Как авторизоваться на YouTube с помощью Python (Request)?
Добрый вечер.
Поставил себе задачу спарсить данный из Youtube Library Music (https://www.youtube.com/audiolibrary/music) методом запросов.
Естественно youtube запросил авторизацию.
Я почти не работал с модулем requests , и не могу точно осознать , какой путь решения данной проблемы будет более правильным:
Попробовать сначала отправить запрос на Авторизацию : ( https://accounts.google.com/signin/v2/identifier?f. ) , а после в сохранённой сессии продолжить выполнять задачу по парсингу..
Или пройти сразу по ссылке (https://www.youtube.com/audiolibrary/music) , и залогиниться там.
Этот вопрос довольно простой , да и проблема не в нём.
Проблема в том , что я не знаю , как залогиниться. При post запросе Form Data ( в ней должны быть отправляемые логин и пароль ) содержит много странностей , но где и куда вставлять пароль я так и не понял.
Понятное дело , что авторизация на ютуб это не на форум для знакомств заходить , но не может же быть всё так проблематично?
В чём моя ошибка и куда стоит смотреть для её решения?
Поискав на хабре нашёл информацию о том , что простыми пост-гет запросами на ютубе не пошарить , неужели без селениума не обойтись? А если и с ним , то как передать открытую с помощью него сессию , чтобы работать с ней дальше через requests?
Буду рад любому мнению.
- Вопрос задан более трёх лет назад
- 837 просмотров
Комментировать
Решения вопроса 1

ScriptKiddo @ScriptKiddo
Алгоритм прост.
Определяете, возможно ли получить данные, отключив JS. Например, с помощью этой инструкции
https://developers.google.com/web/tools/chrome-dev.
Если с отключенным JS нужных данных не появляется, тогда у вас остается два варианта:
— Разбираться в логике получения данных, ковыряя JS скрипты, которые обрабатывают данные. Найти их можно, на вкладке Sources
Вкладка Sources
— Использовать Selenium, имитируя действия пользователя
Для выбора элементов на странице вам пригодится язык запросов XPath Тутор
Расширение для отладки Xpath Helper
Кнопки ищутся примерно по такому селектору:
Epam-meetup-2022″ 17 мая 2022 by Ontico.ru

открыть/закрыть меню
Spring python meetup
На митапе расскажем, как меняются тренды в Python‑разработке и определимся, наконец, есть ли место Python в крупных корпорациях. Подготовимся к обновлениям библиотек, версий или ОС без долгого подбора совместимых друг с другом зависимостей. Для этого сначала разберемся с источниками проблем, посмотрим, как другие экосистемы справляются со схожими задачами, и узнаем, как сохранить свои нервы при следующих обновлениях. В завершение поговорим о прикладном, тактическом программировании: как аккуратно добавлять новые фичи в текущий проект, не поломав его.
MEETUP ОТМЕНЕН
Докладчики и ведущий

Руслан Хюрри
Lead Software Engineer, EPAM
На работе программирую back-end на Python, да и после работы тоже на Python. И чем больше я работаю с этим языком, тем больше проникаюсь его совершенством и лаконичностью.

Константин Периков
Chief Software Engineer, EPAM
Я инженер, работающий в области Search, с опытом работы в индустрии электронной коммерции, химинформатики, патентного дела и других доменов. В свободное от работы время поддерживаю развитие опенсорса и люблю выступать на различных конференциях.

Илья Лебедев
Lead Software Engineer
CTO Zipsale, ex-CTO BestDoctor, соавтор Learn Python. 10 лет занимаюсь разработкой на Python, 5 лет – управлением другими разработчиками.

Григорий Петров
Head of Developer Relations, Evrone
Карьеру специалиста по созданию программ начал в конце 90-х: сначала как разработчик, затем как руководитель разработки. Участвовал в создании Radmin и Advanced IP Scanner, продвигал интерактивное телевидение NPTV и программируемую телефонию Voximplant. Генералист, нейрофизиолог-любитель, организую разработку, конференции, хакатоны.
Закрытый стрим на YouTube‑канале
Бесплатное участие в митапе
Вопросы в прямом эфире
Подарки за лучшие вопросы спикерам
Программа
Requirements.txt: «ахиллесова пята» продакшена
Lead Software Engineer, EPAM
Оказывались ли вы в ситуации, когда после обновления библиотеки, версии Python или операционной системы стабильно работающего приложения вы начинали подбирать совместимые друг с другом зависимости, тратя часы драгоценного времени? Как это получилось, ведь все версии зависимостей были заморожены pip3 freeze, да и сам Python обеспечивает обратную совместимость минимум на 2 последующих релиза? В докладе мы попробуем разобраться с источниками проблем, посмотрим, как другие экосистемы справляются со схожими задачами, и подумаем, как сохранить свои нервы при следующих обновлениях.
Enterprise Data goes Python way
Chief Software Engineer, EPAM
С каждым годом популярность языка Python только растет, но бытует мнение, что это все удел модного датасаенса или очередная не связнная с технологиями разработка в клевом стартапе, где пишется очередное веб-приложение на FastAPI. Тем не менее большие игроки на рынке смещают свой фокус в сторону Python, c каждым годом отказываясь в от базовых JVM- технологий, давших начало тому самому хайпу BigData – Hadoop, HDFS, Spark и многие другие. В этом докладе мы посмотрим на то, как меняются тренды в разработке – не только на основе данных из опросников Stackoverflow, но и на обезличенных данных о позициях в больших компаниях, оценим простоту и гибкость кода для задач, связанных с процессингом данных, и примем-таки решение – есть ли место Python в крупных корпорациях.
Пишем код сверху вниз aka одни фичи без багов

Lead Software Engineer
Давайте поговорим о прикладном, тактическом программировании. Вот вам нужно добавить конкретный, небольшой понятный кусок функциональности в существующий проект. Вам для этого не нужно создавать с нуля архитектуру проекта. Не нужно настраивать кубер, выяснять детали поведения системы в крайних случаях, согласовывать дизайн тоже не нужно. Нужно сесть и бахнуть сотню строк кода. Об этом я и хочу поговорить. Как этот код писать? Где там проектирование? Тесты? Стиль кода? Аннотации типов? Реиспользуемость? Читаемость? Обычно все эти темы обсуждаются отдельно от контекста. Если посмотреть на эти вопросы с максимально практической точки зрения, можно сделать несколько интересных выводов.
Наверняка вы уже слышали о EPAM. Ведь наша компания работает в 40 странах по всему миру.В команде ЕРАМ больше 52 000 специалистов: тестировщики, бизнес-аналитики, проектные менеджеры, архитекторы решений, представители многих других профессий. Вместе мы делаем программное обеспечение для наших заказчиков, среди которых международные финансовые, торговые, медицинские, медиа- и другие компании.
Масштабы компании и мощная система поддержки сотрудников открывают почти безграничные возможности для профессионального развития IT-специалистов. Сотрудники могут выбирать, над чем работать. Задачи найдутся для всех: back-end, full stack и machine learning!
Так, Python-разработчик может участвовать в создании ПО в сфере цифровой связи, Life Sciences, медиа или вместе с коллегами делать и поддерживать highload-платформы, готовить проекты к миграции в облако.
Python-разработчики в EPAM решают задачи бизнеса с помощью кода. Они работают над разными проектами: пишут сервисы, обрабатывают данные, развёртывают инфраструктуру и придумывают ML-алгоритмы. Чем больше у специалиста знаний – тем шире круг проектов, с которыми он может работать. Менторы и программы обучения помогают сотрудникам развиваться и повышать профессиональный уровень.
Хотите стать профи, узнавать новое или выступать сами? Присоединяйтесь к комьюнити опытных питонистов!
Онтико — организатор крупнейших в России профессиональных конференций, таких как HighLoad++, TeamLead Conf, DevOpsConf, PHP Russia, Frontend Conf, TechLead Conf и множества других, которые наверняка у вас на слуху.
Каждый доклад на наших конференциях — это решение конкретной задачи, без лишней рекламы и яркой мишуры.
Читайте новые статьи в нашем Хабраблоге

Подписывайтесь на наш YouTube‑канал.

Связаться с нами
Если у вас возникли проблемы с регистрацией или вы хотите задать нам вопрос, звоните и пишите:
Saved searches
Use saved searches to filter your results more quickly
Cancel Create saved search
You signed in with another tab or window. Reload to refresh your session. You signed out in another tab or window. Reload to refresh your session. You switched accounts on another tab or window. Reload to refresh your session.
Инструмент для полностью автоматического перезалива стрима с YouTube на YouTube (с помощью streamlink и youtube data api)
VityaSchel/reuploader
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Switch branches/tags
Branches Tags
Could not load branches
Nothing to show
Could not load tags
Nothing to show
Name already in use
A tag already exists with the provided branch name. Many Git commands accept both tag and branch names, so creating this branch may cause unexpected behavior. Are you sure you want to create this branch?
Cancel Create
- Local
- Codespaces
HTTPS GitHub CLI
Use Git or checkout with SVN using the web URL.
Work fast with our official CLI. Learn more about the CLI.
Sign In Required
Please sign in to use Codespaces.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching Xcode
If nothing happens, download Xcode and try again.
Launching Visual Studio Code
Your codespace will open once ready.
There was a problem preparing your codespace, please try again.
Latest commit
Git stats
Files
Failed to load latest commit information.
Latest commit message
Commit time
README.md
Автоматический перезалив стримов YouTube
Эта штука следит за тем, стримит ли канал, сама начинает запись и заканчивает, конвертирует и заливает на ютуб как видео.
Как оно работает:
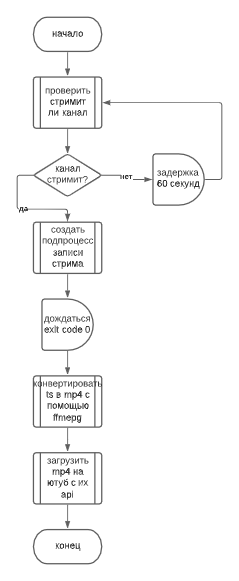
важное уточнение: задержку можно настроить
Способ 1: простой для умных
Если вы выбрали этот способ то вам ничего не нужно объяснять. Делайте пул образа размером 325 мб и переходите к шагу Использование:
mkdir ~/reuploader && cd $_ nano .env nano config.js docker run ghcr.io/vityaschel/reuploader:1.0.3 -v $(pwd)/.env:/root/app/.env -v $(pwd)/config.js:/root/app/config.js -d Чтобы скопировать видеофайл из контейнера:
docker cp [container id]:/root/app/video/[filename].mp4 ~/reuploader/ Способ 2: для тех кто не осилил докер и контейнеры
- Клонируйте репозиторий
git clone https://github.com/VityaSchel/reuploader && cd reuploader && npm i - Установите nodejs 16+, python 3, pip, streamlink с помощью pip и ffmpeg. Все они должны быть доступны из командной строки (добавлены в переменную PATH)
- Заполните .env файл и по желанию config.js, см. формат ниже (nano — обычный текстовый редактор)
nano .env nano config.js Файл .env имеет следующий формат:
CHANNEL_ID=[Id канала YouTube (24 символа, начинается на U)] TELEGRAM_NOTIFICATION_CHAT_ID=[если youtube api выключен, chat_id в телеграме вас для вашего бота] TELEGRAM_NOTIFICATION_BOT_TOKEN=[если youtube api выключен, токен bot api телеграма] CLIENT_ID=[client id приложения в google console developers] CLIENT_SECRET=[client secret приложения в google console developers] VISITOR_TOKEN=[значение куки VISITOR_INFO1_LIVE с сайта youtube.com]
Если у вас есть доступ к YouTube API (см. след пункт), то вы должны прописать CLIENT_ID и CLIENT_SECRET, а TELEGRAM_NOTIFICATION_CHAT_ID и TELEGRAM_NOTIFICATION_BOT_TOKEN необязательные и не будут использоваться.
Если у вас нет доступа к YouTube API, создайте бота в телеграме и запишите токен из bot father и ваш chat_id в .env. Если вам вообще ничего не хочется после конвертации, оставьте 4 поля в .env пустыми и поставьте значение youtubeApiEnabled = null в config.js
CHANNEL_ID и VISITOR_TOKEN в .env обязательно нужно заполнить
Файл config.js имеет следующий формат:
export const checksInterval = [ // moscow time, intervals in seconds from: '9:00', to: '15:50', intervals: 60 >, from: '15:58', to: '16:03', intervals: 10 >, from: '15:50', to: '16:20', intervals: 30 >, ] export const defaultInterval = 60*5 export const youtubeApiEnabled = false
| Название | Описание | Значения |
|---|---|---|
| checksInterval | Интервалы, с которыми в разное время суток будет проверяться канал на наличие стрима. Например, если канал всегда стримит в 16:00 по мск, то вы можете поставить интервал в 10 секунд на проверку в это время, а в остальное время дня раз в 5 минут | Массив объектов |
| defaultInterval | Интервал по-умолчанию, если не найдено значение в checksInterval | Число секунд |
| youtubeApiEnabled | Если true то загружает видео на ютуб, если false отсылает уведомление в телеграм, если значение null, после конвертации ничего не делается | true/false/null |
checksInterval — проверка идет с первого по последний элемент, проверяется начался ли интервал и не закончился ли он, после нахождения скрипт сразу выходит. То есть более короткие интервалы надо ставить в начале, чтобы скрипт сначала проверил их.
Изменить название и описание загружаемых видео можно в файле /src/upload.js, а текст уведомления в /index.js
После всего проделанного просто запустите скрипт на фоне, например с помощью process manager 2:
pm2 start 'npm start' --name='Stream Reuploader' YouTube API (необязательно включать)
Если вы хотите автоматически загружать видео на ютуб, вам понадобится доступ к YouTube Data API. Его не так просто получить, потому что нужно заполнить специальную форму и получить одобрение от гугла. Если вам достаточно просто автоматической записи, то следующие пункты вы можете пропустить, не заполнять CLIENT_ID и CLIENT_SECRET и установить youtubeApiEnabled = false в config.js
- Перейдите в Google Developers Console и создайте проект
- Зайдите в Library и включите YouTube Data API
- Зайдите в Credentials -> Create credentials -> OAuth client ID
- Добавьте https://example.com в список разрешенных редиректов
- Скопируйте client id и client secret в .env файл
- Зайдите в OAuth consent screen -> Test users -> ADD USERS и добавьте почту аккаунта, на канал которого будут загружаться ролики
- Запустите node src/authorize.js и следуйте инструкциям после чего скопируйте код авторизации в аргументе https://example.com/?code=[здесь код]&. ваши токены запишутся в файлы secrets/accessToken и secrets/refreshToken
Теперь вы можете установить youtubeApiEnabled = true в config.js, но обратите внимание, что вы можете загрузить до 6 видео в сутки с помощью API, а далее превысите квоту (квота изменяется запросом в гугл по ссылке в форме ниже). Аккуратнее с тестами.
Более того, все загруженные через API видео будут заблокированы с пометкой «Условия и правила», это потому что с 2020 года необходимо ручное одобрение вашего кейса ютубом. Для этого необходимо заполнить форму: https://support.google.com/youtube/contact/yt_api_form запросите периодическое одобрение и заполните все поля. Никаких советов не могу дать, мне самому еще не одобрили. Если не одобрят, то придется загружать все видео вручную.
Тесты и полезные инструменты
Вы также можете использовать некоторые инструменты в репозитории с cli. Выполните команду: node src/[название файла] [аргументы через пробел]
| Название файла | Описание | Аргументы |
|---|---|---|
| authorize.js | Получить accessToken и refreshToken (второй только если вы даете доступ приложению первый раз, иначе надо запретить доступ вашему приложению через настройки вашего гугл аккаунта) | — |
| convert.js | Конвертирует .ts файлы, созданные streamlink в .mp4 файлы | 1: Путь к файлу .ts (указывается без расширения .ts) |
| isStreaming.js | Проверяет стримит ли канал с помощью http get screen scrape запроса | 1: ID канала (24 символа, начинается на U) |
| record.js | Записывает стрим | 1: ID видео (после /watch?v=) |
2: начало в формате 00:00 или 00:00:00
3: конец в том же формате
- Аккуратнее с трафиком, видео записываются в 720p с фолбеком на 480p и затем на best. Если каким то образом стрим доступен только в 1080p то он будет записываться в full hd, а такие видео весят не мало. Если у вас на сервере не unmetered traffic, то есть смысл вручную записывать стримы и заливать их.
- ctrl+c делает неизвестно что, поэтому просто лучше не нажимайте его во время записи. может однажды я сделаю его обработку и буду передавать в streamlink/ffmpeg чтобы они не портили файлы, а до тех пор просто не трогайте скрипт когда он записывает стрим или конвертирует его в mp4
- .ts файлы не удаляются после конвертации, как и .mp4 файлы
- Если вы хотите использовать мой скрипт для заработка, пожалуйста поставьте звездочку на этот репозиторий или задонатьте любую сумму https://donate.qiwi.com/payin/vityaschel (в зависимости от того, что вам проще сделать)
⚠️ ВАЖНО! ИНФОРМАЦИЯ ПРО ТРАФИК ⚠️
Помимо загрузки стримов на ютуб, которые весят 7 мб/минута (720p), важно еще помнить про поллинг. Пожалуйста, не злоупотребляйте им и не ставьте интервал 1 секунду, потому что тогда в сутки будет тратиться 5,04 Гб. Это только проверка, стримит ли канал, без загрузки самих стримов. Почему так много? Потому что скрипт isStreaming.js запрашивает всю страницу /live (с версии 1.0.3 /embed), чтобы найти значение одного тега в , но сама страница без стилей и жс весит 530 кб (с версии 1.0.3 — 57 кб). Если не менять стандартные интервалы в config.js то в сутки будет тратиться всего 16 мб.
Посчитать, сколько вы будете тратить на поллинг, можно в файле pollingTrafficCalculator.js: node pollingTrafficCalculator.js , он возьмет данные из файла config.js
About
Инструмент для полностью автоматического перезалива стрима с YouTube на YouTube (с помощью streamlink и youtube data api)
Как открыть ссылку в Python. Работа с WebBrowser и решение проблемы с Internet Explorer
В ходе работы над курсачом для универа столкнулся со стандартным модулем Python — WebBrowser. Через этот модуль я хотел реализовать работу голосового помощника — Lora с дефолтным браузером, но всё пошло не так гладко как ожидалось. Давайте для начала расскажу вам что это за модуль и как он вообще работает.
WebBrowser — это вшитый в Python модуль, который предоставляет собой высокоуровневый интерфейс, позволяющий просматривать веб-документы.
Для начала работы импортируйте модуль командой:
import webbrowserТеперь возникает выбор как открыть ссылку. Есть два стула:
1. Написать через одну строчку:
webbrowser.open(url, new=0, autoraise=True)webbrowser.open('https://vk.com', new=2)Если new = 0, URL-адрес открывается, если это возможно, в том же окне браузера. Если переменная new = 1, открывается новое окно браузера, если это возможно. Если new = 2, открывается новая страница браузера («вкладка»), если это возможно.
Значение autoraise можно смело пропускать, ибо оно открывает браузер поверх всех окон, а большинство современных браузеров плюёт на эту переменную даже в значении False.
2. Не мучиться с запоминанием параметров new и писать по-человечески:
webbrowser.open_new(url)Данная конструкция открывает URL-адрес в новом ОКНЕ браузера по умолчанию, если это возможно, в противном случае откроет URL-адрес в единственном окне браузера.
webbrowser.open_new_tab(url)В этом случае URL-адрес откроется на новой странице (”tab») браузера по умолчанию, если это возможно, в противном случае эквивалентно open_new ().
Предположим, что вам не нужен браузер по умолчанию. Для выбора браузера существует классная команда .get()
webbrowser.get(using=None)Грубо говоря, вы просто указываете какой браузер вам использовать.
Например, открытие новой вкладки в Google Chrome:
webbrowser.get(using='google-chrome').open_new_tab('https://vk.com')Таблица названий браузеров:
| Type Name | Class Name |
|---|---|
| ‘mozilla’ | Mozilla(‘mozilla’) |
| ‘firefox’ | Mozilla(‘mozilla’) |
| ‘netscape’ | Mozilla(‘netscape’) |
| ‘galeon’ | Galeon(‘galeon’) |
| ‘epiphany» | Galeon(‘epiphany’) |
| ‘skipstone’ | BackgroundBrowser(‘skipstone’) |
| ‘kfmclient’ | Konqueror() |
| ‘konqueror» | Konqueror() |
| ‘kfm’ | Konqueror() |
| ‘mosaic’ | BackgroundBrowser(‘mosaic’) |
| ‘opera’ | Opera() |
| ‘grail’ | Grail() |
| ‘links’ | GenericBrowser(‘links’) |
| ‘elinks’ | Elinks(‘elinks’) |
| ‘lynx’ | GenericBrowser(‘lynx’) |
| ‘w3m’ | GenericBrowser(‘w3m’) |
| ‘windows-default’ | WindowsDefault |
| ‘macosx’ | MacOSX(‘default’) |
| ‘safari’ | MacOSX(‘safari’) |
| ‘google-chrome’ | Chrome(‘google-chrome’) |
| ‘chrome» | Chrome(‘chrome’) |
| ‘chromium» | Chromium(‘chromium’) |
| ‘chromium-browser’ | Chromium(‘chromium-browser’) |
Но не всегда получается обойтись одним только .get() и в этом случае на помощь приходит функция .register(), например:
import webbrowser webbrowser.register('Chrome', None, webbrowser.BackgroundBrowser('C:\Program Files (x86)\Google\Chrome\Application\chrome.exe')) webbrowser.get('Chrome').open_new_tab('vk.com')Мы указали путь к Google Chrome, назвали его и теперь все ссылки открываются только в нём. Надеюсь немного разобрались с модулем WebBrowser и теперь перейдём к моей маленькой проблеме.
Проблема
Как говорилось ранее, для курсового проекта я выбрал создание голосового ассистента. Хотелось его научить переходить по ссылкам и искать информацию в поисковике. Конечно можно было бы «напиповать» множество библиотек для этого, но принципиально хотелось реализовать это через стандартный модуль WebBrowser.
Так как у большинства современных браузеров строка ввода ссылки и поисковая строка это одно и то же, то, казалось бы, можно просто передать запрос туда же, куда передаётся ссылка.
import webbrowser webbrowser.open_new_tab('https://vk.com') webbrowser.open_new_tab('яблоки')По логике этого кода должны открыться две вкладки:
- Сайт vk.com
- Запрос в поисковике — яблоки
Раз нам позволяют открывать только ссылки в дефолтном браузере, так и будем открывать только ссылки.
Шаги решения

- Делаем поисковый запрос в наш поисковик (яндекс, гугл и т.д. и т.п.)
- Вытаскиваем ссылку

И, как уже многие догадались, просто вставляем нашу ссылку без того, что идёт после «text=»
import webbrowser webbrowser.open_new_tab('https://vk.com') webbrowser.open_new_tab('https://yandex.ru/search/?lr=10735&text=')webbrowser.open_new_tab('https://yandex.ru/search/?lr=10735&text='+'еда')webbrowser.open_new_tab('https://yandex.ru/search/?lr=10735&text=%s'%'еда')webbrowser.open_new_tab('https://yandex.ru/search/?lr=10735&text=<>'.format('еда'))Для начала мы понимаем, что ссылка несёт в себе домен (.ru, .com и т.д.), в запросе же, как правило, точку не ставят (купить машину, фильм онлайн и т.д.), а в ссылке пробел.
Следовательно, мы будем искать точку и пробел в том, что ввёл пользователь. Реализовать мы сможем это благодаря модулю re, который также изначально встроен в Python. Python предлагает две разные примитивные операции, основанные на регулярных выражениях: match выполняет поиск паттерна в начале строки, тогда как search выполняет поиск по всей строке. Мы воспользуемся операцией search.
import webbrowser import re call = input('Введите ссылку или запрос: ') if re.search(r'\.', call): webbrowser.open_new_tab('https://' + call) elif re.search(r'\ ', call): webbrowser.open_new_tab('https://yandex.ru/search/?text='+call) else: webbrowser.open_new_tab('https://yandex.ru/search/?text=' + call)Немного объясню код.
Пользователь вводит ссылку или текст запроса в переменную call.
if re.search(r'\.', call): webbrowser.open_new_tab('https://' + call)Первое условие проверяет переменную call на точку внутри неё. Символ ‘\’ обязателен, иначе модуль не понимает, что перед ним символ точка.
elif re.search(r'\ ', call):В этом условии всё тоже самое что и в первом, но проверка ведётся уже на пробел. А пробел говорит о том, что перед нами поисковой запрос.
else: webbrowser.open_new_tab('https://yandex.ru/search/?text=' + call)А else, в свою очередь, присваивает всё что написал пользователь без пробелов и точек в поисковый запрос.
Проверка на пробел является обязательной, иначе WebBrowser открывает Internet Explorer.
Всем спасибо за внимание! Надеюсь данная статья кому-нибудь окажется полезной.
- python
- python3
- webbrowser
- python webbrowser
- браузер
- работа с браузером
- открытие ссылок в python
- ненормальное программирование