver 1.1-SNAPSHOT
Дальше компилируем примеры вместе с нашим: вызывайте mvn -Phadoop-2.6 -Dhadoop.version=2.6.0 -DskipTests clean package .
Кстати, на моём курсе первым делом учимся maven, gradle и sbt. Это основа основ. Важнее только bash.
У нас получается jar файлик с которым дальше будем работать. Вместо компиляции Spark опять же будем использовать модный Docker.
Обратите внимание на версию Spark – 1.6.1. Важно что б ваш пакет и Spark были одной версией, а то Spark так быстро развивается , что иногда даже слишком быстро.
Помним о безопасности. И еще один интересный момент за Docker – образ для нас собрал непонятно кто, а докер работает от рута (хипстеры писали , что с них взять).Теоретически, это огромная дыра в безопасности. Я-то смело выполняю данные действия — в наипоследнейшей Fedora с включенным selinux, ограждающим дырявый докер. А пользователей убунты не жалко. Кстати, супер крутая и модная версия докера называется chroot.
Запустим контейнер (коробочку, ведерко), экспортируя текущую папку в /shared c правом на только чтение(ro) и перемаркируя selinux контекст в svirt_sandbox_file_t.
Контекст SELinux для песочницы останется и после остановки контейнера. Так же экспортируем нами скомпилированную библиотеку для neo4j-java-driver.
А вот был бы у нас свой центральный репозиторий, например Nexus – было бы проще.
Или как вариант можно поправить pom.xml и собирать со всеми необходимыми зависимостями. У нас получится два контейнера которые должны общаться, поэтому пойдём по пути наименьшего сопротивления – Spark-контейнер будет использовать сетевой стек Neo4j контейнера, разделяя с ним ip адрес.
Для этого вызываем docker ps | grep -i neo4j | awk » и смотрим id контейнера.
docker run -it -v `pwd`:/shared:ro,z \ -v /path/to/neo4j-java-driver/driver/target:/neo4jadapter:ro,z \ --net=container:ca294ee9e614 \ sequenceiq/spark:1.6.0 bash Вот мы оказались в контейнере. У нас есть хадуп и спарк. Но хадуп мы трогать не будем – он нам не мешает, а Spark запустим так, что б он выполнялся локально(—master local[4]):
spark-submit --jars /neo4jadapter/neo4j-java-driver-1.1-SNAPSHOT.jar \ --packages "org.apache.spark:spark-streaming-twitter_2.10:1.6.1" \ --class org.apache.spark.examples.streaming.Twittoneo \ --master local[4] \ --driver-memory 1g \ --executor-memory 1g \ --executor-cores 1 \ --verbous \ /shared/target/spark-examples_2.10-1.6.1.jar Ждем минут хотя бы 10 и смотрим результат. Но чем больше данных соберем, тем интереснее.
.png)
Если хотите краше, динамичнее и может даже в реальном времени, то на mkdev есть курс Екатерины Шпак. Там учат d3.js и прочим хитростям красивого фронтенда. Вообще в Big Data половина дела – это презентовать ваши достижения среднестатистическому менеджеру, у которого хоть и классическое образование, но без картинки не поймёт.
В данном примере есть один важный момент – не используется суперсила Spark. Ведь в Spark мы можем построить сразу готовый граф, аггрегировать все сообщения и только потом заливать в Neo4j. Этим можно значительно повысить количество информации перерабатываемое системой. Но кого это волнует в обучающем примере. Да даже в реальности это мало кого волнует 🙂
Выводы и прогнозы на следующую часть
Полученная база и та выборка, что мы делаем, не практична. Следующий шаг это найти например самых влиятельных пользователей (найти, дать им деньги и пусть рекламируют наш товар). Или отслеживать упоминание вашего бренда и в зависимости от ситуации (ругают, хвалят, кто отзывается) пытаться увеличить прибыль. Это очевидные примеры использования, но в славной стране Германия есть закон запрещающий хранить данные пользователей позволяющие явно идентифицировать оных.
Так вот, используя большой массив данных из разных источников можно пользователя узнавать и по косвенным уликам. Так что тот факт что у меня параноя совсем не отменяет слежки за каждым из нас. И приятнее быть еще и тем, кто следит, чем только тем, за кем следят. И графы тут очень помогают, о чем поговорим в следующей части. Кстати — заодно посмотрим решения, когда Neo4j не хватает, ведь при всех своих достоинствах Neo4j не масштабируется. Авторы Neo4j с этим не согласны, но кто им верит.
Кстати особенность всех nosql решений – база строится исходя из того что и как вы будете запрашивать. Когда кричат, что что-то schemaless – значит либо врут, либо невозможно работать 🙂
Дополнительное чтение
- https://www.coursera.org/learn/teoriya-grafov/home/welcome
- https://www.coursera.org/learn/sluchajnye-graphy
- http://www.kennybastani.com/2015/03/spark-neo4j-tutorial-docker.html
- https://github.com/sequenceiq/docker-spark
- https://www.anchormen.nl/spark-docker/
© Copyright 2014 — 2024 mkdev | Privacy Policy
Доступ к данным Neo4j
Этот урок освещает процесс создания приложения c Neo4J, которое использует Spring Data.
Что вы создадите
Вы будете использовать Neo4j NoSQL графовое хранилище для сборки встроенного Neo4j сервера, сохранения сущностей и разработки запросов.
Что вам потребуется
- Примерно 15 минут свободного времени
- Любимый текстовый редактор или IDE
- JDK 6 и выше
- Gradle 1.11+ или Maven 3.0+
- Вы также можете импортировать код этого урока, а также просматривать web-страницы прямо из Spring Tool Suite (STS), собственно как и работать дальше из него.
Как проходить этот урок
Как и большинство уроков по Spring, вы можете начать с нуля и выполнять каждый шаг, либо пропустить базовые шаги, которые вам уже знакомы. В любом случае, вы в конечном итоге получите рабочий код.
Чтобы начать с нуля, перейдите в Настройка проекта.
- Загрузите и распакуйте архив с кодом этого урока, либо кнонируйте из репозитория с помощью Git: git clone https://github.com/spring-guides/gs-accessing-data-neo4j.git
- Перейдите в каталог gs-accessing-data-neo4j/initial
- Забегая вперед, опишите простую сущность
Когда вы закончите, можете сравнить получившийся результат с образцом в gs-accessing-data-neo4j/complete .
Настройка проекта
Для начала вам необходимо настроить базовый скрипт сборки. Вы можете использовать любую систему сборки, которая вам нравится для сборки проетов Spring, но в этом уроке рассмотрим код для работы с Gradle и Maven. Если вы не знакомы ни с одним из них, ознакомьтесь с соответсвующими уроками Сборка Java-проекта с использованием Gradle или Сборка Java-проекта с использованием Maven.
Создание структуры каталогов
В выбранном вами каталоге проекта создайте следующую структуру каталогов; к примеру, командой mkdir -p src/main/java/hello для *nix систем:
└── src └── main └── java └── hello
Создание файла сборки Gradle
Ниже представлен начальный файл сборки Gradle. Файл pom.xml находится здесь. Если вы используете Spring Tool Suite (STS), то можете импортировать урок прямо из него.
Если вы посмотрите на pom.xml , вы найдете, что указана версия для maven-compiler-plugin. В общем, это не рекомендуется делать. В данном случае он предназначен для решения проблем с нашей CI системы, которая по умолчанию имеет старую(до Java 5) версию этого плагина.
buildscript < repositories < maven < url "http://repo.spring.io/libs-release" >mavenLocal() mavenCentral() > dependencies < classpath("org.springframework.boot:spring-boot-gradle-plugin:1.1.8.RELEASE") >> apply plugin: 'java' apply plugin: 'eclipse' apply plugin: 'idea' apply plugin: 'spring-boot' jar < baseName = 'gs-accessing-data-neo4j' version = '0.1.0' >repositories < mavenLocal() mavenCentral() maven < url "http://repo.spring.io/libs-release" >maven < url "http://m2.neo4j.org" >> dependencies < compile("org.springframework.boot:spring-boot-starter") compile("org.springframework:spring-context") compile("org.springframework:spring-tx") compile("org.springframework.data:spring-data-neo4j") compile("org.hibernate:hibernate-validator") testCompile("junit:junit") >task wrapper(type: Wrapper)
Spring Boot gradle plugin предоставляет множество удобных возможностей:
- Он собирает все jar’ы в classpath и собирает единое, исполняемое «über-jar», что делает более удобным выполнение и доставку вашего сервиса
- Он ищет public static void main() метод, как признак исполняемого класса
- Он предоставляет встроенное разрешение зависимостей, с определенными номерами версий для соответсвующих Spring Boot зависимостей. Вы можете переопределить на любые версии, какие захотите, но он будет по умолчанию для Boot выбранным набором версий
Описание простой сущности
Neo4j описывает сущности и их взаимосвязи, оба из этих сторон одинаково важны. Представьте себе, что вы моделируете систему, где вы сохраняете запись о каждом человеке. Но вы также хотите отслеживать и тех, с кем он работает ( teammates в данном примере). С Neo4j вы можете описать все это несколькими простыми аннотациями.
package hello; import java.util.HashSet; import java.util.Set; import org.neo4j.graphdb.Direction; import org.springframework.data.neo4j.annotation.Fetch; import org.springframework.data.neo4j.annotation.GraphId; import org.springframework.data.neo4j.annotation.NodeEntity; import org.springframework.data.neo4j.annotation.RelatedTo; @NodeEntity public class Person < @GraphId Long id; public String name; public Person() <>public Person(String name) < this.name = name; >@RelatedTo(type="TEAMMATE", direction=Direction.BOTH) public @Fetch Set teammates; public void worksWith(Person person) < if (teammates == null) < teammates = new HashSet(); > teammates.add(person); > public String toString() < String results = name + "'s teammates include\n"; if (teammates != null) < for (Person person : teammates) < results += "\t- " + person.name + "\n"; >> return results; > >Здесь у вас есть класс Person с одним лишь атрибутом name . У вас есть два конструктора, один без, а другой с параметром name . Для использования Neo4j далее, вам необходим конструктор без параметров.
В этом уроке типичные методы получения и установки опущены для краткости.
Следующей важной частью является установка teammates . Это простой Set , но помеченный как @RelatedTo . Это означает, что каждый элемент этого набора сответствует отдельному узлу Person . Обратите внимание, что направление установлено в BOTH . Это означает, что когда вы генерируете TEAMMATE взаимосвязь в одном направлении, оно существует и в другом направлении. Есть ещё @Fetch аннотация в этом поле. Это означает, что элементы будут возвращены сразу. Иначе, вам пришлось бы использовать neo4jTemplate.fetch() .
В методе worksWith() вы можете легко связать людей вместе.
И наконец, у вас есть метод toString() для печати имени человека и его коллег.
Создание простых запросов
Spring Data Neo4j ориентирована на хранение данных в Neo4j. Но он наследует функциональность от проекта Spring Data Commons, включая умение составлять запросы. Фактически, вам не нужно изучать язык запросов Neo4j, а можно просто написать несколько методов и запросы будут написаны за вас.
Чтобы увидеть, как это работает, создайте интерфейс запросов узлов Person .
package hello; import org.springframework.data.repository.GraphRepository; public interface PersonRepository extends GraphRepository < Person findByName(String name); IterablefindByTeammatesName(String name); >PersonRepository расширяет GraphRepository класс и указывает тип, с которым он работает: Person . Из коробки этот интерфейс идет с множеством операций, включая стандартные CRUD (create-read-update-delete) операции.
Но вы можете определить и другие запросы, которые вам необходимы, просто описав сигнатуры метода. В данном случае, вы добавили findByName , он ищет узлы типа Person и находит те, которые соответствуют по name . У вас также есть findByTeammatesName , который ищет Person узел, проверяя в каждом из элементов поля teammates на соответствие значения name .
Приступим к работе и посмотрим, что он найдет!
Создание класса Application
Создайте класс Application со всеми компонентами.
package hello; import org.neo4j.graphdb.GraphDatabaseService; import org.neo4j.graphdb.Transaction; import org.neo4j.graphdb.factory.GraphDatabaseFactory; import org.neo4j.kernel.impl.util.FileUtils; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.CommandLineRunner; import org.springframework.boot.SpringApplication; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.data.neo4j.config.EnableNeo4jRepositories; import org.springframework.data.neo4j.config.Neo4jConfiguration; import org.springframework.data.neo4j.core.GraphDatabase; import java.io.File; @Configuration @EnableNeo4jRepositories(basePackages = "hello") public class Application extends Neo4jConfiguration implements CommandLineRunner < public Application() < setBasePackage("hello"); >@Bean GraphDatabaseService graphDatabaseService() < return new GraphDatabaseFactory().newEmbeddedDatabase("accessingdataneo4j.db"); >@Autowired PersonRepository personRepository; @Autowired GraphDatabase graphDatabase; public void run(String. args) throws Exception < Person greg = new Person("Greg"); Person roy = new Person("Roy"); Person craig = new Person("Craig"); System.out.println("Before linking up with Neo4j. "); for (Person person : new Person[]) < System.out.println(person); >Transaction tx = graphDatabase.beginTx(); try < personRepository.save(greg); personRepository.save(roy); personRepository.save(craig); greg = personRepository.findByName(greg.name); greg.worksWith(roy); greg.worksWith(craig); personRepository.save(greg); roy = personRepository.findByName(roy.name); roy.worksWith(craig); // Мы уже знаем, что Рой работает с Грегом personRepository.save(roy); // Мы уже знаем, что Крейг работает с Роем и Грегом System.out.println("Lookup each person by name. "); for (String name: new String[]) < System.out.println(personRepository.findByName(name)); >System.out.println("Looking up who works with Greg. "); for (Person person : personRepository.findByTeammatesName("Greg")) < System.out.println(person.name + " works with Greg."); >tx.success(); > finally < tx.close(); >> public static void main(String[] args) throws Exception < FileUtils.deleteRecursively(new File("accessingdataneo4j.db")); SpringApplication.run(Application.class, args); >>В конфигурацию вам необходимо добавить аннотацию @EnableNeo4jRepositories , а также наследоваться от класса Neo4jConfiguration для удобства работы с нужными компонентами.
Единственное, чего не хватает, это бина службы графовой БД. В данном случае вы используете EmbeddedGraphDatabase , который создает и переиспользует хранилище в виде файла accessingdataneo4j.db.
В рабочей среде вы скорее всего подключитесь к отдельнозапущенному Neo4j серверу.
Вы вызываете экземпляр PersonRepository , описанный ранее. Spring Data Neo4j будет динамически создавать нужный класс, реализующий этот интерфейс и при необходимости использовать нужный код запроса для удовлетворения потребностей интерфейса.
public static void main использует Spring Boot SpringApplication.run() для запуска приложения и CommandLineRunner для сборки связей.
В данном случае вы создаете три экземпляра Person , Greg, Roy и Craig. Первоначально они существуют только в памяти. Важно отметить, что на данный момент пока ни один из них не является коллегой друг другу.
Чтобы что-то сохранить в Neo4j, вы должны начать транзакцию, используя graphDatabase . здесь вы будете сохранять каждого человека. Затем вы выбираете каждого из них и связываете вместе.
Вначале вы находите Грега и указываете, что он работает с Роем и Крейгом, затем сохраняете его снова. Помните, что связь между ними была определена как BOTH , а значит двунаправлена. Это означает, что Рой и Крейг будут также обновлены.
Поэтому, когда вам необходимо обновить Роя, важно извлечь запись о нем из Neo4j первой. Вам нужен последние данные о коллегах Роя до добавления Крейга в его список.
Почему нет кода для получения Крейга и добавления у него связей? Потому что вы уже сделали это! Грег ранее был связан с Крейгом как коллега, так же как и с Роем. Это означает, что вам не нужно снова обновлять связи Крейга. Вы можете убедиться в этом, когда печатается информация о каждом из них и их связях.
В заключение, проверяется другой запрос, где наоборот, отвечается на вопрос «кто работает с кем?».
Сборка исполняемого JAR
Вы можете собрать единый исполняемый JAR-файл, который содержит все необходимые зависимости, классы и ресурсы. Это делает его легким в загрузке, версионировании и развертывании сервиса как приложения на протяжении всего периода разработки, на различных средах и так далее.
./gradlew build
Затем вы можете запустить JAR-файл:
java -jar build/libs/gs-accessing-data-neo4j-0.1.0.jar
Если вы используете Maven, вы можете запустить приложение, используя mvn spring-boot:run , либо вы можете собрать приложение с mvn clean package и запустить JAR примерно так:
java -jar target/gs-accessing-data-neo4j-0.1.0.jar
Процедура, описанная выше, создает исполняемый JAR. Вы также можете вместо него собрать классический WAR-файл.
Запуск сервиса
Если вы используете Gradle, вы можете запустить ваш сервис из командной строки:
./gradlew clean build && java -jar build/libs/gs-accessing-data-neo4j-0.1.0.jar
Если вы используете Maven, то можете запустить ваш сервис таким образом: mvn clean package && java -jar target/gs-accessing-data-neo4j-0.1.0.jar .
Как вариант, вы можете запустить ваш сервис напрямую из Gradle примерно так:
./gradlew bootRun
С mvn — mvn spring-boot:run .
Вы должны увидеть следующее:
Before linking up with Neo4j. Greg's teammates include Roy's teammates include Craig's teammates include Lookup each person by name. Greg's teammates include - Craig - Roy Roy's teammates include - Craig - Greg Craig's teammates include - Roy - Greg Looking up who works with Greg. Roy works with Greg. Craig works with Greg.
Итог
Поздравляем! Вы только что настроили встроенный Neo4j сервер, сохранили несколько простых, но связанных сущностей и разработали несколько простых запросов.
С оригинальным текстом урока вы можете ознакомиться на spring.io.
Начинаем работать с графовой базой данных Neo4j
В нашем проекте возникла следующая задача — есть база с большим количеством товаров, на уровне сотен тысяч. У каждого товара есть сотни динамически создаваемых характеристик. Необходимо обеспечить быструю фильтрацию по товарам по набору различных характеристик. Время формирования ответа должно быть не более 0.3 секунды, нужно поддерживать сложную логику в стиле.
(характеристика1 = true AND (характеристика2 < 100)) OR (характеристика1 = false AND (характеристика3 >17)) . далее обычно мешанина из AND\OR
У нас все реализовано в рамках MySQL + Symfony2/Doctrine, скорость неудовлетворительная — ответы формируются в течении 1-10 секунд. Мои попытки оптимизировать все это хозяйство — под катом.
Терминология задачи по фильтрации товаров (в упрощенном виде)
- характеристика — определенное свойство товара. Например, объем памяти.
- шаблон товара — набор всех возможных характеристик однотипных товаров, например — перечень возможных характеристик компьютерных мышек. При добавлении нового товара администратор может выбирать характеристики в рамках шаблона. Добавить новую характеристику для одного товара невозможно — нужно добавить характеристику в шаблон для этого товара. Одновременно эта характеристика будет доступна для всех товаров, использующих этот шаблон
- группа товаров — товары на основе одного шаблона. Например, компьютерные мышки. Фильтрация делается только для товаров из одной группы
- критерий — логическое правило, которое состоит из набора формальных требований к характеристикам товара. Например, «геймерская мышка» — это набор требований к характеристикам (размер не миниатюрный) AND (сенсор лазерный) AND (разрешение сенсора не менее 1500)
- фильтр — группа критериев для однотипных товаров. В зависимости от критериев, они могут комбинироваться через AND или OR
Для решения этой задачи я решил опробовать графовую базу данных Neo4j. Для поверхностного ознакомления рекомендую прочитать этот пост.
Терминология Neo4j и графовых баз данных в целом.
- graph database, графовая база данных — база данных построенная на графах — узлах и связях между ними
- Cypher — язык для написания запросов к базе данных Neo4j (примерно, как SQL в MYSQL)
- node, нода — объект в базе данных, узел графа. Количество узлов ограниченно 2 в степени 35 ~ 34 биллиона
- node label, метка ноды — используется как условный «тип ноды». Например, ноды типа movie могут быть связанны с нодами типа actor. Метки нод — регистрозависимые, причем Cypher не выдает ошибок, если набрать не в том регистре название.
- relation, связь — связь между двумя нодами, ребро графа. Количество связей ограниченно 2 в степени 35 ~ 34 биллиона
- relation identirfier, тип связи — в Neo4j у связей. Максимальное количество типов связей 32767
- properties, свойства ноды — набор данных, которые можно назначить ноде. Например, если нода — это товар, то в свойствах ноды можно хранить id товара из базы MySQL
- node ID, ID нода — уникальный идентификатор ноды. По умолчанию, при просмотрах результата отображается именно этот ID. как его использовать в Cypher запросах я не нашел
Схема решения задачи
Для каждого товара создать отдельную ноду, в свойствах ноды хранить id товара в базе MySQL. Для каждого критерия создать свою ноду, в свойствах хранить id критерия. Дальше, связать все ноды товаров с нодами критериев, которые подходят для товара. При изменении характеристик товара или свойств критериев обновлять связи между нодами.
Первый вариант решения — с Neo4j
Учитывая, что я с графовыми базами данных никогда не работал — я решил развернуть локально Neo4j, изучить на базовом уровне Cypher и попробовать реализовать требуемую логику. Если все получиться — провести тестирование скорости работы для базы из 1 миллиона товаров, у каждого 500 характеристик.
Разворачивание системы достаточно простое — скачиваем дистрибутив и устанавливаем его.
У Neo4j сервера есть RestAPI, для php есть библиотека neo4jphp. Также есть bundle для интеграции с Symfony2 — klaussilveira/neo4j-ogm-bundle.
В дистрибутив входит веб сервер и приложение для работы с ним, по умолчанию http://localhost:7474/
Есть еще старая версия клиента, с другим функционалом.
В качестве документации удобно использовать краткую документацию. Примеры кода есть в graphgist. По идее, они должны там выполнятся онлайн, но сейчас это не работает. Чтобы посмотреть код нужно перейти по ссылке из graphgist (например, сюда) и там нажать кнопку Page Source.
Для экспериментов с Neo4j очень удобно использовать встроенный веб клиент Там можно выполнять запросы Cypher и просматривать ответ на запросы вместе со связями и характеристиками нод.
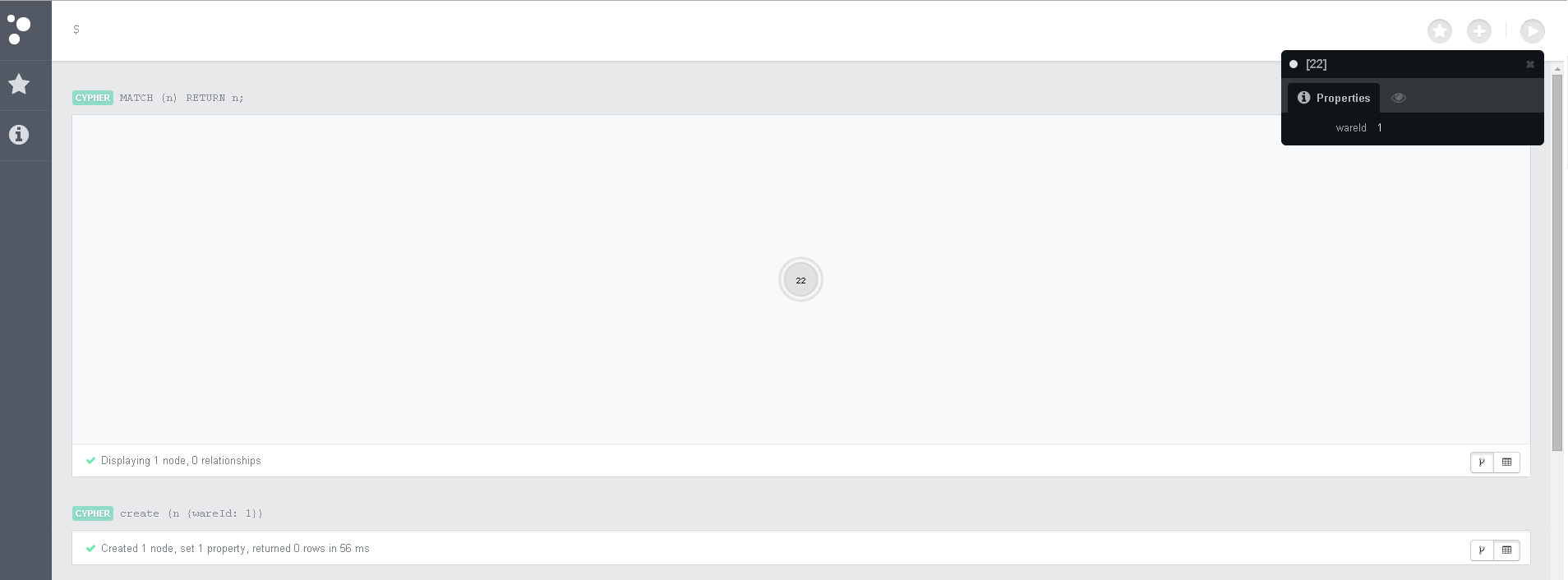
Простые Cypher команды
Создание ноды с меткой
create (n:Ware ); Выбрать все ноды
MATCH (n) RETURN n;Счетчик
MATCH (n:Ware ) RETURN "Our graph have "+count(*)+" Nodes with label Ware and wareId=1" as counter;Создать 2 связанные ноды
CREATE (n)-[r:SUIT]->(m)Связать 2 существующие ноды
MATCH (a ), (b ) MERGE (a)-[r:SUIT]->(b)Удалить все связанные ноды
match (n)-[r]-() DELETE n,r;Удалить все несвязанные ноды — если попробовать запустить эту команду в базе, где есть связанные ноды — она не пройдет. Нужно удалить вначале связанные ноды.
match n DELETE n;Выбрать товары, которым подходит критерий 3
MATCH (a:Ware)-->(b:Criteria ) RETURN a;Сразу несколько Cypher команд веб клиент выполнять не умеет. Тут говорят, что старый клиент это умеет, но я не нашел такой возможности. Поэтому, нужно копировать по 1 строке.
Можно выполнить создание множества нод со связями одной командой, нужно давать разные имена нодам, связям можно не давать имя
CREATE (w1:Ware)-[:SUIT]->(c1:Criteria), (w2:Ware)-[:SUIT]->(c2:Criteria), (w3:Ware)-[:SUIT]->(c3:Criteria), (w4:Ware)-[:SUIT]->(c1), (w5:Ware)-[:SUIT]->(c1), (w4)-[:SUIT]->(c2), (w5)-[:SUIT]->(c3); Получится такая структура. Если у вас выглядит менее понятно — можно переставить мышкой ноды.

Промежуточные тесты скорости Neo4j
Пришло время протестировать скорость заполнения базы и простых выборок из большой базой.
Для этого клонируем neo4jphp
git clone https://github.com/jadell/neo4jphp.gitБазовое описание этой библиотеки есть в этом посте, поэтому я сразу выложу код для заполнения тестовой базы еxamples/test_fill_1.php
makeLabel('Ware'); $neoCriteriaLabel = $neoClient->makeLabel('Criteria'); $wareTemplatesCount = 200; // количество шаблонов товара $criteriasCount = 500; // количество критериев $waresCount = 10000; // количество товаров $commitWares = 100; // количество товаров, которое будет идти в 1 batch $minRelations = 200; // минимальное количество связей товара с критериями $maxRelations = 400; // максимальное количество связей товара с критериями $time = time(); for($wareTemplateId = 0;$wareTemplateId<$wareTemplatesCount;$wareTemplateId++) < $neoClient->startBatch(); print $wareTemplateId." (".$criteriasCount." criterias, ".$waresCount." wares with rand(".$minRelations.",".$maxRelations.") . "; $criterias = array(); // создаем критерии for($criteriaId = 1;$criteriaId <=$criteriasCount;$criteriaId++) < $c = $neoClient->makeNode()->setProperty('criteriaId', $wareTemplateId * $criteriasCount + $criteriaId)->save(); // ->addLabels(array($neoCriteriaLabel)) - не работает с commitBatch $neoCriterias->add($c, 'criteriaId', $wareTemplateId * $wareTemplatesCount + $criteriaId); // ->save() такого метода нет $criterias[] = $c; > // создаем товары for($wareId = 1;$wareId <=$waresCount;$wareId++) < $w = $neoClient->makeNode()->setProperty('wareId', $wareTemplateId * $waresCount + $wareId)->save(); // ->addLabels(array($neoWareLabel)) - не работает с commitBatch $neoWares->add($c, 'wareId', $wareTemplateId * $waresCount + $criteriaId); // каждый товар привязываем к случайному количеству критериев for($i = 1;$i<=rand($minRelations,$maxRelations);$i++) < $w->relateTo($criterias[array_rand($criterias)], "SUIT")->save(); > if(($wareId % $commitWares) == 0) < // комитим, при слишком больших комитах Neo4j зависает $neoClient->commitBatch(); print " [commit ".$commitWares." ".(time() - $time)." sec]"; $time = time(); $neoClient->startBatch(); > > $neoClient->commitBatch(); print " done in ".(time() - $time)." seconds\n"; $time = time(); > Скрипт заполнения базы я оставил на ночь. Примерно спустя 4 часа скрипт перестал добавлять данные и сервис Neo4j начал грузить сервер на 100%. Утром по итогу работы было вставлено 78300 товаров из 8 категорий товаров.
Результаты тестового заполнения базы — примерно 20 товаров в секунду с 200-400 связями. Не очень высокий результат — Mysql и Cassandra выдавали около 10-20 тысяч вставок в секунду (10 полей, 1 primary index, 1 индекс). Но скорость вставки для нас не критична — мы можем обновлять граф данных в фоновом режиме после редактирования товара. А вот скорость выборки данных — критична.
Размер тестовой базы данных на диске — 1781 мегабайт. В ней хранится 78300 товаров, 4000 критериев, 15660000-31320000 связей. Общее количество объектов (нодов и связей) менее 32 миллионов — в среднем по 55 байт на сущность. Многовато, как по мне, но главное требование все же скорость выборок, а не размер базы.
Первая попытка протестировать скорость выборки провалилась — сервер Neo4j опять «ушел» в режим 100% загрузки процессора и за несколько минут так и не выдал ответ на запрос.
MATCH (c )(b ) RETURN a.wareId;Чтобы двигаться дальше нужно разобраться, как оптимизировать запрос в Neo4j. Вначале я хотел ограничить стартовый набор нод в выборке с помощью инструкции START
START n=node:nodeIndexName(key=) MATCH (c)(b) RETURN a.wareId; Для этого нужно, чтобы в базе были индексы. В Neo4j я не нашел команду для просмотра перечня текущих индексов, но в веб приложении Neo4j можно набрать команду
:schemaДобавить индексы можно командой
CREATE INDEX ON :Criteria(criteriaId)Уникальный индекс можно создать командой
CREATE CONSTRAINT ON (n:Criteria) ASSERT n.criteriaId IS UNIQUE;Индексы, добавленные командами выше, нельзя использовать в START директиве. Тут утверждают, что их можно использовать только в where
The indexes created via Cypher are called Schema indexes, and are not to be used in the START clause. The START clause index lookups are reserved for the legacy indexes that you create via autoindexing or through the non-Cypher APIs.
In order to use the :user index you’ve created, you can do this:
match n:user
where n.name=«aapo»
return n;
Если я правильно понял документацию, можно смело использовать WHERE вместо START
START is optional. If you do not specify explicit starting points, Cypher will try and infer starting points from your query. This is done based on node labels and predicates contained in your query. See Chapter 14, Schema for more information. In general, the START clause is only really needed when using legacy indexes.
Так родился первый рабочий запрос
MATCH (a:Ware)-->(c1:Criteria ),(c2:Criteria ),(c3:Criteria ) WHERE (a)-->(c2) AND (a)-->(c3) RETURN a; В нашей тестовой базе индексов не обнаружено, поэтому мы создадим еще одну базу для теста другим способом. Возможности создать независимые наборы данных (аналог базы данных в MySQL) в Neo4j я не нашел. Поэтому для тестирования я просто менял путь к хранилищу данных в настройках Neo4j Community (Database location)
Внимательные читатели возможно обнаружили пару комментариев в коде test_fill_1.php, а именно
$c = $neoClient->makeNode()->setProperty('criteriaId', $wareTemplateId * $criteriasCount + $criteriaId)->save(); // ->addLabels(array($neoCriteriaLabel)) - не работает с commitBatch $neoCriterias->add($c, 'criteriaId', $wareTemplateId * $wareTemplatesCount + $criteriaId); // ->save() такого метода нет
В batch режиме в Neo4jphp у меня не получилось добавить метки к нодам, а индексы почему то не сохранились. Учитывая, что Cypher перестал для меня быть китайской грамотой, я решил заполнять базу хардкорно — на чистом Cypher. Так получился test_fill_2.php
$criteriasCount) < throw new \Exception("maxRelations[".$maxRelations."] should be bigger, that criteriasCount[".$criteriasCount."]"); >$query = new Cypher\Query($neoClient, "CREATE CONSTRAINT ON (n:Criteria) ASSERT n.criteriaId IS UNIQUE;", array()); $result = $query->getResultSet(); $query = new Cypher\Query($neoClient, "CREATE CONSTRAINT ON (n:Ware) ASSERT n.wareId IS UNIQUE;", array()); $result = $query->getResultSet(); for($wareTemplateId = 0;$wareTemplateId<$wareTemplatesCount;$wareTemplateId++) < $time = time(); $queryTemplate = "CREATE "; print $wareTemplateId." (".$criteriasCount." criterias, ".$waresCount." wares with rand(".$minRelations.",".$maxRelations.") . "; $criterias = array(); for($criteriaId = 1;$criteriaId <=$criteriasCount;$criteriaId++) < // создаем нод критерия в виде (w1:Ware) $cId = $criteriaId + $criteriasCount*$wareTemplateId; $queryTemplate .= "(c".$cId.":Criteria), "; $criterias[] = $cId; > for($wareId = 1;$wareId <=$waresCount;$wareId++) < $wId = $wareId + $waresCount*$wareTemplateId; // создаем нод товара в виде (w1:Ware) $queryTemplate .= "(w".$wId.":Ware), "; // создаем связи между нодами в виде (w1)-[:SUIT]->(c1) $possibleLinks = array_merge(array(), $criterias); // clone $criterias не работает for($i = 1;$i<=rand($minRelations,$maxRelations);$i++) < $linkId = $possibleLinks[array_rand($possibleLinks)]; unset($possibleLinks[$linkId]); $queryTemplate .= "w".$wId."-[:SUIT]->c".$linkId.", "; > > $queryTemplate = substr($queryTemplate,0,-2); // удаляем последний ", " $build = time(); $query = new Cypher\Query($neoClient, $queryTemplate, array()); // $queryTemplate будет в районе 42 мегабайт для 10000 товаров, 500 критериев, 200-400 связей между товаром-критерием $result = $query->getResultSet(); print " Query build in ".($build - $time)." seconds, executed in ".(time() - $build)." seconds\n"; // die(); > Скорость добавления данных оказалась предсказуемо большей, чем в первом варианте.
Тестовый скрипт с добавлением 30000 нодов и 500000 — 1000000 связей на cypher отработал за 140 секунд, база заняла на диске 62 мегабайта. При попытке запустить скрипт c $waresCount=1000 (не говоря уже о 10000 товаров) я получил ошибку «Stack overflow error». Я переписал скрипт c использованием.
MATCH (a ), (b ) MERGE (a)-[r:SUIT]->(b) Это привело к катастрофическому падению скорости работы, модифицированный скрипт работал примерно около часа. Я решил протестировать скорость выборки по нескольким критериям и вернуться к вопросу быстрой вставки данных позже.
(b:Criteria ),(c:Criteria ),(c2:Criteria ) WHERE (a)-->(c) AND (a)-->(c2) RETURN a;", array()); $result = $query->getResultSet(); print "Done in ".(microtime() - $time)." seconds\n"; Скрипт выше отработал за 0.02 секунды. В целом — это вполне приемлемо, но проблема как быстро сохранять большое количество связей между нодами при апдейте свойств товара — осталась.
Альтернативное решение
Я решил «для очистки совести» опробовать MySQL в качестве хранилища. Связи между нодами будут храниться в отдельной таблице без дополнительной информации.
CREATE TABLE IF NOT EXISTS `edges` ( `criteriaId` int(11) NOT NULL, `wareId` int(11) NOT NULL, UNIQUE KEY `criteriaId` (`criteriaId`,`wareId`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; Тестовый скрипт для заполнения базы ниже
for($wareId = 1;$wareId <=$waresCount;$wareId++) < $edges = array(); $wId = $wareTemplateId * $waresCount + $wareId; $links = array_rand($criterias,rand($minRelations,$maxRelations)); foreach($links as $linkId) < $edges[] = "(".$criterias[$linkId].",".$wareId.")"; >// заносим сразу связи между товарами и критериями mysql_query("INSERT INTO edges VALUES ".implode(",",$edges)); > print "."; > print " [added ".$wareTemplatesCount." templates in ".(time() - $time)." sec]"; $time = time(); Заполнение базы заняло 12 секунд. Размер таблицы — 37 мегабайт. Поиск по 2 критериям занимает 0.0007 секунд
SELECT e1.wareId FROM `edges` AS e1 JOIN edges AS e2 ON e1.wareId = e2.wareId WHERE e1.criteriaId =17 AND e2.criteriaId =31 Еще один вариант
Под mysql есть полноценное графовое хранилище данных — но я его не тестировал. Судя по документации, он гораздо примитивнее Neo4j.
Выводы
Neo4j — очень крутая штука. Запрос наподобие «Выбрать контакты пользователей, которые лайкнули киноактёров, которые снялись в фильмах, в которых звучали саунтдтреки, которые были написаны музыкантами, которым я поставил лайк» в Neo4j решается тривиально. Примерно так
MATCH (me:User )-[:Like]->(musicants:User)-[:Author]->(s:Soundtrack)-[:Used]->(f:Film)<-[:Starred]-(actor: User)<-[:Like]-(u:User) RETURN u Для SQL это гораздо более хлопотное занятие.
Сравнивать полноценную графовую базу с голой таблицей индексов в MySQL — некорректно, но в рамках решения моей задачи — использование Neo4j никаких плюсов не дало.
UPDATE. Изменил url'ы картинок, по идее должны у всех загрузаться.
UPDATE 2. Предложили еще несколько вариантов — MongoDB, elasticsearch, solr, sphinx, OrientDB. Планирую протестировать MongoDB, результаты тестов выложу тут же.
Neo4j
Neo4j – это графовая база данных NoSQL с открытым исходным кодом, которая использует полнофункциональную модель данных узлов, связанных полноправными отношениями, что лучше подходит для связанных больших данных, чем традиционные подходы с использованием РСУБД. Spring Boot предусматривает несколько вспомогательных средств для работы с Neo4j, включая "стартер" spring-boot-starter-data-neo4j .
Подключение к базе данных Neo4j
Чтобы получить доступ к серверу Neo4j, можно внедрить автоконфигурируемый org.neo4j.driver.Driver . По умолчанию экземпляр будет пытаться подключиться к серверу Neo4j по адресу localhost:7687 , используя протокол Bolt. В следующем примере показано, как внедрить Driver для Neo4j, который даст доступ, помимо всего прочего, к Session :
import org.neo4j.driver.Driver; import org.neo4j.driver.Session; import org.neo4j.driver.Values; import org.springframework.stereotype.Component; @Component public class MyBean // . public String someMethod(String message) < try (Session session = this.driver.session()) < return session.writeTransaction((transaction) ->transaction .run("CREATE (a:Greeting) SET a.message = $message RETURN a.message + ', from node ' + id(a)", Values.parameters("message", message)) .single().get(0).asString()); > > > import org.neo4j.driver.Driver import org.neo4j.driver.Transaction import org.neo4j.driver.Values import org.springframework.stereotype.Component @Component class MyBean(private val driver: Driver) // . fun someMethod(message: String?): String < driver.session().use < session ->return@someMethod session.writeTransaction < transaction: Transaction ->transaction.run( "CREATE (a:Greeting) SET a.message = \$message RETURN a.message + ', from node ' + id(a)", Values.parameters("message", message) ).single()[0].asString() > > > > Можно добавить в конфигурацию различные аспекты драйвера с помощью свойств spring.neo4j.* . В следующем примере показано, как сконфигурировать используемые URI-идентификатор и учетные данные:
Properties
spring.neo4j.uri=bolt://my-server:7687 spring.neo4j.authentication.username=neo4j spring.neo4j.authentication.password=secretspring: neo4j: uri: "bolt://my-server:7687" authentication: username: "neo4j" password: "secret"Автоконфигурируемый Driver создается с помощью ConfigBuilder . Для более тонкой настройки его конфигурации объявите один или несколько бинов ConfigBuilderCustomizer . Каждый из них будет вызываться по порядку через ConfigBuilder , который используется для создания Driver .
Репозитории Spring Data Neo4j
Spring Data содержит средства поддержки репозиториев для Neo4j.
Spring Data Neo4j имеет общую с Spring Data JPA инфраструктуру, как и многие другие модули Spring Data. Можно взять пример для JPA из предыдущего раздела и определить City как @Node для Spring Data Neo4j, а не @Entity для JPA, при этом абстракция хранилища будет работать точно так же, как показано в следующем примере:
import java.util.Optional; import org.springframework.data.neo4j.repository.Neo4jRepository; public interface CityRepository extends Neo4jRepository < OptionalfindOneByNameAndState(String name, String state); > import org.springframework.data.neo4j.repository.Neo4jRepository import java.util.Optional interface CityRepository : Neo4jRepository < fun findOneByNameAndState(name: String?, state: String?): Optional? > "Стартер" spring-boot-starter-data-neo4j активирует поддержку репозиториев, а также управления транзакциями. Spring Boot поддерживает как классические, так и реактивные репозитории Neo4j через бины Neo4jTemplate или ReactiveNeo4jTemplate . Если Project Reactor доступен в classpath, реактивный стиль также автоматически конфигурируется.
Можно настроить местоположения, в которых будет осуществляться поиск репозиториев и сущностей, используя аннотацию @EnableNeo4jRepositories и @EntityScan соответственно на бине, помеченном аннотацией @Configuration .
В приложении, использующем реактивный стиль, ReactiveTransactionManager автоматически не конфигурируется. Чтобы активировать управление транзакциями, в конфигурации должен быть определен следующий бин:
import org.neo4j.driver.Driver; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.data.neo4j.core.ReactiveDatabaseSelectionProvider; import org.springframework.data.neo4j.core.transaction.ReactiveNeo4jTransactionManager; @Configuration(proxyBeanMethods = false) public class MyNeo4jConfiguration < @Bean public ReactiveNeo4jTransactionManager reactiveTransactionManager(Driver driver, ReactiveDatabaseSelectionProvider databaseNameProvider) < return new ReactiveNeo4jTransactionManager(driver, databaseNameProvider); >> import org.neo4j.driver.Driver import org.springframework.context.annotation.Bean import org.springframework.context.annotation.Configuration import org.springframework.data.neo4j.core.ReactiveDatabaseSelectionProvider import org.springframework.data.neo4j.core.transaction.ReactiveNeo4jTransactionManager @Configuration(proxyBeanMethods = false) class MyNeo4jConfiguration < @Bean fun reactiveTransactionManager(driver: Driver, databaseNameProvider: ReactiveDatabaseSelectionProvider): ReactiveNeo4jTransactionManager < return ReactiveNeo4jTransactionManager(driver, databaseNameProvider) >>